《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
第十章 解读卷积神经网络的学习成果
Interpreting what ConvNets learn
运行代码
本章内容
- 解释卷积神经网络如何分解输入图像
- 可视化卷积神经网络学习到的滤波器
- 可视化图像中负责特定分类决策的区域
- Interpreting how ConvNets decompose an input image
- Visualizing the filters learned by ConvNets
- Visualizing areas in an image responsible for a certain classification decision
构建计算机视觉应用时,一个根本性问题是可解释性:为什么分类器会认为某张图像中包含冰箱,而你看到的明明是一辆卡车?这在深度学习用于辅助人类专业知识的应用场景中尤为重要,例如医学影像应用。本章将介绍一系列不同的可视化卷积神经网络学习内容和理解其决策的技术。
人们常说深度学习模型是“黑箱”:它们学习到的表征难以提取并以人类可读的形式呈现。虽然这种说法对某些类型的深度学习模型部分正确,但对卷积神经网络(ConvNets)而言则完全不成立。卷积神经网络学习到的表征非常易于可视化,这很大程度上是因为它们是 对视觉概念的表征(representations of visual concepts)。自 2013 年以来,人们开发了多种可视化和解释这些表征的技术。我们不会一一介绍,但会重点介绍其中三种最易于理解和使用的方法:
- 可视化卷积神经网络的中间输出(中间激活值) ——有助于理解连续的卷积神经网络层如何转换其输入,并初步了解各个卷积神经网络滤波器的含义。
- 可视化卷积神经网络的滤波器——有助于精确理解卷积神经网络中每个滤波器所响应的视觉模式或概念。
- 可视化图像中类别激活的热图——有助于了解图像中哪些部分被识别为属于特定类别,从而帮助您定位图像中的对象。
- Visualizing intermediate ConvNet outputs (intermediate activations) — Useful for understanding how successive ConvNet layers transform their input, and for getting a first idea of the meaning of individual ConvNet filters
- Visualizing ConvNets filters — Useful for understanding precisely what visual pattern or concept each filter in a ConvNet is receptive to
- Visualizing heatmaps of class activation in an image — Useful for understanding which parts of an image were identified as belonging to a given class, thus allowing you to localize objects in images
对于第一种方法——激活可视化——你将使用你在第 8 章中从头开始训练的用于解决猫狗分类问题的小型卷积神经网络。对于接下来的两种方法,你将使用预训练的 Xception 模型。
可视化中间激活
Visualizing intermediate activations
可视化中间激活值是指在给定特定输入的情况下,显示模型中各个卷积层和池化层返回的值(层的输出通常称为其激活值,即激活函数的输出)。这可以让我们了解输入是如何分解成网络学习到的不同滤波器的。我们希望可视化具有三个维度的特征图:宽度、高度和深度(通道数)。每个通道编码相对独立的特征,因此可视化这些特征图的正确方法是将每个通道的内容分别绘制成二维图像。让我们首先加载您在 8.2 节中保存的模型:
1 | >>> import keras |
接下来,你会得到一张输入图像——一张猫的图片,但这并非网络训练所用图像的一部分。
1 | import keras |
清单 10.1:单幅图像的预处理
让我们展示一下图片(见图 10.1)。
1 | import matplotlib.pyplot as plt |
清单 10.2:显示测试图片
 图 10.1:测试猫的图片
图 10.1:测试猫的图片
要提取你想要查看的特征图,你需要创建一个 Keras 模型,该模型以图像批次作为输入,并输出所有卷积层和池化层的激活值。
1 | from keras import layers |
清单 10.3:实例化一个返回层激活值的模型
