《DEEP LEARNING with Python》第五章 机器学习基础
第五章 机器学习基础
Fundamentals of machine learning
运行代码
本章内容
- 理解泛化和优化之间的张力( Understanding the tension between generalization and optimization ),这是机器学习中的一个根本问题
- 机器学习模型的评估方法
- 提高模型拟合度的最佳实践
- 实现更好泛化的最佳实践
读完第四章的三个实例后,你应该开始熟悉如何使用神经网络解决分类和回归问题,并且已经了解了机器学习的核心问题:过拟合(overfitting)。本章将把你对机器学习的一些新理解形式化为一个坚实的理论框架,重点强调准确评估模型的重要性以及训练和泛化之间的平衡。
泛化:机器学习的目标
Generalization: The goal of machine learning
在第四章的三个例子中——预测电影评论、主题分类和房价回归——我们将数据分为训练集、验证集和测试集(a training set, a validation set, and a test set. )。很快我们就发现,不应该用训练数据来评估模型:仅仅几个训练周期后,模型在从未见过的数据上的性能就开始与训练数据上的性能出现偏差,而训练数据的性能总是随着训练的进行而提高。模型开始过拟合。过拟合几乎存在于所有机器学习问题中。
机器学习的核心问题在于优化与泛化之间的矛盾。优化指的是调整模型以使其在训练数据上获得最佳性能的过程(即机器学习中的“学习”),而泛化指的是训练好的模型在从未见过的数据上的表现。当然,最终目标是获得良好的泛化能力,但泛化能力并非完全可控;你只能让模型更好地拟合训练数据。如果拟合过度,就会出现过拟合,从而影响泛化能力。
但过拟合的成因是什么?我们如何才能实现良好的泛化能力?
欠拟合和过拟合
Underfitting and overfitting
对于上一章中提到的所有模型,在预留的验证数据集上的性能都随着训练的进行而逐渐提升,然后不可避免地在一段时间后达到峰值。这种模式(如图 5.1 所示)具有普遍性。无论模型类型或数据集如何,都会出现这种情况。
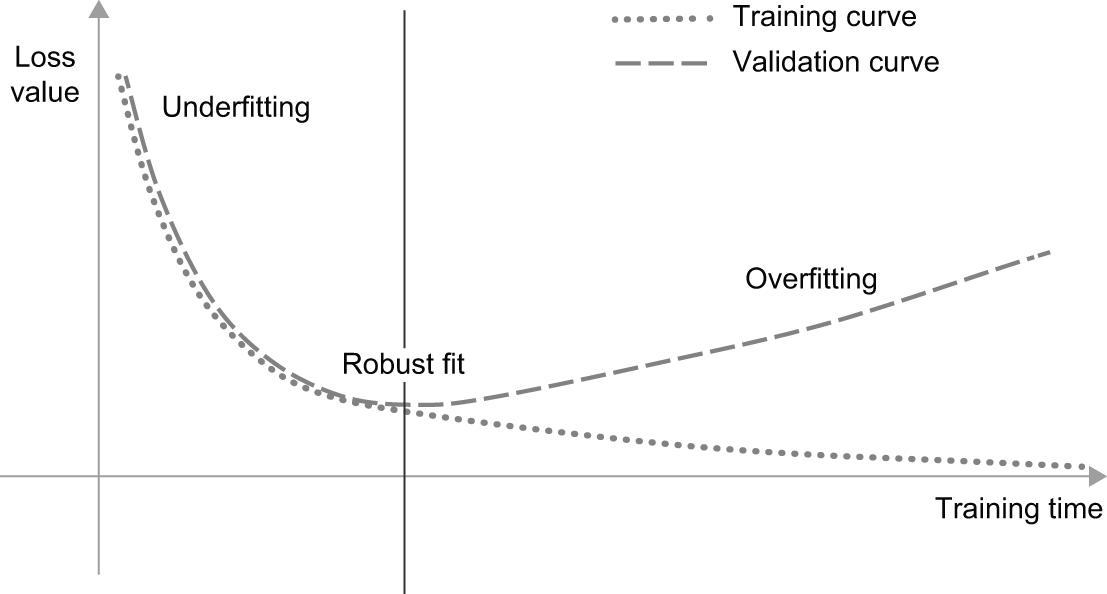
在训练初期,优化和泛化是相关的:训练数据上的损失越低,测试数据上的损失也越低。此时,模型处于欠拟合状态:它还有提升空间;网络尚未对训练数据中的所有相关模式进行建模。但是,经过一定次数的训练迭代后,泛化能力不再提升,验证指标停滞不前,然后开始下降:模型开始过拟合。也就是说,它开始学习一些仅适用于训练数据的模式,而这些模式在新数据上却具有误导性或无关性。
当数据存在噪声、不确定性或包含罕见特征时,特别容易发生过拟合。让我们来看一些具体的例子。
噪声训练数据
Noisy training data
在现实世界的数据集中,一些输入无效是很常见的。例如,MNIST 数字可能是一个全黑的图像,或者像图 5.2 那样的图像。

这些是什么?我们也不知道。但它们都属于 MNIST 训练集。然而,更糟糕的是,有些完全有效的输入最终却被错误标记,就像图 5.3 中所示的那样。

如果模型刻意将这些异常值纳入模型,其泛化性能将会下降,如图 5.4 所示。例如,一个看起来与图 5.3 中错误标记的 4 非常接近的 4,最终可能会被分类为 9。
模糊特征
Ambiguous features
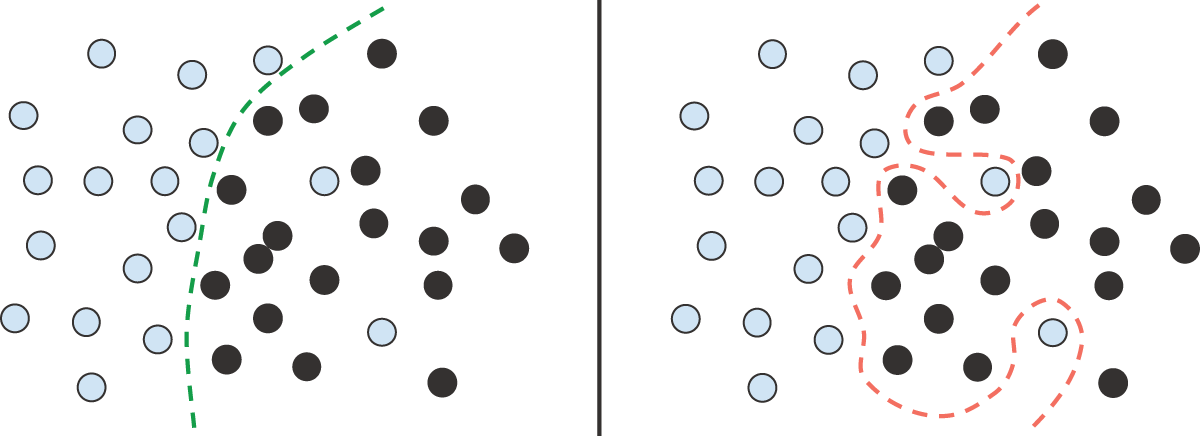
并非所有数据噪声都源于不准确——即使是完全干净且标注清晰的数据,当问题涉及不确定性和模糊性时,也可能存在噪声(见图 5.5)。在分类任务中,输入特征空间的某些区域常常同时与多个类别相关联。假设你正在开发一个模型,该模型接收一张香蕉图像并预测香蕉是未成熟、成熟还是腐烂。这些类别没有客观的界限,因此同一张图片可能被不同的标注者分类为未成熟或成熟。类似地,许多问题都涉及随机性。你可以使用大气压力数据来预测明天是否会下雨,但完全相同的测量结果有时可能预示着下雨,有时则预示着晴空万里——这存在一定的概率。
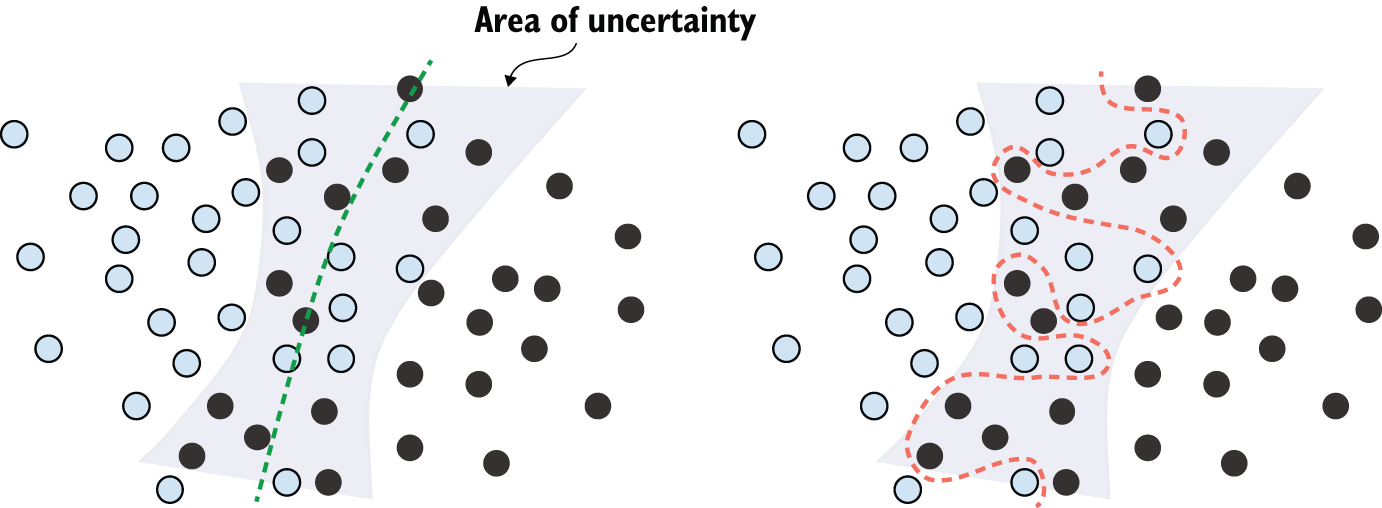
如图 5.6 所示,模型可能会对特征空间中模糊的区域过于自信,从而过度拟合此类概率数据。更稳健的拟合会忽略单个数据点,着眼于整体情况。
罕见特征和虚假相关性
Rare features and spurious correlations
如果你一生中只见过两只橘色虎斑猫,而且它们都非常不合群,你可能会推断橘色虎斑猫普遍都比较不合群。这是过度拟合:如果你接触过更多不同种类的猫,包括更多橘色的猫,你就会发现猫的毛色和性格并没有很强的相关性。
同样,基于包含罕见特征值的数据集训练的机器学习模型极易过拟合。在情感分类任务中,如果“番荔枝”(一种原产于安第斯山脉的水果)一词在训练数据中仅出现于一篇文本,且该文本的情感倾向为负面,那么正则化不足的模型可能会赋予该词极高的权重,并将所有提及番荔枝的新文本都分类为负面,而客观而言,番荔枝本身并没有任何负面含义。 [1]
重要的是,即使某个特征值只出现几次,也可能导致虚假相关性。例如,假设某个词在训练数据中的 100 个样本中出现,并且 54% 的情况下与积极情感相关,46% 的情况下与消极情感相关。这种差异很可能只是统计上的偶然现象,但你的模型却很可能学会将该特征用于分类任务。这是过拟合最常见的原因之一。
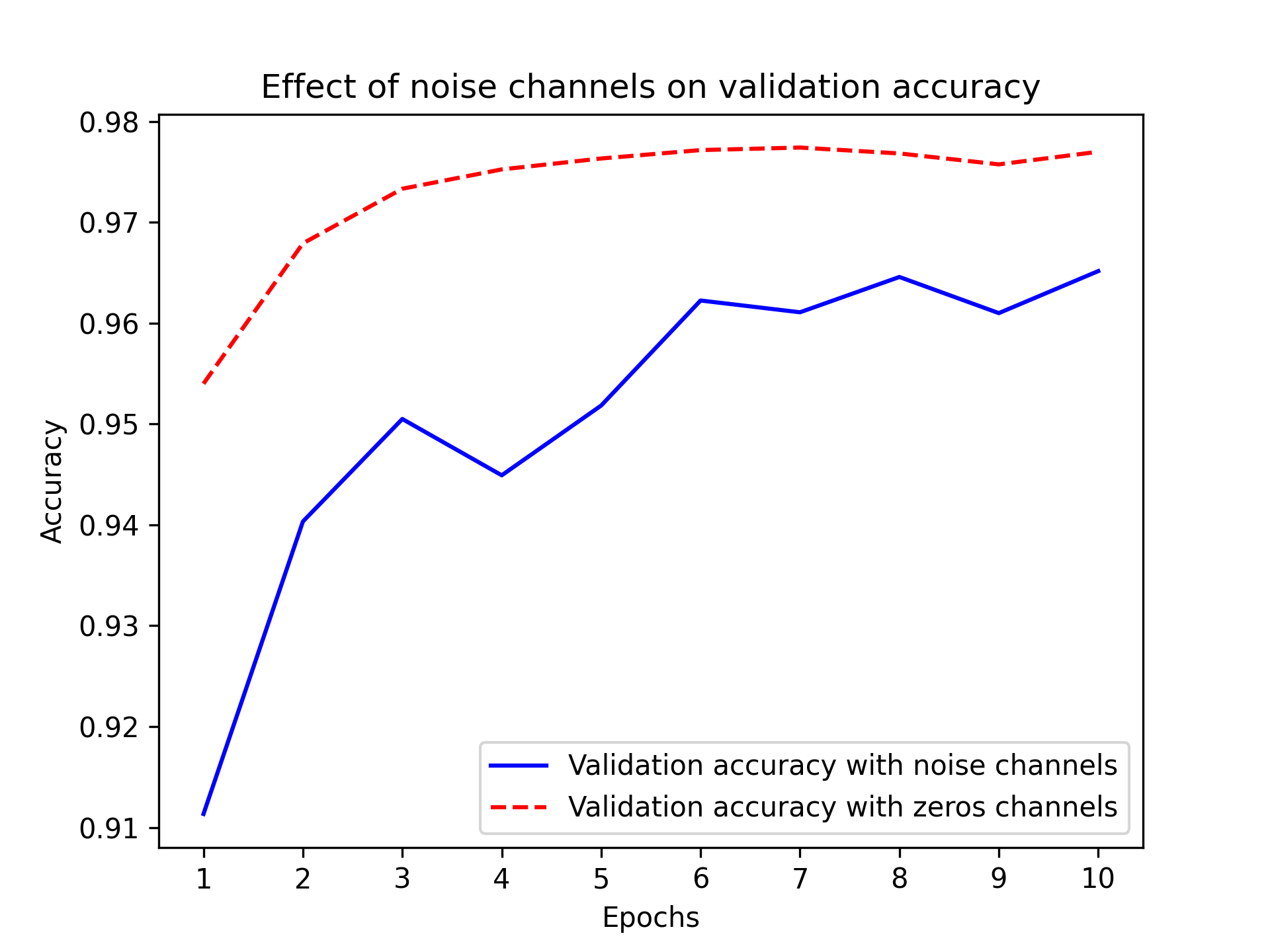
这里有一个非常直观的例子。以 MNIST 数据集为例。通过将 784 个白噪声维度(white noise dimensions)连接到原有数据的 784 个维度上,创建一个新的训练集——这样,一半的数据就变成了噪声。为了进行比较,我们还可以创建一个等效的数据集,方法是将 784 个全零维度连接起来。我们连接这些无意义的特征完全不会影响数据的信息含量:我们只是添加了无关的数据点。人类的分类准确率也不会受到这些转换的影响。
个人注:
白噪声维度?
