《DEEP LEARNING with Python》第一章 什么是深度学习?
第一章 什么是深度学习?
本章内容
- 基本概念的高级定义
- 对机器学习原理的浅显介绍
- 深度学习日益普及及其未来潜力
过去十年,人工智能(AI)一直是媒体热议的话题。机器学习、深度学习和人工智能频频出现在无数文章中,甚至在科技类刊物之外也屡见不鲜。我们被许诺一个充满智能聊天机器人、自动驾驶汽车和虚拟助手的未来——这个未来有时被描绘得阴暗,有时又被描绘成乌托邦,人类工作岗位将变得稀少,大部分经济活动将由机器人或人工智能代理完成。对于机器学习从业者而言,能够在纷繁的信息中识别出真正有价值的信号至关重要,这样才能区分真正具有变革意义的进展和过度炒作的新闻稿。我们的未来岌岌可危,而你也将在其中扮演积极的角色:读完本书后,你将成为开发这些人工智能系统的一员。那么,让我们来探讨以下问题:深度学习迄今为止取得了哪些成就?它的意义有多重大?我们未来的发展方向是什么?你是否应该相信这些炒作?
人工智能、机器学习和深度学习
Artificial intelligence, machine learning, and deep learning
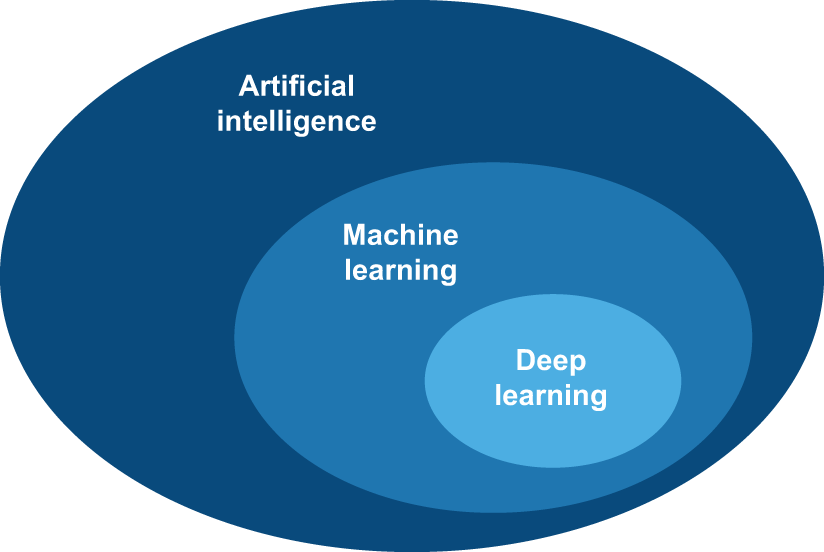
首先,我们需要明确定义我们提到人工智能时究竟在谈论什么。什么是人工智能、机器学习和深度学习(图 1.1)?它们之间有何关系?
人工智能
Artificial intelligence
人工智能诞生于 20 世纪 50 年代,当时计算机科学这个新兴领域的一些先驱者开始探讨计算机是否可以“思考”——这个问题的影响我们今天仍在探索。
虽然许多基本理念在之前的数年甚至数十年里一直在酝酿,但“人工智能”最终在 1956 年成为一个研究领域。当时,达特茅斯学院(Dartmouth College)年轻的数学助理教授约翰·麦卡锡组织了一个暑期研讨会,其提案如下:
这项研究基于这样的假设:学习的各个方面或任何其他智能特征,原则上都可以被精确描述,从而制造出能够模拟它的机器。我们将尝试探索如何让机器使用语言、形成抽象概念、解决目前只有人类才能解决的问题,以及自我改进。我们认为,如果精心挑选一组科学家,利用一个暑假的时间共同研究这些问题,就能在其中一个或多个方面取得重大进展。
夏季结束时,研讨会圆满结束,但它并未完全解开最初设定的谜题。尽管如此,许多后来成为该领域先驱的人都参加了此次研讨会,它也开启了一场至今仍在持续的学术革命。
简而言之,人工智能可以被描述为 自动化通常由人类执行的智力任务的努力(the effort to automate intellectual tasks normally performed by humans.)。因此,人工智能是一个涵盖机器学习和深度学习的通用领域,但也包括许多其他可能不涉及学习的方法。想想看,直到20世纪80年代,大多数人工智能教科书根本没有提到“学习”!例如,早期的国际象棋程序只涉及程序员编写的硬编码规则,并不属于机器学习的范畴。事实上,在相当长的一段时间里,大多数专家认为,通过让程序员手工编写足够多的显式规则来操作存储在显式数据库中的知识,就可以实现人类水平的人工智能。这种方法被称为符号人工智能(symbolic AI)。从20世纪50年代到80年代末,它是人工智能领域的主流范式(dominant paradigm),并在80年代专家系统(expert systems)蓬勃发展时期达到了鼎盛。
尽管符号人工智能已被证明适用于解决定义明确、逻辑清晰的问题,例如下棋,但它却难以找到解决更复杂、模糊问题的明确规则,例如图像分类、语音识别或自然语言翻译。一种新的方法应运而生,取代了符号人工智能:机器学习。
机器学习
Machine learning
在维多利亚时代的英国,艾达·洛夫莱斯夫人是查尔斯·巴贝奇的朋友和合作伙伴,巴贝奇是分析机的发明者,也是已知的第一台通用机械计算机。尽管分析机极具远见卓识,远远超越了时代,但它在19世纪30年代和40年代设计之初并非作为一台通用计算机,因为当时通用计算的概念尚未出现。它仅仅是利用机械操作来自动化数学分析领域的某些计算——因此得名“分析机”。从这个意义上讲,它是早期尝试用齿轮形式编码数学运算的理论的继承者,例如帕斯卡计算器,或是莱布尼茨的步进计算器(帕斯卡计算器的改进版)。帕斯卡计算器由布莱兹·帕斯卡于1642年设计(当时他年仅19岁!),是世界上第一台机械计算器——它可以进行加、减、乘、除运算。
1843年,艾达·洛芙莱斯对分析机的发明发表了评论:
分析机没有任何创造的野心。它只能执行我们知道如何命令它执行的任何操作……它的作用是帮助我们利用我们已经熟悉的事物。
即使隔了182年的历史,洛夫莱斯夫人的观察依然引人深思。通用计算机能否“创造”任何东西?或者它是否永远只能机械地执行我们人类完全理解的流程?它能否拥有任何原创思维?它能否从经验中学习(Could it learn from experience)?它能否展现创造力?
