《DEEP LEARNING with Python》第十一章 图像分割
第十一章 图像分割
Image segmentation
运行代码
本章内容
- 计算机视觉的不同分支包括:图像分类、图像分割和目标检测。
- 从零开始构建分割模型
- 使用预训练的 Segment Anything 模型
- The different branches of computer vision: image classification, image segmentation, and object detection
- Building a segmentation model from scratch
- Using the pretrained Segment Anything Model
第 8 章通过一个简单的用例——二值图像分类——初步介绍了计算机视觉中的深度学习。但计算机视觉远不止图像分类!本章将深入探讨计算机视觉的另一个重要应用——图像分割。
计算机视觉任务
Computer vision tasks
到目前为止,我们主要关注的是图像分类模型:输入一张图像,输出一个标签。“这张图很可能包含一只猫;这张图很可能包含一只狗。” 但图像分类只是深度学习在计算机视觉领域众多应用之一。总的来说,你需要了解以下三个基本的计算机视觉任务:
- 图像分类的目标是为图像分配一个或多个标签。它可以是单标签分类(即类别互斥),也可以是多标签分类(标记图像所属的所有类别,如图 11.1 所示)。例如,当您在 Google Photos 应用中搜索关键词时,实际上您是在查询一个非常庞大的多标签分类模型——该模型包含超过 20,000 个不同的类别,并基于数百万张图像进行训练。
- 图像分割的目标是将图像“分割”或“划分”成不同的区域,每个区域通常代表一个类别(如图 11.1 所示)。例如,当 Zoom 或 Google Meet 在视频通话中显示自定义背景时,它就是使用图像分割模型来区分你的脸和背景,精度可达像素级。
- 目标检测的目标是在图像中围绕感兴趣的物体绘制矩形框(称为边界框),并将每个矩形框与一个类别关联起来。例如,自动驾驶汽车可以使用目标检测模型来监控其摄像头视野范围内的车辆、行人和标志。
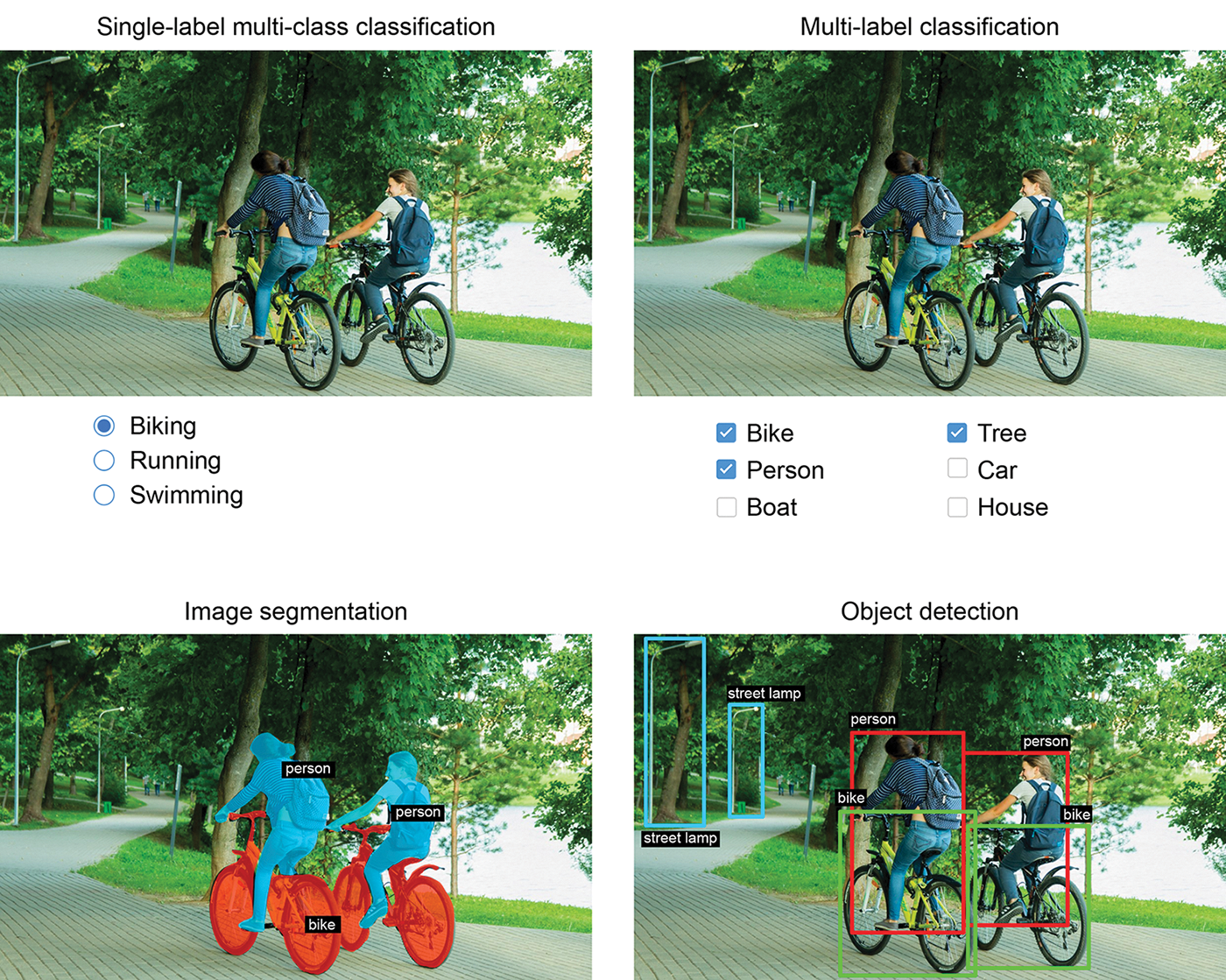 图 11.1:计算机视觉的三大主要任务:分类、分割和检测
图 11.1:计算机视觉的三大主要任务:分类、分割和检测
除了图像分类、图像分割和目标检测这三者之外,深度学习在计算机视觉领域还涵盖了一些更为细分的任务,例如图像相似度评分(评估两幅图像的视觉相似程度)、关键点检测(精确定位图像中感兴趣的属性,例如面部特征)、姿态估计、3D网格估计、深度估计等等。但首先,图像分类、图像分割和目标检测是每位机器学习工程师都应该熟悉的基础。几乎所有计算机视觉应用最终都可以归结为这三者之一。
Deep learning for computer vision also encompasses a number of somewhat more niche tasks besides these three, such as image similarity scoring (estimating how visually similar two images are), keypoint detection (pinpointing attributes of interest in an image, such as facial features), pose