《DEEP LEARNING with Python》第十四章 文本分类
第十四章 文本分类
Text classification
运行代码
本章内容
- 自然语言处理(NLP)领域简介
- 预处理文本输入,将其转换为数值输入
- 构建简单的文本分类模型
- An introduction to the field of natural language processing (NLP)
- Preprocessing text input into numeric input
- Building simple text classification models
本章将为处理文本输入奠定基础,本书接下来的两章将在此基础上继续深入探讨。读完本章,你将能够以多种方式构建一个简单的文本分类器。这将为下一章构建更复杂的模型(例如 Transformer 模型)做好准备。
自然语言处理简史
A brief history of natural language processing
在计算机科学中,我们将英语或汉语等人类语言称为“自然语言”,以区别于专为机器设计的语言,例如 LISP、汇编语言和 XML。每一种机器语言都是人为设计的:它的起点是工程师编写一套形式化的规则,用于描述可以表达哪些语句以及这些语句的含义。规则先于语言出现,人们只有在规则集完善后才开始使用这种语言。而人类语言则恰恰相反:使用先于规则。自然语言的形成过程与生物有机体类似,都是通过进化过程实现的——这正是它“自然”的原因。它的“规则”,例如英语语法,是在事后才形式化的,而且经常被使用者忽略或打破。因此,机器可读语言结构严谨、条理清晰,而自然语言则显得杂乱无章——含糊不清、混乱无序、庞杂冗长且不断变化。
计算机科学家长期以来一直关注能够接收或生成自然语言的系统的潜力。语言,尤其是书面文本,是我们大多数交流和文化生产的基础。几个世纪以来,人类的知识都以文本的形式存储;互联网主要由文本构成,甚至我们的思想也基于语言!利用计算机来解释和处理语言的实践被称为自然语言处理,简称NLP。它最初是在二战后被提出作为一门研究领域的,当时一些人认为我们可以将理解语言视为一种“密码破解”,而自然语言就是用来传输信息的“密码”。
在机器翻译领域的早期,许多人天真地认为可以像编写LISP规则集一样,编写出“英语规则集”。20世纪50年代初,IBM和乔治城大学的研究人员展示了一个可以将俄语翻译成英语的系统。该系统使用包含六条硬编码规则的语法和一个包含数百个元素(单词和后缀)的查找表,能够准确翻译60个精心挑选的俄语句子。其目的是为了激发人们对机器翻译的兴趣并争取资金,从这个意义上讲,它取得了巨大的成功。尽管演示功能有限,但作者声称五年内翻译问题就能得到解决。在接下来的近十年里,资金源源不断地涌入。然而,事实证明,要推广这样一个系统却异常困难。单词的含义会根据上下文发生巨大变化。任何语法规则都需要无数的例外情况。开发一个能够处理几个精心挑选的例句的程序并不难,但要构建一个能够与人类翻译相媲美的强大系统则完全是另一回事。十年后,一份具有影响力的美国报告详细分析了进展缓慢的原因,资金也随之枯竭。
尽管遭遇了这些挫折,也经历了从兴奋到失望的反复起伏,手工编写的规则在20世纪90年代仍然是主流方法。问题显而易见,但除了用符号规则描述语法之外,别无他法。然而,随着20世纪80年代末计算机速度的提升和海量数据的出现,研究开始朝着新的方向发展。当你发现自己构建的系统充斥着大量临时规则时,作为一名聪明的工程师,你很可能会开始思考:“我能否利用语料库来自动查找这些规则?我能否在某个规则空间中搜索规则,而不是自己去创造它们?” 就这样,你就踏入了机器学习的领域。
20世纪80年代末,我们开始看到机器学习方法应用于自然语言处理。最早的方法基于决策树——其目的在于自动化生成类似硬编码语言系统中的if/then/else规则。随后,统计方法开始发展,以逻辑回归为代表。随着时间的推移,参数化学习模型逐渐占据主导地位,而语言学被一些人视为直接嵌入模型中的障碍。早期语音识别研究员弗雷德里克·杰利内克(Frederick Jelinek)在20世纪90年代曾开玩笑说:“我每解雇一位语言学家,语音识别器的性能就会提高。”
正如计算机视觉是将模式识别应用于像素一样,现代自然语言处理领域的核心是将模式识别应用于文本中的词语。其实际应用领域不胜枚举:
- 给定一封电子邮件的内容,它是垃圾邮件的概率是多少?(文本分类 text classification)
- 给定一个英文句子,最可能的俄语翻译是什么?(翻译 (translation)
- 给定一个不完整的句子,接下来最有可能出现的词是什么?(语言建模 language modeling)
本书中你将训练的文本处理模型不会像人类一样理解语言;相反,它们只是在输入数据中寻找统计规律,而这足以在各种现实世界的任务中表现出色。
过去十年,自然语言处理(NLP)研究人员和从业者发现,学习文本相关统计问题的答案竟能带来惊人的效果。2010年代,研究人员开始将长短期记忆网络(LSTM)模型应用于文本处理,这极大地增加了NLP模型的参数数量以及训练所需的计算资源。结果令人鼓舞——LSTM模型能够比以往的方法更准确地泛化到未见过的样本,但最终也遇到了瓶颈。LSTM难以追踪包含大量句子和段落的长文本链中的依赖关系,而且与计算机视觉模型相比,它们的训练速度慢且操作繁琐。
在2010年代末期,谷歌的研究人员发现了一种名为Transformer的新架构,它解决了困扰LSTM的诸多可扩展性问题。只要模型及其训练数据规模同时增加,Transformer的性能似乎就会越来越好。更重要的是,即使对于长序列,训练Transformer所需的计算也可以有效地并行化。如果训练机器的数量翻倍,等待结果所需的时间大约可以缩短一半。
Transformer架构的发现,以及GPU和CPU速度的不断提升,在过去几年里引发了自然语言处理(NLP)模型领域投资和兴趣的爆炸式增长。像ChatGPT这样的聊天系统,能够就看似任意的主题和问题生成流畅自然的文本,吸引了公众的目光。用于训练这些模型的原始文本占据了互联网上所有书面语言的很大一部分,而训练单个模型的计算成本可能高达数千万美元。然而,有些炒作需要理性看待——它们本质上是模式识别机器。尽管我们人类总是倾向于在“会说话的东西”中寻找智能,但这些模型复制和合成训练数据的方式与人类智能截然不同(而且效率低得多!)。不过,公平地说,从极其简单的“猜词”训练设置中涌现出复杂的行为,是过去十年机器学习领域最令人震惊的实证成果之一。
接下来的三章,我们将探讨一系列用于文本数据的机器学习技术。我们将略过20世纪90年代以前盛行的硬编码语言特征,但会涵盖从运行逻辑回归进行文本分类到训练LSTM进行机器翻译等所有内容。我们将深入研究Transformer模型,并探讨其在文本领域如此高效且具有可扩展性的原因。让我们开始吧。
准备文本数据
Preparing text data
让我们来看一个英文句子:
1 | The quick brown fox jumped over the lazy dog. |
在应用前几章提到的任何深度学习技术之前,我们面临着一个显而易见的障碍——我们的输入并非数值型数据!在开始任何建模之前,我们需要将文字转换为数字张量。与图像相对自然的数值表示不同,文本的数值表示可以通过多种方式构建。
一个简单的办法是借鉴标准文本文件格式,使用类似 ASCII 编码的方式。我们可以将输入内容分割成一系列字符,并为每个字符分配一个唯一的索引。另一种直观的方法是构建基于单词的表示,首先将句子按空格和标点符号拆分,然后将每个单词映射到一个唯一的数字表示。
这两种方法都值得尝试。一般来说,所有文本预处理都会包含一个分割(splitting)步骤,即将文本分割成称为“词元”(token)的小单元。正则表达式(regular expressions)是分割文本的强大工具,它可以灵活地匹配文本中的字符模式。
我们来看看如何使用正则表达式将字符串拆分成字符序列。最基本的正则表达式是 (The most basic regex we can apply is ".") ".",它可以匹配输入文本中的任何字符:
1 | import regex as re |
我们可以将该函数应用于我们的示例输入字符串:
1 | >>> chars = split_chars("The quick brown fox jumped over the lazy dog.") |
我们可以轻松地使用正则表达式将文本拆分成单词。"[\w]+" 正则表达式会匹配连续的非空白字符,并且 "[.,!?;]"能够匹配括号内的标点符号。我们可以将两者结合起来,得到一个能够将每个单词和标点符号拆分成一个标记的正则表达式:
1 | def split_words(text): |
它对测试句子做了以下处理:
1 | >>> split_words("The quick brown fox jumped over the dog.") |
分割操作将单个字符串转换为标记序列,但我们仍然需要将字符串标记转换为数值输入。目前最常用的方法是将每个标记映射到一个唯一的整数索引,这通常称为 对输入进行索引。这种标记化输入的表示方法灵活且可逆,可以与各种建模方法兼容。之后,我们可以决定如何将标记索引映射到模型接收的潜在空间。
对于字符标记,我们可以使用 ASCII 查找表来索引每个标记——例如,ord('A') → 65和ord('z') → 122。然而,当涉及到其他语言时,这种方法的扩展性会很差——Unicode 规范中包含超过一百万个字符!一种更稳健的技术是构建一个映射,将训练数据中的特定标记映射到我们关心的数据中出现的索引,这在自然语言处理中被称为词汇表(vocabulary)。这种方法的一个优点是,它既适用于词级标记,也适用于字符级标记。
让我们来看看如何使用词汇表来转换文本。我们将构建一个简单的 Python 字典,将词元映射到索引,将输入拆分成词元,最后为词元建立索引:
1 | vocabulary = { |
输出结果如下:
1 | [0, 2, 3, 4, 5, 6, 1, 0, 7, 8] |
我们在词汇表中引入一个特殊标记,称为"[UNK]"“词元”,它代表词汇表中不存在的词元。这样,即使某些词项仅出现在测试数据中,我们也能索引所有遇到的输入。在前面的示例中,“词元”"lazy"映射到"[UNK]"索引 0,因为它不在我们的词汇表中。
通过这些简单的文本转换,我们已经朝着构建文本预处理流程迈出了重要一步。然而,还有一种更常见的文本处理方式值得我们考虑——标准化(standardization)。
请看以下两个句子:
- “sunset came. i was staring at the Mexico sky. Isnt nature splendid??”
