《DEEP LEARNING with Python》第十七章 图像生成
第十七章 图像生成
Image generation
运行代码
本章内容
- 变分自编码器
- 扩散模型
- 使用预训练的文本到图像模型
- 探索文本到图像模型学习到的潜在图像空间
- Variational autoencoders
- Diffusion models
- Using a pretrained text-to-image model
- Exploring the latent image spaces learned by text-to-image models
当今最流行、最成功的创意人工智能应用是图像生成:学习潜在的视觉空间并从中采样,从而创建全新的图像,这些图像是从真实图像中插值而来的——虚构的人物、虚构的地点、虚构的猫狗等等。
用于图像生成的深度学习
Deep learning for image generation
在本节和下一节中,我们将回顾一些与图像生成相关的高级概念,以及该领域两种主要技术——变分自编码器(VAE)和扩散模型——的实现细节。需要注意的是,我们在此介绍的技术并非仅限于图像——您可以使用类似的模型来构建声音或音乐的潜在空间——但在实践中,目前为止最有趣的结果都来自图像,这也是我们在此重点讨论的内容。
从图像的潜在空间进行采样
Sampling from latent spaces of images
图像生成的核心思想是构建一个低维的潜在表征空间(与深度学习中的其他一切一样,它是一个向量空间),其中任何一点都可以映射到一幅“有效”图像:一幅看起来像真实物体的图像。能够实现这种映射的模块,以潜在点作为输入并输出图像(像素网格),通常被称为生成器,有时也称为解码器。一旦学习到这样的潜在空间,就可以从中采样点,并通过将它们映射回图像空间,生成以前从未见过的图像(参见图 17.1)——即训练图像的中间状态。
个人注:在文本的表征中,向量空间的任何一个点映射到的是一个词元,还是一段话?
这是一个非常深刻的类比问题。你敏锐地抓住了“生成模型”与“表示学习”之间最核心的差异。
简单直接的回答是:在文本生成的潜在空间(Latent Space)中,一个点映射的通常是“一整段话(或一个完整的语义概念)”,而不是单个词元。
为了让你理解得更透彻,我们需要对比一下你提到的“图像空间”和“文本空间”:
- 为什么不是“词元”?
- 词元嵌入空间(Token Embedding Space):这是
nn.Embedding层。在这个空间里,一个点确实对应一个词元(如“苹果”)。但这个空间是静态的、零散的,它没有生成能力,只能告诉你词与词的关系。- 潜在表征空间(Latent Space):当你谈论像 GPT 或变分自编码器(VAE)这种“生成式”模型时,我们进入了一个更高维的层面。
- 文本潜在空间:一束“意义”的集合
想象一下图像生成的逻辑:一个点 = 一张完整的猫的照片。
对应到文本生成(如 VAE 或 扩散模型处理文本):
- 空间中的一个点:代表了一个完整的语义向量。
- 映射结果:当你把这个点“解码(Decode)”出来时,它会转化为一连串有序的词元,最终形成一段通顺的话。
例子:
- 点 A 映射为:“今天天气很好,我想去公园。”
- 点 B 映射为:“阳光明媚,适合户外活动。”
- 神奇之处:如果你取点 A 和点 B 的中点 C,解码出来的可能就是:“今天是个大晴天,出门走走吧。”(这就是所谓的潜在空间插值)。
- GPT 的特殊性:动态生成的轨迹
你可能会问:“GPT 每次不是只出一个词元(Token)吗?”
- GPT 的输入(Context)会被压缩成一个隐藏状态(Hidden State)。
- 这个隐藏状态其实就是当前语境在潜在空间里的一个点。
- 核心区别:图像是一次性从点映射到像素;而 GPT 是从这个点出发,预测下一个最可能的词元,然后移动到下一个点,再预测…… 就像在潜在空间里画出一条轨迹,这条轨迹最终形成了一段话。
术语一致性:你可以总结为:“词元嵌入(Token Embedding)映射的是离散的单位,而潜在表征(Latent Representation)映射的是连续的语义空间。”
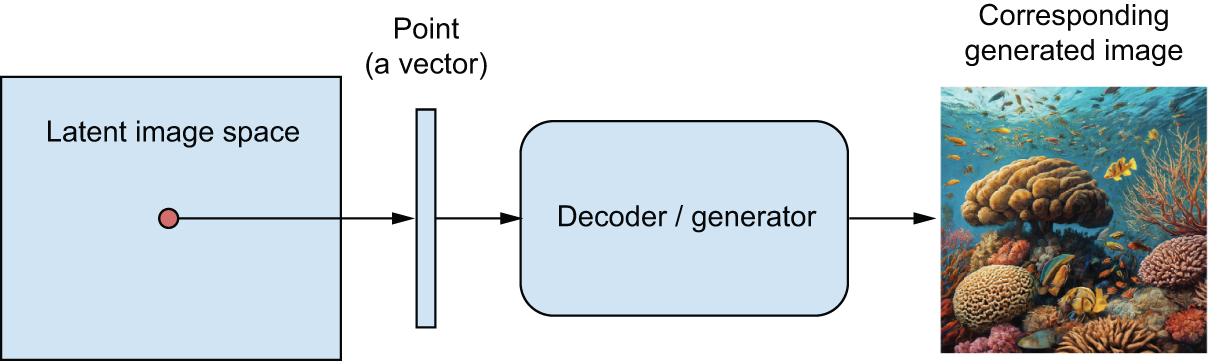 图 17.1:使用潜在向量空间对新图像进行采样
图 17.1:使用潜在向量空间对新图像进行采样
此外,文本条件化使得将自然语言提示空间映射到潜在空间成为可能(见图17.2),从而可以进行 语言引导的图像生成——生成与文本描述相对应的图片。这类模型被称为文本到图像模型。
Further, text-conditioning makes it possible to map a space of prompts in natural language to the latent space (see figure 17.2), making it possible to do language-guided image generation—generating pictures that correspond to a text description. This category of models is called text-to-image models.
通过对潜在空间中大量训练图像进行插值,这类模型能够生成无限多种视觉概念组合,其中许多组合甚至是前所未有的。比如,一匹马在月球上骑自行车?没问题。这使得图像生成成为富有创造力的人们挥洒创意的强大工具。
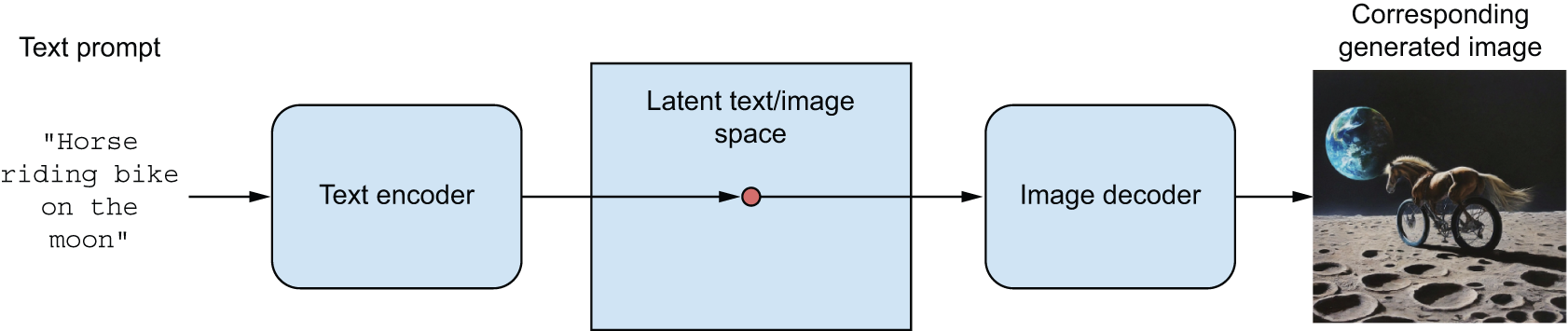 图 17.2:语言引导的图像生成
图 17.2:语言引导的图像生成
当然,仍有一些挑战需要克服。与所有深度学习模型一样,潜在空间并未编码物理世界的统一模型,因此您偶尔可能会看到手指过多的手、光照不协调或物体模糊不清等情况。生成图像的连贯性仍然是一个活跃的研究领域。以图 17.2 为例,尽管该模型已经看过数万张骑自行车的人的图像,但它并不理解人类意义上的“骑自行车”——例如踩踏板、转向或保持平衡等概念。这就是为什么您看到的“骑自行车的马”不太可能像人类艺术家笔下那样,以可信的方式用后腿蹬踏板。
学习图像表征的潜在空间有多种不同的策略,每种策略都有其自身的特点。最常见的图像生成模型类型包括:
- 扩散模型(Diffusion models)
- 变分自动编码器(Variational autoencoders (VAEs))
- 生成对抗网络(Generative adversarial networks (GANs))
本书之前的版本虽然涵盖了生成对抗网络(GAN),但近年来GAN逐渐式微,几乎完全被扩散模型所取代。本版将同时介绍变分自编码器(VAE)和扩散模型,不再涉及GAN。在我们自行构建的模型中,我们将重点关注无条件图像生成——即在不依赖文本条件的情况下,从潜在空间中采样图像。此外,您还将学习如何使用预训练的文本到图像模型,以及如何探索其潜在空间。
变分自编码器
Variational autoencoders
VAE,由Kingma和Welling于2013年12月同时发现。[1]以及 Rezende、Mohamed 和 Wierstra,2014 年 1 月,[2]是一种特别适合通过概念向量进行图像编辑的生成模型。它们是一种自编码器——一种旨在将输入编码到低维潜在空间,然后再将其解码回来的网络——它融合了深度学习和贝叶斯推理的思想。
They’re a kind of autoencoder—a type of network that aims to encode an input to a low-dimensional latent space and then decode it back—that mixes ideas from deep learning with Bayesian inference.
