《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
第十八章 现实世界的最佳实践
Best practices for the real world
运行代码
本章内容
- 超参数调优
- 模型集成
- 在多个 GPU 或 TPU 上训练 Keras 模型
- 混合精度训练
- 量子化
- Hyperparameter tuning
- Model ensembling
- Training Keras models on multiple GPUs or on TPU
- Mixed-precision training
- Quantization
从本书开头到现在,你已经取得了长足的进步。你现在可以训练图像分类模型、图像分割模型、矢量数据分类或回归模型、时间序列预测模型、文本分类模型、序列到序列模型,甚至文本和图像生成模型。你已经掌握了所有基础知识。
然而,你目前的模型都是在小规模下训练的——使用小型数据集和单个GPU——而且在我们考察过的每个数据集上,它们通常都没有达到最佳性能。毕竟,这本书只是一本入门读物。如果你想在现实世界中,在全新的问题上取得最先进的成果,你仍然需要跨越一道鸿沟。
本章旨在弥合机器学习学生与工程师之间的差距,并为你提供从机器学习学生成长为一名成熟的机器学习工程师所需的最佳实践。我们将回顾系统性提升模型性能的关键技术:超参数调优和模型集成。然后,我们将探讨如何利用多GPU和TPU训练、混合精度和量化等方法加速和扩展模型训练。
充分利用您的模型
Getting the most out of your models
如果你只需要一个勉强能用的模型,盲目尝试不同的架构配置也无妨。但在本节中,我们将超越“勉强能用”的范畴,通过一份简明指南,介绍构建最先进深度学习模型所需的一系列必备技巧,助你打造“卓越性能,赢得机器学习竞赛”的模型。
超参数优化
Hyperparameter optimization
构建深度学习模型时,你需要做出许多看似任意的决定:应该堆叠多少层?每层应该有多少个单元或滤波器?应该使用哪个函数relu作为激活函数?是否应该BatchNormalization在特定层之后使用?应该使用多少 dropout?等等。这些架构层面的参数被称为超参数,以区别于 通过反向传播训练的模型参数。
These architecture-level parameters are called hyperparameters to distinguish them from the parameters of a model, which are trained via backpropagation.
在实践中,经验丰富的机器学习工程师和研究人员会随着时间的推移,逐渐建立起对这些选择的有效与无效的直觉——他们发展出超参数调优的技能 ( hyperparameter-tuning skills )。但这并没有什么正式的规则。如果你想在给定任务上达到性能极限,就不能满足于这种随意的选择。即使你拥有非常敏锐的直觉,你的初始决策几乎总是次优的。你可以通过手动调整并反复重新训练模型来优化你的选择——这正是机器学习工程师和研究人员花费大部分时间的工作。但作为人类,你不应该整天摆弄超参数——这最好交给机器来完成。
因此,你需要以系统且有原则的方式,自动地探索所有可能的决策空间。你需要搜索架构空间,并通过经验找到性能最佳的架构。这就是自动超参数优化领域的核心所在:它是一个完整的、重要的研究领域。
Thus, you need to explore the space of possible decisions automatically and systematically in a principled way. You need to search the architecture space and find the best-performing ones empirically. That’s what the field of automatic hyperparameter optimization is about: it’s an entire field of research, and an important one.
超参数优化过程通常如下所示:
- 自动选择一组超参数。
- 构建相应的模型。
- 将其与训练数据进行匹配,并在验证数据上衡量其性能。
- 选择下一组要尝试的超参数(自动)。
- 重复。
- 最后,根据测试数据衡量性能。
- Choose a set of hyperparameters (automatically).
- Build the corresponding model.
- Fit it to your training data, and measure performance on the validation data.
- Choose the next set of hyperparameters to try (automatically).
- Repeat.
- Eventually, measure performance on your test data.
该过程的关键在于分析验证性能与各种超参数值之间关系的算法,从而选择下一组需要评估的超参数。有很多不同的技术可供选择:贝叶斯优化、遗传算法、简单随机搜索等等。
Many different techniques are possible: Bayesian optimization, genetic algorithms, simple random search, and so on.
训练模型权重相对容易:只需在小批量数据上计算损失函数,然后使用反向传播算法将权重调整到正确的方向即可。而更新超参数则面临着独特的挑战。请考虑以下几点:
- 超参数空间通常由离散决策构成,因此它既不连续也不可微。所以,你通常无法在超参数空间中使用梯度下降法。相反,你必须依赖无梯度优化技术,而这些技术的效率自然远低于梯度下降法。
- 计算此优化过程的反馈信号(这组超参数是否能使模型在此任务上表现优异?)可能非常昂贵:它需要从头开始在您的数据集上创建和训练一个新模型。
- 反馈信号可能存在噪声:如果一次训练运行的性能提高了 0.2%,是因为模型配置更好,还是因为初始权重值比较理想?
- The hyperparameter space is typically made of discrete decisions and thus isn’t continuous or differentiable. Hence, you typically can’t do gradient descent in hyperparameter space. Instead, you must rely on gradient-free optimization techniques, which, naturally, are far less efficient than gradient descent.
- Computing the feedback signal of this optimization process (does this set of hyperparameters lead to a high-performing model on this task?) can be extremely expensive: it requires creating and training a new model from scratch on your dataset.
- The feedback signal may be noisy: if a training run performs 0.2% better, is that because of a better model configuration or because you got lucky with the initial weight values?
幸好,有一个工具可以简化超参数调优:KerasTuner。让我们一起来看看。
使用 KerasTuner
Using KerasTuner
我们先来安装 KerasTuner:
1 | !pip install keras-tuner -q |
KerasTuner 的核心思想是允许您将硬编码的超参数值(例如units=32)替换为一系列可能的选择值(例如Int(name="units", min_value=16, max_value=64, step=16))。给定模型中此类选择的集合称为 超参数调优过程的搜索空间。
The set of such choices in a given model is called the search space of the hyperparameter tuning process.
要指定搜索空间,请定义一个模型构建函数(参见下一个例子)。该函数接受一个hp参数,您可以从中采样超参数范围,并返回一个已编译的 Keras 模型。
1 | import keras |
清单 18.1:KerasTuner 模型构建函数
如果你想采用更模块化和可配置的模型构建方法,你也可以继承该类HyperModel并定义一个build方法。
1 | import keras_tuner as kt |
列表 18.2:KerasTunerHyperModel
下一步是定义“调谐器”。从示意图上看,你可以把调谐器想象成一个for循环,它会重复执行相同的操作。
The next step is to define a “tuner.” Schematically, you can think of a tuner as a for loop, which will repeatedly
Pick a set of hyperparameter values
Call the model-building function with these values to create a model
Train the model and record its metrics
选择一组超参数值
使用这些值调用模型构建函数来创建模型
训练模型并记录其指标
KerasTuner 内置了几个调优器——tuner_tuner RandomSearch、BayesianOptimization``tuner_tuner 和 tuner_tuner Hyperband。我们来试试BayesianOptimization``tuner_tuner,它能根据之前的选择结果,智能预测哪些新的超参数值可能表现最佳:
1 | tuner = kt.BayesianOptimization( |
您可以通过以下方式显示搜索范围概览search_space_summary():
1 | >>> tuner.search_space_summary() |
目标最大化和最小化
Objective maximization and minimization
对于内置指标(例如本例中的准确率), KerasTuner 会推断指标的方向(准确率应最大化,损失应最小化)。但是,对于自定义指标,您需要自行指定,如下所示:
1 | objective = kt.Objective( |
最后,我们开始搜索。别忘了传递验证数据,并确保不要使用测试集作为验证数据——否则,你会很快对测试数据产生过拟合,并且你将无法再信任你的测试指标:
1 | (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() |
前面的例子只需几分钟就能运行完毕,因为我们只考虑了几个可能的选择,而且是在 MNIST 数据集上进行训练。但是,对于典型的搜索空间和数据集,您通常会发现超参数搜索需要运行一整夜甚至几天。如果搜索过程崩溃,您可以随时重新启动它——只需overwrite=False在调优器中指定,以便它可以从存储在磁盘上的试验日志中恢复即可。
搜索完成后,您可以查询最佳超参数配置,然后使用这些配置创建高性能模型,并重新训练这些模型。
1 | top_n = 4 |
清单 18.3:查询最佳超参数配置
通常情况下,在重新训练这些模型时,由于不会再对超参数进行任何更改,因此可能需要将验证数据包含在训练数据中,这样就无需再在验证数据上评估模型性能。在我们的示例中,我们将使用原始 MNIST 训练数据集的全部数据来训练最终模型,而不保留验证集。
个人注:怎么理解以上这句话?