- 纯粹的随机性:白噪声不包含任何结构、模式或规律。
- 无相关性:它与你原来的数字图像(784 维数据)之间没有任何逻辑联系。
- 压力测试:将白噪声加入数据,就相当于在考卷中加入了大量乱码。如果 AI 模型仍然能考高分,说明它具备了强大的特征提取能力,能够穿透“迷雾”抓取本质。
这句话描述的是一种在机器学习实验中常用的方法,旨在研究模型如何区分“有用特征”与“无用噪声”。
我们可以把这个过程拆解为以下三个层面来理解:
- 数据的“拓宽”过程
MNIST 数据集的每张图片是 \(28 \times 28\) 像素,展开后就是一个 784 维的向量(每个维度代表一个像素的亮度)。
- 原有维度:784 个维度,包含数字的形状信息(有意义的信号)。
- 白噪声维度:另外生成 784 个维度,里面的数值是完全随机的(没有任何规律的纯噪声)。
- 连接(Concatenation):将这两部分拼在一起。原本每个样本是一个 784 维的向量,现在变成了 1568 维(\(784 + 784\))的向量。
- 形象化的理解:信息的“稀释”
想象你有一张清晰的数字“5”的照片。
- 处理前:整张照片都是数字。
- 处理后:你把这张照片贴在一张同样大小、但全是乱七八糟雪花点(电视机没信号时的那种噪声)的纸旁边。
现在,对于 AI 模型来说,它看到的输入变成了一个“宽屏”图像:左半边是有意义的数字,右半边是毫无意义的干扰。
- 这个实验的目的(为什么要这么做?)
这句话通常出现在讨论过拟合(Overfitting)*或*特征选择的上下文中。其核心意义在于:
- 测试模型的定力:理想情况下,模型应该学会“无视”那后一半的 784 个噪声维度,只根据前一半的有效维度进行分类。
- 观察维度的诅咒:如果模型不够强大或正则化不足,它可能会试图从那 784 个随机噪声中寻找“虚假规律”。例如,它可能会认为“如果第 1002 个像素点很亮,那它就是数字 7”,尽管这只是随机巧合。
- 性能对比:通过对比“纯 784 维”和“加了噪声的 1568 维”的准确率,研究人员可以直观地看到无关特征对模型泛化能力的破坏程度。
总结
这句话的意思是:人为地给数据增加了一倍的“废话”。原本 50% 的信息是有用的,现在 50% 的信息是纯粹用来干扰模型判断的垃圾数据。
1 | from keras.datasets import mnist |
清单 5.1:向 MNIST 添加白噪声通道或全零通道
现在,让我们用这两个训练集来训练第 2 章中的模型。
1 | import keras |
清单 5.2:在具有噪声通道或全零通道的 MNIST 数据上训练相同的模型
尽管两种情况下数据包含的信息相同,但使用噪声通道训练的模型的验证准确率最终却低了约一个百分点——这完全是由于虚假相关性的影响(图 5.6)。添加的噪声通道越多,准确率下降就越严重。
噪声特征不可避免地会导致过拟合。因此,在不确定现有特征是有效信息还是干扰信息时,通常会在训练前进行特征选择。例如,将IMDB数据限制为出现频率最高的10000个词就是一种粗略的特征选择方法。典型的特征选择方法是为每个可用特征计算一个有用性得分——衡量特征相对于任务的信息量,例如特征与标签之间的互信息——并仅保留高于某个阈值的特征。这样做可以滤除前面示例中的白噪声通道。
深度学习中泛化的本质
The nature of generalization in deep learning
深度学习模型的一个显著特点是,只要具有足够的表征能力,它们就可以被训练来适应任何事物。
不信?试试把 MNIST 标签的顺序打乱,然后用这些标签训练模型。即使输入和打乱后的标签之间没有任何关联,训练损失也能很好地下降,即使模型规模相对较小。当然,验证损失不会随着时间的推移而改善,因为在这种情况下模型根本不可能泛化。
1 | (train_images, train_labels), _ = mnist.load_data() |
清单 5.3:使用随机打乱的标签拟合 MNIST 模型
事实上,你甚至不需要对 MNIST 数据进行这样的处理——你可以直接生成白噪声输入和随机标签。只要参数足够,你也可以用这些数据拟合模型。最终,模型会像 Python 字典一样记住特定的输入。
如果真是这样,那么深度学习模型为什么还能泛化呢?它们难道不应该像某种花哨的映射一样,学习训练输入和目标之间的临时映射吗dict?我们凭什么认为这种映射对新的输入也有效呢?
事实证明,深度学习中的泛化能力与深度学习模型本身关系不大,而与现实世界的信息结构关系密切。让我们来看看这其中究竟发生了什么。
流形假设
The manifold hypothesis
MNIST 分类器的输入(预处理前)是一个 28 × 28 的整数数组,取值范围为 0 到 255。因此,可能的输入值总数为 256 的 784 次方——远大于宇宙中的原子数量。然而,这些输入中只有极少数看起来像是有效的 MNIST 样本:实际的手写数字仅占所有可能的 28 × 28 数组构成的父空间中一个很小的子空间(subspace)uint8。更重要的是,这个子空间并非只是父空间中随机分布的点集:它具有高度结构化的特征。
首先,有效手写数字的子空间是连续的(continuous):即使对一个样本稍作修改,它仍然可以被识别为同一个手写数字。此外,有效子空间中的所有样本都通过贯穿该子空间的平滑路径连接起来。这意味着,如果从 MNIST 数据集中随机选取两个数字 A 和 B,则存在一系列“中间”图像,可以将 A 变形为 B,使得两个连续的数字彼此非常接近(参见图 5.7)。或许在两个类别的边界附近会出现一些模糊的形状,但即使是这些形状看起来仍然非常像数字。

该图像由第 17 章中的代码生成。
从技术角度来说,手写数字在可能的 28 × 28 数组空间中构成一个流形(manifold)uint8。这听起来有点复杂,但概念其实很直观。流形是某个父空间的低维子空间,它局部类似于线性(欧几里得)空间。例如,平面上的光滑曲线是二维空间中的一维流形,因为对于曲线上的每个点,都可以画出一条切线(曲线在每个点都可以用直线近似)。三维空间中的光滑曲面是二维流形。以此类推。
个人注:瑞士卷就是很好的例子,是三维空间的二维流形。连续的子空间。
更广义地说,流形假说认为所有自然数据都位于其编码所在的高维空间中的一个低维流形上。这可以说是对宇宙信息结构的一种非常强有力的论断。就我们目前所知,它是准确的,也是深度学习能够奏效的原因。它不仅适用于MNIST数字,也适用于人脸、树木形态、人声,甚至自然语言。
流形假设意味着
- 机器学习模型只需要在其潜在输入空间(潜在流形)内拟合相对简单、低维、高度结构化的子空间。
- 在这些流形中的一个内,总是可以在两个输入之间进行插值 ——也就是说,通过一条连续路径将一个输入变形为另一个输入,该路径上的所有点都落在流形上。
- Machine learning models only have to fit relatively simple, low-dimensional, highly structured subspaces within their potential input space (latent manifolds).
- Within one of these manifolds, it’s always possible to interpolate between two inputs — that is, morph one into another via a continuous path along which all points fall on the manifold.
在深度学习中,理解泛化能力的关键在于能够对样本进行插值。
The ability to interpolate between samples is the key to understanding generalization in deep learning.