人工智能先驱艾伦·图灵后来在其 1950 年的里程碑式论文《计算机器与智能》中引用了她的这番话,称之为“洛夫莱斯夫人的反对意见”。 [1]它引入了图灵测试[2]以及后来塑造人工智能的关键概念。图灵当时的观点——在当时极具争议性——是,原则上可以使计算机模拟人类智能的各个方面。
通常情况下,让计算机完成有用工作的方法是让程序员编写规则——也就是计算机程序——按照这些规则将输入数据转换成相应的答案,就像洛夫莱斯夫人为分析机编写逐步指令一样。机器学习则反其道而行之:机器会查看输入数据和相应的答案,并自行推断出应该遵循的规则(图 1.2)。
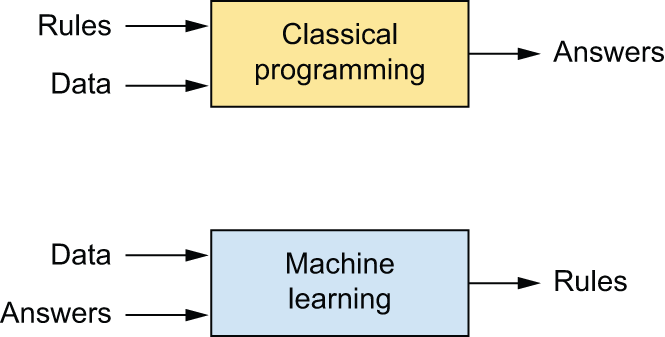
机器学习系统是通过训练而非显式编程实现的。它会被输入大量与特定任务相关的示例,并从中发现统计结构,最终形成自动化任务的规则。例如,如果您希望自动化标记度假照片,您可以向机器学习系统提供许多已由人工标记的照片示例,系统将学习统计规则,从而将特定照片与特定标签(例如“风景”或“食物”)关联起来。
尽管机器学习直到 20 世纪 90 年代才开始蓬勃发展,但它已迅速成为人工智能领域最流行、最成功的子领域,这主要得益于更快的硬件和更大的数据集的出现。机器学习与数理统计相关,但在几个重要方面与统计学有所不同——正如医学与化学相关,但不能被简化为化学一样,因为医学处理的是自身独特的系统及其独特的属性。与统计学不同,机器学习通常处理大型、复杂的数据集(例如包含数百万张图像,每张图像又由数万个像素组成的数据集),而传统的统计分析方法(例如贝叶斯分析)对这类数据集并不适用。因此,机器学习,尤其是深度学习,其数学理论相对较少——或许少得可怜——本质上是一门工程学科。与理论物理或数学不同,机器学习是一个非常注重实践的领域,它由经验发现驱动,并高度依赖于软件和硬件的进步。
从数据中学习规则和表示
Learning rules and representations from data
要定义深度学习并理解它与其他机器学习方法的区别,首先我们需要了解机器学习算法的工作原理。我们刚才提到,机器学习通过给定预期结果的示例,发现执行数据处理任务的规则。因此,要进行机器学习,我们需要三样东西:
输入数据点 ——例如,如果任务是语音识别,这些数据点可以是人说话的音频文件。如果任务是图像标注,它们可以是图片。
预期输出示例 ——在语音识别任务中,这些可以是人工生成的音频文件转录文本。在图像识别任务中,预期输出可以是诸如“狗”、“猫”等标签。
衡量算法性能是否良好的方法 ——这对于确定算法当前输出与其预期输出之间的差距至关重要。该测量结果用作反馈信号,以调整算法的运行方式。我们称这种调整步骤为“学习”(This adjustment step is what we call learning)。
机器学习模型将输入数据转化为有意义的输出,这一过程是通过接触已知的输入输出示例而“学习”的。因此,机器学习和深度学习的核心问题在于如何有效地转换数据:换句话说,就是学习当前输入数据的有用表示——这些表示能够帮助我们更接近预期的输出(to learn useful representations of the input data at hand—representations that get us closer to the expected output)。
