《Introduction to Probability》第 2 章 条件概率
第 2 章 条件概率
Conditional probability
我们已经将概率引入为一种表达我们对事件的置信程度或不确定性的语言。每当我们观察到新的证据(即获得数据)时,我们就获取了可能影响我们不确定性的信息。一个与现有信念一致的新观察结果可能会让我们对该信念更加确定,而一个令人惊讶的观察结果可能会使该信念受到质疑。条件概率正是解决这一根本问题的概念:我们应当如何根据观察到的证据来更新我们的信念?
2.1 条件思维的重要性
The importance of thinking conditionally
条件概率对于科学、医学和法律推理至关重要,因为它展示了如何以逻辑、连贯的方式将证据融入我们对世界的理解中。事实上,一个有用的视角是:所有的概率都是条件的;无论是否明确写出,每个概率中总包含着背景知识(或假设)。
例如,假设某天早晨我们关注事件 \(R\)(当天会下雨)。令 \(P(R)\) 为我们在出门观察前的降雨概率评估。如果我们随后向外看,发现天空乌云密布(事件 \(C\)),那么想必我们认为下雨的概率应该会增加;我们将这个新概率记为 \(P(R|C)\)(读作“在给定 \(C\) 的条件下 \(R\) 的概率”)。当我们从 \(P(R)\) 转换到 \(P(R|C)\) 时,我们称之为“对 \(C\) 进行条件化”。随着一天的进行,我们可能会获得越来越多关于天气状况的信息,并可以不断更新我们的概率。如果我们观察到事件 \(B_1, \dots, B_n\) 发生,那么在给定这些证据的情况下,我们将新的条件概率写为 \(P(R|B_1, \dots, B_n)\)。如果最终我们观察到真的开始下雨了,我们的条件概率就变成了 1。
此外,我们将看到条件化是一种非常强大的解题策略,它通常可以通过分情况讨论,将一个复杂的问题分解为易于处理的小块。正如在计算机科学中,常见的策略是将大问题分解为“一口大小”的碎块(甚至是“字节大小”的碎块),在概率论中,常见的策略是将复杂的概率问题还原为一系列更简单的条件概率问题。特别地,我们将讨论一种被称为第一步分析法(first-step analysis)的策略,它通常允许我们在实验包含多个阶段时获得问题的递归解。
由于条件化既是根据证据更新信念的手段,又是解决问题的核心策略,因此我们说:
条件化是统计学的灵魂。
2.2 定义与直觉
Definition and intuition
定义 2.2.1(条件概率)。若 \(A\) 和 \(B\) 是满足 \(P(B) > 0\) 的事件,则在给定 \(B\) 的条件下 \(A\) 的条件概率,记作 \(P(A|B)\),定义为: \[ P(A|B) = \frac{P(A \cap B)}{P(B)} \] 在这里,\(A\) 是我们想要更新其不确定性的事件,\(B\) 是我们观察到(或想要视为给定)的证据。我们称 \(P(A)\) 为 \(A\) 的先验概率(prior probability),称 \(P(A|B)\) 为 \(A\) 的后验概率(posterior probability)(“先验”意为根据证据更新前,“后验”意为根据证据更新后)。
必须将出现在垂直条件号后面的事件理解为我们已经观察到的证据或正在进行条件化的前提:\(P(A|B)\) 是给定证据 \(B\) 时 \(A\) 的概率,而不是某个叫做 “\(A|B\)” 的实体的概率。正如 2.4.1 节所讨论的,并不存在名为 “\(A|B\)” 的事件。
对于任何事件 \(A\),\(P(A|A) = P(A \cap A) / P(A) = 1\)。一旦观察到 \(A\) 已经发生,我们对 \(A\) 的更新概率就是 1。如果不是这样,我们就需要一个全新的条件概率定义了!
例 2.2.2(两张牌)。一副标准扑克牌经过充分洗牌。随机抽取两张牌,每次一张,无放回。设 \(A\) 为第一张牌是红心的事件,\(B\) 为第二张牌是红牌的事件。求 \(P(A|B)\) 和 \(P(B|A)\)。
解答:
根据概率的原始定义和乘法原理:
\[ P(A \cap B) = \frac{13 \cdot 25}{52 \cdot 51} = \frac{25}{204} \]
因为有利结果由选择 13 张红心之一,然后从剩余的 25 张红牌中任选一张决定。同时,\(P(A) = 1/4\),因为 4 种花色是等可能的;且
\[ P(B) = \frac{26 \cdot 51}{52 \cdot 51} = \frac{1}{2} \]
因为第二张牌有 26 种有利的可能性,而对于其中每一种,第一张牌可以是任何其他牌(回想第 1 章,乘法原理不需要考虑时间顺序)。
一种更巧妙的观察 \(P(B) = 1/2\) 的方法是对称性:在进行实验之前的视角来看,第二张牌等可能地是牌堆中的任何一张牌。
我们现在拥有了应用条件概率定义所需的所有部分:
\[ P(A|B) = \frac{P(A \cap B)}{P(B)} = \frac{25/204}{1/2} = \frac{25}{102} \]
\[ P(B|A) = \frac{P(B \cap A)}{P(A)} = \frac{25/204}{1/4} = \frac{25}{51} \]
这是一个简单的例子,但已有几点值得注意:
务必小心条件号两侧放置的事件。具体来说,\(P(A|B) \neq P(B|A)\)。下一节将探讨这两个量在一般情况下是如何关联的。混淆这两个量被称为检察官谬误(prosecutor's fallacy),将在 2.8 节讨论。如果我们将 \(B\) 定义为第二张牌是红心的事件,那么这两个条件概率将会相等。
\(P(A|B)\) 和 \(P(B|A)\) 在直觉和数学上都有意义;抽牌的时间顺序并不决定我们可以观察哪些条件概率。当我们计算条件概率时,我们考虑的是观察到一个事件能提供关于另一个事件的何种信息,而不是一个事件是否引起了另一个事件。为了进一步获得直觉,想象有人把牌摊开,左手抽一张牌,右手同时抽另一张牌。基于左手的牌和右手的牌来定义 \(A\) 和 \(B\),而不是第一张和第二张,并不会在任何重要方面改变问题的结构。
个人注:以上这个时间顺序的说明很重要!
我们可以通过对条件概率含义的直接解释看到 \(P(B|A) = 25/51\):如果抽到的第一张牌是红心,那么剩下的牌由 25 张红牌和 26 张黑牌组成(所有这些牌下次被抽到的概率均等),因此得到红牌的条件概率是 \(25/(25 + 26) = 25/51\)。
用这种方法找 \(P(A|B)\) 则更难:如果我们得知第二张牌是红牌,我们可能会想“这很有用,但我们真正想知道的是它是不是红心!”本章稍后部分的条件概率结论将为我们提供解决此问题的方法。
为了进一步阐明条件概率的含义,这里有两个直觉解释。
直觉 2.2.3(卵石世界)。考虑一个有限样本空间,其中的结果被想象成总质量为 1 的卵石。由于 \(A\) 是一个事件,它是一组卵石,对于 \(B\) 也是如此。图 2.1(a) 展示了一个示例。
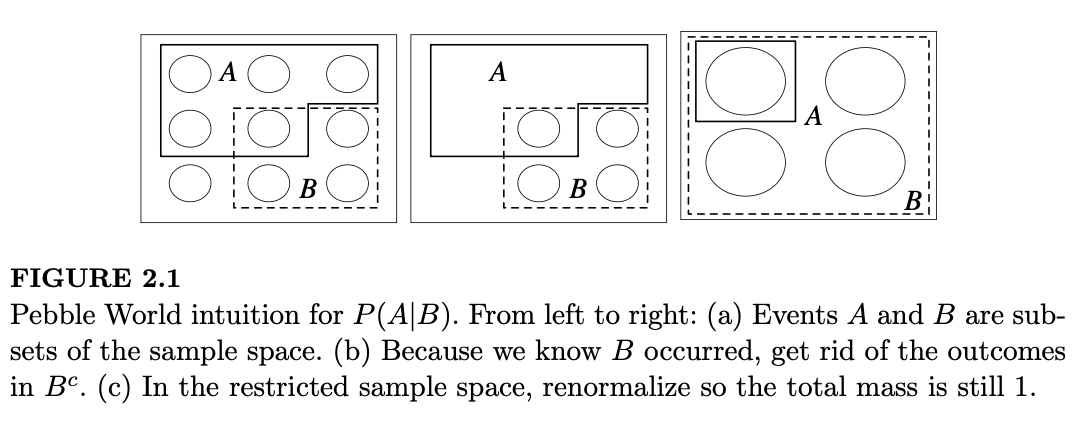
现在假设我们得知 \(B\) 发生了。在图 2.1(b) 中,获取该信息后,我们移除了 \(B^c\) 中的所有卵石,因为它们与“\(B\) 已发生”这一知识不相容。此时,\(P(A \cap B)\) 就是留在 \(A\) 中的卵石的总质量。最后,在图 2.1(c) 中,我们进行归一化(renormalize),即通过除以一个常数,使得剩余卵石的新总质量为 1。这是通过除以 \(P(B)\)(即 \(B\) 中卵石的总质量)来实现的。对应于事件 \(A\) 的结果的更新质量即为条件概率 \(P(A|B) = P(A \cap B) / P(B)\)。
通过这种方式,我们的概率已经根据观察到的证据进行了更新。与证据相矛盾的结果被丢弃,它们的质量被重新分配给剩余的结果,同时保持剩余结果之间的相对质量。例如,如果最初卵石 2 的重量是卵石 1 的两倍,且两者都包含在 \(B\) 中,那么在对 \(B\) 进行条件化后,卵石 2 的重量仍然是卵石 1 的两倍。但如果卵石 2 不在 \(B\) 中,那么在对 \(B\) 进行条件化后,它的质量被更新为 0。
直觉 2.2.4(频率学派解释)。回想一下,概率的频率学派解释是基于大量重复试验中的相对频率。想象一下多次重复我们的实验,生成一长串观察结果。给定 \(B\) 时 \(A\) 的条件概率可以很自然地理解为:在仅关注 \(B\) 发生的试验时,\(A\) 发生的次数所占的比例。

在图 2.2 中,我们实验的结果可以写成一串由 0 和 1 组成的字符串;\(B\) 是第一个数字为 1 的事件,\(A\) 是第二个数字为 1 的事件。对 \(B\) 进行条件化时,我们圈出所有 \(B\) 发生的重复次数,然后观察在这些被圈出的次数中,事件 \(A\) 也发生的次数所占的比例。
用符号表示,设 \(n_A, n_B, n_{AB}\) 分别为在 \(n\) 次大量重复实验中 \(A, B, A \cap B\) 发生的次数。频率学派的解释是:
\[ P(A) \approx \frac{n_A}{n}, \quad P(B) \approx \frac{n_B}{n}, \quad P(A \cap B) \approx \frac{n_{AB}}{n} \]
那么 \(P(A|B)\) 被解释为 \(n_{AB}/n_B\),它等于 \((n_{AB}/n) / (n_B/n)\)。这一解释再次转化为 \(P(A|B) = P(A \cap B) / P(B)\)。
为了练习应用条件概率的定义,让我们再看一些例子。接下来的三个例子都始于“一个有两个孩子的家庭”这一相同的基本场景,但根据具体假设和我们所依据的条件信息,其中会出现微妙的差异。
例 2.2.5(两个孩子)。马丁·加德纳(Martin Gardner)在 20 世纪 50 年代的《科学美国人》专栏中提出了以下谜题:
- 琼斯先生有两个孩子。其中较大的孩子是女孩。两个孩子都是女孩的概率是多少?
- 史密斯先生有两个孩子。其中至少一个是男孩。两个孩子都是男孩的概率是多少?
乍一看,这个问题似乎只是条件概率的简单应用,但几十年来,关于这两部分是否应该有不同的答案、为什么会有不同的答案,以及问题的模糊程度,一直存在争议。加德纳给出的两部分答案分别是 \(1/2\) 和 \(1/3\),这看起来可能有些矛盾:为什么得知大孩子的性别与仅仅得知其中一个孩子的性别会有所不同呢?
