《DEEP LEARNING with Python》第十六章 文本生成
第十六章 文本生成
Text generation
运行代码
本章内容
- 生成模型简史
- 从零开始训练一个微型 GPT 模型
- 使用预训练的Transformer模型构建聊天机器人
- 构建一个能够用自然语言描述图像的多模态模型
- A brief history of generative modeling
- Training a miniature GPT model from scratch
- Using a pretrained Transformer model to build a chatbot
- Building a multimodal model that can describe images in natural language
当我最初提出在不久的将来,我们所消费的大部分文化内容都将在人工智能的大力协助下创作时,我遭到了彻底的质疑,甚至连资深的机器学习从业者也对此表示怀疑。那是2014年。十年过去了,这种质疑以惊人的速度消散了。生成式人工智能工具如今已成为文字处理器、图像编辑器和开发环境中常见的组成部分。运用生成模型创作的文学和艺术作品也屡获殊荣——这引发了相当大的争议和辩论。[1]人工智能与艺术创作常常交织在一起的世界,如今已不再像是科幻小说里的情节。
从实际意义上讲,人工智能远未达到能与人类编剧、画家或作曲家匹敌的程度。但取代人类并非必要,也不应该成为人工智能的目标。在许多领域,尤其是在创意领域,人们会利用人工智能来增强自身能力——与其说是人工智能,不如说是增强智能。( more augmented intelligence than artificial intelligence )
艺术创作很大程度上依赖于模式识别和技术技巧。我们的感知方式、语言和艺术作品都具有统计结构,而深度学习模型擅长学习这种结构。机器学习模型可以学习图像、音乐和故事的统计潜在空间(latent spaces),并从中采样,从而创造出与模型训练数据中特征相似的新艺术作品。这种采样本身几乎算不上艺术创作——它仅仅是一种数学运算。只有作为人类观众的我们进行解读,才能赋予模型生成的作品以意义。但在技艺精湛的艺术家手中,算法生成的图像可以被引导得富有意义,并且充满美感。潜在空间采样可以成为艺术家的画笔,增强我们的创造力,并拓展我们的想象空间。它甚至可以消除对技术技巧和练习的需求,使艺术创作更加普及——建立起一种纯粹表达的新媒介,将艺术与技艺区分开来。
It can even make artistic creation more accessible by eliminating the need for technical skill and practice—setting up a new medium of pure expression, factoring art apart from craft.
 图 16.1:使用生成图像软件 Midjourney 生成的图像。提示是“手绘的科幻景观,居民居住在一栋形状像红色字母 K 的建筑中”。
图 16.1:使用生成图像软件 Midjourney 生成的图像。提示是“手绘的科幻景观,居民居住在一栋形状像红色字母 K 的建筑中”。
A hand-drawn, sci-fi landscape of residents living in a building shaped like a red letter K.
电子音乐和算法音乐的先驱伊阿尼斯·泽纳基斯在 20 世纪 60 年代就以将自动化技术应用于音乐创作为背景,精彩地表达了同样的想法:[2]
摆脱了繁琐的计算,作曲家得以专注于新音乐形式所提出的普遍问题,并在调整输入数据的同时,探索这种形式的方方面面。例如,他可以测试从独奏到室内乐团再到大型管弦乐团的所有乐器组合。借助电子计算机,作曲家就像一位领航员:他按下按钮,输入坐标,操控着一艘宇宙飞船在声音的空间中航行,穿越他过去只能在遥远梦境中瞥见的音响星座和星系。
With the aid of electronic computers the composer becomes a sort of pilot: he presses the buttons, introduces coordinates, and supervises the controls of a cosmic vessel sailing in the space of sound, across sonic constellations and galaxies that he could formerly glimpse only as a distant dream.
生成式人工智能的潜力远不止于艺术创作。在许多行业中,人们创作的内容更需要模式识别:例如,总结大型文档、转录语音、校对错别字或标记代码中的常见错误。这些重复性工作恰恰发挥了深度学习方法的优势。如何在工作场所部署人工智能,以及它对社会产生的切实影响,都值得我们深思。
在接下来的两章中,我们将探索深度学习在辅助内容创作方面的潜力。我们将学习如何在文本和图像领域中挖掘潜在空间,并从中提取新的内容。我们将从文本入手,扩展我们在上一章中首次接触的语言模型概念。这些 大型语言模型(简称LLM)是ChatGPT等数字助手以及众多快速增长的实际应用背后的驱动力。
序列生成简史
A brief history of sequence generation
直到最近,从模型生成序列的想法还只是机器学习领域的一个小众子课题——生成式循环网络直到 2016 年才开始进入主流视野。然而,这些技术有着相当长的历史,可以追溯到 1997 年 LSTM 算法的开发。
2002年,道格拉斯·埃克首次将LSTM应用于音乐生成,并取得了令人瞩目的成果。埃克后来成为谷歌大脑的研究员,并在2016年创立了名为Magenta的新研究团队,致力于运用现代深度学习技术创作引人入胜的音乐。有时候,好的想法需要15年的时间才能付诸实践。
在2000年代末和2010年代初,Alex Graves率先将循环神经网络应用于新型序列数据的生成。尤其值得一提的是,他2013年发表的关于应用循环混合密度网络,利用笔迹时间序列生成类人手写体的研究,被一些人视为一个转折点。Graves在2013年上传到预印本服务器arXiv的LaTeX文件中留下了一条被注释掉的评论:“生成序列数据是计算机最接近做梦的方式。” 这项工作以及“机器会做梦”的概念,在我开发Keras之初就给了我重要的启发。
Generating sequential data is the closest computers get to dreaming. This work and the notion of machines that dream were significant inspirations when I started developing Keras.
2018 年,在我们上一章讨论的论文《注意力是你所需要的一切》发表一年后,一个名为 OpenAI 的组织的研究人员发表了一篇新论文《通过生成式预训练提高语言理解能力》。[3]他们将几种成分混合在一起:
- 无监督语言模型预训练——本质上是训练一个模型来“猜测序列中的下一个词元”,就像我们在第15章中对莎士比亚生成器所做的那样。
- Transformer架构
- 通过数千本自出版书籍收集的各种主题的文本数据
- Unsupervised pretraining of a language model—essentially training a model to “guess the next token” in a sequence, as we did with our Shakespeare generator in chapter 15
- The Transformer architecture
- Textual data on various topics via thousands of self-published books
作者们证明,这种预训练模型可以进行微调,从而在各种文本分类任务上取得最先进的性能——从衡量两个句子的相似度到回答多项选择题。他们将这种预训练模型命名为GPT,即生成式预训练 Transformer 的缩写( Generative Pretrained Transformer.)。
GPT并没有带来任何建模或训练方面的改进。有趣的是,这种通用的训练方案在许多任务上都能胜过更复杂的技术。它无需复杂的文本归一化,也无需针对每个基准测试定制模型架构或训练数据,只需要大量的预训练数据和计算资源。
在接下来的几年里,OpenAI 一心一意地致力于扩展这一理念。模型架构仅做了细微的改动。四年间,OpenAI 发布了三个版本的 GPT,扩展情况如下:
- GPT-1 于 2018 年发布,拥有 1.17 亿个参数,并使用 10 亿个标记进行训练。
- GPT-2 于 2019 年发布,拥有 15 亿个参数,并使用超过 100 亿个 token 进行训练。
- GPT-3 于 2020 年发布,拥有 1750 亿个参数,并使用大约 5000 万亿个 token 进行训练。
语言建模设置使每个模型都能生成文本,OpenAI 的开发人员注意到,随着规模的每一次飞跃,这种生成输出的质量都大幅提高。
对于 GPT-1 来说,模型的生成能力主要是预训练的副产品,而非其主要目标。他们通过添加一个额外的密集层进行分类微调来评估模型,就像我们在上一章中对 RoBERTa 所做的那样。
作者们发现,使用 GPT-2 时,只需向模型提供几个任务示例,无需任何微调即可生成高质量的输出。例如,您可以向模型输入以下内容,使其输出“cheese”(奶酪)一词的法语翻译:
1 | Translate English to French: |
这种设置称为少样本学习,它尝试仅使用少量监督示例来教模型解决一个新问题——对于标准梯度下降来说,示例数量太少了。
This type of setup is called few-shot learning, where you attempt to teach a model a new problem with only a handful of supervised examples—too few for standard gradient descent.
使用 GPT-3 时,并非总是需要示例。您只需向模型提供问题和输入的简单文本描述,通常就能获得高质量的结果:
1 | Translate English to French: |
GPT-3仍然存在一些尚未解决的根本性问题。语言学习模型(LLM)经常出现“幻觉”——其输出结果可能在没有任何预兆的情况下从准确变为完全错误。它们对提示语的措辞极其敏感,看似细微的提示语改动都会导致性能的大幅波动。而且,它们无法适应训练数据中未充分出现的问题。
然而,GPT-3 的生成输出效果足够好,因此该模型成为了 ChatGPT 的基础——ChatGPT 是第一个广泛应用的面向消费者的生成式模型。此后数月乃至数年,ChatGPT 引发了大量的投资和兴趣,推动了语言学习模型 (LLM) 的构建,并探索了其新的应用场景。在下一节中,我们将构建一个微型 GPT 模型,以便更好地理解此类模型的工作原理、功能以及局限性。
训练一个迷你 GPT
Training a mini-GPT
为了开始预训练我们的迷你 GPT,我们需要大量的文本数据。GPT-1 使用了一个名为 BooksCorpus 的数据集,其中包含许多未经作者明确许可而添加的免费自出版(free, self-published books )书籍。该数据集已被其出版商撤下。
我们将使用谷歌于 2020 年发布的名为“Colossal Clean Crawled Corpus”(C4)的较新的预训练数据集。该数据集大小为 750 GB,远大于我们能够合理训练一个书籍示例的数据集,因此我们将使用不到 1% 的整个语料库。
我们先来下载并解压数据:
1 | import keras |
清单 16.1:下载 C4 数据集的一部分
运行本章中的代码
Running the code in this chapter
生成式语言模型体积庞大,运行需要大量的计算资源。尽管我们已尽力使本章代码易于理解,但它仍然是本书中计算量最大的章节。
如果你愿意,可以在免费的 Colab GPU 运行时(截至撰写本文时为 T4 GPU)上运行所有程序,但请做好等待的准备!这个 mini-GPT 示例大约需要 6 个小时的训练时间,而且在运行笔记本的过程中,你需要重启 Colab 运行时以释放 GPU 内存,然后再加载更大的预训练模型。更强大的 GPU 可以更快地运行这些示例;我们是在 A100 上开发了这个示例,它可以在一个多小时内完整运行本章的代码。
您可以随时查看那些昂贵的fit()调用,并减少训练步骤的数量以便快速进行实验。而且,如果您几年后还在运行此程序,这些示例很可能对现代硬件来说只是小菜一碟!