- “Sunset came; I stared at the México sky. Isn’t nature splendid?”
- “日落了。我凝视着墨西哥的天空。大自然真是太壮丽了!
- “夕阳西下,我凝视着墨西哥的天空。大自然真是壮丽啊!”
它们非常相似——事实上,它们几乎完全相同。然而,如果你像之前描述的那样将它们转换为索引,最终会得到截然不同的表示,因为“i”和“I”是两个不同的字符,“Mexico”和“México”是两个不同的单词,“isnt”和“isn't”不一样,等等。机器学习模型事先并不知道“i”和“I”是同一个字母,“é”是带重音符号的“e”,或者“staring”和“stared”是同一个动词的两种形式。文本标准化是一种基本的特征工程方法,旨在消除你不希望模型处理的编码差异。(Standardizing text is a basic form of feature engineering that aims to erase encoding differences that you don’t want your model to have to deal with.)这并非机器学习独有——如果你要构建一个搜索引擎,也需要做同样的事情。
一种简单且广泛应用的标准化方案是将字母转换为小写并删除标点符号。我们的两个句子将变成
- “sunset came i was staring at the mexico sky isnt nature splendid”
- “sunset came i stared at the méxico sky isnt nature splendid”
已经接近目标了。如果我们去掉所有字符上的重音符号,目标还能更接近。
标准化有很多用途,它曾经是提升模型性能的关键领域之一。在自然语言处理领域,几十年来,人们普遍使用正则表达式将单词映射到共同的词根(例如,“tired”→“tire”,“trophies”→“trophy”),这种方法被称为词干提取或 词形还原(stemming or lemmatization)。但随着模型表达能力的增强,这种标准化方法往往弊大于利。单词的时态和复数形式是其含义的必要信号。对于如今使用的大型模型而言,大多数标准化都力求轻量级——例如,在进一步处理之前将所有输入转换为标准字符编码。
通过标准化,我们现在看到了文本预处理的三个不同阶段(图 14.1):
- 标准化(Standardization)——我们使用基本的文本到文本转换来规范化输入。
- 分割(Splitting)——将文本分割成一系列标记。
- 索引(Indexing)——我们使用词汇表将词元映射到索引。
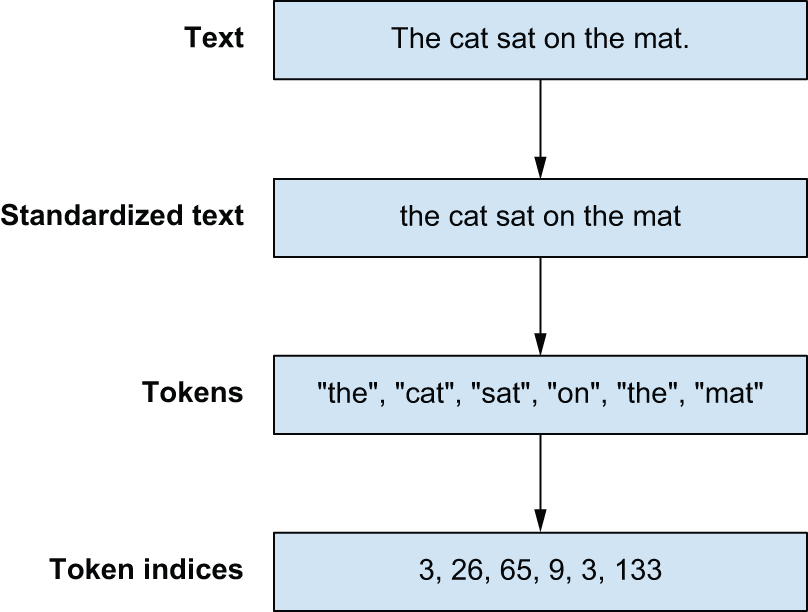 图 14.1:文本预处理流程
图 14.1:文本预处理流程
人们通常将整个过程称为分词(tokenization),并将把文本映射到词元索引序列的对象称为分词器(tokenizer)。让我们尝试构建几个分词器。
字符和词语标记化
Character and word tokenization
首先,我们来构建一个字符级分词器,它将输入字符串中的每个字符映射到一个整数。为了简化操作,我们只使用一个标准化步骤——将所有输入转换为小写。
1 | class CharTokenizer: |
列表 14.1:基本字符级分词器
很简单。在使用这个功能之前,我们还需要构建一个函数,根据输入文本计算词元词汇表。与其简单地将所有字符映射到一个唯一索引,不如让我们能够将词汇表的大小限制在输入数据中最常见的词元范围内。在建模过程中,限制词汇表的大小将是限制模型参数数量的重要方法。
1 | import collections |
清单 14.2:计算字符级词汇表
现在我们可以对词级分词器执行相同的操作。我们可以使用与字符级分词器相同的代码,只需改变分割步骤即可。
1 | class WordTokenizer: |
列表 14.3:一个基本的词级分词器
我们还可以将这条新的拆分规则代入到我们的词汇函数中。
1 | def compute_word_vocabulary(inputs, max_size): |
清单 14.4:计算词级词汇量
让我们用一些真实世界的输入来测试一下我们的分词器——赫尔曼·梅尔维尔的《白鲸》全文。我们首先会为两个分词器构建一个词汇表,然后用它来对一些文本进行分词:
1 | import keras |
让我们来检查一下字符级分词器的计算结果:
1 | >>> print("Vocabulary length:", len(vocabulary)) |
那么词级分词器呢?
1 | vocabulary = compute_word_vocabulary(moby_dick, max_size=2_000) |
我们可以打印出词级分词器的相同数据:
1 | >>> print("Vocabulary length:", len(vocabulary)) |
我们已经可以看到两种分词技术的优缺点。字符级分词器(character-level tokenizer)只需要 64 个词汇就能覆盖整本书,但它会将每个输入编码成一个非常长的序列。词级分词器(word-level tokenizer)可以快速填充一个包含 2000 个词条的词汇表(要索引书中的每个词,你需要一个包含 17000 个词条的词典!),但词级分词器的输出要短得多。
随着机器学习从业者使用越来越多的数据和参数来扩展模型,词级分词和字符级分词的缺点也逐渐显现。词级分词提供的“压缩”功能非常重要——它允许将更长的序列输入模型。然而,如果你尝试为大型数据集(如今,你可能会遇到包含数万亿个单词的数据集)构建词级词汇表,你将得到一个庞大到无法使用的词汇表,其中包含数亿个词项。如果你严格限制词级词汇表的大小,你会将大量文本编码到"[UNK]"词元中,从而丢失宝贵的信息。
这些问题导致了第三种分词方法(称为子词分词 subword tokenization)的流行,该方法试图弥合词级和字符级方法之间的差距。
子词分词
Subword tokenization
子词标记化旨在结合字符级和词级编码技术的优点。我们希望它WordTokenizer既能生成简洁的输出,CharTokenizer又能用较小的词汇量编码广泛的输入。
我们可以将寻找理想的分词器视为寻找理想的输入数据压缩方式。缩短词元长度(个人注:减少文本编码后的词元数量)可以压缩样本的整体长度。较小的词汇表可以减少表示每个词元所需的字节数。如果我们能够同时实现这两点,就能将简短而信息丰富的序列输入到深度学习模型中。
压缩和分词(compression and tokenization)之间的这种类比并非一直显而易见,但事实证明它非常有效。过去十年自然语言处理研究中发现的最实用有效的技巧之一,就是重新利用了20世纪90年代一种名为字节对编码(byte-pair encoding)的无损压缩算法。[1]用于分词。ChatGPT 和许多其他模型至今仍在使用它。在本节中,我们将构建一个使用字节对编码算法的分词器。
字节对编码的思想是从一套基本的字符集开始,逐步将常见的字符对“合并”成越来越长的字符序列。假设我们从以下输入文本开始:
1 | data = [ |
和之前一样WordTokenizer,我们将首先计算文本中所有单词的词频。在创建词频字典时,我们将把所有文本拆分成字符,并用空格连接字符。这样可以方便我们在下一步中处理成对的字符。
1 | def count_and_split_words(data): |
清单 14.5:初始化字节对编码算法的状态
让我们用我们的数据来测试一下:
1 | >>> counts |
