《DEEP LEARNING with Python》第四章 分类与回归
第四章 分类与回归
Classification and regression
运行代码
本章内容
- 您的第一个真实世界机器学习工作流程示例
- 处理二元分类和类别分类问题
- 处理连续回归问题
本章旨在引导你开始使用神经网络解决实际问题。你将巩固从第 2 章和第 3 章中获得的知识,并将所学知识应用于三个新任务,这三个任务涵盖了神经网络的三种最常见应用场景——二元分类、类别分类和标量回归(binary classification, categorical classification, and scalar regression):
- 将电影评论分类为正面或负面(二元分类)
- 按主题对新闻稿进行分类(类别分类)
- 利用房地产数据估算房屋价格(标量回归)
这些示例将是您首次接触端到端机器学习工作流程:您将了解数据预处理、基本模型架构原则和模型评估(data preprocessing, basic model architecture principles, and model evaluation.)。
学完本章后,你将能够使用神经网络处理向量数据的简单分类和回归任务。之后,你将准备好在第五章中开始构建更系统、更具理论基础的机器学习理解。
分类与回归术语表
Classification and regression glossary
分类和回归涉及许多专业术语。您在前面的示例中已经遇到过其中一些,在后面的章节中还会看到更多。它们都有精确的、机器学习特有的定义,您应该熟悉它们:
- 样本或输入 ——输入到模型中的一个数据点。
- 预测或输出 ——模型输出的结果。
- 目标 ——真相。根据外部数据源,你的模型理想情况下应该预测出的结果。
- 预测误差或损失值 ——衡量模型预测值与目标值之间距离的指标。
- 类别 ——分类问题中可供选择的一组标签。例如,在对猫和狗的图片进行分类时,“狗”和“猫”就是两个类别。
- 标签 ——分类问题中类别标注的具体实例。例如,如果图片 #1234 被标注为包含“狗”这一类别,那么“狗”就是图片 #1234 的标签。
- 真实标签或标注 — 数据集的所有目标,通常由人类收集。
- 二元分类 ——一种分类任务,其中每个输入样本应被归类为两个互斥的类别。
- 类别分类或多类分类 ——一种分类任务,其中每个输入样本应被分类到两个以上的类别中:例如,对手写数字进行分类。
- 多标签分类 ——一种分类任务,其中每个输入样本可以被赋予多个标签。例如,一张图像可能同时包含猫和狗,因此需要同时标注“猫”标签和“狗”标签。每张图像的标签数量通常是可变的。
- 标量回归 ——目标值为连续标量值的任务。预测房价就是一个很好的例子:不同的目标价格构成一个连续空间。
- 向量回归 ——目标是一组连续值的任务:例如,一个连续向量。如果您要对多个值(例如图像中边界框的坐标)进行回归,那么您就是在进行向量回归。
- 小批量(或简称批次) ——指模型同时处理的一小批样本(通常介于 8 到 128 个之间)。样本数量通常是 2 的幂,以便于在 GPU 上分配内存。训练时,小批量用于计算应用于模型权重的单次梯度下降更新。
Classification and regression glossary
Classification and regression involve many specialized terms. You’ve come across some of them in earlier examples, and you’ll see more of them in future chapters. They have precise, machine learning-specific definitions, and you should be familiar with them:
- Sample or input — One data point that goes into your model.
- Prediction or output — What comes out of your model.
- Target — The truth. What your model should ideally have predicted, according to an external source of data.
- Prediction error or loss value — A measure of the distance between your model’s prediction and the target.
- Classes — A set of possible labels to choose from in a classification problem. For example, when classifying cat and dog pictures, “dog” and “cat” are the two classes.
- Label — A specific instance of a class annotation in a classification problem. For instance, if picture #1234 is annotated as containing the class “dog,” then “dog” is a label of picture #1234.
- Ground-truth or annotations — All targets for a dataset, typically collected by humans.
- Binary classification — A classification task where each input sample should be categorized into two exclusive categories.
- Categorical classification or multiclass classification — A classification task where each input sample should be categorized into more than two categories: for instance, classifying handwritten digits.
- Multilabel classification — A classification task where each input sample can be assigned multiple labels. For instance, a given image may contain both a cat and a dog and should be annotated with both the “cat” label and the “dog” label. The number of labels per image is usually variable.
- Scalar regression — A task where the target is a continuous scalar value. Predicting house prices is a good example: the different target prices form a continuous space.
- Vector regression — A task where the target is a set of continuous values: for example, a continuous vector. If you’re doing regression against multiple values (such as the coordinates of a bounding box in an image), then you’re doing vector regression.
- Mini-batch or just batch — A small set of samples (typically between 8 and 128) that are processed simultaneously by the model. The number of samples is often a power of 2, to facilitate memory allocation on GPU. When training, a mini-batch is used to compute a single gradient-descent update applied to the weights of the model.
电影评论分类:二元分类示例
Classifying movie reviews: A binary classification example
二分类,或称二元分类,是机器学习中最常见的问题之一。在这个例子中,你将学习如何根据影评的文本内容,将影评分类为正面或负面。
IMDb数据集
The IMDb dataset
你将使用 IMDb 数据集:这是一组来自互联网电影数据库的 50,000 条高度两极分化的评论。这些评论被分为 25,000 条用于训练,25,000 条用于测试,每组评论中负面评论和正面评论各占 50%。
与 MNIST 数据集一样,IMDb 数据集也已包含在 Keras 中。它已经过预处理(preprocessed):评论(单词序列)已被转换为整数序列,其中每个整数代表字典中的一个特定单词。这使我们能够专注于模型的构建、训练和评估。在第 14 章中,您将学习如何从头开始处理原始文本输入。
以下代码将加载数据集(首次运行时,大约 80 MB 的数据将下载到您的计算机)。
1 | from keras.datasets import imdb |
清单 4.1:加载 IMDb 数据集
这种方法num_words=10000意味着训练数据中只会保留出现频率最高的 10,000 个词,而罕见词将被舍弃。这样一来,就可以处理规模适中的向量数据。如果不设置这个限制,训练数据中就会包含 88,585 个不同的词,这显然过于庞大。其中许多词只在单个样本中出现,因此无法有效地用于分类。
变量 a``train_data和test_data``b 是 NumPy 数组,存储评论信息;每条评论都是一个单词索引列表(编码一个单词序列)。c``train_labels和 test_labels``d 是 NumPy 数组,包含 0 和 1,其中 0 代表负面评价,1 代表正面评价。
1 | >>> train_data[0] |
因为你只选取了使用频率最高的10000个词,所以任何词索引都不会超过10000:
1 | >>> max([max(sequence) for sequence in train_data]) |
为了好玩,我们快速地把其中一条评论解码成英文单词。
1 | # word_index is a dictionary mapping words to an integer index. |
列表 4.2:将评论解码回文本
让我们来看看我们得到了什么:
1 | >>> decoded_review[:100] |
请注意,开头部分?对应于添加到每条评论前的起始标记。
数据准备
Preparing the data
你不能直接将整数列表输入神经网络。这些列表长度各不相同,而神经网络需要处理的是连续的数据批次。你必须将列表转换为张量。有两种方法可以做到这一点:
- 将列表填充到相同长度,然后将它们转换为形状为 的整数张量
(samples, max_length),并使用能够处理此类整数张量的层(Embedding我们将在本书后面详细介绍的层)来启动模型。 - 对列表进行多热编码(Multi-hot encode),将其转换为由 0 和 1 组成的向量,以反映所有可能单词的存在与否。例如,这意味着将序列转换
[8, 5]为一个 10,000 维的向量,其中除索引 5 和 8 为 1 外,其余元素均为 0。
我们选择后一种方案来向量化数据。手动操作时,流程如下所示。
个人注:第一种方法的Embedding编码包含了词义!
1 | import numpy as np |
清单 4.3:使用多热编码对整数序列进行编码
以下是样品现在的样子:
1 | >>> x_train[0] |
除了对输入序列进行向量化之外,你也应该对它们的标签进行向量化,这很简单。我们的标签已经是 NumPy 数组了,所以只需将类型从整数转换为浮点数即可:
1 | y_train = train_labels.astype("float32") |
现在数据已经准备好输入神经网络了。
构建你的模型
Building your model
输入数据是向量,标签是标量(1 和 0):这是你所能遇到的最简单的问题设置之一。在这种问题上表现良好的模型是简单的全连接Dense层堆叠,带有relu激活函数。
对于这种多层架构,需要做出两个关键的架构决策 Dense:
- 需要使用多少层?
- 每层应该选择多少个单元?