明确问题的假设非常重要。为了得到加德纳给出的答案,需要做出以下几个隐含假设:
- 假设性别是二元的,因此每个孩子都可以明确地被归类为男孩或女孩。事实上,许多人不完全符合“男性”或“女性”的范畴,并认为自己具有非二元性别。
- 假设无论对于大孩子还是小孩子,都有 \(P(\text{男孩}) = P(\text{女孩})\)。事实上,在大多数国家,男孩的出生率略高于女孩。例如,在美国,通常估计每出生 100 个女孩对应出生 105 个男孩。
- 假设两个孩子的性别是独立的,即知道大孩子的性别不会提供关于小孩子性别的任何信息,反之亦然。如果孩子们是同卵双胞胎,这个假设就不现实了。
在这些(诚然有问题的)简化假设下,我们可以按如下方式解决问题。
解答:
基于上述假设,根据条件概率的定义得:
\[ P(\text{均为女孩} \mid \text{大的是女孩}) = \frac{P(\text{均为女孩},\text{大的是女孩})}{P(\text{大的是女孩})} = \frac{1/4}{1/2} = 1/2 \]
\[ P(\text{均为女孩} \mid \text{至少一个是女孩}) = \frac{P(\text{均为女孩},\text{至少一个是女孩})}{P(\text{至少一个是女孩})} = \frac{1/4}{3/4} = 1/3 \]
(为了方便比较,我们将问题的第二部分改用女孩而非男孩来求解。)两个结果不同可能看起来有违直觉,因为我们没有理由非得关心是大孩子还是小孩子是女孩。事实上,基于对称性: \[ P(\text{均为女孩} \mid \text{小的是女孩}) = P(\text{均为女孩} \mid \text{大的是女孩}) = 1/2 \] 然而,在 \(P(\text{均为女孩} \mid \text{大的是女孩})\) 和 \(P(\text{均为女孩} \mid \text{至少一个是女孩})\) 这两个条件概率之间不存在这种对称性。说“大孩子是女孩”指定了一个特定的孩子,那么另一个孩子(小孩子)是女孩的概率就是 50%。“至少一个”并没有指代特定的孩子。
在样本空间 \(\{GG, GB, BG, BB\}\) 中(例如 \(GB\) 表示大的是女孩,小的是男孩),对“特定孩子是女孩”进行条件化会排除 4 个“卵石”中的 2 个。相比之下,对“至少一个是女孩”进行条件化仅排除了 \(BB\)。
例 2.2.6(随机遇到的孩子是女孩)。一个家庭有两个孩子。你随机遇到了其中一个,发现她是个女孩。在与前一个例子相同的假设下,两个孩子都是女孩的条件概率是多少?同时假设你遇到任何一个孩子的可能性相等,且你遇到哪一个与性别无关。
解答:
直观上,答案应该是 1/2:想象我们遇到的那个孩子就在面前,而另一个在家里。两个都是女孩仅仅意味着在家的那个也是女孩,而这似乎与面前这个是女孩的事实无关。但让我们利用条件概率的定义更仔细地检查一下。这同时也是练习用集合符号表示事件的好机会。
设 \(G_1, G_2\) 和 \(G_3\) 分别为大孩子、小孩子和随机遇到的孩子是女孩的事件。根据假设,\(P(G_1) = P(G_2) = P(G_3) = 1/2\)。根据原始定义,或 2.5 节解释的独立性,\(P(G_1 \cap G_2) = 1/4\)。因此: \[ P(G_1 \cap G_2 \mid G_3) = \frac{P(G_1 \cap G_2 \cap G_3)}{P(G_3)} = \frac{1/4}{1/2} = 1/2 \] 因为 \(G_1 \cap G_2 \cap G_3 = G_1 \cap G_2\)(如果两个孩子都是女孩,这就保证了随机遇到的孩子必然是女孩)。
但请记住,为了得出 1/2,需要对随机选择孩子的方式做一个假设。用统计学的语言来说,我们收集了一个随机样本;这里的样本由两个孩子中的一个组成。统计学中最重要的原则之一是:必须仔细思考样本是如何收集的,而不仅仅是盯着原始数据而不理解它们的来源。举一个简单的极端例子,假设某项压迫性法律禁止有姐姐或妹妹的男孩出门。那么“随机遇到的孩子是女孩”就等同于“至少有一个孩子是女孩”,问题就退化成了例 2.2.5 的第一部分。
例 2.2.7(出生在冬天的女孩)。一个家庭有两个孩子。求在已知至少有一个是出生在冬天的女孩的情况下,两个孩子都是女孩的概率。除了例 2.2.5 中的假设外,假设四季出现的概率相等,且性别与季节相互独立。(这意味着已知性别不会提供关于季节概率的信息,反之亦然;关于独立性的更多内容请参见 2.5 节。)
解答:
根据条件概率的定义: \[ P(\text{双女} \mid \text{至少一冬女}) = \frac{P(\text{双女},\text{至少一冬女})}{P(\text{至少一冬女})} \] 由于一个特定孩子是冬天出生的女孩的概率是 \(1/8\),分母等于:
\[ P(\text{至少一冬女}) = 1 - (7/8)^2 \]
为了计算分子,利用“双女且至少一冬女”与“双女且至少一冬子(指孩子)”是同一个事件这一事实;然后利用性别和季节独立的假设:
\[ P(\text{双女},\text{至少一冬子}) = P(\text{双女}) \cdot P(\text{至少一冬子}) = \frac{1}{4}(1 - (3/4)^2) \]
因此:
\[ P(\text{双女} \mid \text{至少一冬女}) = \frac{\frac{1}{4}(1 - (3/4)^2)}{1 - (7/8)^2} = \frac{7/64}{15/64} = 7/15 \]
起初这个结果看起来很荒谬!在例 2.2.5 中,已知至少一个是女孩时,两个都是女孩的条件概率是 1/3;为什么当我们得知至少一个是冬天出生的女孩时,结果会有所不同?关键在于,关于出生季节的信息使“至少一个是女孩”这一条件向“特定一个是女孩”靠近了。对越来越具体的信息进行条件化,会使概率越来越趋近于 1/2。
例如,对“至少一个是出生在 3 月 31 日晚上 8:20 的女孩”进行条件化,已经非常接近于指定了某个孩子,而得知一个特定孩子的信息并不会给我们提供关于另一个孩子的信息。像出生季节这种看似无关的信息,在例 2.2.5 的两部分答案之间起到了插值作用。习题 29 将这个例子推广到了与性别独立的任意特征。
2.3 贝叶斯法则与全概率公式
Bayes’ rule and the law of total probability
条件概率的定义非常简单——仅仅是两个概率的比值——但它具有深远的影响。第一个推论可以通过将定义中的分母移动到等式另一侧轻松得出。
定理 2.3.1(两个事件交集的概率)。对于任何具有正概率的事件 \(A\) 和 \(B\): \[ P(A \cap B) = P(B)P(A|B) = P(A)P(B|A) \]
这是通过取 \(P(A|B)\) 的定义并在两边乘以 \(P(B)\),以及取 \(P(B|A)\) 的定义并在两边乘以 \(P(A)\) 得出的。乍一看,这个定理似乎没那么有用:它只是条件概率定义的另一种写法,而且既然 \(P(A|B)\) 是根据 \(P(A \cap B)\) 定义的,用 \(P(A|B)\) 来帮助寻找 \(P(A \cap B)\) 似乎是循环论证。但我们将看到,该定理实际上非常有用,因为事实证明,通常无需回到定义即可找到条件概率,在这种情况下,定理 2.3.1 可以帮助我们更容易地找到 \(P(A \cap B)\)。
重复应用定理 2.3.1,我们可以将其推广到 \(n\) 个事件的交集。
定理 2.3.2(\(n\) 个事件交集的概率)。对于任何满足 \(P(A_1, A_2, \dots, A_{n-1}) > 0\) 的事件 \(A_1, \dots, A_n\): \[ P(A_1, A_2, \dots, A_n) = P(A_1)P(A_2|A_1)P(A_3|A_1, A_2) \cdots P(A_n|A_1, \dots, A_{n-1}) \]
公式中的逗号表示交集,例如 \(P(A_3|A_1, A_2)\) 即 \(P(A_3|A_1 \cap A_2)\)。
事实上,这相当于把 \(n!\) 个定理合而为一,因为我们可以随意排列 \(A_1, \dots, A_n\) 而不会影响左侧的结果。在实际应用中,某些排列方式的右侧计算往往比其他排列方式容易得多。例如:
\[ P(A_1, A_2, A_3) = P(A_1)P(A_2|A_1)P(A_3|A_1, A_2) = P(A_2)P(A_3|A_2)P(A_1|A_2, A_3) \]
此外还有 4 种此类形式的展开式。通常需要练习和思考才能知道该使用哪种顺序。
现在我们准备引入本章的两个主要定理——贝叶斯法则(Bayes’ rule)和全概率公式(law of total probability)——它们将使我们能够计算广泛问题中的条件概率。贝叶斯法则是极负盛名且极其有用的结果,它关联了 \(P(A|B)\) 和 \(P(B|A)\)。
定理 2.3.3(贝叶斯法则)。 \[ P(A|B) = \frac{P(B|A)P(A)}{P(B)} \]
这直接推导自定理 2.3.1,而定理 2.3.1 又直接推导自条件概率的定义。然而,贝叶斯法则在概率论和统计学中具有重要的意义和应用,因为我们经常需要寻找条件概率,而直接寻找 \(P(B|A)\) 往往比直接寻找 \(P(A|B)\) 容易得多(反之亦然)。
另一种编写贝叶斯法则的方式是使用几率(odds)而非概率。
定义 2.3.4(几率)。事件 \(A\) 的几率为: \[ \text{odds}(A) = \frac{P(A)}{P(A^c)} \]
例如,如果 \(P(A) = 2/3\),我们说支持 \(A\) 的几率是 2 比 1(有时写为 \(2:1\),有时表述为反对 \(A\) 的几率是 1 比 2;需要注意,有些来源不会明确说明他们是指支持还是反对某个事件的几率)。当然,我们也可以将几率转换回概率:
\[ P(A) = \frac{\text{odds}(A)}{1 + \text{odds}(A)} \]
通过取 \(P(A|B)\) 的贝叶斯法则表达式并将其除以 \(P(A^c|B)\) 的贝叶斯法则表达式,我们就可以得出贝叶斯法则的几率形式。
定理 2.3.5(几率形式的贝叶斯法则)。对于任何具有正概率的事件 \(A\) 和 \(B\),在给定 \(B\) 的条件下,\(A\) 的后验几率为: \[ \frac{P(A|B)}{P(A^c|B)} = \frac{P(B|A)}{P(B|A^c)} \cdot \frac{P(A)}{P(A^c)} \]
口头表述为:后验几率 \(P(A|B)/P(A^c|B)\) 等于先验几率 \(P(A)/P(A^c)\) 乘以因子 \(P(B|A)/P(B|A^c)\),该因子在统计学中被称为似然比(likelihood ratio)。有时,使用这种形式的贝叶斯法则先得到后验几率,然后在需要时再从几率转换回概率会非常方便。
个人注:几率形式的贝叶斯法则的优点是不需要计算分母的无条件概率\(P(B)\)。
全概率公式(LOTP)将条件概率与无条件概率联系起来。它是实现“利用条件概率将复杂概率问题分解为简单部分”这一承诺的核心工具,通常与贝叶斯法则配合使用。
定理 2.3.6(全概率公式)。设 \(A_1, \dots, A_n\) 为样本空间 \(S\) 的一个划分(即 \(A_i\) 是互不相交的事件且它们的并集为 \(S\)),对于所有 \(i\) 都有 \(P(A_i) > 0\)。那么: \[ P(B) = \sum_{i=1}^n P(B|A_i)P(A_i) \]
证明:由于 \(A_i\) 构成了 \(S\) 的一个划分,我们可以将 \(B\) 分解为:
\[ B = (B \cap A_1) \cup (B \cap A_2) \cup \dots \cup (B \cap A_n) \]
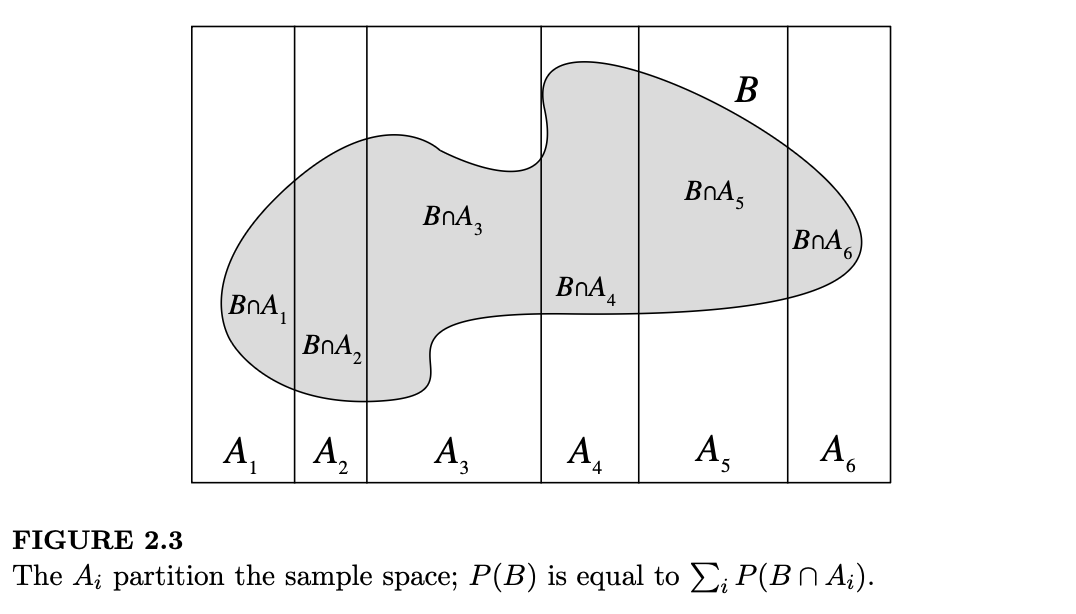
如图 2.3 所示,我们将 \(B\) 切分成了从 \(B \cap A_1\) 到 \(B \cap A_n\) 的较小碎片。根据概率的第二公理,由于这些碎片是互不相交的,我们可以将它们的概率相加得到 \(P(B)\): \[ P(B) = P(B \cap A_1) + P(B \cap A_2) + \dots + P(B \cap n) \]
现在我们可以对每个 \(P(B \cap A_i)\) 应用定理 2.3.1:
\[ P(B) = P(B|A_1)P(A_1) + \dots + P(B|A_n)P(A_n) \]
全概率公式告诉我们,要获得 \(B\) 的无条件概率,我们可以将样本空间划分为不相交的切片 \(A_i\),计算 \(B\) 在每个切片中的条件概率,然后对这些条件概率进行加权求和,权重即为概率 \(P(A_i)\)。如何划分样本空间至关重要:选择得当的划分会将复杂问题简化,而选择不当的划分只会使问题恶化——导致我们需要计算 \(n\) 个困难的概率而不是仅仅一个!
