《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
Introduction to TensorFlow, PyTorch, JAX, and Keras
运行代码
本章内容
- 深入了解所有主要的深度学习框架及其关系
- 概述深度学习核心概念如何在所有框架中转化为代码
本章旨在为您提供开始实践深度学习所需的一切。首先,您将熟悉三种可与 Keras 配合使用的常用深度学习框架:
- TensorFlow(https://tensorflow.org)
- PyTorch ( https://pytorch.org/ )
- JAX(https://jax.readthedocs.io/)
然后,在第 2 章中你第一次接触 Keras 的基础上,我们将回顾神经网络的核心组件以及它们如何转换为 Keras API。
读完本章,你就可以开始学习实际的、现实世界的应用了——这将从第 4 章开始。
深度学习框架简史
A brief history of deep learning frameworks
在实际应用中,你不会像第二章结尾那样从零开始编写底层代码。相反,你会使用框架。除了 Keras 之外,目前主要的深度学习框架还有 JAX、TensorFlow 和 PyTorch。本书将介绍这四个框架。
如果你刚开始接触深度学习,可能会觉得这些框架好像一直都存在。但实际上,它们都相当新,其中 Keras 是四个框架中最古老的(于 2015 年 3 月发布)。然而,这些框架背后的理念却有着悠久的历史——第一篇关于自动微分的论文发表于 1964 年。[1]
所有这些框架都结合了三个关键特征:
- 一种计算任意可微函数梯度的方法(自动微分 automatic differentiation)
- 一种在 CPU 和 GPU(甚至可能在其他专用深度学习硬件)上运行张量计算的方法
- 一种将计算任务分布到多个设备或多台计算机上的方法,例如在一台计算机上使用多个 GPU,甚至在多台独立的计算机上使用多个 GPU。
这三个简单的特性共同解锁了所有现代深度学习。
该领域花了很长时间才开发出针对这三个问题的稳健解决方案,并将这些解决方案打包成可重用的形式。从 20 世纪 60 年代诞生到 21 世纪初,自微分(autodifferentiation)在机器学习中几乎没有实际应用——从事神经网络研究的人员只能手动编写梯度逻辑,通常使用 C++ 等语言。与此同时,GPU 编程几乎是不可能的。
2000 年代后期,情况开始缓慢变化。首先,Python 及其生态系统在科学界逐渐流行起来,逐渐超越了 MATLAB 和 C++。其次,NVIDIA 于 2006 年发布了 CUDA,使得构建可在消费级 GPU 上运行的神经网络成为可能。CUDA 最初的应用重点是物理模拟而非机器学习,但这并没有阻止机器学习研究人员从 2009 年开始实现基于 CUDA 的神经网络。这些通常是单次实现,只能在单个 GPU 上运行,且不具备自动微分功能。
第一个能够利用自动微分和GPU计算来训练深度学习模型的框架是Theano,大约在2009年问世。Theano是所有现代深度学习工具的概念鼻祖。在2013-2014年间,随着ImageNet 2012竞赛结果的公布,全球对深度学习的兴趣日益浓厚,Theano开始在机器学习研究领域获得广泛关注。几乎在同一时期,其他一些支持GPU的深度学习库也开始在计算机视觉领域流行起来,特别是基于Lua的Torch 7和基于C++的Caffe。Keras于2015年初发布,它是一个基于Theano的更高级、更易于使用的深度学习库,并迅速赢得了当时仅有的几千名深度学习爱好者的青睐。
随后在 2015 年末,谷歌发布了 TensorFlow,它借鉴了 Theano 的许多核心理念,并增加了对大规模分布式计算的支持。TensorFlow 的发布是一个里程碑式的时刻,它推动了深度学习在主流开发者群体中的普及。Keras 立即添加了对 TensorFlow 的支持。到 2016 年年中,超过一半的 TensorFlow 用户都是通过 Keras 使用它的。
为了应对 TensorFlow,Meta(当时名为 Facebook)大约一年后推出了 PyTorch,其灵感来源于 Chainer(一个于 2015 年中期推出的、小众但创新的框架,现已停止开发)和 NumPy-Autograd,后者是由 Maclaurin 等人于 2014 年发布的 NumPy 专用 CPU 自动微分库。与此同时,谷歌发布了 TPU 作为 GPU 的替代方案,以及 XLA,这是一个为使 TensorFlow 能够在 TPU 上运行而开发的高性能编译器。
几年后,在谷歌,参与 NumPy-Autograd 开发的 Matthew Johnson 发布了 JAX,作为使用 XLA 进行自动微分的另一种方式。凭借其简洁的 API 和高可扩展性,JAX 迅速获得了研究人员的青睐。如今,Keras、TensorFlow、PyTorch 和 JAX 已成为深度学习领域顶尖的框架。
回顾这段混乱的历史,我们不禁要问:接下来会发生什么?明天会出现新的框架吗?我们会转向新的编程语言还是新的硬件平台?
依我看,今天有三件事是确定的:
- Python 已经胜出。它的机器学习和数据科学生态系统目前发展势头强劲,势不可挡。至少在未来 15 年内,不会出现一种全新的语言来取代它。
- 我们身处一个多框架并存的世界——这四个框架都已相当成熟,并且在未来几年内不太可能被淘汰。因此,了解每个框架的一些知识是很有必要的。然而,未来很可能会出现新的框架,例如苹果最近发布的 MLX。在这种情况下,使用 Keras 就具有显著优势:您可以通过新的 Keras 后端,在任何新兴框架上运行现有的 Keras 模型。Keras 将继续为机器学习开发者提供面向未来的稳定性,就像自 2015 年以来一直如此——当时 TensorFlow、PyTorch 和 JAX 都还不存在。
- 未来肯定会有新的芯片出现,与英伟达的GPU和谷歌的TPU并存。例如,AMD的GPU产品线前景光明。但任何新的芯片都必须与现有框架兼容才能获得市场认可。新硬件不太可能对你的工作流程造成干扰。
这些框架之间是如何相互关联的
How these frameworks relate to each other
Keras、TensorFlow、PyTorch 和 JAX 的功能集并不完全相同,也不能互相替代。它们之间存在一些重叠,但在很大程度上,它们针对不同的应用场景扮演着不同的角色。最大的区别在于 Keras 与其他三者之间。Keras 是一个高级框架,而其他三者则属于底层框架。想象一下建造房屋。Keras 就像一套预制建筑组件:它提供了一个简化的接口,用于设置和训练神经网络。相比之下,TensorFlow、PyTorch 和 JAX 则像是建造房屋所使用的原材料。
正如你在前几章中看到的,训练神经网络主要围绕以下概念展开:
- 首先是底层张量操作——这是所有现代机器学习的基础架构。这指的是TensorFlow和PyTorch中的底层API。[2]以及 JAX:
- 张量,包括存储网络状态(变量)的特殊张量
- 张量运算,例如加法、
relu乘法或乘法。matmul - 反向传播是一种计算数学表达式梯度的方法。
- 其次,高阶深度学习概念——这可以转化为 Keras API:
- 层,它们组合成一个模型
- 损失函数定义了用于学习的反馈信号
- 优化器决定了学习过程如何进行。
- 用于评估模型性能的指标,例如准确率
- 执行小批量随机梯度下降的训练循环
- First, low-level tensor manipulation — The infrastructure that underlies all modern machine learning. This translates to low-level APIs found in TensorFlow, PyTorch, and JAX:
- Tensors, including special tensors that store the network’s state (variables)
- Tensor operations such as addition,
relu, ormatmul - Backpropagation, a way to compute the gradient of mathematical expressions
- Second, high-level deep learning concepts — This translates to Keras APIs:
- Layers, which are combined into a model
- A loss function, which defines the feedback signal used for learning
- An optimizer, which determines how learning proceeds
- Metrics to evaluate model performance, such as accuracy
- A training loop that performs mini-batch stochastic gradient descent
此外,Keras 的独特之处在于它并非一个完全独立的框架。它需要一个后端引擎才能运行(参见图 3.4),就像预制房屋需要从某个地方采购建筑材料一样。TensorFlow、PyTorch 和 JAX 都可以用作 Keras 的后端。另外,Keras 可以在 NumPy 上运行,但由于 NumPy 没有提供梯度 API,因此在 NumPy 上运行的 Keras 工作流仅限于对模型进行预测——无法进行训练。
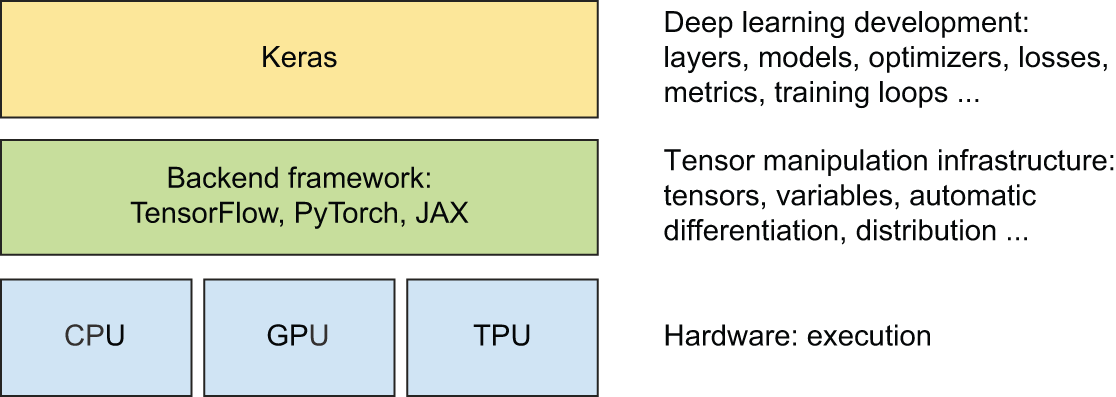
现在您已经更清楚地了解了这些框架的由来以及它们之间的关系,接下来让我们深入了解一下使用它们的实际体验。我们将按时间顺序介绍它们:首先是 TensorFlow,然后是 PyTorch,最后是 JAX。
TensorFlow 简介
Introduction to TensorFlow
TensorFlow 是一个基于 Python 的开源机器学习框架,主要由谷歌开发。它最初于 2015 年 11 月发布,随后分别于 2017 年 2 月和 2019 年 10 月发布了 v1 和 v2 版本。TensorFlow 被广泛应用于业界各种生产级机器学习应用中。
需要注意的是,TensorFlow 不仅仅是一个库,它实际上是一个平台,拥有庞大的组件生态系统,其中一些由 Google 开发,一些由第三方开发。例如,TFX 用于工业级机器学习工作流管理,TF-Serving 用于生产环境部署,TF Optimization Toolkit 用于模型量化和剪枝,以及 TFLite 和 MediaPipe 用于移动应用部署。
这些组件共同涵盖了非常广泛的应用场景,从尖端研究到大规模生产应用。
TensorFlow入门
First steps with TensorFlow
接下来的段落将带你熟悉TensorFlow的所有基础知识。我们将涵盖以下关键概念:
- 张量和变量
- TensorFlow 中的数值运算
- 用
GradientTape - 通过使用即时编译来加快 TensorFlow 函数的运行速度
最后,我们将以一个完整的示例来结束介绍:一个纯 TensorFlow 实现的线性回归。
让我们开始处理这些张量吧。
TensorFlow 中的张量和变量
Tensors and variables in TensorFlow
要在TensorFlow中做任何事情,我们都需要一些张量。创建张量的方法有很多种。
常张量
Constant tensors
张量需要用一些初始值来创建,因此创建张量的常用方法是通过tf.ones``(等效于np.ones) 和tf.zeros``(等效于np.zeros)。您还可以使用 . 从 Python 或 NumPy 值创建张量 tf.constant。
1 | >>> import tensorflow as tf |
列表 3.1:全 1 或全 0 张量
随机张量
Random tensors
您还可以通过子模块的方法之一tf.random(等同于np.random子模块)创建填充随机值的张量。
1 | >>> # Tensor of random values drawn from a normal distribution with |
列表 3.2:随机张量
张量赋值和变量类
Tensor assignment and the Variable class
NumPy 数组和 TensorFlow 张量的一个显著区别在于,TensorFlow 张量不可赋值:它们是常量。例如,在 NumPy 中,你可以执行以下操作。
1 | import numpy as np |
清单 3.3:NumPy 数组可赋值
尝试在 TensorFlow 中执行相同的操作:你会得到一个错误 EagerTensor object does not support item assignment。
1 | x = tf.ones(shape=(2, 2)) |
清单 3.4:TensorFlow 张量不可赋值
要训练模型,我们需要更新它的状态,状态是一组张量。如果张量不可赋值,那我们该如何更新呢?这就需要用到变量了。var``tf.Variable类就是用来管理 TensorFlow 中可修改状态的。
要创建变量,需要提供一些初始值,例如随机张量。
1 | >>> v = tf.Variable(initial_value=tf.random.normal(shape=(3, 1))) |
清单 3.5:创建tf.Variable
变量的状态可以通过其assign方法进行修改。
1 | >>> v.assign(tf.ones((3, 1))) |
清单 3.6:给一个变量赋值Variable
赋值操作也适用于系数的子集。
1 | >>> v[0, 0].assign(3.) |
清单 3.7:给一个子集赋值Variable
类似地,assign_add和分别是和的assign_sub有效等价物 。+=``-=
1 | >>> v.assign_add(tf.ones((3, 1))) |
清单 3.8:使用assign_add
张量运算:在 TensorFlow 中进行数学运算
Tensor operations: Doing math in TensorFlow
与 NumPy 类似,TensorFlow 提供了大量的张量运算来表达数学公式。以下是一些示例。
1 | a = tf.ones((2, 2)) |
清单 3.9:TensorFlow 中的一些基本数学运算
Dense这是与我们在第二章中看到的图层等效的结构:
1 | def dense(inputs, W, b): |
TensorFlow 中的梯度:再次审视 GradientTape API
Gradients in TensorFlow: A second look at the GradientTape api
目前来看,TensorFlow 和 NumPy 非常相似。但 NumPy 做不到一点:它无法获取任意可微表达式关于其任意输入的梯度。只需打开一个GradientTape作用域,对一个或多个输入张量进行计算,然后获取结果关于这些输入的梯度即可。
1 | input_var = tf.Variable(initial_value=3.0) |
清单 3.10:使用GradientTape
这最常用于检索模型损失函数相对于其权重的梯度:gradients = tape.gradient(loss, weights)。
在第 2 章中,你了解了它如何GradientTape处理单个输入或输入列表,以及输入可以是标量或高维张量。
到目前为止,你看到的都是输入张量为 TensorFlow 变量的情况tape.gradient() 。实际上,这些输入可以是任意张量。但是,默认情况下只跟踪可训练变量。对于常量张量,你需要手动调用 trace() 方法来将其标记为已跟踪tape.watch()。
1 | input_const = tf.constant(3.0) |
清单 3.11:使用GradientTape常量张量输入
为什么?因为预先存储计算任何变量相对于任何变量的梯度所需的信息成本太高。为了避免浪费资源,梯度带(gradient tape)需要知道要监视哪些变量。默认情况下,可训练变量会被监视,因为计算损失函数相对于一系列可训练变量的梯度是梯度带(gradient tape)最常见的应用场景。
梯度带是一个功能强大的工具,甚至可以计算 二阶梯度——也就是梯度的梯度。例如,物体位置随时间变化的梯度就是该物体的速度,而二阶梯度就是它的加速度。
个人注:gradient tape 机器翻有时译成梯度磁带,有时候翻译成梯度带。
A context that records operations for automatic differentiation.
一个用于记录计算过程,以便之后自动求梯度的上下文环境。
为什么叫 “Tape”:
这里的 Tape 来自早期自动微分理论中的概念:
- 把 前向计算过程 按顺序记录下来
- 像磁带 (tape) 一样存储计算步骤
- 反向传播时 倒着读取这条“磁带” 计算梯度
如果你测量一个下落的苹果沿垂直轴的位置随时间的变化,并且发现它满足某个条件position(time) = 4.9 * time ** 2,那么它的加速度是多少?让我们用两个嵌套的梯度带来找出答案。
1 | time = tf.Variable(0.0) |
清单 3.12:使用嵌套梯度带计算二阶梯度
利用编译加速 TensorFlow 函数
Making TensorFlow functions fast using compilation
你目前编写的所有 TensorFlow 代码都是“立即执行”的。这意味着操作会在 Python 运行时中逐个执行,就像任何 Python 代码或 NumPy 代码一样。立即执行对于调试非常有用,但通常速度很慢。并行化一些计算,或者说“融合”操作,通常会很有帮助——将两个连续的操作(例如 a 和 b)替换matmul为relu一个更高效的单个操作,该操作无需实例化中间输出即可完成相同的操作。
这可以通过编译来实现。编译的基本思想是,将你用 Python 编写的某些函数提取出来,自动将其重写成一个速度更快、效率更高的“编译程序”,然后从 Python 运行时调用该程序。
编译的主要好处是提升性能。但它也有缺点:你编写的代码不再是实际执行的代码,这会使调试过程变得非常痛苦。只有在 Python 运行时环境中调试完代码之后,才应该启用编译。
你可以通过将任何 TensorFlow 函数包装在tf.function装饰器中来对其进行编译,如下所示:
1 |
|
这样做之后,所有直接调用dense()都会被替换为对已编译程序的调用,该程序实现了该函数的更优化版本。第一次调用该函数会稍慢一些,因为 TensorFlow 需要编译你的代码。但这只会发生一次——之后对同一函数的所有调用都会很快。
TensorFlow 有两种编译模式:
- 首先是默认模式,我们称之为“图形模式”。任何用
@graph装饰的函数都会以@tf.function图形模式运行。 - 其次,可以使用 XLA 进行编译,XLA 是一款高性能的 ML 编译器(全称为 Accelerated Linear Algebra)。您可以通过指定参数来启用它
jit_compile=True,如下所示:
1 |
|
通常情况下,使用 XLA 编译函数会比使用图形模式运行得更快——尽管第一次执行函数时需要更多时间,因为编译器需要做更多的工作。
一个完整的示例:纯 TensorFlow 中的线性分类器
An end-to-end example: A linear classifier in pure TensorFlow
您已经了解张量、变量和张量运算,也知道如何计算梯度。这些足以构建任何基于梯度下降的 TensorFlow 机器学习模型。让我们通过一个完整的示例来确保一切都清晰明了。
在机器学习求职面试中,你可能会被要求从零开始实现一个线性分类器:这项看似简单的任务,实际上是为了筛选出具备基本机器学习基础的候选人和完全没有相关经验的候选人。让我们助你通过这一关,运用你新掌握的 TensorFlow 知识来实现这样一个线性分类器。
首先,让我们生成一些线性可分的合成数据来处理:二维平面上的两类点。
1 | import numpy as np |
清单 3.13:在二维平面上生成两类随机点
negative_samples这positive_samples两个数组的形状均为(1000, 2)。让我们将它们堆叠成一个形状为 的数组(2000, 2)。
1 | inputs = np.vstack((negative_samples, positive_samples)).astype(np.float32) |
清单 3.14:将两个类堆叠成一个形状为 的数组。(2000, 2)
让我们生成相应的目标标签,一个形状为 的 0 和 1 的数组(2000, 1),其中targets[i, 0]0 表示inputs[i]属于类别 0(反之亦然)。
1 | targets = np.vstack( |
清单 3.15:生成相应的目标值(0 和 1)
让我们使用 Matplotlib(一个著名的 Python 数据可视化库,Colab 中已预装了 Matplotlib,因此您无需自行安装)来绘制数据,如图 3.1 所示。
1 | import matplotlib.pyplot as plt |
清单 3.16:绘制两个点类
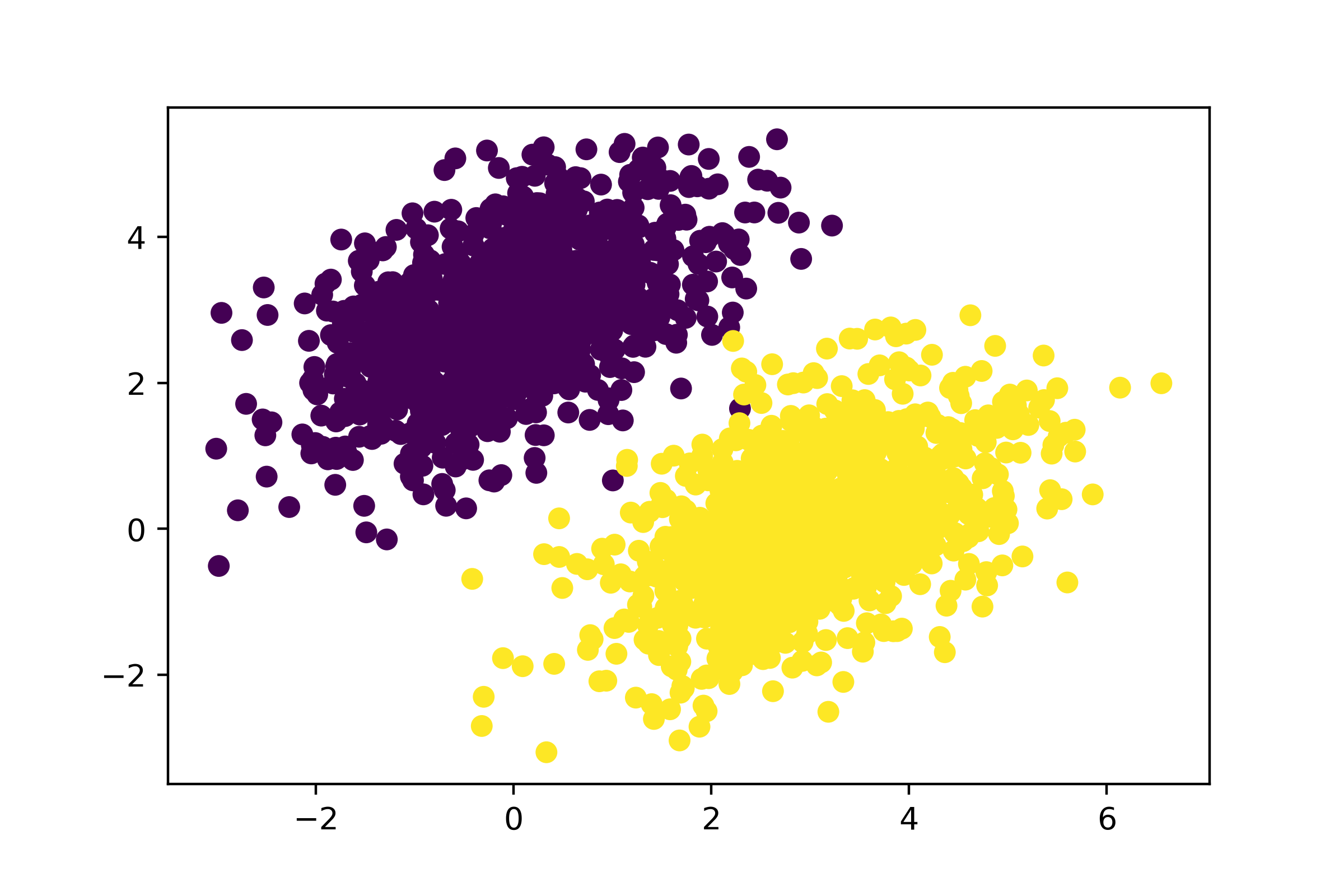
现在,我们来创建一个线性分类器,它可以学习区分这两个斑点。线性分类器是一种仿射变换(prediction = matmul(input, W) + b),其训练目标是最小化预测值与目标值之间差异的平方。
你会发现,这实际上比第二章末尾的玩具两层神经网络的端到端示例要简单得多。但是这一次,你应该能够逐行理解代码的所有内容。
让我们创建变量W和b,分别初始化为随机值和零。
1 | # The inputs will be 2D points. |
清单 3.17:创建线性分类器变量
这是我们的前向传递函数。
1 | def model(inputs, W, b): |
清单 3.18:前向传递函数
由于我们的线性分类器处理的W是二维输入,因此实际上只有两个标量系数:W = [[w1], [w2]]。而则b只有一个标量系数。因此,对于给定的输入点 [x, y],其预测值为 prediction = [[w1], [w2]] • [x, y] + b = w1 * x + w2 * y + b。
这是我们的损失函数。
1 | def mean_squared_error(targets, predictions): |
清单 3.19:均方误差损失函数
现在,我们进入训练步骤,该步骤接收一些训练数据并更新权重W,b以最大限度地减少数据损失。
1 | learning_rate = 0.1 |
清单 3.20:训练步骤函数
为了简化起见,我们将采用批量训练而非小批量训练(batch training instead of mini-batch training):我们将对整个数据集运行每个训练步骤(梯度计算和权重更新),而不是分批迭代处理数据。一方面,这意味着每个训练步骤的运行时间会更长,因为我们需要一次性计算 2000 个样本的前向传播和梯度。另一方面,由于每次梯度更新都包含了所有训练样本的信息,而不是像之前那样仅包含 128 个随机样本的信息,因此在降低训练数据损失方面会更加有效。因此,我们需要的训练步骤会大大减少,并且应该使用比通常用于小批量训练的学习率更大的学习率(我们将使用learning_rate = 0.1之前定义的学习率)。
1 | for step in range(40): |
清单 3.21:批量训练循环
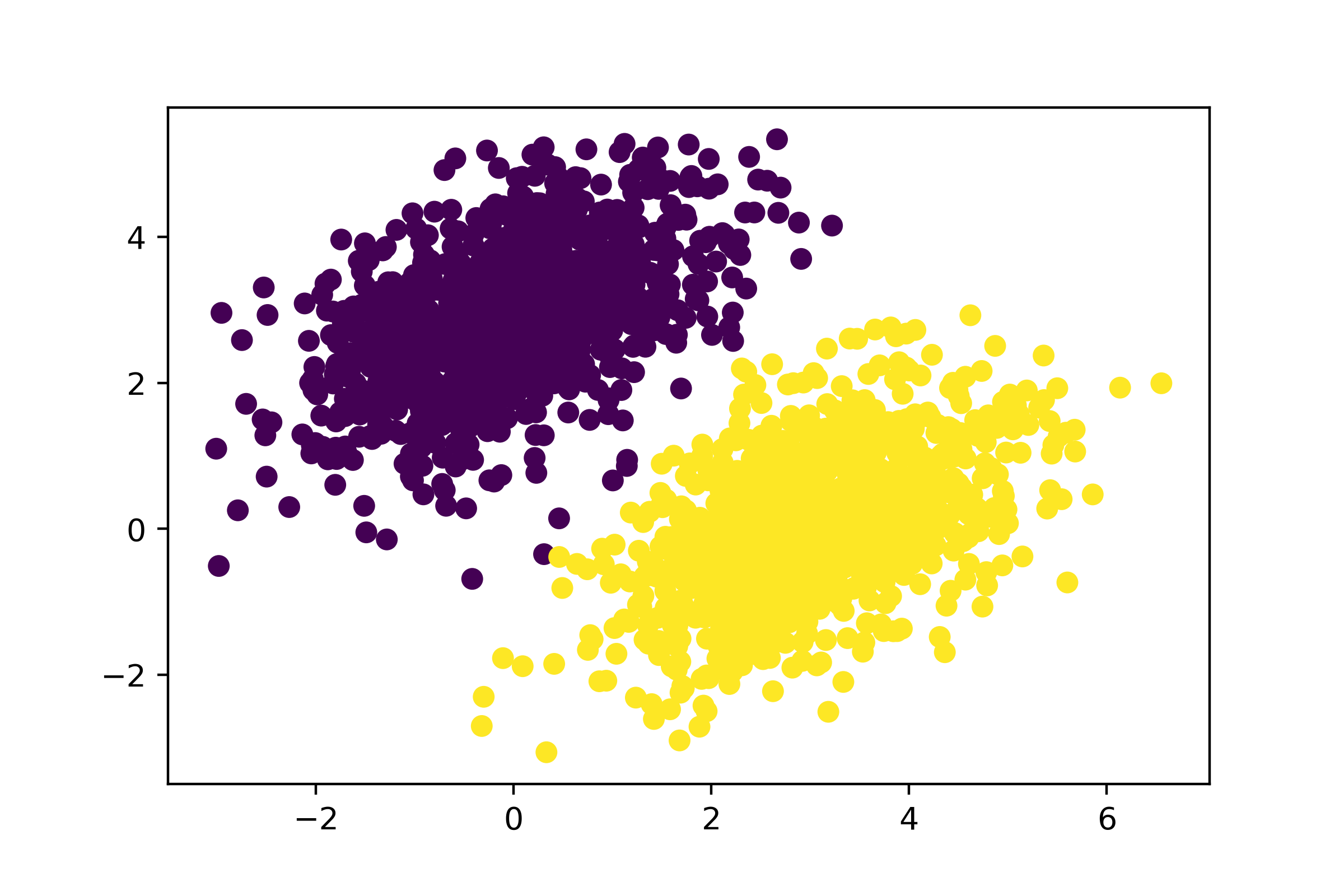
经过 40 步训练后,训练损失似乎稳定在 0.025 左右。让我们绘制线性模型如何对训练数据点进行分类,如图 3.2 所示。由于我们的目标值为 0 和 1,因此如果给定输入点的预测值低于 0.5,则将其分类为“0”;如果高于 0.5,则将其分类为“1”。
1 | predictions = model(inputs, W, b) |
回想一下,给定点的预测值[x, y]就是 prediction == [[w1], [w2]] • [x, y] + b == w1 * x + w2 * y + b。因此,“0”类定义为 w1 * x + w2 * y + b < 0.5,“1”类定义为 w1 * x + w2 * y + b > 0.5。你会注意到,你看到的实际上是二维平面上一条直线的方程:w1 * x + w2 * y + b = 0.5。1 类位于直线上方;0 类位于直线下方。你可能习惯于看到直线方程的格式为y = a * x + b;同样,我们的直线方程变为y = - w1 / w2 * x + (0.5 - b) / w2。
让我们绘制这条线,如图 3.3 所示:
1 | # Generates 100 regularly spaced numbers between -1 and 4, which we |
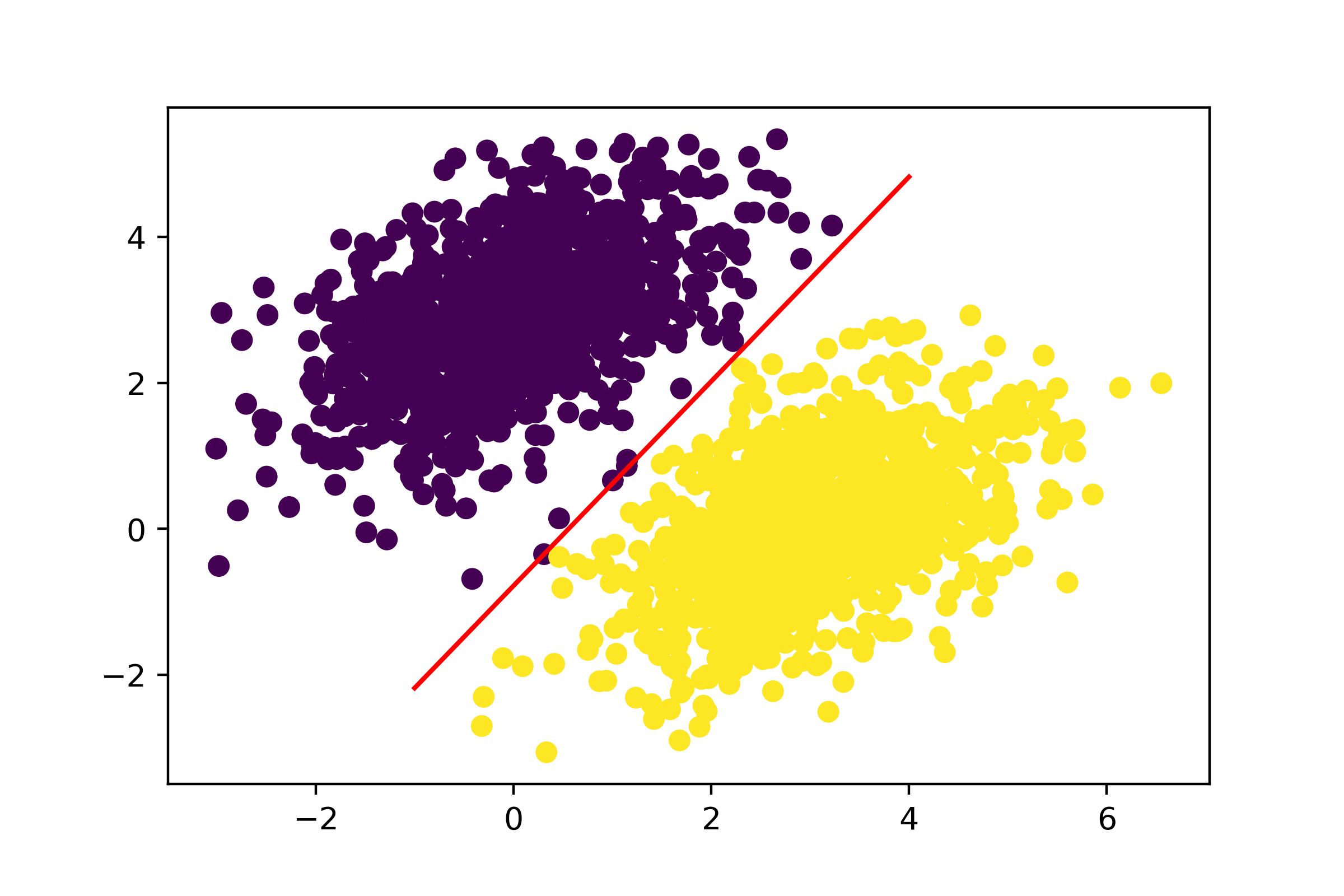
这就是线性分类器的全部意义所在:找到一条直线(或者,在高维空间中,一个超平面)的参数,该直线能够清晰地分隔两类数据。
TensorFlow 方法的独特之处是什么?
