《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
第九章 卷积神经网络架构模式
ConvNet architecture patterns
运行代码
本章内容
- 模型架构的模块化-层次-重用公式
- 卷积神经网络构建标准最佳实践概述:残差连接、批量归一化和深度可分离卷积
- 计算机视觉模型的持续设计趋势
- The modularity-hierarchy-reuse formula for model architecture
- An overview of standard best practices for building ConvNets: residual connections, batch normalization, and depthwise separable convolutions
- Ongoing design trends for computer vision models
模型的“架构”是创建该模型时所有选择的总和:使用哪些层、如何配置它们、以及如何连接它们。这些选择定义了模型的假设空间:梯度下降可以搜索的可能函数空间,由模型的权重参数化。与特征工程类似,一个好的假设空间编码了你对当前问题及其解决方案的先验知识 。例如,使用卷积层意味着你预先知道输入图像中存在的相关模式是平移不变的。为了有效地从数据中学习,你需要对你要寻找的内容做出假设。
A model’s “architecture” is the sum of the choices that went into creating it: which layers to use, how to configure them, in what arrangement to connect them. These choices define the hypothesis space of your model: the space of possible functions that gradient descent can search over, parameterized by the model’s weights. Like feature engineering, a good hypothesis space encodes prior knowledge that you have about the problem at hand and its solution. For instance, using convolution layers means that you know in advance that the relevant patterns present in your input images are translation-invariant. To effectively learn from data, you need to make assumptions about what you’re looking for.
个人注:假设在科学中的重要性!
模型架构往往是成败的关键。如果架构选择不当,模型可能始终停留在次优指标,再多的训练数据也无济于事。反之,优秀的模型架构能够加速学习,使模型高效利用现有训练数据,从而减少对大型数据集的需求。好的模型架构能够缩小搜索空间,或者更容易地收敛到搜索空间中的某个理想点。与特征工程和数据管理一样,模型架构的核心在于 简化梯度下降算法的求解过程——要知道,梯度下降本身就是一个相当简单的搜索过程,因此它需要尽可能多的辅助手段。
Inversely, a good model architecture will accelerate learning and will enable your model to make efficient use of the training data available, reducing the need for large datasets. A good model architecture is one that reduces the size of the search space or otherwise makes it easier to converge to a good point of the search space. Just like feature engineering and data curation, model architecture is all about making the problem simpler for gradient descent to solve—and remember that gradient descent is a pretty stupid search process, so it needs all the help it can get.
模型架构与其说是一门科学,不如说是一门艺术。经验丰富的机器学习工程师往往能够凭直觉在第一次尝试时就构建出高性能模型,而初学者却常常连一个能训练的模型都难以创建。这里的关键词是“凭直觉”(intuitively):没有人能清晰地解释什么有效什么无效。专家们依靠模式匹配,而这种能力是通过大量的实践经验获得的。本书将帮助你培养自己的直觉。然而,这并非完全取决于直觉——其中并没有太多真正的科学原理,但就像任何工程学科一样,也存在一些最佳实践(best practices)。
在接下来的章节中,我们将回顾一些卷积神经网络(ConvNet)架构的最佳实践,特别是 残差连接、批量归一化和可分离卷积(residual connections, batch normalization, and separable convolution.)。一旦掌握了它们的使用方法,您就能构建高效的图像模型。我们将演示如何将它们应用于我们的猫狗分类问题。
