《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
第12章 马尔可夫链蒙特卡罗
Markov chain Monte Carlo
贯穿本书,我们已经看到模拟是概率论中一项强大的技术。如果你无法说服你的朋友在三门问题(Monty Hall problem)中换门是一个好主意,你可以在一秒钟内模拟玩几千次这个游戏,你的朋友就会看到换门的成功率约为 2/3。如果你不确定如何计算随机变量 \(X\) 的期望和方差,但你知道如何从该分布中生成独立同分布(i.i.d.)的抽取值 \(X_1, X_2, \dots, X_n\),你可以使用模拟抽取值的样本均值和样本方差来近似真实的期望和真实的方差: \[ E(X) \approx \bar{X}_n = \frac{1}{n}(X_1 + \dots + X_n), \] \[ Var(X) \approx \frac{1}{n-1} \sum_{j=1}^{n} (X_j - \bar{X}_n)^2. \]
大数定律告诉我们,如果 \(n\) 很大,这些近似将会很好。通过增加 \(n\),即仅仅通过让计算机运行更长时间(而不是不得不挣扎于一个可能无法处理的求和或积分),我们可以得到越来越好的近似。正如第 10 章所讨论的,这种通过生成随机值来近似某个数值的模拟方法被称为蒙特卡罗方法(Monte Carlo method)。
上述蒙特卡罗思想的一个主要局限是,我们需要知道如何生成 \(X_1, X_2, \dots, X_n\)(希望能高效地生成,因为我们希望 \(n\) 很大)。例如,假设我们要从一个连续分布中进行随机抽取,其概率密度函数(PDF)\(f\) 为:
\[ f(x) \propto x^{3.1}(1-x)^{4.2} \]
对于 \(0 < x < 1\),(其他情况为 0)。盯着一个密度函数看并不能立即暗示如何获得一个具有该密度的随机变量。在这种情况下,我们能识别出这是 \(Beta(4.1, 5.2)\) 分布的 PDF,因此假设我们可以使用 \(Unif(0, 1)\) 随机变量,理论上我们可以利用均匀分布的普适性(universality of the Uniform)。不幸的是,求 Beta 分布的累积分布函数(CDF)都很困难,更不用说 CDF 的逆函数了。关于 Beta 模拟问题的更多内容,请参见例 12.1.4。
当然,在现实应用中出现的分布往往比 Beta 分布复杂得多。对于 Beta 分布,我们知道如何用伽马函数来表达归一化常数。但对于许多其他具有科学意义的分布,PDF 或 PMF 中的归一化常数是未知的,超出了目前最快的计算机和最精妙的数学技术所能触及的范围。
本章介绍了马尔可夫链蒙特卡罗(MCMC),这是一组强大的算法,使我们能够利用马尔可夫链从复杂的分布中进行模拟。MCMC 的发展极大地扩展了我们可以模拟的分布范围(包括高维联合分布),从而彻底改变了统计学和科学计算。其基本思想是构建你自己的马尔可夫链,使感兴趣的分布成为该链的平稳分布。
在前一章中,我们研究了转移矩阵 \(Q\) 已知的马尔可夫链,并试图找到该链的平稳分布 \(s\)。在本章中,我们反其道而行之:从一个我们想要模拟的分布 \(s\) 出发,我们将设计一个平稳分布为 \(s\) 的马尔可夫链。如果我们随后运行这个设计好的马尔可夫链很长时间,该链的分布将接近我们想要的 \(s\)。
但是,是否可能创建一个具有我们所期望的平稳分布的转移矩阵 \(Q\)?即使可能,解决这个问题是否比原始的如何从该分布中随机抽取的问题更容易?在令人惊讶的通用性下,MCMC 表明,以一种易于描述的方式创建一个具有所需平稳分布的马尔可夫链是可能的,且无需知道该分布的归一化常数!
MCMC 现在正被应用于生物、自然和物理科学中的大量问题,并且已经开发出了许多不同的 MCMC 算法。在这里,我们将介绍两种最重要且应用最广泛的 MCMC 算法:Metropolis-Hastings 算法和 Gibbs 采样。MCMC 是统计计算中一个巨大且不断增长的领域;关于其理论、方法和应用的更多内容,请参见 Brooks、Gelman、Jones 和 Meng [2]。
12.1 Metropolis-Hastings
Metropolis-Hastings 算法是一个通用的配方,它允许我们从感兴趣的状态空间上的任何不可约马尔可夫链开始,然后将其修改为一个具有所需平稳分布的新马尔可夫链。这种修改包括在原始链中引入一些选择性:根据原始链提出跳转建议(proposals),但该建议可能会被接受,也可能不会被接受。例如,假设原始链处于名为“波士顿”的状态,并且即将转换到“旧金山”。那么对于新链,我们要么接受建议并前往旧金山,要么拒绝建议并在下一步保持在波士顿。通过仔细选择接受建议的概率,这种简单的修改保证了新链具有所需的平稳分布。
算法 12.1.1 (Metropolis-Hastings)。令 \(s = (s_1, \dots, s_M)\) 为状态空间 \(\{1, \dots, M\}\) 上理想的平稳分布。假设对所有 \(i\) 都有 \(s_i > 0\)(如果不是,只需从状态空间中删除任何 \(s_i = 0\) 的状态 \(i\))。假设 \(P = (p_{ij})\) 是状态空间 \(\{1, \dots, M\}\) 上某个马尔可夫链的转移矩阵。直观地说,\(P\) 是一个我们知道如何运行但其平稳分布并非我们所期望的马尔可夫链。
我们的目标是修改 \(P\) 以构造一个平稳分布为 \(s\) 的马尔可夫链 \(X_0, X_1, \dots\)。我们将为此给出一个 Metropolis-Hastings 算法。从任何状态 \(X_0\) 开始(随机选择或确定性选择),并假设新链当前处于 \(X_n\)。为了让新链移动一步,请执行以下操作。
如果 \(X_n = i\),使用原始转移矩阵 \(P\) 的第 \(i\) 行中的转移概率提出一个新状态 \(j\)。
计算接受概率: \[ a_{ij} = \min\left( \frac{s_j p_{ji}}{s_i p_{ij}}, 1 \right) \]
抛一枚概率为 \(a_{ij}\) 出现正面(Heads)的硬币。
如果硬币出现正面,接受该建议(即前往 \(j\)),令 \(X_{n+1} = j\)。否则,拒绝该建议(即留在 \(i\)),令 \(X_{n+1} = i\)。
个人注:在计算机科学和概率模拟中,“生成一个 \([0, 1]\) 之间的随机数 \(u\) 并与 \(a_{ij}\) 比较”,就是实现“抛一枚正面概率为 \(a_{ij}\) 的硬币”最标准、最通用的物理手段。
也就是说,Metropolis-Hastings 链使用原始转移概率 \(p_{ij}\) 来提出下一步去哪里的建议,然后以概率 \(a_{ij}\) 接受该建议,在拒绝的情况下保持在其当前状态。该算法一个特别好的方面是,不需要知道 \(s\) 的归一化常数,因为无论如何它在 \(s_j/s_i\) 中都会被消掉。例如,在某些问题中,我们可能希望平稳分布在所有状态上是均匀的(即 \(s = (1/M, 1/M, \dots, 1/M)\)),但状态数 \(M\) 很大且未知,而计算 \(M\) 将是一个非常困难的计数问题。幸运的是,无论 \(M\) 是多少,\(s_j/s_i = 1\),因此我们可以简单地令 \(s \propto (1, 1, \dots, 1)\),并且我们可以在不必知道 \(M\) 的情况下计算 \(a_{ij}\)。
当算法运行时,\(a_{ij}\) 分母中的 \(p_{ij}\) 永远不会为 0,因为如果 \(p_{ij} = 0\),原始链将永远不会提出从 \(i\) 到 \(j\) 的建议。此外,如果 \(p_{ii} > 0\),建议的状态 \(j\) 有可能等于当前状态 \(i\);在这种情况下,无论建议是否被接受,链都会留在 \(i\)。(拒绝留在 \(i\) 的建议但仍然留在那里,就像一个刚被禁足的孩子说:“是的,我会待在我的房间里,但不是因为你让我这么做的!”)