在深入探讨之前,我们先来了解一下什么是表示。从本质上讲,表示是一种不同的数据呈现方式,用于表示或编码数据。例如,一张彩色图像可以用 RGB 格式(红-绿-蓝)或 HSV 格式(色调-饱和度-亮度)进行编码:这两种表示方式都代表了同一数据的不同形式。有些任务用一种表示方式可能比较困难,但用另一种表示方式则可能变得容易。例如,“选择图像中所有红色像素”的任务用 RGB 格式更容易完成,而“降低图像饱和度”的任务用 HSV 格式则更容易完成。机器学习模型的核心在于找到适合其输入数据的表示方式——对数据进行转换,使其更适合当前的任务。
让我们具体说明一下。考虑一个 x 轴、一个 y 轴,以及一些用 (x, y) 坐标系中的坐标表示的点,如图 1.3 所示。
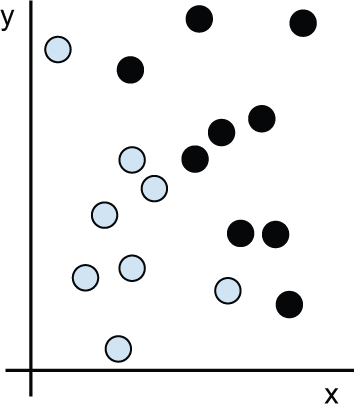
正如你所看到的,我们有一些白点和一些黑点。假设我们想要开发一个算法,该算法可以接收一个点的 (x, y) 坐标,并输出该点可能是黑色还是白色。在这种情况下,
输入数据是各点的坐标。
预期输出结果就是我们点的颜色。
例如,衡量我们的算法是否表现良好的一个方法是,计算正确分类的点的百分比。
我们需要一种新的数据表示方法,能够清晰地区分白点和黑点。除了其他多种方法外,我们还可以使用坐标变换,如图 1.4 所示。
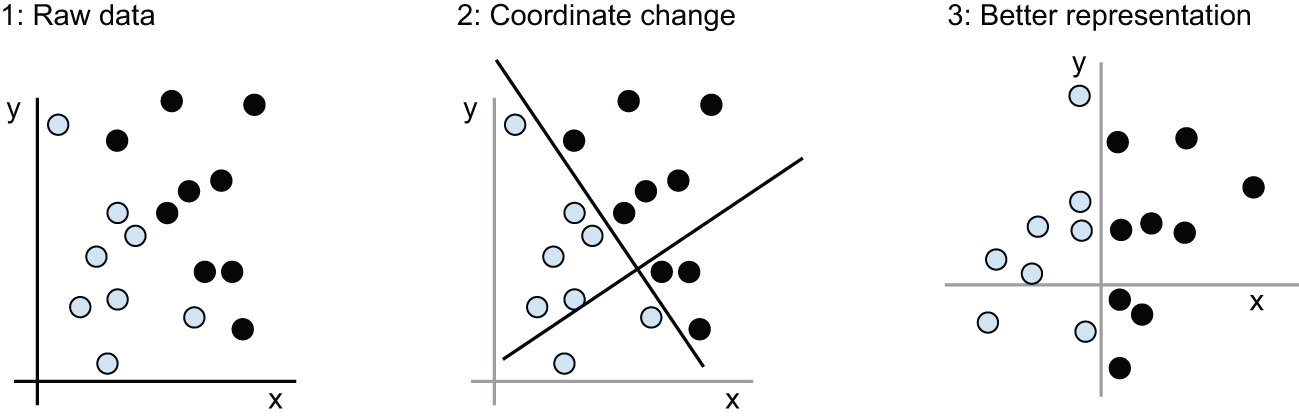
在这个新的坐标系中,我们可以说这些点的坐标代表了我们数据的一种新的表示形式。而且这种表示形式非常有效!有了这种表示形式,黑白分类问题就可以简化为一条简单的规则:“黑点满足 x > 0”,或者“白点满足 x < 0”。这种新的表示形式,结合这条简单的规则,就能巧妙地解决分类问题。
在这种情况下,我们手动定义了坐标变换:我们运用人类的智慧,找到了适合我们数据表示的方法。对于这样一个极其简单的问题,这当然没问题,但如果任务是对手写数字的图像进行分类,你还能做到吗?你能否写出明确的、计算机可执行的图像变换,来区分各种不同笔迹中的6和8、1和7?
这在某种程度上是可行的。基于数字表示的规则,例如“计算闭合环的数量”或垂直和水平像素直方图,可以很好地区分手写数字。但是,手动找到这些有效的表示方法非常困难,而且可以想象,由此产生的基于规则的系统会非常脆弱,维护起来也极其麻烦。每当遇到新的手写示例,打破你精心设计的规则时,你都必须添加新的数据转换和新规则,同时还要考虑它们与之前所有规则的交互作用。
你可能在想,如果这个过程如此繁琐,我们能否将其自动化?如果我们尝试系统地搜索不同的数据自动生成表示及其规则集,并以某个开发数据集中数字正确分类的百分比作为反馈来识别有效的表示,结果会如何?这样我们就实现了机器学习。在机器学习的语境下,“学习”指的是在反馈信号的引导下,自动搜索能够生成有用数据表示的数据转换过程——这些表示能够用更简单的规则来解决当前任务。
这些变换可以是坐标变换(例如我们二维坐标分类示例中的变换),也可以是像素直方图和计数循环(例如我们数字分类示例中的变换),还可以是线性投影、平移和非线性运算(例如“选择所有 x > 0 的点”),等等。机器学习算法通常不会主动寻找这些变换;它们只是在预定义的运算集合(称为假设空间)中进行搜索。例如,所有可能的坐标变换构成的空间就是我们二维坐标分类示例中的假设空间(hypothesis space)。
简而言之,这就是机器学习:在预定义的可能性空间内,利用反馈信号的指导,寻找输入数据的有效表示和规则。这个简单的理念使我们能够解决范围极其广泛的智能任务,从自动驾驶到自然语言问答,无所不包。
既然你已经了解了我们所说的“学习”是什么意思,那么让我们来看看深度学习的独特之处。
“深度学习”中的“深”
The “deep” in “deep learning”
