《Introduction to Probability》第9章 条件期望
第9章 条件期望
Conditional expectation
既然你已经阅读了前面的章节,你已经知道什么是条件期望了:它就是期望,只不过使用了条件概率。这是一个至关重要的概念,其原因与我们需要条件概率的原因类似:
- 条件期望是计算期望的强大工具。 通过使用诸如“对我们希望知道的信息进行条件化”以及“第一步分析”等策略,我们通常可以将复杂的期望问题分解为更简单的部分。
- 条件期望本身就是一个相关的量,它允许我们基于当前可用的任何证据来预测或估计未知量。例如,在统计学中,我们经常希望基于解释变量(如解决的练习题数量或参加职业培训计划的情况)来预测响应变量(如考试成绩或收入)。
关于条件期望,有两个不同但又紧密联系的概念:
- 给定事件下的条件期望 \(E(Y|A)\):设 \(Y\) 是一个随机变量,\(A\) 是一个事件。如果我们获知 \(A\) 发生了,我们对 \(Y\) 更新后的期望记作 \(E(Y|A)\),其计算方法与 \(E(Y)\) 类似,只是使用给定 \(A\) 下的条件概率。
- 给定随机变量下的条件期望 \(E(Y|X)\):一个更微妙的问题是如何定义 \(E(Y|X)\),其中 \(X\) 和 \(Y\) 都是随机变量。直观地说,\(E(Y|X)\) 是一个仅使用从 \(X\) 中获得的信息来最好地预测 \(Y\) 的随机变量。
在本章中,我们将探索这两种形式的条件期望的定义、性质、直觉和应用。
9.1 给定事件下的条件期望
Conditional expectation given an event
回想一下,离散随机变量 \(Y\) 的期望 \(E(Y)\) 是其可能取值的加权平均,其中权重是 PMF 值 \(P(Y=y)\)。在得知事件 \(A\) 发生后,我们希望使用反映这一新信息的更新后的权重。\(E(Y|A)\) 的定义仅仅是将概率 \(P(Y=y)\) 替换为条件概率 \(P(Y=y|A)\)。
类似地,如果 \(Y\) 是连续的,\(E(Y)\) 仍然是 \(Y\) 可能取值的加权平均,只不过用积分代替了求和,用 PDF 值 \(f(y)\) 代替了 PMF 值。如果我们获知 \(A\) 发生,我们通过将 \(f(y)\) 替换为条件 PDF \(f(y|A)\) 来更新对 \(Y\) 的期望。
定义 9.1.1(给定事件下的条件期望)。设 \(A\) 为一个概率为正的事件。如果 \(Y\) 是离散随机变量,则 \(Y\) 在给定 \(A\) 下的条件期望为: \[ E(Y|A) = \sum_{y} yP(Y=y|A) \]
其中求和是在 \(Y\) 的支撑集上进行的。如果 \(Y\) 是 PDF 为 \(f\) 的连续随机变量,则: \[ E(Y|A) = \int_{-\infty}^{\infty} yf(y|A) dy \]
其中条件 PDF \(f(y|A)\) 定义为条件 CDF \(F(y|A) = P(Y \le y|A)\) 的导数,也可以通过混合版本的贝叶斯法则计算: \[ f(y|A) = \frac{P(A|Y=y)f(y)}{P(A)} \]
直觉 9.1.2。为了获得对 \(E(Y|A)\) 的直观认识,让我们考虑通过模拟(或从频率论的角度,基于多次重复同一实验)来近似它。想象生成大量的 \(n\) 次实验复制,其中 \(Y\) 是数值汇总。我们得到了 \(Y\) 值 \(y_1, \dots, y_n\),并且可以近似: \[ E(Y) \approx \frac{1}{n} \sum_{j=1}^{n} y_j \]
为了近似 \(E(Y|A)\),我们仅限于 \(A\) 发生的那些复制,并仅对这些 \(Y\) 值求平均。这可以写成: \[ E(Y|A) \approx \frac{\sum_{j=1}^{n} y_j I_j}{\sum_{j=1}^{n} I_j} \]
其中 \(I_j\) 是第 \(j\) 次复制中 \(A\) 发生的指示函数。如果在模拟中 \(A\) 从未发生,则该式未定义,这是合理的,因为那时没有关于“\(A\) 发生”场景的模拟数据。我们希望 \(n\) 足够大,以便 \(A\) 多次发生(如果 \(A\) 是稀有事件,可能需要更复杂的近似 \(E(Y|A)\) 的技术)。
不过原理很简单:\(E(Y|A)\) 大约是大量 \(A\) 发生的模拟运行中 \(Y\) 的平均值。
9.1.3. 混淆条件期望与无条件期望是一个危险的错误。更广泛地说,如果不能仔细追踪你应该对什么进行条件化,以及你正在对什么进行条件化,那么这就是通往灾难的秘诀。
为了给上述“生物危害”提供一个关乎生死的例子,请考虑预期寿命。
示例 9.1.4(预期寿命)。弗雷德今年 30 岁,他听说他所在国家的平均预期寿命是 80 岁。他是否应该得出结论:平均而言,他还有 50 年的寿命?不,他必须对一条关键信息进行条件化:他已经活到了 30 岁这一事实。令 \(T\) 为弗雷德的寿命,我们有一个令人振奋的消息: \[ E(T) < E(T|T \ge 30) \]
左侧是弗雷德出生时的预期寿命(它隐含地以他出生这一事实为条件),而右侧是弗雷德在达到 30 岁时的预期寿命。
一个更难的问题是如何决定一个合适的估计值来表示 \(E(T)\)。仅仅使用他所在国家的总体平均值 80 吗?在几乎所有国家,女性的平均预期寿命都高于男性,因此对“弗雷德是男性”这一条件进行条件化是有意义的。但我们是否也应该对他出生的城市进行条件化?我们是否应该对他父母的种族和财务信息,或者他出生的具体时间进行条件化?直觉上,我们希望估计值既准确又与弗雷德相关,但这其中存在权衡:如果我们对弗雷德的更多特征进行条件化,那么符合这些特征、可用于估计预期寿命的数据样本(人数)就会减少。
现在考虑美国的一些具体数据。美国社会保障局的一项研究估计,在 1900 年至 2000 年间,美国男性出生时的平均预期寿命从 46 岁增加到 74 岁,女性则从 49 岁增加到 79 岁。这是巨大的进步!但大部分进步归功于儿童死亡率的降低。对于 1900 年的一位 30 岁人士,男性的平均剩余寿命为 35 年,女性为 36 年;而在 2000 年,对应的数字分别是男性 46 年和女性 50 年。
在获得这些估计值时存在一些微妙的统计问题。例如,如果不等到至少 2100 年,如何获得 2000 年出生的人的预期寿命估计值?估计生存分布是生物统计学和精算学中一个非常重要的课题。
全概率公式允许我们通过切分样本空间并计算每个切片中的条件概率来获得无条件概率。同样的想法也适用于计算无条件期望。
定理 9.1.5(全期望公式)。设 \(A_1, \dots, A_n\) 为样本空间的一个划分,且对所有 \(i\) 均有 \(P(A_i) > 0\),并设 \(Y\) 是该样本空间上的一个随机变量。则: \[ E(Y) = \sum_{i=1}^{n} E(Y|A_i)P(A_i) \]
事实上,根据“基本桥梁”,既然所有概率都是期望,那么全概率公式就是全期望公式的一个特例。为了证明这一点,令 \(Y = I_B\)(事件 \(B\) 的指示函数);那么上述定理说明: \[ P(B) = E(I_B) = \sum_{i=1}^{n} E(I_B|A_i)P(A_i) = \sum_{i=1}^{n} P(B|A_i)P(A_i) \]
这正是全概率公式(LOTP)。反过来,全期望公式是一个被称为“亚当法则”(Adam’s Law,定理 9.3.7)的重要结论的特例,因此我们暂不证明它。
有许多有趣的例子通过“一厢情愿法”将无条件期望分解为条件期望。我们先从两个关于仔细条件化以及不要在没有依据的情况下破坏信息的重要性的警示故事开始。
示例 9.1.6(两封信悖论)。一个陌生人给了你两封外观一模一样的密封信。每封信里都有一张金额为正的支票。你被告知,其中一封信里的钱恰好是另一封的两倍。你可以任选其一。你更倾向于哪一封:左边那封还是右边那封?(假设每封信中金额的期望值是有限的——在现实世界中这显然是一个合理的假设!)
解答:
设 \(X\) 和 \(Y\) 分别为左侧和右侧信封中的金额。根据对称性,没有理由偏好其中任何一封(我们假设没有先验信息表明这位陌生人是左撇子,且左撇子更喜欢把更多的钱放在左边)。根据对称性得出 \(E(X) = E(Y)\),看起来你应该不在乎得到哪一封。
但当你幻想信封里的内容时,你想到了另一个论点:假设左边的信封里有 100 美元。那么右边的信封里要么有 50 美元,要么有 200 美元。50 美元和 200 美元的平均值是 125 美元,所以看起来右边的信封更好。但是 100 美元在这里并没有什么特殊的;对于左边信封的任何取值 \(x\),其可能的两倍 \(2x\) 与一半 \(x/2\) 的平均值都大于 \(x\),这暗示右边的信封总是更好。然而这非常荒谬,因为它不仅矛盾于对称性论点,而且同样的推理也可以从右边的信封开始,导致你永远在两封信之间不停地切换!
让我们尝试将这个论点形式化,看看究竟发生了什么。我们有 \(Y = 2X\) 或 \(Y = X/2\) 的概率各占一半。根据定理 9.1.5(全期望公式): \[ E(Y) = E(Y|Y = 2X) \cdot \frac{1}{2} + E(Y|Y = X/2) \cdot \frac{1}{2} \]
有人可能会认为这等于: \[ E(2X) \cdot \frac{1}{2} + E(X/2) \cdot \frac{1}{2} = \frac{5}{4} E(X) \]
这暗示从左信封换到右信封会有 25% 的收益。但这个计算中存在一个严重错误:虽然 \(E(Y|Y = 2X) = E(2X|Y = 2X)\),但在将 \(2X\) 代入 \(Y\) 后,没有理由直接去掉 \(Y = 2X\) 这个条件。
换句话说,设 \(I\) 为事件 \(Y = 2X\) 的指示函数,使得 \(E(Y|Y = 2X) = E(2X|I = 1)\)。如果我们知道 \(X\) 与 \(I\) 相互独立,那么我们就可以去掉条件 \(I = 1\)。但事实上,我们刚刚证明了 \(X\) 与 \(I\) 不可能独立:如果它们独立,我们就会得到一个悖论!令人惊讶的是,观察 \(X\) 的值会提供关于 \(X\) 是较大值还是较小值的信息。如果我们发现 \(X\) 非常大,我们可能会猜测 \(X\) 比 \(Y\) 大。但什么才算“非常大”?\(10^{12}\) 算大吗,即使它相对于 \(10^{100}\) 来说微不足道?两封信悖论告诉我们,无论 \(X\) 的分布是什么,总能找到相对于该分布而言定义“非常大”的合理方式。
在习题 8 中,你将研究一个相关问题,其中两个信封里的金额是独立同分布(i.i.d.)的随机变量。你将证明,如果允许你先看其中一封信的内容,再决定是否交换,存在一种策略能让你以超过 50% 的概率获得金额较多的那一封!
