《Introduction to Probability》第13章 泊松过程
第13章 泊松过程
Poisson processes
泊松过程是事件在时间或空间中发生的简单模型:在一维中,它可以是汽车经过公路检查站;在二维中,是草地上的花朵;在三维中,是星系某个区域内的恒星。泊松过程是更复杂的时间和空间过程的首要构建模块,而这些过程是统计学的一个分支——空间统计学(spatial statistics)的焦点。
泊松过程在概率论中也非常有用,因为它们将许多命名分布联系在一起,并为一些原本推导过程乏味的结果提供了富有洞察力的故事证明。这引出了一种我们将要展示的新解题策略:即使一个问题没有提到泊松过程,有时也可以通过假定随机变量来自某个泊松过程,从而利用便利的泊松过程性质来解题。
在本章中,我们将回顾已经熟悉的一维泊松过程定义,推导并讨论一维泊松过程的三个重要性质,然后将这些性质扩展到更高维度的泊松过程。
13.1 一维泊松过程
Poisson processes in one dimension
在 5.6 节中,我们定义了一维泊松过程并证明了其到达间隔时间(interarrival times)是独立同分布的指数分布。在第 8 章中,我们证明了第 \(j\) 次到达的时间(相对于某个固定的起始时间)服从 Gamma 分布。让我们回顾一下这些结果,并使用有助于推广到高维的符号。
定义 13.1.1(一维泊松过程)。如果满足以下条件,则连续时间内的序列到达是速率为 \(\lambda\) 的泊松过程:
- 长度为 \(t\) 的区间内的到达次数服从 \(Pois(\lambda t)\) 分布。
- 不相交时间区间内的到达次数是相互独立的。
通常我们假设时间轴始于 \(t = 0\),在这种情况下,我们在 \((0, \infty)\) 上有一个泊松过程;但如果我们需要时间轴双向无限,也可以使用相同的条件在 \((-\infty, \infty)\) 上定义泊松过程。
考虑 \((0, \infty)\) 上的一个泊松过程。稍微偏离前几章的符号,令 \(N(t)\) 为 \((0, t]\) 内的到达次数。那么对于 \(0 < t_1 < t_2\),\((t_1, t_2]\) 内的到达次数为 \(N(t_2) - N(t_1)\)。令 \(T_j\) 为第 \(j\) 次到达的时间。由于 \(T_1 > t\) 与 \(N(t) = 0\) 是同一个事件(根据 5.6 节讨论的计数-时间二元性): \[ P(T_1 > t) = P(N(t) = 0) = e^{-\lambda t} \]
因此 \(T_1 \sim Expo(\lambda)\)。接着,让我们以第一次到达时间 \(T_1\) 为条件,观察直到第二次到达所需的额外时间 \(T_2 - T_1\)。那么: \[ (T_2 - T_1) | T_1 \sim Expo(\lambda) \]
根据同样的论证,因为在 \(T_1\) 处开始了一个全新的泊松过程。由于 \((T_2 - T_1) | T_1\) 的条件分布不依赖于 \(T_1\),我们得到 \(T_2 - T_1\) 独立于 \(T_1\),因此 \(T_2 - T_1\) 无条件地也服从 \(Expo(\lambda)\)。
以此类推,到达间隔时间 \(T_j - T_{j-1}\) 是相互独立的,且 \(T_j - T_{j-1} \sim Expo(\lambda)\)。
因此,泊松过程可以从两方面描述:既是到达计数服从泊松分布的过程,也是到达间隔时间服从指数分布的过程。还要注意,由于 \(T_j\) 是 \(j\) 个独立同分布的 \(Expo(\lambda)\) 随机变量之和: \[ T_j \sim Gamma(j, \lambda) \]
这种与指数分布的联系为我们提供了一种生成泊松过程 \(n\) 次到达的简单方法。
故事 13.1.2(一维泊松过程的生成故事)。要在速率为 \(\lambda\) 的 \((0, \infty)\) 泊松过程中生成 \(n\) 次到达:
生成 \(n\) 个独立同分布的 \(Expo(\lambda)\) 随机变量 \(X_1, \dots, X_n\)。
对于 \(j = 1, \dots, n\),设置 \(T_j = X_1 + \dots + X_j\)。
那么我们可以将 \(T_1, \dots, T_n\) 作为到达时间。
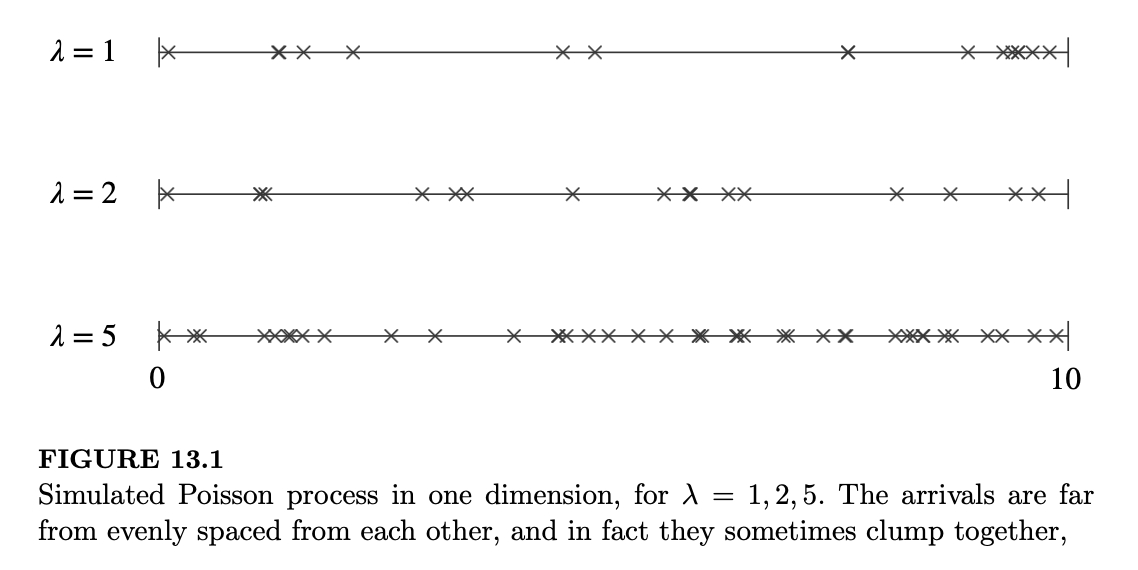
图 13.1 描绘了速率分别为 1、2 和 5 的三个泊松过程的实现,绘制时间截至时间 10。在这三种情况下,我们都可以看到,尽管到达间隔时间是独立同分布的,但到达并不是均匀分布的。相反,到达间隔时间存在很大的波动性,这产生了到达的簇。这种现象被称为泊松丛集(Poisson clumping)。观察到几个在时间上靠得很近的到达簇似乎是一个惊人的巧合,但泊松丛集理论认为,在泊松过程中出现这样的簇是很常见的。
13.2 条件、叠加与稀疏
Conditioning, superposition, and thinning
理解泊松过程最重要的三个性质是条件、叠加和稀疏。这些性质与我们已经见过的泊松分布的性质相对应,因此它们应该是易于理解的。
13.2.1 条件性质
Conditioning
当我们选取一个泊松过程并以一个区间内的事件总数为条件时会发生什么?我们的第一个结果是:在给定一个区间内事件总数的条件下,固定子区间内的事件数量服从二项分布。这遵循定理 4.8.2,我们在那里证明了通过条件化可以从泊松分布得到二项分布。
