《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
第六章 机器学习的通用工作流程
The universal workflow of machine learning
本章内容
- 构建机器学习问题
- 开发工作模型
- 在生产环境中部署和维护您的模型
我们之前的例子都假设我们已经有了一个带标签的数据集,可以立即开始训练模型。但在现实世界中,情况往往并非如此。你不是从数据集开始,而是从问题开始。
想象一下,你正在创办自己的机器学习咨询公司。你注册成立公司,搭建了一个精美的网站,并通知了你的人脉圈。项目开始纷至沓来:
- 一个面向图片分享社交网络的个性化照片搜索引擎——输入“婚礼”,即可检索你在婚礼上拍摄的所有照片,无需任何手动标记。
- 在一款新兴聊天应用中,标记帖子中的垃圾信息和冒犯性文本内容。
- 为在线广播用户构建音乐推荐系统。
- 检测电子商务网站的信用卡欺诈。
- 预测展示广告点击率,以决定在特定时间向特定用户展示哪个广告。
- 在饼干生产线的传送带上标记异常饼干。
- 利用卫星图像预测尚未发现的考古遗址的位置。
如果能直接导入正确的数据集并开始拟合深度学习模型,那就太方便了keras.datasets。可惜的是,在现实世界中,你必须从零开始。
在本章中,你将学习一个通用的循序渐进的蓝图,你可以用它来处理和解决任何机器学习问题,例如前面列出的那些问题。这个模板会将你在第4章和第5章中学到的所有内容整合起来,并为你提供更广泛的背景知识,这将有助于你理解接下来章节的学习内容。
机器学习的通用工作流程大致分为三个部分:
- 明确任务——理解问题领域以及客户需求背后的业务逻辑。收集数据集,了解数据的含义,并选择衡量任务成功与否的方法。
- 开发模型——准备数据以便机器学习模型可以处理它,选择模型评估协议和要超越的简单基线,训练一个具有泛化能力但可能过拟合的第一个模型,然后对模型进行正则化和调整,直到获得最佳的泛化性能。
- 部署模型— 向利益相关者展示您的工作成果,将模型部署到 Web 服务器、移动应用程序、网页或嵌入式设备,监控模型在实际应用中的性能,并开始收集构建下一代模型所需的数据。
- Define the task — Understand the problem domain and the business logic underlying what the customer asked. Collect a dataset, understand what the data represents, and choose how you will measure success on the task.
- Develop a model — Prepare your data so that it can be processed by a machine learning model, select a model evaluation protocol and a simple baseline to beat, train a first model that has generalization power that can overfit, and then regularize and tune your model until you achieve the best possible generalization performance.
- Deploy the model — Present your work to stakeholders, ship the model to a web server, a mobile app, a web page, or an embedded device, monitor the model’s performance in the wild, and start collecting the data you’ll need to build the next model generation.
让我们深入探讨一下。
定义任务
Defining the task
如果不深入了解工作的背景,就无法做好工作。客户为什么要解决这个特定问题?他们能从解决方案中获得什么价值?你的模型将如何使用?它将如何融入客户的业务流程?有哪些数据可用或可以收集?哪些机器学习任务可以映射到这个业务问题?
问题界定
Framing the problem
构建机器学习问题框架通常需要与利益相关者进行多次深入讨论。以下是您应该优先考虑的问题:
- 你的输入数据是什么?你想预测什么?只有拥有训练数据,你才能学习预测:例如,只有同时拥有电影评论和情感标注,你才能学习如何对电影评论的情感进行分类。因此,数据可用性通常是这个阶段的限制因素。在很多情况下,你将不得不自己收集和标注新的数据集(我们将在下一节中介绍)。
- 你面临的是哪种机器学习任务?是二元分类?多类分类?标量回归?向量回归?多类多标签分类?图像分割?排序?还是其他类型的任务,例如聚类、生成或强化学习?在某些情况下,机器学习甚至可能不是理解数据的最佳方法,你应该使用其他方法,例如传统的统计分析:
- 照片搜索引擎项目是一个多类别、多标签的分类任务。
- 垃圾邮件检测项目是一个二元分类任务。如果将“攻击性内容”设定为一个单独的类别,它就变成了一个三元分类任务。
- 事实证明,音乐推荐引擎与其说是通过深度学习,不如说是通过矩阵分解(协同过滤)来处理得更好。
- 信用卡欺诈检测项目是一个二元分类任务。
- 点击率预测项目是一个标量回归任务。
- 异常饼干检测是一个二元分类任务,但它也需要一个目标检测模型作为第一步,以便从原始图像中正确裁剪出饼干。请注意,被称为“异常检测”的机器学习技术集合并不适用于这种情况!