我们有 50 个文本数据分片,每个分片包含大约 75 MB 的原始文本。每一行都包含一个文档,其中换行符已转义。让我们来看第一个分片中的一个文档:
1 | >>> with open(extract_dir / "shard0.txt", "r") as f: |
即使是像我们正在训练的这种小型逻辑模型,我们也需要预处理大量数据才能进行预训练。使用快速分词程序将源文档预处理成整数标记可以简化我们的工作。
我们将使用 SentencePiece 库,该库用于文本数据的子词标记化。实际的标记化技术与我们在第 14 章中自行构建的字节对编码标记化技术相同,但该库使用 C++ 编写以提高速度,并添加了一个detokenize()将整数反转为字符串并将它们连接起来的函数。我们将使用一个预先构建的词汇表,其中包含 32,000 个词汇术语,这些术语以 SentencePiece 库所需的特定格式存储。
和上一章一样,我们可以使用 KerasHub 库来访问一些用于处理大型语言模型的额外函数。KerasHub 将 SentencePiece 库封装成一个 Keras 层。让我们来试一试。
1 | import keras_hub |
清单 16.2:下载 SentencePiece 词汇表并实例化分词器
我们可以使用此分词器将文本双向映射到整数序列:
1 | >>> tokenizer.tokenize("The quick brown fox.") |
让我们使用这一层对输入文本进行分词,然后使用tf.data它将输入窗口化为长度为 256 的序列。
在训练 GPT 时,开发者选择保持简单,并未尝试阻止文档边界出现在样本中间。他们使用特殊<|endoftext|>标记来标记文档边界。我们也将采用相同的方法。同样,我们将使用相同的tf.data输入数据管道,并使用任意后端进行训练。
我们将分别加载每个文件分片,并将输出数据交错整合到一个数据集中。这样可以保证数据加载速度快,而且无需担心文本跨样本边界对齐的问题——每个样本都是独立的。通过交错处理,CPU 上的每个处理器都可以同时读取和标记化一个单独的文件。
1 | import tensorflow as tf |
清单 16.3:Transformer 预训练的文本输入预处理
正如我们在第 8 章中首次所做的那样,我们将以tf.data调用结束我们的流程 prefetch()。这将确保我们始终有一些批次的数据加载到 GPU 上,并准备好供模型使用。
我们有 58,746 个批次。您可以自己统计一下——代码ds.reduce(0, lambda c, _: c + 1)会遍历整个数据集并递增计数器。但即使使用速度不错的 CPU,对如此庞大的数据集进行标记化也需要几分钟时间。
每个批次包含 64 个样本,每个样本包含 256 个 token,总共接近 10 亿个 token。我们先从中取出 500 个批次作为快速验证集,然后就可以开始预训练了:
1 | num_batches = 58746 |
构建模型
Building the model
原始的 GPT 模型简化了我们在上一章看到的序列到序列 Transformer 模型。与我们翻译模型中需要编码器和解码器来处理源序列和目标序列不同,GPT 方法完全摒弃了编码器,只使用解码器。这意味着信息只能在序列中从左到右传递。
这是GPT开发者的一个有趣尝试。仅解码器模型仍然可以处理序列到序列的问题,例如问答。然而,我们不再将问题和答案作为单独的输入,而是必须将它们合并成一个单一的序列才能输入到模型中。因此,与原始Transformer不同,问题标记和答案标记的处理方式完全相同。所有标记都被嵌入到同一个潜在空间中,并使用相同的参数集。
这种方法的另一个后果是,即使对于输入序列,信息流也不再是双向的。给定一个输入,例如“法国的首都在哪里?”,学习到的“在哪里”一词的表示无法在注意力层中同时关注“首都”和“法国”这两个词。这限制了模型的表达能力,但在预训练的简易性方面却具有巨大的优势。我们无需精心构建包含成对输入输出的数据集;所有内容都可以是单个序列。我们可以大规模地训练任何在互联网上找到的文本。
让我们复制TransformerDecoder第 15 章的代码,但移除交叉注意力层,该层允许解码器关注编码器的序列。我们还会做一个小改动,在注意力层和前馈层之后添加 dropout 层。在第 15 章中,我们的编码器和解码器都只使用了一个 Transformer 层,因此我们只需在整个模型的末尾使用一个 dropout 层即可。但对于我们的 GPT 模型,我们将堆叠相当多的层,因此在每个解码器层中添加 dropout 层对于防止过拟合至关重要。
1 | from keras import layers |
清单 16.4:一个不带交叉注意的 Transformer 解码器模块
接下来,我们可以复制PositionalEmbedding第 15 章中的这一层。回想一下,这一层为我们提供了一种简单的方法来学习序列中每个位置的嵌入,并将其与我们的标记嵌入结合起来。
这里有一个巧妙的技巧可以节省一些GPU内存。Transformer模型中权重最大的部分是输入词嵌入和输出密集预测层,因为它们处理的是词汇空间。词嵌入权重的形状为,(vocab_size, hidden_dim)用于嵌入所有可能的词元。输出投影权重的形状为(hidden_dim, vocab_size),用于对每个可能的词元进行浮点预测。
我们实际上可以将这两个权重矩阵联系起来。为了计算模型的最终预测结果,我们将隐藏状态乘以词元嵌入矩阵的转置。你可以把最终的投影看作是“反向嵌入”。它将隐藏空间映射到词元空间,而词元嵌入则是将词元空间映射到隐藏空间。事实证明,对输入和输出投影使用相同的权重是一个好主意。
将其添加到我们的系统中PositionalEmbedding很简单;我们只需reverse 向该call方法添加一个参数,该方法通过转置词嵌入来计算投影。
1 | from keras import ops |
示例 16.5:一种可以反转文本嵌入的位置嵌入层
个人注:GPT 处理的完整流水线
为了让你看清词嵌入的位置,这是 GPT 处理一个句子的标准步骤:
- 输入文本:"I love AI"
- 词元化 (Tokenization):变成词元序列
[40, 3021, 15592]。- 词嵌入 (Token Embedding):将每个 ID 换成高维向量。
- 位置嵌入 (Positional Embedding):把位置信息加到词向量上。
- Transformer 层:进行多次“自注意力”运算。
- 输出预测:最后再变回概率,挑出下一个词元
模型的词嵌入是在训练的时候同步训练的,还是可以使用专门的预训练模型的结果?
简单来说:两种方式都可以,但现代大模型(LLM)几乎全部选择“同步训练”。
我们可以根据技术演进的阶段,把词嵌入的来源分为三个模式:
- 静态预训练模式 (Static Pre-trained)
在 2018 年以前(Word2Vec, GloVe 时代),这是主流。
- 做法:先在巨大的语料库(如维基百科)上单独训练好词向量。
- 使用:在训练你自己的特定任务模型(如情感分析)时,直接加载这些现成的向量。你可以选择“冻结”它们(不更新),也可以选择“微调”它们。
- 缺点:这些向量是静态的。无论“苹果”是指水果还是公司,它的向量都一样,无法处理多义词。
- 随机初始化 + 同步训练 (Random Initialization)
这是 GPT、Llama、BERT 等大模型最常用的方式。
- 做法:在模型开始训练的第一天,词嵌入表里的数值全是随机生成的乱码。
- 原理:随着模型不断通过梯度下降(Backpropagation)学习预测下一个词,词嵌入表会和 Transformer 的参数一起被不断修正。
- 优势:
- 端到端优化 (End-to-End):词嵌入能完美适配模型内部的注意力机制。
- 任务相关性:模型会根据自己的语料分布,自动在向量空间中对齐词元。
- 混合与持续训练 (Continuous Pre-training)
对于一些垂直领域的模型(如医疗、法律):
- 做法:它们可能会基于已有的通用模型(如 Llama 3)的词嵌入层进行二次开发。
- 扩充词表:如果通用模型不认识某些专业词汇,开发者会往词嵌入表里增加新行,然后在新语料上继续训练,让这些新词找到自己的位置。
为什么 GPT 不直接搬运 Word2Vec 的结果?
- 分词粒度不匹配:Word2Vec 是基于“词”的,而 GPT 是基于“子词(词元)”的。
- 维度不兼容:Word2Vec 通常只有 300 维,而 GPT-3 的词嵌入维度高达 12288 维。
- 动态语境需求:大模型的核心竞争力是 Contextual Embedding(语境化嵌入)。虽然底层词嵌入表是固定的,但经过 Transformer 层之后,同一个词元在不同句子里的实际表达会变得完全不同。
让我们来构建模型。我们将把八个解码器层堆叠成一个“迷你”GPT模型。
我们还会启用 Keras 的一项名为“混合精度(mixed precision)”的设置来加速训练。这将使 Keras 能够以牺牲部分数值精度为代价,更快地执行模型的部分计算。目前,这项设置还略显神秘,但完整的解释将在第 18 章中呈现。
1 | # Enables mixed precision (see chapter 18) |
清单 16.6:创建迷你 GPT 功能模型
该模型有 4100 万个参数,对于本书中的模型来说很大,但与当今大多数 LLM 相比却很小,后者的参数数量从几十亿到几万亿不等。
模型预训练
Pretraining the model
训练一个大型 Transformer 模型是出了名的棘手——模型对参数初始化和优化器的选择非常敏感。当堆叠多个 Transformer 层时,很容易出现梯度爆炸,导致参数更新过快,损失函数无法收敛。一个有效的技巧是在若干个预热步骤中线性地过渡到完整的学习率,这样模型参数的初始更新量就会很小。(A trick that works well is to linearly ease into a full learning rate over a number of warmup steps, so our initial updates to our model parameters are small.)这在 Keras 中很容易实现LearningRateSchedule。
1 | class WarmupSchedule(keras.optimizers.schedules.LearningRateSchedule): |
清单 16.7:定义自定义学习率计划
我们可以绘制学习率随时间变化的曲线图,以确保它符合我们的预期(图 16.2):
1 | import matplotlib.pyplot as plt |
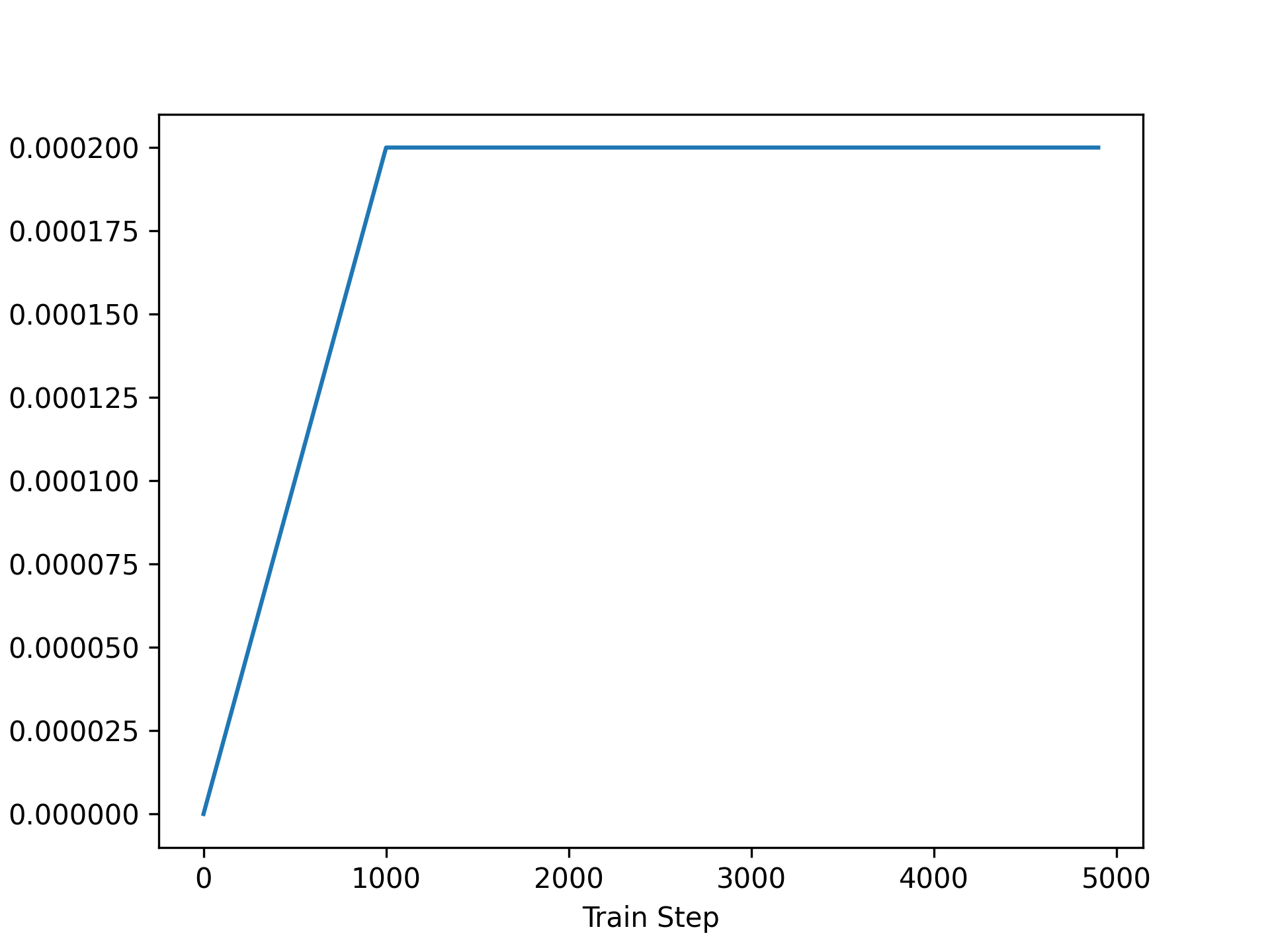 图 16.2:预热使我们在训练开始时对模型参数的更新更小,并且有助于稳定性。
图 16.2:预热使我们在训练开始时对模型参数的更新更小,并且有助于稳定性。
我们将使用 10 亿个 token 进行一次训练,训练周期为 8 个 epoch,以便我们能够不时地检查验证集的损失和准确率。
我们正在训练一个迷你版的 GPT,它的参数量比 GPT-1 少 3 倍,训练步骤也少 100 倍。尽管它的训练成本比最小的 GPT 模型低两个数量级,但这次调用 fit()将是整本书中计算量最大的训练过程。如果你边读边运行代码,请先运行一下,稍作休息!