接下来的例子生动地说明了对所有信息进行条件化的重要性。这里揭示的现象出现在现实生活中许多关于购买什么以及进行什么投资的决策中。
示例 9.1.7(神秘奖品)。另一位陌生人向你走来,给你一个对装有神秘奖品的神秘盒子进行竞标的机会!奖品的价值完全未知,只知道它至少价值 0,最高价值 100 万美元。因此,奖品的真实价值 \(V\) 被认为在 \([0, 1]\) 上服从均匀分布(以百万美元为单位)。
你可以选择出价任何金额 \(b\)(以百万美元为单位)。你有机会以远低于其价值的价格获得奖品,但如果你出价太高,也可能会赔钱。具体来说,如果 \(b < 2V/3\),则出价被拒绝,没有任何得失。如果 \(b \ge 2V/3\),则出价被接受,你的净收益为 \(V - b\)(因为你支付了 \(b\) 来获得价值为 \(V\) 的奖品)。为了使期望收益最大化,你的最优出价 \(b\) 是多少?

解答:
你的出价 \(b \ge 0\) 必须是一个预先确定的常数(不能基于 \(V\),因为 \(V\) 是未知的!)。为了计算期望收益 \(W\),需根据出价是否被接受进行条件化。如果出价被接受,收益为 \(V - b\);如果被拒绝,收益为 0。因此: \[ E(W) = E(W|b \ge 2V/3)P(b \ge 2V/3) + E(W|b < 2V/3)P(b < 2V/3) \] \[ = E(V - b|b \ge 2V/3)P(b \ge 2V/3) + 0 \] \[ = (E(V|V \le 3b/2) - b) P(V \le 3b/2) \]
对于 \(b \ge 2/3\),事件 \(V \le 3b/2\) 的概率为 1,因此右侧为 \(1/2 - b\),这是一个负数。现在假设 \(b < 2/3\)。那么 \(V \le 3b/2\) 的概率为 \(3b/2\)。在已知 \(V \le 3b/2\) 的条件下,\(V\) 的条件分布在 \([0, 3b/2]\) 上服从均匀分布。因此: \[ E(W) = (E(V|V \le 3b/2) - b) P(V \le 3b/2) = (3b/4 - b)(3b/2) = -3b^2/8 \]
上述表达式除了在 \(b = 0\) 时外均为负值,因此最优出价为 0:你不应该玩这个游戏!
或者,根据以下事件是否发生进行条件化:\(A = \{V < b/2\}\),\(B = \{b/2 \le V \le 3b/2\}\),\(C = \{V > 3b/2\}\)。我们有: \[ E(W|A) = E(V - b|A) < E(b/2 - b|A) = -b/2 \le 0 \] \[ E(W|B) = E\left(\frac{b/2 + 3b/2}{2} - b \Big| B\right) = 0 \] \[ E(W|C) = 0 \]
所以我们应该直接设定 \(b = 0\) 然后离开。
这个故事的寓意是要对所有信息进行条件化。在上述计算中,使用 \(E(V|V \le 3b/2)\) 而不是 \(E(V) = 1/2\) 是至关重要的;得知出价被接受这一事实提供了关于神秘奖品价值的信息,因此我们不应破坏该信息。这个问题与所谓的“赢家的诅咒”(winner's curse)有关,它指出在信息不完全的拍卖中,赢家往往获得的利润比预期的要少(除非他们懂概率论!)。这是因为在许多场景下,在获胜的条件下,所竞标物品的价值期望低于他们最初心目中的无条件期望。对于 \(b \ge 2/3\),由于我们预先知道 \(V \le 1\),对 \(V \le 3b/2\) 进行条件化没有任何作用,但这样的出价高得离谱。对于任何 \(b < 2/3\),发现你的出价被接受会降低你的期望: \[ E(V|V \le 3b/2) < E(V) \]
剩下的例子使用第一步分析法来计算无条件期望。首先,正如在第 4 章中所承诺的,我们使用第一步分析法推导几何分布的期望。
示例 9.1.8(几何分布期望的再推导)。令 \(X \sim \text{Geom}(p)\)。将 \(X\) 解释为在一系列单次获胜概率为 \(p\) 的硬币投掷中,第一次出现正面(Heads)之前的反面(Tails)次数。为了得到 \(E(X)\),我们根据第一次投掷的结果进行条件化:如果它是正面,那么 \(X\) 为 0,实验结束;如果它是反面,那么我们浪费了一次投掷,且根据无记忆性,我们回到了起始状态。因此: \[ E(X) = E(X|\text{第一次为 H}) \cdot p + E(X|\text{第一次为 T}) \cdot q \] \[ = 0 \cdot p + (1 + E(X)) \cdot q \]
解得 \(E(X) = q/p\)。
接下来的例子使用两步条件化来推导一些更复杂模式的期望等待时间。
示例 9.1.9(出现 HH 与 HT 的时间对比)。你重复投掷一枚均匀的硬币。出现模式 HT 所需的期望投掷次数是多少?出现模式 HH 所需的期望投掷次数又是多少?
解答:
令 \(W_{HT}\) 为直到出现 HT 的投掷次数。正如我们从图 9.3 中看到的,\(W_{HT}\) 等于等待第一次正面的时间(记作 \(W_1\))加上第一次正面出现后等待第一个反面的额外时间(记作 \(W_2\))。
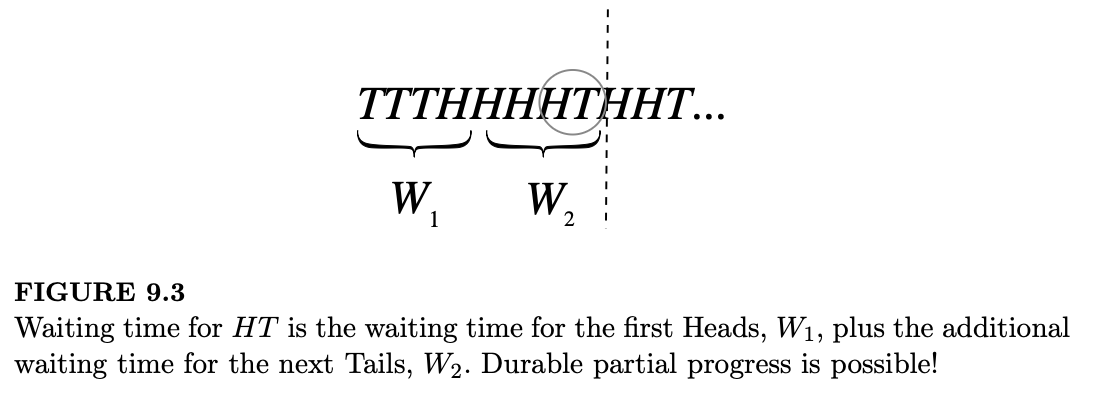
个人注:上图的这种想法太强了,避免了直接找HT的模式,分解成先找H,再找T得两步。
根据首中分布(First Success distribution)的故事,\(W_1\) 和 \(W_2\) 是独立同分布的 \(FS(1/2)\),因此 \(E(W_1) = E(W_2) = 2\),从而 \(E(W_{HT}) = 4\)。
计算 HH 的期望等待时间 \(E(W_{HH})\) 则更为复杂。我们不能套用计算 \(E(W_{HT})\) 的逻辑:如图 9.4 所示,如果第一个正面之后紧跟着一个反面,我们的进度就被摧毁了,必须从头开始。但这恰恰为我们解决问题提供了思路,因为系统会被“重置”这一事实暗示了可以使用第一步分析法。让我们根据第一次投掷的结果进行条件化: \[ E(W_{HH}) = E(W_{HH}|\text{第一次为 H}) \cdot \frac{1}{2} + E(W_{HH}|\text{第一次为 T}) \cdot \frac{1}{2} \]
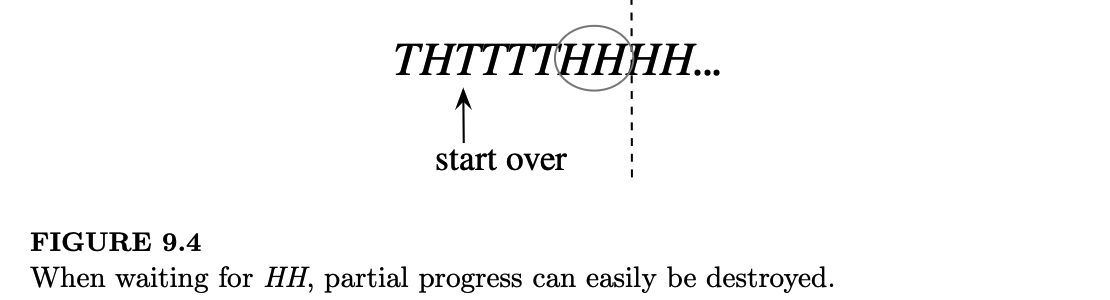
对于第二项,根据无记忆性,有 \(E(W_{HH}|\text{第一次为 T}) = 1 + E(W_{HH})\)。对于第一项,我们通过进一步对第二次投掷的结果进行条件化来计算 \(E(W_{HH}|\text{第一次为 H})\)。如果第二次投掷是正面,我们在两次投掷中得到了 HH。如果第二次投掷是反面,我们浪费了两次投掷且必须重新开始!由此得到: \[ E(W_{HH}|\text{第一次为 H}) = 2 \cdot \frac{1}{2} + (2 + E(W_{HH})) \cdot \frac{1}{2} \]
因此: \[ E(W_{HH}) = \left( 2 \cdot \frac{1}{2} + (2 + E(W_{HH})) \cdot \frac{1}{2} \right) \cdot \frac{1}{2} + (1 + E(W_{HH})) \cdot \frac{1}{2} \]
解关于 \(E(W_{HH})\) 的方程,得到 \(E(W_{HH}) = 6\)。
起初,HH 的期望等待时间大于 HT 的期望等待时间可能令人感到惊讶。既然在两次硬币投掷中,HH 和 HT 出现的概率都是 1/4,我们该如何理解这一差异?为什么根据对称性,平均等待时间会不相同呢?