深度学习是机器学习的一个特定子领域;它是一种从数据中学习表征(representations)的新方法,强调学习层层递进、意义日益丰富的表征。“深度学习”中的“深度”并非指该方法能够获得更深层次的理解,而是指这种层层递进的表征理念。构成数据模型的层数被称为模型的深度。该领域的其他名称可以是分层表征学习(layered representations learnin)或 层次表征学习(hierarchical representations learning)。现代深度学习通常涉及数十甚至数百层连续的表征,这些表征都是通过训练数据自动学习的。与此同时,其他机器学习方法往往只专注于学习数据的一层或两层表征(例如,获取像素直方图并应用分类规则);因此,它们有时被称为浅层学习(shallow learning)。
在深度学习中,这些分层表征是通过称为神经网络的模型来学习的,神经网络的结构就像一个个层层堆叠的图层。神经网络这个术语源于神经生物学,但尽管深度学习的一些核心概念部分借鉴了我们对大脑(特别是视觉皮层)的理解,深度学习模型并非大脑的模型。没有任何证据表明大脑实现了类似于现代深度学习模型中使用的学习机制。你可能会看到一些科普文章宣称深度学习的工作原理类似于大脑,或者说它是模仿大脑构建的,但事实并非如此。对于该领域的新手来说,如果认为深度学习与神经生物学有任何关联,将会造成困惑且适得其反;你不需要那种“就像我们的大脑一样”的神秘感,也完全可以忘记你可能读到过的任何关于深度学习与生物学之间假设联系的说法。就我们的目的而言,深度学习是一个用于从数据中学习表征的数学框架。
深度学习算法学习到的表征是什么样的?让我们来看一下一个多层网络(见图 1.5)如何转换数字图像以识别它是哪个数字。
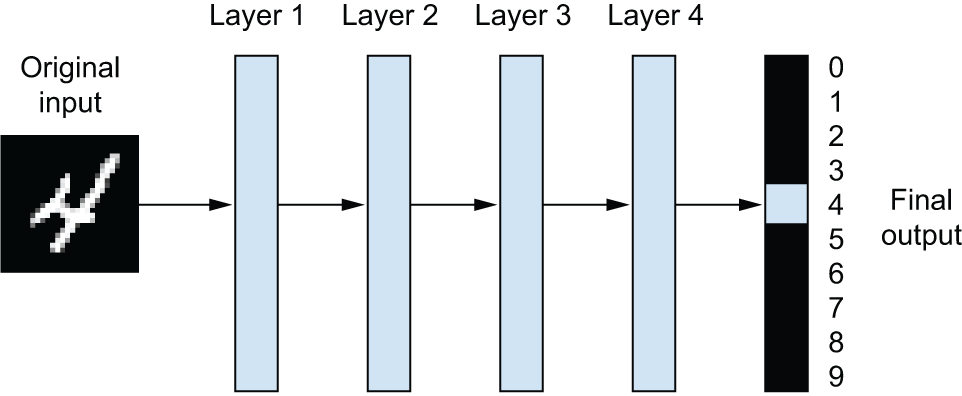
如图 1.6 所示,该网络将数字图像转换为与原始图像差异越来越大、信息量越来越大的表示形式,这些表示形式能够越来越清晰地反映最终结果。您可以将深度网络视为一个多阶段的信息提炼 过程,信息经过一系列过滤器的过滤,最终得到越来越纯净的信息(即,对于特定任务而言非常有用的信息)。
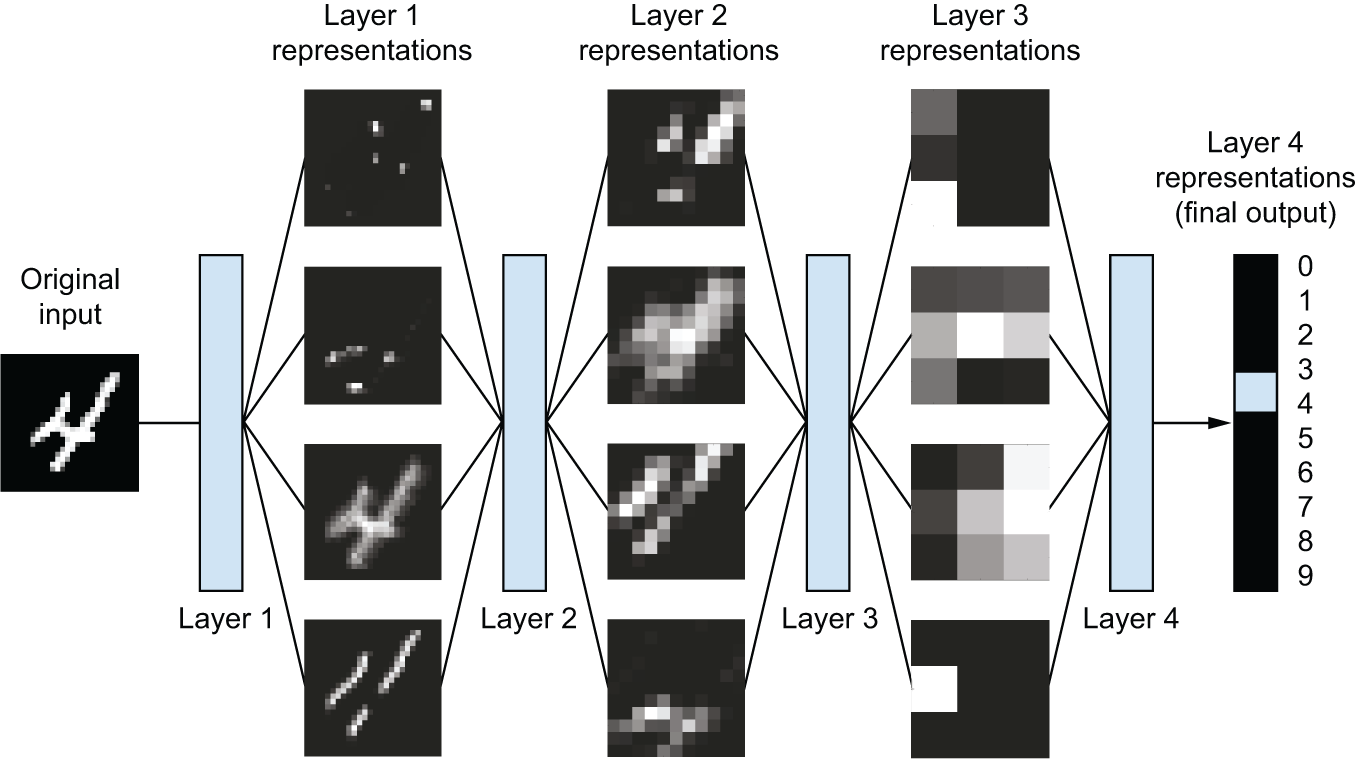
从技术上讲,深度学习就是一个多阶段的数据表征学习方法。它的概念很简单,但事实证明,只要规模足够大,非常简单的机制最终也能产生神奇的效果。
三图解读深度学习的工作原理
Understanding how deep learning works, in three figures
至此,您应该已经了解机器学习的核心在于将输入(例如图像)映射到目标(例如标签“猫”),而这需要观察大量的输入和目标示例。您也应该知道,深度神经网络通过一系列简单的数据转换(层)来实现这种输入到目标的映射,而这些数据转换则是通过接触示例来学习的。现在,让我们具体地看看这种学习是如何发生的。
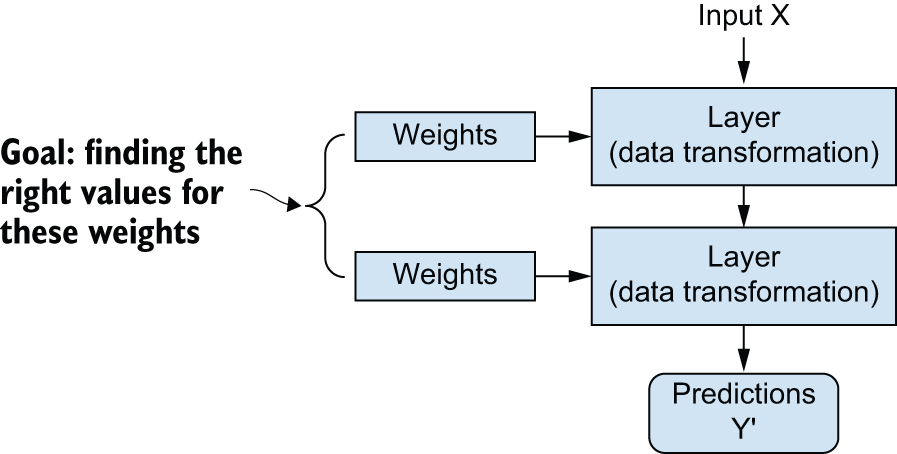
每一层如何处理输入数据的具体规则都存储在该层的权重中,权重本质上是一串数字。用技术术语来说,我们可以说每一层实现的变换是由其权重参数化的(参见图 1.7)。(权重有时也被称为层的参数。)在这种情况下,学习意味着找到网络中所有层的权重值,使得网络能够正确地将示例输入映射到其对应的目标值。但问题在于:一个深度神经网络可能包含数千万个参数。找到所有参数的正确值似乎是一项艰巨的任务,尤其考虑到修改一个参数的值会影响所有其他参数的行为!
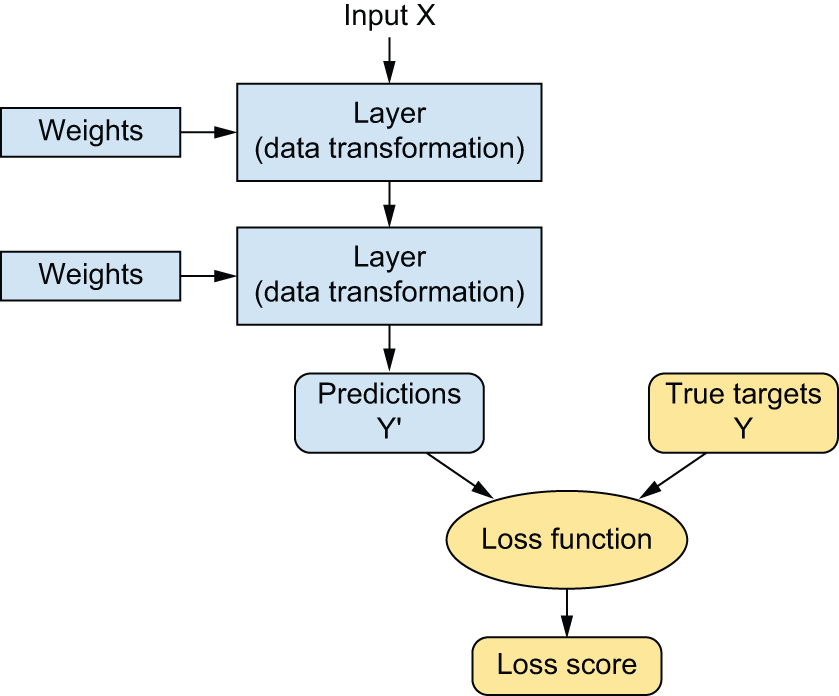
要控制某个事物,首先需要能够观察它。要控制神经网络的输出,需要能够衡量该输出与预期结果之间的差距。这正是网络 损失函数的作用,损失函数有时也称为目标函数或成本函数。损失函数将网络的预测结果与真实目标值(即你希望网络输出的结果)进行比较,计算出一个距离分数,以此来衡量网络在该特定示例中的表现(参见图 1.8)。