接下来的几个例子展示了我们如何结合使用贝叶斯法则和全概率公式,根据观察到的证据来更新我们的信念。
例 2.3.7(随机硬币)。你有一枚公平的硬币,以及一枚不公平的硬币(正面朝上的概率为 3/4)。你随机挑选其中一枚硬币并抛掷三次。结果三次都是正面。已知这一信息,你挑选到的是公平硬币的概率是多少?
解答:
设 \(A\) 为所选硬币三次均正面朝上的事件,\(F\) 为我们选中公平硬币的事件。我们关注的是 \(P(F|A)\),但 \(P(A|F)\) 和 \(P(A|F^c)\) 更容易计算,因为知道手里的硬币类型会很有帮助;这提示我们使用贝叶斯法则和全概率公式。通过计算,我们得到:
\[ P(F|A) = \frac{P(A|F)P(F)}{P(A)} = \frac{P(A|F)P(F)}{P(A|F)P(F) + P(A|F^c)P(F^c)} \]
\[ = \frac{(1/2)^3 \cdot 1/2}{(1/2)^3 \cdot 1/2 + (3/4)^3 \cdot 1/2} \approx 0.23 \]
在抛掷硬币之前,我们认为选中公平硬币和不公平硬币的可能性相等:\(P(F) = P(F^c) = 1/2\)。然而,在观察到三次正面后,选中不公平硬币的可能性变得比公平硬币大得多,因此 \(P(F|A)\) 仅约为 0.23。
2.3.8(先验 vs. 后验)。在上述例子的计算中,在第一步就说“\(P(A) = 1\),因为我们知道 \(A\) 已经发生了”是不正确的。虽然 \(P(A|A) = 1\) 是事实,但 \(P(A)\) 是 \(A\) 的先验概率,\(P(F)\) 是 \(F\) 的先验概率——两者都是我们在实验中观察到任何数据之前的概率。绝不能将它们与给定证据 \(A\) 的后验概率混淆。
例 2.3.9(罕见疾病检测)。一名叫弗雷德(Fred)的患者接受了“状况炎症”(conditionitis)的检测,这是一种在人口中发病率为 1% 的医学状况。检测结果呈阳性,即检测声称弗雷德患有该病。设 \(D\) 为弗雷德患有该病的事件,\(T\) 为他检测呈阳性的事件。
假设该检测的“准确率为 95%”;在医学上衡量检测准确率有不同的指标,但在本题中,假设这意味着 \(P(T|D) = 0.95\) 且 \(P(T^c|D^c) = 0.95\)。量值 \(P(T|D)\) 被称为检测的灵敏度(sensitivity)或真阳性率,而 \(P(T^c|D^c)\) 被称为特异度(specificity)或真阴性率。
根据检测结果提供的证据,求弗雷德患有“状况炎症”的条件概率。
解答:
应用贝叶斯法则和全概率公式,我们有:
\[ P(D|T) = \frac{P(T|D)P(D)}{P(T)} \]
\[ = \frac{P(T|D)P(D)}{P(T|D)P(D) + P(T|D^c)P(D^c)} \]
\[ = \frac{0.95 \cdot 0.01}{0.95 \cdot 0.01 + 0.05 \cdot 0.99} \approx 0.16 \]
因此,在检测呈阳性的情况下,弗雷德患有该病的概率仅为 16%,尽管这项检测看起来相当可靠!
大多数人发现,尽管检测准确率高达 95%,但给定阳性结果时患病的条件概率仅为 16%,这令人十分惊讶。理解这一极低后验概率的关键在于意识到有两个因素在起作用:来自检测的证据,以及我们关于该疾病流行率的先验信息。
虽然检测提供了支持患病的证据,但“状况炎症”也是一种罕见病!条件概率 \(P(D|T)\) 反映了这两个因素之间的平衡,它适当地权衡了疾病的罕见程度与检测出错的罕见程度。
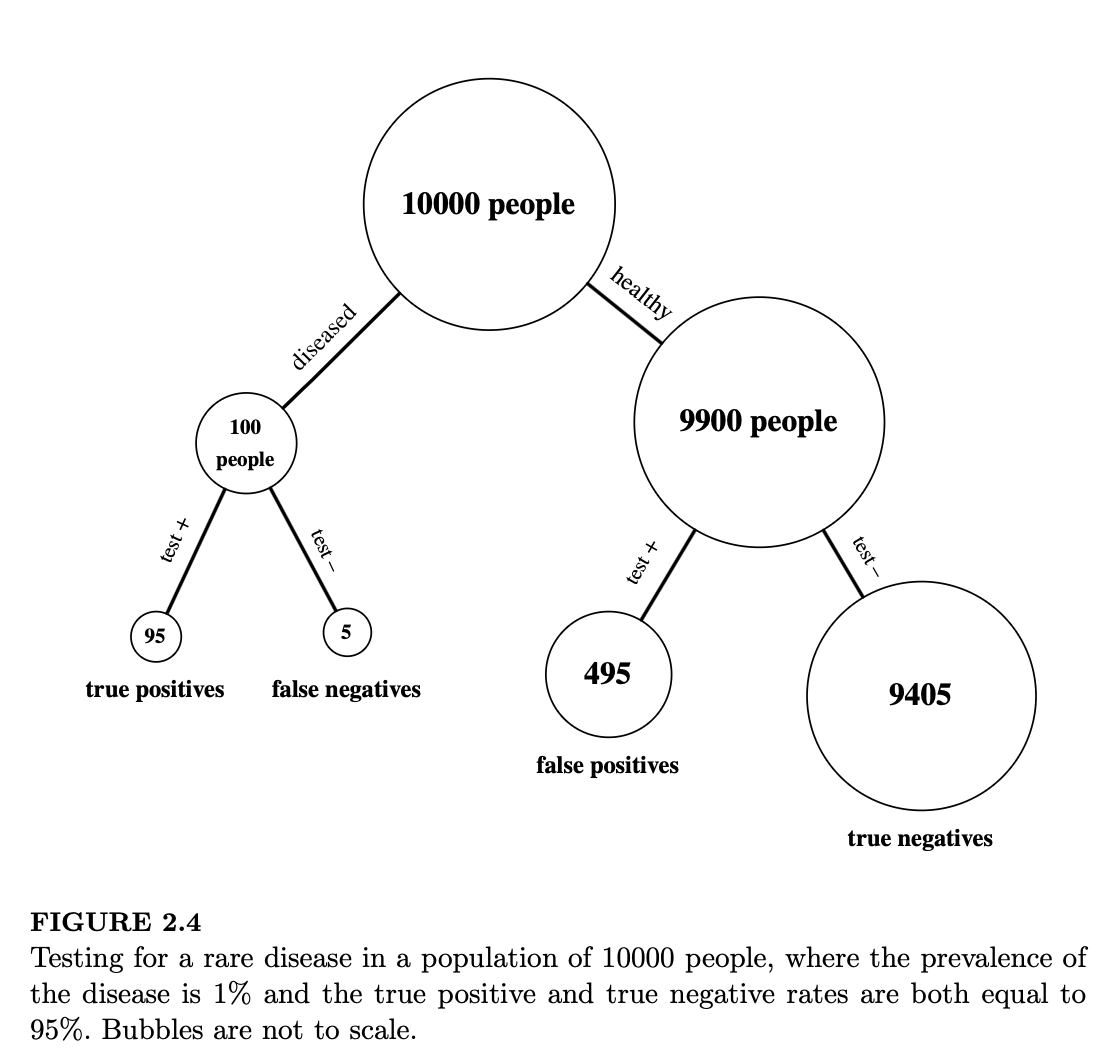
为了进一步获得直觉,考虑如图 2.4 所示的 10,000 人的群体。其中 100 人患病,9,900 人未患病;这对应于 1% 的发病率。如果我们对该群体中的每个人进行检测,我们预期:在 100 名患病个体中,95 人会检测呈阳性,5 人呈阴性。在 9,900 名健康个体中,预期有 \(0.95 \times 9900 = 9405\) 人呈阴性,而 495 人呈阳性。
个人注:上图太直观了!
现在让我们把注意力集中在那些检测呈阳性的个体上;也就是说,让我们对“阳性检测结果”进行条件化。95 名真阳性(即检测呈阳性且确实患病的人)在数量上远少于 495 名假阳性(即检测呈阳性但并未患病的人)。因此,大多数检测呈阳性的人实际上并没有患病。
例 2.3.10(六指男人)。在某个国家发生了一起犯罪。罪犯是该国 \(n\) 个男人中的一个(且仅有一个)。最初,这 \(n\) 个人被认为具有同等的作案嫌疑。随后,一名目击者报告称,罪犯右手有六根手指。
设 \(p_0\) 为一名无辜者右手有六指的概率,\(p_1\) 为罪犯右手有六指的概率,且 \(p_0 < p_1\)。(由于目击者的报告并非 100% 可靠,我们可能得到 \(p_1 < 1\)。)令 \(a = p_0/p_1\),\(b = (1-p_1)/(1-p_0)\)。
鲁根(Rugen)居住在该国。他被发现右手有六根手指。
给定这一信息,鲁根是罪犯的概率是多少?
现在假设对该国所有 \(n\) 个男人的手进行了检查,发现鲁根是唯一一个右手有六指的人。给定这一信息,鲁根是罪犯的概率是多少?
解答:
- 设 \(R\) 为鲁根有罪的事件,\(M\) 为他右手有六指的事件。根据贝叶斯法则和全概率公式(LOTP):
\[ P(R|M) = \frac{P(M|R)P(R)}{P(M|R)P(R) + P(M|R^c)P(R^c)} \]
\[ = \frac{p_1 \cdot \frac{1}{n}}{p_1 \cdot \frac{1}{n} + p_0 \left(1 - \frac{1}{n}\right)} \]
\[ = \frac{p_1}{p_1 + p_0(n-1)} = \frac{1}{1 + a(n-1)} \]
- 设 \(N\) 为该国除鲁根以外没有其他人右手有六指的事件。沿用上述符号:
\[ P(R|M,N) = \frac{P(M,N|R)P(R)}{P(M,N|R)P(R) + P(M,N|R^c)P(R^c)} \]
在分子中,给定 \(R\)(鲁根有罪),事件 \(M \cap N\) 意味着鲁根有六指(概率为 \(p_1\))且其余 \(n-1\) 个无辜者都没有六指(概率为 \((1-p_0)^{n-1}\))。
在分母的第二项中,给定 \(R^c\)(鲁根无辜),这意味着罪犯是另外 \(n-1\) 个人中的某一个。要使 \(M \cap N\) 发生,鲁根必须有六指(概率为 \(p_0\)),真正的罪犯必须没有六指(概率为 \(1-p_1\)),且其余 \(n-2\) 个无辜者也都没有六指(概率为 \((1-p_0)^{n-2}\))。
因此:
\[ P(R|M,N) = \frac{p_1(1-p_0)^{n-1} \cdot \frac{1}{n}}{p_1(1-p_0)^{n-1} \cdot \frac{1}{n} + p_0(1-p_1)(1-p_0)^{n-2} \cdot \frac{n-1}{n}} \]
\[ = \frac{p_1(1-p_0)}{p_1(1-p_0) + p_0(1-p_1)(n-1)} \]
将分子分母同时除以 \(p_1(1-p_0)\),得:
\[ = \frac{1}{1 + \frac{p_0}{p_1} \cdot \frac{1-p_1}{1-p_0} (n-1)} = \frac{1}{1 + ab(n-1)} \]
2.4 条件概率也是概率
Conditional probabilities are probabilities
当我们以事件 \(E\) 为条件时,我们会更新自己的置信度以与这一知识保持一致,这实际上是将我们置于一个已知 \(E\) 发生的宇宙中。然而,在这个新的宇宙中,概率法则的运行方式与之前完全相同。条件概率满足概率的所有性质! 因此,我们之前推导出的关于概率的所有结论,如果在所有无条件概率处替换为以 \(E\) 为条件的概率,这些结论仍然成立。特别是:
- 条件概率介于 0 和 1 之间。
- \(P(S|E) = 1\),\(P(\emptyset|E) = 0\)。
- 如果 \(A_1, A_2, \dots\) 互不相交,则 \(P(\cup_{j=1}^{\infty} A_j | E) = \sum_{j=1}^{\infty} P(A_j | E)\)。
- \(P(A^c|E) = 1 - P(A|E)\)。
- 容斥原理:
\[ P(A \cup B | E) = P(A|E) + P(B|E) - P(A \cap B | E) \]
2.4.1。当我们写下 \(P(A|E)\) 时,这并不意味着 \(A|E\) 是一个事件而我们在计算它的概率;\(A|E\) 并不是一个事件。相反,\(P(\cdot|E)\) 是一个根据 \(E\) 已发生这一知识来分配概率的概率函数,而 \(P(\cdot)\) 是另一个不考虑 \(E\) 是否发生而分配概率的函数。当我们取一个事件 \(A\) 并将其代入 \(P(\cdot)\) 函数时,我们会得到一个数字 \(P(A)\);当我们将其代入 \(P(\cdot|E)\) 函数时,我们会得到另一个数字 \(P(A|E)\),这个数字融入了(如果有的话)已知 \(E\) 发生所提供的信息。
为了从数学上证明条件概率也是概率,固定一个 \(P(E) > 0\) 的事件 \(E\),对于任何事件 \(A\),定义 \(\tilde{P}(A) = P(A|E)\)。这种记法有助于强调我们固定了 \(E\),并将 \(P(\cdot|E)\) 视为我们新的概率函数。我们只需要检查两条概率公理。首先:
\[ \tilde{P}(\emptyset) = P(\emptyset|E) = \frac{P(\emptyset \cap E)}{P(E)} = 0 \]
\[ \tilde{P}(S) = P(S|E) = \frac{P(S \cap E)}{P(E)} = 1 \]
其次,如果 \(A_1, A_2, \dots\) 是互不相交的事件,那么:
\[ \tilde{P}(A_1 \cup A_2 \cup \dots) = \frac{P((A_1 \cap E) \cup (A_2 \cap E) \cup \dots)}{P(E)} = \sum_{j=1}^{\infty} \tilde{P}(A_j) \]
因此,\(\tilde{P}\) 满足概率公理。
反之,所有的概率都可以被视为条件概率:每当我们做出一个概率陈述时,总会有一些我们作为背景信息的条件,即使我们没有显式地说明它。以本章开头的下雨例子为例。将今天下雨的初始概率 \(P(R)\) 建立在过去下雨天数所占比例的基础上是很自然的。但是我们应该看过去的哪些日子呢?如果是 11 月 1 日,我们是否应该只计算过去秋天的雨天,从而以季节为条件?那是以具体的月份为条件,还是具体的日期为条件呢?关于地理位置也可以问同样的问题:我们应该看就在我们所在位置下雨的日子,还是只要在附近某处下雨就够了?