1 | num_epochs = 8 |
清单 16.8:训练 mini-GPT 模型
什么是logit?
What is a logit?
在构建模型的过程中,你会注意到损失函数有了一个新的值 SparseCategoricalCrossentropy(from_logits=True)。什么是logit?
我们Transformer模型的输出投影不包含通常的softmax激活函数。你可以将此输出视为每个词元的“未归一化对数概率( unnormalized log probabilities )”。如果你将每个输出值取指数,并将所有值归一化为总和为1(这就是该softmax函数所做的),你将得到一个概率值。“未归一化对数概率”的常用术语是logit,正如我们将在下一节中看到的,在生成文本时,logit更容易处理。
Keras 允许你选择应用该softmax函数的位置。对于分类问题,你可以将其用作softmax模型的最后一个激活函数并输出概率,或者将其移至softmax损失函数中并输出 logits。要实现后者,你应该将其 SparseCategoricalCrossentropy(from_logits=True)作为分类损失函数传递。
经过训练后,我们的模型在验证集上大约有 36% 的概率预测序列中的下一个标记,尽管这种指标只是一个粗略的启发式方法。
请注意,我们的模型训练不足。验证损失会在每个 epoch 后持续下降,这并不奇怪,因为我们使用的训练步骤比 GPT-1 少了 100 倍。延长训练时间当然是个好主意,但这需要时间和计算资源。
让我们来玩玩我们的迷你 GPT 模型。
生成式解码
Generative decoding
为了获取模型的部分输出,我们可以沿用第15章中生成莎士比亚或西班牙语译文的方法。我们向模型输入一组固定的词元。对于输入序列中的每个位置,模型都会输出下一个词元在整个词汇表中的概率分布。通过选择最后一个位置最有可能的下一个词元,将其添加到序列中,然后重复此过程,我们就能逐个生成新的序列。
1 | def generate(prompt, max_length=64): |
清单 16.9:mini-GPT 模型的一个简单生成函数
我们用文本提示来试试:
1 | >>> prompt = "A piece of advice" |
运行此程序时,您首先会注意到它需要几分钟才能完成。这有点令人费解。在训练期间,我们在参考硬件上每秒可以预测约 20 万个 token。生成循环可能会增加时间,但一分钟的延迟实在太慢了。到底发生了什么?造成速度慢的主要原因(至少在 Jax 和 TensorFlow 后端上)是我们运行的是未编译的计算。
每次运行 keras.getfit()() 或 keras.get () 时predict(),Keras 都会编译处理每批数据的计算。所有keras.ops使用的计算都会从 Python 中提取出来,并由后端框架进行深度优化。对于单个数据批次来说速度较慢,但后续每次调用都会大幅提升速度。然而,如果我们像之前那样直接调用模型,后端框架则需要在每一步都实时运行未经优化的前向传播过程。
这里最简单的解决方案是借助Keras predict()。有了predict()Keras,它会自动处理编译,但需要注意一个重要的陷阱。TensorFlow 或 Jax 编译函数时,会针对特定的输入形状进行编译。如果输入形状已知,后端就可以针对特定硬件进行优化,因为它确切地知道构成张量操作的处理器指令数量。但在我们的生成函数中,我们调用模型时使用的序列在每次预测后都会改变形状。这会导致每次调用函数时都触发重新编译predict()。
相反,如果我们对输入进行填充,使序列始终保持相同长度,就可以避免重新编译predict()函数。我们来试一试。
1 | def compiled_generate(prompt, max_length=64): |
清单 16.10:mini-GPT 模型的编译生成函数
让我们看看这个新功能的速度如何:
1 | >>> import timeit |
通过编译,我们这一代通话时间从几分钟缩短到了不到一秒。这真是一个巨大的进步。
缓存生成
Cached generation
我们刚刚构建的生成函数中还存在一个主要的效率低下之处。你能发现它吗?
每次调用模型时,我们都会针对整个序列进行调用,然后丢弃除单个位置预测结果之外的所有内容。这很浪费——序列在生成步骤之间只会改变一个词元。我们在第 15 章使用 RNN 进行生成时,可以保留 RNN 的状态,并且在每个步骤中只计算单个词元的输出。这个状态向量包含了模型所需的关于过去序列的所有信息。使用因果注意力机制的 Transformer 模型(例如 GPT)实际上也有类似的状态概念。
如果我们仔细思考一下刚刚构建的整个模型,就会发现注意力机制是模型中唯一能够将信息从一个位置传递到另一个位置的地方。Transformer 的前馈模块只是独立地修改每个标记位置的隐藏表示。
个人注:怎么理解以上这段话?
这句话深刻地揭示了 Transformer 架构的核心本质。我们可以从“分工”的角度来拆解这个逻辑:
- 核心矛盾:位置与交互
在处理序列(比如一句话或一段代码)时,模型有两个任务:
理解每个词自己: 比如“逻辑”是什么意思。
理解词与词的关系: 比如“逻辑”和“回归”连在一起是什么意思。
前馈模块(FFN):“孤独的加工厂”
Transformer 每一层都有一个前馈神经网络(Feed-Forward Network)。
- 独立性:它对每个位置(Token)的操作是完全一样的。它只看当前位置的向量,不看左边,也不看右边。
- 比喻:就像工厂流水线上有 100 个工位,每个工位上的工人都只埋头处理自己手里的零件。即使两个工位挨在一起,他们也互不说话,互不传球。
- 结果:如果只有 FFN,模型永远无法知道第 1 个词和第 10 个词之间有什么联系。
- 注意力机制(Attention):“唯一的传声筒”
这是模型中唯一打破“地理位置”限制的地方。
- 跨位置通信:只有在注意力层,第 5 个位置的向量才会去询问第 1 个位置:“你那里有什么信息是对我有用的?”
- 信息流动:它计算权重,然后把其他位置的信息“加权求和”到当前位置。
- 结论:正如你引用的那句话所说,如果没有注意力机制,Transformer 内部的信息就像一潭死水,每个位置都是孤岛。
- 为什么要这样设计?(架构之美)
这种设计实现了极高的并行效率:
- 通信归通信:由注意力机制集中负责(复杂度较高,需要计算两两关系)。
- 加工归加工:由前馈模块负责。既然信息已经通过注意力机制“传”过来了,前馈模块只需要专注于深度挖掘当前位置融合后的特征即可。
💡 总结理解
- 注意力机制 = 路由器/交换机(负责把各处的信息导流、汇聚)。
- 前馈模块 = 单核 CPU(负责对汇聚后的数据进行非线性计算和特征提取)。
这就是为什么说注意力机制是模型中唯一能“传递信息”的地方。如果把 Transformer 比作一个团队,注意力机制就是开会讨论,而前馈模块就是散会后每个人回到工位上写自己的报告。 没有会议,大家就永远不知道彼此在干什么。
key 在注意力机制内部,我们通过向量和向量来整合过去标记的信息value。对于给定query位置的标记,我们通过将标记query与所有先前的key向量进行点积运算,并将所有先前的value向量组合起来,来计算注意力得分。这些向量key和value向量对于序列中过去的标记始终保持不变——过去的输入是固定的,并且因果掩码阻止了Transformer“预见”未来的标记。因此,如果我们缓存所有向量key和 value向量,那么在Transformer的每一层,我们就拥有了相当于RNN状态的信息。我们可以利用这些信息来一次计算单个位置的Transformer输出。
实现起来有点繁琐,因为它涉及到保存和重用Transformer中每个注意力层的中间数组,但这至关重要。你的模型输入长度可以从与输出最大长度相同的长度,到单个标记的长度不等。如果你生成的序列包含数千个标记,缓存可以带来千倍的速度提升!任何高效的生成式采样实现都将包含key缓存 value。
抽样策略
Sampling strategies
我们生成式输出的另一个明显问题是,我们的模型经常重复自身。在我们这次的训练运行中,模型反复重复“明白你在做什么”这组词。
与其说这是一个漏洞,不如说是我们训练目标的直接结果。我们的模型试图预测一段包含约十亿个单词、涵盖众多主题的序列中最有可能出现的下一个词元。如果一段文本序列的下一个词元没有明显的选择,那么一种有效的策略就是猜测常用词或重复出现的词组模式。不出所料,我们的模型在训练过程中几乎立即学会了这样做。如果您过早停止训练我们的模型,它很可能会不断生成单词"the" “incessantly”,因为"the"这是英语中最常见的单词。
在我们的生成循环中,我们总是选择模型输出中最有可能的预测词元。但我们的输出并非仅仅是一个预测词元;它是词汇表中所有32000个词元的概率分布。
在每一代迭代步骤中使用最可能的输出称为贪婪搜索(greedy search)。这是利用模型预测最直接的方法,但绝非唯一方法。如果我们在过程中加入一些随机性,就可以更广泛地探索模型学习到的概率分布。这可以避免我们陷入高概率词序列的循环中。
我们来试试看。首先,我们可以重构生成函数,使其能够传递一个函数,该函数将模型的预测结果映射到下一个标记的选择。我们将此称为采样策略(sampling strategy):
1 | def compiled_generate(prompt, sample_fn, max_length=64): |
现在我们可以将贪婪搜索写成一个简单的函数,并将其传递给 compiled_generate():
1 | def greedy_search(preds): |