定理 13.2.1(条件计数 Conditional counts)。令 \((N(t) : t > 0)\) 为速率为 \(\lambda\) 的泊松过程,且 \(t_1 < t_2\)。在给定 \(N(t_2) = n\) 的条件下,\(N(t_1)\) 的条件分布为: \[ N(t_1) | N(t_2) = n \sim Bin\left(n, \frac{t_1}{t_2}\right) \]
证明。图 13.2 展示了这一设定。该主张是:在已知 \((0, t_2]\) 内共有 \(n\) 次到达的条件下,\((0, t_1]\) 内的到达次数服从二项分布,试验次数为 \(n\),成功概率正比于 \(t_1\)。
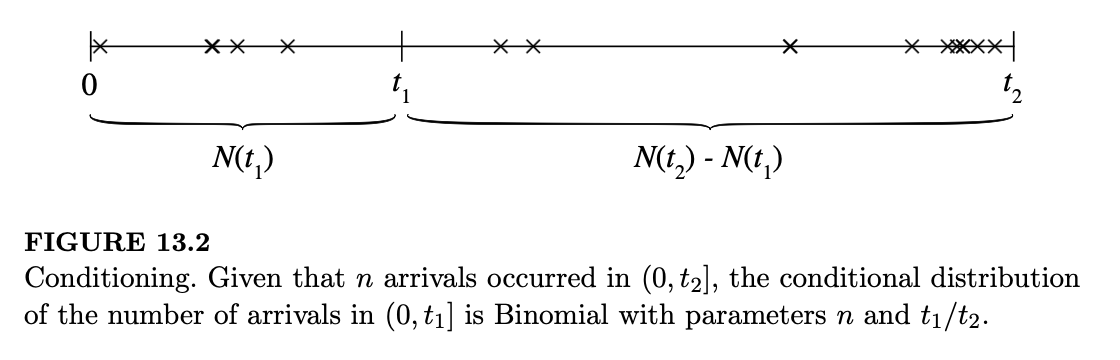
由于 \((0, t_1]\) 和 \((t_1, t_2]\) 是不相交的,\(N(t_1)\) 独立于 \(N(t_2) - N(t_1)\)。前者服从 \(Pois(\lambda t_1)\),后者服从 \(Pois(\lambda(t_2 - t_1))\),它们的和即为 \((0, t_2]\) 内的到达总数 \(N(t_2)\)。根据定理 4.8.2: \[ N(t_1) | N(t_2) = n \sim Bin\left(n, \frac{\lambda t_1}{\lambda t_1 + \lambda(t_2 - t_1)}\right) \]
这恰好是我们想要证明的。
进一步深化对到达次数进行条件化的想法,我们得到了以下惊人的结果:在一个泊松过程中,给定 \(N(t) = n\),到达时间的分布表现得就像我们在 \((0, t)\) 上随机投下了 \(n\) 个独立同分布的 \(Unif(0, t)\) 点。
首先来看只有一个到达的简单情况。
命题 13.2.2。在速率为 \(\lambda\) 的泊松过程中,在给定 \(N(t) = 1\) 的条件下,第一次到达时间 \(T_1\) 服从 \(Unif(0, t)\) 分布。
证明。令 \(0 < s < t\)。根据计数-时间二元性的一种形式: \[ P(T_1 \leq s | N(t) = 1) = \frac{P(T_1 \leq s, N(t) = 1)}{P(N(t) = 1)} = \frac{P(N(s) = 1, N(t) - N(s) = 0)}{P(N(t) = 1)} \] \[ = \frac{(e^{-\lambda s} \lambda s)(e^{-\lambda(t-s)})}{e^{-\lambda t} \lambda t} = \frac{s}{t} \]
因此,\(T_1\) 给定 \(N(t) = 1\) 的条件累积分布函数(CDF)即为 \(Unif(0, t)\) 的 CDF。
更一般地,给定 \(N(t) = n\),到达时间 \(T_j\) 的表现就像 \(n\) 个独立同分布的 \(Unif(0, t)\) 随机变量的顺序统计量。我们略去证明,因为在第 8 章引入顺序统计量时,我们专注于它们的边缘分布。
定理 13.2.3(条件时间Conditional times)。在速率为 \(\lambda\) 的泊松过程中,在给定 \(N(t) = n\) 的条件下,到达时间 \(T_1, \dots, T_n\) 的联合分布与 \(n\) 个独立同分布的 \(Unif(0, t)\) 随机变量的顺序统计量的联合分布相同。
从第 8 章我们知道,\(Unif(0, 1)\) 随机变量的顺序统计量服从 Beta 分布,因此 \(T_j\) 的条件分布是缩放后的 Beta 分布;为了得到标准的 Beta 分布,我们只需将 \(T_j\) 除以 \(t\),使其支撑集变为 \((0, 1)\): \[ t^{-1} T_j | N(t) = n \sim Beta(j, n - j + 1) \]
现在我们有了另一种生成泊松过程到达的方法,这次是针对特定区间而不是特定的到达次数。
故事 13.2.4(泊松过程生成故事,版本 2)。要在区间 \((0, t]\) 内生成速率为 \(\lambda\) 的泊松过程到达:
- 生成该区间内的事件总数 \(N(t) \sim Pois(\lambda t)\)。
- 给定 \(N(t) = n\),生成 \(n\) 个独立同分布的 \(Unif(0, t)\) 随机变量 \(U_1, \dots, U_n\)。
- 对于 \(j = 1, \dots, n\),令 \(T_j = U_{(j)}\)(即第 \(j\) 小的 \(U\) 值)。
这实际上是我们用来创建图 13.1 的生成故事,因为我们知道要在区间 \((0, 10]\) 内进行模拟。
例 13.2.5(网站用户)。用户根据速率为 \(\lambda_1\) 人/分钟的泊松过程访问某个网站。在特定时间“到达”意味着此时有人开始浏览该网站。到达网站后,每个用户浏览网站的时间服从 \(Expo(\lambda_2)\)(然后离开),且各用户之间相互独立。
假设在时间 0 时,没有人在使用该网站。令 \(N_t\) 为在区间 \((0, t]\) 内到达的用户数量,\(C_t\) 为在时间 \(t\) 正在浏览网站的用户数量。
令 \(X\) 为在 \([0, t]\) 均匀分布的时间点到达的用户的到达时间,\(Y\) 为其离开时间。求 \(X\) 和 \(Y\) 的联合 PDF。
令 \(p_t\) 为在 \((0, t]\) 内均匀分布的时间点到达的用户在时间 \(t\) 仍在浏览网站的概率。求 \(p_t\)。
根据 \(\lambda_1, \lambda_2\) 和 \(t\) 求 \(C_t\) 的分布。
利特尔法则(Little's law)是一个非常通用的结果,表述如下:一个稳定系统中的长期平均客户数等于长期平均到达率乘以客户在系统中的平均停留时间。解释当 \(t\) 很大时 \(E(C_t)\) 的变化,以及如何根据利特尔法则来解释这一结果。
