《DEEP LEARNING with Python》第十二章 目标检测
第十二章 目标检测
Object detection
运行代码
本章内容
- 理解目标检测问题
- 两阶段和单阶段目标检测器
- 从零开始训练一个简单的单阶段检测器
- 使用预训练的目标检测器
- Understanding the object detection problem
- Two-stage and single-stage object detectors
- Training a simple single-stage detector from scratch
- Using a pretrained object detector
目标检测的核心在于绘制边界框(也称为边界框)(drawing boxes (called bounding boxes)),将图像中感兴趣的物体框起来(见图 12.1)。这不仅能让你知道图像中有哪些物体,还能让你知道它们的位置。它的一些最常见应用包括:
- 计数——找出图像中某个物体的出现次数。
- 跟踪——通过对电影的每一帧执行对象检测,跟踪场景中物体随时间推移的运动情况。
- 裁剪——识别图像中包含感兴趣对象的区域,将其裁剪出来,并将图像块的更高分辨率版本发送到分类器或光学字符识别 (OCR) 模型。
- Counting—Find out how many instances of an object are in an image.
- Tracking—Track how objects move in a scene over time by performing object detection on every frame of a movie.
- Cropping—Identify the area of an image that contains an object of interest to crop it and send a higher-resolution version of the image patch to a classifier or an Optical Character Recognition (OCR) model.
 图 12.1:目标检测器在图像中的物体周围绘制方框并对其进行标记。
图 12.1:目标检测器在图像中的物体周围绘制方框并对其进行标记。
你可能会想,如果我有一个对象实例的分割掩码,我就可以计算出包含该掩码的最小框的坐标。那么我们岂不是可以直接使用图像分割?我们还需要对象检测模型吗?
实际上,分割是检测的严格超集。它不仅返回检测模型能够返回的所有信息,而且还包含更多信息。这种信息量的增加带来了显著的计算成本:一个优秀的目标检测模型通常比图像分割模型运行速度快得多。此外,它还增加了数据标注成本:训练分割模型需要收集像素级精确的掩码,这比目标检测模型所需的简单边界框的生成要耗时得多。
因此,如果您不需要像素级信息,例如,如果您只想计算图像中的对象数量,那么您总是会想要使用目标检测模型。
单阶段目标检测器与两阶段目标检测器
Single-stage vs. two-stage object detectors
目标检测架构大致可分为两类:
- 两阶段检测器首先提取区域提议,称为基于区域的卷积神经网络(R-CNN)模型。
- 单阶段检测器,例如 RetinaNet 或 You Only Look Once 系列模型。
- Two-stage detectors, which first extract region proposals, known as Region-based Convolutional Neural Networks (R-CNN) models
