《DEEP LEARNING with Python》第八章 图像分类
第八章 图像分类
Image classification
运行代码
本章内容
- 理解卷积神经网络(ConvNets)
- 利用数据增强来缓解过拟合
- 使用预训练的卷积神经网络进行特征提取
- 对预训练卷积神经网络进行微调
- Understanding convolutional neural networks (ConvNets)
- Using data augmentation to mitigate overfitting
- Using a pretrained ConvNet for feature extraction
- Fine-tuning a pretrained ConvNet
计算机视觉是深度学习的第一个重大成功案例。它引领了深度学习在2011年至2015年间的初期发展。一种名为卷积神经网络的深度学习方法 在当时开始在图像分类竞赛中取得显著成果。首先是Dan Ciresan赢得了两项小众竞赛(2011年ICDAR汉字识别竞赛和2011年IJCNN德国交通标志识别竞赛),随后,更引人注目的是,在2012年秋季,Hinton的团队赢得了备受瞩目的ImageNet大规模视觉识别挑战赛。此后,在其他计算机视觉任务中,也涌现出了许多令人瞩目的成果。
有趣的是,这些早期的成功并不足以让深度学习在当时成为主流——这花了几年时间。计算机视觉研究界多年来一直致力于神经网络以外的方法,他们并不急于因为出现了一种新技术就放弃这些方法。在2013年和2014年,深度学习仍然面临着许多资深计算机视觉研究人员的强烈质疑。直到2016年,它才最终占据主导地位。一位作者回忆说,在2014年2月,他曾力劝一位前教授转向深度学习。“这是下一个重大突破!”他说道。“嗯,也许这只是一时的风潮,”教授回答道。到了2016年,他的整个实验室都在从事深度学习研究。一个时代到来的理念是无法阻挡的。
如今,你无时无刻不在与基于深度学习的视觉模型(vision models)互动——通过谷歌相册、谷歌图片搜索、手机摄像头、YouTube、OCR软件等等。这些模型也是自动驾驶、机器人、人工智能辅助医疗诊断、自助零售结账系统,甚至是自主农业等前沿研究的核心。
本章介绍卷积神经网络 (ConvNets或CNNs) ,这是一种被大多数计算机视觉应用广泛使用的深度学习模型。您将学习如何将 ConvNets 应用于图像分类问题——特别是那些涉及小型训练数据集的问题,如果您不是大型科技公司,这通常是最常见的应用场景。
卷积神经网络简介
Introduction to ConvNets
我们将深入探讨卷积神经网络(ConvNet)的理论,以及它们为何在计算机视觉任务中如此成功。但首先,让我们来看一个简单的ConvNet示例。该示例使用ConvNet对MNIST数字进行分类,我们在第二章中使用全连接网络完成了这项任务(当时的测试准确率为97.8%)。尽管ConvNet比较简单,但它的准确率将远远超过第二章中全连接模型的准确率。
以下代码展示了一个基本的卷积神经网络(ConvNet)的结构。它由多层堆叠Conv2D而成MaxPooling2D。稍后您将看到它们的具体作用。我们将使用上一章介绍的函数式 API 来构建模型。
1 | import keras |
清单 8.1:实例化一个小型卷积神经网络
重要的是,卷积神经网络(ConvNet)的输入张量形状为(image_height, image_width, image_channels)(不包括批次维度)。在本例中,我们将配置卷积神经网络处理大小为的输入(28, 28, 1),这正是 MNIST 图像的格式。
让我们展示一下卷积神经网络的架构。
1 | >>> model.summary() |
列表 8.2:显示模型摘要
Conv2D可以看到,每一层的输出MaxPooling2D都是一个形状为 的三维张量(height, width, channels)。随着模型层数的增加,宽度和高度维度会逐渐缩小。通道数由传递给每Conv2D一层的第一个参数(64、128 或 256)控制。
深度学习框架中的图像数据格式
Image data formats in deep learning frameworks
一些深度学习库会将图像张量中通道的位置翻转到第一级(尤其是 PyTorch 生态系统中的许多库)。与其传递形状为 的图像,不如(height, width, channels)传递 (channels, height, width)。
这纯粹是约定俗成的问题,在 Keras 中是可以配置的。你可以调用函数keras.config.set_image_data_format("channels_first")来更改 Keras 的默认值,或者data_format向任何卷积层或池化层传递参数。通常情况下,除非你有特殊需求,否则可以保留默认值 "channels_first"。
经过最后Conv2D一层之后,我们得到一个形状为 的输出 (3, 3, 256)——一个 3×3 的 256 通道特征图。下一步是将此输出输入到一个密集连接分类器中,就像你已经熟悉的那种:由Dense多层堆叠而成。这些分类器处理的是一维向量,而当前输出是一个秩为 3 的张量。为了弥合这种差异,我们GlobalAveragePooling2D在添加Dense层之前,使用一个 层将 3D 输出展平为 1D。该层将对形状为 的张量中每个 3×3 特征图取平均值(3, 3, 256),从而得到一个形状为 的输出向量(256,)。最后,我们将进行 10 路分类,因此最后一层有 10 个输出和一个 softmax 激活函数。
现在,让我们用 MNIST 数字数据集训练 ConvNet。我们将重用第 2 章 MNIST 示例中的大量代码。因为我们要进行 10 路分类,输出为 softmax,所以我们将使用分类交叉熵损失函数;并且因为我们的标签是整数,所以我们将使用稀疏版本 sparse_categorical_crossentropy。
1 | from keras.datasets import mnist |
清单 8.3:在 MNIST 图像上训练卷积神经网络
让我们用测试数据来评估该模型。
1 | >>> test_loss, test_acc = model.evaluate(test_images, test_labels) |
清单 8.4:评估卷积神经网络
第二章中密集连接模型的测试准确率为 97.8%,而基本卷积神经网络的测试准确率则达到了 99.1%:我们相对地降低了约 60% 的错误率。不错!
但是,为什么这种简单的卷积神经网络(ConvNet)比全连接模型效果更好呢?为了解答这个问题,让我们深入了解一下卷积层Conv2D和 MaxPooling2D卷积层的作用。
卷积运算
The convolution operation
全连接层和卷积层之间的根本区别在于:全连接Dense层学习输入特征空间中的全局模式(例如,对于 MNIST 数字,学习涉及所有像素的模式),而卷积层学习局部模式(参见图 8.1):对于图像而言,学习输入图像中二维小窗口内的模式。在前面的例子中,这些窗口均为 3×3。
 图 8.1:图像可以分解为局部模式,如边缘、纹理等。
图 8.1:图像可以分解为局部模式,如边缘、纹理等。
这一关键特性赋予卷积神经网络两个有趣的属性:
- 它们学习到的模式具有平移不变性。卷积神经网络(ConvNet)在学习了图片右下角的某个模式后,就能识别出它出现在图片的任何位置,例如左上角。而如果模式出现在新的位置,全连接模型则需要重新学习。这使得卷积神经网络在处理图像时数据效率很高——因为视觉世界本质上是平移不变的。它们只需要更少的训练样本就能学习到具有泛化能力的表征。
- 它们可以学习模式的空间层级结构(见图 8.2)。第一层卷积层学习诸如边缘之类的小局部模式,第二层卷积层学习由第一层特征构成的大模式,依此类推。这使得卷积神经网络能够高效地学习日益复杂和抽象的视觉概念——因为视觉世界本质上是空间层级结构的。
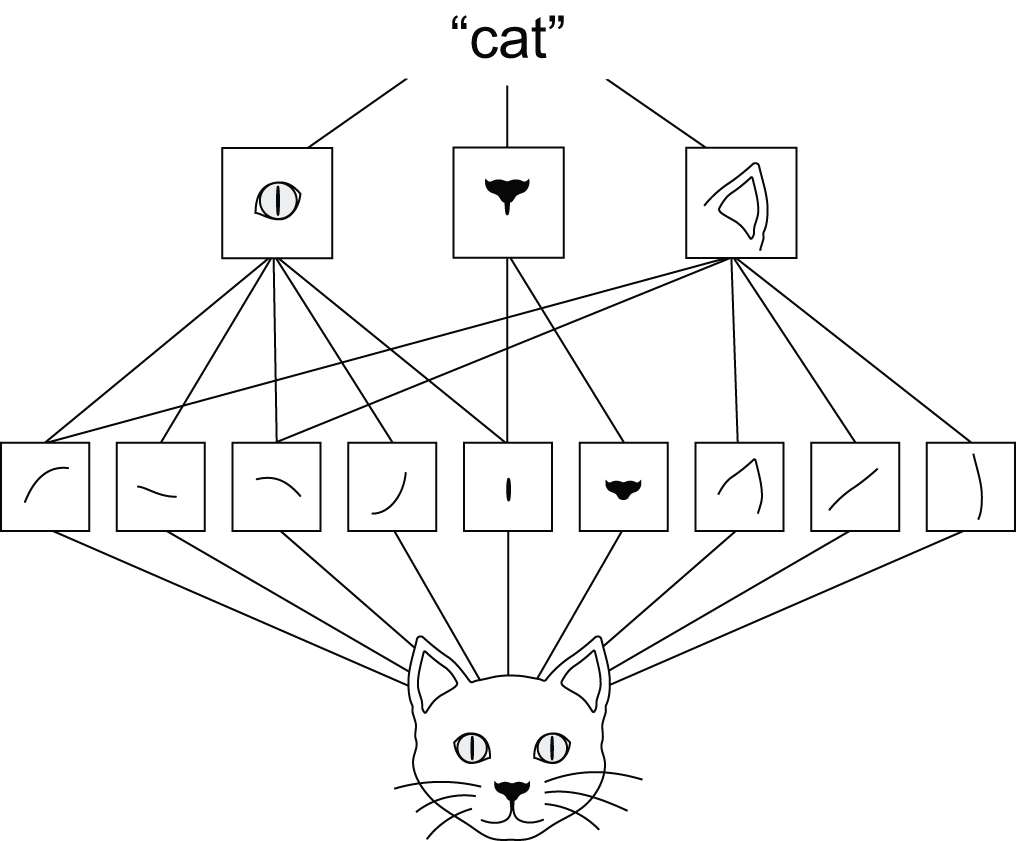 图 8.2:视觉世界形成视觉模块的空间层次结构:基本线条或纹理组合成眼睛或耳朵等简单物体,这些简单物体组合成“猫”等高级概念。
图 8.2:视觉世界形成视觉模块的空间层次结构:基本线条或纹理组合成眼睛或耳朵等简单物体,这些简单物体组合成“猫”等高级概念。
卷积运算作用于秩为 3 的张量,称为特征图,它有两个空间轴(高度和宽度)以及一个深度轴(也称为通道轴)。对于 RGB 图像,深度轴的维度为 3,因为图像有三个颜色通道:红色、绿色和蓝色。对于黑白图像,例如 MNIST 数字,深度为 1(灰度级)。卷积运算从输入特征图中提取图像块,并对所有这些图像块应用相同的变换,从而生成 输出特征图。该输出特征图仍然是一个秩为 3 的张量:它具有宽度和高度。它的深度可以是任意的,因为输出深度是该层的参数,并且该深度轴中的不同通道不再像 RGB 输入那样代表特定的颜色;相反,它们代表 滤波器(filters)。滤波器对输入数据的特定方面进行编码:例如,一个滤波器可以编码“输入中是否存在人脸”的概念。
在 MNIST 示例中,第一个卷积层接收一个大小为 的特征图 (28, 28, 1),并输出一个大小为 的特征图(26, 26, 64):它在其输入上计算 64 个滤波器。这 64 个输出通道中的每一个都包含一个 26 × 26 的值网格,该网格是滤波器对输入的响应图(response map),指示了该滤波器模式在输入中不同位置的响应(参见图 8.3)。这就是“特征图”的含义:深度轴上的每个维度都是一个特征(或滤波器),而秩为 2 的张量是该滤波器对输入响应的output[:, :, n]二维空间 图。
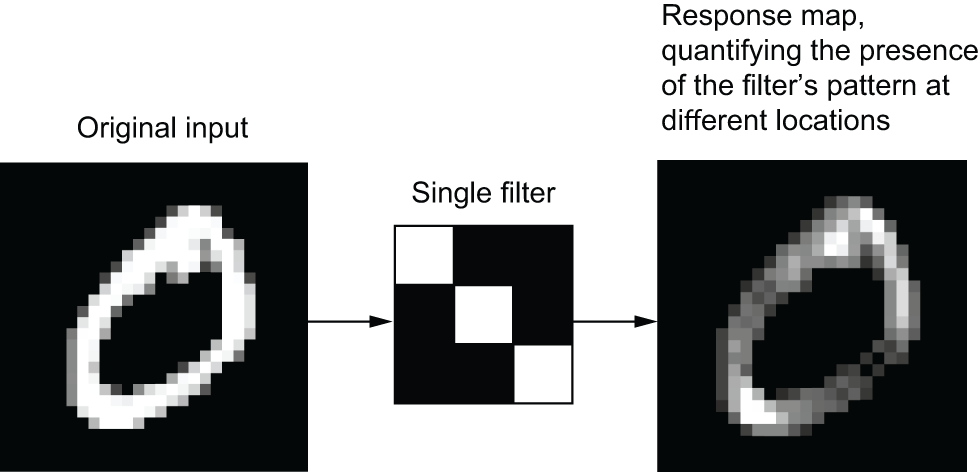 图 8.3:响应图的概念:输入中不同位置出现某种模式的二维图
图 8.3:响应图的概念:输入中不同位置出现某种模式的二维图
卷积由两个关键参数定义:
- 从输入中提取的色块大小 ——通常为 3 × 3 或 5 × 5。在本例中,它们是 3 × 3,这是一个常见的选择。
- 输出特征图的深度 ——卷积运算所计算的滤波器数量。示例的初始深度为 32,最终深度为 64。
- Size of the patches extracted from the inputs — These are typically 3 × 3 or 5 × 5. In the example, they were 3 × 3, which is a common choice.