这句话描述的是机器学习工作流中一个非常经典、但也常让初学者纠结的“最后一步”。
简单来说,它的核心逻辑是:一旦你通过“模拟考试”选出了最好的学生(参数),正式上考场前,你应该让他把模拟考题也背下来,以获得最大的知识量。
我们可以从以下三个维度来拆解这个逻辑:
- 验证集(Validation Set)的使命已完成
在开发模型时,我们把数据切分为“训练集”和“验证集”。
- 训练集:让模型学知识(调权重)。
- 验证集:用来调参数(比如学习率、层数、Top-k 值)。
- 现状:当你决定不再修改任何超参数(Hyperparameter)时,验证集作为“裁判”的使命就结束了。此时,这部分数据如果闲置,就是对宝贵数据资源的浪费。
- “数据量”即“模型上限”
在深度学习(如 MNIST 手写数字识别或大模型训练)中,数据越多,模型越稳。
- 验证集通常占 10%~20% 的数据。
- 如果你在最终发布模型前,把这 20% 的数据重新喂给模型,模型就能看到更多奇异的数字样本、更多的噪声和更多的边缘情况。
- 结果:最终得到的模型虽然无法再被“验证”(因为没有留出的数据了),但它在面对真实世界(测试集/生产环境)时的泛化能力通常会更强。
- 操作流程的“三部曲”
这句话实际上是在建议你执行以下流程:
- 实验阶段:用 50,000 张图训练,10,000 张图验证。不停调整,直到在验证集上达到 99% 准确率。
- 锁定阶段:记录下表现最好的超参数(比如:3 层隐藏层,Dropout=0.5)。
- 最终生产:使用这组锁定的超参数,用全部 60,000 张图(训练+验证)从头开始训练一个新模型。这个模型就是你最终交付给用户的产品。
不过,在利用完整训练数据集进行训练之前,我们还需要确定最后一个参数:最佳训练轮数。
个人注:怎么理解以上这句话?
这句话紧接你上一条关于“合并训练集和验证集”的逻辑。它指出了一项关键的工程挑战:如果你打算用“全部数据”训练最终模型,你该训练多少轮(Epochs)?
理解这句话的关键在于:当验证集消失后,你就失去了“喊停”的信号灯。
- 为什么这是一个“最后的问题”?
在开发阶段,我们通常使用 提前停止(Early Stopping):
- 我们一边训练,一边盯着验证集的损失函数(Validation Loss)。
- 当验证集损失不再下降、反而开始上升时,说明模型开始过拟合(Overfitting)了,我们会立刻停止训练。
- 此时,我们记录下了那个“最佳训练轮数”(例如:第 25 轮效果最好)。
但是,当你按照前文的建议,把验证集并入训练集进行“最终训练”时:
- 你没有独立的验证集来监控了。
- 如果你练得太少,模型没吃透新增的数据;
- 如果你练得太多,模型会把所有数据死记硬背下来,导致泛化能力下降。
- 这里的“Settle(确定)”是指什么?
作者的意思是:在丢掉验证集、开启“全量训练”之前,你必须先通过之前的实验锁定一个确定的数字。
操作逻辑通常是这样的:
实验中:发现模型在第 \(N\) 轮时,验证集表现达到巅峰。
锁定:确定 \(N\) 就是这个任务的“黄金训练时长”。
最终全量训练:把训练集和验证集加在一起,不多不少,正好只练 \(N\) 轮。
为什么不能在全量训练时重新寻找 \(N\)?
因为在全量数据上,模型看到的样本变多了,它的“训练曲线”会发生偏移。但由于你已经没有验证集做参考了,你无法在全量训练的过程中判断当前是第几轮最合适。
所以,你必须“信任”之前在子集上实验得出的结果,并将其作为最终生产的硬性标准。
通常,新模型的训练时间会比搜索阶段更长:在回调patience函数中使用过大的轮数EarlyStopping可以节省搜索时间,但可能导致模型欠拟合。只需使用验证集即可找到最佳轮数:
1 | def get_best_epoch(hp): |
最后,由于训练数据量更大(在本例中为 20%),因此需要在完整数据集上进行比当前 epoch 数稍长一些的训练:
1 | def get_best_trained_model(hp): |
如果你不担心性能略有不足,你可以走一条捷径:只需使用调优器重新加载在超参数搜索期间保存的最佳权重的最佳模型,而无需从头开始重新训练新模型:
1 | best_models = tuner.get_best_models(top_n) |
在进行大规模自动超参数优化时,需要注意的一个重要问题是验证集过拟合。因为超参数的更新是基于使用验证数据计算出的信号,所以实际上是在用验证数据训练模型,因此模型很快就会过拟合验证数据。务必牢记这一点。
构建合适的搜索空间的艺术
The art of crafting the right search space
总而言之,超参数优化是一项强大的技术,是构建任何任务上最先进模型或在机器学习竞赛中获胜的绝对必要条件。想想看:曾经,人们需要手工精心设计浅层机器学习模型的特征。这远非最优解。如今,深度学习实现了分层特征工程的自动化——特征是通过反馈信号学习的,而不是手动调整,这才是正确的方向。同样,你不应该手工构建模型架构;你应该以一种有原则的方式对其进行优化。
Now deep learning automates the task of hierarchical feature engineering—features are learned using a feedback signal, not hand-tuned, and that’s the way it should be.
然而,进行超参数调优并不能取代熟悉模型架构最佳实践:搜索空间会随着选择数量的增加而呈组合式增长,因此将所有因素都转化为超参数并让调优器自动处理成本过高。你需要巧妙地设计合适的搜索空间。超参数调优是自动化,而非魔法:它用于自动化原本需要手动运行的实验,但你仍然需要精心挑选那些有可能产生良好指标的实验配置。
好消息是:通过超参数调优,您需要做的配置决策将从微观决策(例如,这一层应该选择多少个单元?)提升到更高层次的架构决策(例如,是否应该在整个模型中使用残差连接?)。微观决策往往针对特定模型和特定数据集,而更高层次的决策则具有更好的泛化能力,能够更好地应用于不同的任务和数据集:例如,几乎所有图像分类问题都可以通过类似的搜索空间模板来解决。
个人注:怎么理解以上这个好消息?
这句话揭示了超参数调优(Hyperparameter Tuning)在深度学习工程实践中的“层次进化”。
你的理解完全正确:层数和单元数确实是超参数。但作者想表达的是,当你引入了自动化的调优流程(比如使用 KerasTuner, Ray Tune 或 Optuna)后,你的工作重心会发生质变。
我们可以从以下三个维度来理解这种“决策等级的跃升”:
- 从“手动拨号”到“自动驾驶”
在没有自动化调优工具时,你不得不像调收音机频率一样微调每一个数字:
微观决策(Micro-decisions):
“第一层是用 32 个单元还是 64 个?”
“学习率是 0.001 还是 0.0005?”
这些决策非常琐碎,且极其耗费人力。
- 超参数调优的“外包”
当你搭建好一个自动调优系统后,你不再需要自己去拍脑袋定这些数字。你只需要给出一个范围(Search Space):
- 你告诉系统:“单元数在 32 到 512 之间找,层数在 2 到 10 层之间找。”
- 系统会通过算法(如贝叶斯优化)自动帮你选出那个最优的数字。
- 什么是“更高层级的架构决策”?
当数字问题交给机器后,人类专家的精力就被释放出来去思考更本质的架构设计(Architecture Decisions):
- 残差连接(Residual Connections):我们要不要加一条“捷径”来解决深层网络的梯度消失问题?
- 注意力机制(Attention):这个任务是否需要引入自注意力来捕捉长距离依赖?
- 正则化策略:是使用 Dropout 还是 Batch Normalization?