为了将字节对编码应用于我们分割后的单词计数,我们将找到两个字符并将它们合并成一个新符号。我们考虑所有单词中的所有字符对,并仅合并我们找到的最常见字符对。在前面的示例中,最常见的字符对是("o", "w"),它同时出现在单词 "brown"(在我们的数据中出现三次)和"slow"(出现一次)中。我们将此字符对合并成一个新符号"ow",并合并所有出现的字符对"o w"。
然后我们继续,计算词对数量并合并词对,只不过现在"ow"会形成一个单一单元,它可以与其他单元合并,例如,"l"形成"low"。通过逐步合并出现频率最高的符号对,我们构建了一个包含越来越大子词的词汇表。
让我们用我们的玩具数据集来测试一下。
1 | def count_pairs(counts): |
清单 14.6:运行几个字节对合并步骤
我们得到以下结果:
1 | ["t h e", "q u i c k", "b r ow n", "f o x", "s l ow", "f o x h o u n d"] |
我们可以看到常用词是如何完全合并的,而不太常用的词只是部分合并。
现在我们可以将其扩展为一个完整的函数,用于计算字节对编码词汇表。我们首先将输入文本中找到的所有字符添加到词汇表中,然后逐步添加合并符号(越来越长的子词),直到达到所需的长度。我们还维护一个单独的字典,其中包含合并规则及其应用顺序。接下来,我们将了解如何使用这些合并规则对新的输入文本进行分词。
1 | def compute_sub_word_vocabulary(dataset, vocab_size): |
清单 14.7:计算字节对编码词汇表
让我们构建一个SubWordTokenizer应用合并规则对新输入文本进行分词的工具。and``standardize()和 index()steps 步骤可以与 the 保持一致 WordTokenizer,所有更改都在 split()method 方法中进行。
在分割步骤中,我们首先将所有输入分割成词,然后将所有词分割成字符,最后将我们学习到的合并规则应用于分割后的字符。剩余部分是子词——根据输入词在训练数据中的频率,这些子词可能是完整的词、部分词或简单的字符。这些子词就是我们输出中的词元。
1 | class SubWordTokenizer: |
清单 14.8:字节对编码分词器
让我们用分词器处理《白鲸记》的全文:
1 | vocabulary, merges = compute_sub_word_vocabulary(moby_dick, 2_000) |
我们可以查看一下词汇表,并像之前对 and``WordTokenizer和CharTokenizer``:所做的那样,在分词器上尝试一个测试句子:
1 | >>> print("Vocabulary length:", len(vocabulary)) |
对于我们的测试句子,子词分词器的长度SubWordTokenizer略长于WordTokenizer(16 个词元对 13 个词元),但与不同的是WordTokenizer,它可以对《白鲸记》中的每个单词进行分词,而无需使用"[UNK]"单个词元。词汇表包含了源文本中的所有字符,因此最坏情况下的性能表现是将单词分词成单个字符。我们能够在处理词汇量较小的罕见词的同时,实现较短的平均词元长度(average token length)。这就是子词分词器的优势所在。
您可能会注意到,运行这段代码的速度明显慢于单词和字符分词器;在我们的参考硬件上大约需要一分钟。学习合并规则远比简单地统计输入数据集中的单词数量复杂得多。虽然这是子词分词的一个缺点,但在实践中很少会成为重要问题。每个模型只需要学习一次词汇表,而且学习子词词汇表的成本与模型训练相比通常可以忽略不计。
我们现在已经了解了三种不同的输入分词方法。既然我们已经能够将文本输入转换为数字输入,就可以开始训练模型了。
关于分词的最后一点说明——虽然理解分词器的工作原理非常重要,但你很少需要自己构建一个。Keras 和大多数深度学习框架一样,都提供了用于文本输入分词的实用工具。在本章的剩余部分,我们将使用 Keras 的内置分词功能。
我应该使用哪种分词技术?
Which tokenization technique should I use?
在着手解决新的文本建模问题时,首先需要回答的问题之一就是如何对输入文本进行分词。正如我们将在本章末尾看到的,对于给定的预训练模型而言,这个问题非常简单。你必须保留预训练期间使用的精确分词,否则就会丢弃模型权重中包含的输入词元的有效表示。
如果您要从头开始构建模型,可以根据具体问题定制分词方法。一般来说,词分词器和子词分词器提供的压缩效果至关重要,不容忽视。输入文本的平均长度越短,模型就越能更好地追踪文本中的长程依赖关系,从而提升整体性能。这使得子词分词成为现代语言模型的主流选择。它们能够处理罕见词或拼写错误,而不会增加常用输入的词元长度。
然而,并不存在万能的解决方案。自然语言处理中的一些问题,例如拼写纠错,可能受益于对输入文本进行低级字符标记化。另一方面,词级标记化方法既简单易用又易于理解——每个模型输入都对应于人类会阅读的一个词。这使得根据词元对预测结果的重要性进行排序变得容易解释。
本书正文各章节将使用这三种类型的分词器。
集合与序列
Sets vs. sequences
机器学习模型应该如何表示单个词元(token)是一个相对来说没有争议的问题:它们是类别特征(来自预定义集合的值),我们知道如何处理它们。它们应该被编码为特征空间中的维度或类别向量(在本例中为词元向量)。然而,一个更棘手的问题是如何对文本中词元的顺序进行编码。
How a machine learning model should represent individual tokens is a relatively uncontroversial question: they’re categorical features (values from a predefined set), and we know how to handle those. They should be encoded as dimensions in a feature space or as category vectors (token vectors in this case). A much more problematic question, however, is how to encode the ordering of tokens in text.
自然语言中的词序问题非常有趣:与时间序列的步长不同,句子中的词语并没有自然的、规范的顺序。不同的语言对相似的词语的排列方式截然不同。例如,英语的句子结构与日语就大相径庭。即使在同一种语言中,通常也可以通过稍微调整词语顺序来表达相同的意思。如果将一个短句中的词语完全随机排列,有时仍然可以理解其含义——尽管在很多情况下,会产生明显的歧义。词序显然很重要,但它与意义之间的关系并非简单直接。
如何表示词序是各种自然语言处理(NLP)架构的核心问题。最简单的做法是忽略词序,将文本视为无序的词集——这样就得到了词袋模型(bag-of-words)。也可以决定严格按照词出现的顺序逐个处理,就像时间序列中的步骤一样——这时就可以使用上一章提到的循环神经网络(RNN)模型。最后,还有一种混合方法:Transformer架构在技术上与词序无关,但它会将词的位置信息注入到处理的表示中,这使得它能够同时处理句子的不同部分(与RNN不同),同时仍然能够感知词序。由于RNN和Transformer都考虑了词序,因此它们都被称为序列模型。
从历史上看,机器学习在自然语言处理领域的早期应用大多仅限于词袋模型,而忽略了序列数据。直到2015年循环神经网络(RNN)的复兴,人们才开始对序列模型产生兴趣。如今,这两种方法仍然适用。让我们来看看它们是如何工作的,以及何时应该使用哪种方法。