- Depth of the output feature map — The number of filters computed by the convolution. The example started with a depth of 32 and ended with a depth of 64.
在 KerasConv2D层中,这些参数是传递给该层的第一个参数: Conv2D(output_depth, (window_height, window_width))。
卷积运算的工作原理是:将大小为 3×3 或 5×5 的窗口在 3D 输入特征图上滑动(window_height, window_width, input_depth),在每个可能的位置停留,并提取形状为 的周围 3D 特征块。然后,每个这样的 3D 特征块被转换为形状为 的一维向量(output_depth,),这是通过与学习到的权重矩阵(称为卷积核)进行张量积运算实现的——同一个卷积核会被重复用于所有特征块。所有这些向量(每个特征块一个向量)随后被空间重组为形状为 的 3D 输出特征图(height, width, output_depth)。输出特征图中的每个空间位置都对应于输入特征图中的相同位置(例如,输出的右下角包含有关输入右下角的信息)。例如,对于 3×3 的窗口,向量output[i, j, :]来自 3D 特征块input[i-1:i+1, j-1:j+1, :]。完整的过程详见图 8.4。
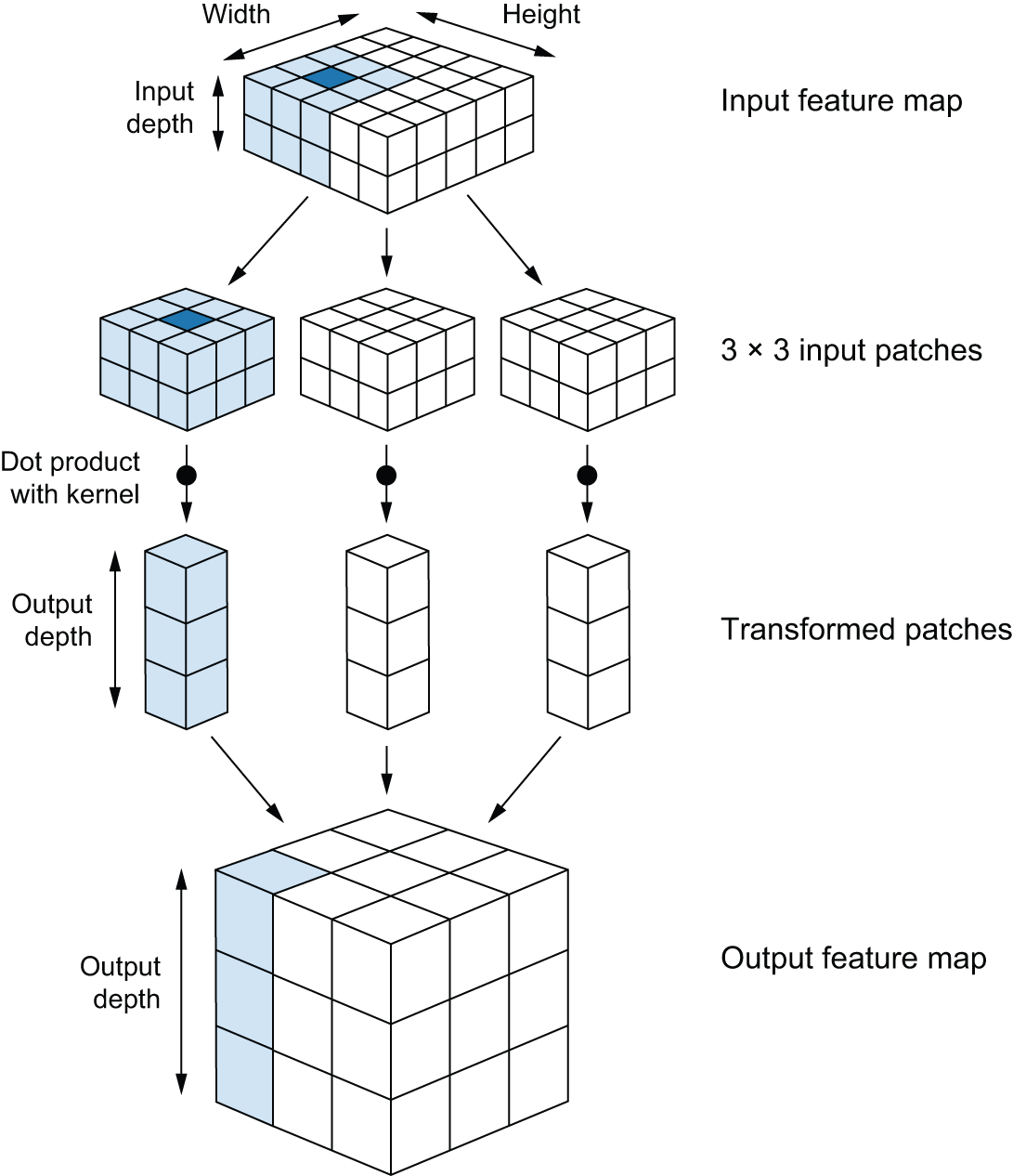 图 8.4:卷积的工作原理
图 8.4:卷积的工作原理
请注意,输出的宽度和高度可能与输入的宽度和高度不同。这可能由以下两个原因造成:
- 边界效应可以通过填充输入特征图来抵消。
- 我们将在下文中定义步幅(strides) 。
- Border effects, which can be countered by padding the input feature map
- The use of strides, which we’ll define in a second
让我们更深入地了解一下这些概念。
了解边框和内边距
Understanding border effects and padding
考虑一个 5×5 的特征图(总共 25 个图块)。只有 9 个图块可以围绕它们放置一个 3×3 的窗口,形成一个 3×3 的网格(参见图 8.5)。因此,输出的特征图将是 3×3 的。它会略微缩小:在本例中,每个维度都缩小了两个图块。你可以在前面的例子中看到这种边界效应:初始输入是 28×28,经过第一个卷积层后变为 26×26。
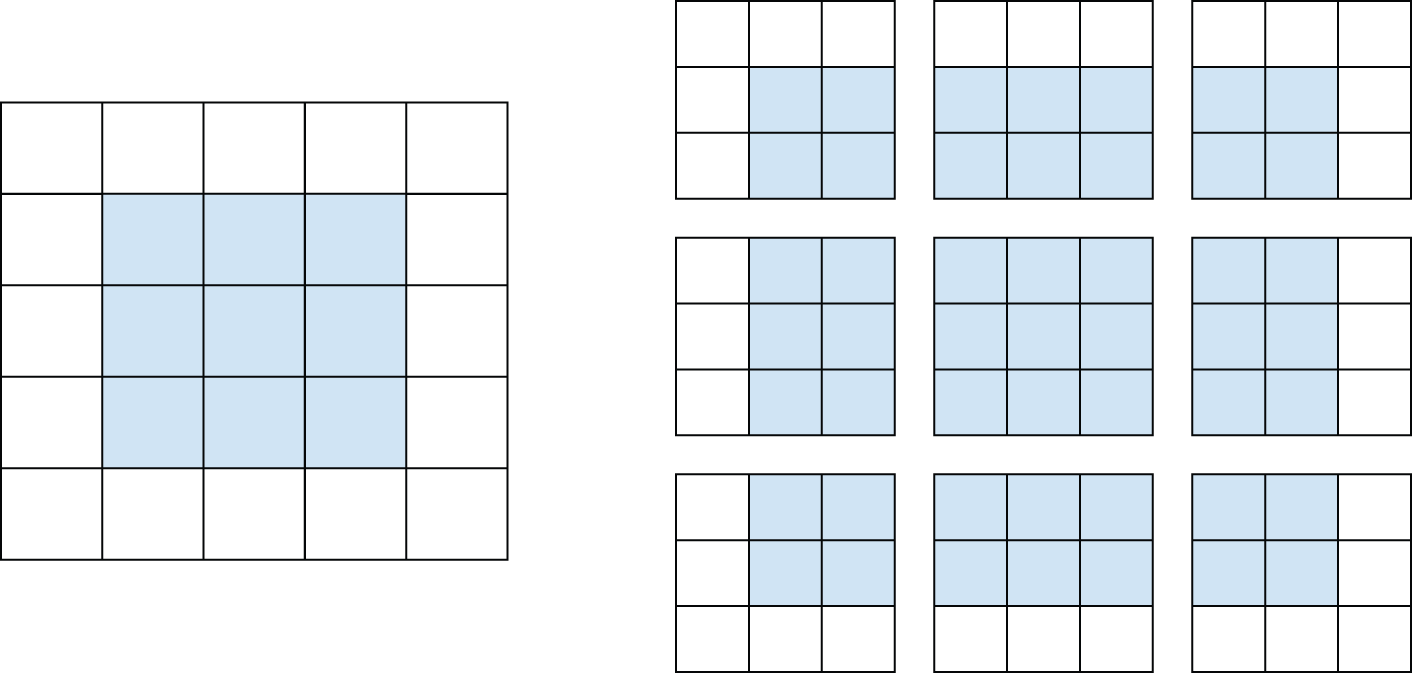 图 8.5:5×5 输入特征图中 3×3 图像块的有效位置
图 8.5:5×5 输入特征图中 3×3 图像块的有效位置
如果想要获得与输入特征图空间维度相同的输出特征图,可以使用填充。填充是指在输入特征图的每一侧添加适当数量的行和列,以便在每个输入图块周围放置居中的卷积窗口。对于 3×3 的窗口,需要在右侧添加一列,左侧添加一列,顶部添加一行,底部添加一行。对于 5×5 的窗口,则需要添加两行(参见图 8.6)。
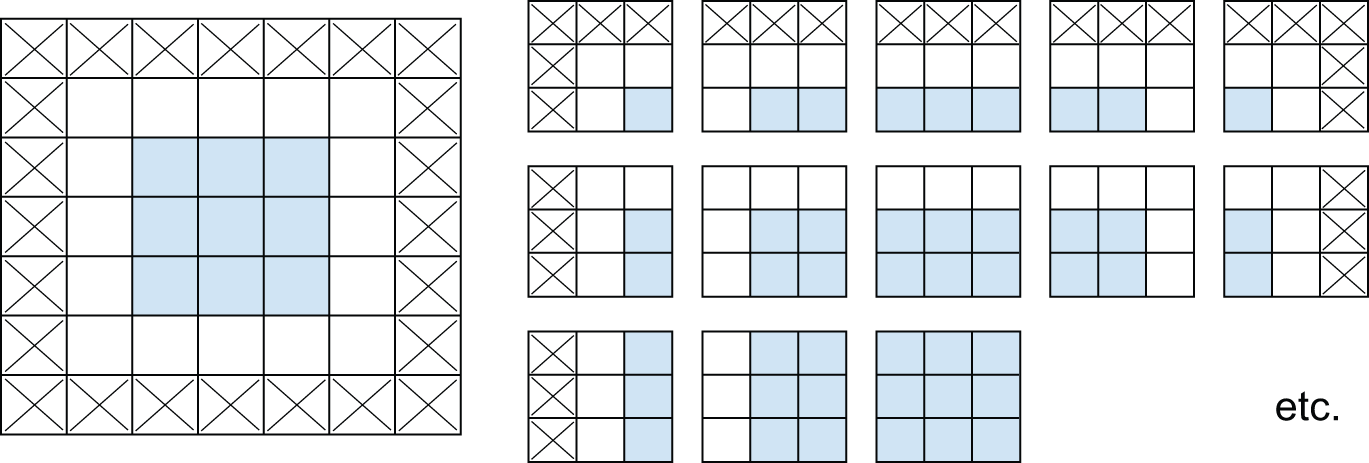 图 8.6:对 5 × 5 输入进行填充,以便提取 25 个 3 × 3 的块。
图 8.6:对 5 × 5 输入进行填充,以便提取 25 个 3 × 3 的块。
在Conv2D图层中,可以通过参数配置填充padding,该参数有两个值:"valid"``--padding,表示不填充(仅使用有效的窗口位置);以及"same"``--padding,表示“以使输出与输入具有相同宽度和高度的方式填充”。该padding 参数的默认值为--padding "valid"。
理解卷积步长
Understanding convolution strides
影响输出大小的另一个因素是步长。到目前为止,卷积的描述都假设卷积窗口的中心图块都是连续的。但两个相邻窗口之间的距离是卷积的一个参数,称为步长,默认值为 1。步长大于 1 的卷积是可以实现的。在图 8.7 中,您可以看到对 5×5 输入(无填充)进行步长为 2 的 3×3 卷积提取出的图像块。
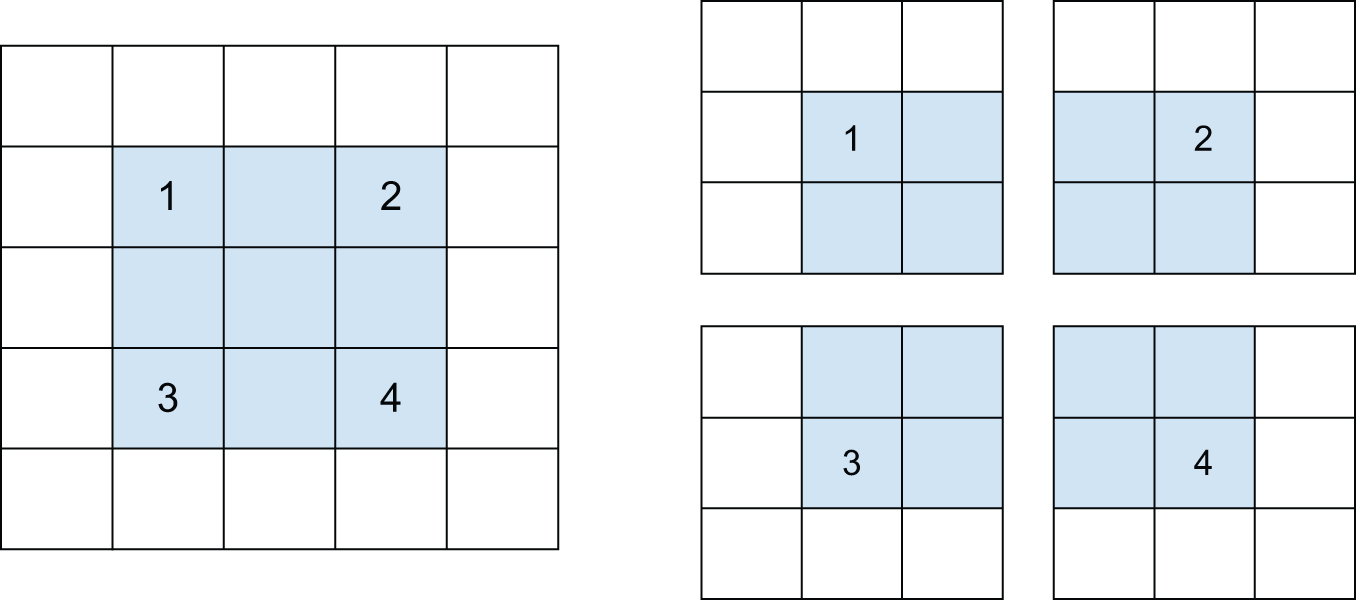 图 8.7:步长为 2 × 2 的 3 × 3 卷积块
图 8.7:步长为 2 × 2 的 3 × 3 卷积块
使用步长 2 意味着特征图的宽度和高度会下采样 2 倍(除了边界效应引起的任何变化之外)。步长卷积在分类模型中很少使用,但它们对某些类型的模型非常有用,您将在下一章中了解到这一点。
个人注:“下采样 2 倍”是指输出的特征图(Feature Map)在物理尺寸上缩小了。
“卷积核走得快了(一步跨两格),所以数出来的数变少了(特征图变小了),模型看到的范围变广了。”
在分类模型中,我们通常使用 最大池化操作来对特征图进行下采样,而不是使用步长——您在我们第一个卷积神经网络示例中已经看到了它的实际应用。让我们更深入地了解一下。
最大池化操作
The max-pooling operation
在卷积神经网络(ConvNet)的示例中,您可能已经注意到,特征图的大小在每MaxPooling2D一层之后都会减半。例如,在第一MaxPooling2D层之前,特征图是 26 × 26,但最大池化操作将其减半至 13 × 13。这就是最大池化的作用:像步长卷积一样,对特征图进行大幅度的下采样。
最大池化是指从输入特征图中提取窗口,并输出每个通道的最大值。它在概念上类似于卷积,区别在于最大池化不是通过学习到的线性变换(卷积核)来变换局部图像块,而是通过硬编码的max张量运算来变换。与卷积的一个显著区别是,最大池化通常使用 2×2 的窗口和步长 2,将特征图下采样(downsample) 2 倍。而卷积通常使用 3×3 的窗口,步长为 1。
为什么要这样对特征图进行下采样?为什么不移除最大池化层,保留足够大的特征图呢?我们来看看这种方法。这样一来,我们的模型就会变成这样。
1 | inputs = keras.Input(shape=(28, 28, 1)) |
示例 8.5:一个结构错误的卷积神经网络,缺少最大池化层。
以下是该模型的概要:
1 | >>> model_no_max_pool.summary() |
这种设置有什么问题?有两个问题:
- 这种方法不利于学习特征的空间层次结构。第三层的 3×3 窗口仅包含来自初始输入中 7×7 窗口的信息。卷积神经网络学习到的高级模式相对于初始输入而言仍然非常小,这可能不足以学习对数字进行分类(尝试仅通过 7×7 像素的窗口来识别数字!)。我们需要最后一个卷积层的特征包含关于整个输入的信息。
- 最终的特征图尺寸为 22 × 22。这非常大——当你对每个 22 × 22 的特征图取平均值时,与特征图只有 3 × 3 时相比,你会丢失很多信息。
简而言之,使用下采样的原因是减小特征图的大小,使它们所包含的信息空间分布越来越少,越来越集中在通道中,同时通过使连续的卷积层“查看”越来越大的窗口(就它们覆盖的原始输入图像的比例而言),来诱导空间滤波器层次结构。
请注意,最大池化并非实现这种下采样的唯一方法。如您所知,您也可以在之前的卷积层中使用步长。此外,您还可以使用平均池化代替最大池化,其中每个局部输入块的变换方式是取该块内每个通道的平均值,而不是最大值。但最大池化通常比这些替代方案效果更好。简而言之,原因在于特征倾向于编码某种模式或概念在特征图不同图块上的空间存在性(因此称为特征图),而观察不同特征的最大存在性比观察它们的平均存在性更有意义。因此,最合理的下采样策略是首先生成密集特征图(通过无步长卷积),然后观察小块上特征的最大激活值,而不是观察输入的稀疏窗口(通过有步长卷积)或对输入块进行平均,后者可能会导致您丢失或稀释特征存在性信息。