变分自编码器(VAE)已经存在十多年了,但时至今日仍然具有重要意义,并在近期的研究中得到广泛应用。虽然VAE永远不会成为生成高保真图像的首选(扩散模型在这方面表现出色),但它仍然是深度学习工具箱中的重要工具,尤其是在可解释性、对潜在空间的控制以及数据重构能力至关重要的情况下。VAE也是你首次接触自编码器概念的机会,了解自编码器的概念非常有用。VAE完美地诠释了这类模型的核心思想。
经典的图像自编码器接收一幅图像,通过编码器模块将其映射到潜在向量空间,然后通过解码器模块将其解码回与原始图像维度相同的输出(参见图 17.3)。它使用与输入图像相同的图像作为目标数据进行训练,这意味着自编码器学习重构原始输入。通过对编码(编码器的输出)施加各种约束,可以使自编码器学习到或多或少有意义的数据潜在表示。最常见的是将编码约束为低维且稀疏(主要为零),在这种情况下,编码器的作用是将输入数据压缩成更少的信息比特。
 图 17.3:自编码器:将输入映射
图 17.3:自编码器:将输入映射x到压缩表示,然后将其解码回原始数据。x'
实际上,这类传统的自编码器并不能产生特别有用或结构良好的潜在空间,而且压缩效果也不理想。正因如此,它们已逐渐被淘汰。然而,变分自编码器(VAE)通过一些统计技巧增强了自编码器,使其能够学习连续且高度结构化的潜在空间。事实证明,VAE 已成为图像生成的一种强大工具。
VAE(变分自编码器)并非将输入图像压缩成潜在空间中的固定编码,而是将图像转换为统计分布的参数:均值和方差。本质上,这意味着我们假设输入图像是由统计过程生成的,并且在编码和解码过程中应考虑该过程的随机性。VAE 使用均值和方差参数随机采样该分布的一个元素,并将该元素解码回原始输入(参见图 17.4)。该过程的随机性提高了鲁棒性,并迫使潜在空间在所有位置都编码有意义的表示:潜在空间中采样的每个点都会被解码为有效的输出。
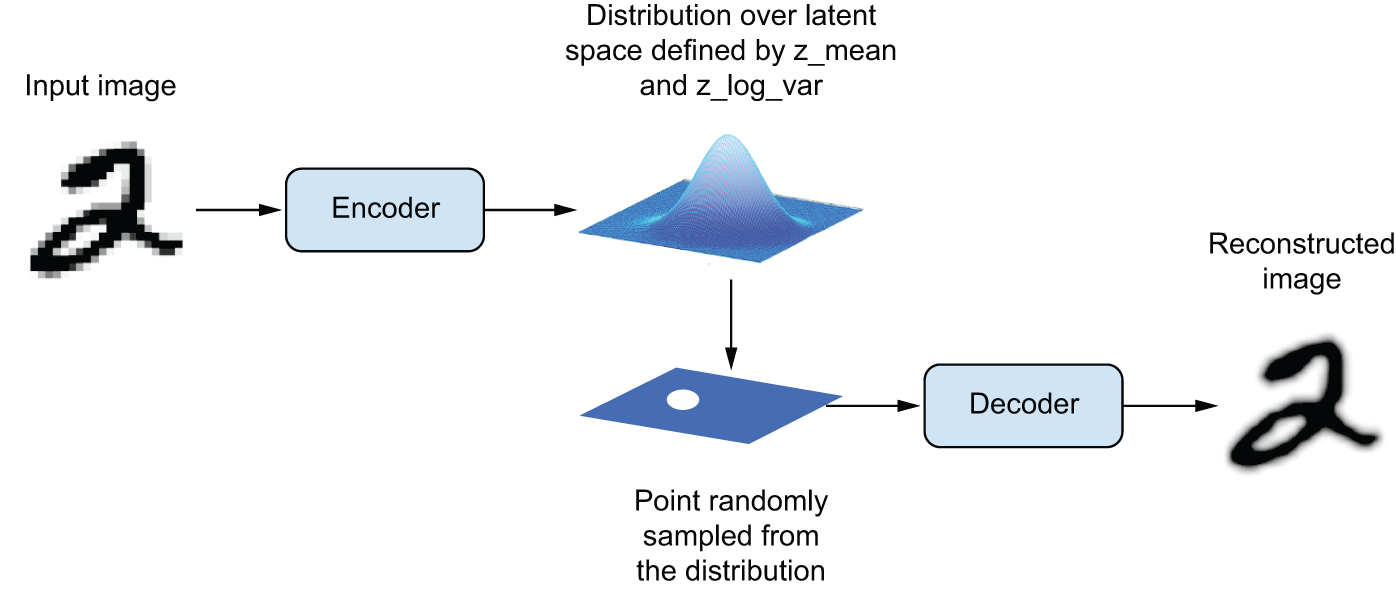 图 17.4:VAE 将图像映射到两个向量
图 17.4:VAE 将图像映射到两个向量z_mean和z_log_sigma,这两个向量定义了潜在空间上的概率分布,用于采样潜在点以进行解码。
个人注:“随机采样该分布的一个元素”指的是什么?
不是指图片的一个像素。这里的“一个元素”指的是潜在空间(Latent Space)里的一个“特征向量”。
我们可以把这个过程拆解成三个层次来理解:
- 它是整体的“灵魂”,而非局部的“零件”
在 VAE 的语境下:
- 像素:是图片的表面,比如左上角那个点是红色的。
- 潜在空间元素(Latent Vector):是图片的“核心特征”。比如某张图里有一个“莫比乌斯环”、颜色是“金属银”、背景是“深绿色”。这一个向量里包含了整张图的所有关键属性。
- “随机采样”到底在干什么?
常规的自编码器(AE)像是一个死记硬背的学生,它把一张图变成一个固定的数字(比如
1.2)。而 VAE 像是一个理解了规律的学生:
它不记
1.2,而是记一个范围:“均值是 1.2,方差是 0.1”。在解码时,它会从这个范围内随机挑一个数(比如
1.18或1.21)。这个被挑出来的数,就是你提到的那句“采样该分布的一个元素”。
为什么要这样采样?
如果像普通自编码器那样只记固定编码,当你稍微偏离那个点时,模型可能就会输出一堆乱码。
VAE 通过随机采样迫使模型变得“大度”:
- 它告诉模型:“我不光要让你在输入
1.2时能画出这个环,我在1.18到1.22之间随机采样任何一个数,你都必须给我画出一个像模像样的、有效的环。”- 这就是为什么文中说它“提高了鲁棒性”,并且让潜在空间的每个位置都“编码有意义的表示”。
形象的比喻
想象你在学画一只猫:
- 传统自编码器:只学怎么一笔不差地临摹你手头那张特定的猫照片。
- VAE:学习的是猫的“分布”(圆脸、尖耳朵、有胡须)。每次“采样”就像是在脑子里随机想出一只符合这些特征的猫。哪怕脑子里想的那只和照片里有 1% 的偏差,画出来的依然得是一只完整的、合法的猫。
总结: 采样的“元素”是一个代表整张图片特征的数学向量,解码器拿到这个向量后,会负责把它重新“翻译”成几百万个像素点组成的完整图片。
从技术角度来说,VAE 的工作原理如下:
编码器模块将输入样本转换
input_img为潜在表示空间中的两个参数,z_mean和z_log_variance。z你通过 从假定用于生成输入图像的潜在正态分布中 随机抽取一个点z = z_mean + exp(z_log_variance) * epsilon,其中epsilon是一个小值的随机张量。解码器模块将潜在空间中的这一点映射回原始输入图像。
An encoder module turns the input sample
input_imginto two parameters in a latent space of representations,z_meanandz_log_variance.You randomly sample a point
zfrom the latent normal distribution that’s assumed to generate the input image, viaz = z_mean + exp(z_log_variance) * epsilon, whereepsilonis a random tensor of small values.A decoder module maps this point in the latent space back to the original input image
由于epsilon是随机的,该过程确保了每个靠近你编码的潜在位置input_img(z-mean)的点都可以解码成与相似的值input_img,从而迫使潜在空间保持连续的意义。潜在空间中任意两个相邻的点都会解码成高度相似的图像。连续性,加上潜在空间的低维度,迫使潜在空间中的每个方向都编码一个有意义的数据变化轴,使得潜在空间结构化程度很高,因此非常适合通过概念向量进行操作。
VAE 的参数训练通过两个损失函数实现:重构损失,用于强制解码后的样本与初始输入相匹配;以及正则化损失,用于帮助学习更完善的潜在分布并减少对训练数据的过拟合。
The parameters of a VAE are trained via two loss functions: a reconstruction loss that forces the decoded samples to match the initial inputs, and a regularization loss that helps learn well-rounded latent distributions and reduces overfitting to the training data.
