《DEEP LEARNING with Python》第二章 神经网络的数学基础
第二章 神经网络的数学基础
The mathematical building blocks of neural networks
运行代码
本章内容
- 神经网络的第一个例子
- 张量和张量运算( Tensors and tensor operations)
- 神经网络如何通过反向传播和梯度下降进行学习
理解深度学习需要熟悉许多简单的数学概念:张量、张量运算、微分、梯度下降(tensors, tensor operations, differentiation, gradient descent)等等。本章的目标是在不涉及过多技术细节的情况下,帮助你建立对这些概念的直觉。特别是,我们将避免使用数学符号,因为这些符号可能会给没有数学基础的人造成不必要的障碍,而且对于清晰地解释概念也并非必要。对数学运算最精确、最明确的描述就是它的可执行代码。
为了充分理解张量和梯度下降的概念,本章将以一个神经网络的实际例子作为开篇。然后,我们将逐一讲解引入的每一个新概念。请记住,这些概念对于理解后续章节中的实际例子至关重要!
读完本章后,你将对深度学习背后的数学理论有一个直观的理解,并准备好在第 3 章中开始深入学习现代深度学习框架。
运行本书中的代码
本书包含大量可运行的 Python 代码。每一章都配有一个 Jupyter Notebook,其中包含了本章的所有代码。Jupyter Notebook 就像一个实时 Python 代码草稿本,您可以在其中交互式地运行代码、绘制数据图表、查看图像等等。如果您在阅读的同时运行并尝试书中的代码,将会获得更多实用的知识。
目前为止,搭建深度学习环境来运行这些笔记本最简单的方法是使用Google Colaboratory(简称 Colab),它是一个托管的 Jupyter Notebook 环境,已成为机器学习从业者的行业标准。借助 Colab,您可以在浏览器中交互式地运行本书的代码,并连接到具有可配置硬件的云运行时。默认情况下,本书中的笔记本将在 Colab 的免费 GPU 运行时上运行。
如果您愿意,也可以在本地计算机上运行这些笔记本。建议使用 GPU,尤其是在本书后面学习更大规模、计算密集型模型时。
本地运行和在 Colab 上运行的说明以及代码可以在https://github.com/fchollet/deep-learning-with-python-notebooks找到。
神经网络初探
A first look at a neural network
让我们来看一个具体的例子,这个神经网络使用机器学习库Keras来学习对手写数字进行分类。本书将大量使用 Keras。它是一个简单易用的高级库,可以帮助我们专注于想要讲解的概念。
除非您已经熟悉 Keras 或类似的库,否则您可能无法立即完全理解这个示例。没关系。在接下来的几个章节中,我们将逐一回顾示例中的每个元素并进行详细解释。所以,即使某些步骤看起来有些随意或像魔法一样,也不用担心!万事开头难。
我们在这里要解决的问题是将手写数字的灰度图像(28 × 28 像素)分类到 10 个类别(0 到 9)中。我们将使用 MNIST 数据集,它是机器学习领域的经典数据集,几乎与机器学习领域本身一样古老,并已被广泛研究。MNIST 数据集包含 60,000 张训练图像和 10,000 张测试图像,由美国国家标准与技术研究院(MNIST 中的 NIST)在 20 世纪 80 年代收集。您可以将“解决”MNIST 问题视为深度学习的“Hello World”程序——它是验证算法是否按预期运行的过程。随着您成为机器学习从业者,您会在科学论文、博客文章等各种场合反复看到 MNIST 的身影。您可以在图 2.1 中看到一些 MNIST 样本。
在机器学习中,分类问题中的一个类别称为类(class)。数据点称为样本(samples)。与特定样本关联的类别称为标签(label)。

MNIST 数据集已预加载到 Keras 中,以四个 NumPy 数组的形式提供。
1 | from keras.datasets import mnist |
清单 2.1:在 Keras 中加载 MNIST 数据集
个人注:在网址中,
#号后面的部分被称为锚点(Anchor)。具体到你提供的这个链接,
#listing-2-1的意思是:
- 精确定位:它告诉浏览器在打开网页后,自动滚动并定位到 ID 为
listing-2-1的 HTML 元素位置。- 代码清单编号:在技术书籍(尤其是 Manning 出版社的书)中,“Listing”通常指代代码清单。因此,
listing-2-1代表的是第 2 章的第 1 个代码示例。- 方便引用:这样你就可以直接分享某个具体的代码段给别人,而不是让别人打开网页后自己去翻找。
简单来说: 这个链接会直接带你跳到《Python 深度学习》第三章中那个编号为“2-1”的代码块。
train_images并train_labels构成训练集,即模型将从中学习的数据。然后,模型将在测试集上进行测试test_images,test_labels图像被编码为 NumPy 数组,标签是一个从 0 到 9 的数字数组。图像和标签一一对应。
NumPy 是一个非常流行的 Python 数值计算库。在你的机器学习学习过程中,你会经常看到它的身影。由于缺乏 GPU 和自动微分支持,它很少用于实现现代机器学习算法,但 NumPy 数组经常被用作数值数据交换格式——例如,这里就用于存储 MNIST 数据集中的数字及其标签。
我们来看一下训练数据:
1 | >>> train_images.shape |
以下是测试数据:
1 | >>> test_images.shape |
工作流程如下。首先,我们将训练数据输入神经网络train_images,train_labels然后,网络将学习将图像和标签关联起来。最后,我们将要求网络对进行预测test_images,并验证这些预测是否与来自的标签匹配test_labels。
让我们来构建网络——再次提醒,你不需要现在就完全理解这个例子。
1 | import keras |
清单 2.2:网络架构
神经网络的核心构建单元是层。你可以把层想象成一个数据过滤器:输入数据后,输出的数据会以更有用的形式呈现。具体来说,层从输入的数据中提取 表征——理想情况下,这些表征对当前问题更有意义。深度学习的大部分工作都是将简单的层串联起来,从而实现某种形式的渐进式数据提炼。深度学习模型就像一个数据处理的筛子,由一系列越来越精细的数据过滤器——层——构成。
我们的模型由两层组成Dense,这两层都是全连接(也称密集连接)神经网络层。第二层(也是最后一层)是一个十分softmax类层,这意味着它会返回一个包含十个概率值的数组(总和为 1)。每个概率值表示当前数字图像属于我们十个数字类别之一的概率。
为了使模型做好训练准备,我们需要在编译步骤中选择另外三项内容:
损失函数——模型如何衡量其在训练数据上的表现,从而如何引导自身朝着正确的方向发展。
优化器——模型根据其看到的训练数据进行自我更新以提高其性能的机制。
训练和测试期间要监控的指标——在这里,我们只关心准确率(被正确分类的图像所占的比例)。
接下来的两章将阐明损失函数和优化器的确切用途。
1 | model.compile( |
清单 2.3:编译步骤
在训练之前,我们将对数据进行预处理,将其重塑为模型期望的形状,并进行缩放,使所有值都在指定[0, 1]区间内。之前,我们的训练图像存储在一个形状(60000, 28, 28)为的数组中uint8,其值位于[0, 255]指定区间内。我们将它转换为一个float32形状为的数组,(60000, 28 * 28) 其值介于00 和 1之间1。
1 | train_images = train_images.reshape((60000, 28 * 28)) |
清单 2.4:准备图像数据
现在我们准备训练模型,在 Keras 中,这是通过调用模型的fit()方法来完成的——我们将模型拟合到其训练数据。
1 | model.fit(train_images, train_labels, epochs=5, batch_size=128) |
清单 2.5:“拟合”模型
训练过程中会显示两个指标:模型在训练数据上的损失和模型在训练数据上的准确率。我们很快就达到了训练数据上 0.989 (98.9%) 的准确率。
现在我们有了一个训练好的模型,我们可以用它来预测新数字的类别概率——这些数字不是训练数据的一部分,例如测试集中的图像。
1 | >>> test_digits = test_images[0:10] |
清单 2.6:利用模型进行预测
该数组中的每个索引数字对应于数字图像属于i该类别的概率。test_digits[0]``i
第一个测试数字在索引 7 处具有最高的概率得分(0.99999106,接近 1),因此根据我们的模型,它一定是 7:
1 | >>> predictions[0].argmax() |
我们可以检查测试标签是否一致:
1 | >>> test_labels[0] |
平均而言,我们的模型在对这些从未见过的数字进行分类方面表现如何?让我们通过计算整个测试集的平均准确率来检验一下。
1 | >>> test_loss, test_acc = model.evaluate(test_images, test_labels) |
清单 2.7:在新数据上评估模型
测试集的准确率达到了 97.8%,错误率几乎是训练集(准确率为 98.9%)的两倍。训练准确率和测试准确率之间的这种差距正是过拟合的一个例子:机器学习模型在新数据上的表现往往比在训练数据上的表现更差。过拟合是第五章的核心内容之一。
第一个示例到此结束。您刚刚看到了如何用不到 15 行 Python 代码构建和训练一个神经网络来识别手写数字。在本章和下一章中,我们将详细介绍刚才预览的每个组成部分,并阐明其背后的工作原理。您将学习张量(模型中存储数据的对象)、张量运算(构成模型的层)以及梯度下降(使模型能够从训练样本中学习)。
神经网络的数据表示
Data representations for neural networks
在前面的例子中,我们从存储在多维 NumPy 数组(也称为张量)中的数据开始。一般来说,所有当前的机器学习系统都使用张量作为其基本数据结构。张量是该领域的基础——其重要性甚至使得 TensorFlow 框架以它命名。那么,什么是张量呢?
张量本质上是数据的容器——通常是数值数据。所以它是数字的容器。你可能已经熟悉矩阵,矩阵是二阶张量:张量是矩阵在任意维度上的推广(注意,在张量的上下文中,维度通常被称为轴)。
At its core, a tensor is a container for data—usually numerical data. So it’s a container for numbers. You may already be familiar with matrices, which are rank-2 tensors:tensors are a generalization of matrices to an arbitrary number of dimensions (note that in the context of tensors, a dimension is often called an axis).