当我们解决这个问题时,实际上注意到了一个重要的不对称性。在等待 HT 时,一旦我们得到了第一个正面,我们就获得了一份不会被摧毁的部分进展:如果该正面之后又是一个正面,我们仍处于和之前相同的位置;如果该正面之后是一个反面,我们就完成了。相比之下,在等待 HH 时,即使得到了第一个正面,如果其后紧跟一个反面,我们就会被送回原点。这表明 HH 的平均等待时间应该更长。对称性意味着 HH 的平均等待时间与 TT 相同,HT 的与 TH 相同,但它并不意味着 HH 和 HT 的平均等待时间相同。
通过考虑一长串硬币投掷,可以获得更深刻的直观理解,如图 9.5 所示。我们立刻注意到,HH 的出现可以发生重叠,而 HT 的出现必须是不相交的。例如,HHHHHH 中有 5 次 HH 出现,但 HTHTHT 中只有 3 次 HT 出现。由于 HH 和 HT 出现的平均次数相同,但 HH 有时会“扎堆”出现,为了补偿这一点,HH 的平均等待时间必须比 HT 的更长。

相关问题出现在信息论的消息压缩中,以及遗传学中寻找 DNA 序列中重复出现的模式(称为基序,motifs)。本节的最后一个例子通过在概率和期望中同时运用“一厢情愿法”,来研究一个关于随机游走的问题。
示例 9.1.10(整数上的随机游走)。一个长生不老的醉汉在整数上随机游荡。他从原点出发,每一步都独立地以相等的概率向右或向左移动 1 个单位。令 \(b\) 为一个古戈尔普勒克斯(googolplex,即 \(10^g\),其中 \(g = 10^{100}\) 是一个古戈尔)。
求出该醉汉在第一次回到原点之前,访问到 \(b\) 的概率的简单表达式。
求出该醉汉在第一次回到原点之前,访问到 \(b\) 的期望次数。
解答:
令 \(B\) 为醉汉在第一次回到原点前访问到 \(b\) 的事件,令 \(L\) 为他第一步向左走的事件。由于任何从 \(-1\) 到 \(b\) 的路径都必须经过 \(0\),所以 \(P(B|L) = 0\)。对于 \(P(B|L^c)\),我们完全处于赌徒破产问题的设定中:玩家 A 持有 1 美元,玩家 B 持有 \((b-1)\) 美元,且每轮游戏是公平的。应用该结果,我们有: \[ P(B) = P(B|L)P(L) + P(B|L^c)P(L^c) = 0 \cdot \frac{1}{2} + \frac{1}{b} \cdot \frac{1}{2} = \frac{1}{2b} \] > 个人注: 以上的第二项详见本书 例2.7.3(赌徒输光问题);也叫赌徒破产问题。
令 \(N\) 为在第一次回到原点前访问 \(b\) 的次数,令 \(p = 1/(2b)\) 为我们在 (a) 中求得的概率。那么: \[ E(N) = E(N|N = 0)P(N = 0) + E(N|N \ge 1)P(N \ge 1) = p E(N|N \ge 1) \]
在给定 \(N \ge 1\) 的条件下,\(N\) 的条件分布是 \(FS(p)\):已知此人到达了 \(b\),根据对称性,在再次访问 \(b\) 之前先回到原点的概率为 \(p\)(称之为“成功”),在回到原点之前先再次访问 \(b\) 的概率为 \(1-p\)(称之为“失败”)。注意,由于每次他位于 \(b\) 时情况都是相同的且独立于过去的历史,因此这些试验是相互独立的。由此得: \[ E(N|N \ge 1) = 1/p \]
以及 \[ E(N) = p E(N|N \ge 1) = p \cdot \frac{1}{p} = 1 \]
令人惊讶的是,结果并不取决于 \(b\) 的取值,而且我们的证明过程甚至不需要知道 \(p\) 的具体数值。
9.2 给定随机变量下的条件期望
Conditional expectation given an r.v.
在本节中,我们将介绍给定随机变量下的条件期望。也就是说,我们想要理解对于一个随机变量 \(X\),写作 \(E(Y|X)\) 的含义。我们将看到,\(E(Y|X)\) 是一个随机变量,从某种意义上说,它是我们在已知 \(X\) 的情况下对 \(Y\) 做出的最佳预测。
理解 \(E(Y|X)\) 的关键是首先理解 \(E(Y|X=x)\)。由于 \(X=x\) 是一个事件,因此 \(E(Y|X=x)\) 只是给定该事件下 \(Y\) 的条件期望,它可以使用给定 \(X=x\) 时 \(Y\) 的条件分布来计算。
如果 \(Y\) 是离散的,我们使用条件 PMF \(P(Y=y|X=x)\) 代替无条件 PMF \(P(Y=y)\): \[ E(Y|X=x) = \sum_{y} yP(Y=y|X=x) \]
类似地,如果 \(Y\) 是连续的,我们使用条件 PDF \(f_{Y|X}(y|x)\) 代替无条件 PDF: \[ E(Y|X=x) = \int_{-\infty}^{\infty} yf_{Y|X}(y|x)dy \]
注意,由于我们是对 \(y\) 进行求和或积分,因此 \(E(Y|X=x)\) 仅仅是 \(x\) 的函数。我们可以给这个函数起个名字,比如 \(g\):设 \(g(x) = E(Y|X=x)\)。我们将 \(E(Y|X)\) 定义为通过找到函数 \(g(x)\) 的形式,然后将 \(x\) 替换为 \(X\) 而得到的随机变量。
定义 9.2.1(给定随机变量下的条件期望)。令 \(g(x) = E(Y|X=x)\)。那么在给定 \(X\) 的条件下 \(Y\) 的条件期望,记作 \(E(Y|X)\),被定义为随机变量 \(g(X)\)。换句话说,如果在进行实验后 \(X\) 具体化为 \(x\),那么 \(E(Y|X)\) 就具体化为 \(g(x)\)。
9.2.2。该定义中的符号有时会引起混淆。它并不是说“因为 \(g(x) = E(Y|X=x)\),所以 \(g(X) = E(Y|X=X)\),而由于 \(X=X\) 总是成立,所以它等于 \(E(Y)\)”。相反,我们应该先计算出函数 \(g(x)\),然后再将 \(X\) 代入 \(x\)。例如,如果 \(g(x) = x^2\),那么 \(g(X) = X^2\)。在 5.3.2 节关于均匀分布万能性中 \(F(X)\) 的含义时,也存在类似的“生物危害”(易错点)。
9.2.3。根据定义,\(E(Y|X)\) 是 \(X\) 的函数,因此它是一个随机变量。(这并不意味着不存在 \(E(Y|X)\) 为常数的例子。常数是一个退化的随机变量,也是 \(X\) 的常数函数。例如,如果 \(X\) 和 \(Y\) 相互独立,那么 \(E(Y|X) = E(Y)\),这是一个常数。)因此,计算诸如 \(E(E(Y|X))\) 和 \(Var(E(Y|X))\)(即随机变量 \(E(Y|X)\) 的均值和方差)这类量是有意义的。在处理条件期望时,很容易陷入范畴错误(category errors),因此必须牢记:形如 \(E(Y|A)\) 的条件期望是数值,而形如 \(E(Y|X)\) 的条件期望是随机变量。
以下是一些如何计算条件期望的简短示例。在这两个示例中,我们不需要通过求和或积分来得到 \(E(Y|X=x)\),因为有更直接的方法。
例 9.2.4。一根长度为 1 的木棒在随机选择的点 \(X\) 处折断,且 \(X\) 服从均匀分布。已知 \(X=x\),我们再在区间 \([0, x]\) 上均匀随机地选择另一个折断点 \(Y\)。求 \(E(Y|X)\) 及其均值和方差。
解:
根据实验描述,\(X \sim \text{Unif}(0,1)\) 且 \(Y|X=x \sim \text{Unif}(0,x)\)。
那么 \(E(Y|X=x) = x/2\),通过将 \(x\) 替换为 \(X\),我们得到: \[ E(Y|X) = X/2 \]
\(E(Y|X)\) 的期望值为: \[ E(E(Y|X)) = E(X/2) = 1/4 \]
(我们将在下一节证明条件期望的一个通用性质,即 \(E(E(Y|X)) = E(Y)\),因此同样可以得出 \(E(Y) = 1/4\)。)\(E(Y|X)\) 的方差为: \[ \text{Var}(E(Y|X)) = \text{Var}(X/2) = 1/48 \]
例 9.2.5。设 \(X, Y\) 独立同分布于 \(\text{Expo}(\lambda)\),求 \(E(\max(X,Y)|\min(X,Y))\)。
解:
令 \(M = \max(X,Y)\),\(L = \min(X,Y)\)。根据无记忆性,\(M-L\) 与 \(L\) 相互独立,且 \(M-L \sim \text{Expo}(\lambda)\)(参见例 7.3.6)。因此: \[ E(M|L=l) = E(L|L=l) + E(M-L|L=l) = l + E(M-L) = l + \frac{1}{\lambda} \]
从而得到 \(E(M|L) = L + \frac{1}{\lambda}\)。
9.3 条件期望的性质
条件期望具有一些非常实用的性质:
- 舍弃独立部分:如果 \(X\) 和 \(Y\) 相互独立,则 \(E(Y|X) = E(Y)\)。
- 提取已知部分:对于任何函数 \(h\),\(E(h(X)Y|X) = h(X)E(Y|X)\)。
- 线性性质:\(E(Y_1 + Y_2|X) = E(Y_1|X) + E(Y_2|X)\),且对于常数 \(c\),\(E(cY|X) = cE(Y|X)\)(后者是提取已知部分的特殊情况)。
- 亚当定律 (Adam’s law):\(E(E(Y|X)) = E(Y)\)。
- 投影解释:随机变量 \(Y - E(Y|X)\) 被称为利用 \(X\) 预测 \(Y\) 的残差,它与任何函数 \(h(X)\) 都不相关。
让我们分别讨论每个性质。
定理 9.3.1(舍弃独立部分)。如果 \(X\) 和 \(Y\) 相互独立,则 \(E(Y|X) = E(Y)\)。
这是成立的,因为独立性意味着对于所有 \(x\),\(E(Y|X=x) = E(Y)\),因此 \(E(Y|X) = E(Y)\)。直观地说,如果 \(X\) 不能提供关于 \(Y\) 的任何信息,那么即使我们知道了 \(X\),对 \(Y\) 的最佳猜测仍然是无条件均值 \(E(Y)\)。然而,其逆命题是错误的:下文的例 9.3.3 给出了一个反例。
定理 9.3.2(提取已知部分)。对于任何函数 \(h\), \[ E(h(X)Y|X) = h(X)E(Y|X) \]
直观地说,当我们求给定 \(X\) 的期望时,我们将 \(X\) 视为已经具体化为一个已知常数。那么在以 \(X\) 为条件时, \(X\) 的任何函数(如 \(h(X)\))也表现得像一个已知常数。“提取已知部分”是无条件事实 \(E(cY) = cE(Y)\) 的条件版本。区别在于 \(E(cY) = cE(Y)\) 断言两个数值相等,而“提取已知部分”断言两个随机变量相等。
例 9.3.3。设 \(Z \sim N(0,1)\) 且 \(Y = Z^2\)。求 \(E(Y|Z)\) 和 \(E(Z|Y)\)。
解: 由于 \(Y\) 是 \(Z\) 的函数,通过提取已知部分可知,\(E(Y|Z) = E(Z^2|Z) = Z^2\)。为了得到 \(E(Z|Y)\),注意到在给定 \(Y=y\) 的条件下,根据标准正态分布的对称性,\(Z\) 以相等的概率等于 \(\sqrt{y}\) 或 \(-\sqrt{y}\)。因此 \(E(Z|Y=y) = 0\),从而 \(E(Z|Y) = 0\)。
在这种情况下,尽管 \(Y\) 提供了大量关于 \(Z\) 的信息(将 \(Z\) 可能的取值缩小到了仅有两个值),但 \(Y\) 只告诉了我们 \(Z\) 的大小而非其符号。出于这个原因,尽管 \(Z\) 和 \(Y\) 之间存在依赖关系,但 \(E(Z|Y) = E(Z)\)。这个例子说明了定理 9.3.1 的逆命题是错误的。
定理 9.3.4(线性性质)。\(E(Y_1 + Y_2|X) = E(Y_1|X) + E(Y_2|X)\)。
这一结果是无条件事实 \(E(Y_1 + Y_2) = E(Y_1) + E(Y_2)\) 的条件版本,且由于条件概率也是概率,因此它是成立的。
9.3.5。写成 “\(E(Y|X_1 + X_2) = E(Y|X_1) + E(Y|X_2)\)” 是错误的;线性性质适用于条件竖线的左侧,而不是右侧!