插值作为概括的来源
Interpolation as a source of generalization
如果你处理的数据点可以进行插值,你就可以通过将它们与流形上相邻的其他点联系起来,来理解那些你以前从未见过的点。换句话说,你只需使用空间的一个样本就能理解整个空间。你可以使用插值来填补空白。
请注意,潜在流形上的插值与父空间中的线性插值不同,如图 5.8 所示。例如,两个 MNIST 数字之间的像素平均值通常不是一个有效的数字。
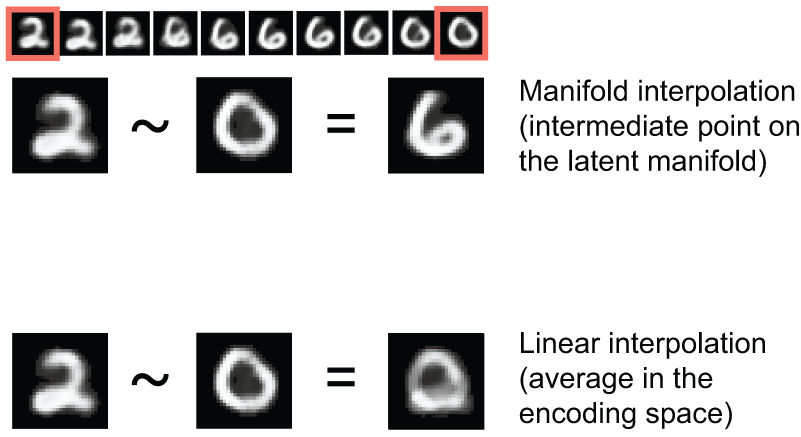
数字潜在流形上的每个点都是一个有效数字,但两个数字的平均值通常不是有效数字。
至关重要的是,虽然深度学习通过对学习到的数据流形近似进行插值来实现泛化,但如果认为插值就是泛化的全部,那就大错特错了。这只是冰山一角。插值只能帮助你理解与你之前见过的事物非常接近的事物:它实现的是局部泛化。但令人惊讶的是,人类一直在应对极其陌生的事物,而且他们做得很好。你不需要预先学习无数个你将来会遇到的情况的例子。你的每一天都与你之前经历过的任何一天都不同,也与自人类诞生以来任何人经历过的任何一天都不同。你可以在纽约待一周,在上海待一周,在班加罗尔待一周之间切换,而无需为每个城市花费数千年的时间来学习和练习。
人类具备极强的概括能力,这得益于除插值之外的其他认知机制——抽象、世界的符号模型、推理、逻辑、常识、关于世界的先验认知——我们通常称之为理性,而非直觉和模式识别。后者本质上很大程度上是插值性的,而前者则不是。两者都是智能的必要组成部分。我们将在第19章对此进行更深入的探讨。
为什么深度学习有效
Why deep learning works
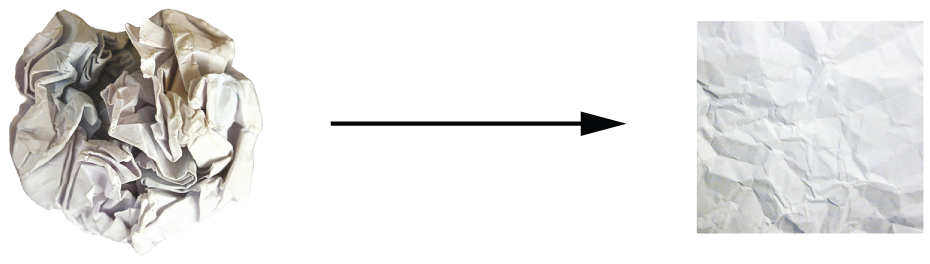
还记得第二章中提到的纸团比喻吗?一张纸代表三维空间中的一个二维流形(图 5.9)。深度学习模型就像是展开纸团的工具——也就是说,是解耦潜在流形的工具。
深度学习模型本质上是一条高维曲线。这条曲线是平滑且连续的(其结构受到模型架构先验的约束),因为它必须可微。这条曲线通过梯度下降法拟合到数据点——平滑且逐步地进行。 从本质上讲,深度学习就是将一条庞大而复杂的曲线(一个流形)的参数逐步调整,直到它与一些训练数据点拟合为止。
这条曲线包含的参数足够多,几乎可以拟合任何数据。事实上,如果让模型训练足够长的时间,它最终会完全记住训练数据,而无法泛化。然而,你拟合的数据并非由稀疏分布在底层空间中的孤立点组成。你的数据在输入空间内构成了一个高度结构化的低维流形——这就是流形假设。由于模型曲线拟合到这些数据的过程是随着时间的推移而逐渐平滑进行的,因此在训练过程中会存在一个中间点,此时模型大致逼近了数据的自然流形,如图 5.10 所示。
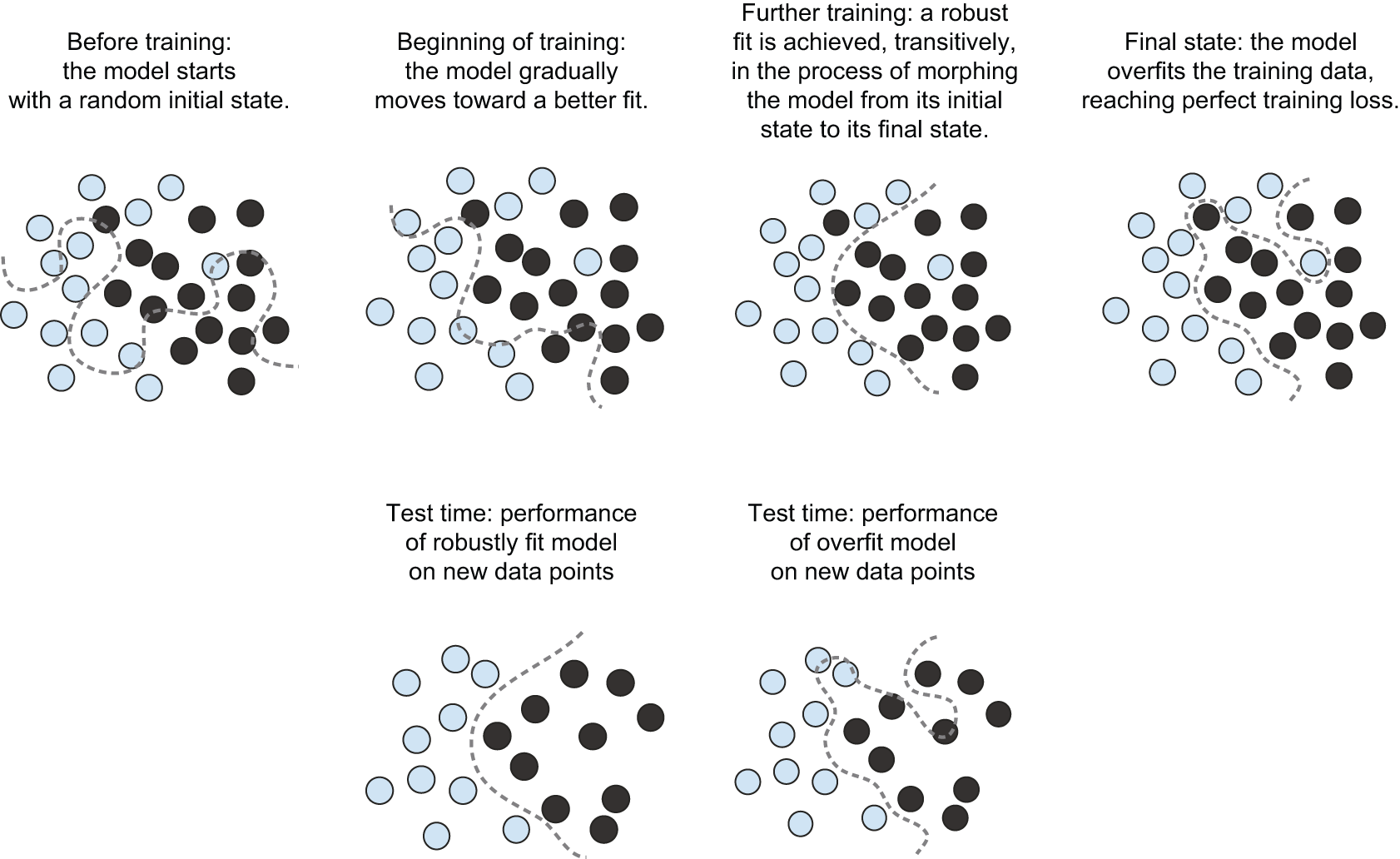
沿着模型在该点学习到的曲线移动,将非常接近于沿着数据的实际潜在流形移动。因此,该模型能够通过训练输入之间的插值来理解从未见过的输入。
除了它们具有足够的表征能力这一显而易见的事实之外,深度学习模型还有一些特性,使得它们特别适合学习潜在流形:
- 深度学习模型实现了从输入到输出的平滑连续映射。这种映射必须是平滑连续的,因为它必然是可微的(否则就无法进行梯度下降)。这种平滑性有助于逼近具有相同性质的潜在流形。
- 深度学习模型通常以某种方式构建,以反映其训练数据中信息的“形状”(通过架构先验)。图像处理模型(参见第8-12章)和序列处理模型(参见第13章)尤其如此。更普遍地说,深度神经网络以分层和模块化的方式构建其学习到的表征,这与自然数据的组织方式相呼应。
个人注:
在机器学习和深度学习的语境下,流形(Manifold)和表征(Representation)是两个紧密相关但视角不同的概念。
简单来说:流形是数据的“本质形状”,而表征是模型对这个形状的“数字化描述”。
- 流形(Manifold):数据的“真身”
流形是一个几何概念。它指的是嵌入在高维空间中的低维结构。
- 直观理解:想象一张平整的纸。它在二维空间里是平的。但如果你把它揉成一个纸团,它就变成了一个存在于三维空间里的复杂物体。尽管它看起来很乱,但它的本质(表面)依然是二维的。这张纸就是“流形”。
- 在 AI 中:一张 \(1024 \times 1024\) 像素的照片有超过一百万个维度,但“猫的照片”并不会随机分布在这个百万维空间里。它们都分布在一个高度卷曲、连续的低维“猫的流形”上。
- 属性:流形是客观存在的规律,它是数据分布的数学本质。
- 表征(Representation):模型的“视角”
表征是一个计算概念。它是指模型如何将原始数据(如像素)转换成一种更容易处理的向量形式。
- 直观理解:同样是“猫”,在你的大脑里的表征可能是“毛茸茸、尖耳朵、喵喵叫”的特征组合;而在神经网络的倒数第二层,它是一串包含 512 个数字的向量。
- 在 AI 中:通过多层非线性变换(如卷积、激活函数),模型把复杂的原始输入投影到一个新的空间里。这个新空间里的坐标点,就是该数据的“表征”。
- 属性:表征是主观构造的,它是模型为了完成任务(如分类、生成)而提取的信息提取方式。
- 两者的核心区别与联系
维度 流形 (Manifold) 表征 (Representation) 本质 几何形状 / 内在规律 数值向量 / 数据编码 视角 客观的:数据本身长什么样? 主观的:模型怎么看待这些数据? 目标 描述数据分布的连续性和结构 提取对特定任务有用的特征 维数 通常指数据的“固有维度” 由模型设计者决定的维度(如 128 维嵌入)
- 它们是如何协同工作的?
深度学习的本质,其实就是流形变换(Manifold Transformation)。
当你训练一个模型时,你实际上是在命令模型去寻找一种更好的表征,使得原始数据那个纠缠不清的流形被“摊平”或“展开”。
- 原始表征(像素):流形极度扭曲,猫和狗的数据点交织在一起,无法用一条直线划开。
- 学习后的表征(高层特征):流形被展开成了平整的平面。在这个新的表征空间里,猫和狗被清晰地分到了两边。
比喻:流形是那个被揉皱的纸团(数据本质),而学习表征的过程就是把纸团小心翼翼地拆解、摊平,直到它变成一张好读的平面地图。
训练数据至关重要
Training data is paramount
虽然深度学习确实非常适合流形学习,但模型的泛化能力更多地取决于数据的自然结构,而非模型本身的任何属性。只有当数据构成一个可以插值的流形时,模型才能实现泛化。特征信息量越大、噪声越小,模型的泛化能力就越强,因为输入空间会更简单、结构更清晰。数据整理和特征工程对于提高泛化能力至关重要。
此外,由于深度学习本质上是曲线拟合,因此模型要想表现良好, 就需要对其输入空间进行密集采样。这里的“密集采样”指的是训练数据应该密集地覆盖整个输入数据流形(见图 5.11)。这一点在决策边界附近尤为重要。通过足够密集的采样,我们可以利用过去训练数据之间的插值来理解新的输入,而无需借助常识、抽象推理或关于世界的外部知识——这些都是机器学习模型无法获取的。
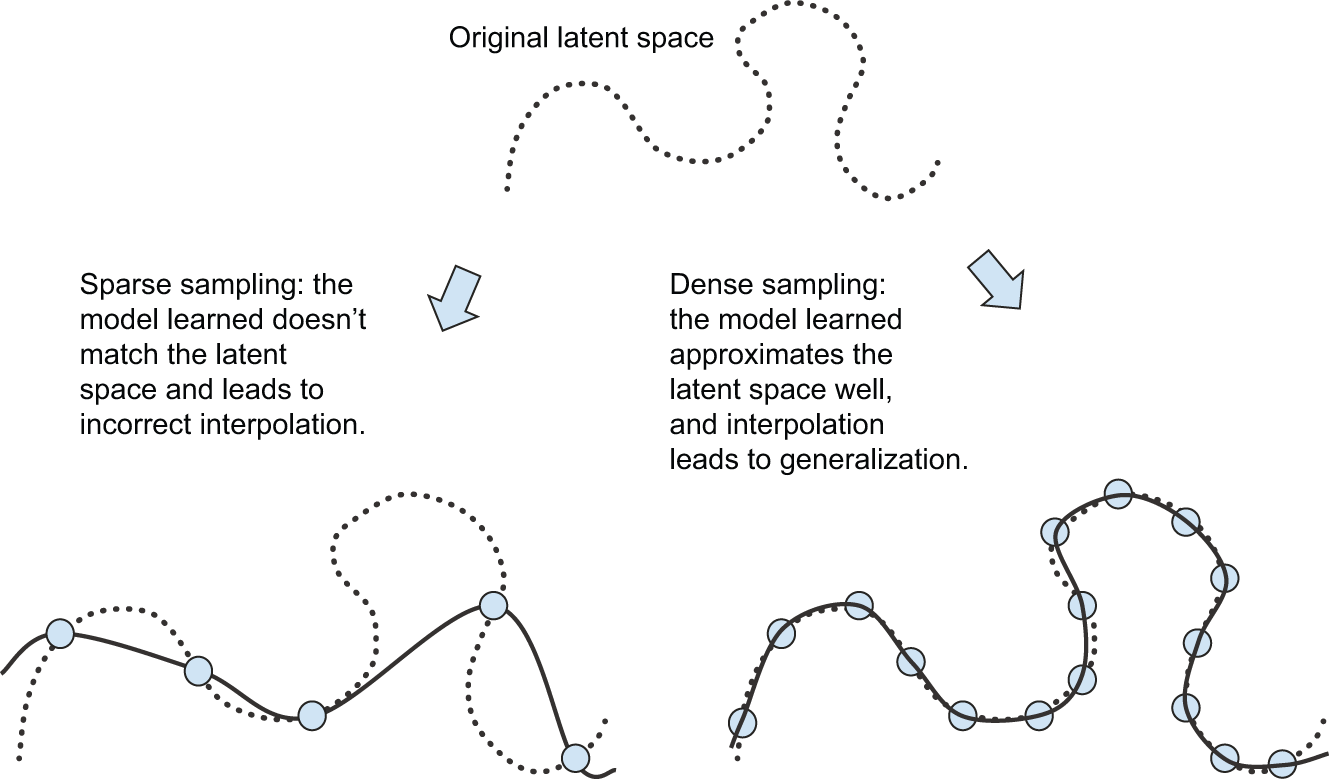
因此,您应该始终牢记,提升深度学习模型的最佳方法是使用更多或更高质量的数据进行训练(当然,添加过多噪声或不准确的数据会损害模型的泛化能力)。输入数据流形的覆盖范围越广,模型的泛化能力就越强。您不应期望深度学习模型能够执行超出训练样本间粗略插值之外的任何操作,因此,您应该尽一切可能简化插值过程。深度学习模型中唯一存在的就是您输入的内容:编码在其架构中的先验信息以及用于训练的数据。
当无法获取更多数据时,次优方案是调整模型允许存储的信息量,或者对模型曲线的平滑度施加约束。如果网络只能记忆少量模式或非常规则的模式,优化过程会迫使它专注于最突出的模式,这些模式更有可能具有良好的泛化能力。这种防止过拟合的方法称为正则化。我们将在 5.4.4 节深入探讨正则化技术。
在开始调整模型以提升其泛化能力之前,你需要一种方法来评估模型当前的性能。在接下来的章节中,你将学习如何在模型开发过程中监控泛化能力:模型评估。
评估机器学习模型
Evaluating machine-learning models
你只能控制你能观察到的事物。由于你的目标是开发能够成功泛化到新数据的模型,因此可靠地衡量模型的泛化能力至关重要。在本节中,我们将正式介绍评估机器学习模型的不同方法。你已经在上一章中见过其中大部分方法的实际应用。
个人注:
验证集:用于模型选择和防过拟合(它是开发循环的一部分)。
测试集:用于最终性能评估(它是独立于开发循环的)。
训练集、验证集和测试集
Training, validation, and test sets
评估模型始终归结为将可用数据分成三组:训练集、验证集和测试集。使用训练集训练模型,并使用验证集评估模型。一旦模型准备就绪,即可在测试集上进行最终测试,测试集应尽可能与生产数据相似。之后,即可将模型部署到生产环境中。
你可能会问,为什么不使用两个数据集:一个训练集和一个测试集呢?你可以用训练数据进行训练,用测试数据进行评估。这样简单多了!