解:
我们有 \(X \sim Unif(0, t)\)。给定 \(X=x\),\(Y\) 是从 \(x\) 开始偏移的 \(Expo(\lambda_2)\) 随机变量,即 \((Y-x)|(X=x) \sim Expo(\lambda_2)\)。因此 \(X\) 和 \(Y\) 的联合 PDF 为: \[ f(x, y) = f_X(x)f_{Y|X}(y|x) = \frac{1}{t} \lambda_2 e^{-\lambda_2(y-x)}, \text{ 对于 } 0 < x < t \text{ 且 } x < y \]
使用 (a) 中的符号,我们想求 \(p_t = P(Y > t)\)。这可以通过在所有满足 \(y > t\) 的 \((x, y)\) 区域上对联合 PDF 进行积分得到: \[ P(Y > t) = \int_{0}^{t} \int_{t}^{\infty} \frac{1}{t} \lambda_2 e^{-\lambda_2(y-x)} dy dx = \frac{1}{t} \int_{0}^{t} e^{\lambda_2 x} \left[ \int_{t}^{\infty} \lambda_2 e^{-\lambda_2 y} dy \right] dx \] \[ = \frac{1}{t} \int_{0}^{t} e^{\lambda_2 x} e^{-\lambda_2 t} dx = \frac{e^{-\lambda_2 t}}{t} \int_{0}^{t} e^{\lambda_2 x} dx = \frac{1 - e^{-\lambda_2 t}}{\lambda_2 t} \]
根据定理 13.2.3,给定 \(N_t = n\),我们在 \((0, t]\) 内的 \(n\) 个到达时间在该区间内是独立同分布且均匀分布的。因此,\(C_t | N_t \sim Bin(N_t, p_t)\),其中 \(p_t\) 如上所述,且 \(N_t \sim Pois(\lambda_1 t)\)。根据“鸡蛋问题”故事(故事 7.1.9): \[ C_t \sim Pois(\lambda_1 p_t t) \]
即: \[ C_t \sim Pois\left( \frac{\lambda_1(1 - e^{-\lambda_2 t})}{\lambda_2} \right) \]
- 当 \(t \to \infty\) 时,\(E(C_t) \to \lambda_1/\lambda_2\)。这与利特尔法则一致,因为该法则指出系统中(正在浏览网站)的长期平均用户数等于用户到达率 (\(\lambda_1\)) 乘以用户单次会话的平均浏览时间 (\(1/\lambda_2\))。
13.2.2 叠加性质
Superposition
我们要研究的下一个性质是叠加:如果我们将两个独立的泊松过程重叠在一起,我们会得到另一个泊松过程。(合并后的过程本身就是一个泊松过程,但我们可以想象这些到达被贴上了标签,以指示它们来自哪一个基础过程。)
定理 13.2.6(叠加)。令 \((N_1(t) : t > 0)\) 和 \((N_2(t) : t > 0)\) 是速率分别为 \(\lambda_1\) 和 \(\lambda_2\) 的独立泊松过程。那么合并过程 \(N(t) = N_1(t) + N_2(t)\) 是一个速率为 \(\lambda_1 + \lambda_2\) 的泊松过程。
证明: 让我们验证泊松过程定义中的两个性质。
- 对于所有 \(t > 0\),\(N_1(t) \sim Pois(\lambda_1 t)\) 且 \(N_2(t) \sim Pois(\lambda_2 t)\),且两者独立,所以根据定理 4.8.1,\(N(t) \sim Pois((\lambda_1 + \lambda_2)t)\)。同样的论证适用于任何长度为 \(t\) 的区间。
- 合并过程中不相交区间的到达是独立的,因为它们在两个单独的过程中是独立的,且这两个过程本身也是相互独立的。
生成叠加过程有一种非常自然的方法。
故事 13.2.7(叠加生成的生成故事)。要生成速率为 \(\lambda_1\) 的独立泊松过程 \((N_1(t) : t > 0)\) 和速率为 \(\lambda_2\) 的 \((N_2(t) : t > 0)\) 的叠加:
- 从泊松过程 \((N_1(t) : t > 0)\) 中生成到达。
- 从泊松过程 \((N_2(t) : t > 0)\) 中生成到达。
- 将步骤 1 和 2 的结果叠加。
图 13.3 描绘了一个由 × 和 ⋄ 组成的叠加泊松过程。让我们称 × 为“1 类事件”,⋄ 为“2 类事件”。一个自然的问题是:观测到 1 类事件先于 2 类事件发生的概率是多少?

定理 13.2.8(1 类事件先于 2 类事件发生的概率)。考虑两个独立的泊松过程:速率为 \(\lambda_1\) 的 1 类到达过程,以及速率为 \(\lambda_2\) 的 2 类到达过程。在两个过程的叠加中,第一次到达是 1 类的概率为 \(\lambda_1/(\lambda_1 + \lambda_2)\)。
证明。令 \(T\) 为直到第一次 1 类事件发生的时间,\(V\) 为直到第一次 2 类事件发生的时间。我们要求 \(P(T \leq V)\)。我们可以利用二维 LOTUS 算法在二维平面上的相关区域对 \(T\) 和 \(V\) 的联合 PDF 进行积分。但事实证明,我们可以完全避开微积分。