当输入图像时,该模型会返回原始模型中各层激活值,以列表形式呈现。这是自第 7 章学习多输出模型以来,本书中你第一次实际接触到多输出模型:此前你所看到的模型都只有一个输入和一个输出。而这个模型有一个输入和九个输出——每个层激活值对应一个输出。
1 | # Returns a list of nine NumPy arrays — one array per layer activation |
清单 10.4:使用该模型计算层激活值
例如,这是猫图像输入的第一个卷积层的激活值:
1 | >>> first_layer_activation = activations[0] |
这是一个 178 × 178 的特征图,有 32 个通道。让我们尝试绘制原始模型第一层激活的第六个通道(见图 10.2)。
1 | import matplotlib.pyplot as plt |
列表 10.5:可视化第六通道
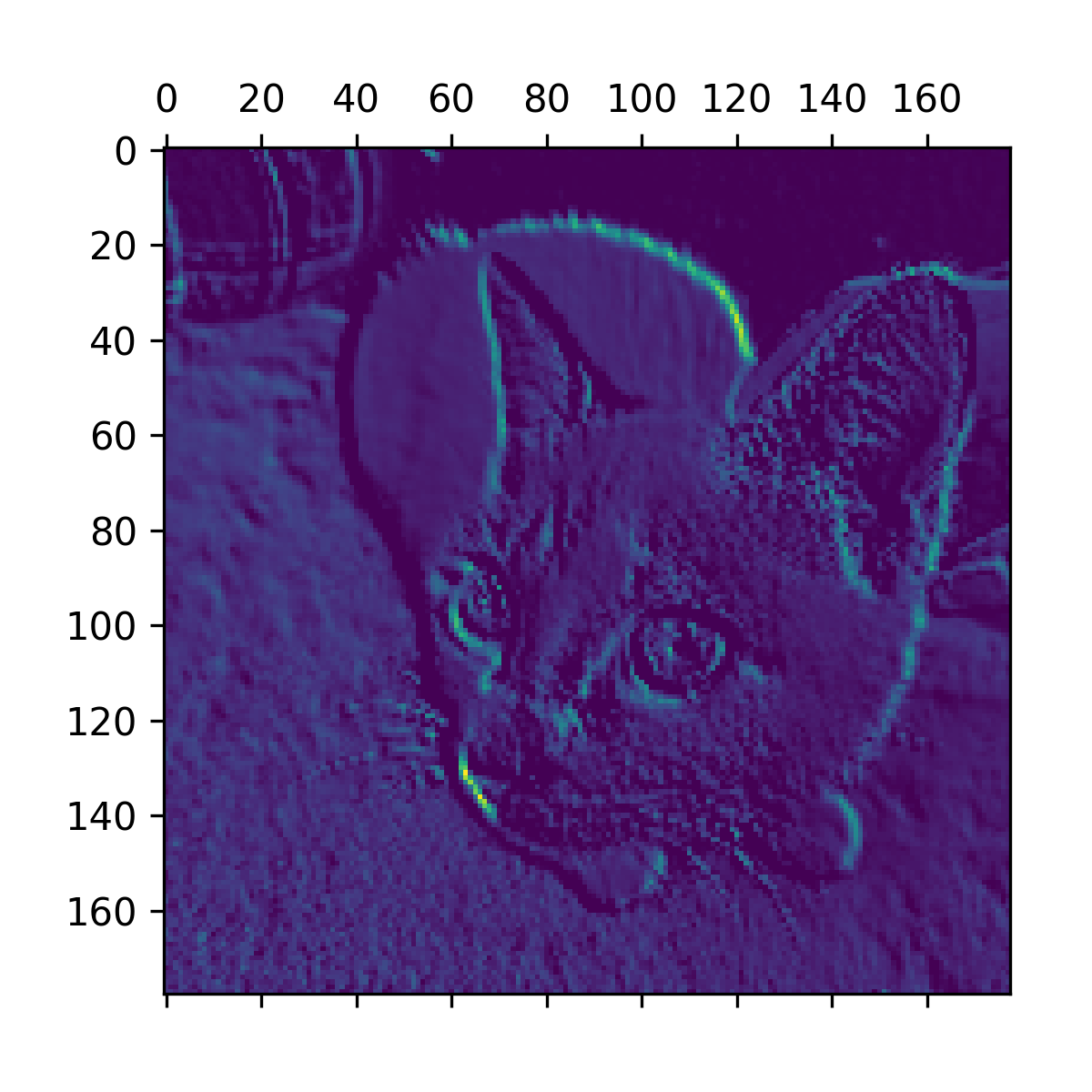 图 10.2:测试猫图片上第一层激活的第六个通道
图 10.2:测试猫图片上第一层激活的第六个通道
该通道似乎编码了一个对角边缘检测器,但请注意,您自己的通道可能会有所不同,因为卷积层学习到的具体滤波器是不确定的。
现在让我们绘制网络中所有激活的完整可视化图(见图 10.3)。我们将提取并绘制每一层激活中的每个通道,并将结果堆叠在一个大网格中,通道并排堆叠。
1 | images_per_row = 16 |
列表 10.6:可视化每个中间激活中的每个通道
 图 10.3:测试猫图片上每一层的每个通道的激活情况
图 10.3:测试猫图片上每一层的每个通道的激活情况
这里有几点需要注意:
- 第一层充当各种边缘检测器的集合。在这个阶段,激活值几乎保留了初始图像中的所有信息。
- 随着层级的提升,激活模式变得越来越抽象,视觉可解释性也越来越低。它们开始编码更高层次的概念,例如“猫耳朵”和“猫眼睛”。更高层次的表征包含的关于图像视觉内容的信息越来越少,而关于图像类别的信息越来越多。
- 随着层数的增加,激活值的稀疏性也随之增加:在第一层,所有滤波器都会被输入图像激活;但在后续层中,越来越多的滤波器处于空白状态。这意味着滤波器编码的模式在输入图像中并不存在。
我们刚刚观察到深度神经网络学习到的表征的一个重要普遍特征:随着层数的增加,每一层提取的特征都变得越来越抽象。更高层的激活值包含的关于特定输入的信息越来越少,而关于目标(在本例中是图像的类别:猫或狗)的信息越来越多。深度神经网络实际上充当着信息提炼管道(information distillation pipeline)的角色,原始数据(在本例中是RGB图像)输入后,会经过反复转换,从而过滤掉无关信息(例如图像的具体视觉外观),并放大和提炼有用的信息(例如图像的类别)。
这与人类和动物感知世界的方式类似:观察一个场景几秒钟后,人类可以记住场景中存在哪些抽象物体(例如自行车、树),但却记不住这些物体的具体外观。事实上,如果你试图凭记忆画出一辆普通的自行车,你很可能根本画不出来,即使你一生中见过成千上万辆自行车(例如,参见图 10.4)。现在就试试:这种现象绝对真实存在。你的大脑已经学会了完全抽象化视觉输入——将其转化为高级视觉概念,同时过滤掉无关的视觉细节——这使得我们很难记住周围事物的本来面目。
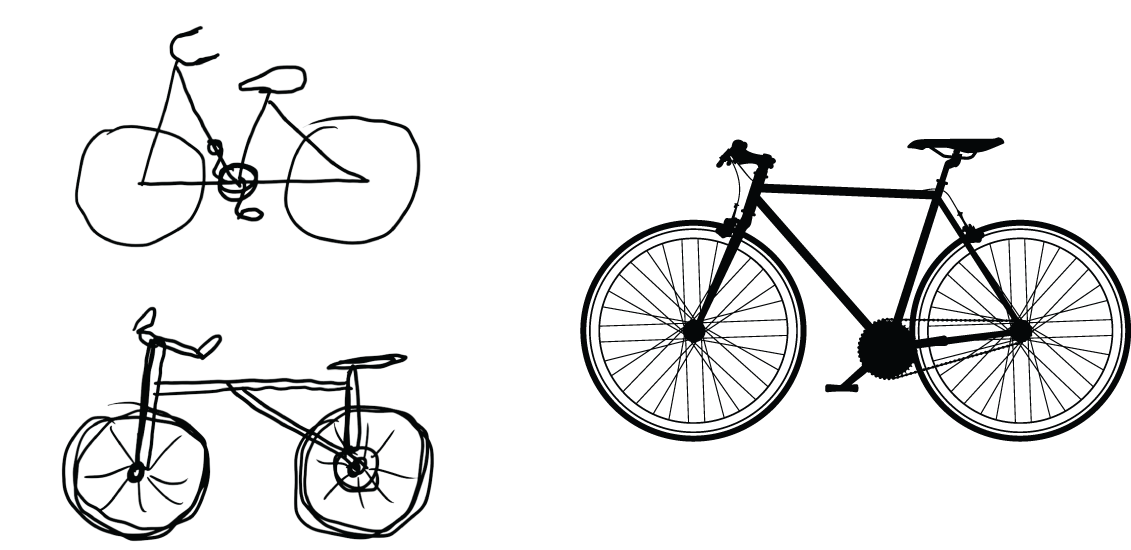 图 10.4:左图:尝试凭记忆画一辆自行车。右图:自行车示意图应有的样子。
图 10.4:左图:尝试凭记忆画一辆自行车。右图:自行车示意图应有的样子。
可视化卷积神经网络滤波器
Visualizing ConvNet filters
检查卷积神经网络(ConvNet)学习到的滤波器的另一种简便方法是显示每个滤波器应该响应的视觉模式。这可以通过输入空间中的梯度上升来实现,即对卷积神经网络的输入图像的值应用梯度下降,从而最大化特定滤波器的响应,初始输入图像为空白图像。最终得到的输入图像将是所选滤波器响应最强的图像。
Another easy way to inspect the filters learned by ConvNets is to display the visual pattern that each filter is meant to respond to. This can be done with gradient ascent in input space, applying gradient descent to the value of the input image of a ConvNet so as to maximize the response of a specific filter, starting from a blank input image. The resulting input image will be one that the chosen filter is maximally responsive to.