原因在于,开发模型总是涉及对其配置进行调整:例如,选择层数或层的大小(称为模型的超参数hyperparameters,以区别于作为网络权重的参数)。这种调整是通过模型在验证集上的表现作为反馈信号来进行的。本质上,这种调整是一种学习:在某个参数空间中寻找一个合适的配置。因此,即使模型从未直接在验证集上训练,基于模型在验证集上的表现来调整其配置也很容易导致模型过拟合验证集。
这一现象的核心在于信息泄露(information leaks)的概念。每次你根据模型在验证集上的表现调整模型的超参数时,都会有一些关于验证集数据的信息泄露到模型中。如果你只针对一个参数进行一次这样的调整,那么泄露的信息量非常少,验证集仍然能够可靠地用于评估模型。但是,如果你重复这个过程很多次——运行一次实验,在验证集上进行评估,并根据结果修改模型——那么就会有越来越多的关于验证集的信息泄露到模型中。
最终,你会发现模型在验证集上的表现异常出色,因为你当初就是针对验证集进行优化的。你真正关心的是在全新数据上的性能,而不是验证集,所以你需要使用一个完全不同、从未见过的数据集来评估模型:测试集。你的模型不应该接触到任何 关于测试集的信息,哪怕是间接的。如果模型的任何参数是基于测试集的性能进行调整的,那么你对模型泛化能力的衡量就会出现偏差。
将数据拆分为训练集、验证集和测试集看似简单,但实际上有一些更高级的方法,在数据量有限的情况下非常实用。我们来回顾三种经典的评估方法:简单的留出验证法、K折交叉验证法和带随机打乱的迭代K折交叉验证法。我们还将讨论如何使用一些常识性的基线方法来检验训练结果是否有效。
简单的留出验证
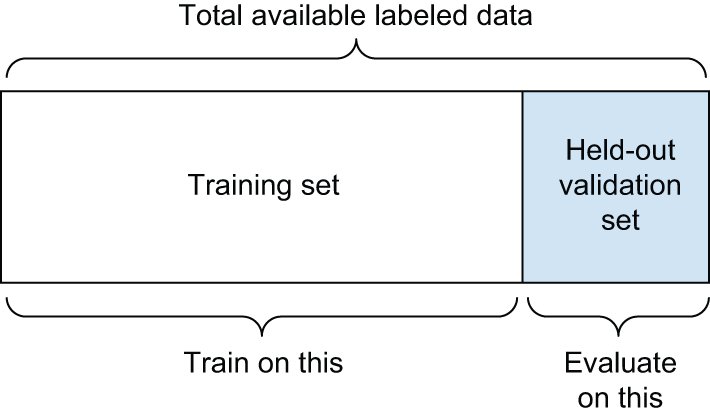
Simple hold-out validation
将一部分数据作为测试集。使用剩余数据进行训练,并在测试集上进行评估。正如你在前面的章节中所看到的,为了防止信息泄露,你不应该基于测试集来调整模型,因此你 也应该保留一个验证集。
从示意图上看,留出验证法如图 5.12 所示。下面的清单展示了一个简单的实现。
1 | num_validation_samples = 10000 |
清单 5.4:留出验证(为简单起见,省略了标签)
这是最简单的评估方案,但它存在一个缺陷:如果可用数据量很少,那么验证集和测试集的样本量可能太少,无法在统计上代表现有数据。这一点很容易识别:如果在拆分之前对数据进行多次随机打乱,最终得到的模型性能指标差异很大,那么就存在这个问题。K折交叉验证和迭代K折交叉验证是两种解决这个问题的方法,我们将在下文中讨论。
K折交叉验证
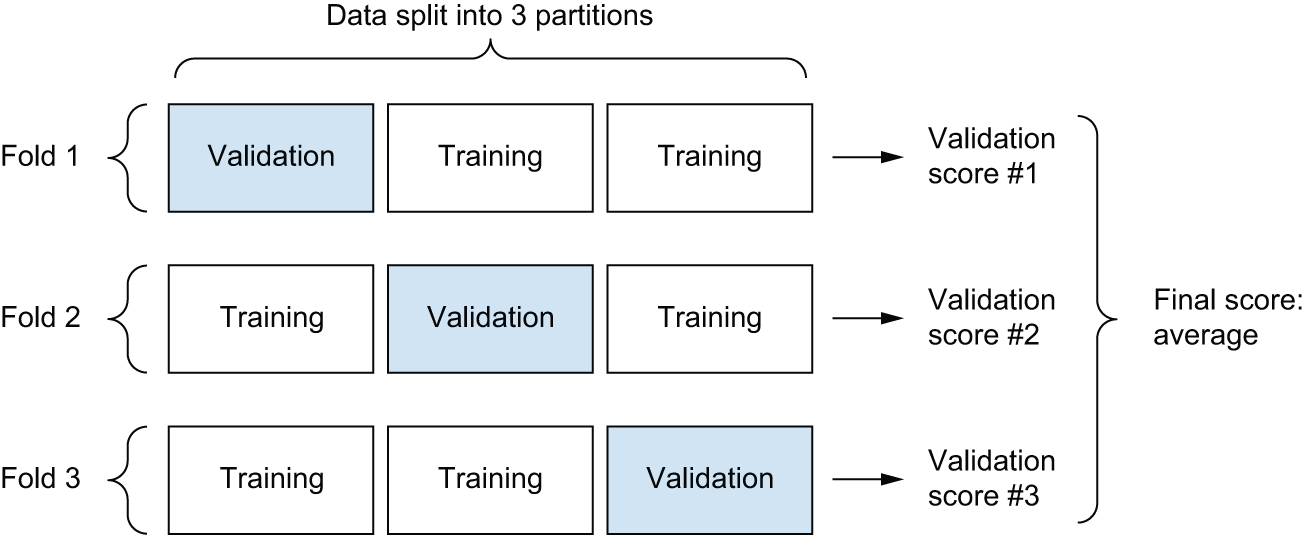
K-fold validation
这种方法将数据分割成K大小相等的若干个分区。对于每个分区i,在剩余的分区上训练模型K - 1,并在分区上评估模型性能i。最终得分是 K 个得分的平均值。当模型性能因训练/测试集划分的不同而出现显著差异时,此方法非常有用。与留出验证法类似,此方法也要求使用独立的验证集进行模型校准。
从示意图上看,K 折交叉验证如图 5.13 所示。清单 5.6 显示了一个简单的实现。
1 | k = 3 |
清单 5.5:K 折交叉验证(为简单起见,省略了标签)
迭代K折交叉验证(带随机化)
Iterated K-fold validation with shuffling
这种方法适用于数据量相对较少,但需要尽可能精确地评估模型的情况。我发现它在 Kaggle 竞赛中非常有用。它通过多次执行 K 折交叉验证来实现,每次验证前都会对数据进行随机打乱K。最终得分是每次 K 折交叉验证得分的平均值。需要注意的是,这种方法需要训练和评估P * K模型(其中 n P是你使用的迭代次数),这可能会非常耗费资源。
超越常识基准
Beating a common-sense baseline
除了您可以使用的各种评估方案之外,您还应该了解的最后一件事是常识基线的使用。
训练深度学习模型有点像按下按钮,在平行世界里发射一枚火箭。你听不到也看不到它。你无法观察流形学习过程——它发生在数千维空间中,即使你把它投影到三维空间,也无法解读。你唯一能获得的反馈就是验证指标——就像你那枚隐形火箭上的高度计。
一个特别重要的点是,你要能够判断你的模型是否已经起步(getting off the ground)。你的起点是多少?你的模型准确率似乎只有 15%,这算好吗?在开始处理数据集之前,你应该始终选择一个最简单的基准,并尝试超越它。如果你能突破这个阈值,就说明你做对了:你的模型确实在利用输入数据中的信息进行泛化预测——你可以继续前进。这个基准可以是随机分类器的性能,也可以是你所能想象的最简单的非机器学习技术的性能。
例如,在 MNIST 数字分类示例中,一个简单的基线是验证准确率大于 0.1(随机分类器);在 IMDB 示例中,验证准确率大于 0.5。在路透社示例中,由于类别不平衡,验证准确率约为 0.18-0.19。如果您有一个二元分类问题,其中 90% 的样本属于 A 类,10% 的样本属于 B 类,那么一个始终预测为 A 类的分类器已经可以达到 0.9 的验证准确率,而您需要做得更好。
当你着手解决一个前所未有的难题时,拥有一个可以参考的常识性基准至关重要。如果你连一个简单的解决方案都无法超越,那么你的模型就毫无价值——或许你使用了错误的模型,又或许你正在解决的问题根本就不适合用机器学习来解决。是时候重新开始了。
模型评估中需要注意的事项
Things to keep in mind about model evaluation
在选择评估方案时,请注意以下几点:
- 数据代表性 ——你需要确保训练集和测试集都能代表当前数据。例如,如果你要对数字图像进行分类,并且初始样本数组已按类别排序,那么将数组的前 80% 作为训练集,剩余的 20% 作为测试集,会导致训练集只包含类别 0-7,而测试集只包含类别 8-9。这看似荒谬的错误,但却非常常见。因此,通常应该在将数据拆分为训练集和测试集之前,先对数据进行随机打乱。
- 时间之箭 ——如果你试图根据过去预测未来(例如,预测明天的天气、股票走势等等),那么在拆分数据之前不应该随意打乱数据顺序,因为这样做会造成时间泄漏:你的模型实际上会使用来自未来的数据进行训练。在这种情况下,你应该始终确保测试集中的所有数据都晚于训练集中的数据。
- 数据冗余 ——如果你的数据中某些数据点出现了两次(这在实际数据中相当常见),那么对数据进行打乱并将其拆分为训练集和验证集会导致训练集和验证集之间出现冗余。实际上,你将使用部分训练数据进行测试,这是最糟糕的做法!请确保你的训练集和验证集互不相交。
- Data representativeness — You want both your training set and test set to be representative of the data at hand. For instance, if you’re trying to classify images of digits, and you’re starting from an array of samples where the samples are ordered by their class, taking the first 80% of the array as your training set and the remaining 20% as your test set will result in your training set containing only classes 0–7, whereas your test set contains only classes 8–9. This seems like a ridiculous mistake, but it’s surprisingly common. For this reason, you usually should randomly shuffle your data before splitting it into training and test sets.