我们已知 \(T \sim Expo(\lambda_1)\) 且 \(V \sim Expo(\lambda_2)\),两者独立。进行缩放,令 \(\tilde{T} = \lambda_1 T, \tilde{V} = \lambda_2 V\)。那么 \(\tilde{T}, \tilde{V}\) 是独立同分布的 \(Expo(1)\)。
令 \(U = \tilde{T}/(\tilde{T} + \tilde{V})\),我们有: \[ P(T \leq V) = P\left(\frac{\tilde{T}}{\lambda_1} \leq \frac{\tilde{V}}{\lambda_2}\right) = P\left(\frac{\tilde{T} + \tilde{V}}{\lambda_1} \frac{\tilde{T}}{\tilde{T} + \tilde{V}} \leq \frac{\tilde{V}}{\lambda_2}\right) \] \[ = P\left( \frac{U}{\lambda_1} \leq \frac{1-U}{\lambda_2} \right) = P\left( U \leq \frac{\lambda_1}{\lambda_1 + \lambda_2} \right) \]
由于 \(\tilde{T}, \tilde{V} \sim Expo(1)\),根据“银行-邮局故事”,\(U \sim Beta(1,1)\)。换句话说,\(U\) 是标准的均匀分布 \(Unif(0,1)\)!因此,\(P(T \leq V) = \lambda_1/(\lambda_1 + \lambda_2)\)。注意当 \(\lambda_1 = \lambda_2\) 时,由于对称性,概率退化为 \(1/2\)。
上述结果适用于合并过程中的第一次到达。然而,第一次到达之后,同样的逻辑也适用于第二次到达:由于无记忆性,距离下一次 1 类事件的时间仍为 \(Expo(\lambda_1)\),距离下一次 2 类事件的时间仍为 \(Expo(\lambda_2)\),且与过去无关。因此,第二次到达是 1 类的概率也是 \(\lambda_1/(\lambda_1 + \lambda_2)\),且独立于第一次。类似地,所有的到达类型都可以看作是独立同分布的抛硬币,正面(1 类)概率为 \(\lambda_1/(\lambda_1 + \lambda_2)\)。
这引出了两个独立泊松过程叠加的另一种生成故事:我们可以先生成一个 \(Expo(\lambda_1 + \lambda_2)\) 随机变量来决定下一次到达何时发生,然后独立地抛一枚正面概率为 \(\lambda_1/(\lambda_1 + \lambda_2)\) 的硬币来决定是哪种类型的到达。
故事 13.2.9(叠加生成的生成故事,版本 2)。要生成速率为 \(\lambda_1\) 和 \(\lambda_2\) 的两个独立泊松过程的叠加:
- 生成独立同分布的 \(Expo(\lambda_1 + \lambda_2)\) 随机变量 \(X_1, X_2, \dots\),令第 \(j\) 次到达的时间为 \(T_j = X_1 + \dots + X_j\)。
- 生成独立同分布的随机变量 \(I_1, I_2, \dots \sim Bern(\lambda_1/(\lambda_1 + \lambda_2))\),且独立于 \(X_1, X_2, \dots\)。如果 \(I_j = 1\),则第 \(j\) 次到达为 1 类,否则为 2 类。
这个故事为我们提供了一个被称为竞争风险定理(competing risks theorem)的快速证明。该定理单独陈述时似乎是一个令人惊讶的独立性结果,但放在泊松过程的背景下就会变得非常直观。
例 13.2.10(竞争风险)。弗雷德的冰箱寿命为 \(Y_1 \sim Expo(\lambda_1)\),洗碗机寿命为 \(Y_2 \sim Expo(\lambda_2)\),两者独立。证明:第一次家电故障的时间 \(\min(Y_1, Y_2)\) 与“冰箱先坏”的指示变量 \(I(Y_1 < Y_2)\) 是相互独立的。这可能看起来很奇怪。例如,如果冰箱平均寿命 15 年,洗碗机平均 7 年,其中一个在 7 年后坏了,自然会猜测是洗碗机坏了。但事实上,我们将证明:知道第一次故障的时间,并不能提供关于“哪个电器坏了”的任何信息。
解:我们将使用嵌入策略(embedding strategy),即使题目没提到泊松过程,我们也要借用它的思想!我们将 \(Y_1\) 和 \(Y_2\) 嵌入到我们自己虚构的一个泊松过程中。想象有一个速率为 \(\lambda_1\) 的冰箱故障泊松过程,和一个速率为 \(\lambda_2\) 的洗碗机故障泊松过程。
我们可以将 \(Y_1\) 解释为冰箱过程中第一次到达的等待时间,将 \(Y_2\) 解释为洗碗机过程中第一次到达的等待时间。这种方法是有效的,因为 \((\min(Y_1, Y_2), I(Y_1 < Y_2))\) 是 \((Y_1, Y_2)\) 的函数,所以重要的是 \((Y_1, Y_2)\) 的联合分布,而我们构造出的联合分布正是正确的。
此外,\(\min(Y_1, Y_2)\) 是两个泊松过程叠加后的第一次到达等待时间,而 \(I(Y_1 < Y_2)\) 是这次到达属于 1 类事件的指示变量。但在上述生成故事中,叠加过程的到达时间和事件类型是完全独立生成的!因此,\(\min(Y_1, Y_2)\) 和 \(I(Y_1 < Y_2)\) 是独立的,且 \(\min(Y_1, Y_2) \sim Expo(\lambda_1 + \lambda_2)\),\(I(Y_1 < Y_2) \sim Bern(\lambda_1/(\lambda_1 + \lambda_2))\)。