让我们用 Xception 模型的滤波器来试试。过程很简单:我们构建一个损失函数,最大化给定卷积层中给定滤波器的值,然后使用随机梯度下降法调整输入图像的值,以最大化该激活值。这将是你看到的第二个底层梯度下降循环的例子(第一个在第 2 章)。我们将分别用 TensorFlow、PyTorch 和 Jax 来演示。
首先,我们实例化在 ImageNet 数据集上训练的 Xception 模型。我们可以再次使用 KerasHub 库,就像我们在第 8 章中所做的那样。
1 | import keras_hub |
清单 10.7:实例化 Xception 卷积基
我们对模型的卷积层——也就是 t层Conv2D 和SeparableConv2D``f 层——很感兴趣。我们需要知道它们的名称才能获取它们的输出。让我们按深度顺序打印出它们的名称。
1 | for layer in model.layers: |
清单 10.8:打印 Xception 中所有卷积层的名称
你会注意到,SeparableConv2D这里的层都以类似 <T> block6_sepconv1、block7_sepconv2``<T>、<T> 等的名称命名——Xception 被组织成块,每个块包含几个卷积层。
现在我们来创建第二个模型,它返回特定层的输出——一个“特征提取器”模型。由于我们的模型是函数式 API 模型,因此它是可检查的:您可以查询其中output某一层的输出,并在新模型中重用它。无需复制整个 Xception 代码。
1 | # You could replace this with the name of any layer in the Xception |
清单 10.9:返回特定输出的特征提取器模型
要使用此模型,我们可以简单地将其应用于一些输入数据,但我们应该小心地应用我们模型特定的图像预处理,以便我们的图像缩放到与 Xception 预训练数据相同的范围。
1 | activation = feature_extractor(preprocessor(img_tensor)) |
清单 10.10:使用特征提取器
让我们使用特征提取模型来定义一个函数,该函数返回一个标量值,用于量化给定输入图像在层中“激活”给定滤波器的程度。这就是我们将在梯度上升过程中最大化的损失函数:
1 | from keras import ops |
model.predict(x)两者之间的区别model(x)
上一章我们使用了predict(x)特征提取。而这里,我们却使用了model(x)。这是为什么呢?
两者(其中y = model.predict(x)是输入数据数组)都表示“对 运行模型并检索输出”。然而,它们并不完全相同。y = model(x)``x``x``y
predict()它分批遍历数据(实际上,您可以通过指定批处理大小predict(x, batch_size=64)),并提取输出的 NumPy 值。其原理与以下代码等效:
1 | def predict(x): |
这意味着predict()调用可以扩展到非常大的数组。而 map model(x)操作在内存中进行,无法扩展。另一方面,map``predict()是不可微的:TensorFlow、PyTorch 和 JAX 都无法对其进行反向传播。
model(x)当你需要获取模型调用的梯度时,应该使用 get_gradient()。而predict()如果你只需要输出值,则应该使用 get_gradient()。换句话说,predict()除非你正在编写底层梯度下降循环(就像我们现在这样),否则应该始终使用 get_gradient()。
一个不太明显的技巧是,为了使梯度上升过程更加平稳,可以将梯度张量除以其 L2 范数(张量中各值平方和的平方根)进行归一化。这可以确保对输入图像所做的更新幅度始终在同一范围内。
我们来设置梯度上升步骤函数。任何涉及梯度的操作都需要调用后端 API,例如GradientTapeTensorFlow、 .backward()PyTorch 和jax.grad()JAX。让我们把这三个后端的代码片段整理出来,首先是 TensorFlow。
个人注:
可视化卷积神经网络(CNN)滤波器的过程,本质上是一个寻找能最大化刺激特定神经元的图像模式的过程。
我们可以把这个过程想象成:“如果你想让一个滤波器(比如专门识别‘狗耳朵’的滤波器)‘最兴奋’,什么样的图片才能做到?”
这个过程并非直观地把滤波器的权重转化为图片,而是采用了一种逆向生成的数学方法。以下是详细的步骤和原理:
- 核心原理:激活最大化 (Activation Maximization)
我们不是让网络去预测图片,而是让网络去生成一张图片。
- 目标:给定一个已经训练好的 CNN 模型(如 VGG16)和一个特定的滤波器(例如第 10 层的第 5 个卷积核)。
- 方法:通过梯度下降法(Gradient Descent),不断修改一张初始图像,使得模型在该滤波器上的激活值(Activation Value)逐渐变大,直到达到最大。
- 详细的执行步骤
步骤一:准备初始图像
- 动作:准备一张完全是随机噪声的图片(看起来像雪花屏)。
- 目的:提供一个空白的“画布”让模型去修改。
步骤二:前向传播 (Forward Pass)
- 动作:将这张噪声图片输入到训练好的神经网络中。
- 目的:计算并提取指定层、指定滤波器的激活值。这个激活值代表了模型目前对这张噪声图的“兴奋程度”。
步骤三:计算梯度 (Calculate Gradient)
- 动作:以激活值最大化为目标函数,计算图像中每个像素点相对于目标的梯度(偏导数)。
- 目的:这一步是关键。它告诉我们,如果想让激活值变大,应该如何修改图像中的每一个像素(是让某个位置的像素变亮还是变暗,变红还是变蓝)。
步骤四:更新图像 (Update Image)
- 动作:根据计算出的梯度,利用反向传播(Backpropagation)直接修改图像的像素值。这就像我们在更新模型权重,但这里更新的是图片本身。
- 目的:让图像变得更像能激发该滤波器特征的样子。
步骤五:循环迭代 (Iteration)
- 动作:重复“前向传播 \(\rightarrow\) 计算梯度 \(\rightarrow\) 更新图像”这个过程数十次或数百次。
- 目的:随着迭代次数增加,原本的随机噪声会逐渐演变成清晰、规则、重复的图案。这就是该滤波器所“偏爱”的特征模式。
- 可视化结果意味着什么?
