《Introduction to Probability》第3章 随机变量及其分布
第3章 随机变量及其分布
Random variables and their distributions
在本章中,我们将引入随机变量。这是一个极其有用的概念,它既能简化记号,又能增强我们量化不确定性以及总结实验结果的能力。随机变量在本书后续内容以及整个统计学中都至关重要,因此,从直觉和数学两个层面深入思考其含义是至关重要的。
3.1 随机变量
Random variables
为了理解为什么现有的记号会迅速变得笨重难处理,请再次考虑第 2 章中的赌徒输光问题。在这个问题中,我们可能对每一时刻每位赌徒拥有的财富非常感兴趣。于是我们可能会创造一些记号,比如令 \(A_{jk}\) 代表“赌徒 A 在 \(k\) 轮后恰好拥有 \(j\) 美元”的事件,并为赌徒 B 类似地定义事件 \(B_{jk}\)(针对所有的 \(j\) 和 \(k\))。
这已经太复杂了。此外,我们可能还会对其他量感兴趣,例如 \(k\) 轮后两人的财富差(赌徒 A 的减去赌徒 B 的),或者游戏的持续时间(直到其中一名玩家破产所经历的轮数)。如果要用 \(A_{jk}\) 和 \(B_{jk}\) 来表达“游戏持续时间为 \(r\) 轮”这一事件,将涉及一长串令人头疼的并集和交集。再者,如果我们想用欧元而非美元来表示赌徒 A 的财富呢?我们可以将一个代表美元的数字乘以汇率,但我们无法将一个“事件”乘以汇率。
与其使用这种掩盖了各物质量之间关系的晦涩记号,如果能像下面这样表述不是更好吗?
设 \(X_k\) 为赌徒 A 在 \(k\) 轮后的财富。那么 \(Y_k = N - X_k\) 就是赌徒 B 在 \(k\) 轮后的财富(其中 \(N\) 是固定的总财富);\(X_k - Y_k = 2X_k - N\) 是 \(k\) 轮后的财富差;\(c_k X_k\) 是赌徒 A 在 \(k\) 轮后以欧元计的财富(其中 \(c_k\) 是 \(k\) 轮后的欧元兑美元汇率);而持续时间为 \(R = \min\{n : X_n = 0 \text{ 或 } Y_n = 0\}\)。
随机变量的概念正能让我们实现这一点!不过,它的引入需要十分谨慎,以确保其在概念和技术层面都是正确的。
有时,“随机变量”被定义为“取随机值的变量”,这种近乎同义反复的说法非常苍白,它未能说明随机性究竟源自何处,也无法帮助我们推导随机变量的性质:我们熟悉如何处理像 \(x^2 + y^2 = 1\) 这样的代数方程,但如果 \(x\) 和 \(y\) 是随机变量,合法的数学运算又是什么呢?为了使随机变量的概念精确化,我们将其定义为一个将样本空间映射到实数轴的函数。(关于函数的概念复习,请参见数学附录。)
个人注:这本书终于把随机变量的概念讲清楚了。
定义 3.1.1(随机变量)。给定一个样本空间为 \(S\) 的实验,随机变量(random variable,简写为 r.v.)是一个从样本空间 \(S\) 到实数集 \(\mathbb{R}\) 的函数。通常(但非必须)用大写字母表示随机变量。因此,随机变量 \(X\) 为实验的每一个可能结果 \(s\) 分配一个数值 \(X(s)\)。随机性源于我们进行的是随机实验(其概率由概率函数 \(P\) 描述);而映射过程本身是确定性的,如图 3.1 所示。图 3.2 的左栏以更简单的方式展示了同一个随机变量,即将数值直接标在代表结果的“鹅卵石”内部。
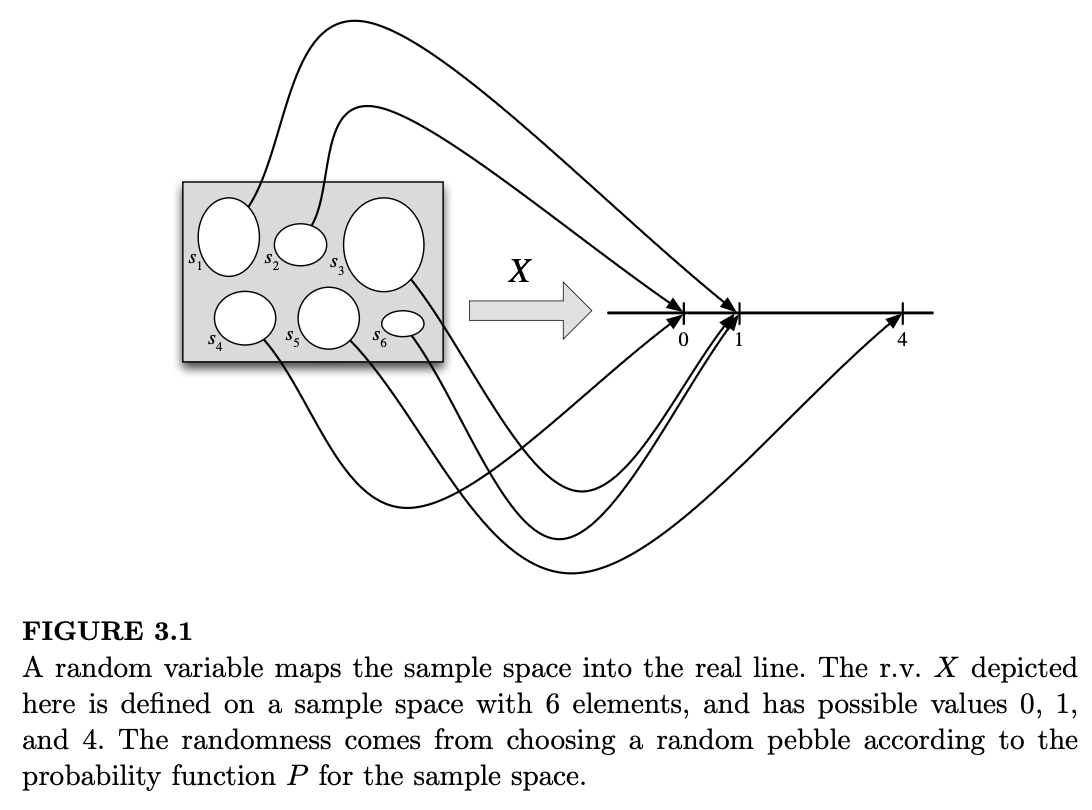
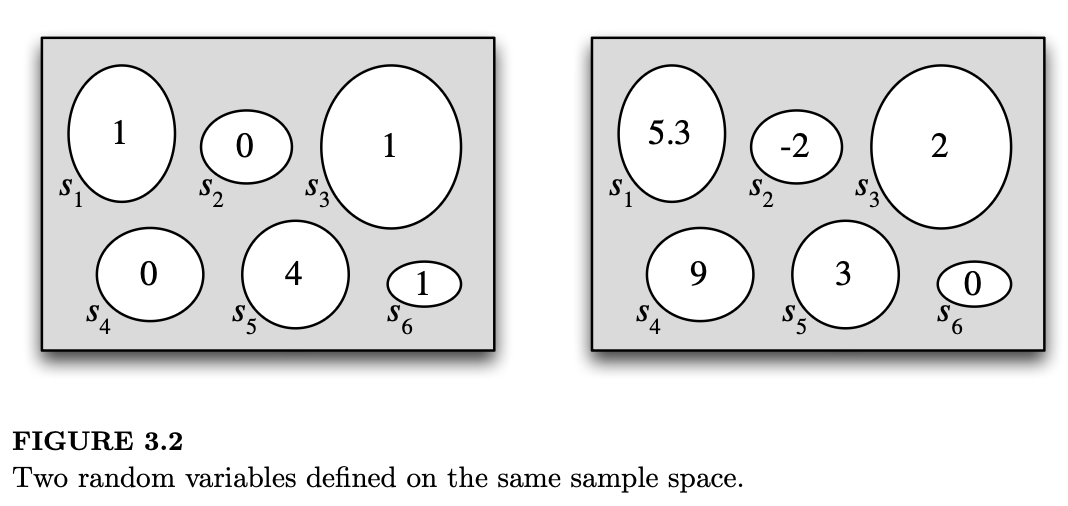
这个定义虽然抽象却是基础性的;在学习概率论和统计学时,最重要的技能之一就是能够在抽象概念与具体实例之间灵活切换。与之相关的是,要努力学会识别问题的本质模式或结构,并思考它与你之前研究过的问题有何联系。我们经常会讨论抛硬币或从瓮中抽球的故事,因为它们是简单且易于操作的场景,但许多其他问题都是与之同构的:它们具有相同的本质结构,只是以不同的面目出现。
首先,让我们考虑一个抛硬币的例子。该问题的结构是我们有一系列试验,每次试验都有两种可能的结果。在这里,我们将可能的结果视为 \(H\)(正面)和 \(T\)(反面),但我们同样可以将其视为“成功”与“失败”,或者 \(1\) 与 \(0\)。
例 3.1.2(抛硬币)。考虑一个抛掷两次公平硬币的实验。样本空间包含四个可能的结果:\(S = \{HH, HT, TH, TT\}\)。以下是该空间上的一些随机变量(作为练习,你可以构思一些自己的随机变量)。每个随机变量都是实验某些方面的数值总结。
- 设 \(X\) 为正面的次数。这是一个可能取值为 \(0, 1, 2\) 的随机变量。作为函数,\(X\) 将数值 \(2\) 分配给结果 \(HH\),将 \(1\) 分配给结果 \(HT\) 和 \(TH\),将 \(0\) 分配给结果 \(TT\)。即:
\[ X(HH) = 2, X(HT) = X(TH) = 1, X(TT) = 0 \]
设 \(Y\) 为反面的次数。用 \(X\) 来表示,我们有 \(Y = 2 - X\)。换句话说,\(Y\) 和 \(2 - X\) 是同一个随机变量:对于所有的 \(s\),都有 \(Y(s) = 2 - X(s)\)。
设 \(I\) 在第一次抛掷为正面时取 \(1\),否则取 \(0\)。那么 \(I\) 为结果 \(HH\) 和 \(HT\) 分配数值 \(1\),为结果 \(TH\) 和 \(TT\) 分配数值 \(0\)。这个随机变量是所谓的指示随机变量(indicator random variable)的一个例子,因为它指示了第一次抛掷是否为正面,用 \(1\) 表示“是”,\(0\) 表示“否”。
我们也可以将样本空间编码为 \(\{(1,1), (1,0), (0,1), (0,0)\}\),其中 \(1\) 是正面的代码,\(0\) 是反面的代码。这样我们可以给出 \(X, Y, I\) 的显式公式: \[ X(s_1, s_2) = s_1 + s_2, \quad Y(s_1, s_2) = 2 - s_1 - s_2, \quad I(s_1, s_2) = s_1 \]
为了简单起见,我们记 \(X(s_1, s_2)\) 来表示 \(X((s_1, s_2))\),依此类推。
对于我们将要考虑的大多数随机变量,以这种方式写出显式公式是冗长乏味甚至不可行的。幸运的是,这样做通常是不必要的,因为(正如我们在本例中所见)还有其他方式来定义随机变量,而且(正如我们将在本书余下部分所见)除了通过显式公式计算每个结果 \(s\) 的映射值之外,还有许多方法可以研究随机变量的性质。
正如前几章所述,对于一个结果数量有限的样本空间,我们可以将这些结果想象成鹅卵石,鹅卵石的质量对应其概率,所有鹅卵石的总质量为 1。随机变量仅仅是给每块鹅卵石贴上一个数字标签。图 3.2 展示了定义在同一个样本空间上的两个随机变量:鹅卵石(即结果)是相同的,但分配给这些结果的实数却不同。
正如我们之前提到的,随机变量中随机性的来源是实验本身,在实验中,样本结果 \(s \in S\) 是根据概率函数 \(P\) 选出的。在我们进行实验之前,结果 \(s\) 尚未实现,因此我们不知道 \(X\) 的值,尽管我们可以计算 \(X\) 取某个给定值或取值范围的概率。在我们完成实验且结果 \(s\) 实现之后,随机变量就“结晶”成了数值 \(X(s)\)。
随机变量提供了有关实验的数值总结。这非常方便,因为实验的样本空间往往极其复杂或具有高维特征,且结果 \(s \in S\) 可能是非数值型的。例如,实验可能是对某城市的居民进行随机抽样并询问各种问题,其答案可能是数值型的(如年龄或身高),也可能是非数值型的(如所属政党或最喜欢的电影)。随机变量取数值这一事实,相较于必须始终处理 \(S\) 的全部复杂性而言,是一种非常便捷的简化。
个人注:随机变量只是一个“生成事件的机器”
- 事件:是样本空间里的一个集合
- 随机变量:是一个从样本空间到实数的函数
它们不是同一类对象,但:
任何关于随机变量的描述,最终都会变成事件
例如:Ω(样本空间);ω 事件
你给它一个条件,它就吐出一个事件。
P(X ≤ 3) P(X = 1) P(X ∈ A)
但这些表面上是 X, 实际上都是事件:
- {ω ∈ Ω : X(ω) ≤ 3}
3.2 分布与概率质量函数
Distributions and probability mass functions
在实践中使用的随机变量主要有两种类型:离散型随机变量和连续型随机变量。在本章和下一章中,我们的重点是离散型随机变量。连续型随机变量将在第 5 章中引入。
定义 3.2.1(离散型随机变量)。如果存在一个有限的数值列表 \(a_1, a_2, \dots, a_n\) 或一个无限的数值列表 \(a_1, a_2, \dots\),使得 \(P(X = a_j \text{ 对于某个 } j) = 1\),则称随机变量 \(X\) 是离散型的。如果 \(X\) 是离散型随机变量,那么使得 \(P(X = x) > 0\) 的有限或可数无限数值集合 \(x\) 被称为 \(X\) 的支撑集(support)。
个人注: \(P(X = a_j \text{ 对于某个 } j) = 1\)的意思是 P(X ∈ {j}) = 1;直观的意思是,结果一定是落在列表中。
在应用中,离散型随机变量的支撑集最常见的是整数集。相比之下,连续型随机变量可以取区间内的任何实数值(甚至可能是整个实数轴);此类随机变量在第 5 章中有更精确的定义。此外,也可能存在离散和连续混合型的随机变量,例如通过抛硬币,如果硬币正面朝上则生成一个离散型随机变量,如果硬币反面朝上则生成一个连续型随机变量。但理解此类随机变量的起点是理解离散型和连续型随机变量。
给定一个随机变量,我们希望能够用概率语言来描述它的行为。例如,我们可能想回答关于随机变量落入给定范围的概率问题:如果 \(L\) 是随机选取的美国大学毕业生的终身收入,那么 \(L\) 超过一百万美元的概率是多少?如果 \(M\) 是未来五年内加利福尼亚州发生大地震的次数,那么 \(M\) 等于 0 的概率是多少?