estimation, 3D mesh estimation, depth estimation, and so on. But to start with, image classification, image segmentation, and object detection form the foundation that every machine learning engineer should be familiar with. Almost all computer vision applications boil down to one of these three.
你已经在第8章中了解了图像分类的实际应用。接下来,我们将深入探讨图像分割。图像分割是一种非常实用且用途广泛的技术,你可以运用目前为止所学的知识轻松上手。然后,在下一章中,你将详细学习目标检测。
图像分割的类型
Types of image segmentation
基于深度学习的图像分割是指利用模型为图像中的每个像素分配一个类别,从而将图像分割成不同的区域(例如“背景”和“前景”或“道路”、“汽车”和“人行道”)。这类技术可应用于图像和视频编辑、自动驾驶、机器人、医学成像等众多领域,并具有广泛的应用价值。
你应该了解三种不同的图像分割方法:
- 语义分割,其中每个像素都被独立地分类到一个语义类别,例如“猫”。如果图像中有两只猫,则对应的像素都映射到同一个通用的“猫”类别(见图 11.2)。
- 实例分割旨在解析出单个对象实例。在一张包含两只猫的图像中,实例分割会区分属于“猫 1”的像素和属于“猫 2”的像素(见图 11.2)。
- 全景分割结合了语义分割和实例分割,它为图像中的每个像素分配一个语义标签(例如“猫”)和一个实例标签(例如“猫2”)。这是三种分割类型中信息量最大的。
- Semantic segmentation, where each pixel is independently classified into a semantic category, like “cat.” If there are two cats in the image, the corresponding pixels are all mapped to the same generic “cat” category (see figure 11.2).
- Instance segmentation, which seeks to parse out individual object instances. In an image with two cats in it, instance segmentation would distinguish between pixels belonging to “cat 1” and pixels belonging to “cat 2” (see figure 11.2).
- Panoptic segmentation, which combines semantic segmentation and instance segmentation by assigning to each pixel in an image both a semantic label (like “cat”) and an instance label (like “cat 2”). This is the most informative of all three segmentation types.