故事 13.2.9 的一个直接推论是:如果我们把叠加后的泊松过程投影到离散时间中(即保留 1 类和 2 类到达的顺序,但丢弃具体的到达时间),我们剩下的就是独立同分布的 \(Bern(\lambda_1/(\lambda_1 + \lambda_2))\) 序列。图 13.4 展示了从泊松过程中移除连续时间信息的含义,定理 13.2.11 正式阐述了这一结果。
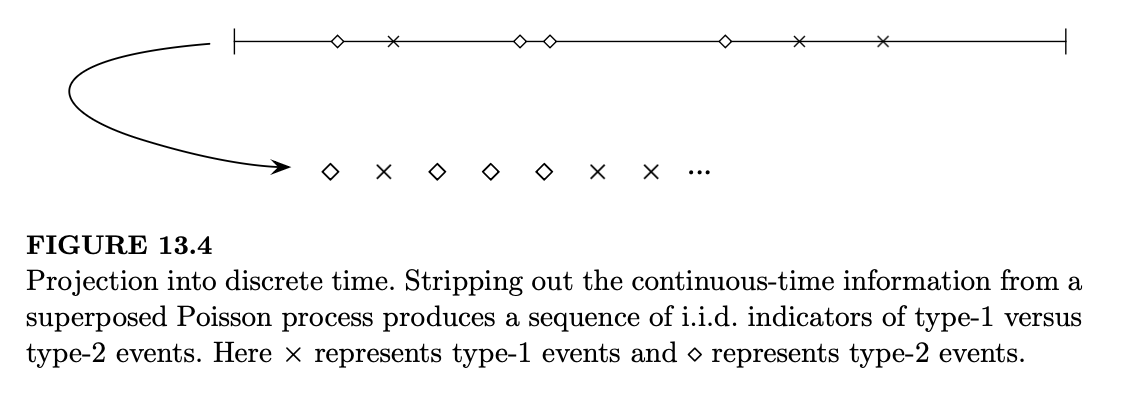
定理 13.2.11(叠加过程投影至离散时间)。考虑两个速率分别为 \(\lambda_1\) 和 \(\lambda_2\) 的独立泊松过程的叠加过程 \((N(t) : t > 0)\)。对于 \(j = 1, 2, \dots\),令 \(I_j\) 为第 \(j\) 个事件来自速率为 \(\lambda_1\) 的过程的指示变量。那么 \(I_j\) 是独立同分布的 \(Bern(\lambda_1/(\lambda_1 + \lambda_2))\)。
利用这一结果,我们可以通过“故事”来证明:泊松分布的 Gamma 混合分布是负二项分布。我们曾在布洛奇维尔的弗雷德历险记中首次学到这一点(故事 8.4.5)。我们先看一个特例。
定理 13.2.12(泊松分布的指数混合是几何分布)。假设 \(X \sim Expo(\lambda)\) 且 \(Y|X = x \sim Pois(x)\)。那么 \(Y \sim Geom(\lambda/(\lambda + 1))\)。
证明。与竞争风险定理一样,我们将 \(X\) 和 \(Y\) 嵌入到泊松过程中。考虑两个独立的泊松过程:一个是以速率 1 到达的“失败”过程,另一个是以速率 \(\lambda\) 到达的“成功”过程。令 \(X\) 为第一次成功的时间,则 \(X \sim Expo(\lambda)\)。令 \(Y\) 为第一次成功之前的失败次数。根据速率为 1 的泊松过程定义,已知 \(X = x\) 时,\(Y\) 的分布为 \(Pois(x)\)。因此 \(X\) 和 \(Y\) 满足定理的条件。
为了得到 \(Y\) 的边缘分布,剔除连续时间信息!在离散时间中,我们拥有成功概率为 \(\lambda/(\lambda + 1)\) 的独立同分布伯努利试验,而 \(Y\) 被定义为第一次成功前的失败次数。根据几何分布的故事,\(Y \sim Geom(\lambda/(\lambda + 1))\)。
一般情况的推理是类似的:
定理 13.2.13(泊松分布的 Gamma 混合是负二项分布)。假设 \(X \sim Gamma(r, \lambda)\) 且 \(Y|X = x \sim Pois(x)\)。那么 \(Y \sim NBin(r, \lambda/(\lambda + 1))\)。
证明。考虑两个独立的泊松过程,失败速率为 1,成功速率为 \(\lambda\)。令 \(X\) 为第 \(r\) 次成功的时间,因此 \(X \sim Gamma(r, \lambda)\)。令 \(Y\) 为第 \(r\) 次成功之前的失败次数。根据泊松过程的定义,仍有 \(Y|X = x \sim Pois(x)\)。由于 \(Y\) 是独立同分布伯努利试验序列(成功概率 \(\lambda/(\lambda + 1)\))中第 \(r\) 次成功前的失败次数,因此 \(Y \sim NBin(r, \lambda/(\lambda + 1))\)。
13.2.3 稀疏性质
Thinning
我们要讨论的泊松过程最后一个性质是稀疏:如果我们取一个泊松过程,并对每次到达独立地抛硬币来决定它是 1 类事件还是 2 类事件,最终会得到两个独立的泊松过程。
定理 13.2.14(稀疏)。令 \((N(t) : t > 0)\) 为速率为 \(\lambda\) 的泊松过程。将每次到达以概率 \(p\) 归类为 1 类事件,以概率 \(1-p\) 归类为 2 类事件,分类过程相互独立且独立于到达时间。那么,1 类事件构成速率为 \(\lambda p\) 的泊松过程,2 类事件构成速率为 \(\lambda(1-p)\) 的泊松过程,且这两个过程相互独立。
证明。令 \(\lambda_1 = \lambda p\) 且 \(\lambda_2 = \lambda(1-p)\),则 \(\lambda = \lambda_1 + \lambda_2\) 且 \(p = \lambda_1/(\lambda_1 + \lambda_2)\)。这让我们回到了故事 13.2.9。然而,故事 13.2.7 和 13.2.9 是叠加过程的两个等效生成故事!由于输出的概率结构完全相同,我们可以假定是使用故事 13.2.7 生成的过程。在这种情况下,我们从一开始就知道 1 类过程与 2 类过程是独立的。
因此,我们可以通过叠加独立的泊松过程得到一个合并的泊松过程,也可以将一个泊松过程拆分为独立的泊松过程。图 13.5 是稀疏性质的插图。我们只需将图 13.3 倒过来,这是非常恰当的,因为稀疏正是叠加的另一面!

稀疏性质是“鸡蛋问题”在泊松过程中的对应物。假设我们按照定理 13.2.14 稀疏一个速率为 \(\lambda\) 的泊松过程,令 \((N_i(t) : t > 0)\) 为 \(i\) 类到达过程。将 1 类到达视为孵化的蛋,根据鸡蛋故事可以直接得出:\(N_1(t) \sim Pois(\lambda pt)\),\(N_2(t) \sim Pois(\lambda(1-p)t)\),且两者独立。
为了练习并感受稀疏性质的优雅,让我们用两种不同的方法来求随机和(random sum)的分布:使用 MGF 和条件期望,以及使用稀疏性质。