个人注:Metropolis-Hastings (MH) 算法的核心机制:“提议” (Proposal) 与 “接受” (Acceptance) 的两步走策略。
拆解公式:\(q_{ij} = p_{ij} a_{ij}\)
在 MH 算法中,从状态 \(i\) 转移到状态 \(j\)(且 \(i \neq j\))的实际转移概率 \(q_{ij}\) 是由两个独立事件的概率相乘得到的:
\(p_{ij}\) (提议概率):
算法首先从当前的提议分布(Proposal Distribution)中采样。它决定了:“如果我在 \(i\),我有多少概率想要跳到 \(j\)?”。
\(a_{ij}\) (接受概率):
一旦提议了 \(j\),算法会根据目标分布 \(s\) 进行计算,决定:“我是否同意这次跳转?”。
只有当“提议了 \(j\)”且“接受了 \(j\)”同时发生时,状态才会发生转移。 因此,根据概率的乘法公式,实际的转移概率就是两者的乘积。
具体的采样例子见《MCMC算法的例子.md》
如果你不进行这个随机判定,而是强行每次都按比例“劈开”状态(比如把 0.25 个自己挪过去,0.75 个自己留下来),那你做的就不是采样(Sampling),而是在做数值计算(Numerical Computing)去解平稳分布了。采样算法的精髓就在于:通过大量的“跳”或“不跳”的随机实验,在宏观统计上逼近那个理论概率。
现在我们将证明 Metropolis-Hastings 链是可逆的,且平稳分布为 \(s\)。
证明。令 \(Q\) 为 Metropolis-Hastings 链的转移矩阵。我们只需要检查所有 \(i\) 和 \(j\) 的可逆性条件 \(s_i q_{ij} = s_j q_{ji}\)。对于 \(i = j\) 这是显而易见的,所以假设 \(i \neq j\)。如果 \(q_{ij} > 0\),那么 \(p_{ij} > 0\)(如果链甚至不能提出从 \(i\) 到 \(j\) 的建议,它就无法从 \(i\) 到 \(j\))且 \(p_{ji} > 0\)(否则接受概率将为 0)。反之,如果 \(p_{ij} > 0\) 且 \(p_{ji} > 0\),则 \(q_{ji} > 0\)。因此 \(q_{ij}\) 和 \(q_{ji}\) 要么同为零,要么同为非零。我们可以假设它们都非零。
那么有: \[ q_{ij} = p_{ij} a_{ij} \]
因为从 \(i\) 开始,到达 \(j\) 的唯一方法是先提出这样做,然后接受该建议。首先考虑 \(s_j p_{ji} \leq s_i p_{ij}\) 的情况。我们有: \[ a_{ij} = \frac{s_j p_{ji}}{s_i p_{ij}}, \quad a_{ji} = 1 \]
因此: \[ s_i q_{ij} = s_i p_{ij} a_{ij} = s_i p_{ij} \frac{s_j p_{ji}}{s_i p_{ij}} = s_j p_{ji} = s_j p_{ji} a_{ji} = s_j q_{ji} \]
对称地,如果 \(s_j p_{ji} > s_i p_{ij}\),通过在上述计算中交换 \(i\) 和 \(j\) 的角色,我们再次得到 \(s_i q_{ij} = s_j q_{ji}\)。由于可逆性条件成立,因此 \(s\) 是转移矩阵为 \(Q\) 的链的平稳分布。
个人注:太牛了!
12.1.2. Metropolis-Hastings 算法是构造具有所需平稳分布的马尔可夫链的一种极其通用的方法。在上述表述中,\(s\) 和 \(P\) 都是非常通用的,除了要求它们在同一个状态空间上之外,没有规定它们之间有任何联系。然而在实践中,建议分布(proposal distribution)的选择极其重要,因为它会对链收敛到平稳分布的速度产生巨大影响。
如何选择一个好的建议分布是一个复杂的主题,这里不作详细讨论。直观地说,接受率非常低的建议分布收敛速度会很慢(因为链很少移动)。但高接受率也可能并不理想,因为它可能表明该链倾向于做出微小、胆怯的建议。在一个巨大的状态空间中,这样的链将需要非常长的时间才能探索整个空间。
以下是几个关于如何使用 Metropolis-Hastings 算法从分布中进行模拟的例子。
例 12.1.3 (Zipf 分布模拟)。令 \(M \geq 2\) 为一个整数。如果随机变量 \(X\) 的 PMF 为: \[ P(X=k) = \frac{1/k^a}{\sum_{j=1}^{M}(1/j^a)} \]
对于 \(k=1, 2, \dots, M\)(其他情况为 0),则称 \(X\) 服从参数为 \(a > 0\) 的 Zipf 分布。该分布在语言学中广泛用于研究单词出现的频率。
创建一个马尔可夫链 \(X_0, X_1, \dots\),其平稳分布为 Zipf 分布,且对所有 \(n\) 满足 \(|X_{n+1}-X_n| \leq 1\)。你的回答应提供关于如何获得链的每一步移动的简单、精确的描述,即如何对每个 \(n\) 从 \(X_n\) 转移到 \(X_{n+1}\)。
解:
在确定建议分布后,我们可以使用 Metropolis-Hastings 算法。有许多可能的建议分布,但一个简单的选择是以下在 \(\{1, 2, \dots, M\}\) 上的随机游走。对于状态 \(i\) 且 \(i \neq 1, i \neq M\),以 \(1/2\) 的概率移动到状态 \(i-1\) 或 \(i+1\)。对于状态 1,以 \(1/2\) 的概率留在原处或移动到状态 2。对于状态 \(M\),以 \(1/2\) 的概率留在原处或移动到状态 \(M-1\)。该链如下图所示。

令 \(P\) 为该链的转移矩阵。由于 \(P\) 是对称矩阵,根据命题 11.4.3,\(P\) 的平稳分布是均匀分布。Metropolis-Hastings 允许我们将 \(P\) 转化(transmogrify)为一个平稳分布为 Zipf 分布的链。
令 \(X_0\) 为任意起始状态,按如下方式生成序列 \(X_0, X_1, \dots\)。如果链当前处于状态 \(i\),则:
- 根据建议链 \(P\) 生成一个建议状态 \(j\)。
- 以概率 \(\min(i^a/j^a, 1)\) 接受该建议。如果建议被接受,则前往 \(j\);否则,留在 \(i\)。
这个链易于实现,且每步移动所需的计算量非常小;请注意,运行该链并不需要知道归一化常数 \(\sum_{j=1}^{M}(1/j^a)\)。
个人注:知道Q之后:
对应的下一步操作 “系统稳定后是什么样子?” 解 \(sQ=s\) 得到平稳分布。 “走 \(n\) 步后会在哪?” 计算 \(Q^n\)。 “平均多少步能回到起点?” 求平稳分布后取倒数 \(1/s_i\)。 “平均多少步会被‘吸收’?” 计算基本矩阵 \((I-T)^{-1}\)。 采样流程图:
\[\text{初始状态 } X_0 \xrightarrow{\text{运行 } Q} \underbrace{X_1, \dots, X_k}_{\text{丢弃(Burn-in)}} \rightarrow \underbrace{X_{k+1}, \dots, X_N}_{\text{保留(采样)}} \xrightarrow{\text{稀疏化}} \text{最终样本}\]
MCMC 采样:得到的是一串模拟出的“实际经历”(比如得到一份包含 300 个雨天、700 个晴天的 1000 天天气记录)。
例 12.1.4 (Beta 分布模拟)。现在让我们回到本章开头介绍的 Beta 分布模拟问题。假设我们想要生成 \(W \sim \text{Beta}(a, b)\),但我们不知道 R 语言中的 rbeta 命令。相反,我们拥有的是独立同分布的 \(\text{Unif}(0, 1)\) 随机变量。
如果 \(a\) 和 \(b\) 是正整数,如何利用“故事”和均匀分布的普适性来精确生成 \(W\)?
如果 \(a\) 和 \(b\) 是任何正实数,如何借助状态空间 \((0, 1)\) 上的马尔可夫链生成近似服从 \(\text{Beta}(a, b)\) 的 \(W\)?
解:
- 直接对 Beta 分布应用均匀分布普适性较难,所以我们先使用“银行-邮局故事”:如果 \(X \sim \text{Gamma}(a, 1)\) 和 \(Y \sim \text{Gamma}(b, 1)\) 是独立的,那么 \(X/(X + Y) \sim \text{Beta}(a, b)\)。因此,如果我们能模拟 Gamma 分布,就能模拟 Beta 分布!