- 这个利用卫星图像寻找新考古遗址的项目是一个图像相似度排序任务:你需要检索出与已知考古遗址最相似的新图像。
- 现有的解决方案是什么样的?也许您的客户已经拥有一个精心设计的算法来处理垃圾邮件过滤或信用卡欺诈检测——其中包含大量嵌套
if语句。也许目前是由专人负责手动处理相关流程——例如监控饼干工厂的传送带并手动移除损坏的饼干,或者为喜欢特定歌手的用户创建歌曲推荐播放列表。您应该确保了解现有系统及其运作方式。 - 您需要应对哪些特殊限制?例如,您可能会发现您正在为其构建垃圾邮件检测系统的应用程序采用了严格的端到端加密,因此垃圾邮件检测模型必须部署在最终用户的手机上,并且必须使用外部数据集进行训练。或许,Cookie 过滤模型存在严重的延迟限制,因此需要在工厂的嵌入式设备上运行,而不是在远程服务器上运行。您应该充分了解您的工作将要应用的完整环境。
完成调研后,你应该清楚你的输入是什么,你的目标是什么,以及这个问题属于哪种类型的机器学习任务。在这个阶段,你需要清楚地认识到你所做的假设:
- 你假设根据输入数据可以预测目标值。
- 你假设现有数据(或即将收集的数据)具有足够的信息量,可以了解输入和目标之间的关系。
在建立起一个可行的模型之前,这些都只是假设,等待着被验证或推翻。并非所有问题都能用机器学习解决;即使你收集了输入 X 和目标 Y 的示例,也不意味着 X 包含足够的信息来预测 Y。例如,如果你试图根据股票近期的价格历史来预测其在股市上的走势,你不太可能成功,因为价格历史本身并不包含太多预测信息。
关于伦理的说明
Note on ethics
你有时可能会接到一些在伦理上颇有争议的项目,例如“构建一个人工智能,根据人脸照片评估其可信度”。首先,这个项目的有效性令人质疑:为什么可信度会反映在人的脸上?其次,这样的任务会引发各种各样的伦理问题。收集用于此任务的数据集,实际上就等于记录了那些给照片贴标签的人的偏见和成见。你用这些数据训练的模型,只不过是将这些偏见编码到一个黑箱算法中,从而赋予它们一层薄薄的合法性外衣。在我们这样一个技术素养普遍较低的社会里,“人工智能算法说这个人不可信”这句话,似乎比“约翰·史密斯说这个人不可信”更有分量,也更客观——尽管前者只是后者的近似值。你的模型实际上是在大规模地粉饰和运用人类判断中最糟糕的一面,会对人们的真实生活造成负面影响。
技术从来都不是中立的。如果你的工作对世界产生任何影响,那么这种影响就带有道德指向:技术选择也是伦理选择。始终要慎重考虑你希望自己的工作支持哪些价值观。
收集数据集
Collecting a dataset
一旦你了解了任务的性质,并且知道了你的输入和目标是什么,就到了数据收集的时候了——这是大多数机器学习项目中最为艰巨、耗时和成本最高的部分:
- 这个图片搜索引擎项目要求你先选择要分类的标签集——你选定了10000个常用的图片类别。然后,你需要手动将数十万张用户过去上传的图片用这些标签集中的标签进行标记。
- 对于聊天应用垃圾信息检测项目,由于用户聊天内容采用端到端加密,因此无法直接使用聊天内容训练模型。您需要获取一个包含数万条未经过滤的社交媒体帖子的独立数据集,并手动将其标记为垃圾信息、冒犯性内容或正常内容。
- 对于音乐推荐引擎,您只需使用用户的“点赞”数据即可,无需收集任何新数据。同样,对于点击率预测项目,您拥有多年来广告点击率的详细记录。
- 对于饼干标记模型,您需要在传送带上方安装摄像头来采集数万张图像,然后需要有人手动标记这些图像。目前饼干工厂里就有人会做这项工作——但这似乎并不难,您应该可以培训其他人来做。
- 卫星图像项目需要一个考古学家团队来收集现有遗址的数据库,并且需要为每个遗址找到不同天气条件下拍摄的现有卫星图像。为了获得一个良好的模型,需要数千个不同的遗址。
在第五章中,你已经了解到模型的泛化能力几乎完全取决于训练数据的属性——数据点的数量、标签的可靠性以及特征的质量。一个好的数据集是一项值得精心维护和投入的宝贵资产。如果你有额外的50个小时可以投入到一个项目中,那么最有效的分配方式很可能是收集更多的数据,而不是寻求模型的渐进式改进。
数据比算法更重要的观点,最著名的阐述来自谷歌研究人员2009年发表的一篇题为《数据的惊人有效性》(标题是对尤金·维格纳1960年出版的著名著作《 数学在自然科学中的惊人有效性》的戏仿)的论文。当时深度学习尚未流行,但令人惊讶的是,深度学习的兴起反而提升了数据的重要性。
The point that data matters more than algorithms was most famously made in a 2009 paper by Google researchers titled “The Unreasonable Effectiveness of Data” (the title is a riff on the well-known 1960 book The Unreasonable Effectiveness of Mathematics in the Natural Sciences by Eugene Wigner). This was before deep learning was popular, but remarkably, the rise of deep learning has only increased the importance of data.
如果你进行监督学习,那么一旦你收集了输入(例如图像),你就需要对它们进行标注(例如这些图像的标签):你将训练你的模型来预测的目标。
有时,标注信息可以自动获取——例如,在我们的音乐推荐任务或点击率预测任务中。但通常情况下,你需要手动标注数据。这是一个非常耗时的过程。
投资数据标注基础设施
Investing in data annotation infrastructure
数据标注过程将决定目标数据的质量,而目标数据的质量又决定模型的质量。请仔细考虑您可用的选项:
- 是否应该自己对数据进行标注?
- 是否应该使用像 Mechanical Turk 这样的众包平台来收集标签?
- 是否应该使用专业数据标注公司的服务?
外包或许能帮你节省时间和金钱,但也会让你失去控制权。使用像 Mechanical Turk 这样的平台可能成本低廉且易于扩展,但你的标注最终可能会变得非常嘈杂。
为了选择最佳方案,请考虑您所面临的限制条件:
- 数据标注者必须是相关领域的专家吗?还是任何人都可以标注数据?猫狗图像分类问题的标签可以由任何人选择,但犬种分类任务的标签则需要专业知识。而标注骨折CT扫描图像则几乎需要医学学位。
- 如果数据标注需要专业知识,能否培训人员来完成这项工作?如果不能,如何才能接触到相关专家?