What makes the TensorFlow approach unique
您现在已经熟悉了所有基于 TensorFlow 的工作流所需的基本 API,即将深入学习更多框架——特别是 PyTorch 和 JAX。使用 TensorFlow 与其他框架有何不同?何时应该使用 TensorFlow,何时可以使用其他框架?
如果您问我们,TensorFlow 的主要优势如下:
- 由于采用了图形模式和 XLA 编译,它的速度很快。通常情况下,它比 PyTorch 和 NumPy 快得多,而 JAX 通常更快。
- 它功能极其完善。在所有框架中,它独树一帜,不仅支持字符串张量,还支持“不规则张量”(不同条目维度可能不同的张量——对于处理序列非常有用,无需将其填充到统一长度)。此外,它还通过高性能
tf.dataAPI 提供出色的数据预处理支持。TensorFlowtf.data如此优秀,甚至连 JAX 都推荐它用于数据预处理。无论您需要做什么,TensorFlow 都能提供解决方案。 - 它的生产部署生态系统是所有框架中最成熟的,尤其是在移动设备或浏览器部署方面。
然而,TensorFlow 也存在一些明显的缺陷:
- 它拥有庞大的API——这是功能非常齐全的另一面。TensorFlow包含了数千种不同的操作。
- 它的数值 API 有时与 NumPy API 不一致,如果您已经熟悉 NumPy,那么上手起来会稍微困难一些。
- 流行的预训练模型共享平台 Hugging Face 对 TensorFlow 的支持较少,这意味着最新的生成式 AI 模型可能并不总是能在 TensorFlow 中使用。
现在,我们来学习 PyTorch。
PyTorch简介
Introduction to PyTorch
PyTorch 是一个基于 Python 的开源机器学习框架,主要由 Meta(前身为 Facebook)开发。它最初于 2016 年 9 月发布(旨在应对 TensorFlow 的发布),其 1.0 版本于 2018 年发布,2.0 版本于 2023 年发布。PyTorch 的编程风格源自现已停止开发的 Chainer 框架,而 Chainer 本身又受到了 NumPy-Autograd 的启发。PyTorch 在机器学习研究领域得到了广泛应用。
与 TensorFlow 一样,PyTorch 处于一个庞大的相关软件包生态系统的核心,例如torchvision、torchaudio或流行的模型共享平台 Hugging Face。
PyTorch API 比 TensorFlow 和 JAX 的 API 更高级:它包含了层和优化器,类似于 Keras。当您将 Keras 与 PyTorch 后端一起使用时,这些层和优化器与 Keras 工作流兼容。
PyTorch入门
First steps with PyTorch
接下来的段落将带你熟悉 PyTorch 的所有基础知识。我们将涵盖以下关键概念:
- 张量和参数
- PyTorch中的数值运算
backward()用该方法计算梯度Module使用类进行打包计算- 利用编译加速 PyTorch
我们将用纯 PyTorch 重新实现我们的线性回归端到端示例,以此结束介绍。
PyTorch 中的张量和参数
Tensors and parameters in PyTorch
关于 PyTorch,首先要注意的是,它的包名不是 <package_name> pytorch,而是 <package_name> torch。你需要通过 pip install pytorch 安装它pip install torch,然后通过 import pytorch 导入它import torch。
与 NumPy 和 TensorFlow 类似,该框架的核心对象是张量。首先,让我们来了解一下 PyTorch 张量。
常张量
Constant tensors
以下是一些常量张量。
1 | >>> import torch |
列表 3.22:全 1 或全 0 张量
随机张量
Random tensors
随机张量的创建与 NumPy 和 TensorFlow 类似,但语法有所不同。例如normal,该函数不接受形状参数。相反,均值和标准差应作为 PyTorch 张量提供,并具有预期的输出形状。
1 | >>> # Equivalent to tf.random.normal(shape=(3, 1), mean=0., stddev=1.) |
列表 3.23:随机张量
至于如何创建一个随机均匀张量,可以使用 . 函数torch.rand。与 .``np.random.uniform或 . 不同tf.random.uniform,输出形状需要作为每个维度的独立参数提供,如下所示:
1 | # Equivalent to tf.random.uniform(shape=(3, 1), minval=0., |
张量赋值和参数类
Tensor assignment and the Parameter class
与 NumPy 数组类似,但与 TensorFlow 张量不同的是,PyTorch 张量是可赋值的。你可以执行如下操作:
1 | >>> x = torch.zeros(size=(2, 1)) |
虽然你可以使用普通的张量torch.Tensor来存储模型的可训练状态,但 PyTorch 提供了一个专门用于此目的的张量子类:TrainableState 类torch.nn.parameter.Parameter。与普通张量相比,TrainableState 提供了语义上的清晰性——如果你看到一个 ParameterTrainableState,你就知道它是一段可训练状态,而 TrainableState``Tensor 可以是任何值。因此,它使得 PyTorch 能够自动跟踪和检索Parameters你分配给 PyTorch 模型的 TrainableState——类似于 Keras 对 KerasVariable实例的处理方式。
这里有一个Parameter。
1 | x = torch.zeros(size=(2, 1)) |
清单 3.24:创建 PyTorch 参数
张量运算:在 PyTorch 中进行数学运算
Tensor operations: Doing math in PyTorch
PyTorch 中的数学运算与 NumPy 或 TensorFlow 中的数学运算完全相同,尽管与 TensorFlow 类似,PyTorch API 经常在一些细微之处与 NumPy API 有所不同。
1 | a = torch.ones((2, 2)) |
示例 3.25:PyTorch 中的一些基本数学运算
这里有一个致密的层:
1 | def dense(inputs, W, b): |
使用 PyTorch 计算梯度
Computing gradients with PyTorch
PyTorch 中并没有显式的“梯度带”。虽然存在类似的机制:当你在 PyTorch 中运行任何计算时,框架会创建一个一次性的计算图(称为“梯度带”),记录刚刚发生的情况。然而,这个梯度带对用户是隐藏的。使用它的公共 API 位于张量层面:你可以调用 tensor.backward()反向传播函数,遍历所有先前执行的、最终得到该张量的操作。这样做会填充.grad所有跟踪梯度的张量的属性。
1 | >>> # To compute gradients with respect to a tensor, it must be created |
清单 3.26:计算梯度.backward()
backward()如果连续多次调用该.grad属性,则会“累积”梯度:每次新的调用都会将新的梯度与先前存在的梯度相加。例如,在以下代码中, input_var.grad并非square(input_var)相对于的梯度input_var;而是该梯度与先前计算的梯度之和——其值自上次代码片段以来已翻倍:
1 | >>> result = torch.square(input_var) |
要重置渐变,只需设置.grad为None:
1 | input_var.grad = None |
现在让我们付诸实践!
一个完整的示例:纯 PyTorch 编写的线性分类器
An end-to-end example: A linear classifier in pure PyTorch
现在你已经掌握了足够的知识,可以用 PyTorch 重写我们的线性分类器。它将与 TensorFlow 的分类器非常相似——唯一的重大区别在于我们计算梯度的方式。
我们先来创建模型变量。别忘了传递参数requires_grad=True,以便我们能够计算它们的梯度:
1 | input_dim = 2 |
这是我们的模型——目前为止没有任何变化。我们只是tf.matmul从torch.matmul:
1 | def model(inputs, W, b): |
这是我们的损失函数。我们只需将函数值从 切换tf.square到torch.square,再从切换tf.reduce_mean到torch.mean:
1 | def mean_squared_error(targets, predictions): |
现在进入训练阶段。具体操作如下:
loss.backward()从loss输出节点开始运行反向传播,并填充tensor.grad参与计算的所有张量的属性loss。tensor.grad表示损失相对于该张量的梯度。- 我们使用该
.grad属性来恢复损失函数关于W和 的梯度b。 - 我们更新
W并b使用这些梯度。由于这些更新并非反向传播的一部分,因此我们将其置于一个torch.no_grad()单独的作用域内,这样该作用域内的所有内容都会跳过梯度计算。 - 我们通过将其设置为 来重置
and参数.grad的属性内容。如果不这样做,梯度值会在多次调用and时累积,从而导致无效值:W``b``None``training_step()
1 | learning_rate = 0.1 |
这还可以做得更简单——让我们看看怎么做。
使用模块类对状态和计算进行打包
Packaging state and computation with the Module class
PyTorch 还提供了一个更高级别的面向对象的 API 来执行反向传播,这需要依赖两个新类:torch.nn.Module类和来自模块的优化器类torch.optim,例如torch.optim.SGD(相当于keras.optimizers.SGD)。
总体思路是定义一个子类torch.nn.Module,该子类将
- 保留一些空间
Parameters,用于存储状态变量。这些变量在方法中定义__init__()。 - 在方法中实现前向传递计算
forward()。
它应该看起来像如下一样。
1 | class LinearModel(torch.nn.Module): |
清单 3.27:定义一个torch.nn.Module
现在我们可以实例化我们的LinearModel:
1 | model = LinearModel() |
使用实例时torch.nn.Module,与其forward() 直接调用方法,不如使用__call__()(即直接在输入上调用模型类),这会重定向到,forward()但会向其添加一些框架钩子:
1 | torch_inputs = torch.tensor(inputs) |
现在,让我们来获取一个 PyTorch 优化器。要实例化它,您需要提供优化器要更新的参数列表。您可以通过Module以下方式从我们的实例中获取该列表.parameters():
1 | optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) |
利用我们的Module实例和 PyTorchSGD优化器,我们可以运行一个简化的训练步骤:
1 | def training_step(inputs, targets): |
之前,更新模型参数的步骤如下:
1 | with torch.no_grad(): |
现在我们可以这么做了optimizer.step()。
类似地,以前我们需要手动对tensor.grad = None每个参数进行重置梯度操作。现在我们可以直接执行此操作model.zero_grad()。
总的来说,这可能有点令人困惑——损失张量、优化器和Module实例似乎都通过某种隐藏的后台机制相互感知。它们之间仿佛在进行着某种神秘的远程交互。不过别担心——你可以把这一系列步骤(loss.backward()-- optimizer.step())model.zero_grad()当作一段魔法咒语,每次需要编写训练步骤函数时都念诵一遍。但务必记住,千万别忘了 model.zero_grad()。否则就会出现一个严重的错误(而且不幸的是,这种情况相当常见)!
