《DEEP LEARNING with Python》第十五章 语言模型和Transformer
第十五章 语言模型和Transformer
Language models and the Transformer
运行代码
本章内容
- 如何使用深度学习模型生成文本
- 训练一个模型,用于将英语翻译成西班牙语
- Transformer 是一种用于文本建模问题的强大架构
- How to generate text with a deep learning model
- Training a model to translate from English to Spanish
- The Transformer, a powerful architecture for text modeling problems
上一章介绍了文本预处理(text preprocessing)和建模的基础知识,本章将探讨一些更复杂的语言问题,例如机器翻译。我们将深入理解Transformer模型,该模型为ChatGPT等产品提供支持,并引发了自然语言处理(NLP)领域的投资热潮。
语言模型
The language model
在上一章中,我们学习了如何将文本数据转换为数值输入,并使用这种数值表示对电影评论进行分类。然而,文本分类在很多方面都是一个极其简单的问题。对于二元分类,我们只需要输出一个浮点数;而 对于N元(N-way)分类,最多也只需要输出N 个数字。
那么,对于其他基于文本的任务,例如问答或翻译呢?对于许多现实世界的问题,我们感兴趣的是一个能够根据给定的输入生成文本输出的模型。正如我们需要分词器和词嵌入来帮助我们处理输入到模型中的文本一样,我们也必须构建一些技术才能生成输出文本。
我们无需从零开始;我们可以继续沿用整数序列作为文本自然数值表示的概念。在前一章中,我们讨论了字符串的标记化( tokenizing ),即将输入拆分成标记(token),并将每个标记映射到一个整数。我们可以通过反向操作来对序列进行反标记化——将整数映射回字符串标记并将它们连接起来。采用这种方法,我们的问题就变成了构建一个能够预测整数标记序列的模型。
最简单的方案或许是对所有可能的输出整数序列进行直接分类,但简单的估算就能证明这几乎不可能实现。词汇表包含 20,000 个单词,那么可能的 4 个单词序列就有 20,000^4,也就是 160 千万亿个,而可能的 20 个单词序列的数量甚至比宇宙中的原子数量还要少。无论我们如何设计模型,试图将每个输出序列都表示为一个唯一的分类器输出都会使计算资源不堪重负。
解决这类预测问题的实用方法是构建一个每次只预测单个词元输出的模型。语言模型 最简单的形式是学习一个简单而深刻的概率分布:p(token|past tokens)给定一个包含所有已观测词元的序列,语言模型会尝试输出一个关于所有可能出现的下一个词元的概率分布。一个包含 20,000 个词的词汇表意味着模型只需要预测 20,000 个输出,但通过 反复预测下一个词元,我们就能构建一个可以生成长文本序列的模型。
为了更具体地说明这一点,我们构建一个简单的语言模型,用于预测字符序列中的下一个字符。我们将训练一个能够输出类似莎士比亚风格文本的小型模型。
训练莎士比亚语言模型
Training a Shakespeare language model
首先,我们可以下载一些莎士比亚戏剧和十四行诗的合集。
1 | import keras |
清单 15.1:下载莎士比亚作品节选集
我们来看一些数据:
1 | >>> shakespeare[:250] |
为了基于此输入构建语言模型,我们需要对源文本进行处理。首先,我们将数据分割成等长的块,以便进行批处理并用于模型训练,这与我们在时间序列章节中处理天气测量数据的方式类似。由于我们将使用字符级分词器,因此可以直接对字符串输入进行分块。一个 100 个字符的字符串将映射到一个 100 个整数的序列。
我们还会将每个输入拆分成两个单独的特征序列和标签序列(feature and label sequences),每个标签序列只是输入序列偏移一个字符而已。
1 | import tensorflow as tf |
清单 15.2:将文本分割成块以进行语言模型训练
我们来看一个(x, y)输入示例。序列中每个位置的标签都是序列中的下一个字符:
1 | >>> x, y = next(dataset.as_numpy_iterator()) |
为了将此输入映射到整数序列,我们可以再次使用 TextVectorization上一章中看到的层。为了学习字符级词汇表而不是单词级词汇表,我们可以更改split 参数。"whitespace"我们不使用默认的分割方式,而是按逗号分割 "character"。这里我们不做标准化处理——为了简单起见,我们将保留大小写并直接传递标点符号。
1 | from keras import layers |
列表 15.3TextVectorization :通过层 学习字符级词汇
让我们来检查一下词汇:
1 | >>> vocabulary_size = tokenizer.vocabulary_size() |
我们只需要 67 个字符就能处理完整的源文本。
接下来,我们可以将分词层应用于输入文本。最后,我们可以对数据集进行打乱、批处理和缓存,这样就无需在每个 epoch 都重新计算:
1 | dataset = dataset.map( |
这样一来,我们就可以开始建模了。
为了构建我们简单的语言模型,我们希望根据所有先前的字符来预测当前字符的概率。在本书目前为止介绍的所有建模方法中,循环神经网络(RNN)是最合适的选择,因为每个单元的循环状态允许模型在预测当前字符的标签时传播先前字符的信息。我们还可以使用向量Embedding(如上一章所述),将每个输入字符嵌入为一个唯一的 256 维向量。
为了保持模型小巧易于训练,我们将只使用一个循环层。任何循环层都可以,但为了简单起见,我们将使用一个GRU,它速度快,内部状态也比一个简单LSTM。
1 | embedding_dim = 256 |
清单 15.4:构建微型语言模型
让我们来看一下模型概要:
1 | >>> model.summary() |
该模型会为词汇表中的每个字符输出一个softmax概率值,我们将compile()使用交叉熵损失函数来衡量它。请注意,我们的模型仍然是在训练一个分类问题,只不过我们会对序列中的每个词元进行一次分类预测。对于包含64个样本(每个样本100个字符)的批次,我们将预测6400个不同的标签。训练期间Keras报告的损失和准确率指标,首先在每个序列上取平均值,其次在每个批次上取平均值。
接下来,我们来训练语言模型。
1 | model.compile( |
清单 15.5:训练微型语言模型
经过 20 个训练周期后,我们的模型最终能够以大约 70% 的准确率预测输入序列中的下一个字符。
莎士比亚的创作
Generating Shakespeare
现在我们已经训练了一个能够较为准确地预测下一个单词的模型,接下来我们希望利用它来推断整个预测序列。我们可以通过在循环中调用该模型来实现这一点,其中模型在一个时间步的预测输出会成为下一个时间步的输入。这种用于反馈循环的模型有时被称为 自回归模型(autoregressive model)。
为了运行这样的循环,我们需要对刚刚训练好的模型进行一些小的修改。在训练过程中,我们的模型只处理长度固定为 100 个 token 的序列,并且单元GRU格的状态是在调用层时隐式处理的。在生成过程中,我们希望一次预测一个输出 token,并显式输出单元格的状态GRU。我们需要在下次调用模型时传播这个状态,其中包含了模型对过去输入字符的所有编码信息。
我们来创建一个每次处理单个输入字符并允许显式传递 RNN 状态的模型。由于该模型具有相同的计算结构,只是输入和输出略有不同,我们可以将一个模型的权重分配给另一个模型。
1 | # Creates a model that receives and outputs the RNN state |
清单 15.6:修改自回归推断的语言模型
这样,我们就可以循环调用模型来预测输出序列。在此之前,我们将创建显式的查找表,以便将字符转换为整数,并选择一个提示——一段文本片段,我们将在开始预测新词元之前将其作为输入提供给模型:
1 | tokens = tokenizer.get_vocabulary() |
为了开始生成,我们首先需要用提示信息“初始化”GRU的内部状态。为此,我们将提示信息逐个输入到模型中。这将计算出如果在训练过程中遇到该提示信息,模型将会看到的RNN状态。
当我们把提示信息的最后一个字符输入模型时,模型的状态输出将包含整个提示序列的信息。我们可以保存最终的输出预测结果,以便稍后选择生成响应的第一个字符。
1 | input_ids = [char_to_id[c] for c in prompt] |
清单 15.7:使用固定提示计算语言模型的初始状态
现在我们准备让模型预测新的输出序列。在一个循环中(循环长度需达到预设值),我们将不断选择模型预测的最有可能的下一个字符,将其输入模型,并保存新的 RNN 状态。这样,我们就可以一次预测一个字符,从而预测整个序列。
1 | import numpy as np |
示例 15.8:使用语言模型一次预测一个词元
让我们将输出的整数序列转换为字符串,看看模型的预测结果。为了对输入进行反标记化,我们只需将所有标记 ID 映射到字符串并将它们连接起来:
1 | output = "".join([id_to_char[token_id] for token_id in generated_ids]) |
我们得到以下输出:
1 | KING RICHARD III: |
我们尚未创作出下一部伟大的悲剧,但考虑到仅用两分钟时间在最小数据集上进行训练,这已经相当不错了。这个简单示例旨在展示语言模型设置的强大功能。我们训练模型解决的问题是每次猜测一个字符,但仍然将其用于更广泛的问题,即生成开放式的、类似莎士比亚风格的文本回复。
需要注意的是,这种训练设置之所以有效,是因为循环神经网络只按序列向前传递信息。如果你愿意,可以尝试将该GRU层替换为循环神经网络Bidirectional(GRU(...))。训练准确率会立即飙升至 99% 以上,并且生成过程将完全停止。在训练过程中,我们的模型在每个训练步骤中都会看到整个序列。如果我们“作弊”,允许序列中下一个标记的信息影响当前标记的预测,那么我们就把问题变得过于简单了。
这种语言建模设置是文本领域无数问题的基础。与本书迄今为止介绍的其他建模问题相比,它也具有一些独特之处。我们不能简单地调用函数model.predict()来获得所需的输出。这里存在一个完整的循环,以及相当多的逻辑,这些逻辑仅在推理(inference)阶段出现!RNN单元中的状态循环发生在训练和推理阶段,但在训练过程中,我们绝不会将模型的预测标签作为输入反馈到自身。
序列到序列学习
Sequence-to-sequence learning
让我们借鉴语言模型的思想,并将其扩展到解决一个重要问题——机器翻译。翻译属于一类建模问题,通常被称为序列到序列建模(或简称seq2seq,以减少击键次数)。我们的目标是构建一个模型,该模型能够接收一个固定的源文本序列作为输入,并生成相应的翻译文本序列。问答系统是另一个经典的序列到序列问题。
序列到序列模型的一般模板如图 15.1 所示。在训练过程中,会发生以下情况:
- 编码器模型将源序列转换为中间表示。
- 解码器使用我们之前看到的语言建模设置进行训练。它会递归地预测目标序列中的下一个词元,方法是查看所有之前的目标词元以及编码器对源序列的表示。
- An encoder model turns the source sequence into an intermediate repre sen tation.
- A decoder is trained using the language modeling setup we saw previously. It will recursively predict the next token in the target sequence by looking at all previous target tokens and our encoder’s representation of the source sequence.