乍一看,了解张量的细节可能有点抽象。但这绝对值得——操作张量将是你编写任何机器学习代码的基础。
标量(0阶张量)
Scalars (rank-0 tensors)
只包含一个数字的张量称为标量(或标量张量、零阶张量或 0 维张量)。在 NumPy 中,一个float32数字float64就是一个标量张量(或标量数组)。您可以通过 x 属性显示 NumPy 张量的轴数ndim;标量张量有 0 个轴(0 ndim == 0)。张量的轴数也称为其秩(rank)。以下是一个 NumPy 标量张量示例:
1 | >>> import numpy as np |
向量(秩为 1 的张量)
Vectors (rank-1 tensors)
数字数组称为向量(或秩为 1 的张量或一维张量)。秩为 1 的张量只有一个轴。以下是一个 NumPy 向量:
1 | >>> x = np.array([12, 3, 6, 14, 7]) |
这个向量有五个元素,因此被称为五维向量。不要把五维向量和五维张量混淆!五维向量只有一个轴,沿该轴有五个维度,而五维张量有五个轴(每个轴的维度数可以任意)。 维度可以表示特定轴上的元素个数(如我们的五维向量),也可以表示张量的轴数(例如五维张量),这有时会让人感到困惑。在后一种情况下,严格来说,应该说一个 五阶张量(张量的阶数即轴数),但“五维张量”这种含义模糊的表示方法仍然很常见。
This vector has five entries and so is called a 5-dimensional vector. Don’t confuse a 5D vector with a 5D tensor! A 5D vector has only one axis and has five dimensions along its axis, whereas a 5D tensor has five axes (and may have any number of dimensions along each axis). Dimensionality can denote either the number of entries along a specific axis (as in the case of our 5D vector) or the number of axes in a tensor (such as a 5D tensor), which can be confusing at times. In the latter case, it’s technically more correct to talk about a tensor of rank 5 (the rank of a tensor being the number of axes), but the ambiguous notation 5D tensor is common regardless
个人注:确实很容易混淆五维向量和五维张量的叫法。
矩阵(秩为 2 的张量)
Matrices (rank-2 tensors)
向量数组就是一个矩阵(或称二阶张量、二维张量)。矩阵有两个轴(通常称为行和列)。你可以将矩阵直观地理解为一个矩形数字网格。以下是一个 NumPy 矩阵:
1 | >>> x = np.array([[5, 78, 2, 34, 0], |
第一个轴上的元素称为行,第二个轴上的元素称为列。在前面的例子中, [5, 78, 2, 34, 0]是的第一行x,[5, 6, 7]是第一列。
3阶张量及更高阶张量
Rank-3 tensors and higher-rank tensors
如果将这类矩阵打包到一个新数组中,就会得到一个 3 阶张量(或 3D 张量),可以将其直观地解释为一个数字立方。以下是一个 NumPy 3 阶张量示例:
1 | >>> x = np.array([[[5, 78, 2, 34, 0], |
通过将秩为 3 的张量打包到一个数组中,可以创建一个秩为 4 的张量,依此类推。在深度学习中,通常情况下你会操作秩为 0 到 4 的张量,但如果处理视频数据,则可能需要处理秩为 5 的张量。
关键属性
Key attributes
张量由三个关键属性定义:
- 轴数(秩)Number of axes (rank) ——例如,秩为 3 的张量有三个轴,而矩阵有两个轴。
ndim在 NumPy、JAX、TensorFlow 和 PyTorch 等 Python 库中,张量也被称为“张量”。(This is also called the tensor’s ndim in Python libraries such as NumPy, JAX, TensorFlow, and PyTorch.) - 形状 Shape——这是一个整数元组,用于描述张量在每个轴上的维度数。例如,前面的矩阵示例的形状为
(3, 5),而秩为 3 的张量示例的形状为(3, 3, 5)。向量的形状包含一个元素,例如(5,),而标量的形状为空,即()。 - 数据类型(通常
dtype在 Python 库中称为)Data type (usually called dtype in Python libraries) ——这是张量中包含的数据类型;例如,张量的类型可以是float16, float32,float64, uint8, bool等等。在 TensorFlow 中,您也可能会遇到string张量。
为了更具体地说明这一点,让我们回顾一下在 MNIST 示例中处理的数据。首先,我们加载 MNIST 数据集:
1 | from keras.datasets import mnist |
接下来,我们显示张量的轴数train_images,即该ndim属性:
1 | >>> train_images.ndim |
它的形状如下:
1 | >>> train_images.shape |
这是它的数据类型,即dtype属性:
1 | >>> train_images.dtype |
所以这里我们看到的是一个秩为 3 的 8 位整数张量。更准确地说,它是一个包含 60,000 个 28 × 28 整数矩阵的数组。每个这样的矩阵都是一幅灰度图像,其系数介于 0 和 255 之间。
让我们使用 Matplotlib 库(标准科学 Python 套件的一部分)显示这个 3 阶张量的第四位数字;参见图 2.2。
1 | import matplotlib.pyplot as plt |
示例 2.8:显示第四位数字
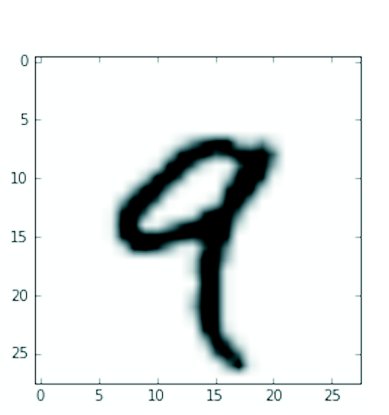
自然而然,对应的标签就是整数 9:
1 | >>> train_labels[4] |
在 NumPy 中操作张量
Manipulating tensors in NumPy
在前面的例子中,我们使用语法选择了第一个轴上的一个特定数字 train_images[i]。选择张量中的特定元素称为 张量切片(tensor slicing)。接下来,我们来看看可以对 NumPy 数组执行哪些张量切片操作。
以下示例选择数字 #10 到 #100(不包括 #100),并将它们放入形状为 的数组中(90, 28, 28):
1 | >>> my_slice = train_images[10:100] |
它等价于这种更详细的表示法,该表示法为每个张量轴指定了切片的起始索引和终止索引。请注意,这:等价于选择整个轴:
1 | >>> # Equivalent to the previous example |
通常,您可以选择每个张量轴上任意两个索引之间的切片。例如,要选择所有图像右下角 14 × 14 像素的区域,您可以这样做:
1 | my_slice = train_images[:, 14:, 14:] |
也可以使用负索引。与 Python 列表中的负索引类似,它们表示相对于当前轴末端的位置。要将图像裁剪成以中心为中心的 14 × 14 像素的块,请执行以下操作:
1 | my_slice = train_images[:, 7:-7, 7:-7] |
数据批次的概念
The notion of data batches
一般来说,在深度学习中遇到的所有数据张量中,第一个轴(轴 0,因为索引从 0 开始)都是样本轴(samples axis)。在 MNIST 示例中,“样本”指的是数字图像。
此外,深度学习模型不会一次性处理整个数据集;相反,它们会将数据分成若干个小的“批次”,即固定大小的样本组。具体来说,以下是我们 MNIST 数字数据集的一个批次,批次大小为 128:
1 | batch = train_images[:128] |
接下来是下一批:
1 | batch = train_images[128:256] |
还有第nt 批:
1 | n = 3 |
在考虑这样的批次张量时,第一个轴(轴 0)被称为批次轴(或批次维度)。在使用 Keras 和其他深度学习库时,你会经常遇到这个术语。
数据张量的实际应用示例
Real-world examples of data tensors
让我们通过几个与你稍后会遇到的情况类似的例子,使数据张量的概念更加具体。你将要处理的数据几乎总是属于以下几类之一:
- 向量数据(Vector data)——形状为 的秩 2 张量
(samples, features),其中每个样本都是一个数值属性(“特征”)的向量 - 时间序列数据或序列数据(Timeseries data or sequence data) ——形状为 的秩 3 张量
(samples, timesteps, features),其中每个样本都是一个(长度为timesteps)特征向量序列。 - 图像(Images)——形状为 的 4 阶张量
(samples, height, width, channels),其中每个样本都是一个二维像素网格,每个像素由一个值向量(“通道”)表示。 - 视频(Video)——形状为 的 5 阶张量
(samples, frames, height, width, channels),其中每个样本都是一个(长度为frames)的图像序列。
向量数据
Vector data
向量数据是最常见的情况之一。在这样的数据集中,每个数据点都可以编码为一个向量,因此一批数据将被编码为一个秩为 2 的张量(即向量数组),其中第一个轴是样本轴,第二个轴是特征轴。
我们来看两个例子:
这是一个包含人员信息的精算数据集,其中我们考虑每个人的年龄、性别和收入。每个人都可以用一个包含三个值的向量来表示,因此,包含 100,000 人的整个数据集可以存储在一个形状为 的秩为 2 的张量中
(100000, 3)。这是一个文本数据集,其中每个文档都用每个单词在文档中出现的次数来表示(字典中包含 20,000 个常用词)。每个文档都可以编码为一个包含 20,000 个值的向量(字典中每个单词对应一个计数),因此,包含 500 个文档的整个数据集可以存储在一个形状为 的张量中
(500, 20000)。
时间序列数据或序列数据
Timeseries data or sequence data
当时间在数据中起着重要作用(或者说序列顺序的概念)时,将其存储在具有明确时间轴的 3 阶张量中是合理的。每个样本都可以编码为一系列向量(2 阶张量),因此一批数据将被编码为 3 阶张量(参见图 2.3)。
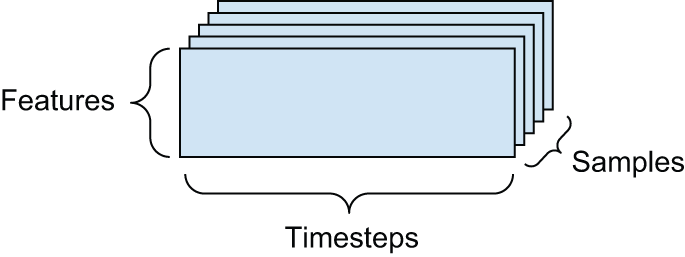
按照惯例,时间轴始终是第二个轴(索引为 1 的轴)。我们来看几个例子:
股票价格数据集——我们每分钟存储股票的当前价格、过去一分钟的最高价格和最低价格。因此,每分钟的数据被编码为一个三维向量,一整天的交易数据被编码为一个形状为 的矩阵
(390, 3)(一个交易日有 390 分钟),而 250 天的数据可以存储在一个形状为 的秩为 3 的张量中(250, 390, 3)。这里,每个样本代表一天的数据。一个推文数据集,其中每条推文被编码为一个由 128 个唯一字符组成的字母表中的 280 个字符的序列——在这种情况下,每个字符都可以编码为一个大小为 128 的二进制向量(一个全零向量,除了与该字符对应的索引处的值为 1)。然后,每条推文都可以被编码为一个形状为 的秩为 2 的张量
(280, 128),而包含 100 万条推文的数据集可以存储在一个形状为 的张量中(1000000, 280, 128)。
图像数据
Image data
图像通常具有三个维度:高度、宽度和颜色深度(color depth)。虽然灰度图像(例如我们的 MNIST 数字)只有一个颜色通道,因此可以存储在二阶张量中,但按照惯例,图像张量始终是三阶的,灰度图像只有一个颜色通道。因此,一批 128 张大小为 256 × 256 的灰度图像可以存储在一个形状为 的张量中(128, 256, 256, 1),而一批 128 张彩色图像可以存储在一个形状为 的张量中(128, 256, 256, 3)(参见图 2.4)。
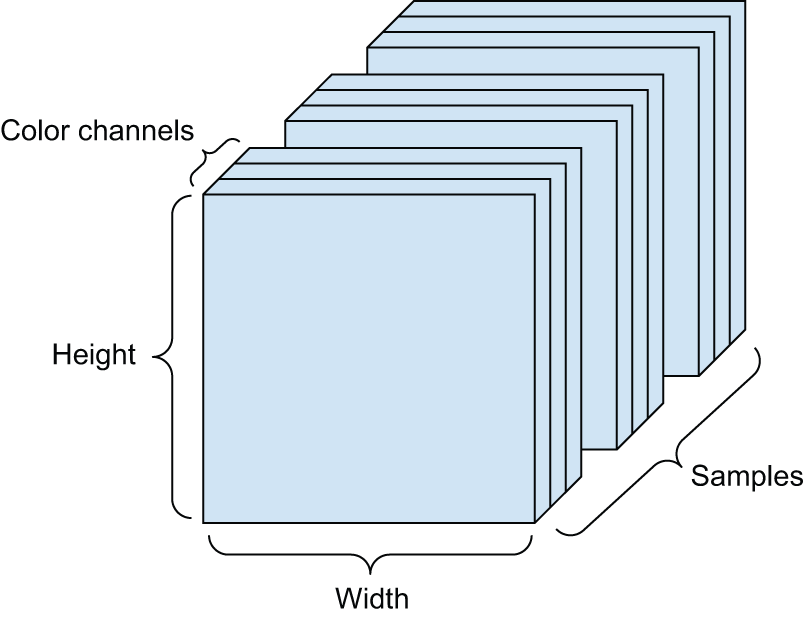
图像张量的形状有两种约定:通道后置约定(这是 JAX 和 TensorFlow 以及大多数其他深度学习工具的标准)和通道先置约定(这是 PyTorch 的标准)。
通道后置约定将颜色深度轴放在末尾: (samples, height, width, color_depth)。而通道先置约定则将颜色深度轴放在批处理轴之后: (samples, color_depth, height, width)。采用通道先置约定,前面的示例将变为(128, 1, 256, 256) 和(128, 3, 256, 256)。Keras API 同时支持这两种格式。
视频数据
Video data
视频数据是少数几种需要使用 5 阶张量的实际数据类型之一。视频可以理解为一系列帧,每一帧都是一张彩色图像。由于每一帧都可以存储在 3 阶张量中(height, width, color_depth),因此一系列帧可以存储在 4 阶张量中(frames, height, width, color_depth),进而可以将一批不同的视频存储在形状为 的 5 阶张量中(samples, frames, height, width, color_depth)。
例如,一段时长 60 秒、分辨率为 144 × 256 的 YouTube 视频片段,以每秒 4 帧的采样率拍摄,将包含 240 帧。四个这样的视频片段将被存储在一个形状为 的张量中(4, 240, 144, 256, 3)。这总共包含 106,168,320 个值!如果dtype该张量的位数为float32,则每个值将以 32 位存储,因此该张量将占用 425 MB 的空间。非常庞大!你在现实生活中遇到的视频要小得多,因为它们并非以 存储float32,而且通常会经过大幅压缩(例如 MPEG 格式)。
神经网络的齿轮:张量运算
The gears of neural networks: Tensor operations
就像任何计算机程序最终都可以简化为对二进制输入进行少量二进制运算(例如AND,OR加法、NOR乘法等等)一样,深度神经网络学习到的所有变换都可以简化为对数值数据张量应用少量张量运算(或张量函数)。例如,可以对张量进行加法运算、乘法运算等等。
Dense在最初的示例中,我们通过逐层堆叠的方式构建模型。Keras 层实例如下所示:
1 | keras.layers.Dense(512, activation="relu") |
这一层可以解释为一个函数,它以一个矩阵作为输入,并返回另一个矩阵——输入张量的新表示。具体来说,该函数如下(其中W是一个矩阵,b 是一个向量,两者都是该层的属性):
1 | output = relu(matmul(input, W) + b) |
让我们来详细分析一下。这里有三个张量运算:
matmul输入张量与名为 的张量之间的张量积 ( )W。+将所得矩阵与向量相加( )b。操作
relu:relu(x)是max(x, 0)。"relu"代表“整流线性单元”。A tensor product (matmul) between the input tensor and a tensor named W.