我们将使用一个著名的文本分类基准数据集——IMDb 电影评论情感分类数据集——来演示每种方法。在第 4 章和第 5 章中,您使用的是 IMDb 数据集的预向量化版本;现在,让我们处理原始的 IMDb 文本数据,就像您在现实世界中处理新的文本分类问题时所做的那样。
正在加载 IMDb 分类数据集
Loading the IMDb classification dataset
首先,让我们下载并提取数据集。
1 | import os, pathlib, shutil, random |
列表 14.9:下载 IMDb 电影评论数据集
让我们列出目录结构:
1 | >>> for path in imdb_extract_dir.glob("*/*"): |
我们可以看到包含正例(positive)和负例(negative)的训练集和测试集。IMDb 网站上用户评分低的电影评论被归类到neg/ “训练集”中,评分高的评论被归类到“测试pos/集”中。我们还可以看到一个unsup/“无监督”目录,它是数据集创建者故意未标注的评论;这些评论可能是正面的,也可能是负面的。
我们来看几个文本文件的内容。无论你处理的是文本数据还是图像数据,在开始建模之前,务必先检查数据的结构。这将有助于你更好地理解模型的实际运行机制。
1 | >>> print(open(imdb_extract_dir / "train" / "pos" / "4077_10.txt", "r").read()) |
列表 14.10:预览一篇 IMDb 评论
在开始对输入文本进行分词之前,我们将复制一份训练数据,并进行一些重要的修改。目前我们可以忽略无监督评论,并创建一个单独的验证集,以便在训练过程中监控准确率。具体做法是将 20% 的训练文本文件拆分到一个新目录中。
1 | train_dir = pathlib.Path("imdb_train") |
清单 14.11:从 IMDb 数据集中拆分验证
现在我们可以加载数据了。还记得第 8 章中我们如何使用 image_dataset_from_directory工具为目录结构创建Dataset图像及其标签吗?您也可以使用该工具对文本文件执行完全相同的操作text_dataset_from_directory。让我们创建三个Dataset 对象,分别用于训练、验证和测试。
1 | from keras.utils import text_dataset_from_directory |
清单 14.12:加载 IMDb 数据集以供 Keras 使用
最初我们有 25,000 个训练样本和 25,000 个测试样本,在验证集划分之后,我们有 20,000 条评论用于训练,5,000 条评论用于验证。让我们尝试从这些数据中学习一些东西。
设置模型
Set models
对于文本中词元的顺序,最简单的处理方法就是忽略它。我们仍然像往常一样将输入的评论文本分词为词元 ID 序列,但在分词之后,我们会立即将整个训练样本转换为一个集合——一个简单的无序“词元包”,其中包含电影评论中存在或不存在的词元。
这里的想法是利用这些数据集构建一个非常简单的模型,该模型为评论中的每个词分配一个权重。某个词的出现 "terrible"可能(但不总是)表明这是一条差评,也 "riveting"可能表明这是一条好评。我们可以构建一个能够学习这些权重的小型模型——称为词袋模型。
例如,假设你有一个简单的输入句子和词汇表:
1 | "this movie made me cry" |
我们会将这条简短的评论标记化为
1 | [0, 1, 3, 0, 5] |
忽略顺序,我们可以将其转换为一组令牌 ID:
1 | {0, 1, 3, 5} |
最后,我们可以使用多热编码将集合转换为与词汇表长度相同的固定大小的向量:
1 | [1, 1, 0, 1, 0, 1] |
这里第五位的 0 表示该词"laugh"在我们的评论中不存在,第六位的 1 表示"cry"该词存在。这种简单的输入评论编码可以直接用于训练模型。
训练词袋模型
Training a bag-of-words model
要用代码实现这种文本处理,可以很容易地扩展 WordTokenizer本章前面提到的方法。更简单的解决方案是使用TextVectorizationKeras 内置的文本处理层。该层可以处理TextVectorization单词和字符标记化,并提供了一些附加功能,包括对层输出进行多热编码。
TextVectorization与 Keras 中的许多预处理层一样, 该层也提供了一种adapt()从输入数据中学习层状态的方法。在本例中 TextVectorization,adapt()它会通过迭代输入数据集来动态学习数据集的词汇表。让我们用它来对输入数据进行分词和编码。我们将构建一个包含 20,000 个单词的词汇表,这对于文本分类问题来说是一个很好的起点。
1 | from keras import layers |
列表 14.13:将词袋编码应用于 IMDb 评论
让我们来看一段预处理后的输入数据:
1 | >>> x, y = next(bag_of_words_train_ds.as_numpy_iterator()) |
你可以看到,经过预处理后,我们批次中的每个样本都被转换成一个包含 20,000 个数字的向量,每个数字跟踪一个词汇术语的存在或缺失。
接下来,我们可以训练一个非常简单的线性模型。我们将模型构建代码保存为一个函数,以便以后再次使用。
1 | def build_linear_classifier(max_tokens, name): |
清单 14.14:构建词袋回归模型
让我们来看一下模型的概要:
1 | >>> model.summary() |
这个模型非常简单。我们只有 20,001 个参数,词汇表中的每个词对应一个参数,还有一个偏置项。让我们开始训练它。我们将添加 EarlyStopping第七章中首次介绍的回调函数,该函数会在验证损失停止改善时自动停止训练,并从最佳迭代次数恢复权重。
1 | early_stopping = keras.callbacks.EarlyStopping( |
清单 14.15:训练词袋回归模型
我们的模型训练时间远低于一分钟,考虑到其规模,这并不令人意外。实际上,输入数据的分词和编码比更新模型参数的开销要大得多。让我们绘制模型准确率图(图 14.2):
1 | import matplotlib.pyplot as plt |
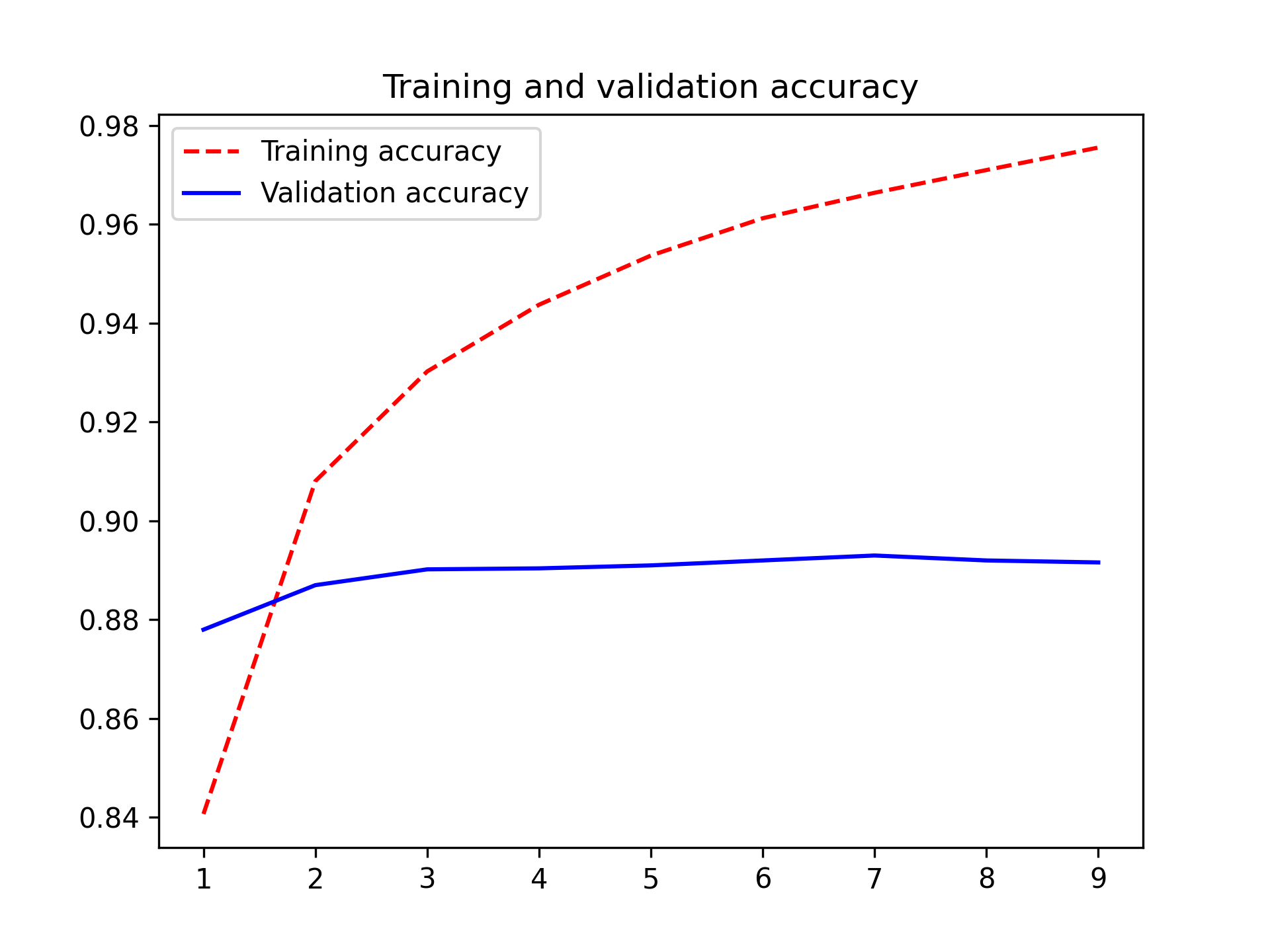 图 14.2:词袋模型的训练和验证指标
图 14.2:词袋模型的训练和验证指标
我们可以看到验证集的性能趋于稳定,而不是显著下降;我们的模型非常简单,所以不太可能出现过拟合。让我们尝试在测试集上评估一下。
1 | >>> test_loss, test_acc = model.evaluate(bag_of_words_test_ds) |
清单 14.16:评估词袋回归模型
我们能够以 88% 的准确率预测评论的情感倾向,而且训练任务足够轻量级,可以在单个 CPU 上高效运行。
值得注意的是,我们在这个例子中选择了词级分词。避免使用字符级分词的原因显而易见——一篇影评中所有字符的“集合”几乎无法提供任何关于其内容的信息。使用足够大的词汇表进行子词分词是一个不错的选择,但在这里几乎没有必要。由于我们训练的模型规模很小,因此使用训练速度快且权重与实际英语单词相对应的词汇表更为方便。
高效预处理文本
Preprocessing text efficiently
在所有应用机器学习中,预处理的速度和效率都是至关重要的。更快的程序运行速度固然重要,但当加速器(GPU 和 TPU)成本如此之高时,这一点就显得尤为迫切。您肯定不希望在预处理输入数据时让昂贵的 GPU 闲置!