在推理过程中,我们无法访问目标序列——我们尝试从头开始预测它。我们将一次生成一个标记(token),就像我们生成莎士比亚诗歌一样:
- 我们从编码器获得编码后的源序列。
- 解码器首先查看编码后的源序列以及初始“种子”标记(例如字符串
"[start]"),并利用它们来预测序列中的第一个实际标记。 - 到目前为止预测的序列会循环反馈到解码器中,直到生成停止标记(例如字符串
"[end]")。
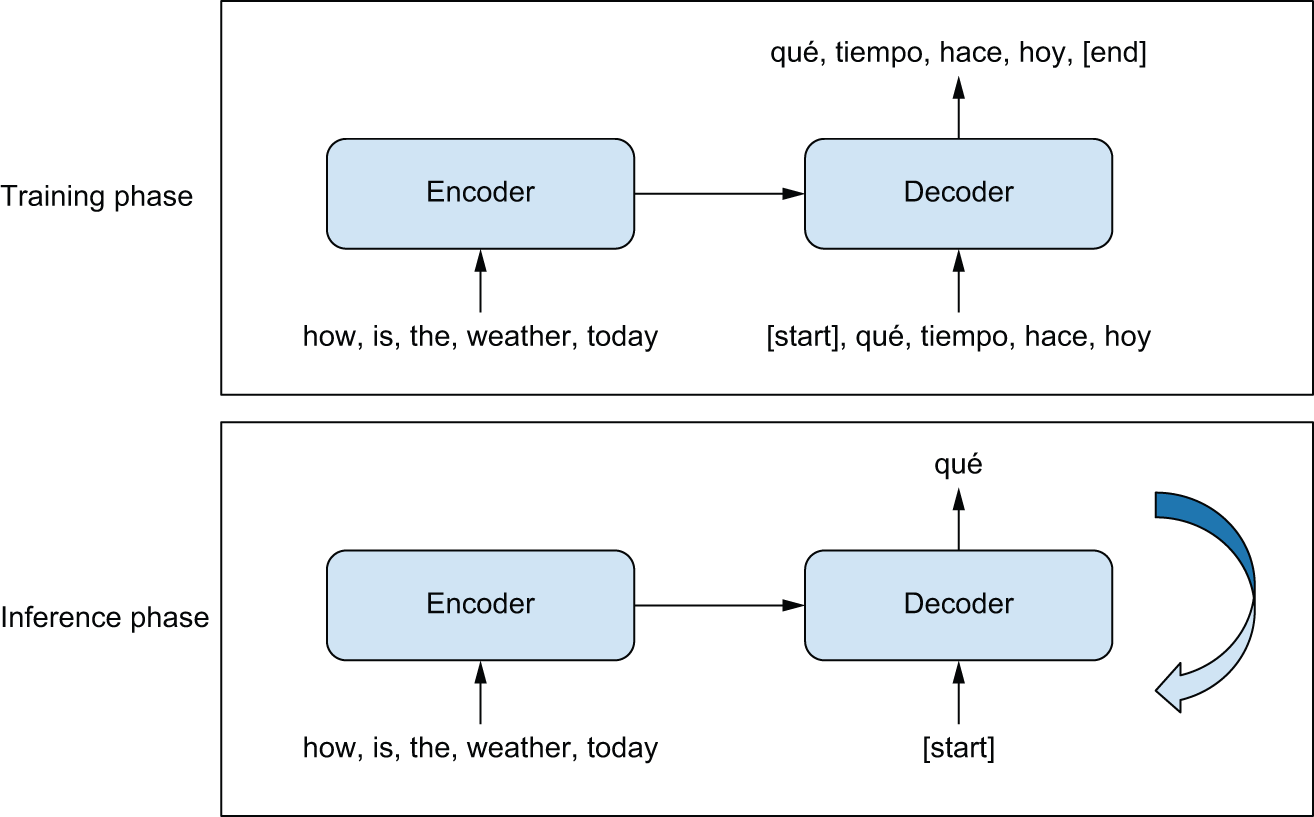 图 15.1:序列到序列学习:源序列经编码器处理后发送到解码器。解码器查看当前目标序列,并预测未来一个步长的目标序列。在推理过程中,我们一次生成一个目标标记,并将其反馈给解码器。
图 15.1:序列到序列学习:源序列经编码器处理后发送到解码器。解码器查看当前目标序列,并预测未来一个步长的目标序列。在推理过程中,我们一次生成一个目标标记,并将其反馈给解码器。
个人注:token的翻译问题。
这是一个非常典型的技术术语本土化过程中的“分歧”现象。简单来说:“词元”更具学术准确性,而“标记”更具计算机底层工具属性。
目前主流共识确实在向“词元”统一,但在不同的语境下,这两个词承载的含义微有侧重。
- 为什么会有两种称呼?
译法一:词元 (Token) —— 语言学视角
- 侧重点:强调它是语言的基本单位。
- 适用场景:当你讨论 BPE 算法、词表大小 (Vocab Size)、或者 NLP 语义理解时。
- 理由:在语言学中,“元”代表基本单位(如单元、元素)。在大模型中,Token 是构成句子的“乐高积木”,翻译成“词元”最能体现它作为语言构建块的身份。
译法二:标记 (Token) —— 计算机编译视角
- 侧重点:强调它是被特殊处理过的符号。
- 适用场景:在编写代码、处理 JSON 数据、或者讨论 Tokenizer(分词器) 的具体实现时。
- 理由:在计算机科学中,
Token早就存在于编译原理中(指代语法分析中的最小单位)。程序员习惯将其称为“标记”或“令牌”。当你看到[CLS]、[SEP]、[PAD]时,称它们为“特殊标记”比“特殊词元”听起来更符合工程直觉。
- 统一成“词元”是否更合理?
是的,在讨论大语言模型(LLM)的语境下,统一翻译成“词元”确实更合理。
原因如下:
- 区分度:中文里的“标记”对应的英文很多(Mark, Label, Tag, Flag)。如果 Token 也叫标记,容易产生混淆。
- 专业性:随着《大语言模型》相关教材和论文的规范化,“词元”已成为学术界的标准译名。它能准确传达“这是经过分词后的子词单位”这一核心概念。
- 理解成本:你之前提到的“缩短词元长度可以压缩样本整体长度”,如果说成“缩短标记长度”,听起来更像是某种视觉上的打标符号,容易产生歧义。
总结
“词元”是灵魂(语义),“标记”是躯壳(工程)。 在讨论 LLM 的逻辑和原理时,闭眼选“词元”准没错。
让我们构建一个序列到序列的翻译模型。
英译西
English-to-Spanish translation
我们将使用一个英译西的翻译数据集。让我们下载它:
1 | import pathlib |
该文本文件每行包含一个示例:一个英文句子,后跟一个制表符,再后跟对应的西班牙语句子。让我们解析一下这个文件:
1 | with open(text_path) as f: |
我们的text_pairs造型是这样的:
1 | >>> import random |
让我们重新排列这些数据集,并将它们分成通常的训练集、验证集和测试集:
1 | import random |
接下来,我们准备两个独立的TextVectorization层:一个用于英语,一个用于西班牙语。我们需要自定义字符串的预处理方式:
- 我们需要保留插入的
"[start]"and标记。默认情况下,字符and会被移除,但我们希望保留它们,以便将单词与起始标记区 分开来。"[end]"``[``]``"start"``"[start]" - 标点符号在不同的语言中有所不同!在西班牙语
TextVectorization层,如果我们要删除标点符号,我们也需要删除字符¿。 - We need to preserve the "[start]" and "[end]" tokens that we’ve inserted. By default, the characters [ and ] would be stripped, but we want to keep them around so we can distinguish the word "start" from the start token "[start]".
- Punctuation is different from language to language! In the Spanish TextVectorization layer, if we’re going to strip punctuation characters, we need to also strip the character ¿.
请注意,对于非玩具(non-toy)级别的翻译模型,我们会将标点符号视为单独的标记,而不是将其移除,因为我们需要能够生成标点正确的句子。为了简化起见,在本例中,我们将移除所有标点符号。
1 | import string |
列表 15.9:学习英语和西班牙语文本的词元词汇
最后,我们可以将数据转换成一个tf.data管道。我们希望它返回一个元组,(inputs, target, sample_weights)其中<key>inputs是一个字典,包含两个键:`<key>` `"english"`(分词后的英文句子)和`"spanish"(分词后的西班牙文句子),target是向前偏移一步的西班牙文句子。sample_weights这里将使用 <key> 来告诉 Keras 在计算损失和指标时使用哪些标签。我们的输出翻译长度并不完全相同,并且一些标签序列会用零填充。我们只关心代表实际翻译文本的非零标签的预测结果。
这与我们在刚刚构建的生成模型中设置的“差一(off by one)”标签相符,并增加了固定编码器输入,这将在我们的模型中单独处理。
1 | batch_size = 64 |
清单 15.10:对翻译数据进行分词和准备
以下是我们的数据集输出结果:
1 | >>> inputs, targets, sample_weights = next(iter(train_ds)) |
数据已准备就绪——是时候构建一些模型了。
基于循环神经网络的序列到序列学习
Sequence-to-sequence learning with RNNs
在尝试之前提到的双编码器/解码器设置之前,让我们先考虑一些更简单的方案。使用循环神经网络 (RNN) 将一个序列转换为另一个序列最简单、最直接的方法是,保留每个时间步的 RNN 输出,并据此预测输出标记。在 Keras 中,代码如下所示:
1 | inputs = keras.Input(shape=(sequence_length,), dtype="int32") |
然而,这种方法存在一个关键问题。由于循环神经网络(RNN)的逐步运算特性,模型只能通过查看0...N源序列中的词元来预测N目标序列中的词元。例如,考虑翻译句子“I will bring the bag to you.”,在西班牙语中是“Te traeré la bolsa”,其中“Te”(译文的第一个词)对应于英语原文中的“you”。如果不看到英语原文的最后一个词,就根本无法输出译文的第一个词!