Note that max pooling isn’t the only way you can achieve such downsampling. As you already know, you can also use strides in the prior convolution layer. And you can use average pooling instead of max pooling, where each local input patch is transformed by taking the average value of each channel over the patch, rather than the max. But max pooling tends to work better than these alternative solutions. In a nutshell, the reason is that features tend to encode the spatial presence of some pattern or concept over the different tiles of the feature map (hence the term feature map), and it’s more informative to look at the maximal presence of different features than at their average presence. So the most reasonable subsampling strategy is to first produce dense maps of features (via unstrided convolutions) and then look at the maximal activation of the features over small patches, rather than looking at sparser windows of the inputs (via strided convolutions) or averaging input patches, which could cause you to miss or dilute feature-presence information.
到目前为止,你应该已经了解了卷积神经网络的基础知识——特征图、卷积和最大池化(feature maps, convolution, and max pooling)——并且知道如何构建一个小型卷积神经网络来解决诸如 MNIST 数字分类之类的简单问题。现在,让我们来看看更实用、更实际的应用。
在小型数据集上从头开始训练卷积神经网络
Training a ConvNet from scratch on a small dataset
使用极少的数据训练图像分类模型是一种常见情况,如果您在专业领域从事计算机视觉工作,很可能会遇到这种情况。“少量”样本可能意味着几百张到几万张图像。举个实际例子,我们将重点关注如何将图像分类为狗或猫。我们将使用一个包含 5000 张猫狗图片的数据集(2500 张猫,2500 张狗),该数据集取自 Kaggle 原始数据集。我们将使用 2000 张图片进行训练,1000 张进行验证,2000 张进行测试。
在本节中,我们将回顾解决此问题的一种基本策略:利用现有少量数据从头开始训练一个新模型。首先,我们将使用 2000 个训练样本简单地训练一个小型卷积神经网络 (ConvNet),不进行任何正则化,以此设定一个基准,了解模型能够达到的性能水平。这将使我们的分类准确率达到约 80%。此时,主要问题是过拟合。接下来,我们将介绍数据增强,这是一种在计算机视觉中缓解过拟合的强大技术。通过使用数据增强,我们将改进模型,使其测试准确率达到约 84%。
Then we’ll introduce data augmentation, a powerful technique for mitigating overfitting in computer vision.
下一节,我们将回顾另外两种将深度学习应用于小型数据集的关键技术:使用预训练模型进行特征提取 和微调预训练模型(这将使我们最终达到 98.5% 的准确率)。这三种策略——从头开始训练小型模型、使用预训练模型进行特征提取以及微调预训练模型(training a small model from scratch, doing feature extraction using a pretrained model, and fine-tuning a pretrained model)——将构成您未来解决小型数据集图像分类问题的工具箱。
深度学习对小数据问题的相关性
The relevance of deep learning for small-data problems
训练模型所需的“足够样本”是相对的——首先,这取决于你要训练的模型的大小和深度。仅凭几十个样本无法训练卷积神经网络 (ConvNet) 来解决复杂问题,但如果模型规模较小、正则化良好且任务简单,几百个样本可能就足够了。由于卷积神经网络学习的是局部的、平移不变的特征,因此它们在感知问题上的数据效率非常高。(Because ConvNets learn local, translation-invariant features, they’re highly data efficient on perceptual problems)即使数据量相对不足,从零开始在非常小的图像数据集上训练卷积神经网络仍然可以得到合理的结果,而无需任何自定义特征工程。你将在本节中看到这方面的实际应用。
此外,深度学习模型本质上具有高度可重用性:例如,你可以将一个在大规模数据集上训练的图像分类或语音转文本模型,稍作修改后,就能将其应用于截然不同的问题。具体来说,在计算机视觉领域,许多预训练的分类模型都可以公开下载,并可用于仅使用少量数据构建强大的视觉模型。这正是深度学习最大的优势之一:特征重用。你将在下一节中深入探讨这一点。
What’s more, deep learning models are by nature highly repurposable: you can take, say, an image-classification or speech-to-text model trained on a large-scale dataset and reuse it on a significantly different problem with only minor changes. Specifically, in the case of computer vision, many pretrained classification models are publicly available for download and can be used to bootstrap powerful vision models out of very little data. This is one of the greatest strengths of deep learning: feature reuse. You’ll explore this in the next section.
我们先来获取数据。
正在下载数据
Downloading the data
我们将使用的“狗 vs. 猫”数据集并未包含在 Keras 中。该数据集由 Kaggle 在 2013 年底的一次计算机视觉竞赛中发布,当时卷积神经网络(ConvNets)尚未普及。您可以从 Kaggle 官方网站 下载原始数据集 www.kaggle.com/c/dogs-vs-cats/data(如果您还没有 Kaggle 账号,则需要创建一个——别担心,过程非常简单)。您也可以使用 Kaggle API 在 Colab 中下载该数据集。
在 Google Colaboratory 中下载 Kaggle 数据集
Downloading a Kaggle dataset in Google Colaboratory
Kaggle 提供了一个易于使用的 API,可以通过编程方式下载 Kaggle 托管的数据集。例如,您可以使用它将 Dogs vs. Cats 数据集下载到 Colab notebook 中。此 API 可通过kagglehub Colab 预装的软件包访问。
在下载数据集之前,我们需要做两件事:
- 请访问https://www.kaggle.com/并登录。
- 前往https://www.kaggle.com/c/dogs-vs-cats/data,向下滚动并点击加入比赛。
- 请访问https://www.kaggle.com/settings并生成 Kaggle API 密钥。
这样我们就可以将数据下载到笔记本中了。首先,请使用您的 Kaggle API 密钥登录:
1 | import kagglehub |
然后,下载比赛数据:
1 | download_path = kagglehub.competition_download("dogs-vs-cats") |
这将下载两个新文件,train.zip分别是训练数据和 test1.zip测试数据。这里我们只使用训练数据。让我们解压缩它:
1 | import zipfile |
全部完成!