Transformer 的输出定义了一个类别分布,其中每个标记在每个时间步都有一定的输出概率。我们不仅可以选择最有可能出现的标记,还可以直接对这个分布进行采样。 keras.random.categorical()我们将预测结果通过 softmax 函数处理,得到一个概率分布,然后对其进行随机采样。让我们来试试:
1 | def random_sample(preds, temperature=1.0): |
我们的输出结果更加多样化,模型也不再陷入循环。但是,我们的采样范围过广,输出结果波动剧烈,缺乏连续性。
你会注意到我们添加了一个名为 的参数temperature。我们可以使用它来收窄或拓宽概率分布,从而使我们的采样对分布的探索程度降低或提高。
如果温度设置得很低,softmax 函数处理前所有 logits 的值都会增大,这使得最可能的输出结果出现的概率更高。如果温度设置得很高,softmax 函数处理前 logits 的值会更小,概率分布也会更加分散。我们来尝试几次,看看这会如何影响我们的采样:
1 | >>> from functools import partial |
高温下,我们的输出不再像英语,而是看似随机地排列词元。低温下,我们的模型行为开始类似于贪婪搜索(greedy search),反复重复某些文本模式。
另一种常用的分布优化方法是将采样范围限制在最有可能出现的词元集合中。这被称为前k采样,其中K是需要探索的候选词元数量。图16.3展示了前k采样如何在贪婪采样和随机采样之间找到平衡点。
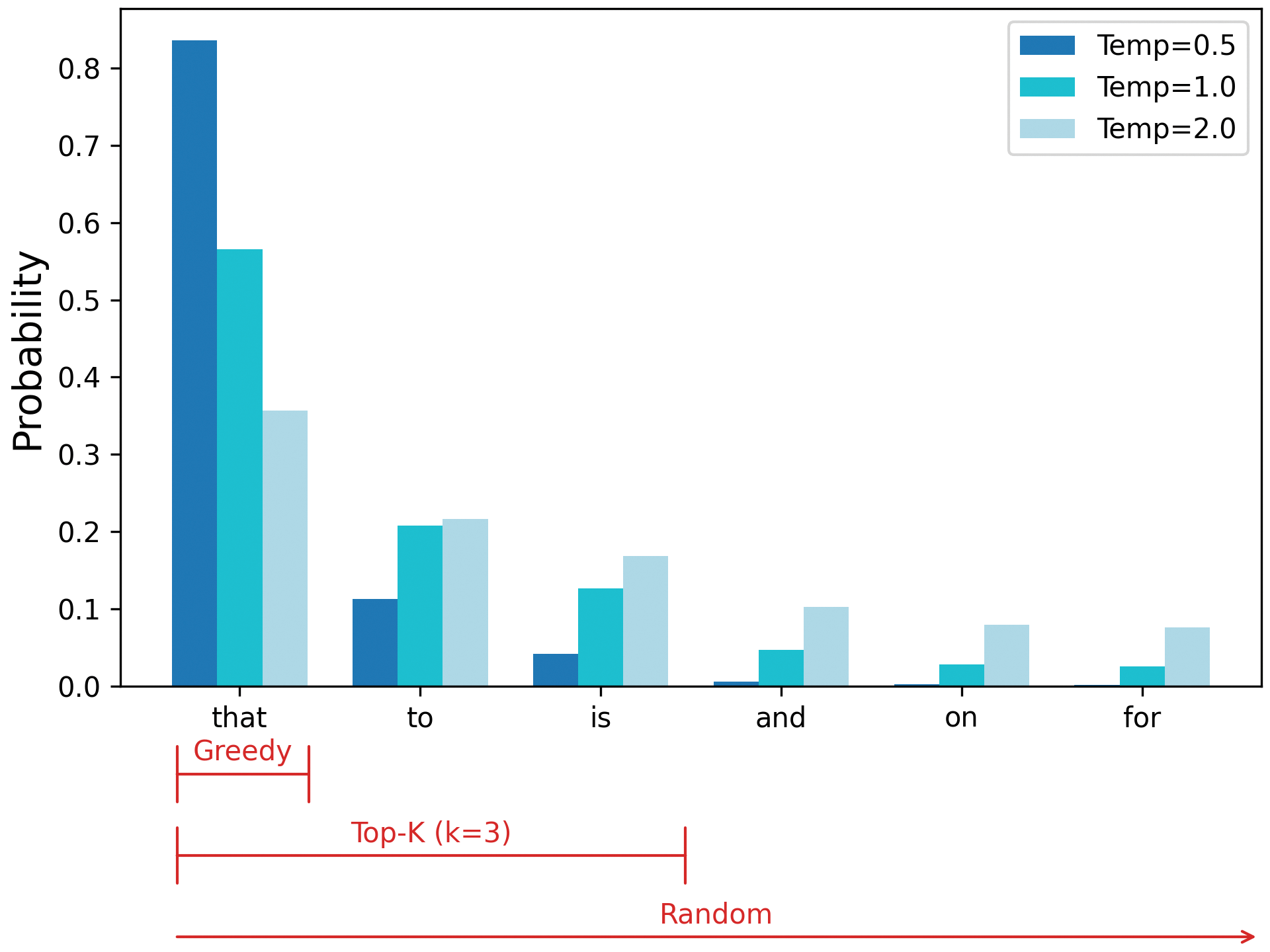 图 16.3:贪婪抽样、top-k 抽样和随机抽样策略在同一概率分布上显示
图 16.3:贪婪抽样、top-k 抽样和随机抽样策略在同一概率分布上显示
让我们用代码来试试。我们可以用它keras.ops.top_k来查找数组的前 K 个元素:
1 | def top_k(preds, k=5, temperature=1.0): |
我们可以尝试几种不同的 top-k 变体,看看它对采样有何影响:
1 | >>> compiled_generate(prompt, partial(top_k, k=5)) |
通过前 k 个候选词的筛选与温度采样不同。通过较低的温度会提高可能存在的词元的概率,但不会排除任何词元。前 k 个候选词的采样则会将 K 个候选词之外的任何词元的概率归零。您可以将两者结合起来,例如,对温度为 0.5 的前五个候选词进行采样:
1 | >>> compiled_generate(prompt, partial(top_k, k=5, temperature=0.5)) |
在文本生成过程中,采样策略是一项重要的控制手段,而且有很多种方法可供选择。例如,束搜索( heuristically explores )是一种启发式技术,它通过在每个时间步保持固定数量的“束”(不同的预测词元链)进行探索,从而探索多条预测词元链。
通过 top-k 采样,我们的模型生成的文本更接近于合理的英文文本,但这种输出几乎没有任何实际用途。这与 GPT-1 的结果相符。对于最初的 GPT 论文而言,生成的输出更多的是一种好奇心,而最先进的结果只有通过微调分类模型才能实现。我们的 mini-GPT 的训练程度远低于 GPT-1。
以上这句话的意思:
- 实际用途的缺失:当时的 GPT-1 能够续写一段看起来还不错的科幻小说或者新闻(即“合理的文本”),但如果你问它:“请帮我总结这篇文章”或者“写一个 Python 爬虫”,它完全做不到。
- 结论:它具备了生成语言的能力,但还没具备解决问题的指令遵循能力(这是后来 GPT-3 和 ChatGPT 通过强化学习才解决的)。
这句话翻译成大白话就是:
“虽然我们用了一些采样技巧让机器说话不再像复读机,听起来挺顺耳的,但它现在还是个‘废话文学大师’。它能写出漂亮的句子,但处理不了任何具体的任务。这跟当年的 GPT-1 表现一模一样。”
为了达到如今生成式LLM的规模,我们需要将参数数量至少增加100倍,训练步数至少增加1000倍。如果能够做到这一点,我们将看到与OpenAI的GPT模型类似的质量飞跃。而且我们完全可以做到!我们之前使用的训练方案正是目前所有LLM训练者所使用的蓝图。唯一缺少的是大量的计算资源以及一些跨多台机器训练的技巧,我们将在第18章中介绍这些技巧。
为了采取更实际的方法,我们将过渡到使用预训练模型。这将使我们能够探索当前规模下 LLM 的行为。
使用预训练的LLM
Using a pretrained LLM
既然我们已经从零开始训练了一个迷你语言模型,接下来让我们尝试使用一个拥有十亿参数的预训练模型,看看它的表现如何。鉴于预训练 Transformer 模型的成本极其高昂,业内大多数公司都倾向于使用少数几家公司开发的预训练模型。这不仅是出于成本考虑,也是出于环境考虑——生成模型训练如今已占大型科技公司数据中心总能耗的很大一部分。
Meta公布了其于2023年发布的机器学习模型Llama 2的一些环境数据。Llama 2比GPT-3小得多,但据估计,它的训练过程需要消耗130万千瓦时的电力——相当于约4.5万个美国家庭的日用电量。如果每个使用机器学习模型的机构都自行进行预训练,那么能源消耗规模将占全球能源消耗的相当大一部分。
让我们来体验一下谷歌预训练的生成模型 Gemma。我们将使用 Gemma 模型的第三版,该版本于 2025 年公开发布。为了使本书中的示例易于理解,我们将使用 Gemma 的最小版本,其参数量接近 10 亿。这个“小型”模型使用了大约 2 万亿个预训练数据标记进行训练——比我们刚刚训练的 mini-GPT 的数据标记数量多 2000 倍!
使用 Gemma 模型进行文本生成
Text generation with the Gemma model
要加载这个预训练模型,我们可以使用 KerasHub,就像我们在前面的章节中所做的那样。
获取 Gemma 权重
Accessing Gemma weights
如果您要自行运行本章代码,则需要先接受 Gemma 模型的使用条款才能下载权重。模型权重存储在 Kaggle 上,我们可以kagglehub像第 8 章那样使用 API 登录。在此之前,您需要完成以下两项操作:
- 请访问https://www.kaggle.com/models/keras/gemma3,并接受页面顶部的 Gemma 使用条款。
- 前往https://www.kaggle.com/settings,生成 Kaggle API 密钥(如果您尚未在第 8 章中执行此操作)。
这样,我们就可以使用 API 密钥从笔记本中对 Kaggle 进行身份验证了:
1 | import kagglehub |
随着LLMs功能日益强大,类似的条款也变得越来越普遍。Gemma的使用条款禁止将该模型用于生成垃圾邮件或仇恨言论等用途。
1 | gemma_lm = keras_hub.models.CausalLM.from_preset( |
清单 16.11:使用 KerasHub 实例化预训练 LLM
CausalLM这是高级任务 API 的另一个示例,类似于 本书前面提到的 ImageClassifierand任务。该任务会将分词器和正确初始化的架构合并到一个 Keras 模型中。KerasHub 会将 Gemma 权重加载到正确初始化的架构中,并为预训练权重加载匹配的分词器。ImageSegmenter``CausalLM
让我们来看一下Gemma模型的概要:
1 | >>> gemma_lm.summary() |
与其自己实现生成例程,我们可以利用generate()类自带的函数来简化操作CausalLM 。generate()正如我们在上一节中探讨的那样,该函数可以编译成不同的采样策略:
1 | >>> gemma_lm.compile(sampler="greedy") |
我们可以立即注意到几点。首先,输出结果比我们的迷你 GPT 模型更加连贯。很难将这段文本与 C4 数据集中的大部分训练数据区分开来。其次,输出结果仍然不太实用。该模型会生成大致合理的文本,但其具体用途尚不明确。
Second, the output is still not that useful. The model will generate vaguely plausible text, but what you could do with it is unclear.
正如我们在 mini-GPT 示例中所看到的,这与其说是一个 bug,不如说是我们预训练目标的必然结果。Gemma 模型和 mini-GPT 一样,都使用“猜测下一个词”的目标进行训练,这意味着它实际上就是一个功能强大的网络自动补全工具。它会不断地重复输入序列中最有可能的词,就好像你的提示是一段从网络上随机找到的文本片段一样。
As we saw with the mini-GPT example, this is not so much a bug as a consequence of our pretraining objective. The Gemma model was trained with the same “guess the next word” objective we used for mini-GPT, which means it’s effectively a fancy autocomplete for the internet. It will just keep rattling off the most probable word in its single sequence as if your prompt was a snippet of text found in a random document on the web.