通过这个过程生成的图像,直观地展示了不同层级的滤波器学到了什么:
- 浅层(靠近输入端):生成的图像通常是简单的线段、边缘、圆点或特定颜色的色块。这说明浅层滤波器在关注基础的局部几何特征。
- 中层:生成的图像会呈现出重复的、具有纹理感的图案(如波浪纹、蜂窝状、螺旋纹)。这说明它们开始组合浅层特征,形成复杂的纹理模式。
- 深层(靠近输出端):生成的图像会变得极度抽象但又隐约可见物体的轮廓(如像眼睛的图案、像狗脸的几何拼贴)。这说明深层滤波器学到了具有语义信息的物体部分或特定组合。
总结
可视化滤波器不是静态地看权重的数值,而是通过数学手段“逆向合成”出能最大化激活该滤波器的理想图像。它是我们窥探深度网络“黑盒”内部是如何进行逐层特征抽象的关键途径。
整张热力图里的所有像素值加起来求平均,得到一个孤立的数值。
目的:我们将这个“平均得分”定义为
loss(损失值)。
- 如果平均分高,说明整张图非常契合这个滤波器的特征。
- 如果平均分低,说明图片完全没对上滤波器的路子。
TensorFlow 中的梯度上升
对于 TensorFlow,我们可以直接打开一个GradientTape作用域,并在其中计算损失来获取所需的梯度。我们将使用@tf.function 装饰器来加速计算:
1 | import tensorflow as tf |
示例 10.11:基于随机梯度上升的损失最大化:TensorFlow
PyTorch 中的梯度上升
对于 PyTorch,我们使用loss.backward()和image.grad来获得损失函数相对于输入图像的梯度,如下所示。
1 | import torch |
示例 10.12:基于随机梯度上升的损失最大化:PyTorch
由于图像张量在每次迭代中都会重新创建,因此无需重置梯度。
JAX 中的梯度上升
对于 JAX,我们用它jax.grad()来获取一个函数,该函数返回损失函数相对于输入图像的梯度。
1 | import jax |
列表 10.13:基于随机梯度上升的损失最大化:JAX
过滤器可视化循环
现在你已经掌握了所有要素。让我们将它们组合成一个 Python 函数,该函数以滤波器索引作为输入,并返回一个张量,该张量表示使目标层中指定滤波器的激活值最大化的模式。
1 | img_width = 200 |
清单 10.14:生成筛选可视化的函数
生成的图像张量是一个形状为 的浮点数组(200, 200, 3),其中 内的值可能不是整数[0, 255]。因此,您需要对该张量进行后处理,将其转换为可显示的图像。您可以使用以下简单的实用函数来完成此操作。
1 | def deprocess_image(image): |
清单 10.15:将张量转换为有效图像的实用函数
我们来试一试(见图 10.5):
1 | plt.axis("off") |
 图 10.5:该层中第二个通道
图 10.5:该层中第二个通道block3_sepconv1响应最大的 模式
似乎图层中的第二个过滤器block3_sepconv1对水平线条图案有反应,有点像水或毛皮。
现在有趣的部分来了:您可以开始可视化层中的每个过滤器,甚至可以可视化模型中每一层中的每个过滤器(参见图 10.6)。
1 | # Generates and saves visualizations for the first 64 filters in the |
清单 10.16:生成所有滤波器响应模式的网格
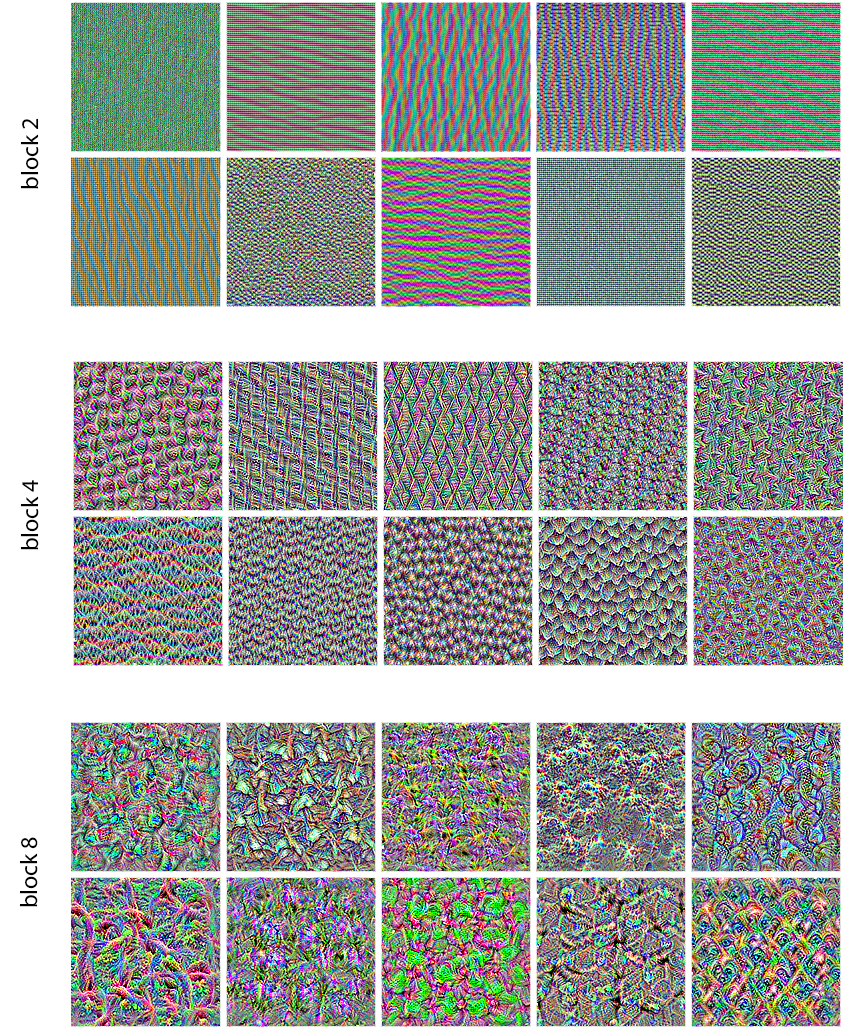 图 10.6:图层 、 和 的一些
图 10.6:图层 、 和 的一些block2_sepconv1滤波器block4_sepconv1模式block8_sepconv1
这些滤波器可视化图可以让你深入了解卷积神经网络(ConvNet)各层如何感知世界:卷积神经网络中的每一层都会学习一组滤波器,使得它们的输入可以表示为这些滤波器的组合。这类似于傅里叶变换将信号分解为一组余弦函数。随着模型层数的增加,这些卷积神经网络滤波器组中的滤波器会变得越来越复杂和精细:
- 模型第一层的滤波器对简单的方向性边缘和颜色(或在某些情况下对彩色边缘)进行编码。
- 堆栈上层一些的滤镜,例如
block4_sepconv1,对由边缘和颜色组合而成的简单纹理进行编码。 - 更高层级的滤镜开始呈现出类似自然图像中的纹理:羽毛、眼睛、树叶等等。
个人注:可视化中间激活(Visualizing intermediate activations) 和可视化卷积神经网络滤波器(Visualizing ConvNet filters)的区别?