这些决策无法简单地通过在一个范围内“滑动机标”来解决,它们涉及到对模型信息流的根本性改动。
核心总结
这句话的意思是:
“有了自动调优,你不再是一个‘调参工人’(天天纠结该选 128 还是 256),而变成了一个‘架构设计师’(思考模型的骨架该怎么搭)。那些细微的数字交给算法去跑,你来决定模型的大方向。”
基于此逻辑,KerasTuner 致力于提供 与各类问题(例如图像分类)相关的预构建搜索空间( premade search spaces )kt.applications.HyperXception。只需添加数据、运行搜索,即可获得相当不错的模型。您还可以尝试超模型,kt.applications.HyperResNet它们实际上是 Keras Applications 模型的可调版本。
模型集成
Model ensembling
另一种在任务上获得最佳结果的强大技术是模型集成。集成是指将一组不同模型的预测结果汇集在一起,从而产生更优的预测结果。如果你观察机器学习竞赛——尤其是 Kaggle 上的竞赛——你会发现,获胜者通常使用非常庞大的模型集成,这些集成模型最终都能胜过任何单个模型,无论单个模型多么优秀。
集成学习依赖于这样一个假设:独立训练的不同模型之所以表现良好,很可能是因为它们各自基于不同的原因:每个模型都会关注数据的不同方面来进行预测,从而获得部分“真相”,但并非全部。你可能熟悉盲人摸象的寓言:一群盲人第一次遇到大象,试图通过触摸来了解大象。每个人都触摸大象身体的不同部位——例如象鼻或象腿。然后,他们互相描述大象的样子:“像蛇一样”、“像柱子或树一样”,等等。这些盲人本质上就是机器学习模型,它们试图理解训练数据的复杂性,每个模型都从自己的角度出发,基于各自的假设(这些假设由模型的独特架构和独特的随机权重初始化提供)。每个模型都获得了部分数据真相,但并非全部真相。通过汇集它们的视角,你可以获得对数据更准确的描述。大象是由各个部分组成的:没有哪个盲人能够完全了解它,但如果把它们放在一起采访,就能讲述一个相当准确的故事。
我们以分类为例。将一组分类器的预测结果汇总起来(即集成分类器)的最简单方法是在推理时对它们的预测结果取平均值:
1 | # Uses four different models to compute initial predictions |
然而,这种方法只有在分类器的性能大致相当的情况下才有效。如果其中一个分类器的性能明显逊于其他分类器,那么最终的预测结果可能不如该组中性能最佳的分类器。
更智能的集成分类器方法是进行加权平均,其中权重是在验证数据上学习得到的——通常,性能更好的分类器会被赋予更高的权重,而性能较差的分类器会被赋予更低的权重。为了找到一组好的集成权重,可以使用随机搜索或简单的优化算法,例如 Nelder-Mead 算法:
1 | preds_a = model_a.predict(x_val) |
有很多可能的变体:例如,你可以对预测结果进行指数平均。一般来说,使用基于验证数据优化的权重进行简单的加权平均,可以提供一个非常可靠的基准。
集成学习成功的关键在于分类器集合的多样性(diversity)。多样性就是力量。如果所有盲人摸象都只摸到象鼻,他们就会认为大象像蛇,永远无法了解大象的真相。多样性正是集成学习成功的关键。用机器学习的术语来说,如果所有模型都存在相同的偏差,那么集成模型也会保留这种偏差。如果模型存在 不同的偏差,这些偏差就会相互抵消,集成模型就会更加稳健、更加准确。
If your models are biased in different ways, the biases will cancel each other out, and the ensemble will be more robust and more accurate.
因此,你应该集成尽可能优秀 且尽可能不同的模型。这通常意味着使用截然不同的架构,甚至不同品牌的机器学习方法。一种基本不值得尝试的做法是,将同一个网络使用不同的随机初始化独立训练多次后再进行集成。如果模型之间的唯一区别在于它们的随机初始化以及它们接触训练数据的顺序,那么你的集成模型多样性将很低,并且相比任何单个模型,性能提升都非常有限。
我发现,在实践中效果显著的一种方法——尽管它并非适用于所有问题领域——是将基于树的方法(例如随机森林或梯度提升树)与深度神经网络集成起来。2014 年,我和 Andrei Kolev 在 Kaggle 上的希格斯玻色子衰变检测挑战赛(www.kaggle.com/c/higgs-boson)中,使用各种树模型和深度神经网络的集成模型获得了第四名。值得注意的是,集成模型中的一个模型与其他模型采用的方法不同(它是一个正则化的贪婪森林),并且得分明显低于其他模型。不出所料,它在集成模型中的权重很小。但令我们惊讶的是,它最终大幅提升了整体集成模型的性能,因为它与其他所有模型都截然不同:它提供了其他模型无法获取的信息。这正是集成方法的意义所在。关键不在于你最好的模型有多好,而在于你的候选模型集的多样性。
个人注:随机森林(Random Forest)和梯度提升树(Gradient Boosting Decision Tree, GBDT)的核心思想。
随机森林(Random Forest)和梯度提升树(Gradient Boosting Decision Tree, GBDT)是机器学习中表现最稳健的两大“集成学习”算法。虽然它们都由决策树组成,但它们的底层哲学完全不同。
我们可以把它们类比为“民主投票”与“学霸纠错”。
- 随机森林 (Random Forest):民主投票
随机森林的核心思想是“并行集成(Bagging)”。它的目标是通过“群体智慧”来降低单个模型的误差(方差)。
核心逻辑:
- 随机采样(Bootstrap):从原始数据中有放回地抽取多份不同的子集。
- 特征随机:在构建每一棵决策树时,只随机选取一部分特征(属性),而不是全部特征。
- 独立生长:让成百上千棵决策树互不干扰地生长。
- 多数表决:对于分类任务,每棵树投一票,得票最多的类别为最终结果。
直观理解:
想象你由于身体不适去求医。你找了 100 个背景各异的普通医生,每个人只看你的部分检查报告。虽然单个医生可能看走眼,但如果 80 个医生都说你是“感冒”,那么最终结论大概率就是感冒。这种方法极其耐造,不容易过拟合。
- 梯度提升树 (GBDT):学霸纠错
梯度提升树的核心思想是“串行集成(Boosting)”。它的目标是通过“不断迭代”来减少模型与真实值之间的差距(偏差)。
核心逻辑:
- 起步:先建立第一棵非常简单的树(通常表现很差)。
- 计算残差(Residual):计算这棵树的预测值与真实值之间的差距(即“错误在哪里”)。
- 针对性改进:建立第二棵树,这棵树不负责预测原始目标,而是专门负责预测第一棵树留下的残差。
- 累加迭代:将新树的结果加到旧模型上,再计算新的残差,循环往复。
直观理解:
想象一个学生在做数学卷子。
第一遍做完,得了 60 分。
第二遍,他专门盯着错题本(残差)练,下次能得 80 分。
第三遍,他再盯着剩下那 20 分的难点练。
经过多次迭代,他的成绩会无限趋近于 100 分。这种方法精度极高,是各大算法竞赛的常客(如 XGBoost, LightGBM)。
- 核心差异对比
特性 随机森林 (Random Forest) 梯度提升树 (GBDT) 构建方式 并行(树与树之间独立) 串行(后一棵树依赖前一棵) 主要目标 降低方差(防止过拟合) 降低偏差(提高准确度) 对异常值 非常鲁棒,不易受噪声影响 比较敏感,容易学到噪声(过拟合) 调参难度 容易(树越多越稳,不会变差) 较难(需要细心控制步长和树的数量)
使用多台设备扩展模型训练
Scaling up model training with multiple devices
回想一下我们在第7章中介绍的“进步循环”概念:你的想法的质量取决于它经历了多少次改进循环(图18.1)。而你迭代想法的速度取决于你设置实验的速度、运行实验的速度,以及最终分析结果数据的能力。
 图 18.1:进度循环
图 18.1:进度循环
随着你对 Keras API 的熟练掌握,编写深度学习实验代码的速度将不再是瓶颈。下一个瓶颈将是模型训练的速度。快速的训练基础设施意味着你可以在 10 到 15 分钟内获得结果,从而每天进行数十次迭代。更快的训练速度能够直接提升 深度学习解决方案的质量。
在本节中,您将学习如何通过使用多个 GPU 或 TPU 来扩展训练运行规模。
多GPU训练
Multi-GPU training
尽管GPU的性能每年都在提升,但深度学习模型的规模也越来越大,需要越来越多的计算资源。在单个GPU上进行训练会严重限制训练速度。解决方案是什么?只需增加GPU数量,即可开始进行多GPU分布式训练( multi-GPU distributed training )。
有两种方法可以将计算分布到多个设备上: 数据并行和模型并行。(data parallelism and model parallelism.)