深度学习的基本技巧是利用这个分数作为反馈信号,对权重进行微调,使其朝着降低当前样本损失分数的方向发展(见图 1.9)。这种调整由优化器完成,它实现了所谓的反向传播算法:这是深度学习的核心算法。下一章将更详细地解释反向传播的工作原理。
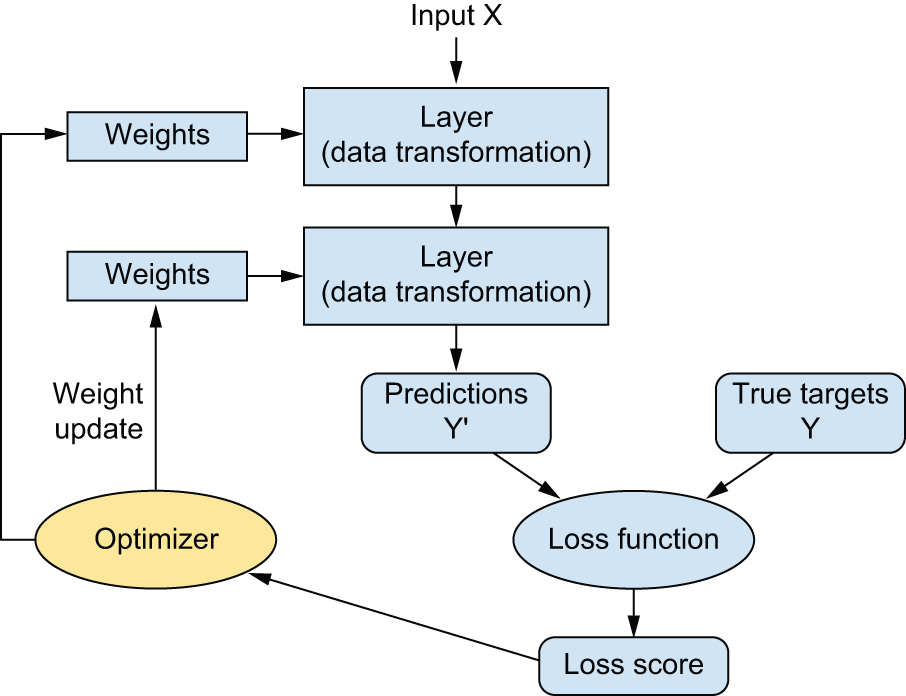
最初,网络的权重被赋予随机值,因此网络只是执行一系列随机变换。自然,其输出与理想状态相差甚远,损失值也因此非常高。但随着网络处理的每个样本,权重都会朝着正确的方向进行微调,损失值也随之降低。这就是训练循环,重复足够多次(通常是对数千个样本进行数十次迭代)后,就能得到使损失函数最小化的权重值。损失最小的网络,其输出尽可能接近目标值:这就是一个训练好的网络。再次强调,这是一个简单的机制,但一旦规模化,就会展现出神奇的效果。
深度学习有何不同之处?
What makes deep learning different
深度神经网络有什么特别之处,使其成为企业投资和研究人员蜂拥而至的“正确”方法?20年后我们还会使用深度神经网络吗?
深度学习的诸多特性足以证明其作为人工智能革命的地位,而且它将长期存在。或许几十年后我们不再使用神经网络,但无论我们使用什么技术,都将直接继承现代深度学习及其核心概念。这些重要特性大致可以分为三类:
简洁性 ——深度学习让问题解决变得更加轻松,因为它自动化了机器学习工作流程中最关键的一步:特征工程。以往的机器学习技术——浅层学习——仅涉及将输入数据转换到一到两个连续的表示空间,这对于大多数问题来说表达力不足。因此,人们必须花费大量精力来使初始输入数据更适合这些方法的处理:他们必须手动构建良好的数据表示。这被称为 特征工程。而深度学习则完全自动化了这一步骤:借助深度学习,只需一次迭代即可学习所有特征,无需手动构建。这极大地简化了机器学习工作流程,通常可以用一个简单、端到端的深度学习模型来取代复杂的多阶段流程。
可扩展性 ——深度学习非常适合在GPU或其他更专业的机器学习硬件上进行并行化,因此可以充分利用摩尔定律。此外,深度学习模型通过迭代处理小批量数据进行训练,这使得它们能够处理任意大小的数据集。(唯一的瓶颈是可用的并行计算能力,而得益于摩尔定律,这一瓶颈正在快速提升。)
多功能性和可重用性 ——与许多以往的机器学习方法不同,深度学习模型无需从头开始即可利用更多数据进行训练,使其能够进行持续的在线学习——这对于超大型生产模型而言至关重要。此外,训练好的深度学习模型可以重新用于其他用途,从而实现可重用性:这正是“基础模型”的核心理念——基于海量数据训练的大型模型,只需少量甚至无需重新训练即可应用于众多新任务。
生成式人工智能时代
The age of generative AI
如今,深度学习最广为人知的例子或许就是近期涌现的生成式人工智能应用——例如 ChatGPT、Gemini 和 Claude 等聊天机器人助手,以及 Midjourney 等图像生成服务。这些应用能够根据简单的提示生成信息丰富甚至富有创意的内容,模糊了人类创造力和机器创造力之间的界限,因此备受公众关注。
生成式人工智能由庞大的“基础模型”驱动,这些模型学习如何重构输入的文本和图像内容——例如,从噪声图像中重建清晰图像、预测句子中的下一个词等等。这意味着图 1.8 中的目标值直接来源于输入数据本身。这被称为自监督学习(self-supervised learning),它使这些模型能够利用海量的未标记数据。摒弃了以往机器学习领域中限制其发展的繁琐的手动数据标注工作,使得规模达到了前所未有的高度——一些基础模型拥有数千亿个参数,并使用超过 1 PB 的数据进行训练,耗资数千万美元。