让我们从宏观角度来看:系统架构的模块化-层次-重用(MHR)公式。
模块化、层级结构和重用
Modularity, hierarchy, and reuse
如果你想简化一个复杂的系统,有一个通用的方法:只需将你那团杂乱无章的复杂性结构化为模块,将这些模块组织成一个层级结构,然后根据需要在多个地方复用相同的模块(“复用”是抽象的另一种说法)。这就是模块化-层级-复用(MHR)公式(见图 9.1),它几乎是所有使用“架构”一词的领域中系统架构的基础 。它是任何具有实际复杂度的系统组织的核心,无论是教堂、你的身体、美国海军,还是 Keras 代码库。
If you want to make a complex system simpler, there’s a universal recipe you can apply: just structure your amorphous soup of complexity into modules, organize the modules into a hierarchy, and start reusing the same modules in multiple places as appropriate (“reuse” is another word for abstraction). That’s the modularity-hierarchy-reuse (MHR) formula (see figure 9.1), and it underlies system architecture across pretty much every domain where the term architecture is used. It’s at the heart of the organization of any system of meaningful complexity, whether it’s a cathedral, your own body, the US Navy, or the Keras codebase.
个人注:这段话把架构的概念讲得很清晰!
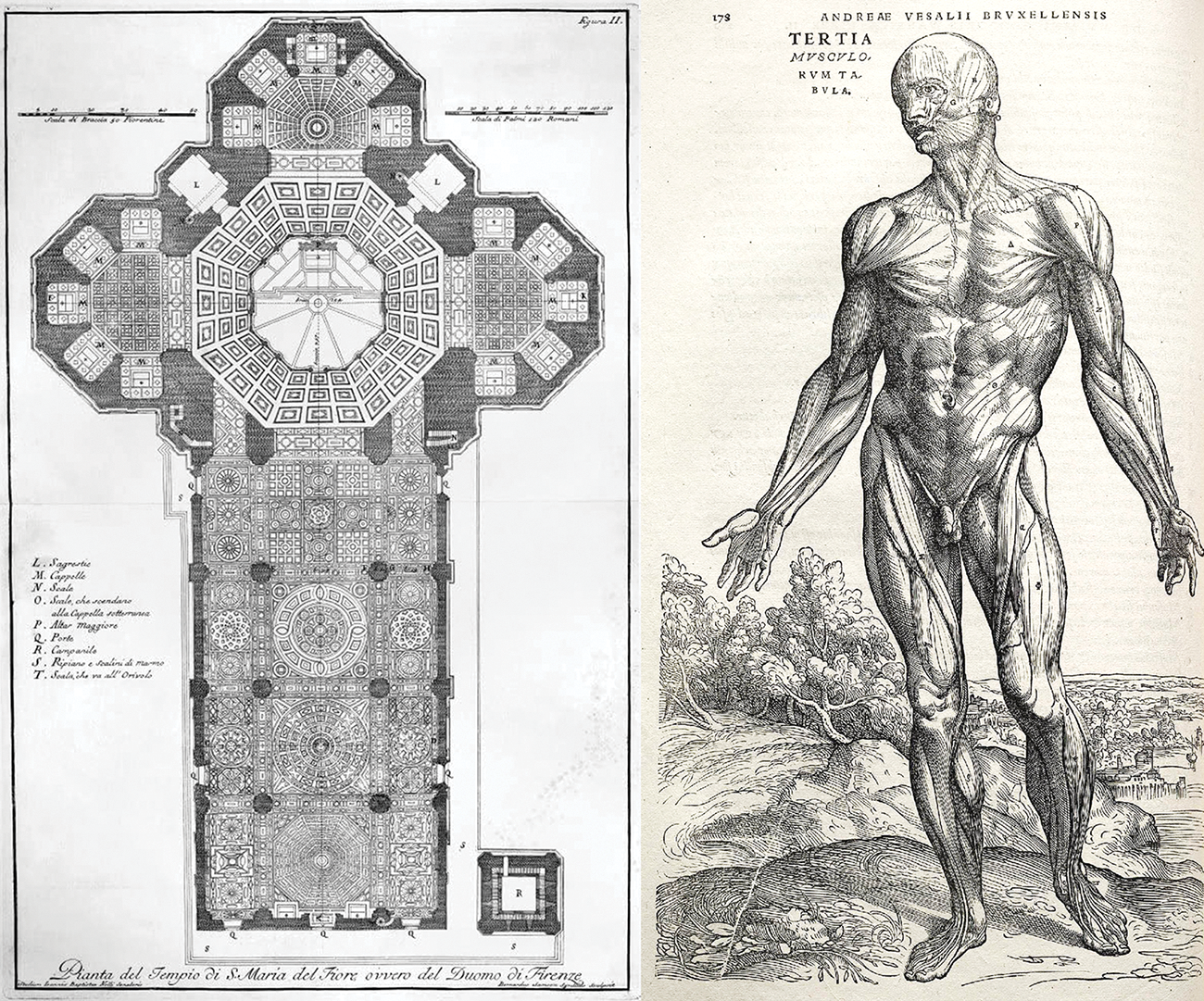 图 9.1:复杂系统遵循层次结构,并被组织成不同的模块,这些模块会被多次重复使用(例如你的 4 个肢体,它们都是同一蓝图的不同变体,或者你的 20 个手指)。
图 9.1:复杂系统遵循层次结构,并被组织成不同的模块,这些模块会被多次重复使用(例如你的 4 个肢体,它们都是同一蓝图的不同变体,或者你的 20 个手指)。
如果你是一名软件工程师,你肯定对这些原则非常熟悉:高效的代码库应该是模块化的、分层的,并且避免重复实现相同的功能,而是依赖于可重用的类和函数。如果你遵循这些原则来重构代码,那么你就是在进行“软件架构”。
深度学习本身就是将此方法应用于梯度下降的连续优化:采用经典的优化技术(在连续函数空间上进行梯度下降),将搜索空间构建成模块(层),组织成一个深度层次结构(通常只是一个堆栈,这是最简单的层次结构),在其中尽可能地重用任何信息(例如,卷积就是在不同的空间位置重用相同的信息)。
同样,深度学习模型架构的核心在于巧妙地利用模块化、层次结构和可重用性。你会注意到,所有流行的卷积神经网络(ConvNet)架构不仅由层组成,而且还由重复的层组(称为块或模块)组成。例如,上一章中使用的 Xception 架构就是由重复的块组成的 SeparableConv(SeparableConv参见MaxPooling图 9.2)。
此外,大多数卷积神经网络(ConvNet)通常具有金字塔状结构(特征层级)。例如,回想一下我们在上一章构建的第一个卷积神经网络中使用的卷积滤波器的数量变化:32、64、128。滤波器的数量随着层深度的增加而增加,而特征图的大小则相应缩小。您会在 Xception 模型的各个模块中看到同样的模式(参见图 9.2)。
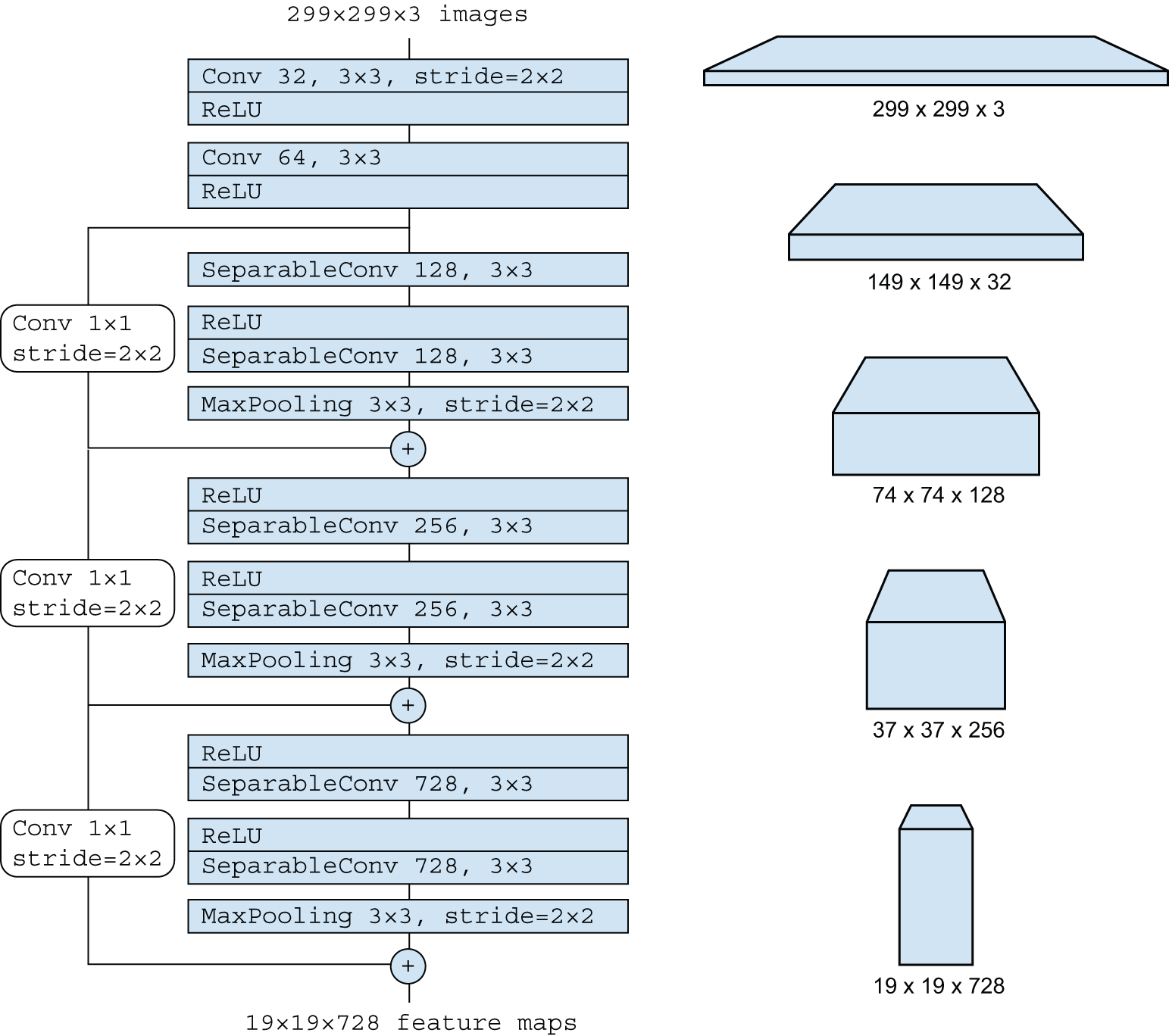 图 9.2:Xception 架构的“入口流程”:注意重复的图层块和逐渐缩小和加深的特征图,从 299 x 299 x 3 到 19 x 19 x 728。
图 9.2:Xception 架构的“入口流程”:注意重复的图层块和逐渐缩小和加深的特征图,从 299 x 299 x 3 到 19 x 19 x 728。
更深的层级结构本质上是有益的,因为它们鼓励特征重用,从而实现抽象。一般来说,由较深的窄层堆叠而成的模型比由较浅的宽层堆叠而成的模型性能更好。然而,层级堆叠的深度是有限的:梯度消失问题。这就引出了我们第一个重要的模型架构模式:残差连接。
Deeper hierarchies are intrinsically good because they encourage feature reuse and, therefore, abstraction. In general, a deep stack of narrow layers performs better than a shallow stack of large layers. However, there’s a limit to how deep you can stack layers: the problem of vanishing gradients. This leads us to our first essential model architecture pattern: residual connections.