- 你自己是否了解专家们是如何进行标注的?如果不了解,你就只能把数据集当作黑箱来对待,无法进行手动特征工程——这虽然不是致命的,但可能会造成局限性。
如果您决定自行标注数据,请先考虑使用什么软件来记录标注信息。您很可能需要自行开发这款软件。高效的数据标注软件可以节省您大量时间,因此值得在项目初期就进行投资。
注意非代表性数据
Beware of nonrepresentative data
机器学习模型只能理解与之前见过的数据相似的输入。因此,用于训练的数据必须能够代表生产数据,这一点至关重要。所有数据收集工作都应以此为根本。
假设你正在开发一款应用,用户可以拍摄菜肴照片来查找其名称。你使用来自一个美食爱好者常用的图片分享社交网络的图片训练模型。到了正式上线的时候,愤怒的用户反馈纷至沓来:你的应用十次里有八次都答错了。这是怎么回事?你在测试集上的准确率可是超过 90% 啊!快速查看用户上传的数据后发现,用户用随机的智能手机拍摄的随机餐厅的随机菜肴照片,与你用来训练模型的专业级、光线充足、诱人的照片截然不同: 你的训练数据根本无法代表实际生产环境的数据。这可是大忌——欢迎来到机器学习的地狱。(your training data wasn’t representative of the production data. That’s a cardinal sin—welcome to machine learning hell.)
如果可能,请直接从模型实际使用环境中收集数据。例如,电影评论情感分类模型应该用于IMDb上的新评论,而不是Yelp上的餐厅评论或Twitter状态更新。如果要对推文的情感进行评分,首先要收集并标注真实的推文——这些推文应来自与预期生产环境中用户群体相似的用户群体。如果无法使用生产环境数据进行训练,则务必充分了解训练数据和生产环境数据之间的差异,并积极纠正这些差异。
您应该注意的一个相关现象是概念漂移。几乎所有现实世界的问题都会遇到概念漂移,尤其是在处理用户生成数据的问题中。当生成数据的属性随时间发生变化时,就会发生概念漂移,导致模型准确率逐渐下降。例如,2013 年训练的音乐推荐引擎在今天可能效果不佳。同样,您使用的 IMDB 数据集是在 2011 年收集的,基于该数据集训练的模型在 2020 年的评论上的表现可能不如 2012 年的评论,因为词汇、表达方式和电影类型都会随着时间推移而变化。在信用卡欺诈检测等对抗性环境中,概念漂移尤为严重,因为欺诈模式几乎每天都在变化。应对快速的概念漂移需要不断地收集数据、标注数据和重新训练模型。
A related phenomenon you should be aware of is concept drift. You’ll encounter concept drift in almost all real-world problems, especially those that deal with user-generated data. Concept drift occurs when the properties of the production data change over time, causing model accuracy to gradually decay.
请记住,机器学习只能用于记忆训练数据中存在的模式。它只能识别你以前见过的事物。使用基于历史数据训练的机器学习模型来预测未来,就等于假设未来会像过去一样发展。但事实往往并非如此。
抽样偏差问题
The problem of sampling bias
抽样偏差是数据不具代表性的一个特别隐蔽且常见的例子 。当数据收集过程与你试图预测的目标相互影响时,就会出现抽样偏差,从而导致测量结果出现偏差。一个著名的历史案例发生在1948年的美国总统大选中。选举之夜,《芝加哥论坛报》刊登了“杜威击败杜鲁门”的头条新闻。第二天早上,杜鲁门却成为了胜选者。《论坛报》的编辑轻信了一项电话调查的结果——但1948年的电话用户并非选民群体的随机代表性样本。他们更有可能是富裕人士、保守派,并且倾向于投票给共和党候选人杜威。如今,所有电话调查都会考虑抽样偏差。但这并不意味着抽样偏差在政治民意调查中已经消失——恰恰相反。但与1948年不同的是,现在的民意调查机构意识到了抽样偏差的存在,并采取措施加以纠正。
 图 6.1:“杜威击败杜鲁门”:抽样偏差的著名例子
图 6.1:“杜威击败杜鲁门”:抽样偏差的著名例子
了解您的数据
Understanding your data
将数据集视为黑箱是一种糟糕的做法。在开始训练模型之前,您应该探索并可视化您的数据,以深入了解其预测能力——这将指导特征工程——并筛查潜在问题:
It’s bad practice to treat a dataset as a black box. Before you start training models, you should explore and visualize your data to gain insights about what makes it predictive— which will inform feature engineering—and screen for potential issues:
- 如果您的数据包含图像或自然语言文本,请直接查看一些示例(及其标签)。
- 如果你的数据包含数值特征,最好绘制特征值的直方图,以便了解取值范围和不同值的频率。
- 如果你的数据包含位置信息,请将其绘制在地图上。是否能发现任何明显的规律?
- 某些样本中是否存在某些特征的缺失值?如果是,则需要在准备数据时处理此问题(我们将在下一节中介绍如何操作)。
- 如果你的任务是分类问题,请打印出数据中每个类别的实例数量。各个类别的实例数量大致相等吗?如果不是,你需要考虑这种不平衡现象。
- 检查目标泄露——即数据中是否存在一些特征,它们提供了关于目标的信息,而这些信息在生产环境中可能无法获取。例如,如果您正在使用医疗记录训练模型来预测某人未来是否会接受癌症治疗,而这些记录中包含“此人已被诊断出患有癌症”这一特征,那么您的目标信息就被人为地泄露到了数据中。务必始终问自己:数据中的每个特征在生产环境中是否都能以相同的形式获取?
Check for target leaking—the presence of features in your data that provide information about the targets that may not be available in production. If you’re training a model on medical records to predict whether someone will be treated for cancer in the future, and the records include the feature “This person has been diagnosed with cancer,” then your targets are being artificially leaked into your data. Always ask yourself, is every feature in your data something that will be available in the same form in production?