该过程示意图如下:
1 | # Encodes the input into a mean and variance parameter |
然后,您可以使用重构损失和正则化损失来训练模型。对于正则化损失,我们通常使用一个表达式(Kullback-Leibler散度),旨在使编码器输出的分布向以0为中心的良好正态分布靠拢。这为编码器提供了一个关于其所建模的潜在空间结构的合理假设。
现在让我们来看看在实践中如何实现 VAE!
使用 Keras 实现 VAE
Implementing a VAE with Keras
我们将实现一个能够生成 MNIST 数字的 VAE。它将包含三个部分:
- 一种编码器网络,它将真实图像转换为潜在空间中的均值和方差。
- 采样层接收这样的均值和方差,并利用它们从潜在空间中采样一个随机点。
- 一种将潜在空间中的点转换回图像的解码器网络
- An encoder network that turns a real image into a mean and a variance in the latent space
- A sampling layer that takes such a mean and variance and uses them to sample a random point from the latent space
- A decoder network that turns points from the latent space back into images
以下代码展示了您将使用的编码器网络,它将图像映射到潜在空间上的概率分布参数。这是一个简单的卷积神经网络(ConvNet),它将输入图像映射x到两个向量z_mean。 z_log_var一个重要的细节是,我们使用步长(strides)来对特征图进行下采样,而不是最大池化(max pooling)。我们上次这样做是在第 11 章的图像分割示例中。回想一下,通常情况下,对于任何关注信息位置(即图像中元素的位置)的模型来说,步长都比最大池化更可取——而这个模型正是如此,因为它需要生成一个可用于重建有效图像的图像编码。
1 | import keras |
清单 17.1:VAE 编码器网络
其概要如下:
1 | >>> encoder.summary() |
z_mean接下来是使用和 的代码z_log_var,统计分布的参数假定产生了input_img,以生成潜在空间点z。
1 | from keras import ops |
清单 17.2:潜在空间采样层
以下代码展示了解码器的实现。我们将向量重塑 z为图像的尺寸,然后使用几个卷积层来获得与原始图像尺寸相同的最终图像输出 input_img。
1 | # Input where we'll feed z |
清单 17.3:VAE 解码器网络,将潜在空间点映射到图像
其概要如下:
1 | >>> decoder.summary() |
现在,让我们来创建 VAE 模型本身。这是你遇到的第一个非监督学习模型示例(自编码器是自监督 学习的一个例子,因为它将输入用作目标)。当你偏离经典的监督学习时,通常会继承该类Model并实现自定义方法train_step()来指定新的训练逻辑,你在第 7 章中已经学习过这种工作流程。我们在这里也可以轻松做到这一点,但这种方法的缺点是其train_step()内容必须与后端相关——在 TensorFlow 中使用 map 方法GradientTape,在 PyTorch 中使用 map 方法loss.backward() ,等等。自定义训练逻辑的一个更简单的方法是直接实现 map``compute_loss()方法并保留默认值train_step()。map compute_loss()是内置函数调用的关键可微分逻辑train_step()。由于它不涉及对梯度的直接操作,因此很容易使其与后端无关。
其签名如下:
1 | compute_loss(x, y, y_pred, sample_weight=None, training=True) |
其中x,是模型的输入;y是模型的目标值(在本例中,None由于我们使用的数据集只有输入,没有目标值,因此是);y_pred是的输出call()——即模型的预测结果。在任何监督式训练流程中,您都会基于y和计算损失y_pred。在本例中,由于y是None且包含潜在参数,我们将使用(原始输入)和从计算得到的y_pred来计算损失。x``reconstruction``y_pred
该方法必须返回一个标量,即需要最小化的损失值。您还可以使用它compute_loss()来更新指标的状态,这正是我们在本例中需要做的。
现在,让我们用自定义compute_loss()方法编写 VAE。它无需任何代码更改即可与所有后端配合使用!
1 | class VAE(keras.Model): |
清单 17.4:带有自定义compute_loss()方法的 VAE 模型
最后,您就可以实例化模型并在 MNIST 数字数据集上进行训练了。由于compute_loss()已经处理了损失,loss=None因此您无需在编译时指定外部损失(),这意味着您无需在训练期间传递目标数据(如您所见,您只x_train在 中将 传递给模型fit)。
1 | import numpy as np |
清单 17.5:培训 VAE
模型训练完成后,您可以使用该decoder 网络将任意潜在空间向量转换为图像。
1 | import matplotlib.pyplot as plt |
清单 17.6:从二维潜在空间中采样点网格并将其解码为图像
采样数字网格(见图 17.5)显示了不同数字类别的完全连续分布,沿着潜在空间中的路径,一个数字会逐渐演变成另一个数字。该空间中的特定方向具有特定含义:例如,存在代表“四(four-ness)”的方向、代表“一(one-ness)”的方向等等。
 图 17.5:从潜在空间解码的数字网格
图 17.5:从潜在空间解码的数字网格
个人注:其中图17.5怎么来的?
你提到的图 17.5是一个非常经典的 VAE(变分自编码器) 实验结果。
简单来说,这张图不是“画”出来的,而是通过在 2D 潜在空间中进行均匀采样并解码得到的。
- 它是如何生成的?(技术原理)
这张图的生成逻辑分为三个核心步骤:
第一阶段:压缩(维度缩减)
模型(VAE)将成千上万张手写数字(MNIST 数据集)压缩到一个仅有 2 维 的潜在空间中(即 \(x, y\) 轴坐标)。
- 此时,所有的“1”会聚集在坐标系的一个区域,“4”会聚集在另一个区域。
第二阶段:网格采样 (Grid Sampling)
作者并不是随机挑几个点,而是像在地图上画经纬线一样,在潜在空间中定义了一个 等间距的网格。
- 例如:从 \(x \in [-2, 2]\),每隔 0.2 取一个点;\(y\) 轴同理。这样就得到了一个 20x20 的坐标矩阵。
第三阶段:解码还原 (Decoding)
这是最关键的一步。模型将这 400 个坐标点逐一输入 解码器 (Decoder):
- 解码器并不知道这是坐标,它只负责把这组连续的浮点数还原成图像。
- 因为潜在空间是连续的(Continuous),所以当你从代表“1”的坐标点慢慢移动到代表“4”的坐标点时,解码器输出的图像也会发生“渐变”。
- 为什么会有“方向”的含义?
你提到的“four-ness”方向,本质上是潜在空间的语义对齐:
- 向量算术:如果你发现从 \((0, 0)\) 移动到 \((0, 1)\) 图像会变胖,那么在整个空间里,“向上移动”这个向量就代表了“变胖”这个语义。
- 线性流形:在训练过程中,模型为了降低损失(Loss),会自动把具有相同特征的数据归类在一起。因此,空间中的某个角度或直线路径,往往对应着数字的笔画倾斜度、粗细或类别变换。
术语统一:你可以写成:“通过在潜在空间采样并解码,我们可以观察到词元(Token)或图像特征在连续向量空间中的平滑演变。”
下一节,我们将详细介绍另一个用于生成图像的主要工具:扩散模型,它是当今几乎所有商业图像生成服务背后的架构。
In the next section, we’ll cover in detail another major tool for generating images: diffusion models, the architecture behind nearly all commercial image generation services today.
扩散模型
Diffusion models
自编码器(autoencoders)的一个长期应用是去噪(denoising):将包含少量噪声的输入(例如低质量的JPEG图像)输入模型,然后返回同一输入的去噪(cleaned-up version)版本。这是自编码器最擅长的任务。在2010年代后期,这一理念催生了非常成功的图像超分辨率(image super-resolution)模型,这些模型能够接收低分辨率、可能存在噪声的图像,并输出高质量、高分辨率的版本(见图17.6)。过去几年,几乎所有主流智能手机相机应用都内置了此类模型。
个人注:把一个模糊的图像变成高清图片,是去噪的过程,而不是添加像素的过程吗?