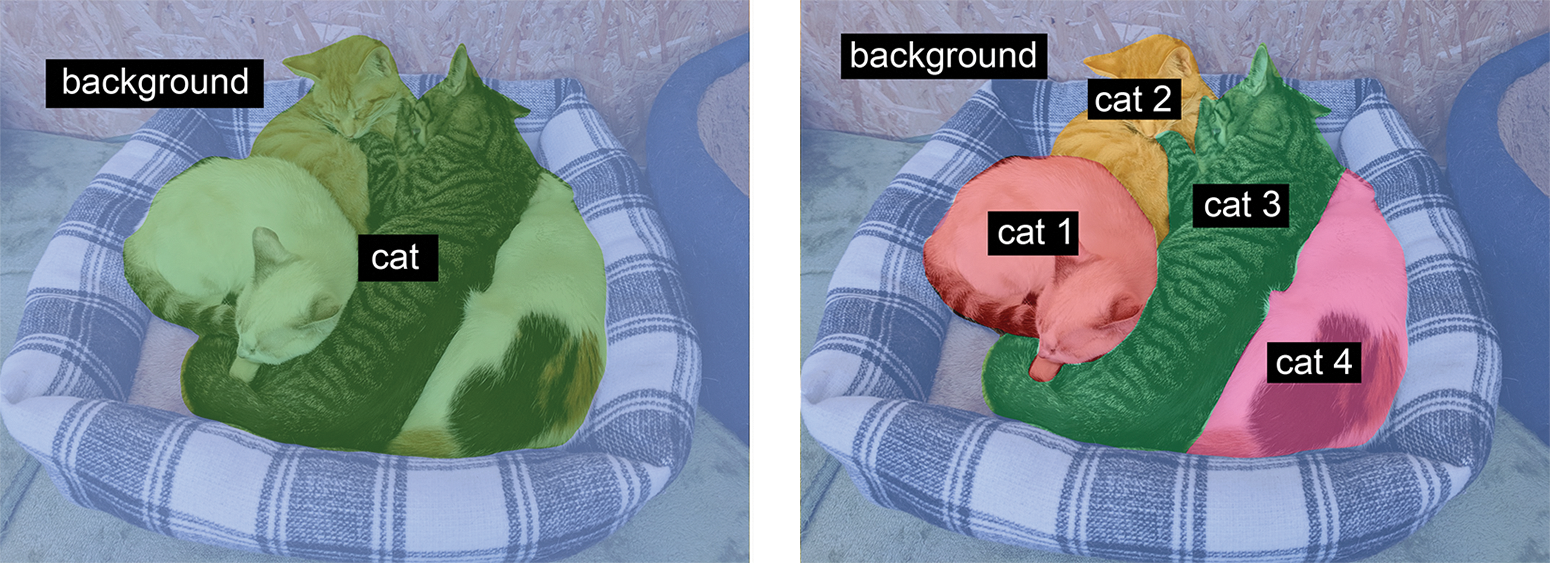 图 11.2:语义分割与实例分割
图 11.2:语义分割与实例分割
为了更好地了解分割,让我们从头开始,用您自己的数据训练一个小型分割模型。
从零开始训练分割模型
Training a segmentation model from scratch
在第一个例子中,我们将重点关注语义分割。我们将再次观察猫和狗的图像,这次我们将学习如何区分主体和背景。
下载分割数据集
Downloading a segmentation dataset
我们将使用牛津大学-IIIT宠物数据集(https://www.robots.ox.ac.uk/~vgg/data/pets/),该数据集包含7390张不同品种猫狗的图片,以及每张图片的前景-背景分割掩码。分割掩码相当于图像分割中的标签:它是一个与输入图像大小相同的图像,只有一个颜色通道,其中每个整数值对应于输入图像中相应像素的类别。在我们的例子中,分割掩码的像素可以取以下三个整数值之一:
- 1(前景 foreground)
- 2(背景 background)
- 3(轮廓 contour)
首先,我们使用 shell 工具下载并解压缩数据wget集tar :
1 | !wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz |
输入图片以 JPG 文件形式存储在images/文件夹(例如images/Abyssinian_1.jpg)中,相应的分割掩码以同名 PNG 文件形式存储在annotations/trimaps/文件夹(例如annotations/trimaps/Abyssinian_1.png)中。
让我们准备输入文件路径列表以及对应的掩码文件路径列表:
1 | import pathlib |
那么,这些输入之一及其掩码是什么样的呢?让我们快速看一下(见图 11.3)。
1 | import matplotlib.pyplot as plt |
 图 11.3:示例图像
图 11.3:示例图像
我们再来看一下它的目标掩码(见图 11.4):
1 | def display_target(target_array): |
 图 11.4:对应的目标掩模
图 11.4:对应的目标掩模
接下来,我们将输入和目标值加载到两个 NumPy 数组中。由于数据集非常小,我们可以将所有内容加载到内存中:
1 | import numpy as np |
和往常一样,我们将数组分成训练集和验证集:
1 | # Reserves 1,000 samples for validation |
构建和训练分割模型
现在,是时候定义我们的模型了:
1 | import keras |
模型的前半部分与用于图像分类的卷积神经网络(ConvNet)非常相似:由一系列Conv2D层堆叠而成,滤波器尺寸逐渐增大。我们将图像以两倍的因子进行三次下采样,最终得到大小为 的激活值 (25, 25, 256)。前半部分的目的是将图像编码成更小的特征图,其中每个空间位置(或“像素”)都包含原始图像中较大空间区域的信息。您可以将其理解为一种压缩。