利用编译加速 PyTorch 模块
Making PyTorch modules fast using compilation
最后一点。类似于 TensorFlow 允许你编译函数以提升性能,PyTorch 也允许你Module通过torch.compile()实用程序编译函数甚至实例。这个 API 使用的是 PyTorch 自带的编译器,名为 Dynamo。
让我们在线性回归模型中尝试一下Module:
1 | compiled_model = torch.compile(model) |
生成的对象旨在与原对象完全相同——只是正向和反向传播速度应该更快。
你也可以将torch.compile()其用作函数装饰器:
1 |
|
实际上,大多数 PyTorch 代码并不使用编译,而是直接运行,因为编译器并非总能兼容所有模型,即使兼容也未必能带来速度提升。与 TensorFlow 和 Jax 不同,后者从一开始就内置了编译功能,而 PyTorch 的编译器是相对较新的功能。
PyTorch 方法的独特之处是什么?
What makes the PyTorch approach unique
与我们接下来要介绍的 TensorFlow 和 JAX 相比,PyTorch 的优势是什么?你为什么应该使用它,或者不应该使用它?
以下是 PyTorch 的两大主要优势:
- PyTorch 代码默认以立即执行的方式运行,这使得调试变得容易。需要注意的是,TensorFlow 和 JAX 代码也是如此,但一个很大的区别在于,PyTorch 通常旨在始终以立即执行的方式运行,而任何严肃的 TensorFlow 或 JAX 项目都不可避免地需要在某个时候进行编译,这可能会严重影响调试体验。
- 广受欢迎的预训练模型共享平台 Hugging Face 对 PyTorch 提供了顶级的支持,这意味着你想要使用的任何模型都可能在 PyTorch 版本中可用。这正是如今 PyTorch 被广泛采用的主要原因。
与此同时,使用 PyTorch 也存在一些缺点:
- 与 TensorFlow 类似,PyTorch API 与 NumPy 并不一致。此外,它的内部机制也存在差异。例如,常用的关键字
axis有时会dim根据函数的不同而使用不同的名称。一些伪随机数生成操作需要seed参数,而另一些则不需要。诸如此类。这使得 PyTorch 的学习过程令人沮丧,尤其是对于从 NumPy 转过来的用户而言。 - 由于 PyTorch 注重即时执行,因此速度相当慢——在所有主流框架中,它的速度明显最慢。对于大多数模型,使用 JAX 可以提升 20% 到 30% 的速度。对于某些模型——尤其是大型模型——即使使用其他方法,使用 JAX 的速度提升甚至可达 3 倍或 5 倍
torch.compile()。 - 虽然可以通过一些方法提升 PyTorch 代码的运行速度
torch.compile(),但截至目前(2025 年),PyTorch Dynamo 编译器仍然效率低下,且漏洞百出。因此,只有极少数 PyTorch 用户会使用编译。或许未来的版本会对此有所改进!
JAX简介
Introduction to JAX
JAX 是一个用于可微分计算的开源库,主要由谷歌开发。自 2018 年发布以来,JAX 迅速在研究界获得广泛关注,尤其因其能够大规模利用谷歌的 TPU 而备受青睐。如今,JAX 已被生成式人工智能领域的大多数顶尖公司所采用,例如 DeepMind、苹果、Midjourney、Anthropic 和 Cohere 等。
JAX 采用无状态计算方式,这意味着 JAX 中的函数不维护任何持久状态。这与传统的命令式编程形成鲜明对比,在传统命令式编程中,变量可以在函数调用之间保持值。
JAX 函数的无状态特性具有诸多优势。尤其值得一提的是,它能够高效地实现自动并行化和分布式计算,因为函数可以独立执行,无需同步。JAX 的超强可扩展性对于处理像 Google 和 DeepMind 这样的公司所面临的大规模机器学习问题至关重要。
JAX入门
First steps with JAX
我们将探讨以下几个关键概念:
类
arrayJAX 中的随机操作
JAX 中的数值运算
jax.grad通过以下方式计算梯度:jax.value_and_grad利用即时编译来加快 JAX 函数的运行速度
The
arrayclassRandom operations in JAX
Numerical operations in JAX
Computing gradients via
jax.gradandjax.value_and_gradMaking JAX functions fast by leveraging just-in-time compilation
我们开始吧。
JAX 中的张量
Tensors in JAX
JAX 最棒的特性之一在于它并没有尝试实现自己独立且与 NumPy 类似但略有不同的数值 API。相反,它直接实现了 NumPy API。它以jax.numpy命名空间的形式提供,您经常会看到它被简写为 jnp`JAX_ ...
以下是一些 JAX 数组。
1 | >>> from jax import numpy as jnp |
列表 3.28:全 1 或全 0 张量
不过,它与实际的 NumPy API 之间存在两个细微差别jax.numpy:随机数生成和数组赋值。让我们来看一下。
JAX 中的随机数生成
Random number generation in JAX
JAX 和 NumPy 的第一个区别在于 JAX 处理随机操作的方式——也就是所谓的“伪随机数生成”(PRNG)操作。我们之前说过 JAX 是无状态的,这意味着 JAX 代码不能依赖任何隐藏的全局状态。请看下面的 NumPy 代码。
1 | >>> np.random.normal(size=(3,)) |
列表 3.29:随机张量
第二次调用是如何np.random.normal()知道要返回与第一次调用不同的值的呢?没错——这是隐藏的全局状态。实际上,你可以通过 get 获取该全局状态,np.random.get_state()并通过 set 设置它np.random.seed(seed)。
在无状态框架中,我们不能拥有任何全局状态。相同的 API 调用必须始终返回相同的值。因此,在无状态版本的 NumPy 中,您必须通过向调用传递不同的种子参数np.random来获取不同的值。
个人注:理解这句话“JAX 和 NumPy 的第一个区别在于 JAX 处理随机操作的方式——也就是所谓的“伪随机数生成”(PRNG)操作”的核心在于 “确定性” 与 “函数式编程”。
在 NumPy 中,生成随机数是基于隐式状态的;而在 JAX 中,它是基于显式状态的。这种差异决定了 JAX 能够实现完美的可复现性和并行化。
- NumPy 的方式:全局隐式状态
NumPy 使用的是一种类似“状态机”的机制。当你设置了
np.random.seed(42),NumPy 会在后台维护一个全局的随机数发生器状态。
- 机制:每次你调用
np.random.rand(),NumPy 都会做两件事:
- 根据当前状态计算出一个随机数。
- 自动更新后台的全局状态,为下一次调用做准备。
- 问题:在并行计算中,这种方式会出大问题。如果你同时启动两个进程去生成随机数,它们可能会争夺同一个全局状态,导致结果不可预测,或者产生相同的随机数序列。
- JAX 的方式:显式 PRNG Key
JAX 遵循函数式编程。函数不应该修改全局变量,也不应该有“副作用”。因此,JAX 把随机数状态设计成了一个普通的变量,称为
key(或 PRNGKey)。
- 机制:
- 你必须手动传入一个
key给随机函数。- 随机函数不会自动帮你更新这个
key。如果你用同一个key调用函数 100 次,你会得到 100 个完全相同的数字。- 如果你想生成下一个随机数,你必须手动使用
jax.random.split(key)将当前的key“分裂”成两个新的key。
- 为什么要这么麻烦?(JAX 的设计哲学)
JAX 这样设计主要为了解决以下三个问题:
可复现性(Reproducibility):
在深度学习中,模型初始化和数据打乱都涉及随机数。JAX 这种显式传递
key的方式确保了无论你在什么设备(CPU/GPU/TPU)上运行,只要key相同,结果就绝对一致。并行化(Parallelization):
当你需要在 8 颗核心上并行生成随机数时,你可以把
key分裂成 8 个子key分发下去。每个核心独立计算,互不干扰,不需要去读取同一个全局状态。兼容 JIT 编译:
JAX 的核心功能(如
jit编译)要求函数必须是“纯函数”(输入相同,输出必相同)。如果随机函数依赖于后台偷偷变化的全局状态,jit就无法正常工作。总结
- NumPy 像抽奖机:你只管拉摇杆(调用函数),机器内部自动跳到下一个状态。
- JAX 像数学公式:\(f(key) \rightarrow (random\_number, new\_key)\)。一切都是透明的、可控的。
“伪随机数”(Pseudo-Random Numbers)是指通过确定性的数学算法产生的数字序列。
虽然这些数字看起来是随机的(统计学上分布均匀、不可预测),但因为它们是由公式计算出来的,所以只要知道初始输入,整个序列就是可以被预言的。
通常情况下,伪随机数生成器 (PRNG) 的调用会在被多次调用的函数中进行,并且每次调用都需要使用不同的随机值。如果您不想依赖任何全局状态,则需要在目标函数之外管理种子状态,如下所示:
1 | def apply_noise(x, seed): |
JAX 的基本原理相同。但是,JAX 不使用整数种子,而是使用称为键的特殊数组结构。您可以像这样从一个整数值创建一个键:
1 | import jax |
为了强制您始终为 PRNG 调用提供种子“密钥”,所有使用 JAX PRNG 的操作都将key(随机种子)作为其第一个位置参数。使用方法如下random.normal():
1 | >>> seed_key = jax.random.key(0) |
两次random.normal()使用相同种子键的调用将始终返回相同的值。
1 | >>> seed_key = jax.random.key(123) |
示例 3.30:在 Jax 中使用随机种子
如果需要新的种子密钥,您可以直接使用该jax.random.split()函数从现有密钥创建新的密钥。此过程是确定性的,因此相同的分割序列始终会产生相同的最终种子密钥:
1 | >>> seed_key = jax.random.key(123) |
这肯定比使用伪随机数生成器 (PRNG) 更费力np.random!但无状态的优势远远大于劣势:它使你的代码可向量化(即,JAX 编译器可以自动将其转换为高度并行的代码),同时保持确定性(即,你可以两次运行相同的代码并获得相同的结果)。这是使用全局 PRNG 状态无法实现的。
张量赋值
Tensor assignment
JAX 和 NumPy 的第二个区别在于张量赋值。与 TensorFlow 类似,JAX 数组不支持原地赋值。这是因为任何形式的原地修改都违背了 JAX 的无状态设计。相反,如果需要更新张量,必须创建一个新的张量并赋予其所需的值。JAX 通过提供 at()/ set()API 简化了这一过程。这些方法允许您创建一个新的张量,并将更新后的元素赋值给指定的索引。以下示例展示了如何将 JAX 数组的第一个元素更新为新值。
1 | x = jnp.array([1, 2, 3], dtype="float32") |
示例 3.31:修改 JAX 数组中的值
很简单!