- The arrow of time — If you’re trying to predict the future given the past (for example, tomorrow’s weather, stock movements, and so on), you should not randomly shuffle your data before splitting it because doing so will create a temporal leak: your model will effectively be trained on data from the future. In such situations, you should always make sure all data in your test set is posterior to the data in the training set.
- Redundancy in your data — If some data points in your data appear twice (fairly common with real-world data), then shuffling the data and splitting it into a training set and a validation set will result in redundancy between the training and validation sets. In effect, you’ll be testing on part of your training data, which is the worst thing you can do! Make sure your training set and validation set are disjoint.
拥有可靠的方法来评估模型的性能,就能监控机器学习核心的矛盾——优化与泛化、欠拟合与过拟合之间的矛盾。
提高模型拟合度
Improving model fit
为了达到完美拟合,首先必须进行过拟合。由于事先无法确定过拟合的边界,因此必须跨越边界才能找到它。所以,在着手解决问题时,你的初始目标是构建一个具有一定泛化能力且能够过拟合的模型。一旦有了这样的模型,接下来就要专注于通过抑制过拟合来提升模型的泛化能力。
在这个阶段,你会遇到三个常见问题:
- 训练没有开始:你的训练损失不会随着时间推移而减少。
- 训练开始得很顺利,但是你的模型无法有效地泛化:你无法超越你设定的常识性基准。
- 训练损失和验证损失都会随着时间的推移而下降,你可以超越你的基线,但你似乎无法过拟合,这表明你仍然处于欠拟合状态。
让我们看看如何解决这些问题,以实现机器学习项目的第一个重大里程碑:获得一个具有一定泛化能力(可以胜过一个简单的基线)并且能够过拟合的模型。
调整关键梯度下降参数
Tuning key gradient descent parameters
有时候,训练无法启动或过早停滞,损失函数也卡住了。但这总能克服:记住,你可以用随机数据拟合模型。即使你的问题本身毫无意义,你仍然应该能够训练出一个模型——哪怕只是通过记住训练数据。
出现这种情况,通常是梯度下降过程的配置出了问题:优化器的选择、模型权重初始值的分布、学习率或批次大小。所有这些参数都相互关联,因此,通常只需调整学习率和批次大小,同时保持其他参数不变即可。
让我们来看一个具体的例子:让我们用一个不合适的大学习率(值为 1)来训练第 2 章中的 MNIST 模型。
1 | (train_images, train_labels), _ = mnist.load_data() |
示例 5.6:使用过高的学习率训练 MNIST 模型
该模型很快就能达到 20% 到 40% 的训练和验证准确率,但之后就无法突破这个范围了。我们尝试将学习率降低到一个更合理的数值1e-2:
1 | model = keras.Sequential( |
示例 5.7:采用更合适的学习率的相同模型
该模型现在可以进行训练了。
如果你发现自己身处类似情况,不妨试试
- 降低或提高学习率。学习率过高可能导致更新幅度过大,严重偏离正确拟合值,就像前面的例子一样;而学习率过低则可能导致训练速度过慢,甚至停滞不前。
- 增加批次大小。批次样本越多,得到的梯度信息越丰富,噪声越小(方差越低)。
你最终会找到一种可以开始训练的配置。
利用更好的架构先验信息
Using better architecture priors
你的模型拟合效果很好,但不知为何验证指标却丝毫没有提升。它们仍然和随机分类器一样糟糕:你的模型训练成功了,但泛化能力却很差。这是怎么回事?
这或许是你在机器学习中可能遇到的最糟糕的情况。这表明你的方法存在根本性的问题,而且可能很难确定问题出在哪里。以下是一些建议。
首先,可能是你使用的输入数据本身包含的信息不足以预测目标值:问题本身无法解决。之前我们尝试拟合一个标签被打乱的 MNIST 模型时就遇到了这种情况:模型可以正常训练,但验证准确率始终停留在 10%,因为这样的数据集显然无法进行泛化。
也可能是你使用的模型类型不适合当前问题。例如,在第 13 章中,你会看到一个时间序列预测问题的例子,其中密集连接架构无法超越一个简单的基线模型,而更合适的循环架构却能很好地泛化。使用对问题做出正确假设的模型对于实现泛化至关重要:你应该使用正确的架构先验信息。
在接下来的章节中,您将学习适用于各种数据模态(例如图像、文本、时间序列等)的最佳架构。一般来说,您应该始终确保事先了解您所要处理的任务类型的最佳架构实践——因为您很可能不是第一个尝试这样做的人。
提高模型容量
Increasing model capacity
如果你成功构建了一个拟合度良好的模型,验证指标持续下降,并且模型似乎至少具备一定的泛化能力,那么恭喜你:你已经接近成功了。接下来,你需要让你的模型开始过拟合。
考虑以下小型模型——一个简单的逻辑回归模型——该模型在 MNIST 像素上进行了训练。
1 | model = keras.Sequential([layers.Dense(10, activation="softmax")]) |
示例 5.8:基于 MNIST 数据集的简单逻辑回归
你会得到类似这样的损耗曲线(见图 5.14):
1 | import matplotlib.pyplot as plt |
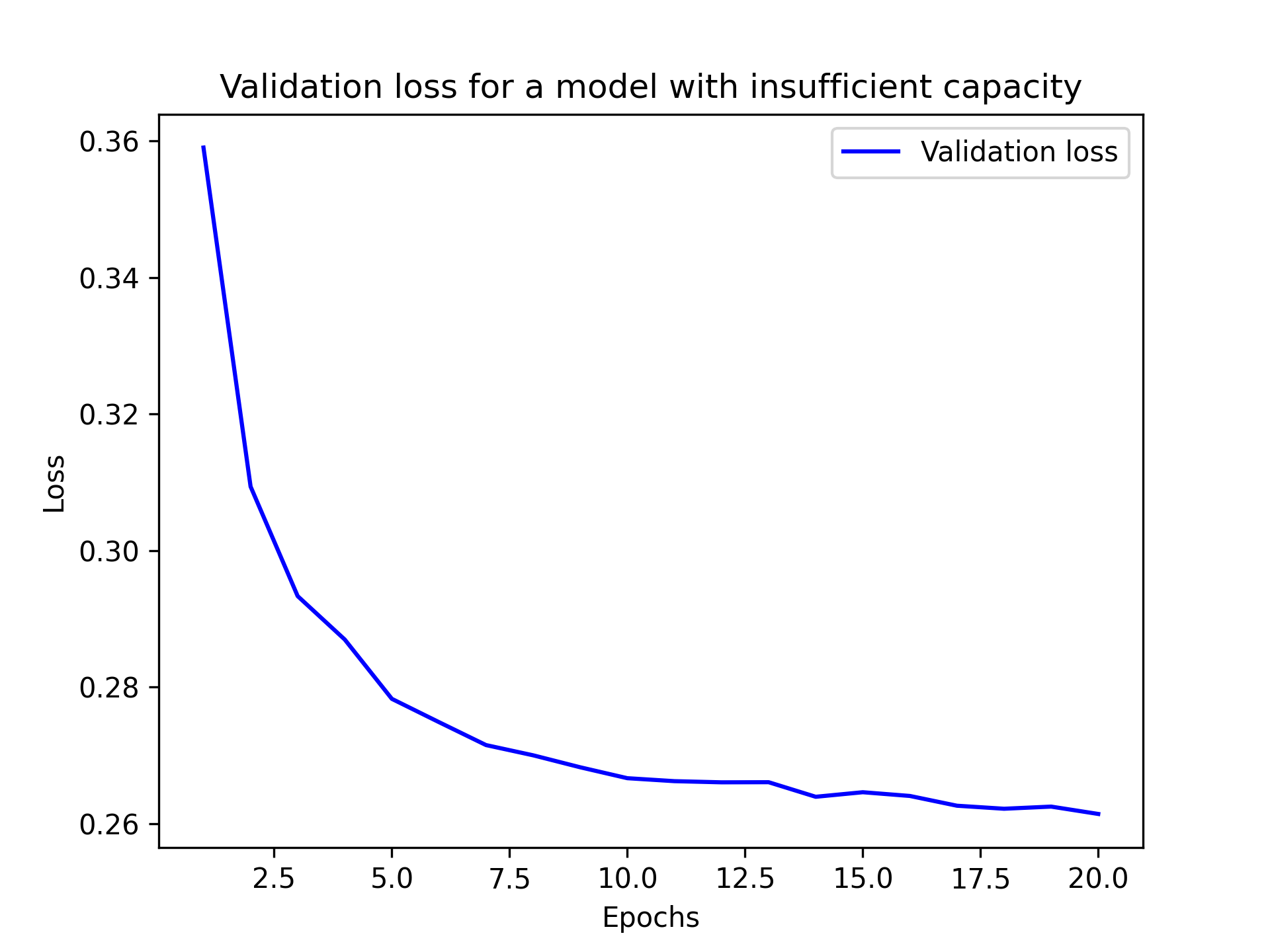
验证指标似乎停滞不前或改善速度非常缓慢,而不是达到峰值并开始回升。验证损失达到 0.26 后就一直保持不变。虽然模型可以拟合,但即使经过多次训练迭代,也无法明显看出过拟合。在你的职业生涯中,你很可能会经常遇到类似的曲线。
记住,过拟合总是可能发生的。就像“训练损失没有下降”的问题一样,过拟合总是可以解决的。如果你始终无法实现过拟合,那很可能是模型表征能力的问题:你需要一个更大的模型,一个容量更大的模型——也就是说,一个能够存储更多信息的模型。你可以通过增加层数、使用更大的层(参数更多的层)或者使用更适合当前问题的层类型(更好的架构先验)来提高表征能力。
我们来尝试训练一个更大的模型,一个有两个中间层,每个中间层有 128 个单元的模型:
1 | model = keras.Sequential( |