文本预处理的特殊之处在于它必须始终在 CPU 上运行。GPU 严格处理数值输入,因此所有分词都必须在 GPU 的训练步骤之前完成。一种方法是预先计算分词后的输入——分词不依赖于模型权重,因此您可以在开始训练之前对所有输入文本文件进行分词,并将其重新保存为整数序列。然而,这种方法并非总是可行。动态分词可以实现更快速的实验。如果您要对一个未见过的样本进行推理,则无法预先计算分词后的输入;您需要快速地进行分词并运行前向传播。
实时预处理文本输入的关键在于“速度要足够快”。你需要确保昂贵的GPU始终有新的预处理数据可供处理。如果这样做,GPU就成了瓶颈,提升分词速度也就毫无意义了。
个人注:文本预处理的特殊之处在于它必须始终在 CPU 上运行。GPU 严格处理数值输入,因此所有分词都必须在 GPU 的训练步骤之前完成。
这句话揭示了深度学习流水线中一个非常底层的硬件分工问题。
简单来说:GPU 是一个极其强大的“算盘”,而 CPU 是一个灵活的“调度员”。
以下是文本预处理必须在 CPU 上运行的几个核心原因:
- GPU 只认数字,不认字符
GPU 的核心设计目标是进行大规模的并行浮点运算(矩阵点积、加法等)。它的内部架构(CUDA 核心)是为处理张量(Tensor)而生的。
- 文本是什么? 文本是字符串(String),是变长的、非数值的数据。
- 预处理做了什么? 分词(Tokenization)、查表(Vocabulary Lookup)、标准化。这些操作涉及大量的字符串匹配、逻辑判断(if-else)和字典查找。
- 冲突点: GPU 无法直接对“Hello World”进行矩阵运算。在数据进入 GPU 的内存(显存)之前,必须先由 CPU 将其转化成数字(整数索引或 Embedding)。
- 逻辑复杂性与分支预测
文本预处理通常包含复杂的逻辑:
- 分词规则: 遇到空格切分,遇到标点符号过滤,处理特殊的前缀/后缀。
- 字典映射: 将每个词映射为数字
{"apple": 1, "banana": 2}。- CPU 的优势: CPU 拥有复杂的控制流单元和强大的分支预测能力,处理这种“如果遇到 A,就执行 B,否则查字典”的逻辑任务非常快。
- GPU 的短板: GPU 擅长的是“对 100 万个数字同时做平方”。一旦出现复杂的逻辑分支(Branching),GPU 的数千个核心就会被迫等待彼此,性能严重下降。
- 内存访问模式
- CPU 缓存(Cache): 文本预处理涉及频繁访问词典。词典通常存储在系统内存(RAM)中,CPU 的多级缓存可以极快地加速这种随机查找。
- 数据搬运成本: 如果把原始字符串传给 GPU 处理,GPU 需要频繁地回访 CPU 的内存来查找词典,这种跨硬件的通信开销(PCIe 总线带宽限制)远比在 CPU 上直接处理完再传数字要大得多。
- 异步并行处理(流水线优化)
在现代深度学习架构(如 TensorFlow 的
tf.data或 PyTorch 的DataLoader)中,通常采用生产者-消费者模型:
- CPU(生产者): 负责从硬盘读文本、分词、转成数字张量。
- GPU(消费者): 负责拿着这些张量跑反向传播、更新权重。
- 优势: 当 GPU 正在计算第 \(N\) 个批次(Batch)时,CPU 已经在提前预处理第 \(N+1\) 个批次了。这种并行协作能让 GPU 始终处于满载状态,不被缓慢的字符串操作拖后腿。
总结
“分词”本质上是一个逻辑查找过程,而不是数学运算过程。
正如你读到的那本书所言,GPU 就像一个只吃“加工好的数字罐头”的猛兽。CPU 则负责在厨房里把原始的“文本蔬菜”洗净、切好(分词)、装罐(数值化),然后通过 PCIe 总线递给 GPU。如果让 GPU 自己去洗菜,它那笨拙的“手指”会效率极低。
我们在前面的章节中已经看到tf.data,我们使用它的一个重要原因是,该库旨在避免 CPU 成为 GPU 或 TPU 的瓶颈。本章中我们将使用它——例如,keras.utils.text_dataset_from_directory()加载一个模型tf.data.Dataset,并通过应用一个转换层来转换我们的输入数据。它的工作原理是在多个 CPU 核心上并行运行文本预处理,这通常足以避免在训练过程中出现加速器瓶颈。map()``TextVectorization``tf.data
需要注意的是,本章中的代码仍然是多后端兼容的(实际上,本章的输出是使用 Jax 生成的)。您可以将其 tf.data与 PyTorch、JAX 或 TensorFlow 本身一起使用——Keras 会自动将输入张量转换为给定后端所需的正确格式。
训练二元语法模型
Training a bigram model
当然,我们可以凭直觉猜到,完全忽略词序是非常简化的,因为即使是基本概念也可以用多个词来表达:“美国(United States)”这个词所传达的概念与“州(states)”和“联合(united)”这两个词单独来看的含义截然不同。一部“还不错(not bad)”的电影和一部“很糟糕(bad)”的电影,其情感评分应该有所不同。
因此,即使对于我们目前正在构建的这些简单的基于集合的模型,通常也应该在模型中注入一些关于局部词序的信息。一个简单的方法是考虑二元语法——二元语法是指输入文本中连续出现的两个词元(One easy way to do that is to consider bigrams—a term for two tokens that appear consecutively in the input text. )。以我们的例子“这部电影让我哭了(this movie made me cry)”为例,是输入中所有一元(unigrams){"this", "movie", "made", "me", "cry"}语法的集合, {"this movie" , "movie made", "made me", "me cry"} 是所有二元语法的集合。我们刚刚训练的词袋模型可以等价地称为一元语法模型,而术语“n-gram”指的是任意n个词元的有序序列。
为了将二元词组添加到我们的模型中,我们需要在构建词汇表时考虑所有二元词组的出现频率。我们可以通过两种方式实现:一是创建一个仅包含二元词组的词汇表,二是允许二元词组和一元词组竞争同一个词汇表中的空间。对于后一种情况,如果一个词组在输入文本中出现频率更高,"United States"则会优先将其添加到词汇表中。"ventriloquism"
For the latter case, the term "United States" will be included in our vocabulary before "ventriloquism" if it occurs more frequently in the input text.
个人注:"ventriloquism":虽然是一个合法的英文单词,但因为它太冷门了,算法觉得没必要为了它专门在词表里留个位置,不如用现有的字母组合拼凑它。
"ventriloquism":如果它还没被加入词表,它会被拆成碎片(比如ventril+oquism),处理它需要 2 个或更多 Tokens。
结论:高频词优先“合体”,低频词暂时“碎着”。
同样,我们可以通过扩展WordTokenizer本章前面提到的模型来构建它,但没有必要。TextVectorization该模型已经开箱即用地提供了此功能。我们将训练一个稍大的词汇表来处理二元语法、adapt()新词汇表以及包含二元语法的多热编码输出向量。
1 | max_tokens = 30_000 |
列表 14.17:对 IMDb 评论应用二元语法编码
让我们再次检查一批预处理后的输入数据:
1 | >>> x, y = next(bigram_train_ds.as_numpy_iterator()) |
如果我们看一下词汇表中的一小部分,就会发现其中既有单字词,也有双字词:
1 | >>> text_vectorization.get_vocabulary()[100:108] |
利用我们对输入数据的新编码方式,我们可以训练一个与之前完全相同的线性模型。
1 | model = build_linear_classifier(max_tokens, "bigram_classifier") |
清单 14.18:训练二元语法回归模型
这个模型比我们的词袋模型略大(参数数量为 30,001 个,而不是 20,001 个),但训练时间大致相同。它的表现如何?
1 | >>> test_loss, test_acc = model.evaluate(bigram_test_ds) |
清单 14.19:评估二元回归模型
我们现在的测试准确率达到了 90%,这是一个显著的进步!
我们可以通过考虑三元组(三个词组成的词组)来进一步提高这个数值,但一旦超出三元组,问题就会迅速变得难以处理。英语中可能的四元组词组空间极其庞大,而且随着序列长度的增加,问题呈指数级增长。你需要一个极其庞大的词汇表才能对四元组词组进行充分的覆盖,而你的模型也会失去泛化能力,仅仅记住带有权重的完整句子片段。为了稳健地处理更长的有序文本序列,我们需要更高级的建模技术。
序列模型
Sequence models
我们之前的两个模型表明序列信息很重要。我们通过添加包含局部词序信息的特征,改进了一个基本的线性模型。
然而,这种方法是通过手动构建输入特征实现的,我们可以看出它只能扩展到几个词的局部排序。正如深度学习中常见的情况,与其尝试自行构建这些特征,不如将模型暴露给原始词序列,让它直接学习词元之间的位置依赖关系。
能够接收完整词元序列的模型,顾名思义,就叫做 序列模型。这里我们有几种架构选择。我们可以像刚才进行时间序列建模那样,构建一个循环神经网络(RNN)模型。我们也可以构建一个一维卷积神经网络(1D ConvNet),类似于我们的图像处理模型,但它只在一个序列维度上进行卷积运算。正如我们将在下一章深入探讨的那样,我们还可以构建一个Transformer模型。
在采用任何这些方法之前,我们必须将输入预处理成有序序列。我们需要的是一个整数序列的词元 ID,就像我们在本章的词元化部分看到的那样,但这里还有一个需要处理的特殊情况。当我们对一批输入进行计算时,我们希望所有输入都是矩形的,这样所有计算才能有效地在 GPU 上并行处理。然而,词元化的输入几乎总是长度不一的。例如,IMDb 电影评论的长度从几句话到几段不等,字数也各不相同。
为了解决这个问题,我们可以截断输入序列,或者用另一个特殊标记"[PAD]"(类似于"[UNK]"我们之前使用的标记)来“填充”它们。例如,给定两个输入句子,期望长度为 8 个。
1 | "the quick brown fox jumped over the lazy dog" |
我们将对以下标记进行标记化,得到整数 ID:
1 | ["the", "quick", "brown", "fox", "jumped", "over", "the", "lazy"] |
这将使我们的批量计算速度更快,但我们需要小心使用填充标记,以确保它们不会影响模型预测的质量。
为了控制输入规模,我们可以将 IMDb 评论截断至前 600 个单词。这是一个合理的选择,因为评论的平均长度为 233 个单词,只有 5% 的评论超过 600 个单词。我们再次使用该TextVecotorization层,它提供了填充或截断输入的选项,并"[PAD]"在索引为 0 的位置包含了已学习词汇表。
1 | max_length = 600 |
列表 14.20:将 IMDb 评论填充到固定序列长度
我们来看一个单独的输入批次:
1 | >>> x, y = next(sequence_test_ds.as_numpy_iterator()) |
预处理后的每个批次都有其形状(batch_size, sequence_length),几乎所有训练样本的末尾都有若干个 0 用于填充。
训练循环模型
Training a recurrent model
我们来尝试训练一个 LSTM 模型。正如我们在上一章中看到的,LSTM 可以高效地处理序列数据。但在应用之前,我们仍然需要将 token ID整数映射到层可以接收的浮点数据Dense。
最直接的方法是将输入 ID 进行独热编码,类似于我们之前对整个序列进行的多热编码。每个词元都会变成一个长向量,其中所有元素均为 0,只有对应词元在词汇表中索引处的元素为 1。接下来,我们构建一个层来对输入序列进行独热编码。
1 | from keras import ops |
清单 14.21:使用 Keras 操作构建独热编码层
让我们用单个输入批次来测试一下这一层:
1 | >>> x, y = next(sequence_train_ds.as_numpy_iterator()) |
我们可以直接将这一层构建到模型中,并使用双向 LSTM 来允许信息沿着词元序列向前和向后传播。稍后,当我们讨论生成过程时,就会发现需要单向序列模型(其中词元状态仅依赖于其前一个词元的状态)。对于分类任务,双向 LSTM 是一个不错的选择。
让我们来构建模型。
1 | hidden_dim = 64 |
清单 14.22:构建 LSTM 序列模型
我们可以查看模型摘要,了解参数数量:
1 | >>> model.summary() |
与一元语法和二元语法模型相比,这个模型的规模要大得多。它拥有大约 1500 万个参数,是本书迄今为止训练过的最大的模型之一,而且只有一个 LSTM 层。让我们来尝试训练这个模型。
1 | model.fit( |
清单 14.23:训练 LSTM 序列模型
它的性能如何?