An addition (+) between the resulting matrix and a vector b.
A relu operation: relu(x) is max(x, 0). "relu" stands for “REctified Linear Unit.”
尽管本节完全围绕线性代数表达式展开,但本书中不会出现任何数学符号。我发现,如果将数学概念用简短的 Python 代码片段而非数学公式来表达,那么没有数学背景的程序员更容易掌握这些概念。因此,我们将全程使用 NumPy 代码。
逐元素运算
Element-wise operations
加法运算relu是逐元素运算:即对所考虑张量中的每个元素独立执行的运算。这意味着这些运算非常适合大规模并行实现(向量化实现,该术语源于20 世纪 70 年代至 90 年代的向量处理器超级计算机架构)。如果您想用 Python 编写一个简单的逐元素运算实现,可以使用for循环,如下一个简单的逐元素relu 运算实现示例:
1 | def naive_relu(x): |
加法也可以用同样的方法:
1 | def naive_add(x, y): |
根据同样的原理,你可以进行逐元素乘法、减法等等。
实际上,在处理 NumPy 数组时,这些操作可以通过经过优化的内置 NumPy 函数来实现,这些函数本身会将繁重的计算工作委托给基本线性代数子程序 (BLAS) 实现。BLAS 是底层、高度并行且高效的张量操作例程,通常用 Fortran 或 C 语言实现。
因此,在 NumPy 中,您可以执行以下逐元素操作,速度会非常快:
1 | import numpy as np |
我们来实际计时一下:
1 | import time |
这只需要 0.02 秒。而最简单的版本却需要惊人的 2.45 秒:
1 | t0 = time.time() |
同样,当在 GPU 上运行 JAX/TensorFlow/PyTorch 代码时,逐元素操作是通过完全向量化的 CUDA 实现来执行的,这样可以最大限度地利用高度并行的 GPU 芯片架构。
广播
Broadcasting
我们之前简单的实现naive_add仅支持形状相同的二阶张量的加法运算。但在Dense前面介绍的层中,我们将一个二阶张量与一个向量相加。当两个待加张量的形状不同时,加法运算会发生什么?
如果可能且不存在歧义,较小的张量将被 广播以匹配较大张量的形状。广播过程包括两个步骤:
- 将轴(称为广播轴)添加到较小的张量中,以匹配
ndim较大张量的轴。 - 较小的张量沿着这些新轴重复出现,以匹配较大张量的完整形状。
让我们来看一个具体的例子。考虑X形状为(32, 10)和y 形状为 的图形(10,):
1 | import numpy as np |
首先,我们向 中添加一个空的第一轴y,其形状变为(1, 10):
1 | # The shape of y is now (1, 10). |
然后,我们沿着这个新轴重复y32 次,最终得到一个Y形状为 的张量(32, 10),其中Y[i, :] == y 对于:i``range(0, 32)
1 | # Repeat y 32 times along axis 0 to obtain Y with shape (32, 10). |
此时,我们可以将它们相加X,Y 因为它们形状相同。
在实现方面,不会创建新的 2 阶张量,因为这样做效率极低。重复操作完全是虚拟的:它发生在算法层面,而不是内存层面。但将向量沿着新的轴重复 32 次是一个有用的思维模型。以下是一个简单的实现示例:
1 | def naive_add_matrix_and_vector(x, y): |
通过广播,通常可以对两个张量进行逐元素运算,其中一个张量的形状为(a, b, … n, n + 1, … m),另一个张量的形状为 (n, n + 1, … m)。然后,广播将自动应用于a通过的轴n - 1。
maximum以下示例通过广播对两个不同形状的张量应用逐元素运算:
1 | import numpy as np |
张量积
Tensor product
张量积,也称为点积或矩阵乘法 (“矩阵乘法”的缩写),是最常见、最有用的张量运算之一。
The tensor product, also called dot product or matmul (short for “matrix multiplication”) is one of the most common, most useful tensor operations.
在 NumPy 中,张量积使用 tf.tf 函数完成np.matmul,而在 Keras 中,则使用 keras.ops.matmultf.tf 函数完成。其简写形式@在 Python 中是 tf.tf 运算符:
1 | x = np.random.random((32,)) |
在数学符号中,你会用点号(•)来表示这种运算(因此得名“点积”):
1 | z = x • y |
从数学角度来看,这个matmul运算做了什么?我们先来看两个向量的乘积x。y它的计算方法如下:
1 | def naive_vector_product(x, y): |
你会注意到,两个向量的乘积是一个标量,并且只有元素个数相同的向量才能进行此运算。
x你还可以计算矩阵和向量的乘积y,返回一个向量,其中系数是矩阵 y与向量各行之间的乘积x。实现方式如下:
1 | def naive_matrix_vector_product(x, y): |
您还可以重用我们之前编写的代码,该代码突出了矩阵向量乘积和向量乘积之间的关系:
1 | def naive_matrix_vector_product(x, y): |
注意,一旦两个张量中的一个ndim大于 1, matmul就不再对称,也就是说,它matmul(x, y)与 不相同matmul(y, x)。
当然,张量积可以推广到具有任意轴数的张量。最常见的应用是两个矩阵的乘积。当且仅当矩阵 Ax和y B的乘积为 1 时,才能计算它们的乘积。结果是一个形状为 n 的矩阵,其系数是 A 的行 与 B 的列的向量积。以下是一个简单的实现:matmul(x, y)``x.shape[1] == y.shape[0]``(x.shape[0], y.shape[1])``x``y
1 | def naive_matrix_product(x, y): |
为了理解向量积形状兼容性,将输入和输出张量对齐以可视化它们,如图 2.5 所示,会有所帮助。
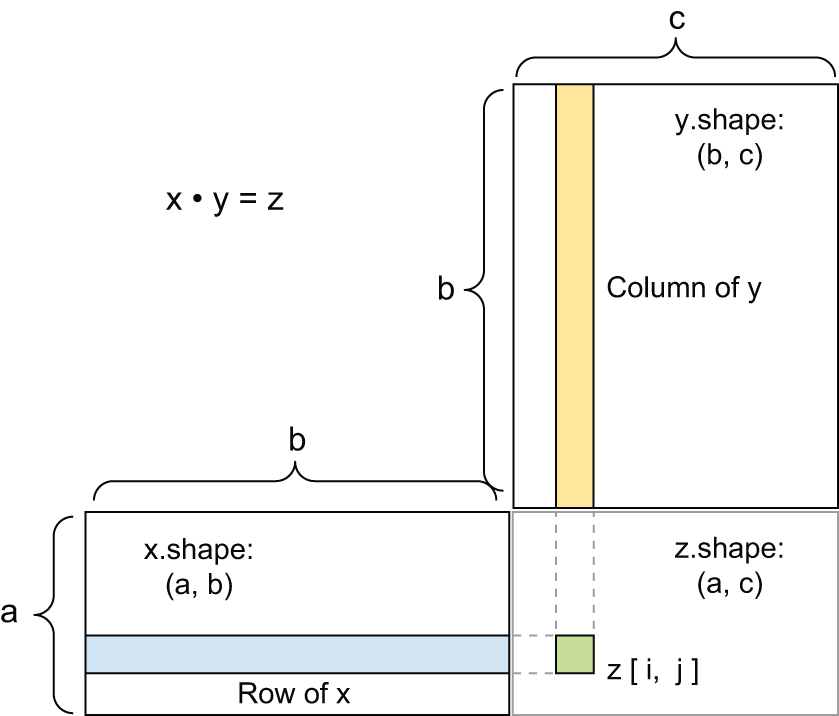
x,,y和z被表示为矩形(即系数的方框)。由于的行x和的列y必须大小相同,因此的宽度x必须与的高度相同y。如果你继续开发新的机器学习算法,你很可能会经常绘制这样的图表。
更一般地,您可以计算高维张量的乘积,遵循与前面针对二维情况概述的形状兼容性规则相同的规则:
1 | (a, b, c, d) • (d,) -> (a, b, c) |
等等。
张量重塑
Tensor reshaping
第三种需要理解的张量运算是张量重塑。虽然在我们第一个神经网络示例中的各层中没有用到它Dense,但我们在将数字数据输入模型之前对其进行预处理时使用了它:
1 | train_images = train_images.reshape((60000, 28 * 28)) |
重塑张量是指重新排列其行和列,使其符合目标形状。当然,重塑后的张量与初始张量具有相同的系数总数。通过简单的例子可以更好地理解重塑:
1 | >>> x = np.array([[0., 1.], |
矩阵重塑中一个常见的特殊情况是转置。 转置矩阵意味着交换它的行和列,因此矩阵x[i, :]变为x[:, i]:
1 | >>> # Creates an all-zeros matrix of shape (300, 20) |
张量运算的几何解释
Geometric interpretation of tensor operations
由于张量运算所处理的张量的内容可以解释为某个几何空间中点的坐标,因此所有张量运算都具有几何解释。例如,我们考虑加法运算。我们从以下向量开始:
1 | A = [0.5, 1] |
它是二维空间中的一个点(见图 2.6)。通常将向量想象成连接原点和该点的箭头,如图 2.7 所示。
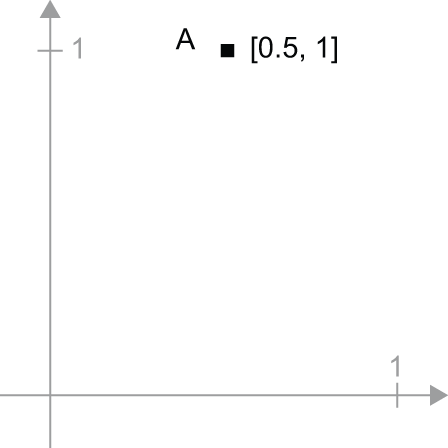
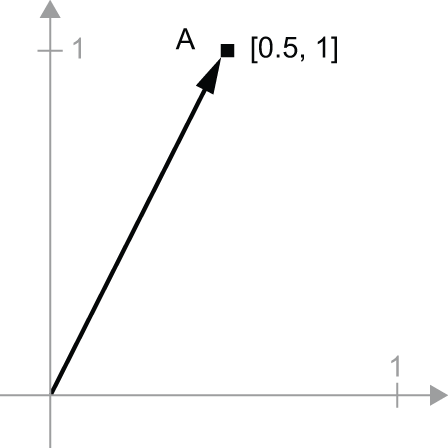
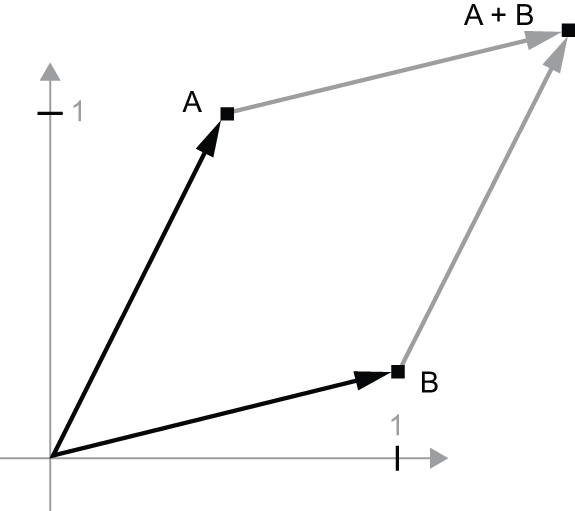
我们考虑一个新的点,B = [1, 0.25]将其添加到之前的点上。这可以通过几何方式实现,即将向量箭头连接起来,最终得到的位置是表示前两个向量之和的向量(见图 2.8)。正如你所看到的,将一个向量加到B 另一个向量上,A相当于将点复制A到一个新的位置,其与原点的距离和方向A由向量决定B。如果将同样的向量加法应用于平面上的一组点(一个“对象”),则会在新的位置创建整个对象的副本(见图 2.9)。因此,张量加法表示将一个对象沿特定方向平移一定距离(移动对象而不使其变形)的操作。
一般来说,平移、旋转、缩放、倾斜等基本几何运算都可以表示为张量运算(In general, elementary geometric operations, such as translation, rotation, scaling, skewing, and so on, can be expressed as tensor operations.)。以下是一些示例:
- 平移——正如你刚才看到的,给一个点加上一个向量,就会使该点沿固定方向移动固定的距离。应用于一组点(例如二维物体)时,这被称为“平移”(参见图 2.9)。
- 旋转——二维向量逆时针旋转角度θ(见图2.10)可通过与2×2矩阵的乘积实现
R = [[cos(theta), -sin(theta)], [sin(theta), cos(theta)]]。
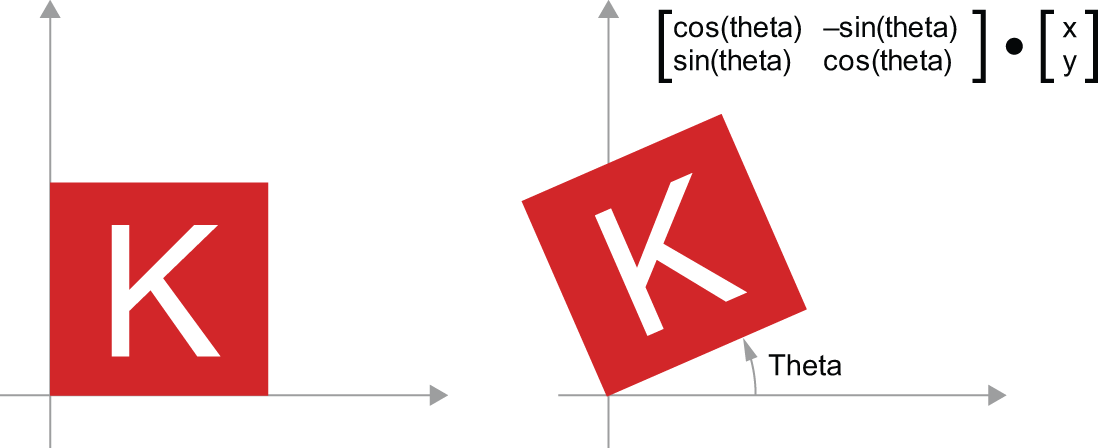
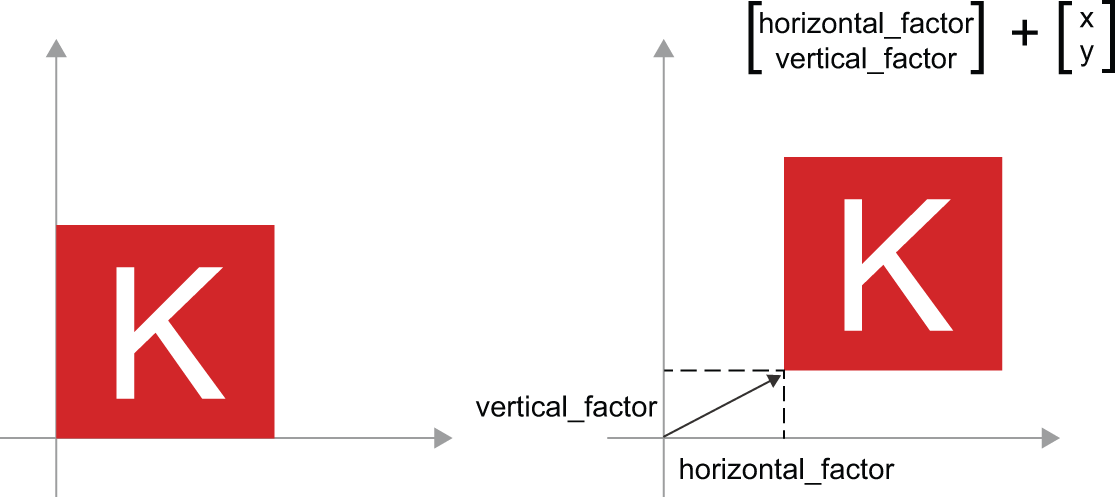
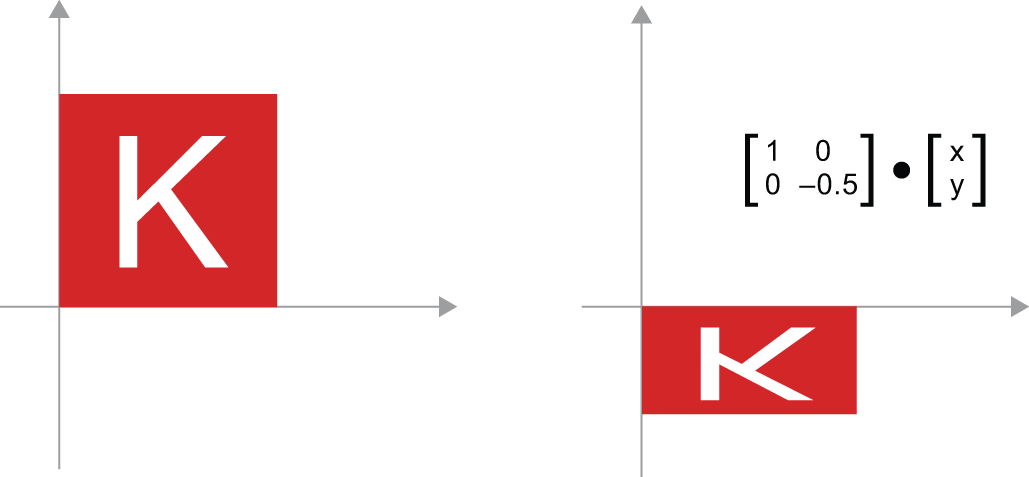
- 缩放——图像的垂直和水平缩放(见图 2.11)可以通过与 2 × 2 矩阵的乘积来实现
S = [[horizontal_factor, 0], [0, vertical_factor]](请注意,这样的矩阵被称为“对角矩阵”,因为它的系数仅在其“对角线”上非零,从左上角到右下角)。
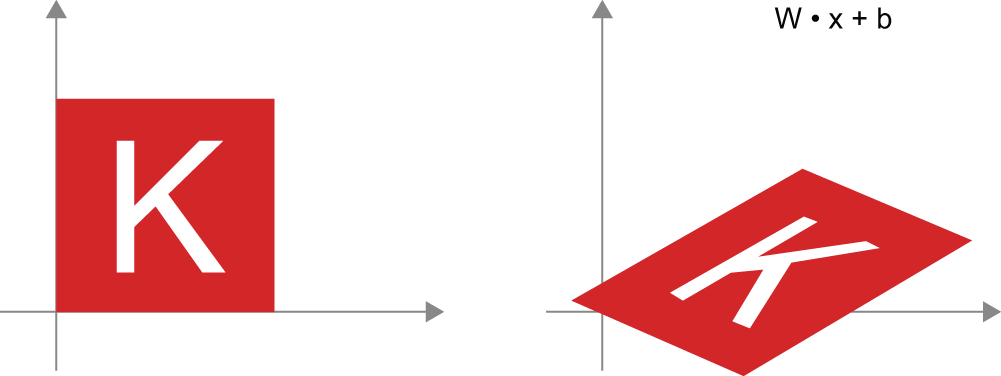
线性变换——任意矩阵的乘积即可实现线性变换。请注意,前面提到的缩放和旋转,根据定义,都是线性变换。
仿射变换——仿射变换(见图 2.12)是线性变换(通过矩阵乘法实现)和平移(通过向量加法实现)的组合。正如你可能已经意识到的,这正是
y = W @ x + b该Dense层实现的计算!Dense没有激活函数的层就是仿射层。
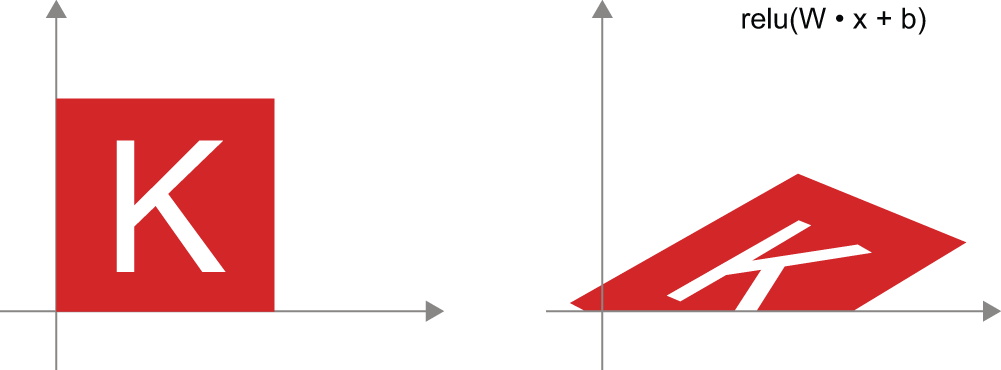
Dense``relu带激活函数的层(Dense layer with relu activation)——关于仿射变换的一个重要观察结果是,即使重复应用多个仿射变换,最终得到的仍然是仿射变换(所以一开始只需应用一个仿射变换即可)。我们来尝试两个仿射变换:。affine2(affine1(x)) = W2 @ (W1 @ x + b1) + b2 = (W2 @ W1) @ x + (W2 @ b1 + b2)这是一个仿射变换,其中线性部分是矩阵W2 @ W1,平移部分是向量W2 @ b1 + b2。因此,一个完全由Dense没有激活函数的层组成的多层神经网络将等价于一个单层Dense网络。这个“深度”神经网络实际上只是一个伪装的线性模型!这就是为什么我们需要激活函数,例如relu(如图 2.13 所示)。借助激活函数,Dense我们可以构建一个层链来实现非常复杂的非线性几何变换,从而为深度神经网络提供非常丰富的假设空间。我们将在下一章更详细地介绍这个概念。
深度学习的几何解释
A geometric interpretation of deep learning
你刚刚了解到,神经网络完全由一系列张量运算构成,而所有这些张量运算都只是对输入数据进行简单的几何变换。由此可见,你可以将神经网络解释为高维空间中非常复杂的几何变换,这种变换是通过一系列简单的步骤实现的。
在三维空间中,以下图像或许能有所帮助。想象两张彩色纸:一张红色,一张蓝色。将一张叠在另一张上面。然后将它们揉成一个小球。这个揉成一团的纸球就是你的输入数据,而每张纸则代表分类问题中的一个数据类别。神经网络的任务是找到一种变换方法,将纸球展开,使两个类别的数据再次清晰可分(见图 2.14)。在深度学习中,这可以通过一系列简单的三维空间变换来实现,就像你可以用手指一次移动纸球一样。
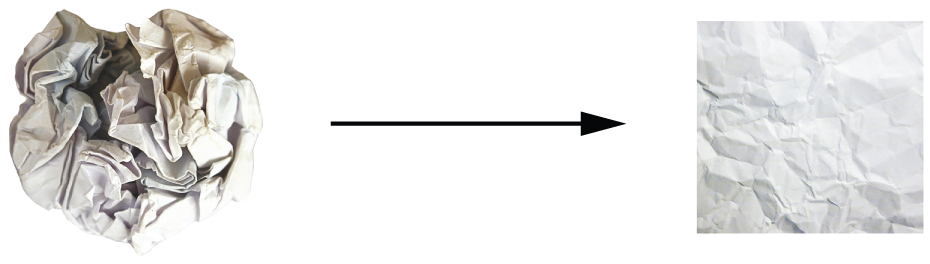
机器学习的本质就在于将纸团展开:在高维空间中为复杂、高度折叠的数据流形找到简洁的表示(流形是一个连续的曲面,就像我们手中的皱巴巴的纸一样)。此时,你应该对深度学习为何擅长此道有了相当清晰的认识:它采用的方法是将复杂的几何变换逐步分解成一系列基本变换,这与人类展开纸团的策略非常相似。深度网络中的每一层都会应用一种变换来解耦数据——而多层网络的叠加使得极其复杂的解耦过程变得可控。
神经网络的引擎:基于梯度的优化
The engine of neural networks: Gradient-based optimization
正如你在上一节中看到的,我们第一个模型示例中的每个神经网络层都按如下方式转换其输入数据:
1 | output = relu(matmul(input, W) + b) |
在这个表达式中,W和b是张量,它们是该层的属性。它们被称为该层的权重或可训练参数kernel(分别对应和bias属性)。这些权重包含了模型从训练数据中学习到的信息。
最初,这些权重矩阵会被填充一些小的随机值(这一步骤称为随机初始化relu(matmul(input, W) + b))。当然,当W和都是随机值时,我们无法期望b得到任何有用的表示。得到的表示是无意义的——但它们是一个起点。接下来,我们需要根据反馈信号逐步调整这些权重。这种逐步调整,也称为训练,本质上就是机器学习的核心所在。
这发生在所谓的训练循环中,其工作原理如下:循环重复以下步骤,直到损失值足够低为止:
- 绘制一批训练样本
x和相应的目标y_true。 - 运行模型(称为前向传递的
x步骤)以获得预测结果。y_pred - 计算模型在该批次上的损失,衡量模型
y_pred与目标之间的不匹配程度y_true。 - 更新模型的所有权重,以略微降低该批次的损失。
1、Draw a batch of training samples x and corresponding targets y_true.