现在的训练曲线看起来完全符合预期:模型拟合速度很快,但在八个 epoch 后开始过拟合(见图 5.15):
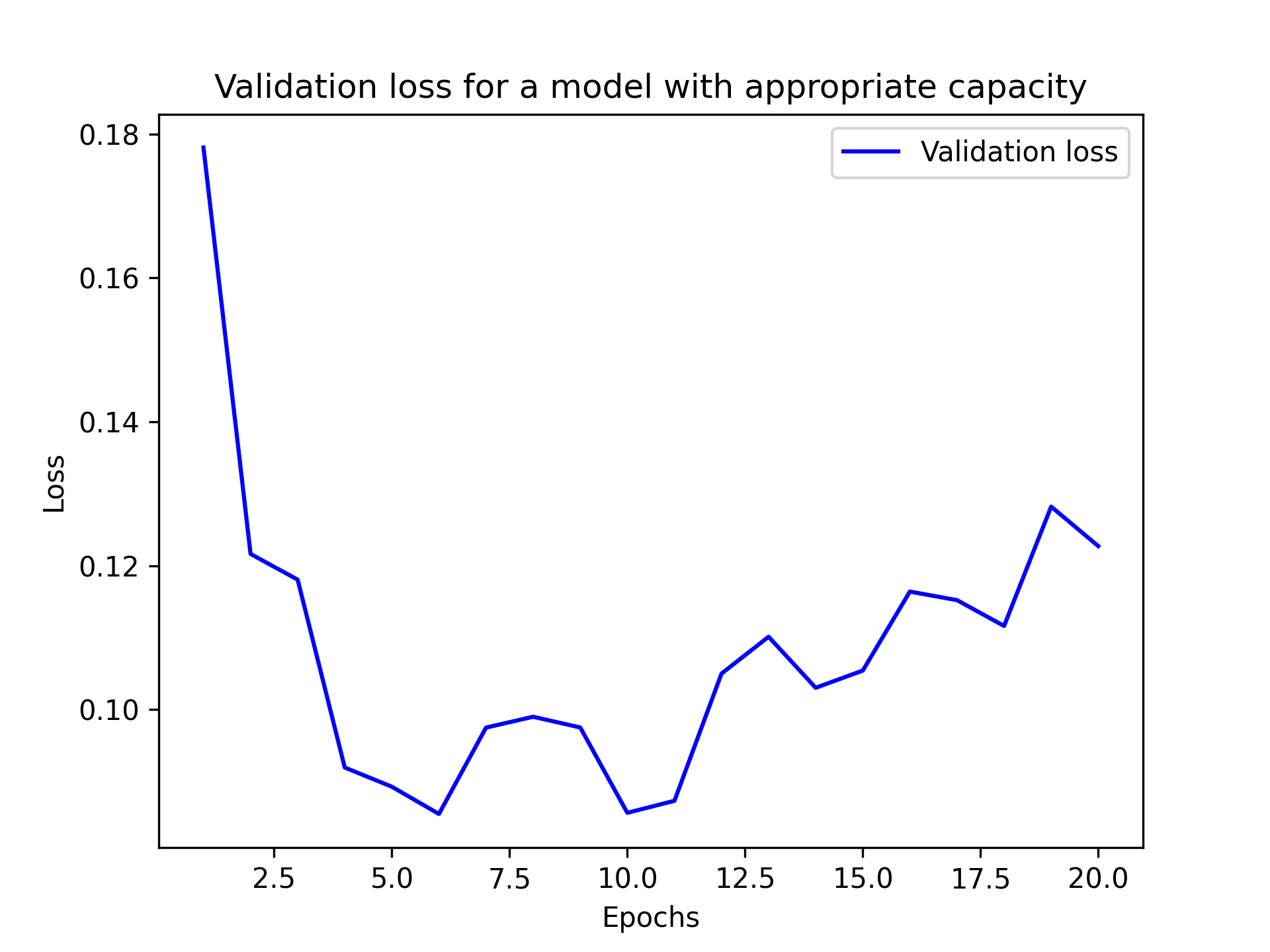
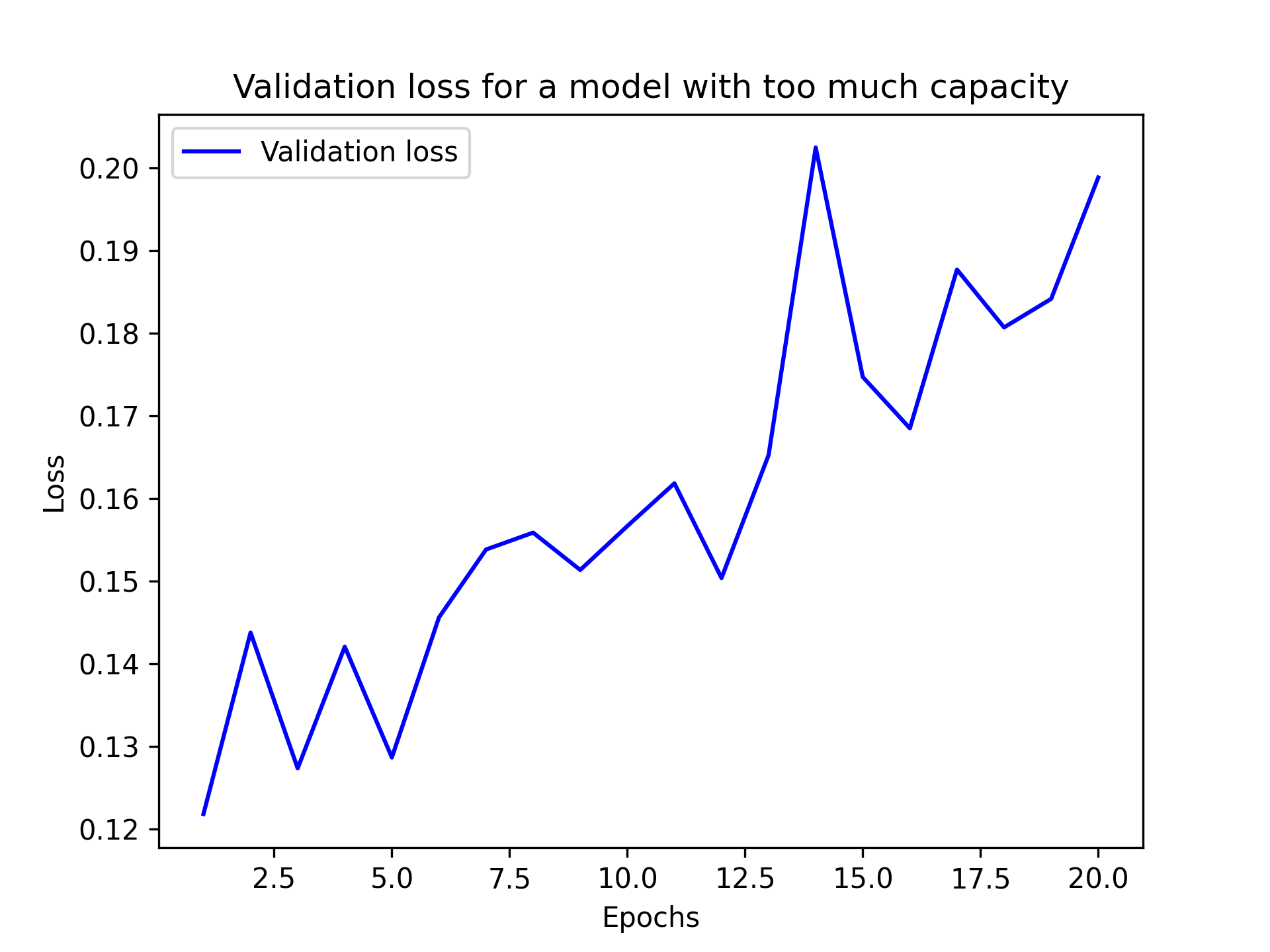
请注意,虽然使用参数过多的模型来解决当前问题是很常见的,但模型的记忆容量过大也是有可能 的。如果模型立即出现过拟合现象,则说明模型规模过大。下图展示了一个包含三个中间层、每层包含 2048 个单元的 MNIST 模型的情况(见图 5.16):
1 | model = keras.Sequential( |
提高泛化能力
Improving generalization
一旦你的模型表现出一定的泛化能力并且能够过拟合,就应该将重点转移到最大化泛化能力上。
数据集整理
Dataset curation
你已经了解到,深度学习的泛化能力源于数据的潜在结构。如果你的数据允许样本间平滑插值,那么你就能训练出一个具有泛化能力的深度学习模型。但如果你的问题噪声过大或本质上是离散的,例如列表排序,那么深度学习就帮不上忙了。深度学习本质上是曲线拟合,而不是魔法。
因此,确保使用合适的数据集至关重要。投入更多精力和资金进行数据收集几乎总是比投入同样的资金开发更好的模型带来更大的投资回报:
- 确保你拥有足够的数据。记住,你需要 对输入-输出空间进行密集采样。更多的数据会带来更好的模型。有时,一些看似无法解决的问题,随着数据集的增大,反而能够迎刃而解。
- 尽量减少标签错误——可视化您的输入以检查异常情况,并校对您的标签。
- 清理数据并处理缺失值(我们将在下一章中介绍)。
- 如果你有很多功能,但不确定哪些功能真正有用,那就进行功能选择。
提高数据泛化能力的一个特别重要的方法是特征工程。对于大多数机器学习问题而言, 特征工程是成功的关键要素。让我们来看一下。
特征工程
Feature engineering
特征工程是指利用你对数据和当前机器学习算法(在本例中为神经网络)的了解,通过在数据输入模型之前对其应用硬编码(非学习)的转换,来优化算法性能的过程。在许多情况下,期望机器学习模型能够从完全任意的数据中学习是不合理的。数据需要以一种能够简化模型工作的方式呈现给模型。
我们来看一个直观的例子。假设你要开发一个模型,输入是一张时钟图像,输出的是当前时间(见图 5.17)。如果你选择使用图像的原始像素作为输入数据,那么你就面临着一个棘手的机器学习问题。你需要一个卷积神经网络来解决这个问题,而且训练这个网络需要消耗大量的计算资源。
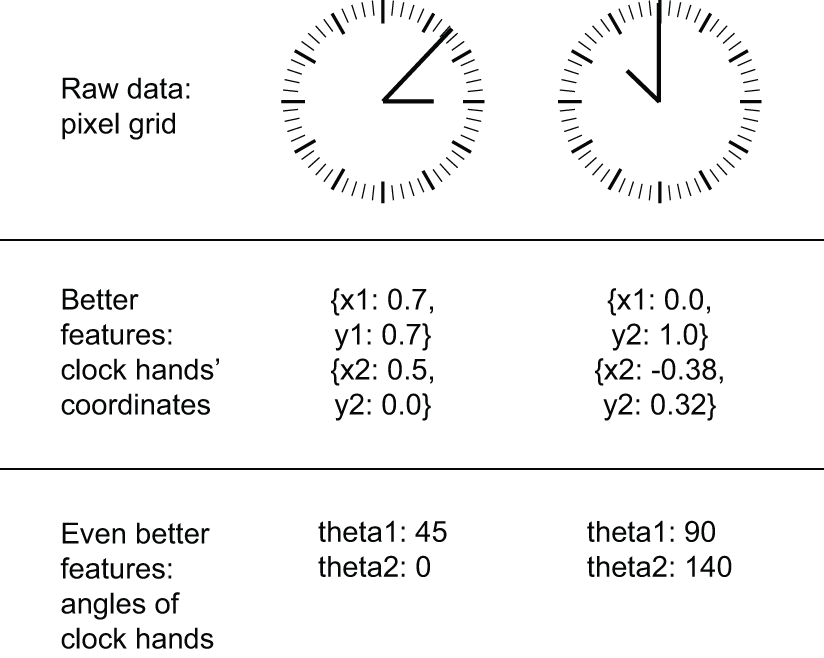
但是,如果你已经从宏观层面理解了问题(例如,你了解人类如何通过钟面读取时间),那么你就可以为机器学习算法设计出更好的输入特征:例如,编写一个五行 Python 脚本来追踪时钟指针的黑色像素,并输出(x, y)每根指针尖端的坐标,就非常简单。然后,一个简单的机器学习算法就可以学习将这些坐标与一天中的相应时间关联起来。
你还可以更进一步:进行坐标变换,将(x, y) 坐标表示为相对于图像中心的极坐标。这样,你的输入就变成了theta每根指针的角度。此时,你的特征已经使问题变得如此简单,无需机器学习;只需简单的四舍五入和字典查找即可恢复大致时间。
这就是特征工程的本质:通过更简洁的方式表达问题,从而简化问题。使潜在流形更平滑、更简洁、更有条理。这通常需要对问题有深入的理解。
在深度学习出现之前,特征工程曾是机器学习工作流程中最重要的一环,因为传统的浅层算法缺乏足够丰富的假设空间来自主学习有用的特征。数据呈现方式对算法的成功至关重要。例如,在卷积神经网络成功解决 MNIST 数字分类问题之前,解决方案通常基于硬编码的特征,例如数字图像中的循环次数、每个数字在图像中的高度、像素值的直方图等等。
幸运的是,现代深度学习消除了大部分特征工程的需求,因为神经网络能够自动从原始数据中提取有用特征。这是否意味着只要使用深度神经网络就无需担心特征工程?并非如此,原因有二:
- 优秀的功能仍然能够让你以更优雅的方式解决问题,同时减少资源消耗。例如,用卷积神经网络来解决读取钟面时间的问题就显得非常荒谬。
- 好的特征能让你用更少的数据解决问题。深度学习模型自主学习特征的能力依赖于大量的训练数据;如果只有少量样本,那么特征的信息价值就至关重要。
提前停车
Using early stopping
在深度学习中,我们总是使用参数过多的模型:它们的自由度远远超过拟合数据潜在流形所需的最小自由度。这种过度参数化并非问题,因为你永远无法完全拟合深度学习模型。完全拟合的模型根本无法泛化。你总会在达到最小训练损失之前很久就停止训练。
在训练过程中找到达到最佳泛化效果的确切点——即欠拟合曲线和过拟合曲线之间的确切边界——是提高泛化能力最有效的方法之一。
在上一章的示例中,我们首先会训练模型比实际需要的时间更长,以便找出能够获得最佳验证指标的训练轮数,然后再用相同的轮数重新训练一个新模型。这是一种相当标准的做法。然而,它需要进行冗余操作,有时会很耗费资源。当然,你也可以在每个轮次结束时保存模型,然后在找到最佳轮次后,重用之前保存的最近一个模型。在 Keras 中,通常使用EarlyStopping回调函数来实现这一点。回调函数会在验证指标不再提升时中断训练,同时记住最佳模型状态。你将在第 7 章学习如何使用回调函数。
对模型进行正则化
Regularizing your model
正则化技术是一系列最佳实践,旨在主动限制模型完美拟合训练数据的能力,从而提升模型在验证阶段的表现。之所以称之为“正则化”,是因为它往往能使模型更简洁、更“正则化”,曲线更平滑、更“通用”——从而降低模型对训练集的依赖性,使其能够通过更精确地逼近数据的潜在流形而更好地泛化。请记住,“正则化”模型是一个需要始终遵循精确评估流程的过程。只有能够衡量泛化能力,才能真正实现泛化。
Regularization techniques are a set of best practices that actively impede the model’s ability to fit perfectly to the training data, with the goal of making the model perform better during validation. This is called “regularizing” the model because it tends to make the model simpler, more “regular(规则、规律的意思),” its curve smoother, and more “generic”—thus less specific to the training set and better able to generalize by more closely approximating the latent manifold of the data. Keep in mind that “regularizing” a model is a process that should always be guided by an accurate evaluation procedure. You will only achieve generalization if you can measure it.