例 9.3.6。设 \(X_1, \dots, X_n\) 独立同分布,且 \(S_n = X_1 + \dots + X_n\)。求 \(E(X_1|S_n)\)。
解:
基于对称性, \[ E(X_1|S_n) = E(X_2|S_n) = \dots = E(X_n|S_n) \]
根据线性性质, \[ E(X_1|S_n) + \dots + E(X_n|S_n) = E(S_n|S_n) = S_n \]
因此, \[ E(X_1|S_n) = S_n/n = \bar{X}_n \]
即 \(X_j\) 的样本均值。这是一个直观的结果:如果我们有两个独立同分布的随机变量 \(X_1, X_2\) 且得知 \(X_1 + X_2 = 10\),那么猜测 \(X_1\) 为 5(占总数的一半)是合理的。类似地,如果我们有 \(n\) 个独立同分布的随机变量并知道了它们的总和,那么对其中任何一个的最佳猜测就是样本均值。
下一个定理将条件期望与无条件期望联系起来。它有许多名称,包括全期望公式(law of total expectation)、迭代期望法则(law of iterated expectation,其英文缩写 LIE 对于一个闪烁着真理光芒的法则来说实在不太好听)以及塔性(tower property)。我们将其称为“亚当定律”(Adam’s law),因为它被使用得如此频繁,理应有一个简练的名字,而且它经常与我们稍后会遇到的另一个名字互补的法则结合使用。
定理 9.3.7(亚当定律)。对于任何随机变量 \(X\) 和 \(Y\), \[ E(E(Y|X)) = E(Y) \]
证明。我们给出 \(X\) 和 \(Y\) 均为离散型随机变量时的证明(其他情况的证明与之类似)。令 \(E(Y|X) = g(X)\)。我们通过应用无意识统计学家法则(LOTUS),展开 \(g(x)\) 的定义得到一个二重级数,然后交换求和顺序: \[ E(g(X)) = \sum_{x} g(x)P(X=x) \] \[ = \sum_{x} \left( \sum_{y} yP(Y=y|X=x) \right) P(X=x) \] \[ = \sum_{x} \sum_{y} yP(X=x)P(Y=y|X=x) \] \[ = \sum_{y} y \sum_{x} P(X=x, Y=y) \] \[ = \sum_{y} yP(Y=y) = E(Y) \]
亚当定律是全期望公式(定理 9.1.5)更紧凑、更通用的版本。对于离散型 \(X\),以下表述: \[ E(Y) = \sum_{x} E(Y|X=x)P(X=x) \]
与 \[ E(Y) = E(E(Y|X)) \]
含义相同。因为如果我们令 \(E(Y|X=x) = g(x)\),那么: \[ E(E(Y|X)) = E(g(X)) = \sum_{x} g(x)P(X=x) = \sum_{x} E(Y|X=x)P(X=x) \]
有了亚当定律,我们就有了一个计算期望 \(E(Y)\) 的强大策略:通过对一个我们“希望已知”的随机变量 \(X\) 进行条件化。首先通过将 \(X\) 视为已知来求出 \(E(Y|X)\),然后对 \(E(Y|X)\) 取期望。我们将在本章稍后看到各种相关的示例。
正如第 2 章中讨论的贝叶斯法则和全概率公式(LOTP)存在带有额外条件的形式一样,亚当定律也有带有额外条件的形式。
定理 9.3.8(带有额外条件的亚当定律)。对于任何随机变量 \(X, Y, Z\), \[ E(E(Y|X,Z)|Z) = E(Y|Z) \]
上述等式即为亚当定律,只是在每一处都插入了关于 \(Z\) 的额外条件。这是成立的,因为条件概率也是概率。因此,我们可以自由地使用亚当定律来帮助我们求解无条件期望和条件期望。
个人注:直观理解:层层过滤
我们可以把期望 \(E(\cdot | \dots)\) 理解为一种“信息过滤”:
- \(E(Y | X, Z)\):这是在已知 \(X\) 和 \(Z\) 两个信息源时,对 \(Y\) 的最佳预测。
- 外层的 \(E(\cdot | Z)\):这意味着我们现在要抛弃 \(X\) 的信息,仅保留 \(Z\) 的信息。
当你对“基于 \(X\) 和 \(Z\) 的预测值”再次根据“仅有 \(Z\)”进行平均时,关于 \(X\) 的细节就被抵消(平均掉)了,剩下的自然就是仅基于 \(Z\) 对 \(Y\) 的预测。
利用亚当定律,我们还可以证明条件期望性质列表中的最后一项。
定理 9.3.9(投影解释)。对于任何函数 \(h\),随机变量 \(Y - E(Y|X)\) 与 \(h(X)\) 不相关。等价地, \[ E((Y - E(Y|X))h(X)) = 0 \]
(由于根据线性性质和亚当定律可知 \(E(Y - E(Y|X)) = 0\),因此这二者是等价的。)
证明。我们有 \[ E((Y - E(Y|X))h(X)) = E(h(X)Y) - E(h(X)E(Y|X)) \] \[ = E(h(X)Y) - E(E(h(X)Y|X)) \]
根据定理 9.3.2(这里我们在内部期望中使用了“放回已知部分”)。根据亚当定律,第二项等于 \(E(h(X)Y)\)。
从几何角度来看,我们可以将定理 9.3.9 视觉化为如图 9.6 所示。在某种意义上(如下所述),\(E(Y|X)\) 是 \(X\) 的所有函数中与 \(Y\) 最接近的一个;我们说 \(E(Y|X)\) 是 \(Y\) 在所有 \(X\) 的函数构成的空间上的投影。图中从 \(Y\) 到 \(E(Y|X)\) 的“线”与该“平面”正交(垂直),因为从 \(Y\) 到 \(E(Y|X)\) 的任何其他路径都会更长。这种正交性正是定理 9.3.9 的几何解释。
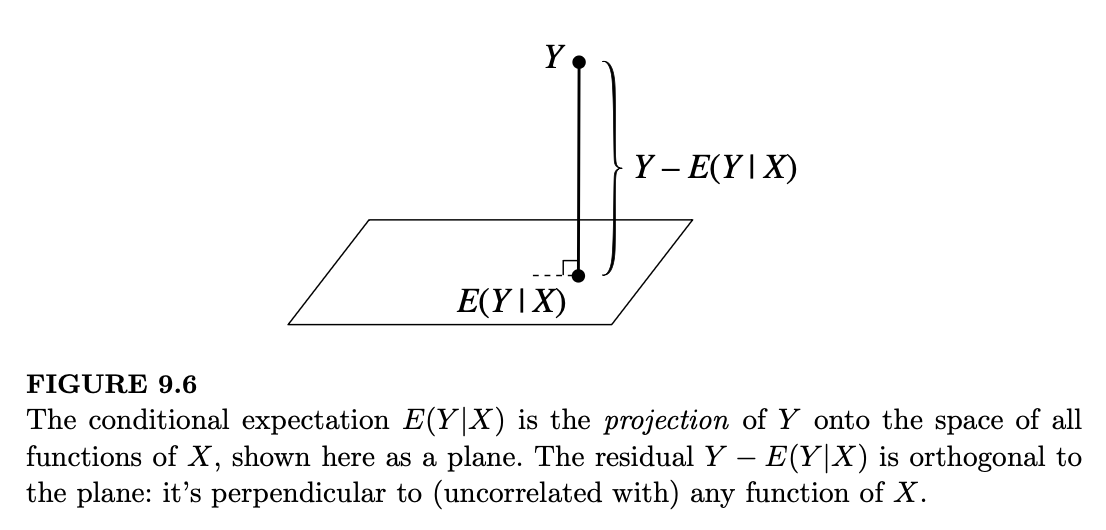
有关这一视角的细节将在下一节给出,由于该节需要线性代数知识,因此标注了星号。但即使不深入研究线性代数,投影图示也能提供一些有用的直觉。如前所述,我们可以将 \(E(Y|X)\) 视为基于 \(X\) 对 \(Y\) 的预测。这是统计学中一个极其常见的问题:根据数据预测或估计未来的观测值或未知参数。条件期望的投影解释意味着 \(E(Y|X)\) 是基于 \(X\) 预测 \(Y\) 的最佳预测器,其含义是:在 \(X\) 的所有函数中,它的均方误差(\(Y\) 与预测值之间差值的平方期望)最低。
例 9.3.10(线性回归)。在统计学的数据分析中,一种应用极其广泛的方法是线性回归。在其最基本的形式中,线性回归模型使用单个解释变量 \(X\) 来预测响应变量 \(Y\),并且假设 \(Y\) 的条件期望关于 \(X\) 是线性的: \[ E(Y|X) = a + bX \]
- 证明表达这一点的等价方式是写作: \[ Y = a + bX + \epsilon \]
其中 \(\epsilon\) 是一个满足 \(E(\epsilon|X) = 0\) 的随机变量(称为误差项)。
- 用 \(E(X)\)、\(E(Y)\)、\(\text{Cov}(X,Y)\) 和 \(\text{Var}(X)\) 来求解常数 \(a\) 和 \(b\)。
解:
- 设 \(Y = a + bX + \epsilon\),且 \(E(\epsilon|X) = 0\)。那么根据线性性质: \[ E(Y|X) = E(a|X) + E(bX|X) + E(\epsilon|X) = a + bX \]
反之,假设 \(E(Y|X) = a + bX\),并定义: \[ \epsilon = Y - (a + bX) \]
那么 \(Y = a + bX + \epsilon\),且: \[ E(\epsilon|X) = E(Y|X) - E(a + bX|X) = E(Y|X) - (a + bX) = 0 \]
- 首先,根据亚当定律,对等式两边取期望得: \[ E(Y) = a + bE(X) \]
注意到 \(\epsilon\) 的均值为 0,且 \(X\) 与 \(\epsilon\) 不相关,因为: \[ E(\epsilon) = E(E(\epsilon|X)) = E(0) = 0 \]