为了确定看似无条件的概率 \(P(R)\),我们实际上必须决定以哪些背景信息作为条件!这些选择需要仔细思考,不同的人可能会得出不同的先验概率 \(P(R)\)(尽管每个人都能就如何根据新证据进行更新达成一致)。
由于所有概率都是以背景信息为条件的,我们可以想象总是存在一条垂直的条件号,背景知识 \(K\) 位于垂直号的右侧。那么无条件概率 \(P(A)\) 只是 \(P(A|K)\) 的简写;背景知识被吸收进了字母 \(P\) 中,而不是显式地写出来。
简要总结我们的讨论:
条件概率就是概率,而所有概率都是条件的。
现在我们给出贝叶斯法则和全概率公式的条件形式。这些形式是通过取贝叶斯法则和全概率公式的普通形式,并在垂直号右侧各处添加 \(E\) 而得到的。
定理 2.4.2(带额外条件的贝叶斯法则)。在 \(P(A \cap E) > 0\) 且 \(P(B \cap E) > 0\) 的前提下,有: \[ P(A|B,E) = \frac{P(B|A,E)P(A|E)}{P(B|E)} \]
定理 2.4.3(带额外条件的全概率公式)。设 \(A_1, \dots, A_n\) 为样本空间 \(S\) 的一个划分。在对于所有 \(i\) 均有 \(P(A_i \cap E) > 0\) 的前提下,有: \[ P(B|E) = \sum_{i=1}^n P(B|A_i,E)P(A_i|E) \]
贝叶斯法则和全概率公式的这些额外条件形式,证明过程类似于我们验证 \(\tilde{P}\) 满足概率公理的过程,但它们也直接遵循“条件概率也是概率”这一“元定理”。
例 2.4.4(随机硬币,续)。延续例 2.3.7 的场景,假设我们现在已经看到选中的硬币三次正面朝上。如果我们第四次抛掷该硬币,那么它再次正面朝上的概率是多少?
解答:
同前所述,设 \(A\) 为选中硬币三次正面朝上的事件,并定义新事件 \(H\) 为选中硬币在第四次抛掷时正面朝上。我们关注的是 \(P(H|A)\)。如果能知道我们是否拿到了公平硬币,将会非常有帮助。带额外条件的全概率公式将 \(P(H|A)\) 给出为 \(P(H|F,A)\) 和 \(P(H|F^c,A)\) 的加权平均值,而在后两个条件概率中,我们确实已知拿到了哪枚硬币:
\[ P(H|A) = P(H|F,A)P(F|A) + P(H|F^c,A)P(F^c|A) \]
\[ P(H|A) \approx \frac{1}{2} \cdot 0.23 + \frac{3}{4} \cdot (1 - 0.23) \approx 0.69 \]
其中,后验概率 \(P(F|A)\) 和 \(P(F^c|A)\) 来自例 2.3.7 的计算结果。
解决此问题的等价方法是定义一个新的概率函数 \(\tilde{P}\),使得对于任何事件 \(B\),有 \(\tilde{P}(B) = P(B|A)\)。这个新函数分配的是根据“\(A\) 已发生”这一知识更新后的概率。那么根据普通的全概率公式:
\[ \tilde{P}(H) = \tilde{P}(H|F)\tilde{P}(F) + \tilde{P}(H|F^c)\tilde{P}(F^c) \]
这与我们使用带额外条件的全概率公式完全一致。这再次说明了“条件概率也是概率”这一原理。
例 2.4.5(一致同意)。莱莎·齐加(Lisa Zyga)在文章《为什么证据太多可能是件坏事》中写道:
在古代犹太法典中,如果一名受审嫌疑人被所有法官一致判定有罪,那么该嫌疑人将被无罪释放。这种推理听起来有违直觉,但当时的立法者已经注意到,一致同意往往预示着司法程序中存在系统性错误。
现有 \(n\) 名法官对一起案件进行裁决。嫌疑人有罪的先验概率为 \(p\)。每位法官投票决定定罪或释放嫌疑人。系统性错误(例如辩护方无能)发生的概率为 \(s\)。如果发生系统性错误,则法官们会一致投票定罪(即所有 \(n\) 名法官都投有罪票)。系统性错误是否发生与嫌疑人是否有罪相互独立。
在已知未发生系统性错误且嫌疑人有罪的情况下,每位法官独立地以概率 \(c\) 投有罪票。在已知未发生系统性错误且嫌疑人无罪的情况下,每位法官独立地以概率 \(w\) 投有罪票。假设:\(0 < p < 1, 0 < s < 1\),且 \(0 < w < \frac{1}{2} < c < 1\)。
仅就本小题而言,假设 \(n\) 名法官中恰好有 \(k\) 名投了有罪票,其中 \(k < n\)。已知这一信息,求嫌疑人有罪的概率。
现在假设所有 \(n\) 名法官都投了有罪票。已知这一信息,求嫌疑人有罪的概率。
- 小题的答案作为 \(n\) 的函数,是否为递增函数?请给出简短的直觉性文字解释。
解答:
- 由于 \(k < n\),说明系统性错误没有发生。在本小题中我们将隐含地以此为条件。设 \(G\) 为嫌疑人有罪的事件,\(X\) 为投有罪票的法官人数。利用贝叶斯法则、全概率公式和二项分布的概率质量函数(PMF):
\[ P(G|X=k) = \frac{P(X=k|G)P(G)}{P(X=k)} = \frac{pc^k(1-c)^{n-k}}{pc^k(1-c)^{n-k} + (1-p)w^k(1-w)^{n-k}} \]
- 设 \(U\) 为事件 \(X=n\),\(B\) 为发生系统性错误的事件。则:
\[ P(G|U) = \frac{P(U|G)P(G)}{P(U)} = \frac{p P(U|G)}{p P(U|G) + (1-p)P(U|G^c)} \]
利用带额外条件的全概率公式:
\[ P(U|G) = P(U|G,B)P(B|G) + P(U|G,B^c)P(B^c|G) = s + (1-s)c^n \]
\[ P(U|G^c) = P(U|G^c,B)P(B|G^c) + P(U|G^c,B^c)P(B^c|G^c) = s + (1-s)w^n \]
因此:
\[ P(G|U) = \frac{p(s + (1-s)c^n)}{p(s + (1-s)c^n) + (1-p)(s + (1-s)w^n)} \]
- 不是。因为 \(n\) 的取值很大时,会导致系统性错误发生的可能性极高,而如果发生了系统性错误,法官的投票对于判断嫌疑人是否有罪就失去了信息价值。当 \(n \to \infty\) 时,(b) 的答案会退回到先验概率 \(p\)。
我们经常需要以多个信息片段为条件,现在我们有几种方法可以做到。例如,以下是寻找 \(P(A|B,C)\) 的几种途径:
我们可以将 \(B, C\) 视为单个事件 \(B \cap C\),利用条件概率的定义得到:
\[ P(A|B,C) = \frac{P(A,B,C)}{P(B,C)} \]
如果将 \(B\) 和 \(C\) 放在一起考虑最容易,这就是一种自然的方法。然后我们可以尝试评估分子和分母。例如,我们可以对分子和分母都使用全概率公式,或者将分子写成 \(P(B,C|A)P(A)\)(这将得到贝叶斯法则的一个版本)并利用全概率公式来处理分母。
我们可以使用带额外条件 \(C\) 的贝叶斯法则:
\[ P(A|B,C) = \frac{P(B|A,C)P(A|C)}{P(B|C)} \]
如果我们希望将问题中的所有内容都视为以 \(C\) 为条件的,这是一种自然的方法。
我们可以使用带额外条件 \(B\) 的贝叶斯法则:
\[ P(A|B,C) = \frac{P(C|A,B)P(A|B)}{P(C|B)} \]
这与前一种方法相同,只是交换了 \(B\) 和 \(C\) 的角色。我们特意提到它,是为了强调:如果不思考哪个事件应该扮演哪个角色就直接套用公式是不明智的。
这类条件化问题存在多种处理方式,这既是挑战,也是其强大之处。
2.5 事件的独立性
Independence of events
我们已经看过了好几个例子,其中以一个事件为条件会改变我们对另一个事件概率的看法。如果事件之间互不提供信息,这种情况就被称为独立性。
个人注:“独立性”本质上是关于“信息”的!