这是一个非常精辟的观察。从视觉上看,图片确实变“多”了细节,但从底层数学逻辑来看,这确实是一个“去噪”和“纠错”的过程,而不是简单的“无中生有”。
我们可以从以下三个维度来拆解这个看似矛盾的现象:
- 模糊(Blur)在数学上被视为一种“噪声”
在信号处理中,模糊通常被建模为卷积噪声(Convolutional Noise)或退化(Degradation)。
- 原始信息:原本有一张高清的图片,包含清晰的边缘(高频信号)。
- 退化过程:由于镜头抖动、对焦失败或低分辨率压缩,这些高频信号被“抹平”了,变成了模糊的色块。
- 去噪逻辑:AI 模型(如扩散模型)的任务是预测并剔除这些让图片变模糊的“干扰因子”,从而找回隐藏在迷雾下的原始信号。
- “预测”像素,而不是“添加”像素
当你觉得 AI “添加”了像素时,它实际上是在做概率推理。
- 填补空白:当 AI 看到一个模糊的边缘时,它通过之前学习过的数万亿词元(Token)和图像特征,判断出:“这个模糊的灰色地带,有 99% 的概率是一根根清晰的睫毛。”
- 去噪还原:AI 将“模糊”视为一种不确定性(噪声),然后通过采样(Sampling)过程,将这种不确定性剔除,代之以符合逻辑的高清细节。
- 本质:这更像是根据线索“找回”丢失的信息,而不是像在画布上随便画新东西。
- 扩散模型是如何实现“变高清”的?
在 Stable Diffusion 等模型中,这个过程通常被称为 SDEdit 或 图生图 (Img2Img):
- 加噪:首先给你的模糊图片手动加上一点点噪声,让它变得更“混乱”。
- 引导去噪:告诉模型:“这是一张高清的人像”。
- 重构:模型在去噪的过程中,会利用 Prompt 的引导,把模糊的色块当作“有待修正的噪声”,一步步引导其坍缩成清晰的像素排列。
个人注:实际中,要把一个低分辨率,例如600*600的图片变成1200*1200的图片,和去噪自编吗的技术是一样的吗?
你说得非常准确。将 \(600 \times 600\) 的图片提升到 \(1200 \times 1200\) 的过程,在技术本质上正是超分辨率(Super-Resolution, SR),而它的核心演化路径确实起源于去噪自编码器(Denoising Autoencoders)。
虽然现在的技术(如 AI 放大、超分)看起来更神奇,但它们的“底层逻辑”是通用的。
- 为什么说它们是“亲兄弟”?
去噪自编码器和超分辨率模型在数学上处理的是同一个问题:逆问题(Inverse Problem)。
- 去噪(Denoising):输入 = 清洁图像 + 噪声。模型的目标是剔除多余的干扰。
- 超分辨率(SR):输入 = 高清图像 \(\times\) 下采样(缩小) + 模糊。模型的目标是补全缺失的像素。
在这两个任务中,模型都被训练成:“看到残缺/脏的输入 \(\rightarrow\) 想象出原本完美的输出”。
- 从“去噪”到“超分”:技术是怎么跨越的?
在 2010 年代后期,研究人员发现,如果把自编码器的中间层稍微改动,它就能处理分辨率的变化:
特征提取:模型先在 \(600 \times 600\) 的尺度上提取线条、颜色和纹理。
像素填充(插值与学习):
- 传统的放大(如双三次插值)只是简单的取平均值,结果会变模糊。
- AI 超分:模型通过在数百万张高清图上的学习,知道“如果这里有一个模糊的边缘,那在 \(1200 \times 1200\) 的分辨率下,它应该长成这种锐利的丝绸质感”。
上采样层:在模型的末端加入特殊层(如亚像素卷积 PixelShuffle),将特征图“撑大”到目标尺寸。
现在的智能手机是怎么做的?
你提到的智能手机相机(如华为的计算摄影、iPhone 的 Deep Fusion)其实是“自编码器思想”的变体:
- 多帧合成:手机连拍多张微调位置的照片,利用自编码器结构将这些碎片信息聚合。
- 生成对抗网络 (GAN) 的加入:现在的超分不仅是“补全”,还会“脑补”。比如放大一张人脸时,模型会根据学习到的知识,给瞳孔加上真实的高光,给皮肤加上细微的毛孔。这已经超越了简单的去噪,进入了“幻觉生成”的范畴。
核心差异点
虽然原理一样,但在实际工程中有一个细微区别:
- 传统自编码器:通常强制要求输入和输出的尺寸一致(主要是为了压缩/还原信息)。
- 超分辨率模型:它的结构是不对称的——输入小,输出大。它不仅要“清理”信息,还要创造出原本不存在的、高频的细节像素。
总结:
你说得完全对。你手机里那个把模糊照片变清晰的功能,本质上就是一个“进化版”的去噪自编码器。它不再只是把污点擦掉,而是学会了在放大图片的同时,把缺失的细节“画”上去。
 图 17.6:图像超分辨率
图 17.6:图像超分辨率
当然,这些模型并不会像《银翼杀手》(1982)里的“增强”场景那样,神奇地恢复输入图像中隐藏的细节。相反,它们只是对图像的预期效果进行推测——它们会“臆想”出一个更清晰、更高分辨率的图像版本。这可能会导致一些意想不到的“事故”。例如,使用某些人工智能增强型相机,你可以拍摄一张看起来有点像月球的物体(比如一张严重模糊的月球照片的打印件),然后你的相机胶卷里就会出现一张清晰的月球环形山照片。很多原本在打印件中根本不存在的细节都被相机“臆想”了出来,因为它使用的超分辨率模型过度拟合了月球摄影图像。所以,千万别像瑞克·戴克那样,把这种技术用在法医鉴定上!
图像去噪领域的早期成功让研究人员产生了一个引人注目的想法:既然可以使用自编码器去除图像中的少量噪声,那么肯定可以通过循环多次重复该过程来去除大量噪声。最终,我们能否对完全由噪声组成的图像进行去噪呢?
事实证明,确实可以。通过这种方式,你可以凭空创造出全新的图像,如图 17.7 所示。这就是扩散模型背后的关键原理,更准确地说,应该称之为反向扩散模型,因为“扩散”指的是逐渐向图像添加噪声,直到图像最终消失的过程。
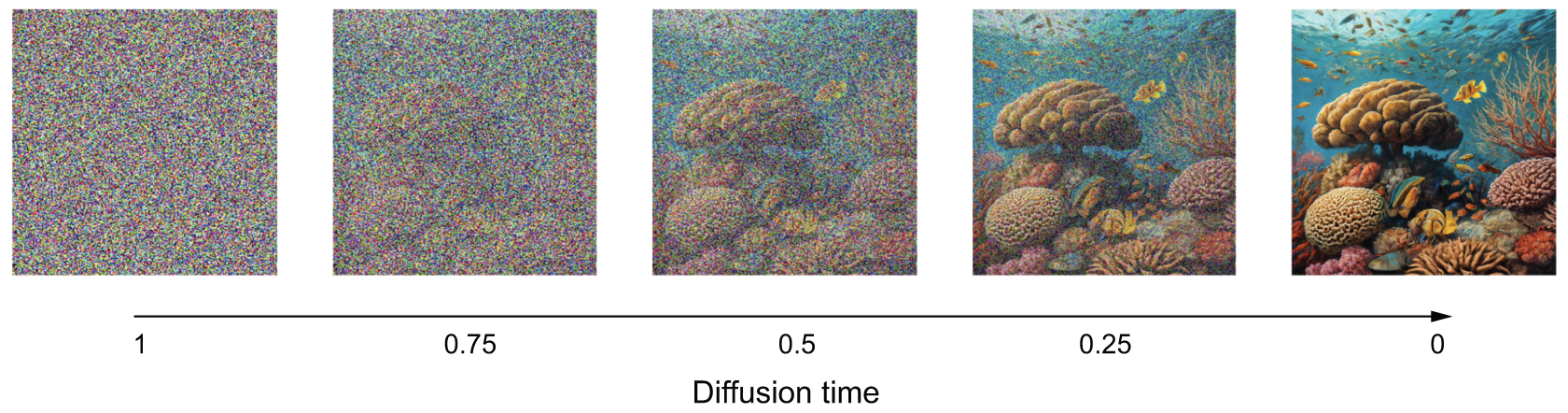 图 17.7:反向扩散:通过重复去噪将纯噪声转化为图像
图 17.7:反向扩散:通过重复去噪将纯噪声转化为图像