在第五章中,你将学习一些正式的原则来指导你做出这些选择。目前,你只能相信我们做出的以下架构选择:
- 两层中间层(intermediate layer),每层16个单元
- 第三层将输出关于当前评论情感的标量预测结果
图 4.1 展示了模型的结构。以下是 Keras 的实现,类似于您之前看到的 MNIST 示例。
1 | import keras |
清单 4.4:模型定义
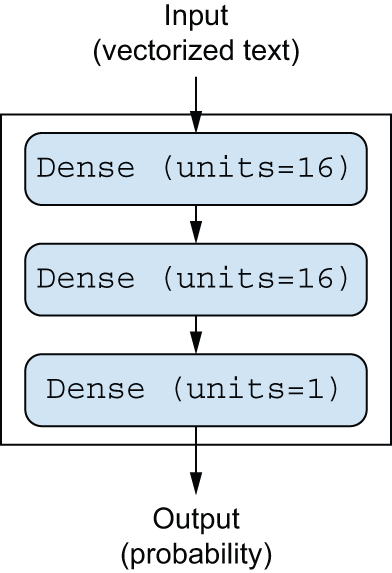
传递给每一层的第一个参数是该层中的单元Dense数:即该层表示空间的维度。你可能还记得第 2 章和第 3 章的内容,每个带有激活函数的层都实现了以下一系列张量运算:Dense``relu
1 | output = relu(dot(input, W) + b) |
拥有 16 个单元意味着权重矩阵的W形状为 (input_dimension, 16):与的点积W会将输入数据投影到 16 维表示空间(然后加上偏置向量b并应用运算relu)。你可以直观地理解表示空间的维度,即“你允许模型在学习内部表示时拥有多大的自由度”。拥有更多单元(更高维度的表示空间)可以让模型学习更复杂的表示,但这会增加模型的计算成本,并可能导致学习到不必要的模式(这些模式可以提高训练数据上的性能,但对测试数据没有帮助)。
中间层使用relu作为激活函数,而最后一层使用 sigmoid 激活函数输出概率值(介于 0 和 1 之间的分数,表示评论为正面的可能性)。relu(修正线性单元rectified linear unit)函数旨在将负值置零(参见图 4.2),而 sigmoid 函数则将任意值“压缩”到区间内[0, 1](参见图 4.3),输出可以解释为概率的值。
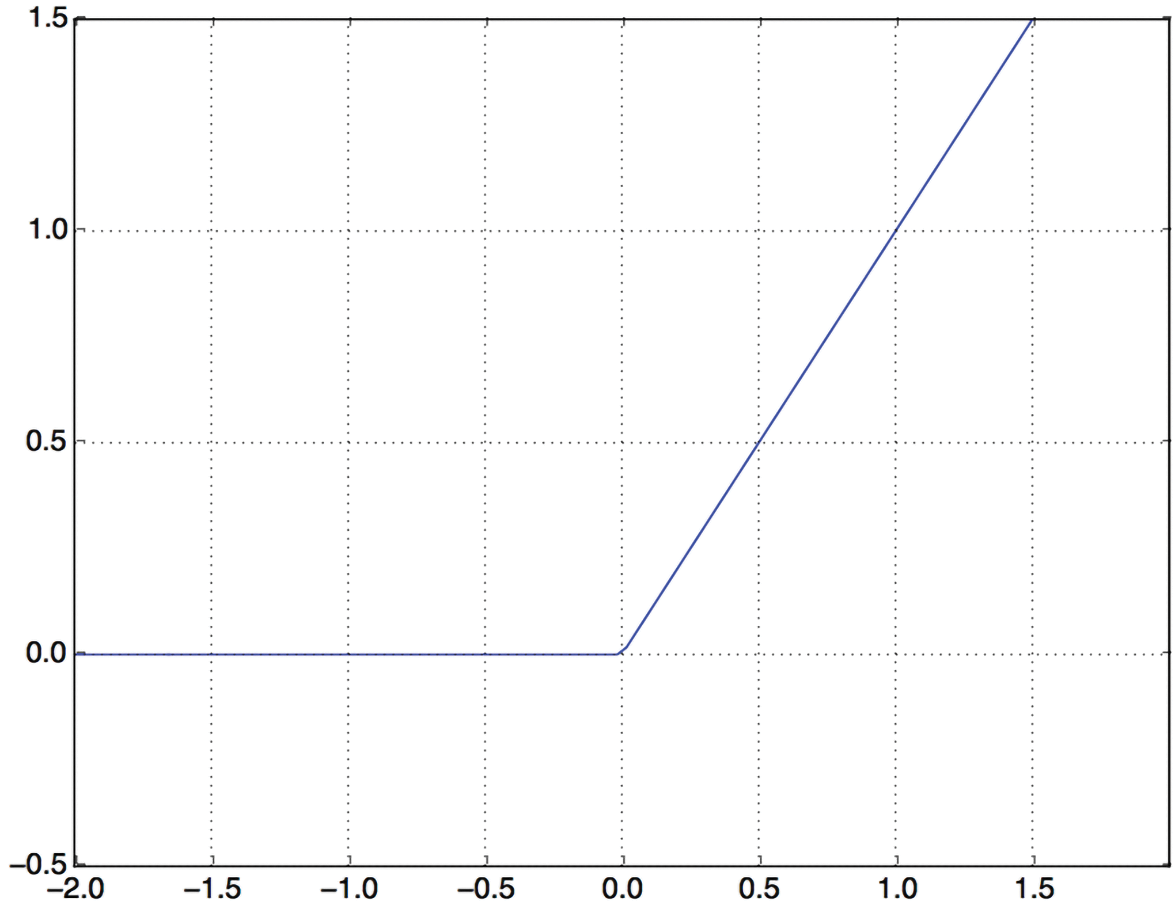
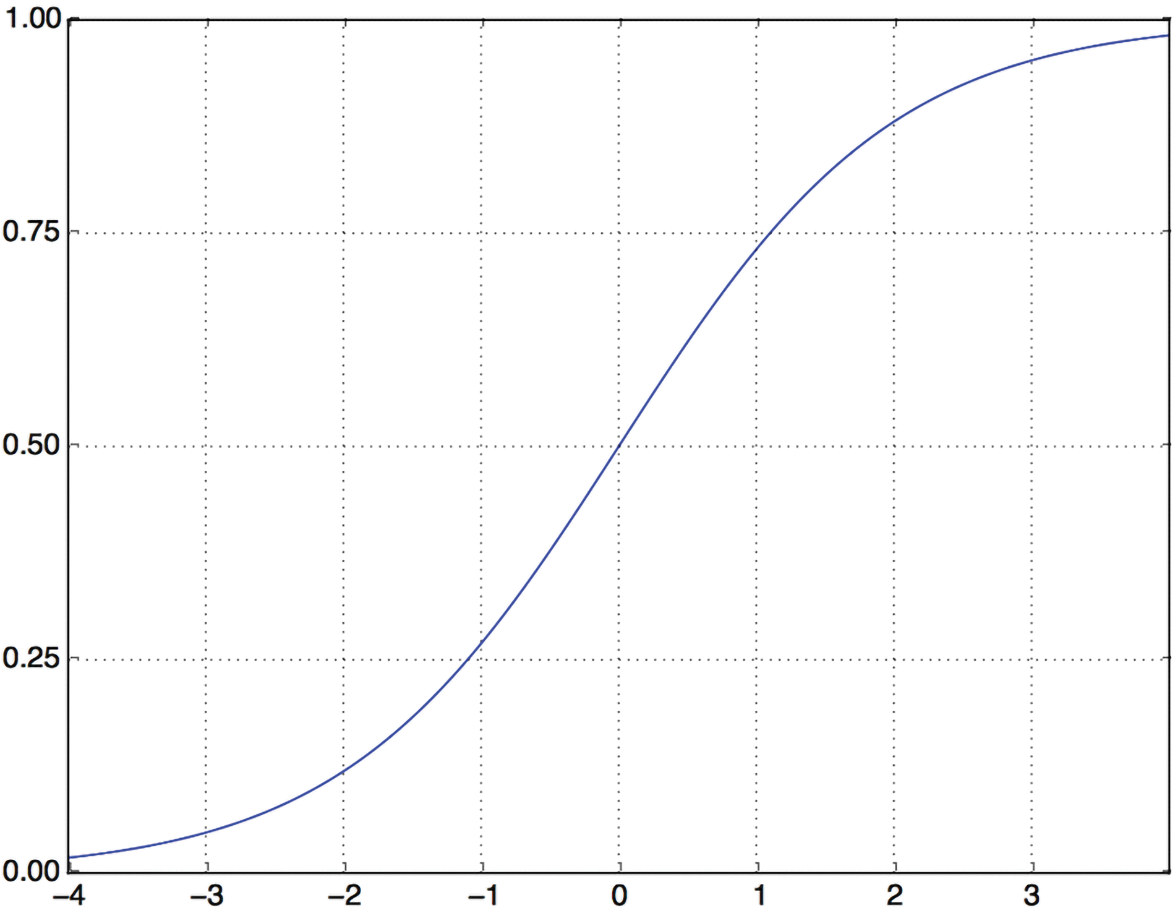
什么是激活函数?为什么需要激活函数?
What are activation functions, and why are they necessary?
如果没有激活函数relu(也称为非线性),该Dense层将由两个线性运算组成——点积和加法:
1 | output = dot(input, W) + b |
因此,该层只能学习输入数据的 线性变换(仿射变换):该层的假设空间是输入数据到 16 维空间的所有可能的线性变换的集合。这样的假设空间过于局限,无法从多层表示中获益,因为即使堆叠多层线性层,最终实现的仍然是线性运算:增加更多层并不会扩展假设空间(正如你在第二章中看到的)。
为了获得更丰富的假设空间(这将受益于深度表征),你需要一个非线性函数或激活函数。 relu是深度学习中最常用的激活函数,但还有许多其他候选函数,它们的名称都同样奇怪:prelu、 elu等等。
最后,你需要选择损失函数和优化器。由于你面临的是一个二元分类问题,并且模型的输出是一个概率值(你的模型以一个带有 sigmoid 激活函数的单单元层结尾),因此最好使用交叉熵 binary_crossentropy损失函数。当然,这并非唯一可行的选择:例如,你也可以使用其他方法mean_squared_error。但对于输出概率值的模型,交叉熵通常是最佳选择。交叉熵是信息论领域的一个量,它衡量概率分布之间的距离,在本例中,指的是真实分布与预测分布之间的距离。
至于优化器的选择,我们将选择adam,这通常是解决几乎所有问题的良好默认选择。
接下来,您需要配置模型,包括adam优化器和binary_crossentropy损失函数。请注意,您还需要在训练过程中监控准确率。
1 | model.compile( |
清单 4.5:编译模型
验证你的方法
Validating your approach
正如你在第三章中学到的,深度学习模型绝不应该直接使用训练数据进行评估——通常的做法是使用“验证集”来监控模型在训练过程中的准确性。在这里,你将通过从原始训练数据中分离出 10,000 个样本来创建一个验证集。
你可能会问,为什么不直接用测试数据来评估模型呢?那样似乎更简单。原因在于,你需要利用验证集上的结果来指导下一步的训练决策——例如,选择合适的模型大小或训练轮数。一旦你开始这样做,验证集的分数就无法准确反映模型在新数据上的性能,因为模型已经被刻意修改以使其在验证集上表现更佳。因此,最好保留一组从未见过的样本,以便用完全客观的方式进行最终的评估,而测试集正是如此。我们将在下一章详细讨论这一点。
1 | x_val = x_train[:10000] |
清单 4.6:预留验证集
现在,您将使用 512 个样本的小批量训练模型 20 个 epoch(对训练数据中的所有样本进行 20 次迭代)。同时,您需要监控预留的 10,000 个样本的损失和准确率。您可以通过将验证数据作为validation_data参数传递给model.fit().