论消融研究在深度学习研究中的重要性
On the importance of ablation studies in deep learning research
深度学习架构往往是不断演化而非精心设计的——它们是通过反复尝试并选择有效方法而开发的。就像生物系统一样,如果你采用任何复杂的实验性深度学习设置,很可能可以移除一些模块(或用随机特征替换一些训练过的特征)而不会损失性能。
深度学习研究人员面临的激励机制加剧了这种情况:他们通过使系统比实际需要更复杂,使其看起来更有趣或更新颖,从而提高论文通过同行评审的几率。如果你阅读过大量的深度学习论文,你会发现它们在风格和内容上往往都针对同行评审(the peer review process.)进行了优化,这反而损害了解释的清晰度和结果的可靠性。例如,深度学习论文中的数学很少用于清晰地形式化概念或推导出不显而易见的结论——相反,它被用作一种严肃性的象征,就像销售人员身上穿着昂贵的西装一样。;)
研究的目标不应仅仅是发表论文,而应是产生可靠的知识(reliable knowledge)。至关重要的是,理解系统中的因果关系(understanding causality)是产生可靠知识最直接的方法。而探究因果关系的方法非常简便: 消融研究(ablation studies)。消融研究是指系统地移除系统的部分组件——也就是简化系统——从而确定系统性能的真正来源。如果你发现 X + Y + Z 组合能带来良好的结果,那么不妨也尝试 X、Y、Z、X + Y、X + Z、Y + Z 的组合,看看会发生什么。
如果你成为一名深度学习研究员,就要在研究过程中排除干扰:对你的模型进行消融实验。始终要问自己:有没有更简单的解释?这种额外的复杂性真的有必要吗?为什么?
残差连接
Residual connections
你可能听说过“传话游戏”(或称“中国式耳语”), 在英国也叫“Chinese whispers” ,在法国叫“téléphone arabe”。游戏规则是:玩家先将一条信息悄悄告诉其中一位,然后这位玩家再将信息告诉下一位,以此类推。最终传递的信息与最初的版本往往大相径庭。这个游戏巧妙地比喻了在嘈杂信道上进行连续传输时累积误差的过程。
巧合的是,序列深度学习模型中的反向传播与传话游戏非常相似。你会看到一系列函数,例如:
1 | y = f4(f3(f2(f1(x)))) |
f4游戏的目标是根据模型输出(损失函数)记录的误差来调整链中每个函数的参数。为了调整损失函数f1,你需要将误差信息传递到函数链f2、f3函数和f4函数中。然而,链中的每个后续函数都会引入一定量的噪声。如果你的函数链过深,这些噪声会淹没梯度信息,反向传播就会停止工作。你的模型将无法训练。这就是所谓的梯度消失问题。
解决方法很简单:只需强制链中的每个函数都采用非破坏性操作——即保留先前输入中包含的信息的无噪声版本。最简单的实现方法是残差连接。它非常简单:只需将某一层或若干层块的输入加回其输出即可(参见图 9.3)。残差连接就像一条信息捷径 ,绕过了破坏性或噪声较大的模块(例如包含 ReLU 激活函数或 dropout 层的模块),使得来自早期层的误差梯度信息能够无噪声地在深度网络中传播。这项技术于 2015 年随 ResNet 系列模型(由微软的 He 等人开发)引入。[1]
个人注:在深度神经网络中,“残差连接”(Residual Connection)这个名字的核心在于数学上的“残差”(Residual)概念。
要理解这个名字,我们需要对比“普通网络”和“残差网络”在学习目标上的差异。
- 普通网络的学习目标
在传统的深度网络(如 VGG)中,每一层都在尝试学习一个完整的映射函数 \(H(x)\)。
- 输入:\(x\)
- 输出:\(H(x)\)
- 学习目标:直接拟合出输出值 \(H(x)\)。
随着网络变深,直接学习这个复杂的非线性映射 \(H(x)\) 会变得非常困难,容易出现梯度消失或退化问题。
- 残差网络的学习目标
何恺明(Kaiming He)等人在 ResNet 中改变了思路。他们不再让网络层直接学习 \(H(x)\),而是让它学习输入与输出之间的差值。
- 输入:\(x\)
- 期望输出:\(H(x)\)
- 网络层实际学习的内容:\(F(x) = H(x) - x\)
这里的 \(F(x)\) 在数学上就被称为“残差” (Residual)。
- 为什么叫“残差”?