选择衡量成功的标准
Choosing a measure of success
要掌控事物,首先需要观察它。要成功完成一个项目,首先必须定义“成功”的含义。是准确率?精确率和召回率?还是客户留存率?你的成功指标将指导你在整个项目过程中做出的所有技术选择。它应该与你的更高层次目标直接相关,例如客户的业务成功。
对于类别平衡的分类问题(即每个类别出现的概率相等),准确率和受试者工作特征曲线(receiver operating characteristic ROC曲线)下的面积(area under curve AUC) 是常用的评价指标。对于类别不平衡问题、排序问题或多标签分类问题,可以使用精确率和召回率,或者使用计算假阳性、真阳性、假阴性和真阴性的指标。此外,自定义指标来衡量成功也并不罕见。为了更好地了解机器学习成功指标的多样性以及它们与不同问题领域的关联,浏览Kaggle(https://kaggle.com)上的数据科学竞赛会很有帮助;它展示了各种各样的问题和评估指标。
For balanced classification problems, where every class is equally likely, accuracy and area under curve (AUC) of the receiver operating characteristic (ROC) are common metrics. For class-imbalanced problems, ranking problems, or multilabel classification, you can use precision and recall or a metric that counts false positives, true positives, false negatives, and true negatives. And it isn’t uncommon to have to define your own custom metric by which to measure success. To get a sense of the diversity of machine learning success metrics and how they relate to different problem domains, it’s helpful to browse the data science competitions on Kaggle (https:/ /kaggle.com); it showcases a wide range of problems and evaluation metrics.
开发模型
Developing a model
一旦你明确了如何衡量进度,就可以开始模型开发了。大多数教程和研究项目都假定这是唯一的步骤——忽略了问题定义和数据集收集(假设这些已经完成),也忽略了模型部署和维护(假设这些由其他人负责)。事实上,模型开发只是机器学习工作流程中的一个步骤,而且在我看来,它并不是最难的。机器学习中最难的是定义问题以及收集、标注和清洗数据。所以别灰心,接下来的步骤相比之下会容易得多!
数据准备
Preparing the data
正如你之前所了解的,深度学习模型通常不直接处理原始数据。数据预处理旨在使手头的原始数据更适合神经网络。这包括向量化、归一化或处理缺失值。许多预处理技术都具有领域特定性(Many preprocessing techniques are domain specific)(例如,特定于文本数据或图像数据);我们将在后续章节中通过实际示例介绍这些技术。现在,我们将回顾所有数据领域通用的基础知识。
向量化
Vectorization
神经网络中的所有输入和目标通常都必须是浮点数据张量(或者在特定情况下,是整数或字符串张量)。无论你需要处理什么数据——声音、图像、文本——都必须首先将其转换为张量,这一步骤称为数据向量化。例如,在前两章的文本分类示例中,我们从以整数列表(代表单词序列)表示的文本开始,并使用多热编码将其转换为float32数据张量。在数字分类和房价预测的示例中,数据已经是向量化形式,因此可以跳过这一步骤。
值归一化
Value normalization
在第二章的 MNIST 数字分类示例中,您最初使用的是编码为 0-255 范围内整数的图像数据,这些数据编码的是灰度值。在将这些数据输入网络之前,您需要将其转换为float32 浮点数并除以 255,从而得到 0-1 范围内的浮点值。类似地,在预测房价时,您最初使用的特征值范围各不相同——有些特征值较小,属于浮点数;有些特征值较大,属于整数。在将这些数据输入网络之前,您需要分别对每个特征进行归一化,使其标准差为 1,均值为 0。
一般来说,将取值范围较大的数据(例如,远大于网络权重初始值的多位数整数)或异构数据(例如,一个特征的取值范围为 0-1,而另一个特征的取值范围为 100-200)输入神经网络是不安全的。这样做可能会触发较大的梯度更新,从而阻止网络收敛。为了便于网络学习,您的数据应具备以下特征:
- 取较小的值(Take small values) ——通常,大多数值应该在 0-1 的范围内。
- 保持同质性(Be homogeneous)——也就是说,所有特征的值应该大致在相同的范围内。
此外,以下更严格的规范化做法很常见,并且可能有所帮助,尽管并非总是必要的(例如,在数字分类示例中,您就没有这样做):
- 将每个特征分别归一化,使其均值为 0。
- 将每个特征分别归一化,使其标准差为 1。
使用 NumPy 数组很容易做到这一点:
1 | # Assuming x is a 2D data matrix of shape (samples, features) |
处理缺失值
Handling missing values
您的数据中有时可能会出现缺失值。例如,在房价示例中,第二个特征是该地区房屋的中位年龄。如果并非所有样本都包含此特征怎么办?那么训练数据或测试数据中就会出现缺失值。
你可以完全放弃这个功能,但你不一定非要这样做:
- 如果特征是类别型的,可以安全地创建一个新类别来表示“值缺失”。模型会自动学习这对于目标值意味着什么。
- 如果特征是数值型的,请避免输入任意值(例如 0),因为这可能会在特征构成的潜在空间中造成不连续性,从而降低基于该特征训练的模型的泛化能力。相反,可以考虑用数据集中该特征的平均值或中位数来替换缺失值。您还可以训练一个模型,根据其他特征的值来预测该特征的值。
请注意,如果您预期测试数据中存在缺失的类别特征,但网络是在没有任何缺失值的数据上训练的,那么网络将无法学会忽略缺失值!在这种情况下,您应该人为地生成包含缺失值的训练样本:多次复制一些训练样本,并删除一些您预期在测试数据中可能缺失的类别特征。
选择评估方案
Choosing an evaluation protocol
正如你在上一章中所学到的,模型的目的是实现泛化,而你在模型开发过程中做出的每一个建模决策都将以验证指标为指导,这些指标旨在衡量模型的泛化性能。你的验证协议的目标是准确估计你选择的成功指标(例如准确率)在实际生产数据上的表现。该过程的可靠性对于构建一个有用的模型至关重要。
在第五章中,我们回顾了三种常见的评估方案:
- 维护一个预留验证集 ——当你拥有大量数据时,这是最佳做法。
- 进行 K 折交叉验证 ——当样本量太少,无法通过留出法验证获得可靠结果时,这是正确的选择。
- 进行迭代 K 折交叉验证 ——用于在数据量较少的情况下进行高精度模型评估。
随便选一个就行。大多数情况下,第一个就足够了。正如你之前学到的,一定要注意验证集的代表性 ,并且注意不要让训练集和验证集之间存在重复样本。
击败底线
Beating a baseline
当你开始着手构建模型本身时,你的最初目标是达到统计功效,正如你在第 5 章中所看到的——也就是说,开发一个能够胜过简单基线的小型模型。
现阶段,你应该重点关注以下三件事:
- 特征工程——过滤掉无信息特征(特征选择),并利用你对问题的了解来开发可能有用的新特征。
- 选择合适的架构先验——您将使用哪种模型架构?密集连接网络、卷积神经网络、循环神经网络还是Transformer?深度学习是否适合这项任务,还是应该使用其他方法?