该模型前半部分与之前你看到的分类模型的一个重要区别在于下采样的方式:在第 8 章的分类卷积神经网络中,我们使用MaxPooling2D层来对特征图进行下采样。而在这里,我们通过给每隔一个卷积层添加步长来进行下采样(如果你不记得卷积步长的工作原理,请参阅第 8 章 8.1.1 节)。这样做是因为在图像分割中,我们非常关注图像中信息的空间位置,因为我们需要生成每个像素的目标掩码作为模型的输出。当你进行 2×2 最大池化时,你会完全破坏每个池化窗口内的位置信息:每个窗口返回一个标量值,而你完全不知道这个值来自窗口中的哪个位置。
因此,虽然最大池化层在分类任务中表现良好,但在分割任务中却会造成相当大的负面影响。与此同时,步长卷积在下采样特征图的同时,能够更好地保留位置信息。在本书中,你会注意到,对于任何需要关注特征位置的模型,例如第 17 章中的生成模型,我们倾向于使用步长卷积而不是最大池化。
模型的后半部分是由一系列Conv2DTranspose层堆叠而成。这些层是什么呢?模型前半部分的输出是一个形状为 的特征图(25, 25, 256),但我们希望最终输出能够预测每个像素的类别,使其与原始空间维度相匹配。最终模型的输出形状为(200, 200, num_classes),如图所示(200, 200, 3)。因此,我们需要应用一种与之前应用的变换相反的操作,即对特征图进行上采样而不是下采样。这就是 层的作用Conv2DTranspose:你可以把它看作是一个学习上采样的卷积层。如果你有一个形状为 的输入(100, 100, 64),并将其输入到 层,Conv2D(128, 3, strides=2, padding="same")你会得到一个形状为 的输出(50, 50, 128)。如果你将这个输出输入到 层 Conv2DTranspose(64, 3, strides=2, padding="same"),你会得到一个形状为 的输出(100, 100, 64),与原始输入相同。因此,在(25, 25, 256)通过一系列Conv2D 层将输入压缩成形状为 的特征图之后,我们可以简单地应用相应的层序列,Conv2DTranspose 最后加上一个最终Conv2D层,从而生成形状为 的输出(200, 200, 3)。
为了评估模型,我们将使用 交并比( Intersection over Union)(IoU) 指标。它衡量的是真实分割掩码和预测掩码之间的匹配程度。可以分别计算每个类别的 IoU,也可以对多个类别取平均值。其工作原理如下:
- 计算掩码之间的交集,即预测结果与真实值重叠的区域。
- 计算两个掩码的并集,即两个掩码共同覆盖的总面积。这就是我们感兴趣的整个空间——目标对象以及模型可能错误包含的任何额外部分。
- 将交集面积除以并集面积即可得到交并比 (IoU)。IoU 是一个介于 0 和 1 之间的数字,其中 1 表示完全匹配,0 表示完全不匹配。