如果你是一名人工翻译,你会先通读整个源句子,然后再开始翻译。这一点在处理词序差异极大的语言时尤为重要。而这正是标准序列到序列模型的工作原理。在一个标准的序列到序列模型设置中(参见图 15.2),你会首先使用编码器 RNN 将整个源序列转换为源文本的单一表示。这可以是 RNN 的最终输出,也可以是其最终的内部状态向量。在语言模型设置中,我们可以将这种表示用作解码器 RNN 的初始状态,而不是像我们在莎士比亚生成器中使用的零初始状态。该解码器学习根据当前翻译单词预测西班牙语翻译的下一个单词,所有关于英语序列的信息都来自该初始 RNN 状态。
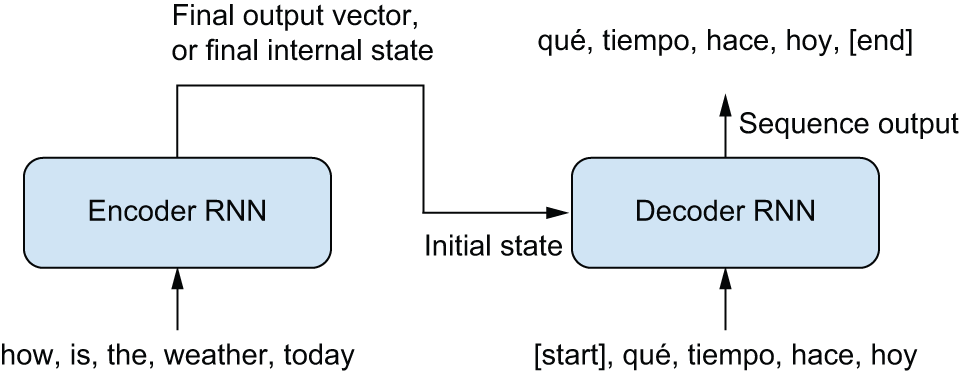 图 15.2:序列到序列 RNN:RNN 编码器用于生成对整个源序列进行编码的向量,该向量用作 RNN 解码器的初始状态。
图 15.2:序列到序列 RNN:RNN 编码器用于生成对整个源序列进行编码的向量,该向量用作 RNN 解码器的初始状态。
让我们用 Keras 实现这个功能,使用基于 GRU 的编码器和解码器。我们可以先从编码器开始。由于我们实际上并不预测编码器序列中的词元,因此不必担心模型会“作弊”,将序列末尾的信息传递到开头。事实上,这样做是好事,因为我们需要对源序列进行丰富的表示。我们可以通过一个Bidirectional层来实现这一点。
1 | embed_dim = 256 |
清单 15.11:构建序列到序列编码器
接下来,我们添加解码器——一个简单的GRU层,其初始状态为编码后的源句子。在其之上,我们添加一个Dense层,该层为每个输出步骤生成一个西班牙语词汇表的概率分布。这里,我们希望仅根据前面的词元来预测下一个词元,因此 Bidirectional使用循环神经网络(RNN)会使损失函数过于简单,从而破坏训练过程。
1 | target = keras.Input(shape=(None,), dtype="int32", name="spanish") |
清单 15.12:构建序列到序列解码器
让我们完整地看一下 seq2seq 模型:
1 | >>> seq2seq_rnn.summary() |
我们的模型和数据都已准备就绪。现在我们可以开始训练翻译模型了:
1 | seq2seq_rnn.compile( |
我们选择准确率作为一种粗略的方法来监控训练过程中验证集的性能。我们达到了 65% 的准确率:平均而言,模型有 65% 的概率正确预测西班牙语句子中的下一个词。然而,在实践中,下一个词元准确率并不是衡量机器翻译模型的理想指标,尤其因为它假设在预测下一个词元时,从第一个 词元0到第二个词元的正确目标词元N是已知的N + 1。实际上,在推理过程中,目标句子是从零开始生成的,你不能依赖之前生成的词元 100% 正确。在开发实际的机器翻译系统时,必须更仔细地设计指标。有一些标准指标,例如 BLEU 分数,可以衡量机器翻译文本与一组高质量参考译文的相似度,并且可以容忍轻微的序列错位。
最后,让我们用模型进行推理。我们将从测试集中选取几个句子,看看模型是如何翻译它们的。我们从种子标记开始"[start]",将其与编码后的英文源句一起输入到解码器模型中。我们将获取下一个标记的预测结果,并将其重复输入到解码器中,每次迭代都采样一个新的目标标记,直到达到"[end]"或超过句子的最大长度。
1 | import numpy as np |
清单 15.13:使用 seq2seq RNN 生成翻译
由于最终模型权重取决于权重的随机初始化和输入数据的随机打乱,因此每次运行的具体结果都会有所不同。以下是我们得到的结果:
1 | - |
我们的模型作为玩具模型来说效果还不错,尽管它仍然存在许多基本错误。
请注意,这种推理设置虽然非常简单,但效率低下,因为每次采样新词时,我们都会重新处理整个源句子和整个生成的目标句子。在实际应用中,应该避免重复计算任何未发生变化的状态。实际上,解码器预测新词元只需要当前词元和之前的 RNN 状态,我们可以在每次循环迭代之前缓存这些信息。
这个玩具模型有很多改进空间。我们可以使用多层循环层堆叠作为编码器和解码器,也可以尝试其他RNN层LSTM,等等。然而,除了这些调整之外,RNN方法在序列到序列学习方面存在一些根本性的局限性:
- 源序列表示必须完全保存在编码器状态向量中,这大大限制了您可以翻译的句子的大小和复杂性。
- RNN 难以处理非常长的序列,因为它们往往会逐渐忘记过去——当序列达到第 100 个标记时,关于序列的开头几乎没有信息了。
- The source sequence representation has to be held entirely in the encoder state vector, which significantly limits the size and complexity of the sentences you can translate.
- RNNs have trouble dealing with very long sequences since they tend to progressively forget about the past—by the time you’ve reached the 100th token in either sequence, little information remains about the start of the sequence.
在2010年代中期,循环神经网络(RNN)主导了序列到序列的学习。大约在2017年,谷歌翻译就采用了 LSTM类似我们刚才创建的架构,由七个大型层堆叠而成。然而,RNN的这些局限性最终促使研究人员开发了一种新型的序列模型,称为Transformer。
Transformer架构
The Transformer architecture
个人注:关于Transformer架构的具体的细节建议看书籍《Hands-On Large Language Models》。
不过本章很多宏观的思想还是概括得很好。
2017 年,Vaswani 等人在开创性论文《Attention Is All You Need》中引入了 Transformer 架构。[1]作者们当时正在研究类似我们刚刚构建的翻译系统,而关键发现就体现在标题中。事实证明,一种名为注意力机制(mechanism called attention)的简单机制可以用来构建强大的序列模型,而这些模型完全不需要循环层。注意力机制的概念并不新鲜,在他们发表论文时,它已经在自然语言处理系统中应用了几年。但注意力机制如此有效,以至于可以作为传递序列信息的唯一机制,这在当时确实令人惊讶。
这一发现引发了自然语言处理乃至更广泛领域的革命性变革。注意力机制迅速成为深度学习中最具影响力的理念之一。在本节中,您将深入了解其工作原理以及它在序列建模中如此有效的原因。之后,我们将利用注意力机制重建我们的英西翻译模型。
那么,经过这么多铺垫,注意力究竟是什么?它又如何取代我们目前使用的循环神经网络呢?
注意力机制最初是为了增强像我们刚才构建的这种循环神经网络(RNN)模型而开发的。研究人员注意到,虽然RNN在建模局部邻域内的依赖关系方面表现出色,但随着序列长度的增加,其召回率(recall)却会下降。假设你正在构建一个系统来回答关于某个源文档的问题。如果文档长度过长,RNN的回答就会变得非常糟糕,与人类的表现相去甚远。
不妨做一个思想实验:想象一下,用这本书来构建一个天气预报模型。如果你时间充裕,或许会通读全书,但当你真正开始实现模型时,你会特别关注时间序列相关的章节。即使在同一个章节内,你也可能会找到一些特定的代码示例和解释,并经常参考。另一方面,在编写代码时,你不会特别在意图像卷积的细节。这本书的总字数超过十万字,远远超过我们以往处理过的任何序列长度,但人类在从文本中提取信息时,往往会根据上下文进行选择 和理解(selective and contextual )。
另一方面,循环神经网络(RNN)缺乏直接回溯序列先前部分的机制。所有信息都必须按照设计,在RNN单元的内部状态中循环传递,遍历序列中的每个位置。这有点像读完一本书,合上书,然后试图完全凭记忆实现其中的天气预报模型。注意力机制的核心思想是构建一种机制,使神经网络能够根据当前处理的输入,在上下文上赋予序列的某些部分更高的权重,而降低其他部分的权重(图15.3)。
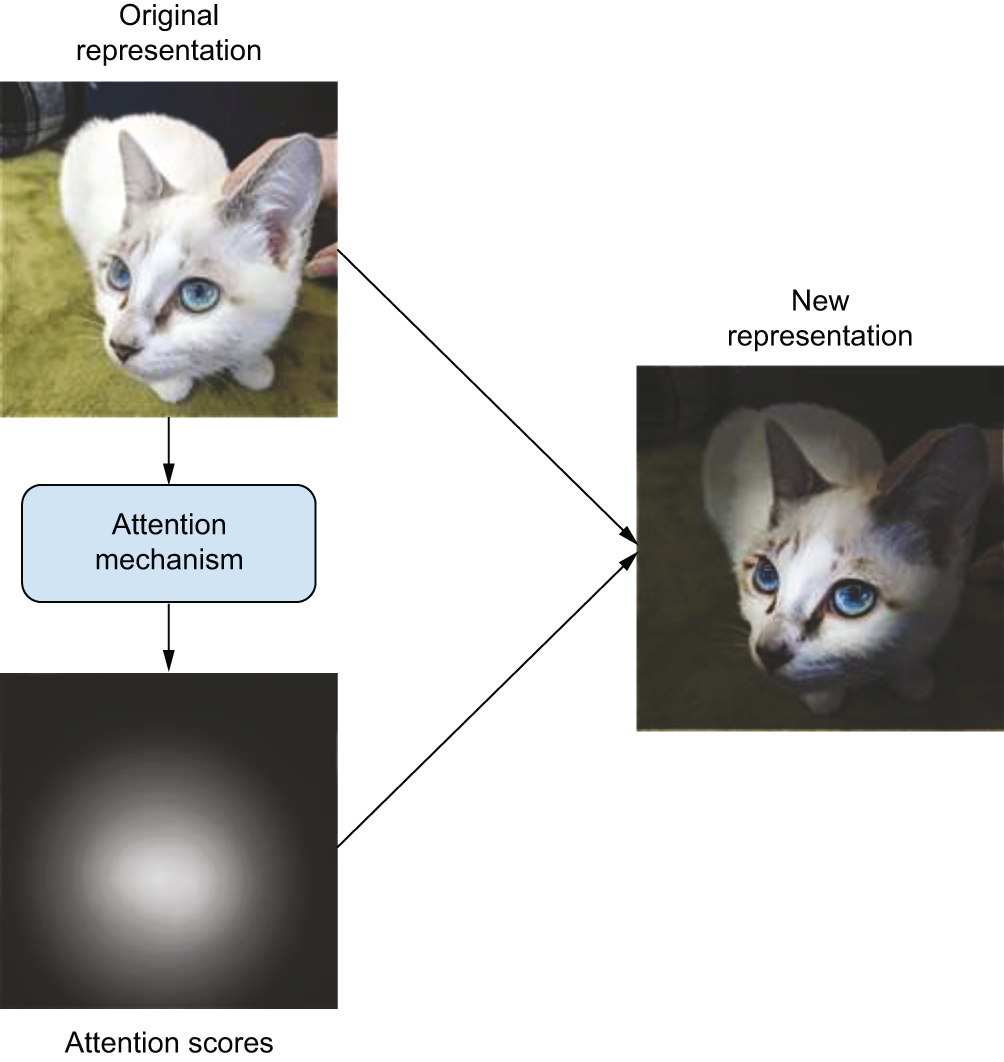 图 15.3:深度学习中注意力的一般概念:输入特征被赋予注意力分数,这些分数可用于指导输入的下一个表示。
图 15.3:深度学习中注意力的一般概念:输入特征被赋予注意力分数,这些分数可用于指导输入的下一个表示。
什么是Einsum符号?