在深度学习的调试和理解中,这两者虽然都涉及“看一眼模型内部”,但它们的视角和目的完全不同。
简单来说:“中间激活”看的是数据,“滤波器”看的是知识。
- 可视化中间激活 (Visualizing Intermediate Activations)
核心定义: 展示特定输入(如一张猫的照片)经过某一隐藏层后,输出的特征图(Feature Maps)。
- 看的是什么: 看的是“这张具体的图在这一层变成了什么样?”。
- 输入依赖性: 强依赖。换一张狗的照片,激活图就会完全不同。
- 直观表现:
- 浅层:保留了原图的大部分轮廓、边缘(比如猫的胡须、耳朵轮廓)。
- 深层:图像变得越来越抽象、稀疏。你可能看不出那是猫,但模型在这一层可能只激活了“眼睛”或“耳朵”的抽象特征点。
- 目的: 了解模型是如何层层分解、过滤输入数据的,以及哪些特征对当前预测起到了作用。
- 可视化卷积神经网络滤波器 (Visualizing ConvNet Filters)
核心定义: 展示卷积层里的权重(Weights)本身,通常通过“梯度上升”法生成一张最能让该滤波器兴奋的图像。
- 看的是什么: 看的是“这个神经元(滤波器)到底在找什么?”。
- 输入依赖性: 无。它只与模型的权重有关,反映的是模型通过训练“学到了什么规律”。
- 直观表现:
- 浅层滤波器:通常是简单的线条、颜色块、特定角度的边缘。
- 中层滤波器:开始出现纹理、复杂的几何图案(如圆圈、格子)。
- 深层滤波器:呈现出具体的物体局部(如鸟的羽毛、眼睛、植物的叶脉)。
- 目的: 探索模型内部的“知识库”。它能告诉我们,模型并不是在乱猜,而是真的学会了识别特定模式。
- 形象对比表
特性 可视化中间激活 (Activations) 可视化滤波器 (Filters) 比喻 “X光片”:看特定的病人在扫描仪下是什么样。 “模板/模具”:看工厂里生产零件的模具长什么样。 对象 层的输出(Feature Maps)。 层的权重(Weights/Patterns)。 变化 给它一张猫,它变样;给它一张狗,它又变样。 只要模型训练好了,它就固定在那。 解释力 解释为什么这张图被判定为“猫”。 解释模型具备识别哪些视觉模式的能力。 技术手段 直接提取 model.predict()的中间层输出。梯度上升法(由噪声图演化出能让激活值最大的图)。 总结
- 如果你想知道模型现在在看这张图的哪里,去看激活(Activations)。
- 如果你想知道模型这辈子都学到了哪些视觉概念,去看滤波器(Filters)。
可视化类别激活热图
Visualizing heatmaps of class activation
最后介绍一种可视化技术——它有助于理解给定图像的哪些部分引导卷积神经网络(ConvNet)做出最终分类决策。这对于“调试”卷积神经网络的决策过程非常有帮助,尤其是在出现分类错误的情况下(这属于模型可解释性问题)。它还可以帮助你定位图像中的特定对象。
这类技术被称为类激活图(CAM)可视化,其原理是生成输入图像的类激活热图。类激活热图是一个二维网格,网格上显示了与特定输出类别相关的分数,这些分数针对任何输入图像中的每个位置计算,表明每个位置相对于所考虑类别的重要性。例如,给定一张输入到“狗与猫”卷积神经网络的图像,CAM 可视化可以生成“猫”类别的热图,指示图像中不同部分与猫的相似程度;还可以生成“狗”类别的热图,指示图像中不同部分与狗的相似程度。我们将使用 Selvaraju 等人描述的具体实现。[1]
Grad-CAM算法首先获取卷积层的输出特征图(给定输入图像),然后根据类别相对于该通道的梯度对该特征图中的每个通道进行加权。直观地理解,这种方法是将“输入图像激活不同通道的强度”的空间图与“每个通道对类别的重要性”进行加权,从而得到“输入图像激活该类别的强度”的空间图。
个人注:可视化类别激活热图(Class Activation Map, CAM) 与我们之前讨论的“可视化滤波器”不同。
- 可视化滤波器:是在问“这个神经元喜欢什么样的通用模式?”(比如螺旋纹、眼睛)。
- 可视化热图 (CAM/Grad-CAM):是在问“对于这张特定的图片,模型是因为看到了哪个区域才判断它是‘狗’的?”