- Single-stage detectors, such as RetinaNet or the You Only Look Once family of models
它们是这样运作的。
两阶段 R-CNN 检测器
Two-stage R-CNN detectors
基于区域的卷积神经网络(R-CNN)模型是一个两阶段模型。第一阶段接收一幅图像,并在图像中生成数千个部分重叠的边界框,这些边界框围绕着看起来像物体的区域。这些边界框被称为区域提议(region proposals)。这一阶段的智能程度不高,因此我们当时无法确定提议的区域是否包含物体,如果包含,也无法确定它们包含的是什么物体。
这就是第二阶段的任务——卷积神经网络(ConvNet)会检查每个区域提议,并将其分类到若干个预先设定的类别中,就像你在第9章中看到的模型一样(参见图12.2)。所有类别得分都很低的区域提议会被丢弃。这样我们就得到了一个规模小得多的框集,每个框在某一特定类别中都具有较高的类别存在度得分。最后,每个对象周围的边界框会被进一步细化,以消除重复项,并使每个边界框尽可能精确。
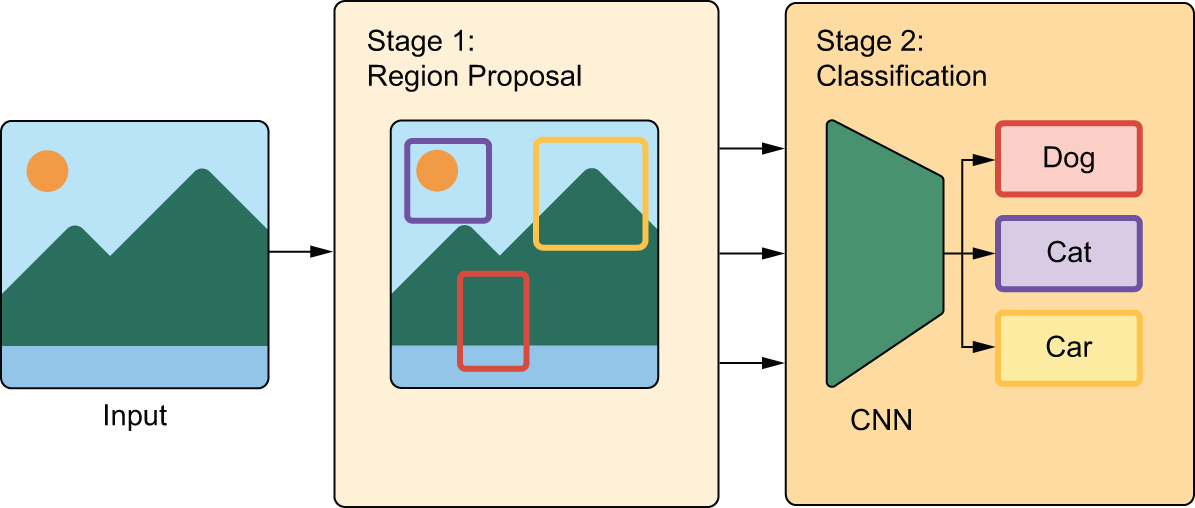 图 12.2:R-CNN 首先提取区域提议,然后使用 ConvNet(CNN)对提议进行分类。
图 12.2:R-CNN 首先提取区域提议,然后使用 ConvNet(CNN)对提议进行分类。
在早期版本的 R-CNN 中,第一阶段是一个名为 选择性搜索的启发式模型(heuristic model called Selective Search),它利用空间一致性(spatial consistency)的定义来识别类似物体的区域。启发式(Heuristic)是机器学习领域一个经常听到的术语——它简单来说就是“一套人为设定的硬编码规则”。它通常与学习模型(规则是自动生成的)或理论模型相对立。在 R-CNN 的后续版本中,例如 Faster-R-CNN,边界框生成阶段变成了一个深度学习模型,称为区域提议网络(Region Proposal Network)(RPN)。
R-CNN 的两阶段方法在实践中效果很好,但计算成本相当高,最主要的原因是它需要对每张图像处理中的数千个图像块进行分类。这使得它不适用于大多数实时应用和嵌入式系统。我的观点是,在实际应用中,通常不需要像 R-CNN 这样计算成本高的目标检测系统,因为如果你使用性能强大的 GPU 进行服务器端推理,那么使用分割模型(例如我们在上一章中看到的 Segment Anything 模型)可能效果更好。而如果你的资源有限,那么你应该使用计算效率更高的目标检测架构——单阶段检测器。
单阶段探测器
Single-stage detectors
大约在2015年,研究人员和从业者开始尝试使用单个深度学习模型来联合预测边界框坐标及其标签,这种架构被称为单阶段检测器。单阶段检测器的主要系列包括RetinaNet、单次多框检测器(SSD)和You Only Look Once系列(简称YOLO)。没错,就是那个梗。故意这么叫的。
个人注:
在计算机视觉领域,它是 You Only Look Once(你只看一次)的缩写,由 Joseph Redmon 在 2015 年提出。但这个名字其实是故意套用了当时社交网络上极其火爆的一个流行语:YOLO —— You Only Live Once(你只活一次)。
单阶段检测器,尤其是最新的YOLO迭代版本,相比两阶段检测器,速度更快、效率更高,尽管精度可能略有下降。如今,YOLO可以说是最流行的目标检测模型,尤其是在实时应用中。YOLO通常每年都会推出新版本——有趣的是,每个新版本往往由不同的组织开发。
下一节,我们将从头开始构建一个简化的 YOLO 模型。
从零开始训练一个 YOLO 模型
Training a YOLO model from scratch