我们可以直接使用 Keras 内置的指标,而无需自己构建:
1 | foreground_iou = keras.metrics.IoU( |
现在我们可以编译并拟合我们的模型了:
1 | model.compile( |
让我们展示一下训练损失和验证损失(见图 11.5):
1 | epochs = range(1, len(history.history["loss"]) + 1) |
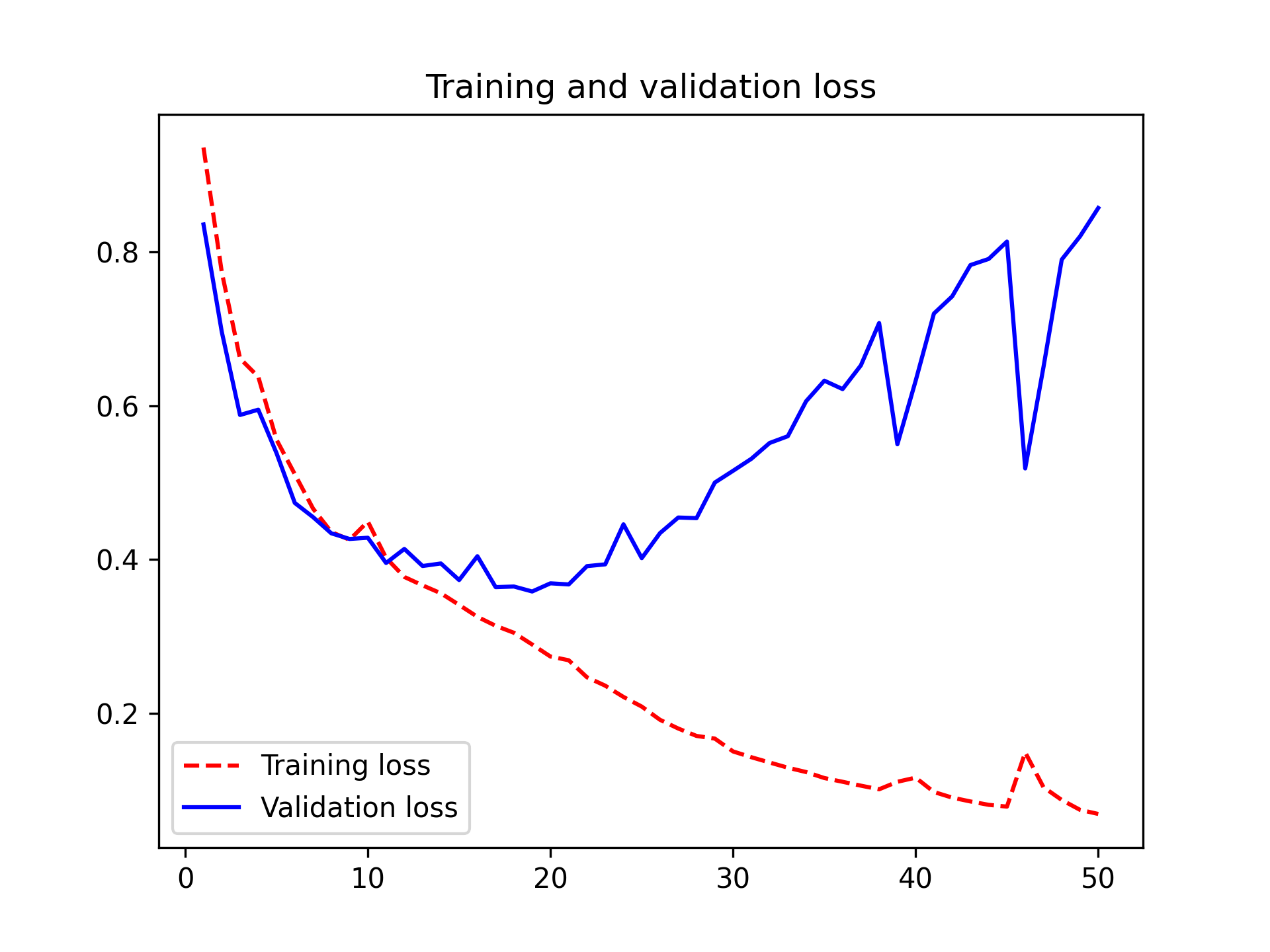 图 11.5:显示训练和验证损失曲线
图 11.5:显示训练和验证损失曲线
你可以看到,我们在大约第 25 个 epoch 左右开始出现过拟合现象。让我们根据验证损失重新加载性能最佳的模型,并演示如何使用它来预测分割掩码(参见图 11.6):
1 | model = keras.models.load_model("oxford_segmentation.keras") |
 图 11.6:测试图像及其预测的分割掩码
图 11.6:测试图像及其预测的分割掩码
我们预测的掩模中存在一些细微的瑕疵,这是由前景和背景的几何形状造成的。尽管如此,我们的模型看起来运行良好。
使用预训练分割模型
Using a pretrained segmentation model
在第 8 章的图像分类示例中,您已经看到,使用预训练模型可以显著提高准确率——尤其是在只有少量样本可供训练的情况下。图像分割也是如此。
细分任何事物模型(The Segment Anything Model)[1]SAM(或简称 SAM)是一款功能强大的预训练分割模型,几乎可以用于任何场景。它由 Meta AI 开发,于 2023 年 4 月发布。该模型使用 1100 万张图像及其分割掩码进行训练,涵盖超过 10 亿个对象实例。如此庞大的训练数据使模型具备了对自然图像中几乎所有对象的内置知识。
SAM 的主要创新之处在于它不局限于预定义的对象类别。您只需提供一个示例来描述您要查找的对象,即可使用它来分割新的对象。您甚至无需事先对模型进行微调。让我们看看它是如何工作的。
下载 Segment Anything 模型
Downloading the Segment Anything Model
首先,我们实例化 SAM 模型并下载其权重。同样,我们可以使用 KerasHub 包来使用这个预训练模型,而无需从头开始自行实现。
还记得ImageClassifier我们在上一章用到的任务吗?我们可以使用另一个 KerasHub 任务ImageSegmenter,将预训练的图像分割模型封装成一个具有标准输入输出的高级模型。这里,我们将使用 sam_huge_sa1b预训练模型,其中sam代表模型,huge 代表模型中的参数数量, 代表sa1b与模型一起发布的 SA-1B 数据集,其中包含 10 亿个带标注的掩码。现在就下载吧:
1 | import keras_hub |
首先我们可以注意到的一点是,我们的模型确实非常庞大:
1 | >>> model.count_params() |
SAM模型拥有6.41亿个参数,是本书迄今为止我们使用过的最大模型。预训练模型规模越来越大、使用的数据量越来越大的趋势,将在第16章中进行更详细的讨论。
Segment Anything 的工作原理
How Segment Anything works
在尝试使用该模型进行分割之前,我们先来详细了解一下SAM的工作原理。该模型的强大功能很大程度上源于其预训练数据集的规模。Meta公司在开发模型的同时还开发了SA-1B数据集,其中部分训练好的模型被用于辅助数据标注过程。也就是说,数据集和模型是在一个反馈循环中共同开发的。
SA-1B 数据集的目标是创建完全分割的图像,其中图像中的每个对象都被赋予一个唯一的分割掩码。参见图 11.7 的示例。数据集中的每张图像平均有约 100 个掩码,有些图像甚至包含超过 500 个单独掩码的对象。这是通过一个逐步自动化的数据采集流程实现的。最初,专家们手动分割了一个小型示例数据集,并用它来训练一个初始模型。该模型用于驱动半自动化的数据采集阶段,在该阶段,图像首先由 SAM 进行分割,然后通过人工校正和进一步标注进行改进。
 图 11.7:SA-1B 数据集中的示例图像
图 11.7:SA-1B 数据集中的示例图像
该模型使用(image, prompt, mask)三元组进行训练。image和prompt 是模型的输入。图像可以是任何输入图像,提示信息可以采用以下几种形式:
- 要遮罩的物体内部点(A point inside the object to mask)
- 用方框框住物体以进行遮罩(A box around the object to mask)
给定image输入prompt,该模型应生成提示所指示对象的准确预测掩码,并将其与真实mask标签进行比较。
该模型由几个独立的组件构成。其中一个图像编码器类似于我们在前几章中使用的 Xception 模型,它会接收输入图像并输出一个更小的图像嵌入。我们已经知道如何构建这个编码器。
接下来,我们添加一个提示编码器,它负责将前面提到的任何形式的提示映射到嵌入向量;以及一个掩码解码器,它接收图像嵌入和提示嵌入作为输入,并输出几个可能的预测掩码。这里我们不详细介绍提示编码器和掩码解码器,因为它们使用了一些建模技术,我们将在后面的章节中介绍。我们可以像本章前面部分那样,将这些预测掩码与真实掩码进行比较(参见图 11.8)。
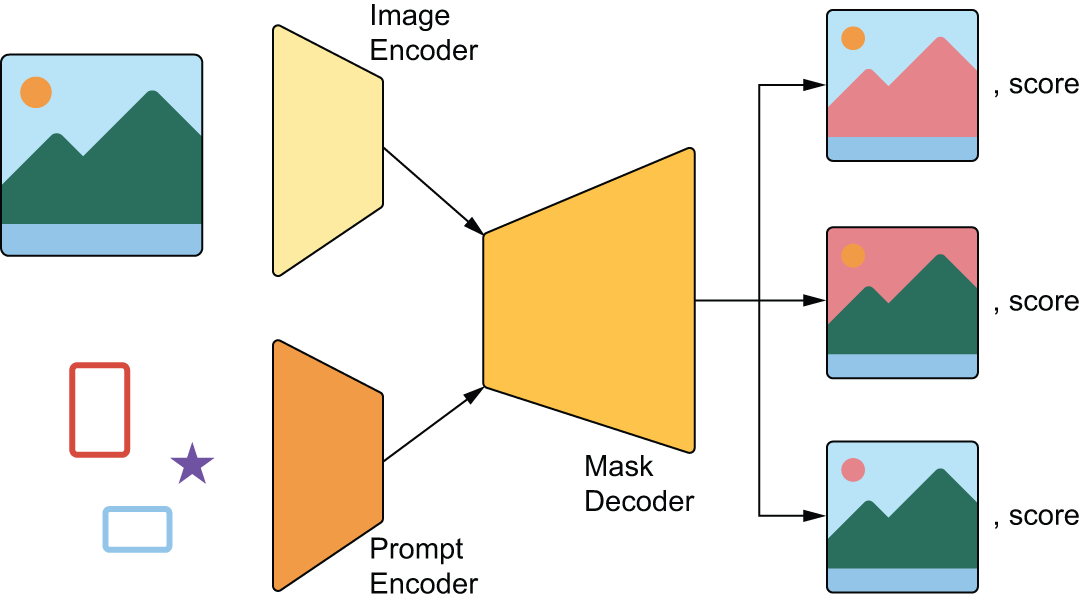 图 11.8:Segment Anything 高级架构概述
图 11.8:Segment Anything 高级架构概述
所有这些子组件都通过 (image, prompt, mask)从 SA-1B 图像和掩码数据中生成新的三元组批次进行同时训练。这个过程其实很简单。对于给定的输入图像,首先在输入中随机选择一个掩码。然后,随机选择创建框提示还是点提示。要创建点提示,在掩码标签内随机选择一个像素。要创建框提示,则在掩码标签内的所有点周围绘制一个框。我们可以无限重复这个过程, (image, prompt, mask)从每个图像输入中采样若干个三元组。