具体的见《独立性中物理上的独立和信息上的关联的区别.md》
定义 2.5.1(两个事件的独立性)。如果满足以下条件,则称事件 \(A\) 和 \(B\) 是独立的:
\[ P(A \cap B) = P(A)P(B) \]
如果 \(P(A) > 0\) 且 \(P(B) > 0\),则这等价于:
\[ P(A|B) = P(A) \]
同时也等价于 \(P(B|A) = P(B)\)。
口头表述为:如果两个事件的交集概率可以通过它们各自概率的乘积得出,那么这两个事件就是独立的。或者说,如果得知 \(B\) 发生并不能提供任何会改变我们对 \(A\) 发生概率的信息(反之亦然),那么 \(A\) 和 \(B\) 就是独立的。
注意,独立性是一种对称关系:如果 \(A\) 独立于 \(B\),那么 \(B\) 也独立于 \(A\)。
2.5.2。独立性与互斥性(Disjointness)完全不同。如果 \(A\) 和 \(B\) 是互斥的,那么 \(P(A \cap B) = 0\),因此互斥事件只有在 \(P(A) = 0\) 或 \(P(B) = 0\) 时才可能是独立的。已知 \(A\) 发生告诉我们 \(B\) 肯定没有发生,所以 \(A\) 显然传递了关于 \(B\) 的信息,这意味着这两个事件不是独立的(除非 \(A\) 或 \(B\) 本身的概率已经为零)。
直观上,如果 \(A\) 不提供关于 \(B\) 是否发生的信息,那么它也不应该提供关于 \(B^c\) 是否发生的信息。我们现在来证明一个符合这一直觉的简便结论。
命题 2.5.3。如果 \(A\) 和 \(B\) 独立,那么 \(A\) 与 \(B^c\) 独立,\(A^c\) 与 \(B\) 独立,且 \(A^c\) 与 \(B^c\) 独立。
证明:设 \(A\) 和 \(B\) 独立。我们首先证明 \(A\) 与 \(B^c\) 独立。如果 \(P(A) = 0\),那么 \(A\) 独立于任何事件,包括 \(B^c\)。故假设 \(P(A) \neq 0\),则:
\[ P(B^c|A) = 1 - P(B|A) = 1 - P(B) = P(B^c) \]
因此 \(A\) 与 \(B^c\) 独立。交换 \(A\) 和 \(B\) 的角色,可知 \(A^c\) 与 \(B\) 独立。利用“\(A, B\) 独立意味着 \(A, B^c\) 独立”这一事实,并让 \(A^c\) 扮演 \(A\) 的角色,可知 \(A^c\) 与 \(B^c\) 也独立。
我们还经常需要讨论三个或更多事件的独立性。
定义 2.5.4(三个事件的独立性)。如果以下所有等式都成立,则称事件 \(A, B, C\) 是独立的: \[ P(A \cap B) = P(A)P(B) \]
\[ P(A \cap C) = P(A)P(C) \]
\[ P(B \cap C) = P(B)P(C) \]
\[ P(A \cap B \cap C) = P(A)P(B)P(C) \]
如果仅前三个条件成立,我们称 \(A, B, C\) 为两两独立(Pairwise independent)。两两独立并不意味着独立:可能仅仅得知 \(A\) 或仅仅得知 \(B\) 对预测 \(C\) 是否发生毫无用处,但同时得知 \(A\) 和 \(B\) 发生可能对预测 \(C\) 依然高度相关。下面是关于这一区别的一个简单例子。
例 2.5.5(两两独立并不意味着独立)。考虑两次公平且独立的投硬币实验,设 \(A\) 为第一次是正面的事件,\(B\) 为第二次是正面的事件,\(C\) 为两次投掷结果相同的事件。那么 \(A\)、\(B\) 和 \(C\) 是两两独立的,但不是相互独立的,因为 \(P(A \cap B \cap C) = 1/4\),而 \(P(A)P(B)P(C) = 1/8\)。其核心点在于:仅仅知道 \(A\) 或仅仅知道 \(B\) 无法为我们提供关于 \(C\) 的任何信息,但同时知道 \(A\) 和 \(B\) 的结果则会为我们提供关于 \(C\) 的信息(事实上,在这种情况下,它为我们提供了关于 \(C\) 的完美信息)。
另一方面,\(P(A \cap B \cap C) = P(A)P(B)P(C)\) 并不意味着两两独立;观察极端情况 \(P(A) = 0\) 即可快速发现这一点,此时等式变为 \(0 = 0\),这并没有告诉我们关于 \(B\) 和 \(C\) 的任何信息。
我们可以类似地定义任意数量事件的独立性。直觉上,其核心思想是:知道事件集中任何特定子集的情况,都不会为我们提供关于该子集之外事件情况的任何信息。
定义 2.5.6(多个事件的独立性)。要使 \(n\) 个事件 \(A_1, A_2, \dots, A_n\) 相互独立,我们需要:任意两个事件满足 \(P(A_i \cap A_j) = P(A_i)P(A_j)\)(对于 \(i \neq j\));任意三个事件满足 \(P(A_i \cap A_j \cap A_k) = P(A_i)P(A_j)P(A_k)\)(对于 \(i, j, k\) 互不相同);以此类推,对于所有四个、五个以及更多事件的组合均需满足。这很快就会变得笨重难处理,但稍后我们将讨论思考独立性的其他方式。对于无限多个事件,如果它们的每一个有限子集都是独立的,我们就称它们是独立的。
条件独立性的定义与独立性类似。
定义 2.5.7(条件独立性)。如果在给定 \(E\) 的条件下,满足 \(P(A \cap B|E) = P(A|E)P(B|E)\),则称事件 \(A\) 和 \(B\) 在给定 \(E\) 的条件下是条件独立的。
2.5.8。由于混淆“独立性”和“条件独立性”而导致严重错误是非常容易发生的。两个事件可能在给定 \(E\) 时是条件独立的,但在给定 \(E^c\) 时不是。两个事件可能在给定 \(E\) 时是条件独立的,但本身并不独立。两个事件可能相互独立,但在给定 \(E\) 时不是条件独立的。
特别地,\(P(A, B) = P(A)P(B)\) 并不意味着 \(P(A, B|E) = P(A|E)P(B|E)\);我们不能像从全概率公式(LOTP)推导带额外条件的 LOTP 那样,简单地在各处插入“给定 \(E\)”。这是因为 LOTP 始终成立(它是概率公理的推论),而 \(P(A, B)\) 是否等于 \(P(A)P(B)\) 取决于 \(A\) 和 \(B\) 具体是什么。
接下来的几个例子说明了这些区别。在处理条件概率和条件独立性时需要格外小心!
例 2.5.9(给定 \(E\) 与给定 \(E^c\) 时的条件独立性)。假设有两类课程:优质课和劣质课。在优质课上,如果你努力学习,就很有可能获得 A。在劣质课上,教授不看学生的努力程度,而是随机分配成绩。设 \(G\) 为课程优质的事件,\(W\) 为你努力学习的事件,\(A\) 为你获得 A 的事件。那么 \(W\) 和 \(A\) 在给定 \(G^c\) 时是条件独立的,但在给定 \(G\) 时不是条件独立的。
例 2.5.10(条件独立并不意味着独立)。再次回到例 2.3.7 的场景:假设我们选了一枚公平硬币或一枚正面概率为 3/4 的偏差硬币,但我们不知道选了哪一枚。我们抛掷硬币若干次。在选定公平硬币的条件下,各次抛掷是独立的,每次正面概率为 1/2。同样,在选定偏差硬币的条件下,各次抛掷也是独立的,每次正面概率为 3/4。
然而,这些抛掷在无条件的情况下并不是相互独立的。因为如果我们不知道选了哪枚硬币,那么观察抛掷序列就会为我们提供关于手里拿的是公平硬币还是偏差硬币的信息。这反过来又帮助我们预测同一枚硬币未来抛掷的结果。
正式地说,设 \(F\) 为选中公平硬币的事件,设 \(A_1\) 和 \(A_2\) 为第一次和第二次抛掷结果为正面的事件。在给定 \(F\) 的条件下,\(A_1\) 和 \(A_2\) 是独立的;但 \(A_1\) 和 \(A_2\) 在无条件时不是独立的,因为 \(A_1\) 提供了关于 \(A_2\) 的信息。
例 2.5.11(独立并不意味着条件独立)。我的朋友爱丽丝(Alice)和鲍勃(Bob)是仅有的会给我打电话的两个人。每天,他们都会独立决定当天是否给我打电话。设 \(A\) 为爱丽丝下周五给我打电话的事件,\(B\) 为鲍勃下周五给我打电话的事件。假设 \(A\) 和 \(B\) 是无条件独立的,且 \(P(A) > 0, P(B) > 0\)。
然而,在已知我下周五恰好收到一个电话的条件下,\(A\) 和 \(B\) 不再独立:这个电话来自爱丽丝当且仅当它不是来自鲍勃。换句话说,设 \(C\) 为我下周五恰好收到一个电话的事件,\(P(B|C) > 0\) 但 \(P(B|A,C) = 0\),因此在给定 \(C\) 的条件下,\(A\) 和 \(B\) 不是条件独立的。
例 2.5.12(宝宝为什么在哭?)。某个宝宝当且仅当她饿了、累了或两者兼有时才会哭。设 \(C\) 为宝宝在哭的事件,\(H\) 为她饿了的事件,\(T\) 为她累了的事件。令 \(P(C) = c, P(H) = h, P(T) = t\),其中 \(c, h, t\) 均不为 0 或 1。设 \(H\) 和 \(T\) 相互独立。
用 \(h\) 和 \(t\) 表示 \(c\)。
求 \(P(H|C), P(T|C)\) 以及 \(P(H,T|C)\)。
在给定 \(C\) 的条件下,\(H\) 和 \(T\) 是否条件独立?请用两种方式解释:利用 (b) 中的量进行代数推导,以及文字上的直觉解释。
解答:
- 由于 \(H\) 和 \(T\) 独立,我们有:
\[ P(C) = P(H \cup T) = P(H) + P(T) - P(H \cap T) = h + t - ht \]
- 根据贝叶斯法则:
\[ P(H|C) = \frac{P(C|H)P(H)}{P(C)} = \frac{h}{c} \]
\[ P(T|C) = \frac{P(C|T)P(T)}{P(C)} = \frac{t}{c} \]
\[ P(H,T|C) = \frac{P(C|H,T)P(H,T)}{P(C)} = \frac{ht}{c} \]
(注意:如果 \(H\) 或 \(T\) 发生,则 \(P(C|H) = 1, P(C|T) = 1, P(C|H,T) = 1\)。)
- 不独立。在给定 \(C\) 的条件下,\(H\) 和 \(T\) 不是条件独立的,因为:
\[ P(H,T|C) = \frac{ht}{c} \neq \frac{h}{c} \cdot \frac{t}{c} = P(H|C)P(T|C) \]
(由于 \(c < 1\),所以 \(ht/c > ht/c^2\)。)
我们也可以直观地看出为什么它们在给定 \(C\) 时不是条件独立的:如果宝宝在哭但并不饿,那么她一定是累了。
2.6 贝叶斯法则的一致性
Coherency of Bayes’ rule
贝叶斯法则的一个重要性质是它是一致的(coherent):如果我们收到多条信息并希望更新概率以整合所有信息,那么无论是顺序更新(每次考虑一条证据进行更新)还是同步更新(一次性使用所有证据进行更新),结果都是一样的。例如,假设我们进行一项为期一周的实验,每天结束时都会产生数据。我们可以每天使用贝叶斯法则根据当天的数据更新概率;或者我们可以休假一周,周五下午回来后利用全周的数据进行一次性更新。两种方法将得到相同的结果。
让我们来看这个原则的具体应用。
例 2.6.1(罕见疾病检测,续)。在例 2.3.9 中检测呈阳性的患者弗雷德决定接受第二次检测。新检测与原检测是独立的(在给定其患病状态的情况下),且具有相同的灵敏度和特异度。对弗雷德来说不幸的是,第二次检测结果依然呈阳性。请通过两种方式计算弗雷德患病的概率:一步法(同时以两次检测结果为条件)和两步法(先根据第一次检测结果更新概率,然后再根据第二次结果再次更新)。
解答:
设 \(D\) 为患病事件,\(T_1\) 为第一次检测呈阳性,\(T_2\) 为第二次检测呈阳性。在例 2.3.9 中,我们使用了贝叶斯法则和全概率公式求得 \(P(D|T_1)\)。另一种快速解法是使用几率形式的贝叶斯法则:
\[ \frac{P(D|T_1)}{P(D^c|T_1)} = \frac{P(D)}{P(D^c)} \cdot \frac{P(T_1|D)}{P(T_1|D^c)} = \frac{1}{99} \cdot \frac{0.95}{0.05} \approx 0.19 \]
由于 \(P(D|T_1) / (1 - P(D|T_1)) = 0.19\),我们得到 \(P(D|T_1) = 0.19 / (1 + 0.19) \approx 0.16\),这与之前的答案一致。在这种情况下,几率形式的贝叶斯法则更快,因为我们不需要计算普通贝叶斯法则分母中的无条件概率 \(P(T_1)\)。现在,再次使用几率形式,来看看如果弗雷德第二次检测仍为阳性会发生什么。
一步法:同时根据两次检测结果进行更新,我们有
\[ \frac{P(D|T_1 \cap T_2)}{P(D^c|T_1 \cap T_2)} = \frac{P(D)}{P(D^c)} \cdot \frac{P(T_1 \cap T_2|D)}{P(T_1 \cap T_2|D^c)} = \frac{1}{99} \cdot \frac{0.95^2}{0.05^2} = \frac{361}{99} \approx 3.646 \]
对应的概率约为 0.78。
两步法:第一次检测后,弗雷德患病的后验几率为
\[ \frac{P(D|T_1)}{P(D^c|T_1)} = \frac{1}{99} \cdot \frac{0.95}{0.05} \approx 0.19 \]
(如上所述)。这个后验几率变成了新的先验几率,然后根据第二次检测进行更新:
\[ \frac{P(D|T_1 \cap T_2)}{P(D^c|T_1 \cap T_2)} = \frac{P(D|T_1)}{P(D^c|T_1)} \cdot \frac{P(T_2|D, T_1)}{P(T_2|D^c, T_1)} = \left( \frac{1}{99} \cdot \frac{0.95}{0.05} \right) \cdot \frac{0.95}{0.05} = \frac{361}{99} \approx 3.646 \]
结果与上述一致。
注意,随着第二次阳性结果的出现,弗雷德患病的概率从 0.16 跃升至 0.78,这使我们更加确信弗雷德确实患有“状况炎症”。这个故事的寓意是:寻求“第二意见”(复查)是一个好主意。
2.7 条件化作为解题工具
Conditioning as a problem-solving tool
条件化是解决问题的强大工具,因为它允许我们进行“一厢情愿的思考”(wishful thinking):当我们遇到一个如果已知事件 \(E\) 是否发生就会变得更容易的问题时,我们可以分别以 \(E\) 和 \(E^c\) 为条件考虑这些可能性,然后使用全概率公式(LOTP)将它们组合起来。
个人注:所以这也是第2.3节把贝叶斯法则与全概率公式放在同一节的原因了。
2.7.1 策略:以你“希望知道”的信息为条件
Strategy: condition on what you wish you knew
例 2.7.1(蒙提·霍尔问题)。在由蒙提·霍尔(Monty Hall)主持的节目《让我们来做个交易》(Let's Make a Deal)中,参赛者在三扇关闭的门中选择一扇。其中两扇门后是山羊,一扇门后是汽车。蒙提知道汽车在哪,他会开启剩下的两扇门中的一扇。他开启的门后总是山羊(他绝不会揭晓汽车!)。如果他有选择余地,他会以等概率随机选择一扇门。随后,蒙提为参赛者提供换到另一扇未开启门的机会。如果参赛者的目标是得到汽车,她应该换门吗?