“残差”在统计学和数学中通常指:观测值与真实值之间的差。
在神经网络的语境下:
- 我们希望得到的最终结果是 \(H(x)\)。
- 我们已经手握现成的基础信息 \(x\)(通过一条“捷径”直接传过来的)。
- 那么,剩下的、还没学好的那部分“差额”(即 \(H(x) - x\)),就是这一层需要补齐的“残差”。
因此,这种通过“捷径”(Shortcut Connection)将输入直接加到输出上,迫使卷积层只去拟合“差额”的结构,就被命名为残差连接。
- 为什么要这么做?(解决梯度下降问题)
“残差连接”之所以能解决深层网络的训练难题,主要有两个原因:
恒等映射(Identity Mapping)的便利性:
如果某一层实际上不需要进行任何处理(即最理想的状态是 \(H(x) = x\)),在普通网络中,模型很难通过调整参数把 \(H(x)\) 恰好学成 \(x\);但在残差网络中,只要把残差部分 \(F(x)\) 学习成 0 即可。让参数趋近于 0 比精确拟合出恒等映射要容易得多。
梯度的“高速公路”:
在反向传播计算梯度时,残差连接提供了一条导数为 1 的直接通道。
由于 \(H(x) = F(x) + x\),在对 \(x\) 求导时,\(\frac{dH}{dx} = \frac{dF}{dx} + 1\)。
即使残差部分的梯度 \(\frac{dF}{dx}\) 变得很小,由于后面那个 “+1” 的存在,梯度依然能有效地传回前面的层,从而彻底解决了深层网络中的梯度消失(Gradient Vanishing)问题。
总结
叫“残差连接”是因为它让网络不再从头学习输出,而是学习输入与输出之间的残余差值。这个小小的数学转变,让神经网络的深度从十几层跨越到了上千层。
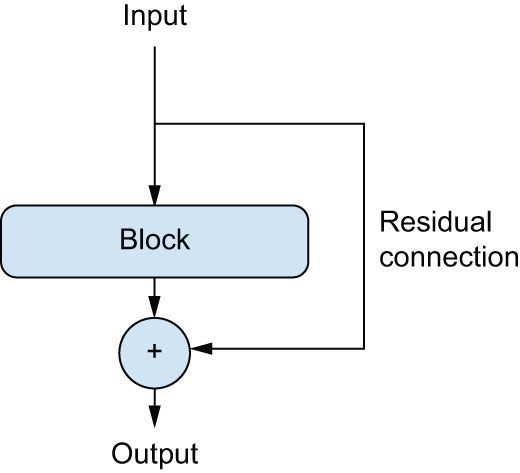 图 9.3:处理块周围的残差连接
图 9.3:处理块周围的残差连接
在实践中,您可以实现如下列表中所示的残差连接。
1 | # Some input tensor |
清单 9.1:伪代码中的残差连接
请注意,将输入加回模块的输出意味着输出应该与输入具有相同的形状。但如果模块包含卷积层(滤波器数量较多)或最大池化层,则情况并非如此。在这种情况下,可以使用一个 1×1 的Conv2D无激活层将残差线性投影到所需的输出形状。通常,您会padding="same" 在目标模块的卷积层中使用此方法,以避免因填充而导致的空间下采样;并且,您需要在残差投影中使用步长来匹配最大池化层造成的任何下采样。
1 | import keras |
清单 9.2:目标模块更改输出滤波器的数量
1 | inputs = keras.Input(shape=(32, 32, 3)) |
清单 9.3:包含最大池化层的目标块
为了使这些概念更加具体,这里有一个简单的卷积神经网络示例,它由一系列模块组成,每个模块由两个卷积层和一个可选的最大池化层组成,每个模块周围都有一个残差连接:
1 | inputs = keras.Input(shape=(32, 32, 3)) |
让我们来看一下模型概要:
1 | >>> model.summary() |
利用残差连接,您可以构建任意深度的网络,而无需担心梯度消失问题。现在,让我们继续讨论下一个重要的卷积神经网络架构模式: 批量归一化。
批量归一化
Batch normalization
机器学习中的归一化是一类广泛的方法,旨在使机器学习模型所看到的不同样本彼此更加相似,从而帮助模型更好地学习和泛化到新数据。最常见的数据归一化方法在本书中已经多次出现:通过从数据中减去均值将数据中心化到零,并通过将数据除以其标准差来赋予数据单位标准差。实际上,这种方法假设数据服从正态(或高斯)分布,并确保该分布被中心化并缩放到单位方差。
1 | normalized_data = (data - np.mean(data, axis=...)) / np.std(data, axis=...) |
本书前面的例子在将数据输入模型之前都对其进行了归一化处理。但是,网络每次转换之后,数据归一化都可能成为一个问题:即使输入到模型Dense或Conv2D网络的数据均值为 0、方差为 1,也不能预先认为输出的数据也如此。对中间激活值进行归一化是否有帮助呢?
BatchNormalization批量归一化正是实现这一功能。它是Keras 中的一种层,由 Ioffe 和 Szegedy 于 2015 年引入;[2]即使训练过程中均值和方差随时间变化,它也能自适应地对数据进行归一化。在训练过程中,它使用当前数据批次的均值和方差来归一化样本;而在推理过程中(当可能没有足够大的代表性数据批次可用时),它使用训练过程中所见数据的批次均值和方差的指数移动平均值。
尽管 Ioffe 和 Szegedy 的原始论文指出批量归一化通过“减少内部协变量偏移”来发挥作用,但没有人真正确切地知道批量归一化究竟为何有效。存在各种假设,但没有确凿的答案。你会发现,深度学习中的许多事物都是如此——深度学习并非一门精确的科学,而是一套不断变化、基于经验的工程最佳实践,并由一些不可靠的理论串联起来。你有时会觉得,你手头的书告诉你如何 做某件事,但却没有令人满意地解释其原理:那是因为我们知道怎么做,却不知道为什么。每当有可靠的解释时,我们都会确保提及。但批量归一化并非如此。
实际上,批量归一化的主要作用在于它有助于梯度传播——类似于残差连接——从而允许构建更深的网络。一些非常深的网络只有包含多层才能进行训练BatchNormalization。例如,Keras 自带的许多高级卷积神经网络架构,如 ResNet50、EfficientNet 和 Xception,都大量使用了批量归一化。
个人注:这句话核心在于揭示了批量归一化(Batch Normalization, 简称 BN)在深度学习中的本质价值:它不仅仅是用来加速训练的工具,更是保证深层网络能够“练得动”的关键基础设施。
我们可以从以下三个维度来拆解理解:
- 为什么说它“有助于梯度传播”?