利用数据并行技术,单个模型会被复制到多个设备或多台机器上。每个模型副本处理不同的数据批次,然后将结果合并。
模型并行是指将单个模型的不同部分运行在不同的设备上,同时处理同一批数据。这种方法最适用于本身就具有并行架构的模型,例如具有多个分支的模型。实际上,模型并行仅用于模型过大而无法在任何单个设备上运行的情况:它并非用于加速常规模型的训练,而是用于训练更大型的模型。
当然,你也可以将数据并行和模型并行结合起来:一个模型可以拆分到多个设备(例如 4 个设备)上,并且该拆分后的模型可以复制到多个设备组(例如,复制两次,总共使用 2 * 4 = 8 个设备)。
让我们详细看看它是如何运作的。
数据并行:在每个 GPU 上复制模型
Data parallelism: Replicating your model on each gpu
数据并行是分布式训练中最常见的形式。它的工作原理很简单:分而治之。每个GPU都会收到整个模型的副本,称为一个模型副本(replica)。传入的数据批次会被分成N 个子批次,每个子批次由一个模型副本并行处理。这就是它被称为数据并行的原因:不同的样本(数据点)被并行处理。例如,使用两块GPU,一个大小为128的批次会被分成两个大小为64的子批次,分别由两个模型副本处理。
- 在推理过程中——我们会检索每个子批次的预测结果,并将它们连接起来以获得整个批次的预测结果。
- 在训练过程中,我们会获取每个子批次的梯度,求平均值,并基于梯度平均值更新所有模型副本。此时,模型的状态与使用包含 128 个样本的完整批次进行训练时的状态相同。这被称为同步训练,因为所有副本都保持同步——它们的权重始终相同。虽然存在非同步训练方法,但效率较低,在实践中已不再使用。
- In inference — We would retrieve the predictions for each sub-batch and concatenate them to obtain the predictions for the full batch.
- In training — We would retrieve the gradients for each sub-batch, average them, and update all model replicas based on the gradient average. The state of the model would then be the same as if you had trained it on the full batch of 128 samples. This is called synchronous training, since all replicas are kept in sync — their weights have the same value at all times. Nonsynchronous alternatives exist, but they are less efficient and aren’t used anymore in practice.
数据并行是一种简单且高度可扩展的模型训练加速方式。如果设备数量增加,只需增大批次大小,训练吞吐量就会相应提高。但它也有一个限制:模型必须能够放入单个设备中。然而,现在训练拥有数百亿参数的基础模型已十分常见,而这些模型无法放入任何单个 GPU 中。
模型并行化:将模型分布在多个GPU上
Model parallelism: Splitting your model across multiple gpus
这就是模型并行发挥作用的地方。数据并行是通过将数据批次拆分成子批次并并行处理这些子批次来实现的,而模型并行则是通过将模型拆分成子模型并在不同的设备上并行运行每个子模型来实现的。例如,考虑以下模型。
1 | model = keras.Sequential( |
清单 18.4:大型密集连接模型
每个样本有 16,000 个特征,并通过两层模型被分类到 8,000 个可能重叠的类别中Dense。这两层模型规模庞大——第一层约有 10 亿个参数,最后一层约有 5.12 亿个参数。如果您使用两台小型设备,则无法使用数据并行,因为单个设备无法容纳如此庞大的模型。您可以将模型的单个实例 拆分到多个设备上。这通常称为模型分片或分区。将模型拆分到多个设备主要有两种方式:水平分区和垂直分区。
This is often called sharding or partitioning a model. There are two main ways to split a model across devices: horizontal partitioning and vertical partitioning.
在水平分区中,每个设备处理模型的不同层。例如,在之前的模型中,一个GPU处理第一Dense层,另一个GPU处理第二Dense层。这种方法的主要缺点是会引入通信开销。例如,第一层的输出需要先复制到第二个设备,才能被第二层处理。这可能会成为瓶颈,尤其是在第一层的输出很大的情况下——否则可能会导致GPU闲置。
在垂直分区中,每一层都会被分配到所有可用设备上。由于层通常以 matmul``or``convolution操作来实现,而这些操作具有高度并行性,因此这种策略在实践中易于实现,并且几乎总是大型模型的最佳选择。例如,在前面的模型中,您可以将第一Dense层的内核和偏置分成两半,这样每个设备就只接收一个形状为 k (16000, 32000)(沿其最后一个轴分割)的内核和一个形状为 k 的偏置 (32000,)。您可以matmul(inputs, kernel) + bias使用每个设备的这半个内核和半个偏置进行计算,并将两个输出通过如下方式连接起来:
1 | half_kernel_0 = kernel[:, :32000] |
实际上,您需要将数据并行和模型并行结合起来。例如,您可以将模型拆分到四个设备上运行,然后将拆分后的模型复制到多个两台设备一组的设备组(假设每组两台设备)中,每个设备组并行处理一个数据子批次。这样,您将拥有两个副本,每个副本运行在四个设备上,总共使用八个设备(图 18.2)。
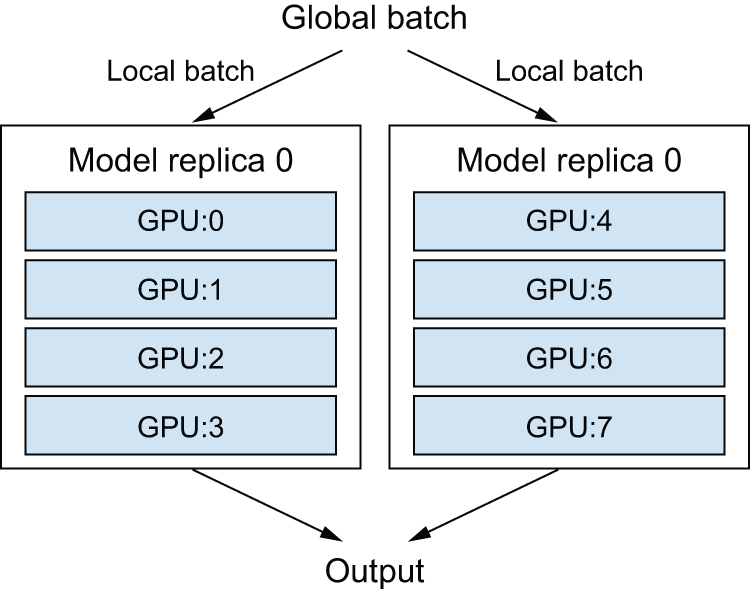 图 18.2:将模型分布在八个设备上:两个模型副本,每个副本由一组四个设备处理。
图 18.2:将模型分布在八个设备上:两个模型副本,每个副本由一组四个设备处理。
分布式实践培训
Distributed training in practice
现在让我们看看如何在实践中应用这些概念。我们将只介绍 JAX 后端,因为它是各种 Keras 后端中性能最高、可扩展性最强的,遥遥领先。如果你正在进行任何类型的大规模分布式训练,却没有使用 JAX,那就大错特错了——你会浪费大量资金,消耗远超实际所需的计算资源。
获取两块或更多GPU
Getting your hands on two or more gpus
首先,你需要获取多个 GPU 的访问权限。目前,Google Colab 只允许你使用单个 GPU,因此你需要执行以下两项操作之一:
- 购置两到八块GPU,将它们安装在一台机器上(这将需要一个功率强大的电源),并安装CUDA驱动程序、cuDNN等。对于大多数人来说,这并不是最佳选择。
- 在 Google Cloud、Azure 或 AWS 上租用多 GPU 虚拟机 (VM)。您可以使用预装了驱动程序和软件的虚拟机镜像,几乎无需任何设置。对于不需要 24/7 全天候训练模型的用户来说,这可能是最佳选择。
- Acquire two to eight GPUs, mount them on a single machine (it will require a beefy power supply), and install CUDA drivers, cuDNN, etc. For most people, this isn’t the best option.