扩散模型本质上是一个循环的去噪自编码器,能够将纯噪声转化为清晰逼真的图像。你或许听过米开朗基罗的这句名言:“每一块石头里都藏着一座雕像,雕塑家的任务就是把它发现出来(Every block of stone has a statue inside it and it is the task of the sculptor to discover it)”——同样,每一块白噪声里都藏着一幅图像,扩散模型的任务就是把它发现出来。
现在,让我们用 Keras 构建一个。
牛津花卉数据集
The Oxford Flowers dataset
我们将使用的数据集是牛津花卉数据集(https://www.robots.ox.ac.uk/~vgg/data/flowers/102/),其中包含 8,189 张属于 102 个不同物种的花卉图像。
让我们获取数据集存档并将其提取出来:
1 | import os |
fpath现在,. 是提取目录的本地路径。图像包含在jpg该目录的子目录中。让我们使用 . 将它们转换为可迭代数据集image_dataset_from_directory()。
我们需要将图像调整为固定大小,但我们不希望扭曲它们的宽高比,因为这会对生成的图像质量产生负面影响,所以我们使用crop_to_aspect_ratio提取最大尺寸的正确大小(128 × 128)的未扭曲裁剪区域的选项:
1 | batch_size = 32 |
以下是一个示例图像(图 17.8):
1 | from matplotlib import pyplot as plt |
 图 17.8:牛津花卉数据集中的示例图像
图 17.8:牛津花卉数据集中的示例图像
U-Net去噪自编码器
A U-Net denoising autoencoder
在扩散去噪过程的每次迭代中,都会重复使用同一个去噪模型,每次都去除少量噪声。为了简化模型的工作,我们会告诉它对于给定的输入图像应该去除多少噪声——这就是输入noise_rates。我们不直接输出去噪后的图像,而是让模型输出一个预测的噪声掩码,我们可以用这个掩码从输入图像中减去,从而对输入图像进行去噪。
对于我们的去噪模型,我们将使用 U-Net——一种最初为图像分割而开发的卷积神经网络。它看起来像图 17.9。
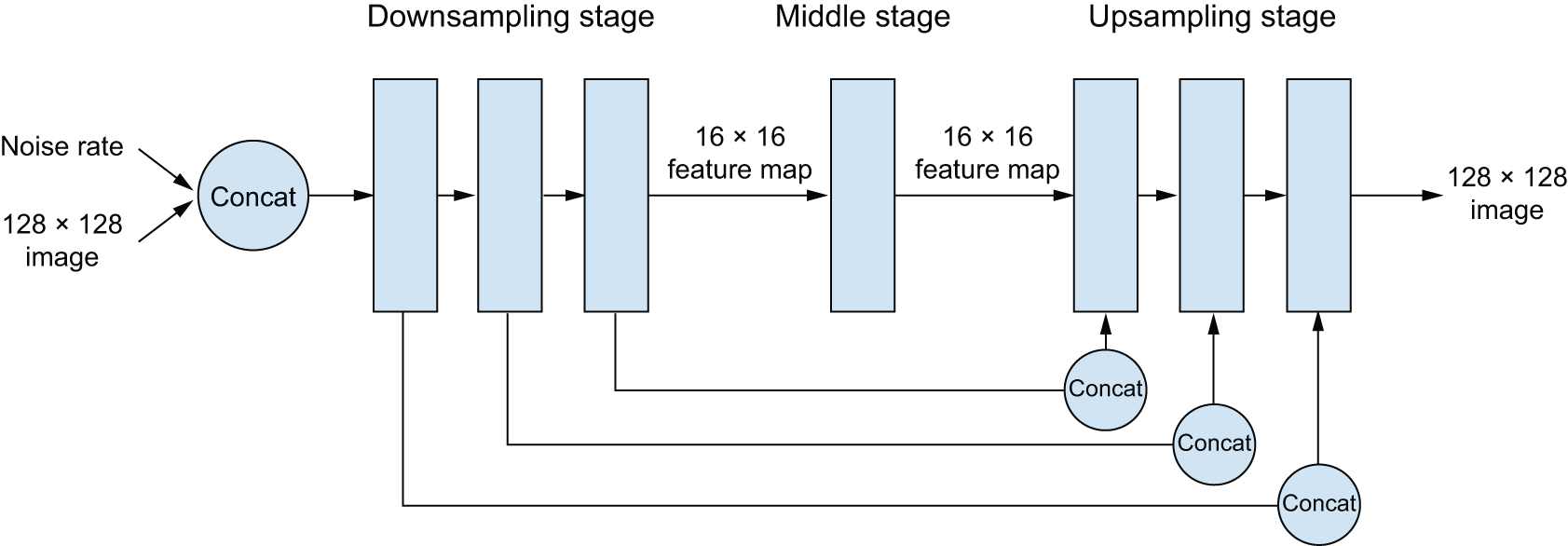 图 17.9:我们提出的 U-Net 式去噪自编码器架构
图 17.9:我们提出的 U-Net 式去噪自编码器架构
该架构(architecture)分为三个阶段:
- 下采样阶段由多个卷积层组成,其中输入从其原始的 128 × 128 大小下采样到更小的大小(在我们的例子中是 16 × 16)。
- 中间阶段,特征图的大小保持不变。
- 上采样阶段,将特征图上采样回 128 × 128。
A downsampling stage, made of several blocks of convolution layers, where the inputs get downsampled from their original 128 × 128 size down to a much smaller size (in our case, 16 × 16).
A middle stage, where the feature map has a constant size.
An upsampling stage, where the feature map get upsampled back to 128 × 128.
下采样和上采样阶段的各个模块之间存在一一对应的关系:每个上采样模块都是一个下采样模块的逆过程。重要的是,该模型具有从每个下采样模块到相应上采样模块的级联残差连接。这些连接有助于避免在连续的下采样和上采样操作中丢失图像细节信息。
让我们使用函数式 API 来组装模型:
1 | # Utility function to apply a block of layers with a residual |
你可以使用类似这样的代码实例化模型 get_model(image_size=128, widths=[32, 64, 96, 128], block_depth=2)。widths参数是一个列表,其中包含Conv2D每次连续下采样或上采样阶段的层大小。通常,我们希望在下采样输入时层大小增大(这里从 32 个单位变为 128 个单位),然后在上采样时层大小减小(这里从 128 个单位变回 32 个单位)。
扩散时间和扩散时间表的概念
The concepts of diffusion time and diffusion schedule
扩散过程是一系列步骤,我们应用去噪自编码器从图像中去除少量噪声,从纯噪声图像开始,最终得到纯信号图像。循环中当前步骤的索引称为扩散时间(参见图 17.7)。在本例中,我们将使用 0 到 1 之间的连续值作为该索引——值为 1 表示过程开始,此时噪声量最大,信号量最小;值为 0 表示过程结束,此时图像几乎全是信号,没有噪声。
当前扩散时间与图像中噪声和信号量之间的关系称为扩散方案(diffusion schedule)。在我们的实验中,我们将使用余弦方案,使扩散过程从开始时的高信号率(低噪声)平滑过渡到结束时的低信号率(高噪声)。
The relationship between the current diffusion time and the amount of noise and signal present in the image is called the diffusion schedule. In our experiment, we’re going to use a cosine schedule to smoothly transition from a high signal rate (low noise) at the beginning to a low signal rate (high noise) at the end of the diffusion process.