它的本质是定位模型在做出分类决策时,注意力(Attention) 集中在图片的哪些像素上。
让我们使用预训练的 Xception 模型来演示这项技术。考虑图 10.7 中所示的两头非洲象(可能是母象和幼象)在稀树草原上漫步的图像。我们可以先下载这张图片,并将其转换为 NumPy 数组,如图 10.7 所示。
 图 10.7:非洲象的测试图片
图 10.7:非洲象的测试图片
1 | # Downloads the image and stores it locally under the path img_path |
清单 10.17:对 Xception 的输入图像进行预处理
目前为止,我们仅使用 KerasHub 实例化了一个基于骨干类的预训练特征提取器网络。对于 Grad-CAM,我们需要完整的 Xception 模型,包括分类头——回想一下,Xception 是在 ImageNet 数据集上训练的,该数据集包含约 100 万张标注图像,分属 1000 个不同的类别。
KerasHub为常见的端到端工作流程(例如图像分类、文本分类、图像生成等)提供了一个高级任务API。一个任务将预处理、特征提取网络和特定于任务的头部封装到一个易于使用的类中。让我们来试用一下:
1 | >>> model = keras_hub.models.ImageClassifier.from_preset( |
该图像预测的前五大类别如下:
- 非洲象(概率为 90%)
- 巨牙鲨(概率为 5%)
- 印度象(概率为 2%)
- 三角龙和墨西哥无毛犬的概率均小于0.1%
网络识别出图像中包含数量不明的非洲象。预测向量中激活程度最高的条目是索引为 386 的“非洲象”类别:
1 | >>> np.argmax(preds[0]) |
为了直观地了解图像的哪些部分最像非洲象,让我们设置 Grad-CAM 流程。
你会注意到,在调用任务模型之前,我们不需要对图像进行预处理。这是因为 KerasHubImageClassifier已经为我们预处理了输入predict()。现在让我们自己预处理图像,以便可以直接使用预处理后的输入:
1 | # KerasHub tasks like ImageClassifier have a preprocessor layer. |
首先,我们创建一个模型,将输入图像映射到最后一个卷积层的激活值。
1 | last_conv_layer_name = "block14_sepconv2_act" |
清单 10.18:返回最后一个卷积输出
其次,我们创建了一个模型,将最后一个卷积层的激活映射到最终的类别预测。
1 | classifier_input = last_conv_layer.output |
清单 10.19:从最后一个卷积输出到最终预测
然后,我们计算输入图像预测结果最高的类别相对于最后一个卷积层激活值的梯度。同样,由于需要计算梯度,我们必须使用后端 API。
获取顶层类的梯度:TensorFlow 版本
让我们从 TensorFlow 版本开始,再次使用GradientTape。
1 | import tensorflow as tf |
清单 10.20:使用 TensorFlow 计算顶级类梯度
获取顶层类的梯度:PyTorch 版本
.backward()接下来,这是使用 PyTorch和 的版本.grad。
1 | def get_top_class_gradients(img_array): |
清单 10.21:使用 PyTorch 计算顶级类梯度
获取顶层类的渐变:JAX 版本
最后,我们来实现 JAX。我们定义一个独立的损失计算函数,该函数接收最后一层的输出,并返回与预测结果最高的类别对应的激活通道。我们将这个激活值用作损失,从而计算梯度。
1 | import jax |
清单 10.22:使用 Jax 计算顶级类梯度
显示类别激活热图
现在,我们对梯度张量应用池化和重要性加权,以获得类别激活的热图。
1 | # This is a vector where each entry is the mean intensity of the |
清单 10.23:梯度池化和通道重要性加权
为了便于可视化,您还需要将热图归一化到 0 到 1 之间。结果如图 10.8 所示。
1 | heatmap = np.maximum(heatmap, 0) |
清单 10.24:热图后处理
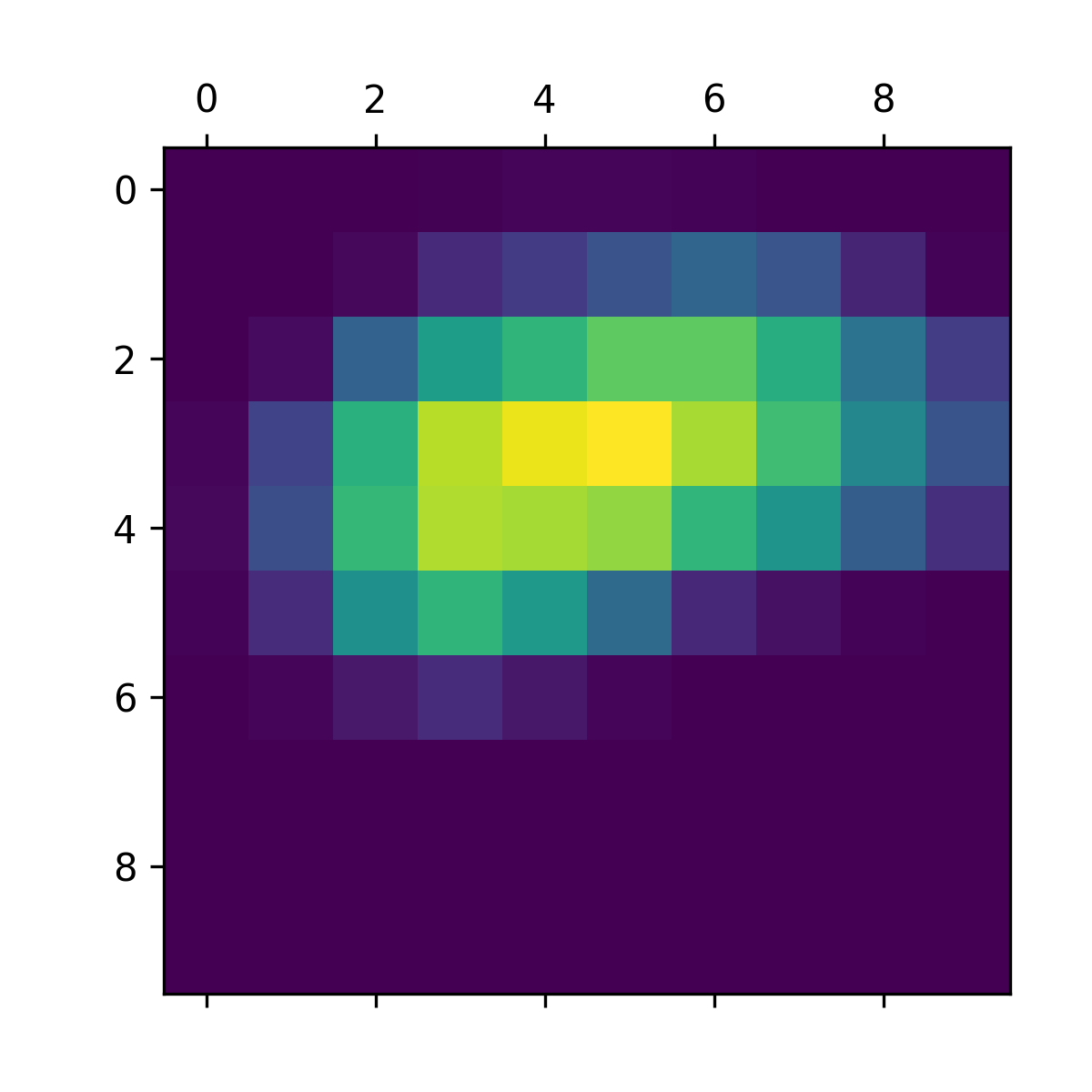 图 10.8:独立类激活热图
图 10.8:独立类激活热图
最后,让我们生成一张图像,将原始图像叠加到你刚刚获得的热图上(见图 10.9)。
1 | import matplotlib.cm as cm |
图 10.25:将热图叠加到原始图片上
 图 10.9:测试图片上非洲象类别的激活热图
图 10.9:测试图片上非洲象类别的激活热图
这种可视化技术回答了两个重要问题:
- 为什么电视台认为这张图片中包含非洲象?