What is Einsum notation?
在机器学习代码库中,你会经常看到类似这样的代码片段:np.einsum('ij,jk->ik', a, b)。这被称为Einsum 符号,即爱因斯坦求和符号的缩写。一旦你学会阅读它们,它们就能成为编写复杂数组运算的清晰方法。因此,你会在 Transformer 代码中经常看到它们。
Einsum 方程的思想是用一个唯一的字母来表示输入的每个轴。例如,你可以用 表示一个秩为 3 的输入ijk。然后,你可以写出一个包含任意数量输入和一个输出的方程 input1,input2->output。该方程的规则如下:
- 如果输入内容中出现重复字母,则将这些轴上的值相乘。这些维度的大小应该相同。
- 对于输入中存在但输出中不存在的任何字母,对这些轴求和,使其不出现在返回的数组中。
- 输出轴可以按任意顺序返回。
如果我们看一些例子,这一点就更清楚了:
1 | # Transposes |
在 Keras 中,你可以用两种方式使用 einsum。keras.ops.einsum一种是直接替换 einsum np.einsum,另keras.layers.EinsumDense一种是将Denseeinsummatmul替换为 einsumeinsum操作的层。
点积注意力
Dot-product attention
让我们重新审视一下我们的翻译循环神经网络(RNN),并尝试加入选择性注意力机制。考虑预测单个词元。将目标词元source 和target源词序列分别经过GRU各层后( After passing the source and target sequences through our GRU layers ),我们将得到一个向量,表示即将预测的目标词元,以及一个向量序列,该序列包含源文本中每个词的向量。
我们的目标是让模型能够根据源序列中每个向量与当前待预测词的相关性对其进行评分(图 15.4)。如果源词的向量表示得分很高,我们就认为它特别重要;否则,我们就不太在意它。现在,我们假设我们有以下函数。score(target_vector, source_vector)
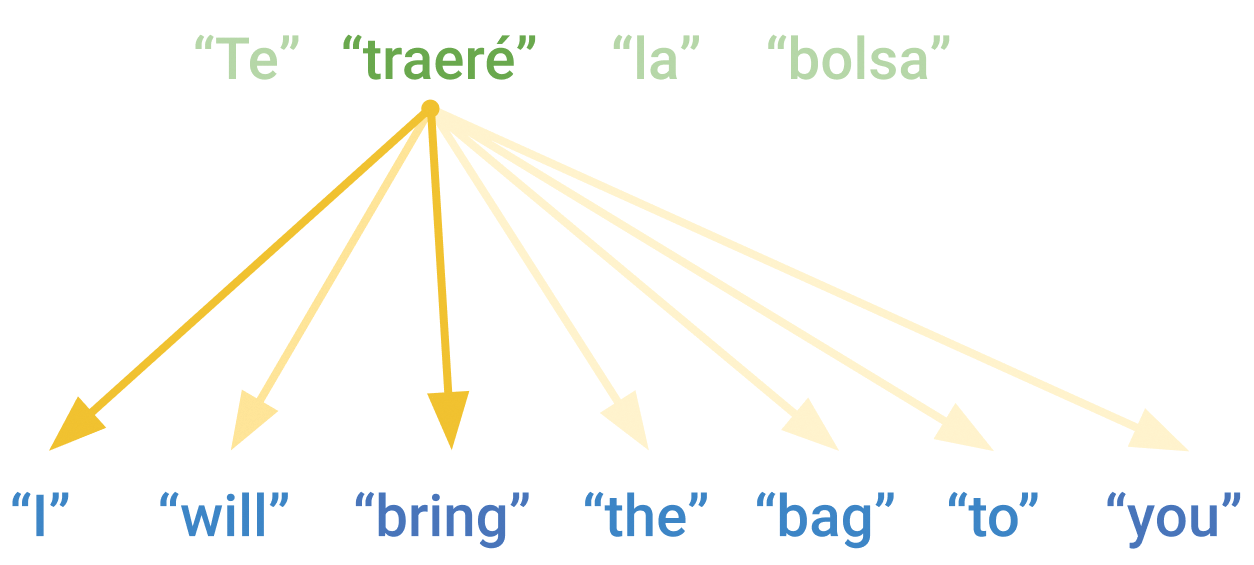 图 15.4:注意力机制为源序列中的每个向量与目标序列中的每个向量分配一个相关性分数。
图 15.4:注意力机制为源序列中的每个向量与目标序列中的每个向量分配一个相关性分数。
为了使注意力机制有效运作,我们需要避免将重要词元的信息传递到一个可能与源序列和目标序列总长度相同的循环中——这正是循环神经网络(RNN)开始失效的地方。一个简单的解决方法是基于我们计算出的分数,对所有源向量进行加权求和。如果给定目标的所有注意力分数之和为 1,那就更好了,因为这样可以使加权和具有可预测的大小。我们可以通过一个函数来实现这一点softmax——类似如下的 NumPy 伪代码:
1 | scores = [score(target, source) for source in sources] |
但是我们应该如何计算这种相关性得分呢?当研究人员最初研究注意力机制时,这个问题曾是一个重要的研究课题。事实证明,最直接的方法之一就是最佳方法。我们可以使用点积来简单地衡量目标向量和源向量之间的距离。如果源向量和目标向量彼此接近,我们就假设源标记与我们的预测相关。在本章末尾,我们将探讨为什么这个假设符合直觉。
让我们更新一下伪代码。我们可以通过一次性处理整个目标序列来完善代码片段——这相当于对目标序列中的每个词元循环运行之前的代码片段。当 a target和source``b 都是序列时,注意力分数将是一个矩阵。每一行表示目标词在加权和中对源词的权重(参见图 15.5)。我们将使用 Einsum 符号来方便地表示点积和加权和:
1 | def dot_product_attention(target, source): |
 图 15.5:当目标和源均为序列时,注意力得分是一个二维矩阵。每一行显示我们试图预测的单词(绿色)的注意力得分。
图 15.5:当目标和源均为序列时,注意力得分是一个二维矩阵。每一行显示我们试图预测的单词(绿色)的注意力得分。
如果我们给模型参数来控制注意力得分,就能极大地丰富这种注意力机制的假设空间Dense。如果我们用层来投影源向量和目标向量,模型就能找到一个合适的共享空间,在这个空间中,如果源向量和目标向量有助于提高整体预测质量,它们就会彼此接近。类似地,我们应该允许模型在合并源向量之前,以及在求和之后,分别将它们投影到一个完全独立的空间中。
We can make the hypothesis space of this attention mechanism much richer if we give the model parameters to control the attention score. If we project both source and target vectors with Dense layers, the model can find a good shared space where source vectors are close to target vectors if they help the overall prediction quality. Similarly, we should allow the model to project the source vectors into an entirely separate space before they are combined and once again after the summation.
我们还可以采用一种略有不同的输入命名方式,这种方式已成为该领域的标准。我们刚才写的内容大致可以概括为 sum(score(target, source) * source)。我们将使用不同的输入名称将其等效地写成sum(score(query, key) * value)。这种三参数版本更通用——在极少数情况下,您可能不希望使用同一个向量来对源输入进行评分,也不希望使用同一个向量来对源输入求和。
这些术语源自搜索引擎和推荐系统。想象一下一个用于在数据库中查找照片的搜索工具——“查询”是你的搜索词,“键”是你用来与查询匹配的照片标签,“值”则是照片本身(图 15.6)。我们正在构建的注意力机制与这种查找方式大致类似。
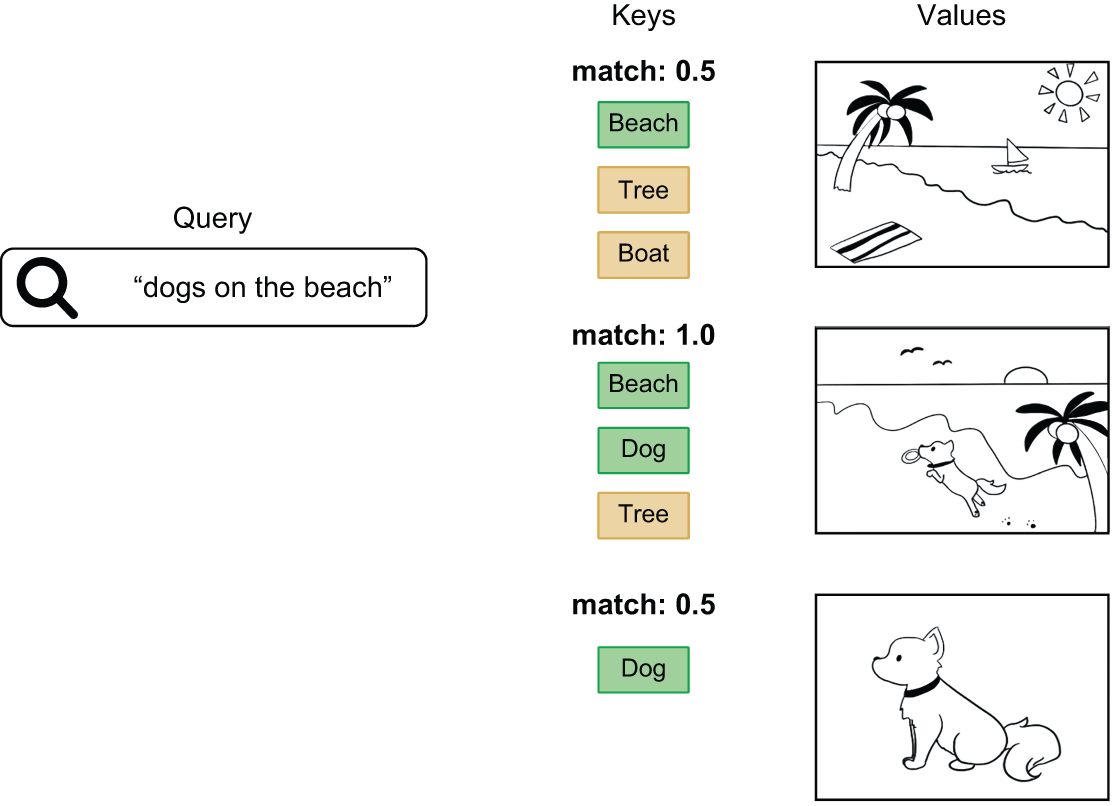 图 15.6:从数据库中检索图像:将查询与一组键进行比较,并使用匹配分数对值(图像)进行排名。
图 15.6:从数据库中检索图像:将查询与一组键进行比较,并使用匹配分数对值(图像)进行排名。
让我们更新伪代码,以便使用我们的新术语实现参数化注意力机制:
1 | query_dense = layers.Dense(dim) |
这个模块是一个功能完善的注意力机制!我们刚刚编写了一个函数,它可以让模型根据我们正在解码的目标词,从源序列中的任何位置提取上下文信息。
《注意力机制就是一切》的作者们通过反复试验,对我们的机制又做了两项改进。第一项是简单的缩放因子。当输入向量变长时,点积得分可能会变得非常大,这会影响softmax梯度的稳定性。解决方法很简单:我们可以稍微缩小softmax得分。按向量长度的平方根进行缩放,对任何大小的向量都有效。
另一个问题与注意力机制的表达能力有关。我们使用的softmax求和功能非常强大——它允许在序列中相距较远的部分之间建立直接联系。但这种求和方式也比较粗糙:如果模型试图同时关注太多的词元,那么各个源词元的有趣特征就会在组合表示中被“冲淡”。一个简单有效的技巧是,对同一序列多次执行注意力操作,每次使用不同的注意力头(attention heads),并采用不同的参数运行相同的计算:
1 | query_dense = [layers.Dense(head_dim) for i in range(num_heads)] |