为了模拟 \(X \sim \text{Gamma}(a, 1)\),我们可以使用 \(X_1 + X_2 + \dots + X_a\),其中 \(X_j\) 是独立同分布的 \(\text{Expo}(1)\);类似地,我们可以将 \(Y \sim \text{Gamma}(b, 1)\) 模拟为 \(b\) 个独立同分布的 \(\text{Expo}(1)\) 随机变量之和。最后,通过对 \(\text{Expo}(1)\) 的 CDF 求逆并应用均匀分布普适性,对于 \(U \sim \text{Unif}(0, 1)\),\(-\log(1-U) \sim \text{Expo}(1)\),因此我们可以根据需要轻松构造任意数量的 \(\text{Expo}(1)\) 随机变量。
- 让我们使用 Metropolis-Hastings 算法。虽然我们只介绍了针对有限状态空间的 Metropolis-Hastings,但对于无限状态空间,其思想是类似的。我们可用的一个简单建议链由独立的 \(\text{Unif}(0, 1)\) 随机变量组成。也就是说,在区间 \((0, 1)\) 上建议的状态始终是一个全新的、独立于当前状态的 \(\text{Unif}(0, 1)\) 变量。由此产生的 Metropolis-Hastings 链被称为独立采样器(independence sampler)。
令 \(W_0\) 为任何起始状态,并按如下方式生成链 \(W_0, W_1, \dots\)。如果链当前处于状态 \(w\),则:
- 通过抽取一个 \(\text{Unif}(0, 1)\) 随机变量生成一个建议 \(u\)。
- 以概率 \(\min\left( \frac{u^{a-1}(1-u)^{b-1}}{w^{a-1}(1-w)^{b-1}}, 1 \right)\) 接受该建议。如果建议被接受,则前往 \(u\);否则,留在 \(w\)。
同样,运行该链不需要归一化常数。在获得接受概率时,\(\text{Beta}(a, b)\) 的 PDF 扮演了 \(s\) 的角色(因为它是所需的平稳分布),而 \(\text{Unif}(0, 1)\) 的 PDF 扮演了 \(p_{ij}\)(以及 \(p_{ji}\))的角色,因为建议是独立于当前状态的 \(\text{Unif}(0, 1)\) 随机变量。
通过运行该马尔可夫链,当 \(n\) 很大时,\(W_n, W_{n+1}, W_{n+2}, \dots\) 近似服从 \(\text{Beta}(a, b)\)。请注意,这些是相关的随机变量,而不是独立同分布的抽取。
12.1.5(MCMC 生成相关的样本)。在为蒙特卡罗计算运行马尔可夫链 \(X_0, X_1, \dots\) 时,一个主要问题是运行多长时间。部分原因在于,通常很难知道在时间 \(n\) 时链的分布与平稳分布有多接近。另一个问题是 \(X_0, X_1, \dots\) 通常是相关的。有些链倾向于陷入状态空间的某些区域,而不是探索整个空间。如果一个链很容易被困住,那么 \(X_n\) 与 \(X_{n+1}\) 之间可能存在高度的正相关。滞后 \(k\) 的自相关性(autocorrelation at lag \(k\))是指当 \(n\) 增长到极限时,\(X_n\) 与其 \(k\) 步之后的值 \(X_{n+k}\) 之间的相关性。我们希望滞后 \(k\) 的自相关性随着 \(k\) 的增加而迅速趋于 0。高自相关性往往意味着蒙特卡罗近似的方差较大。关于运行链多长时间的分析以及寻找判断链是否运行足够长的诊断方法是目前活跃的研究领域。一些通用的建议是将你的链运行非常大的步数,并尝试从不同的起点运行多条链,以观察结果的稳定性。
Metropolis-Hastings 即使对于巨大的状态空间也通常是有用的。它甚至可以用于一些起初听起来与模拟分布毫无关系的课题,例如破译密码。
例 12.1.6(破译密码)。马尔可夫链最近已被应用于破译密码;本例将介绍实现这一目标的一种方式。(有关此类应用的进一步信息,请参阅 Diaconis [6] 以及 Chen 和 Rosenthal [3]。)代换密码(substitution cipher)是字母 a 到 z 的一个置换 \(g\),通过将每个字母 \(\alpha\) 替换为 \(g(\alpha)\) 来对消息进行加密。例如,如果 \(g\) 是由下式给出的置换:
abcdefghijklmnopqrstuvwxyz
zyxwvutsrqponmlkjihgfedcba
其中第二行顺序列出了 \(g(a), g(b), \dots, g(z)\) 的值,那么我们会将单词“statistics”加密为“hgzgrhgrxh”。(如果需要,我们还可以包括大写字母、空格和标点符号。)状态空间是字母 a 到 z 的所有 \(26! \approx 4 \cdot 10^{26}\) 种置换。这是一个极其巨大的空间:如果我们必须尝试使用这些置换中的每一个来解码一段文本,并且每纳秒能处理一个置换,那么处理完所有置换仍需要超过 120 亿年。因此,一个一个检查每个置换的暴力研究是不可行的;相反,我们将研究随机置换。
- 考虑这样一个马尔可夫链:在 1 到 26 之间随机选取两个不同的坐标,并交换第二行的对应项。例如,如果我们选取 7 和 20,那么:
abcdefghijklmnopqrstuvwxyz
zyxwvutsrqponmlkjihgfedcba
变为:
abcdefghijklmnopqrstuvwxyz
zyxwvugsrqponmlkjihtfedcba
求从置换 \(g\) 经过一步转移到置换 \(h\) 的概率(对所有 \(g, h\)),并求该链的平稳分布。
- 假设我们有一个系统为每个置换 \(g\) 分配一个正的“评分”\(s(g)\)。直观地说,这可以衡量在已知 \(g\) 为所用密码的前提下,获得观察到的加密文本的可能性。使用 Metropolis-Hastings 算法构造一个马尔可夫链,其平稳分布与所有评分 \(s(g)\) 的列表成正比。
解:
从 \(g\) 到 \(h\) 经过一步转移的概率为 0,除非 \(h\) 可以通过交换 \(g\) 第二行的两个项得到。假设 \(h\) 可以通过这种方式得到,由于共有 \(\binom{26}{2}\) 种此类交换且概率均等,故概率为 \(1/\binom{26}{2}\)。由于通过执行足够多的交换可以从任何置换变到任何其他置换,因此该马尔可夫链是不可约的。(想象一下通过每次交换两张牌来重新排列一副扑克牌;通过这样做足够多次,可以将牌重新排序为任何想要的配置。)注意 \(p(g,h) = p(h,g)\),其中 \(p(g,h)\) 是从 \(g\) 到 \(h\) 的转移概率。由于转移矩阵是对称的,平稳分布在字母 a 到 z 的所有 \(26!\) 个置换上是均匀分布的。
对于我们的建议链,我们将使用 (a) 中的链。从任何状态 \(g\) 开始,使用 (a) 中的链生成一个建议 \(h\)。抛一枚正面朝上概率为 \(\min(s(h)/s(g), 1)\) 的硬币。如果正面朝上,前往 \(h\);如果是反面,留在 \(g\)。
为了证明这具有所需的平稳分布,我们可以援引算法 12.1.1 的一般性证明,或者直接检查可逆性条件。作为练习,我们进行后者:我们需要对所有 \(g\) 和 \(h\) 满足 \(s(g)q(g,h) = s(h)q(h,g)\),其中 \(q(g,h)\) 是修改后的链中从 \(g\) 到 \(h\) 的转移概率。如果 \(g=h\) 或 \(q(g,h) = 0\),等式显然成立,所以假设 \(i \neq j\) 且 \(q(g,h) \neq 0\)。令 \(p(g,h)\) 为 (a) 中的转移概率(即处于 \(g\) 时建议 \(h\) 的概率)。
首先考虑 \(s(g) \leq s(h)\) 的情况。则 \(q(g,h) = p(g,h)\) 且 \[ q(h,g) = p(h,g) \frac{s(g)}{s(h)} = p(g,h) \frac{s(g)}{s(h)} = q(g,h) \frac{s(g)}{s(h)}, \]