这些基础模型就像一个模糊的人类知识数据库,无需专门的编程或重新训练,即可应用于非常广泛的领域。由于它们已经记住了大量的知识,因此只需通过提示即可解决新问题——查询它们已学习的知识表示,并返回最有可能与提示相关的输出。
生成式人工智能直到2022年才真正进入主流视野,但它其实有着悠久的历史——最早的文本生成实验可以追溯到20世纪90年代。本书第一版于2017年出版,其中就包含一个篇幅颇长的章节,题为“生成式人工智能”,探讨了当时的文本生成和图像生成技术,并提出了一个在当时看来颇为大胆的设想:不久的将来,我们所消费的大部分文化内容都将借助人工智能的力量创造出来。
深度学习迄今为止取得的成就
What deep learning has achieved so far
在过去的十年里,深度学习取得了堪称一场技术革命的成就,从 2013 年到 2017 年在感知任务上取得的显著成果开始,到 2017 年到 2022 年在自然语言处理任务上取得快速进展,最终在 2022 年至今掀起了一波变革性的生成式人工智能应用浪潮。
深度学习已经取得了重大突破,所有突破都集中在那些长期以来机器都难以解决的极具挑战性的问题上:
- ChatGPT 和 Gemini 等流畅且功能强大的聊天机器人
- GitHub Copilot 等编程助手
- 照片级真实感图像生成
- 人类水平图像分类
- 人声水平语音转录
- 人级手写转录和印刷文本转录
- 机器翻译显著改进
- 文本转语音转换效率显著提升
- 人类水平的自动驾驶技术,截至2025年,已在凤凰城、旧金山、洛杉矶和奥斯汀等城市向公众部署。
- 改进的推荐系统,例如 YouTube、Netflix 或 Spotify 使用的推荐系统。
- 超人般的围棋、象棋和扑克水平
我们仍在探索深度学习的全部潜力。我们已经开始将其成功应用于各种各样的问题,而这些问题在几年前还被认为不可能解决——例如自动转录梵蒂冈秘密档案馆中保存的数万份古代手稿,利用简单的智能手机检测和分类田间植物病害,协助肿瘤科医生或放射科医生解读医学影像数据,预测洪水、飓风甚至地震等自然灾害。随着每一个里程碑的取得,我们正一步步接近这样一个时代:深度学习将在人类活动的各个领域——科学、医学、制造业、能源、交通运输、软件开发、农业,甚至艺术创作——为我们提供帮助。
警惕短期炒作
Beware of the short-term hype
这一系列看似势不可挡的成功引发了一波强烈的炒作,其中一些说法有一定道理,但大多数不过是天方夜谭。2023年初,OpenAI发布GPT-4后不久,许多专家就声称“没人需要工作了”,大规模失业将在一年内到来,或者经济生产力将很快飙升10到100倍。当然,两年过去了,这些预言都没有实现——美国的失业率仍然很低,而生产力指标也远未达到预期的爆发式增长。但请不要误解:人工智能(尤其是生成式人工智能)的影响已经相当显著,而且增长速度惊人。截至2025年中期,生成式人工智能每年创造的收入已达数百亿美元,对于一个两年前还不存在的行业来说,这无疑是令人瞩目的成就!但这对整体经济的影响还不大,与它刚开始时我们被铺天盖地的无底线承诺相比,更是相形见绌。
尽管关于人工智能带来的失业问题和百倍生产力提升的讨论已经引发了人们的焦虑,但人工智能热潮背后还有更耸人听闻的一面。这一面宣称,人类水平的通用智能(AGI),甚至是远远超越人类能力的“超级智能”即将到来。这些说法引发的担忧远不止经济动荡——人类本身或许也面临着被我们创造的数字技术所取代的危险。