通过对查询和键进行不同的投影,一个注意力头可以学习匹配源句的主语,而另一个注意力头则可以关注标点符号。这种多头注意力( multi-headed attention )机制避免了需要使用单个softmax求和来合并整个源序列的限制(图15.7)。
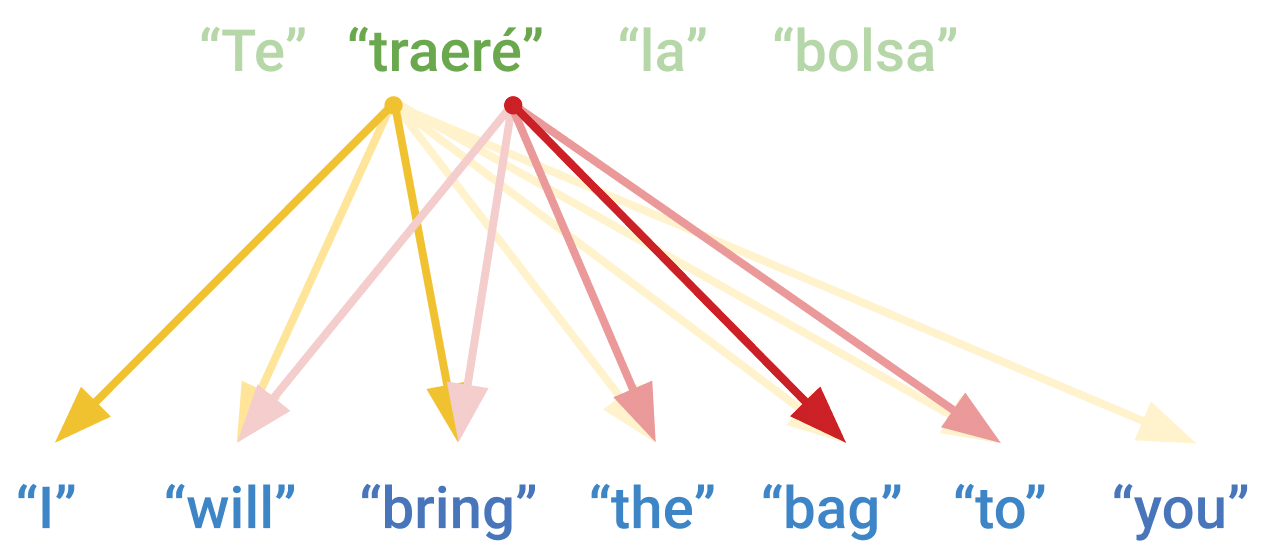 图 15.7:多头注意力机制允许每个目标词关注源序列的不同部分,这些部分是最终输出向量的不同分区。
图 15.7:多头注意力机制允许每个目标词关注源序列的不同部分,这些部分是最终输出向量的不同分区。
当然,在实际应用中,您肯定希望将这段代码编写成一个可重用的层。Keras 正好可以满足这一需求。我们可以 MultiHeadAttention按如下方式使用该层重新创建之前的代码:
1 | multi_head_attention = keras.layers.MultiHeadAttention( |
Transformer编码器模块
Transformer encoder block
使用该MultiHeadAttention层的一种方法是将其添加到我们现有的 RNN 翻译模型中。我们可以将编码器和解码器的序列输出传递给注意力层,并利用其输出在预测之前更新目标序列。注意力机制能够使模型处理文本中原本GRU难以处理的长程依赖关系。事实上,这确实提升了 RNN 模型的性能,而注意力机制最初就是在 2010 年代中期被应用的。
然而,《Attention is all you need》的作者们意识到,注意力机制可以更进一步,成为处理模型中所有序列数据的通用机制。虽然到目前为止,我们只将注意力机制视为处理两个序列之间信息传递的一种方式,但你也可以利用注意力机制让序列关注自身:
1 | multi_head_attention(key=source, value=source, query=source) |
这被称为自注意力机制( self-attention ),它非常强大。借助自注意力机制,每个词元可以关注自身序列中的每个词元,包括它自身,从而使模型能够学习到该词在上下文中的表示。
考虑以下例句:“The train left the station on time.(火车准时离开车站)。” 现在,考虑句子中的一个词:“station(车站)”。我们指的是哪种车站?是广播电台吗?还是国际空间站?借助自注意力机制,模型可以学习给“station(车站)”和“train(火车)”这对词赋予较高的注意力值,将表示“火车”的向量加到表示“车站”的向量中。
自注意力机制为模型提供了一种有效的方法,使其能够从孤立地表示一个词,转变为根据序列中出现的所有其他词元来表示该词。这听起来很像循环神经网络(RNN)应该做的事情。我们可以直接用自注意力机制替换RNN层吗MultiHeadAttention?
差不多了!但还不够;我们仍然需要一个深度神经网络必不可少的要素——非线性激活函数。该MultiHeadAttention层将源序列中每个元素的线性投影组合起来,仅此而已。从某种意义上说,它是一种表达力很强的池化操作。考虑极端情况,即标记长度为 1。在这种情况下,注意力得分矩阵始终为 1,整个层简化为源序列的线性投影,没有任何非线性。即使堆叠 100 个注意力层,仍然可以将整个计算简化为一次矩阵乘法!这正是我们模型表达力不足的真正问题。
在某些时刻,所有循环单元都会将每个词元的输入向量通过密集投影传递,并应用激活函数;我们需要一个类似的方案。《注意力机制就是一切》的作者决定以最简单的方式将其添加回来——堆叠一个由两层密集层组成的前馈网络,中间带有一个激活函数。注意力机制负责在序列中传递信息,而前馈网络则负责更新各个序列项的表示。
我们准备开始构建 Transformer 模型。首先,让我们替换翻译模型的编码器。我们将使用自注意力机制来传递源英语单词序列的信息。此外,我们还会添加在第 9 章中学习到的构建卷积神经网络时特别重要的两个要素:归一化和残差连接。
1 | class TransformerEncoder(keras.Layer): |
清单 15.14:Transformer编码器模块
你会注意到,我们这里使用的归一化层 BatchNormalization与图像模型中使用的归一化层不同。这是因为图像模型中的归一化层BatchNormalization并不适用于序列数据。相反,我们使用了LayerNormalization一种能够独立于批次中其他序列对每个序列进行归一化的层——如下一段类似 NumPy 的伪代码:
1 | # Input shape: (batch_size, sequence_length, embedding_dim) |
BatchNormalization与(训练期间)相比:
1 | # Input shape: (batch_size, height, width, channels) |
虽然BatchNormalization它从许多样本中收集信息以获得特征均值和方差的准确统计数据,但LayerNormalization 它将每个序列内的数据分别汇总,这更适合序列数据。
我们还向该MultiHeadAttention层传递一个名为 <input_name> 的 新输入attention_mask。这个布尔张量输入将被广播到与注意力分数相同的形状(batch_size, target_length, source_length)。当设置 <input_name> 时,它会将特定位置的注意力分数置零,从而阻止这些位置的源标记被用于注意力计算。我们将使用此方法来防止序列中的任何标记关注不包含任何信息的填充标记。我们的编码器层接收一个source_mask输入,该输入会标记输入中所有非填充标记,并将其升序到与 <input_name> 相同的形状, (batch_size, 1, source_length)以用作 <input_name>attention_mask``。
请注意,该层的输入和输出具有相同的形状,因此编码器块可以彼此堆叠,从而构建出对输入英语句子越来越有表现力的表示。
Transformer解码器模块
Transformer decoder block
接下来是解码器模块。这一层与编码器模块几乎完全相同,区别在于我们希望解码器使用编码器的输出序列作为输入。为此,我们可以两次使用注意力机制。首先,我们应用一个类似于编码器的自注意力层,它允许目标序列中的每个位置利用来自其他目标位置的信息。然后,我们添加另一个MultiHeadAttention层,该层接收源序列和目标序列作为输入。我们将这个注意力层称为交叉注意力层,因为它将信息传递到编码器和解码器之间。
1 | class TransformerDecoder(keras.Layer): |
清单 15.15:Transformer解码器模块
我们的解码器层同时接收 atarget和source。与 类似 TransformerEncoder,我们接收一个source_mask标记源输入中所有填充位置的 a(True对于非填充,False对于填充),并将其用作attention_mask交叉注意力层的 。
对于解码器的自注意力层,我们需要一种不同的注意力掩码。回想一下,我们在构建 RNN 解码器时,特意避免使用Bidirectional RNN。如果我们使用了 RNN,模型就能通过将其试图预测的标签视为特征来作弊!注意力本质上是双向的;在自注意力机制中,目标序列中的任何标记位置都可以关注任何其他位置。如果没有特别的保护,我们的模型就会学会将序列中的下一个标记作为当前标签传递,从而无法生成新的翻译。
我们可以使用一种特殊的“因果”注意力掩码来实现单向信息流。假设我们传递一个注意力掩码,其下三角部分全部为 1,如下所示:
1 | [ |
每一行都i可以理解为位置处目标标记的注意力掩码i。在第一行中,第一个标记只能关注自身。在第二行中,第二个标记可以同时关注第一个和第二个标记,依此类推。这与我们的 RNN 层效果相同,信息只能在序列中向前传播,而不能向后传播。在 Keras 中,只需在调用use_casual_mask该 MultiHeadAttention层时传递参数即可指定此下三角掩码。图 15.8 展示了编码器层和解码器层堆叠成 Transformer 模型时的可视化表示。