故 \(s(g)q(g,h) = s(h)q(h,g)\)。现在考虑 \(s(h) < s(g)\) 的情况。通过对称参数(交换 \(g\) 和 \(h\) 的角色),我们再次得到 \(s(g)q(g,h) = s(h)q(h,g)\)。因此,\(g\) 的平稳概率与它的评分 \(s(g)\) 成正比。
换句话说,通过使用 Metropolis-Hastings 算法,我们从一个长期来看访问所有密码概率均等的马尔可夫链开始,创建了一个新的马尔可夫链,其平稳分布会根据评分对密码进行排序,在长期运行中访问最有希望的密码的频率最高。
这是另一个具有巨大状态空间的 MCMC 示例,乍一看似乎与模拟分布没有太大关系。这个例子指出了一个事实:MCMC 不仅可以用于采样,还可以用于优化。
例 12.1.7(背包问题)。窃贼比尔博在史矛革的巢穴中发现了 \(m\) 件宝物。比尔博正在决定偷走哪些宝物(或者说是公正地收回,这取决于一个人的视角);由于他能携带的最大重量为 \(w\) 磅,他无法一次性带走所有东西。将宝物标记为 1 到 \(m\),并假设第 \(j\) 件宝物价值 \(g_j\) 枚金币,重 \(w_j\) 磅。因此,比尔博必须选择一个向量 \(x = (x_1, \dots, x_m)\),如果他偷走第 \(j\) 件宝物,则 \(x_j\) 为 1,否则为 0,且满足 \(x_j = 1\) 的宝物总重量不超过 \(w\)。令 \(C\) 为所有此类向量的空间,因此 \(C\) 由所有满足 \(\sum_{j=1}^{m} x_j w_j \leq w\) 的二元向量 \((x_1, \dots, x_m)\) 组成。
比尔博希望将带走的宝物总价值最大化。寻找最优解是一个极其困难的问题,被称为背包问题(knapsack problem),它在计算机科学领域有着悠久的历史。通常情况下,暴力破解法是完全不可行的。比尔博决定改用 MCMC 来探索空间 \(C\)——幸运的是,他随身带着一台运行 R 语言的笔记本电脑。
考虑以下马尔可夫链。从 \((0, 0, \dots, 0)\) 开始。该链的一步移动如下:假设当前状态为 \(x = (x_1, \dots, x_m)\)。在 \(\{1, 2, \dots, m\}\) 中均匀随机地选择一个 \(J\),并将 \(x_J\) 替换为 \(1-x_J\)(即切换是否带走该宝物)从而得到 \(y\)。如果 \(y\) 不在 \(C\) 中,则留在 \(x\);如果 \(y\) 在 \(C\) 中,则移动到 \(y\)。证明在该链中,\(C\) 上的均匀分布是平稳的。
证明 (a) 中的链是不可约的,并且它可能是非周期的,也可能不是(取决于 \(w, w_1, \dots, w_m\))。
- 中的链是获得近似均匀解的有效方法,但比尔博更感兴趣的是找到那些(以金币计)价值较高的解。在本部分中,目标是构造一个马尔可夫链,其平稳分布赋予任何特定的高价值解的概率远高于任何特定的低价值解。具体而言,假设我们想要从如下分布中进行模拟: \[ s(x) \propto e^{\beta V(x)} \]
其中 \(V(x) = \sum_{j=1}^{m} x_j g_j\) 是以金币计的 \(x\) 的价值,而 \(\beta\) 是一个正数常数。该分布背后的思想是赋予每个高价值解比每个低价值解指数级更多的概率。创建一个平稳分布符合要求的马尔可夫链。
解:
转移矩阵是对称的,因为对于 \(x \neq y\),从 \(x\) 到 \(y\) 以及从 \(y\) 到 \(x\) 的转移概率要么同为 0,要么同为 \(1/m\)。因此,平稳分布在 \(C\) 上是均匀的。
我们可以通过一次丢弃一件宝物,从任何 \(x \in C\) 到达 \((0, 0, \dots, 0)\)。我们可以通过一次捡起一件宝物,从 \((0, 0, \dots, 0)\) 到达任何 \(y \in C\)。结合这两点,我们可以从任何地方到达任何地方,因此该链是不可约的。
为了研究周期性,让我们看一些简单的情况。首先考虑 \(w_1 + \dots + w_m < w\) 的简单情况,即比尔博可以同时带走所有宝物。此时允许所有长度为 \(m\) 的二元向量。那么 \((0, 0, \dots, 0)\) 的周期为 2,因为从该状态出发,比尔博需要捡起然后再放下宝物才能回到该状态。事实上,如果比尔博从 \((0, 0, \dots, 0)\) 开始,经过任何奇数步移动后,他携带的宝物数量都将是奇数。
现在考虑 \(w_1 > w\) 的情况,即第一件宝物对比尔博来说太重了。从任何 \(x \in C\) 出发,都有 \(1/m\) 的机会尝试捡起第一件宝物,如果发生这种情况,链将停留在 \(x\)。因此每个状态的周期为 1。
- 我们可以应用 Metropolis-Hastings 算法,利用 (a) 中的链来提出建议。从 \((0, 0, \dots, 0)\) 开始。假设当前状态为 \(x = (x_1, \dots, x_m)\)。那么:
- 在 \(\{1, 2, \dots, m\}\) 中均匀随机地选择一个 \(J\),并通过将 \(x_J\) 替换为 \(1-x_J\) 从 \(x\) 得到 \(y\)。
- 如果 \(y\) 不在 \(C\) 中,留在 \(x\)。如果 \(y\) 在 \(C\) 中,抛一枚正面朝上概率为 \(\min(1, e^{\beta(V(y)-V(x))})\) 的硬币。如果硬币正面朝上,前往 \(y\);否则,留在 \(x\)。
该链将收敛到所需的平稳分布。但是应该如何选择 \(\beta\) 呢?如果 \(\beta\) 非常大,那么最佳解会被赋予非常高的概率,但链收敛到平稳分布的速度可能会非常慢,因为它很容易陷入局部众数(local modes):链可能会发现自己处于一个状态,该状态虽然不是全局最优的,但仍优于通过一步移动可以到达的其他状态,那么拒绝前往别处的建议的概率可能会非常高。另一方面,如果 \(\beta\) 接近 0,那么链很容易探索整个空间,但链发现优秀解的动力却不足。
一种被称为模拟退火(simulated annealing)的优化技术避免了必须选择单一 \(\beta\) 值的麻烦。相反,人们指定一个 \(\beta\) 值的序列,使得 \(\beta\) 随时间逐渐增加。起初,\(\beta\) 很小,可以广泛探索空间 \(C\)。随着 \(\beta\) 变得越来越大,平稳分布越来越集中在最佳的一个或多个解上。“模拟退火”这个名字来源于与金属退火的类比,金属退火是将金属加热到高温,然后逐渐冷却,直到达到非常坚固、稳定的状态的过程;\(\beta\) 对应于温度的倒数。
正如例 12.1.4 中提到的,Metropolis-Hastings 算法也可以应用于连续状态空间,只需将概率质量函数(PMF)替换为概率密度函数(PDF)。这在贝叶斯推断中极其有用,因为我们经常需要研究未知参数的后验分布。该后验分布在分析上可能非常复杂,且可能具有未知的归一化常数。
MCMC 方法是获取大量来自某个马尔可夫链的抽取值,而该链的平稳分布正是所需的后验分布。然后,我们可以利用这些抽取值来近似真实的后验分布。例如,我们可以使用这些抽取值的样本均值来估计后验均值,使用样本中位数来估计后验中位数。
Gelman 等人 [10] 和 McElreath [18] 对贝叶斯思维和贝叶斯数据分析进行了详尽的介绍,涵盖了广泛的应用,并侧重于统计建模和模拟。这两本书的各种补充材料可以分别在 和 找到。
例 12.1.8(正态-正态共轭性)。令 \(Y|\theta \sim N(\theta, \sigma^2)\),其中 \(\sigma^2\) 已知但 \(\theta\) 未知。在贝叶斯框架下,我们将 \(\theta\) 视为随机变量,其先验分布由 \(\theta \sim N(\mu, \tau^2)\) 给出(\(\mu\) 和 \(\tau^2\) 为已知常数)。也就是说,我们有如下双层模型: \[ \theta \sim N(\mu, \tau^2) \] \[ Y|\theta \sim N(\theta, \sigma^2) \]
描述在观测到 \(Y\) 的值后,如何使用 Metropolis-Hastings 算法找到 \(\theta\) 的后验均值和方差。
解:
在观测到 \(Y=y\) 后,我们可以根据贝叶斯法则更新我们对 \(\theta\) 的先验不确定性。由于我们感兴趣的是 \(\theta\) 的后验分布,任何不依赖于 \(\theta\) 的项都可以被视为归一化常数的一部分。因此:
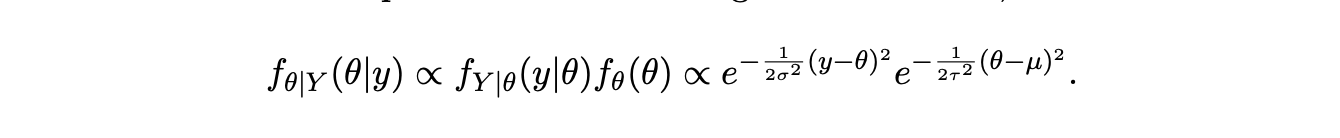
由于指数部分是关于 \(\theta\) 的二次函数,我们认出 \(\theta\) 的后验 PDF 是一个正态分布的 PDF。后验分布仍保持在正态族中,这告诉我们正态分布是正态分布的共轭先验。事实上,通过配方(这是一项相当乏味的计算,我们在此省略),我们可以得到 \(\theta\) 后验分布的显式公式:
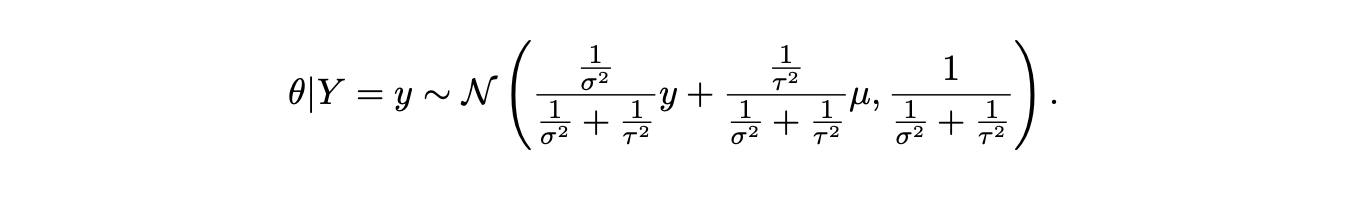
让我们来理解一下这个公式:
- 它说明 \(\theta\) 的后验均值 \(E(\theta|Y=y)\) 是先验均值 \(\mu\) 和观测数据 \(y\) 的加权平均。权重取决于我们在获取数据之前对 \(\theta\) 的确定程度,以及数据的测量精度。如果我们在获取数据前就已经非常确定 \(\theta\) 的值,那么 \(\tau^2\) 会很小,\(1/\tau^2\) 会很大,这会给先验均值 \(\mu\) 赋予很大权重。另一方面,如果数据非常精确,那么 \(\sigma^2\) 会很小,\(1/\sigma^2\) 会很大,这会给数据 \(y\) 赋予很大权重。
- 对于后验方差,如果我们定义“精度”为方差的倒数,那么结果简单地说明 \(\theta\) 的后验精度是先验精度 \(1/\tau^2\) 与数据精度 \(1/\sigma^2\) 之和。
这一切都很好,但假设我们不知道如何配方,或者我们想针对 \(y, \sigma^2, \mu, \tau^2\) 的特定值来检查我们的计算。我们可以通过从 \(\theta\) 的后验分布中进行模拟来实现这一点,即利用 Metropolis-Hastings 算法构造一个平稳分布为 \(f_{\theta|Y}(\theta|y)\) 的马尔可夫链。同样的方法也可以应用于许多在分析上比正态分布复杂得多的分布。用于生成 \(\theta_0, \theta_1, \dots\) 的 Metropolis-Hastings 算法如下:
如果 \(\theta_n = x\),根据某种转移规则提出一个新状态 \(x'\)。在连续状态空间中执行此操作的一种方法是生成一个均值为 0 的正态随机变量 \(\epsilon_n\),并将其加到当前状态以获得建议状态:换句话说,我们生成 \(\epsilon_n \sim N(0, d^2)\)(\(d\) 为常数),然后设置 \(x' = x + \epsilon_n\)。这是连续状态空间中转移矩阵的类似物。唯一的额外细节是确定 \(d\);在实践中,我们尝试选择一个既不太大也不太小的适中值。
接受概率为: \[ a(x, x') = \min\left( \frac{s(x')p(x', x)}{s(x)p(x, x')}, 1 \right) \]
其中 \(s\) 是所需的平稳 PDF(离散情况下为 PMF),而 \(p(x, x')\) 是从 \(x\) 提出 \(x'\) 的概率密度(离散情况下为 \(p_{ij}\))。
在本题中,我们希望平稳 PDF 是 \(f_{\theta|Y}\),因此我们将其用作 \(s\)。至于 \(p(x, x')\),从 \(x\) 提出 \(x'\) 等同于 \(\epsilon_n = x' - x\),因此我们在 \(x' - x\) 处评估 \(\epsilon_n\) 的 PDF,得到: \[ p(x, x') = \frac{1}{\sqrt{2\pi}d} e^{-\frac{1}{2d^2}(x'-x)^2} \]
然而,由于 \(p(x', x) = p(x, x')\),这些项在接受概率中会被消去,剩下: \[ a(x, x') = \min\left( \frac{f_{\theta|Y}(x'|y)}{f_{\theta|Y}(x|y)}, 1 \right) \]
归一化常数再次在接受概率的分子和分母中被消去。
抛一枚独立于马尔可夫链的硬币,其正面朝上的概率为 \(a(x, x')\)。
如果硬币正面朝上,接受建议并设置 \(\theta_{n+1} = x'\)。否则,保持在原位并设置 \(\theta_{n+1} = x\)。
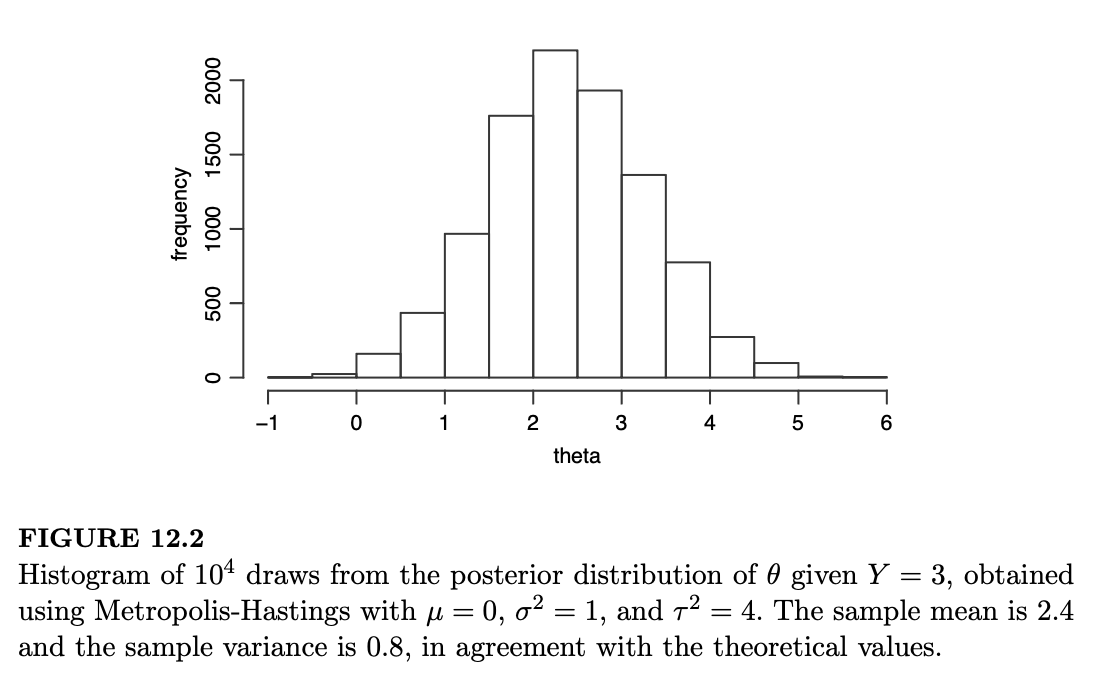
我们以 \(Y=3, \mu=0, \sigma^2=1, \tau^2=4\) 以及 \(d=1\) 为设置,将该算法运行了 \(10^4\) 次迭代。图 12.2 显示了所得 \(\theta\) 后验分布抽取值的直方图。后验分布看起来确实像一条正态曲线。我们可以使用样本均值和样本方差来估计后验均值和方差。在我们获得的抽取值中,样本均值为 2.4,样本方差为 0.8。这些结果与理论值非常吻合: \[ E(\theta|Y = 3) = \frac{\frac{1}{\sigma^2}y + \frac{1}{\tau^2}\mu}{\frac{1}{\sigma^2} + \frac{1}{\tau^2}} = \frac{1 \cdot 3 + \frac{1}{4} \cdot 0}{1 + \frac{1}{4}} = 2.4 \] \[ Var(\theta|Y = 3) = \frac{1}{\frac{1}{\sigma^2} + \frac{1}{\tau^2}} = \frac{1}{1 + \frac{1}{4}} = 0.8 \]
(注:原文中期望计算结果 2.8 疑似笔误,按公式计算应为 2.4)。后验均值比先验均值更接近观测数据,这是合理的,因为 \(\tau^2\) 大于 \(\sigma^2\),对应于相对较高的先验不确定性水平。使用本章 R 语言部分提供的代码,你可以观察后验分布如何随 \(y, \mu, \sigma^2\) 和 \(\tau^2\) 的不同取值而变化。
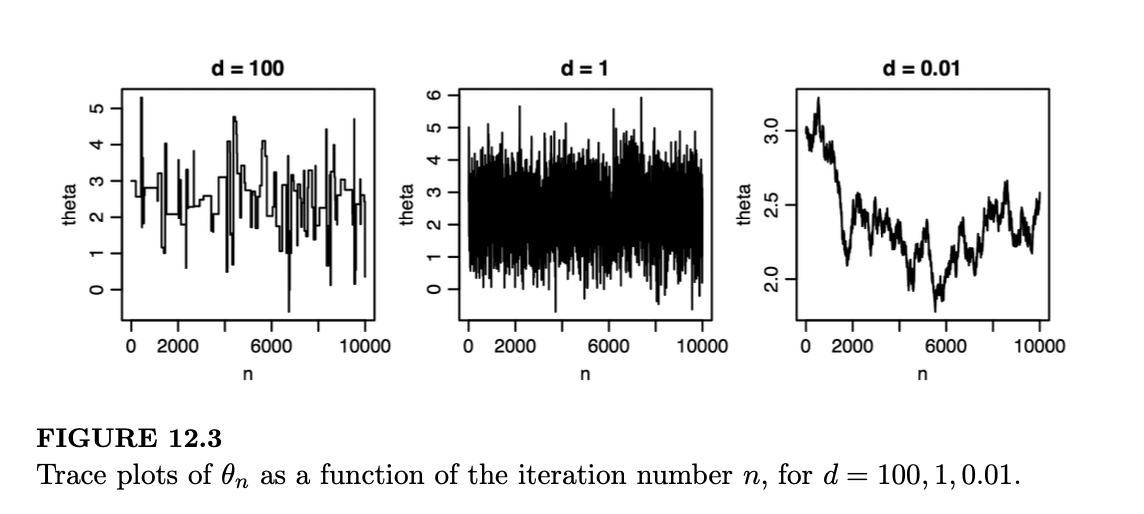
为了帮助诊断我们的马尔可夫链是否充分探索了状态空间,我们可以制作迹图(trace plot),即样本 \(\theta_n\) 随 \(n\) 变化的图形。图 12.3 显示了对应于建议分布标准差 \(d\) 的三种不同选择(即 \(d = 100, d = 1, d = 0.01\))的三张迹图。\(d = 100\) 的迹图有许多平坦区域,说明链停留在原位。这表明 \(d\) 太大了,导致建议经常被拒绝。另一方面,\(d = 0.01\) 又太小了;从迹图中我们可以看到,链每步移动极其微小,无法从起点探索到很远的地方。\(d = 1\) 的迹图恰到好处,既没有 \(d = 100\) 时的低接受率,也没有 \(d = 0.01\) 时的移动受限。
在这个例子中,\(\theta\) 的后验分布可以通过解析方法获得,因此我们使用 MCMC 是出于演示目的,以展示 MCMC 获得的结果与其理论对应值是一致的。但同样的技术也适用于先验不共轭且后验不是已知分布的问题。
12.2 吉布斯采样
Gibbs sampling
吉布斯采样是一种用于从联合分布中获取近似抽取值的 MCMC 算法,其基础是每次从一个条件分布中进行采样:在每个阶段,通过从该变量给定所有其他变量的条件分布中进行抽取,来更新其中一个变量(保持所有其他变量固定)。在这些条件分布易于处理的问题中,这种方法特别有用。
首先,我们将了解吉布斯采样器在二元情况下的工作原理,其中理想的平稳分布是离散随机变量 \(X\) 和 \(Y\) 的联合 PMF。根据更新执行的顺序,吉布斯采样器有几种形式。我们将介绍两种主要的吉布斯采样器:系统扫描(systematic scan),即更新按确定的顺序扫描各分量;以及随机扫描(random scan),即在每个阶段更新随机选择的分量。
算法 12.2.1(系统扫描吉布斯采样器 Systematic scan Gibbs sampler)。令 \(X\) 和 \(Y\) 为离散随机变量,联合 PMF 为 \(p_{X,Y}(x,y) = P(X=x, Y=y)\)。我们希望构造一个二维马尔可夫链 \((X_n, Y_n)\),其平稳分布为 \(p_{X,Y}\)。系统扫描吉布斯采样器通过交替更新 \(X\) 分量和 \(Y\) 分量来运行。如果当前状态为 \((X_n, Y_n) = (x_n, y_n)\),则我们在保持 \(Y\) 分量固定的情况下更新 \(X\) 分量,然后在保持 \(X\) 分量固定的情况下更新 \(Y\) 分量:
- 从 \(X\) 给定 \(Y=y_n\) 的条件分布中抽取 \(x_{n+1}\),并设置 \(X_{n+1} = x_{n+1}\)。
- 从 \(Y\) 给定 \(X=x_{n+1}\) 的条件分布中抽取 \(y_{n+1}\),并设置 \(Y_{n+1} = y_{n+1}\)。
不断重复步骤 1 和 2,链 \((X_0, Y_0), (X_1, Y_1), (X_2, Y_2), \dots\) 的平稳分布即为 \(p_{X,Y}\)。
算法 12.2.2(随机扫描吉布斯采样器Random scan Gibbs sampler)。同上,令 \(X\) 和 \(Y\) 为离散随机变量,联合 PMF 为 \(p_{X,Y}(x,y)\)。我们希望构造一个二维马尔可夫链 \((X_n, Y_n)\),其平稳分布为 \(p_{X,Y}\)。随机扫描吉布斯采样器的每一步移动都会均匀随机地选取一个分量,并根据给定另一个分量的条件分布来更新它:
以相等的概率选择要更新的分量。
如果选择了 \(X\) 分量,则从 \(X\) 给定 \(Y=y_n\) 的条件分布中抽取一个值 \(x_{n+1}\),并设置 \(X_{n+1} = x_{n+1}, Y_{n+1} = y_n\)。
同样,如果选择了 \(Y\) 分量,则从 \(Y\) 给定 \(X=x_n\) 的条件分布中抽取一个值 \(y_{n+1}\),并设置 \(X_{n+1} = x_n, Y_{n+1} = y_{n+1}\)。
不断重复步骤 1 和 2,链 \((X_0, Y_0), (X_1, Y_1), (X_2, Y_2), \dots\) 的平稳分布即为 \(p_{X,Y}\)。
吉布斯采样可以自然地推广到高维。如果我们想从 \(d\) 维联合分布中采样,我们构造的马尔可夫链将是一个 \(d\) 维随机向量序列。在每个阶段,我们选择向量的一个分量进行更新,并从该分量给定其他分量最新值的条件分布中进行抽取。我们可以按系统顺序循环更新向量的分量,也可以每次随机选择一个分量进行更新。
个人注:直观类比:走迷宫
想象你在一个二维坐标系上移动:
- 系统扫描:规定你必须“先向右走,再向上走”。每一步完成后,你的 \(x\) 和 \(y\) 通常都变了。
- 随机扫描:你掷硬币。
- 正面:你只能左右走(更新 \(X\)),高度(\(Y\))不能变。
- 反面:你只能上下走(更新 \(Y\)),水平位置(\(X\))不能变。
因此,在随机扫描的序列中,你会观察到一种“阶梯状”或“锯齿状”的移动,每一步都只改动一个坐标轴的值。
如果此时你把 \(Y\) 也顺便更新了,那就不叫“随机扫描”了,而退化成了某种形式的系统扫描或全块更新。保持 \(y_{n+1} = y_n\) 是为了确保这一步转移严格限制在选定的维度上。
吉布斯采样器在无法选择建议分布的意义上不如 Metropolis-Hastings 算法灵活;但这在不需要选择建议分布的意义上也使它更简单。吉布斯采样和 Metropolis-Hastings 的风格相当不同,吉布斯侧重于条件分布,而 Metropolis-Hastings 侧重于接受概率。但如下所示,这两种算法是紧密联系的。
定理 12.2.3(作为 Metropolis-Hastings 特例的随机扫描吉布斯)。随机扫描吉布斯采样器是 Metropolis-Hastings 算法的一个特例,其中建议总是被接受。特别地,由此推导出随机扫描吉布斯采样器的平稳分布符合要求。
证明。我们将在二维空间中证明这一点,但在任何维度上的证明都是相似的。令 \(X\) 和 \(Y\) 为离散随机变量,其联合 PMF 为理想的平稳分布。让我们看看 Metropolis-Hastings 算法在使用以下建议分布时会做什么:从 \((x,y)\) 开始,通过运行一步随机扫描吉布斯采样器来随机更新一个坐标。
为了简化符号,记:
\[ P(X=x, Y=y) = p(x,y), P(Y=y|X=x) = p(y|x), P(X=x|Y=y) = p(x|y) \]
更正式地说,我们应该写 \(p_{Y|X}(y|x)\) 而不是 \(p(y|x)\),以避免诸如疑惑 \(p(5|3)\) 是什么意思之类的问题。但写成 \(p(y|x)\) 更简洁,且在此证明中不会产生歧义。
让我们计算从 \((x,y)\) 到 \((x',y')\) 的 Metropolis-Hastings 接受概率。状态 \((x,y)\) 和 \((x',y')\) 必须至少有一个分量相等,因为建议只更新一个分量。假设 \(x = x'\)(\(y = y'\) 的情况可以对称处理)。那么接受概率为: \[ \frac{p(x, y') p(y|x) \frac{1}{2}}{p(x, y) p(y'|x) \frac{1}{2}} = \frac{p(x) p(y'|x) p(y|x)}{p(x) p(y|x) p(y'|x)} = 1 \]
因此,这个 Metropolis-Hastings 算法总是接受建议!所以它就是在不加修改地运行随机扫描吉布斯采样器。
让我们研究一些吉布斯采样器的具体例子。
例 12.2.4(图着色Graph coloring)。令 \(G\) 为一个网络(也称为图):有 \(n\) 个节点,对于每一对不同的节点,要么有边相连,要么没有。我们有一组 \(k\) 种颜色,例如,如果 \(k=7\),颜色集可以是 {红、橙、黄、绿、蓝、靛、紫}。网络的 \(k\)-着色是指为每个节点分配一种颜色,使得由边连接的两个节点颜色不能相同。例如,下图展示了一个网络的 3-着色。图着色是计算机科学中的一个重要课题,具有广泛的应用,如任务调度和数独游戏。
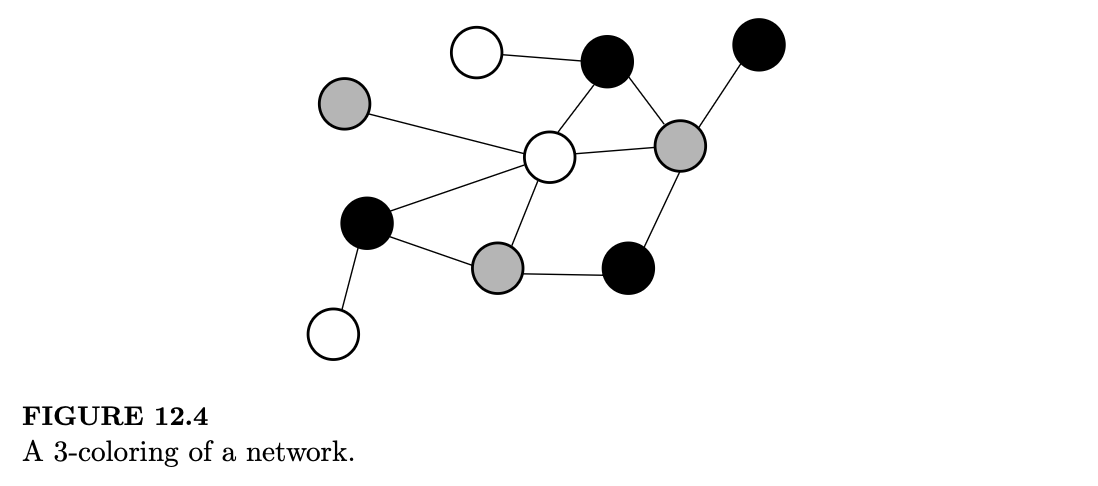
假设对 \(G\) 进行 \(k\)-着色是可能的。在 \(G\) 的所有 \(k\)-着色空间上形成一个马尔可夫链,转移方式如下:从 \(G\) 的一个 \(k\)-着色开始,随机均匀地选取一个节点,找出该节点所有合法的颜色,然后用随机均匀选取的一种合法颜色对该节点重新着色(注意,这种随机颜色可能与当前颜色相同)。证明这个马尔可夫链是可逆的,并求出其平稳分布。
解:
令 \(C\) 为 \(G\) 的所有 \(k\)-着色集合,\(q_{ij}\) 为从 \(C\) 中任意 \(k\)-着色 \(i\) 转移到 \(j\) 的概率。我们将证明 \(q_{ij} = q_{ji}\),这意味着平稳分布在 \(C\) 上是均匀的。
对于任何 \(k\)-着色 \(i\) 和节点 \(v\),令 \(L(i,v)\) 为节点 \(v\) 的合法着色数量(保持所有其他节点的颜色与 \(i\) 中相同)。如果 \(k\)-着色 \(i\) 和 \(j\) 有超过一个节点不同,则 \(q_{ij} = 0 = q_{ji}\)。如果 \(i=j\),显然 \(q_{ij} = q_{ji}\)。如果 \(i\) 和 \(j\) 恰好在节点 \(v\) 上不同,那么 \(L(i,v) = L(j,v)\),因此: \[ q_{ij} = \frac{1}{n} \cdot \frac{1}{L(i,v)} = \frac{1}{n} \cdot \frac{1}{L(j,v)} = q_{ji} \]
因此,转移矩阵是对称的,这表明平稳分布在状态空间上是均匀分布。
个人注:这个公式完美体现了随机扫描的逻辑:
- 外层的 \(1/n\) 是扫描策略(随机选一个点);
- 内层的 \(1/L(i,v)\) 是条件概率抽样(在约束下选颜色)。
这如何成为吉布斯采样的例子?将图中的每个节点视为一个可以取 \(k\) 个可能值的离散随机变量。这些节点具有联合分布,且“相连节点不能颜色相同”的约束在节点之间施加了复杂的依赖结构。
我们希望对整个图的一个随机 \(k\)-着色进行采样;也就是说,我们想从所有节点的联合分布中进行抽取。由于这很困难,我们转而以除一个节点外的所有节点为条件。如果联合分布在所有合法图中是均匀的,那么一个节点给定所有其他节点的条件分布在它的合法颜色上就是均匀的。因此,在算法的每个阶段,我们都在从一个节点给定所有其他节点的条件分布中进行抽取:我们运行的是一个随机扫描吉布斯采样器!