在没有 BN 的深层网络中,每一层参数的微小变化都会在后续层中不断累积和放大。这会导致靠近输入层的梯度要么变得极小(梯度消失),要么变得极大(梯度爆炸),使得底层参数无法有效更新。
BN 的做法是:
在每一层的激活函数之前,强行将神经元的输出拉回到均值为 0、方差为 1 的标准分布。
- 物理意义:它确保了数据始终落在激活函数(如 ReLU 或 Sigmoid)的“敏感区域”,避免神经元进入饱和区。
- 结果:这使得反向传播时的梯度能够更加平滑、稳定地流向网络的深处。
- 为什么说它“类似于残差连接”?
虽然两者的实现逻辑完全不同,但它们在工程目标上殊途同归:
- 残差连接(Residual Connection):通过一条“捷径(Shortcut)”让梯度直接绕过复杂的层,直接传回前一层,提供了一条梯度的“高速公路”。
- 批量归一化(BN):通过“重新标定数据分布”,消除了层与层之间的相互干扰(即内部协变量偏移),确保梯度在穿过每一层时都不会因数据分布畸变而“枯萎”。
共同点:它们都充当了梯度的“护航者”,解决了深层网络训练中由于网络过深导致的退化问题。
- “允许构建更深的网络”意味着什么?
在 BN 和残差连接出现之前,神经网络很难超过 20 层(例如 VGG19 已经接近极限)。
- 如果没有这些技术,增加层数往往会导致训练误差反而上升。
- 有了 BN 后,梯度可以像穿过平原一样穿过上百层网络。这让我们可以构建像 ResNet-101 甚至更深的模型,而不用担心网络因为太深而导致底层参数“学不动”。
总结
这句话的意思是:BN 的功劳在于它“疏通”了梯度的传递路径。 它像是一个流量调节阀,保证了无论网络多深,信息流(梯度)都能稳定地传到底,从而打破了网络深度的天花板。
该BatchNormalization图层可以用于任何图层之后——例如Dense,,Conv2D等等:
1 | x = ... |
两者Dense都Conv2D包含一个“偏置向量”,这是一个学习变量,其目的是使层具有仿射性而非纯线性。例如,Conv2D示意图中,返回 ,y = conv(x, kernel) + bias而Dense返回y = dot(x, kernel) + bias。由于归一化步骤会将层的输出中心化到零,因此在使用时不再需要偏置向量BatchNormalization,并且可以通过选项 来创建不带偏置向量的层use_bias=False。这使得层结构略微精简。
重要的是,我通常建议将前一层的激活函数放在 批量归一化层之后(尽管这一点仍存在争议)。所以,与其这样做,不如这样做:
1 | x = layers.Conv2D(32, 3, activation="relu")(x) |
清单 9.4:如何避免使用批量归一化
实际上,你应该这样做:
1 | # Note the lack of activation here. |
清单 9.5:如何使用批量归一化
直观的解释是,批量归一化会将输入值中心化到零,而 ReLU 激活函数则以零为基准来决定保留或丢弃激活的通道:在激活之前进行归一化可以最大程度地利用 ReLU。也就是说,这种顺序并非绝对必要,所以即使你采用卷积-激活-批量归一化的顺序,模型仍然可以训练,并且不一定会得到更差的结果。
批量归一化有很多特性。其中一个主要特性与微调有关:当微调包含BatchNormalization多个层的模型时,我建议冻结这些层(将其trainable属性设置为 true False)。否则,它们会不断更新其内部均值和方差,这可能会干扰应用于周围层的微小更新Conv2D。
现在,让我们来看看本系列中的最后一个架构模式:深度可分离卷积。
深度可分离卷积
Depthwise separable convolutions
如果我们告诉你,有一个层可以作为现成的替代品,Conv2D它能让你的模型更小(减少可训练的权重参数)、更精简(减少浮点运算),并且还能让它在任务上提升几个百分点,你会相信吗?这正是深度可分离卷积层(SeparableConv2D在 Keras 中)的功能。如图 9.4 所示,该层首先对输入的每个通道独立地执行空间卷积,然后再通过逐点卷积(1×1 卷积)混合输出通道。
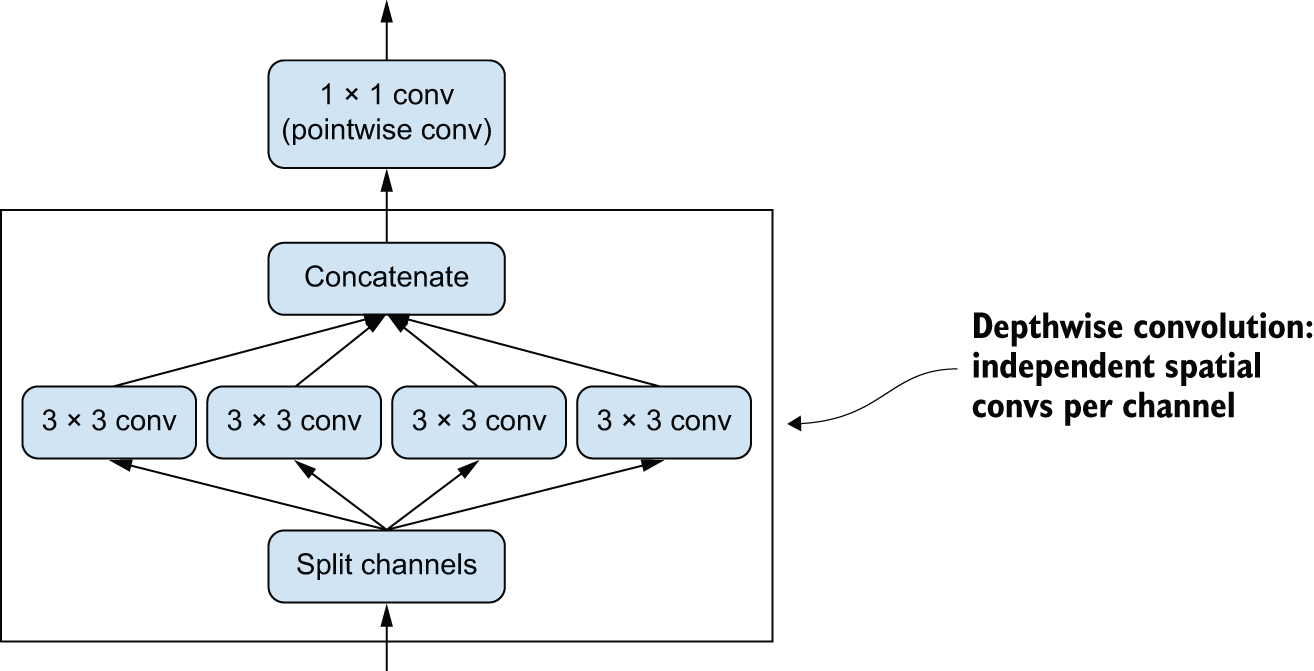 图 9.4:深度可分离卷积:先进行深度卷积,再进行逐点卷积
图 9.4:深度可分离卷积:先进行深度卷积,再进行逐点卷积
这相当于将空间特征的学习和通道特征的学习分开。正如卷积依赖于图像中的模式与特定位置无关的假设一样,深度可分离卷积依赖于 中间激活的空间位置高度相关,但不同通道高度独立的假设。由于这一假设通常适用于深度神经网络学习到的图像表示,因此它可以作为有用的先验信息,帮助模型更有效地利用训练数据。只要先验信息准确,拥有更强信息结构先验信息的模型就是更好的模型。
与常规卷积相比,深度可分离卷积所需的参数更少,计算量也更小,同时却拥有相当的表征能力。这使得模型体积更小、收敛速度更快、更不容易过拟合。当使用有限的数据从头开始训练小型模型时,这些优势尤为重要。
对于大规模模型而言,深度可分离卷积是 Xception 架构的基础,Xception 是一个高性能的卷积神经网络,它与 Keras 集成在一起。您可以在论文“Xception: Deep Learning with Depthwise Separable Convolutions”中了解更多关于深度可分离卷积和 Xception 的理论基础。[3]
个人注:
在深度学习(尤其是轻量化网络如 MobileNet)中,深度可分离卷积(Depthwise Separable Convolution) 是核心技术。
简单来说,它的核心思想是:将传统卷积一步完成的“空间特征提取”和“通道信息融合”拆分为两个独立的步骤。