- Rent a multi-GPU virtual machine (VM) on Google Cloud, Azure, or AWS. You’ll be able to use VM images with pre-installed drivers and software, and you’ll have very little setup overhead. This is likely the best option for anyone who isn’t training models 24/7.
我们不会详细介绍如何启动多 GPU 云虚拟机,因为此类说明的生命周期相对较短,而且这些信息很容易在网上找到。
使用 JAX 进行数据并行
Using data parallelism with JAX
使用 Keras 和 JAX 进行数据并行非常简单:在构建模型之前,只需添加以下代码行:
1 | keras.distribution.set_distribution(keras.distribution.DataParallel()) |
就是这样。
如果您需要更精细的控制,可以指定要使用的设备。您可以通过以下方式列出可用设备:
1 | keras.distribution.list_devices() |
它将返回一个字符串列表——即您的设备名称,例如"gpu:0","gpu:1"等等。然后您可以将这些名称传递给DataParallel构造函数:
1 | keras.distribution.set_distribution( |
理想情况下,在N 个GPU 上进行训练可以带来N倍的加速。然而,在实际应用中,分布式训练会引入一些开销——特别是,合并来自不同设备的权重差异需要一些时间。实际获得的加速比取决于所使用的 GPU 数量:
- 使用两块 GPU,速度提升接近 2 倍。
- 使用四个组件,速度提升约为 3.8 倍。
- 八个的话,大约是 7.3 倍。
这假设你使用了足够大的全局批处理大小,以确保每个 GPU 都满负荷运行。如果你的批处理大小太小,局部批处理大小将不足以让 GPU 保持满负荷运转。
使用 JAX 的模型并行性
Using model parallelism with JAX
Keras 还提供了强大的工具,可以完全自定义分布式训练的方式,包括模型并行训练以及你能想到的任何数据并行和模型并行训练的组合。让我们深入了解一下。
DeviceMesh API
The DeviceMesh api
首先,你需要理解设备网格的概念。设备网格就是一个设备阵列。例如,考虑以下包含八个 GPU 的场景:
1 | gpu:0 | gpu:4 |
其核心思想是将设备分成若干组,并按轴线进行组织。通常,一个轴线负责数据并行,另一个轴线负责模型并行(如图 18.2 所示,您的设备形成一个网格,其中水平轴处理数据并行,垂直轴处理模型并行)。
设备网格不一定是二维的——它可以是任何你想要的形状。但实际上,你只会看到一维和二维网格。
让我们在 Keras 中创建一个 2 × 4 的设备网格:
1 | device_mesh = keras.distribution.DeviceMesh( |
请注意,您也可以明确指定要使用的设备:
1 | devices = [f"gpu:{i}" for i in range(8)] |
正如您可能从论证中猜到的那样axis_names,我们打算使用沿轴 0 的设备进行数据并行处理,使用沿轴 1 的设备进行模型并行处理。由于沿轴 0 有两个设备,沿轴 1 有四个设备,我们将把模型的计算任务分配到四个 GPU 上,并创建两个模型副本,分别并行运行这两个副本,每个副本处理不同的数据子批次。
现在我们已经有了网格模型,接下来需要告诉 Keras 如何将不同的计算任务分配到各个设备上。为此,我们将使用LayoutMapAPI。
布局地图 API
The LayoutMap api
为了指定不同计算步骤的执行位置,我们使用变量 作为参照系。我们会将变量拆分或复制到不同的设备上,并让编译器将与该变量相应部分关联的所有计算任务转移到对应的设备上。
考虑一个变量。假设它的形状是(32, 64)。你可以对这个变量做两件事:
- 您可以沿着网格的某个轴复制它,以便该轴上的每个设备都能看到相同的值。
- 您可以沿着网格的轴线将其分割
(32, 16)(拆分)——例如,您可以将其分割成四个形状的块——这样,沿该轴线的每个设备都可以看到一个不同的块。 - You could replicate it (copy it) across an axis of your mesh so each device along that axis sees the same value.
- You could shard it (split it) across an axis of your mesh — for instance, you could shard it into four chunks of shape
(32, 16)— so that each device along that axis sees one different chunk.
请注意,我们的变量有两个维度。重要的是,您可以针对变量的每个维度分别独立地做出“分片”或“复制”决策。
您将使用 API 来告知 Keras 此类决策,该 API 是 LayoutMapA 类。A``LayoutMap类似于字典。它将模型变量(例如,模型中第一个密集层的内核变量)映射到有关如何在设备网格上复制或分片该变量的信息。具体来说,它将变量路径映射 到一个元组,该元组的条目数与变量的维度数相同,其中每个条目指定如何处理该变量维度。它的结构如下:
1 | { |
这是你第一次接触变量路径的概念——它其实就是一个字符串标识符,格式类似于 <variable_path> "sequential/dense_1/kernel"。这是一种无需持有实际变量实例的句柄即可引用变量的有效方法。
以下是如何打印模型中所有变量路径的方法:
1 | for v in model.variables: |
以清单 18.4 中的示例模型为例,我们得到以下结果:
1 | sequential/dense/kernel |
现在让我们对这些变量进行分片和复制。对于像这样的简单模型,变量分片的常用经验法则如下:
- 将变量的最后一个维度沿
"model"网格轴分割。 - 其他维度保持不变。
很简单,对吧?就像这样:
1 | layout_map = keras.distribution.LayoutMap(device_mesh) |
最后,我们通过设置分布配置来告诉 Keras 在实例化变量时引用此分片布局,如下所示:
1 | model_parallel = keras.distribution.ModelParallel( |
分布式配置设置完成后,您就可以创建模型并fit()运行它了。代码的其他部分无需更改——模型定义代码和训练代码都保持不变。无论您是使用内置 API 还是fit()自evaluate()定义训练逻辑,情况都是如此。假设您拥有变量的权限LayoutMap,那么您刚才看到的这些代码片段足以分布式计算,用于任何大型语言模型的训练运行——它可以扩展到您拥有的所有设备,并且支持任意大小的模型。
要检查变量的分片方式,您可以variable.value.sharding像这样检查该属性:
1 | >>> model.layers[0].kernel.value.sharding |
您甚至可以通过 JAX 工具将其可视化jax.debug.visualize_sharding:
1 | import jax |
tf.data 性能提升技巧
tf.data performance tips
tf.data.Dataset进行分布式训练时,为了保证最佳性能,请始终以对象的形式提供数据(以 NumPy 数组的形式传递数据也可以,因为 map 会将其转换为Dataset对象fit())。此外,您还应该确保使用数据预取:在将数据集传递给 map 之前fit(),调用 map.prefetch dataset.prefetch(buffer_size)。如果您不确定应该选择多大的缓冲区大小,可以尝试使用 --buffer-size``dataset.prefetch(tf.data.AUTOTUNE)选项,该选项会自动为您选择一个缓冲区大小。
TPU训练
TPU training
除了GPU之外,深度学习领域普遍存在一种趋势,即把工作流程迁移到专为深度学习工作流程设计的专用硬件上;这种单用途芯片被称为ASIC(专用集成电路)。许多大大小小的公司都在研发新型芯片,但目前这方面最引人注目的是谷歌的张量处理单元( Tensor Processing Unit )(TPU),它可在谷歌云和谷歌Colab上使用。
在 TPU 上进行训练确实需要一些额外的步骤,但这些额外的工作是值得的:TPU 的速度真的非常快。在 TPU v2(可在 Colab 上获取)上进行训练通常比在 NVIDIA P100 GPU 上训练快 15 倍。对于大多数模型而言,TPU 训练的平均成本效益比 GPU 训练低 3 倍。
实际上,您可以在 Colab 中免费使用 TPU v2。在 Colab 菜单的“运行时”选项卡下,找到“更改运行时类型”选项,您会发现除了 GPU 运行时之外,还可以访问 TPU 运行时。对于更复杂的训练任务,Google Cloud 还提供速度更快的 TPU v3 到 v5。
在支持 TPU 的笔记本上运行使用 JAX 后端的 Keras 代码时,只需调用 keras.distribution.set_distribution(distribution)tpu.env 并传入一个DataParallelTPUModelParallel分发实例即可开始使用 TPU 核心。请务必在创建模型之前调用此方法!