例 12.2.5(达尔文的雀鸟Darwin’s finches)。当查尔斯·达尔文访问加拉帕戈斯群岛时,他记录了在每个岛屿上观察到的雀鸟物种。表 12.1 总结了达尔文的数据,每一行对应一个物种,每一列对应一个岛屿。表中条目 \((i,j)\) 出现 1 表示在岛屿 \(j\) 上观察到了物种 \(i\)。
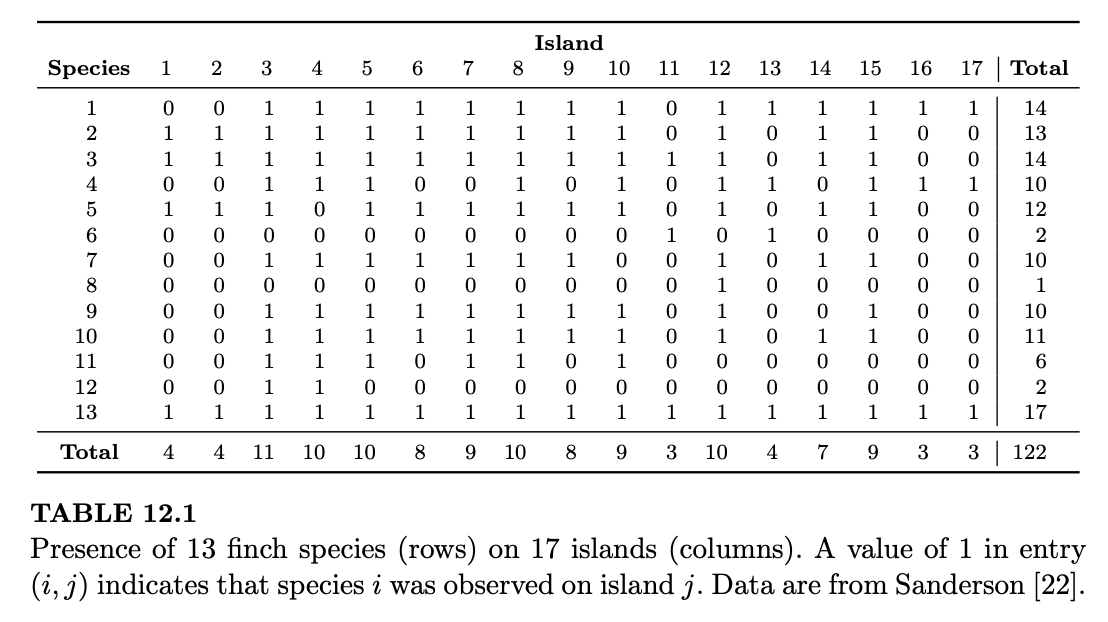
给定这些数据,我们可能感兴趣的是:表中观察到的 0 和 1 的模式在某种程度上是否异常?例如,行和列之间是否存在依赖关系?是否某些物种对经常一起出现在同一个岛屿上,其频率超过了随机情况下的预期?这些模式可能揭示物种间合作或竞争的动态。测试此类模式的一种方法是观察大量具有与观测表相同行和列和的随机表,看看观测表与这些随机表相比如何。这在统计学中是一种常见的技术,被称为拟合优度检验。
Given these data, we might be interested in knowing whether the pattern of 0’s and 1’s observed in the table is anomalous in some way. For example, does there appear to be dependence between the rows and columns? Do some pairs of species frequently occur together on the same islands, more often than one would expect by chance? These patterns may shed light on the dynamics of inter-species cooperation or competition. One way to test for such patterns is by looking at a lot of random tables with the same row and column sums as the observed table, to see how the observed table compares to the random ones. This is a common technique in statistics known as a goodness-of-fit test.
但是我们如何生成与表 12.1 具有相同行和列和的随机表呢?满足这些约束的表数量是无法穷举的。MCMC 前来救援:我们将在所有具有这些行和列和的表空间上创建一个马尔可夫链,其平稳分布在所有此类表上是均匀的。
为了构造马尔可夫链,我们需要一种在不改变行或列和的情况下从一个表转移到另一个表的方法。从观测表开始,随机选择两行和两列。如果它们交叉处的四个条目具有以下两种模式之一:
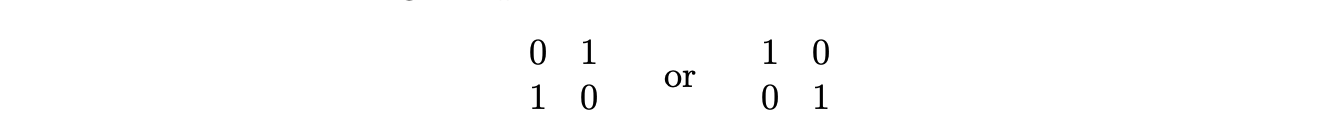
则以 1/2 的概率切换到相反的模式;否则保持原地。例如,如果我们选择了第 1 行和第 3 行以及第 1 栏和第 17 栏,我们将以 1/2 的概率将它们交叉处的四个条目从 0 1 / 1 0 切换为 1 0 / 0 1。这是一个对称的转移规则(对于所有表 \(t\) 和 \(t'\),从 \(t\) 到 \(t'\) 的转移概率等于从 \(t'\) 到 \(t\) 的转移概率),转移永远不会改变行或列和,并且可以证明以此方式定义的马尔可夫链是不可约的。因此,平稳分布在具有给定行和列和的所有表上是均匀的,符合要求。
要将此过程解释为吉布斯采样器,请考虑以表中除第 1、3 行和第 1、17 列交叉处的四个条目以外的所有条目为条件。如果平稳分布在具有给定行和列和的所有表上是均匀的,那么这四个条目的条件分布必须在不改变行和列和的所有配置上是均匀的,即在 0 1 / 1 0 和 1 0 / 0 1 上是均匀的。因此,在每个阶段,我们都在从给定其余所有条目时这四个条目的条件分布中进行抽取。
与 Metropolis-Hastings 一样,吉布斯采样也适用于连续分布,只需将条件 PMF 替换为条件 PDF。
例 12.2.6(参数未知的鸡兔同笼/鸡蛋问题 Chicken-egg with unknown parameter)。一只母鸡产下 \(N\) 枚蛋,其中 \(N \sim Pois(\lambda)\)。每枚蛋孵化的概率为 \(p\),其中 \(p\) 是未知的;我们令 \(p \sim Beta(a,b)\)。常数 \(\lambda, a, b\) 是已知的。
难点在于:我们无法观测到 \(N\)。相反,我们只能观测到孵化出的蛋的数量 \(X\)。描述如何使用吉布斯采样来求 \(E(p|X=x)\),即在观测到 \(x\) 个孵化出的蛋后,\(p\) 的后验均值。
解:
根据“鸡蛋问题”的故事,\(X\) 在给定 \(p\) 时的分布为 \(Pois(\lambda p)\)。\(p\) 的后验 PDF 与下式成正比: \[ f(p|X=x) \propto P(X=x|p)f(p) \propto e^{-\lambda p}(\lambda p)^x p^{a-1}q^{b-1}, \]
此处我们省去了所有不依赖于 \(p\) 的项。
这并不是一个已命名的分布,所以看起来我们似乎陷入了困境,但我们可以通过条件思维走出这种困局。我们希望知道什么?蛋的总数!在观测到 \(N=n\) 且已知 \(p\) 的真实值的前提下,\(X\) 的分布将是 \(Bin(n,p)\)。通过以蛋的总数为条件,我们恢复了 \(p\) 和 \(X\) 之间的 Beta-Binomial 共轭性。这使我们能够利用故事 8.3.3 立即写出后验分布: \[ p|X=x, N=n \sim Beta(x+a, n-x+b). \]
“以 \(N\) 为条件会让事情变得如此美好”这一事实启发我们使用吉布斯采样来解决这个问题。我们在“以 \(N\) 为条件对 \(p\) 进行采样”和“以 \(p\) 为条件对 \(N\) 进行采样”之间交替进行,如下文所述。在整个过程中,我们还必须以 \(X=x\) 为条件,因为我们寻求学习的是在证据给定的前提下参数的后验分布。