我们数据集中的图片是中等分辨率的彩色JPEG图像。图8.8展示了一些示例。
 图 8.8:来自“狗与猫”数据集的样本。样本大小未做修改:这些样本具有不同的大小、颜色、背景等。
图 8.8:来自“狗与猫”数据集的样本。样本大小未做修改:这些样本具有不同的大小、颜色、背景等。
不出所料,早在2013年举办的首届猫狗大战Kaggle竞赛,最终的赢家就是使用卷积神经网络(ConvNets)的参赛者。最佳参赛作品的准确率高达95%。在本例中,我们将在下一节中尽可能接近这一准确率,尽管我们训练模型所用的数据量不到参赛者的10%。
这个数据集包含 25,000 张猫狗图片(每类 12,500 张),压缩后大小为 543 MB。下载并解压缩数据后,我们将创建一个包含三个子集的新数据集:一个包含每类 1,000 个样本的训练集,一个包含每类 500 个样本的验证集,以及一个包含每类 1,000 个样本的测试集。为什么要这样做呢?因为你在工作中遇到的许多图像数据集只有几千个样本,而不是几万个。拥有更多的数据会使问题更容易解决——因此,使用小型数据集进行学习是一个很好的实践。
我们将使用的子抽样数据集具有以下目录结构:
1 | dogs_vs_cats_small/ |
让我们通过几次调用来实现它shutil,这是一个用于运行类似 shell 命令的 Python 库。
1 | import os, shutil, pathlib |
清单 8.6:将图像复制到训练、验证和测试目录
我们现在有 2000 张训练图像、1000 张验证图像和 2000 张测试图像。每个划分都包含相同数量的来自每个类别的样本:这是一个平衡的二元分类问题,这意味着分类准确率将是衡量成功的合适指标。
构建你的模型
Building your model
我们将重用你在第一个示例中看到的相同通用模型结构:卷积神经网络将是一个交替的Conv2D(带有relu激活函数的)MaxPooling2D层堆叠。
但由于我们要处理更大的图像和更复杂的问题,因此我们将相应地增大模型:增加两个“ Conv2D+ MaxPooling2D”级。这样做既可以增强模型的容量,又可以进一步减小特征图的尺寸,使其在到达池化层时不会过大。这里,由于我们初始输入图像的尺寸为 180 × 180 像素(这是一个略显随意的选择),因此在池化层之前,我们最终得到的特征图尺寸为 7 × 7 GlobalAveragePooling2D。
模型中特征图的深度逐渐增加(从 32 层到 512 层),而特征图的尺寸则逐渐减小(从 180 × 180 减小到 7 × 7)。这几乎是所有卷积神经网络的共同特征。
因为我们面对的是一个二元分类问题,所以我们会在模型末尾添加一个单元(Dense大小为 1 的层)和一个sigmoid 激活函数。这个单元将编码模型正在处理某一类或另一类的概率。
最后还有一个小区别:我们将从模型的一个Rescaling 层开始,该层会将图像输入(其值最初在 [0, 255] 范围内)重新缩放到 [0, 1] 范围。
1 | import keras |
清单 8.7:实例化一个用于狗与猫分类的小型卷积神经网络
让我们来看看特征图的尺寸是如何随着每一层的变化而变化的:
1 | >>> model.summary() |
在编译步骤中,您将像往常一样使用adam优化器。由于您最终的模型只有一个 sigmoid 单元,因此您将使用二元交叉熵作为损失函数(提醒一下,请查看第 6 章中的表 6.1,其中提供了在各种情况下使用损失函数的速查表)。
1 | model.compile( |
清单 8.8:配置模型以进行训练
数据预处理
Data preprocessing
如您所知,数据在输入模型之前,需要格式化为经过适当预处理的浮点张量。目前,数据以 JPEG 文件的形式存储在硬盘上,因此将其导入模型的步骤大致如下:
- 阅读图片文件。
- 将JPEG内容解码为RGB像素网格。
- 将它们转换为浮点张量。
- 将它们调整为相同的大小(我们将使用 180 x 180)。
- 将它们分批打包(我们将使用 32 张图片为一批)。
这看起来可能有点复杂,但幸运的是,Keras 提供了一些实用工具来自动完成这些步骤。特别是,Keras 提供了一个实用函数 image_dataset_from_directory,可以让你快速设置数据管道,自动将磁盘上的图像文件转换为预处理后的张量批次。这就是你在这里要用到的。
首先,该函数image_dataset_from_directory(directory)会列出所有子目录,directory并假定每个子目录都包含来自某个类的图像。然后,它会对每个子目录中的图像文件进行索引。最后,它会创建一个对象并返回tf.data.Dataset该对象,该对象配置为读取这些文件、打乱顺序、将它们解码为张量、将它们调整为统一大小,并将它们打包成批次。
1 | from keras.utils import image_dataset_from_directory |
清单 8.9:用于image_dataset_from_directory从目录中读取图像
了解 TensorFlow 数据集对象
Understanding TensorFlow Dataset objects
TensorFlow 提供了tf.data用于创建高效机器学习模型输入管道的 API。其核心类是tf.data.Dataset。
该类Dataset可用于任何框架(不仅限于 TensorFlow)中的数据加载和预处理。您可以将其与 JAX 或 PyTorch 结合使用。当您将其与 Keras 模型一起使用时,其工作方式与您当前使用的后端无关。
对象Dataset本身就是一个迭代器:你可以在for循环中使用它。它通常会返回一批批的输入数据和标签。你可以Dataset 直接将对象传递给fit()Keras 模型的方法。
该类Dataset处理了许多关键特性,否则自己实现起来会很麻烦,特别是跨多个 CPU 核心的预处理逻辑并行化,以及异步数据预取(在模型处理前一批数据时预处理下一批数据,从而保持执行流畅而不中断)。
该类Dataset还提供了一个函数式风格的 API,用于修改数据集。这里有一个简单的例子:让我们Dataset从一个 NumPy 随机数数组创建一个实例。我们考虑 1000 个样本,其中每个样本都是一个大小为 16 的向量。
1 | import numpy as np |
清单 8.10:Dataset从 NumPy 数组 实例化一个对象
最初,我们的数据集只包含单个样本。
1 | >>> for i, element in enumerate(dataset): |
清单 8.11:迭代数据集
你可以使用该.batch()方法对数据进行批量处理。
1 | >>> batched_dataset = dataset.batch(32) |
清单 8.12:批量处理数据集
更广泛地说,您可以使用一系列有用的数据集方法,例如以下这些:
.shuffle(buffer_size)将缓冲区内的元素重新排列。.prefetch(buffer_size)将预先在 GPU 内存中加载一个元素缓冲区,以实现更好的设备利用率。.map(callable)将对数据集中的每个元素应用任意变换(该函数callable预期以数据集产生的单个元素作为输入)。
这种方法.map(function, num_parallel_calls)你以后会经常用到。举个例子:我们用它将玩具数据集中的元素从一种形状重塑成另一种(16,) 形状(4, 4)。
1 | >>> reshaped_dataset = dataset.map( |
清单 8.13Dataset :使用以下方法对元素应用转换map()
map()接下来的章节中,你将会看到更多精彩的动作场面。
模型拟合
Fitting the model
我们来看一下其中一个对象的输出Dataset:它生成若干批次的 180 × 180 RGB 图像(形状为(32, 180, 180, 3))和整数标签(形状为(32,))。每个批次包含 32 个样本(批次大小为 32)。
1 | >>> for data_batch, labels_batch in train_dataset: |
清单 8.14:显示由以下方式产生的形状Dataset
让我们用数据集拟合模型。我们使用validation_data参数fit()来监控一个独立Dataset对象的验证指标。
请注意,我们还使用ModelCheckpoint回调函数在每个训练周期结束后保存模型。我们通过配置文件保存路径以及参数 --metric 和 --metric-id 来设置save_best_only=True回调monitor="val_loss"函数:这些参数指示回调函数仅在当前指标值val_loss低于训练期间任何先前值时才保存新文件(覆盖任何先前的文件)。这确保了保存的文件始终包含模型在验证集上表现最佳的训练周期对应的状态。因此,如果模型开始过拟合,我们无需重新训练一个训练周期数更少的新模型:只需重新加载已保存的文件即可。
1 | callbacks = [ |
清单 8.15:使用以下方法拟合模型Dataset
让我们绘制模型在训练期间对训练数据和验证数据的损失和准确率(见图 8.9)。
1 | import matplotlib.pyplot as plt |
清单 8.16:显示训练过程中的损失和准确率曲线
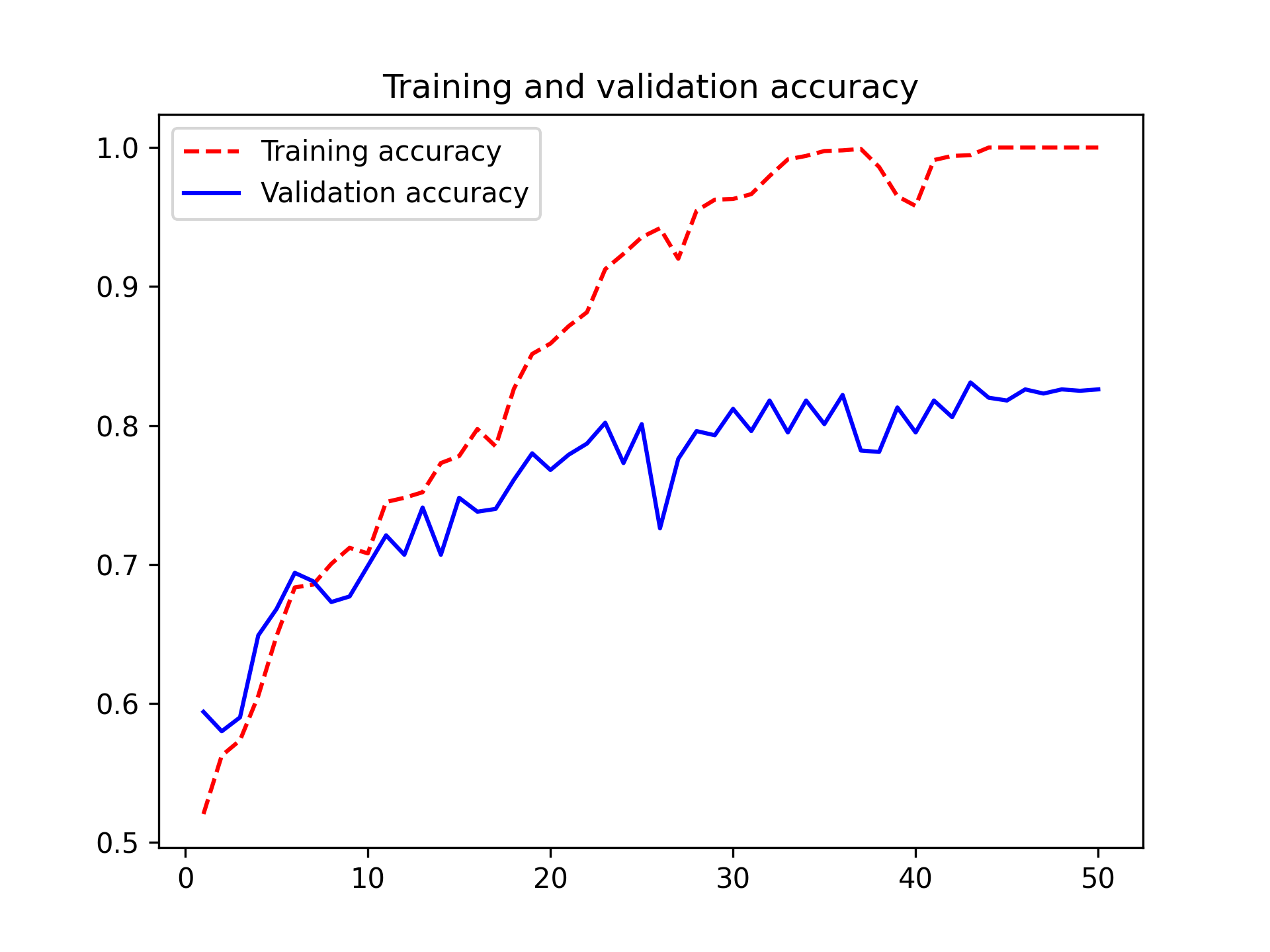
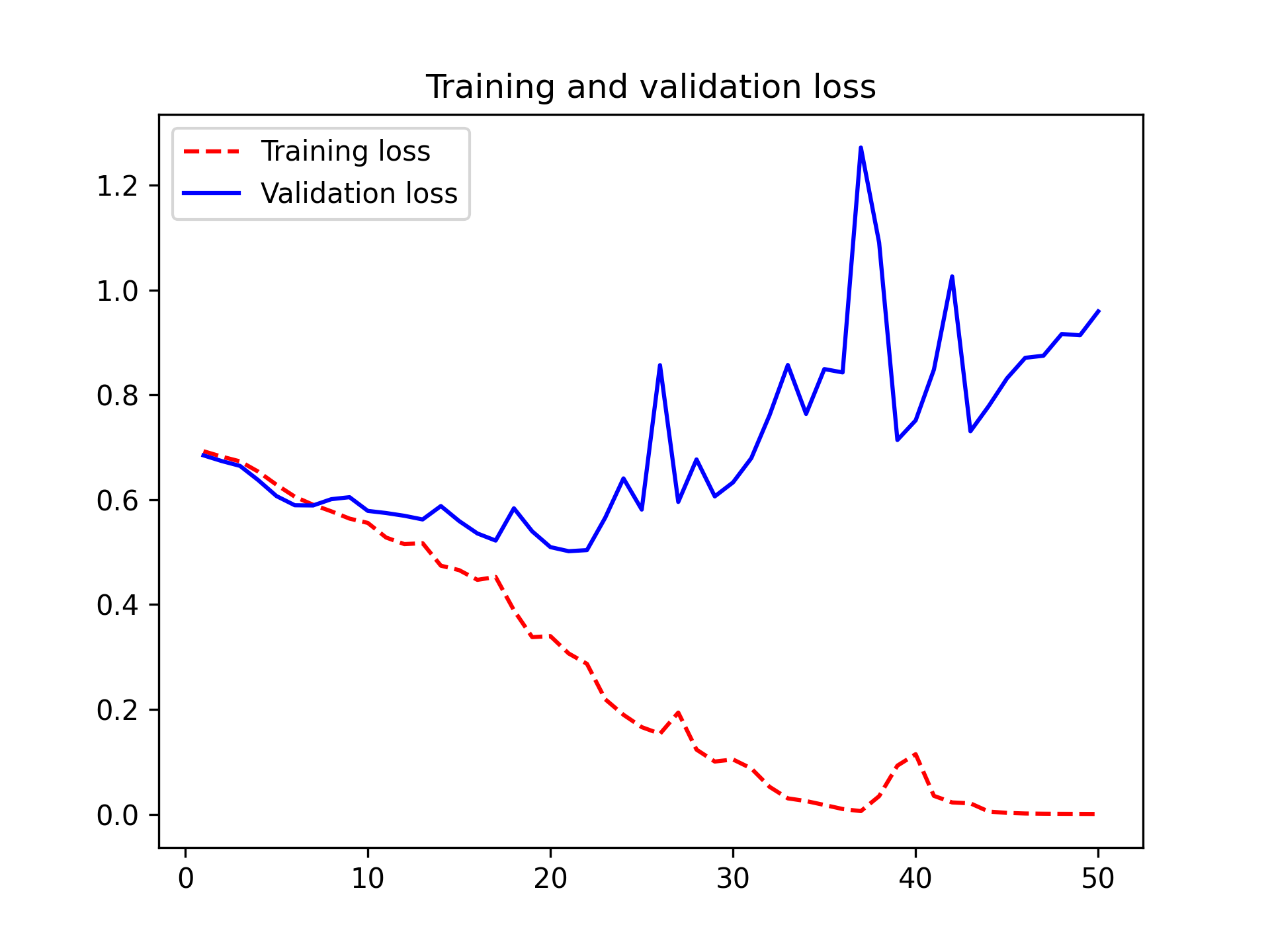 图 8.9:简单卷积神经网络的训练和验证指标
图 8.9:简单卷积神经网络的训练和验证指标
这些曲线图是过拟合的典型特征。训练准确率随时间线性增长,直至接近 100%,而验证准确率则在 80% 左右达到峰值。验证损失在仅 10 个 epoch 后达到最小值并停滞不前,而训练损失则随着训练的进行持续线性下降。
我们来检查一下测试准确率。我们将从保存的文件中重新加载模型,以便评估它在过拟合之前的状态。
1 | test_model = keras.models.load_model("convnet_from_scratch.keras") |
清单 8.17:在测试集上评估模型
我们得到的测试准确率为 78.6%(由于神经网络初始化的随机性,您可能会得到与此相差几个百分点的数字)。
由于训练样本相对较少(2000 个),过拟合将是首要问题。您已经了解一些可以帮助缓解过拟合的技术,例如 dropout 和权重衰减(L2 正则化)。现在我们将介绍一种新的技术,它专门用于计算机视觉,并且在使用深度学习模型处理图像时几乎被普遍采用:数据增强。
Because you have relatively few training samples (2,000), overfitting will be your number-one concern. You already know about a number of techniques that can help mitigate overfitting, such as dropout and weight decay (L2 regularization). We’re now going to work with a new one, specific to computer vision and used almost universally when processing images with deep learning models: data augmentation.