准备测试图像
Preparing a test image
让我们通过实际测试模型来具体说明这一点。我们可以先加载一张测试图像进行分割。我们将使用一张水果碗的图片(见图 11.9):
1 | # Downloads the image and returns the local file path |
 图 11.9:我们的测试图像
图 11.9:我们的测试图像
SAM 期望输入图像为 1024 × 1024。然而,强制将任意图像调整为 1024 × 1024 会扭曲其宽高比——例如,我们的图像并非正方形。更好的做法是先调整图像大小,使其最长边变为 1024 像素,然后用填充值(例如 0)填充剩余像素。我们可以使用操作pad_to_aspect_ratio 中的参数来实现这一点keras.ops.image.resize(),如下所示:
1 | from keras import ops |
接下来,我们来定义一些在使用模型时会用到的实用工具。我们需要……
- 显示图像。
- 在图像上叠加显示分割掩码。
- 突出显示图像中的特定点。
- 在图像上叠加显示框。
我们所有的实用程序都接受一个 Matplotlibaxis对象(记为ax),以便它们都可以写入同一个图形:
1 | import matplotlib.pyplot as plt |
用目标点提示模型
Prompting the model with a target point
要使用 SAM,您需要发出提示。这意味着我们需要以下选项之一:
- 点提示— 选择图像中的一个点,让模型分割出该点所属的对象。
- 框提示——在物体周围画一个大致的框(不需要特别精确),让模型将物体分割到框内。
我们先从一个点提示开始。这些点都带有标签,1 表示前景(你要分割的对象),0 表示背景(对象周围的一切)。在情况不明确时,为了提高分割效果,你可以传递多个带标签的点,而不是单个点,这样可以更精确地定义哪些区域应该包含在分割范围内(标记为 1 的点),哪些区域应该排除在外(标记为 0 的点)。
我们尝试使用单个前景点(见图 11.10)。以下是一个测试点:
1 | import numpy as np |
 图 11.10:一个提示点落在桃子上
图 11.10:一个提示点落在桃子上
让我们用它提示SAM:
1 | outputs = model.predict( |
返回值outputs包含一个字段,其中包含四个目标对象的 256 × 256 候选掩码,按匹配质量降序排列。掩码的质量分数作为模型输出的一部分,"masks"在该字段下可用:"iou_pred"
1 | >>> outputs["masks"].shape |
让我们将第一个蒙版叠加到图像上(见图 11.11):
1 | def get_mask(sam_outputs, index=0): |
 图 11.11:桃子
图 11.11:桃子
不错!