且 \[ E(\epsilon X) = E(E(\epsilon X|X)) = E(XE(\epsilon|X)) = E(0) = 0 \]
在 \(Y = a + bX + \epsilon\) 的两边同时取与 \(X\) 的协方差,我们有: \[ \text{Cov}(X,Y) = \text{Cov}(X,a) + b\text{Cov}(X,X) + \text{Cov}(X,\epsilon) = b\text{Var}(X) \]
因此: \[ b = \frac{\text{Cov}(X,Y)}{\text{Var}(X)} \] \[ a = E(Y) - bE(X) = E(Y) - \frac{\text{Cov}(X,Y)}{\text{Var}(X)} \cdot E(X) \]
9.4 *条件期望的几何解释
Geometric interpretation of conditional expectation
本节使用线性代数中的一些概念,更详细地解释图 9.6 中所示的几何视角。考虑由某个概率空间上所有具有有限方差的随机变量构成的向量空间。空间中的每个向量或点都是一个随机变量(这里我们是在线性代数意义上使用“向量”一词,而不是指第 7 章中的随机向量)。定义两个随机变量 \(U\) 和 \(V\) 的内积为:
This section explains in more detail the geometric perspective shown in Figure 9.6, using some concepts from linear algebra. Consider the vector space consisting of all random variables on a certain probability space, such that the random variables all have finite variance. Each vector or point in the space is a random variable (here we are using “vector” in the linear algebra sense, not in the sense of a random vector from Chapter 7). Define the inner product of two r.v.s U and V to be: \[ \langle U,V \rangle = E(UV) \]
(为了使该定义满足内积公理,我们需要约定:如果两个随机变量以概率 1 相等,则视它们为同一个变量。)
随机变量 \(X\) 的长度平方为: \[ \|X\|^2 = \langle X,X \rangle = EX^2 \]
而两个随机变量 \(U\) 和 \(V\) 之间的距离平方为: \[ \|U-V\|^2 = E(U-V)^2 \]
如果 \(E(U) = E(V) = 0\),这些解释会变得特别优美,因为此时:
- \(\|U\|^2 = \text{Var}(U)\),且 \(\|U\| = \text{SD}(U)\)。
- \(\langle U,V \rangle = \text{Cov}(U,V)\),且 \(U\) 与 \(V\) 之间“夹角”的余弦值就是 \(\text{Corr}(U,V)\)。
- \(U\) 与 \(V\) 正交(即 \(\langle U,V \rangle = 0\))当且仅当它们不相关。
为了从几何上解释 \(E(Y|X)\),考虑所有可以表示为 \(X\) 的函数(且具有有限方差)的随机变量所构成的空间。这是上述向量空间的一个子空间。在图 9.6 中,形式为 \(h(X)\) 的随机变量子空间用一个平面表示。为了得到 \(E(Y|X)\),我们将 \(Y\) 投影到该平面上。那么残差 \(Y-E(Y|X)\) 与所有函数 \(h(X)\) 正交,且 \(E(Y|X)\) 是预测 \(Y\) 效果最好的 \(X\) 的函数。这里的“最好”是指通过选择 \(g(X) = E(Y|X)\) 使得均方误差 \(E(Y-g(X))^2\) 最小。
投影解释是思考条件期望许多性质的一种有效方式。例如,如果 \(Y = h(X)\) 是 \(X\) 的一个函数,那么 \(Y\) 本身已经位于该平面内,因此它的投影就是它自己;这解释了为什么 \(E(h(X)|X) = h(X)\)。
我们也可以将无条件期望看作一种投影:\(E(Y)\) 可以被看作 \(E(Y|0)\),即 \(Y\) 在所有常数构成的空间上的投影(事实上,\(E(Y)\) 是使 \(E(Y-c)^2\) 最小的常数 \(c\),正如我们在定理 6.1.4 中证明的那样)。
现在我们还可以给亚当定律一个几何解释:\(E(Y)\) 代表将 \(Y\) 一步投影到所有常数构成的空间上;\(E(E(Y|X))\) 代表分两步完成:先投影到平面上得到 \(E(Y|X)\),再将 \(E(Y|X)\) 投影到该平面内的一条直线——常数空间上。亚当定律指出,一步法和两步法产生的结果是相同的。
在下一节中,我们将介绍夏娃定律(Eve’s law),它对方差的作用类似于亚当定律对期望的作用。作为预告并进一步探索条件期望的几何解释,让我们从本节的角度来看看 \(\text{Var}(Y)\)。假设 \(E(Y) = 0\)(如果 \(E(Y) \neq 0\),我们可以通过减去 \(E(Y)\) 对 \(Y\) 进行中心化;这样做对方差没有影响)。
我们可以将 \(Y\) 分解为两个正交项:残差 \(Y-E(Y|X)\) 和条件期望 \(E(Y|X)\): \[ Y = (Y-E(Y|X)) + E(Y|X) \]
这两项是正交的,因为 \(Y-E(Y|X)\) 与 \(X\) 的任何函数都不相关,而 \(E(Y|X)\) 是 \(X\) 的函数。因此,根据勾股定理: \[ \|Y\|^2 = \|Y-E(Y|X)\|^2 + \|E(Y|X)\|^2 \]
即: \[ \text{Var}(Y) = \text{Var}(Y-E(Y|X)) + \text{Var}(E(Y|X)) \]
正如我们将在下一节看到的,这个等式是夏娃定律的一种形式。因此事实证明,夏娃定律虽然乍看之下有些晦涩,但其实可以解释为以 \(Y-E(Y|X)\)、\(E(Y|X)\) 和 \(Y\) 为边构成的“三角形”的勾股定理。
个人注;条件期望提取了 \(Y\) 中所有能由 \(X\) 解释的部分,剩下的残差与 \(X\) 处于完全不同的“维度”,因此它们是正交(不相关)的。
这一性质是著名的最小均方误差(MMSE)估计的基础。
9.5 条件方差
Conditional variance
一旦我们定义了给定随机变量下的条件期望,我们就有了一种自然的方式来定义给定随机变量下的条件方差:即将无条件方差定义中的所有 \(E(\cdot)\) 替换为 \(E(\cdot|X)\)。
定义 9.5.1(条件方差)。给定 \(X\) 下 \(Y\) 的条件方差为: \[ \text{Var}(Y|X) = E((Y - E(Y|X))^2|X) \]
这等价于: \[ \text{Var}(Y|X) = E(Y^2|X) - (E(Y|X))^2 \]
9.5.2。与 \(E(Y|X)\) 一样,\(\text{Var}(Y|X)\) 也是一个随机变量,且它是 \(X\) 的函数。
由于条件方差是根据条件期望定义的,我们可以利用关于条件期望的结论来帮助我们计算条件方差。以下是一个示例。
例 9.5.3。设 \(Z \sim N(0,1)\) 且 \(Y = Z^2\)。求 \(\text{Var}(Y|Z)\) 和 \(\text{Var}(Z|Y)\)。
解:
无需任何计算,我们就可以看出 \(\text{Var}(Y|Z) = 0\):在给定 \(Z\) 的条件下,\(Y\) 是一个已知常数,而常数的方差为 0。同理,对于任何函数 \(h\),\(\text{Var}(h(Z)|Z) = 0\)。
为了得到 \(\text{Var}(Z|Y)\),应用定义: \[ \text{Var}(Z|Z^2) = E(Z^2|Z^2) - (E(Z|Z^2))^2 \]