1 | history = model.fit( |
清单 4.7:训练你的模型
论点validation_split
The validation_split argument
除了手动从训练数据中分离验证数据并将其作为validation_data参数传递之外,您还可以使用 validation_splitvalidationData 参数fit()。它指定要用作验证数据的训练数据比例,如下所示:
1 | history = model.fit( |
x_train在这个例子中,数组中的 20% 样本y_train被排除在训练之外,用作验证数据。
在 CPU 上,每个 epoch 的训练时间不到 2 秒——整个训练过程只需 20 秒。每个 epoch 结束时,模型会稍作停顿,以便计算其在 10,000 个验证样本上的损失和准确率。
请注意,正如您在第 3 章中看到的,该调用会model.fit()返回一个对象。该对象有一个成员,它是一个字典,其中包含有关训练期间发生的所有数据。让我们来看一下:History``history
1 | >>> history_dict = history.history |
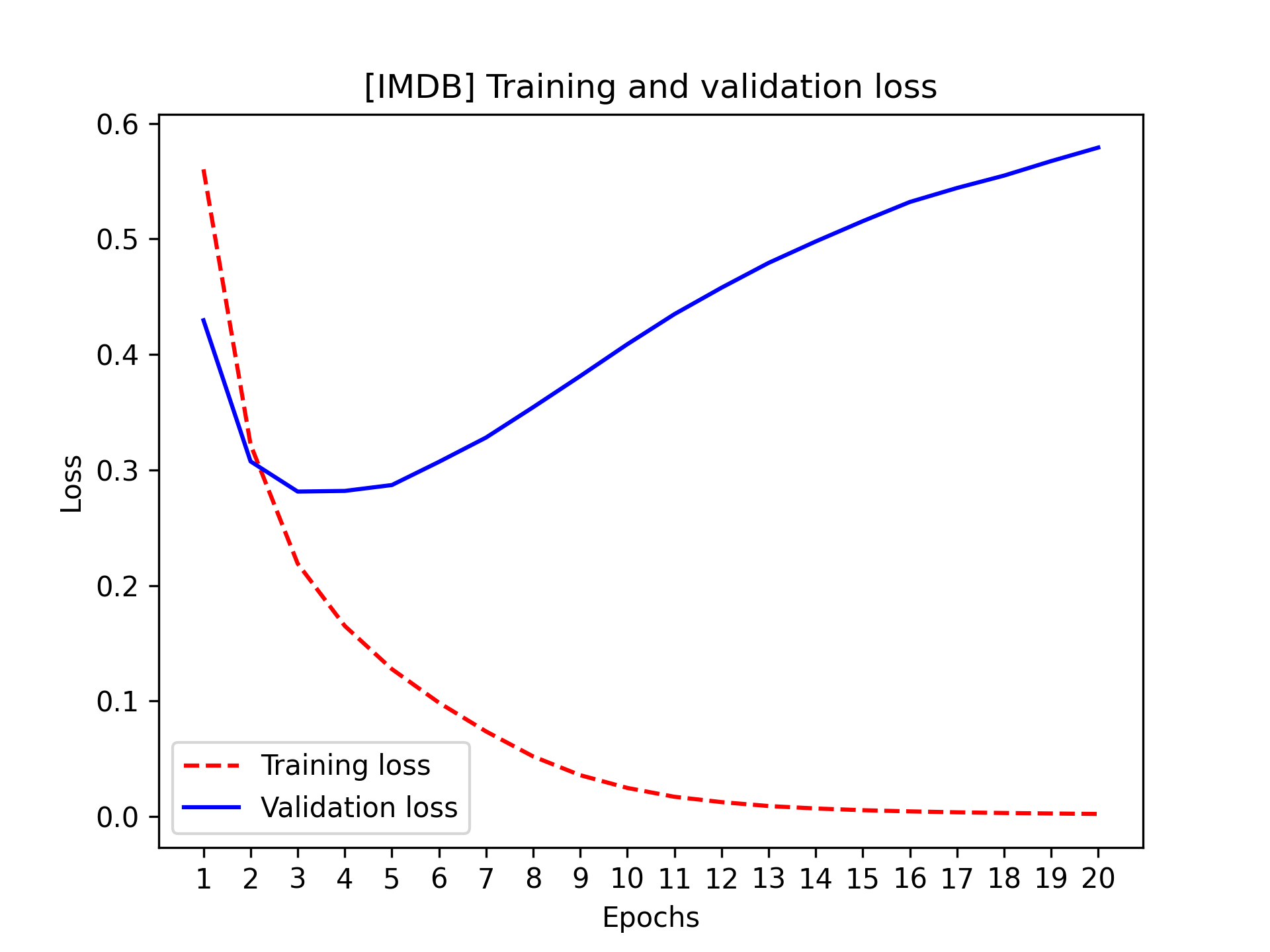
该字典包含四个条目:分别对应训练和验证过程中监测的四个指标。在接下来的两个示例中,我们将使用 Matplotlib 并排绘制训练损失和验证损失(见图 4.4),以及训练准确率和验证准确率(见图 4.5)。请注意,由于模型的随机初始化方式不同,您的结果可能会略有差异。
1 | import matplotlib.pyplot as plt |
清单 4.8:绘制训练损失和验证损失曲线
1 | # Clears the figure |
清单 4.9:绘制训练和验证准确率图
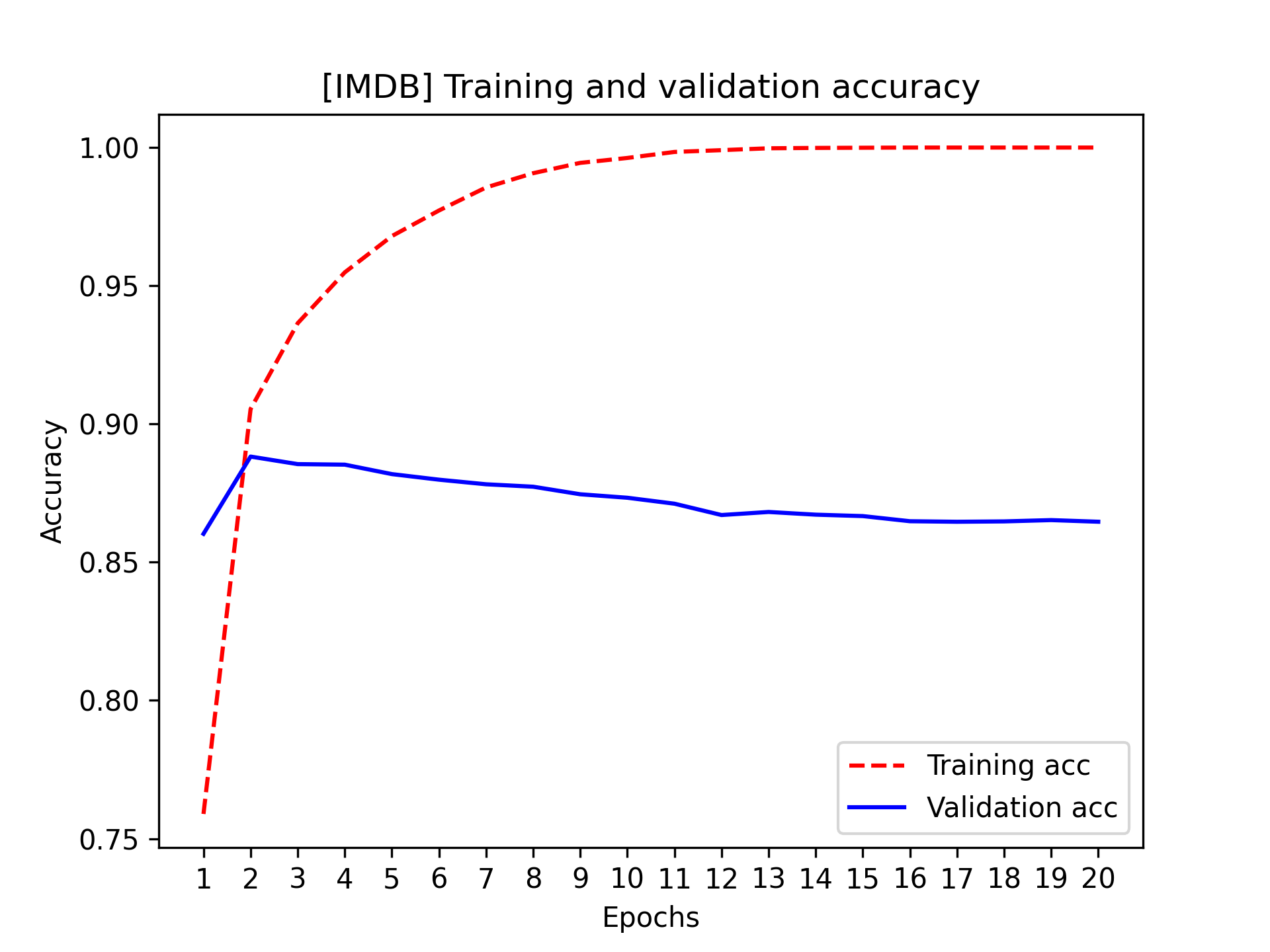
正如你所见,训练损失随着每个epoch的增加而减少,训练准确率随着每个epoch的增加而提高。这正是运行梯度下降优化算法的预期结果——你试图最小化的量应该随着每次迭代而减小。但验证损失和准确率并非如此:它们似乎在第四个epoch达到了峰值。这正是我们之前警告过的一个例子:在训练数据上表现良好的模型,并不一定能在它从未见过的数据上表现更好。准确地说,你看到的是过拟合:在第四个epoch之后,你过度优化了训练数据,最终学习到的表征仅适用于训练数据,无法泛化到训练集之外的数据。
在这种情况下,为了防止过拟合,你可以在训练四个周期后停止训练。一般来说,你可以使用一系列技术来缓解过拟合,我们将在第五章中介绍这些技术。
让我们从头开始训练一个新模型,训练 4 个周期,然后在测试数据上对其进行评估。
1 | model = keras.Sequential( |
清单 4.10:训练模型四个周期
最终结果如下:
1 | >>> results |
这种较为简单的方法可以达到 88% 的准确率。采用最先进的方法,准确率应该可以接近 95%。
使用训练好的模型对新数据进行预测
Using a trained model to generate predictions on new data
predict模型训练完成后,您需要将其应用于实际场景。您可以使用第三章中学到的方法来计算评论为正面的可能性:
1 | >>> model.predict(x_test) |
如您所见,该模型对某些样本(0.99 或更高,或 0.01 或更低)具有较高的置信度,但对其他样本(0.6、0.4)的置信度较低。
进一步实验
Further experiments
以下实验将帮助你确信,你所做的架构选择都相当合理,尽管仍有改进的空间:
- 在最终分类层之前,你使用了两个表征层。尝试使用一个或三个表征层,看看这样做对验证和测试准确率有何影响。
- 尝试使用单元数更多或更少的图层:32 个单元、64 个单元等等。
- 尝试使用
mean_squared_error损失函数代替binary_crossentropy。 - 尝试使用
tanh激活函数(一种在神经网络早期流行的激活函数)代替relu。
总结
Wrapping up
从这个例子中你应该记住以下几点:
- 通常需要对原始数据进行大量的预处理,才能将其以张量的形式输入神经网络。词序列可以编码为二进制向量,但还有其他编码方式可供选择。
- Dense带有激活函数的多层堆叠relu可以解决各种各样的问题(包括情感分类),你会经常用到它们。
- 在二元分类问题(两个输出类别)中,你的模型应该以一个Dense包含一个单元和一个sigmoid 激活值的层结束:你的模型的输出应该是介于 0 和 1 之间的标量,表示一个概率。
- 对于二元分类问题,如果输出是标量 sigmoid 函数,则应使用损失函数binary_crossentropy。
- 无论你遇到什么问题,优化adam器通常都是一个不错的选择。这样你就少了一件需要操心的事。
- 随着神经网络在训练数据上的表现越来越好,它们最终会开始过拟合,并在从未见过的数据上得到越来越差的结果。务必始终监控神经网络在训练集之外的数据上的性能!