利用数据增强
Using data augmentation
过拟合是由于可供学习的样本数量过少造成的,导致模型无法泛化到新数据。如果数据量无限大,模型就能接触到数据分布的每一个可能特征,从而避免过拟合。数据增强的方法是通过对现有训练样本进行一系列随机变换,生成更多训练数据,最终得到看起来逼真的图像。其目标是确保在训练过程中,模型永远不会看到完全相同的图像两次。这有助于模型接触到更多数据特征,从而提升泛化能力。
在 Keras 中,这可以通过数据增强层来实现。可以通过以下两种方式之一添加此类层:
- 模型开始时——在模型内部。在我们的例子中,图层会紧挨着图层
Rescaling。 - 在数据管道内部——模型 外部
Dataset。在我们的例子中,我们会通过map()调用将它们应用到我们的模型中。 - At the start of the model — Inside the model. In our case, the layers would come right before the
Rescalinglayer. - Inside the data pipeline — Outside the model. In our case, we’d apply them to our
Datasetvia amap()call.
这两种方案的主要区别在于,模型内部的数据增强操作会像模型的其他部分一样在GPU上运行。而数据管道中的数据增强操作则会在CPU上运行,通常是在多个CPU核心上并行执行。有时,前者可能带来性能优势,但后者通常是更好的选择。所以我们选择后者!
1 | # Defines the transformations to apply as a list |
清单 8.18:定义数据增强阶段
以上仅列举了部分可用层(更多层请参见 Keras 文档)。我们快速浏览一下这段代码:
RandomFlip("horizontal")将对随机抽取的 50% 的图像进行水平翻转。RandomRotation(0.1)将输入图像旋转 [-10%, +10%] 范围内的随机值(这些是完整圆的一部分——以度为单位,范围为 [-36 度, +36 度])。RandomZoom(0.2)将图像按 [-20%, +20%] 范围内的随机因子放大或缩小。
让我们来看一下增强后的图像(见图 8.10)。
1 | plt.figure(figsize=(10, 10)) |
列表 8.19:显示一些随机增强的训练图像
 图 8.10:通过随机数据增强生成优秀男孩的各种变体
图 8.10:通过随机数据增强生成优秀男孩的各种变体
如果使用这种数据增强配置训练新模型,模型将永远不会看到两次相同的输入。但由于原始图像数量有限,输入之间仍然存在高度相关性——你无法生成新信息,只能重新组合现有信息。因此,这可能不足以完全消除过拟合。为了进一步抑制过拟合,你还需要Dropout在全连接分类器之前添加一个层。
1 | inputs = keras.Input(shape=(180, 180, 3)) |
清单 8.20:定义一个包含 dropout 的新型卷积神经网络
让我们使用数据增强和dropout来训练模型。由于我们预期过拟合会在训练后期出现,因此我们将训练的epoch数翻倍,达到100。请注意,我们使用未经增强的图像进行评估——数据增强通常只在训练阶段进行,因为它是一种正则化技术。
1 | callbacks = [ |
清单 8.21:在增强图像上训练正则化卷积神经网络
让我们再次绘制结果图;参见图 8.11。由于采用了数据增强和 dropout,我们过拟合的出现时间要晚得多,大约在第 60-70 个 epoch 左右(相比之下,原始模型在第 10 个 epoch 就出现了过拟合)。验证准确率最终达到了 85% 以上——相比第一次尝试有了显著提升。
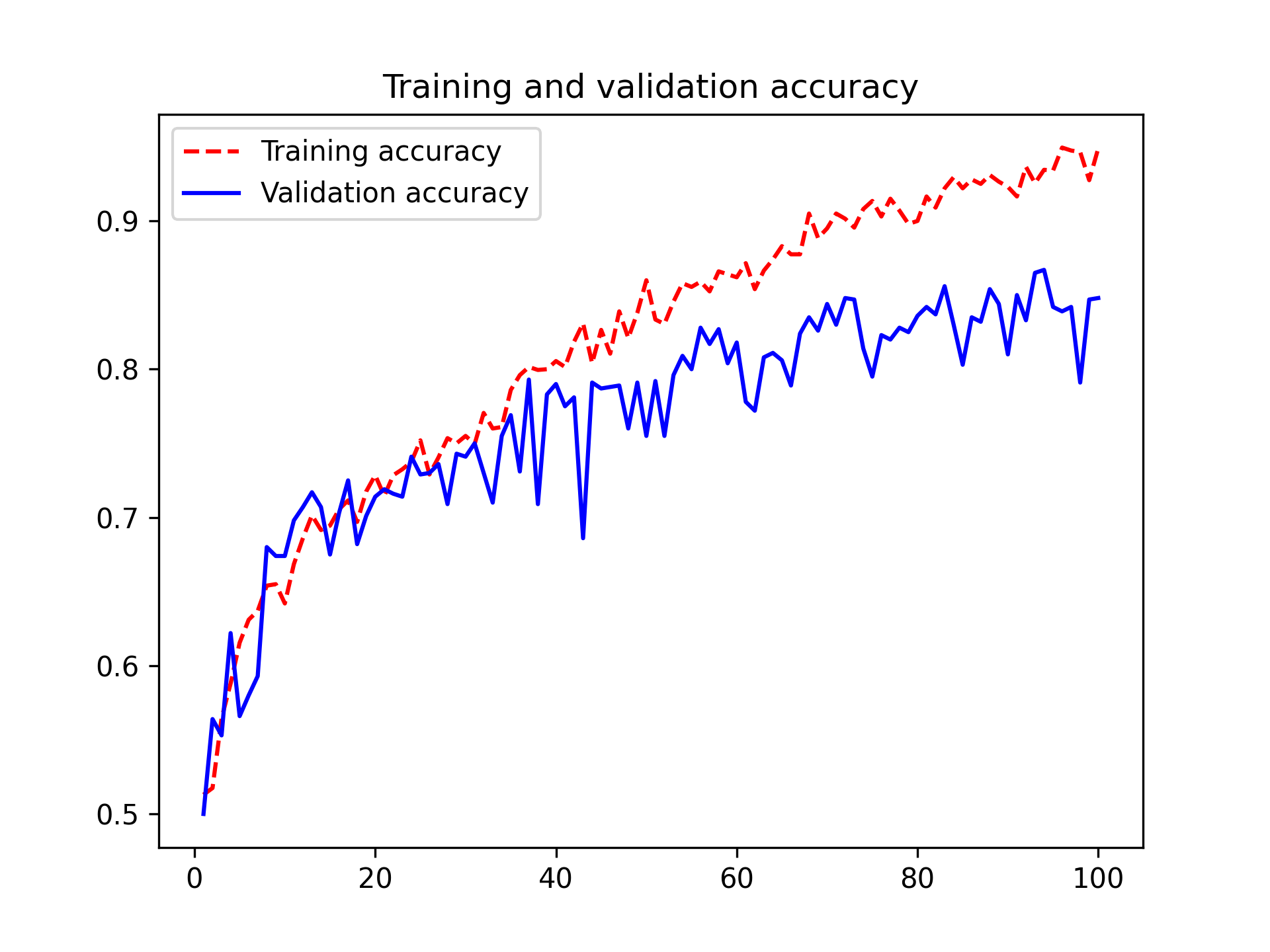
 图 8.11:数据增强后的训练和验证指标
图 8.11:数据增强后的训练和验证指标
我们来检验一下测试的准确性。
1 | test_model = keras.models.load_model( |
清单 8.22:在测试集上评估模型
我们得到了 83.9% 的测试准确率。情况开始好转!如果您使用的是 Colab,请务必下载保存的文件(convnet_from_scratch_with_augmentation.keras),因为我们将在下一章的一些实验中使用它。
通过进一步调整模型的配置(例如每个卷积层的滤波器数量或模型中的层数),您或许可以获得更高的准确率,可能高达 90%。但是,由于数据量有限,仅靠从头开始训练自己的卷积神经网络很难进一步提高准确率。为了进一步提高此问题的准确率,您需要使用预训练模型,这也是接下来两节的重点。
使用预训练模型
Using a pretrained model
在小型图像数据集上进行深度学习时,一种常见且高效的方法是使用预训练模型。预训练模型是指先前在大型数据集上训练过的模型,通常是针对大规模图像分类任务进行的训练。如果原始数据集足够大且足够通用,那么预训练模型学习到的空间特征层次结构可以有效地作为视觉世界的通用模型,因此其特征可以应用于许多不同的计算机视觉问题,即使这些新问题涉及的类别与原始任务完全不同。例如,您可以在 ImageNet 数据集(其中类别主要为动物和日常物品)上训练一个模型,然后将该训练好的模型用于识别图像中的家具等看似毫不相关的任务。这种学习特征在不同问题之间的可移植性是深度学习相对于许多较旧的浅层学习方法的关键优势,也使得深度学习在处理小数据问题时非常有效。
在这种情况下,我们考虑一个在 ImageNet 数据集(140 万张带标签的图像和 1000 个不同的类别)上训练的大型卷积神经网络。ImageNet 包含许多动物类别,包括不同种类的猫和狗,因此可以预期它在猫狗分类问题上表现良好。
我们将使用 Xception 架构。这可能是你第一次接触到这些可爱的模型名称——Xception、ResNet、EfficientNet 等等;如果你继续学习计算机视觉方面的深度学习,就会经常用到它们,所以你会逐渐习惯它们。你将在下一章学习 Xception 的架构细节。
使用预训练模型有两种方法:特征提取和 微调。我们将介绍这两种方法。首先来看特征提取。
There are two ways to use a pretrained model: feature extraction and fine-tuning. We’ll cover both of them. Let’s start with feature extraction.