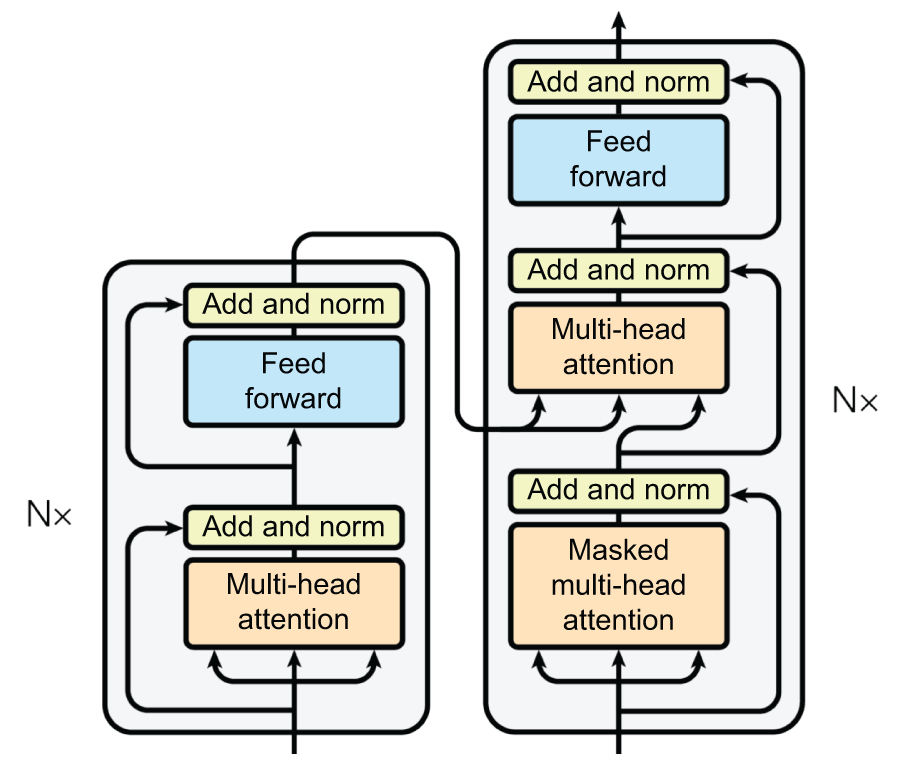 图 15.8
图 15.8TransformerEncoder :两个TransformerDecoder模块 计算过程的可视化表示
使用 Transformer 进行序列到序列学习
Sequence-to-sequence learning with a Transformer
让我们尝试把所有这些整合起来。我们将使用与 RNN 模型相同的基本设置,只是将GRU层替换为我们自己的TransformerEncoder层 TransformerDecoder。除了前馈模块之外,我们将256在整个模型中使用作为嵌入维度。在前馈模块中,我们在非线性运算之前将嵌入维度扩展到2048,之后再缩回到模型的隐藏层维度。这种较大的中间维度在实践中效果很好。
1 | hidden_dim = 256 |
清单 15.16:搭建Transformer模型
让我们来看一下Transformer模型的概要:
1 | >>> transformer.summary() |
我们的模型结构几乎与我们之前训练的翻译模型完全相同GRU,只是现在用注意力机制代替了循环层,作为在序列中传递信息的机制。让我们尝试训练这个模型:
1 | transformer.compile( |
训练后,我们的准确率达到了大约 58%:平均而言,模型有 58% 的概率正确预测西班牙语句子中的下一个单词。这肯定有问题。训练结果比 RNN 模型差了 7 个百分点。要么是 Transformer 架构名不副实,要么是我们的实现中遗漏了什么。你能找出问题所在吗?
本节表面上是关于序列模型的。在前一章中,我们看到了词序对语义的重要性。然而,我们刚刚构建的Transformer模型实际上并非序列模型。你注意到了吗?它由密集层和注意力层组成。密集层独立处理序列中的每个词元,而注意力层则将这些词元视为一个集合。你可以改变序列中词元的顺序,得到相同的成对注意力得分和相同的上下文感知表示。即使你完全重排每个英语源句子中的每个词,模型也不会察觉,你仍然会得到相同的准确率。注意力机制是一种集合处理机制,它关注的是序列元素对之间的关系——它并不关心这些元素出现在序列的开头、结尾还是中间。那么,为什么我们说Transformer是一个序列模型呢?如果它不考虑词序,又怎么可能适用于机器翻译呢?
对于循环神经网络(RNN),我们依赖于层计算来感知顺序。而对于Transformer,我们则直接将位置信息注入到嵌入序列本身。这被称为位置嵌入。让我们来看一下。
嵌入位置信息
Embedding positional information
位置嵌入背后的思想非常简单:为了让模型能够获取词序信息,我们将单词在句子中的位置添加到每个词嵌入中。我们的输入词嵌入将包含两个部分:一个是通常的词向量,它表示单词本身,不依赖于任何特定的上下文;另一个是位置向量,它表示单词在当前句子中的位置。我们希望模型能够找到最佳方式来利用这些额外信息。
添加位置信息的最直接方法是将每个词的位置与其嵌入向量连接起来。你可以在向量中添加一个“位置”轴,并分别用0序列中第一个词、1第二个词,依此类推地填充该轴。
然而,这可能并不理想,因为位置值可能非常大,这将扰乱嵌入向量的值域。如您所知,神经网络不喜欢非常大的输入值或离散的输入分布。
《注意力机制》的作者们使用了一种有趣的技巧来编码词的位置:他们在词嵌入中添加了一个向量,[-1, 1]该向量包含的值会根据词的位置循环变化(他们使用余弦函数来实现这一点)。这个技巧提供了一种方法,可以通过一个包含小值的向量来唯一地刻画大范围内的任何整数。这很巧妙,但实际上我们可以做更简单、更有效的事情:我们将以学习词索引嵌入的相同方式来学习位置嵌入向量。然后,我们将位置嵌入添加到相应的词嵌入中,从而得到一个位置感知的词嵌入。这被称为位置嵌入( positional embedding )。让我们来实现它。
个人注:位置不是固定明确的存在吗?为什么还有学习位置嵌入这种说法?
这是一个非常深刻的问题。直觉上,位置(1, 2, 3...)确实是固定且明确的,但在深度学习的数学世界里,“明确的数字”并不等同于“模型能理解的特征”。
我们可以从以下三个核心维度来理解,为什么我们要“学习”位置嵌入,而不是简单地传给模型一个数字。
- 深度学习是“语义空间”的运算
神经网络处理的不是原始数字,而是高维向量空间。
- 词嵌入 (Word Embedding):将“苹果”转换成一个 512 维的向量。
- 问题所在:如果你直接把数字
5(代表第 5 个位置)加到这个 512 维的向量上,这就像是在一份精密的化学配方里突然倒进了一筐秤砣——数值跨度太大,会直接冲毁原本词嵌入的语义结构。学习位置嵌入的本质,是让模型自己找到一种“数学语言”,既能代表第 5 位,又能和词向量(如“苹果”)完美融合(相加),而不会产生严重的干扰。
- 相对距离比绝对数值更重要
对于模型来说,知道一个词在“第 5 位”没那么重要,重要的是知道它“离第 1 个词有多远”或者“它在谁的左边”。
- 固定编码(正余弦):是通过数学公式硬性规定了这种距离感。
- 学习编码(Learned Embedding):是给模型 512 个“空格”(假设词向量维度是 512),让模型通过训练发现:“哦,如果我在第 1 维加上 0.1,第 2 维减去 0.05,就能最好地表达‘我在开头’这个特征。”
这种学习出来的向量能够自发地捕捉到序列中的统计规律。
- 为什么说“学习”更简单、更有效?
虽然《Attention Is All You Need》最初使用正余弦函数是为了处理“比训练时更长的句子”,但后来的研究发现:
- 灵活性:学习出来的嵌入能更好地适应特定的任务。如果你的数据集里句式很固定(比如总是主谓宾),模型能学到特定的位置模式。
- 工程实现:正如你摘录的那段话所言,学习位置嵌入的代码极其简单——它本质上就是一个查找表(Lookup Table),和词嵌入的逻辑完全一样。
- 表现一致:在绝大多数现代大模型(如 BERT, GPT 系列)中,学习位置嵌入的效果往往不亚于甚至优于复杂的数学公式。
1 | from keras import ops |
清单 15.17:学习位置嵌入层
我们会PositionalEmbedding像使用普通Embedding层一样使用这一层。让我们看看它的实际效果,我们再来尝试训练一次Transformer模型。
1 | hidden_dim = 256 |
清单 15.18:构建带有位置嵌入的 Transformer 模型
现在模型中已经添加了位置嵌入,让我们再次尝试训练:
1 | transformer.compile( |
将位置信息重新加入模型后,情况有了显著改善。我们预测下一个单词的准确率达到了 67%。这比之前的GRU模型有了明显的提升,考虑到该模型的参数量只有 GRU 模型的一半,这一结果就更加令人印象深刻了。
关于这次训练,还有一点需要注意。训练速度明显快于 RNN——每个 epoch 的耗时大约只有 RNN 的三分之一。即使我们采用与 RNN 模型相同的参数数量,这一结论仍然成立,这得益于我们消除了GRU层间循环状态传递的副作用。使用注意力机制后,训练过程中无需处理循环计算,这意味着在 GPU 或 TPU 上,我们可以一次性完成所有注意力计算。这使得Transformer在加速器上训练速度更快。
让我们Transformer用新训练好的模型重新运行生成过程。我们可以使用与 RNN 采样相同的代码。
1 | import numpy as np |
清单 15.19:使用 Transformer 生成翻译
运行生成代码后,我们得到以下输出:
1 | - |
主观上来说,Transformer模型比基于GRU的转换模型表现明显更好。它仍然是个玩具模型,但它是个更好的玩具模型。
Transformer 是一种强大的架构,它为文本处理模型领域的蓬勃发展奠定了基础。就深度学习模型而言,它也相当复杂。了解了所有这些实现细节后,人们可能会合理地质疑这一切是否过于随意。有太多细小的细节需要我们去相信。我们又如何能确定这种层选择和配置是最优的呢?