- 普通卷积(Standard Convolution)
普通卷积是“全能型”操作。
- 操作:每一个卷积核都会同时处理输入的所有通道。
- 计算逻辑:如果输入有 3 个通道(RGB),一个卷积核就像一个 3 层的厚片,一次性把这 3 层的信息压缩成输出的一个点。
- 缺点:计算量非常大,因为参数量随着(输入通道 × 输出通道 × 卷积核大小)乘积增长。
- 深度可分离卷积(Depthwise Separable)
它将过程拆分为两步:
第一步:逐通道卷积(Depthwise Convolution)
- 做法:给输入的每一个通道单独配一个卷积核。
- 目的:只提取空间特征(宽和高),不进行通道间的融合。
- 结果:输入 3 个通道,输出还是 3 个通道,彼此独立。
第二步:逐点卷积(Pointwise Convolution)
- 做法:使用 \(1 \times 1\) 的卷积核。
- 目的:将第一步得到的多个通道的信息进行加权融合(跨通道特征组合)。
- 结果:通过改变 \(1 \times 1\) 卷积核的数量,可以自由控制最终输出的通道数。
- 核心区别:效率对比
特性 普通卷积 深度可分离卷积 步骤 一步到位 拆分为两步 (Depthwise + Pointwise) 参数量 很高 (\(D_k^2 \cdot M \cdot N\)) 极低 (\(D_k^2 \cdot M + M \cdot N\)) 计算量 (FLOPs) 很大 约为普通卷积的 \(1/8\) 到 \(1/9\) 应用场景 高精度、大算力模型 (ResNet, VGG) 移动端、实时监测 (MobileNet, Xception) 公式直观理解:
如果使用 \(3 \times 3\) 的卷积核,深度可分离卷积的计算量大约只有普通卷积的 \(1/9\) 左右,而性能损失却非常微小。
- 为什么要这么做?
这其实是对信息冗余的剔除。
研究发现,卷积核在提取空间信息(左边是不是边缘)和通道信息(红色和蓝色怎么组合)时,并不一定要同时进行。拆分后,模型可以用更少的参数达到相近的效果。
这也是为什么你可以在手机端流畅运行实时的人脸识别或图像分割模型,而不需要背着一台高性能服务器。
硬件、软件和算法的共同演化
The co-evolution of hardware, software, and algorithms
考虑一个常规的卷积运算,其窗口大小为 3×3,输入通道数为 64,输出通道数为 64。它使用 3×3×64×64 = 36,864 个可训练参数,当将其应用于图像时,需要执行与参数数量成正比的浮点运算次数。而考虑一个等效的深度可分离卷积:它仅涉及 3×3×64 + 64×64 = 4,672 个可训练参数,并且浮点运算次数也相应减少。随着滤波器数量或卷积窗口大小的增大,这种效率提升会更加显著。
因此,你可能会认为深度可分离卷积的速度会显著提升,对吧?别急。如果你用简单的 CUDA 或 C++ 实现这些算法,那确实如此——事实上,在 CPU 上运行确实能获得显著的速度提升,因为底层实现是并行化的 C++。但在实际应用中,你很可能使用的是 GPU,而你在 GPU 上执行的远非“简单”的 CUDA 实现:它是一个 cuDNN 内核,一段经过极其优化的代码,优化程度甚至细致到每一条机器指令。当然,花费大量精力优化这段代码是合理的,因为 NVIDIA 硬件上的 cuDNN 卷积每天都要进行数百亿亿次浮点运算。但这种极致的微优化带来的一个副作用是,其他方法几乎没有机会在性能上与之匹敌——即使是像深度可分离卷积这样本身具有显著优势的方法。
尽管多次向 NVIDIA 提出请求,但深度可分离卷积并未像常规卷积那样获得同等程度的软硬件优化,因此,即使其参数和浮点运算次数呈平方级减少,其速度也仅与常规卷积大致相当。不过,即使深度可分离卷积无法带来速度提升,使用它仍然是一个好主意:其更少的参数意味着过拟合的风险更低,并且其通道不相关的假设有助于模型更快收敛并生成更鲁棒的表示。
在这种情况下,这只是一个小小的麻烦,但在其他情况下,它却可能变成一道难以逾越的障碍:因为深度学习的整个硬件和软件生态系统都针对一组非常特定的算法(特别是通过反向传播训练的卷积神经网络)进行了微优化,所以偏离既定路线的代价极其高昂。如果你尝试使用其他算法,例如无梯度优化或脉冲神经网络,那么你最初实现的几个并行 C++ 或 CUDA 版本的速度都会比传统的卷积神经网络慢几个数量级——无论你的想法多么巧妙高效。即使你的方法确实更好,也很难说服其他研究人员采用你的方法。
可以说,现代深度学习是硬件、软件和算法共同演化的产物:NVIDIA GPU 和 CUDA 的出现促成了反向传播训练的卷积神经网络的早期成功,进而促使 NVIDIA 针对这些算法优化其硬件和软件,最终推动了相关研究群体的整合。如今,想要另辟蹊径需要对整个生态系统进行长达数年的重构。
组装完成:一个迷你版的Xception模型
Putting it together: A mini Xception-like model
作为回顾,以下是您目前为止学到的卷积神经网络架构原则:
- 你的模型应该由重复的层块组成,通常由多个卷积层和一个最大池化层构成。
- 随着空间特征图尺寸的减小,图层中的过滤器数量应该增加。
- 深而窄比宽而浅好。
- 在层块周围引入残差连接有助于训练更深的网络。
- 在卷积层之后引入批量归一化层可能是有益的。
- 用参数效率更高的层替换
Conv2D层可能是有益的。SeparableConv2D - Your model should be organized into repeated blocks of layers, usually made of multiple convolution layers and a max pooling layer.