第一项等于 \(Z^2\)。正如我们在例 9.3.3 中发现的,根据对称性,第二项等于 0。因此 \(\text{Var}(Z|Z^2) = Z^2\),我们可以写成 \(\text{Var}(Z|Y) = Y\)。
在下一个示例中,我们将练习在二元正态分布背景下处理条件期望和条件方差。
例 9.5.4(二元正态分布中的条件期望和条件方差)。设 \((Z,W)\) 服从二元正态分布,其中 \(\text{Corr}(Z,W) = \rho\),且 \(Z,W\) 的边缘分布均为 \(N(0,1)\)。求 \(E(W|Z)\) 和 \(\text{Var}(W|Z)\)。
解: 我们可以假设 \((Z,W)\) 是按照例 7.5.10 中的方式构造的,因为 \(E(W|Z)\) 和 \(\text{Var}(W|Z)\) 仅取决于 \((Z,W)\) 的联合分布,而与创建 \((Z,W)\) 的具体方法无关。因此,令: \[ Z = X \] \[ W = \rho X + \sqrt{1-\rho^2}Y \]
其中 \(X,Y\) 独立同分布于 \(N(0,1)\)。这样我们就可以非常巧妙地解决问题,而无需诉诸基于二元正态联合 PDF 的繁琐积分。
条件期望为: \[ E(W|Z) = E(W|X) = \rho X + \sqrt{1-\rho^2}E(Y|X) = \rho X + \sqrt{1-\rho^2}E(Y) = \rho Z \]
因为 \(X\) 和 \(Y\) 相互独立。条件方差为: \[ \text{Var}(W|Z) = \text{Var}(W|X) = \text{Var}(\sqrt{1-\rho^2}Y|X) = (1-\rho^2)\text{Var}(Y) = 1-\rho^2 \]
因为在给定 \(X\) 时,\(\rho X\) 充当常数,且 \(Y\) 与 \(X\) 相互独立。
有趣的是,将 \(Z\) 和 \(W\) 的角色互换使用相同的论证可以得出 \(E(Z|W) = \rho W\) 且 \(\text{Var}(Z|W) = 1-\rho^2\)。
人们可能会猜测,如果从 \(Z\) 的观测值映射到 \(W\) 的预测值需要乘以 \(\rho\),那么从 \(W\) 的观测值映射到 \(Z\) 的预测值就应该除以 \(\rho\)。但上述结果表明,无论使用 \(Z\) 预测 \(W\) 还是反之,都要乘以同一个 \(\rho\)!这与相关性是对称的(\(\text{Corr}(Z,W) = \rho = \text{Corr}(W,Z)\))这一事实密切相关,也与统计学中一个被称为“向均值回归”的重要概念有关。
我们在前一节了解到,亚当定律将条件期望与无条件期望联系起来。与亚当定律相伴的一个结论是夏娃定律(Eve’s law),它将条件方差与无条件方差联系起来。
定理 9.5.5(夏娃定律)。对于任何随机变量 \(X\) 和 \(Y\), \[ \text{Var}(Y) = E(\text{Var}(Y|X)) + \text{Var}(E(Y|X)) \]
等式右侧 \(E\) 和 \(\text{Var}\) 的顺序拼写为 EVVE,这正是“夏娃定律”名字的由来。夏娃定律也被称为全方差公式(law of total variance)或方差分解公式。
证明。令 \(g(X) = E(Y|X)\)。根据亚当定律,\(E(g(X)) = E(Y)\)。那么: \[ E(\text{Var}(Y|X)) = E(E(Y^2|X) - g(X)^2) = E(Y^2) - E(g(X)^2) \] \[ \text{Var}(E(Y|X)) = E(g(X)^2) - (Eg(X))^2 = E(g(X)^2) - (EY)^2 \]
将这两个等式相加,即可得到夏娃定律。
为了直观地理解夏娃定律(Eve’s law),想象一个群体,其中每个人都有一个 \(X\) 值和一个 \(Y\) 值。我们可以根据 \(X\) 的每个可能取值将这个群体划分为若干子群体。例如,如果 \(X\) 代表年龄,\(Y\) 代表身高,我们可以按年龄对人群进行分组。那么在总体中,造成人们身高差异的变异来源有两个。第一,在每个年龄组内部,人们的身高各不相同。每个年龄组内身高变异的平均量就是组内变异(within-group variation),即 \(E(\text{Var}(Y|X))\)。第二,不同年龄组之间的平均身高是不同的。各年龄组平均身高的方差就是组间变异(between-group variation),即 \(\text{Var}(E(Y|X))\)。夏娃定律指出,要得到 \(Y\) 的总方差,我们只需将这两个变异来源相加即可。
图 9.7 展示了在只有三个年龄组的简单情况下夏娃定律的含义。在 \(X = 1, X = 2\) 和 \(X = 3\) 各组内部的平均散布程度是组内变异 \(E(\text{Var}(Y|X))\)。而各组均值 \(E(Y|X = 1), E(Y|X = 2)\) 和 \(E(Y|X = 3)\) 的方差则是组间变异 \(\text{Var}(E(Y|X))\)。
思考夏娃定律的另一种方式是从预测的角度出发。如果我们想仅根据年龄来预测某人的身高,理想的情况是每个年龄组内的每个人身高完全相同,而不同年龄组之间的身高各不相同。这样,给定某人的年龄,我们就能完美地预测其身高。换句话说,预测的理想情况是身高没有组内变异,因为组内变异无法由年龄差异来解释。出于这个原因,组内变异也被称为未解释变异(unexplained variation),而组间变异也被称为已解释变异(explained variation)。夏娃定律说明 \(Y\) 的总方差是未解释变异与已解释变异之和。
我们也可以将夏娃定律写成如下形式: \[ \text{Var}(Y) = \text{Var}(Y - E(Y|X)) + \text{Var}(E(Y|X)) \]
因为,若令 \(W\) 为残差 \(Y - E(Y|X)\),则: \[ \text{Var}(Y - E(Y|X)) = E(W^2) = E(E(W^2|X)) = E(\text{Var}(Y|X)) \]
这再次表明我们可以将方差分解为组内变异加上组间变异。
9.5.6。设 \(Y\) 为随机变量,\(A\) 为事件。说“\(\text{Var}(Y) = \text{Var}(Y|A)P(A) + \text{Var}(Y|A^c)P(A^c)\)”是错误的,尽管这看起来与全期望公式很相似。(举一个简单的反例:设 \(Y \sim \text{Bern}(1/2)\),\(A\) 为事件 \(Y = 0\)。那么 \(\text{Var}(Y|A)\) 和 \(\text{Var}(Y|A^c)\) 均为 0,但 \(\text{Var}(Y) = 1/4\)。)
相反,如果我们想根据事件 \(A\) 是否发生来进行条件化,我们应该使用夏娃定律:令 \(I\) 为 \(A\) 的指示函数, \[ \text{Var}(Y) = E(\text{Var}(Y|I)) + \text{Var}(E(Y|I)) \]
为了看清这个表达式与那个“错误表达式”之间的关系,令:
\[ p = P(A), q = P(A^c), a = E(Y|A), b = E(Y|A^c), v = \text{Var}(Y|A), w = \text{Var}(Y|A^c) \]
那么 \(E(Y|I)\) 以概率 \(p\) 取 \(a\),以概率 \(q\) 取 \(b\);而 \(\text{Var}(Y|I)\) 以概率 \(p\) 取 \(v\),以概率 \(q\) 取 \(w\)。因此: \[ E(\text{Var}(Y|I)) = vp + wq = \text{Var}(Y|A)P(A) + \text{Var}(Y|A^c)P(A^c) \]
这恰好就是那个“错误表达式”,而 \(\text{Var}(Y)\) 由此项加上另一项组成: \[ \text{Var}(E(Y|I)) = a^2p + b^2q - (ap + bq)^2 \]
同时考虑组内变异和组间变异是至关重要的。
9.6 亚当与夏娃定律示例
Adam and Eve examples