使用预训练模型进行特征提取
Feature extraction with a pretrained model
特征提取是指利用先前训练的模型学习到的特征表示,从新样本中提取感兴趣的特征。然后,将这些特征输入到一个新的分类器中,该分类器是从头开始训练的。
如前所述,用于图像分类的卷积神经网络(ConvNets)由两部分组成:它以一系列池化层和卷积层开始,以全连接分类器结束。第一部分称为模型的卷积基或骨干网络。对于卷积神经网络而言,特征提取包括:使用先前训练好的网络的卷积基,将新数据输入该网络,并基于输出训练一个新的分类器(参见图 8.12)。
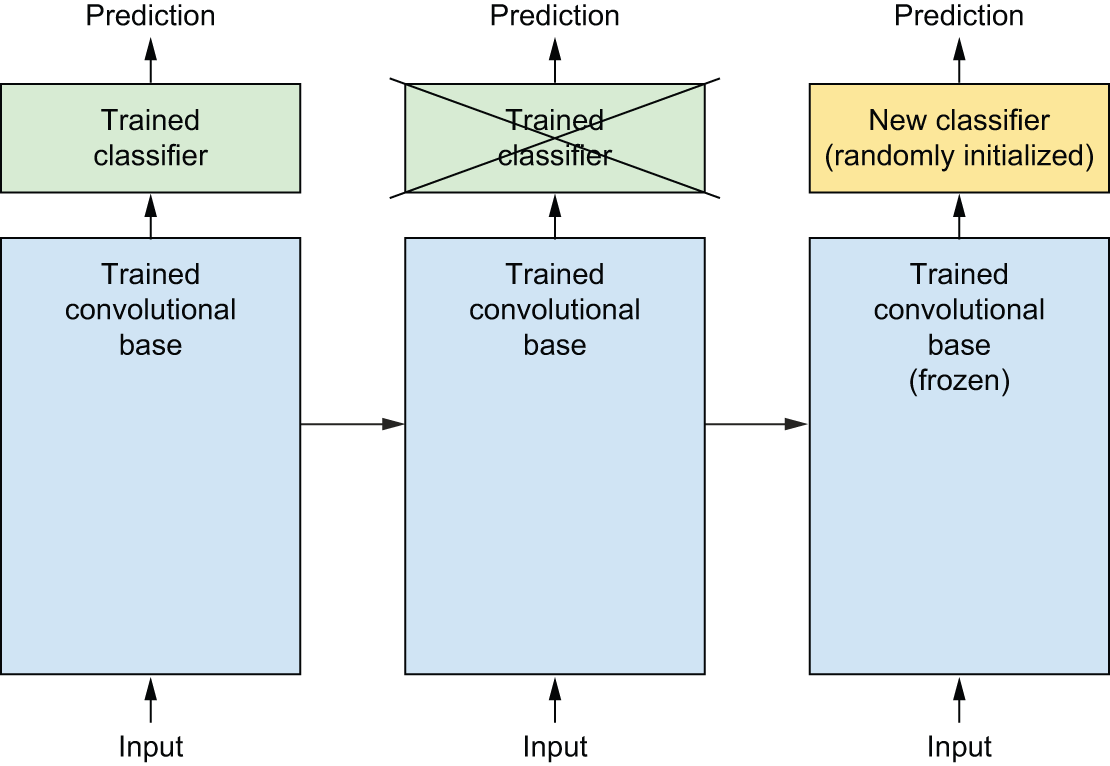 图 8.12:在保持相同卷积基不变的情况下交换分类器
图 8.12:在保持相同卷积基不变的情况下交换分类器
为什么只复用卷积层?能否也复用全连接分类器?通常应该避免这样做。原因在于卷积层学习到的表征往往更通用,因此更易于复用:卷积神经网络的特征图是图像中通用概念的存在性图,无论实际的计算机视觉问题是什么,这些特征图都可能有用。但分类器学习到的表征必然是针对模型训练所用的类别集而言的——它们只包含某个类别在整幅图像中出现的概率信息。此外,全连接层中的表征不再包含任何关于物体在输入图像中位置的信息:这些层消除了空间的概念,而物体的位置仍然由卷积特征图描述。对于物体位置至关重要的问题,全连接特征基本上毫无用处。
请注意,特定卷积层提取的特征表示的通用性(以及由此而来的可重用性)取决于该层在模型中的深度。模型中较靠前的层提取的是局部的、高度通用的特征图(例如视觉边缘、颜色和纹理),而较靠上的层则提取更抽象的概念(例如“猫耳朵”或“狗眼睛”)。因此,如果您的新数据集与训练原始模型的数据集差异很大,那么最好只使用模型的前几层进行特征提取,而不是使用整个卷积层。
在这种情况下,由于 ImageNet 分类集包含多个狗和猫类别,重用原始模型全连接层中包含的信息可能是有益的。但我们选择不这样做,以便涵盖更一般的情况,即新问题的分类集与原始模型的分类集不重叠。让我们通过实际操作来验证这一点:使用预训练模型的卷积层从猫和狗的图像中提取特征,然后基于这些特征训练一个区分狗和猫的分类器。
我们将使用KerasHub库来创建本书中使用的所有预训练模型。KerasHub 包含常用预训练模型架构的 Keras 实现,并配有可下载到本地的预训练权重。它包含许多卷积神经网络(ConvNet),例如 Xception、ResNet、EfficientNet 和 MobileNet,以及我们将在本书后续章节中使用的更大型的生成模型。让我们尝试使用它来实例化在 ImageNet 数据集上训练的 Xception 模型。
KerasHub 是一个独立于 Keras 的软件包。该软件包已预装在 Colab 和 Kaggle notebooks 中,但如果您想在这些环境之外使用它,可以使用以下命令自行安装pip install keras-hub。
1 | import keras_hub |
清单 8.23:实例化 Xception 卷积基
你会注意到几点。首先,KerasHub 使用术语“ backbone”(骨干网络)来指代底层特征提取网络,而不包括分类头(这比“convolutional base”(卷积基网络)更容易输入)。它还使用一个名为 configuration 的特殊构造函数from_preset()来下载 Xception 模型的配置和权重。
我们使用的模型名称中的“41”是什么意思?按照惯例,预训练的卷积神经网络通常以其“深度”命名。在这个例子中,“41”表示我们的 Xception 模型有 41 个可训练层(卷积层和全连接层),层层堆叠。就本书目前为止所用到的模型而言,它是“最深”的,而且优势非常明显。
在使用这个模型之前,我们还需要完成一个步骤。每个预训练的卷积神经网络在预训练之前都会对图像进行缩放和调整大小。确保输入图像与预训练检查点匹配至关重要;否则,我们的模型将需要重新学习如何从输入范围完全不同的图像中提取特征。与其跟踪哪些预训练模型使用[0, 1]特定范围的像素值输入,哪些使用[-1, 1] 特定范围,我们可以使用一个名为 Rescale_Image 的 KerasHub 层,ImageConverter它会将图像缩放到与预训练检查点匹配。它 from_preset()与主干类具有相同的特殊构造函数。
1 | preprocessor = keras_hub.layers.ImageConverter.from_preset( |
清单 8.24:实例化与 Xception 模型配对的预处理
此时,你有两种方法可以继续:
将卷积基运算应用于你的数据集,并将输出记录到磁盘上的 NumPy 数组中,然后将这些数据作为输入,输入到一个独立的、全连接分类器中,类似于你在第 4 章和第 5 章中看到的分类器。这种解决方案运行速度快且成本低,因为它只需要对每个输入图像运行一次卷积基运算,而卷积基运算是整个流程中最耗时的部分。但正因如此,这种方法无法使用数据增强。
在现有模型的基础上
conv_base添加Dense层,并对输入数据进行端到端的运行,即可扩展模型。这样就可以使用数据增强,因为每次模型处理输入图像时,图像都会经过卷积层。但正因如此,这种方法比第一种方法成本更高。
我们将介绍这两种技术。首先,让我们逐步了解设置第一种方法所需的代码:记录conv_base数据的输出,并将这些输出用作新模型的输入。
无需数据增强的快速特征提取
Fast feature extraction without data augmentation
我们将首先通过调用模型predict()的方法,conv_base在训练集、验证集和测试集上提取特征,并将结果保存为 NumPy 数组。接下来,我们将遍历数据集,提取预训练模型的特征。
1 | def get_features_and_labels(dataset): |
清单 8.25:提取图像特征及其对应的标签
重要的是,predict()它只期望图像,不期望标签,但我们当前的数据集产生的批次既包含图像也包含标签。
提取的特征目前形状如下(samples, 6, 6, 2048):
1 | >>> train_features.shape |
此时,您可以定义您的密集连接分类器(注意使用 dropout 进行正则化),并根据您刚刚记录的数据和标签对其进行训练。
1 | inputs = keras.Input(shape=(6, 6, 2048)) |
清单 8.26:定义和训练密集连接分类器
由于只需要处理Dense两层,训练速度非常快——即使在 CPU 上,一个 epoch 也只需不到 1 秒。
让我们来看一下训练期间的损失和准确率曲线(见图 8.13)。
1 | import matplotlib.pyplot as plt |
清单 8.27:绘制结果
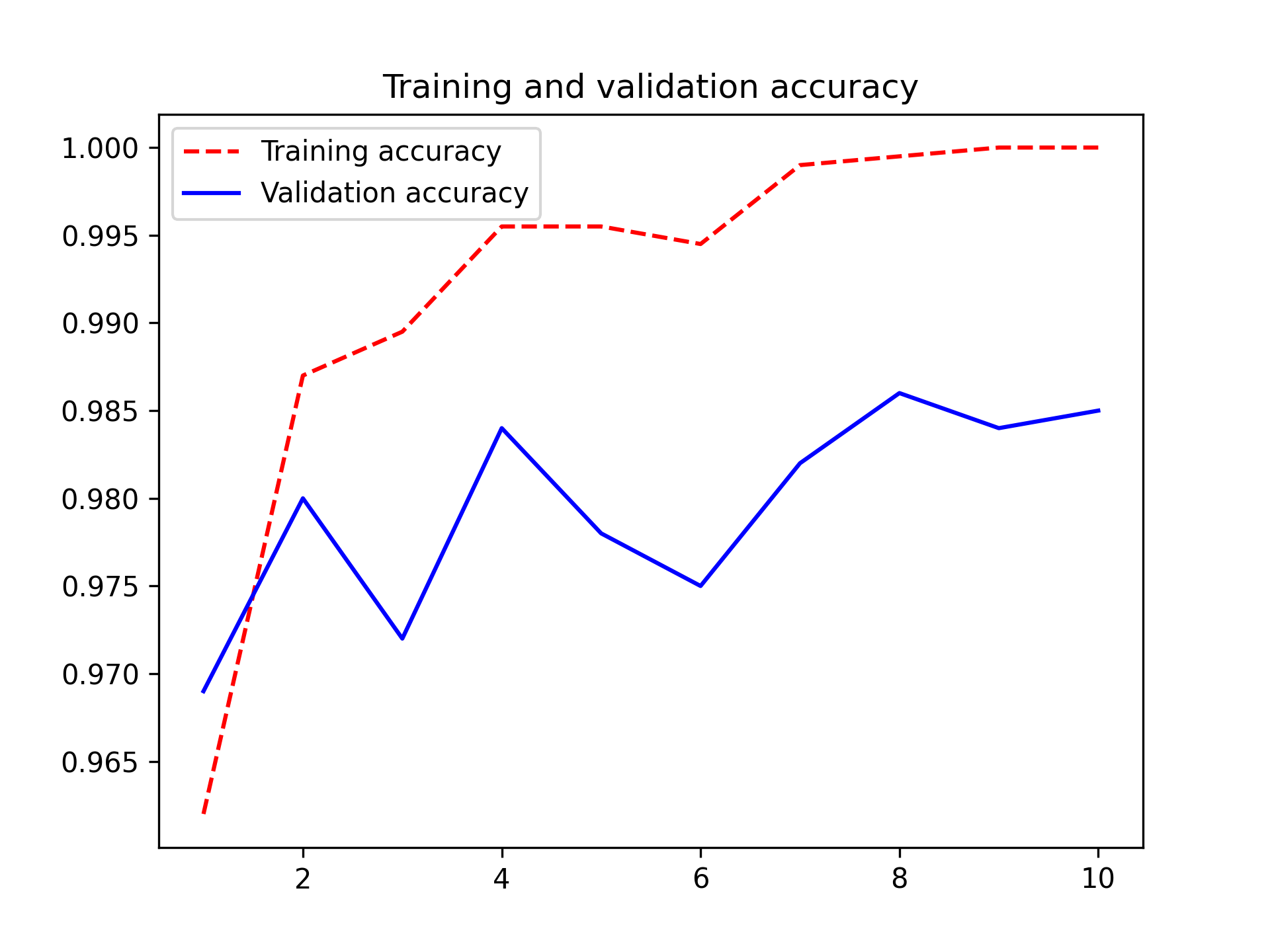
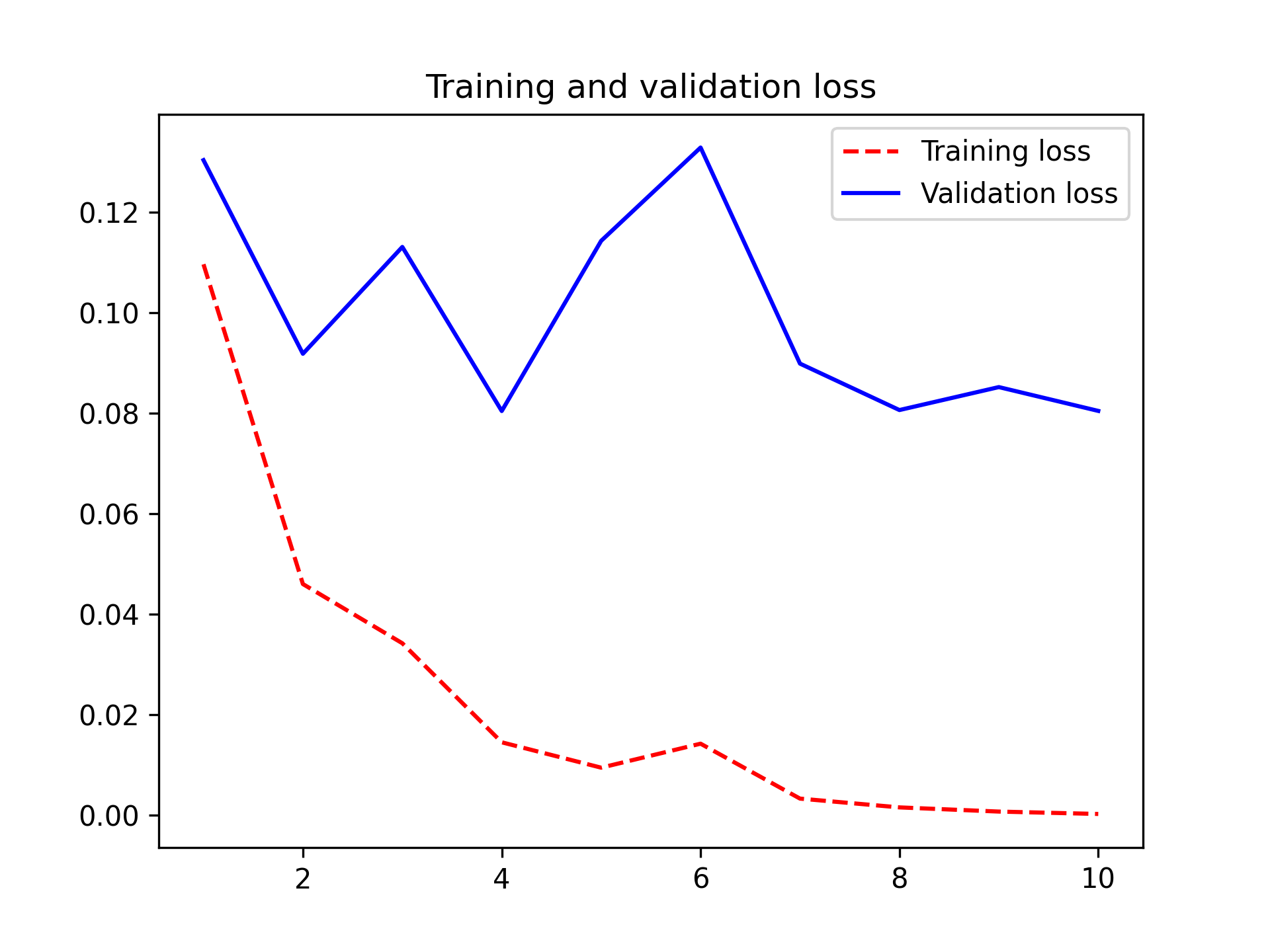 图 8.13:普通特征提取的训练和验证指标
图 8.13:普通特征提取的训练和验证指标
你的验证准确率达到了略高于 98%——比上一节中从零开始训练的小模型所取得的成绩要好得多。然而,这样的比较并不完全公平,因为 ImageNet 包含大量的猫狗样本,这意味着我们的预训练模型已经掌握了完成当前任务所需的全部知识。但使用预训练特征时,情况并非总是如此。
然而,图表也表明,尽管使用了相当大的 dropout 率,但几乎从一开始就出现了过拟合。这是因为该技术没有使用数据增强,而数据增强对于防止小型图像数据集出现过拟合至关重要。
让我们来检验一下测试的准确性:
1 | test_model = keras.models.load_model("feature_extraction.keras") |
我们的测试准确率达到了 98.1%——相比从头开始训练模型,这是一个非常好的进步!