答案很简单——并非如此。多年来,人们通过改进注意力机制、归一化和位置嵌入等方式,对Transformer架构提出了诸多改进。如今,随着序列长度的不断增长,许多新的研究模型正在用计算复杂度更低的机制完全取代注意力机制。最终,或许在你读到这本书的时候,Transformer架构已被其他架构取代,成为语言建模领域的主流架构。
我们能从Transformer模型中学到很多经得起时间考验的东西。在本章末尾,我们将探讨Transformer模型如此高效的原因。但值得注意的是,机器学习领域整体上是经验驱动的。注意力机制源于增强循环神经网络(RNN)的尝试,经过无数人的多年摸索和验证,最终催生了Transformer模型。我们没有理由认为这个过程已经结束。
使用预训练 Transformer 进行分类
Classification with a pretrained Transformer
在“Attention is all you need”发表之后,人们开始注意到Transformer模型的训练扩展性非常强,尤其与之前的模型相比更是如此。正如我们刚才提到的,它的一大优势是训练速度比RNN更快。训练过程中不再需要循环,这在使用GPU或TPU时尤为重要。
它也是一种非常消耗数据的模型架构。我们在上一节中已经略有体会。我们的RNN翻译模型在经过大约5个epoch的训练后,验证性能就趋于稳定,而Transformer模型在经过30个epoch的训练后,验证分数仍在不断提高。
这些观察结果促使许多人尝试使用更多的数据、层数和参数来扩展Transformer模型,并取得了显著成果。这导致该领域出现了一个显著的转变,即转向使用大型预训练模型。这些模型的训练成本可能高达数百万美元,但在文本领域的各种问题上表现明显更佳。
在文本部分的最后一个代码示例中,我们将重新审视 IMDb 文本分类问题,这次使用预训练的 Transformer 模型。
预训练Transformer编码器
Pretraining a Transformer encoder
最早在自然语言处理领域流行起来的预训练Transformer模型之一是BERT,它是Bidirectional Encoder Representations from Transformers(来自Transformer的双向编码器表示)的缩写。[2]这篇论文和模型是在《Attention Is All You Need》发表一年后发布的。该模型的结构与我们刚刚构建的翻译Transformer的编码器部分完全相同。这个编码器模型是双向的,序列中的每个位置都可以关注其前后位置。这意味着它非常适合计算输入文本的丰富表示,但不适合循环运行生成过程。
BERT 的训练参数规模在 1 亿到 3 亿之间,远大于我们刚刚训练的 1400 万参数的 Transformer。这意味着该模型需要大量的训练数据才能表现良好。为了实现这一点,作者采用了一种基于经典语言建模方法的改进方案,称为掩码语言模型 (Masked Language Modeling )。为了预训练模型,我们取一段文本序列,并将大约 15% 的词元替换为一个特殊[MASK]词元。在训练过程中,模型会尝试预测原始掩码词元的值。经典的语言模型(有时也称为因果语言模型)尝试预测的是原始值,p(token|past tokens)而掩码语言模型则尝试预测的是 原始值p(token|surrounding tokens)。
While the classic language model, sometimes called a causal language model, attempts to predict p(token|past tokens), the masked language model attempts to predict p(token|surrounding tokens).
这种训练方式是无监督的。你不需要为输入的文本添加任何标签;对于任何文本序列,你都可以轻松地选择一些随机标记并将其屏蔽掉。这使得作者能够轻松找到训练如此大规模模型所需的大量文本数据。他们主要从维基百科获取数据。
This training setup is unsupervised. You don’t need any labels about the text you feed in; for any text sequence, you can easily choose some random tokens and mask them out. That made it easy for the authors to find a large amount of text data needed to train models of this size. For the most part, they pulled from Wikipedia as a source.
在BERT发布时,使用预训练词嵌入已经是一种常见的做法——我们在上一章中已经看到了这一点。但是,预训练整个Transformer模型带来了更强大的功能——能够计算一个词在其周围词的上下文中的词嵌入。而且,Transformer模型能够以当时前所未有的规模和质量实现这一点。
BERT 的作者们利用这个在海量文本上预训练的模型,对其进行了专门优化,使其在当时的多个自然语言处理基准测试中取得了最先进的结果。这标志着该领域发生了显著的转变,即开始使用规模庞大的预训练模型,通常只需进行少量微调。让我们来尝试一下。
加载预训练的Transformer
Loading a pretrained Transformer
这里我们不使用 BERT,而是使用一个名为 RoBERTa 的后续模型。[3]RoBERTa 是 Robustly Optimized BERT 的缩写。RoBERTa 对 BERT 的架构进行了一些简化,但最显著的改进是使用了更多的训练数据来提升性能。BERT 使用了 16 GB 的英文文本,主要来自维基百科。而 RoBERTa 的作者使用了来自网络各处的 160 GB 文本。据估计,RoBERTa 当时的训练成本高达数十万美元。由于使用了额外的训练数据,在参数数量相同的情况下,RoBERTa 的性能明显优于 BERT。
要使用预训练模型,我们需要准备以下几样东西:
- 匹配分词器——与预训练模型配合使用。所有文本的分词方式必须与预训练期间相同。如果 IMDb 评论中的词语映射到的词元索引与预训练期间不同,我们就无法在模型中使用每个词元的学习表示。
- 匹配的模型架构 ——要使用预训练模型,我们需要精确地重现模型内部用于预训练的数学运算。
- 预训练权重——这些权重是通过在 1,024 个 GPU 和数十亿个输入词上训练模型约一天而创建的。
- A matching tokenizer — Used with the pretrained model itself. Any text must be tokenized in the same way as during pretraining. If the words of our IMDb reviews map to different token indices than they would have during pretraining, we cannot use the learned representations of each token in the model.
- A matching model architecture — To use the pretrained model, we need to recreate the math used internally by the model for pretraining exactly.
- The pretrained weights — These weights were created by training the model for about a day on 1,024 GPUs and billions of input words.
重新编写分词器和架构代码并不难。模型内部结构几乎与TransformerEncoder我们之前构建的完全相同。然而,匹配模型实现是一个耗时的过程,而且正如本书前面所述,我们可以使用 KerasHub 库来访问 Keras 的预训练模型实现。
我们使用 KerasHub 加载 RoBERTa 分词器和模型。我们可以使用特殊的构造函数from_preset()从磁盘加载预训练模型的权重、配置和分词器资源。我们将加载 RoBERTa 的基础模型,它是 RoBERTa 论文中发布的几个预训练检查点中最小的一个。
1 | import keras_hub |
清单 15.20:使用 KerasHub 加载 RoBERTa 预训练模型
Tokenizer正如我们所预期的,文本到整数序列的映射关系是存在的。还记得我们在上一章构建的那个分词SubWordTokenizer器吗?RoBERTa 的分词器几乎与它相同,只是做了一些细微的调整,以处理来自任何语言的 Unicode 字符。
鉴于 RoBERTa 预训练数据集的规模,子词分词是必不可少的。使用字符级分词器会导致输入序列过长,从而大大增加模型的训练成本。而使用词级分词器则需要庞大的词汇表才能覆盖来自网络数百万篇文档中的所有不同词汇。要获得良好的词汇覆盖率,词汇表规模将会急剧膨胀,导致Embedding Transformer 前端层过于庞大而无法运行。使用子词分词器则只需 5 万个词条的词汇表即可让模型处理任何单词:
1 | >>> tokenizer("The quick brown fox") |
我们刚刚加载的是什么Backbone?我们在第 8 章中看到,骨干网络(backbone)是计算机视觉中常用的一个术语,指的是将输入图像映射到潜在空间的网络——本质上是一个没有预测头的视觉模型。在 KerasHub 中,骨干网络指的是任何尚未针对特定任务进行专门训练的预训练模型。我们刚刚加载的模型接收一个输入序列,并将其嵌入到形状为 的输出序列中(batch_size, sequence_length, 768),但它没有针对特定的损失函数进行设置。你可以将它用于任何下游任务——例如句子分类、识别包含特定信息的文本片段、词性识别等等。
What is this Backbone we just loaded? We saw in chapter 8 that a backbone is a term often used in computer vision for a network that maps from input images to a latent space — basically a vision model without a head for making predictions. In KerasHub, a backbone refers to any pretrained model that is not yet specialized for a task. The model we just loaded takes in an input sequence and embeds it to an output sequence with shape (batch_size, sequence_length, 768), but it’s not set up for a particular loss function. You could use it for any number of downstream tasks — classifying sentences, identifying text spans with certain information, identifying parts of speech, etc.
接下来,我们将在这个主干系统上添加一个分类头,使其专门用于我们对 IMDb 影评分类的微调。你可以把它想象成给螺丝刀装上不同的刀头:十字头用于一种任务,一字头用于另一种任务。
让我们来看看我们的主干网络。这里我们加载的是RoBERTa 的最小版本,但它仍然有 1.24 亿个参数,这是我们在本书中使用过的最大模型:
1 | >>> backbone.summary() |
RoBERTa 使用了 12 个堆叠在一起的 Transformer 编码器层。这比我们的转换模型有了很大的进步!
IMDb 电影评论预处理
Preprocessing IMDb movie reviews
我们可以直接复用第 14 章中使用的 IMDb 加载代码。这将把电影评论数据下载到 a``train_dir和 b文件中test_dir,并将验证数据集拆分为 a 和 b 两部分val_dir:
1 | from keras.utils import text_dataset_from_directory |
加载完成后,我们再次拥有一个包含 20,000 条电影评论的训练集和一个包含 5,000 条电影评论的验证集。
在微调分类模型之前,我们必须使用已加载的 RoBERTa 分词器对电影评论进行分词。在预训练期间,RoBERTa 使用了一种特定的“打包”方式将词元排列成序列,类似于我们对翻译模型的处理方式。每个序列都以一个<s>词元开头,以一个 </s>词元结尾,后面可以跟任意数量的<pad>词元,如下所示:
1 | [ |
尽可能保持与预训练时相同的标记顺序非常重要;这样做可以提高模型的训练速度和准确性。KerasHub 提供了一个名为 set_token_packing 的层,用于这种类型的标记打包StartEndPacker。该层会添加起始标记、结束标记和填充标记,并在必要时将过长的序列修剪到给定的长度。让我们将它与分词器一起使用。
1 | def preprocess(text, label): |
列表 15.21:使用 RoBERTa 的分词器预处理 IMDb 电影评论
我们来看一个预处理后的批次:
1 | >>> next(iter(preprocessed_train_ds)) |
输入数据预处理完毕后,我们就可以开始微调模型了。
预训练数据来自哪里?
Where does pretraining data come from?