随机变量的分布(distribution)提供了这些问题的答案;它规定了与该随机变量相关的所有事件的概率,例如它等于 3 的概率以及它至少为 110 的概率。我们将看到,有几种等价的方法可以表达随机变量的分布。对于离散型随机变量,最自然的方法是使用概率质量函数,我们现在给出其定义。
定义 3.2.2(概率质量函数 Probability mass function)。离散型随机变量 \(X\) 的概率质量函数(PMF)是函数 \(p_X\),定义为 \(p_X(x) = P(X = x)\)。注意,如果 \(x\) 在 \(X\) 的支撑集中,则该值为正,否则为 0。
3.2.3 在书写 \(P(X = x)\) 时,我们使用 \(X = x\) 来表示一个事件,该事件由 \(X\) 为其分配数值 \(x\) 的所有结果 \(s\) 组成。这个事件也写作 \(\{X = x\}\);正式地说,\(\{X = x\}\) 被定义为 \(\{s \in S : X(s) = x\}\),但写作 \(\{X = x\}\) 更简洁且更直观。回到例 3.1.2,如果 \(X\) 是两次公平硬币抛掷中正面的次数,那么 \(\{X = 1\}\) 由样本结果 \(HT\) 和 \(TH\) 组成,这是 \(X\) 为其分配数值 1 的两个结果。由于 \(\{HT, TH\}\) 是样本空间的一个子集,因此它是一个事件。所以谈论 \(P(X = 1)\) 或更一般的 \(P(X = x)\) 是有意义的。如果 \(\{X = x\}\) 不是事件,那么计算它的概率就没有意义了!书写“\(P(X)\)”是没有意义的;我们只能取事件的概率,而不能取随机变量的概率。
让我们看几个概率质量函数的例子。
例 3.2.4(抛硬币续)。在本例中,我们将求出例 3.1.2(两次公平抛硬币实验)中所有随机变量的 PMF。以下是我们定义的随机变量及其对应的 PMF:
- \(X\),正面的次数。由于当发生 \(TT\) 时 \(X\) 等于 0,发生 \(HT\) 或 \(TH\) 时等于 1,发生 \(HH\) 时等于 2,因此 \(X\) 的 PMF 是如下函数 \(p_X\):
\[ p_X(0) = P(X = 0) = 1/4 \]
\[ p_X(1) = P(X = 1) = 1/2 \]
\[ p_X(2) = P(X = 2) = 1/4 \]
且对于所有其他 \(x\) 值,\(p_X(x) = 0\)。
- \(Y = 2 - X\),反面的次数。根据上述推理,或者利用以下事实:
\[ P(Y = y) = P(2 - X = y) = P(X = 2 - y) = p_X(2 - y) \]
得到 \(Y\) 的 PMF 为: \[ p_Y(0) = P(Y = 0) = 1/4 \]
\[ p_Y(1) = P(Y = 1) = 1/2 \]
\[ p_Y(2) = P(Y = 2) = 1/4 \]
且对于所有其他 \(y\) 值,\(p_Y(y) = 0\)。
注意,\(X\) 和 \(Y\) 具有相同的 PMF(即 \(p_X\) 和 \(p_Y\) 是同一个函数),尽管 \(X\) 和 \(Y\) 并不是同一个随机变量(即 \(X\) 和 \(Y\) 是从 \(\{HH, HT, TH, TT\}\) 到实数轴的两个不同的函数)。
- \(I\),第一次抛掷为正面的指示变量。由于当发生 \(TH\) 或 \(TT\) 时 \(I\) 等于 0,发生 \(HH\) 或 \(HT\) 时等于 1,因此 \(I\) 的 PMF 为:
\[ p_I(0) = P(I = 0) = 1/2 \]
\[ p_I(1) = P(I = 1) = 1/2 \]
且对于所有其他 \(i\) 值,\(p_I(i) = 0\)。
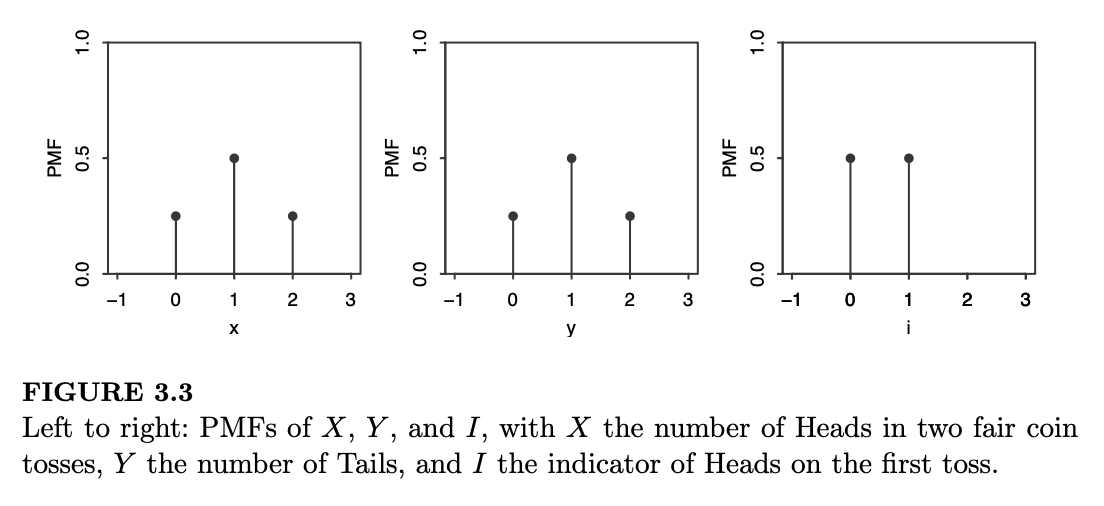
\(X, Y\) 和 \(I\) 的 PMF 绘制在图 3.3 中。图中画出了垂直条线,以便于比较不同点的高度。
例 3.2.5(骰子点数之和)。我们投掷两枚公平的 6 面骰子。令 \(T = X + Y\) 为两次投掷的点数总和,其中 \(X\) 和 \(Y\) 分别是各次投掷的点数。该实验的样本空间包含 36 个等可能的结果: \[ S = \{(1,1), (1,2), \dots, (6,5), (6,6)\} \]
例如,下表展示了 36 个结果 \(s\) 中的 7 个,以及对应的 \(X, Y\) 和 \(T\) 的值。实验执行后,我们观察 \(X\) 和 \(Y\) 的值,随后观察到的 \(T\) 值即为这两个值的和。

由于骰子是公平的,因此 \(X\) 的 PMF 为: \[ P(X = j) = 1/6 \]
对于 \(j = 1, 2, \dots, 6\)(其他情况 \(P(X = j) = 0\));我们称 \(X\) 在 \(1, 2, \dots, 6\) 上服从离散均匀分布。类似地,\(Y\) 在 \(1, 2, \dots, 6\) 上也服从离散均匀分布。注意,\(Y\) 与 \(X\) 具有相同的分布,但 \(Y\) 并不是与 \(X\) 相同的随机变量。事实上,我们有: \[ P(X = Y) = 6/36 = 1/6 \]
在这个实验中,另外两个与 \(X\) 分布相同的随机变量是 \(7-X\) 和 \(7-Y\)。为了理解这一点,我们可以利用这样一个事实:对于标准骰子,如果 \(X\) 是顶部的点数,那么 \(7-X\) 就是底部的点数。如果顶部点数等概率地取 \(1, 2, \dots, 6\) 中的任一数字,那么底部点数也是如此。请注意,尽管 \(7-X\) 与 \(X\) 具有相同的分布,但在任何一次实验运行中,它永远不会等于 \(X\)!
现在让我们求 \(T\) 的 PMF。根据概率的古典定义: \[ P(T = 2) = P(T = 12) = 1/36 \]
\[ P(T = 3) = P(T = 11) = 2/36 \]
\[ P(T = 4) = P(T = 10) = 3/36 \]
\[ P(T = 5) = P(T = 9) = 4/36 \]
\[ P(T = 6) = P(T = 8) = 5/36 \]
\[ P(T = 7) = 6/36 \]
对于所有其他的 \(t\) 值,\(P(T = t) = 0\)。仅通过观察两枚骰子可能的总和,我们就能直接看出 \(T\) 的支撑集是 \(\{2, 3, \dots, 12\}\),但作为检查,请注意: \[ P(T = 2) + P(T = 3) + \dots + P(T = 12) = 1 \]
这表明所有的可能性都已计算在内。上述 \(T\) 的对称性质 \(P(T = t) = P(T = 14-t)\) 是合理的,因为每一个使 \(T = t\) 的结果 \(\{X = x, Y = y\}\),都对应一个概率相同且使 \(T = 14-t\) 的结果 \(\{X = 7-x, Y = 7-y\}\)。
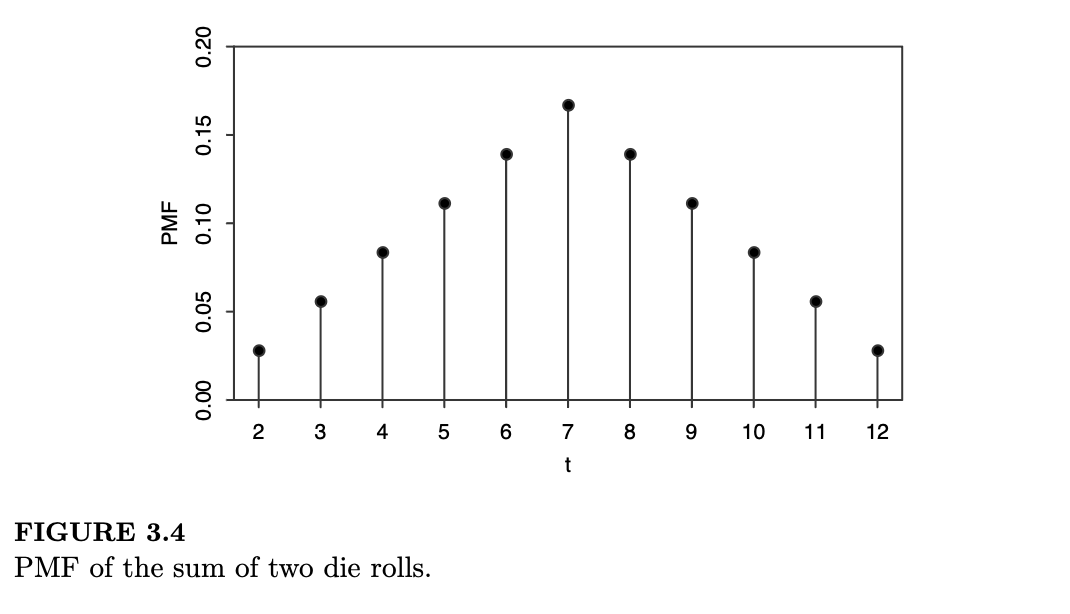
\(T\) 的 PMF 绘制在图 3.4 中;它呈现出三角形,且上述的对称性非常明显。
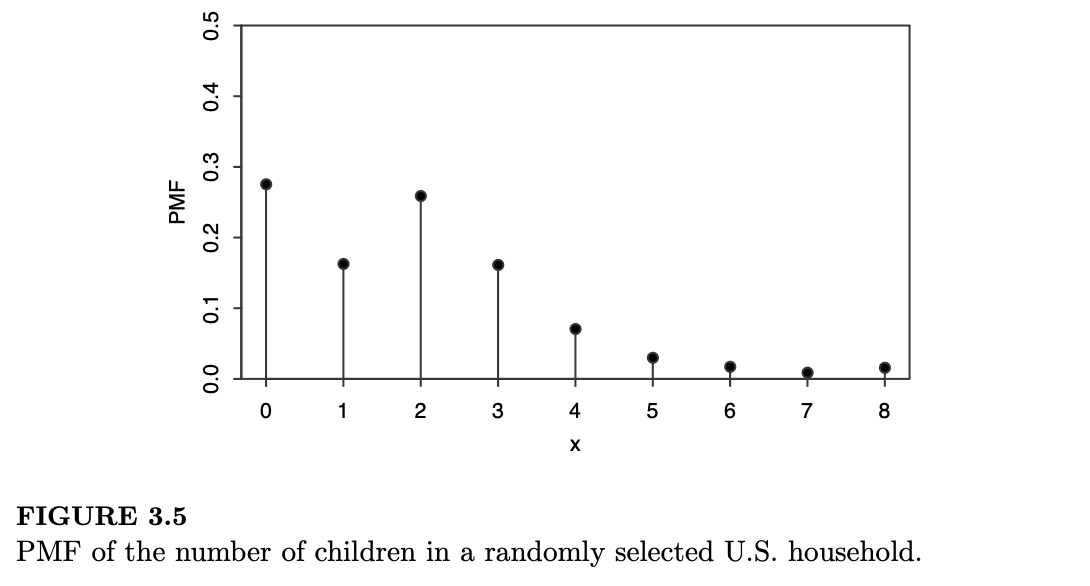
例 3.2.6(美国家庭中的儿童数量)。假设我们随机选择一个美国家庭。令 \(X\) 为该家庭中的儿童数量。由于 \(X\) 只能取整数值,因此它是一个离散型随机变量。\(X\) 取值为 \(x\) 的概率与美国拥有 \(x\) 个儿童的家庭数量成正比。
利用 2010 年综合社会调查 [23] 的数据,我们可以估算出拥有 0 个、1 个、2 个等儿童的家庭比例,从而近似得出 \(X\) 的 PMF,其图形绘制在图 3.5 中。
现在我们阐述一个有效 PMF 的性质。
定理 3.2.7(有效 PMF)。设 \(X\) 为支撑集为 \(x_1, x_2, \dots\) 的离散型随机变量(假设这些值互不相同;为了记号简洁,假设支撑集是可数无限的,支撑集有限时结论类似)。\(X\) 的 PMF \(p_X\) 必须满足以下两个标准:
- 非负性:如果 \(x = x_j\) 对于某个 \(j\) 成立,则 \(p_X(x) > 0\),否则 \(p_X(x) = 0\);
- 总和为 1:\(\sum_{j=1}^{\infty} p_X(x_j) = 1\)。
证明:第一条标准成立是因为概率是非负的。第二条成立是因为 \(X\) 必须取某个值,且事件 \(\{X = x_j\}\) 是互斥的,因此: \[ \sum_{j=1}^{\infty} P(X = x_j) = P\left(\bigcup_{j=1}^{\infty} \{X = x_j\}\right) = P(X = x_1 \text{ 或 } X = x_2 \text{ 或 } \dots) = 1 \]
反之,如果指定了互不相同的值 \(x_1, x_2, \dots\) 且有一个满足上述两个标准的函数,那么该函数就是某个随机变量的 PMF;我们将在第 5 章中展示如何构造这样的随机变量。
我们之前声称 PMF 是表达离散型随机变量分布的一种方式。这是因为一旦我们知道了 \(X\) 的 PMF,就可以通过对相应的 \(x\) 值求和,来计算 \(X\) 落入实数集给定子集的概率,如下例所示。
例 3.2.8。回到例 3.2.5,令 \(T\) 为两个公平骰子点数之和。我们已经计算了 \(T\) 的 PMF。现在假设我们对 \(T\) 落在区间 \([1, 4]\) 内的概率感兴趣。在区间 \([1, 4]\) 内,\(T\) 只能取三个值,即 2、3 和 4。通过 \(T\) 的 PMF,我们已知这些值的概率,因此: \[ P(1 \le T \le 4) = P(T = 2) + P(T = 3) + P(T = 4) = 6/36 \]
通常情况下,给定一个离散型随机变量 \(X\) 和一个实数集合 \(B\),如果我们已知 \(X\) 的 PMF,就可以通过在 \(X\) 的 PMF 图中将属于 \(B\) 的各点处的垂直条高度相加,来求得 \(P(X \in B)\)(即 \(X\) 在 \(B\) 中的概率)。已知一个离散型随机变量的 PMF 即可确定其分布。