- 选择合适的训练配置——应该使用哪种损失函数?批次大小和学习率应该是多少?
选择合适的损失函数
Picking the right loss function
通常情况下,我们无法直接优化衡量问题成功与否的指标。有时,将指标转化为损失函数并非易事;毕竟,损失函数需要能够在仅使用少量数据的情况下计算(理想情况下,损失函数甚至只需一个数据点即可计算),并且必须是可微的(否则,就无法使用反向传播来训练网络)。例如,广泛使用的分类指标 ROC AUC 就无法直接优化。因此,在分类任务中,通常会优化 ROC AUC 的替代指标,例如交叉熵。一般来说,交叉熵越低,ROC AUC 值就越高。
个人注:终于明白为什么需要损失函数,而不是直接使用指标来优化了!
表 6.1 可以帮助您为一些常见问题类型选择最后一层激活函数、损失函数和指标。
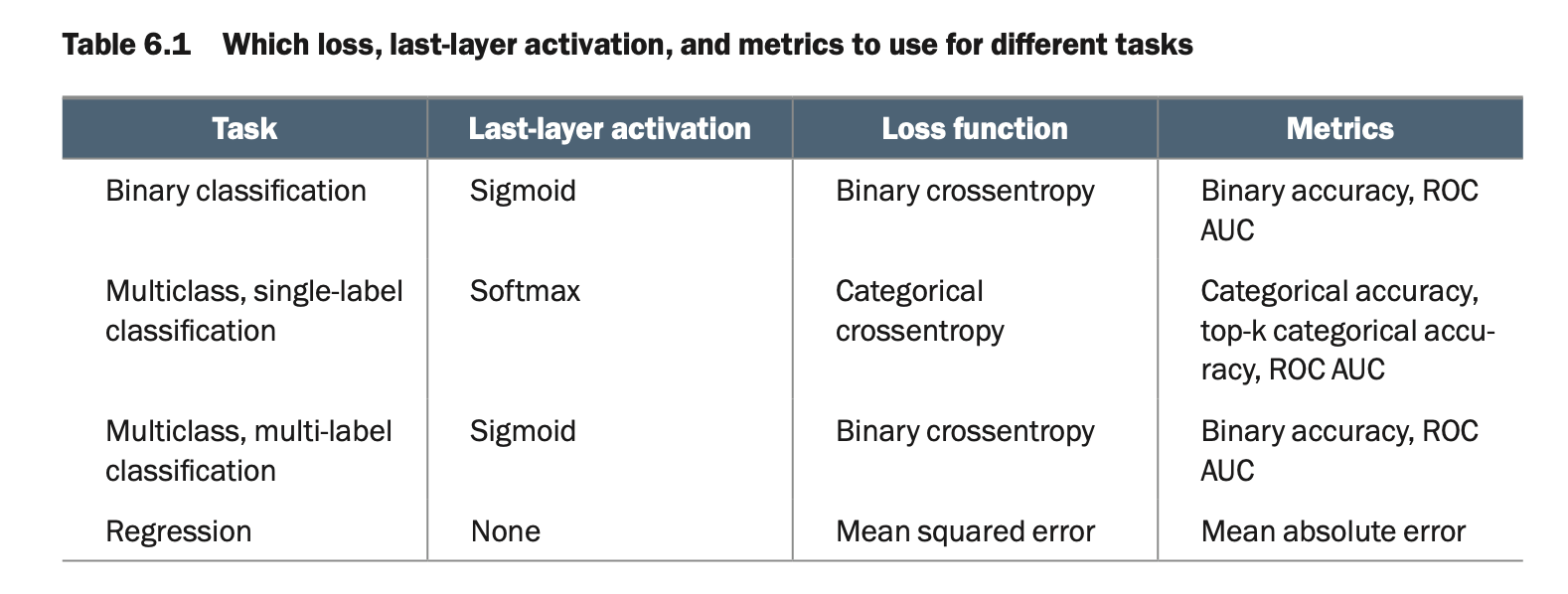
| 任务 | 最后一层激活 | 损失函数 | 指标 |
|---|---|---|---|
| 二元分类 | Sigmoid | 二元交叉熵 | 二元准确率、ROC曲线下面积 |
| 多类单标签分类 | Softmax | 分类交叉熵 | 分类准确率、前k个分类准确率、ROC曲线下面积 |
| 多类多标签分类 | Sigmoid | 二元交叉熵 | 二元准确率、ROC曲线下面积 |
| 回归 | None | 均方误差 | 平均绝对误差 |
表 6.1:不同任务应使用的损失函数、最后一层激活函数和指标
对于大多数问题,都有现成的模板可供参考。你并非第一个尝试构建垃圾邮件检测器、音乐推荐引擎或图像分类器的人。务必研究现有技术,以确定最有可能在你的任务中表现良好的特征工程技术和模型架构。
请注意,并非总是能够达到统计功效。如果您尝试了多种合理的架构后仍然无法超越简单的基线,则可能是您所提出问题的答案并不存在于输入数据中。请记住,您提出了两个假设:
- 你假设根据输入可以预测输出。
- 你假设现有数据足以提供足够的信息来了解输入和输出之间的关系。
这些假设很可能是错误的,在这种情况下,你必须重新开始。
规模化:开发一个过拟合的模型
Scaling up: Developing a model that overfits
一旦你获得了一个具有统计功效的模型,问题就变成了:你的模型是否足够强大?它是否拥有足够的层数和参数来恰当地模拟当前问题?例如,逻辑回归模型在 MNIST 数据集上具有统计功效,但不足以很好地解决当前问题。记住,机器学习中普遍存在的矛盾在于优化和泛化之间的平衡;理想的模型恰好处于欠拟合和过拟合、容量不足和容量过剩的临界点。要找到这个临界点,首先你必须跨越它。
要确定所需的模型规模,您必须开发一个过拟合模型。这相当容易,正如您在第 5 章中所学到的:
- 添加图层。
- 将图层放大。
- 训练更多轮次。
始终监控训练损失和验证损失,以及你关注的任何指标的训练值和验证值。当模型在验证数据上的性能开始下降时,就说明模型过拟合了。
对模型进行正则化和调优
Regularizing and tuning your model
一旦统计效力达到一定水平,并且能够实现过拟合,就说明你走对了路。此时,你的目标就变成了最大化泛化性能。
这个阶段耗时最长:你需要反复修改模型,进行训练,用验证数据(此时还不是测试数据)进行评估,再次修改,如此循环往复,直到模型达到最佳状态。以下是一些你可以尝试的方法:
- 尝试不同的架构;增加或删除层。
- 添加辍学。Add dropout.