本章最后通过几个示例来说明亚当定律和夏娃定律如何帮助我们求解复杂随机变量的均值和方差,特别是在涉及多层随机性的情况下。
在第一个示例中,我们关注的随机变量是一个随机和(random sum):即随机个数个随机变量之和。这里存在两层随机性:首先,和式中的每一项都是随机变量;其次,求和项的数量本身也是一个随机变量。
例 9.6.1(随机和)。一家商店一天接待 \(N\) 个顾客,其中 \(N\) 是一个具有有限均值和方差的随机变量。设 \(X_j\) 为第 \(j\) 个顾客在商店的消费金额。假设每个 \(X_j\) 的均值为 \(\mu\),方差为 \(\sigma^2\),且 \(N\) 与所有 \(X_j\) 之间相互独立。用 \(\mu, \sigma^2, E(N)\) 和 \(\text{Var}(N)\) 来表示随机和 \(X = \sum_{j=1}^{N} X_j\)(即商店一天的总收入)的均值和方差。
解:
由于 \(X\) 是一个和,我们的第一冲动可能是根据线性性质断言“\(E(X) = N\mu\)”。唉,这将是一个范畴错误,因为 \(E(X)\) 是一个数值,而 \(N\mu\) 是一个随机变量。关键在于 \(X\) 不仅仅是一个和,而是一个随机和;我们要相加的项数本身是随机的,而线性性质适用于项数固定的求和。
然而,这个范畴错误实际上暗示了正确的策略:如果我们被允许将 \(N\) 视为常数,那么线性性质就会适用。因此,让我们对 \(N\) 进行条件化。根据条件期望的线性性质: \[ E(X|N) = E\left(\sum_{j=1}^{N} X_j \middle| N\right) = \sum_{j=1}^{N} E(X_j|N) = \sum_{j=1}^{N} E(X_j) = N\mu \]
我们利用了 \(X_j\) 与 \(N\) 的独立性来断言对于所有 \(j\),\(E(X_j|N) = E(X_j)\)。请注意,“\(E(X|N) = N\mu\)”这一表述并不是范畴错误,因为等式两边都是作为 \(N\) 的函数的随机变量。最后,根据亚当定律: \[ E(X) = E(E(X|N)) = E(N\mu) = \mu E(N) \]
这是一个令人愉悦的结果:平均总收入等于每个顾客的平均消费金额乘以平均顾客人数。
对于 \(\text{Var}(X)\),我们再次对 \(N\) 进行条件化以得到 \(\text{Var}(X|N)\): \[ \text{Var}(X|N) = \text{Var}\left(\sum_{j=1}^{N} X_j \middle| N\right) = \sum_{j=1}^{N} \text{Var}(X_j|N) = \sum_{j=1}^{N} \text{Var}(X_j) = N\sigma^2 \]
夏娃定律告诉我们如何获取 \(X\) 的无条件方差: \[ \text{Var}(X) = E(\text{Var}(X|N)) + \text{Var}(E(X|N)) \] \[ = E(N\sigma^2) + \text{Var}(N\mu) \] \[ = \sigma^2 E(N) + \mu^2 \text{Var}(N) \]
在下一个示例中,两层随机性的产生是因为我们的实验分两个阶段进行。我们先从一组城市中抽样一个城市,然后在该城市内对市民进行抽样。这是多层模型(multilevel model)的一个例子。
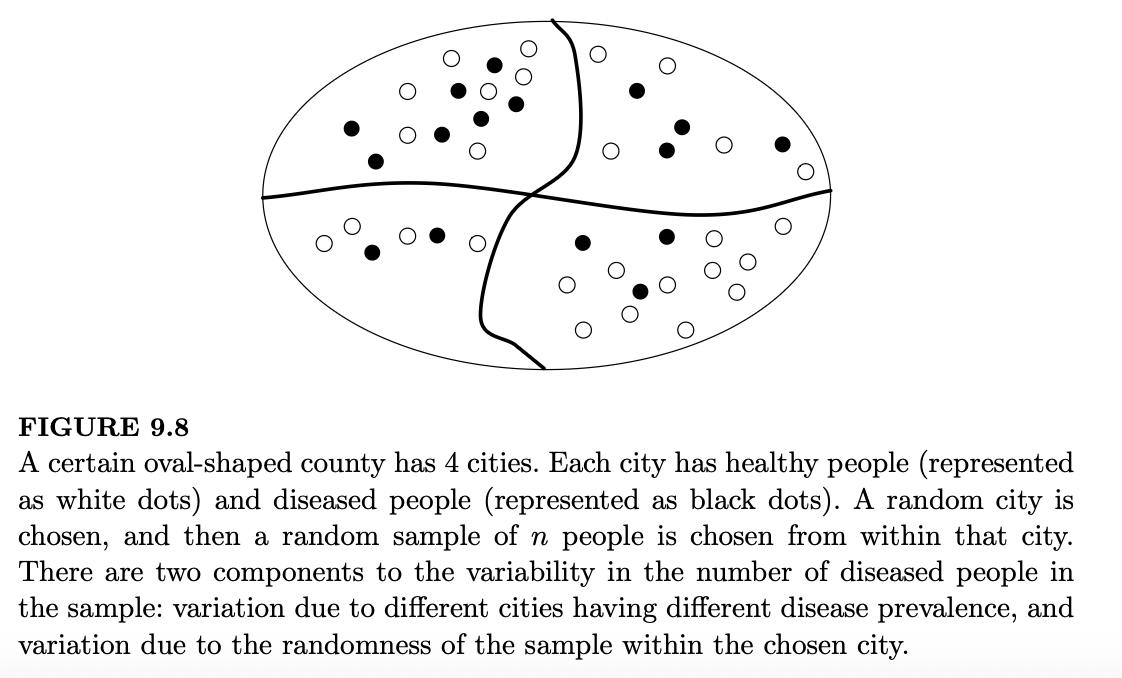
例 9.6.2(随机城市的随机样本)。为了研究某县内若干个城市的疾病流行率,我们随机挑选一个城市,然后从该城市中随机抽取 \(n\) 个人作为样本。这是一种被广泛使用的调查技术,称为整群抽样(cluster sampling)。
令 \(Q\) 为所选城市中患病者的比例,并令 \(X\) 为样本中患病者的人数。如图 9.8 所示(其中白点代表健康个体,黑点代表患病个体),不同城市的流行率可能大不相同。由于每个城市都有自己的疾病流行率,因此 \(Q\) 是一个随机变量。假设 \(Q \sim \text{Unif}(0,1)\)。还假设在给定 \(Q\) 的条件下,样本中的每个人独立地以概率 \(Q\) 患病;如果我们对所选城市进行有放回抽样,这一点是成立的;如果是无放回抽样但总体规模很大,这一点也近似成立。求 \(E(X)\) 和 \(\text{Var}(X)\)。
解:
根据我们的假设,\(X|Q \sim \text{Bin}(n,Q)\);这一符号表示在已知所选城市的疾病流行率的情况下,我们可以将 \(Q\) 视为常数,每个抽样个体都是一个成功概率为 \(Q\) 的独立伯努利试验。利用二项分布的均值和方差,可知 \(E(X|Q) = nQ\) 且 \(\text{Var}(X|Q) = nQ(1-Q)\)。此外,利用标准均匀分布的矩,可知 \(E(Q) = 1/2\),\(E(Q^2) = 1/3\),且 \(\text{Var}(Q) = 1/12\)。现在我们可以应用亚当定律和夏娃定律来得到 \(X\) 的无条件均值和方差: \[ E(X) = E(E(X|Q)) = E(nQ) = \frac{n}{2} \] \[ \text{Var}(X) = E(\text{Var}(X|Q)) + \text{Var}(E(X|Q)) \] \[ = E(nQ(1-Q)) + \text{Var}(nQ) \] \[ = nE(Q) - nE(Q^2) + n^2\text{Var}(Q) \] \[ = \frac{n}{6} + \frac{n^2}{12} \]
请注意,此问题的结构与贝叶斯台球(Bayes’ billiards)故事中的结构完全相同。因此,我们实际上知道 \(X\) 的分布,而不仅仅是它的均值和方差:\(X\) 在 \(\{0, 1, 2, \dots, n\}\) 上服从离散均匀分布。但是,无论推导 \(X\) 的分布是否可行,当 \(Q\) 具有更复杂的分布,或者多层模型中存在更多层级时,都可以应用“亚当与夏娃”方法。例如,我们可以研究国家内部的州,州内部的县,县内部的城市,城市内部的人。
最后但也同样重要的是,我们重新审视前一章中的故事 8.4.5,即伽马-泊松(Gamma-Poisson)问题。
例 9.6.3(再谈伽马-泊松)。回想一下,弗雷德(Fred)决定通过在公交车站等待 \(t\) 小时并计算公交车数量 \(Y\),来了解布洛奇维尔(Blotchville)公交车泊松过程的速率。随后,他利用观测数据更新了他的先验分布 \(\lambda \sim \text{Gamma}(r_0, b_0)\)。因此,弗雷德使用的是如下两层模型: \[ \lambda \sim \text{Gamma}(r_0, b_0) \] \[ Y|\lambda \sim \text{Pois}(\lambda t) \]
我们发现,在弗雷德的模型下,\(Y\) 的边缘分布是参数为 \(r = r_0\) 且 \(p = b_0/(b_0 + t)\) 的负二项分布。特别地: \[ E(Y) = \frac{rq}{p} = \frac{r_0 t}{b_0} \] \[ \text{Var}(Y) = \frac{rq}{p^2} = \frac{r_0 t(b_0 + t)}{b_0^2} \]
让我们用亚当定律和夏娃定律独立验证这一点。利用泊松分布的结论,给定 \(\lambda\) 下 \(Y\) 的条件均值和方差为 \(E(Y|\lambda) = \text{Var}(Y|\lambda) = \lambda t\)。利用伽马分布的结论,\(\lambda\) 的边缘均值和方差为 \(E(\lambda) = r_0/b_0\) 且 \(\text{Var}(\lambda) = r_0/b_0^2\)。对于亚当和夏娃来说,这些信息就足够了: \[ E(Y) = E(E(Y|\lambda)) = E(\lambda t) = \frac{r_0 t}{b_0} \] \[ \text{Var}(Y) = E(\text{Var}(Y|\lambda)) + \text{Var}(E(Y|\lambda)) \] \[ = E(\lambda t) + \text{Var}(\lambda t) \] \[ = \frac{r_0 t}{b_0} + \frac{r_0 t^2}{b_0^2} = \frac{r_0 t(b_0 + t)}{b_0^2} \]