新闻通讯分类:多类别分类示例
Classifying newswires: A multiclass classification example
在上一节中,您了解了如何使用密集连接的神经网络将向量输入分类到两个互斥的类别中。但是,当类别超过两个时会发生什么呢?
在本节中,您将构建一个模型,将路透社新闻报道分类为 46 个互斥的主题。由于类别众多,这是一个多分类问题;而由于每个数据点只能被归类到一个类别中,因此更具体地说,这是一个单标签多分类(single-label, multiclass classification.)问题。如果每个数据点可以属于多个类别(在本例中为主题),那么您将面临一个多标签多分类(multilabel, multiclass classification )问题。
路透社数据集
The Reuters dataset
你将使用路透社数据集,这是一组路透社于 1986 年发布的短篇新闻报道及其主题。这是一个简单且广泛使用的文本分类示例数据集。该数据集包含 46 个不同的主题;某些主题的样本数量较多,但每个主题在训练集中至少有 10 个样本。
与 IMDb 和 MNIST 一样,路透社数据集也包含在 Keras 的软件包中。我们来看一下。
1 | from keras.datasets import reuters |
清单 4.11:加载路透社数据集
与 IMDb 数据集一样,该参数num_words=10000将数据限制为数据中出现频率最高的 10,000 个单词。
您有 8,982 个训练样本和 2,246 个测试样本:
1 | >>> len(train_data) |
与 IMDb 评论一样,每个示例都是一个整数列表(单词索引):
1 | >>> train_data[10] |
如果你好奇的话,这里教你如何把它解码回单词。
1 | word_index = reuters.get_word_index() |
列表 4.12:将新闻稿解码回文本
与示例关联的标签是介于 0 和 45 之间的整数——主题索引:
1 | >>> train_labels[10] |
数据准备
Preparing the data
您可以使用与上一个示例完全相同的代码对数据进行向量化。
1 | # Vectorized training data |
清单 4.13:输入数据的编码
要将标签向量化,有两种方法:您可以保留标签的整数形式,也可以使用独热编码(one-hot encoding.)。独热编码是一种广泛用于分类数据的格式,也称为分类编码(categorical encoding)。在这种情况下,标签的独热编码是将每个标签嵌入到一个全零向量中,并在标签索引处填充 1。以下是一个示例。
1 | def one_hot_encode(labels, num_classes=46): |
清单 4.14:标签编码
请注意,Keras 内置了实现此功能的方法:
1 | from keras.utils import to_categorical |
构建你的模型
Building your model
这个主题分类问题看起来与之前的电影评论分类问题类似:两者都是要对短文本片段进行分类。但这里有一个新的限制:输出类别的数量从 2 个增加到了 46 个。输出空间的维度也大大增加。
在你使用的这种多层堆叠结构中Dense,每一层只能访问前一层输出中的信息。如果某一层丢失了与分类问题相关的信息,后续层将无法恢复这些信息:每一层都可能成为信息瓶颈。在之前的例子中,你使用了 16 维的中间层,但 16 维的空间可能太小,不足以学习区分 46 个不同的类别:如此小的层可能会成为信息瓶颈,永久性地丢失相关信息。
因此,你需要使用更大的中间层。我们这里就用64个单元吧。
1 | model = keras.Sequential( |
清单 4.15:模型定义
关于这种建筑风格,还有两点需要注意:
- 模型最后
Dense一层的大小为 46。这意味着对于每个输入样本,网络将输出一个 46 维向量。该向量中的每个元素(每个维度)都将编码一个不同的输出类别。 - 最后一层使用