3.3 伯努利分布与二项分布
Bernoulli and Binomial
某些分布在概率论和统计学中无处不在,以至于它们拥有自己的名称。我们将贯穿全书介绍这些命名的分布,从一个非常简单但有用的情况开始:一个只能取 0 和 1 两个可能值的随机变量。
定义 3.3.1(伯努利分布 Bernoulli distribution)。如果随机变量 \(X\) 满足 \(P(X = 1) = p\) 且 \(P(X = 0) = 1 - p\),其中 \(0 < p < 1\),则称 \(X\) 服从参数为 \(p\) 的伯努利分布。我们记作 \(X \sim \text{Bern}(p)\)。符号 \(\sim\) 读作“服从分布……”。
任何可能取值为 0 和 1 的随机变量都服从 \(\text{Bern}(p)\) 分布,其中 \(p\) 是该随机变量等于 1 的概率。\(\text{Bern}(p)\) 中的数字 \(p\) 被称为该分布的参数;它决定了我们具体拥有哪一个伯努利分布。因此,并不只存在一个伯努利分布,而是一个由 \(p\) 索引的伯努利分布族。例如,如果 \(X \sim \text{Bern}(1/3)\),说“\(X\) 是伯努利分布”是正确但不完整的;为了完全指定 \(X\) 的分布,我们应该同时说出它的名称(伯努利)和它的参数值(1/3),这正是符号 \(X \sim \text{Bern}(1/3)\) 的意义所在。
任何事件都自然关联着一个伯努利随机变量:如果事件发生则等于 1,否则等于 0。这被称为该事件的指示随机变量;我们将看到,此类随机变量极其有用。
定义 3.3.2(指示随机变量 Indicator random variable)。事件 \(A\) 的指示随机变量是指在 \(A\) 发生时等于 1、否则等于 0 的随机变量。我们将 \(A\) 的指示随机变量记为 \(I_A\) 或 \(I(A)\)。注意 \(I_A \sim \text{Bern}(p)\),其中 \(p = P(A)\)。
我们经常通过抛硬币来想象伯努利随机变量,但这只是为了讨论以下通用背景而使用的便捷语言。
背景 3.3.3(伯努利试验 Bernoulli trial)。一个可能导致“成功”或“失败”(但不能两者兼有)的实验被称为一次伯努利试验。伯努利随机变量可以被视为一次伯努利试验中成功的指示器:如果试验成功则等于 1,如果失败则等于 0。
基于这个背景,参数 \(p\) 通常被称为 \(\text{Bern}(p)\) 分布的成功概率。一旦我们开始思考伯努利试验,就很难不去思考当我们进行多次试验时会发生什么。
背景 3.3.4(二项分布Binomial distribution)。假设进行了 \(n\) 次独立的伯努利试验,每次试验的成功概率均为 \(p\)。令 \(X\) 为成功的次数。\(X\) 的分布被称为参数为 \(n\) 和 \(p\) 的二项分布。我们记作 \(X \sim \text{Bin}(n, p)\),表示 \(X\) 服从参数为 \(n\) 和 \(p\) 的二项分布,其中 \(n\) 是正整数且 \(0 < p < 1\)。
请注意,我们定义二项分布时并非通过其概率质量函数(PMF),而是通过一个关于“何种类型的实验会产生服从二项分布的随机变量”的背景故事。统计学中最著名的分布都有各自的故事,解释了为什么它们常被用作数据模型,或作为构建更复杂分布的基石。
首先从背景故事的角度来理解这些命名的分布具有诸多益处。它有助于模式识别,让我们能洞察两个问题在结构上是否本质相同;它通常能带来更简洁的解法,从而完全避免 PMF 计算;它还能帮助我们理解这些命名的分布之间是如何相互关联的。在这里可以很清楚地看到,\(\text{Bern}(p)\) 与 \(\text{Bin}(1, p)\) 是同一种分布:伯努利分布是二项分布的一种特殊情况。
利用二项分布的背景故事定义,让我们来推导它的 PMF。
定理 3.3.5(二项分布 PMF)。若 \(X \sim \text{Bin}(n, p)\),则 \(X\) 的 PMF 为: \[ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k} \]
对于 \(k = 0, 1, \dots, n\)(其他情况 \(P(X = k) = 0\))。
3.3.6 为了节省篇幅,通常会默认 PMF 在未指定非零值的区域均为零。但无论如何,理解随机变量的支撑集非常重要,且检查 PMF 是否有效也是一种良好的习惯。如果两个离散型随机变量具有相同的 PMF,则它们必然具有相同的支撑集。因此,我们有时会提到“离散分布的支撑集”,即指任何服从该分布的随机变量的支撑集。
证明:一个由 \(n\) 次独立伯努利试验组成的实验会产生一串“成功”与“失败”的序列。任何包含 \(k\) 次成功和 \(n-k\) 次失败的特定序列,其概率均为 \(p^k(1-p)^{n-k}\)。由于我们只需选定成功出现的位置,因此共有 \(\binom{n}{k}\) 种这样的序列。设 \(X\) 为成功次数,则有: \[ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k} \]
对于 \(k = 0, 1, \dots, n\),其他情况 \(P(X = k) = 0\)。这是一个有效的 PMF,因为它非负,且根据二项式定理,其总和为 1。
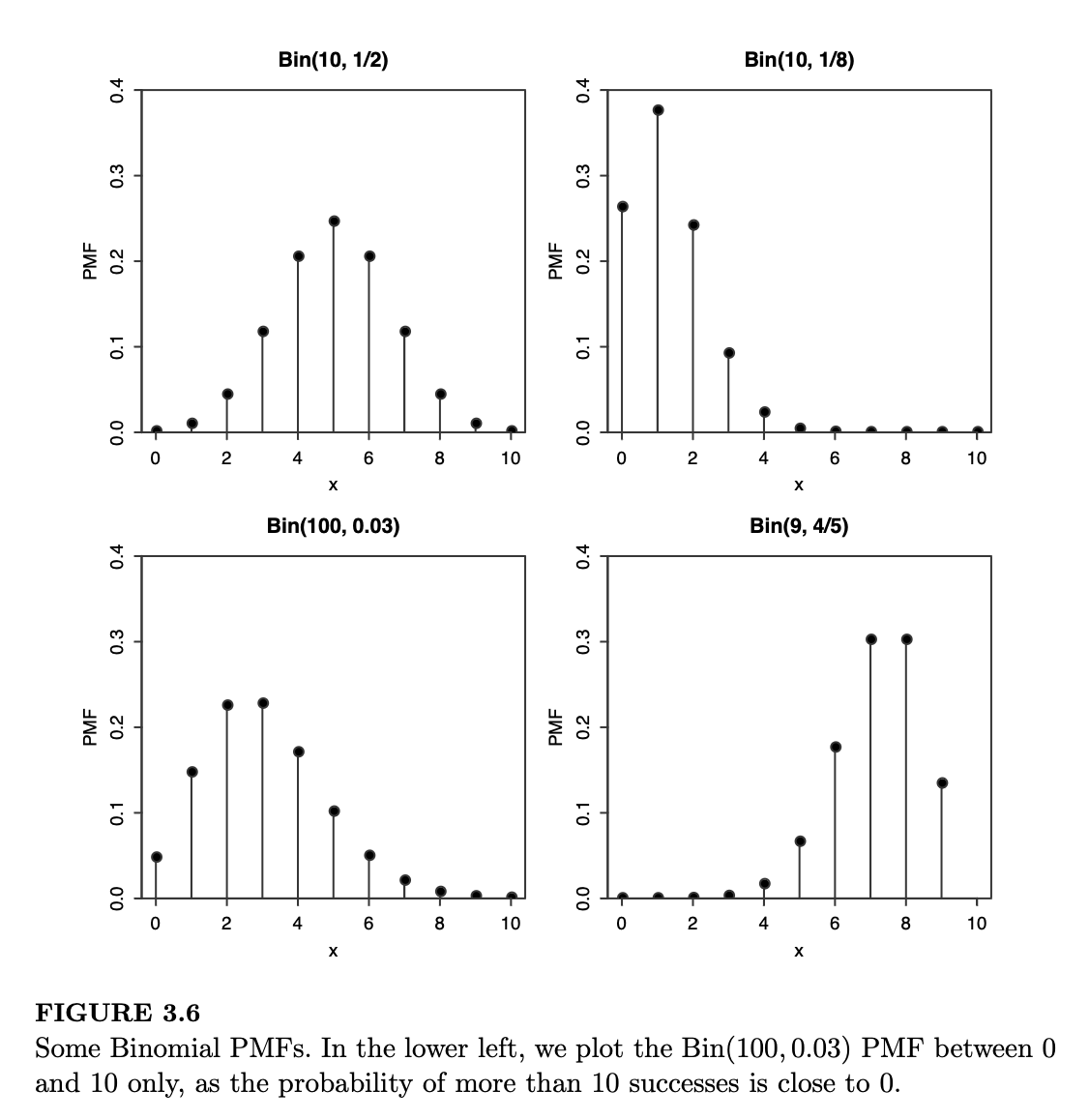
图 3.6 展示了不同 \(n\) 和 \(p\) 取值下的二项分布 PMF 图。注意,\(\text{Bin}(10, 1/2)\) 分布的 PMF 关于 5 对称,但当成功概率不等于 \(1/2\) 时,PMF 会发生偏斜。对于固定的试验次数 \(n\),当成功概率高时 \(X\) 倾向于取较大值,反之则倾向于取较小值,这正符合我们对二项分布背景故事的预期。同时请记住,在任何 PMF 图中,所有垂直条的高度之和必须为 1。
我们利用背景故事 3.3.4 推导出了 \(\text{Bin}(n, p)\) 的 PMF。该故事还为“若 \(X\) 服从二项分布,则 \(n-X\) 也服从二项分布”这一事实提供了一个直观的证明。
定理 3.3.7。设 \(X \sim \text{Bin}(n, p)\),且 \(q = 1 - p\)(我们常用 \(q\) 表示伯努利试验的失败概率)。那么 \(n - X \sim \text{Bin}(n, q)\)。
证明:利用二项分布的背景故事,将 \(X\) 解释为 \(n\) 次独立伯努利试验中的成功次数。那么 \(n - X\) 就是这些试验中的失败次数。交换成功与失败的角色,我们即得 \(n - X \sim \text{Bin}(n, q)\)。
或者,我们也可以检查 \(n - X\) 是否符合 \(\text{Bin}(n, q)\) 的 PMF。令 \(Y = n - X\),则 \(Y\) 的 PMF 为: \[ P(Y = k) = P(X = n - k) = \binom{n}{n-k} p^{n-k} q^k = \binom{n}{k} q^k p^{n-k} \]
对于 \(k = 0, 1, \dots, n\)。
推论 3.3.8。设 \(X \sim \text{Bin}(n, p)\),其中 \(p = 1/2\) 且 \(n\) 为偶数。那么 \(X\) 的分布关于 \(n/2\) 对称,即对于所有非负整数 \(j\),有 \(P(X = n/2 + j) = P(X = n/2 - j)\)。
证明:根据定理 3.3.7,\(n - X\) 同样服从 \(\text{Bin}(n, 1/2)\),因此对于所有非负整数 \(k\): \[ P(X = k) = P(n - X = k) = P(X = n - k) \]
令 \(k = n/2 + j\),即可得到所需结论。这解释了为什么在图 3.6 中,\(\text{Bin}(10, 1/2)\) 的 PMF 关于 5 对称。
例 3.3.9(抛硬币续)。回到例 3.1.2,我们现在知道 \(X \sim \text{Bin}(2, 1/2)\),\(Y \sim \text{Bin}(2, 1/2)\),且 \(I \sim \text{Bern}(1/2)\)。这与定理 3.3.7 一致,\(X\) 与 \(Y = 2 - X\) 具有相同的分布;同时也与推论 3.3.8 一致,\(X\)(以及 \(Y\))的分布关于 1 对称。
3.4 超几何分布
Hypergeometric
如果我们有一个装有 \(w\) 个白球和 \(b\) 个黑球的瓮,那么在有放回的情况下抽取 \(n\) 个球,所得到的白球数量服从 \(\text{Bin}(n, w/(w+b))\) 分布,因为每次抽取都是独立的伯努利试验,且成功的概率恒为 \(w/(w+b)\)。如果我们改为无放回抽样(如图 3.7 所示),那么白球的数量则服从超几何分布。
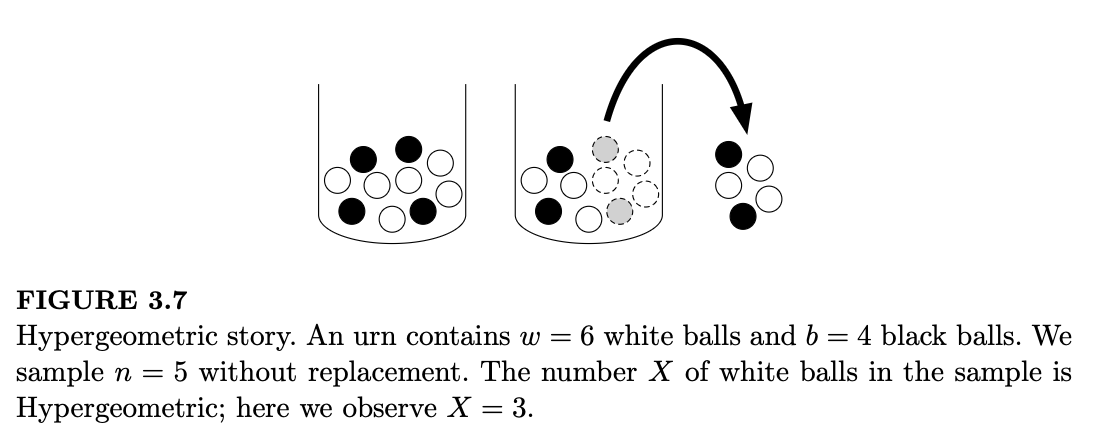
背景故事 3.4.1(超几何分布 Hypergeometric distribution)。考虑一个装有 \(w\) 个白球和 \(b\) 个黑球的瓮。我们从中随机抽取 \(n\) 个球(无放回),使得所有 \(\binom{w+b}{n}\) 种样本组合都是等可能的。令 \(X\) 为样本中白球的数量。则称 \(X\) 服从参数为 \(w, b, n\) 的超几何分布;记作 \(X \sim \text{HGeom}(w, b, n)\)。
与二项分布一样,我们可以从背景故事中推导出超几何分布的 PMF。
定理 3.4.2(超几何分布 PMF)。若 \(X \sim \text{HGeom}(w, b, n)\),则 \(X\) 的 PMF 为: \[ P(X=k) = \frac{\binom{w}{k}\binom{b}{n-k}}{\binom{w+b}{n}} \]