- 如果你的模型规模较小,可以添加 L1 或 L2 正则化。
- 尝试不同的超参数(例如每层的单元数或优化器的学习率)以找到最佳配置。
- (可选)迭代数据整理或特征工程:收集和标注更多数据,开发更好的特征,或删除似乎没有信息量的特征。
- Try different architectures; add or remove layers.
- Add dropout.
- If your model is small, add L1 or L2 regularization.
- Try different hyperparameters (such as the number of units per layer or the learning rate of the optimizer) to find the optimal configuration.
- Optionally, iterate on data curation or feature engineering: collect and annotate more data, develop better features, or remove features that don’t seem to be informative.
可以使用诸如 KerasTuner 之类的自动化超参数调优软件来自动化完成大部分工作 。我们将在第 18 章中详细介绍。
请注意以下几点:每次使用验证过程的反馈来调整模型时,都会将验证过程的信息泄露到模型中。偶尔几次这样做无伤大雅;但如果多次迭代都这样做,最终会导致模型过拟合验证过程(即使模型没有直接使用任何验证数据进行训练)。这会降低评估过程的可靠性。
一旦你构建出一个令人满意的模型配置,就可以使用所有可用数据(训练集和验证集)训练最终的生产模型,并在测试集上进行最后一次评估。如果测试集上的性能明显低于验证集上的性能,这可能意味着你的验证过程本身就不可靠,或者你在调整模型参数时对验证集产生了过拟合。在这种情况下,你可能需要切换到更可靠的评估方案(例如迭代 K 折交叉验证)。
部署您的模型
Deploying your model
当您的模型成功通过测试集上的最终评估后,即可部署并开始其生产生命周期。
向利益相关者解释你的工作并设定预期
Explaining your work to stakeholders and setting expectations
成功和客户信任的关键在于持续满足甚至超越人们的期望;而你实际交付的系统仅仅是成功的一半。另一半在于上线前设定合理的预期。
非专业人士对人工智能系统的期望往往不切实际。例如,他们可能期望系统“理解”其任务,并能够在任务情境中运用类似人类的常识。为了解决这个问题,您应该考虑展示一些模型失效模式的示例(例如,展示错误分类的样本是什么样子,特别是那些错误分类令人意外的样本)。
他们可能还会期望模型达到人类水平的性能,尤其是在以前由人工处理的流程方面。大多数机器学习模型由于训练目的(并不完美)是为了近似模拟人类生成的标签,因此远未达到这个水平。您应该清晰地传达模型性能预期。避免使用“模型准确率达到 98%”(大多数人会将其四舍五入为 100%)之类的抽象表述,而应该使用例如漏报率和误报率等更具体的指标。您可以这样说:“在这些设置下,欺诈检测模型的漏报率为 5%,误报率为 2.5%。平均每天会有 200 笔合法交易被标记为欺诈交易并送去人工审核,同时平均会漏掉 14 笔欺诈交易。平均每天会正确识别出 266 笔欺诈交易。” 将模型的性能指标与业务目标明确关联起来。
您还应该与利益相关者讨论关键启动参数的选择,例如,交易被标记的概率阈值(不同的阈值会产生不同的漏报率和误报率)。这类决策涉及权衡取舍,只有深入了解业务背景才能妥善处理。
发送推理模型
Shipping an inference model
机器学习项目并非止于生成一个可以保存训练模型的 Colab notebook。你很少会将训练过程中操作过的同一个 Python 模型对象直接投入生产环境。
首先,您可能需要将模型导出为 Python 以外的其他格式:
- 您的生产环境可能根本不支持 Python——例如,如果它是一个移动应用程序或嵌入式系统。
- 如果应用程序的其他部分不是用 Python 编写的(可能是用 JavaScript、C++ 等编写的),那么使用 Python 来提供模型可能会造成很大的开销。
其次,由于您的生产模型仅用于输出预测结果(称为推理阶段),而不是用于训练,因此您可以进行各种优化,使模型运行速度更快,内存占用更少。
让我们快速了解一下您可以使用的不同模型部署选项。
将模型部署为 REST API
Deploying a model as a rest api
将模型转化为产品最简单的方法或许是通过 REST API 在线提供服务。目前有很多库可以实现这一点。Keras 开箱即用地支持两种最流行的方案——TensorFlow Serving和ONNX(Open Neural Network Exchange 的缩写)。这两个库的工作原理是将所有模型权重和计算图从 Python 程序中分离出来,因此您可以从多种不同的环境(例如 C++ 服务器)提供服务。如果您觉得这听起来很像第三章讨论的编译机制,那就对了。TensorFlow Serving 本质上是一个用于提供tf.function具有特定权重集的计算图的库。
Keras 允许通过一种简单易用的 export()方法访问 TensorFlow Serving 和 ONNX,该方法适用于所有 Keras 型号。以下代码片段展示了如何使用该方法访问 TensorFlow Serving:
1 | # Exports the model as a TensorFlow SavedModel artifact |
ONNX也存在类似的流程:
1 | model.export("path/to/location", format="onnx") |
当……时,您应该使用此部署设置。
- 使用模型预测结果的应用程序必须能够可靠地访问互联网(这是显而易见的)。例如,如果您的应用程序是移动应用,通过远程 API 提供预测结果意味着该应用在飞行模式或网络连接较差的环境下将无法使用。
- 该应用程序对延迟没有严格的要求:请求、推理和响应的往返通常需要大约 500 毫秒。