Transformer 模型对数据的需求量非常大。输入数据越多,它们的性能就越好,其规模之大在深度学习领域前所未见。最初的 Transformer 模型是用数百万个词元的翻译数据进行训练的。不久之后,Transformer 模型就用数十亿个词元进行训练,而如今,词元数量已达到数万亿。这相当于海量的文字。
那么,这些数据都来自哪里呢?答案随着时间推移而有所变化,但简而言之,就是互联网。另一种解释是,这已逐渐成为一个秘密。公司通常不会公布用于训练模型的确切数据,也不会描述训练过程中使用的具体数据源组合。
我们可以看一下一些预训练数据集随时间的变化:
- 第一个 Transformer 模型是在著名的英德翻译数据集上训练的,该数据集包含 400 万个句子对。
- BERT 使用了英文维基百科的转储数据以及包含 7,000 本自出版书籍的数据集。
- ChatGPT 的前身 GPT2 通过跟踪 Reddit 上的外部链接来抓取数据集。
- Meta发布的预训练Transformer模型Llama的最新版本,是基于“来自公开渠道的15万亿个数据标记”进行训练的。现在越来越常见的做法是模糊数据的具体构成。
下一章我们将探讨预训练数据源的具体组合有多么重要。尽可能地,密切关注模型数据的来源总是有益的,因为这会影响模型的偏差和性能。
对预训练的Transformer进行微调
Fine-tuning a pretrained Transformer
在对用于预测电影评论的主干网络进行微调之前,我们需要对其进行更新,使其输出二元分类标签。主干网络输出一个形状为 的完整序列(batch_size, sequence_length, 768),其中每个 768 维向量代表一个输入词及其周围词的上下文。在预测标签之前,我们必须将此序列压缩为每个样本一个向量。
一种方法是对整个序列进行均值池化或最大池化,计算所有标记向量的平均值。但效果稍好一些的方法是直接使用第一个标记的表示作为池化值。这是因为我们模型中注意力机制的特性——最终编码器层的第一个位置能够关注序列中的所有其他位置并从中提取信息。因此,注意力机制允许我们根据序列的上下文信息进行池化,而不是像取平均值那样使用粗略的方法 。
现在,让我们在主干网络中添加一个分类头。在生成输出预测之前,我们还会添加一个 Dense带有非线性的最终投影。
1 | inputs = backbone.input |
清单 15.22:扩展基础 RoBERTa 模型以进行分类
这样一来,我们就可以对 IMDb 数据集进行微调和评估了。
1 | classifier.compile( |
清单 15.23:训练 RoBERTa 分类模型
最后,我们来评估一下训练好的模型:
1 | >>> classifier.evaluate(preprocessed_test_ds) |
仅经过一个训练周期,我们的模型准确率就达到了 93%,相比上一章 90% 的上限有了显著提升。当然,这比我们之前构建的简单二元分类器要昂贵得多,但使用如此庞大的模型也有其显而易见的优势。而且这还是在 RoBERTa 模型规模较小的情况下取得的。如果使用更大的、拥有 3 亿参数的模型,我们甚至可以达到 95% 以上的准确率。
是什么让Transformer如此有效?
What makes the Transformer effective?
2013年,在谷歌,托马斯·米科洛夫和他的同事们注意到了一些非凡的现象。他们正在构建一个名为“Word2Vec”的预训练词嵌入模型,类似于我们在上一章中构建的连续词袋模型(CBOW)。与我们的CBOW模型类似,他们的训练目标是将词语之间的相关性转化为词嵌入空间中的距离关系:词汇表中的每个词都关联一个向量,并且这些向量经过优化,使得表示频繁共现词的向量之间的点积(余弦邻近度)更接近1,而表示不常共现词的向量之间的点积更接近0。
他们发现,由此产生的嵌入空间远不止捕捉语义相似性那么简单。它展现了一种涌现式学习(emergent learning)——一种类似“词语算术”的能力。在这个空间中存在一个向量,你可以将它添加到许多男性名词上,从而得到一个接近其女性对应词的点,例如 V(king) - V(man) + V(woman) = V(queen),这是一个性别向量。这相当令人惊讶;该模型并没有针对此进行任何显式训练。似乎存在数十个这样的神奇向量——复数向量、将野生动物名称映射到其最接近的宠物名称的向量等等。
快进十年——我们现在进入了大型预训练Transformer模型的时代。表面上看,这些模型与原始的Word2Vec模型截然不同。Transformer可以生成流畅自然的语言——这是Word2Vec完全无法做到的。正如我们将在下一章中看到的,这类模型似乎对几乎任何主题都了如指掌。然而,它们实际上与经典的Word2Vec有很多共同之处。
两种模型都试图将词元(单词或子词)嵌入到向量空间中。它们都基于相同的基本原理来学习这个空间:同时出现的词元在嵌入空间中会彼此靠近。两种模型都使用余弦距离来比较词元。甚至嵌入空间的维度也相似:每个词元都用一个维度在 1000 到 10000 之间的向量来表示。
此时你可能会插话:Transformer 的训练目的是预测序列中缺失的词,而不是将词元分组到嵌入空间中。语言模型的损失函数与 Word2Vec 最大化共现词元点积的目标有何关系?答案是注意力机制。
注意力机制无疑是Transformer架构中最关键的组成部分。它通过线性重组先前空间中的词嵌入来学习新的词嵌入空间,并以加权组合的方式赋予彼此“更接近”(即点积更高)的词更大的权重。它会将原本就接近的词的向量聚集在一起,最终形成一个词相关性转化为嵌入邻近性(以余弦距离衡量)的空间。Transformer的工作原理是学习一系列逐步细化的嵌入空间,每个空间都基于对前一个空间元素的重组。
注意力机制为Transformer提供了两个关键特性:
- 它们学习到的嵌入空间在语义上是连续的——也就是说,在嵌入空间中移动一个位,只会改变相应词元的人类可理解含义一个位。Word2Vec空间也展现了这一特性。
- 它们学习到的嵌入空间是语义插值的——也就是说,在嵌入空间中取两个点之间的中间点,就能得到一个代表对应词元之间“中间含义”的点。这是因为每个新的嵌入空间都是通过对前一个空间中的向量进行插值构建的。
- The embedding spaces they learn are semantically continuous — that is, moving a bit in an embedding space only changes the human-facing meaning of the corresponding tokens by a bit. The Word2Vec space also exhibited this property.
- The embedding spaces they learn are semantically interpolative — that is, taking the intermediate point between two points in an embedding space produces a point representing the “intermediate meaning” between the corresponding tokens. This comes from the fact that each new embedding space is built by interpolating between vectors from the previous space.
这与大脑的学习方式并非完全不同。大脑学习的关键原则是赫布学习(Hebbian learning)——简而言之,“同时激活的神经元会连接在一起”。神经元激活事件(可能代表动作或感知输入)之间的相关关系在大脑网络中转化为邻近关系,就像Transformer和Word2Vec将相关关系转化为向量邻近关系一样。两者都是信息空间的映射。
当然,Word2Vec 和 Transformer 之间存在显著差异。Word2Vec 并非为生成式文本采样而设计。Transformer 的规模可以远超 Word2Vec,并且能够编码更为复杂的转换。问题在于,Word2Vec 本质上只是一个玩具模型:它之于当今的语言模型,就像基于 MNIST 像素的逻辑回归之于最先进的计算机视觉模型一样。虽然基本原理大体相同,但这个玩具模型缺乏任何有意义的表征能力。Word2Vec 甚至算不上深度神经网络——它采用的是浅层的单层架构。而如今的 Transformer 模型拥有迄今为止训练过的所有模型中最强大的表征能力——它们包含数十个堆叠的注意力层和前馈层,参数数量高达数十亿。
与 Word2Vec 类似,Transformer 在将词元组织成向量空间的过程中,会学习到有用的语义函数。但得益于更强大的表示能力和更精细的自回归优化目标,我们不再局限于性别向量或复数向量之类的线性变换。Transformer 可以存储任意复杂的向量函数——事实上,它们复杂到更准确地说是向量程序而非函数。
Word2Vec 可以让你执行一些基本操作,例如plural(cat) → cats…… male_to_female(king) → queen。而大型 Transformer 模型则可以实现一些神奇的功能,例如write_this_in_style_of_shakespeare("...your poem...") → "...new poem..."……。一个模型甚至可以包含数百万个这样的程序。
你可以把Transformer看作类似于数据库:它存储着你可以通过传入的令牌检索的信息。但是Transformer和数据库之间有两个重要的区别。
首先,Transformer 是一种连续的、可插值的数据库。它并非将数据存储为一组离散的条目,而是将其存储为一个向量空间——一条曲线。你可以在这条曲线上移动(正如我们之前讨论的,它在语义上是连续的),探索附近相关的点。你还可以对不同数据点进行插值,找到它们的中间状态。这意味着你可以从数据库中检索到比输入更多的信息——尽管并非所有信息都准确或有意义。插值可以带来泛化能力,但也可能导致“幻觉”——这是当今训练的生成式语言模型面临的一个重大问题。
第二个区别在于,Transformer 模型不仅仅包含数据。对于像 RoBERTa 这样的模型来说,它基于从互联网抓取的数十万份文档进行训练,因此包含大量数据:事实、地点、人物、日期、事物和关系。但它同时也是一个程序数据库——或许它最重要的功能就是程序。
请注意,它们与您通常接触的程序有所不同。它们不像 Python 程序那样——一系列符号语句逐步处理数据。相反,这些向量程序是高度非线性的函数,它们将潜在嵌入空间映射到自身,类似于 Word2Vec 的“魔法向量”,但要复杂得多。
在下一章中,我们将把Transformer模型推向一个全新的规模。这些模型将使用数十亿个参数,并在数万亿个单词上进行训练。这些模型的输出常常令人感觉神奇——仿佛有一个智能操作员坐在模型内部,操控着一切。但重要的是要记住,这些模型本质上是插值模型——由于注意力机制的存在,它们学习了一个包含大量英语文本的插值嵌入空间。探索这个嵌入空间可能会带来一些有趣且意想不到的泛化结果,但它无法合成出任何接近真正人类智能的全新事物。
概括
- 语言模型是一种学习特定概率分布的模型——
p(token|past tokens):- 语言模型应用广泛,但最重要的是,你可以通过循环调用它们来生成文本,其中一个时间步的输出标记会成为下一个时间步的输入标记。
- 掩码语言模型学习相关的概率分布
p(tokens|surrounding tokens),有助于对文本和单个词元进行分类。 - 序列到序列语言模型通过学习预测目标序列中已有的词元以及一个完全独立、固定的源序列中的下一个词元。序列到序列模型在翻译和问答等问题中非常有用。
- 序列到序列模型通常包含两个独立的组件。 编码器计算源序列的表示,解码器 以该表示作为输入,并根据过去的标记预测目标序列中的下一个标记。
- 注意力机制允许模型根据当前正在处理的词元的上下文,有选择地从序列中的任何位置提取信息:
- 注意力机制避免了循环神经网络在处理文本中的长程依赖关系时遇到的问题。
- 注意力机制的工作原理是计算两个向量的点积来获得注意力分数。在嵌入空间中彼此接近的向量会在注意力机制中被求和。
- Transformer是一种序列建模架构,它使用注意力机制作为在序列中传递信息的唯一机制:
- Transformer 的工作原理是堆叠交替注意力模块和两层前馈网络。
- Transformer 可以扩展到许多参数和大量训练数据,同时还能提高语言建模问题的准确性。
- 与 RNN 不同,Transformer 在训练时不涉及序列长度循环,这使得模型更容易在多台机器上并行训练。
- Transformer编码器利用双向注意力机制来构建序列的丰富表示。
- Transformer解码器利用因果注意力来预测语言模型设置中的下一个词。
脚注
- Vaswani 等人,“注意力就是你所需要的一切”,第 31 届国际神经信息处理系统会议论文集 (2017),https://arxiv.org/abs/1706.03762。
- Devlin 等人,“BERT:用于语言理解的深度双向 Transformer 的预训练”,2019 年北美计算语言学协会会议论文集:人类语言技术,第 1 卷 (2019),https://arxiv.org/abs/1810.04805。
- Liu 等人,“RoBERTa:一种鲁棒优化的 BERT 预训练方法”(2019),https://arxiv.org/abs/1907.11692。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论