总的来说,构建一个目标检测器可能是一项相当繁琐的工作——倒不是说它在理论上有什么复杂之处。只是需要编写大量的代码来处理边界框和预测输出。为了简化操作,我们将重现 2015 年的第一个 YOLO 模型。截至撰写本文时,YOLO 已经有 12 个版本,但最初的版本更容易上手。
下载 COCO 数据集
Downloading the COCO dataset
在开始创建模型之前,我们需要用于训练的数据。COCO 数据集 [1]Common Objects in Context(简称Common Objects )是最著名、最常用的目标检测数据集之一。它包含来自多个不同来源的真实世界照片以及人工标注,其中包括目标标签、边界框标注和完整的分割掩码。我们将忽略分割掩码,仅使用边界框。
我们来下载 2017 年版的 COCO 数据集。虽然以今天的标准来看,它不算是一个大型数据集,但这个 18 GB 的数据集将是本书中使用的最大数据集。如果您正在边阅读边运行代码,现在正好可以稍作休息。
1 | import keras |
清单 12.1:下载 2017 年 COCO 数据集
在使用这些数据之前,我们需要进行一些输入处理。第一次下载会得到一个包含所有 COCO 图像的未标记目录。第二次下载则通过 JSON 文件包含了所有图像元数据。COCO 将每个图像文件与一个 ID 关联起来,每个边界框也与这些 ID 中的一个配对。我们需要将所有边界框和图像数据整理在一起。
每个边界框都包含x, y, width, height从图像左上角开始的像素坐标。加载数据时,我们可以将所有边界框坐标重新缩放,使它们成为[0, 1]单位正方形内的点。这样可以更轻松地操作这些边界框,而无需检查每个输入图像的大小。
1 | import json |
清单 12.2:解析 COCO 数据
我们来看一下刚刚加载的数据。
1 | >>> len(metadata) |
清单 12.3:检查 COCO 数据
我们有 117,266 张图像。每张图像可以包含 1 到 63 个对象,每个对象都有一个对应的边界框。对象标签只有 91 种可能,这些标签由 COCO 数据集的创建者选定。
我们可以使用 KerasHub 工具keras_hub.utils.coco_id_to_name(id)将这些整数标签映射到人类可读的名称,类似于我们在第 8 章中用于将 ImageNet 预测解码为文本标签的工具。
为了更具体地说明这一点,我们来看一个示例图像。我们可以定义一个函数,使用 Matplotlib 绘制图像,然后再定义一个函数,在该图像上绘制一个带标签的边界框。本章中我们将用到这两个函数。我们可以使用 HSV 色彩空间这个简单的技巧,为每个新标签生成新的颜色。通过固定颜色的饱和度和亮度,只更新其色调,我们可以生成鲜艳的新颜色,使其在图像中清晰可见。
1 | import matplotlib.pyplot as plt |
示例 12.4:可视化带有框标注的 COCO 图像
让我们使用新的可视化工具来查看示例图像。[2]我们之前检查过(见图 12.3):
1 | sample = metadata[435] |
 图 12.3:YOLO 为每个图像区域输出边界框预测和类别标签。
图 12.3:YOLO 为每个图像区域输出边界框预测和类别标签。
虽然用全部 18 GB 的输入数据进行训练很有趣,但我们希望本书中的示例能够在配置一般的硬件上轻松运行。如果我们只使用包含四个或更少方框的图像,就能简化训练问题,并将数据量减少一半。让我们这样做,并对数据进行打乱——图像是按对象类型分组的,这对训练非常不利:
1 | import random |
数据加载完毕!接下来我们开始创建YOLO模型。
创建 YOLO 模型
Creating a YOLO model