改变输出结果的一种方法是,用更长的输入提示模型,这样就能更清楚地表明我们想要哪种类型的输出。例如,如果我们用布朗尼蛋糕食谱的前两句话提示 Gemma 模型,就能得到更有帮助的输出:
1 | >>> gemma_lm.generate( |
虽然在使用一个能够“说话”的模型时,我们很容易想象它会以某种人类对话的方式来解读我们的提示,但事实并非如此。我们只是构建了一个提示,相比于模仿论坛上寻求烘焙帮助的帖子,它更有可能提供一个实际的布朗尼食谱。
在构建提示方面,你还可以做更多的事情。例如,你可以用一些自然语言指令来提示模型,告诉它应该扮演什么角色;"You are a large language model that gives short, helpful answers to people's questions."或者,你可以向模型提供一份包含大量有害话题的提示,这些话题不应该出现在任何生成的回复中。
如果这一切听起来有点含糊不清且难以控制,那你的评价很中肯。尝试通过提示来探索模型分布的不同部分通常很有用,但预测模型对特定提示的反应却非常困难。
逻辑逻辑模型面临的另一个有据可查的问题是幻觉。模型总会给出一些结论——对于给定的序列,总会有一个最可能的下一个标记。在我们的逻辑逻辑模型分布中找到那些没有事实依据的位置很容易:
1 | >>> gemma_lm.generate( |
当然,这完全是无稽之谈,但模型找不到更合理的完成此提示的方法。
幻觉和不可控的输出是语言模型的根本问题。如果存在万全之策,我们至今尚未找到。然而,一种非常有帮助的方法是,使用你期望的特定类型生成输出的示例来进一步微调模型。
如果要构建一个能够执行指令的聊天机器人,这种训练方式就叫做指令微调。让我们用 Gemma 做一些指令微调,让她作为对话伙伴更加得心应手。
Hallucinations and uncontrollable output are fundamental problems with language models. If there is a silver bullet, we have yet to find it. However, one approach that helps immensely is to further fine-tune a model with examples of the specific types of
generative outputs you would like.
In the specific case of wanting to build a chatbot that can follow instructions, this type of training is called instruction fine-tuning. Let’s try some instruction fine-tuning with Gemma to make it a lot more useful as a conversation partner.
个人注:指令微调和强化学习区别
在 GPT 系列从“只会写顺口溜”进化到“能写代码、做数学题”的过程中,这两项技术起到了决定性的作用。
简单来说:指令微调(SFT)是让模型“学会听话”,而强化学习(RLHF)是让模型“学会做人(追求卓越)”。
- 指令微调 (Supervised Fine-Tuning, SFT)
这是模型进化的第一步。
- 做法:给模型喂大量的“高质量问答对”。例如:
- 输入:“请写一首关于春天的诗。”
- 输出:(由人类专家写好的精美诗歌)。
- 本质:模仿学习。模型通过这些例子发现:“噢,当人类用这种语气跟我说话时,我应该给出这种格式的回报。”
- 局限性:模型只是在机械地模仿人类的答案。如果人类给的答案只有 70 分,模型永远学不到 100 分。
- 强化学习 (RLHF - 基于人类反馈的强化学习)
这是模型进化的第二步,也是让 ChatGPT 超越同类模型的关键。
- 做法:模型生成多个不同的答案(A, B, C),然后让人类来打分或排序(比如 A 比 B 好)。
- 奖励模型 (Reward Model):根据人类的打分,训练一个“小老师”模型,专门用来给大模型的回答打分。
- PPO 优化:大模型在“小老师”的指导下不断练习,目标是拿到最高分。
- 本质:择优学习。它不再是模仿某一个标准答案,而是在无限的可能中寻找让用户“最满意”的路径。
- 核心区别对比表
特性 指令微调 (SFT) 强化学习 (RLHF) 数据形式 问题 + 标准答案 (Pairs) 问题 + 多个候选答案的排序 (Ranking) 学习目标 模仿人类的回答方式 追求人类最喜欢的回答效果 解决的问题 能力对齐:让模型懂指令、懂格式 价值观对齐:让模型有用、真实、无害 形象类比 老师给出一道例题,让你背下来。 老师让你自己做题,做得好就给奖励。
指令微调
Instruction fine-tuning
指令微调涉及向模型提供输入/输出对——用户指令后跟模型响应。我们将这些输入/输出对合并成一个单一序列,作为模型的新训练数据。为了在训练过程中清晰地区分指令或响应的结束,我们可以在合并后的序列中添加特殊的标记,例如 \n "[instruction]"和 \"[response]"n。只要标记保持一致,具体的标记形式并不重要。
我们可以将组合后的序列作为常规训练数据,并使用与预训练语言学习模型 (LLM) 时相同的“猜测下一个词”损失函数。通过使用包含预期响应的示例进行进一步训练,我们实际上是在引导模型的输出朝着我们想要的方向发展。我们在这里不会学习语言的潜在空间;这已经在数万亿个词元的预训练中完成了。我们只是对学习到的表征进行一些微调,以控制输出的语气和内容。
首先,我们需要一个指令-响应对的数据集。训练聊天机器人是一个热门话题,因此有很多专门为此目的创建的数据集。我们将使用Databricks公司公开的数据集。该数据集包含15000条指令和手写回复,由员工贡献。让我们下载该数据集,并将其合并成一个序列。
1 | import json |
清单 16.12:加载指令微调数据集
请注意,有些示例包含额外的上下文信息——与指令相关的文本信息。为了简化说明,我们暂时忽略这些示例。
让我们来看数据集中的一个元素:
1 | >>> data["prompts"][0] |
我们的提示模板赋予示例可预测的结构。虽然 Gemma 不是像我们的英西翻译器那样的序列到序列模型,但我们仍然可以通过在类似这样的提示上进行训练,并在标记之后生成输出,将其用于序列到序列的场景中"[response]"。
让我们创建一个tf.data.Dataset并拆分一些验证数据:
1 | ds = tf.data.Dataset.from_tensor_slices(data).shuffle(2000).batch(2) |
我们CausalLM从 KerasHub 库加载的是一个用于端到端因果语言建模的高级对象。它封装了两个对象:一个preprocessor 用于预处理文本输入的层,以及一个backbone包含模型前向传播数值结果的模型。
预处理默认包含在 Keras 的高级函数(例如 preprocessing``fit() 和 preprocessing.batch )中predict()。但为了更好地了解预处理的具体作用,我们不妨只对单个批次运行预处理:
1 | >>> preprocessor = gemma_lm.preprocessor |
预处理层会将所有输入填充到固定长度,并计算一个填充掩码来跟踪哪些 token ID 输入只是填充了零。该 sample_weight张量允许我们仅计算响应 token 的损失值。我们并不关心用户提示的损失;它是固定的,而且我们绝对不想计算刚刚添加的零填充的损失。
如果我们打印出一部分词元 ID 和标签,我们可以看到这是常规的语言模型设置,其中每个标签都是下一个词元值:
1 | >>> x["token_ids"][0, :5], y[0, :5] |
低秩自适应(LoRA)
Low-Rank Adaptation (LoRA)
如果我们现在在配备 16 GB 设备内存的 Colab GPU 上运行fit(),很快就会触发内存不足错误。但我们已经加载了模型并运行了生成过程,为什么现在会内存不足呢?
我们这个拥有10亿参数的模型占用了大约3.7 GB的内存。您可以在我们之前的模型概要中看到这一点。我们使用的优化器需要为每个Adam参数跟踪三个额外的浮点数——实际梯度、速度值和动量值。总而言之,仅权重和优化器状态就需要15 GB的内存。我们还需要几GB的内存来跟踪模型前向传播过程中的中间值,但我们已经没有多余的内存了。运行程序会在第一个训练步骤就崩溃。这是训练LLM时常见的问题。由于这些模型的参数数量庞大,因此GPU和CPU的吞吐量是次要的,模型应该优先在加速器内存上进行拟合。fit()
本书前面已经介绍过如何在微调过程中冻结模型的某些部分。但我们没有提到的是,这样做可以节省大量内存!对于冻结的参数,我们无需跟踪任何优化器变量——它们永远不会更新。这使我们能够在加速器上节省大量空间。
研究人员已经对Transformer模型在微调过程中冻结不同参数进行了大量实验,结果表明(或许符合直觉),最应该保持未冻结状态的权重位于注意力机制中。但是,我们的注意力层仍然有数亿个参数。我们能否做得更好?
2021年,微软的研究人员提出了一种名为LoRA( 大型语言模型的低秩自适应)的技术,专门用于解决这一内存问题。[4]为了解释这一点,我们想象一个简单的线性投影层:
1 | class Linear(keras.Layer): |
LoRA论文提出冻结kernel矩阵并添加一个新的“低秩”核投影分解。该分解有两个新的投影矩阵,alpha和beta,它们分别从内部矩阵 投影到 和 从 rank。让我们来看一下:
1 | class LoraLinear(keras.Layer): |
如果我们的kernel数据集形状为 2048 × 2048,那么就有 4,194,304 个冻结参数。但如果我们保留rank较低的秩,比如 8,那么低秩分解就只有 32,768 个参数。这种更新的表达能力不如原始核函数;在中间的狭窄区域,整个更新必须用八个浮点数来表示。但在 LLM 微调过程中,你不再需要预训练阶段所需的表达能力(图 16.4)。
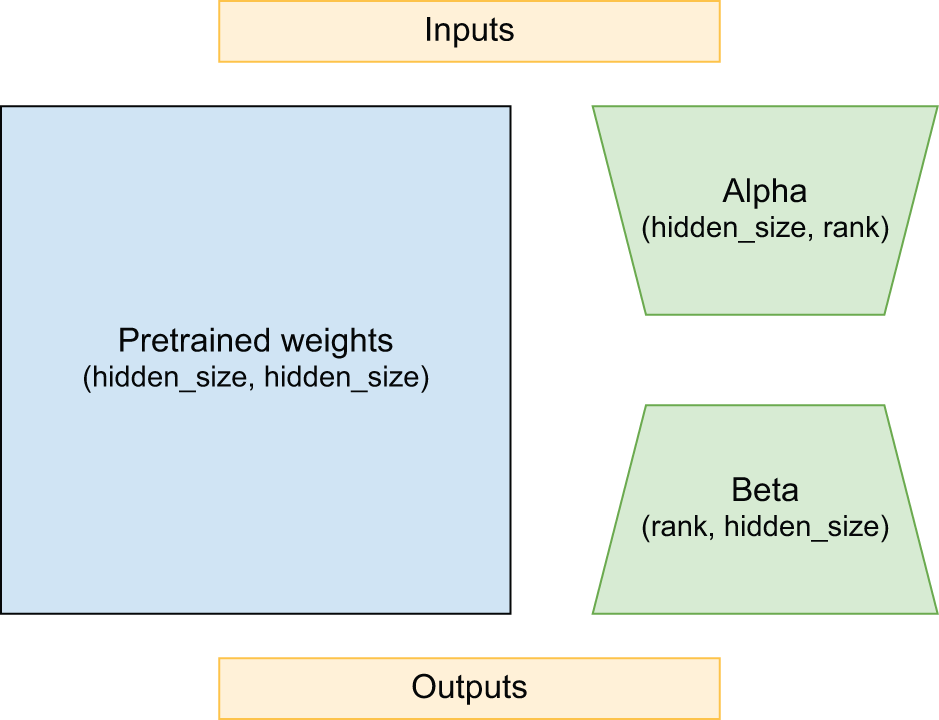 图 16.4:低秩核分解包含的参数比核本身少得多。
图 16.4:低秩核分解包含的参数比核本身少得多。
LoRA 的作者建议冻结整个 Transformer 模型,仅在注意力层的查询和键投影中添加 LoRA 权重。我们来尝试一下。KerasHub 模型内置了 LoRA 训练方法。
1 | gemma_lm.backbone.enable_lora(rank=8) |
清单 16.13:为 KerasHub 模型启用 LoRa 训练
定制 LoRA 培训
Customizing LoRA training
该enable_lora()方法也适用于各个Dense层。我们可以通过遍历 Transformer 的各个层,以更冗长的方式等效地编写之前的调用:
1 | # Sets all layers to not be trainable |
通过这种方法,我们可以在模型中更早或更晚添加更多可训练参数,还可以将 LoRA 添加到价值预测中。
让我们再来看一下模型概要:
1 | >>> gemma_lm.summary() |
尽管我们的模型参数仍然占用 3.7 GB 的空间,但我们的可训练参数现在仅使用 5 MB 的数据——减少了一千倍!这可以将我们的优化器状态从几 GB 减少到 GPU 上的几 MB(图 16.5)。
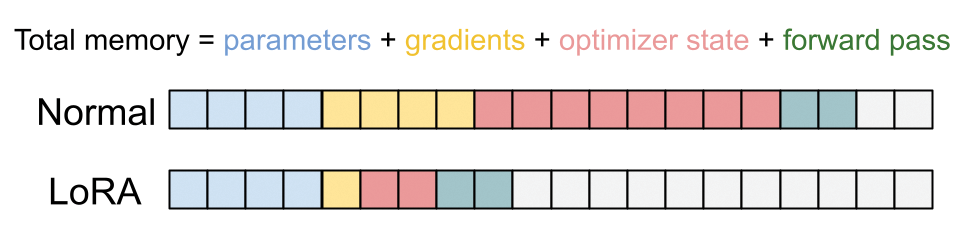 图 16.5:LoRA 大大减少了我们存储梯度和优化器状态所需的内存。
图 16.5:LoRA 大大减少了我们存储梯度和优化器状态所需的内存。
优化完成后,我们终于可以对 Gemma 模型进行指令调优了。让我们试一试。
1 | gemma_lm.compile( |
清单 16.14:微调预训练的 LLM
经过训练,我们的模型在预测下一个单词方面的准确率达到了 55%。这相比我们之前 mini-GPT 模型 35% 的准确率有了显著提升。这充分展现了更大规模模型和更全面的预训练所带来的强大优势。
我们的微调是否提高了模型的指令执行能力?让我们来验证一下:
1 | >>> gemma_lm.generate( |
好多了。我们的模型现在可以回答问题,而不是仅仅试图延续提示文本的内容。
我们解决幻觉问题了吗?