让我们回顾一些最常见的正则化技术,并在实践中应用它们来改进第 4 章中的电影分类模型。
缩小网络规模
Reducing the network’s size
你已经了解到,模型规模过小不会导致过拟合。缓解过拟合最简单的方法是减小模型规模(模型中可学习参数的数量,由层数和每层单元数决定)。如果模型的记忆资源有限,它就无法简单地记住训练数据。为了最小化损失,它必须学习对目标具有预测能力的压缩表示——这正是我们感兴趣的表示类型。同时,请记住,你应该使用参数量足够的模型,以避免欠拟合:你的模型不应该因为缺乏记忆资源而无法充分发挥其潜力。我们需要在模型 容量过大和容量不足之间找到一个平衡点。
遗憾的是,并没有神奇的公式可以确定合适的层数或每层的合适大小。您必须评估一系列不同的架构(当然,是在验证集上,而不是测试集上),才能找到适合您数据的正确模型大小。寻找合适模型大小的一般流程是:从相对较少的层数和参数开始,然后增加层的大小或添加新层,直到验证损失不再增加为止。
我们来用电影评论分类模型试试这个方法。这是第四章中模型的简化版本。
1 | from keras.datasets import imdb |
清单 5.9:原模型
现在我们来尝试用这个更小的型号替换它。
1 | model = keras.Sequential( |
清单 5.10:容量较低的型号版本
图 5.18 显示了原始模型和较小模型的验证损失的比较。
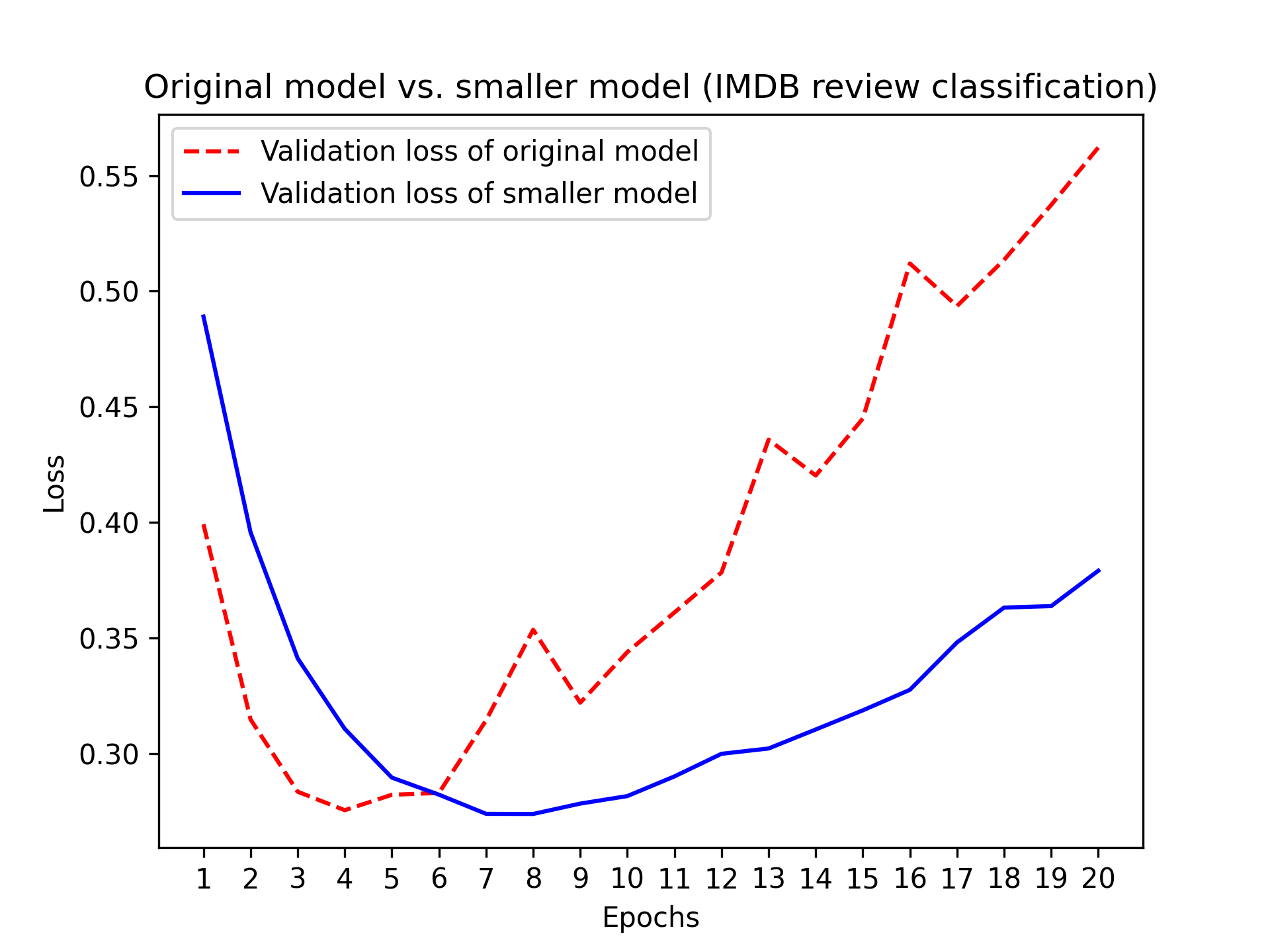
正如你所看到的,较小的模型比参考模型更晚开始过拟合(在六个 epoch 之后而不是四个 epoch 之后),而且一旦开始过拟合,其性能下降的速度也更慢。
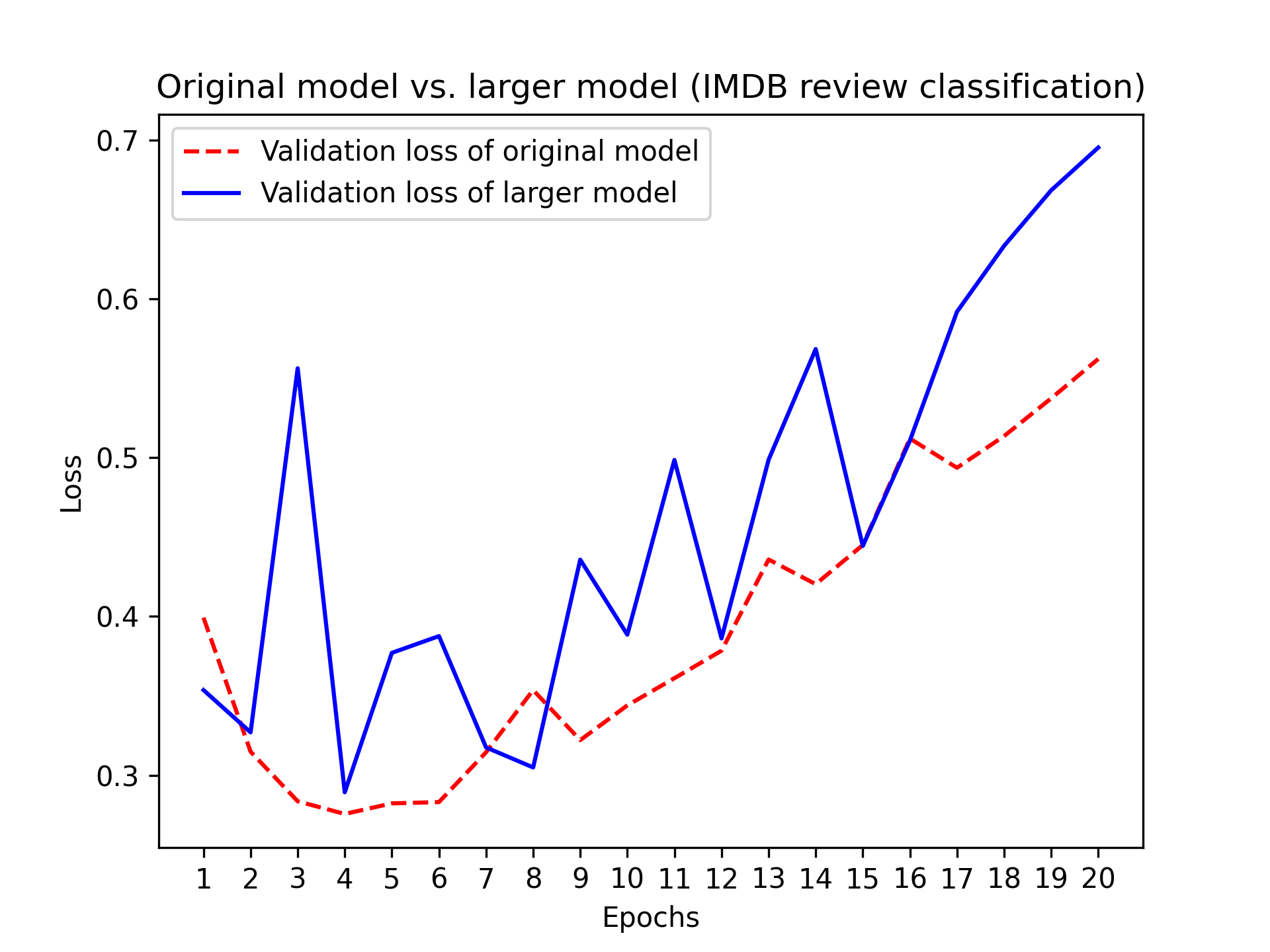
现在,让我们在基准测试中加入一个容量更大的模型——远远超过问题所需的容量。
1 | model = keras.Sequential( |
清单 5.11:容量更高的型号版本
图 5.19 展示了规模更大的模型与参考模型相比的表现。规模更大的模型几乎立即开始过拟合,仅经过一个 epoch 后就出现了过拟合现象,而且过拟合程度更严重。其验证损失也更加嘈杂。训练损失很快就接近于零。模型容量越大,对训练数据的建模速度就越快(从而训练损失越低),但越容易过拟合(导致训练损失和验证损失之间的差异越大)。
添加权重正则化
Adding weight regularization
你可能熟悉奥卡姆剃刀原理:对于同一事物的两种解释,最有可能正确的解释是最简单的那一种——即假设最少的那一种。(the principle of Occam’s razor: given two explanations for something, the explanation most likely to be correct is the simplest one—the one that makes fewer assumptions. )这个原理同样适用于神经网络学习到的模型:给定一些训练数据和网络架构,多组权重值(多个模型)都可以解释这些数据。与复杂的模型相比,简单的模型更不容易过拟合。
在这种情况下,简单模型指的是参数值分布熵较小的模型(或者如上一节所述,参数较少的模型)。因此,缓解过拟合的常用方法是限制模型的复杂度,强制其权重只能取较小的值,从而使权重值的分布更加规则。这称为权重正则化,其实现方式是在模型的损失函数中添加一个与大权重相关的代价。该代价有两种形式:
- L1 正则化——增加的成本与权重系数的绝对值(权重的L1 范数) 成正比。
- L2 正则化——增加的代价与权重系数的平方成正比(权重的L2 范数)。在神经网络中,L2 正则化也称为权重衰减。不要被不同的名称所迷惑:权重衰减在数学上与 L2 正则化是相同的。
在 Keras 中,可以通过将权重正则化器 实例作为关键字参数传递给层来添加权重正则化。让我们为电影评论分类模型添加 L2 权重正则化。
1 | from keras.regularizers import l2 |
清单 5.12:向模型添加 L2 权重正则化
l2(0.002)这意味着层权重矩阵中的每个系数都会增加 0.002 * weight_coefficient_value ** 2模型的总损失。请注意,由于此惩罚项仅在训练时添加,因此该模型在训练时的损失将远高于测试时的损失。
图 5.20 显示了 L2 正则化惩罚的效果。如图所示,即使两个模型具有相同数量的参数,采用 L2 正则化的模型也比参考模型更能抵抗过拟合:参见图 5.20:
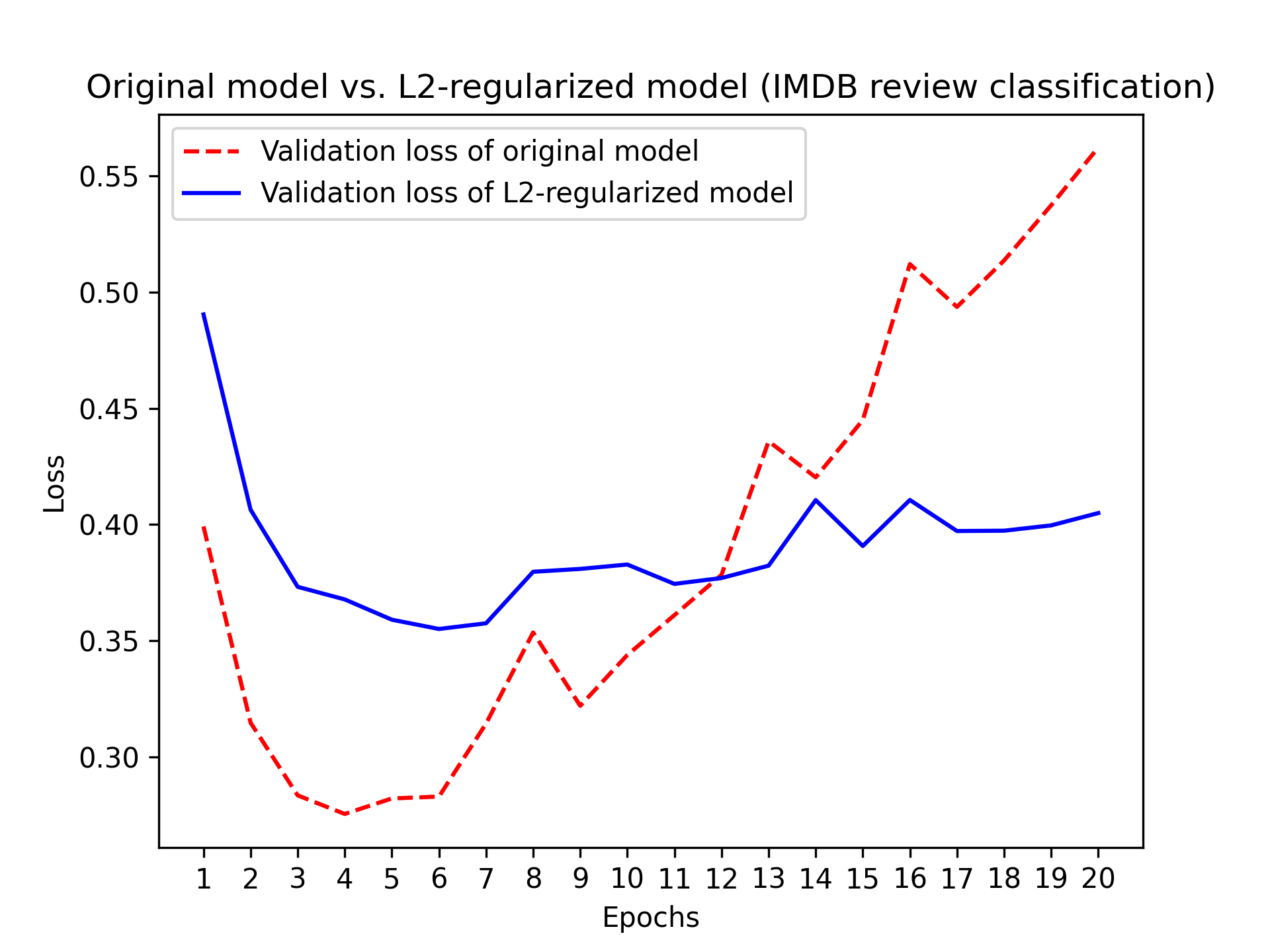
除了 L2 正则化之外,您还可以使用以下 Keras 权重正则化器之一。
1 | from keras import regularizers |
清单 5.13:Keras 中提供的不同重量调节器