- The number of filters in your layers should increase as the size of the spatial feature maps decreases.
- Deep and narrow is better than broad and shallow.
- Introducing residual connections around blocks of layers helps you train deeper networks.
- It can be beneficial to introduce batch normalization layers after your convolution layers.
- It can be beneficial to replace
Conv2Dlayers withSeparableConv2Dlayers, which are more parameter efficient.
让我们把所有这些想法整合到一个模型中。它的架构类似于简化版的 Xception。我们将把它应用到上一章的猫狗对抗任务中。对于数据加载和模型训练,只需重复使用与第 8 章 8.2 节中完全相同的设置——但将模型定义替换为以下卷积神经网络:
1 | import keras |
该卷积神经网络的可训练参数数量为 721,857,远低于上一章模型的 1,569,089 个可训练参数,但却取得了更好的结果。图 9.5 显示了训练曲线和验证曲线。
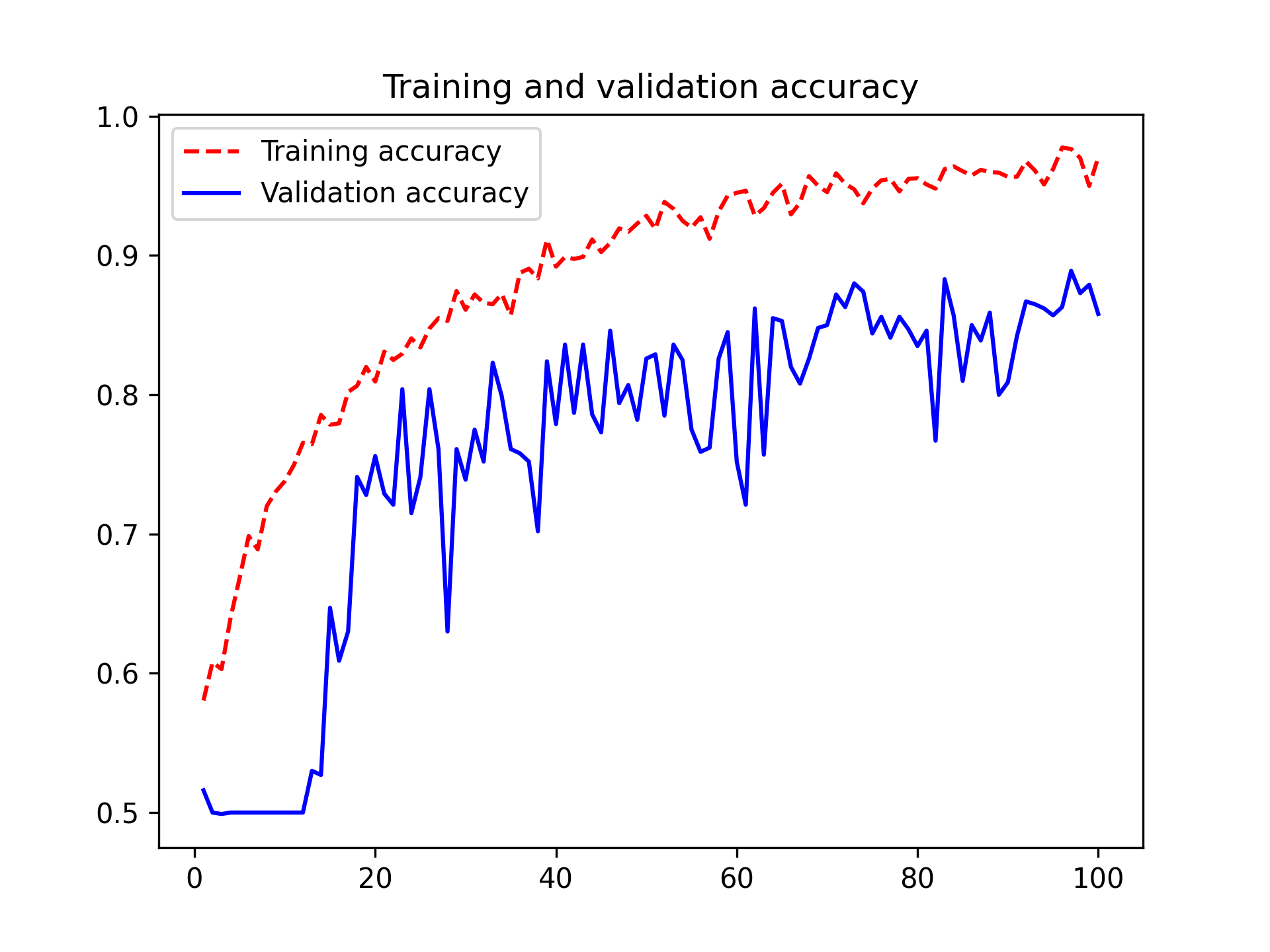
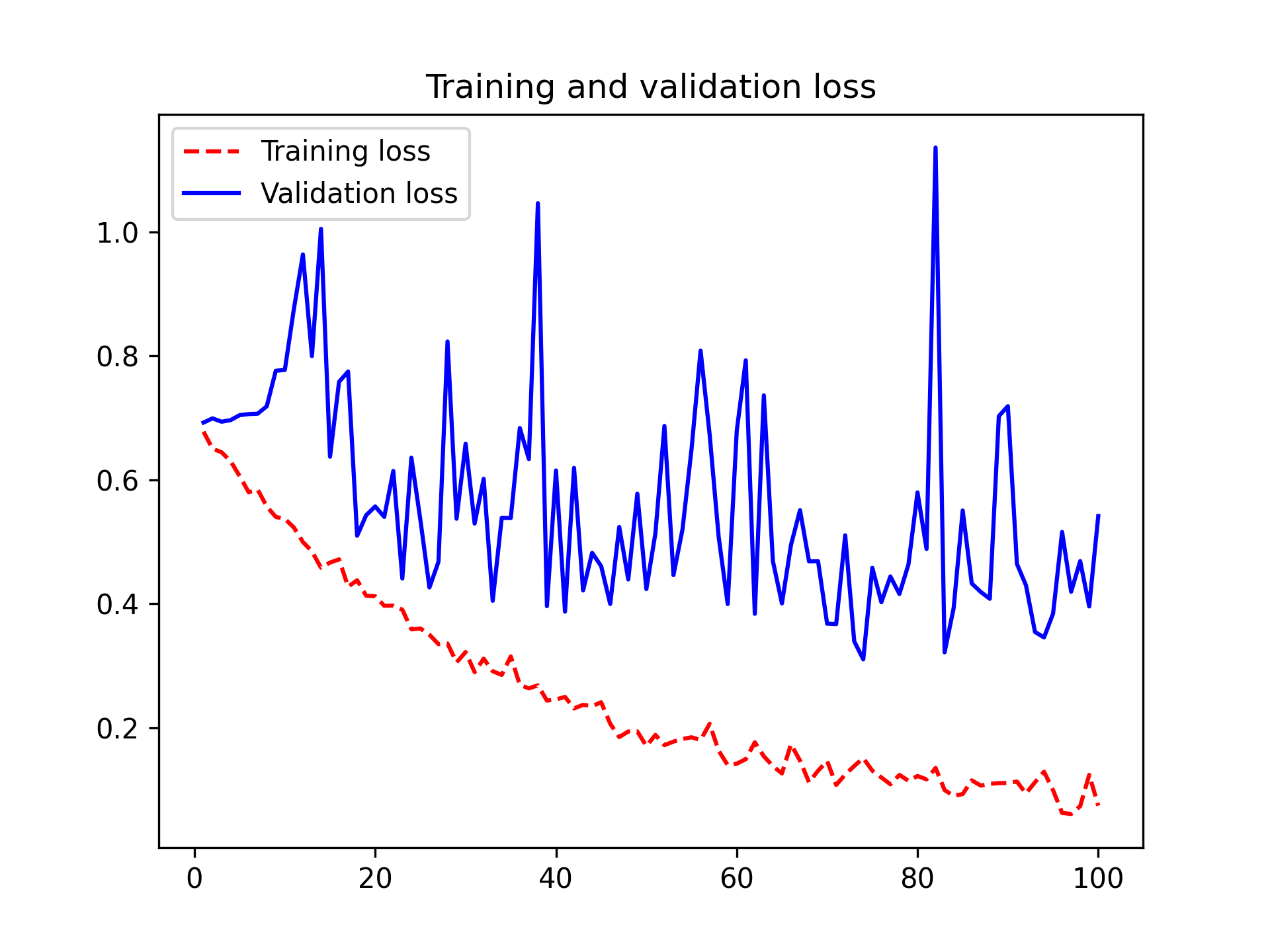 图 9.5:采用类似 Xception 架构的训练和验证指标
图 9.5:采用类似 Xception 架构的训练和验证指标
你会发现,我们的新模型测试准确率达到了 90.8%,而之前的模型只有 83.9%。由此可见,遵循最佳架构实践确实能对模型性能产生立竿见影的显著影响!
此时,如果您想进一步提高性能,就应该开始系统地调整架构的超参数——我们将在第 18 章详细介绍这一主题。我们在这里还没有完成这一步骤,因此先前模型的配置完全来自我们概述的最佳实践,此外,在衡量模型大小时,还包含少量直觉。
超越卷积:视觉变形
Beyond convolution: Vision Transformers
自 2010 年代中期以来,卷积神经网络 (ConvNets) 一直主导着计算机视觉领域,但近年来,一种名为 Vision Transformer(简称 ViTs)的替代架构开始对其构成竞争。从长远来看,ViTs 很可能会最终取代 ConvNets——不过,就目前而言,ConvNets 在大多数情况下仍然是最佳选择。