如前所述,YOLO模型是一个单阶段检测器。它并非先尝试识别场景中的所有候选对象,然后再对对象区域进行分类,而是一次性生成边界框和对象标签。
我们的模型会将图像分割成网格,并在每个网格位置预测两个独立的输出——边界框和类别标签。在 Redmon 等人的原始论文中……[3]该模型实际上预测每个网格位置会有多个盒子,但为了简单起见,我们只预测每个网格方格内的一个盒子。
大多数图像中的物体并非均匀分布在网格上,为了解决这个问题,模型会为每个方框输出一个置信度分数(confidence score ),如图 12.4 所示。我们希望在检测到物体时置信度较高,而未检测到物体时置信度为零。大多数网格位置都没有物体,因此置信度应接近于零。
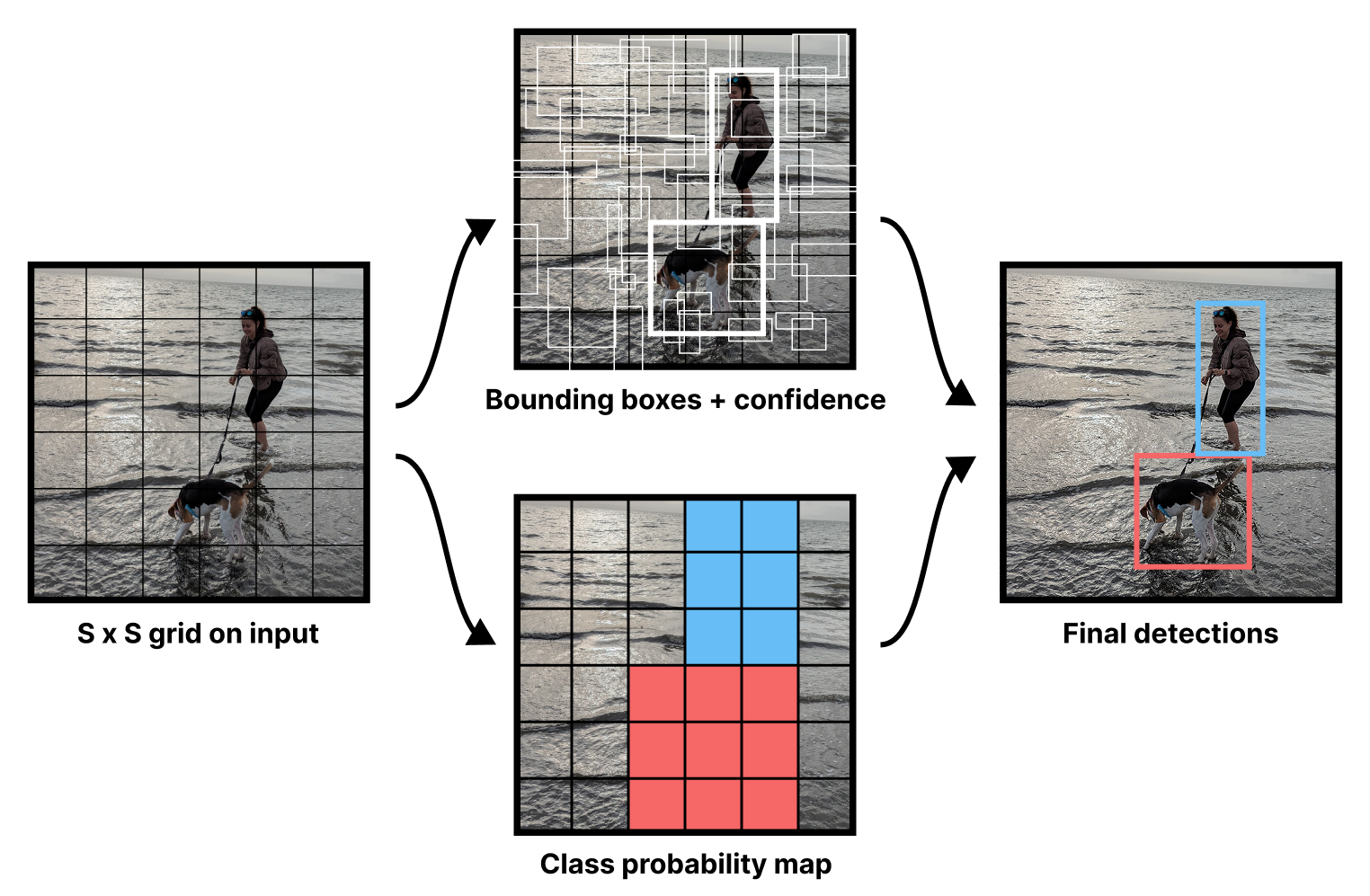 图 12.4:YOLO 输出结果可视化图(见第一篇 YOLO 论文)
图 12.4:YOLO 输出结果可视化图(见第一篇 YOLO 论文)
与计算机视觉领域的许多模型一样,YOLO 模型使用卷积神经网络(ConvNet) 作为骨干网络(backbone),从输入图像中提取有价值的高级特征,我们在第 8 章中首次探讨了这一概念。在他们的论文中,作者创建了自己的骨干网络模型(backbone model),并使用 ImageNet 数据集对其进行预训练以进行分类。与其自己进行这些操作,我们不如使用 KerasHub 加载预训练的骨干网络。
我们将不再使用本书前几章一直使用的 Xception 主干网络,而是改用 ResNet,这是我们在第 9 章首次提到的一系列模型。ResNet 的结构与 Xception 非常相似,但它使用步长卷积而非池化层来对图像进行下采样。正如我们在第 11 章中提到的,当需要关注输入的空间位置时,步长卷积的效果更佳。
让我们加载预训练模型和相应的预处理文件(用于调整图像大小)。我们将图像大小调整为 448 × 448;图像输入大小对于目标检测任务至关重要。
1 | image_size = 448 |
清单 12.5:加载 ResNet 模型
接下来,我们可以通过添加新的层来将主干网络转换为检测模型,这些新层用于输出边界框和类别预测。YOLO 论文中提出的设置非常简单。将卷积神经网络(ConvNet)主干网络的输出输入到两个中间带有激活函数的全连接层中。然后,对输出进行分割。前五个数字将用于边界框预测(四个用于边界框,一个用于边界框置信度)。其余数字将用于生成 图 12.4 所示的类别概率图——该图显示了每个网格位置在所有 91 个可能标签下的分类预测。
我们来把它写下来。
1 | from keras import layers |
清单 12.6:安装 YOLO 预测头
我们可以通过查看模型概要来更好地了解该模型:
1 | >>> model.summary() |
我们的主干网络输出形状(batch_size, 14, 14, 2048)为 401,408,即每张图像有 401,408 个输出浮点数,这对于我们的密集层来说有点太多了。我们使用步长卷积层将特征图下采样,使其 (batch_size, 6, 6, 512)每张图像包含更易于管理的 18,432 个浮点数。
接下来,我们可以添加两个全连接层。我们将整个特征图展平,使其通过一个Dense带有relu激活函数的层,然后再通过一个最终层,该最终层Dense输出预测的数量与我们设定的数量完全一致——边界框和置信度为 5,每个网格位置的每个对象类别为 91。
最后,我们将输出结果重新调整为 6×6 网格,并拆分边界框预测和类别预测。与分类输出一样,我们对分类输出应用 softmax 函数。边界框输出需要更特殊的处理;我们稍后会详细介绍。
看起来不错!请注意,由于我们在分类层中将整个特征图展平,因此每个网格检测器都可以使用整幅图像的特征;不存在局部性限制。这是有意为之——大型物体不会局限于单个网格单元内。