由于 TPU 可以极快地处理批量数据,因此从 Google Cloud Storage (GCS) 读取数据的速度很容易成为瓶颈。如果您的数据集足够小,则应将其保存在虚拟机内存中。您可以通过调用实例来实现这一点dataset.cache()。tf.data.Dataset这样,数据只需从 GCS 读取一次。
采用步进融合提高TPU利用率
Using step fusing to improve tpu utilization
由于 TPU 拥有强大的计算能力,你需要使用非常大的批次进行训练,才能让 TPU 核心保持满负荷运转。对于小型模型,所需的批次大小可能非常大——每个批次超过 10,000 个样本。使用超大批次时,你应该相应地提高优化器的学习率:虽然权重更新的次数会减少,但每次更新的精度会更高(因为梯度是基于更多的数据点计算的);因此,每次更新时,权重的调整幅度应该更大。
不过,有一个简单的技巧可以帮助你在保持 TPU 充分利用的同时,控制训练批次的大小:步进融合(step fusing)。其思路是在每个 TPU 执行步骤中运行多个训练步骤。简单来说,就是在虚拟机内存和 TPU 之间进行两次往返操作,从而完成更多的工作。要实现这一点,只需steps_per_execution在 tpu.tpu.stepfusing 函数中指定参数即可compile()——例如, steps_per_execution=8在每次 TPU 执行期间运行八个训练步骤。对于 TPU 利用率不足的小型模型,这可以显著提升速度:
个人注:步进融合的主要思想。
在深度学习的大规模训练中,步进融合(Step Fusing) 是一种专门针对 TPU(张量处理单元)等高速硬件的优化技术。它的核心思想可以用一句话概括:“合多次小步为一次大步,减少 CPU 与 TPU 之间的打招呼次数。”
为了理解它,我们需要先看看 TPU 的一个“脾气”:启动开销(Launch Overhead)。
- 核心矛盾:计算太快,指挥太慢
TPU 的计算速度极快,但它需要听从 CPU 的指令。
- 普通模式:每训练一个批次(Batch),CPU 都要发指令给 TPU:“嘿,算一下这 128 个数据。” TPU 算完后反馈,CPU 再发下一条。
- 问题:如果你的 Batch Size 设得很小(比如为了优化模型效果),TPU 可能花 1 毫秒就算完了,但 CPU 发指令和处理反馈可能要花 2 毫秒。
- 结果:TPU 大部分时间都在等指令,利用率极低。
- 步进融合(Step Fusing)是怎么做的?
步进融合不再是“一个批次发一次指令”,而是“一次性发 \(N\) 个批次的指令”。
- 逻辑变化:CPU 告诉 TPU:“这里有 10 组数据,你一口气把这 10 个步骤(Steps)全部跑完,中间不要停,最后再把结果告诉我。”
- 硬件视角:在 TPU 内部,这 \(N\) 个步骤被串联成了一个大的计算图(Graph)。TPU 会在自己的高带宽内存(HBM)中循环处理这些数据。
- 它解决了什么核心权衡?
在没有步进融合之前,你面临一个艰难的选择:
- 选大 Batch Size:TPU 利用率高,但模型收敛可能变差,或者显存溢出。
- 选小 Batch Size:模型收敛好,但 TPU 跑得像蜗牛一样慢。
步进融合的魔力:
它让你在数学上维持小 Batch Size 的更新逻辑(梯度依然按小批次计算和更新),但在硬件执行层面享受到了大任务的高效率。
- 形象类比:去餐厅点菜
- 普通模式:你每吃一口菜,就叫一次服务员:“再给我夹一口肉。” 服务员跑来跑去(CPU 开销),你等得心烦(TPU 空转)。
- 步进融合:你直接跟服务员说:“把这盘肉分成 10 份,每隔 1 分钟给我端上一份,剩下的时间你不用管我。” 你吃得节奏没变(小 Batch),但服务员只需要来一次(单次指令)。
- 什么时候需要它?
如果你发现:
- 你的训练任务在 TPU 上运行,但 TPU 利用率(Utilization) 很低。
- 你的模型逻辑比较简单(单步计算极快),导致 输入流水线(Input Pipeline) 成了瓶颈。
- 你需要保持较小的全域批次大小(Global Batch Size)来稳定训练。
1 | model.compile(..., steps_per_execution=8) |
利用低精度计算加速训练和推理
Speeding up training and inference with lower-precision computation
如果我告诉你有一种简单的技巧,可以让你几乎免费地将任何模型的训练和推理速度提高两倍,你会相信吗?这听起来好得难以置信,但这种技巧确实存在。要理解它的原理,首先我们需要了解计算机科学中的“精度”概念。
了解浮点精度
Understanding floating-point precision
精度之于数字,正如分辨率之于图像。由于计算机只能处理 1 和 0,因此计算机看到的任何数字都必须编码为二进制字符串。例如,你可能熟悉uint8整数,整数是用 8 位编码的:100000000表示255,255表示 255。要表示大于 255 的整数,你需要增加位数——8 位不够用。大多数整数都存储在 32 位上,用 32 位可以表示从 -2147483648 到 2147483647 的有符号整数。0``uint8``11111111
浮点数也是如此。在数学中,实数构成一个连续的轴:任意两个实数之间都有无穷多个点。你可以随时放大实数轴。但在计算机科学中,情况并非如此:例如,3 和 4 之间只有有限个中间点。具体有多少个呢?这取决于你使用的精度:也就是你用来存储数字的位数。你只能放大到一定的分辨率。
通常情况下,你会用到三个精度级别:
- 半精度,或
float16称16位精度,其中数字存储在16位上。 - 单精度浮点数,或
float32称32位精度浮点数,其中数字存储在32位上。 - 双精度浮点数,或
float64称 64 位浮点数,其中数字存储在 64 位上。 - Half precision, or
float16, where numbers are stored on 16 bits - Single precision, or
float32, where numbers are stored on 32 bits - Double precision, or
float64, where numbers are stored on 64 bits
你甚至可以达到更高的水平float8,稍后你就会看到了。
关于浮点编码
On floating-point encoding
关于浮点数的一个反直觉的事实是,可表示的数字并非均匀分布。较大的数字精度较低:对于任何N2 ** N ,介于 1 和 2 之间的可表示值的数量与介于 1 和 2 之间的可表示值的数量相同。2 ** (N + 1)
A counterintuitive fact about floating-point numbers is that representable numbers are not uniformly distributed. Larger numbers have lower precision: there’s the same number of representable values between 2 ** N and 2 ** (N + 1) as there is between 1 and 2, for any N.