例 13.2.15(首个成功前的指数分布随机和)。令 \(X_1, X_2, \dots\) 为独立同分布的 \(Expo(\lambda)\) 随机变量,且 \(N \sim FS(p)\)(首个成功分布),\(N\) 与 \(X_j\) 相互独立。求随机和 \(Y = \sum_{j=1}^N X_j\) 的分布。
解:
我们将用两种方法解决这个问题:首先使用第 9 章的工具,然后使用涉及稀疏性质的泊松过程故事。
方法一:MGF 与条件期望
我们认出 \(Y\) 是随机个数个随机变量之和。我们可以通过以 \(N\) 为条件并使用亚当法则(Adam's Law)来求 \(Y\) 的矩生成函数(MGF)。回忆 \(Expo(\lambda)\) 的 MGF 为 \(\frac{\lambda}{\lambda - t}\)(对于 \(t < \lambda\)),我们有: \[ E(e^{tY}) = E(E(e^{t \sum_{j=1}^N X_j} | N)) \] \[ = E(E(e^{tX_1}) E(e^{tX_2}) \dots E(e^{tX_N}) | N) \] \[ = E\left( \left( \frac{\lambda}{\lambda - t} \right)^N \right) \]
利用 LOTUS 算法和 \(FS(p)\) 的 PMF(\(P(N=k) = q^{k-1}p\),其中 \(k=1,2,\dots\)),求和式为: \[ \sum_{k=1}^\infty \left( \frac{\lambda}{\lambda - t} \right)^k q^{k-1}p \]
经过代数运算并求几何级数之和,简化结果为 \(\frac{\lambda p}{\lambda p - t}\)(对于 \(t < \lambda p\))。这是 \(Expo(\lambda p)\) 的 MGF,因此 \(Y \sim Expo(\lambda p)\)。
方法二:泊松过程故事(稀疏性质)
现在让我们看看泊松过程如何免去代数运算,并提供关于为何 \(Y\) 服从指数分布的深刻见解。使用嵌入策略:由于 \(X_j\) 是独立同分布的 \(Expo(\lambda)\),我们可以自由地将 \(X_j\) 解释为速率为 \(\lambda\) 的泊松过程的到达间隔时间。
想象这样一个泊松过程,并进一步想象每次到达都有概率 \(p\) 被独立地标记为“特殊到达”。那么我们可以将 \(N\) 解释为直到出现第一个特殊到达前的总到达次数,而 \(Y\) 正是第一个特殊到达出现的等待时间。根据稀疏性质,特殊到达构成一个速率为 \(\lambda p\) 的泊松过程。因此,第一个特殊到达的等待时间服从 \(Expo(\lambda p)\) 分布。
当存在两种以上类型时,稀疏性质同样适用。在这种情境下,稀疏性质有时被称为着色定理(Coloring Theorem)。
定理 13.2.16(着色)。令 \((N(t) : t > 0)\) 为速率为 \(\lambda\) 的泊松过程,\(C\) 为一组有限的“颜色”,标记为 \(1\) 到 \(c\)。假设每次到达都被随机分配 \(C\) 中的一种颜色,颜色 \(i\) 的概率为 \(p_i\)。颜色分配相互独立,且独立于到达时间。令 \((N_i(t) : t > 0)\) 为颜色 \(i\) 的过程。那么 \((N_i(t) : t > 0)\) 是速率为 \(\lambda p_i\) 的泊松过程(\(i = 1, 2, \dots, c\)),且这 \(c\) 个单色过程相互独立。
证明。我们对 \(c\) 使用数学归纳法。
- 当 \(c = 1\) 时,无需证明。
- 当 \(c = 2\) 时,结论即为我们已经证明的稀疏定理。
- 假设结论对 \(c\) 种颜色成立,证明它对 \(c+1\) 种颜色也成立。
我们将颜色 1 称为“绿色”。利用稀疏性质,将每次到达以概率 \(p_1\) 分类为绿色,以概率 \(1 - p_1\) 分类为“非绿色”。这会将泊松过程分解为两个独立过程:速率为 \(\lambda p_1\) 的绿色过程和速率为 \(\lambda(1 - p_1)\) 的非绿色过程。根据归纳假设,我们可以进一步将非绿色过程分解为 \(c\) 个独立过程(对应颜色 \(2, 3, \dots, c+1\)),其中颜色 \(j\) 在非绿色过程中的条件概率为: \[ \tilde{p}_j = \frac{p_j}{1 - p_1} = \frac{p_j}{p_2 + p_3 + \dots + p_{c+1}} \]
由此,我们得到了 \(c+1\) 个独立的泊松过程,且颜色 \(j\) 的过程速率为 \(\lambda p_j\)。
接下来的例子展示了如何通过“着色”将复杂的泊松过程分解为更容易处理的组成部分。
例 13.2.17(高速公路上的车辆)。假设汽车从同一个入口进入一条单向高速公路,进入过程服从速率为 \(\lambda\) 的泊松过程。第 \(i\) 辆车的速度为 \(V_i\),并始终以该速度行驶;车辆超车时不损失时间。假设 \(V_i\) 是独立同分布的离散随机变量,其支撑集是一组有限的正值。该过程从时间 0 开始,我们将高速公路入口视为位置 0。
对于高速公路上固定的位置 \(a\) 和 \(b\)(满足 \(0 < a < b\)),令 \(Z_t\) 为在时间 \(t\) 位于区间 \([a, b]\) 内的车辆数量。(例如,在一条从西向东横穿美国中西部的州际公路上,\(a\) 可以是堪萨斯城,\(b\) 可以是圣路易斯;那么 \(Z_t\) 就是在时间 \(t\) 位于密苏里州境内高速公路上的车辆数。)图 13.6 展示了问题的设定和 \(Z_t\) 的定义。