需要注意的是,权重正则化通常用于较小的深度学习模型。大型深度学习模型往往参数过多,因此对权重值施加约束对模型容量和泛化能力的影响不大。在这种情况下,更推荐使用另一种正则化技术:dropout。
添加 Dropout
Adding dropout
Dropout由多伦多大学的 Geoff Hinton 及其学生开发,是神经网络中最有效、最常用的正则化技术之一。Dropout 应用于神经网络层时,会在训练过程中随机丢弃(置零)该层的部分输出特征。假设一个层[0.2, 0.5, 1.3, 0.8, 1.1]在训练过程中通常会为给定的输入样本返回一个向量。应用 Dropout 后,该向量中会随机分布一些零值,例如:[0, 0.5, 1.3, 0, 1.1]。Dropout 率是指被置零的特征比例,通常设置在 0.2 到 0.5 之间。在测试阶段,不会丢弃任何单元;相反,该层的输出值会按 Dropout 率进行缩放,以平衡测试阶段比训练阶段更多的单元。
layer_output考虑一个形状为 的NumPy 矩阵,其中包含某一层的输出(batch_size, features)。在训练时,我们会随机将矩阵中的一部分值置零:
1 | # At training time, drops out 50% of the units in the output |
在测试阶段,我们将输出结果按丢包率进行缩减。这里,我们缩减 0.5 倍(因为我们之前已经丢弃了一半的单元):
1 | # At test time |
请注意,该过程可以通过在训练时执行这两个操作,并在测试时保持输出不变来实现,这通常是实践中实现的方式(参见图 5.21):
1 | # At training time |
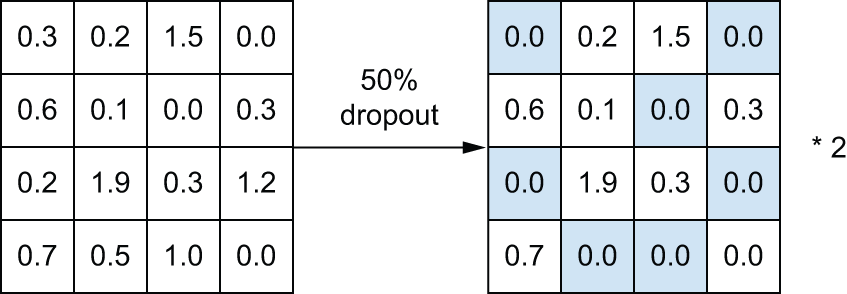
这种方法看起来可能很奇怪,也很随意。为什么它有助于减少过拟合呢?辛顿说,他的灵感来源之一是银行使用的一种防欺诈机制:
我去银行。柜员总是换来换去,我问其中一个为什么。他说他也不知道,但确实经常调来调去。我猜想,这肯定是因为要成功诈骗银行需要员工之间合作。这让我意识到,在每个样本中随机移除一部分神经元可以防止串谋,从而减少过拟合。
核心思想是,在层的输出值中引入噪声可以打破不重要的偶然模式(Hinton 称之为阴谋),如果没有噪声,模型就会开始记住这些模式。
在 Keras 中,你可以通过 dropout 层在模型中引入 dropout Dropout,dropout 会应用于它前面一层的输出。让我们Dropout 在 IMDB 模型中添加两个 dropout 层,看看它们在减少过拟合方面效果如何。
1 | model = keras.Sequential( |
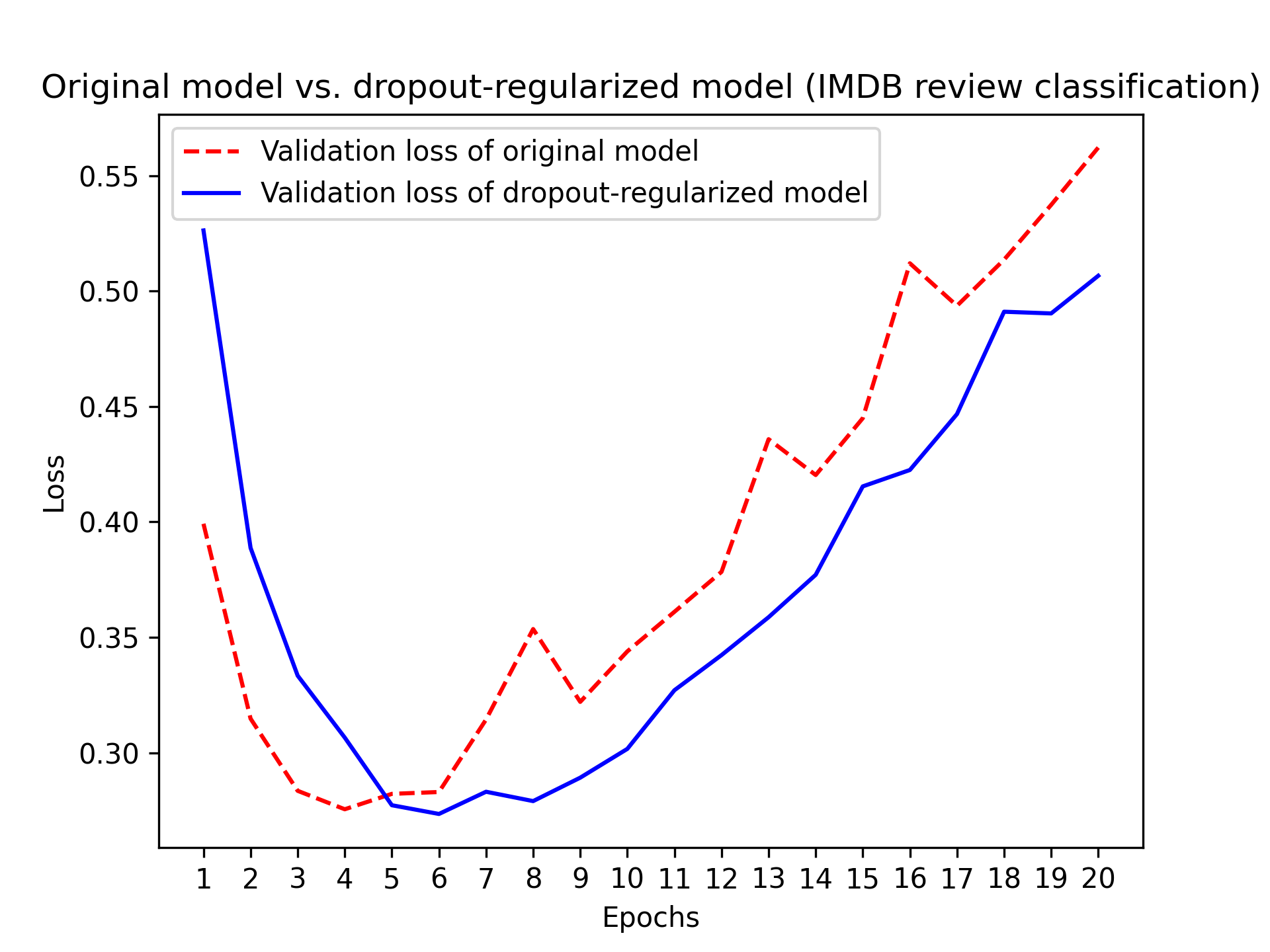
清单 5.14:向 IMDB 模型添加 dropout
图 5.22 显示了结果图。与参考模型相比,这是一个明显的改进。而且,由于达到的最低验证损失有所降低,它似乎也比 L2 正则化效果更好:
总而言之,以下是提高神经网络泛化能力和防止过拟合的最常用方法:
- 获取更多训练数据或更好的训练数据
- 开发更好的功能
- 降低模型容量
- 添加权重正则化(针对较小模型)
- 添加 Dropout
概括
- 机器学习模型的目的是泛化:即对从未见过的输入也能做出准确的预测。这比看起来要难得多。
- 深度神经网络通过学习一个参数模型来实现泛化能力,该模型能够成功地在训练样本之间进行插值。可以说,这样的模型已经学习了训练数据的潜在流形。这就是为什么深度学习模型只能理解与训练过程中所见数据非常接近的输入数据的原因。
- 机器学习的根本问题在于 优化与泛化之间的矛盾:为了实现泛化,首先必须使模型很好地拟合训练数据,但随着时间的推移,不断提升模型对训练数据的拟合度必然会损害其泛化能力。所有深度学习的最佳实践都旨在解决这一矛盾。
- 深度学习模型的泛化能力源于它们能够学习近似其数据的潜在流形,从而可以通过插值理解新的输入。
- 在模型开发过程中,准确评估其泛化能力至关重要。您可以使用多种评估方法,从简单的留出验证到 K 折交叉验证,再到带随机打乱的迭代 K 折交叉验证。请务必保留一个完全独立的测试集用于最终模型评估,因为验证数据中的信息可能已经泄露到模型中。
- 当你开始构建模型时,你的首要目标是获得一个具有一定泛化能力且能够过拟合的模型。实现这一目标的最佳实践包括调整学习率和批次大小、使用更好的架构先验信息、增加模型容量,或者简单地延长训练时间。
- 当模型开始过拟合时,你的目标就应该转向通过模型正则化来提升泛化能力。你可以降低模型容量、添加 dropout 或权重正则化,以及使用早停法。当然,更大或更好的数据集始终是提升模型泛化能力的最佳途径。
脚注
- 马克·吐温甚至称之为“人类已知的最美味的水果”。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论