2、Run the model on x (a step called the forward pass) to obtain predictions y_pred.
3、Compute the loss of the model on the batch, a measure of the mismatch between y_pred and y_true.
4、Update all weights of the model in a way that slightly reduces the loss on this batch.
最终你会得到一个训练数据损失非常低的模型:预测值y_pred与预期目标值 之间的偏差很小y_true。该模型已经“学习”将输入映射到正确的目标值。从表面上看,这似乎很神奇,但当你将其简化为基本步骤时,就会发现其实很简单。
第一步听起来很简单——只是简单的I/O代码。第二步和第三步也只是应用一些张量运算,所以你可以完全根据上一节学到的知识来实现这两步。难点在于第四步:更新模型的权重。给定模型中的一个权重系数,如何计算该系数应该增加还是减少,以及增加或减少多少?
一种简单的解决方法是冻结模型中除一个标量系数之外的所有权重,并尝试该系数的不同值。假设该系数的初始值为 0.3。在对一批数据进行前向传播后,模型在该批次数据上的损失为 0.5。如果将该系数的值改为 0.35 并重新运行前向传播,损失会增加到 0.6。但如果将该系数降低到 0.25,损失会降至 0.4。在这种情况下,将该系数更新 -0.05 似乎有助于最小化损失。这需要对模型中的所有系数重复进行。
但这种方法效率极低,因为对于每个系数(通常至少有几千个,甚至可能高达数十亿个),都需要计算两次前向传播(这非常耗时)。幸运的是,有一种更好的方法:梯度下降法(gradient descent)。
梯度下降是现代神经网络的核心优化技术。简而言之,模型中使用的所有函数(例如matmul或+)都以平滑连续的方式变换其输入:例如,观察z = x + y, 的微小变化y只会导致 的微小变化z;如果您知道 的变化方向y,就可以推断出 的变化方向z。从数学角度来说,这些函数是可微的。如果将这些函数串联起来,得到的更大函数仍然是可微的。特别地,这适用于将模型系数映射到模型在某批数据上的损失的函数:模型系数的微小变化会导致损失值的微小且可预测的变化。这使得您可以使用称为梯度的数学运算 符来描述损失如何随着模型系数向不同方向移动而变化。如果计算出这个梯度,就可以利用它将系数(一次性更新,而不是一次更新一个)向减少损失的方向移动。
如果您已经了解可微性以及梯度的概念,则可以跳过接下来的两节。否则,以下内容将帮助您理解这些概念。
什么是导数?
What’s a derivative?
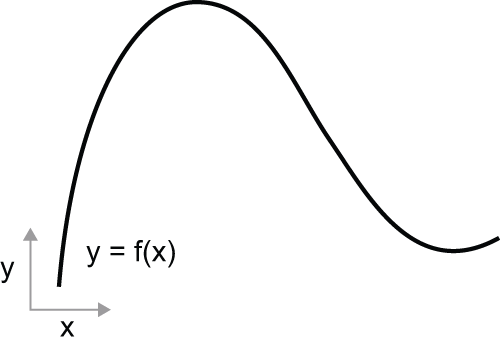
考虑一个连续、光滑的函数f(x) = y,它将一个数映射x 到另一个数y。我们可以用图 2.15 中的函数作为示例。
因为函数是连续的,所以 x 的微小变化x只会导致 y 的微小变化——这就是连续性y背后的直觉 。假设 x 增大一个很小的因子:这会导致 y 发生微小的变化,如图 2.16 所示。x``epsilon_x``epsilon_y``y
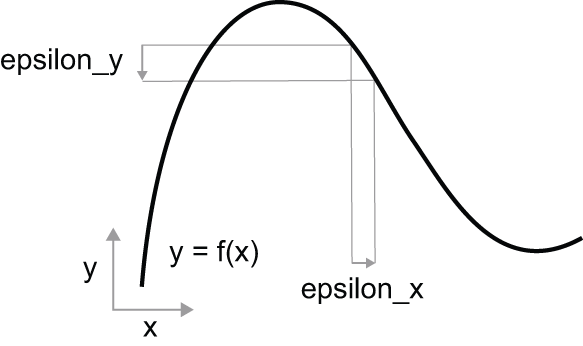
此外,由于该函数是光滑的 (其曲线没有任何突变角),当epsilon_x足够小时,在某一点附近p,可以将其近似f为斜率为的线性函数a,因此epsilon_y变为a * epsilon_x:
1 | f(x + epsilon_x) = y + a * epsilon_x |
x 显然,这种线性近似仅在足够接近时有效p。
斜率a称为对的导数。如果为负值,则表示附近微小的增加会导致 减小,如图 2.17 所示;如果为正值,则表示 微小的增加 会导致 增大。此外, 的绝对值 (导数的大小)表示这种增加或减小的速度。f``p``a``x``p``f(x)``a``x``f(x)``a
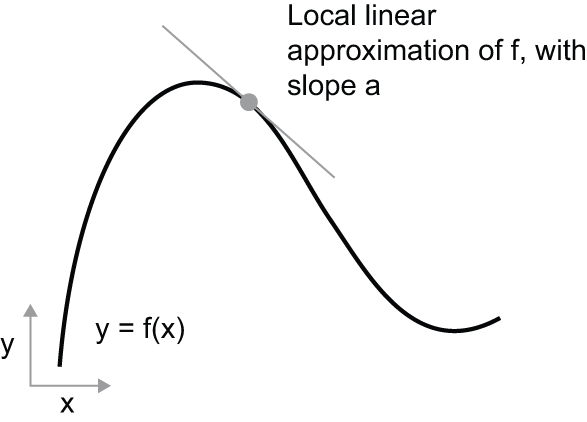
对于每个可微函数f(x)(可微意味着“可以导出”:例如,光滑连续函数可以导出),都存在一个导函数f'(x),它将函数值映射x到这些点处函数局部线性近似的斜率f。例如,函数的导数cos(x)是-sin(x),函数的导数 f(x) = a * x是f'(x) = a,依此类推。
函数导数能力在 优化问题中是一项非常强大的工具,优化任务是找到使x目标函数值最小化的函数值f(x)。如果你试图x通过改变某个因子epsilon_x 来最小化目标函数值f(x),并且你知道函数的导数f,那么你的任务就完成了:导数完整地描述了f(x) 当改变目标函数值时,目标函数值是如何变化的x。如果你想减小目标函数值f(x),你只需要x沿着导数的反方向稍微改变目标函数值即可。
张量运算的导数:梯度
Derivative of a tensor operation: The gradient
我们刚才看到的函数将一个标量值转换x成另一个标量值y:你可以把它绘制成二维平面上的曲线。现在,想象一个将一组标量值转换(x, y)成一个标量值的函数z:这就是一个向量运算。你可以把它绘制成三维空间(通过坐标索引)中的二维曲面x, y, z。同样地,你可以想象以矩阵作为输入的函数,以三阶张量作为输入的函数等等。
只要函数所描述的曲面是连续且光滑的,导数的概念就可以应用于任何此类函数。张量运算(或张量函数)的导数称为梯度。梯度只是将导数的概念推广到以张量为输入的函数。还记得标量函数的导数是如何表示函数曲线的局部斜率的吗?同样地,张量函数的梯度表示 该函数所描述的多维曲面的曲率。它刻画了函数的输出如何随其输入参数的变化而变化。
让我们来看一个基于机器学习的例子。
- 输入向量
x(数据集中的一个样本) - 矩阵
W(模型的权重) - 目标
y_true(模型应该学习与之关联的对象x) - 损失函数
loss(旨在衡量模型当前预测与预期之间的差距y_true)。
您可以利用该方法W计算目标候选值,然后计算目标候选值与目标值y_pred之间的损失或不匹配度:y_pred``y_true
1 | # We use the model weights W to make a prediction for x. |
现在,我们想利用渐变来实现W缩小loss_value效果。该怎么做呢?