其中整数 \(k\) 满足 \(0 \le k \le w\) 且 \(0 \le n-k \le b\),其他情况 \(P(X=k)=0\)。
证明:为了求得 \(P(X=k)\),我们首先计算从瓮中恰好抽取 \(k\) 个白球和 \(n-k\) 个黑球的所有可能方式(不区分得到同一组球的不同顺序)。如果 \(k > w\) 或 \(n-k > b\),则这种抽取是不可能的。否则,根据乘法原理,抽取 \(k\) 个白球和 \(n-k\) 个黑球共有 \(\binom{w}{k}\binom{b}{n-k}\) 种方式,而抽取 \(n\) 个球的总方式共有 \(\binom{w+b}{n}\) 种。由于所有样本都是等可能的,根据概率的古典定义: \[ P(X=k) = \frac{\binom{w}{k}\binom{b}{n-k}}{\binom{w+b}{n}} \]
对于满足 \(0 \le k \le w\) 且 \(0 \le n-k \le b\) 的整数 \(k\) 成立。该 PMF 是有效的,因为根据范德蒙德恒等式(例 1.5.3),分子对所有 \(k\) 求和等于 \(\binom{w+b}{n}\),因此 PMF 的总和为 1。
超几何分布出现在许多表面上与“瓮中黑白球”几乎没有共同点的场景中。超几何背景故事的本质结构是:总体中的个体使用两组标签进行分类。在瓮的故事中,每个球要么是白的、要么是黑的(这是第一组标签),同时每个球要么被选中、要么未被选中(这是第二组标签)。此外,至少有一组标签是完全随机分配的(在瓮的故事中,球是随机抽取的,所有固定大小的集合被选中的概率相等)。那么 \(X \sim \text{HGeom}(w, b, n)\) 就代表了拥有双重标签的个体数量:在瓮的故事中,即既是白色的又被抽中的球。
接下来的两个例子展示了看似不同但实际上与瓮的故事同构的场景。
例 3.4.3(麋鹿的捕获-再捕获)。森林中有 \(N\) 只麋鹿。今天,其中的 \(m\) 只被捕获、贴上标签并释放回野外。此后某天,随机再次捕获 \(n\) 只麋鹿。假设这 \(n\) 只被再次捕获的麋鹿等概率地为森林中 \(N\) 只麋鹿的任意 \(n\) 只子集(例如,假设被捕获过的麋鹿并不会因此学会如何避免再次被捕获)。
根据超几何分布的背景故事,再次捕获的样本中带有标签的麋鹿数量服从 \(\text{HGeom}(m, N-m, n)\) 分布。在这个故事中,\(m\) 只带标签的麋鹿对应白球,\(N-m\) 只不带标签的麋鹿对应黑球。我们不是从瓮中抽取 \(n\) 个球,而是从森林中再次捕获 \(n\) 只麋鹿。
例 3.4.4(扑克牌手中的 A)。从洗好的标准扑克牌中随机抽取 5 张,手中的 A 的数量服从 \(\text{HGeom}(4, 48, 5)\) 分布。这可以将 A 看作白球,非 A 看作黑球。利用超几何分布的 PMF,手中恰好有 3 张 A 的概率为: \[ \frac{\binom{4}{3}\binom{48}{2}}{\binom{52}{5}} \approx 0.0017 \]
下表总结了上述例子如何用“两组标签”来理解。在每个例子中,我们感兴趣的随机变量都是同时落入第二列和第四列的项目数量:白球且被抽中、带标签且被再捕获、是 A 且在手中。

接下来的定理描述了两个参数不同的超几何分布之间的对称性;其证明源于在超几何背景故事中交换两组标签。
定理 3.4.5。\(\text{HGeom}(w, b, n)\) 和 \(\text{HGeom}(n, w+b-n, w)\) 分布是相同的。也就是说,如果 \(X \sim \text{HGeom}(w, b, n)\) 且 \(Y \sim \text{HGeom}(n, w+b-n, w)\),则 \(X\) 和 \(Y\) 具有相同的分布。
证明:利用超几何分布的背景故事,想象一个有 \(w\) 个白球和 \(b\) 个黑球的瓮,并进行样本量为 \(n\) 的无放回抽样。令 \(X \sim \text{HGeom}(w, b, n)\) 为样本中白球的数量,此时将“白/黑”视为第一组标签,将“抽中/未抽中”视为第二组标签。接着令 \(Y \sim \text{HGeom}(n, w+b-n, w)\) 为白球中“被抽中球”的数量,此时将“抽中/未抽中”视为第一组标签,将“白/黑”视为第二组标签。\(X\) 和 \(Y\) 统计的都是“既是白色又被抽中”的球的数量,因此它们具有相同的分布。
或者,我们可以通过代数方法检查 \(X\) 和 \(Y\) 是否具有相同的 PMF: \[ P(X=k) = \frac{\binom{w}{k}\binom{b}{n-k}}{\binom{w+b}{n}} \]
\[ P(Y=k) = \frac{\binom{n}{k}\binom{w+b-n}{w-k}}{\binom{w+b}{w}} \]
两者展开后均为: \[ \frac{w! b! n! (w+b-n)!}{k! (w+b)! (w-k)! (n-k)! (b-n+k)!} \]
我们更倾向于背景故事的证明,因为它更简洁且更易于记忆。
3.4.6(二项分布 vs. 超几何分布)。二项分布和超几何分布经常被混淆。两者都是在 0 到 \(n\) 之间取整数值的离散分布,且都可以解释为 \(n\) 次伯努利试验中的成功次数(对于超几何分布,再捕获样本中每只带标签的麋鹿可视为一次“成功”,不带标签的视为一次“失败”)。然而,二项分布背景故事的关键部分在于所涉及的伯努利试验是独立的。而超几何分布中的伯努利试验是相关的,因为抽样是无放回的:已知样本中的第一只麋鹿带有标签,会降低第二只麋鹿也带标签的概率。
3.5 离散均匀分布
Discrete Uniform
一个非常简单的背景故事,它与概率的古典定义紧密相连,描述了从某个有限的可能性集合中随机抽取一个数字。
背景故事 3.5.1(离散均匀分布)。设 \(C\) 为一个有限且非空的数字集合。从中均匀随机地选择一个数字(即 \(C\) 中的所有值都是等可能的)。将选中的数字称为 \(X\)。则称 \(X\) 服从参数为 \(C\) 的离散均匀分布;我们记作 \(X \sim \text{DUnif}(C)\)。
由于 PMF 的总和必须为 1,因此 \(X \sim \text{DUnif}(C)\) 的 PMF 为: \[ P(X = x) = \frac{1}{|C|} \]
对于 \(x \in C\)(其他情况为 0)。与基于概率古典定义的问题一样,基于离散均匀分布的问题可以简化为计数问题。具体而言,对于 \(X \sim \text{DUnif}(C)\) 和任何 \(A \subseteq C\),我们有: \[ P(X \in A) = \frac{|A|}{|C|} \]
例 3.5.2(随机纸条)。帽子里有 100 张纸条,每张纸条上写着 \(1, 2, \dots, 100\) 中的一个数字,且没有数字重复出现。从中一次一张地抽取五张纸条。
首先考虑有放回的随机抽样(概率相等):
抽中的纸条中,数值至少为 80 的张数服从什么分布?
第 \(j\) 次抽取的数值(对于 \(1 \le j \le 5\))服从什么分布?
数字 100 至少被抽中一次的概率是多少?
现在考虑无放回的随机抽样(所有五张纸条的组合被选中的概率相等):
抽中的纸条中,数值至少为 80 的张数服从什么分布?
第 \(j\) 次抽取的数值(对于 \(1 \le j \le 5\))服从什么分布?
数字 100 出现在样本中的概率是多少?
解答:
根据二项分布的背景故事,该分布为 \(\text{Bin}(5, 0.21)\)。(注:由于 80 到 100 共有 21 个数,\(p = 21/100 = 0.21\))
设 \(X_j\) 为第 \(j\) 次抽取的数值。由对称性可知,\(X_j \sim \text{DUnif}(1, 2, \dots, 100)\)。并不存在某些纸条特别喜欢在第 \(j\) 次被选中,而另一些纸条避开在那时被选中;所有纸条都是等可能的。
利用补集法: \[ P(\text{至少有一个 } j \text{ 满足 } X_j = 100) = 1 - P(X_1 \neq 100, \dots, X_5 \neq 100) \]
根据概率的古典定义,这等于: \[ 1 - (99/100)^5 \approx 0.049 \]
这个解法只是对第 1 章中的概念使用了新的记号。这种新记号非常有用,因为它简洁且灵活。在上述计算中,理解为什么 \[ P(X_1 \neq 100, \dots, X_5 \neq 100) = P(X_1 \neq 100) \cdots P(X_5 \neq 100) \] 是很重要的。
在这种情况下,这可以由概率的古典定义得出,但思考此类陈述的一种更通用的方式是通过随机变量的独立性(这一概念将在 3.8 节中详细讨论)。
根据超几何分布的背景故事,该分布为 \(HGeom(21, 79, 5)\)。
设 \(Y_j\) 为第 \(j\) 次抽取的数值。由对称性可知,\(Y_j \sim DUnif(1, 2, \dots, 100)\)。
得知任何一个 \(Y_i\) 的值都会提供关于其他数值的信息(因此根据 3.8 节的定义,\(Y_1, \dots, Y_5\) 并不是独立的),但对称性依然成立,因为在无条件的情况下,抽中的第 \(j\) 张纸条等概率地为任何一张纸条。这是 \(Y_j\) 的无条件分布:即我们站在尚未抽取任何纸条的时间点进行考虑。
为了进一步理解为什么每一个 \(Y_1, \dots, Y_5\) 都服从离散均匀分布,以及如何从无条件角度思考 \(Y_j\),请想象:不是一个人一次一张地抽取五张纸条,而是五个人每人抽取一张,所有人同时伸手进入帽子,且谁拿到哪张纸条的所有可能性都是等概率的。这种表述并未在任何重要方面改变原问题,且有助于避免被无关的时间顺序细节所干扰。以某种方式(例如按年龄从小到大)给这五个人标记为 \(1, 2, \dots, 5\),并令 \(Z_j\) 为第 \(j\) 个人抽到的数值。由对称性可知,对每个 \(j\) 都有 \(Z_j \sim DUnif(1, 2, \dots, 100)\);这些 \(Z_j\) 是相关的,但单独来看,每个人抽到的都是一张均匀随机的纸条。