softmax激活函数。您在 MNIST 示例中已经见过这种模式。这意味着模型将输出一个涵盖 46 个不同输出类别的概率分布——对于每个输入样本,模型将生成一个 46 维输出向量,其中output[i]表示样本属于类别 的概率i。这 46 个概率值之和为 1。
在这种情况下,最佳损失函数是categorical_crossentropy。它衡量两个概率分布之间的距离——这里指的是模型输出的概率分布与标签的真实分布之间的距离。通过最小化这两个分布之间的距离,可以训练模型输出尽可能接近真实标签的结果。
和上次一样,我们也会监测准确率。不过,在这种情况下,准确率是一个比较粗略的指标:如果模型对某个样本的第二选择是正确的类别,而第一选择是错误的,那么该模型在该样本上的准确率仍然为零——即使这样的模型比随机猜测要好得多。在这种情况下,更细致的指标是前k个准确率,例如前3个或前5个准确率。它衡量的是模型的前k个预测结果中是否包含正确的类别。让我们为模型添加前3个准确率。
1 | top_3_accuracy = keras.metrics.TopKCategoricalAccuracy( |
清单 4.16:编译模型
验证你的方法
Validating your approach
让我们从训练数据中取出 1000 个样本作为验证集。
1 | x_val = x_train[:1000] |
清单 4.17:预留验证集
现在,让我们训练模型 20 个周期。
1 | history = model.fit( |
清单 4.18:训练模型
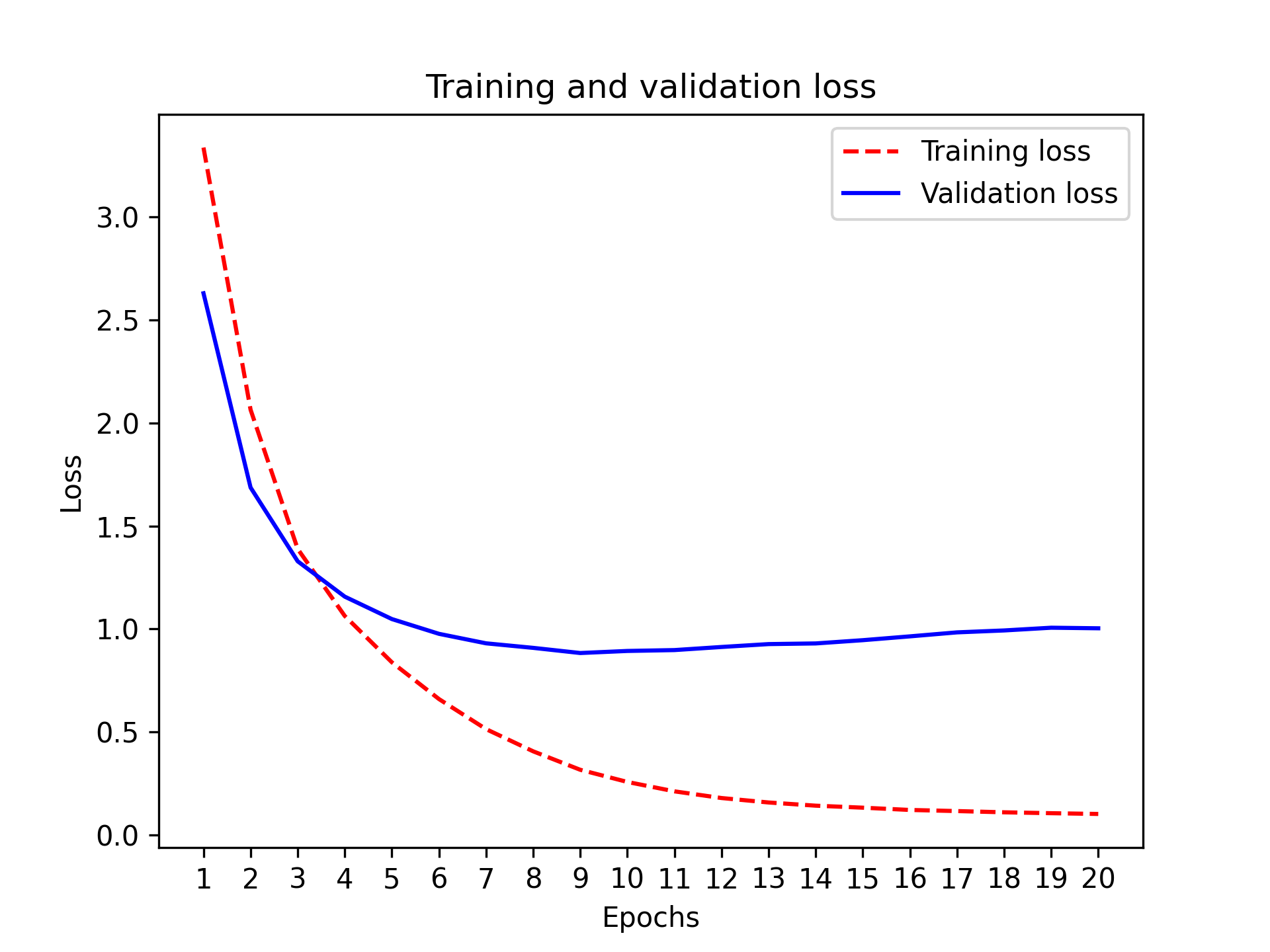
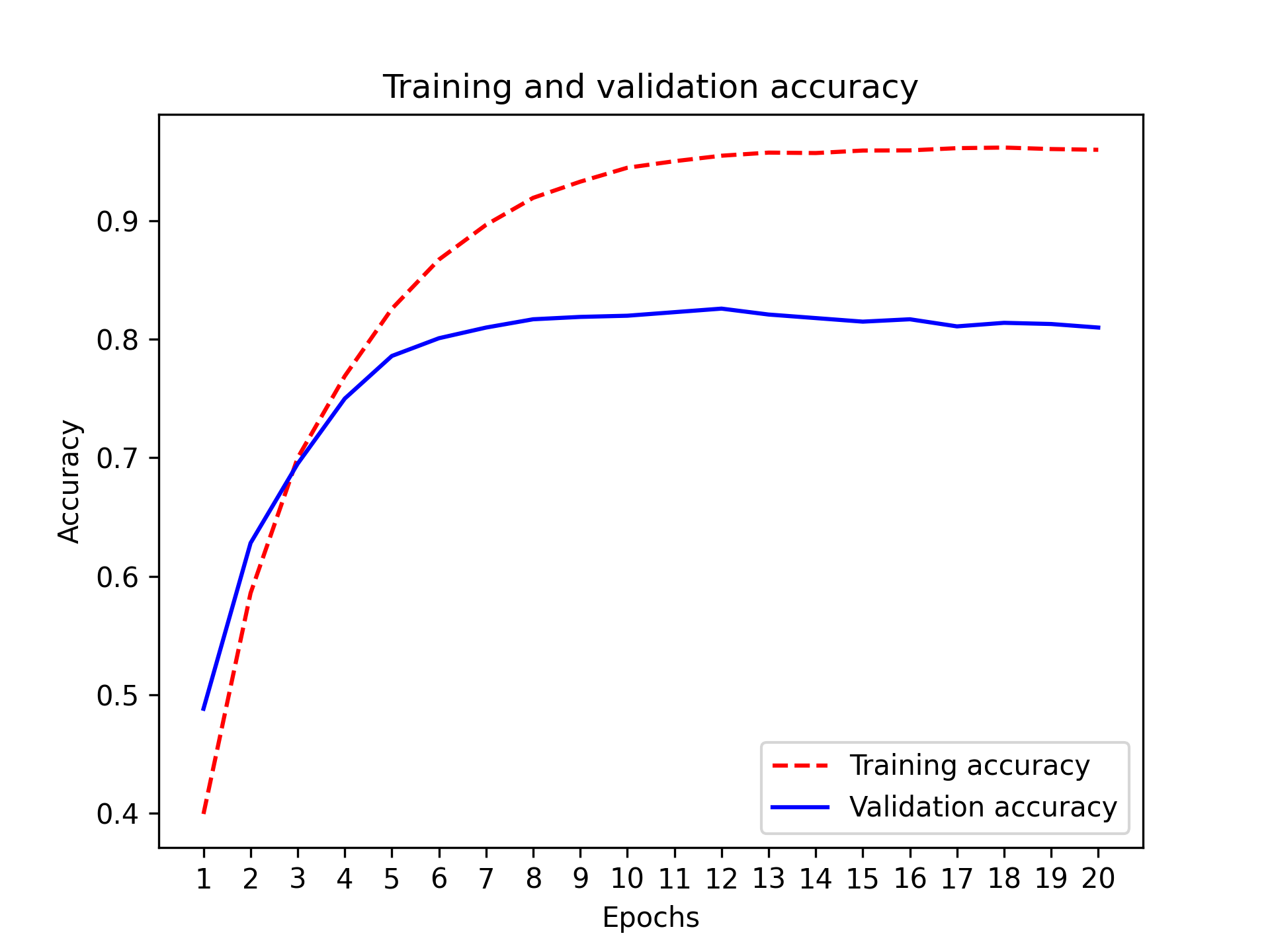
最后,让我们展示它的损失曲线和准确率曲线(见图 4.6 和图 4.7)。
1 | loss = history.history["loss"] |
清单 4.19:绘制训练损失和验证损失曲线
1 | plt.clf() |
清单 4.20:绘制训练集和验证集准确率
1 | plt.clf() |
清单 4.21:绘制训练集和验证集前 3 名准确率
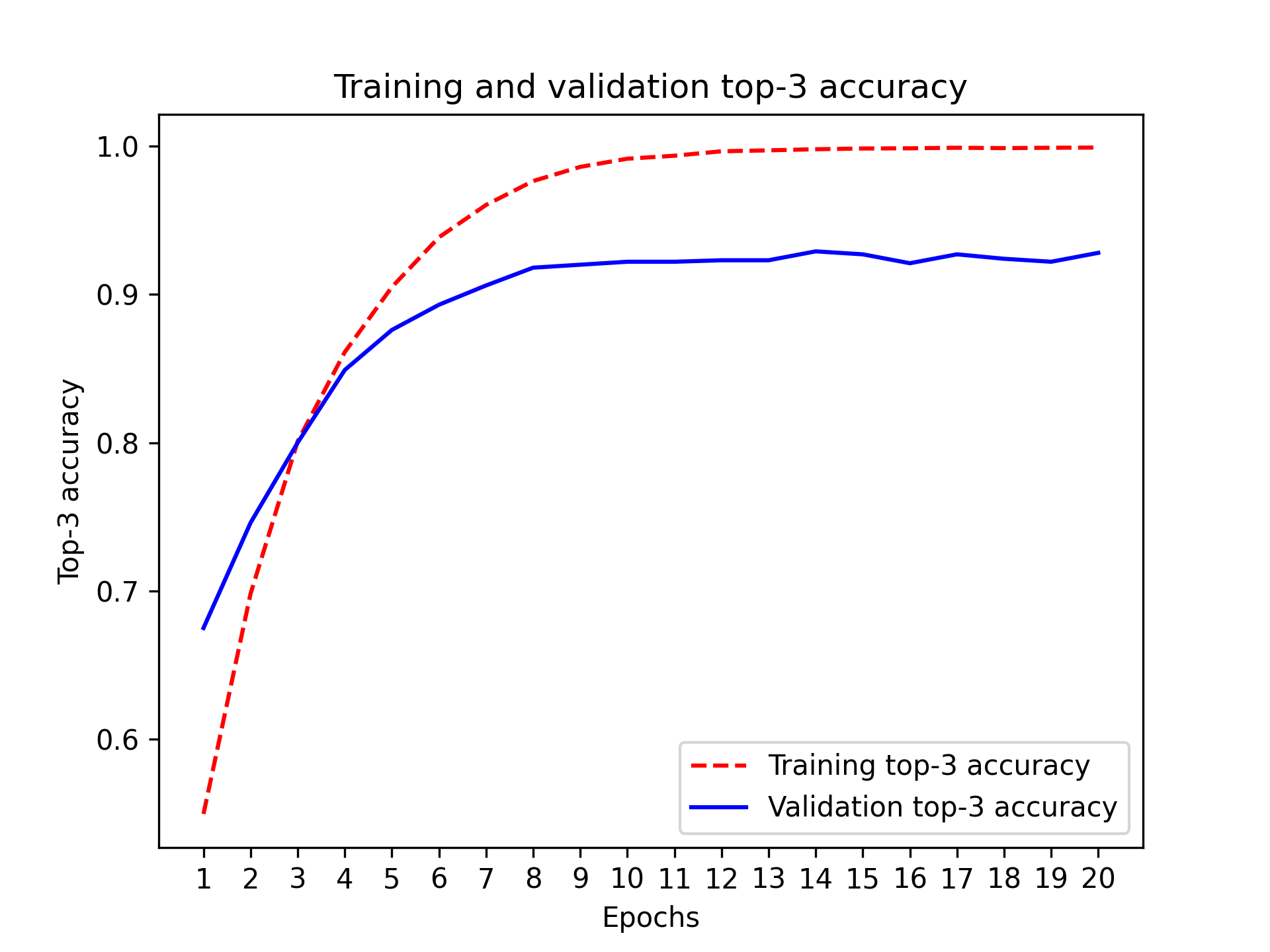
模型在训练九个周期后开始过拟合。让我们从头开始训练一个新模型,训练九个周期,然后在测试集上进行评估。
1 | model = keras.Sequential( |
清单 4.22:从头开始重新训练模型
以下是最终结果:
1 | >>> results |
这种方法可以达到大约 80% 的准确率。对于一个平衡的二元分类问题,纯随机分类器的准确率约为 50%。但在这个例子中,我们有 46 个类别,它们的分布可能并不均衡。那么,随机基线模型的准确率会是多少呢?我们可以尝试快速实现一个基线模型来验证这一点:
1 | >>> import copy |
如您所见,随机分类器的分类准确率约为 19%,因此从这个角度来看,我们模型的结果似乎相当不错。
基于新数据生成预测
Generating predictions on new data
对新样本调用模型的predict方法,会返回每个样本在所有 46 个主题上的类别概率分布。让我们为所有测试数据生成主题预测:
1 | predictions = model.predict(x_test) |
“预测”中的每个条目都是一个长度为 46 的向量:
1 | >>> predictions[0].shape |
该向量中的系数之和为 1,因为它们构成了一个概率分布:
1 | >>> np.sum(predictions[0]) |
最大的条目代表预测类别——即概率最高的类别:
1 | >>> np.argmax(predictions[0]) |
处理标签和损失的另一种方法
A different way to handle the labels and the loss
我们之前提到过,另一种对标签进行编码的方法是将其保持为整数张量,就像这样:
1 | y_train = train_labels |
这种方法唯一需要改变的是损失函数的选择。清单 4.22 中使用的损失函数categorical_crossentropy要求标签采用类别编码。对于整数标签,您应该使用sparse_categorical_crossentropy:
1 | model.compile( |
这个新的损失函数在数学上仍然与原来的损失函数相同 categorical_crossentropy;它只是接口不同。
中间层足够大的重要性
The importance of having sufficiently large intermediate layers
我们之前提到过,由于最终输出是 46 维的,所以应该避免使用单元数远少于 46 的中间层。现在让我们看看,如果中间层维度远小于 46 维(例如 4 维),从而引入信息瓶颈会发生什么情况。
1 | model = keras.Sequential( |
清单 4.23:存在信息瓶颈的模型
该模型目前的验证准确率峰值约为 71%,绝对值下降了 8%。这一下降主要是由于您试图将大量信息(足以恢复 46 个类别的分离超平面)压缩到一个维度过低的中间空间。该模型能够将大部分必要信息塞进这些 4 维表示中,但并非全部。
进一步实验
Further experiments
与之前的例子一样,我们鼓励您尝试以下实验,以训练您对使用此类模型时需要做出的配置决策的直觉:
- 尝试使用更大或更小的图层:32 个单位、128 个单位等等。
- 在最终的softmax分类层之前,你使用了两个中间层。现在尝试使用一个中间层,或者三个中间层。
总结
Wrapping up
从这个例子中你应该记住以下几点:
- 如果你要对N 个
Dense类别中的数据点进行分类,你的模型应该以大小为N的层结束。 - 在单标签多类分类问题中,你的模型应该以
softmax激活函数结束,以便输出N 个输出类别的概率分布。 - 对于这类问题,分类交叉熵几乎总是应该使用的损失函数。它旨在最小化模型输出的概率分布与目标真实分布之间的距离。
- 在多分类问题中,处理标签有两种方法:
- 通过类别编码(也称为独热编码)对标签进行编码,并将
categorical_crossentropy其用作损失函数。 - 将标签编码为整数并使用
sparse_categorical_crossentropy损失函数
- 通过类别编码(也称为独热编码)对标签进行编码,并将
- 如果需要将数据分类到大量类别中,则应避免由于中间层过小而导致模型中出现信息瓶颈。
预测房价:回归分析示例
Predicting house prices: A regression example
前两个例子都属于分类问题,其目标是预测输入数据点的单个离散标签。另一种常见的机器学习问题是回归,它预测的是连续值而非离散标签:例如,根据气象数据预测明天的温度,或者根据软件项目的规格预测其完成时间。
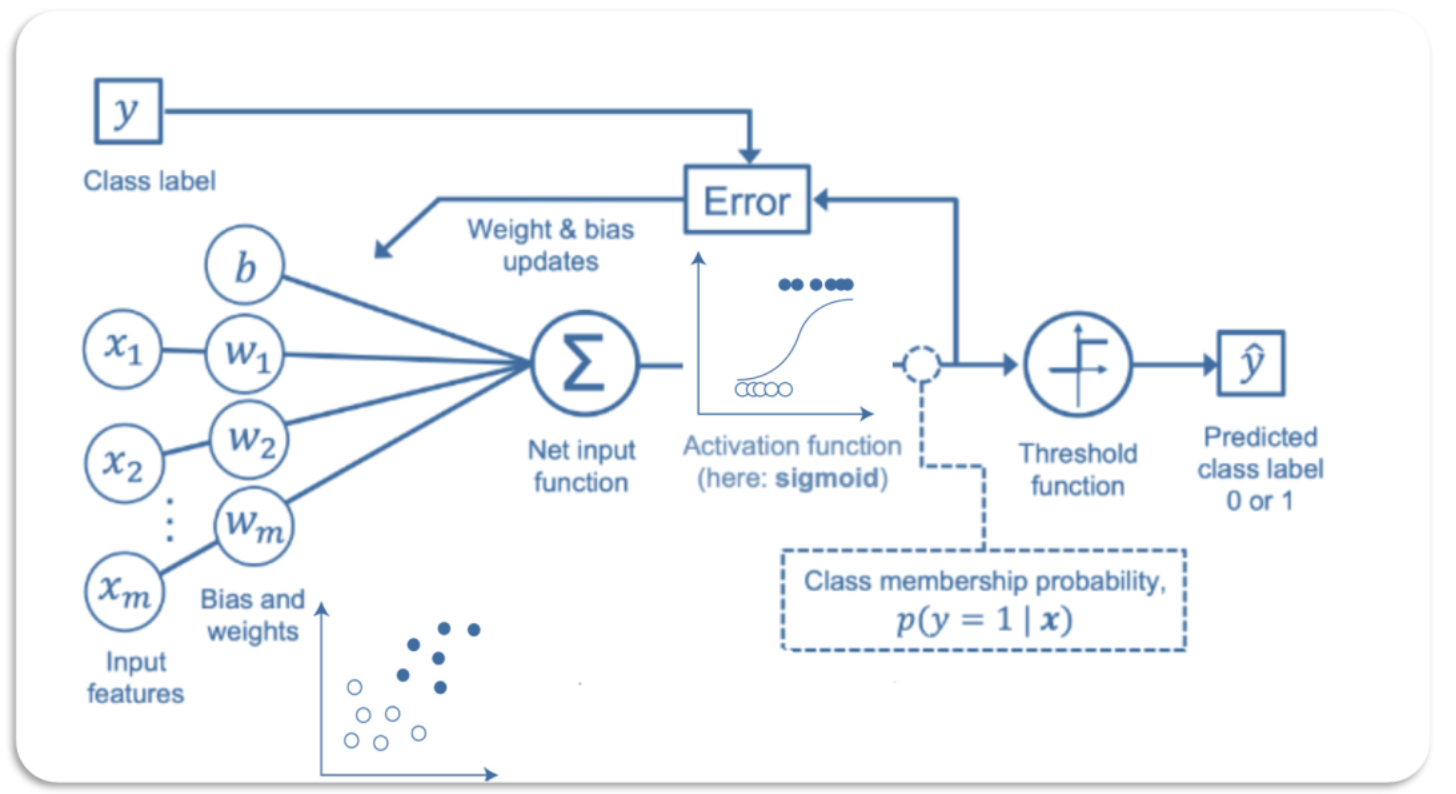
令人困惑的是,逻辑回归并不是回归算法,而是一种分类算法。
个人注:
回归是映射成连续值;分类是映射成离散值!
逻辑回归在机器学习中是激活函数使用逻辑函数,函数值是0到1的概率,故是回归;而随后按照设定的阈值,进行分类,故最终是分类。详见后图。
这句话是初学者最容易产生误解的地方。要理解它,我们可以从它的名字来源、核心原理以及最终目的三个维度来拆开看。
- 为什么叫“逻辑”(Logistic)?
这里的“逻辑”并不是指逻辑推理(Logic),而是指 Logistic 函数(也叫 Sigmoid 函数)。
- 线性回归的输出范围是 \((-\infty, +\infty)\),这在预测房价时很有用,但如果你想预测“明天是否下雨”,这个范围就不合适了。
- 逻辑回归通过把线性回归的结果套进 Sigmoid 函数中,将数值压缩到了 \((0, 1)\) 之间。
- 这个 \((0, 1)\) 之间的数值,在数学上可以被解释为概率。
- 为什么叫“回归”(Regression)?
既然是分类,为什么要挂着“回归”的羊头?
- 数学本质:从算法底层来看,逻辑回归确实是在做“回归”。它实际上是在预测“输入样本属于正类的概率值”。
- 概率是一个连续的数值(比如 \(0.75\) 或 \(0.32\)),预测连续数值的行为在统计学中就被定义为“回归”。
- 为什么它又是“分类”(Classification)?