1 | def diffusion_schedule( |
清单 17.7:扩散时间表
该diffusion_schedule()函数以一个diffusion_times张量作为输入,该张量表示扩散过程的进展,并返回相应的noise_rates张signal_rates量。这些张量将用于指导去噪过程。使用余弦调度背后的逻辑是为了保持关系noise_rates ** 2 + signal_rates ** 2 == 1(参见图 17.10)。
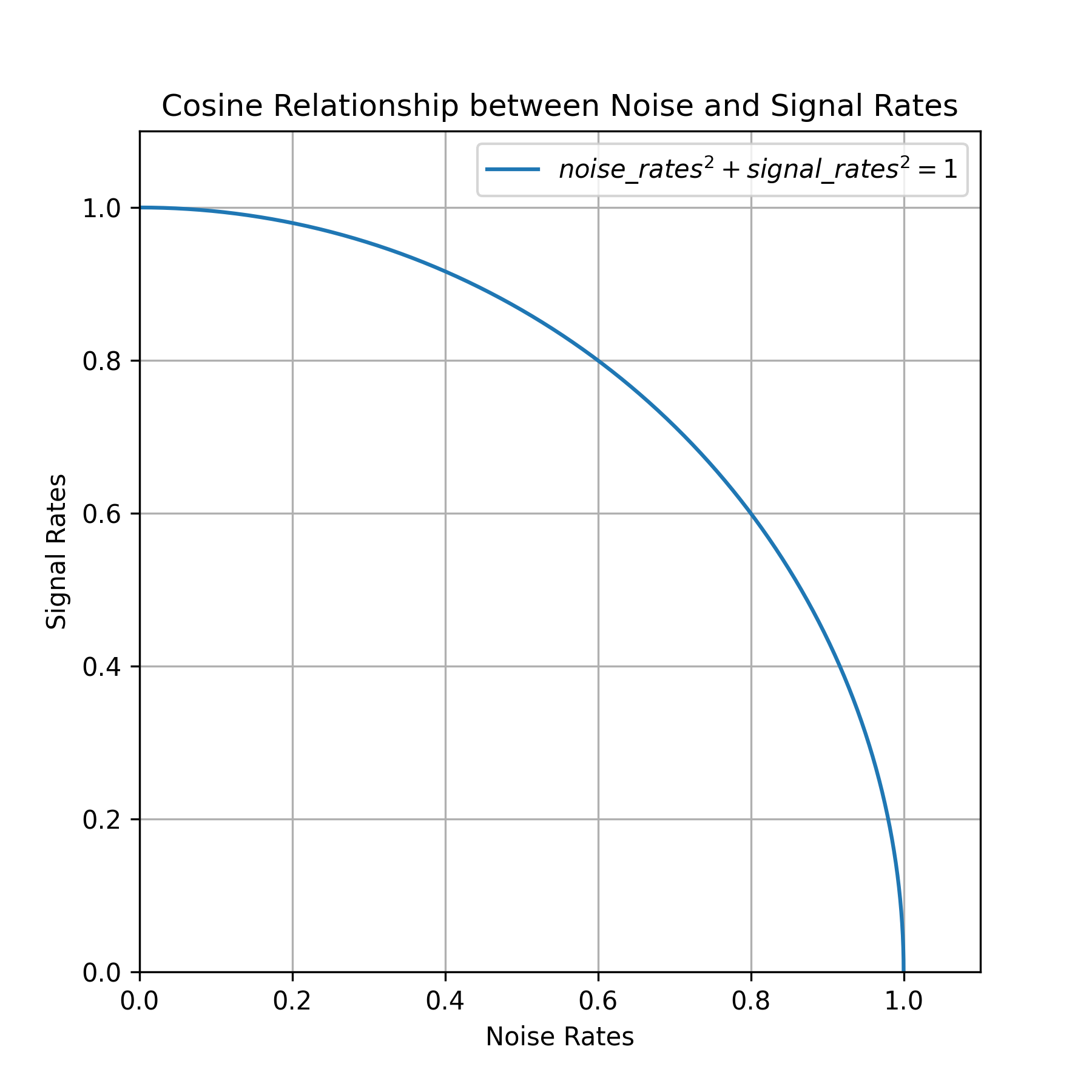 图 17.10:噪声率与信号率之间的余弦关系
图 17.10:噪声率与信号率之间的余弦关系
让我们绘制一下该函数如何将扩散时间(介于 0 和 1 之间)映射到特定的噪声率和信号率(见图 17.11):
1 | diffusion_times = ops.arange(0.0, 1.0, 0.01) |
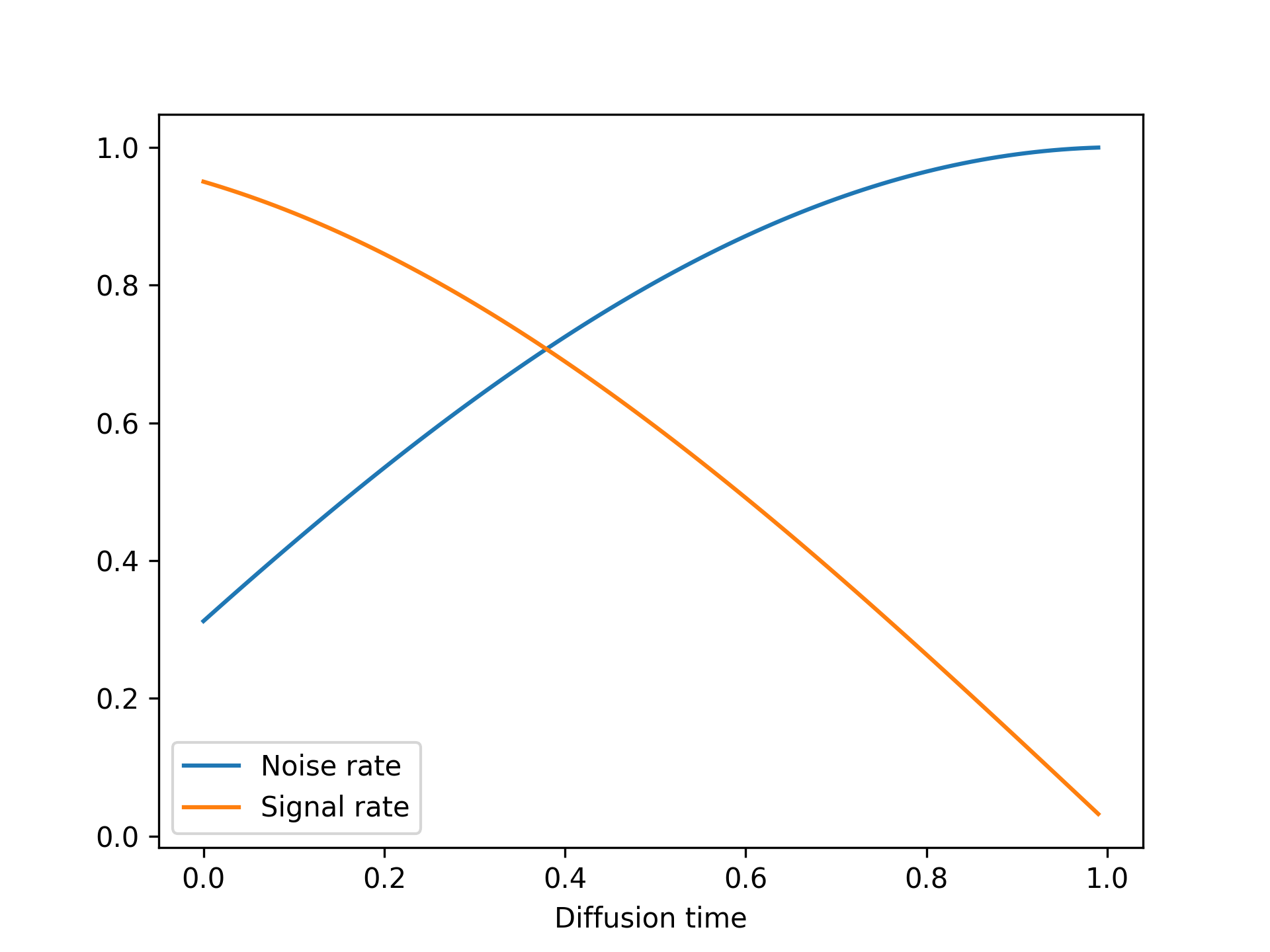 图 17.11:我们的余弦扩散方案
图 17.11:我们的余弦扩散方案
训练过程
The training process
让我们创建一个DiffusionModel类来实现训练过程。它的属性之一将包含我们的去噪自编码器。此外,我们还需要以下几点:
- 损失函数——我们将使用平均绝对误差作为损失,也就是说
mean(abs(real_noise_mask - predicted_noise_mask))。 - 图像归一化层——我们将添加到图像中的噪声具有单位方差和零均值,因此我们也希望将图像归一化为这样,使噪声的值范围与图像的值范围相匹配。
- A loss function — We’ll use mean absolute error as our loss, that is to say
mean(abs(real_noise_mask - predicted_noise_mask)). - An image normalization layer — The noise we’ll add to the images will have unit variance and zero mean, so we’d like our images to be normalized as such too, for the value range of the noise to match the value range of the images.
我们先来编写模型构造函数:
1 | class DiffusionModel(keras.Model): |
我们需要用到的第一个方法是去噪方法。它简单地调用去噪模型来获取预测的噪声掩码,并使用该掩码重建去噪后的图像:
1 | def denoise(self, noisy_images, noise_rates, signal_rates): |
接下来是训练逻辑。这是最重要的部分!就像在 VAE 示例中一样,我们将实现一个自定义compute_loss() 方法,以确保模型与后端无关。当然,如果您坚持使用某个特定的后端,也可以编写一个train_step()包含完全相同逻辑的自定义方法,外加后端特有的梯度计算和权重更新逻辑。
由于compute_loss()接收 的输出作为输入call(),我们将把去噪前向传播过程放在 中call()。我们的call()接收一批干净的输入图像,并应用以下步骤:
- 对图像进行归一化处理
- 随机采样扩散时间(去噪模型需要用完整的扩散时间范围进行训练)
- 计算相应的噪声率和信号率(使用扩散方案)
- 向干净的图像添加随机噪声(基于计算出的噪声率和信号率)
- 对图像进行去噪
它回来了
- 预测的去噪图像
- 预测噪声掩蔽
- 它实际应用的噪声掩蔽
- Normalizes the images
- Samples random diffusion times (the denoising model needs to be trained on the full spectrum of diffusion times)
- Computes corresponding noise rates and signal rates (using the diffusion schedule)
- Adds random noise to the clean images (based on the computed noise rates and signal rates)
- Denoises the images
It returns
- The predicted denoised images
- The predicted noise masks
- The actual noise masks it applied
最后这两个量用于compute_loss()计算模型在噪声掩码预测任务上的损失:
1 | def call(self, images): |
生成过程
The generation process
最后,我们来实现图像生成过程。我们从纯随机噪声开始,反复应用该denoise()方法,直到获得高信号、低噪声的图像。
个人注:纯噪声,去噪后图像唯一吗?