That’s because floating-point numbers are encoded in three parts — the sign, the significant value (called the mantissa), and the exponent in the form
1 | {sign} * (2 ** ({exponent} - 127)) * 1.{mantissa} |
For example, figure 18.3 demonstrates how you would encode the closest float32 value approximating Pi:
这是因为浮点数由三部分编码而成——符号、有效值(称为尾数)和指数,形式为:
1 | {sign} * (2 ** ({exponent} - 127)) * 1.{mantissa} |
例如,图 18.3 展示了如何对最接近float32π 的值进行编码:
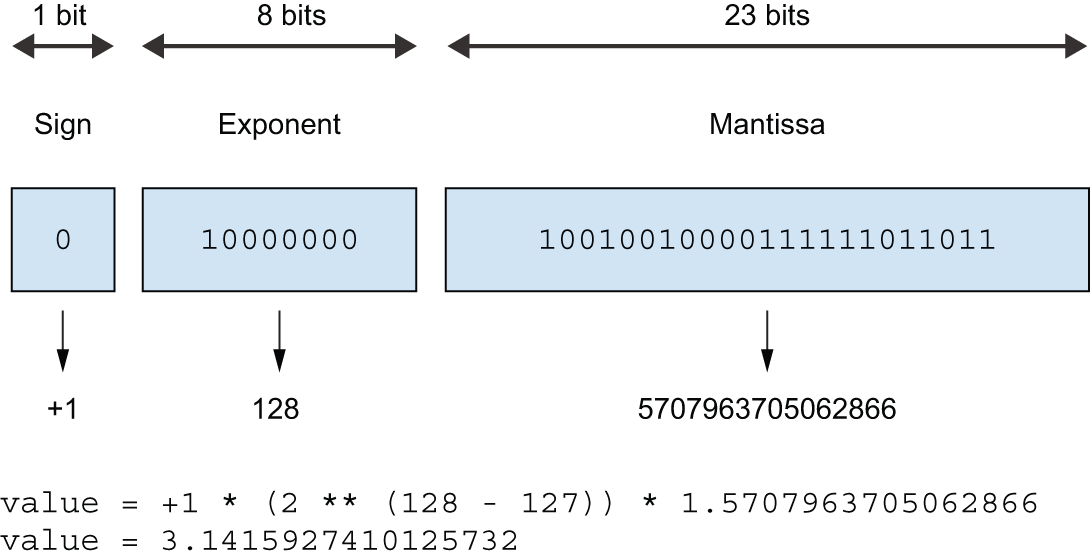 图 18.3:π 的单精度编码,由符号位、整数指数和整数尾数组成。
图 18.3:π 的单精度编码,由符号位、整数指数和整数尾数组成。
因此,将数字转换为浮点表示时产生的数值误差会因所考虑的具体值而异,并且对于绝对值较大的数字,误差往往会更大。
理解浮点数分辨率的方法是,看它能安全处理的两个任意数字之间的最小距离。单精度浮点数的最小距离约为 1e-7,双精度浮点数约为 1e-16,而半精度浮点数的最小距离仅为 1e-3。
Float16 推断
Float16 inference
到目前为止,本书中你看到的每一个模型都使用了单精度数:它将状态存储为float32权重变量,并对输入进行计算float32。这种精度足以运行模型的前向和后向传播而不会丢失任何信息——尤其是在进行小梯度更新时(回想一下,典型的学习率为 1e-3,而权重更新在 1e-6 量级是很常见的)。
现代 GPU 和 TPU 配备了专用硬件,可以比执行等效的 32 位运算更快地运行 16 位运算,并且占用更少的内存。尽可能使用这些低精度运算,可以显著提高在这些设备上的训练速度。您可以float16 通过以下方式在 Keras 中设置默认浮点精度:
1 | import keras |
请注意,此操作应在定义模型之前完成。这样做可以显著提升模型推理速度,例如,通过…… model.predict()。在 GPU 和 TPU 上,速度提升应接近 2 倍。
还有一种替代方案float16在某些设备上(尤其是 TPU)表现更佳:* bfloat16。* bfloat16也是一种 16 位精度的浮点类型,但float16其结构与 * 不同:它使用 8 位指数而不是 5 位,以及 7 位尾数而不是 10 位(参见表 18.1)。这意味着它可以覆盖更宽的值域,但在此范围内的“分辨率”较低。某些设备针对 * 进行了更好的优化bfloat16,float16因此最好在最终选择速度最快的方案之前,同时尝试这两种类型。
| 数据类型 | float16 |
bfloat16 |
|---|---|---|
| 指数位 | 5 | 8 |
| 尾数位 | 10 | 7 |
| 信号比特 | 1 | 1 |
表 18.1:float16两者之间的差异bfloat16
混合精度训练
Mixed-precision training
将默认浮点精度设置为 16 位是加快推理速度的有效方法。然而,在训练过程中,情况就变得复杂了。梯度下降过程在float16或 中无法顺利运行bfloa16,因为我们无法表示像 1e-5 或 1e-6 这样非常常见的微小梯度更新。
不过,您也可以采用混合方法:这就是混合精度训练的核心。其理念是在精度要求不高的地方使用 16 位计算,而在其他地方使用 32 位值以保持数值稳定性——尤其是在处理梯度和变量更新时。通过保持模型中对精度敏感的部分使用全精度,您可以在不显著影响模型质量的前提下,获得 16 位计算的大部分速度优势。
你可以像这样启用混合精度:
1 | import keras |
通常情况下,模型的大部分前向传播过程会在 std::vector 中完成float16 (除了像 softmax 这样数值不稳定的操作),而模型的权重则会存储在 std::vector 中并进行更新float32。在更新变量之前,float16梯度会被转换为std::vector 类型。float32``float32
Keras 层具有 int``variable_dtype和 int``compute_dtype属性。默认情况下,这两个属性都设置为 int float32。启用混合精度后, compute_dtype大多数层的 int 属性会切换到 int float16。因此,这些层会将它们的输入转换为 int float16,并在 int 中执行计算float16 (使用权重的半精度副本)。但是,由于它们的 int 属性variable_dtype 仍然是 int float32,因此它们的权重能够float32从优化器接收精确更新,而不是半精度更新。
某些运算(特别是 softmax 和交叉熵运算)在数值上可能不稳定float16。如果您需要为特定层禁用混合精度,只需将参数传递dtype="float32"给该层的构造函数即可。
使用混合精度损失缩放
Using loss scaling with mixed precision
在训练过程中,梯度可能会变得非常小。使用混合精度时,梯度值会保持不变float16(与前向传播相同)。因此,可表示数值范围有限会导致较小的梯度值被向下舍入为零。这会阻碍模型有效地学习。
梯度值与损失值成正比,因此,为了使梯度值更大,一个简单的技巧是将损失值乘以一个较大的标量因子。这样,梯度值被舍入为零的可能性就会大大降低。
Keras 让这一切变得简单。如果您想使用固定的损失缩放因子,只需loss_scale_factor像这样向优化器传递一个参数即可:
1 | optimizer = keras.optimizers.Adam(learning_rate=1e-3, loss_scale_factor=10) |
如果您希望优化器自动计算出合适的缩放因子,您也可以使用以下LossScaleOptimizer包装器:
1 | optimizer = keras.optimizers.LossScaleOptimizer( |
使用LossScaleOptimizer通常是最佳选择:正确的缩放值可以在训练过程中发生变化!
超越混合精度:float8 训练
Beyond mixed precision: float8 training
如果以 16 位精度运行前向传播能带来如此显著的性能提升,你可能会问:我们能否进一步降低精度?8 位精度呢?4 位呢?2 位呢?答案是,这很复杂。
在前向传播中使用混合精度训练float16是最后一个“即插即用”的精度级别——float16该精度拥有足够的位数来表示所有中间张量(梯度更新除外,这也是我们使用float32更高精度的原因)。如果精度降低到更低,情况就不同了float8:你会丢失太多信息。虽然float8在某些计算中仍然可以使用,但这需要对前向传播进行大量修改。你不能简单地将精度设置compute_dtype为 1float8就运行。
Keras 框架提供了一个内置的float8训练实现。由于它专门针对 Transformer 的使用场景,因此仅涵盖了有限的几层:Dense``T、T(该层使用EinsumDense的版本)和T 层。它的工作原理并不简单——它会跟踪过去的激活值,以便在每一步重新调整激活值,从而利用 T 中可表示的全部值范围。它还需要重写反向传播的一部分,以便对梯度值执行相同的操作。Dense``MultiHeadAttention``Embedding``float8
重要的是,这种额外的开销会带来计算成本。如果你的模型太小,或者你的GPU性能不够强,那么这种成本就会超过在np.mt中执行某些操作所带来的收益float8,你会看到速度下降而不是加快。np.mt``float8训练仅适用于非常大的模型(通常超过50亿个参数)以及NVIDIA H100等大型、最新的GPU。float8除了基础模型训练之外,np.mt在实践中很少使用。
量化加速推理
Faster inference with quantization
在模型内部运行推理float16(甚至直接运行float8)可以显著提升模型速度。但你还可以使用另一种技巧:int8量化。其核心思想是,将已训练好的模型及其权重float32转换为低精度数据类型(通常为int8),同时尽可能保持前向传播的数值准确性。
Running inference in float16—or even float8—will result in a nice speedup for your models. But there’s also another trick you can use: int8 quantization. The big idea is to take an already trained model with weights in float32 and convert these weights to a lower-precision dtype (typically int8) while preserving the numerical correctness of the forward pass as much as possible.