给定固定的输入x和y_true,前面的操作可以解释为将W(模型的权重)的值映射到损失值的函数:
1 | # f describes the curve (or high-dimensional surface) formed by loss |
假设 的当前值为W。那么 在该点W0的导数是一个张量,其形状与 相同,其中每个系数表示当 时观察到的的变化方向和大小。该张量是函数 在 中的梯度,也称为“关于 在附近的梯度”。f``W0``grad(loss_value, W0)``W``grad(loss_value, W0)[i, j]``loss_value``W0[i, j]``grad(loss_value, W0)``f(W) = loss_value``W0``loss_value``W``W0
张量运算grad(f(W), W) (以矩阵作为输入W)可以表示为标量函数的组合 grad_ij(f(W), w_ij),每个标量函数都会返回loss_value = f(W)关于W[i, j]的系数的导数W,假设所有其他系数都是常数。 grad_ij称为关于的偏导数。f``W[i, j]
具体来说,它grad(loss_value, W0)代表什么?你之前已经看到,单系数函数的导数f(x)可以解释为曲线的斜率f。同样地, grad(loss_value, W0) 可以解释为描述曲线 在点附近的曲率的张量。每个偏导数都描述了曲线在特定方向上的曲率。loss_value = f(W)``W0``f
我们刚才看到,对于一个函数f(x),可以通过沿导数方向的反方向f(x)移动x一点来减小其值。同样地,对于f(W)张量的函数,可以 通过沿梯度方向的反方向 loss_value = f(W)移动来减小其值,例如更新,其中是一个小的比例因子。这意味着逆着曲率移动,直观上应该会使你在曲线上的位置更低。注意,需要比例因子是因为 只有在接近时才能近似曲率,所以你不希望远离。W``W1 = W0 - step * grad(f(W0), W0)``step``step``grad(loss_value, W0)``W0``W0
随机梯度下降
Stochastic gradient descent
对于一个可微函数,理论上可以解析地找到它的最小值:已知函数的最小值是导数为 0 的点,所以你只需要找到导数为 0 的所有点,然后检查函数在这些点中哪个点的值最小。
应用于神经网络,这意味着要解析地找到使损失函数最小的权重值组合。这可以通过求解方程来实现grad(f(W), W) = 0。W这是一个关于N变量的多项式方程,其中N是模型中系数的个数。虽然理论上可以求解出N = 2或N = 3,但对于实际的神经网络来说,这样做是不可行的,因为神经网络的参数数量通常不少于几千个,有时甚至高达数十亿个。
或者,您可以使用本节开头概述的四步算法:根据随机数据批次上的当前损失值,逐步调整参数。由于您处理的是可微函数,因此可以计算其梯度,从而有效地实现步骤 4。如果您沿与梯度相反的方向更新权重,则每次损失都会略微减少:
- 绘制一批训练样本
x和相应的目标y_true。 - 运行模型
x以获得预测结果y_pred(这称为前向传递)。 - 计算模型在该批次上的损失,衡量模型
y_pred与目标之间的不匹配程度y_true。 - 计算损失函数相对于模型参数的梯度(这称为反向传播)。
- 将参数稍微向梯度相反的方向移动——例如
W -= learning_rate * gradient——从而略微降低批次的损失。学习率(learning_rate此处)是一个标量因子,用于调节梯度下降过程的“速度”。
很简单!我们刚才描述的方法叫做 小批量随机梯度下降(mini-batch stochastic gradient descent)(mini-batch SGD)。“随机”一词指的是每个数据批次都是随机抽取的(“随机”是“随机”的科学同义词 stochastic is a scientific synonym of random)。图 2.18 展示了在 1D 情况下,当模型只有一个参数且只有一个训练样本时会发生什么。
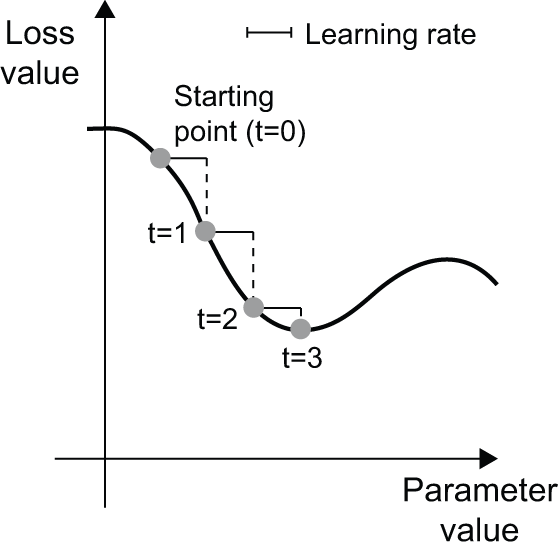
我们可以直观地看出,选择一个合理的learning_rate因子值非常重要。如果因子太小,沿着曲线下降的过程需要多次迭代,并且可能陷入局部最小值。如果learning_rate因子太大,更新操作最终可能会将你带到曲线上完全随机的位置。
注意,小批量随机梯度下降算法的一个变体是在每次迭代中只抽取一个样本和目标值,而不是抽取一批数据。这才是真正的随机梯度下降(而非小批量随机梯度下降)。或者,走向另一个极端,你可以对所有可用数据进行每次迭代,这被称为批量梯度下降。每次更新都会更加精确,但计算成本也更高。在这两种极端情况之间取得有效平衡的方法是使用大小合理的小批量数据。
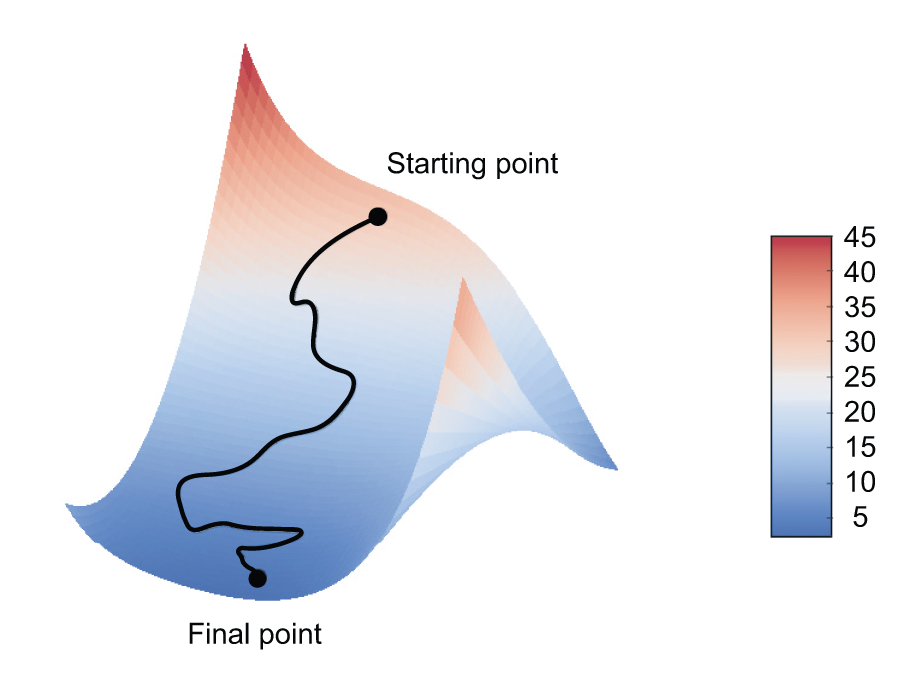
尽管图 2.18 展示了一维参数空间中的梯度下降,但在实践中,梯度下降通常是在高维空间中进行的:神经网络中的每个权重系数都是空间中的一个自由维度,而且可能存在数万甚至数百万个权重系数。为了帮助你建立对损失函数的直观理解,你也可以将梯度下降可视化为二维损失函数,如图 2.19 所示。但是,你不可能直观地看到神经网络训练的实际过程——你无法用人类能够理解的方式来表示一个百万维空间。因此,需要记住的是,你通过这些低维表示所建立的直觉在实践中可能并不总是准确的。这在深度学习研究领域一直是一个问题。
此外,随机梯度下降法(SGD)存在多种变体,它们的区别在于,在计算下一次权重更新时,会考虑之前的权重更新,而不仅仅是当前的梯度值。例如,有带动量的SGD,以及Adagrad、RMSprop等其他一些算法。这些变体被称为优化方法或 优化器。尤其值得关注的是动量的概念,它在许多变体中都有应用。动量解决了SGD的两个问题:收敛速度和局部最小值。图2.20展示了损失函数随模型参数变化的曲线。
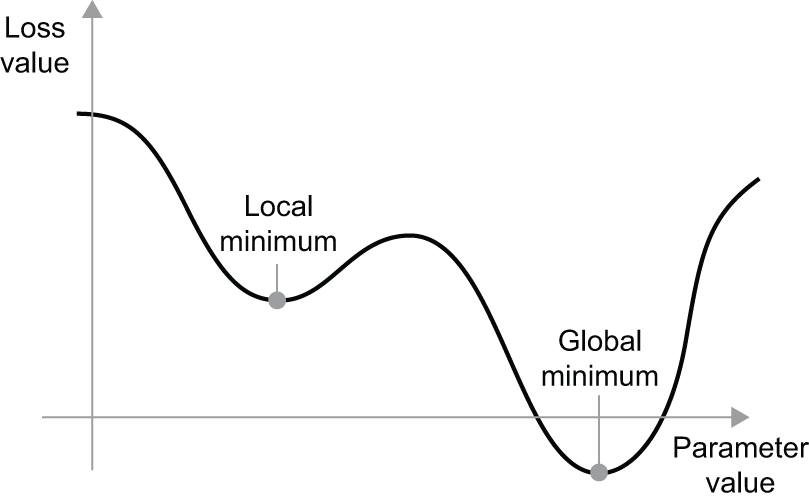
如您所见,在某个参数值附近存在一个局部最小值:在该点附近,向左移动会导致损失增加,向右移动也会导致损失增加。如果使用学习率较小的随机梯度下降法 (SGD) 来优化该参数,那么优化过程就会陷入局部最小值,而无法找到全局最小值。