虽然它的中间产物是概率值,但我们使用它的最终意图是做判断题:
- 我们通常会设定一个阈值(Threshold),最常用的是 \(0.5\)。
- 如果预测概率 \(> 0.5 \rightarrow\) 判定为“是”(类别 A)。
- 如果预测概率 \(\leq 0.5 \rightarrow\) 判定为“否”(类别 B)。
总结:一个形象的比喻
想象你在看一场足球比赛:
- 线性回归:预测整场比赛结束时,主队的控球时间(可以是 40 分钟、55 分钟等,是连续的)。
- 逻辑回归:预测主队赢球的几率。
- 回归部分:计算出胜率是 \(70\%\)(这是一个数值回归过程)。
- 分类部分:既然胜率超过了 \(50\%\),我们就直接断定“主队会赢”(这是一个分类决策过程)。
一句话总结:逻辑回归是用回归的方法,算出属于某个类别的概率,最后通过比较概率大小来实现分类。
加州房价数据集
The California Housing Price dataset
你将尝试根据 1990 年人口普查数据预测加利福尼亚州不同地区的房屋中位价。
数据集中的每个数据点代表一个“街区组”的信息,街区组是指位于同一区域的一组房屋。您可以将其理解为一个区域。该数据集有两个版本:“小型”版本仅包含 600 个区域,“大型”版本包含 20,640 个区域。我们使用小型版本,因为现实世界中的数据集通常很小,您需要了解如何处理这种情况。
对于每个地区,我们知道
- 该区域大致地理中心的经度和纬度。
- 该地区房屋的平均年龄。
- 该区的人口。这些区都比较小:平均人口为1425.5人。
- 家庭户总数。
- 这些家庭的收入中位数。
- 该地区所有住宅的房间总数。通常情况下,这个数字在几千间左右。
- 该地区卧室总数。
总共有八个变量(经度和纬度算作两个变量)。目标是利用这些变量预测该地区房屋的中位价。让我们从加载数据开始。
1 | from keras.datasets import california_housing |
列表 4.24:正在加载加州房价数据集
我们来看一下数据:
1 | >>> train_data.shape |
如您所见,我们有 480 个训练样本和 120 个测试样本,每个样本包含 8 个数值特征。目标是所选区域内房屋价值的中位数(以美元计):
1 | >>> train_targets |
价格在 6 万美元到 50 万美元之间。如果这听起来很便宜,请记住这是 1990 年的价格,而且这些价格没有根据通货膨胀进行调整。
数据准备
Preparing the data
如果输入到神经网络中的值范围差异极大,就会出现问题。模型或许能够自动适应这种异构数据,但这无疑会增加学习难度。处理此类数据的常用最佳实践是进行特征归一化(normalization):对于输入数据中的每个特征(输入数据矩阵中的一列),减去该特征的均值并除以标准差,使该特征以 0 为中心,标准差为 1。这在 NumPy 中很容易实现。
1 | mean = train_data.mean(axis=0) |
清单 4.25:数据归一化
个人注:什么情况下需要进行归一化?多特征?
请注意,用于归一化测试数据的量是使用训练数据计算的。即使是数据归一化这样简单的操作,您也绝不应该在工作流程中使用任何基于测试数据计算的量。
此外,我们还应该调整目标值。我们归一化的输入值范围很小,接近于 0,而模型的权重初始化为较小的随机值。这意味着在训练开始时,模型的预测值也会很小。如果目标值在 60,000 到 500,000 之间,模型就需要非常大的权重值才能输出这些值。如果学习率很小,则需要很长时间才能达到这个目标值。最简单的解决方法是将所有目标值除以 100,000,这样最小的目标值就变为 0.6,最大的目标值就变为 5。然后,我们可以将模型的预测值乘以 100,000,从而将其转换回美元值。
1 | y_train = train_targets / 100000 |
清单 4.26:目标规模的调整
构建你的模型
Building your model
由于可用样本数量极少,您将使用一个非常小的模型,该模型包含两个中间层,每个中间层有 64 个单元。一般来说,训练数据越少,过拟合就越严重,而使用小型模型是缓解过拟合的一种方法。
1 | def get_model(): |
清单 4.27:模型定义
该模型以一个单元结束,且没有激活函数:它将是一个线性层。这是标量回归的典型设置——标量回归旨在预测一个连续值。应用激活函数会限制输出的范围;例如,如果对sigmoid最后一层应用激活函数,模型只能学习预测 0 到 1 之间的值。而在这里,由于最后一层是纯线性层,模型可以自由地学习预测任意范围内的值。
请注意,您需要使用均方误差(即预测值与目标值之差的平方)作为mean_squared_error 损失函数 来构建模型。这是回归问题中广泛使用的损失函数。
在训练过程中,您还会监控一个新的指标:平均绝对误差 (mean absolute error )(MAE)。它是预测值与目标值之间差异的绝对值。例如,对于这个问题,MAE 为 0.5 意味着您的预测值平均偏差为 5 万美元(请记住目标值的缩放比例为 10 万倍)。
使用 K 折交叉验证来验证你的方法
Validating your approach using K-fold validation
为了在不断调整模型参数(例如训练轮数)的同时评估模型,您可以像之前的示例一样,将数据拆分为训练集和验证集。但由于数据点数量有限,验证集最终会非常小(例如,大约只有 100 个样本)。因此,验证分数可能会因您选择哪些数据点用于验证和哪些数据点用于训练而发生很大变化:验证分数可能对验证集的划分方式有很高的 方差。这将使您无法可靠地评估模型。
在这种情况下,最佳实践是使用K 折交叉验证(参见图 4.9)。它包括将可用数据分成K 个分区(通常K = 4 或 5),实例化K 个相同的模型,并在K – 1个分区上训练每个模型,同时在剩余的分区上进行评估。所用模型的验证分数是获得的K 个验证分数的平均值 。从代码角度来看,这很简单。
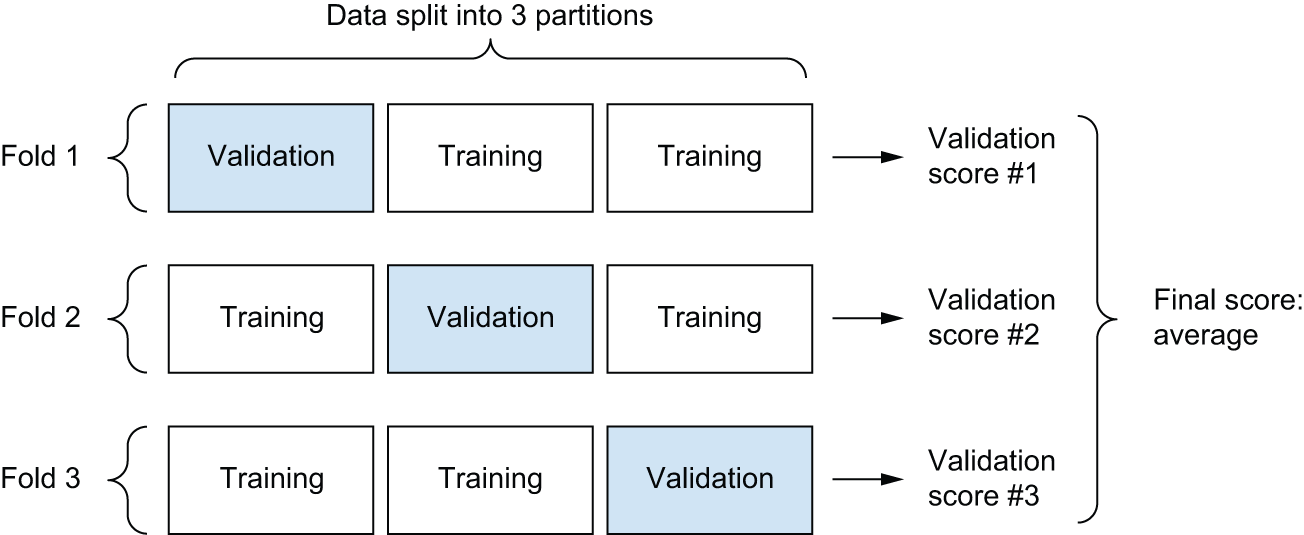
1 | k = 4 |
清单 4.28:K 折交叉验证
运行此命令会num_epochs = 50得到以下结果:
1 | >>> [round(value, 3) for value in all_scores] |
不同批次(轮次?也不是!)的验证结果确实存在显著差异(The different runs do indeed show meaningfully different validation scores),从 0.232 到 0.349 不等。平均值 (0.296) 比任何单一分数都更可靠——这正是 K 折交叉验证的意义所在。在这种情况下,平均误差为 29,600 美元,考虑到价格区间在 60,000 美元到 500,000 美元之间,这个误差相当大。
The different runs do indeed show meaningfully different validation scores, from 0.232 to 0.349. The average (0.296) is a much more reliable metric than any single score—that’s the entire point of K-fold cross-validation. In this case, you’re off by 29,600 on average, which is significant considering that the prices range from 60,000 to 500,000.