解答:
我们将门标记为 1 到 3 号。不失一般性,假设参赛者选择了 1 号门(如果她没选 1 号,我们只需重新编号,或在解答中置换门号)。蒙提打开了一扇门,露出了一只山羊。在参赛者决定是否换到另一扇未开启的门时,她真正“希望知道”的是什么?显然,如果她知道汽车在哪,决定就会容易得多!这提示我们应该以汽车的位置为条件。设 \(C_i\) 为汽车在 \(i\) 号门后的事件(\(i=1,2,3\))。根据全概率公式:
\[ P(\text{得到车}) = P(\text{得到车}|C_1) \cdot \frac{1}{3} + P(\text{得到车}|C_2) \cdot \frac{1}{3} + P(\text{得到车}|C_3) \cdot \frac{1}{3} \]
假设参赛者采用“换门策略”。如果汽车在 1 号门后,换门会失败,所以 \(P(\text{得到车}|C_1) = 0\)。如果汽车在 2 号或 3 号门后,由于蒙提总是展示山羊,剩下的那扇未开启的门必然是汽车,因此换门会成功。于是:
\[ P(\text{得到车}) = 0 \cdot \frac{1}{3} + 1 \cdot \frac{1}{3} + 1 \cdot \frac{1}{3} = \frac{2}{3} \]
所以换门策略有 2/3 的成功率。参赛者应该换门。
上图是我们刚才概述的论证的树状图:使用换门策略,只要汽车在 2 号或 3 号门后(概率为 2/3),参赛者就会赢。我们也可以给出一个支持换门的直观频率学派论证。想象玩这个游戏 1000 次。通常,大约有 333 次你最初对汽车位置的猜测是正确的,在这种情况下换门会失败。其余 667 次左右,你都会通过换门获胜。
这里有一个微妙之处:当参赛者选择是否换门时,她还知道蒙提打开的是哪扇门。我们证明了成功的无条件概率是 2/3(采用换门策略时),但让我们也证明一下,在给定蒙提提供的信息的情况下,换门成功的条件概率也是 2/3。
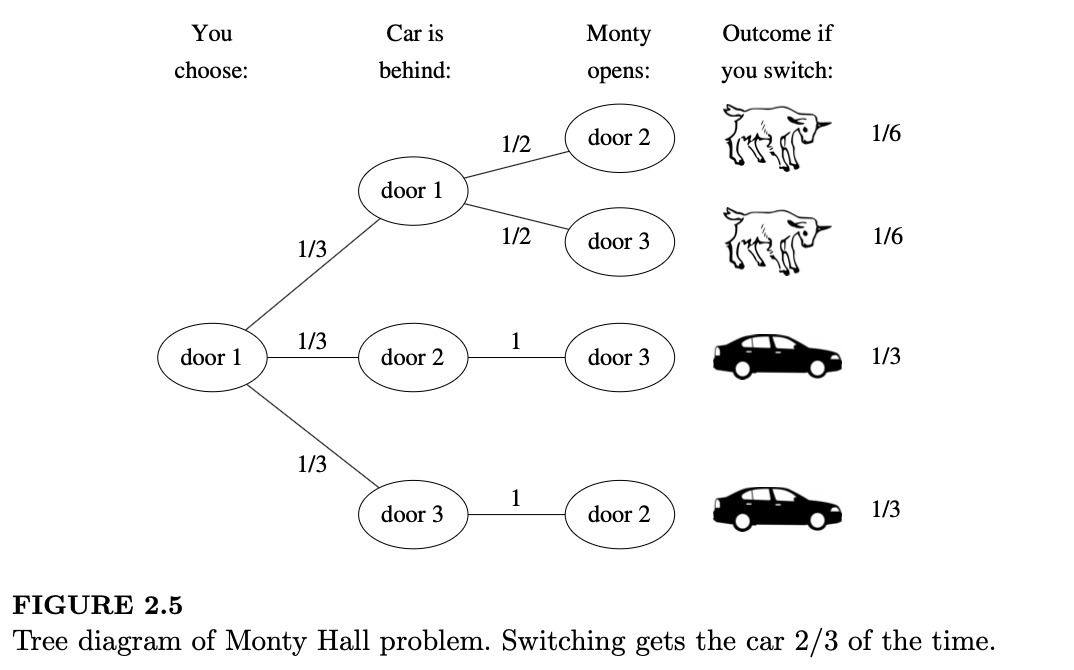
设 \(M_j\) 为蒙提开启 \(j\) 号门的事件(\(j=2,3\))。则:
\[ P(\text{得到车}) = P(\text{得到车}|M_2)P(M_2) + P(\text{得到车}|M_3)P(M_3) \]
根据对称性,\(P(M_2) = P(M_3) = 1/2\) 且 \(P(\text{得到车}|M_2) = P(\text{得到车}|M_3)\)。这里的对称性在于题目陈述中没有区分 2 号门和 3 号门;相比之下,习题 40 考虑了蒙提比 3 号门更喜欢开 2 号门的情形。
设 \(x = P(\text{得到车}|M_2) = P(\text{得到车}|M_3)\)。代入已知量:
\[ \frac{2}{3} = P(\text{得到车}) = \frac{x}{2} + \frac{x}{2} = x \]
得证。
贝叶斯法则在给定证据下寻找换门策略的条件成功概率时也非常奏效。假设蒙提打开了 2 号门。使用上述记号和结果:
\[ P(C_1|M_2) = \frac{P(M_2|C_1)P(C_1)}{P(M_2)} = \frac{(1/2)(1/3)}{1/2} = \frac{1}{3} \]
所以,在已知蒙提打开 2 号门的情况下,参赛者最初选择的门里有车的概率是 1/3,这意味着换门策略成功的概率是 2/3。
许多人第一次看到这个问题时,会争辩说换门没有优势:“剩下两扇门,其中一扇有车,所以概率是 50-50。”在学习了上一章后,我们认识到这种观点误用了概率的原始定义。然而,即使在不适用的情况下,原始定义对人们的直觉仍有强大的控制力。当玛丽莲·沃斯·莎凡特(Marilyn vos Savant)于 1990 年在《Parade》杂志的专栏中给出蒙提·霍尔问题的正确解法时,她收到了成千上万封读者(甚至是数学家)的来信,坚称她是错的。
为了建立正确的直觉,让我们考虑一个极端情况。假设有一百万扇门,其中 999,999 扇后面是山羊,1 扇后面是汽车。在参赛者初步选择后,蒙提打开了 999,998 扇后面是山羊的门,并提供换门的机会。在这种极端情况下,很明显这两扇未开启门的概率不是 50-50;很少有人会固执地坚持最初的选择。三扇门的情况也是如此。
正如我们在例 2.2.6 中必须对如何遇到那个随机女孩做出假设一样,这里换门策略 2/3 的成功率取决于我们对蒙提如何决定开哪扇门的假设。在习题中,我们将考虑蒙提·霍尔问题的几种变体和推广,其中一些会改变换门策略的优劣。
2.7.2 策略:以第一步为条件
Strategy: condition on the first step
在具有递归结构的问题中,以实验的第一步为条件通常非常有用。接下来的两个例子应用了这一策略,我们称之为第一步分析法(first-step analysis)。
例 2.7.2(分支过程)。一只名叫波波(Bobo)的单细胞阿米巴原虫生活在池塘里。一分钟后,波波会以等概率选择死亡、分裂成两个,或保持现状。在随后的每一分钟里,所有存活的阿米巴原虫都会以相同的方式独立地行动。请问阿米巴种群最终灭绝的概率是多少?
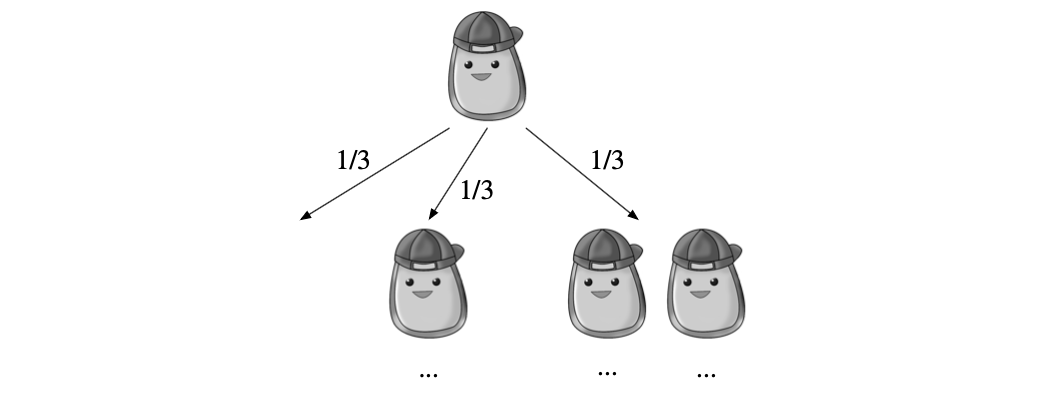
解答:
设 \(D\) 为种群最终灭绝的事件;我们要寻找 \(P(D)\)。我们通过以第一步的结果为条件来处理:设 \(B_i\) 为一分钟后波波变为 \(i\) 个阿米巴原虫的事件(\(i=0, 1, 2\))。
我们已知 \(P(D|B_0) = 1\)(如果它死了,种群就灭绝了),以及 \(P(D|B_1) = P(D)\)(如果波波保持现状,我们就回到了起点)。如果波波分裂成两个,那么我们就有两个相互独立的原始问题的副本!我们需要这两个后代各自的种群都最终灭绝,因此 \(P(D|B_2) = P(D)^2\)。现在我们已经穷举了所有可能的情况,可以用全概率公式将它们组合起来:
\[ P(D) = P(D|B_0) \cdot \frac{1}{3} + P(D|B_1) \cdot \frac{1}{3} + P(D|B_2) \cdot \frac{1}{3} \]
\[ P(D) = 1 \cdot \frac{1}{3} + P(D) \cdot \frac{1}{3} + P(D)^2 \cdot \frac{1}{3} \]
解这个关于 \(P(D)\) 的二次方程,得到 \(P(D) = 1\):阿米巴种群最终灭绝的概率为 1。
第一步分析策略之所以奏效,是因为这个问题本质上是自相似的:当波波继续作为单个个体存在或分裂为两个时,我们最终面对的是原始问题的一个或两个新版本。以第一步为条件让我们能够用 \(P(D)\) 自身来表达 \(P(D)\)。
个人注:结果挺违反直觉。
例 2.7.3(赌徒输光问题)。两名赌徒 A 和 B 进行一系列 1 美元的赌博。在每一局中,赌徒 A 赢的概率为 \(p\),赌徒 B 赢的概率为 \(q = 1-p\)。赌徒 A 初始资金为 \(i\) 美元,赌徒 B 初始资金为 \(N-i\) 美元;两人的总财富保持不变(恒为 \(N\)),因为每次 A 输掉 1 美元,这 1 美元就归 B,反之亦然。
个人注:这道题太经典了。数学建模的典型!
我们可以将此游戏可视化为在整数 \(0\) 到 \(N\) 之间的随机游走(random walk),其中 \(p\) 是在给定步中向右移动的概率:想象一个人从位置 \(i\) 开始,在每个时间点,以概率 \(p\) 向右移动一步,以概率 \(q = 1-p\) 向左移动一步。当 A 或 B 其中一人输光时,游戏结束,即随机游走到达 \(0\) 或 \(N\)。请问 A 赢得比赛(带着所有的钱离开)的概率是多少?