你可以利用动量来避免这类问题,动量的概念源于物理学。一个有用的形象比喻是将优化过程想象成一个小球沿着损失曲线滚动。如果动量足够大,小球就不会陷入困境,最终会到达全局最小值。动量的实现方式是,在每一步中,不仅根据当前的斜率值(当前加速度),还根据当前的速度(由过去的加速度决定)来移动小球。实际上,这意味着w不仅要根据当前的梯度值来更新参数,还要根据之前的参数更新来更新参数,例如以下这个简单的实现:
1 | past_velocity = 0.0 |
导数链式求解:反向传播算法
Chaining derivatives: The Backpropagation algorithm
在前面讨论的算法中,我们想当然地认为,既然函数可微,就可以轻松计算其梯度。但事实果真如此吗?在实践中,我们如何计算复杂表达式的梯度?在我们之前提到的双层网络示例中,如何获得损失函数关于权重的梯度?这就需要用到反向传播算法了。
链式法则
The chain rule
反向传播是一种利用简单运算(例如加法、relu张量积等)的导数来轻松计算任意复杂组合的梯度的方法。关键在于,神经网络由许多串联的张量运算组成,每个运算都有简单且已知的导数。例如,我们第一个示例中的模型可以表示为一个由变量W1、b1、W2和b2 (分别属于第一层和第二Dense层)参数化的函数,其中包含原子运算matmul、relu、softmax和+,以及我们的损失函数 ,loss所有这些都很容易微分:
1 | loss_value = loss( |
微积分告诉我们,这样的函数链可以用以下恒等式推导出来,称为链式法则。考虑两个函数f和g,以及复合函数 , fg使得y = fg(x) == f(g(x)):
1 | def fg(x): |
然后,链式法则指出,。这使得只要知道和的导数grad(y, x) == grad(y, x1) * grad(x1, x),就可以计算的导数。链式法则之所以这样命名,是因为当你添加更多中间函数时,它看起来就像一条链子:fg``f``g
1 | def fghj(x): |
将链式法则应用于神经网络梯度值的计算,就产生了一种称为反向传播的算法。让我们具体看看它是如何运作的。
利用计算图进行自动微分
Automatic differentiation with computation graphs
理解反向传播的一个有效方法是将其视为计算图。计算图是深度学习革命的核心数据结构。它是一个有向无环图,表示操作——在我们的例子中,是张量操作。例如,图 2.21 展示了我们第一个模型的计算图表示。
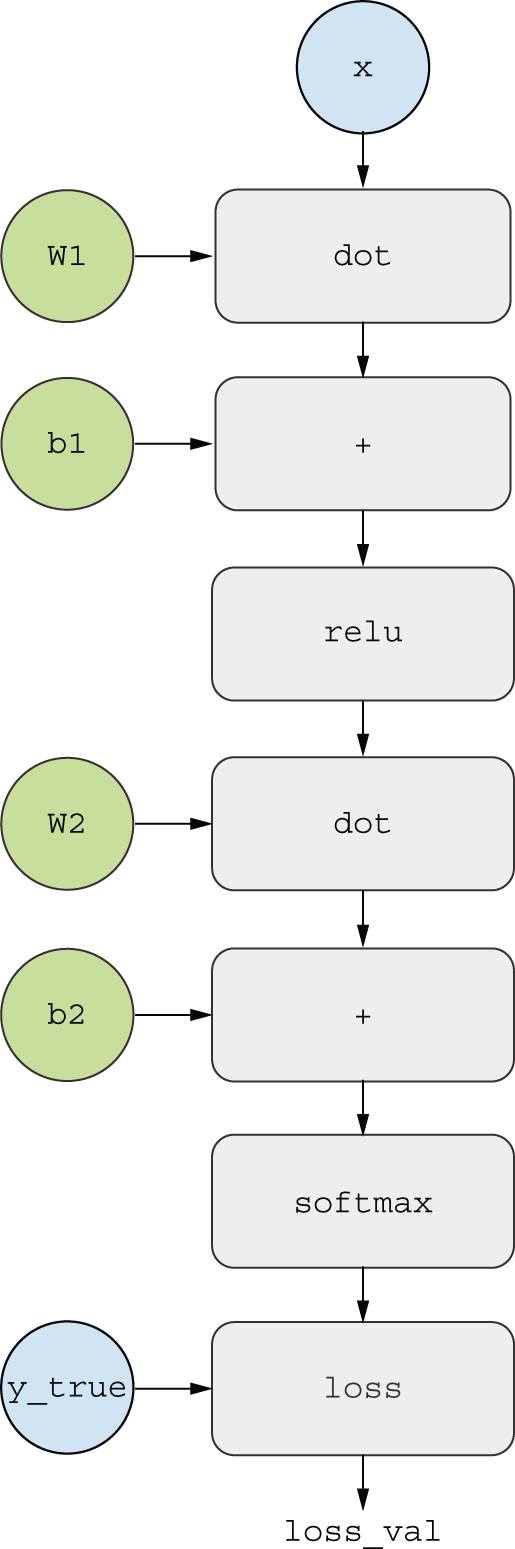
计算图在计算机科学中是一种极其成功的抽象概念,因为它使我们能够将计算视为数据:一个可计算表达式被编码为机器可读的数据结构,可以作为另一个程序的输入或输出。例如,你可以想象一个程序接收一个计算图,并返回一个新的计算图,该计算图实现了同一计算的大规模分布式版本——这意味着你可以分发任何计算,而无需自己编写分发逻辑。或者想象一下……一个程序接收一个计算图,并能自动生成它所表示表达式的导数。如果你的计算被表达为显式的图数据结构,而不是例如.py文件中的 ASCII 字符行,那么实现这些操作就容易得多。
为了更清晰地解释反向传播,我们来看一个非常简单的计算图示例。我们将考虑图 2.21 的简化版本,其中只有一个线性层,所有变量均为标量,如图 2.22 所示。我们将取两个标量变量 w和 ,b一个标量输入x,并对它们进行一些运算,将它们组合成一个输出y。最后,我们将应用绝对值误差损失函数: 。由于我们希望以最小化 的方式loss_val = abs(y_true - y)来更新w和,因此我们关注的是计算 和。b``loss_val``grad(loss_val, b)``grad(loss_val, w)
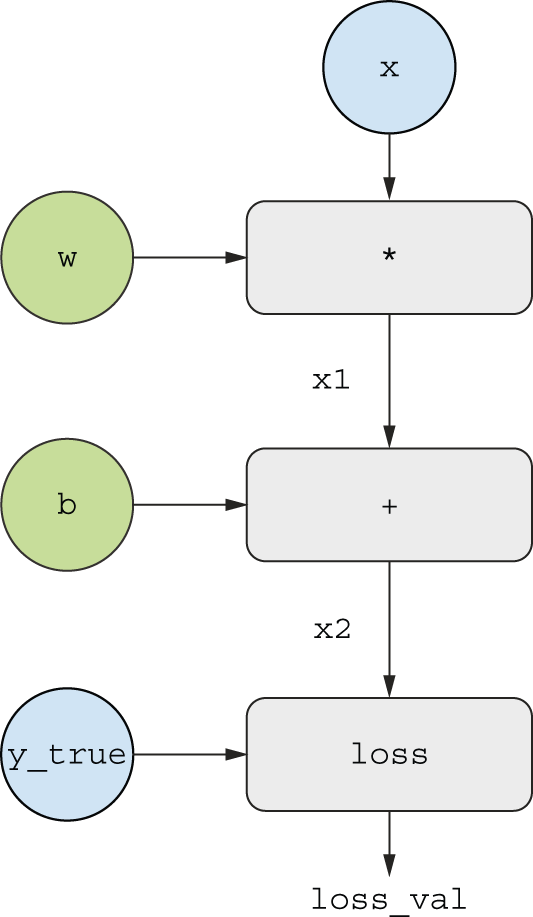
让我们为图中的“输入节点”设定具体值——即输入值x、目标值y_true和(图 2.23 w)b。我们将这些值从上到下传播到图中的所有节点,直到到达loss_val。这就是前向传播。
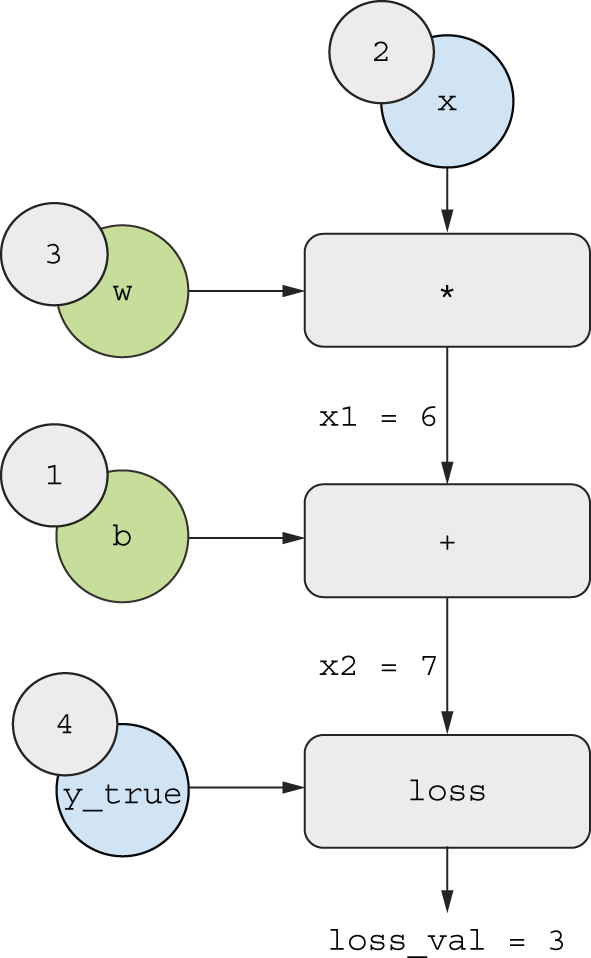
现在让我们“反转”这个图:对于图中每条从A 到 的边B,我们创建一个从B到 的反向边,并提出问题:“当 变化时, 变化A多少 ?”也就是说, 是多少?我们将用这个值标记每条反向边(图 2.24)。这个反向图表示反向传递过程。B``A``grad(B, A)
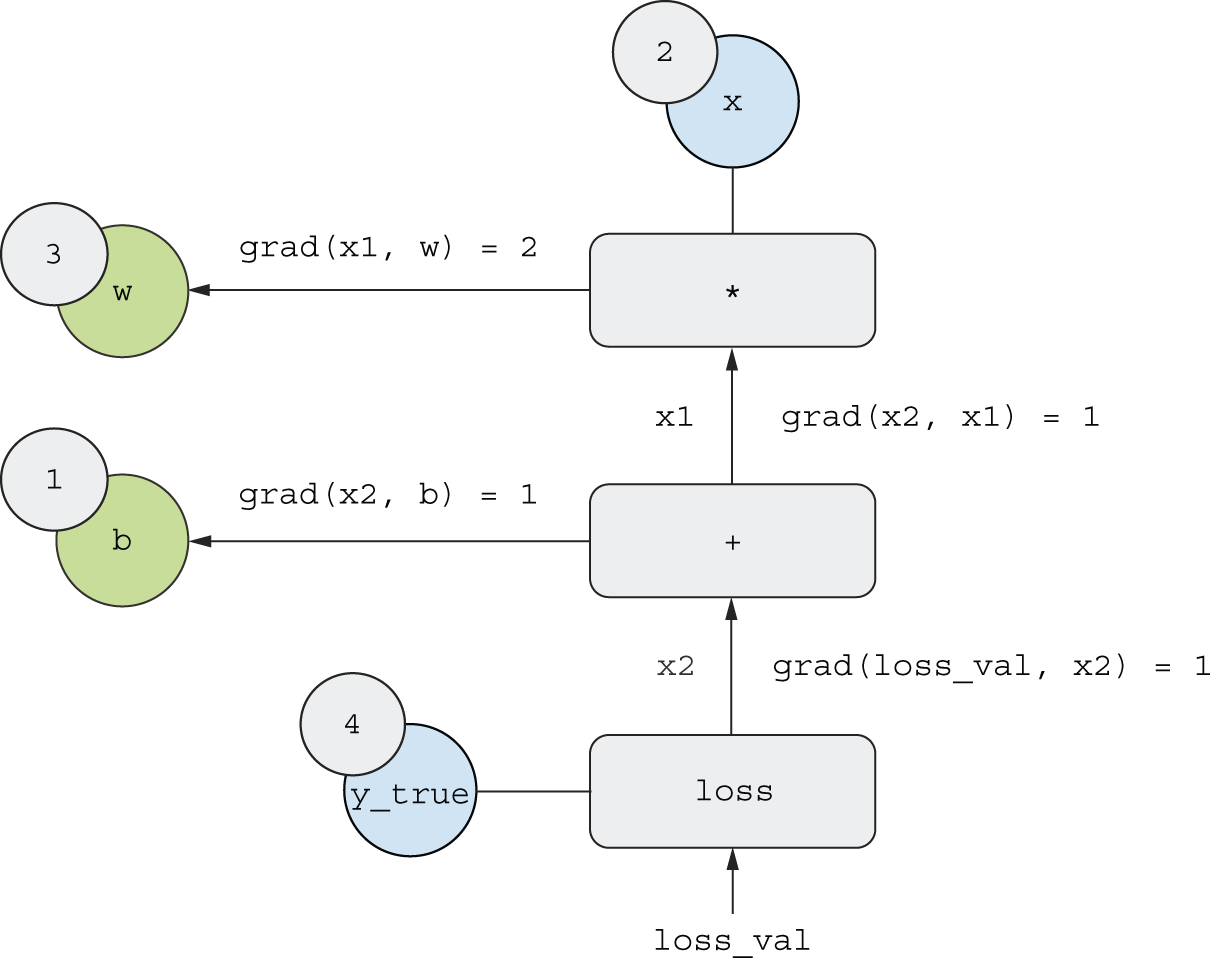
我们有
grad(loss_val, x2) = 1因为当x2变化量为ε时,loss_val = abs(4 - x2)变化量也为ε。grad(x2, x1) = 1因为当x1变化量为ε时,x2 = x1 + b = x1 + 1变化量也为ε。grad(x2, b) = 1因为当b变化量为ε时,x2 = x1 + b = 6 + b变化量也为ε。grad(x1, w) = 2因为w随着ε的变化而变化,x1 = x * w = 2 * w变化量为2 * epsilon。
链式法则在这个反向图中表明,你可以通过 将连接两个节点的路径上每条边的导数相乘来获得一个节点相对于另一个节点的导数。例如, grad(loss_val, w) = grad(loss_val, x2) * grad(x2, x1) * grad(x1, w)。
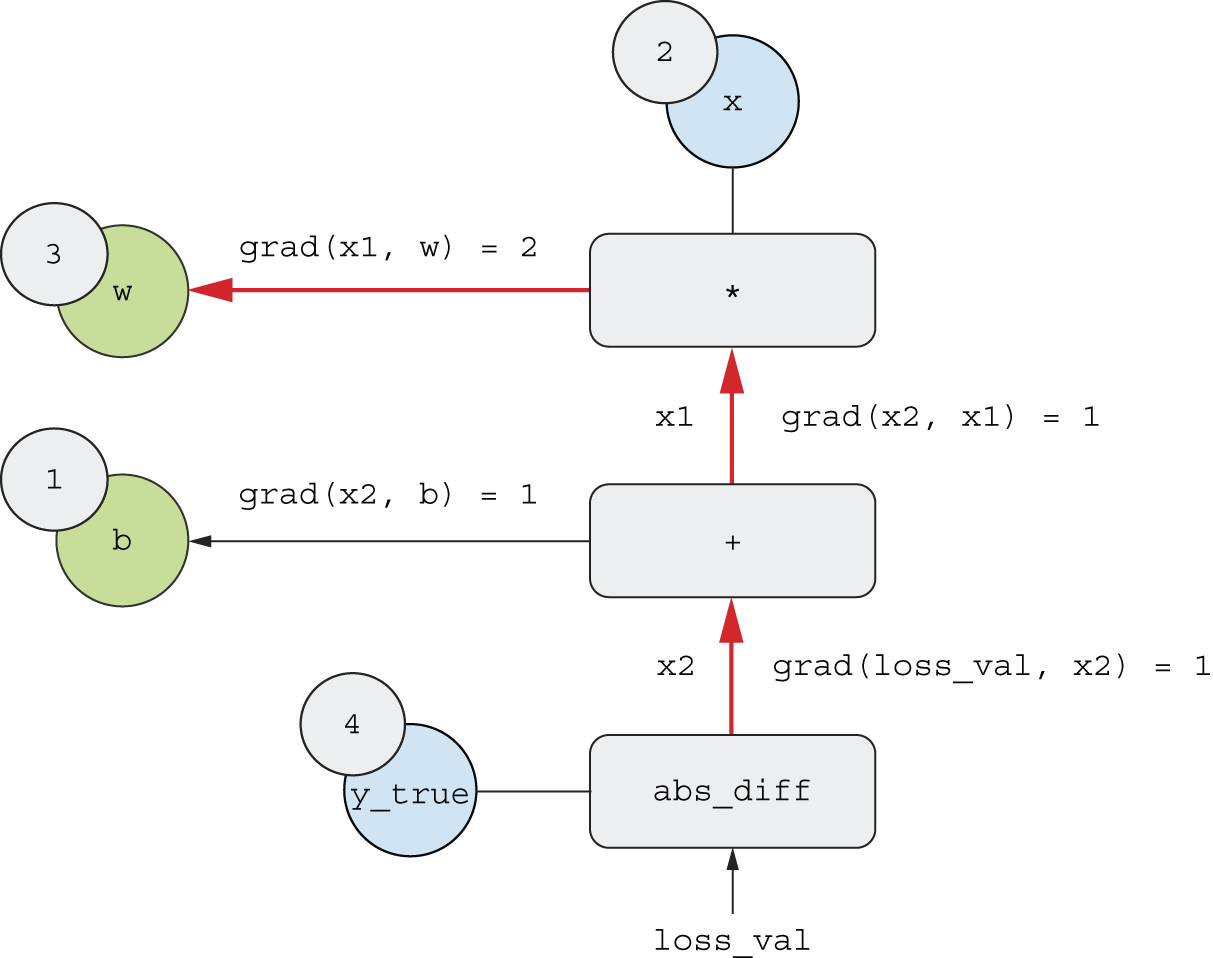
通过对我们的图应用链式法则,我们得到了我们想要的结果:
grad(loss_val, w) = 1 * 1 * 2 = 2grad(loss_val, b) = 1 * 1 = 1
如果在反向图中,连接两个感兴趣的节点有多条路径,我们将a通过对所有路径的贡献求和来获得结果。b``grad(b, a)
就这样,你刚才就看到了反向传播的实际应用!反向传播其实就是将链式法则应用于计算图。就这么简单。反向传播从最终损失值开始,从顶层到底层反向传播,计算每个参数对损失值的贡献。这就是“反向传播”名称的由来:我们将计算图中不同节点的损失贡献“反向传播”出去。
如今,人们使用诸如 JAX、TensorFlow 和 PyTorch 等支持自动微分的现代框架来实现神经网络。自动微分是通过之前介绍的计算图实现的。自动微分使得无需额外操作(只需编写前向传播过程)即可获取任意可微张量运算组合的梯度。2000 年代我用 C 语言编写第一个神经网络时,还得手动计算梯度。现在,得益于现代自动微分工具,你再也不用自己实现反向传播了。真是太幸运了!