- 用于推理的输入数据并不高度敏感:数据需要以解密形式存储在服务器上,因为模型需要看到这些数据(但请注意,您应该对 HTTP 请求和响应使用 SSL 加密)。
例如,图像搜索引擎项目、音乐推荐系统、信用卡欺诈检测项目和卫星图像项目都非常适合通过 REST API 提供服务。
将模型部署为 REST API 时,一个重要的问题是:您是想自行托管代码,还是想使用完全托管的第三方云服务?例如,谷歌的 Cloud AI Platform 允许您轻松地将 TensorFlow 模型上传到 Google Cloud Storage (GCS),并提供一个 API 端点供您查询。它负责处理许多实际细节,例如批量预测、负载均衡和扩展。
在设备上部署模型
Deploying a model on a device
有时,您可能需要将模型与运行该模型的应用程序集成在同一设备上——例如智能手机、机器人上的嵌入式 ARM CPU 或微型设备上的微控制器。举例来说,您可能见过能够自动检测拍摄对象(包括人脸)的摄像头:那很可能就是直接运行在摄像头上的小型深度学习模型。
你应该在以下情况下使用此设置:
- 您的模型对延迟有严格的要求,或者需要在低连接环境下运行。如果您正在构建沉浸式增强现实应用程序,查询远程服务器并非可行方案。
- 您的模型可以做得足够小,以便在目标设备的内存和功耗限制下运行。
- 对于你的任务来说,获得尽可能高的精度并不是至关重要的:运行时效率和精度之间总是存在权衡,因此内存和功耗的限制通常要求你交付的模型不如你在大型 GPU 上运行的最佳模型那么好。
- 输入数据高度敏感,因此不应在远程服务器上解密。
例如,我们的垃圾邮件检测模型需要作为聊天应用的一部分在终端用户的智能手机上运行,因为消息是端到端加密的,因此远程托管的模型根本无法读取。同样,恶意 Cookie 检测模型对延迟有严格的要求,需要在工厂运行。幸运的是,在这种情况下,我们没有任何电力或空间限制,因此我们可以在 GPU 上运行该模型。
For instance, our spam detection model will need to run on the end user’s smartphone as part of the chat app, because messages are end-to-end encrypted and thus cannot be read by a remotely hosted model at all. Likewise, the bad-cookie-detection model has strict latency constraints and will need to run at the factory. Thankfully, in this case, we don’t have any power or space constraints, so we can actually run the model on a GPU.
个人注:这段话的核心逻辑它展示了部署环境决定技术方案:
- 手机端:是为了解决数据隐私和加密限制(不得不跑在本地)。
- 工厂端:是为了解决实时响应速度(必须跑在本地),且利用了工业级硬件资源。
这种根据实际业务场景(如隐私、延迟、功耗)来平衡模型运行位置的做法,在现代 AI 工程化中被称为边缘 AI(Edge AI)。
要在智能手机或嵌入式设备上部署 Keras 模型,您可以再次使用该export()方法创建包含计算图的 TensorFlow 或 ONNX 模型保存文件。TensorFlow Lite ( https://www.tensorflow.org/lite ) 是一个高效的设备端深度学习推理框架,可在 Android 和 iOS 智能手机以及 ARM CPU、Raspberry Pi 或某些微控制器上运行。它使用与 TensorFlow Serving 相同的 TensorFlow 模型保存格式。ONNX 运行时也可以在移动设备上运行。
在浏览器中部署模型
Deploying a model in the browser
深度学习常用于基于浏览器或桌面端的 JavaScript 应用程序中。虽然通常可以通过 REST API 让应用程序查询远程模型,但让模型直接在用户计算机的浏览器中运行(如果可用,还可以利用 GPU 资源)则具有显著优势。
使用此设置时
- 您希望将计算任务卸载到最终用户,这样可以大幅降低服务器成本。
- 输入数据需要保留在最终用户的计算机或手机上。例如,在我们的垃圾邮件检测项目中,聊天应用程序的网页版和桌面版(使用 JavaScript 编写的跨平台应用程序)都应该使用本地运行的模型。
- 您的应用程序有严格的延迟限制:虽然在最终用户的笔记本电脑或智能手机上运行的模型可能比在您自己的服务器上的大型 GPU 上运行的模型慢,但您没有额外的 100 毫秒网络往返时间。
- 在模型下载并缓存后,您的应用程序需要能够在没有网络连接的情况下继续运行。
当然,只有当你的模型足够小,不会占用用户笔记本电脑或智能手机的 CPU、GPU 或内存资源时,才应该选择这种方式。此外,由于整个模型都会下载到用户设备上,因此你应该确保模型的任何信息都不需要保密。请注意,对于训练好的深度学习模型,通常可以恢复一些关于训练数据的信息:如果你的模型是用敏感数据训练的,最好不要公开。
要在 JavaScript 中部署模型,TensorFlow 生态系统包含 TensorFlow.js(https://www.tensorflow.org/js),而 ONNX 则支持原生 JavaScript 运行时。TensorFlow.js 甚至实现了几乎所有 Keras API(它最初以 WebKeras 的名义开发),以及许多底层 TensorFlow API。您可以轻松地将已保存的 Keras 模型导入 TensorFlow.js,以便在基于浏览器的 JavaScript 应用或桌面 Electron 应用中查询该模型。
推理模型优化
Inference model optimization
在对可用功耗和内存有严格限制的环境(例如智能手机和嵌入式设备)或对延迟要求极高的应用场景中,优化模型以提升推理性能尤为重要。在将模型导入 TensorFlow.js 或导出到 TensorFlow Lite 之前,务必先对其进行优化。