准备用于 YOLO 模型的 COCO 数据
Readying the COCO data for the YOLO model
我们的模型相对简单,但仍需对输入进行预处理,使其与预测网格对齐。每个网格检测器负责检测中心位于网格框内的所有方框。模型将输出五个浮点数来表示该方框(x, y, w, h, confidence)。其中,a``x和 b``y分别表示物体中心相对于网格单元边界的位置(取值范围为 0 到 1)。c``w和 d``h分别表示物体相对于图像尺寸的大小。
我们的训练数据中已经包含了正确的 xw和 yh值。但是,我们需要将这些 xx和 yy值与网格数据进行相互转换。让我们定义两个实用工具:
1 | def to_grid(box): |
让我们重新处理训练数据,使其符合新的网格结构。我们可以创建两个数组,长度与我们的网格数据集的长度相同:
- 第一个单元格将包含我们的类别概率图。我们将用正确的标签标记所有与边界框相交的网格单元格。为了简化代码,我们暂不考虑边界框重叠的情况。
- 第二个区域将包含所有方框本身。我们将所有方框映射到网格上,并用方框的坐标标记正确的网格单元格。对于标签数据中实际存在的方框,其置信度始终为 1,而对于所有其他位置,其置信度均为 0。
1 | import numpy as np |
清单 12.7:创建 YOLO 目标
让我们用辅助绘图工具(图 12.5)可视化 YOLO 训练数据。我们将在第一张输入图像上绘制整个类别激活图。[4]并将方框的置信度评分与其标签一起添加。
1 | def draw_prediction(image, boxes, classes, cutoff=None): |
清单 12.8:可视化 YOLO 目标
 图 12.5:YOLO 为每个图像区域输出边界框预测和类别标签。
图 12.5:YOLO 为每个图像区域输出边界框预测和类别标签。
最后,我们来tf.data加载图像数据。我们将从磁盘加载图像,应用预处理,然后进行批处理。我们还应该划分一个验证集来监控训练过程。
1 | import tensorflow as tf |
清单 12.9:创建用于训练的数据集
至此,我们的数据已准备好用于训练。
这个训练示例清晰地展示了流式库的用处tf.data。一次性加载这个大型数据集中的所有图像会耗尽系统内存(请记住,图像张量比压缩后的 JPEG 文件大得多)。使用流式库tf.data,我们可以分批加载图像数据,并在完成后释放内存,只在特定时刻映射数据集中我们需要的部分。调用流prefetch(2)式库会将tf.data两个批次的数据缓冲起来,并在使用前准备就绪,这样我们就无需中断每个批次的训练来加载和调整更多图像的大小。
This training example shows clearly why a streaming library like tf.data is helpful. Loading all the images in this large dataset in one go would overwhelm our system memory (remember an image tensor is much larger than a compressed JPEG file). With tf.data, we can load our image data in batch by batch and release the memory when we are done, only mapping in the particular parts of the dataset we need at a given moment. The prefetch(2) call will cause tf.data to keep two batches buffered and ready before they are used so we don’t interrupt training each batch to load and resize more images.