你现在还不了解 Transformer 是什么,因为我们将在第 15 章介绍它。简而言之,Transformer 架构是为处理文本而开发的——它本质上是一种序列处理架构。Transformer 在这方面非常出色,这就引出了一个问题:我们是否也可以用它们来处理图像?
由于 ViT 是一种 Transformer 模型,它们也能够处理序列:它们将图像分割成一维的图像块序列,将每个图像块转换为一个平面向量,然后处理该向量序列。Transformer 架构使得 ViT 能够捕捉图像不同部分之间的长程关系,而这正是 ConvNet 有时难以处理的问题。
我们使用Transformer模型的总体经验是,如果您处理的是海量数据集,它们是一个不错的选择。它们在利用大量数据方面表现出色。然而,对于较小的数据集,它们往往并非最佳选择,原因有二。首先,它们缺乏卷积神经网络(ConvNets)的空间先验信息——ConvNets基于二维图像块的架构包含了更多关于视觉空间局部结构的假设,使其数据效率更高。其次,为了充分发挥Transformer模型的优势,它们需要处理非常大的数据集。对于小于ImageNet的数据集,它们最终会变得难以驾驭。
图像识别领域的竞争远未结束,但虚拟神经网络(ViTs)无疑开启了激动人心的新篇章。您很可能会在大规模生成图像模型中使用这种架构——我们将在第17章中讨论这一主题。然而,对于小规模图像分类需求,卷积神经网络(ConvNets)仍然是您的最佳选择。
至此,我们对卷积神经网络(ConvNet)架构最佳实践的介绍就结束了。掌握了这些原则,您将能够开发出性能更高的模型,并应用于各种计算机视觉任务。您现在已经朝着成为一名熟练的计算机视觉从业者迈出了坚实的一步。为了进一步加深您的专业知识,我们还需要讨论最后一个重要主题:解释模型如何得出预测结果。
概括
- 深度学习模型的架构编码了关于当前问题本质的关键假设。
- 模块化-层次化-重用公式是几乎所有复杂系统(包括深度学习模型)架构的基础。
- 计算机视觉的关键架构模式包括残差连接、批量归一化和深度可分离卷积。
- 视觉变换器是卷积神经网络的一种新兴替代方案,适用于大规模计算机视觉任务。
脚注
- Kaiming He 等人,“用于图像识别的深度残差学习”,计算机视觉与模式识别会议 (2015),https://arxiv.org/abs/1512.03385。
- Sergey Ioffe 和 Christian Szegedy,“批量归一化:通过减少内部协变量偏移加速深度网络训练”,第 32 届国际机器学习会议论文集(2015),https://arxiv.org/abs/1502.03167。
- François Chollet,“Xception:基于深度可分离卷积的深度学习”,计算机视觉与模式识别会议(2017),https://arxiv.org/abs/1610.02357。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论