接下来,我们来试试香蕉。我们将向模型输入坐标(300, 550),该坐标指向从左边数第二个香蕉(见图 11.12):
1 | input_point = np.array([[300, 550]]) |
 图 11.12:香蕉瓣
图 11.12:香蕉瓣
那么,其他掩码候选方案呢?它们在处理含义模糊的提示时非常有用。让我们尝试绘制其他三个掩码(见图 11.13):
1 | fig, axes = plt.subplots(1, 3, figsize=(20, 60)) |
 图 11.13:香蕉提示的替代分割掩码
图 11.13:香蕉提示的替代分割掩码
正如您在这里看到的,模型找到的另一种分割方式包含了香蕉。
使用目标框提示模型
Prompting the model with a target box
除了提供一个或多个目标点之外,您还可以提供近似于待分割对象位置的框。这些框应通过其左上角和右下角的坐标传递。下图是芒果周围的框(参见图 11.14):
1 | input_box = np.array( |
 图 11.14:芒果周围的框提示
图 11.14:芒果周围的框提示
让我们用它来提示 SAM(参见图 11.15):
1 | outputs = model.predict( |
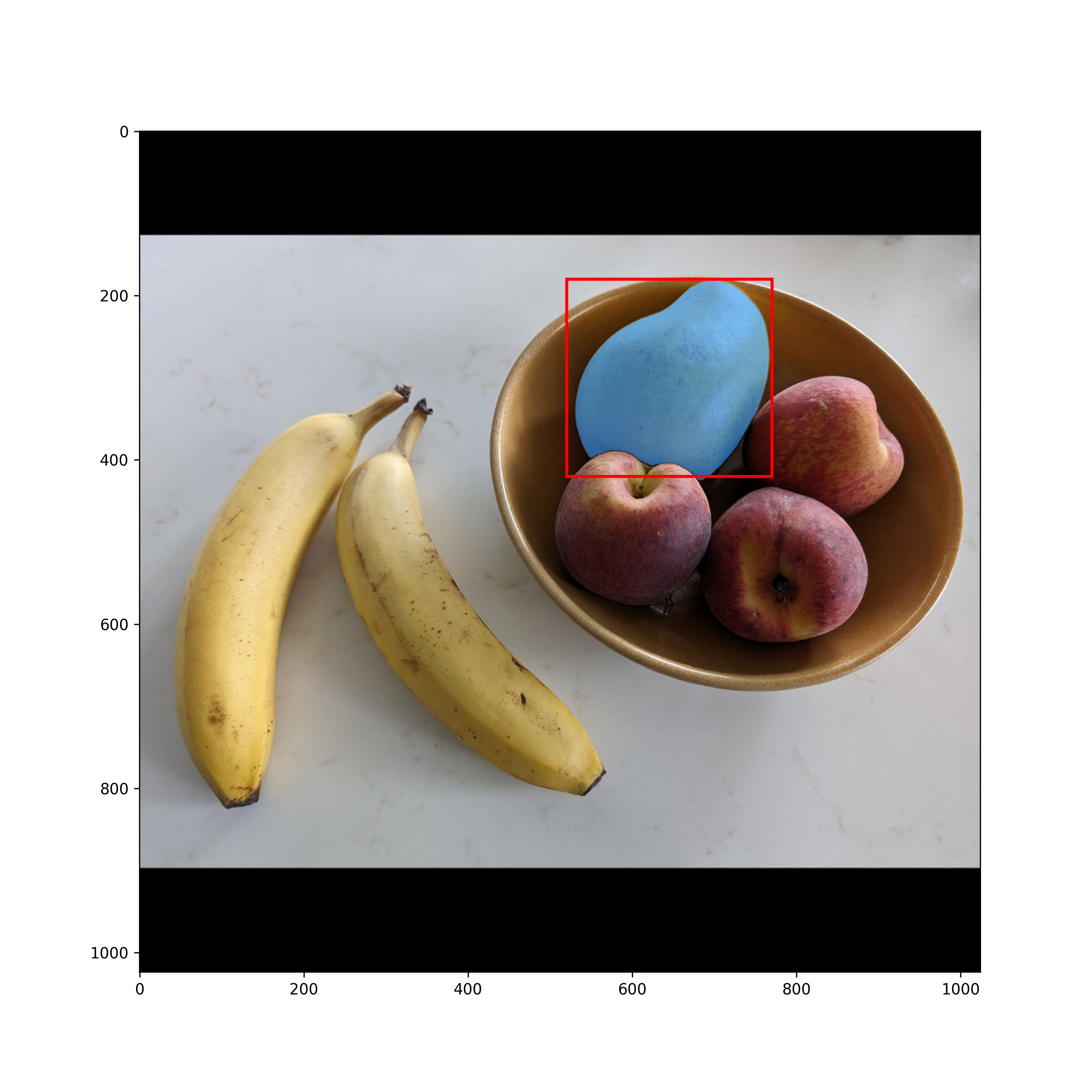 图 11.15:芒果瓣
图 11.15:芒果瓣
SAM 可以成为快速创建带有分割掩码标注的大型图像数据集的强大工具。
概括
- 图像分割是计算机视觉任务的主要类别之一。它包括计算分割掩码,这些掩码在像素级别上描述图像的内容。
- 要构建自己的分割模型,可以使用一系列步长
Conv2D层将输入图像“压缩”成更小的特征图,然后再使用一系列相应的Conv2DTranspose层将特征图“扩展”成与输入图像大小相同的分割掩码。 - 您还可以使用预训练的分割模型。KerasHub 中包含的 Segment Anything 就是一个功能强大的模型,它支持图像提示、文本提示、点提示和框提示。
脚注
- Kirillov 等人,“分割任何事物”,发表于 IEEE/CVF 国际计算机视觉会议论文集,arXiv (2023)
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论