如果你想从头开始实现量化,数学原理很简单:基本思路是将所有matmul输入张量乘以一个特定的因子,使其系数落在 的可表示范围内int8,即[-127, 127]总共 256 个可能的值。缩放输入后,将它们转换为int8并以 的精度执行matmul操作int8,这应该比 快得多float16。最后,将输出转换回float32,并除以输入缩放因子的乘积。由于matmul是一个线性运算,最终的反缩放操作会抵消初始缩放,你应该得到与使用原始值相同的输出——任何精度损失都仅来自将输入转换为 时发生的数值舍入int8。
让我们用一个例子来具体说明。假设你想执行以下操作matmul(x, kernel),并使用以下值:
1 | from keras import ops |
如果直接将这些值转换为int8整数而不进行缩放,将会造成很大的破坏——例如,你的值x会变成[[0, 0], [1, 0]]。因此,让我们应用“绝对最大值”缩放方案,该方案将每个张量的值分散到整个范围内[-127, 127]:
1 | def abs_max_quantize(value): |
现在我们可以执行更快的操作matmul,并对输出进行缩放:
1 | int_y = ops.matmul(int_x, int_kernel) |
它的准确度如何?让我们将我们的y结果与以下输出进行比较float32 matmul:
1 | >>> y |
相当准确!对于大型数据集matmul,这样做可以节省大量计算资源,因为int8计算速度可能比计算速度快得多float16,而你只需要在计算图中添加相当快的逐元素操作即可abs—— max,,,,,,。clip``cast``divide``multiply
当然,我并不指望你手动实现量化——那极其不切实际。与此类似float8,int8量化功能直接内置于特定的 Keras 层中:<T> Dense、EinsumDense``<T> 和Embedding<T>。这使得int8任何基于 Transformer 的模型都能进行推理。以下是如何将其与包含这些层的任何 Keras 模型一起使用:
1 | # Instantiates a model (or any quantizable layer) |
个人注:
Int8 量化(Int8 Quantization) 的核心思想是将模型中原本使用 30 位浮点数(FP32)表示的数值,压缩为 8 位整数(Int8)。
这就像是将一把刻度极其精细的长钢尺,映射到一把只有 256 个刻度的短塑料尺上。
- Int8 量化的核心思想:映射与缩放
Int8 量化本质上是一个线性映射过程。其数学公式通常表示为:
\[Real\_Value = Scale \times (Quantized\_Value - Zero\_Point)\]
- Scale(缩放因子):确定 FP32 的范围如何对应到 Int8 的 -128 到 127。
- Zero-Point(零点):确保 FP32 中的“0”在量化后也能精确表示(这对 ReLU 等激活函数至关重要)。
- 模型参数需要改变吗?
是的,参数必须改变。
为了实现 Int8 推理,模型的权重(Weights)必须经历以下变化:
数值转换:原本存储在内存里的
0.123456...这样的浮点数,会被转换成类似42这样的整数。存储空间压缩:参数在磁盘和内存中的占用直接减少为原来的 1/4(从 4 字节降到 1 字节)。
计算算子切换:推理时不再调用昂贵的浮点运算单元(FPU),而是调用极快的整数运算单元(ALU)或专用的向量指令集。
如何理解“精度损失仅来自输入转换时的舍入”?
你提到的这句话(通常出现在特定的硬件优化文档中,如 TPU 或特定的推理引擎介绍)看起来与“改变参数会带来损失”相矛盾,但实际上它是在特定的计算假设下说的。我们可以从以下两个角度来理解:
A. 参数已经“离线”补偿(离线量化)
在模型部署前,我们会进行量化感知训练(QAT)或校准(Calibration)。
- 我们通过复杂的算法,尽可能找到一组 Int8 权重,使其在矩阵运算后的效果与 FP32 几乎一致。
- 理解点:此时我们认为参数的精度损失在“部署前”已经通过优化降到了最低。在实际推理(Inference)瞬间,参数是固定的常数。
B. 动态范围的“瓶颈”在于输入
在很多硬件加速器中,最不稳定的因素是实时输入的信号:
- 输入是连续的:模型参数是死数据,可以反复打磨;但每一个进入模型的输入数据(如一张图片的像素、一段音频的采样)都是实时的。
- 舍入误差(Rounding Error):当你把输入的 FP32 乘以 Scale 变成 Int8 时,必须进行四舍五入。例如
1.6变成2。- 累积效应:如果输入端的舍入误差很大,那么即便后续的整数矩阵运算(GEMM)在数学上是“精确的整数相乘”,最终还原回浮点数的结果也会偏离真实值。
更严谨的解释: > 很多高性能推理框架会使用 Int32 来存储中间累加结果。这意味着,在矩阵相乘的中间步骤里,并没有精度损失。真正的损失发生在两头:
- 开头:将输入(Input)舍入为 Int8。
- 结尾:将计算结果重新缩放(Re-scale)回下一层所需的范围。
所以,那句话的意思是:只要参数已经通过校准达到了最优,那么推理过程中最大的不确定性就来自于将“瞬息万变”的输入信号强行塞进 8 位刻度时产生的舍入偏差。
要把原本“精细”的浮点数权重 \(W_{fp32}\) 变成“粗糙”的 \(Int8\) 整数 \(W_{int8}\),且保证误差最小,这本质上是一个寻找最优映射范围的过程。
这个过程主要通过以下三个关键步骤实现:
- 寻找“统计分布”的边界(关键的第一步)
权重并不是均匀分布在所有数值上的。如果你画出模型权重的直方图,通常会发现它们呈现一个以 0 为中心的正态分布(长尾分布)。
- 问题:如果权重里有一个极大的离群值(比如 \(100.0\)),而 99% 的权重都在 \([-1, 1]\) 之间,如果你直接按 \(100\) 来缩放,那么 \([-1, 1]\) 之间的微小差异在 \(Int8\) 里就会全部变成同一个整数(比如都变成了 \(0\))。
- 解决方法:校准过程会使用成千上万个样本来观察权重的分布。它不会死板地取“最大值”,而是使用 KL 散度(Kullback-Leibler Divergence) 等数学工具。
- 它会尝试不同的截断点(Clipping Threshold)。
- 计算“截断后的 \(Int8\) 分布”与“原始 \(FP32\) 分布”之间的信息损失。
- 找到那个让两个分布最接近的最佳截断范围。
- 计算缩放因子(Scale)
一旦选定了最佳范围(假设是 \([ -max_{clip}, +max_{clip} ]\)),计算 \(Scale\) 就变成了简单的除法:
\[Scale = \frac{max_{clip}}{127}\]
有了这个 \(Scale\),原本的浮点数权重就可以通过以下公式变成整数:
\[W_{int8} = \text{round} \left( \frac{W_{fp32}}{Scale} \right)\]
注意:在这个过程中,我们已经把最适合这个模型特征的“刻度”找出来了。
- “离线”优化的优势
为什么说这有“充足的时间”?
- 不计成本:在部署到手机或嵌入式设备之前,我们可以在强大的服务器上跑好几个小时的校准算法。
- 误差补偿:有些高级技术(如 AdaRound)甚至会微调 \(Int8\) 的取值。比如一个数是 \(1.5\),通常四舍五入是 \(2\),但如果把它变成 \(1\) 能让这一层的整体输出误差更小,算法就会强制让它变成 \(1\)。
- 结果固定:一旦这套 \(W_{int8}\) 和 \(Scale\) 算好了,它们就被硬编码进模型文件中。推理时,硬件直接读取这些整数常数,不再需要任何复杂的寻找过程。
核心总结
模型部署前的“校准”就像是给模型量体裁衣:
- 先看模型权重的“身材”分布(统计分析)。
- 确定最合适的尺码范围(确定截断点)。
- 把浮点数按比例“刻”进 \(Int8\) 的格子里(生成固定常量)。
所以,当你最终运行模型时,权重已经是经过“千锤百炼”筛选出的、最能代表原始逻辑的整数了。
概括
- 您可以使用超参数调优和 KerasTuner 来自动完成寻找最佳模型配置的繁琐工作。但请注意验证集过拟合!
- 多种模型的集成通常可以显著提高预测质量。
- 为了进一步扩展工作流程,您可以使用数据并行性在多个设备上训练模型,只要模型足够小,可以安装在单个设备上即可。
- 对于较大的模型,您还可以使用模型并行性将模型的变量和计算拆分到多个设备上。
- 开启混合精度可以加快 GPU 或 TPU 上的模型训练速度——通常情况下,速度会大幅提升,而且几乎没有任何成本。
float16你还可以通过使用精度甚至量化来加快推理速度int8。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论