这是一个非常深刻的哲学与数学兼具的问题。简单直接的答案是:不唯一。 (仁者见仁智者见智)
虽然你从“同一段纯噪声”出发,但在实际的 AI 生成(如 Stable Diffusion 或 DALL-E)过程中,去噪后的结果取决于多个变量。如果这些变量稍有不同,最终的图像就会完全不同。
我们可以从以下三个层面来理解这种“不唯一性”:
- 引导信号的力量(Prompt / Conditioning)
纯噪声本身是“混沌”的,它包含了生成任何图像的可能性。去噪过程之所以能产生有意义的图像,是因为模型接收到了引导信号。
- 实验:如果你给同一段噪声(相同的 Seed),但输入不同的 Prompt:
- Prompt A:“一只奔跑的柯基” \(\rightarrow\) 生成图像 A。
- Prompt B:“星空下的雪山” \(\rightarrow\) 生成图像 B。
- 原理:去噪函数
denoise()每一轮都在问:“在这团噪声中,哪个方向最像‘柯基’?”由于你的目标(Prompt)不同,噪声被剔除的方向就完全不同。
- 采样算法的随机性(Stochastic Sampling)
即便噪声相同、Prompt 也相同,图像依然可能不唯一,这取决于你使用的 采样器(Sampler):
- 确定性采样(如 DDIM):如果你固定了所有参数,它确实会产生唯一的图像。
- 随机性采样(如 Ancestral Samplers):在每一轮
denoise()的过程中,算法会故意注入一丁点新的微小噪声,以增加图像的细节和多样性。这就像是在下山的过程中,每走一步都轻微摇晃一下身体,最终落脚的点就会有偏差。
- 潜在空间的“多对一”映射
你摘录的那句话提到“从纯随机噪声开始”,这实际上是在潜在空间(Latent Space)中探路。
- 多路径效应:去噪过程本质上是一个常微分方程(ODE)的求解过程。从一个起点(噪声)出发,理论上可以有无数条平滑的曲线通往不同的“有效图像”区域。
- 收敛点:正如你之前看到的图 17.5,潜在空间是连续的。纯噪声就像是站在山顶,而每一幅“有效图像”都是山脚下的一个村庄。虽然你从同一个山顶出发,但只要下山时的重心稍微偏了一点点,你最终到达的村庄就可能完全不同。
术语统一:既然我们之前统一了术语,你可以写成:“去噪过程实际上是在不断修正词元(Token)或像素的分布,使其从无意义的噪声回归到高概率的语义空间。”
1 | def generate(self, num_images, diffusion_steps): |
使用自定义回调函数可视化结果
Visualizing results with a custom callback
我们目前没有合适的指标来评判生成图像的质量,因此你需要在训练过程中自行可视化生成的图像,以判断模型是否取得了进展。一个简单的方法是使用自定义回调函数。以下回调函数generate()在每个训练周期结束时使用该方法显示一个 3 × 6 的生成图像网格:
1 | class VisualizationCallback(keras.callbacks.Callback): |
行动时间到了!
It’s go time!
现在终于到了用牛津花卉数据集训练扩散模型的时候了。让我们实例化模型:
1 | model = DiffusionModel(image_size, widths=[32, 64, 96, 128], block_depth=2) |
我们将使用AdamW作为优化器,并启用一些巧妙的选项来帮助稳定训练并提高生成图像的质量:
- 学习率衰减——我们在训练过程中通过计划逐步降低学习率
InverseTimeDecay。 - 模型权重的指数移动平均——也称为 Polyak 平均。该技术在训练过程中维护模型权重的移动平均值。每训练 100 个批次,我们就用这组平均权重覆盖模型的现有权重。这有助于在损失函数分布噪声较大的情况下稳定模型的表示。
- Learning rate decay — We gradually reduce the learning rate during training, via an
InverseTimeDecayschedule. - Exponential moving average of model weights — Also known as Polyak averaging. This technique maintains a running average of the model’s weights during training. Every 100 batches, we overwrite the model’s weights with this averaged set of weights. This helps stabilize the model’s representations in scenarios where the loss landscape is noisy.
代码是
1 | model.compile( |
让我们来拟合模型。我们将使用VisualizationCallback回调函数在每个训练周期结束后绘制生成的图像示例,并将模型的权重保存在ModelCheckpoint回调函数中:
1 | model.fit( |
如果您在 Colab 上运行程序,可能会遇到“缓冲数据达到输出大小限制后被截断”的错误。这是因为日志中fit()包含图像,图像会占用大量空间,而单个笔记本单元格允许的输出大小有限。要解决此问题,您可以简单地model.fit(..., epochs=20)在五个连续的单元格中调用五个函数。这相当于一次fit(..., epochs=100)调用。
经过 100 个 epoch(在免费的 Colab GPU T4 上大约需要 90 分钟),我们得到了像这样的非常有生成性的花朵(见图 17.12)。
 图 17.12:生成的花朵示例
图 17.12:生成的花朵示例
你可以继续训练更长时间,并获得越来越接近实际效果的结果。
这就是扩散图像生成的工作原理!现在,要充分发挥它们的潜力,下一步就是添加文本条件,这将产生一个文本到图像的模型,能够生成与给定文本描述相匹配的图像。
文本转图像模型
Text-to-image models
我们可以使用相同的基本扩散过程来创建一个将文本输入映射到图像输出的模型。为此,我们需要一个预训练的文本编码器(例如第 15 章中提到的 RoBERTa 等 Transformer 编码器),它可以将文本映射到连续嵌入空间中的向量。然后,我们可以训练一个扩散模型,模型基于 (prompt, image)文本对,其中每个提示都是对输入图像的简短文本描述。
我们可以像之前一样处理图像输入,将带噪的输入映射到逐渐接近输入图像的去噪输出。关键在于,我们可以通过将嵌入的文本提示传递给去噪模型来扩展此设置。因此,我们的去噪模型不再仅仅接收一个 noisy_images输入,而是接收两个输入:noisy_images和 text_embeddings。这比我们之前训练的花朵去噪器更胜一筹。模型不再学习如何在没有任何额外信息的情况下去除图像噪声,而是可以利用最终图像的文本表示来指导去噪过程。
训练完成后,事情就变得更有趣了。因为我们已经训练了一个模型,它能够根据文本的矢量表示将纯噪声映射到图像,所以现在我们可以输入纯噪声和一个从未见过的提示信息,并将其去噪后得到提示信息对应的图像。
我们来试试看。本书中我们不会从头开始训练这些模型——虽然你已经拥有所有必要的条件,但训练一个效果良好的文本到图像扩散模型既费时又费钱。因此,我们将使用 KerasHub 上一个流行的预训练模型,名为 Stable Diffusion(图 17.13)。Stable Diffusion 由一家名为 Stability AI 的公司开发,该公司专门制作用于图像和视频生成的开源模型。我们只需几行代码即可在 KerasHub 上使用他们的第三版图像生成模型:
1 | import keras_hub |
清单 17.8:创建稳定的扩散文本到图像模型
 图 17.13:我们Stable Diffusion模型的一个输出示例
图 17.13:我们Stable Diffusion模型的一个输出示例
CausalLM和上一章介绍的任务类似,这个TextToImage任务是一个高级类,用于根据文本输入生成图像。它将分词和扩散过程封装到一个高级的生成调用中。
Stable Diffusion模型实际上在其模型中添加了第二个“负面提示”,该提示可用于引导扩散过程避开某些文本输入。这并非什么神奇之处。要添加负面提示,只需训练一个基于三元组的模型即可:(image, positive_prompt, negative_prompt),其中正面提示是对图像的描述,而负面提示是一系列不描述图像的词语。通过将正面和负面文本嵌入输入到去噪器中,去噪器将学习如何引导噪声流向与正面提示匹配的图像,并避开与负面提示匹配的图像(图 17.14)。让我们尝试从输入中移除蓝色:
1 | task.generate( |
 图 17.14:使用否定提示引导模型避开蓝色
图 17.14:使用否定提示引导模型避开蓝色
Stable Diffusion输出中的视觉伪影
Visual artifacts in the Stable Diffusion output
仔细观察我们的Stable Diffusion输出结果,你会发现很多视觉瑕疵。尤其值得注意的是,我们的第二头大象竟然有两根相同的象牙!