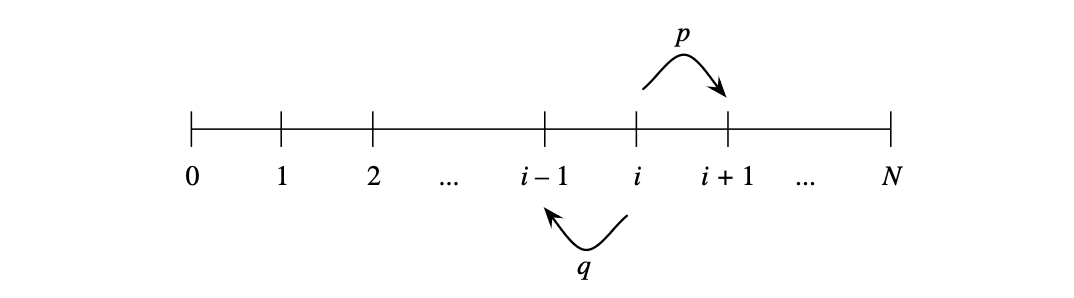
解答:
我们认识到,这个博弈与波波的繁殖过程类似,都具有递归结构:第一步之后,博弈的性质完全没有改变,唯一的区别是 A 的财富现在变成了 \(i+1\) 或 \(i-1\)。设 \(p_i\) 为 A 在拥有 \(i\) 美元初始资金时赢得博弈的概率。我们将使用第一步分析法来求解 \(p_i\)。
个人注:以下可以看出条件概率和全概率公式的联系。
设 \(W\) 为 A 赢得博弈的事件。根据全概率公式,对第一局的结果进行条件化,我们有:
\[ p_i = P(W \mid A \text{从} i \text{开始,第一局赢}) \cdot p + P(W \mid A \text{从} i \text{开始,第一局输}) \cdot q \]
\[ = P(W \mid A \text{从} i+1 \text{开始}) \cdot p + P(W \mid A \text{从} i-1 \text{开始}) \cdot q \]
\[ = p_{i+1} \cdot p + p_{i-1} \cdot q \]
这一等式对所有 \(i \in \{1, \dots, N-1\}\) 都成立,此外我们还有边界条件 \(p_0 = 0\)(输光了)和 \(p_N = 1\)(赢了所有的钱)。现在我们可以通过解这个差分方程(difference equation)来获得 \(p_i\)。
个人注:
差分方程:一个量在离散时间点上,如何由“前一步”的值决定“下一步”的值。
差分方程是“平移不变”的。
斐波那契数列数列也是差分方程,下一项由前两项决定,这同样是一个差分方程,只是高阶的。
它研究的不是连续变化,而是一步一步的演化关系,本质上和微分方程是一致的。
对比一下:
- 微分方程:\(\dfrac{dx}{dt}\)(连续变化)
- 差分方程:\(x_{n+1} - x_n\)(离散变化)
该差分方程的特征方程为 \(px^2 - x + q = 0\),其根为 \(1\) 和 \(q/p\)。
如果 \(p \neq 1/2\):根是互异的,通解为 \(p_i = a \cdot 1^i + b \cdot (q/p)^i\)。
利用边界条件 \(p_0 = 0\) 和 \(p_N = 1\),我们求得系数:
\[ a = -b = \frac{1}{1 - (q/p)^N} \]
如果 \(p = 1/2\):特征方程有重根,通解为 \(p_i = a \cdot 1^i + b \cdot i \cdot 1^i\)。
利用边界条件可得 \(a = 0\) 且 \(b = 1/N\)。
综上所述,A 在初始财富为 \(i\) 时获胜的概率为:
\[ p_i = \begin{cases} \frac{1-(q/p)^i}{1-(q/p)^N} & \text{若 } p \neq 1/2, \\ \frac{i}{N} & \text{若 } p = 1/2. \end{cases} \] \(p = 1/2\) 的情形与 \(p \neq 1/2\) 的情形是一致的,即:
\[ \lim_{p \to 1/2} \frac{1-(q/p)^i}{1-(q/p)^N} = \frac{i}{N} \]
我们可以通过洛必达法则(L'Hôpital's rule)证明这一点。
对于 \(p = 1/2\)(公平博弈)的情况,答案有一个简单的解释:A 获胜的概率等于其初始财富占总财富的比例。因此,如果 A 的初始资金远少于 B,即使博弈是公平的,A 获胜的机会也很小。而如果 \(p < 1/2\),即使 \(p\) 仅仅比 \(1/2\) 小一点点,A 获胜的概率也会骤降。例如,如果 \(p = 0.49\) 且双方各有 \(100\) 美元,A 获胜的概率仅约为 \(1.8\%\)。
个人注:有点像马太效应!
我们关注了 A 获胜的概率,那 B 呢?我们可以利用对称性:除了符号不同,博弈的描述中没有任何区别 A 和 B 的地方。因此,B 在拥有 \(N-i\) 财富时获胜的概率只需将 \(p\) 与 \(q\) 互换,并将 \(i\) 替换为 \(N-i\) 即可。可以验证,对于所有 \(i\) 和 \(p\),\(P(\text{A 获胜}) + P(\text{B 获胜}) = 1\)。这意味着博弈保证会结束:永远在中间状态振荡而不结束的概率为 \(0\)。
个人注:为什么“两个概率加起来等于 1”这么重要?
在概率论里,一个系统的所有互斥且穷尽的结果,其概率之和必须等于 1。
在这里,可能发生的事情理论上有三类:
- A 最终获胜
- B 最终获胜
- 游戏永远不结束(无限振荡)
如果你能证明:
P(A 获胜) + P(B 获胜) = 1
那就意味着:
P(永远不结束) = 0
也就是说:
第三种情况在数学上“不存在”,或者说发生的概率为零。
这句话真正想传达的“思想结论”:
这句话不是在算概率,而是在排除一种哲学上的担忧:
会不会存在一种状态,使得游戏永远卡在中间,不生不死?
结论是:
- 数学上允许这种路径存在
- 但概率论明确告诉你: 你永远不用担心它发生
2.8 陷阱与悖论
Pitfalls and paradoxes
接下来的两个例子是法律背景下出现的条件化思维谬误。检察官谬误(Prosecutor’s fallacy)是指混淆了 \(P(A|B)\) 与 \(P(B|A)\);而辩护律师谬误(Defense attorney’s fallacy)是指未能以所有证据为条件进行考量。
2.8.1 检察官谬误(Prosecutor’s fallacy)1998 年,萨莉·克拉克(Sally Clark)因两名儿子在出生后不久相继死亡而受审。在审判期间,控方的一名专家证人作证说,新生儿死于婴儿猝死综合征(SIDS)的概率为 \(1/8500\),因此一个家庭中发生两起 SIDS 死亡的概率为 \((1/8500)^2\),即大约 7300 万分之一。随后他断言,克拉克无罪的概率就是 7300 万分之一。
这种推理方式至少存在两个重大问题:
第一,独立性假设的错误。专家证人通过将单个事件概率相乘,得出了“长子死于 SIDS”和“次子死于 SIDS”交集的概率。正如我们所知,这仅在同一个家庭内的 SIDS 死亡相互独立时才成立。然而,如果遗传或其他特定家庭的风险因素导致某些家庭内的所有新生儿面临更高的 SIDS 风险,这种独立性就不复存在。
第二,概率方向的混淆。这位所谓的专家混淆了两个截然不同的条件概率:\(P(\text{无罪} | \text{证据})\) 与 \(P(\text{证据} | \text{无罪})\)。证人声称,如果被告是无罪的,观察到两名新生儿死亡的概率极低;即 \(P(\text{证据} | \text{无罪})\) 很小。然而,我们真正关心的是 \(P(\text{无罪} | \text{证据})\),即在已知所有证据的情况下,被告无罪的概率。
根据贝叶斯法则:
\[ P(\text{无罪} | \text{证据}) = \frac{P(\text{证据} | \text{无罪}) P(\text{无罪})}{P(\text{证据})} \] 因此,要计算给定证据下的无罪条件概率,我们必须考虑 \(P(\text{无罪})\),即无罪的先验概率。这个概率是非常高的:虽然 SIDS 导致双重死亡很罕见,但双重杀婴案同样罕见!将分母展开为:
\[ P(\text{证据} | \text{无罪}) P(\text{无罪}) + P(\text{证据} | \text{有罪}) P(\text{有罪}) \] 注意,如果 \(P(\text{有罪})\) 足够小,使得第二项相对于第一项可以忽略不计,那么 \(P(\text{无罪} | \text{证据})\) 的分母就近似等于分子,从而使 \(P(\text{无罪} | \text{证据})\) 接近 \(1\)。
给定证据后的无罪后验概率高度取决于两个因素:极其微小的 \(P(\text{证据} | \text{无罪})\) 和极其巨大的 \(P(\text{无罪})\)。专家给出的 7300 万分之一的概率(其本身就值得商榷)仅仅是等式的一部分。
悲剧的是,克拉克被定罪并被送往监狱,部分原因正是基于该专家错误的证词。她在监狱里度过了三年多,直到定罪被撤销。萨莉·克拉克案中对条件概率的误用引起了巨大的社会反响,促使人们对数百起使用类似错误逻辑的控方案件进行了重新审查。
个人注:以上检查官的推理方式常常作为雄辩的政客的主要煽动人心的话术,从直观上冲击普通人的感情!
2.8.2 辩护律师谬误(Defense attorney’s fallacy)一名妇女被谋杀,她的丈夫因这项罪名受审。有证据显示,被告曾有虐待妻子的历史。辩护律师辩称,虐待证据与本案无关,应予以排除,因为在虐待妻子的男性中,随后谋杀妻子的比例仅为 万分之一。法官是否应该批准辩护律师排除该证据的动议?
假设辩护律师给出的“万分之一”数据是正确的,并进一步假设相关人群(丈夫与妻子)的以下数据:
- 10% 的丈夫虐待妻子。
- 在被谋杀的妻子中,有 1/5(即 20%)是被丈夫杀害的。
- 杀害妻子的丈夫中,有 50% 此前曾虐待过妻子。
- 此外假设:如果被谋杀妻子的丈夫并非凶手,那么他虐待妻子的概率退回到无条件的虐待概率(即 10%)。
如何定义“相关人群”以及如何估算这些概率是困难的课题(例如:是看全市、全州还是全国的数据?如何统计未报告的虐待和未破获的命案?)。在本题中,我们假设已经商定了一个合理的样本范围,且上述概率已知正确。
设 \(A\) 为丈夫虐待妻子的事件,\(G\) 为丈夫有罪的事件。辩护律师的论点是 \(P(G|A) = 1/10,000\),因此在已知虐待史的情况下,有罪的可能性依然极低。
然而,辩护律师未能以一个关键事实为条件:在本案中,我们已经知道妻子被谋杀了。因此,相关的概率不是 \(P(G|A)\),而是 \(P(G|A,M)\),其中 \(M\) 是妻子被谋杀的事件。
利用带额外条件的全概率公式和贝叶斯法则:
\[ P(G|A,M) = \frac{P(A|G,M)P(G|M)}{P(A|G,M)P(G|M) + P(A|G^c,M)P(G^c|M)} \] 代入已知数据:
- \(P(A|G,M) = 0.5\)(杀妻者中有 50% 曾施虐)
- \(P(G|M) = 0.2\)(被杀妻子中 20% 是被丈夫杀害的)
- \(P(A|G^c,M) = 0.1\)(如果丈夫无罪,其施虐概率为无条件概率 10%)
- \(P(G^c|M) = 0.8\)(1 - 0.2)
\[ P(G|A,M) = \frac{0.5 \cdot 0.2}{0.5 \cdot 0.2 + 0.1 \cdot 0.8} = \frac{0.1}{0.1 + 0.08} = \frac{5}{9} \approx 0.56 \]
因此,有罪的后验概率 \(P(G|A,M)\) 超过了 55%,是辩护律师所强调的 \(P(G|A)\) 的 5000 多倍。以虐待证据为条件,将有罪概率从 \(P(G|M) = 0.2\) 提升到了 \(P(G|A,M) \approx 0.56\)。因此,被告的虐待史提供了非常重要的信息,这与辩护律师的论点恰恰相反。
在上述计算中,我们根本没有用到辩护律师提供的“万分之一”这个数字;它对我们的计算是无关的,因为它没有考虑到“妻子已被谋杀”这一既定事实。我们必须以所有已知证据为条件。
例 2.8.3 辛普森悖论(Simpson’s Paradox)希伯特医生(Dr. Hibbert)和尼克医生(Dr. Nick)每人都执行两种类型的手术:心脏手术和创可贴拆除。每种手术的结果要么成功,要么失败。两位医生的记录如下表及图 2.6 所示(白点代表成功,黑点代表失败):
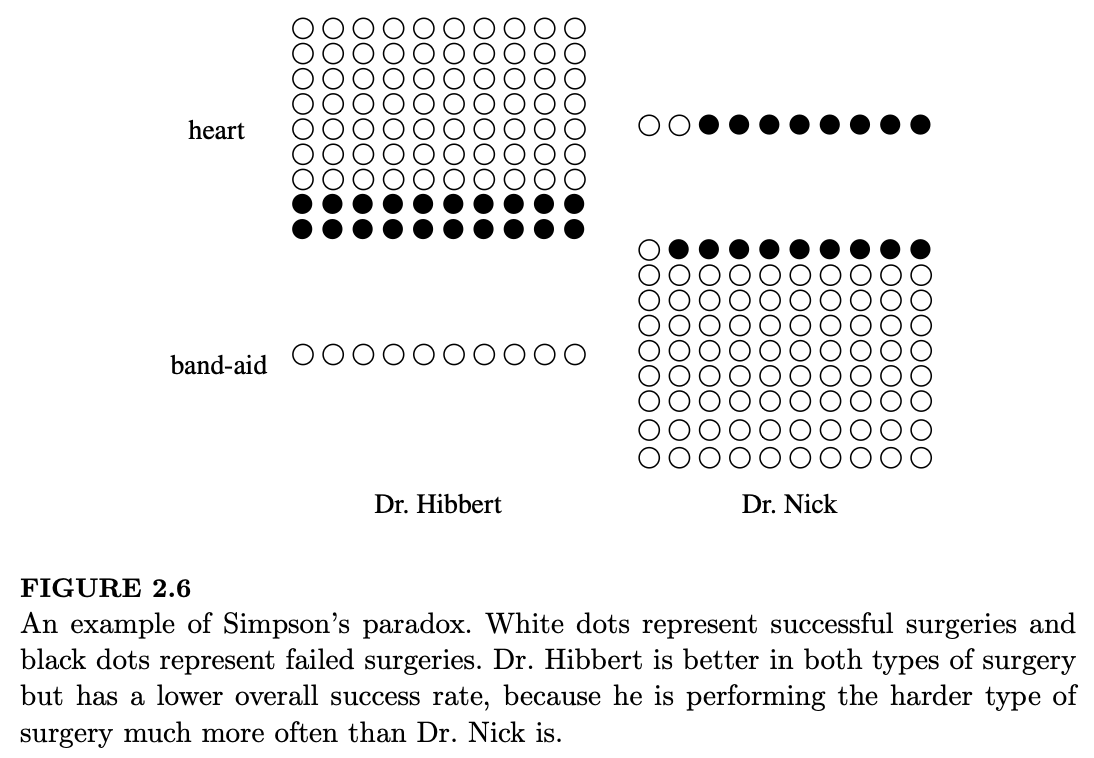
在心脏手术中,希伯特医生的成功率更高(90 次中成功 70 次 vs 10 次中成功 2 次);在创可贴拆除中,也是希伯特医生更高(10/10 vs 81/90)。但是,如果我们聚合这两类手术来比较总成功率,希伯特医生在 100 次手术中成功了 80 次,而尼克医生成功了 83 次:尼克医生的总成功率反而更高!