- 事件 \(Y_1 = 100, \dots, Y_5 = 100\) 是互斥的,因为我们现在是无放回抽样,所以: \[ P(Y_j = 100 \text{ 对某个 } j) = P(Y_1 = 100) + \dots + P(Y_5 = 100) = 0.05 \]
合理性检查:这个答案在直觉上是合理的,因为我们同样可以先从 100 张空白纸条中随机选出 5 张,然后再将 1 到 100 的数字随机写在所有纸条上,这样数字 100 出现在那 5 张被选中纸条上的概率显然是 \(5/100\)。
如果 (c) 的答案大于或等于 (f) 的答案,那将非常奇怪,因为无放回抽样使得找到数字 100 变得更容易。(出于同样的原因,在寻找丢失的财物时,无放回地搜索各个位置比有放回地搜索更有意义。)而 (c) 的答案仅略小于 (f) 的答案也是合理的,因为在 (c) 中,同一张纸条被重复抽中的概率很低(尽管根据“生日问题”,这种可能性比许多人猜测的要高一些)。
更一般地,如果无放回地抽取 \(k\) 张纸条(其中 \(0 \le k \le 100\)),那么同样的推理可以得出:抽中数字 100 的概率为 \(k/100\)。注意这在极端情况 \(k = 100\) 下也是成立的,因为那时我们抽走了所有的纸条。
3.6 累积分布函数
Cumulative distribution functions
另一种描述随机变量分布的函数是累积分布函数(CDF)。与仅离散型随机变量拥有的 PMF 不同,CDF 对所有随机变量都有定义。
定义 3.6.1。随机变量 \(X\) 的累积分布函数(CDF)是函数 \(F_X\),定义为 \(F_X(x) = P(X \le x)\)。在不会产生歧义的情况下,我们有时会省去下标,直接用 \(F\)(或其他字母)表示 CDF。
接下来的例子证明了对于离散型随机变量,我们可以在 CDF 和 PMF 之间自由转换。
例 3.6.2。设 \(X \sim \text{Bin}(4, 1/2)\)。图 3.8 展示了 \(X\) 的 PMF 和 CDF。
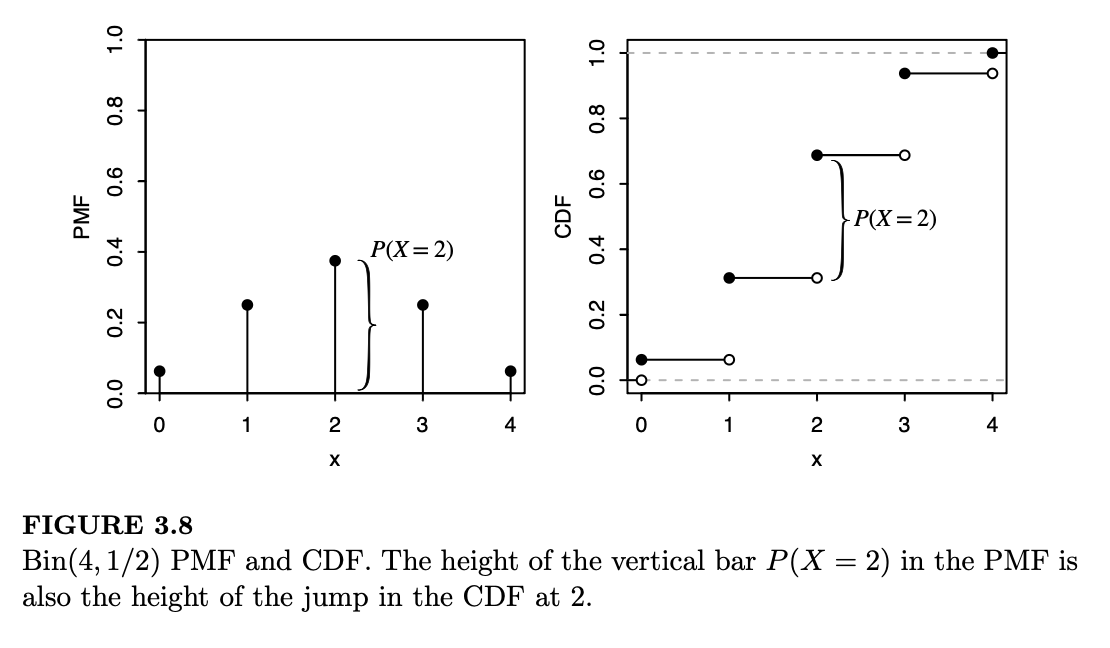
- 从 PMF 到 CDF:为了求 \(P(X \le 1.5)\)(即在 1.5 处的 CDF 值),我们将支撑集中所有小于或等于 1.5 的值的 PMF 进行求和:
\[ P(X \le 1.5) = P(X = 0) + P(X = 1) = \binom{4}{0} \left(\frac{1}{2}\right)^4 + \binom{4}{1} \left(\frac{1}{2}\right)^4 = \frac{5}{16} \]
同理,CDF 在任意点 \(x\) 处的值,等于 PMF 中所有小于或等于 \(x\) 的值处的垂直条高度之和。
- 从 CDF 到 PMF:离散型随机变量的 CDF 由阶跃(跳跃)和平坦区域组成。CDF 在 \(x\) 处的跳跃高度等于 \(x\) 处的 PMF 值。例如在图 3.8 中,CDF 在 2 处的跳跃高度与 PMF 中对应的垂直条高度相同;图中用花括号标出了这一点。CDF 的平坦区域对应于 \(X\) 支撑集之外的值,因此在这些区域 PMF 等于 0。
有效的 CDF 满足以下标准。
定理 3.6.3(有效 CDF)。任何 CDF \(F\) 都具有以下性质:
单调不减:如果 \(x_1 \le x_2\),则 \(F(x_1) \le F(x_2)\)。
右连续:如图 3.8 所示,CDF 除了可能存在一些跳跃外是连续的。在任何有跳跃的地方,CDF 都是右连续的。也就是说,对于任何 \(a\),我们有:
\[ F(a) = \lim_{x \to a^+} F(x) \]
- 极限值为 0 和 1:
\[ \lim_{x \to -\infty} F(x) = 0 \quad \text{且} \quad \lim_{x \to \infty} F(x) = 1 \]
个人注:右连续指从右边靠过来的值和点上的值一样。
证明:上述标准对所有 CDF 均成立,但为简单起见,我们仅针对 \(F\) 是取值为 \(0, 1, 2, \dots\) 的离散型随机变量 \(X\) 的 CDF 的情况进行证明。作为如何直观理解这些标准的例子,请参考图 3.8:图中显示的 CDF 是单调不减的(带有若干平坦区域),且是右连续的(除了跳跃点外均连续,且每个跳跃点底部为开点,顶部为实点),并且当 \(x \to -\infty\) 时趋于 0,当 \(x \to \infty\) 时趋于 1(在本例中,它实际达到了 0 和 1;在某些例子中,可能会趋近其中一个或两个值但永远无法达到)。
第一条标准成立,是因为事件 \(\{X \le x_1\}\) 是事件 \(\{X \le x_2\}\) 的子集,因此 \(P(X \le x_1) \le P(X \le x_2)\)。
对于第二条标准,请注意: \[ P(X \le x) = P(X \le \lfloor x \rfloor) \]
其中 \(\lfloor x \rfloor\) 是小于或等于 \(x\) 的最大整数。例如,由于 \(X\) 取整数值,\(P(X \le 4.9) = P(X \le 4)\)。因此,对于任何足够小的 \(b > 0\)(只要满足 \(a + b < \lfloor a \rfloor + 1\)),都有 \(F(a + b) = F(a)\)。例如当 \(a = 4.9\) 时,该式对 \(0 < b < 0.1\) 均成立。这意味着 \(F(a) = \lim_{x \to a^+} F(x)\)(事实上,这比极限定义更强,因为它说明当 \(x\) 在 \(a\) 右侧且足够接近 \(a\) 时,\(F(x)\) 就等于 \(F(a)\))。
对于第三条标准,当 \(x < 0\) 时 \(F(x) = 0\),且: \[ \lim_{x \to \infty} F(x) = \lim_{x \to \infty} P(X \le \lfloor x \rfloor) = \lim_{x \to \infty} \sum_{n=0}^{\lfloor x \rfloor} P(X = n) = \sum_{n=0}^{\infty} P(X = n) = 1 \]
反之亦然:我们将在第 5 章中证明,给定任何满足这些标准的函数 \(F\),我们都可以构造出一个以 \(F\) 为累积分布函数的随机变量。
总结一下,我们现在已经看到了三种表达随机变量分布的等价方式。其中两种是 PMF(概率质量函数)和 CDF(累积分布函数):我们知道这两个函数包含相同的信息,因为我们总能从 PMF 推导出 CDF,反之亦然。通常对于离散型随机变量,使用 PMF 会更加简便,因为计算 CDF 需要进行求和。
第三种描述分布的方法是使用一个(以精确方式)解释该分布如何产生的背景故事。我们利用了二项分布和超几何分布的背景故事来推导出相应的 PMF。因此,背景故事和 PMF 也包含相同的信息,尽管通过背景故事往往能比通过 PMF 计算获得更直观的证明。
3.7 随机变量的函数
Functions of random variables
在本节中,我们将讨论对随机变量取函数意味着什么,并理解为什么随机变量的函数仍然是一个随机变量。也就是说,如果 \(X\) 是一个随机变量,那么 \(X^2\)、\(e^X\) 和 \(\sin(X)\) 也是随机变量;对于任何函数 \(g: \mathbb{R} \to \mathbb{R}\),\(g(X)\) 同样是随机变量。
例如,想象两支篮球队(A 队和 B 队)正在进行一场七局四胜制的比赛,令 \(X\) 为 A 队的胜场数(如果两队势均力敌且各场比赛相互独立,则 \(X \sim \text{Bin}(7, 1/2)\))。令 \(g(x) = 7 - x\),并令 \(h(x) = 1\)(若 \(x \ge 4\))以及 \(h(x) = 0\)(若 \(x < 4\))。那么 \(g(X) = 7 - X\) 就是 B 队的胜场数,而 \(h(X)\) 是 A 队赢得系列赛(赢得多数比赛)的指示变量。由于 \(X\) 是一个随机变量, \(g(X)\) 和 \(h(X)\) 也都是随机变量。
为了看清如何正式地定义随机变量的函数,让我们回顾一下。在本章开始时,我们考虑了定义在包含 6 个元素的样本空间上的随机变量 \(X\)。图 3.1 使用箭头展示了 \(X\) 如何将样本空间中的每个“小石子”(样本点)映射到一个实数,图 3.2 的左半部分展示了我们如何等效地想象 \(X\) 在每个小石子内部写下一个实数。
现在,如果愿意,我们可以对所有写在小石子内部的数字应用相同的函数 \(g\)。现在我们得到的不再是数字 \(X(s_1)\) 到 \(X(s_6)\),而是数字 \(g(X(s_1))\) 到 \(g(X(s_6))\)。这产生了一个从样本结果到实数的新映射——我们创建了一个新的随机变量 \(g(X)\)。
定义 3.7.1(随机变量的函数)。对于一个样本空间为 \(S\) 的实验、一个随机变量 \(X\) 以及一个函数 \(g: \mathbb{R} \to \mathbb{R}\),\(g(X)\) 是指对于所有 \(s \in S\),将 \(s\) 映射到 \(g(X(s))\) 的随机变量。
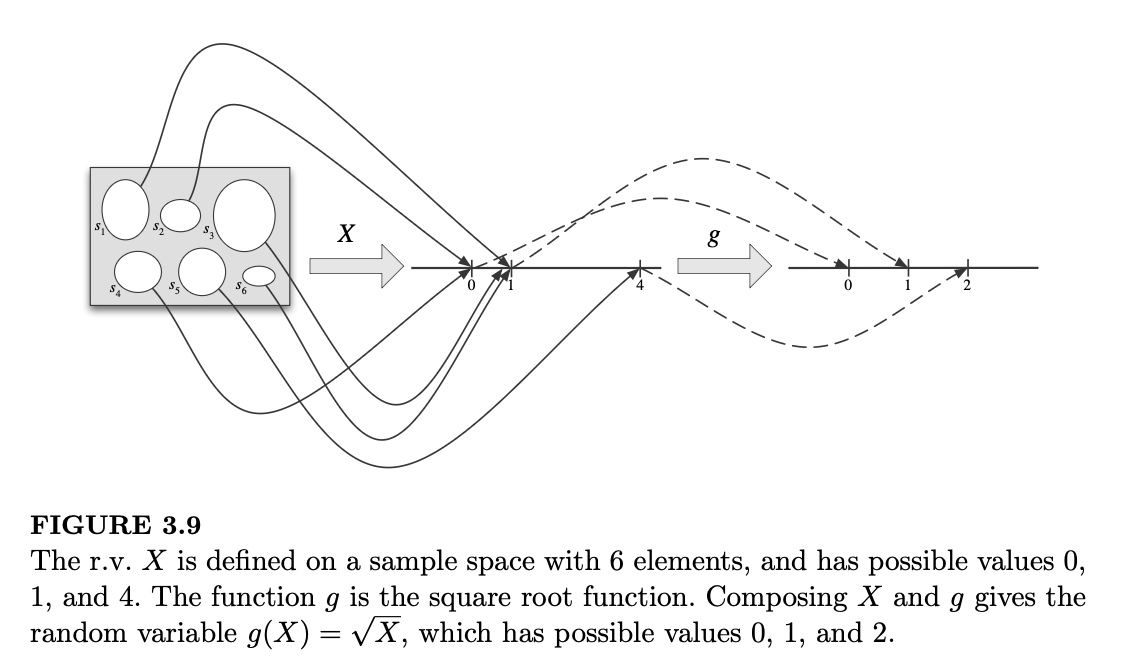
具体以 \(g(x) = \sqrt{x}\) 为例,图 3.9 展示了 \(g(X)\) 是函数 \(X\) 和 \(g\) 的复合,即“先应用 \(X\),再应用 \(g\)”。
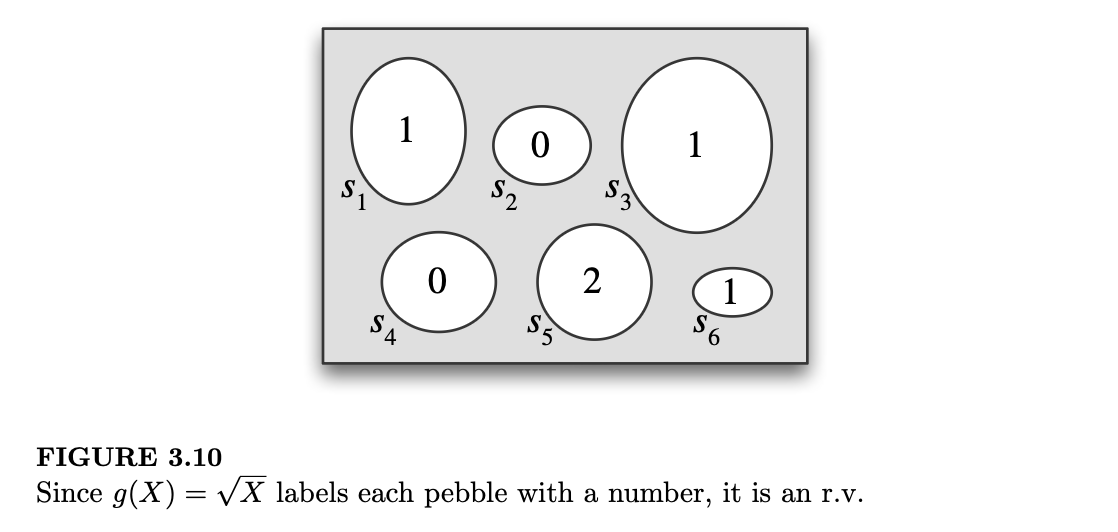
图 3.10 通过直接标记样本结果更简洁地表示了 \(g(X)\)。两幅图都向我们展示了 \(g(X)\) 是一个随机变量;如果 \(X\) 观测值(晶格化)为 4,那么 \(g(X)\) 的观测值即为 2。
已知离散型随机变量 \(X\) 的 PMF,我们如何求 \(Y = g(X)\) 的 PMF?