这与我们之前的答案一致。区别在于,当使用亚当和夏娃定律时,我们不需要知道 \(Y\) 服从负二项分布!如果我们当时懒得推导 \(Y\) 的边缘分布,或者如果我们没那么幸运地得到一个有名字的分布,亚当和夏娃定律依然能提供 \(Y\) 的均值和方差(尽管不能提供 PMF)。
最后,让我们比较一下两层模型下 \(Y\) 的均值和方差,与如果弗雷德完全确定 \(\lambda\) 的真实值时所得到的均值和方差。换句话说,假设我们将 \(\lambda\) 替换为其均值 \(E(\lambda) = r_0/b_0\),使 \(\lambda\) 成为一个常数而非随机变量。那么在新假设下,公交车数量(我们称之为 \(\tilde{Y}\))的边缘分布将仅仅是参数为 \(r_0 t/b_0\) 的泊松分布。于是我们会有: \[ E(\tilde{Y}) = \frac{r_0 t}{b_0} \] \[ \text{Var}(\tilde{Y}) = \frac{r_0 t}{b_0} \]
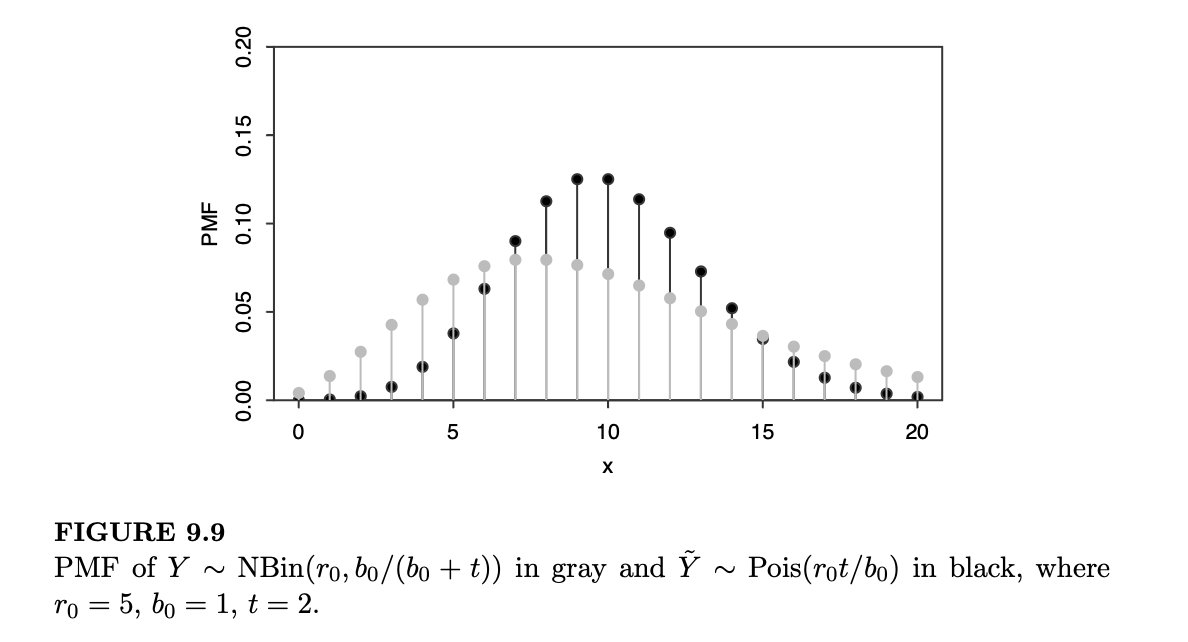
注意到 \(E(\tilde{Y}) = E(Y)\),但 \(\text{Var}(\tilde{Y}) < \text{Var}(Y)\):来自夏娃定律的额外项 \(r_0 t^2 / b_0^2\) 消失了。直观上,当我们把 \(\lambda\) 固定在其均值时,我们消除了模型中的一层不确定性,这导致了无条件方差的减少。图 9.9 叠印了两个 PMF 的图像:灰色代表 \(Y \sim \text{NBin}(r_0, b_0/(b_0+t))\),黑色代表 \(\tilde{Y} \sim \text{Pois}(r_0 t/b_0)\)。参数值被任意选择为 \(r_0 = 5, b_0 = 1, t = 2\)。这两个 PMF 具有相同的质心(均值),但 \(Y\) 的 PMF 明显更加分散。
9.7 本章小结
要计算无条件期望,我们可以划分样本空间并使用全期望公式: \[ E(Y) = \sum_{i=1}^{n} E(Y|A_i)P(A_i) \]
但我们必须注意不要在后续步骤中丢失信息(例如在漫长的计算过程中忘记对需要条件化的项进行条件化)。在具有递归结构的问题中,我们还可以对期望使用第一步分析法。
条件期望 \(E(Y|X)\) 和条件方差 \(\text{Var}(Y|X)\) 是 \(X\) 的函数,即随机变量;它们是通过将 \(X\) 视为已知常数而得到的。如果 \(X\) 和 \(Y\) 相互独立,则 \(E(Y|X) = E(Y)\) 且 \(\text{Var}(Y|X) = \text{Var}(Y)\)。条件期望具有以下性质: \[ E(h(X)Y|X) = h(X)E(Y|X) \] \[ E(Y_1 + Y_2|X) = E(Y_1|X) + E(Y_2|X) \]
这与无条件期望的性质 \(E(cY) = cE(Y)\) 和 \(E(Y_1 + Y_2) = E(Y_1) + E(Y_2)\) 相类似。条件期望 \(E(Y|X)\) 也是使残差 \(Y - E(Y|X)\) 与 \(X\) 的任何函数都不相关的随机变量,这意味着我们可以将其在几何上解释为一种投影。
最后,亚当定律(Adam’s law)和夏娃定律(Eve’s law): \[ E(Y) = E(E(Y|X)) \] \[ \text{Var}(Y) = E(\text{Var}(Y|X)) + \text{Var}(E(Y|X)) \]
在具有多种形式或多层随机性的问题中,它们经常帮助我们计算 \(E(Y)\) 和 \(\text{Var}(Y)\)。
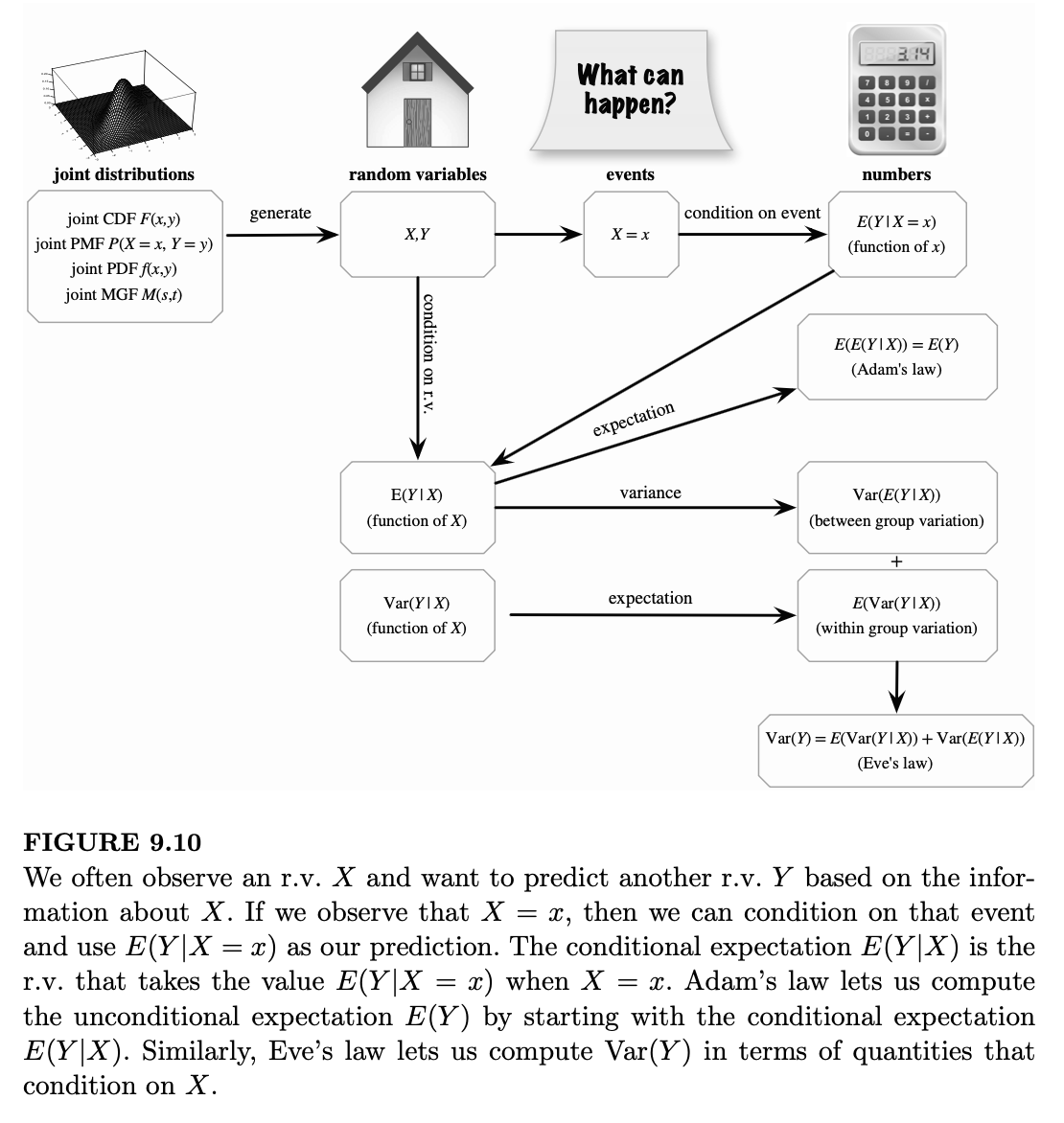
图 9.10 展示了数值 \(E(Y|X=x)\) 是如何与随机变量 \(E(Y|X)\) 联系起来的,根据亚当定律,后者的期望为 \(E(Y)\)。此外,它还展示了夏娃定律中的各项是如何构成的,以及它们如何组合在一起,从而根据以 \(X\) 为条件的各项指标对 \(\text{Var}(Y)\) 进行有用的分解。
9.8 R
神秘奖金模拟
我们可以通过模拟来证明,在例 9.1.7(对价值未知的神秘奖金进行竞标)中,任何出价平均而言都会导致负收益。
首先选择一个出价 \(b\)(我们选择 0.6);然后模拟大量假设的神秘奖金价值并将其存储在 v 中:
R
1 | b <- 0.6 |
如果 \(b > (2/3)v\),则出价被接受。为了获得出价被接受情况下的平均利润,我们使用方括号仅保留满足条件的 v 值:
R
1 | mean(v[b > (2/3)*v]) - b |
你会发现无论 \(b\) 取何值,该值都是负数,你可以通过尝试不同的 \(b\) 值进行实验验证。
出现 HH 与 HT 的时间
为了验证例 9.1.9 的结果,我们可以先生成一长串公平硬币的投掷序列。这可以通过 sample 命令完成。我们使用 paste 函数配合 collapse="" 参数将这些投掷结果转为一个由 “H” 和 “T” 组成的字符串:
R
1 | paste(sample(c("H","T"),100,replace=TRUE),collapse="") |
长度为 100 的序列足以几乎保证 HH 和 HT 都至少出现一次。
为了确定看到 HH 和 HT 平均需要多少次投掷,我们需要生成许多投掷序列。为此,我们使用熟悉的朋友 replicate:
R
1 | r <- replicate(10^3,paste(sample(c("H","T"),100,replace=T), |
现在 r 包含 1000 个硬币投掷序列,每个序列长度为 100。要找到每个序列中 HH 第一次出现的位置,你可以使用 stringr 包中的 str_locate 命令。在安装并加载该包后:
R
1 | t <- str_locate(r,"HH") |
这将创建一个两列的表格 t,各列分别包含每个序列中 HH 第一次出现的起始位置和结束位置。(使用 head(t) 可以显示表格的前几行,让你了解结果的样式。)
我们想要的是第二列给出的结束位置。特别地,我们想要第二列的平均值,它是对 HH 平均等待时间的近似:
R
1 | mean(t[,2]) |
你的答案是在 6 左右吗?将 “HH” 换成 “HT” 再试一次,你的答案是在 4 左右吗?
线性回归
在例 9.3.10 中,我们推导了线性回归模型斜率和截距的公式,这些公式可用于通过解释变量预测响应变量。让我们尝试将这些公式应用于模拟数据集:
R
1 | x <- rnorm(100) |
向量 x 包含 100 个随机变量 \(X \sim N(0,1)\) 的实现值,向量 y 包含 100 个随机变量 \(Y = a + bX + \epsilon\) 的实现值,其中 \(\epsilon \sim N(0,1)\)。我们可以看到,该数据集的 \(a\) 和 \(b\) 真实值分别为 3 和 5。我们可以通过 plot(x,y) 将数据可视化为散点图。
现在让我们看看是否能利用例 9.3.10 中的公式得到 \(a\) 和 \(b\) 真实值的良好估计:
R
1 | b <- cov(x,y) / var(x) |
这里 cov(x,y)、var(x) 和 mean(x) 分别提供了样本协方差、样本方差和样本均值,用于分别估计 \(\text{Cov}(X,Y)\)、\(\text{Var}(X)\) 和 \(E(X)\)。(我们在前面的章节中详细讨论过样本均值和样本方差。样本协方差的定义与之类似,是估计真实协方差的一种自然方式。)
你会发现 \(b\) 接近 5 而 \(a\) 接近 3。这些估计值定义了最佳拟合线。abline 命令让我们可以将最佳拟合线绘制在散点图之上:
R
1 | plot(x,y) |
abline 的第一个参数是直线的截距,第二个参数是斜率。
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程