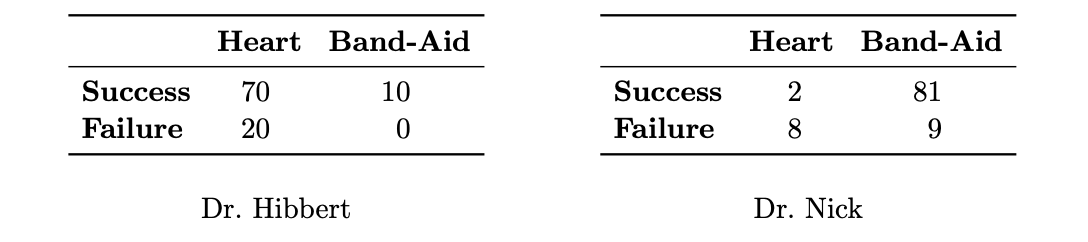
造成这种现象的原因是,希伯特医生可能由于医术更高超、名气更大,承担了更多数量的心脏手术,而心脏手术本质上比创可贴拆除风险大得多。他的总成功率较低并不是因为他在某一类特定手术上的技能较差,而是因为他承担了更高比例的高风险手术。
为了精确描述,我们称事件 \(A, B, C\) 构成了辛普森悖论,如果满足:
- \(P(A|B,C) < P(A|B^c,C)\)
- \(P(A|B,C^c) < P(A|B^c,C^c)\)
- 但 \(P(A|B) > P(A|B^c)\)
在这个例子中:
- \(A\):手术成功的事件。
- \(B\):医生是尼克医生的事件。
- \(C\):手术是心脏手术的事件。
全概率公式从数学上告诉了我们为什么会发生这种情况:
\[ P(A|B) = P(A|C,B)P(C|B) + P(A|C^c,B)P(C^c|B) \]
\[ P(A|B^c) = P(A|C,B^c)P(C|B^c) + P(A|C^c,B^c)P(C^c|B^c) \]
上述等式将 \(P(A|B)\) 表示为条件概率的加权平均值。如果两组加权平均值的权重(即 \(P(C|B)\) 和 \(P(C|B^c)\))相同,辛普森悖论就不会发生。但这里的权重完全不同:尼克医生进行心脏手术的概率 \(P(C|B)\) 远低于希伯特医生 \(P(C|B^c)\)。
数值上,这两个加权平均值为:
- 尼克 (B):\(0.83 = (2/10) \cdot 0.1 + (81/90) \cdot 0.9\)
- 希伯特 (\(B^c\)):\(0.80 = (70/90) \cdot 0.9 + (10/10) \cdot 0.1\)
尼克医生的等式在第二项(较简单的手术)上分配了更大的权重。对不同类型手术的聚合掩盖了医生能力的真实图景,因为我们丢失了关于“哪个医生倾向于做哪种手术”的信息。当可能存在混杂变量(如手术类型)时,我们应该观察分层数据来探究真相。
现实生活中的例子:
- 大学录取的性别歧视:1970 年代,加州大学伯克利分校的研究生录取中,男性总体录取率显著高于女性,引发了歧视指控。然而,在大多数具体系别中,女性的录取率反而更高。原因是女性倾向于申请竞争更激烈的系别,而男性倾向于申请竞争较小的系别。
- 棒球击球率:球员 1 在赛季上半程和下半程的击球率都可能高于球员 2,但全赛季总击球率却低于球员 2。这取决于两名球员在不同半程的“打数”分配。
- 吸烟与健康:Cochran 发现,在任何年龄段内,香烟吸烟者的死亡率都高于雪茄吸烟者。但由于香烟吸烟者平均年龄更年轻,总体的死亡率反而看起来更低。
2.9 本章小结
在给定 \(B\) 的条件下,\(A\) 的条件概率定义为:
\[ P(A|B) = \frac{P(A \cap B)}{P(B)} \] 条件概率具有与普通概率完全相同的性质。\(P(\cdot|B)\) 实际上是根据观察到的证据 \(B\) 更新了我们对事件的不确定性。如果在观察到证据 \(B\) 后,事件的概率保持不变,则称该事件与 \(B\) 相互独立。两个事件也可以在给定第三个事件 \(E\) 的条件下条件独立。需要注意的是,条件独立并不意味着无条件独立,无条件独立也不意味着条件独立。
关于条件概率有两个极其重要的结论:
- 贝叶斯法则(Bayes’ rule):它建立了 \(P(A|B)\) 与 \(P(B|A)\) 之间的联系。
- 全概率公式(LOTP):它允许我们通过划分样本空间并计算每个切片内的条件概率,从而获得无条件概率。
贝叶斯法则公式为:
\[ P(A|B) = \frac{P(B|A)P(A)}{P(B)} \]
全概率公式(对于样本空间的任何划分 \(A_1, \dots, A_n\))为:
\[ P(B) = \sum_{i=1}^n P(B|A_i)P(A_i) \]
在实际应用中,贝叶斯法则和全概率公式经常协同使用。
条件化是解决问题的极佳工具,因为它允许我们将问题分解为更小的部分,分别考虑所有可能的情况,然后将它们组合起来。在使用这一策略时,我们应该尝试以“如果你知道后问题会变得更简单”的信息为条件,即所谓的“以你希望知道的信息为条件”。当问题涉及多个阶段时,以“第一步”为条件来建立递归关系(第一步分析法)通常非常有效。
思考条件概率时常见的错误包括:
- 混淆先验概率 \(P(A)\) 与后验概率 \(P(A|B)\)。
- 检察官谬误:混淆 \(P(A|B)\) 与 \(P(B|A)\)。
- 辩护律师谬误:未能以所有已知证据为条件进行考量。
- 忽视辛普森悖论,以及在决定是否聚合数据时缺乏审慎思考。
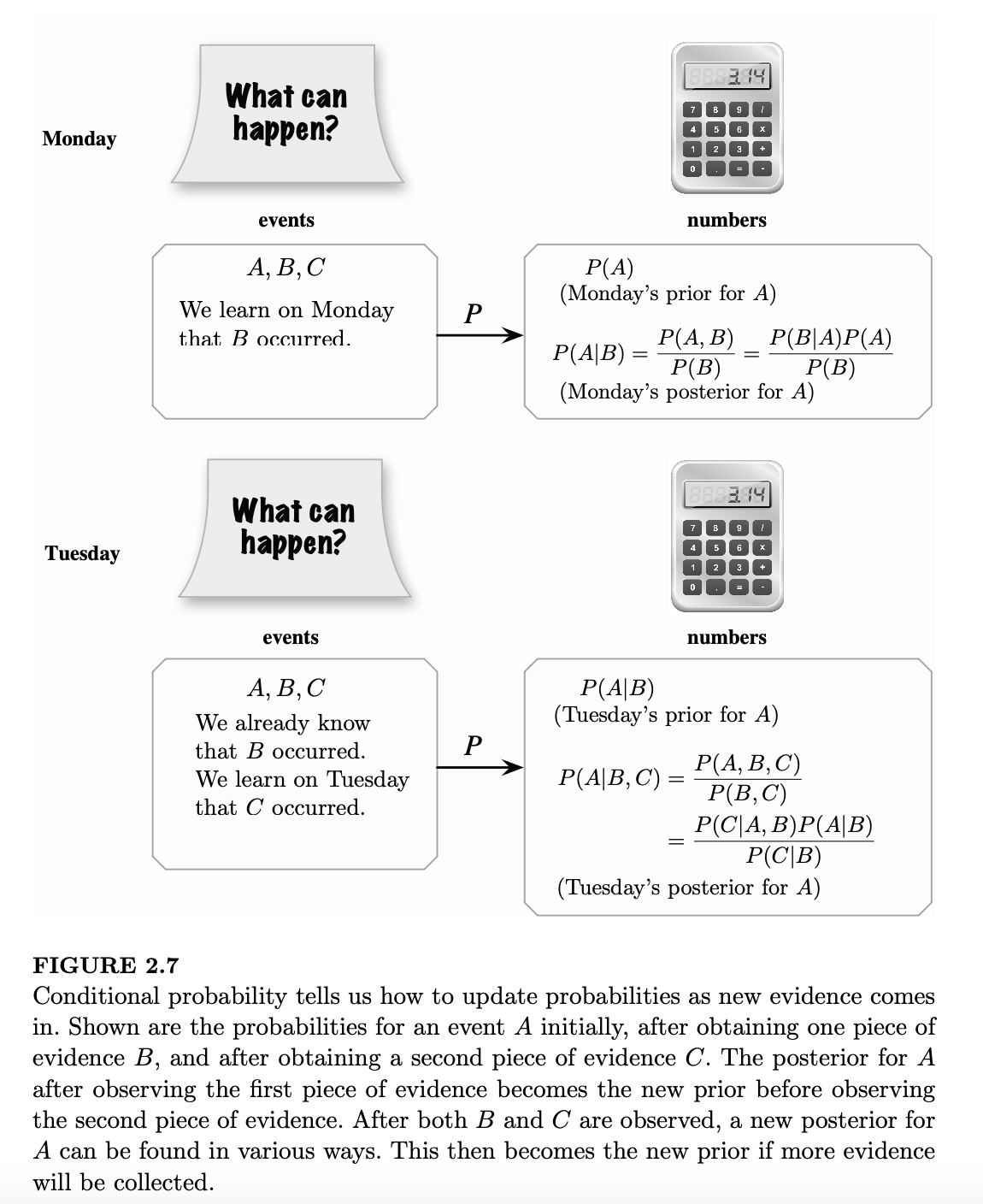
图 2.7 展示了概率如何随着新证据的接连出现而不断更新。假设我们对某个事件 \(A\) 感兴趣:
- 周一早上:我们的初始置信度是先验概率 \(P(A)\)。
- 周一下午:观察到证据 \(B\) 发生,使用贝叶斯法则计算后验概率 \(P(A|B)\)。
- 周二早上:周一的后验概率成为新的“先验概率”。
- 周二下午:观察到新证据 \(C\) 发生,我们可以计算新的后验概率 \(P(A|B,C)\)(通常使用带额外条件 \(B\) 的贝叶斯法则)。
这个过程可以循环往复,随着证据的积累,我们的认识会越来越接近真相。
2.10 R 语言实现
模拟频率学派解释
回想一下,条件概率的频率学派解释基于实验的大量重复次数 \(n\):\(P(A|B) \approx n_{AB}/n_B\),其中 \(n_{AB}\) 是 \(A \cap B\) 发生的次数,\(n_B\) 是 \(B\) 发生的次数。
让我们通过模拟来验证例 2.2.5 的结果。我们模拟 \(10^5\) 个家庭,每个家庭有两个孩子。
R
1 | n <- 10^5 |
这里 child1 是一个长度为 \(n\) 的向量,每个元素为 1 或 2。让 1 代表“女孩”,2 代表“男孩”。
场景 1:已知老大是女孩
设 \(A\) 为两个孩子都是女孩的事件,\(B\) 为老大是女孩的事件。
R
1 | n.b <- sum(child1 == 1) |
结果约为 0.50,符合 \(P(\text{双女} | \text{老大是女}) = 1/2\)。
场景 2:已知至少一个是女孩
此时 \(B\) 变为“至少一个是女孩”。
R
1 | n.b <- sum(child1 == 1 | child2 == 1) # 使用 | 运算符代表“或” |
结果约为 0.33,符合 \(P(\text{双女} | \text{至少一女}) = 1/3\)。
蒙提·霍尔问题的模拟
许多关于蒙提·霍尔问题的激烈争论都可以通过简单的模拟来化解。
批量模拟策略:
假设参赛者总是选 1 号门。那么“不换门”策略成功的唯一条件就是车在 1 号门后。
R
1 | n <- 10^5 |
模拟结果约为 0.334,非常接近理论值 \(1/3\)。由此推论,换门成功的概率必然接近 \(2/3\)。
交互式模拟函数:
如果你想亲自玩这个游戏,可以在 R 中定义如下函数:
R
1 | monty <- function() { |
print和paste:用于将文字和变量组合输出到屏幕。scan:交互式请求用户输入。what = integer()用于读取整数,what = character()用于读取文本。doors[-c(...)]:这是 R 中非常有用的语法,表示“除了括号内索引以外的所有元素”。
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程