在 \(g\) 是一双一(单射)函数的情况下,答案非常直接:\(Y\) 的支撑集是 \(X\) 支撑集中所有 \(x\) 对应的 \(g(x)\) 集合,且: \[ P(Y = g(x)) = P(g(X) = g(x)) = P(X = x) \]
下表展示了 \(g\) 为单射函数时 \(Y = g(X)\) 的情况;其核心思想是,如果 \(X\) 的不同可能取值为 \(x_1, x_2, \dots\),对应的概率分别为 \(p_1, p_2, \dots\),那么 \(Y\) 的不同可能取值就是 \(g(x_1), g(x_2), \dots\),其对应的概率列表仍为 \(p_1, p_2, \dots\)。

这为寻找具有陌生分布的随机变量的 PMF 提供了一种策略:尝试将该随机变量表示为一个已知分布随机变量的单射函数。接下来的例子说明了这种方法。
例 3.7.2(随机游走)。一个粒子在数轴上移动 \(n\) 步。该粒子从 0 点出发,每一步以相等的概率向右或向左移动 1 个单位。假设所有步骤相互独立。令 \(Y\) 为粒子在 \(n\) 步后的位置。求 \(Y\) 的 PMF。
解答:
将每一步看作一次伯努利试验,其中向右移动视为“成功”,向左移动视为“失败”。那么粒子向右移动的步数是一个 \(\text{Bin}(n, 1/2)\) 随机变量,我们将其命名为 \(X\)。如果 \(X = j\),则粒子向右走了 \(j\) 步,向左走了 \(n - j\) 步,最终位置为 \(j - (n - j) = 2j - n\)。因此,我们可以将 \(Y\) 表示为 \(X\) 的一个单射函数,即 \(Y = 2X - n\)。由于 \(X\) 的取值范围是 \(\{0, 1, 2, \dots, n\}\),故 \(Y\) 的取值范围是 \(\{-n, 2-n, 4-n, \dots, n\}\)。
通过 \(X\) 的 PMF 可以求得 \(Y\) 的 PMF: \[ P(Y = k) = P(2X - n = k) = P\left(X = \frac{n + k}{2}\right) = \binom{n}{\frac{n+k}{2}} \left(\frac{1}{2}\right)^n \]
前提是 \(k\) 为 \(-n\) 到 \(n\) 之间(含边界)且使得 \(n + k\) 为偶数的整数。
如果 \(g\) 不是单射函数,那么对于给定的 \(y\),可能存在多个 \(x\) 值使得 \(g(x) = y\)。为了计算 \(P(g(X) = y)\),我们需要将 \(X\) 取这些候选 \(x\) 值的所有概率求和。
定理 3.7.3(\(g(X)\) 的 PMF)。设 \(X\) 为离散型随机变量,\(g: \mathbb{R} \to \mathbb{R}\)。则 \(g(X)\) 的支撑集是所有满足 \(g(x) = y\) 且 \(x\) 在 \(X\) 支撑集内的 \(y\) 的集合。\(g(X)\) 的 PMF 为: \[ P(g(X) = y) = \sum_{x: g(x) = y} P(X = x) \]
对于 \(g(X)\) 支撑集内的所有 \(y\) 均成立。
例 3.7.4。延续上一个例子,令 \(D\) 为 \(n\) 步后粒子距离原点的距离。假设 \(n\) 为偶数。求 \(D\) 的 PMF。
解答:
我们可以写出 \(D = |Y|\);这是 \(Y\) 的函数,但它不是单射的。事件 \(D = 0\) 与事件 \(Y = 0\) 相同。对于 \(k = 2, 4, \dots, n\),事件 \(D = k\) 与事件 \(\{Y = k\} \cup \{Y = -k\}\) 相同。因此 \(D\) 的 PMF 为: \[ P(D = 0) = \binom{n}{\frac{n}{2}} \left(\frac{1}{2}\right)^n \]
\[ P(D = k) = P(Y = k) + P(Y = -k) = 2 \binom{n}{\frac{n+k}{2}} \left(\frac{1}{2}\right)^n \]
对于 \(k = 2, 4, \dots, n\)。在最后一步中,我们利用了对称性(想象一个新的随机游走,当原游走右移时它左移,反之亦然)从而得知 \(P(Y = k) = P(Y = -k)\)。
处理单个随机变量函数所用的相同推理可以扩展到处理多个随机变量的函数。我们已经见过加法函数(将两个数 \(x, y\) 映射为它们的和 \(x + y\))的例子:在例 3.2.5 中,我们看到了如何将 \(T = X + Y\) 视为一个独立的随机变量,其中 \(X\) 和 \(Y\) 是通过投掷骰子获得的。
定义 3.7.5(两个随机变量的函数)。给定一个样本空间为 \(S\) 的实验,如果 \(X\) 和 \(Y\) 是分别将 \(s \in S\) 映射为 \(X(s)\) 和 \(Y(s)\) 的随机变量,那么 \(g(X, Y)\) 就是将 \(s\) 映射为 \(g(X(s), Y(s))\) 的随机变量。
注意,我们假设 \(X\) 和 \(Y\) 定义在同一个样本空间 \(S\) 上。通常我们假设 \(S\) 被选择得足够丰富,能够包含我们希望处理的任何随机变量。例如,如果 \(X\) 基于硬币投掷,其初始样本空间为 \(S_1 = \{H, T\}\),而 \(Y\) 基于骰子投掷,其初始样本空间为 \(S_2 = \{1, 2, 3, 4, 5, 6\}\),我们可以很容易地重新定义 \(X\) 和 \(Y\),使它们都定义在更丰富的空间 \(S = S_1 \times S_2 = \{(s_1, s_2) : s_1 \in S_1, s_2 \in S_2\}\) 上。
理解随机变量 \(g(X, Y)\) 所代表的从 \(S\) 到 \(\mathbb{R}\) 的映射的一种方法是:列出一张表,显示在各种可能结果下 \(X\)、\(Y\) 和 \(g(X, Y)\) 的值。将 \(X + Y\) 解释为一个随机变量是很直观的:如果我们观察到 \(X = x\) 且 \(Y = y\),那么 \(X + Y\) 就观测(晶格化)为 \(x + y\)。对于像 \(\max(X, Y)\) 这样不太熟悉的例子,学生们往往不确定如何将其解释为一个随机变量。但思路是一样的:如果我们观察到 \(X = x\) 且 \(Y = y\),那么 \(\max(X, Y)\) 就观测为 \(\max(x, y)\)。
例 3.7.6(两个骰子点数的最大值)。我们投掷两枚公平的 6 面骰子。令 \(X\) 为第一枚骰子的点数,\(Y\) 为第二枚骰子的点数。下表给出了在样本空间 36 个结果中的 7 个结果下,\(X\)、\(Y\) 以及 \(\max(X, Y)\) 的值,类似于例 3.2.5 中的表格。
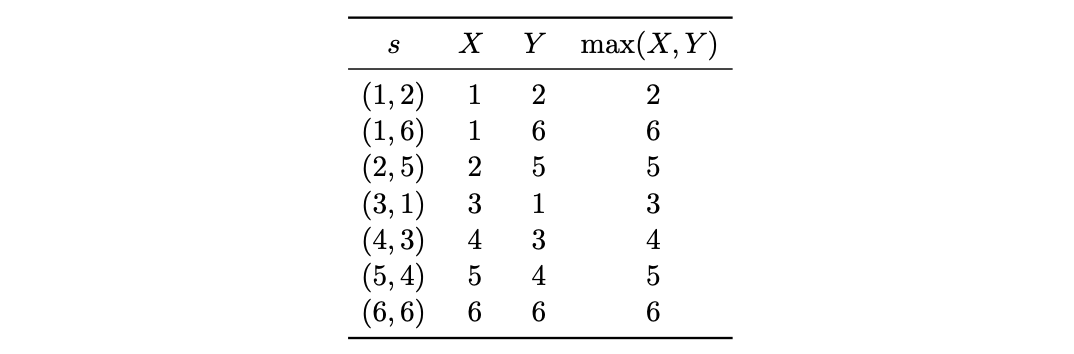
因此,\(\max(X, Y)\) 为每个样本结果分配了一个数值。其 PMF 为: \[ P(\max(X, Y) = 1) = 1/36 \]
\[ P(\max(X, Y) = 2) = 3/36 \]
\[ P(\max(X, Y) = 3) = 5/36 \]
\[ P(\max(X, Y) = 4) = 7/36 \]
\[ P(\max(X, Y) = 5) = 9/36 \]
\[ P(\max(X, Y) = 6) = 11/36 \]
这些概率可以通过在 \(6 \times 6\) 的网格中列出 \(\max(x, y)\) 的值并计算每个值出现的次数来获得,或者通过如下计算获得: \[ P(\max(X, Y) = 5) = P(X = 5, Y \le 4) + P(X \le 4, Y = 5) + P(X = 5, Y = 5) \]
\[ = 2P(X = 5, Y \le 4) + 1/36 = 2(4/36) + 1/36 = 9/36 \]
3.7.7(范畴错误与交感巫术 Category errors and sympathetic magic)。概率论中许多常见的错误都可以追溯到将以下四种基本对象相互混淆:分布、随机变量、事件和数值(distributions, random variables, events, and numbers)。此类错误属于范畴错误(category errors)。通常,范畴错误不仅恰好是错误的,而且由于它基于错误的对象类别,实际上是必然错误的。例如,回答“波士顿有多少居民?”时说“\(-42\)”或“\(\pi\)”或“粉色大象”就是范畴错误——我们可能不知道一个城市的具体人口规模,但我们知道在任何时间点它都必须是一个非负整数。为了避免出现范畴上的错误,请始终思考答案应该属于哪一类。
一种极其常见的范畴错误是将随机变量与其分布混淆。我们称这种错误为交感巫术(sympathetic magic);这个术语源于人类学,指代一种认为可以通过操纵某个对象的表现形式(代表物)来影响该对象本身的信仰。以下格言阐明了随机变量与其分布之间的区别:
“言语并非事物本身;地图并非疆域。” —— 阿尔弗雷德·柯日布斯基(Alfred Korzybski)
我们可以将随机变量的分布看作是描述该随机变量的地图或蓝图。正如不同的房子可以共享同一份蓝图,不同的随机变量也可以拥有相同的分布,即使它们所总结的实验以及它们所映射的样本空间并不相同。
以下是“交感巫术”的两个例子:
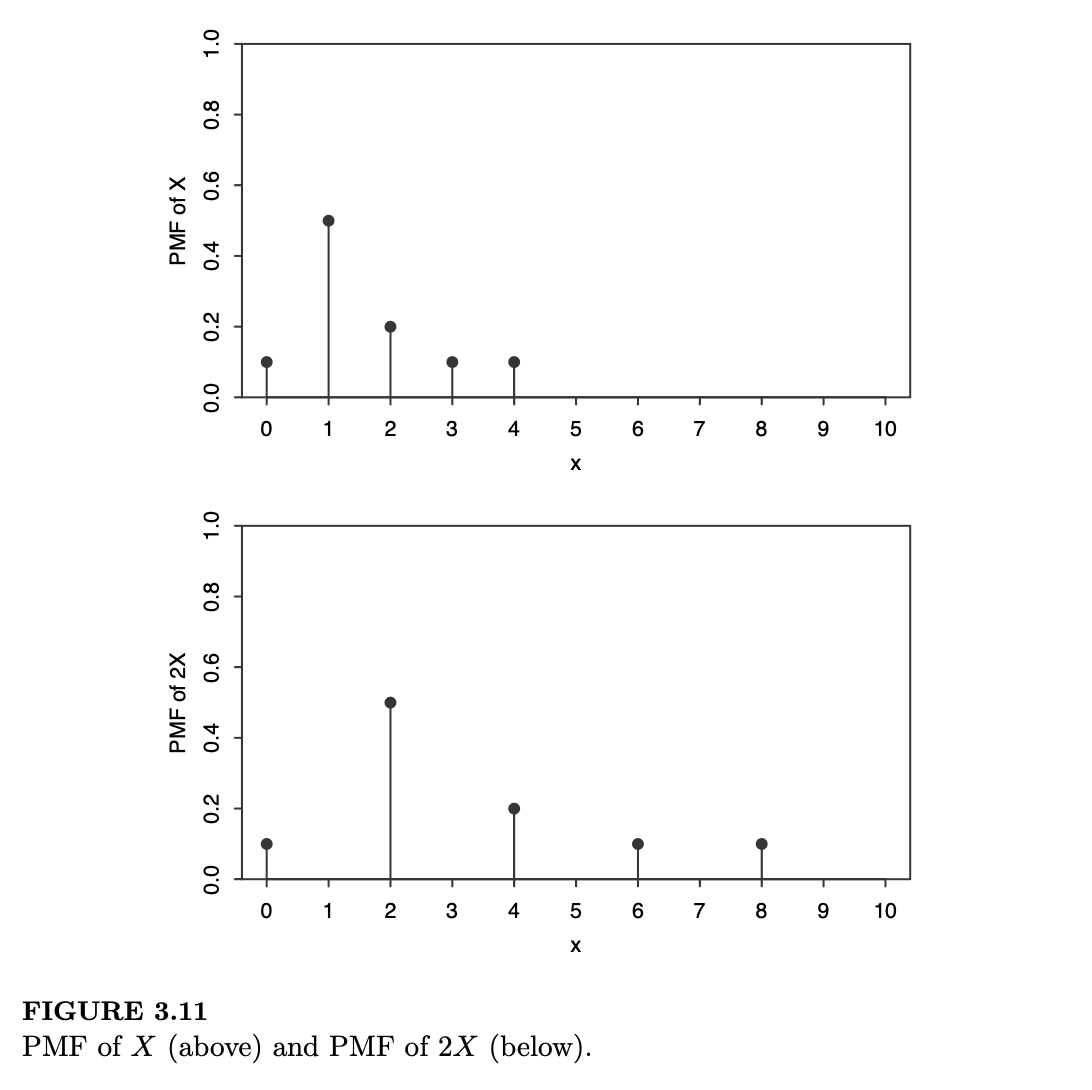
- 给定随机变量 \(X\),试图通过将 \(X\) 的 PMF 乘以 2 来获得 \(2X\) 的 PMF。将 PMF 乘以 2 是没有意义的,因为这样概率之和就不再为 1 了。正如我们在上文所看到的,如果 \(X\) 以概率 \(p_j\) 取值 \(x_j\),那么 \(2X\) 以概率 \(p_j\) 取值 \(2x_j\)。因此,\(2X\) 的 PMF 是 \(X\) 的 PMF 在水平方向上的拉伸;它并不是垂直方向上的拉伸(将 PMF 乘以 2 会导致垂直拉伸)。图 3.11 展示了一个支撑集为 \(\{0, 1, 2, 3, 4\}\) 的离散型随机变量 \(X\) 的 PMF,以及 \(2X\) 的 PMF(其支撑集为 \(\{0, 2, 4, 6, 8\}\))。注意,\(X\) 可以取奇数值,但 \(2X\) 必然是偶数。
- 声称因为 \(X\) 和 \(Y\) 具有相同的分布,所以 \(X\) 必须始终等于 \(Y\),即 \(P(X = Y) = 1\)。两个随机变量具有相同的分布并不意味着它们总是相等,甚至不意味着它们曾经相等。我们在例 3.2.5 中已经看到了这一点。再举一个例子,考虑抛掷一枚公平硬币一次。令 \(X\) 为正面朝上的指示变量,而 \(Y = 1 - X\) 为反面朝上的指示变量。\(X\) 和 \(Y\) 都服从 \(\text{Bern}(1/2)\) 分布,但事件 \(X = Y\) 是不可能发生的。\(X\) 和 \(Y\) 的 PMF 是同一个函数,但 \(X\) 和 \(Y\) 是从样本空间到实数集的不同映射。
如果 \(Z\) 是第二次抛掷(独立于第一次抛掷)正面朝上的指示变量,那么 \(Z\) 也服从 \(\text{Bern}(1/2)\),但 \(Z\) 与 \(X\) 并不是同一个随机变量。在这种情况下: \[ P(Z = X) = P(HH \text{ 或 } TT) = 1/2 \]
3.8 随机变量的独立性
Independence of r.v.s
正如我们有事件独立性的概念一样,我们也可以定义随机变量的独立性。直观地说,如果两个随机变量 \(X\) 和 \(Y\) 是独立的,那么知道 \(X\) 的值不会提供任何关于 \(Y\) 的值的信息,反之亦然。定义将这一思想正式化。
定义 3.8.1(两个随机变量的独立性)。如果对于所有 \(x, y \in \mathbb{R}\),满足 \[ P(X \le x, Y \le y) = P(X \le x)P(Y \le y) \]
则称随机变量 \(X\) 和 \(Y\) 是独立的。
在离散情况下,这等价于如下条件:对于 \(x\) 属于 \(X\) 的支撑集且 \(y\) 属于 \(Y\) 的支撑集的所有 \(x, y\),满足 \[ P(X = x, Y = y) = P(X = x)P(Y = y) \]
对于两个以上随机变量的定义是类似的。
定义 3.8.2(多个随机变量的独立性)。如果对于所有 \(x_1, \dots, x_n \in \mathbb{R}\),满足 \[ P(X_1 \le x_1, \dots, X_n \le x_n) = P(X_1 \le x_1) \dots P(X_n \le x_n) \]
则称随机变量 \(X_1, \dots, X_n\) 是独立的。对于无穷多个随机变量,如果它们的任意有限子集都是独立的,我们就说它们是独立的。
将此与 \(n\) 个事件独立性的标准进行比较,可能会觉得奇怪:\(X_1, \dots, X_n\) 的独立性只需要一个等式,而对于事件,我们需要验证所有 \(\binom{n}{2}\) 个两两组合的独立性、所有 \(\binom{n}{3}\) 个三三组合的独立性,依此类推。然而,仔细观察定义就会发现,随机变量的独立性要求等式对所有可能的 \(x_1, \dots, x_n\) 都成立——这包含了无穷多个条件!如果我们能找到哪怕一组 \(x_1, \dots, x_n\) 的值使得上述等式不成立,那么 \(X_1, \dots, X_n\) 就不是独立的。
3.8.3。如果 \(X_1, \dots, X_n\) 是独立的,那么它们也是两两独立的,即对于 \(i \neq j\),\(X_i\) 与 \(X_j\) 独立。证明 \(X_i\) 与 \(X_j\) 独立的思路是让独立性定义中除 \(x_i, x_j\) 以外的所有 \(x_k\) 趋于 \(\infty\),因为我们已知 \(X_k < \infty\) 必然成立(尽管完整证明这个极限需要一些工作)。但两两独立通常并不意味着相互独立,正如我们在第 2 章中看到的事件的情况。
例 3.8.4。在投掷两枚公平骰子时,如果 \(X\) 是第一枚骰子的点数,\(Y\) 是第二枚骰子的点数,那么 \(X+Y\) 与 \(X-Y\) 不是独立的,因为: \[ 0 = P(X+Y = 12, X-Y = 1) \neq P(X+Y = 12)P(X-Y = 1) = \frac{1}{36} \cdot \frac{5}{36} \]
(注:\(X-Y=1\) 的情况有 \((2,1), (3,2), (4,3), (5,4), (6,5)\) 共 5 种)。知道总和是 12 告诉我们差值必须是 0,因此这两个随机变量互相提供了关于对方的信息。
如果 \(X\) 和 \(Y\) 是独立的,那么例如 \(X^2\) 与 \(Y^4\) 也是独立的。因为如果 \(X^2\) 提供了关于 \(Y^4\) 的信息,那么 \(X\) 就会提供关于 \(Y\) 的信息(以 \(X^2\) 和 \(Y^4\) 为中介:\(X\) 决定了 \(X^2\),\(X^2\) 提供关于 \(Y^4\) 的信息,而 \(Y^4\) 反过来又提供关于 \(Y\) 的信息)。更一般地,我们有以下结论(此处省略正式证明)。
定理 3.8.5(独立随机变量的函数)。如果 \(X\) 和 \(Y\) 是独立的随机变量,那么 \(X\) 的任何函数与 \(Y\) 的任何函数也是相互独立的。
定义 3.8.6(i.i.d.)。我们经常会处理相互独立且具有相同分布的随机变量。我们称此类随机变量为独立同分布(independent and identically distributed),简称 i.i.d.。
3.8.7(独立 vs. 同分布)。“独立”与“同分布”是两个经常被混淆但完全不同的概念。如果随机变量互不提供关于对方的信息,则它们是独立的;如果它们具有相同的 PMF(或等价地,相同的 CDF),则它们是同分布的。两个随机变量是否独立,与它们是否具有相同的分布毫无关系。我们可以拥有以下几种类型的随机变量:
- 独立且同分布:令 \(X\) 为一次掷骰子的结果,令 \(Y\) 为第二次独立的掷骰子结果。那么 \(X\) 和 \(Y\) 是 i.i.d. 的。
- 独立但不同分布:令 \(X\) 为一次掷骰子的结果,令 \(Y\) 为一个月后道琼斯指数(一种股市指数)的收盘价。那么 \(X\) 和 \(Y\) 互不提供信息(人们虔诚地希望如此),且 \(X\) 和 \(Y\) 显然不具有相同的分布。
- 相关且同分布:令 \(X\) 为 \(n\) 次独立公平硬币投掷中正面朝上的次数,令 \(Y\) 为同组 \(n\) 次投掷中反面朝上的次数。那么 \(X\) 和 \(Y\) 都服从 \(\text{Bin}(n, 1/2)\) 分布,但它们高度相关:如果我们知道 \(X\),就能完美推断出 \(Y\)。