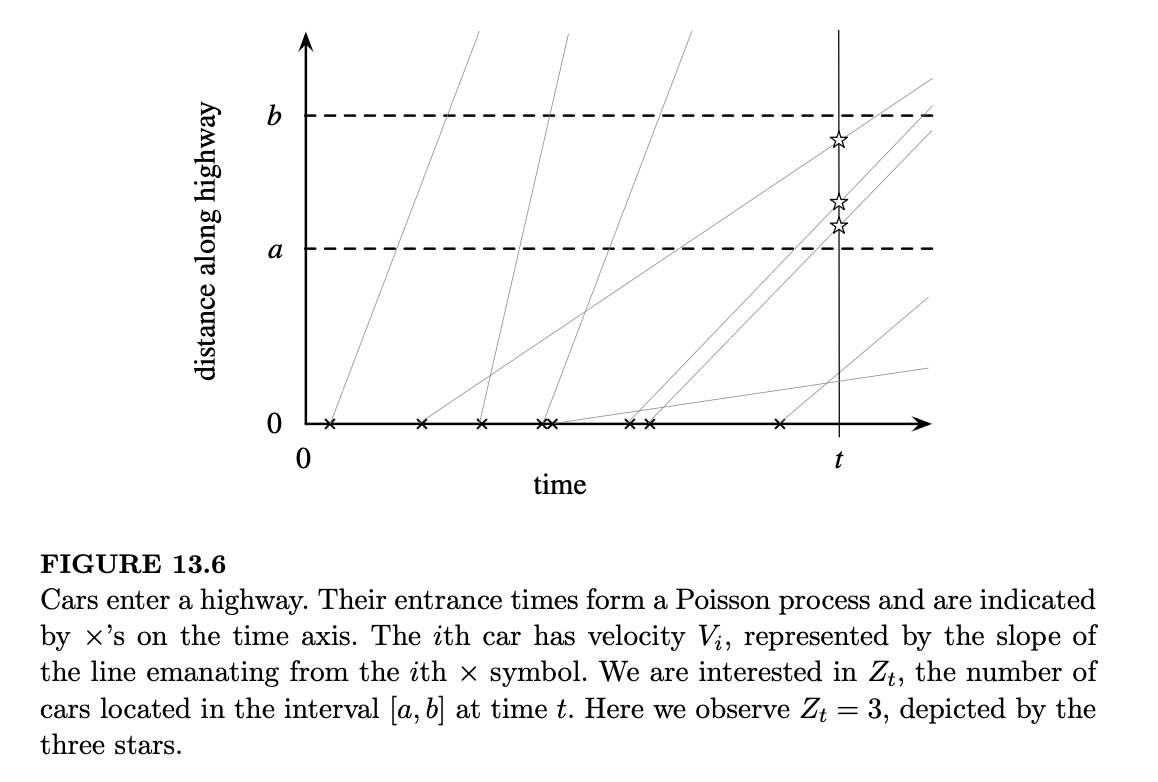
假设 \(t\) 足够大,使得对于 \(V_i\) 的所有可能取值均有 \(t > b/V_i\)。证明 \(Z_t\) 服从泊松分布,其均值为 \(\lambda(b - a)E(V_i^{-1})\)。
解:
由于 \(V_i\) 是具有有限支撑集的离散随机变量,我们可以枚举所有可能的速度 \(v_1, \dots, v_m\) 及其对应的概率 \(p_1, \dots, p_m\)。完成枚举后,我们意识到进入高速公路的车辆代表了 \(m\) 种类型的到达,每种类型对应不同的速度。这启发我们将整体泊松过程分解为更简单的过程。让我们根据车辆的速度对泊松过程进行 \(m\) 路着色,从而得到:速度为 \(v_1\) 的车辆对应的泊松过程速率为 \(\lambda p_1\),速度为 \(v_2\) 的车辆对应的泊松过程速率为 \(\lambda p_2\),依此类推。
对于这 \(m\) 个独立的泊松过程,我们可以分别询问:来自该过程的车辆必须在哪个时间区间内进入高速公路,才能在时间 \(t\) 处于 \([a, b]\) 之间?这是一个物理问题,而非统计问题: \[ \text{距离} = \text{速度} \times \text{时间} \]
因此,一辆在时间 \(s\) 以速度 \(v\) 进入高速公路的汽车,在时间 \(t\) 的位置将是 \((t - s)v\)。为了让汽车的位置处于 \(a\) 和 \(b\) 之间,我们要求其到达时间 \(s\) 满足: \[ a \leq (t - s)v \leq b \implies t - \frac{b}{v} \leq s \leq t - \frac{a}{v} \]
(根据 \(t\) 足够大的假设,我们不必担心 \(t - b/v\) 为负数。)如果汽车在 \(t - b/v\) 之前到达,它在时间 \(t\) 已经驶过了 \(b\) 点;如果汽车在 \(t - a/v\) 之后到达,它在时间 \(t\) 尚未到达 \(a\) 点。
现在我们得到了每个独立泊松过程的答案。在速度为 \(v_j\) 的过程中,于 \([t - b/v_j, t - a/v_j]\) 之间到达的车辆数(我们称之为 \(Z_{tj}\))服从 \(Pois(\lambda p_j (b-a)/v_j)\) 分布:因为该过程的速率是 \(\lambda p_j\),且时间区间的长度是 \((b - a)/v_j\)。
由于各分支过程是相互独立的,因此 \(Z_{t1}, \dots, Z_{tm}\) 是独立的泊松随机变量。从而: \[ Z_t = Z_{t1} + \dots + Z_{tm} \sim Pois \left( \lambda(b-a) \sum_{j=1}^m \frac{p_j}{v_j} \right) \]
根据 LOTUS 算法,\(\sum_{j=1}^m p_j/v_j\) 正是 \(V_i^{-1}\) 的期望。这正是我们想要证明的结论。
为了总结本节内容,下表描述了泊松过程的性质与泊松分布的性质之间的对应关系。在第二列中,\(Y_1 \sim Pois(\lambda_1)\) 和 \(Y_2 \sim Pois(\lambda_2)\) 是相互独立的。

13.3 多维泊松过程
Poisson processes in multiple dimensions
多维泊松过程的定义与一维泊松过程类似:我们只需将“长度”的概念替换为“面积”或“体积”。为了具体起见,我们现在定义二维泊松过程,之后通过类比,如何定义更高维度的泊松过程也就显而易见了。
定义 13.3.1(二维泊松过程)。如果满足以下条件,则平面 \(\mathbb{R}^2\) 上的事件构成强度为 \(\lambda\) 的二维泊松过程:
- 区域 \(A\) 内的事件数量服从 \(Pois(\lambda \cdot \text{area}(A))\) 分布。
- 不相交区域内的事件数量相互独立。
正如人们所料,条件、叠加和稀疏性质同样适用于二维泊松过程。令 \(N(A)\) 为区域 \(A\) 内的事件数量,并令 \(B \subseteq A\)。给定 \(N(A) = n\),\(N(B)\) 的条件分布为二项分布: \[ N(B) | N(A) = n \sim Bin\left(n, \frac{\text{area}(B)}{\text{area}(A)}\right) \]
在给定较大区域 \(A\) 内事件总数的条件下,事件落入子区域的概率与该子区域的面积成正比;因此,事件的位置在条件上是均匀分布的(Uniform)。我们可以这样生成区域 \(A\) 内的二维泊松过程:首先生成事件总数 \(N(A) \sim Pois(\lambda \cdot \text{area}(A))\),然后将这些事件随机均匀地放置在 \(A\) 中。图 13.7 显示了在正方形 \([0, 5] \times [0, 5]\) 内,强度分别为 \(\lambda = 1, 2, 5\) 的模拟二维泊松过程。
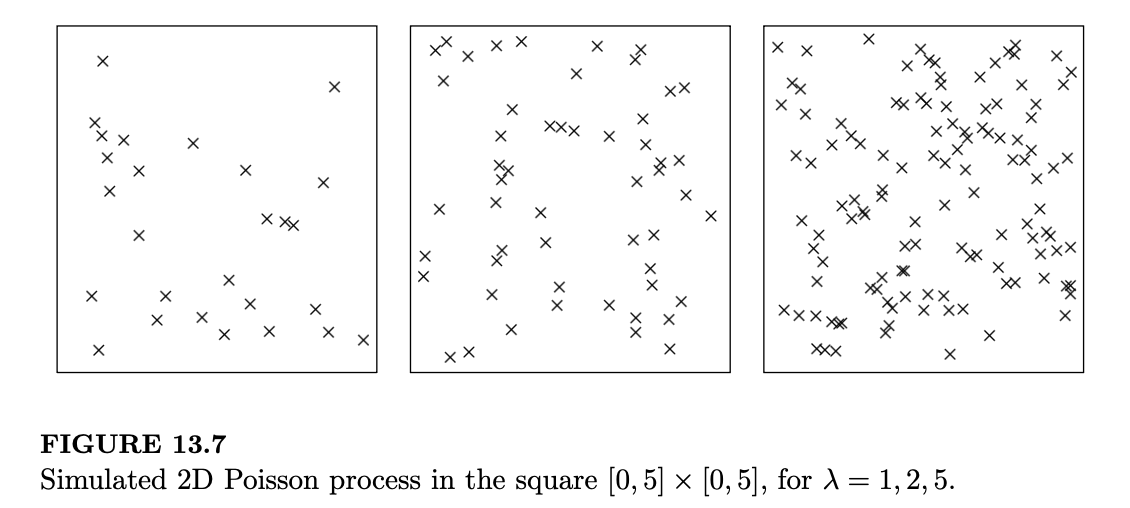
与一维情况一样,独立二维泊松过程的叠加仍是二维泊松过程,且强度相加。我们也可以通过稀疏一个二维泊松过程来得到独立的二维泊松过程。
对于一维泊松过程,我们尚未给出其高维类比的一个性质是“计数-时间二元性”。接下来的例子(本章最后一个例子)将引导我们找到一个空间的类比:计数-距离二元性。
例 13.3.2(最近的恒星)。某个宇宙中的恒星根据强度为 \(\lambda\) 的三维泊松过程分布。如果你生活在这个宇宙中,你距离最近恒星的距离分布是怎样的?