1 | >>> gemma_lm.generate( |
完全不是。不过,我们仍然可以利用指令调优来取得一些进展。一种常见的技巧是使用大量的指令/响应对来训练模型,其中期望的响应是“是”或"I don't know"“否” "As a language model, I cannot help you with that"。这可以训练模型避免尝试回答某些特定主题,因为在这些主题上它往往会给出质量较差的结果。
Going further with LLMs
我们现在已经从零开始训练了一个 GPT 模型,并将一个语言模型微调成我们自己的聊天机器人。然而,我们今天对语言模型的研究还只是冰山一角。在本节中,我们将介绍一些针对基本“互联网自动补全”语言模型设置的扩展和改进,但这些扩展和改进并非全部。
基于人类反馈的强化学习
Reinforcement Learning with Human Feedback (RLHF)
我们刚才进行的这种指令微调通常被称为监督式微调。之所以称为监督式,是因为我们需要手动整理一份我们希望模型给出的示例提示和响应列表。
The type of instruction fine-tuning we just did is often called supervised fine-tuning. It is supervised because we are curating, by hand, a list of example prompts and responses we want from the model.
任何需要手动编写文本示例的情况几乎都会成为瓶颈——获取此类数据既缓慢又昂贵。此外,这种方法会受到人类在指令执行任务上的表现上限的限制。如果我们想在类似聊天机器人的体验中超越人类的表现,就不能依赖手动编写的输出来监督LLM的训练。
我们真正想要优化的问题是我们对某些反应的偏好。如果样本量足够大,这种偏好问题就能被完美定义,但如何将“我们的偏好”转化为可用于计算梯度的损失函数却相当棘手。这正是基于人类反馈的强化学习( RLHF)试图解决的问题。
RLHF 微调的第一步与我们在上一节中所做的完全相同——使用手写提示和回复进行监督式微调。这使我们能够获得良好的基准性能;现在我们需要在此基础上进行改进。为此,我们将构建一个奖励模型( reward model ),该模型可以作为人类偏好的代理。我们可以收集大量的提示和对这些提示的回复。其中一些回复可以是手写的;其他回复可以由模型生成。回复甚至可以由其他聊天机器人语言学习模型 (LLM) 生成。然后,我们需要让评估人员根据偏好对这些回复进行排序。给定一个提示和几个可能的回复,评估人员的任务是将它们从最有帮助到最没帮助进行排序。这种数据收集方式成本高昂且耗时,但仍然比手动编写所有所需的回复要快。
我们可以使用这个排序偏好数据集来构建奖励模型。该模型接收一个提示-响应对,并输出一个浮点值。值越高,响应越好。这个奖励模型通常是另一个规模较小的Transformer。它不是预测下一个词元,而是读取整个序列并输出一个浮点数——即对给定响应的评分。
然后,我们可以利用这个奖励模型,通过强化学习的方式进一步调整模型。本书不会深入探讨强化学习的细节,但请不要被这个术语吓到——它指的是任何一种训练设置,在这种设置中,深度学习模型通过做出预测(称为动作)并获得关于这些预测的反馈(称为 奖励)来学习。简而言之,模型自身的预测就成为了它的训练数据。
在我们的例子中,操作就是对输入提示生成响应,就像我们之前用函数所做的那样generate()。奖励则是将该字符串输出应用一个单独的回归模型。以下是一个简单的伪代码示例。
1 | for prompts in dataset: |
清单 16.15:最简单的 RLHF 算法的伪代码
在这个简单的例子中,我们使用奖励阈值过滤生成的响应,并将“良好”的输出作为新的训练数据,用于后续的监督式微调,就像我们在上一节中所做的那样。在实践中,通常不会丢弃不良响应,而是使用专门的梯度更新算法,利用所有响应和奖励来调整模型的参数。毕竟,不良响应能够很好地提示我们哪些事情不应该做。OpenAI 最初在 2022 年的一篇论文中描述了 RLHF。[5]并利用这种训练设置,从 GPT-3 的初始预训练参数发展到 ChatGPT 的第一个版本。
这种设置的优势在于其迭代性。你可以利用新训练的模型,生成对提示的新的、改进的响应,根据人类的偏好对这些响应进行排序,然后训练一个新的、改进的奖励模型。
使用通过 RLHF 训练的聊天机器人
Using a chatbot trained with rlhf
我们可以通过尝试使用这种迭代偏好调优方式训练的模型来更具体地说明这一点。由于构建聊天机器人是大型 Transformer 模型的“杀手级应用(killer app)”,因此像 Gemma 这样的预训练模型发布公司通常会发布专门针对聊天场景的“指令调优”版本。现在让我们尝试加载一个。这将是一个拥有 40 亿个参数的模型,是我们刚刚加载的模型的四倍,也是本书中我们将使用的最大模型:
1 | gemma_lm = keras_hub.models.CausalLM.from_preset( |
清单 16.16:加载指令优化的 Gemma 变体
为大型模型选择数据类型
Choosing a dtype for large models
您可能已经注意到,我们dtype="float32"在第一次创建 Gemma 模型时通过了测试,dtype="bfloat16"现在又通过了。这是怎么回事?
对于像 Gemma 这样拥有超过十亿个参数的模型,每个浮点数占用的字节数是一个重要的考虑因素。在训练模型时,通常建议每个参数使用 32 位(4 字节)。32 位浮点数可以表示非常小的值,这有助于保持训练梯度的稳定性。这里我们不进行任何训练,因此我们传递 bfloat16一个仅使用 2 字节的参数。我们无需担心梯度稳定性,并且通过使用较低的精度可以节省数 GB 的内存。
第 18 章将详细讨论浮点精度。
就像我们之前自行微调的 Gemma 模型一样,这个指令调整后的检查点也带有一个用于格式化输入的特定模板。同样,具体的文本内容并不重要,重要的是我们的提示模板要与用于调整模型的模板相匹配:
1 | PROMPT_TEMPLATE = """<start_of_turn>user |
我们试着问它一个问题:
1 | >>> prompt = "Why can't you assign values in Jax tensors? Be brief!" |
这个拥有40亿参数的模型首先在14万亿个文本标记上进行预训练,然后经过大量的微调,使其在回答问题时更加有效。部分微调采用了监督式微调(如上一节所述),部分微调采用了强化学习高频(RLHF,如本节所述),还有一些微调采用了其他技术,例如使用一个更大的模型作为“教师”来指导训练。问答能力的提升显而易见。
让我们用这个模型来处理那个一直困扰我们、让我们产生幻觉的提示:
1 | >>> prompt = "Who is the 542nd president of the United States?" |
这个更强大的模型拒绝上钩。这并非源于新的建模技术,而是经过大量针对类似我们刚才收到的这类陷阱问题的训练的结果。事实上,你可以清楚地看到,为什么消除幻觉有点像打地鼠——尽管它拒绝产生美国总统的幻觉,但现在它却能编造出今天的日期。
多模态LLMs
Multimodal LLMs
聊天机器人的一项显而易见的扩展功能是处理新的输入方式。能够响应语音输入并处理图像的助手,远比只能处理文本的助手更有用。
将 Transformer 模型扩展到不同模态的方法在概念上很简单。Transformer 并非文本专用模型;它是一种高效的序列数据模式学习模型。如果我们能够找到将其他数据类型强制转换为序列表示的方法,就可以将该序列输入 Transformer 模型并进行训练。
事实上,我们刚刚加载的 Gemma 模型正是如此。该模型自带一个独立的 4.2 亿参数图像编码器,它将输入图像分割成 256 个图像块,并将每个图像块编码为一个向量,该向量的维度与 Gemma 隐藏层 Transformer 的维度相同。每个图像将被嵌入为一个(256, 2560)序列。由于 Gemma Transformer 模型的隐藏层维度为 2560,因此在词元嵌入层之后,可以直接将这种图像表示拼接到我们的文本序列中。您可以将其视为代表图像的 256 个特殊词元,其中每个(1, 2560)向量有时被称为“软词元”(图 16.6)。与我们通常的“硬词元”不同,在硬词元中,每个词元 ID 只能在词元嵌入矩阵中取固定数量的向量,而这些图像软词元可以取视觉编码器输出的任何向量值。
![]() 图 16.6:通过将文本标记和软图像标记拼接在一起来处理图像输入
图 16.6:通过将文本标记和软图像标记拼接在一起来处理图像输入
让我们加载一张图片,更详细地看看它是如何工作的(图 16.7):
1 | import matplotlib.pyplot as plt |
 图 16.7:Gemma 模型的测试图像
图 16.7:Gemma 模型的测试图像
我们可以使用 Gemma 来询问一些关于这张图片的问题:
1 | >>> # Limits the maximum input size of the model |
我们的每个输入提示都包含一个特殊标记<start_of_image>。该标记在我们的输入序列中被转换为 256 个占位符值,而这些占位符值又会被替换为代表我们图像的软标记。
训练这种多模态模型与常规的LLM预训练和微调非常相似。通常,你需要先单独预训练图像编码器,就像我们在本书第8章中所做的那样。然后,你可以简单地进行相同的“猜测下一个词”预训练,并将混合的图像和文本内容输入到一个序列中。我们的Transformer模型不会被训练来输出图像软标记;我们只需将这些图像标记位置的损失值设为零即可。
个人注:
这句话描述了当前多模态大模型(如 GPT-4o, Llama-3-Vision)最主流的训练范式。我们可以把这个过程拆解为三个通俗的步骤来理解:
- 零件准备:单独预训练图像编码器
- 理解:在让模型“看图说话”之前,它必须先具备“看懂图片”的基础能力。
- 做法:通常会找一个现成的骨干网络(Backbone),比如 CLIP。这个编码器的作用是把一张复杂的图片变成一串数字(向量)。
- 比喻:就像在教学生写看图作文前,先确保他不是色盲,且能分辨出什么是猫、什么是树。
- 核心逻辑:“猜词”游戏的升级版
- 理解:多模态训练并没有发明什么新的魔法,它依然沿用了 LLM 最擅长的 Next Token Prediction(预测下一个词)。
- 操作:
- 把图片切成小块(Patches),通过编码器转成“图像标记”(Image Tokens)。
- 把这些“图像标记”和普通的“文本标记”拼在一起,塞进一个序列里。
- 输入序列:
[图像标记1][图像标记2]...[图像标记n] 请问这张图里有什么?- 输出序列:
图中有一只猫。- 本质:Transformer 根本不在乎输入的是文字还是图片转换来的数字,它只负责根据前面的数据,预测后面该出现什么字。
- “屏蔽”图像输出:损失值设为零
这是你引用的段落中最关键的技术细节。
- 为什么这么做? * 这个模型的目标是理解图像并输出文字,而不是生成图像。
- 在预训练时,模型会尝试预测序列中的每一个位置。如果让它去预测下一个“图像标记”长什么样(输出图像软标记),那它就变成了一个图像生成模型(类似 Stable Diffusion),这会让任务变得极其复杂且难以收敛。
- 怎么操作?(Loss Masking):
- 计算损失函数(Loss)时,我们只关心它预测的那个“字”对不对。
- 对于那些属于“图片”本身的位置,模型预测得再离谱,我们也给它 0 权重(损失值为零)。
- 比喻:这就像闭卷考试。卷子上给了一张图,让你写描述。我们只根据你写的文字内容打分,至于你脑子里脑补出来的图片细节(图像标记位)对不对,老师完全不在乎,也不给你打分。
总结
这段话的意思是:
- 架构通用:多模态模型依然是一个 Transformer。
- 输入混合:图片和文字被“平等”地喂给模型。
- 目标纯粹:我们只训练它理解图片后说出正确的话,而不要求它掌握画出图片的能力。
这种“偷懒”的做法极大地降低了多模态模型的训练难度,也是为什么现在的 AI 进步如此神速的原因。
我们只需将图像数据添加到语言学习模型(LLM)中,这听起来似乎很神奇,但考虑到我们所用的序列模型的强大功能,这其实是一个意料之中的结果。我们使用了一个Transformer模型,将图像输入转换为序列数据,并进行了大量的额外训练。该模型既保留了原语言模型接收和生成文本的能力,又学会了将图像嵌入到Transformer的潜在空间中。
基础模型
Foundation models