- 相关且不同分布:令 \(X\) 为下次选举后美国多数党是否保留众议院控制权的指示变量,令 \(Y\) 为选举前一个月内民调中该党的平均好感度。那么 \(X\) 和 \(Y\) 是相关的,且 \(X\) 和 \(Y\) 不具有相同的分布。
通过对 i.i.d. 的伯努利随机变量求和,我们可以用代数形式写出二项分布的故事。
定理 3.8.8。若 \(X \sim \text{Bin}(n, p)\),视其为 \(n\) 次成功概率为 \(p\) 的独立伯努利试验中的成功次数,则我们可以写成 \(X = X_1 + \dots + X_n\),其中 \(X_i\) 是 i.i.d. 的 \(\text{Bern}(p)\)。
证明:如果第 \(i\) 次试验成功,令 \(X_i = 1\);如果失败,则令 \(X_i = 0\)。这就像我们为每次试验分配了一个人,并要求如果其负责的试验成功就举手。如果我们计算举手的总数(这等同于将 \(X_i\) 相加),我们就得到了总的成功次数。
关于二项分布的一个重要事实是:具有相同成功概率的独立二项分布随机变量之和仍然服从二项分布。
定理 3.8.9。若 \(X \sim \text{Bin}(n, p)\),\(Y \sim \text{Bin}(m, p)\),且 \(X\) 与 \(Y\) 独立,则 \(X + Y \sim \text{Bin}(n + m, p)\)。
证明:我们提供三种证明方法,因为每种方法都展示了一种有用的技术。
- 全概率公式(LOTP):我们可以通过对 \(X\)(或 \(Y\),视个人偏好而定)进行条件概率分解,并利用全概率公式直接求出 \(X+Y\) 的 PMF:
\[ P(X + Y = k) = \sum_{j=0}^{k} P(X + Y = k | X = j) P(X = j) \]
\[ = \sum_{j=0}^{k} P(Y = k - j) P(X = j) \]
\[ = \sum_{j=0}^{k} \binom{m}{k-j} p^{k-j} q^{m-k+j} \binom{n}{j} p^j q^{n-j} \]
\[ = p^k q^{n+m-k} \sum_{j=0}^{k} \binom{m}{k-j} \binom{n}{j} \]
\[ = \binom{n+m}{k} p^k q^{n+m-k} \]
在第二行中,我们利用 \(X\) 和 \(Y\) 的独立性,去掉了条件概率中的条件: \[ P(X + Y = k | X = j) = P(Y = k - j | X = j) = P(Y = k - j) \]
在最后一行中,我们利用了范德蒙德恒等式(Vandermonde’s identity): \[ \sum_{j=0}^{k} \binom{m}{k-j} \binom{n}{j} = \binom{n+m}{k} \]
所得表达式正是 \(\text{Bin}(n+m, p)\) 的 PMF,因此 \(X+Y \sim \text{Bin}(n+m, p)\)。
- 随机变量表示法:一个简单得多的证明是将 \(X\) 和 \(Y\) 都表示为 i.i.d. 的 \(\text{Bern}(p)\) 随机变量之和:\(X = X_1 + \dots + X_n\) 且 \(Y = Y_1 + \dots + Y_m\),其中所有的 \(X_i\) 和 \(Y_j\) 都是 i.i.d. 的 \(\text{Bern}(p)\)。那么 \(X+Y\) 就是 \(n+m\) 个 i.i.d. 的 \(\text{Bern}(p)\) 随机变量之和,根据前一个定理,其分布为 \(\text{Bin}(n+m, p)\)。
- 背景故事法:根据二项分布的故事,\(X\) 是 \(n\) 次独立试验中的成功次数,而 \(Y\) 是另外 \(m\) 次独立试验中的成功次数(所有试验的成功概率相同)。因此,\(X+Y\) 就是这 \(n+m\) 次试验中的总成功次数,这正是 \(\text{Bin}(n+m, p)\) 分布的故事定义。
当然,既然我们有了随机变量独立性的定义,也就应该有相应的条件独立性定义。
定义 3.8.10(随机变量的条件独立性)。给定随机变量 \(Z\),如果对于所有 \(x, y \in \mathbb{R}\) 以及 \(Z\) 支撑集内的所有 \(z\),均满足: \[ P(X \le x, Y \le y | Z = z) = P(X \le x | Z = z)P(Y \le y | Z = z) \]
则称随机变量 \(X\) 和 \(Y\) 在给定 \(Z\) 的条件下是条件独立的。
对于离散型随机变量,等价的定义是要求: \[ P(X = x, Y = y | Z = z) = P(X = x | Z = z)P(Y = y | Z = z) \]
正如其名称所暗示的那样,这就是独立性的定义,只不过我们在每一处都加上了以 \(Z = z\) 为条件,并要求等式对 \(Z\) 支撑集内的所有 \(z\) 都成立。
定义 3.8.11(条件 PMF)。对于任何离散型随机变量 \(X\) 和 \(Z\),当固定 \(z\) 时,关于 \(x\) 的函数 \(P(X = x | Z = z)\) 称为在 \(Z = z\) 条件下 \(X\) 的条件概率质量函数(条件 PMF)。
随机变量的独立性并不意味着条件独立性,反之亦然。首先,让我们看看为什么独立性不意味着条件独立性。
例 3.8.12(配对硬币)。考虑一个简单的“配对硬币”游戏。两位玩家 A 和 B 各持一枚公平的硬币。他们独立地抛掷硬币。如果两枚硬币面朝上的结果一致(同为正面或同为反面),则 A 赢;否则 B 赢。令 \(X\) 在 A 的硬币为正面时取 1,否则取 \(-1\);对 B 的硬币同样定义 \(Y\)(随机变量 \(X\) 和 \(Y\) 被称为随机符号)。
令 \(Z = XY\),如果 A 赢则 \(Z = 1\),如果 B 赢则 \(Z = -1\)。那么 \(X\) 和 \(Y\) 在无条件时是独立的,但在给定 \(Z = 1\) 的情况下,我们知道 \(X = Y\)(硬币结果必须一致)。因此,在给定 \(Z\) 的条件下,\(X\) 和 \(Y\) 是条件相关的。
例 3.8.13(两个朋友)。再次考虑例 2.5.11 中“只有两个朋友会给我打电话”的场景,只不过现在使用随机变量记号。令 \(X\) 为下周五 Alice 给我打电话的指示变量,\(Y\) 为下周五 Bob 给我打电话的指示变量,\(Z\) 为下周五恰好他们中的一个人给我打电话的指示变量。那么 \(X\) 和 \(Y\) 是独立的(根据假设)。但在给定 \(Z = 1\) 的情况下,\(X\) 和 \(Y\) 是完全相关的:已知 \(Z = 1\) 时,必有 \(Y = 1 - X\)。
接下来,让我们看看为什么条件独立性不意味着独立性。
例 3.8.14(神秘对手)。假设你要和一对同卵双胞胎中的一人打两场网球比赛。与其中一人对阵时,你们旗鼓相当(获胜概率 1/2);与另一人对阵时,你有 3/4 的获胜机会。假设在两场比赛结束前,你无法分辨自己是在和谁对赛。令 \(Z\) 为你与旗鼓相当的对手对赛的指示变量,并令 \(X\) 和 \(Y\) 分别为第一场和第二场比赛获胜的指示变量。
在给定 \(Z = 1\) 的条件下,\(X\) 和 \(Y\) 是 i.i.d. 的 \(\text{Bern}(1/2)\);在给定 \(Z = 0\) 的条件下,\(X\) 和 \(Y\) 是 i.i.d. 的 \(\text{Bern}(3/4)\)。因此,在给定 \(Z\) 的条件下,\(X\) 和 \(Y\) 是条件独立的。但在无条件的情况下,\(X\) 和 \(Y\) 是相关的,因为观察到 \(X = 1\)(第一场赢了)会让我们觉得更有可能是在和那个水平较弱的对手对赛。也就是说: \[ P(Y = 1 | X = 1) > P(Y = 1) \]
过去的比赛提供了信息,帮助我们推断对手是谁,而这反过来又帮助我们预测未来的比赛!请注意,这个例子与例 2.3.7 中的“随机硬币”场景是同构的。
3.9 二项分布与超几何分布的联系
Connections between Binomial and Hypergeometric
二项分布与超几何分布在两个重要方面存在联系。在本节中,我们将看到:可以通过条件概率从二项分布得到超几何分布,也可以通过取极限从超几何分布得到二项分布。我们先从一个启发性的例子开始。
例 3.9.1(费希尔精确检验,Fisher exact test)。一位科学家希望研究女性或男性谁更有可能患某种疾病,或者两者的患病概率是否相等。科学家收集了由 \(n\) 名女性和 \(m\) 名男性组成的随机样本,并对每人进行了疾病检测(假设在本题中检测完全准确)。样本中患病的女性和男性人数分别为 \(X\) 和 \(Y\),且 \(X \sim \text{Bin}(n, p_1)\),\(Y \sim \text{Bin}(m, p_2)\),两者相互独立。这里 \(p_1\) 和 \(p_2\) 是未知的,我们感兴趣的是检验 \(p_1 = p_2\) 是否成立(这在统计学中被称为原假设 null hypothesis )。
考虑一个 \(2 \times 2\) 列联表,行对应患病状态,列对应性别。每个单元格是同时满足该患病状态和性别的总人数,因此 \(n+m\) 是所有 4 个单元格数值的总和。假设观察到 \(X + Y = r\)。
费希尔精确检验基于对行和与列和的同时约束(即固定 \(n, m, r\)),然后观察 \(X\) 的观测值在这一条件分布下是否属于“极端值”。在原假设成立的前提下,求给定 \(X+Y=r\) 时 \(X\) 的条件 PMF。
解答:
首先,我们在固定 \(n, m, r\) 的情况下构建这个 \(2 \times 2\) 列联表。

接下来,计算条件 PMF \(P(X=x | X+Y=r)\)。根据贝叶斯定理: \[ P(X=x | X+Y=r) = \frac{P(X+Y=r | X=x)P(X=x)}{P(X+Y=r)} = \frac{P(Y=r-x)P(X=x)}{P(X+Y=r)} \]
步骤 \(P(X+Y=r | X=x) = P(Y=r-x)\) 的成立基于 \(X\) 和 \(Y\) 的独立性。假设原假设成立并令 \(p = p_1 = p_2\),则有 \(X \sim \text{Bin}(n, p)\) 且 \(Y \sim \text{Bin}(m, p)\),两者独立,因此 \(X+Y \sim \text{Bin}(n+m, p)\)。于是: \[ P(X=x | X+Y=r) = \frac{\binom{m}{r-x} p^{r-x}(1-p)^{m-r+x} \binom{n}{x} p^x(1-p)^{n-x}}{\binom{n+m}{r} p^r(1-p)^{n+m-r}} = \frac{\binom{n}{x} \binom{m}{r-x}}{\binom{n+m}{r}} \]
因此,\(X\) 的条件分布是参数为 \(n, m, r\) 的超几何分布。
为了理解为什么超几何分布会“凭空出现”,让我们将此问题与超几何分布的“麋鹿故事”联系起来。在麋鹿故事中,我们感兴趣的是再次捕获的样本中带标记麋鹿数量的分布。类比一下,把女性看作“带标记的麋鹿”,把男性看作“不带标记的麋鹿”。我们不是从森林里随机抓回 \(r\) 只麋鹿,而是令 \(X+Y=r\) 个人患病;在原假设下,这组病人群体等概率地为 \(n+m\) 个人中任何 \(r\) 个人的组合。因此,在给定 \(X+Y=r\) 的条件下,\(X\) 代表 \(r\) 个患病个体中女性的数量。这与再次捕获的样本中带标记麋鹿的数量完全类似,其服从 \(HGeom(n, m, r)\) 分布。
一个有趣且在统计学中非常有用的事实是:\(X\) 的条件分布不依赖于 \(p\)。在无条件时 \(X \sim \text{Bin}(n, p)\),但在条件分布的参数中,\(p\) 消失了!深思之后这便显得合理:一旦我们知道了 \(X+Y=r\),我们就可以直接处理一个拥有 \(r\) 个病人和 \(n+m-r\) 个健康人的群体,而无需担心最初生成该群体的 \(p\) 值是多少。
这个启发性的例子证明了以下定理:
定理 3.9.2。若 \(X \sim \text{Bin}(n, p)\),\(Y \sim \text{Bin}(m, p)\),且 \(X\) 与 \(Y\) 相互独立,则在给定 \(X+Y=r\) 的条件下,\(X\) 的条件分布为 \(HGeom(n, m, r)\)。
在另一个方向上,二项分布是超几何分布的一个极限情况。
定理 3.9.3。若 \(X \sim HGeom(w, b, n)\),且当 \(N = w + b \to \infty\) 时,\(p = w/(w+b)\) 保持不变,则 \(X\) 的 PMF 收敛于 \(\text{Bin}(n, p)\) 的 PMF。
证明:我们对 \(HGeom(w, b, n)\) 的 PMF 取上述极限: \[ P(X=k) = \frac{\binom{w}{k}\binom{b}{n-k}}{\binom{w+b}{n}} = \binom{n}{k} \frac{w!(b)!(w+b-n)!}{(w-k)!(b-n+k)!(w+b)!} \]
\[ \dots = \binom{n}{k} \frac{w(w-1)\dots(w-k+1) \cdot b(b-1)\dots(b-n+k+1)}{(w+b)(w+b-1)\dots(w+b-n+1)} \]
将分子分母同时除以 \(N^n\),由于 \(w/N = p\) 且 \(b/N = q\): \[ = \binom{n}{k} \frac{p(p-\frac{1}{N})\dots(p-\frac{k-1}{N}) \cdot q(q-\frac{1}{N})\dots(q-\frac{n-k-1}{N})}{1(1-\frac{1}{N})(1-\frac{2}{N})\dots(1-\frac{n-1}{N})} \]
当 \(N \to \infty\) 时,分母趋于 1,分子趋于 \(p^k q^{n-k}\)。因此: \[ P(X=k) \to \binom{n}{k} p^k q^{n-k} \]
这正是 \(\text{Bin}(n, p)\) 的 PMF。
二项分布和超几何分布的“故事”为这一结果提供了直观解释:给定一个装有 \(w\) 个白球和 \(b\) 个黑球的瓮,二项分布产生于从瓮中有放回地抽取 \(n\) 个球,而超几何分布产生于无放回抽取。当瓮中球的总数相对于抽取的次数变得非常大时,有放回抽样和无放回抽样变得基本等价。在实际应用中,该定理告诉我们,如果 \(N = w + b\) 相对于 \(n\) 很大,我们可以用 \(\text{Bin}(n, w/(w+b))\) 的 PMF 来近似 \(HGeom(w, b, n)\) 的 PMF。
“生日问题”意味着,如果有放回抽样,某些球被重复抽中的可能性大得惊人;例如,如果从 1,000,000 个球中随机有放回地抽取 1,200 个,那么某个球被抽中一次以上的概率约为 51%!但随着 \(N\) 的增长,这种情况的可能性会越来越小。而且,即使很可能出现几次重复,只要样本中绝大多数球极大概率只被抽中一次,该近似仍然是合理的。
3.10 本章小结
随机变量(r.v.)是一个将实数分配给实验中每个可能结果的函数。随机变量 \(X\) 的分布是对与 \(X\) 相关事件(例如 \(\{X = 3\}\) 和 \(\{1 \le X \le 5\}\))概率的完整描述。
离散型随机变量的分布可以通过 PMF、CDF 或背景故事来定义。\(X\) 的 PMF 是对于 \(x \in \mathbb{R}\) 的函数 \(P(X = x)\)。\(X\) 的 CDF 是对于 \(x \in \mathbb{R}\) 的函数 \(P(X \le x)\)。\(X\) 的背景故事描述了一个能够产生与 \(X\) 具有相同分布的随机变量的实验。
一个有效的 PMF 必须是非负的且总和为 1。一个有效的 CDF 必须是单调不减的、右连续的、且当 \(x \to -\infty\) 时收敛于 0,当 \(x \to \infty\) 时收敛于 1。
区分随机变量及其分布至关重要:分布是构建随机变量的蓝图,但不同的随机变量可以具有相同的分布,正如不同的房子可以根据同一份蓝图建造一样。
个人注:分布是针对随机变量而言,所以一个分布要清楚的说明其对应的随机变量是什么,而随机变量是事件的生成器!