对于初涉此领域的人来说,很容易认为正是生成式人工智能的实际成功才促成了人们对通用人工智能(AGI)即将实现的信念,但事实恰恰相反。对AGI即将实现的论断先于生成式人工智能出现,并且极大地推动了其发展。早在2013年,科技精英们就担心AGI可能在几年内到来。当时,人们普遍认为,被谷歌收购的伦敦人工智能研究初创公司DeepMind正在朝着实现AGI的目标稳步前进。正是这种信念促成了OpenAI在2015年的成立,OpenAI最初的目标是成为DeepMind的开源竞争对手。OpenAI在推动生成式人工智能发展方面发挥了关键作用,因此,颇为奇特的是,正是对AGI即将实现的信念推动了生成式人工智能的崛起,而非反之。2016年,OpenAI的招聘口号是:它将在2020年实现AGI!不过公平地说,当时科技行业中只有少数人相信如此乐观的时间表。但到了2023年初,旧金山湾区相当一部分工程师似乎确信,通用人工智能(AGI)将在未来几年内实现。
对于这类说法,保持一定的怀疑态度至关重要。尽管名为“人工智能”,但如今更准确的描述应该是“认知自动化”——即对人类技能和知识的编码和运用。人工智能擅长解决需求明确或有大量精确示例可供参考的问题。它的目的是增强计算机的能力,而不是复制人类思维。
需要明确的是,认知自动化非常有用。但智能——认知自主性——则完全是另一回事。不妨这样理解:人工智能就像一个卡通人物,而智能则像一个活生生的人。卡通人物无论多么逼真,都只能按照预先设定的场景表演。而活生生的人则能够适应意料之外的情况。
你可能会问:“如果卡通画得足够逼真,场景也足够多,那又有什么区别呢?” 如果一个大型语言模型在被问到问题时能够给出足够像人类的回答,那么它是否拥有真正的认知自主性还有意义吗?关键的区别在于适应能力。智能是面对未知、适应未知并从中学习的能力。即使是最好的自动化系统,也只能处理它经过训练或预先编程的情况。这就是为什么创建强大的自动化系统如此具有挑战性——它需要考虑每一种可能的情况。
所以,不必担心人工智能会突然产生自我意识并统治人类。目前的技术发展方向并非如此。即使取得了显著进步,人工智能也仍然只是一种精密的工具,而非有感知能力的个体。这就好比指望更精准的钟表就能实现时间旅行——它们完全是两码事。
夏天可能会变成冬天
Summer can turn to winter
短期预期过高的危险在于,当技术不可避免地无法达到预期目标时,研发投入可能会枯竭,从而长期阻碍发展。这种情况以前也发生过。人工智能领域曾两次经历先是极度乐观,随后是失望和怀疑,最终导致资金匮乏的循环。这一切始于20世纪60年代的符号人工智能。在早期,人们对人工智能的期望值很高。符号人工智能方法最著名的先驱和倡导者之一是马文·明斯基,他在1967年声称:“在一代人的时间内……创造‘人工智能’的问题将得到实质性解决。”三年后,在1970年,他做出了一个更为精确的量化预测:“在三到八年内,我们将拥有一台具备普通人一般智能的机器。” 2025年,这样的成就似乎仍然遥不可及——甚至我们无法预测它需要多长时间才能实现——但在20世纪60年代和70年代初,一些专家认为它近在眼前(就像今天许多人一样)。几年后,随着这些美好的期望未能实现,研究人员和政府资金纷纷撤离该领域,标志着人工智能领域第一个“寒冬”的开始 (这里指的是核冬天,因为当时正值冷战高峰期之后不久)。
这并非最后一次。上世纪80年代,一种新的符号人工智能方法—— 专家系统——开始在大公司中兴起。一些最初的成功案例引发了一波投资热潮,世界各地的公司纷纷建立自己的内部人工智能部门来开发专家系统。大约在1985年,企业每年在这项技术上的投入超过10亿美元;但到了20世纪90年代初,这些系统被证明维护成本高昂、难以扩展且应用范围有限,人们的兴趣也随之消退。由此,人工智能的第二次寒冬开始了。我们目前可能正在经历人工智能热潮和失望的第三次周期——而我们仍然处于极度乐观的阶段。