解:
在强度为 \(\lambda\) 的三维泊松过程中,空间区域 \(V\) 内的事件数量服从均值为 \(\lambda \cdot \text{volume}(V)\) 的泊松分布。令 \(R\) 为你到最近恒星的距离。关键的观察是:为了使事件 \(R > r\) 发生,在你周围半径为 \(r\) 的球体内必须没有恒星;事实上,这两个事件是等价的。对于任何 \(r > 0\),令 \(N_r\) 为距离你半径 \(r\) 范围内的事件数量,则 \(N_r \sim Pois(\lambda \cdot \frac{4}{3}\pi r^3)\)。于是我们有了计数-距离二元性: \[ R > r \text{ 与 } N_r = 0 \text{ 是同一个事件} \]
因此: \[ P(R > r) = P(N_r = 0) = e^{-\frac{4}{3}\lambda \pi r^3} \]
由此得到 \(R\) 的累积分布函数(CDF)为: \[ P(R \leq r) = 1 - e^{-\frac{4}{3}\lambda \pi r^3} \]
对于 \(r > 0\)(否则为 0)。这是一个韦伯分布(Weibull,见例 6.5.5)。具体来说: \[ R \sim \text{Wei}\left(\frac{4\pi \lambda}{3}, 3\right) \]
泊松过程有许多扩展,其中一些在习题中有所探讨。我们可以允许 \(\lambda\) 随时间或空间变化,而不是保持常数,这被称为非齐次泊松过程(inhomogeneous Poisson process)。我们也可以允许 \(\lambda\) 本身是一个随机变量,这被称为考克斯过程(Cox process)。最后,我们可以允许速率在每次连续到达后增加 \(\lambda\),这被称为尤尔过程(Yule process)。
13.4 总结(Recap)
一维泊松过程是一个到达序列,其满足:任何区间内的到达次数均服从泊松分布(均值与区间长度成正比),且不相交区间内的到达次数相互独立。我们可以对泊松过程进行几种基本操作:条件化(Conditioning)、叠加(Superposition)和稀疏(Thinning)。
- 条件化:以区间内到达总数为条件,可以将这些到达视为在该区间上独立同分布的均匀分布点。
- 叠加与稀疏:这两者是互补的,允许我们在方便时拆分或合并泊松过程。
这些性质在更高维度中也都有对应的类比。
泊松过程将本书研究过的许多命名分布紧密联系在了一起:
- 泊松分布:描述到达次数。
- 指数分布与 Gamma 分布:描述到达间隔时间和到达时刻。
- 二项分布:描述给定总数时的条件计数。
- 均匀分布与(缩放后的)Beta 分布:描述给定的条件到达时刻。
- 几何分布与负二项分布:描述特殊到达出现前的离散等待时间。
此外,泊松过程特别适用于故事证明。我们在本章中多次使用的一种解题策略是将随机变量嵌入到泊松过程中,以期发现某种故事证明,即使原始问题看起来与泊松过程毫无关联。
泊松过程以一种自然的方式,将本书的两个重要主题——“命名分布”和“故事”统一在了一起。我们认为,用一个能够交织全书故事线索的课题作为结尾是非常合适的。
13.5 R
一维泊松过程
在第5章中,我们讨论了如何通过利用到达间隔时间是独立同分布(i.i.d.)的指数分布这一事实,来模拟一维泊松过程中指定数量的到达事件。在本章中,故事 13.2.4 告诉我们如何在指定区间 \((0, L]\) 内模拟泊松过程。我们首先生成到达次数 \(N(L)\),它服从 \(Pois(\lambda L)\) 分布。在给定 \(N(L) = n\) 的条件下,到达时间服从 \(n\) 个独立同分布的 \(Unif(0, L)\) 随机变量的顺序统计量分布。以下代码模拟了在区间 \((0, 5]\) 上速率为 10 的泊松过程的到达情况:
1 | L <- 5 |
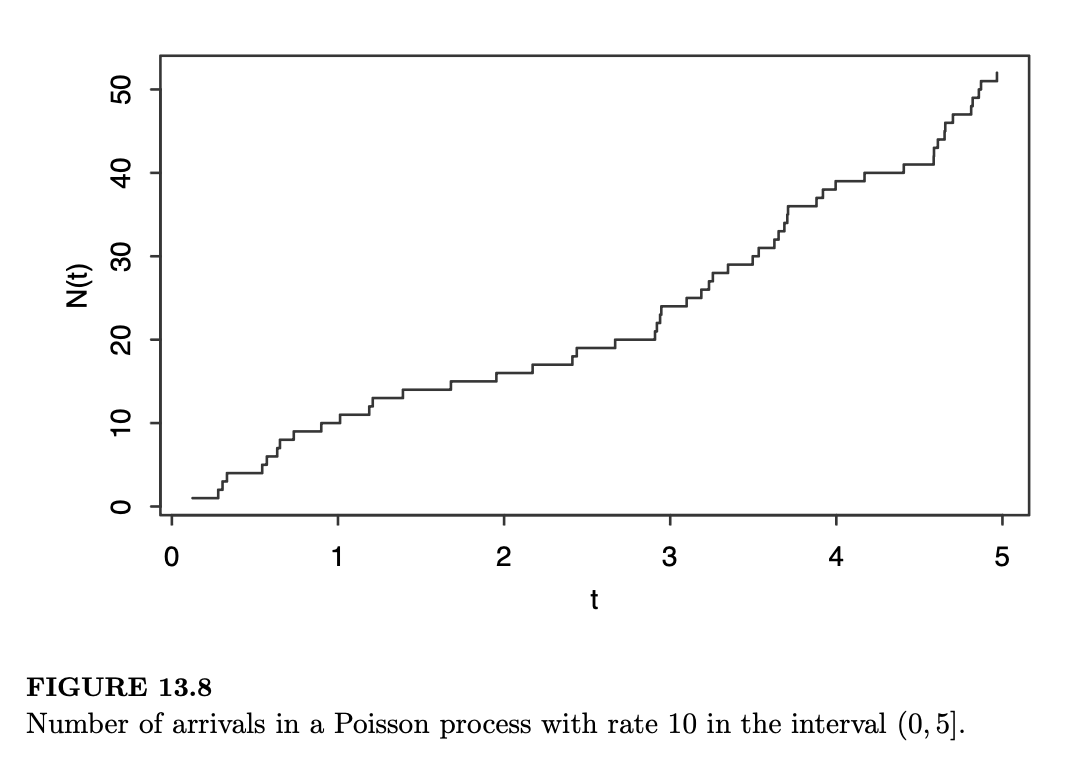
为了直观展示我们生成的泊松过程,我们可以绘制累计到达次数 \(N(t)\) 随时间 \(t\) 变化的函数图:
1 | plot(t,1:n,type="s") |
这会产生如图 13.8 所示的阶梯图。
筛选(Thinning)
在 R 中对泊松过程进行筛选是非常直接的。以下代码从如上生成的速率为 \(\lambda\) 的某区间内的到达时间向量 t 和相应的到达次数 n 开始。对于每一次到达,我们抛一枚正面概率为 \(p\) 的硬币;这些硬币抛掷的结果存储在向量 y 中。最后,硬币为正面的到达被标记为类型 1;其余的被标记为类型 2。根据定理 13.2.14,所得的到达时间向量 t1 和 t2 是速率分别为 \(\lambda p\) 和 \(\lambda(1-p)\) 的独立泊松过程的实现。
我们可以按如下方式执行 \(p = 0.3\) 的操作:
1 | p <- 0.3 |
二维泊松过程
在正方形区域内模拟速率为 \(\lambda\) 的二维泊松过程几乎与模拟一维泊松过程一样简单。在正方形 \((0, L] \times (0, L]\) 中,到达次数服从 \(Pois(\lambda L^2)\) 分布。在给定到达次数的条件下,到达的位置是该正方形内独立同分布的均匀分布点。根据示例 7.1.23,这些点中每一个点的坐标都是独立同分布的 \(Unif(0, L)\)。因此,对于 \(L = 5\),$ = 10$,我们可以输入:
1 | L <- 5 |
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程