随着大型语言模型(LLM)涉足不同模态,“大型语言模型”这个名称可能会有些误导。它们确实可以对语言进行建模,但也可以对图像、音频,甚至结构化数据进行建模。在下一章中,我们将看到一种独特的架构,称为扩散模型(diffusion models),它在底层结构方面与大型语言模型截然不同,但本质上却很相似——它们也使用“互联网规模”的海量数据进行训练,并采用自监督损失函数。
这类模型的总称是基础模型(foundation models)。更具体地说,基础模型是指任何基于广泛数据(通常使用大规模自监督)训练的模型,它可以针对各种下游任务进行微调。
个人注:自监督学习 (Self-Supervised Learning, SSL) 是现代 AI(尤其是 GPT 和 BERT)能够从海量互联网数据中“进化”出的核心底层技术。
简单来说:它是一种“不需要人类打标签,模型自己跟自己玩,从而学会知识”的学习方式。
- 核心逻辑:数据即标签
在传统的监督学习中,你需要雇佣成千上万的人去给图片标“这是猫”,或者给句子标“这是正面情感”。
在自监督学习中,模型会玩一个“猜谜游戏”:
- 做法:从原始数据(如一段文本)中拿掉一部分,然后让模型去预测被拿掉的部分。
- 标签来源:原本在那里的数据就是“标准答案”。模型通过不断尝试预测对,就学会了数据背后的逻辑。
- 常见的自监督训练“游戏”
A. 掩码预测 (Masked Language Modeling) —— BERT 的拿手戏
把一句话里的某个词挖掉,让模型根据上下文猜出来。
- 例子:
“北京是中国的 [MASK]。”- 学习效果:模型为了猜出“首都”,必须理解地理、政治以及中文的语法结构。
B. 下一个词预测 (Next Token Prediction) —— GPT 的核心
给模型一句话的前半部分,让它猜下一个词。
- 例子:
“人工智能的未来...”\(\rightarrow\) 模型预测“充满”\(\rightarrow\) 预测“挑战”。- 学习效果:通过读完整个互联网的文本,模型学会了人类说话的逻辑、知识甚至推理能力。
C. 图像拼图 / 旋转预测 —— 计算机视觉 (CV)
把一张猫的照片切成九宫格打乱,让模型还原。或者把照片旋转,让模型猜旋转了多少度。
- 学习效果:为了完成任务,模型必须学会识别什么是“耳朵”、什么是“胡须”,从而掌握了物体的特征。
为什么要用自监督学习?(痛点解决)
突破数据瓶颈:人类标注的数据是有限且昂贵的(百万级),但互联网上的原始数据是近乎无限的(万亿级)。自监督学习让 AI 可以“生吞”整个互联网。
通用性极强:通过自监督学习得到的 预训练模型 (Pre-trained Model) 拥有极其深厚的“内功”,只需要极少量的指令微调 (SFT),就能在翻译、写代码、总结等任务上表现出色。
一般来说,你可以把基础模型理解为:给定互联网上大量数据的部分表示,学习如何重构 这些数据。虽然LLMs是这类模型中最早也是最知名的,但还有许多其他模型。基础模型的显著特征是:其目标函数是自监督学习(即重构损失),并且这些模型并非专门针对单一任务,而是可以用于多种下游应用。
个人注:基础模型 (Foundation Models)和骨干网络 (Backbone)的区别?
简单来说:它们不是同一个意思。虽然它们都处于模型的核心位置,但“基础模型”是一个行业地位和商业概念,而“骨干网络”是一个纯粹的架构和工程概念。
你可以把它们想象成:“全才天才(基础模型)” 和 “人体的脊椎(骨干网络)”。
- 骨干网络 (Backbone):战术层面的“特征提取器”
在深度学习的架构中,Backbone 指的是模型中最底层的、负责提取原始特征的部分。
- 功能:它的任务是把原始数据(如像素、音频波形、文本序列)转化成计算机能理解的“高级向量”。
- 结构:它通常不包含最后处理具体任务的“头”(Head,如分类头、检测头)。
- 例子:在计算机视觉中,ResNet、EfficientNet、Swin Transformer 都是经典的 Backbone。你可以把这些 Backbone 后面接个“检测头”用来找猫,或者接个“分割头”用来自动驾驶。
- 基础模型 (Foundation Models):战略层面的“通才大脑”
这是一个由斯坦福大学提出的术语,指代那些在大规模数据上训练、可以适应多种下游任务的模型。
- 核心特征:
- 规模大(海量参数)。
- 通用性(一个模型能写诗、写代码、翻译、做数学题)。
- 可塑性:通过微调(Fine-tuning)或提示词(Prompting),它可以变身成任何工具。
- 例子:GPT-4、Claude 3.5、Llama 3、BERT、CLIP。
- 两者的本质区别
维度 骨干网络 (Backbone) 基础模型 (Foundation Model) 定义角度 软件工程/架构(它是模型的一部分) 功能/生态(它是整个 AI 的基石) 关注点 关注算子(卷积、注意力机制、层数) 关注能力(推理、跨模态、通用知识) 独立性 通常只是模型的一个组件,不能单独工作 作为一个完整的黑盒系统,可以直接通过对话使用 比喻 发动机(需要装在车、船或飞机上) 电力基础设施(插上插头就能用在任何电器上)
- 它们什么时候会产生联系?
在现代 AI 开发中,它们经常重合:
- 基础模型包含 Backbone:比如 GPT-4 这个基础模型,它的内部架构(Transformer)就是它的 Backbone。
- Backbone 进化为基础模型:以前 ResNet 只是一个 Backbone,但现在有些像 DINOv2 这样的大规模视觉模型,既可以被看作是超强的 Backbone,也可以被称作是视觉领域的基础模型。
一句话总结
骨干网络说的是这个模型长什么样(它的物理结构),而基础模型说的是这个模型能干什么(它的社会功能)。你现在用的 DeepSeek,是一个基础模型,而它内部复杂的 MoE 架构,就是它的骨干网络。
这是机器学习漫长发展历程中近期发生的一项重要且引人注目的转变。与其从零开始训练模型来处理你的数据集,通常情况下,使用基础模型来获取输入(无论是图像、文本或其他类型)的丰富表征会更好,然后针对最终的下游任务对该模型进行专门化处理。当然,这样做也存在缺点,即需要运行具有数十亿参数的大型模型,因此它并不适用于所有机器学习的实际应用。
检索增强生成
Retrieval Augmented Generation (RAG)
在提示信息中添加额外信息不仅有助于处理图像数据,还可以作为扩展 LLM 功能的通用方法。一个显著的例子是使用 LLM 进行搜索。如果我们简单地将 LLM 与搜索引擎进行比较,它存在一些致命缺陷:
- 逻辑学习模型(LLM)偶尔会捏造数据。它会输出一些训练数据中不存在但可以通过插值推断出来的错误“事实”。这些信息可能具有误导性,甚至会造成危险。
- 逻辑学习模型(LLM)对世界的认知存在一个截止日期——充其量,是模型预训练的日期。训练LLM的成本相当高昂,而且持续地使用新数据进行训练是不切实际的。因此,在某个任意的时间点,LLM对世界的认知就会停止。
- An LLM will occasionally make things up. It will output false “facts” that were not present in the training data but could be interpolated from the training data. This information can range from misleading to dangerous.
- An LLM’s knowledge of the world has a cutoff date—at best, the date the model was pretrained. Training an LLM is quite expensive, and it is not feasible to train continuously on new data. So at some arbitrary point in time, an LLM’s knowledge of the world will just stop.
没人想用一个只能告诉你六个月前发生的事情的搜索引擎。但如果我们把语言学习模型(LLM)看作更像是“对话软件”,它可以处理提示中的任何序列数据,那么如果我们把这个模型用作与传统搜索方式检索信息的接口呢?这就是检索增强生成(RAG)背后的理念。
RAG 的工作原理是:首先获取用户的初始问题,然后通过某种查询方式提取更多文本上下文。这个查询可以指向数据库、搜索引擎,或者任何能够提供用户所提问题相关信息的来源。这些额外信息随后会直接添加到提示信息中。例如,您可以构建如下提示信息:
1 | Use the following pieces of context to answer the question. |
查找相关信息的一种常用方法是使用向量数据库。要构建向量数据库,可以使用 LLM或任何其他模型,将一系列源文档嵌入为向量。文档文本将存储在数据库中,嵌入向量用作键。在检索过程中,可以再次使用 LLM 将用户查询嵌入为向量。向量数据库负责搜索与查询向量接近的键向量,并显示相应的文本。这听起来很像注意力机制本身——回想一下,“查询”、“键”和“值”这些术语实际上都源自数据库系统。
提供有助于生成的信息可以实现以下几个目标:
- 它提供了一种显而易见的绕过模型截止日期的方法。
- 它允许模型访问私有数据。公司可能希望使用基于公共数据训练的LLM作为访问私有信息的接口。
- 它可以帮助模型建立事实基础。虽然没有万全之策能完全消除幻觉,但如果提示中提供了关于主题的正确背景信息,LLM就不太可能捏造事实。
个人注:检索与生成(实际问答)
- 用户提问:用户输入问题。
- 问题向量化:把用户的问题也转换成一个向量。
- 相似度检索 (Retrieval):在数据库里找和问题向量“距离最近”的几个文字块。
- 注入上下文 (Augmentation):把找回来的文字块和原始问题拼接在一起,做成一个超长的 Prompt。
- 模型输出 (Generation):大模型阅读这些参考资料,给出一个有理有据的回答。
“推理”模型
“Reasoning” models
自首批LLMs问世以来,研究人员多年来一直苦苦应对一个众所周知的事实:这些模型在数学问题和逻辑谜题方面表现糟糕。模型或许能在其训练数据中完美解答某个问题,但如果将提示中的几个人名或数字替换掉,就会发现模型根本无法理解它试图解决的问题。对于自然语言处理领域的许多问题,LLM 提供了一条简单的改进途径:增加训练数据量,提高基准测试分数。然而,小学数学题却让这些改进束手无策。
2023年,谷歌的研究人员发现,如果你用一些数学题的“展示解题步骤”的例子来引导模型——就像做作业一样把解题步骤写出来——模型也会开始模仿。当模型模仿写出中间步骤时,它会更加关注自己的输出,从而更快地找到正确答案。他们将这种方法称为“思维链(chain-of-thought)”引导,这个名称沿用至今。另一组研究人员发现,甚至不需要例子;你只需用“让我们一步一步地思考”这句话来引导模型,就能获得更好的输出。
自这些发现以来,人们对直接训练LLMs以提高其链式推理能力产生了浓厚的兴趣。像 OpenAI 的 o1 和 DeepSeek 的 r1 这样的模型,通过训练模型“大声思考”难题,在数学和编程问题上取得了显著进步,并因此成为新闻热点。
这种循序渐进的微调方法与RLHF非常相似。首先,我们会用一些监督学习的例子来训练模型,这些例子要求学习者“展示解题步骤”并得出正确答案。接下来,我们会给模型一个新的数学题,并检查模型是否给出了正确的答案。最后,我们会利用这些新生成的输出来进一步调整模型的权重。
我们来用 Gemma 模型试试。我们可以自己编写一个应用题,并启用随机抽样,这样每次都能得到一个略微随机的结果:
1 | prompt = """Judy wrote a 2-page letter to 3 friends twice a week for 3 months. |
我们来尝试生成几个响应:
1 | >>> gemma_lm.generate(PROMPT_TEMPLATE.format(prompt)) |
第一次尝试中,我们的模型纠结于每封信有两页这个无关紧要的细节。第二次尝试中,模型就正确解决了这个问题。我们使用的这个经过指令调整的Gemma模型已经针对类似的数学问题进行了优化;而上一节中未经调整的Gemma模型则无法达到如此好的效果。
我们可以将这个想法扩展到一种非常简单的思维导图训练形式:
- 收集一些基础数学和推理题以及期望答案。
- 生成(带有一定的随机性)若干响应。
- 通过字符串解析找出所有正确答案。您可以像之前那样,指示模型使用特定的文本标记来表示最终答案。
- 对正确响应进行监督式微调,包括所有中间输出。
- 重复!