特征提取与数据增强
Feature extraction together with data augmentation
现在,让我们回顾一下我们提到的第二种特征提取技术,这种技术速度更慢、成本更高,但允许你在训练期间使用数据增强:创建一个模型,将conv_base新密集分类器与现有模型连接起来,并对输入进行端到端训练。
为此,我们首先要冻结卷积层。 冻结一层或几层意味着阻止它们在训练过程中更新权重。如果不这样做,卷积层先前学习到的表征将在训练过程中被修改。由于Dense上层是随机初始化的,非常大的权重更新会传播到整个网络,从而有效地破坏先前学习到的表征。
在 Keras 中,您可以通过将图层或模型的trainable属性设置为 来冻结它False。
1 | import keras_hub |
清单 8.28:创建冻结卷积基
设置trainable为False会清空层或模型的可训练权重列表。
个人注:
在 Keras 中,您可以通过将图层或模型的trainable属性设置为 来冻结它False。
设置trainable为False会清空层或模型的可训练权重列表。
第一句(操作):trainable = False是一个“开关”。当你把它关掉时,你是在告诉优化器(Optimizer):“在反向传播更新参数时,请跳过这个层。”
第二句(底层):Keras 是如何实现“跳过”的呢?它的做法非常干脆——直接把这个层的权重从“可训练列表”中拿走。
1 | >>> conv_base.trainable = True |
清单 8.29:打印冻结前后的可训练重量列表
现在,我们可以创建一个新模型,将我们冻结的卷积基模型和密集分类器连接起来,如下所示:
1 | inputs = keras.Input(shape=(180, 180, 3)) |
在这种设置下,只会训练您添加的两层的权重Dense。总共有四个权重张量:每层两个(主权重矩阵和偏置向量)。请注意,要使这些更改生效,您必须先编译模型。如果在编译后修改了权重的可训练性,则应重新编译模型,否则这些更改将被忽略。
让我们开始训练模型。我们将重用已增强的数据集augmented_train_dataset。由于数据增强,模型需要更长时间才会出现过拟合,因此我们可以训练更多轮次——我们训练 30 轮:
1 | callbacks = [ |
这种方法成本很高,只有在可以使用GPU(例如Colab中提供的免费GPU)的情况下才应该尝试——在CPU上根本无法实现。如果你的代码无法在GPU上运行,那么之前的方法才是最佳选择。
让我们再次绘制结果图(见图 8.14)。该模型的验证准确率达到了 98.2%。
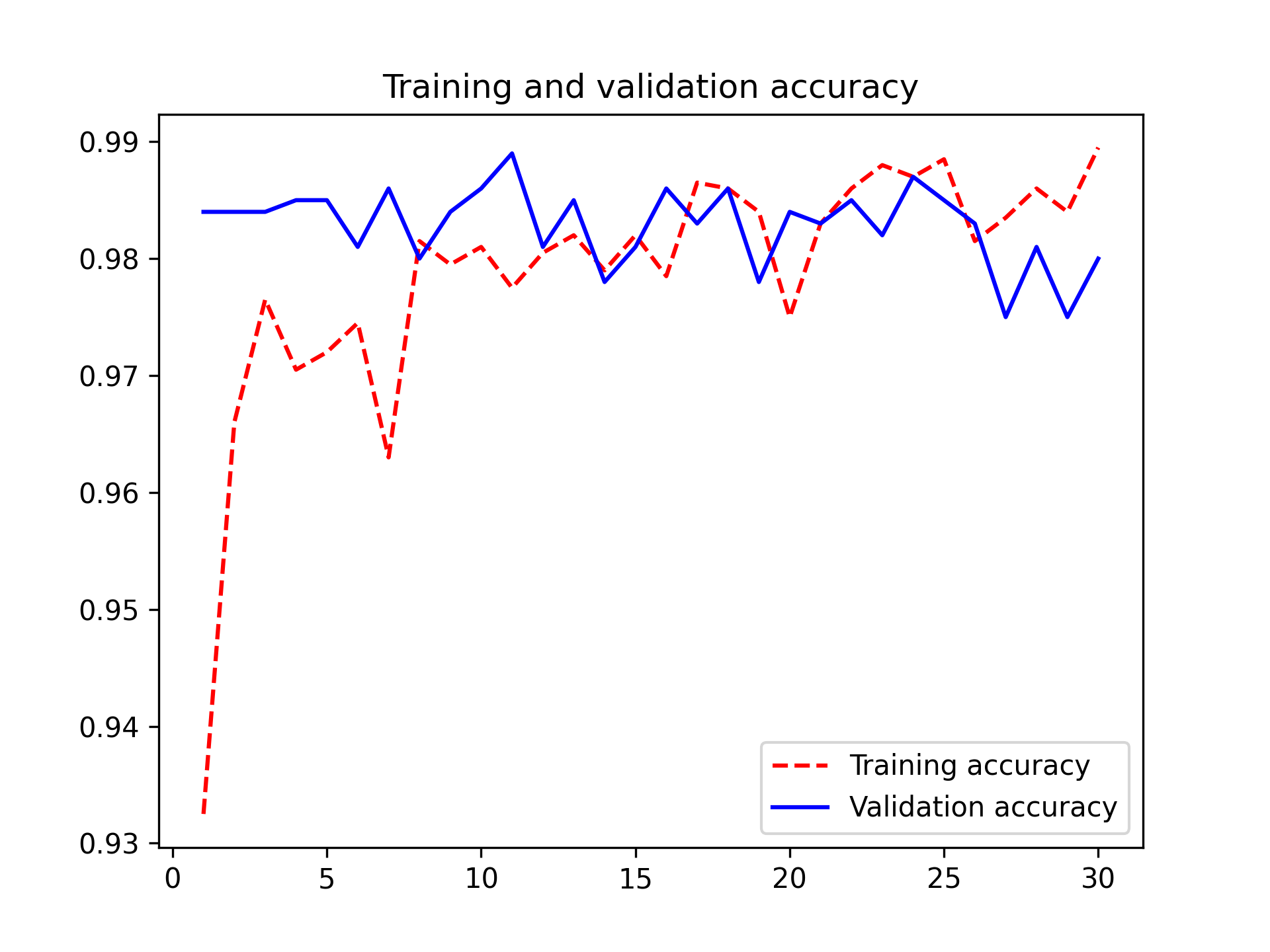
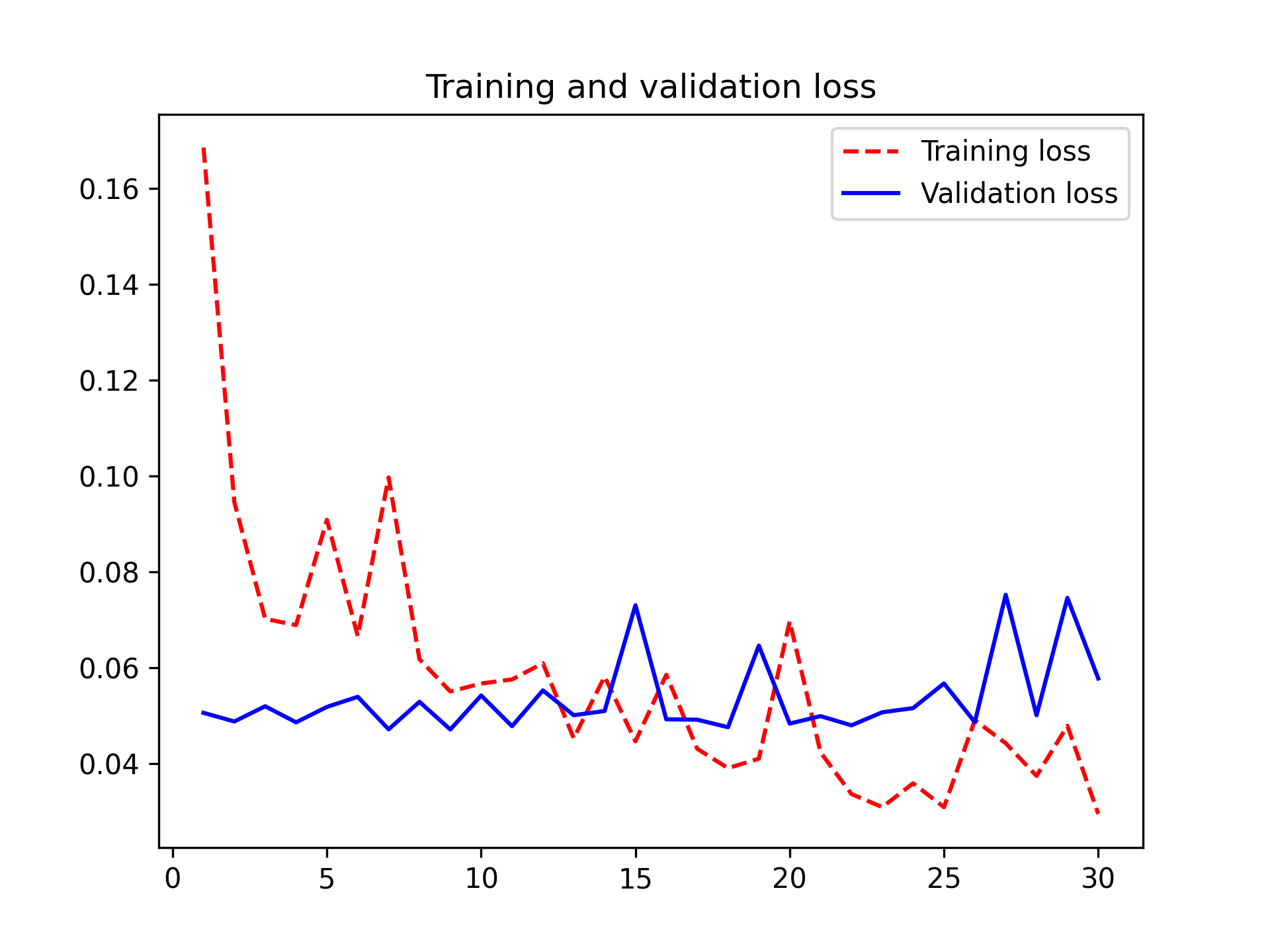 图 8.14:基于数据增强的特征提取的训练和验证指标
图 8.14:基于数据增强的特征提取的训练和验证指标
我们来检验一下测试的准确性。
1 | test_model = keras.models.load_model( |
清单 8.30:在测试集上评估模型
我们得到的测试准确率为 98.4%。这比之前的模型没有改进,有点令人失望。这可能表明我们的数据增强配置与测试数据的分布并不完全匹配。让我们看看最新的尝试能否取得更好的结果。
对预训练模型进行微调
Fine-tuning a pretrained model
另一种广泛用于模型重用的技术是微调(参见图 8.15),它是特征提取的补充。微调包括解冻用于特征提取的冻结模型基,并联合训练模型中新添加的部分(在本例中为全连接分类器)和基模型。之所以称为微调,是因为它对被重用模型的抽象表示进行微调,使其更适用于当前问题。
我们之前提到过,必须先冻结预训练的卷积层,才能在其上训练一个随机初始化的分类器。同样,只有在顶层分类器训练完成后,才能对卷积层进行微调。如果分类器尚未训练,那么训练过程中误差信号在网络中传播会过大,导致之前被微调层学习到的表征被破坏。因此,网络微调的步骤如下:
- 在已训练好的基础网络之上添加您的自定义网络。
- 冻结基础网络。
- 训练你新增的那部分。
- 解冻基础网络。
- 将这两层以及你添加的部分一起进行联合训练。
1 Add your custom network on top of an already trained base network.
2 Freeze the base network.
3 Train the part you added.
4 Unfreeze the base network.
5 Jointly train both these layers and the part you added.
个人注:
理解微调(Fine-tuning)中的“冻结”与“解冻”,核心在于控制模型中哪些参数允许根据新数据进行修改,哪些参数保持不变。
我们可以把这个过程想象成“入职培训”:
- 为什么要“冻结”?(保留通用知识)
预训练模型(如 BERT 或 ResNet)已经学习了海量的通用知识(比如语言的语法、图片的轮廓)。
- 动作:将
trainable属性设为False。- 目的:保护这些已经学好的“通用才华”不被新数据破坏。
- 底层变化:正如你之前看到的,这会将参数从“可训练列表”移出,优化器在训练时会直接跳过这些层。
- 为什么要“解冻”?(精细化定制)
当你发现模型虽然懂通用知识,但在处理你的特定任务(比如识别某种罕见的医学影像)时不够精准,就需要“解冻”。
- 动作:将
trainable设为True。- 目的:允许模型微调其内部的细节,使其更适应当前的数据分布。
- 标准的微调过程:先“冻”后“放”
通常我们不会一上来就全解冻,而是分阶段进行:
第一阶段:只练“新人”(完全冻结预训练部分)
- 操作:把整个预训练模型冻结,只给它接一个全新的分类层(随机初始化的)。
- 理解:先让这个“新员工”学会基本的分类逻辑。如果此时不冻结预训练模型,由于新层是随机的,产生的巨大误差(Loss)会通过反向传播把预训练模型里的好知识全给冲垮了(这叫“灾难性遗忘”)。
第二阶段:整体磨合(解冻部分或全部)
- 操作:在训练一段时间后,把预训练模型的一部分(通常是靠近输出的顶层)解冻,然后以极小的学习率继续训练。
- 理解:此时新层已经基本稳健了,我们可以稍微调动一下预训练模型的知识,让它和新层配合得更好。
请注意,您不应解冻“批量归一化”层(BatchNormalization)。批量归一化及其对微调的影响将在下一章中解释。
你已经完成了特征提取的前三个步骤。接下来进行第四步:你需要解冻你的conv_base……
局部微调
Partial fine-tuning
在这种情况下,我们选择解冻并微调 Xception 卷积基的所有层。然而,在处理大型预训练模型时,有时可能只会解冻卷积基的部分顶层,而保持底层冻结。您可能想知道,为什么只微调部分层?为什么特指顶层?原因如下:
- 卷积神经网络底层较早的层编码的是更通用、可复用的特征,而较高层则编码的是更专业的特征。微调这些专业特征更有用,因为这些特征需要在新的问题中重新利用。微调较低层带来的收益会迅速递减。
- 训练的参数越多,过拟合的风险就越大。卷积神经网络有 1500 万个参数,因此尝试用你的小数据集训练它是很冒险的。
- Earlier layers in the convolutional base encode more-generic, reusable features, whereas layers higher up encode more-specialized features. It’s more useful to fine-tune the more specialized features because these are the ones that need to be repurposed on your new problem. There would be fast-decreasing returns in fine-tuning lower layers.
- The more parameters you’re training, the more you’re at risk of overfitting. The convolutional base has 15 million parameters, so it would be risky to attempt to train it on your small dataset.
因此,只对卷积层中的前三到四层进行微调可能是一个不错的策略。你可以这样做:
1 | conv_base.trainable = True |
让我们先用非常低的学习率来微调模型。使用低学习率的原因在于,我们希望限制对正在微调的层表示所做的修改幅度。过大的更新可能会破坏这些表示。
1 | model.compile( |
清单 8.31:模型微调
现在终于可以使用测试数据来评估该模型了(见图 8.15):
1 | model = keras.models.load_model("fine_tuning.keras") |
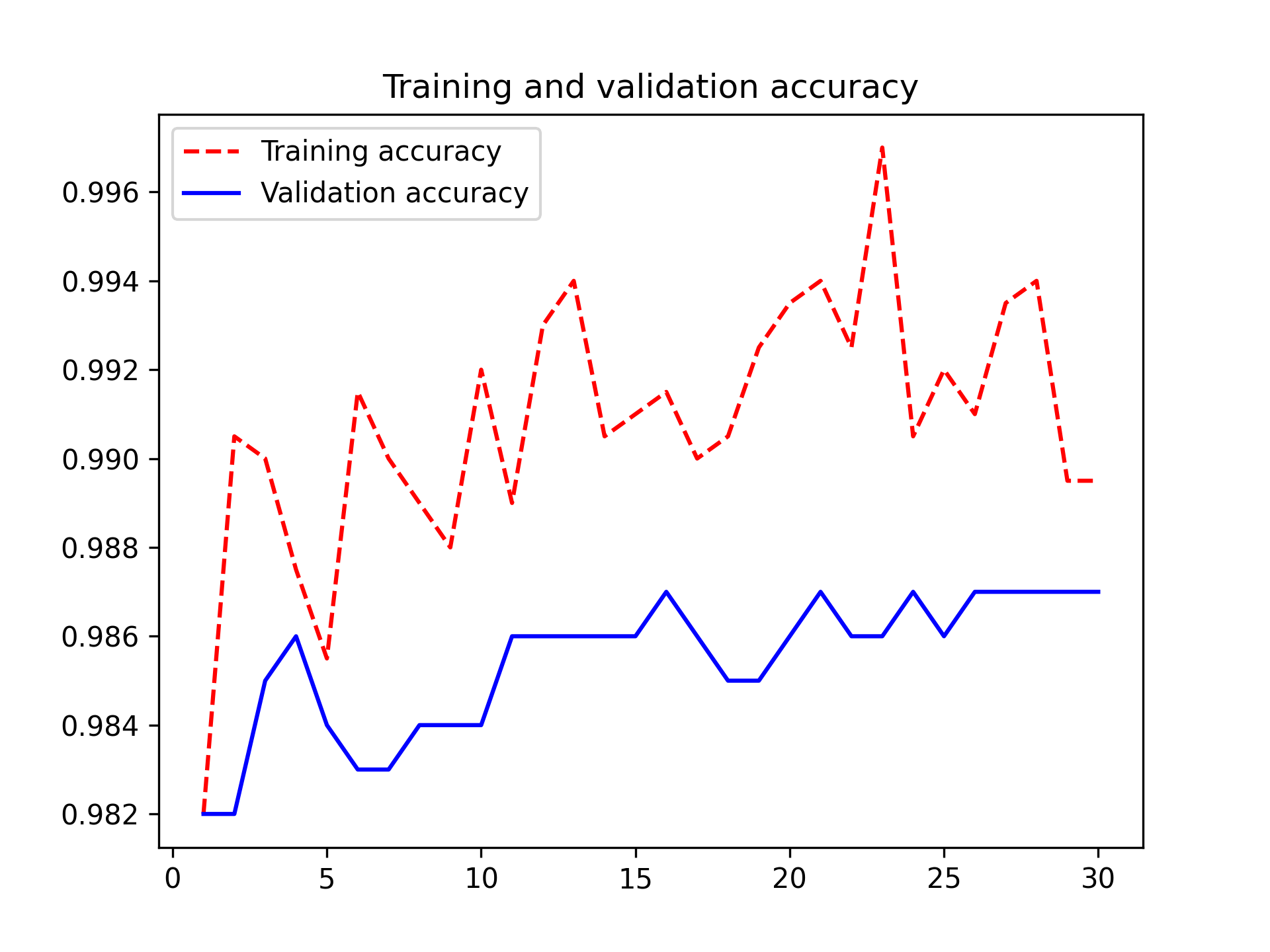
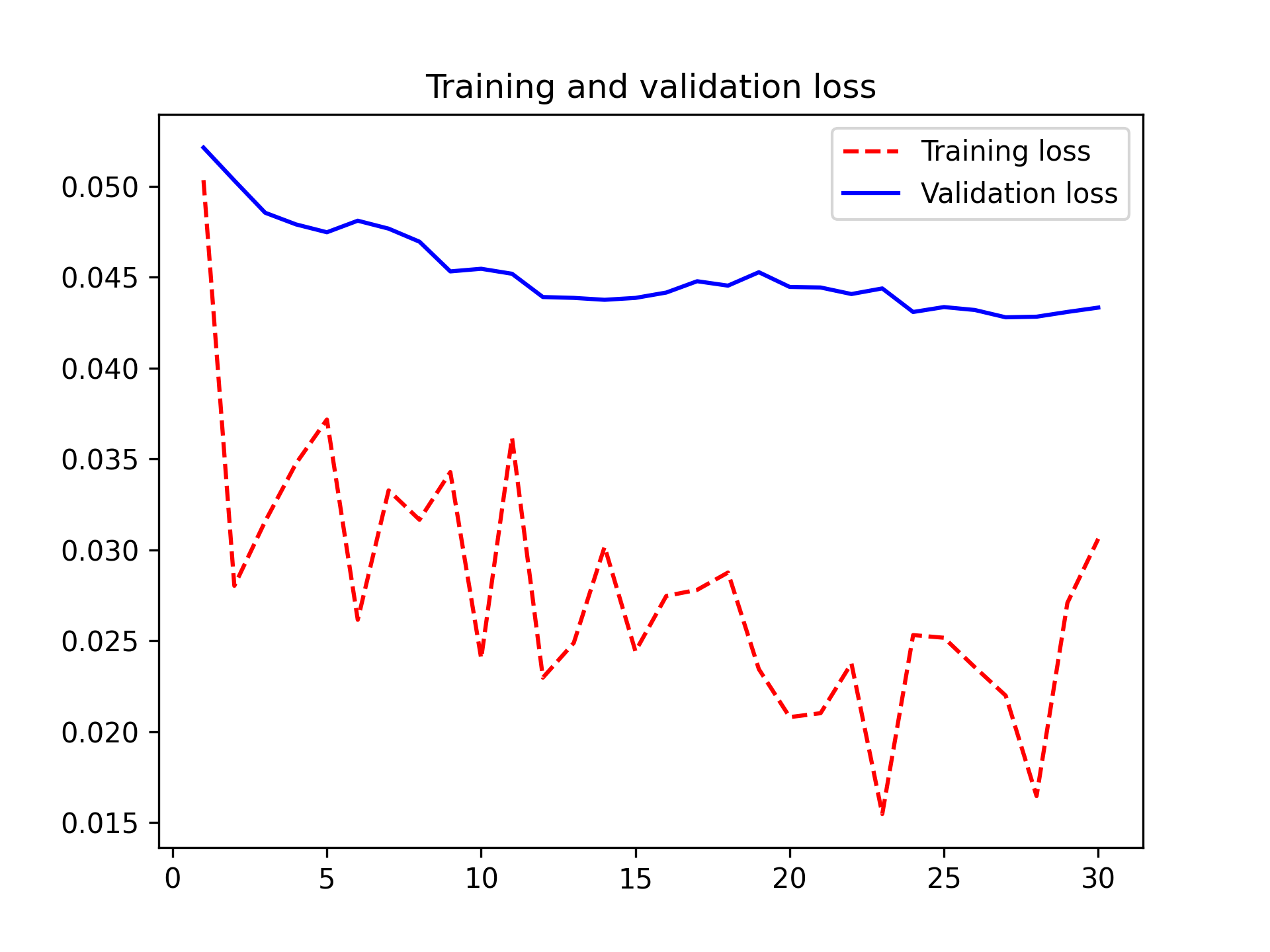 图 8.15:用于微调的训练和验证指标
图 8.15:用于微调的训练和验证指标
这里,你的测试准确率达到了 98.6%(当然,你自己的结果可能与此相差不到 0.5 个百分点)。在最初围绕该数据集举办的 Kaggle 竞赛中,这绝对是顶尖成绩之一。不过,这样的比较并不完全公平,因为你使用了预训练特征,这些特征已经包含了关于猫狗的先验知识,而当时的参赛者无法使用这些特征。
从积极的方面来看,通过运用现代深度学习技术,你们仅使用比赛可用训练数据的一小部分(约10%)就取得了这样的结果。能够用20000个样本进行训练和只有2000个样本进行训练之间有着巨大的差别!
现在您拥有了一套可靠的工具来处理图像分类问题——特别是处理小型数据集。
概括
- 卷积神经网络(ConvNets)在计算机视觉任务中表现出色。即使使用非常小的数据集,也可以从头开始训练一个卷积神经网络,并获得不错的结果。
- 卷积神经网络的工作原理是学习模块化模式和概念的层次结构来表示视觉世界。
- 对于小型数据集,过拟合是主要问题。数据增强是处理图像数据时对抗过拟合的有效方法。
- 通过特征提取,可以轻松地将现有的卷积神经网络复用于新的数据集。这对于处理小型图像数据集来说是一种非常有效的技术。
- 除了特征提取之外,你还可以使用微调,它将现有模型先前学习到的一些表征调整到新的问题中。这可以进一步提升性能。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论