- 图片中的非洲象位于哪里?
尤其值得注意的是,小象的耳朵被强烈激活:这可能是神经网络能够区分非洲象和印度象的方式。
个人注:可视化类别激活热图(Class Activation Map, CAM) 与我们之前讨论的“可视化滤波器”不同。
- 可视化滤波器:是在问“这个神经元喜欢什么样的通用模式?”(比如螺旋纹、眼睛)。
- 可视化热图 (CAM/Grad-CAM):是在问“对于这张特定的图片,模型是因为看到了哪个区域才判断它是‘狗’的?”
它的本质是定位模型在做出分类决策时,注意力(Attention) 集中在图片的哪些像素上。
- 核心原理:特征图的加权求和
在深层卷积神经网络(如 ResNet 或 VGG)中,最后一层卷积层输出的特征图(Feature Maps) 包含了最丰富的语义信息。
每个特征图可以看作是某种特征的“探测器”。例如:
- 通道 1 探测到了“毛茸茸的耳朵”。
- 通道 2 探测到了“湿润的鼻子”。
- 通道 3 探测到了“草地”。
当模型判定这张图是“狗”时,它会给“耳朵”和“鼻子”通道分配极高的权重,而给“草地”分配极低的权重。将这些特征图按照权重叠加在一起,就能得到一张反映“狗”特征分布的地图。
- Grad-CAM 的具体过程(目前最主流的方法)
传统的 CAM 要求修改网络结构(必须有全局平均池化层),而 Grad-CAM(Gradient-weighted CAM) 不需要,它通过梯度来计算权重。其过程如下:
第一步:前向传播 (Forward Pass)
- 动作:将一张图片输入模型,得到分类结果(比如“金毛寻回犬”)。
- 记录:保存最后一层卷积层输出的特征图(通常记为 \(A\))。
第二步:反向传播计算梯度 (Backward Pass)
- 动作:选择你感兴趣的类别(狗),计算该类别的得分(Logit)相对于最后一层卷积层特征图 \(A\) 的梯度。
- 意义:梯度代表了特征图中每个像素对最终分类得分的“贡献度”。
第三步:计算通道权重 (Importance Weights)
- 动作:对每一个通道的梯度进行“全局平均池化”,得到每个通道的一个标量权重 \(\alpha\)。
- 意义:这个权重告诉我们,第 \(k\) 个通道对于判定“这是狗”到底有多重要。
第四步:加权合成热力图 (Heatmap Generation)
- 动作:将所有特征图按权重相加:\(Heatmap = ReLU(\sum \alpha_k A_k)\)。
- ReLU 的作用:我们只关心对分类有正面贡献的特征(剔除负面干扰)。
第五步:叠加显示 (Overlay)
- 动作:将生成的小尺寸热力图(比如 \(7 \times 7\))放大回原图尺寸(比如 \(224 \times 224\)),并以伪彩色(红色代表高热度,蓝色代表低热度)覆盖在原图上。
可视化热图有什么用?
解释性:如果模型把一张猫的照片判成了狗,通过热图发现它盯着的是背景里的狗窝,你就能明白模型“被带偏了”。
信任度:在医疗 AI(如判断肿瘤)中,医生需要看到模型关注的是病灶区域,而不是胶片上的噪点,才敢使用结果。
弱监督定位:即使你只告诉模型这张图里有狗(没有画框),模型也能通过热图告诉你狗大概在哪个位置。
总结
- 滤波器可视化:是看模型的“偏好”(脑子里想什么)。
- 类别激活热图 (CAM):是看模型的“证据”(眼睛在瞄哪)。
个人注:感觉在线阅读版少了10.4
Visualizing the latent space of a ConvNet
I’ll introduce one last model inspection technique: latent space visualization. All
deep learning models work by embedding their inputs in a latent space, a manifold (or
curve) where points that are spatially close to each other represent semantically similar
inputs. On this manifold, different classes of inputs become nicely separable, which is
what enables classification.
Can we visualize in two dimensions what this manifold looks like?
The general idea is to pick a certain layer in the model, typically the one right before
the classification layer, and record its activations for a set of inputs. The activations for
each input represent the coordinates of the corresponding point on the latent man-
ifold. They’re points on a curve. To visualize that curve—the latent manifold—all we
need to do is to plot these points.
Note that this process can be done with any layer in your model—each layer encodes
a different latent space, and these latent spaces get gradually more semantically orga-
nized as your go up the model. Remember our analogy about how deep learning models
are machines for uncrumpling paper balls? The latent space of each layer is a snapshot
of the paper ball at different stages of its uncrumpling. This is why it’s most interesting
to target the second-before-last layer, when the paper ball is almost fully flattened into
a nice sheet.
Now there’s just one obstacle. The human visual system is very much limited to
low-dimensional objects. We can interpret 2D, 3D, maybe 4D visualizations. We’re gen-
erally happiest with simple 2D spaces. Meanwhile, the point coordinates we’d like to
plot are in a space that has typically hundreds of dimensions, and possibly thousands.
To visualize them, we’re going to need to project them on a 2D surface, while trying to
retain as much of the organization of the original manifold as feasible.
This task is not as impossible as it may sound. You see, while the points you’re working
with may be, say, 2048-dimensional, the curve they represent has a much lower intrinsic
dimensionality. That’s precisely why we refer to it as a manifold—a manifold is a lower-dimensional
curve inside a higher-dimensional space. For instance, while planet Earth
is a three-dimensional object, its surface is actually 2D, and so it possible to project it on
a 2D plane. That’s what world maps are all about.