1 | >>> test_loss, test_acc = model.evaluate(sequence_test_ds) |
清单 14.24:评估 LSTM 序列模型
这个模型虽然能用,但训练速度非常慢,尤其与上一节的轻量级模型相比。这是因为我们的输入数据量非常大:每个输入样本都被编码成一个大小为(600, 30000)600 个单词(每个样本 600 个单词,总共 30,000 个单词)的矩阵。也就是说,一篇电影评论就需要处理 18,000,000 个浮点数!我们的双向 LSTM 模型需要处理大量的数据。除了速度慢之外,该模型的测试准确率也只有 84%——远不如我们速度极快的基于集合的模型。
显然,使用独热编码将单词转换为向量(这是我们能做的最简单的事情)并不是一个好主意。还有更好的方法——词嵌入。
Clearly, using one-hot encoding to turn words into vectors, which was the simplest thing we could do, wasn’t a great idea. There’s a better way—word embeddings.
理解词嵌入
Understanding word embeddings
当你使用独热编码对数据进行编码时,你实际上是在进行特征工程决策。你将一个关于特征空间结构的基本假设注入到模型中。这个假设是,你编码的不同词元彼此独立:实际上,独热向量彼此正交。但对于词语而言,这个假设显然是错误的。词语构成了一个结构化的空间:它们彼此共享信息。“movie”(电影)和“film”(影片)在大多数句子中可以互换使用,因此表示“movie”的向量不应该与表示“film”的向量正交——它们应该是同一个向量,或者至少非常接近。
更抽象地说,两个词向量之间的几何关系应该反映这两个词之间的语义关系。例如,在一个合理的词向量空间中,同义词应该嵌入到相似的词向量中;一般来说,任意两个词向量之间的几何距离(例如余弦距离或L2距离)应该与这两个词之间的“语义距离”相关。含义不同的词应该彼此远离,而相关的词应该彼此靠近。
词嵌入是词语的向量表示,它正是实现了这一点:将人类语言映射到结构化的几何空间。
独热编码得到的向量是二进制的、稀疏的(主要由零组成),并且维度非常高(维度与词汇表中的单词数量相同),而词嵌入则是低维浮点向量(即稠密向量,而非稀疏向量);参见图 14.3。处理非常大的词汇表时,常见的词嵌入维度为 256 维、512 维或 1024 维。另一方面,对于我们当前的词汇表,独热编码通常会得到 30000 维的向量。因此,词嵌入能够在更少的维度中打包更多信息。
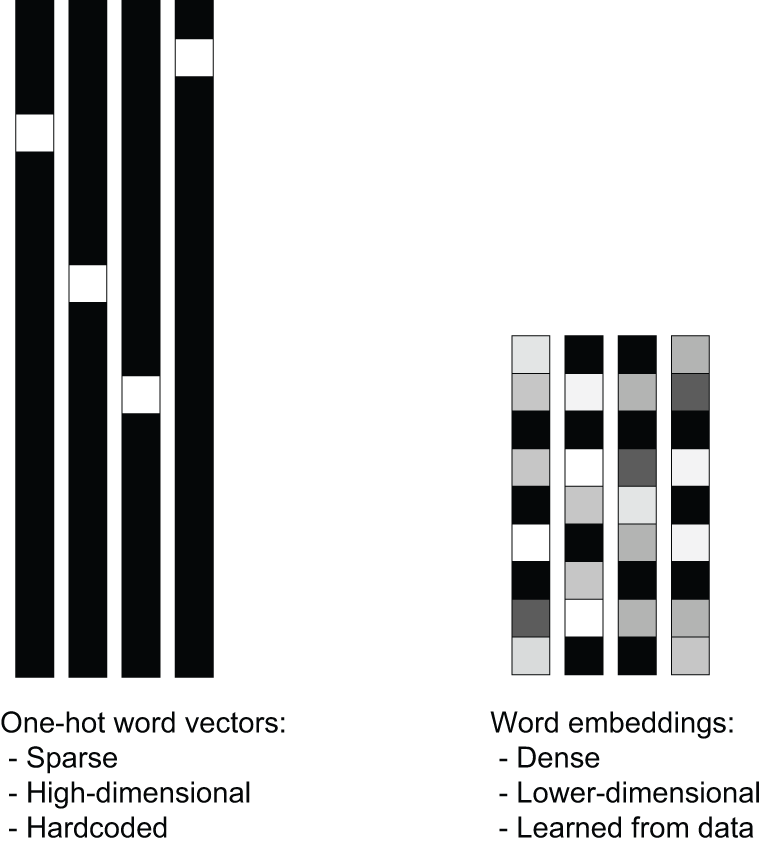 图 14.3:通过独热编码或哈希得到的词表示是稀疏的、高维的且硬编码的。词嵌入是稠密的、相对低维的,并且是从数据中学习得到的。
图 14.3:通过独热编码或哈希得到的词表示是稀疏的、高维的且硬编码的。词嵌入是稠密的、相对低维的,并且是从数据中学习得到的。
除了是稠密表示之外,词嵌入也是结构化表示,其结构是从数据中学习得到的。相似的词会被嵌入到相近的位置,而且嵌入空间中的特定方向是有意义的。为了更清楚地说明这一点,我们来看一个具体的例子。在图 14.4 中,四个词被嵌入到一个二维平面上:猫、狗、狼和老虎。利用我们选择的向量表示,这些词之间的一些语义关系可以被编码为几何变换。例如,同一个向量允许我们从猫变换到老虎,从狗变换到狼:这个向量可以被解释为“从宠物到野生动物”的向量。类似地,另一个向量允许我们从狗变换到猫,从狼变换到老虎,这可以被解释为“从犬科动物到猫科动物”的向量。
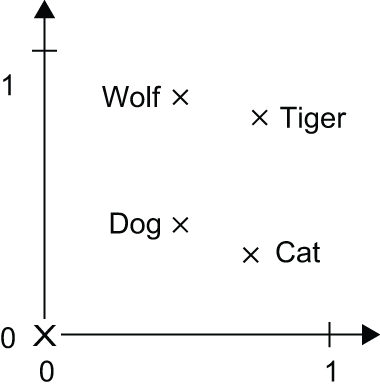 图 14.4:词嵌入空间的简单示例
图 14.4:词嵌入空间的简单示例
在现实世界的词嵌入空间中,有意义的几何变换的典型例子是“性别”向量和“复数”向量。例如,将“女性”向量添加到“国王”向量中,即可得到向量“女王”。添加“复数”向量,即可得到“国王们”。词嵌入空间通常包含数千个此类可解释且可能有用的向量。
让我们来看看如何在实践中使用这样的嵌入空间。
使用词嵌入
Using a word embedding
是否存在一个理想的词嵌入空间,能够完美映射人类语言并适用于任何自然语言处理(NPL)任务?或许存在,但我们尚未计算出这样的空间。此外,也不存在我们可以尝试映射的单一人类语言——语言种类繁多,彼此并不同构,因为语言反映了特定的文化和语境。更实际地说,一个好的词嵌入空间很大程度上取决于你的任务:一个用于英语电影评论情感分析模型的理想词嵌入空间,可能与一个用于英语法律文件分类模型的理想词嵌入空间截然不同,因为某些语义关系的重要性会因任务而异。
因此,对于每个新任务,学习一个新的嵌入空间是合理的。幸运的是,反向传播使得这一点变得容易,而 Keras 则让这一切变得更加简单。关键在于学习 KerasEmbedding层的权重。
可以把这一层Embedding理解为一个字典,它将整数索引(代表特定单词)映射到稠密向量。它以整数作为输入,在内部字典中查找对应的整数,并返回关联的向量。这实际上就是一个字典查找操作(参见图 14.5)。
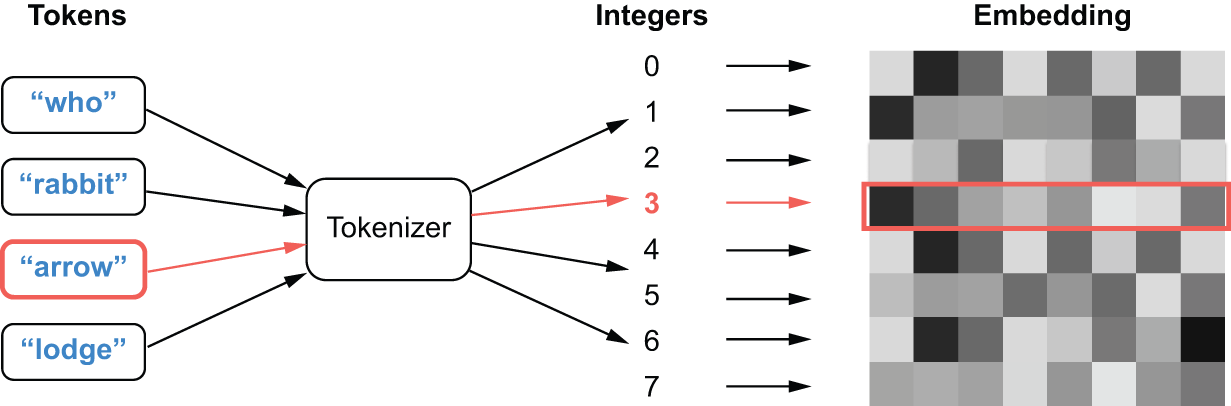 图 14.5:一个
图 14.5:一个Embedding层充当字典,将整数映射到浮点向量。
该Embedding层以形状为的秩为 2 的张量作为输入(batch_size, sequence_length),其中每个元素都是一个整数序列。该层返回形状为的浮点张量(batch_size, sequence_length, embedding_size)。
当你实例化一个Embedding层时,它的权重(即其内部的词向量字典)最初是随机的,就像其他任何层一样。在训练过程中,这些词向量会通过反向传播逐步调整,从而将嵌入空间构建成下游模型可以利用的结构。一旦完全训练完成,嵌入空间就会展现出丰富的结构——这种结构是专门针对你正在训练模型解决的特定问题而设计的。
让我们构建一个包含一个Embedding层的模型,并对我们的任务进行基准测试。
1 | hidden_dim = 64 |
清单 14.25:构建一个带有Embedding层的 LSTM 序列模型
该层的前两个参数Embedding相当简单明了。 第一个参数input_dim设置了该层整数输入的所有可能取值范围——也就是说,字典查找中可能存在的键的数量。第二个参数 output_dim设置了我们查找的输出向量的维度——也就是说,我们用于存储单词的结构化向量空间的维度。
第三个参数mask_zero=True稍微复杂一些。这个参数告诉 Keras 我们序列中的哪些输入是"[PAD]"标记(token),以便我们 稍后在模型中屏蔽这些条目。
请记住,在预处理序列输入时,我们可能会在原始输入中添加大量填充标记,因此标记序列可能如下所示:
1 | ["the", "movie", "was", "awful", "[PAD]", "[PAD]", "[PAD]", "[PAD]"] |
所有这些填充标记都会先被嵌入,然后再输入到该LSTM 层。这意味着我们从LSTM单元接收到的最后一个表示可能包含对标记表示进行反复处理的结果"[PAD]"。我们并不太关心前一个序列中LSTM 最后一个"[PAD]"标记的学习表示。相反,我们关心的是"awful"最后一个非填充标记的表示。或者等价地,我们希望屏蔽所有"[PAD]"标记,使它们不影响我们最终的输出预测。