前面描述的过程是一种强化学习算法。我们的答案检查充当了 环境,而生成的输出则是模型用来学习的动作。与 RLHF 类似,在实践中,你会使用更复杂的梯度更新步骤来利用所有响应(即使是错误的响应)的信息,但基本原理是相同的。
The previously described process is a reinforcement learning algorithm. Our answer checking acts as the environment, and the generated outputs are the actions the model uses to learn. As with RLHF, in practice you would use a more complex gradient update step to use information from all responses (even the incorrect ones), but the basic principle is the same.
同样的思路也被用于提升其他领域中学习LLMs的性能,这些领域对于文本提示的答案显而易见且可验证。编码是其中重要的一环——你可以提示LLM输出代码,然后实际运行该代码来测试响应的质量。
在所有这些领域,一个趋势显而易见——随着模型学习解决更复杂的问题,它会在得出最终答案之前花费越来越多的时间“展示其解题过程”。你可以把这理解为模型在学习搜索 自身输出的潜在解决方案。我们将在本书最后一章进一步探讨这一观点。
LLMs的未来发展方向是什么?
Where are LLMs heading next?
鉴于本章开头讨论的LLM发展轨迹,LLM的未来发展方向似乎显而易见:更多参数!更优的性能!从总体上看,这或许没错,但我们的发展轨迹可能并非如此线性。
假设你有一个固定的预训练预算,比如一百万美元,你可以大致把它理解为购买一定数量的计算资源或浮点运算次数(flops)。你可以选择用这些浮点运算次数来训练更多的数据,或者训练一个更大的模型。最近的研究指出,GPT-3 拥有 1750 亿个参数,远远超出了其计算预算。如果用更多的数据训练一个更小的模型,就能获得更好的模型性能。因此,近年来,模型规模的增长趋势趋于平缓,而数据规模的增长趋势却在不断上升。
但这并不意味着扩展会停止——更强大的计算能力通常会 带来更好的LLM性能,而且我们尚未看到任何迹象表明下一词元预测性能( next token prediction performance )会趋于平缓。各公司仍在持续投入数十亿美元用于扩展LLM,并探索由此产生的新功能。
图 16.8 展示了 2018 年至 2025 年间发布的一些主要 LLM 的详细信息。我们可以注意到,虽然用于预训练的 token 总数稳步且大幅增长,但自 GPT-3 以来,模型参数数量却发生了显著变化。部分原因是我们现在知道 GPT-3 存在欠训练问题,但更实际的原因也在于此。在部署模型时,为了获得更适合低成本硬件的小型模型,牺牲一些性能通常是值得的。如果运行成本过高,即使模型性能再好也无济于事。
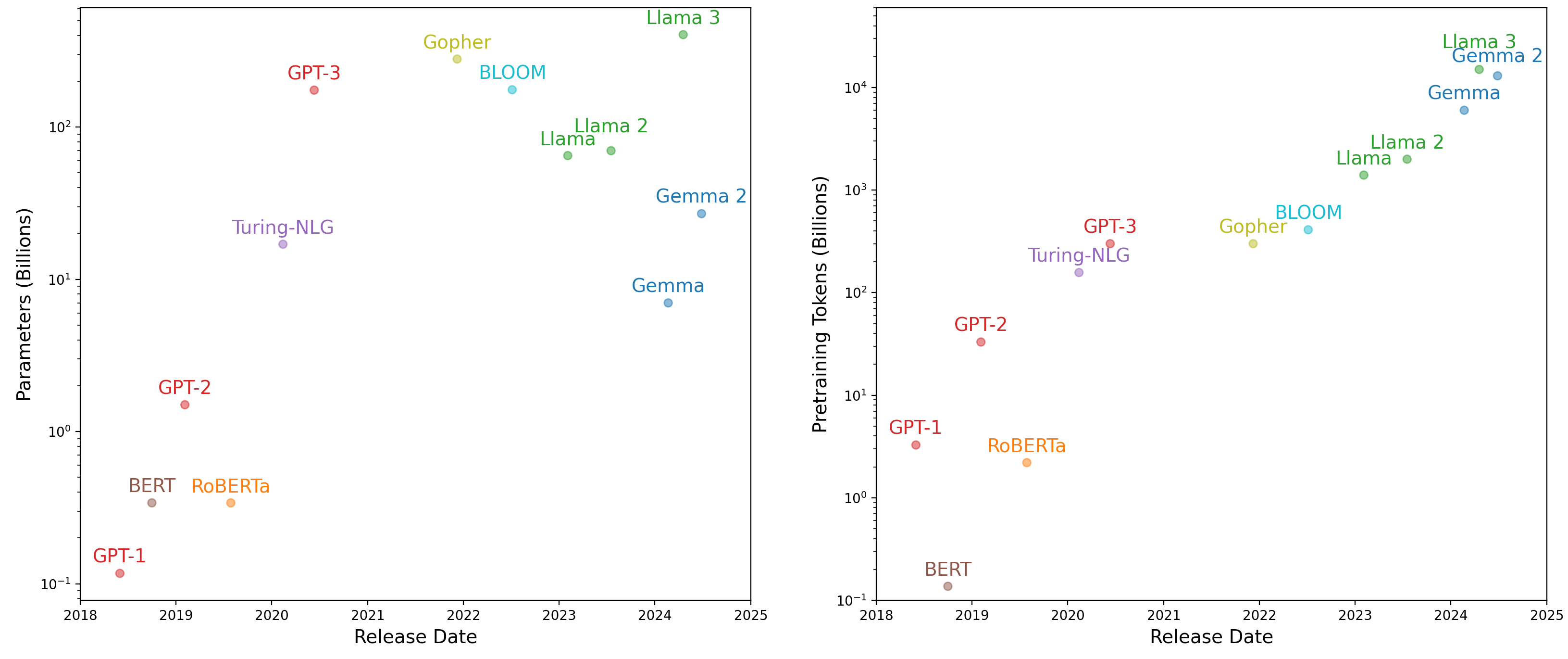 图 16.8:LLM 参数数量(左)和预训练数据集大小(右)随时间的变化。许多近期推出的专有 LLM(例如 GPT-4 和 Gemini)未包含在内,因为模型细节尚未公开。
图 16.8:LLM 参数数量(左)和预训练数据集大小(右)随时间的变化。许多近期推出的专有 LLM(例如 GPT-4 和 Gemini)未包含在内,因为模型细节尚未公开。
我们可能无法盲目地扩展这些模型,还有另一个原因:预训练数据开始告罄!科技公司越来越难以找到更多高质量、公开的、由人类撰写的内容用于预训练。模型甚至开始“自相矛盾”,大量使用其他语言学习模型(LLM)创建的内容进行训练,这又引发了一系列新的问题。这也是强化学习近期备受关注的原因之一。如果你能创建一个具有挑战性的、自包含的环境,为语言学习模型生成新的问题,你就找到了一种利用模型自身输出继续训练的方法——无需再费力地在网络上搜寻更多优质文本素材。
我们讨论过的所有解决方案都无法彻底解决LLM面临的所有问题。归根结底,根本问题依然是LLM的学习效率远低于人类。模型能力的提升只能依靠训练数据,而训练数据量远超人类一生所能阅读的文本量。随着LLM规模的不断扩大,如何构建能够在数据有限的情况下快速学习的模型的基础研究也将持续进行。
尽管如此,LLM 代表着构建流畅自然语言界面的能力,仅此一项就将极大地改变我们利用计算设备所能完成的事情。在本章中,我们阐述了许多 LLM 用于实现这些功能的基本方法。
概括
- 大型语言模型(LLM)是由几个关键要素组合而成的:
- Transformer架构
- 语言建模任务(根据过去的词元预测下一个词元)
- 大量未标记的文本数据
- LLM学习用于预测单个词元的概率分布。这可以与采样策略相结合,生成一长串文本。有很多常用的文本采样方法:
- 贪婪搜索在每一代步骤中都选择最有可能预测的令牌。
- 随机抽样直接对所有标记的预测类别分布进行抽样。
- Top-k 抽样将类别分布限制在前 K 个候选对象中。
- LLM 使用数十亿个参数,并用数万亿个单词的文本进行训练。
- LLM 的输出不可靠,所有 LLM 都会偶尔产生与事实不符的幻觉信息。
- 可以对 LLM 进行微调,使其能够遵循聊天对话中的指令。这种微调称为指令微调:
- 最简单的指令微调形式是直接使用指令和响应对来训练模型。
- 更高级的教学微调形式涉及强化学习。
- 使用 LLM 时最常见的资源瓶颈是加速器内存。
- LoRA 是一种通过冻结大多数 Transformer 参数并仅更新注意力投影权重的低秩分解来减少内存使用量的技术。
- 如果能够弄清楚如何将这些输入或输出构建成序列预测问题中的序列,LLM 就可以输入或输出来自不同模态的数据。
- 基础模型是一个通用术语,指的是使用自监督训练的任何模态的模型,用于执行各种下游任务。
脚注
- 2022年,杰森·艾伦(Jason Allen)利用图像生成软件Midjourney赢得了一项数字艺术家奖项;2024年,九段理惠(Rie Kudan)凭借一部大量运用生成软件创作的小说,荣获日本最负盛名的文学奖项之一。
- 伊安尼斯·泽纳基斯(Iannis Xenakis),“音乐形式:音乐作曲的新原理”,《音乐评论》特刊,第 10 期。 253-254(1963)。
- Alec Radford、Karthik Narasimhan、Tim Salimans 和 Ilya Sutskever,“通过生成式预训练提高语言理解能力”,(2018 年),https://mng.bz/GweD。
- J. Edward Hu 等人,“LoRA:大型语言模型的低秩自适应”,arXiv (2021),https://arxiv.org/abs/2106.09685。
- Ouyang 等人,“训练语言模型以根据人类反馈遵循指令”,第 36 届国际神经信息处理系统会议论文集 (2022),https://arxiv.org/abs/2203.02155。