In fact, world maps illustrate both the feasibility and the challenges of lower-dimensional
projections of higher-dimensional manifolds. All projections distort real-
ity. The widely used Mercator map projection distorts distances, in particular by making
areas near the equator look smaller than they actually are, and inversely by making
areas near the poles stretch towards infinity. And that’s even though the surface you’re
projecting is in fact 2D—whereas deep learning latent manifolds may be much higher-dimensional
than that.
There’s no projection that won’t destroy at least some information.
卷积神经网络(ConvNets)潜空间的可视化
我将介绍最后一种模型检查技术:潜空间(latent space)可视化。所有深度学习模型的工作原理都是将其输入嵌入到一个潜空间中,这是一个流形(或曲线),其中空间上相互靠近的点代表语义上相似的输入。在这个流形上,不同类别的输入变得很好分离,从而实现了分类。
我们能否在二维空间中可视化这个流形的样子?
基本思路是选择模型中的某个特定层(通常是紧邻分类层之前的那一层),并记录其针对一系列输入的激活值。每个输入的激活值代表了潜流形上对应点的坐标。它们是曲线上的点。为了可视化那条曲线——即潜流形——我们只需要将这些点绘制出来即可。
请注意,这一过程可以针对模型中的任何层进行——每一层都编码了一个不同的潜空间,并且随着模型层级的上升,这些潜空间在语义上的组织变得越来越有序。还记得我们关于深度学习模型是“摊平纸团的机器”的比喻吗?每一层的潜空间都是纸团在不同摊平阶段的快照。这就是为什么针对倒数第二层最有趣的原因,因为此时纸团几乎已经完全摊平成了一张漂亮的纸。
现在只有一个障碍。人类的视觉系统非常局限于低维物体。我们可以理解二维、三维,或许还有四维的可视化。我们通常最习惯简单的二维空间。而我们想要绘制的点坐标通常处在几百甚至几千维的空间中。为了可视化它们,我们需要将它们投影到二维平面上,同时尽力保留原始流形中尽可能多的组织结构。
这项任务并非听起来那么不可能。你看,虽然你处理的点可能是 2048 维的,但它们所代表的曲线具有更低的固有维度。这正是我们将其称为“流形”的原因——流形是高维空间内部的低维曲线。例如,虽然地球是一个三维物体,但它的表面实际上是二维的,因此将其投影到二维平面上是可能的。世界地图正是为此而存在的。
事实上,世界地图既展示了高维流形低维投影的可行性,也展示了其挑战。所有的投影都会扭曲现实。广泛使用的墨卡托(Mercator)地图投影会扭曲距离,特别是使赤道附近的区域看起来比实际小,反之使两极附近的区域向无穷大延伸。即使你投影的表面实际上是二维的,情况也是如此——而深度学习的潜流形维度可能比这高得多。
没有任何投影是不破坏至少一部分信息的。
个人注:什么是潜空间(Latent Space)
在深度学习(尤其是生成模型,如变分自编码器 VAE 或 GAN)中,潜空间(Latent Space) 是一个非常核心且迷人的概念。
简单来说,潜空间就是数据的“灵魂压缩包”。它是一个低维的空间,里面存储着数据最本质、最核心的特征。
- 形象的比喻:警察画肖像
想象一个警察正在根据目击者的描述画嫌疑人的肖像:
- 原始数据空间(高维):嫌疑人的真实照片。这张照片包含数百万个像素点(高维度),每个像素都有颜色和亮度信息。
- 潜空间(低维):目击者大脑中的记忆。目击者不会记得每一个像素,他只记得几个核心特征(Latent Variables):
- 性别(男/女)
- 脸型(圆/长)
- 是否戴眼镜(是/否)
- 头发长度(长/短)
- 潜空间的意义:这 4 个简单的维度,就足以“重建”出一张像模像样的肖像。这 4 个维度构成的空间,就是潜空间。
- 潜空间的三大特性
A. 降维(Compression)
原始数据(如一张 \(256 \times 256\) 的彩色图片)拥有 \(196,608\) 个维度。但在潜空间中,我们可能只需要 \(128\) 个维度就能表达这张图。模型学会了丢弃掉那些“没用的噪声”(比如背景里的微小尘埃),只保留最重要的信息。
B. 语义聚类(Semantic Clustering)
在理想的潜空间里,相似的事物会靠在一起。
- 如果你在潜空间里找到“猫”的点,稍微移动一点点距离,你可能会找到“长毛猫”或者“小老虎”。
- 这意味着潜空间捕捉到了数据背后的数学规律,而不仅仅是像素的堆砌。
C. 可流形操作(Latent Space Arithmetic)
这是潜空间最神奇的地方。因为它是连续的数学空间,你可以进行“向量加减法”。
最经典的例子:
\[\text{国王的向量} - \text{男性的向量} + \text{女性的向量} = \text{女王的向量}\]
这说明潜空间真的理解了“性别”和“地位”这两个隐藏的概念。
- 为什么叫“潜”空间?
之所以叫“潜(Latent)”,是因为这些特征是隐藏的、不可直接观测的。
- 在原始照片里,你看不到一个专门标着“性别”的像素。
- 但在潜空间里,模型通过训练,自动挖掘出了这些支撑数据生成的隐藏变量。
作者 Francois Chollet 经常提到“学习表示(Learning Representations)”。潜空间其实就是模型学到的最极致的“表示”。
- 编码器(Encoder):负责把繁琐的原始数据“压缩”进潜空间。
- 解码器(Decoder):负责把潜空间里的一个点“翻译”回人能看懂的数据(图片、文字)。
总结一下:
潜空间就像是数据的一种“数学速记法”。它去掉了表面的冗余,把万千世界的规律浓缩成了空间里的坐标点。当你掌握了潜空间,你也就掌握了生成新数据的“上帝视角”。
概括
- 卷积神经网络通过应用一组已学习的滤波器来处理图像。早期层的滤波器检测边缘和基本纹理,而后期层的滤波器则检测越来越抽象的概念。
- 您可以可视化滤波器检测到的模式以及滤波器在图像上的响应图。
- 您可以使用 Grad-CAM 技术来可视化图像中的哪些区域导致了分类器的决策。
- 这些技术结合起来,使得卷积神经网络具有很高的可解释性。
脚注
- Ramprasaath R. Selvaraju 等人,“Grad-CAM:基于梯度定位的深度网络可视化解释”,arxiv (2019),https://arxiv.org/abs/1610.02391。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论