训练 YOLO 模型
Training the YOLO model
我们的模型和训练数据都已准备就绪,但在实际运行之前,还需要最后一个要素fit():损失函数。我们的模型输出预测的方框和预测的网格标签。我们在第 7 章中看到,我们可以为每个输出定义多个损失函数——Keras 会在训练过程中将这些损失函数相加。我们可以 sparse_categorical_crossentropy像往常一样处理分类损失。
然而,框损失需要一些特殊考虑。YOLO 作者提出的基本损失相当简单。他们使用目标框参数与预测框参数之差的平方误差和。我们仅计算标注数据中包含实际框的网格单元的此误差。
损失函数的难点在于边界框置信度输出。作者希望置信度输出不仅反映物体是否存在,还要反映预测边界框的准确度。为了平滑地估计边界框预测的准确度,作者提出使用上一章中提到的交并比(IoU)指标。如果网格单元为空,则该位置的预测置信度应为零。但是,如果网格单元包含物体,我们可以使用当前预测边界框与实际边界框之间的 IoU 值作为目标置信度值。这样,随着模型预测边界框位置能力的提高,IoU 值和学习到的置信度值也会随之提高。
这就需要自定义损失函数。我们可以先定义一个效用函数来计算目标框和预测框的 IoU 分数。
1 | from keras import ops |
清单 12.10:计算两个盒子的 IoU
让我们使用这个工具来定义自定义损失函数。Redmon 等人提出了一些损失函数缩放技巧来提高训练质量:
- 他们将盒子放置损失放大五倍,使其成为整体训练中更重要的一部分。
- 由于大多数网格单元都是空的,因此空位置的置信度损失也减半。这样可以防止这些零置信度预测对损失造成过大的影响。
- 在计算损失之前,他们会对宽度和高度取平方根。这是为了防止大框的影响过大。我们将使用一个
sqrt能够保留输入符号的函数,因为我们的模型在训练初期可能会预测出负的宽度和高度。
我们来把它写下来。
1 | def signed_sqrt(x): |
清单 12.11:定义 YOLO 边界框损失
我们终于可以开始训练 YOLO 模型了。为了保持示例简洁,我们将略过指标部分。在实际应用中,您需要很多指标,例如模型在不同置信度阈值下的准确率。
1 | model.compile( |
清单 12.12:训练 YOLO 模型
在 Colab 免费 GPU 运行时上训练耗时超过一小时,而且我们的模型仍然欠训练(验证损失仍在下降!)。让我们尝试可视化模型的输出(图 12.6)。我们将使用较低的置信度阈值,因为我们的模型目前还不是一个很好的目标检测器。
1 | # Rebatches our dataset to get a single sample instead of 16 |
清单 12.13:训练 YOLO 模型
 图 12.6:样本图像的预测结果
图 12.6:样本图像的预测结果
我们可以看到,我们的模型已经开始理解方框的位置和类别标签,尽管准确率仍然不高。让我们可视化模型预测的每个方框(图 12.7),即使是置信度为零的方框:
1 | draw_prediction(path, boxes, classes, cutoff=None) |
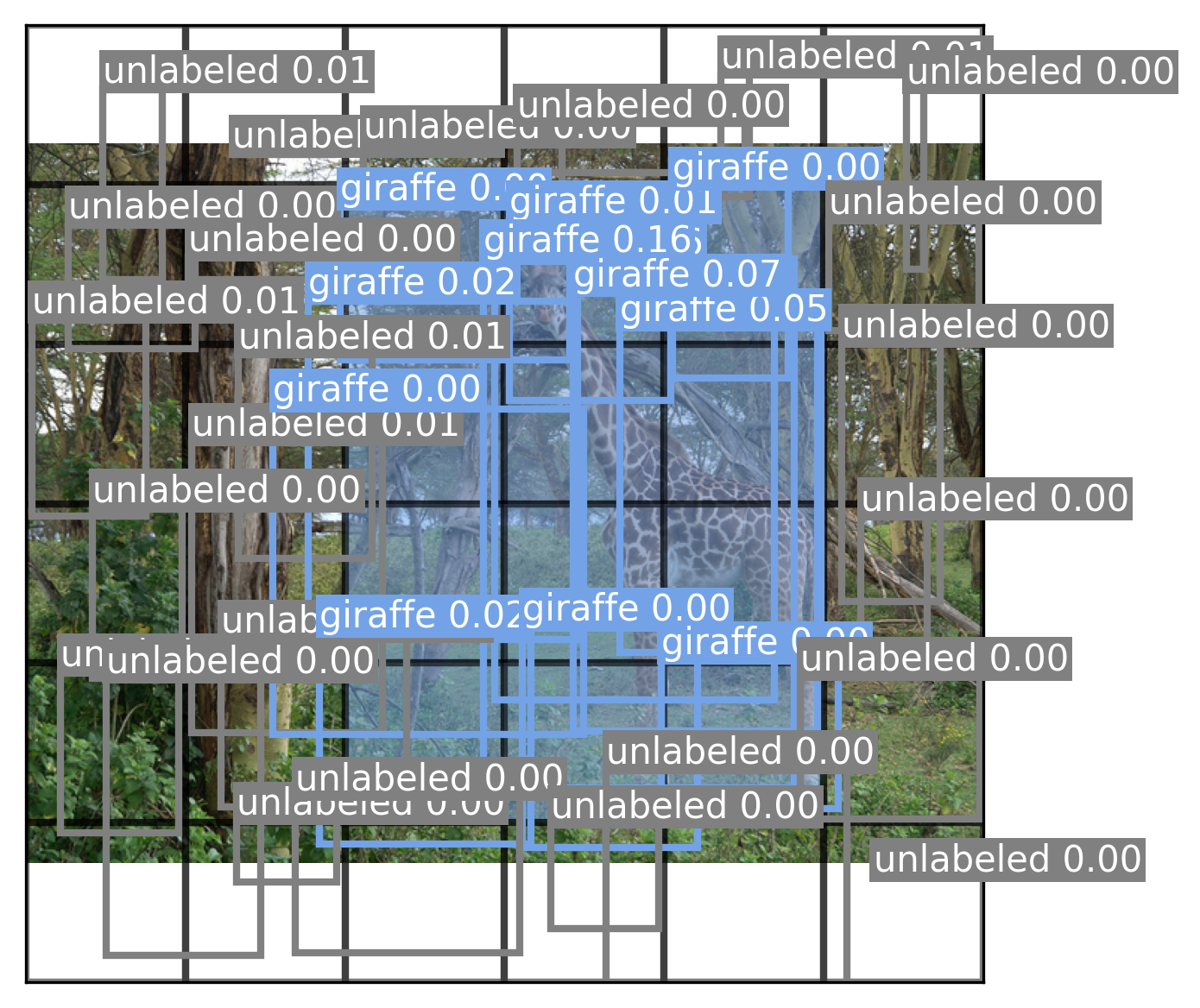 图 12.7:YOLO 模型预测的每个边界框
图 12.7:YOLO 模型预测的每个边界框
我们的模型学习到的置信度值非常低,因为它尚未学会稳定地定位场景中的物体。为了进一步改进模型,我们应该尝试以下几种方法:
- 训练更多轮次
- 使用整个 COCO 数据集
- 数据增强(例如,平移和旋转输入图像和方框)
- 改进重叠框的类别概率图
- 使用更大的输出网格预测每个网格位置的多个方框
所有这些都会对模型性能产生积极影响,并使我们更接近最初的 YOLO 训练方案。然而,这个例子实际上只是为了了解目标检测训练——从头开始训练一个精确的 COCO 目标检测模型需要大量的计算资源和时间。因此,为了了解性能更优的目标检测模型,我们不妨尝试使用一个名为 RetinaNet 的预训练目标检测模型。
使用预训练的 RetinaNet 检测器
Using a pretrained RetinaNet detector
RetinaNet 也是一种单阶段目标检测器,其基本原理与 YOLO 模型相同。我们的模型与 RetinaNet 之间最大的概念区别在于,RetinaNet 对其底层卷积神经网络的使用方式不同,因此能够更好地同时处理大小不同的目标。
在我们的YOLO模型中,我们直接将卷积神经网络的最终输出用于构建目标检测器。这些输出特征映射到输入图像上的大片区域——因此,它们在寻找场景中的小目标方面效果不佳。
解决这种尺度问题的一种方法是直接使用卷积神经网络(ConvNet)中早期层的输出。这样可以提取映射到输入图像局部小区域的高分辨率特征。然而,这些早期层的输出语义意义不大。它们可能映射到边缘和曲线等不同类型的简单特征,但只有在卷积神经网络的后续层中,我们才开始构建整个对象的潜在表示。
RetinaNet 使用的解决方案称为特征金字塔网络。 Conv2DTranspose与上一章所述类似,卷积神经网络 (ConvNet) 基础模型的最终特征通过渐进层进行上采样。但关键在于,我们还加入了横向连接(lateral connections),将这些上采样后的特征图与原始 ConvNet 中相同大小的特征图进行叠加。这使得 ConvNet 末端语义丰富但分辨率较低的特征与 ConvNet 前端高分辨率、小尺度的特征相结合。图 12.8 展示了该架构的大致示意图。
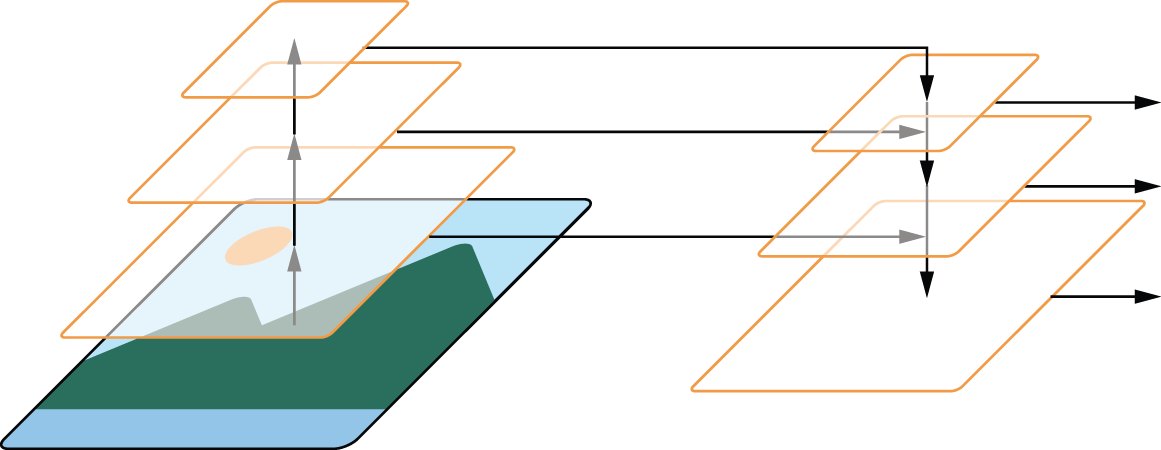 图 12.8:特征金字塔网络在不同尺度上创建语义有趣的特征图。
图 12.8:特征金字塔网络在不同尺度上创建语义有趣的特征图。
特征金字塔网络能够针对像素大小不同的物体构建有效的特征,从而显著提升性能。YOLO 的最新版本也采用了相同的设置。
接下来我们来试试 RetinaNet 模型,它也是在 COCO 数据集上训练的。为了增加一些趣味性,我们来尝试一张超出模型分布范围的图像——点彩画《 大碗岛的星期日下午》。
我们可以先下载图像并将其转换为 NumPy 数组:
1 | url = "https://s3.us-east-1.amazonaws.com/book.keras.io/3e/seurat.jpg" |
接下来,我们下载模型并进行预测。和上一章一样,我们可以使用 KerasHub 中的高级任务 API 来创建ObjectDetector 和使用它——包括预处理步骤。
1 | detector = keras_hub.models.ObjectDetector.from_preset( |
清单 12.14:创建 ResNet 模型
你会注意到我们传递了一个额外的参数来指定边界框格式。对于大多数支持边界框的 Keras 模型和层,我们都可以这样做。我们传递的参数 "rel_xywh"是为了使用与 YOLO 模型相同的格式,这样我们就可以使用相同的边界框绘制工具。这里,rel表示相对于图像大小的边界框尺寸(例如,取值范围为 [0, 1])。让我们来检查一下刚刚做出的预测:
1 | >>> [(k, v.shape) for k, v in predictions.items()] |