张量运算:在 JAX 中进行数学运算
Tensor operations: Doing math in JAX
在 JAX 中进行数学运算与在 NumPy 中进行数学运算完全相同。这次无需学习任何新东西!
1 | a = jnp.ones((2, 2)) |
示例 3.32:JAX 中的一些基本数学运算
这里有一个致密的层:
1 | def dense(inputs, W, b): |
使用 JAX 计算梯度
Computing gradients with JAX
与 TensorFlow 和 PyTorch 不同,JAX 采用元编程方法进行梯度计算。元编程指的是函数返回函数 ——你可以称之为“元函数”。实际上,JAX 允许你将损失计算函数转换为梯度计算函数。因此,在 JAX 中计算梯度是一个三步过程:
- 定义损失函数,
compute_loss()。 - 调用
grad_fn = jax.grad(compute_loss)以检索梯度计算函数。 - 调用此函数
grad_fn以获取梯度值。
损失函数应满足以下条件:
- 它应该返回一个标量损失值。
- 它的第一个参数(在下面的例子中,也是唯一的参数)应该包含我们需要计算梯度的状态数组。这个参数通常被命名为
<state>state。例如,第一个参数可以是单个数组、数组列表或数组字典。
我们来看一个简单的例子。这是一个损失计算函数,它接受一个标量作为输入,input_var并返回一个标量损失值——即输入的平方:
1 | def compute_loss(input_var): |
现在我们可以对这个损失函数调用 JAX 工具jax.grad()。它返回一个梯度计算函数——该函数接受与原始损失函数相同的参数,并返回损失函数相对于某个变量的梯度input_var:
1 | grad_fn = jax.grad(compute_loss) |
一旦你获得了grad_fn(),就可以使用与相同的参数调用它compute_loss(),它将返回与第一个参数对应的梯度数组compute_loss()。在我们的例子中,第一个参数是一个单独的数组,因此grad_fn()它直接返回损失函数相对于该数组的梯度:
1 | input_var = jnp.array(3.0) |
JAX梯度计算最佳实践
JAX gradient-computation best practices
目前为止一切顺利!元编程听起来很复杂,但其实很简单。不过,在实际应用中,还有一些其他因素需要考虑。我们一起来看看。
返还损失值
Returning the loss value
通常情况下,你需要的不仅仅是梯度数组,还需要损失值。在函数外部独立地重新计算损失值效率很低grad_fn(),因此,你可以配置函数grad_fn()使其同时返回损失值。这可以通过使用 JAX 工具 jax.value_and_grad()而不是函数来实现jax.grad()。它的工作方式相同,但返回的是一个元组,其中第一个元素是损失值,第二个元素是梯度:
1 | grad_fn = jax.value_and_grad(compute_loss) |
求复杂函数的梯度
Getting gradients for a complex function
那么,如果你需要计算多个变量的梯度呢?如果你的compute_loss()函数有多个输入呢?
假设你的状态包含三个变量,分别为ax、by 和cy',损失函数有两个输入,分别为 x'x和 y y''。你可以这样构建它:
1 | # state contains a, b, and c. It must be the first argument. |
请注意,它state不一定是元组——它可以是字典、列表,或者任何由元组、字典和列表嵌套而成的结构。在 JAX 术语中,这种嵌套结构被称为树。
返回辅助输出
Returning auxiliary outputs
最后,如果你的compute_loss()函数需要返回的不仅仅是损失值呢?假设你想返回一个output作为损失计算副产品而得到的额外值,该如何获取呢?
你可以使用以下has_aux论点:
- 修改损失函数,使其返回一个元组,其中第一个元素是损失,第二个元素是你的额外输出。
- 将参数传递
has_aux=True给函数value_and_grad()。这告诉函数value_and_grad()不仅返回梯度,还要返回函数的“辅助”输出compute_loss(),如下所示:
1 | def compute_loss(state, x, y): |
诚然,事情现在确实变得相当复杂了。不过别担心,这已经是 JAX 最难的部分了!相比之下,其他部分都简单得多。
使用 @jax.jit 加速 JAX 函数
Making JAX functions fast with @jax.jit
还有一点。作为 JAX 用户,您会经常使用@jax.jit装饰器,它的行为与装饰器完全相同@tf.function(jit_compile=True)。它将任何无状态的 JAX 函数转换为 XLA 编译的代码片段,通常可以显著提高执行速度:
1 |
|
请注意,您只能装饰无状态函数——任何由该函数更新的张量都应该是其返回值的一部分。
一个完整的示例:纯 JAX 中的线性分类器
An end-to-end example: A linear classifier in pure JAX
现在你已经掌握了足够的 JAX 知识,可以编写我们线性分类器示例的 JAX 版本了。它与你已经看到的 TensorFlow 和 PyTorch 版本有两个主要区别:
- 我们创建的所有函数都将是无状态的。这意味着状态(数组
W和b)将作为函数参数提供,如果函数修改了状态,则函数将返回状态的新值。 - 使用 JAX 工具计算梯度
value_and_grad()。
我们开始吧。模型函数和均方误差函数应该看起来很熟悉:
1 | def model(inputs, W, b): |
为了计算梯度,我们需要将损失计算封装在一个compute_loss()函数中。该函数返回总损失值(标量),state其第一个参数是一个元组,其中包含我们需要计算梯度的所有张量:
1 | def compute_loss(state, inputs, targets): |
调用jax.value_and_grad()此函数会得到一个新函数,其参数与 相同compute_loss,该函数返回损失函数以及损失函数相对于 元素的梯度state:
1 | grad_fn = jax.value_and_grad(compute_loss) |
接下来,我们可以设置训练步骤函数。它看起来很简单。请注意,与 TensorFlow 和 PyTorch 中的对应函数不同,它必须是无状态的,因此必须返回张量的更新W值b :
1 | learning_rate = 0.1 |
因为在我们的示例中,我们不会改变该值learning_rate,所以我们可以将其视为函数本身的一部分,而不是模型的状态。如果我们想在训练过程中修改学习率,我们也需要将其传递给该函数。
最后,我们准备运行完整的训练循环。我们初始化 Wa 和 b b,并通过无状态调用 update 函数反复更新它们training_step():
1 | input_dim = 2 |
搞定!现在你已经可以用 JAX 编写自定义训练循环了。
JAX 方法的独特之处
What makes the JAX approach unique
JAX 在现代机器学习框架中独树一帜的主要特点在于其函数式、无状态的设计理念。虽然这种理念乍看之下可能会带来一些不便,但它恰恰释放了 JAX 的强大功能——能够编译成速度极快的代码,并可扩展到任意规模的模型和任意数量的设备。
JAX有很多值得称道的地方:
- 它速度很快。对于大多数模型而言,它是你目前为止见过的所有框架中最快的。
- 它的数值 API 与 NumPy 完全一致,因此学习起来很愉快。
- 它最适合在 TPU 上训练模型,因为它从一开始就是为 XLA 和 TPU 开发的。
使用 JAX 也可能给开发人员带来一些不便:
- 与纯粹的立即执行相比,它使用元编程和编译会使调试变得更加困难。
- 与 TensorFlow 或 PyTorch 相比,底层训练循环往往更加冗长且更难编写。
至此,您已经掌握了 TensorFlow、PyTorch 和 JAX 的基础知识,可以使用这些框架从零开始实现一个基本的线性分类器。这为您打下了坚实的基础。现在是时候迈向更高效的深度学习之路:Keras API。
Keras简介
Introduction to Keras
Keras 是一个用于 Python 的深度学习 API,它提供了一种便捷的方式来定义和训练任何类型的深度学习模型。它于 2015 年 3 月发布,v2 版本于 2017 年发布,v3 版本于 2023 年发布。
Keras 的用户群体十分广泛,涵盖了从初创公司到大型企业的学术研究人员、工程师和数据科学家,到研究生和业余爱好者。谷歌、Netflix、Uber、YouTube、欧洲核子研究中心 (CERN)、美国国家航空航天局 (NASA)、Yelp、Instacart、Square、Waymo 等众多知名企业,以及成千上万家规模较小的组织都在使用 Keras 来解决各行各业的各种问题。你的 YouTube 推荐视频就源自 Keras 模型。Waymo 的自动驾驶汽车也依靠 Keras 模型来处理传感器数据。此外,Keras 还是机器学习竞赛网站 Kaggle 上的热门框架。
由于 Keras 的用户群体十分广泛,它不会强迫你遵循单一的“正确”模型构建和训练方法。相反,它支持从高层到底层的各种工作流程,以满足不同用户的需求。例如,你可以使用多种方法来构建模型,也可以使用多种方法来训练模型,每种方法都代表着可用性和灵活性之间的一种权衡。在第 7 章中,我们将详细回顾这些工作流程中的大部分。
Keras入门
First steps with Keras
在开始编写 Keras 代码之前,在导入库之前设置库时需要考虑一些事项。
选择后端框架
Picking a backend framework
Keras 可以与 JAX、TensorFlow 或 PyTorch 结合使用。它们是 Keras 的“后端框架”。通过这些后端框架,Keras 可以运行在不同类型的硬件上(参见图 3.4)——GPU、TPU 或普通 CPU——可以无缝扩展到数千台机器,并可以部署到各种平台上。