我们来尝试延长模型训练时间:200 个周期(epochs 轮次?)。为了记录模型在每个周期(epoch)的表现,你需要修改训练循环,保存每个周期(epoch)的验证分数日志。
Let’s try training the model a bit longer: 200 epochs. To keep a record of how well the model does at ea
1 | k = 4 |
清单 4.29:保存每次折叠时的验证日志
然后,您可以计算所有折叠的每个 epoch 平均绝对误差 (MAE) 分数的平均值。
1 | average_mae_history = [ |
清单 4.30:构建连续平均 K 折交叉验证得分的历史记录
让我们绘制这个图;参见图 4.10。
1 | epochs = range(1, len(average_mae_history) + 1) |
清单 4.31:绘制验证分数
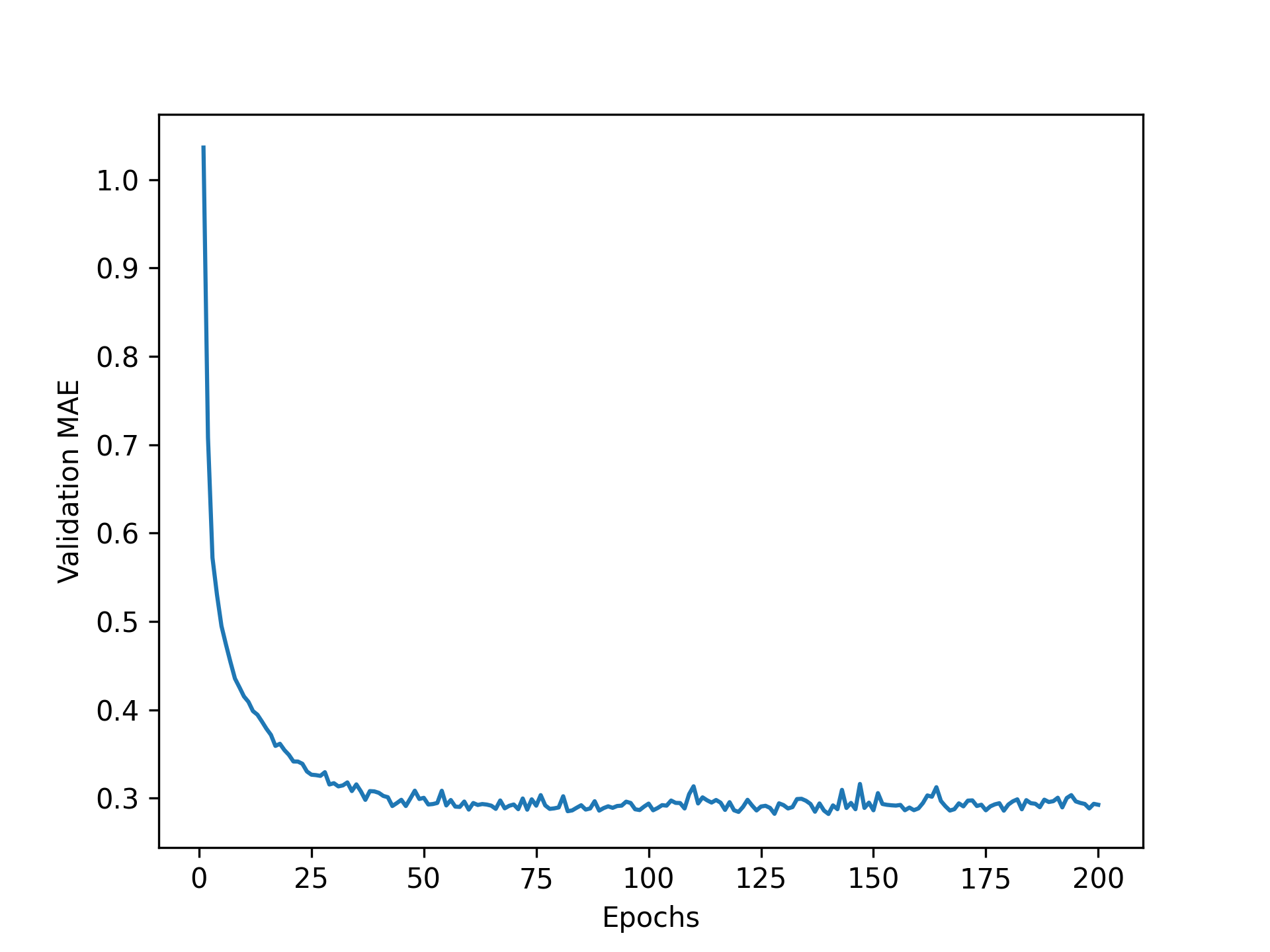
由于比例尺问题,图表可能难以解读:前几个 epoch 的验证 MAE 值明显高于后续值。我们省略前 10 个数据点,因为它们的比例尺与其他曲线不同。
1 | truncated_mae_history = average_mae_history[10:] |
清单 4.32:绘制验证分数图,排除前 10 个数据点
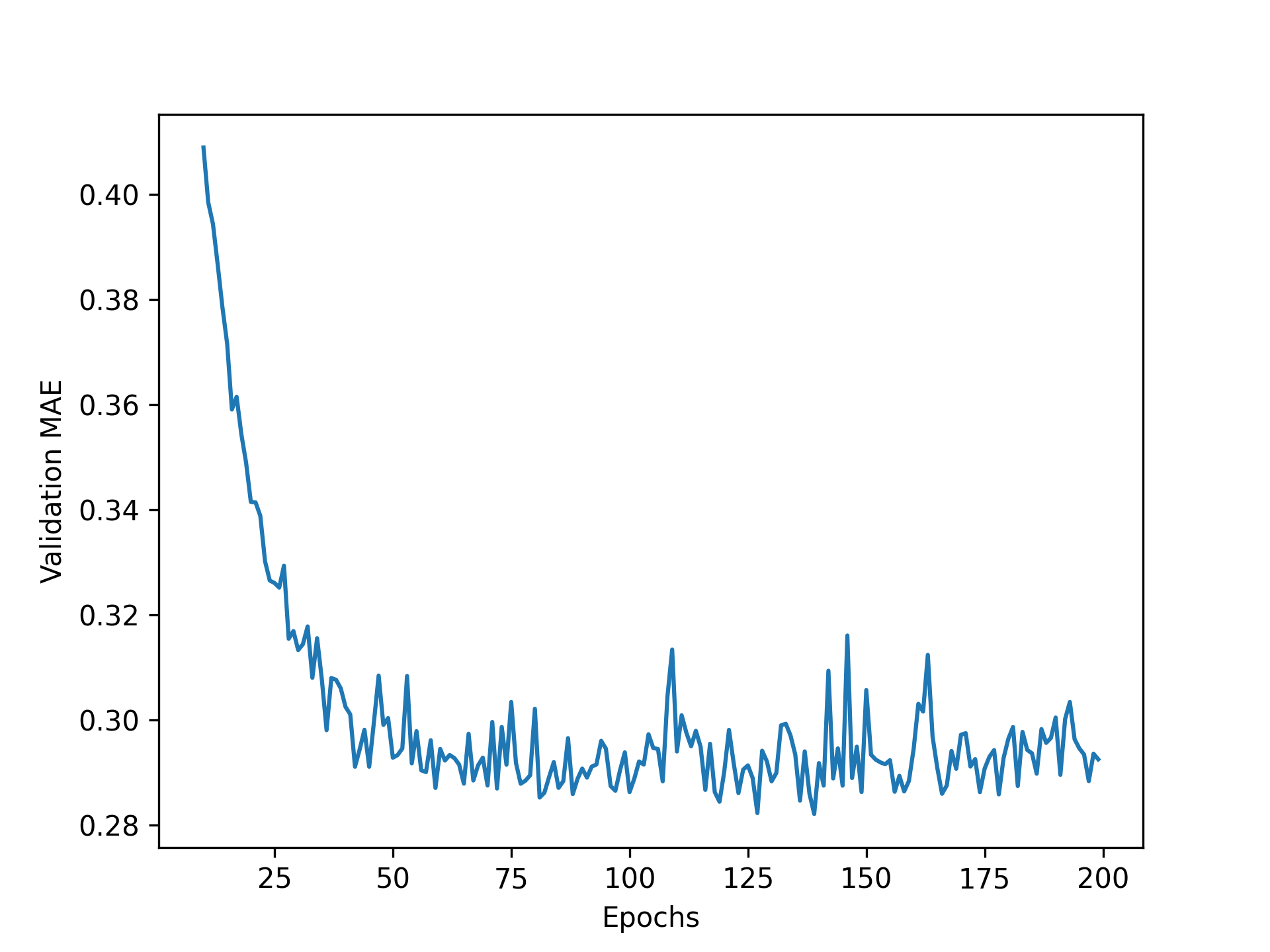
根据这张图(见图 4.11),验证集平均绝对误差 (MAE) 在 120-140 个 epoch 后不再显著改善(该数字包含我们省略的 10 个 epoch)。超过这个点,就开始出现过拟合现象。
完成模型其他参数的调整(除了训练轮数之外,还可以调整中间层的大小)后,可以使用最佳参数在所有训练数据上训练最终的生产模型,然后查看其在测试数据上的性能。
Once you’re finished tuning other parameters of the model (in addition to the number of epochs, you could also adjust the size of the intermediate layers), you can train a final production model on all of the training data, with the best parameters, and then look at its performance on the test data.
1 | # Gets a fresh, compiled model |
清单 4.33:训练最终模型
最终结果如下:
1 | >>> round(test_mean_absolute_error, 3) |
我们平均还是有大约 31,000 美元的误差。
基于新数据生成预测
Generating predictions on new data
predict()调用我们的二元分类模型时,我们为每个输入样本获取了一个介于 0 和 1 之间的标量分数。使用我们的多类分类模型时,我们为每个样本获取了所有类别的概率分布。现在,使用这个标量回归模型,predict()返回模型对样本价格的预测值(以数十万美元为单位):
1 | >>> predictions = model.predict(x_test) |
测试集中第一个区域的平均房价预计约为 283,000 美元。
总结
Wrapping up
从这个标量回归示例中,你应该记住以下几点:
- 回归分析使用的损失函数与分类分析使用的损失函数不同。均方误差(MSE)是回归分析中常用的损失函数。
- 同样,回归分析所用的评估指标与分类分析所用的评估指标不同;显然,准确率的概念并不适用于回归分析。常用的回归评估指标是平均绝对误差(MAE)。
- 当输入数据中的特征值处于不同范围内时,应在预处理步骤中对每个特征进行独立缩放。
- 当数据较少时,使用 K 折交叉验证是可靠评估模型的好方法。
- 当训练数据较少时,最好使用中间层较少的较小模型(通常只有一到两层),以避免严重的过拟合。
概括
- 向量数据上最常见的三种机器学习任务是二分类、多分类和标量回归。每种任务都使用不同的损失函数:
binary_crossentropy二元分类categorical_crossentropy用于多类分类mean_squared_error对于标量回归
- 通常需要先对原始数据进行预处理,然后再将其输入神经网络。
- 当你的数据具有不同范围的特征时,在预处理过程中,应分别对每个特征进行缩放。
- 随着训练的进行,神经网络最终会开始过拟合,并在从未见过的数据上获得更差的结果。
- 如果训练数据不多,请使用只有一到两个中间层的小型模型,以避免严重的过拟合。
- 如果你的数据被分成很多类别,而中间层又太小,就可能导致信息瓶颈。
- 当数据量较少时,K折交叉验证可以帮助可靠地评估模型。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论