mask_zero=True``mask只是 Keras 中实现掩码的一种简写方式Embedding。Keras 会标记序列中所有初始值为零的元素,其中零被假定为该标记的 ID "[PAD]"。该掩码将在层内部使用LSTM。它不会输出整个序列的最后一个学习到的表示,而是输出最后一个未被掩码的表示。
这种掩码方式是隐式的,使用起来也很方便,但如果需要,您也可以明确指定要掩码序列中的哪些项。该LSTM图层接受一个可选的mask调用参数,用于显式或自定义掩码。
在训练这个新模型之前,我们先来看一下模型概要:
1 | >>> model.summary() |
我们将独热编码 LSTM 模型的参数数量从 1500 万减少到 200 万。接下来,让我们训练并评估该模型。
1 | >>> model.fit( |
清单 14.26Embedding :训练和评估带有一个层的 LSTM
利用词嵌入,我们将训练时间和模型规模都降低了一个数量级。显然,学习到的词嵌入比对输入进行独热编码要高效得多。
然而,LSTM 的整体性能并没有改善。准确率始终徘徊在 84% 左右,与词袋模型和二元语法模型相比仍然相差甚远。这是否意味着输入词元的“结构化嵌入空间”在实际应用中并不实用?或者说,它对文本分类任务没有用处?
恰恰相反,训练良好的词嵌入空间可以显著提升此类模型的实际性能上限。本案例的问题在于我们的训练设置。我们仅有的2万条评论样本数据量不足以有效地训练出高质量的词嵌入。经过10个训练周期后,我们的训练集准确率已经突破了99%。我们的模型开始过拟合并记忆输入数据,而且在我们尚未针对当前任务学习到最优词嵌入集之前,它就已经表现得如此出色了。
对于这种情况,我们可以采用预训练。与其将词嵌入与分类任务联合训练,不如使用更多数据单独训练它,而无需正面和负面评论标签。让我们来看一下。
增强文本数据
Augmenting text data
了解了数据增强在计算机视觉问题中的重要性之后,你可能会想,我们是否也能将同样的方法应用于文本处理呢?答案是肯定的,尽管在文本领域效果远不如计算机视觉。
基本的文本增强技术旨在寻找可以对输入文本进行的基本编辑,以增强模型的鲁棒性。例如,我们可以随机删除或交换句子中的单词位置,将句子“The rain in Spain falls mostly on the plain”变为“The rain Spain falls plain on the mostly”。使用这种经过编辑的输入训练模型,可以使其对拼写错误和语法错误具有鲁棒性。
然而,这个例子也简洁地揭示了文本增强的一个主要缺陷——很容易在无意中改变输入文本的含义。与图像数据不同,图像数据可以裁剪、旋转和调整猫的图片颜色,最终得到的仍然是一只可辨认的猫,而语言依赖于语序,并且对细微的变化极其敏感。一个句子中两个词互换的位置,其含义可能与输入句子完全相反。一些增强技术试图通过替换已知同义词表中的词语来解决这个问题,但如果我们选择了错误的含义,这种方法也同样不可靠。这些问题使得文本增强在实践中难以普及。通常来说,与其花费时间研究文本增强技术,不如寻找更多的文本示例。
我们将在后续章节中看到的生成模型,正逐渐提供一种新的文本增强方式,可以缓解这些痛点。通过让已经学会如何生成连贯一致文本的模型输出,我们可以创建与输入数据高度相似的、完全未知的文本。这固然带来了新的挑战,但也为文本增强开辟了新的领域,尤其是在数据稀少且难以收集的情况下。
预训练词嵌入
Pretraining a word embedding
过去十年自然语言处理(NLP)的飞速发展恰逢 预训练方法成为文本建模问题的主流策略。一旦我们从简单的基于集合的回归模型转向拥有数百万甚至数十亿参数的序列模型,文本模型对数据的需求就变得异常庞大。我们通常会受到文本领域中特定问题标注样本数量的限制。
其思路是设计一个无监督任务来训练模型参数,而无需使用标注数据。预训练数据可以是与最终任务领域相似的文本,甚至是任何我们感兴趣的语言的任意文本。预训练使我们能够学习语言中的通用模式,有效地在将模型专门用于最终任务之前对其进行预处理。
词嵌入是文本预训练领域最早取得重大成功的技术之一,本节将展示如何预训练词嵌入。还记得 unsup/我们在准备 IMDb 数据集时忽略的那个目录吗?它包含了另外 25,000 条评论——与我们的训练数据量相同。我们将把所有训练数据合并在一起,并展示如何使用无监督任务预训练层的参数Embedding。
训练词嵌入最直接的方法之一是连续词袋模型(Continuous Bag of Words)(CBOW)。[2]其思路是,在数据集中的所有文本上滑动一个窗口,不断尝试根据缺失单词左右两侧出现的单词来猜测它(图 14.6)。例如,如果我们得到的“单词袋”中包含“sail”、“wave”和“mast”,我们可能会猜测中间的单词是“boat”或“ocean”。
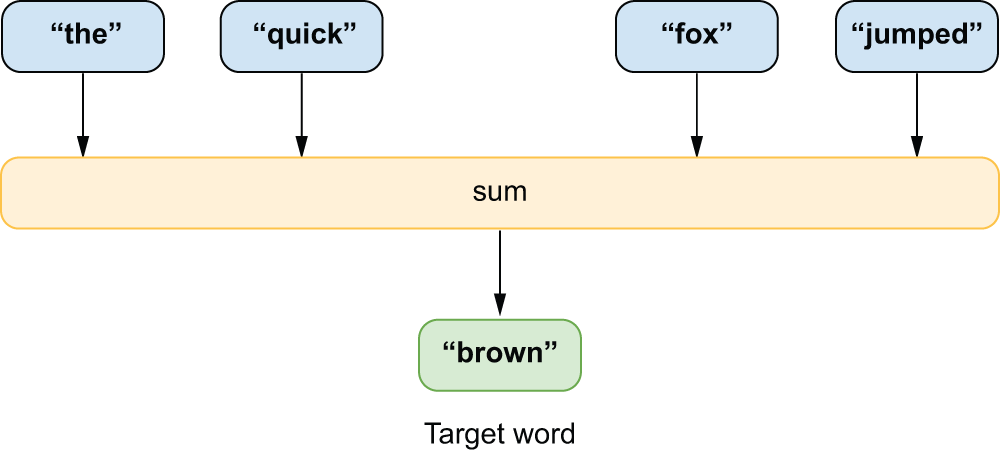 图 14.6:连续词袋模型利用浅层神经网络,根据单词的上下文预测单词。
图 14.6:连续词袋模型利用浅层神经网络,根据单词的上下文预测单词。
在我们这个特定的 IMDb 分类问题中,我们感兴趣的是“初始化”我们刚刚训练的 LSTM 模型的词嵌入。我们可以重用 TextVectorization之前计算的词汇表。我们在这里所做的只是为该词汇表中的每个词学习一个合适的 64 维向量。
我们可以创建一个TextVectorization使用相同词汇表的新层,该层不会截断或填充输入。我们将通过在文本上滑动上下文窗口来预处理该层的输出标记。
1 | imdb_vocabulary = text_vectorization.get_vocabulary() |
清单 14.27:移除TextVectorization预处理层 的内边距
为了预处理数据,我们将在训练数据上滑动一个窗口,创建包含九个连续词元的“词袋”。然后,我们使用中间的词作为标签,其余八个词作为无序上下文来预测标签。
为此,我们将再次使用它tf.data来预处理我们的输入,尽管这种选择并不限制我们用于实际模型训练的后端。
1 | import tensorflow as tf |
清单 14.28:预处理 IMDb 数据以预训练 CBOW 模型
经过预处理后,我们可以看到有八个整数标记 ID 作为上下文,每个标记 ID 对应一个标签。
我们用这些数据训练的模型非常简单。我们将使用一个 Embedding层来嵌入所有上下文标记,并使用一个层GlobalAveragePooling1D来计算上下文标记“包”的平均嵌入向量。然后,我们使用该平均嵌入向量来预测中间标签标记的值。
The model we train with this data is exceedingly simple. We will use an Embedding layer to embed all context tokens and a GlobalAveragePooling1D to compute the average embedding of our “bag” of context tokens. Then, we use that average embedding to predict the value of our middle label token.