在使用扩散模型时,有些问题是不可避免的。例如,要真正画出一个穿着宇航服的人坐在纸做的大象上,需要一定的解剖学和物理学知识,而我们的模型恰恰缺乏这些知识。模型会尽力根据训练数据插值生成输出,但它对试图表示的物体本身并没有真正的理解。
然而,还有一个很容易解决的问题:我们使用的是 Stable Diffusion 3 的低配版。我们使用的“中等”模型是 Stability AI 发布的最小版本,总共使用了约 30 亿个参数。还有一个更大的模型,拥有 90 亿个参数,可以生成质量更高、视觉伪影更少的图像。我们没有使用它,仅仅是为了让本书中的代码示例易于理解——90 亿个参数需要大量的内存!
generate()与上一章中用于文本模型的方法类似,我们可以传递一些额外的参数来控制生成过程。让我们尝试向模型传递可变数量的扩散步骤,以观察去噪过程(图 17.15):
1 | import numpy as np |
 图 17.15:控制扩散步骤数
图 17.15:控制扩散步骤数
探索文本到图像模型的潜在空间
Exploring the latent space of a text-to-image model
要了解深度神经网络的插值特性,文本扩散模型或许是最佳途径。我们模型使用的文本编码器会学习一个平滑的低维流形来表示输入提示。它是连续的,这意味着我们学习到了一个空间,在这个空间中,我们可以从一个提示的文本表示延伸到另一个提示的文本表示,并且每个中间点都具有语义意义。我们可以将此与扩散过程相结合,只需用文本提示描述每个最终状态,即可在两幅图像之间进行变形。
在此之前,我们需要将高层generate() 函数分解成各个组成部分。让我们来尝试一下。
1 | from keras import random |
清单 17.9generate() :函数 分解
我们的生成过程分为三个不同的步骤:
- 首先,我们将提示信息进行分词,然后使用文本编码器将其嵌入文本中。
- 其次,我们利用文本嵌入和纯噪声,逐步“去噪”,最终得到一幅图像。这与我们刚才构建的花朵模型相同。
- 最后,我们将模型输出映射回
[-1, 1]原点[0, 255],以便渲染图像。
- First, we take our prompts, tokenize them, and embed them with our text encoder.
- Second, we take our text embeddings and pure noise and progressively “denoise” the noise into an image. This is the same as the flower model we just built.
- Lastly, we map our model outputs, which are from
[-1, 1]back to[0, 255]so we can render the image.
需要注意的是,我们的文本嵌入实际上包含四个独立的张量:
1 | >>> [x.shape for x in embeddings] |
Stable Diffusion 的作者并没有仅仅将最终的嵌入文本向量传递给去噪模型,而是选择同时传递最终的输出向量和文本编码器学习到的整个标记序列的最终表示。这有效地为去噪模型提供了更多信息。作者对正负提示都采用了这种方法,因此我们总共得到了四个张量:
- 肯定提示的编码器序列
- 否定提示的编码器序列
- 肯定提示的编码器向量
- 否定提示的编码器向量
- The positive prompt’s encoder sequence
- The negative prompt’s encoder sequence
- The positive prompt’s encoder vector
- The negative prompt’s encoder vector/
函数分解完成后generate(),我们现在可以尝试遍历两个文本提示之间的潜在空间。为此,我们构建一个函数来对模型输出的文本嵌入进行插值。
1 | from keras import ops |
清单 17.10:用于插值文本嵌入的函数
你会注意到我们使用了一种名为“slerp在文本嵌入之间移动”的特殊插值函数。它是球面线性插值的缩写 ——这种函数在计算机图形学中已经使用了几十年,用于对球面上的点进行插值。
You’ll notice we use a special interpolation function called slerp to walk between our text embeddings. This is short for spherical linear interpolation—it’s a function that has been used in computer graphics for decades to interpolate points on a sphere.
不必过于纠结数学细节;它对我们的例子并不重要,但理解其背后的动机至关重要。如果我们把文本流形想象成一个球体,把两个提示信息想象成球体上的随机点,那么直接在这两个点之间进行线性插值会将我们置于球体内部,不再位于球面上。我们希望保持在由文本嵌入学习到的光滑流形的表面上——这正是嵌入点对我们的去噪模型有意义的地方。参见图 17.16。
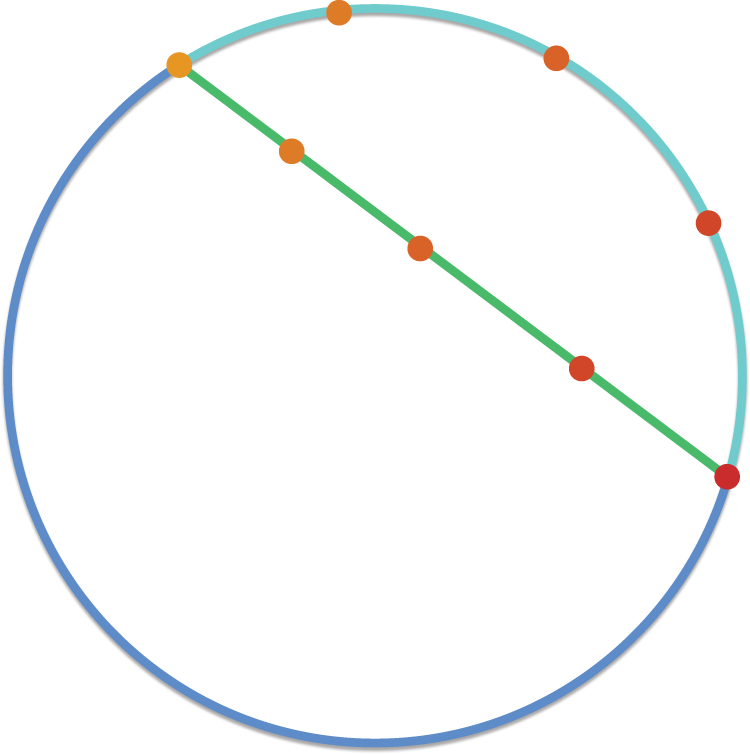 图 17.16:球面插值使我们靠近流形的表面。
图 17.16:球面插值使我们靠近流形的表面。
当然,我们的文本嵌入模型学习到的流形实际上并不是球面。但它是一个由数值构成的光滑曲面,所有数值的大小大致相同——它类似于球面,而且像在球面上一样进行插值比像在直线上一样进行插值要好得多。
定义好插值后,我们尝试在两个提示的文本嵌入之间移动,并在每个插值输出处生成图像。我们将 slerp 函数从 0.5 运行到 0.6(范围为 0 到 1),以放大插值区域的中心,此时“变形”在视觉上变得明显(图 17.17):
1 | prompt1 = "A friendly dog looking up in a field of flowers" |
 图 17.17:在两个提示之间进行插值并生成输出
图 17.17:在两个提示之间进行插值并生成输出
第一次尝试时,你可能会觉得这很神奇,但其实并非如此——插值是深度神经网络学习的基础。这将是本书中我们讨论的最后一个实质性模型,也是一个绝佳的视觉隐喻,可以作为本书的结尾。深度神经网络本质上就是插值机器;它们将复杂的现实世界概率分布映射到低维流形上。即使对于像人类语言这样复杂的输入和像自然图像这样复杂的输出,我们也能利用这一特性。
概括
- 利用深度学习进行图像生成,是通过学习潜在空间来实现的,这些潜在空间能够捕捉图像数据集的统计信息。通过对潜在空间中的点进行采样和解码,可以生成前所未见的图像。实现这一目标主要有三种工具:变分自编码器(VAE)、扩散模型和生成对抗网络(GAN)。
- VAE能够生成高度结构化、连续的潜在空间表征。因此,它们非常适合在潜在空间中进行各种图像编辑:例如换脸、将皱眉的脸变成微笑的脸等等。它们也非常适合制作基于潜在空间的动画,例如模拟沿着潜在空间横截面行走的动画,展现初始图像如何以连续的方式缓慢演变成不同的图像。
- 扩散模型能够生成非常逼真的图像,是目前图像生成领域的主流方法。其工作原理是从纯噪声开始,反复对图像进行去噪。扩散模型可以轻松地与文本描述结合,创建文本到图像的转换模型。
- Stable Diffusion 3 是一款最先进的预训练文本到图像模型,您可以使用它来创建高度逼真的图像。
- 此类文本到图像扩散模型学习到的视觉潜在空间本质上是插值的。这一点可以通过对用作扩散过程输入的文本嵌入进行插值,并在输出图像之间实现平滑插值来验证。
脚注
- Diederik P. Kingma 和 Max Welling,“自编码变分贝叶斯”,arXiv (2013),https://arxiv.org/abs/1312.6114。
- Danilo Jimenez Rezende、Shakir Mohamed 和 Daan Wierstra,“深度生成模型中的随机反向传播和近似推理”,arXiv (2014),https://arxiv.org/abs/1401.4082。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论