我们有四种不同的模型输出:边界框、置信度、标签和检测总数。这与我们的 YOLO 模型非常相似。该模型可以针对每个输入预测总共 100 个对象。
让我们尝试使用我们的框线绘制工具来显示预测结果(图 12.9)。
1 | fig, ax = plt.subplots(dpi=300) |
清单 12.15:使用 RetinaNet 运行推理
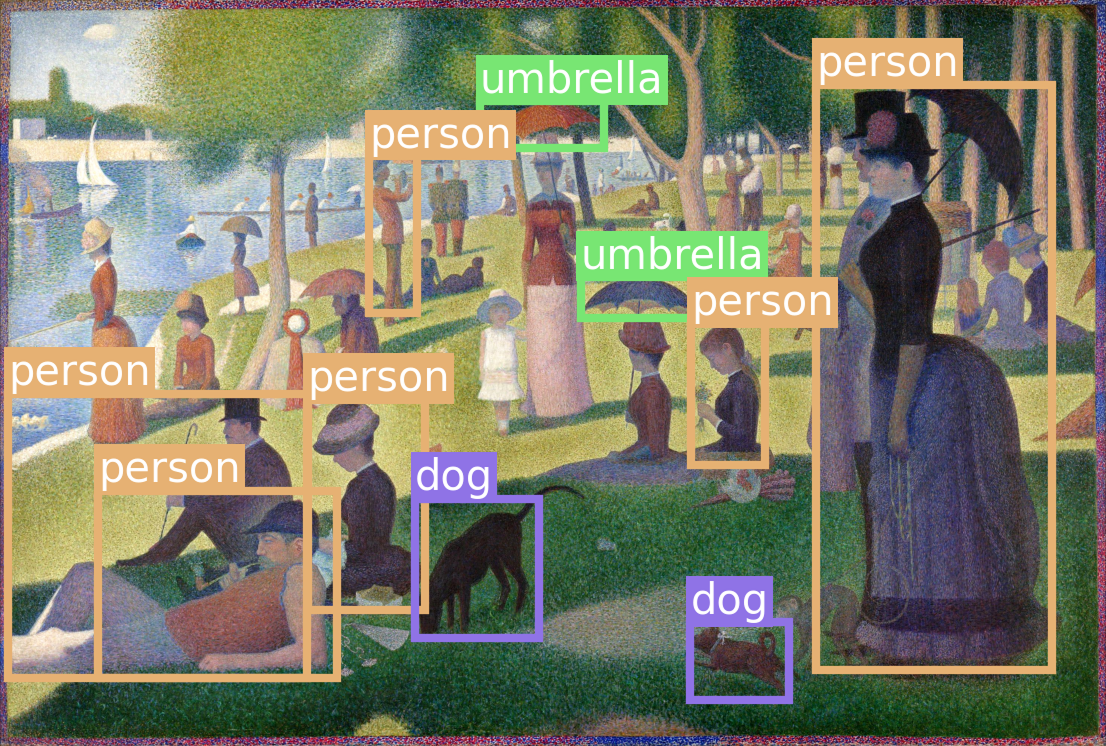 图 12.9:RetinaNet 模型对测试图像的预测结果
图 12.9:RetinaNet 模型对测试图像的预测结果
RetinaNet模型能够轻松泛化到点彩画,即使它从未接受过此类输入的训练!这实际上是单阶段目标检测器的优势之一。绘画和照片在像素层面上截然不同,但在宏观层面上却有着相似的结构。相比之下,像R-CNN这样的两阶段检测器则被迫孤立地对输入图像的小块区域进行分类,当这些小块像素与训练数据差异很大时,分类难度会显著增加。单阶段检测器可以利用整个输入的特征,并且对测试时的新输入更具鲁棒性(robust)。
至此,本书计算机视觉部分就结束了!我们从零开始训练了图像分类器、分割器和目标检测器。我们对卷积神经网络(ConvNets)的工作原理有了很好的理解,它是深度学习时代的第一个重大成功案例。不过,我们还没有完全告别图像;在第17章中,我们将开始生成图像输出,届时您将再次看到图像。
概括
- 目标检测利用边界框识别并定位图像中的物体。它本质上是图像分割的简化版,但运行效率更高。
- 目标检测主要有两种方法:
- 基于区域的卷积神经网络(R-CNN)是一种两阶段模型,它首先提出感兴趣的区域,然后使用卷积神经网络(ConvNet)对其进行分类。
- 单阶段检测器(例如 RetinaNet 和 YOLO)可以在一步内完成这两项任务。单阶段检测器通常速度更快、效率更高,因此适用于实时应用(例如自动驾驶汽车)。
- YOLO 在训练过程中同时计算两个独立的输出——可能的边界框和类别概率图:
- 每个候选边界框都与一个置信度分数配对,该分数经过训练,目标是预测框和真实框的交并比。
- 类别概率图将图像的不同区域分类为属于不同的对象。
- RetinaNet 在此基础上,利用特征金字塔网络 (FPN) 构建了一个更先进的网络,该网络结合了多个卷积神经网络层的特征,创建了不同尺度的特征图,从而能够更准确地检测不同大小的物体。
脚注
- COCO 2017 检测数据集可在https://cocodataset.org/ 上查看。本章中的大多数图像均来自该数据集。
- 图片来自 COCO 2017 数据集,https://cocodataset.org/。图片来自 Flickr,http://farm8.staticflickr.com/7250/7520201840_3e01349e3f_z.jpg,CC BY 2.0 许可协议[https://creativecommons.org/licenses/by/2.0/。 ]
- Redmon 等人,“You Only Look Once: Unified, Real-Time Object Detection,” CoRR (2015), https://arxiv.org/abs/1506.02640 .
- 图片来自 COCO 2017 数据集,https://cocodataset.org/。图片来自 Flickr,http://farm9.staticflickr.com/8081/8387882360_5b97a233c4_z.jpg,CC BY 2.0 许可协议[https://creativecommons.org/licenses/by/2.0/。 ]
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论