后端是一个底层张量计算平台;Keras 是一个高级深度学习 API。
后端框架是可插拔的:编写了一些 Keras 代码后,您可以切换到不同的后端框架 。您不会被锁定在单一框架和生态系统中——您可以根据当前需求将模型从 JAX 迁移到 TensorFlow 或 PyTorch。例如,开发 Keras 模型时,您可以使用 PyTorch 进行调试,使用 JAX 在 TPU 上进行训练以获得最高效率,最后使用 TensorFlow 生态系统中优秀的工具进行推理。
Keras 目前的默认后端是 TensorFlow,因此如果您import keras在一个全新的环境中运行 Keras,而没有进行任何配置,那么您将使用 TensorFlow。有两种方法可以选择不同的后端:
- 设置环境变量
KERAS_BACKEND。在启动pythonREPL 之前,您可以运行以下 shell 命令来使用 JAX 作为 Keras 后端:export KERAS_BACKEND=jax。或者,您可以将以下代码片段添加到 Python 文件或 notebook 的顶部(请注意,它必须放在第一个<script>标签之前import keras):
1 | import os |
- 编辑本地 Keras 配置文件
~/.keras/keras.json。如果您之前已经导入过 Keras,则该文件已使用默认设置创建。您可以使用任何文本编辑器打开并修改它——这是一个易于阅读的 JSON 文件。它应该如下所示:
1 | { |
配置 Keras 后端时,应该使用字符串 "torch"<PyTorch> 来引用 PyTorch 后端,而不是字符串 <PyTorch> "pytorch",因为后者无效。这是因为 PyTorch 包名是<PyTorch>torch(如 `<PyTorch>import torch或
现在,你可能会问,我应该选择哪个后端?这完全取决于你的个人选择:本书其余部分的所有 Keras 代码示例都兼容这三种后端。如果需要特定后端的代码(例如在第 7 章中),我会向你展示所有三个版本——TensorFlow、PyTorch 和 JAX。如果你没有特别的后端偏好,我个人推荐 JAX。它通常是性能最高的后端。
后端配置完成后,就可以开始构建和训练 Keras 模型了。让我们来看一下。
层:深度学习的构建模块
Layers: The building blocks of deep learning
神经网络的基本数据结构是层,我们在第二章已经介绍过。层是一个数据处理模块,它接收一个或多个张量作为输入,并输出一个或多个张量。有些层是无状态的,但更常见的是具有状态的层:层权重,即通过随机梯度下降法学习到的一个或多个张量,它们共同包含了网络的知识。
不同类型的层适用于不同的张量格式和不同的数据处理类型。例如,简单的矢量数据(存储在形状为 的二维张量中(samples, features))通常由 密集连接层(也称为全连接层 或密集层, DenseKeras 中的类)处理。序列数据(存储在形状为 的三维张量中(samples, timesteps, features))通常由 循环层(例如LSTM层)或一维卷积层处理Conv1D。图像数据(存储在秩为 4 的张量中)通常由二维卷积层处理Conv2D。
你可以把层想象成深度学习的乐高积木,Keras 明确地运用了这种比喻。在 Keras 中构建深度学习模型,就是通过将兼容的层拼接在一起,形成有用的数据转换管道。
LayerKeras 中的基础类
The base Layer class in Keras
一个简单的 API 应该有一个统一的抽象层,所有功能都围绕它展开。在 Keras 中,这个抽象层就是Layer类。Keras 中的一切要么是类Layer,要么是与类紧密交互的对象Layer。
ALayer是一个对象,它封装了一些状态(权重)和一些计算(前向传播)。权重通常在 a 中定义build()(尽管它们也可以在构造函数中创建__init__()),而计算则在 call()c 方法中定义。
在上一章中,我们实现了一个NaiveDense包含两个权重的类W,b并应用了计算 output = activation(matmul(input, W) + b)。下面是同一层在 Keras 中的实现方式。
1 | import keras |
清单 3.33:在 Keras 中从头开始创建一个简单的密集层
下一节我们将详细介绍这些方法build()及其 用途call()。如果您现在还不能完全理解,请不要担心!
一旦实例化,像这样的层就可以像函数一样使用,以张量作为输入:
1 | >>> # Instantiates our layer, defined previously |
现在,你可能在想,既然我们最终是通过直接调用层(也就是使用其方法)来使用它,为什么还要实现call() and 呢?这是因为我们希望能够即时创建状态。让我们看看它是如何工作的。build()``__call__
自动形状推断:动态构建图层
Automatic shape inference: Building layers on the fly
就像乐高积木一样,你只能将兼容的图层“拼接”在一起。这里的图层兼容性特指每个图层只能接受特定形状的输入张量,并返回特定形状的输出张量。请看以下示例:
1 | from keras import layers |
该层将返回一个非批次维度为 32 的张量。它只能连接到以 32 维向量作为输入的下游层。
使用 Keras 时,大多数情况下您无需担心尺寸兼容性问题,因为添加到模型中的层会根据输入数据的形状动态构建。例如,假设您编写了以下代码:
1 | from keras import models |
这些层没有接收到任何关于输入形状的信息。相反,它们会自动推断出输入形状,即它们看到的第一个输入的形状。
在我们第二章实现的简化版图层中Dense,为了创建其权重,我们必须显式地将图层的输入大小传递给构造函数。这并非理想方案,因为这会导致模型看起来像这样:每个新图层都需要知道前一个图层的形状。
1 | model = NaiveSequential( |
如果某个层用于生成输出形状的规则很复杂,情况会更糟。例如,如果我们的层返回形状为“?”的输出,该怎么办 (batch, input_size * 2 if input_size % 2 == 0 else input_size * 3)?
如果我们把我们的NaiveDense层重新实现为能够自动进行形状推断的 Keras 层,它看起来会像该SimpleDense层,以及它的build()``and``call()方法。
在 Keras 中SimpleDense,我们不再像之前的例子那样在构造函数中创建权重。相反,我们在一个专门的状态创建方法中创建权重build(),该方法接收层遇到的第一个输入形状作为参数。该build()方法会在层首次被调用时(通过其 call()setState 方法)自动调用。事实上,这就是我们为什么要在单独的方法中定义计算,call()而不是__call__()直接在 setState 方法中定义的原因!__call__()基础层的 setState 方法示意图如下所示:
1 | def __call__(self, inputs): |
借助自动形状推断功能,我们之前的例子变得简单明了:
1 | model = keras.Sequential( |
请注意,自动形状推断并非该类方法处理的唯一任务Layer 。__call__()它还负责许多其他事项,特别是即时执行和图执行之间的路由,以及输入掩码(我们将在第 14 章中介绍)。现在,您只需记住:在实现您自己的层时,请将前向传播放在该call()方法中。
从图层到模型
From layers to models
深度学习模型是一个由多个层组成的图。在 Keras 中,这被称为 ModelMap 类。目前,你只接触过Sequential``Map 模型(Map 的一个子类Model),它们只是简单的层堆叠,将单个输入映射到单个输出。但随着学习的深入,你将接触到更多种类的网络拓扑结构。一些常见的拓扑结构包括:
- 双分支网络
- 多头网络
- 残余连接
网络拓扑结构可能非常复杂。例如,图 3.5 展示了 Transformer 的层拓扑图,Transformer 是一种常见的用于处理文本数据的架构。
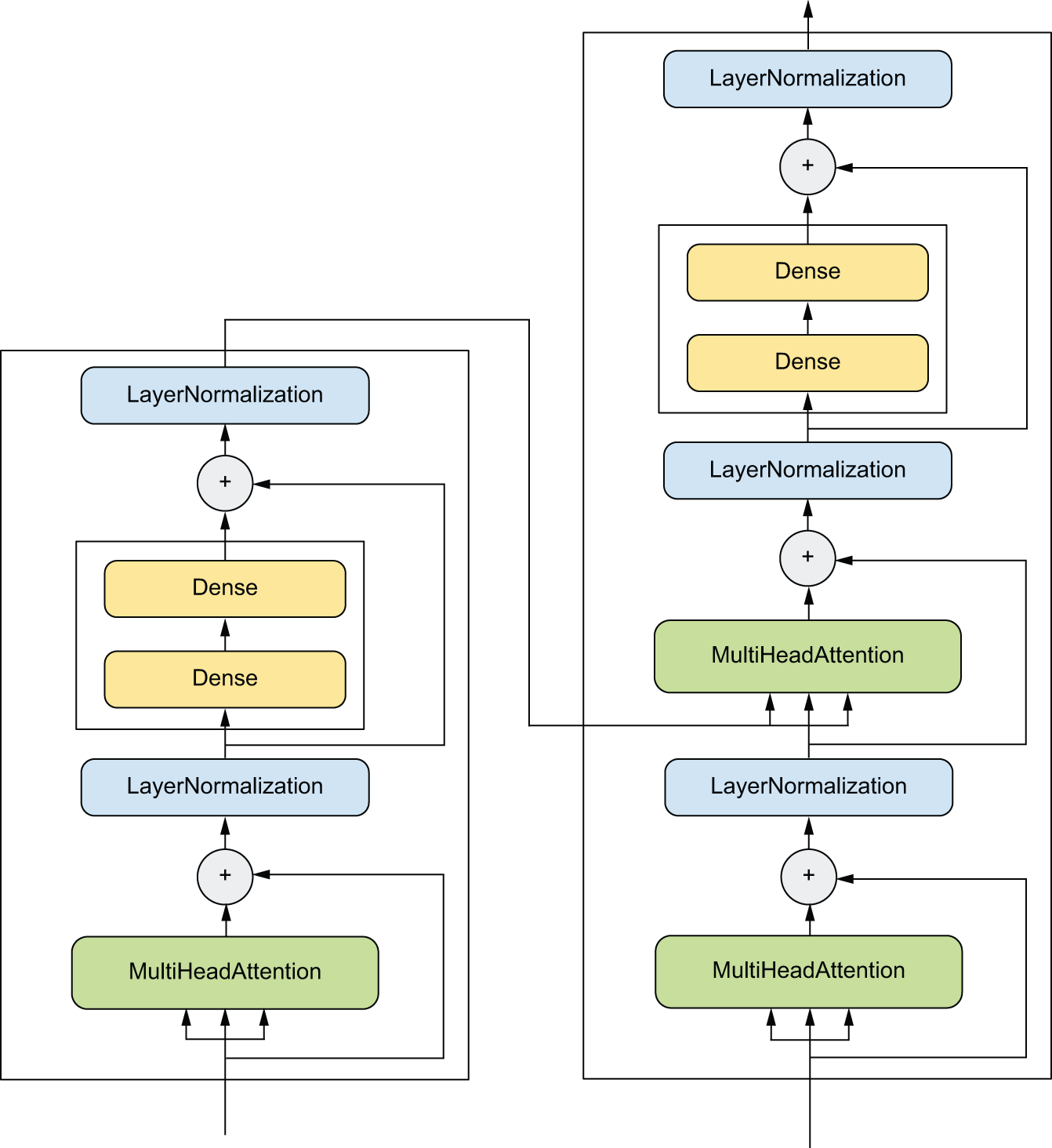
这里涉及的内容很多。在接下来的几章中,你将逐步理解它(在第 15 章)。
在 Keras 中构建此类模型通常有两种方法:您可以直接继承该类Model,也可以使用函数式 API,后者可以让您用更少的代码实现更多功能。我们将在第 7 章介绍这两种方法。
模型的拓扑结构定义了一个假设空间。你可能还记得,在第一章中,我们将机器学习描述为“在预定义的 可能性空间内,利用反馈信号的指导,寻找输入数据的有用表示”。通过选择网络拓扑结构,你可以将可能性空间(假设空间)限制在一系列特定的张量运算范围内,从而将输入数据映射到输出数据。接下来,你需要寻找的是一组合适的权重张量值,这些权重张量用于这些张量运算。
要从数据中学习,就必须对数据做出假设。这些假设决定了我们可以学习到什么。因此,假设空间的结构——也就是模型的架构——至关重要。它编码了你对问题的假设,也就是模型初始所依赖的先验知识。例如,如果你正在处理一个二分类问题,而模型只有一层,Dense且没有激活函数(纯仿射变换),那么你就假设这两个类别是线性可分的。
选择合适的网络架构与其说是一门科学,不如说是一门艺术。虽然有一些最佳实践和原则可以借鉴,但只有实践才能帮助你成为一名合格的神经网络架构师。接下来的几章将不仅教授你构建神经网络的具体原则,还会帮助你培养直觉,判断哪些方法适用于特定问题,哪些方法无效。你将对不同类型的模型架构适用于哪些问题、如何在实践中构建这些网络、如何选择合适的学习配置以及如何调整模型直到获得预期结果等方面建立起扎实的直觉。
“编译”步骤:配置学习过程
The “compile” step: Configuring the learning process
模型架构确定后,您还需要选择以下三件事:
损失函数(目标函数) ——训练过程中需要最小化的量。它代表了当前任务的成功程度。
优化器 ——根据损失函数确定网络的更新方式。它实现了随机梯度下降(SGD)的特定变体。