回顾我们的第一个例子
Looking back at our first example
本章即将结束,您现在应该对神经网络的工作原理有了大致的了解。本章开头那个神秘的黑盒子现在已经变得清晰明了,如图 2.26 所示:模型由多个层级串联而成,它将输入数据映射到预测结果。损失函数随后将这些预测结果与目标值进行比较,生成一个损失值:该值衡量模型预测结果与预期结果的匹配程度。优化器使用这个损失值来更新模型的权重。
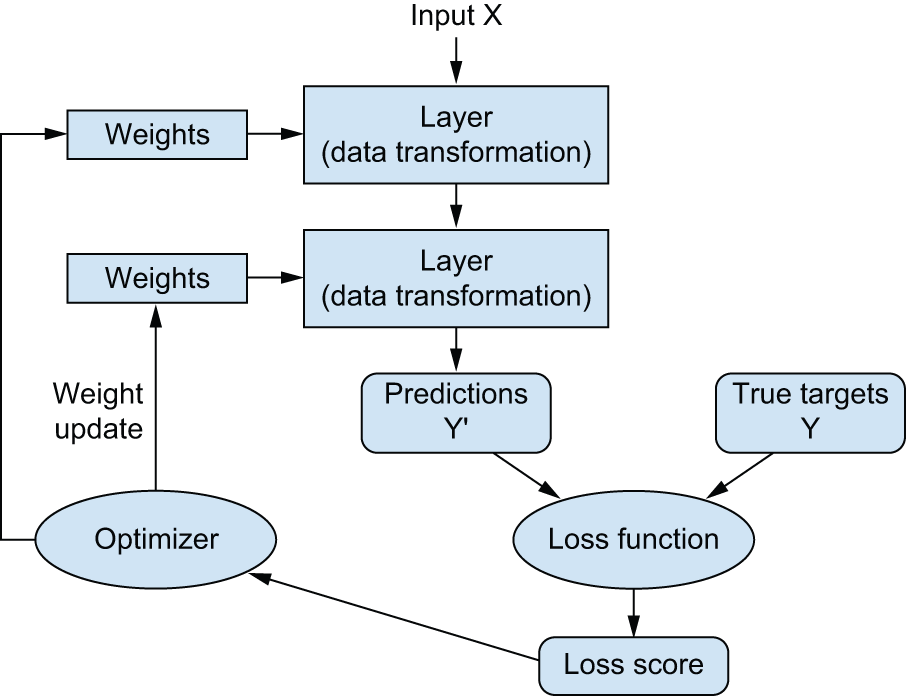
让我们回到第一个例子,并根据你在前面章节中学到的知识,逐一回顾其中的各个部分。
以下是输入数据:
1 | (train_images, train_labels), (test_images, test_labels) = mnist.load_data() |
现在你应该明白,输入图像存储在 NumPy 张量中,这里分别格式化为float32形状为(60000, 784) (训练数据)和(10000, 784)(测试数据)的张量。
这是我们的模型:
1 | model = keras.Sequential( |
现在您应该明白,这个模型由两层组成Dense,每一层都对输入数据应用一些简单的张量运算,而这些运算都涉及权重张量。权重张量是各层的属性,模型的知识就蕴藏在这些张量之中。
这是模型编译步骤:
1 | model.compile( |
现在您应该明白,"sparse_categorical_crossentropy"损失函数用作学习权重张量的反馈信号,训练阶段的目标是最小化该损失。您也知道,损失的减少是通过小批量随机梯度下降实现的。梯度下降的具体使用规则由"adam"作为第一个参数传递的优化器定义。
最后,这就是训练循环:
1 | model.fit( |
现在您应该明白调用该函数后会发生什么了fit:模型将开始以 128 个样本为一组的小批量对训练数据进行迭代,重复 5 次(每次迭代对所有训练数据进行一次称为一个epoch)。对于每个小批量,模型将计算损失函数相对于权重的梯度(使用反向传播算法,该算法源于微积分中的链式法则),并调整权重以减小该小批量的损失值。
经过这 5 个 epoch 后,该模型将执行 2,345 次梯度更新(每个 epoch 469 次),模型的损失将足够低,以至于该模型能够以较高的准确率对手写数字进行分类。
至此,你已经掌握了神经网络的大部分知识。让我们通过逐步重现第一个示例的简化版本来证明这一点,全程只使用底层操作。
从头开始重新实现我们的第一个示例
Reimplementing our first example from scratch
还有什么比从零开始实现所有功能更能展现全面、清晰的理解呢?当然,“从零开始”在这里是相对的:我们不会重新实现基本的张量运算,也不会实现反向传播。但我们会深入到非常底层,让每个计算步骤都清晰明了。
如果你现在还不能完全理解这个例子中的每一个细节,别担心。下一章会更深入地讲解 Keras API。现在,你只需要把握整体思路——这个例子的目的是通过具体的实现来帮助你更好地理解深度学习的数学原理。开始吧!
一个简单的 Dense 类
A simple Dense class
您之前已经了解到,该Dense层实现了以下输入变换,其中W和b是模型参数,activation 是一个逐元素函数(通常为relu):
1 | output = activation(matmul(input, W) + b) |
让我们实现一个简单的 Python 类NaiveDense,该类创建两个 Keras 变量W,b并公开一个__call__()应用上述转换的方法:
1 | # keras.ops is where you will find all the tensor operations you need. |
一个简单的 Sequential 类
A simple Sequential class
现在,我们来创建一个NaiveSequential类来串联这些层。它封装了一个层列表,并公开了一个__call__()方法,该方法会按顺序调用底层层对输入的处理。它还提供了一个weights属性,方便跟踪各层的参数:
1 | class NaiveSequential: |
利用这NaiveDense两个类NaiveSequential,我们可以创建一个模拟的 Keras 模型:
1 | model = NaiveSequential( |
批处理生成器
A batch generator
接下来,我们需要一种方法来分批遍历 MNIST 数据。这很容易:
1 | import math |
跑一个训练步骤
Running one training step
整个过程中最困难的部分是“训练步骤”:在用一批数据运行模型后,更新模型的权重。我们需要……
- 计算模型对批次中图像的预测结果。
- 计算给定实际标签时这些预测的损失值
- 计算损失函数关于模型权重的梯度
- 将权重沿梯度相反的方向略微移动一点。
1 | def one_training_step(model, images_batch, labels_batch): |
清单 2.9:单步训练
权重更新步骤
The weight update step
如您所知,“权重更新”步骤(由函数表示)的目的update_weights()是将权重向能够减少此批次损失的方向移动“一点”。移动的幅度由“学习率”决定,通常是一个较小的值。实现此update_weights()函数的最简单方法是从每个权重中减去gradient * learning_rate:
1 | learning_rate = 1e-3 |
实际上,你几乎永远不会手动实现这样的权重更新步骤。相反,你会使用OptimizerKeras 中的一个实例,就像这样:
1 | from keras import optimizers |
梯度计算
Gradient computation
现在,我们还缺少一样东西:梯度计算(如get_gradients_of_loss_wrt_weights()清单 2.9 中的函数所示)。在前一节中,我们概述了如何使用链式法则,根据函数链中各个函数的导数来计算它们的梯度,这个过程称为反向传播。我们可以从头开始重新实现反向传播,但这会相当繁琐,尤其因为我们使用了softmax运算和交叉熵损失,它们的导数都相当冗长。
相反,我们可以依赖 Keras 支持的底层框架(例如 TensorFlow、JAX 或 PyTorch)内置的自动微分机制。为了便于举例,我们这里选择 TensorFlow。您将在下一章中了解更多关于 TensorFlow、JAX 和 PyTorch 的内容。
您可以使用 TensorFlow 的自动微分功能,而实现此功能的 API 就是 TensorFlow_Driving``tf.GradientTape对象。它是一个 Python 作用域,会以计算图(有时称为磁带)的形式“记录”其中运行的张量运算。然后,可以使用此图来检索任何标量值相对于任何输入值集的梯度:
1 | import tensorflow as tf |
让我们one_training_step()使用 TensorFlow重写我们的函数GradientTape (无需编写单独的get_gradients_of_loss_wrt_weights()函数):
1 | def one_training_step(model, images_batch, labels_batch): |
现在我们的分批次训练步骤已经准备就绪,我们可以继续实施整个训练周期。
完整的训练循环
The full training loop
一次训练周期(epoch)就是对训练数据中的每个批次重复训练步骤,而完整的训练循环就是重复一次训练周期:
1 | def fit(model, images, labels, epochs, batch_size=128): |
我们来试驾一下:
1 | from keras.datasets import mnist |
模型评估
Evaluating the model
argmax我们可以通过计算模型对测试图像的预测结果,并将其与预期标签进行比较来评估模型:
1 | >>> predictions = model(test_images) |
大功告成!正如你所见,用几行 Keras 代码就能完成的事情,手动操作却相当费时费力。但正因为你完成了这些步骤,现在你应该对调用神经网络时内部的运作机制有了清晰的理解fit()。有了这种底层逻辑的理解,你就能更好地利用 Keras API 的高级功能。
概括
- 张量是现代机器学习系统的基础。它们有多种形式
dtype,例如rank、 和shape。 - 你可以通过张量运算 (例如加法、张量积或逐元素乘法)来操作数值张量,这些运算可以解释为编码几何变换。总的来说,深度学习中的一切都可以进行几何解释。
- 深度学习模型由一系列简单的张量运算组成,这些运算由权重参数化,而权重本身也是张量。模型的“知识”就存储在权重中。
- 学习是指找到一组模型权重值,使得给定一组训练数据样本及其对应目标的损失函数最小化。
- 学习过程通过随机抽取数据样本及其目标值批次,并计算模型参数相对于该批次损失的梯度来实现。然后,模型参数会沿梯度的反方向移动一小段距离(移动的幅度由学习率决定)。这被称为小批量梯度下降。
- 整个学习过程之所以成为可能,是因为神经网络中的所有张量运算都是可微的,因此可以应用链式求导法则来找到将当前参数和当前数据批次映射到梯度值的梯度函数。这被称为反向传播。
- 在后续章节中,你会频繁看到两个关键概念:损失函数和 优化器。在开始将数据输入模型之前,你需要先定义这两个概念:
- 损失是你在训练过程中试图最小化的量,因此它应该代表你试图解决的任务的成功程度。
- 优化器指定损失梯度将用于更新参数的确切方式:例如,它可以是 RMSProp 优化器、带动量的 SGD 等。
书籍各章的机翻md文件:
《DEEP LEARNING with Python》第一章 什么是深度学习?
《DEEP LEARNING with Python》第二章 神经网络的数学基础
《DEEP LEARNING with Python》第三章 TensorFlow、PyTorch、JAX 和 Keras 简介
《DEEP LEARNING with Python》第四章 分类与回归
《DEEP LEARNING with Python》第五章 机器学习基础
《DEEP LEARNING with Python》第六章 机器学习的通用工作流程
《DEEP LEARNING with Python》第七章 深入了解 Keras
《DEEP LEARNING with Python》第八章 图像分类
《DEEP LEARNING with Python》第九章 卷积神经网络架构模式
《DEEP LEARNING with Python》第十章 解读卷积神经网络的学习成果
《DEEP LEARNING with Python》第十一章 图像分割
《DEEP LEARNING with Python》第十二章 目标检测
《DEEP LEARNING with Python》第十三章 时间序列预测
《DEEP LEARNING with Python》第十四章 文本分类
《DEEP LEARNING with Python》第十五章 语言模型和Transformer
《DEEP LEARNING with Python》第十六章 文本生成
《DEEP LEARNING with Python》第十七章 图像生成
《DEEP LEARNING with Python》第十八章 现实世界的最佳实践
《DEEP LEARNING with Python》第十九章 人工智能的未来
《DEEP LEARNING with Python》第二十章 结论