我目前的看法是,我们不太可能看到像上世纪90年代那样对人工智能研究的全面撤退。即便真的会经历寒冬,那也应该非常温和。人工智能已经展现了其改变世界的价值。然而,2023-2024年人工智能泡沫的破裂似乎不可避免。目前,人工智能领域的投资(主要集中在数据中心和GPU)每年超过1000亿美元,而实际收入却远低于此,接近100亿美元。企业高管和投资者现在评判人工智能的标准并非它已经取得的成就,而是它未来可能实现的功能——其中许多功能将长期超出现有技术的范畴。某种局面终将改变。但人工智能泡沫破裂后究竟会发生什么,目前仍是未知数。
人工智能的前景
The promise of AI
尽管我们可能对人工智能的短期发展抱有不切实际的期望,但从长远来看,前景一片光明。我们才刚刚开始将深度学习应用于许多重要问题,而它有望带来变革性的影响,从医疗诊断到数字助理,无所不包。
2017年,我在这本书里写道:
现在,人工智能或许难以想象它会对我们的世界产生如此巨大的影响,因为它尚未得到广泛应用——就像1995年人们难以相信互联网未来的影响一样。当时,大多数人看不到互联网与自身有何关联,也无法预见它将如何改变他们的生活。如今,深度学习和人工智能也面临着同样的困境。但毋庸置疑,人工智能时代即将到来。在不久的将来,人工智能将成为你的助手,甚至是你的朋友;它将回答你的问题,帮助你的孩子学习,守护你的健康。它将为你送货上门,并为你提供出行服务。它将成为你与日益复杂且信息密集型世界交互的界面。更重要的是,人工智能将助力全人类进步,它将帮助人类科学家在从基因组学到数学等各个科学领域取得突破性发现。
快进到 2025 年,这些事情大多已经实现或即将实现——而这仅仅是个开始:
- 数以千万计的人每天都在使用ChatGPT、Gemini和Claude等AI聊天机器人作为助手。事实上,问答和“辅导孩子”(作业辅导)已成为这些聊天机器人最热门的应用!对许多人来说,人工智能已经成为获取世界信息的首选界面。
- 成千上万的人通过 Character.ai 等应用程序与人工智能“朋友”互动。
- 在凤凰城、旧金山、洛杉矶和奥斯汀等城市,全自动驾驶技术已经大规模部署。
- 人工智能正在为加速科学发展做出重大贡献。DeepMind 公司的 AlphaFold 模型正帮助生物学家以前所未有的精度预测蛋白质结构。著名数学家陶哲轩认为,到 2026 年左右,如果使用得当,人工智能有望成为数学研究和其他领域中可靠的合作者。
人工智能革命,曾经遥不可及的愿景,如今正迅速在我们眼前展开。在此过程中,我们或许会遭遇一些挫折——就像互联网行业在1998-1999年被过度炒作,随后遭遇崩盘,导致21世纪初投资锐减一样。但我们终将抵达目标。人工智能最终将像今天的互联网一样,应用于构成我们社会和日常生活的几乎所有环节。
不要被短期炒作所迷惑,但要相信长远愿景。人工智能要发挥其真正的潜力或许还需要一段时间——这种潜力之大,至今无人敢奢望——但人工智能终将到来,它将以一种奇妙的方式改变我们的世界。
脚注
- A.M.图灵,《计算机器与智能》,《心灵》59卷,第236期(1950年):433-460页。
- 尽管图灵测试有时被解读为一种字面意义上的测试——这也是人工智能领域应该努力达到的目标——但图灵最初只是将其作为哲学讨论中关于认知本质的一种概念工具。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论