指标——指在训练和验证过程中需要监控的成功衡量标准,例如分类准确率。与损失函数不同,训练过程不会直接针对这些指标进行优化。因此,指标无需是可微的。
选定损失函数、优化器和指标后,就可以使用内置的 train``compile()和fit()``train 方法开始训练模型了。或者,你也可以编写自定义训练循环——我们将在第 7 章介绍如何操作。但这需要更多的工作!现在,让我们先来看看 train 和 compile()train方法fit()。
该compile()方法用于配置训练过程——您在第二章的第一个神经网络示例中已经接触过它。它接受以下参数:a optimizer、loss``b 和metrics``c(一个列表):
1 | # Defines a linear classifier |
在之前的调用中compile(),我们将优化器、损失和指标作为字符串传递(例如 $($($($($($($($($($($($($($($"rmsprop"("rmsprop")keras.optimizers.RMSprop()`...
1 | model.compile( |
如果您想传递自定义损失或指标,或者如果您想进一步配置正在使用的对象(例如,通过learning_rate向优化器传递参数),这将非常有用:
1 | model.compile( |
在第 7 章中,我们将介绍如何创建自定义损失和指标。一般来说,您无需从头开始创建自己的损失、指标或优化器,因为 Keras 提供了丰富的内置选项,很可能包含您所需的一切:
- 优化器
SGD()(无论是否具有动量)RMSprop()Adam()- ETC。
- 损失
CategoricalCrossentropy()SparseCategoricalCrossentropy()BinaryCrossentropy()MeanSquaredError()KLDivergence()CosineSimilarity()- ETC。
- 指标
CategoricalAccuracy()SparseCategoricalAccuracy()BinaryAccuracy()AUC()Precision()Recall()- ETC。
在本书中,您将看到这些选项中的许多具体应用。
选择损失函数
Picking a loss function
为合适的问题选择合适的损失函数至关重要:你的神经网络会不惜一切代价来最小化损失。因此,如果目标函数与当前任务的成功率没有完全相关性,你的神经网络最终可能会做出一些你意想不到的事情。想象一下,一个愚蠢的、无所不能的人工智能,通过随机梯度下降法(SGD)训练,并被赋予了这样一个糟糕的目标函数:“最大化所有活着的人的平均福祉”。为了简化任务,这个人工智能可能会选择杀死除少数人以外的所有人,然后专注于提高剩余人的福祉,因为平均福祉不受剩余人类数量的影响。这可能并非你的本意!请记住,你构建的所有神经网络都会毫不留情地降低损失函数值,所以务必谨慎选择目标函数,否则你将不得不面对意想不到的副作用。
幸运的是,对于分类、回归和序列预测等常见问题,有一些简单的指导原则可以帮助你选择合适的损失函数。例如,对于二分类问题,你可以使用二元交叉熵损失函数;对于多分类问题,你可以使用类别交叉熵损失函数,以此类推。只有在研究真正全新的问题时,你才需要开发自己的损失函数。在接下来的几章中,我们将详细介绍针对各种常见任务应该选择哪些损失函数。
理解拟合方法
Understanding the fit method
接下来compile()是fit()。该fit方法实现了训练循环本身。它的关键参数是
- 用于训练的数据(输入和目标)。通常情况下,数据会以 NumPy 数组或 TensorFlow 对象的形式传递
Dataset。您将Dataset在后续章节中了解更多关于 API 的信息。
- 训练轮数:训练循环应该对传递的数据进行多少次迭代。
- 小批量梯度下降的每个 epoch 中使用的批次大小:用于计算一次权重更新步骤的梯度的训练样本数量。
- The data (inputs and targets) to train on. It will typically be passed either in the form of NumPy arrays or a TensorFlow
Datasetobject. You’ll learn more about theDatasetAPI in the next chapters.
- The number of epochs to train for: how many times the training loop should iterate over the data passed.
- The batch size to use within each epoch of mini-batch gradient descent: the number of training examples considered to compute the gradients for one weight update step.
1 | history = model.fit( |
清单 3.34:fit使用 NumPy 数据 调用
该调用fit返回一个History对象。此对象包含一个history字段,该字段是一个字典,将键(例如"loss"特定指标名称)映射到其每个 epoch 的值列表:
1 | >>> history.history |
监测损失和验证数据的指标
Monitoring loss and metrics on validation data
机器学习的目标并非仅仅是获得在训练数据上表现良好的模型——这很容易,只需沿着梯度前进即可。其目标是获得在一般情况下表现良好的模型,尤其是在模型从未遇到过的数据点上。仅仅因为一个模型在其训练数据上表现良好,并不意味着它在从未见过的数据上也能表现出色!例如,你的模型最终可能只是记住了训练样本与其目标值之间的映射关系,这对于预测模型从未见过的数据的目标值毫无用处。我们将在第五章更详细地探讨这一点。
为了密切关注模型在新数据上的表现,通常的做法是将一部分训练数据保留为“验证数据”:您不会使用这些数据训练模型,而是用它来计算损失值和指标值。您可以通过validation_data在 . 函数中使用 validate 参数来实现这一点fit()。与训练数据一样,验证数据可以作为 NumPy 数组或 TensorFlow 对象传递Dataset。
1 | model = keras.Sequential([keras.layers.Dense(1)]) |
清单 3.35:使用验证数据参数
验证数据上的损失值称为 验证损失,以区别于训练损失(validation loss, to distinguish it from the training loss. )。请注意,必须严格区分训练数据和验证数据:验证的目的是监控模型学习到的知识是否真正适用于新数据。如果模型在训练过程中已经接触过任何验证数据,则验证损失和相关指标将会出现偏差。
如果想在训练完成后计算验证损失和指标,可以调用以下evaluate方法:
1 | loss_and_metrics = model.evaluate(val_inputs, val_targets, batch_size=128) |
evaluate()它将以批次(大小为batch_size)的形式遍历传入的数据,并返回一个标量列表,其中第一个元素是验证损失,后续元素是验证指标。如果模型没有指标,则仅返回验证损失(而不是列表)。
推理:训练后使用模型
Inference: Using a model after training
模型训练完成后,接下来需要用它来对新数据进行预测。这称为推理。一种简单的方法是直接对__call__模型进行如下操作:
1 | # Takes a NumPy array or a tensor for your current backend and returns |
但是,这将一次性处理所有输入new_inputs,如果您要查看大量数据,这可能不可行(特别是,它可能需要比您的 GPU 拥有的内存更多的内存)。
更好的推理方法是使用该predict()方法。它会以小批量的方式迭代数据,并返回一个包含预测结果的 NumPy 数组。与之前的方法不同__call__,它还可以处理 TensorFlowDataset对象:
1 | # Takes a NumPy array or a Dataset and returns a NumPy array |
例如,如果我们用predict()之前训练的线性模型对一些验证数据进行测试,我们会得到与模型对每个输入样本的预测相对应的标量分数:
1 | >>> predictions = model.predict(val_inputs, batch_size=128) |
目前,关于 Keras 模型你需要了解的就这些了。接下来,你将学习下一章,学习如何使用 Keras 解决实际的机器问题。
概括
- TensorFlow、PyTorch 和 JAX 是三种流行的底层数值计算和自动微分框架。它们各有各的实现方式、优势和劣势。
- Keras 是一个用于构建和训练神经网络的高级 API。它可以与 TensorFlow、PyTorch 或 JAX 一起使用——只需选择你最喜欢的后端即可。
- Keras 的核心类是层
Layer。层封装了一些权重和一些计算。层被组装成模型。 - 在开始训练模型之前,你需要选择一个优化器、一个损失函数和一些指标,这些可以通过该
model.compile()方法指定。 - 要训练模型,您可以使用该
fit()方法,它会为您运行小批量梯度下降法。您还可以使用它来监控模型在验证数据上的损失和指标,验证数据是一组模型在训练过程中不会看到的输入数据。 - 模型训练完成后,就可以使用该
model.predict()方法对新的输入进行预测。
脚注
- R.E. Wengert,“一个简单的自动导数计算程序”,《ACM通讯》,第7卷第8期(1964年)。
- 请注意,PyTorch 的情况比较特殊:它主要是一个底层框架,但也包含自己的层和优化器。但是,如果您将 PyTorch 与 Keras 结合使用,则只会与 PyTorch 的底层 API(例如张量运算)进行交互。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论