本章命名了四种离散分布:伯努利分布、二项分布、超几何分布和离散均匀分布。每一种实际上都是一个由参数索引的分布族;要完整指定其中一个分布,我们需要给出名称和参数值。
- \(\text{Bern}(p)\) 随机变量是成功概率为 \(p\) 的伯努利试验中成功的指示变量。
- \(\text{Bin}(n, p)\) 随机变量是 \(n\) 次独立且成功概率均为 \(p\) 的伯努利试验中的成功总次数。
- \(HGeom(w, b, n)\) 随机变量是从装有 \(w\) 个白球和 \(b\) 个黑球的瓮中,无放回地抽取 \(n\) 个球所得到的白球数量。
- \(DUnif(C)\) 随机变量是通过从有限集合 \(C\) 中随机选择一个元素获得的,每个元素被选中的概率相等。
随机变量的函数仍然是随机变量。如果我们已知 \(X\) 的 PMF,可以通过将事件 \(\{g(X) = k\}\) 转化为涉及 \(X\) 的等价事件,然后利用 \(X\) 的 PMF 来求得 \(P(g(X) = k)\),即 \(g(X)\) 的 PMF。
个人注:g(x)是否需要单调?
1、一个不单调但完全没问题的例子
例 1:平方函数(明显不单调)
设:
- X ∈ {−2, −1, 0, 1, 2}
- PMF 已知
- g(x) = x²
问:\(P(g(X) = 1)\)?
计算 \[ g(X) = 1 ⇔ X² = 1 ⇔ X = −1 或 1 \] 所以:
\[ P(g(X) = 1) = P(X = −1) + P(X = 1) \]
- 完全可算
- -完全不需要单调
2、什么时候“单调性”才是必须的?
下面这个表非常重要:
场景 是否需要 g 单调 离散变量 + PMF + 枚举事件 不需要 连续变量 + PDF + 变量变换 通常需要 使用逆函数公式 需要 使用分布函数法(CDF) 常要求 3、为什么连续型里常常“要单调”?
因为你会写:
\[F_Y(y) = P(g(X) ≤ y)\]
要把它改写成:
\[P(X ≤ g⁻¹(y))\]
这一步 隐含假设:
- g 可逆
- 且不改变不等号方向
4、这就是单调性的来源
随机变量变换的本质是“事件的拉回”; 单调性不是必须条件,只是让“不等式”好处理的技术假设。
如果知道一个随机变量的值不能提供关于另一个随机变量值的任何信息,则称这两个随机变量是独立的。这与两个随机变量是否同分布无关。在第 7 章中,我们将学习如何通过联合考虑(而非单独考虑)相关随机变量来处理它们。
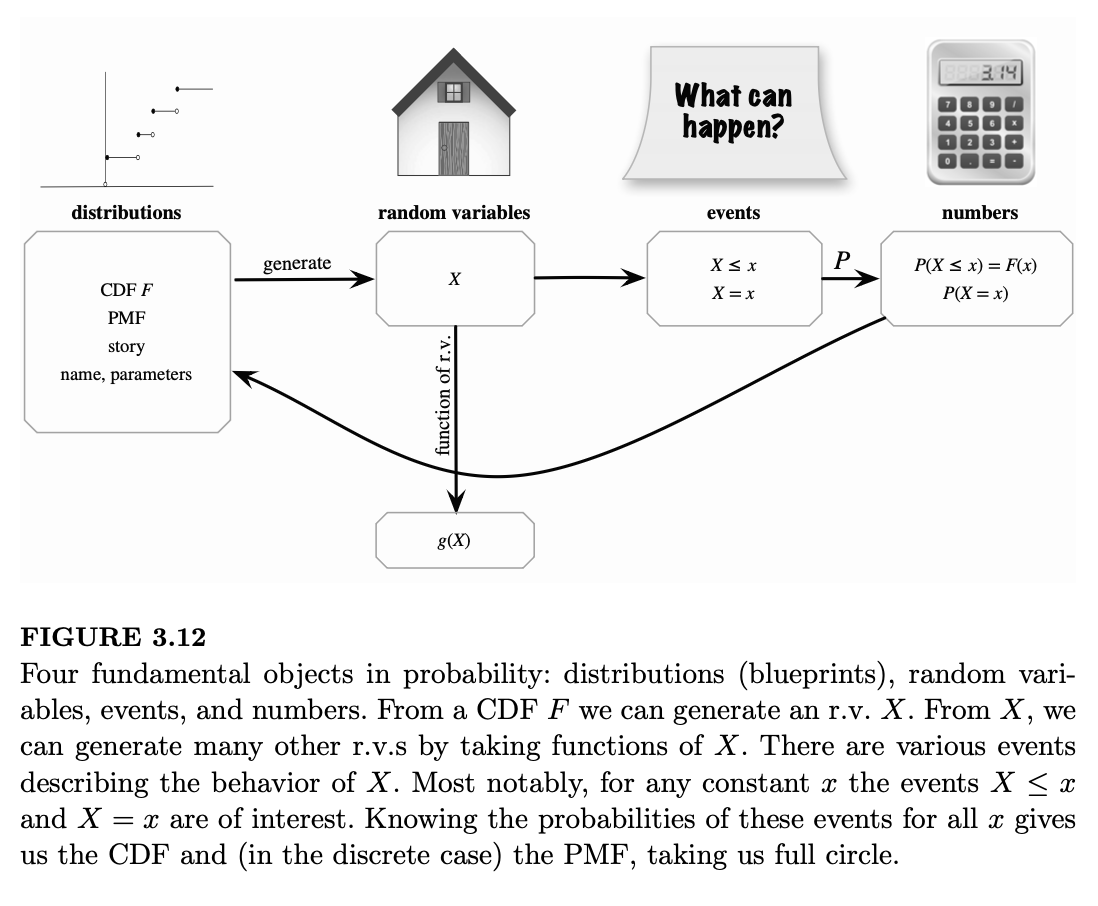
我们现在已经见过了概率论中的四种基本对象:分布、随机变量、事件和数值。图 3.12 展示了这四种基本对象之间的联系。CDF 可以作为生成随机变量的蓝图,然后存在各种描述该随机变量行为的事件,例如对于所有 \(x\) 的事件 \(X \le x\)。了解这些事件的概率就确定了 CDF,从而完成了一个闭环。对于离散型随机变量,我们也可以将 PMF 作为蓝图,从分布到随机变量,再到事件,最后回到分布。
个人注:以下这张图把概率论的最基础的概念讲得太透彻了!
3.11 R 语言实现
R 中的分布
本书中我们将遇到的所有命名分布都已在 R 中实现。在本节中,我们将解释如何在 R 中处理二项分布和超几何分布。我们还将解释通常如何从任何具有有限支撑集的离散分布中生成随机变量。输入 help(distributions) 可以得到一份方便的内置分布列表;此外,通过加载 R 包还可以获得更多其他的分布。
通常,对于许多命名的离散分布,以 d、p 和 r 开头的三个函数分别提供 PMF(概率质量函数)、CDF(累积分布函数)和随机数生成。请注意,以 p 开头的函数不是 PMF,而是 CDF。
二项分布
二项分布与以下三个 R 函数相关:dbinom、pbinom 和 rbinom。对于伯努利分布,我们只需使用 \(n=1\) 的二项分布函数即可。
- dbinom 是二项分布的 PMF。它需要三个输入:第一个是计算 PMF 的值 \(x\),第二和第三个是参数 \(n\) 和 \(p\)。例如,dbinom(3, 5, 0.2) 返回概率 \(P(X = 3)\),其中 \(X \sim \text{Bin}(5, 0.2)\)。换句话说:
\[ dbinom(3, 5, 0.2) = \binom{5}{3} (0.2)^3(0.8)^2 = 0.0512 \]
- pbinom 是二项分布的 CDF。它需要三个输入:第一个是计算 CDF 的值 \(x\),第二和第三个是参数。pbinom(3, 5, 0.2) 是概率 \(P(X \le 3)\),其中 \(X \sim \text{Bin}(5, 0.2)\)。因此:
\[ pbinom(3, 5, 0.2) = \sum_{k=0}^{3} \binom{5}{k} (0.2)^k(0.8)^{5-k} = 0.9933 \]
rbinom 是一个用于生成二项随机变量的函数。对于 rbinom,第一个输入是我们要生成的随机变量的数量,第二和第三个输入仍然是参数。因此,命令 rbinom(7, 5, 0.2) 会产生 7 个 i.i.d. \(\text{Bin}(5, 0.2)\) 随机变量的观测值。当我们运行此命令时,得到了:
2 1 0 0 1 0 0
但当你尝试时,可能会得到不同的结果!
我们还可以在整个数值向量上计算 PMF 和 CDF。例如,回想一下 0:n 是列出从 \(0\) 到 \(n\) 的整数的快捷方式。命令 dbinom(0:5, 5, 0.2) 会返回 6 个数字,即 \(P(X = 0), P(X = 1), \dots, P(X = 5)\),其中 \(X \sim \text{Bin}(5, 0.2)\)。
超几何分布
超几何分布同样有三个函数:dhyper、phyper 和 rhyper。正如预期的那样,dhyper 是超几何分布的 PMF,phyper 是其 CDF,而 rhyper 用于生成超几何随机变量。由于超几何分布有三个参数,因此这些函数中的每一个都需要四个输入。对于 dhyper 和 phyper,第一个输入是我们希望计算 PMF 或 CDF 的值,其余输入是分布的参数。
因此,dhyper(k, w, b, n) 返回 \(P(X = k)\),其中 \(X \sim HGeom(w, b, n)\);而 phyper(k, w, b, n) 返回 \(P(X \le k)\)。对于 rhyper,第一个输入是我们要生成的随机变量的数量,其余输入是参数;rhyper(100, w, b, n) 会生成 100 个 i.i.d. \(HGeom(w, b, n)\) 随机变量。
有限支撑集的离散分布
我们可以使用 sample 命令从任何具有有限支撑集的离散分布中生成随机变量。当我们最初介绍 sample 命令时,曾提到它可以用 sample(n, k) 或 sample(n, k, replace=TRUE) 的形式从整数 1 到 \(n\) 中进行 \(k\) 次无放回或有放回抽样。例如,要生成 5 个独立的 \(DUnif(1, 2, \dots, 100)\) 随机变量,我们可以使用命令:
sample(100, 5, replace=TRUE)。
事实证明,sample 的功能远不止于此。如果我们想以概率 \(p_1, \dots, p_n\) 从数值 \(x_1, \dots, x_n\) 中抽样,我们只需创建一个包含所有 \(x_i\) 的向量 x 和一个包含所有 \(p_i\) 的向量 p,然后将它们输入 sample 即可。假设我们想要获得 i.i.d. 随机变量 \(X_1, \dots, X_{100}\) 的观测值,其 PMF 为: \[ P(X_j = 0) = 0.25 \]
\[ P(X_j = 1) = 0.5 \]
\[ P(X_j = 5) = 0.1 \]
\[ P(X_j = 10) = 0.15 \]
且对于所有其他 \(x\) 值,\(P(X_j = x) = 0\)。首先,我们使用 c 函数创建包含分布支撑集及其对应概率的向量:
R
1 | x <- c(0, 1, 5, 10) |
接下来,使用 sample。以下是从上述 PMF 中获取 100 次抽取结果的方法:
sample(x, 100, prob=p, replace=TRUE)
输入项分别是:用于抽样的向量 x、样本量(本例中为 100)、从 x 中抽样时使用的概率 p(如果省略,则假定概率相等),以及是否进行有放回抽样。
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程