您可以应用两种常用的优化技术:
- 权重剪枝——权重张量中的每个系数对预测的贡献并不相同。通过仅保留最重要的系数,可以显著减少模型层中的参数数量。这可以降低模型的内存和计算占用,而性能指标的损失很小。通过调整剪枝的程度,您可以控制模型大小和准确率之间的权衡。
- 权重量化——深度学习模型使用单精度浮点数(
floatfloat32)权重进行训练。然而,我们可以将权重量化为 8 位有符号整数(intint8),从而获得一个仅用于推理的模型,该模型的大小仅为原始模型的四分之一,但精度却接近原始模型。Keras 模型提供了一个内置quantize()API 来辅助完成此操作。只需调用weight_quantity()函数即可将model.quantize("int8")模型中的每个权重压缩为一个字节。 - Weight pruning — Not every coefficient in a weight tensor contributes equally to the predictions. It’s possible to considerably lower the number of parameters in the layers of your model by only keeping the most significant ones. This reduces the memory and compute footprint of your model at a small cost in performance metrics. By tuning how much pruning you want to apply, you are in control of the tradeoff between size and accuracy.
- Weight quantization — Deep learning models are trained with single-precision floating-point (
float32) weights. However, it’s possible to quantize weights to 8-bit signed integers (int8) to get an inference-only model that’s four times smaller but remains near the accuracy of the original model. Keras models come with a built-inquantize()API that can help with this. Simply callmodel.quantize("int8")to compress each weight in your model to a single byte.
在实际环境中监测您的模型
Monitoring your model in the wild
您已经导出推理模型,并将其集成到应用程序中,并且已经在生产数据上进行了试运行——模型运行完全符合预期。您还编写了单元测试以及日志记录和状态监控代码——完美!现在是时候按下部署按钮,将其部署到生产环境了。
但这还不是结束。模型部署完成后,还需要持续监控其行为、在新数据上的性能、与应用程序其他部分的交互,以及最终对业务指标的影响:
- 部署新的音乐推荐系统后,您的在线电台用户参与度是上升了还是下降了?切换到新的点击率预测模型后,平均广告点击率是否有所提高?考虑使用随机A/B测试 来隔离模型本身的影响与其他因素的影响:一部分用户使用新模型,另一部分用户则继续使用旧模型作为对照。一旦处理了足够多的案例,两组结果的差异很可能归因于模型本身。
- 如果条件允许,应定期对模型在生产数据上的预测结果进行人工审核。通常可以复用与数据标注相同的架构:将一部分生产数据送去进行人工标注,然后将模型的预测结果与新的标注结果进行比较。例如,图像搜索引擎和恶意 Cookie 标记系统就应该这样做。
- 当无法进行人工审核时,可以考虑其他评估途径,例如用户调查(例如,在垃圾邮件和冒犯性内容标记系统中)。
维护您的模型
Maintaining your model
最后,没有哪个模型是永恒的。您已经了解了概念漂移:随着时间的推移,您的生产数据的特征会发生变化,逐渐降低模型的性能和相关性。您的音乐推荐系统的寿命可能以周计算。信用卡欺诈检测系统的寿命可能只有几天;而图像搜索引擎即使在最好的情况下也只能维持几年。
模型一旦上线,就应该着手训练下一代模型来取代它:
- 密切关注生产数据的变化。是否有新功能可用?是否需要扩展或以其他方式编辑标签集?
- 持续收集和标注数据,并不断改进标注流程。尤其要注意收集那些对当前模型来说难以分类的样本——这类样本最有可能提升模型性能。
至此,机器学习的通用工作流程就结束了——需要记住的内容很多。成为专家需要时间和经验,但别担心,你现在比几章前要明智得多。你现在已经熟悉了全局——机器学习项目涉及的方方面面。虽然本书的大部分内容将侧重于模型开发部分,但你现在也意识到这只是整个工作流程的一部分。始终牢记全局!
概括
- 当你着手一个新的机器学习项目时,首先要明确当前的问题:
- 了解你所要做的事情的更广泛背景——最终目标是什么?有哪些限制条件?
- 收集并标注数据集;确保你对数据有深入的了解。
- 选择你将如何衡量问题解决的成功。你将监控验证数据的哪些指标?
- 一旦你理解了问题并拥有了合适的数据集,就可以开发模型了:
- 准备好数据。
- 选择你的评估方案。是留出法验证?还是K折交叉验证?你应该使用哪一部分数据进行验证?
- 获得统计优势:超越一个简单的基线。
- 扩大规模:开发一个可以过拟合的模型。
- 根据模型在验证数据上的表现,对模型进行正则化并调整其超参数。许多机器学习研究往往只关注这一步骤,但要记住全局的重要性。
- 当你的模型准备就绪并在测试数据上表现良好时,就可以进行部署了:
- 首先,务必与利益相关者设定合理的预期。
- 优化最终推理模型,并将模型部署到选定的部署环境——Web 服务器、移动设备、浏览器、嵌入式设备等。
- 监控模型在生产环境中的性能,并不断收集数据,以便开发下一代模型。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论