就是这样!通过不断改进我们的嵌入空间,使我们能够根据附近的词嵌入来预测单词,我们就学习到了电影评论中使用的词元的丰富嵌入。
1 | hidden_dim = 64 |
清单 14.29:构建 CBOW 模型
1 | >>> cbow_model.summary() |
由于我们的模型非常简单,我们可以使用较大的批次大小来加快训练速度,而不用担心内存限制。
我们还会调用cache()这个批处理数据集,以便将整个预处理后的数据集存储在内存中,而不是每个训练周期都重新计算。这是因为对于这个非常简单的模型,瓶颈在于预处理而非训练。也就是说,在 CPU 上对文本进行分词和计算滑动窗口比在 GPU 上更新模型参数要慢。
在这种情况下,将预处理后的输出结果保存到内存或磁盘通常是个好主意。你会注意到,后面的训练轮次比第一个轮次快了三倍以上。这要归功于预处理训练数据的缓存。
1 | dataset = dataset.batch(1024).cache() |
清单 14.30:训练 CBOW 模型
训练结束后,我们仅凭相邻的八个单词,就能有大约 12% 的概率猜出中间的单词。这听起来可能不算理想,但考虑到每次我们需要从 3 万个单词中进行猜测,这其实是一个相当不错的准确率。
让我们利用这个词嵌入来提高 LSTM 模型的性能。
使用预训练嵌入进行分类
Using the pretrained embedding for classification
现在我们已经训练好了一个新的词嵌入,将其应用到我们的 LSTM 模型中就很简单了。首先,我们按照之前的步骤创建模型。
1 | inputs = keras.Input(shape=(max_length,)) |
清单 14.31:构建另一个带有Embedding层 的 LSTM 序列模型
然后,我们将 CBOW 嵌入层的嵌入权重应用到 LSTM 嵌入层。这有效地为 LSTM 模型中大约 200 万个嵌入参数提供了一个新的、更好的初始化器。
1 | lstm_embedding.embeddings.assign(cbow_embedding.embeddings) |
清单 14.32:重用 CBOW 嵌入来初始化 LSTM 模型
这样,我们就可以像往常一样编译和训练我们的 LSTM 模型了。
1 | model.compile( |
清单 14.33:使用预训练嵌入训练 LSTM 模型。
让我们来评估一下我们的 LSTM 模型。
1 | >>> test_loss, test_acc = model.evaluate(sequence_test_ds) |
清单 14.34:使用预训练嵌入评估 LSTM 模型
利用预训练的嵌入权重,我们将 LSTM 的性能提升到了与基于集合的模型大致相同的水平。我们比一元语法模型略好,但比二元语法模型略差。
投入了这么多精力之后,这似乎有点令人失望。难道利用顺序信息对整个序列进行训练真的是个糟糕的想法吗?问题在于,我们最终的 LSTM 模型仍然受到数据限制。该模型表达能力强,功能强大,如果电影评论足够多,我们就能轻松超越基于集合的方法,但我们需要在有序数据上进行更多训练,才能达到模型的性能极限。
只要有足够的计算资源,这个问题很容易解决。下一章我们将介绍Transformer模型。该模型在学习较长词序之间的依赖关系方面略胜一筹,但最关键的是,这些模型通常使用大量的英文文本进行训练,包括所有词序信息。这使得模型能够粗略地学习支配语言的语法模式的统计形式。正是这些围绕词序的统计模式,导致我们当前的LSTM模型由于数据限制而无法有效学习。
然而,当我们转向规模更大、更高级的模型,以突破文本分类性能的极限时,值得指出的是,像我们提出的二元语法模型这样简单的基于集合的回归方法,能带来极高的性价比。基于集合的模型速度极快,参数数量也只需几千个,这与如今新闻中充斥的数十亿参数的大型语言模型相比,简直天壤之别。
如果你的工作环境计算能力有限,并且可以牺牲一些准确性,那么基于集合的模型通常是最具成本效益的方法。
个人注:这是一个非常专业的问题。简单直接的结论是:在现代 NLP(大语言模型时代)中,几乎 100% 使用的是“子词分词(Subword Tokenization)”。
传统的“词级分词(Word-level Tokenization)”在 2018 年以后(即 BERT 出现后)已经基本退出了主流舞台。
- 为什么“词级分词”被淘汰了?
在 Word2Vec 或 GloVe 时代,我们确实使用词级分词。但它有两大致命缺陷:
- OOV (Out-Of-Vocabulary) 问题:如果词表里只有 "apple" 和 "boy",当遇到 "apples" 或 "boyfriend" 时,模型就会把它标记为
[UNK](未知词),导致信息丢失。- 词表爆炸:为了覆盖所有单词及其变体(各种时态、单复数),词表需要达到几十万甚至上百万量级,这会消耗巨大的显存和计算资源。
- 子词分词(Subword)的统治地位
子词分词结合了“词级”和“字符级”的优点。它将高频词完整保留,将低频词拆分成有意义的片段。
- 例子:单词
unhappiness- 词级:
[unhappiness](如果不在词表就是[UNK])- 子词 (BPE/WordPiece):
[un, happi, ness]- 优势:
- 零 OOV:即使是新造的词,也可以通过基础子词拼凑出来。
- 语义共享:模型能学到
un-代表否定,ness代表名词后缀。- 效率高:词表通常控制在 3w 到 10w 之间,兼顾了计算效率和表达能力。
- 主流模型的选择
模型类型 代表模型 使用的分词方法 早期模型 Word2Vec, GloVe 词级 (Word-level) Encoder 家族 BERT, RoBERTa WordPiece / BPE (子词) Decoder 家族 GPT-3, GPT-4, Llama Byte-level BPE (子词) 中英文混合 ChatGLM, Baichuan SentencePiece (子词) 强调一下:Word Embedding 是将 Token 映射为向量,而 Tokenization 是将文本切分为 Token。两者是前后的流水线关系。
概括
- 所有文本建模问题都涉及一个预处理步骤,即文本被分解并转换为整数数据,称为分词。
- 分词可以分为三个步骤:标准化、 拆分和索引。标准化对文本进行规范化,拆分将文本分解成词元,索引为每个词元分配一个唯一的整数 ID。
- 分词主要分为三种类型:字符分词、词分词和 子词分词。对于表达能力足够强且训练数据充足的模型,子词分词通常是最有效的。
- 自然语言处理模型的主要区别在于处理输入词元的顺序:
- 集合模型会忽略大部分顺序信息,仅基于输入中词元的有无来学习简单快速的模型。 二元或三元模型会考虑两个或三个连续词元的有无。集合模型的训练和部署速度都非常快。
- 序列模型试图从输入数据中有序的词元序列中进行学习。序列模型需要大量数据才能有效地学习。
- 词嵌入是一种将词元ID转换为可学习的潜在空间的有效方法。词嵌入通常可以使用梯度下降法进行训练。
- 预训练对于序列模型至关重要,因为它能有效解决这类模型对数据量极高的问题。在预训练过程中,无监督任务可以让模型从大量未标记的文本数据中学习。学习到的参数随后可以迁移到下游任务中。
脚注
- Phillip Gage,“一种新的数据压缩算法”,《C 用户期刊档案》(1994 年),https://dl.acm.org/doi/10.5555/177910.177914。
- Mikolov 等人,“向量空间中词表示的有效估计”,国际学习表征会议 (2013),https://arxiv.org/abs/1301.3781。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论