我们对 \(p\) 和 \(N\) 做一个初始猜测,然后迭代以下步骤:
- 在给定 \(N=n\) 且 \(X=x\) 的条件下,从 \(Beta(x+a, n-x+b)\) 分布中抽取一个新的 \(p\) 的猜测值。
- 在给定 \(p\) 且 \(X=x\) 的条件下,根据鸡蛋问题的故事,未孵化的蛋的数量为 \(Y \sim Pois(\lambda(1-p))\),因此我们可以从 \(Pois(\lambda(1-p))\) 分布中抽取 \(Y\),并设置 \(N\) 的新猜测值为 \(N=x+Y\)。
经过多次迭代后,我们得到了 \(p\) 和 \(N\) 的抽取值。如果愿意,我们可以忽略 \(N\) 的抽取值,因为 \(N\) 仅仅是帮助我们采样 \(p\) 的一种手段。但为了趣味性,我们会将两者都绘出:图 12.5 显示了当 \(\lambda=10, a=b=1\)(对应于 \(p\) 的 \(Unif(0,1)\) 先验),且我们观测到 \(X=7\) 个孵化出的蛋时,\(p\) 和 \(N\) 后验抽取值的直方图。
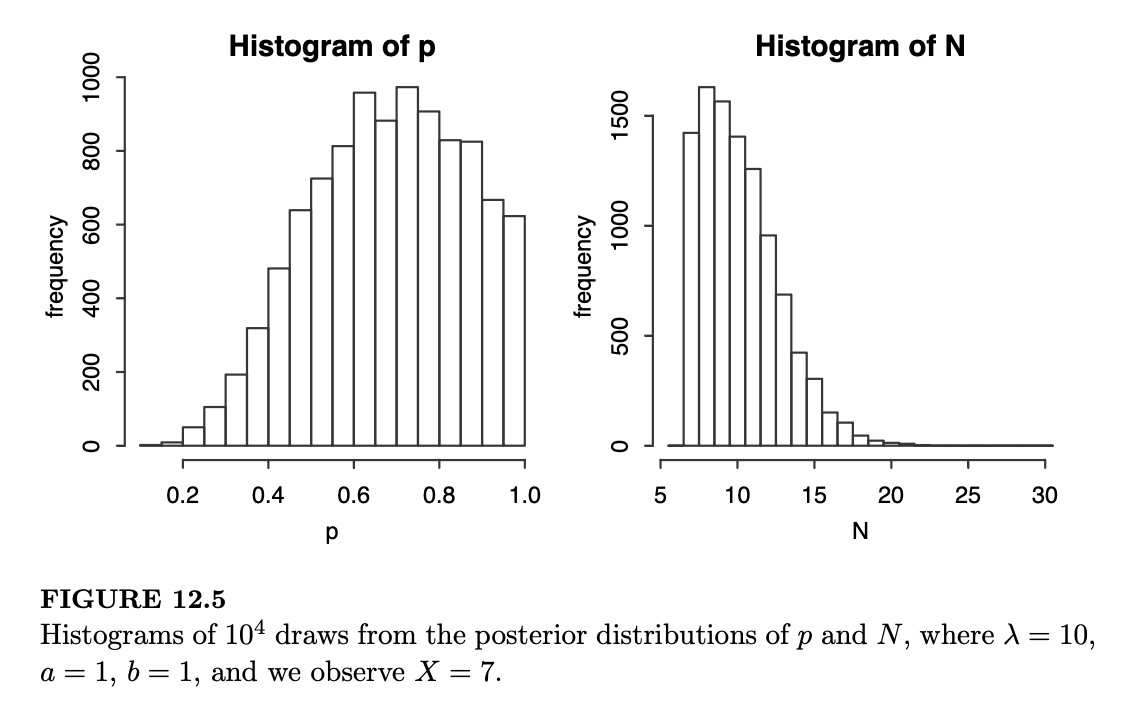
至于题目最初要求的后验均值 \(E(p|X=x)\),我们可以对 \(p\) 的抽取值取样本均值来获得良好的近似。在这种情况下,样本均值为 0.68。利用本章 R 语言部分提供的代码,你可以尝试更改 \(\lambda, a, b\) 和 \(x\) 的值,看看直方图和后验均值如何受到影响。解决这个问题的关键策略是将未观测到的蛋数 \(N\) 添加到模型中,以便我们拥有易于处理的条件分布,从而可以方便地使用吉布斯采样。
12.3 总结(Recap)
马尔可夫链蒙特卡罗(MCMC)允许我们利用马尔可夫链从复杂的分布中进行采样。近年来,MCMC 已被应用于极其广泛的问题中。MCMC 算法背后的核心思想是构造一个马尔可夫链,使其平稳分布正是我们希望采样的分布。在运行该马尔可夫链较长时间后,马尔可夫链所取的值就可以作为来自理想分布的抽取值。
本章讨论的两种 MCMC 算法是 Metropolis-Hastings 和吉布斯采样(Gibbs sampling)。Metropolis-Hastings 算法利用状态空间上的任何不可约马尔可夫链来生成建议,然后接受或拒绝这些建议,从而产生一个具有所需平稳分布的修改后的马尔可夫链。此外,所得的链是可逆的。在实践中,建议分布的选择极其重要,因为糟糕的建议分布可能导致收敛到平稳分布的速度非常缓慢。
吉布斯采样是一种通过每次更新一个分量(在给定所有其他分量的条件下)来从 \(d\) 维联合分布中抽取样本的方法。这可以通过系统扫描(按固定顺序确定性地循环更新各分量)或随机扫描(在每个阶段随机选择要更新的分量)来完成。
12.4 R
Metropolis-Hastings
以下是例 12.1.8 中正态-正态模型的 Metropolis-Hastings 算法实现方法。首先,我们选择观测值 \(Y\) 并确定常数 \(\sigma\)、\(\mu\) 和 \(\tau\) 的取值:
1 | y <- 3 |
我们还需要根据例 12.1.8 中的说明,为算法第 1 步选择提议分布的标准差;针对本问题,我们令 \(d = 1\)。我们设定运行的迭代次数,并分配一个长度为 \(10^4\) 的向量 theta,用于存放模拟抽样:
1 | d <- 1 |
现在进入主循环。我们将 \(\theta\) 初始化为观测值 \(y\),然后运行例 12.1.8 中描述的算法:
1 | theta[1] <- y |
让我们逐步解析循环内部的每一行。\(\theta\) 的建议值是 theta.p,它等于 \(\theta\) 的前一个值加上一个均值为 0、标准差为 \(d\) 的正态随机变量(注意 rnorm 的输入是标准差而非方差)。比率 \(r\) 是: \[
\frac{f_{\theta|Y}(x'|y)}{f_{\theta|Y}(x|y)} = \frac{e^{-\frac{1}{2\sigma^2}(y-x')^2} e^{-\frac{1}{2\tau^2}(x'-\mu)^2}}{e^{-\frac{1}{2\sigma^2}(y-x)^2} e^{-\frac{1}{2\tau^2}(x-\mu)^2}}
\]
其中 theta.p 扮演 \(x'\) 的角色,theta[i-1] 扮演 \(x\) 的角色。用于决定接受还是拒绝建议的硬币投掷结果是 flip,这是一个正面朝上概率为 \(\min(r, 1)\) 的随机试验(将正面编码为 1,反面编码为 0)。最后,如果硬币为正面,我们将 theta[i] 设为建议值,否则保持为前一个值。
向量 theta 现在包含了我们所有的模拟抽样。我们通常会丢弃一些初始抽样,以便给链一些时间来接近平稳分布。以下这行代码丢弃了前一半的抽样:
1 | theta <- theta[-(1:(niter/2))] |
要查看剩余抽取值的情况,我们可以使用 hist(theta) 创建直方图。我们还可以计算汇总统计量,如 mean(theta) 和 var(theta),从而得到样本均值和样本方差。
吉布斯采样 (Gibbs)
现在让我们针对例 12.2.6 实现吉布斯采样,即孵化概率未知且未孵化鸡蛋不可见的鸡兔同笼(鸡蛋与小鸡)故事。第一步是确定观测值 \(X\) 以及常数 \(\lambda\)、\(a\)、\(b\):
1 | x <- 7 |
接下来,我们决定运行的迭代次数,并为结果分配空间,创建两个长度为 \(10^4\) 的向量 \(p\) 和 \(N\),用于存放模拟抽样:
1 | niter <- 10^4 |
最后,我们准备好运行吉布斯采样器。我们将 \(p\) 和 \(N\) 分别初始化为 \(0.5\) 和 \(2x\),然后按照例 12.2.6 中解释的算法运行:
1 | p[1] <- 0.5 |
同样地,我们丢弃初始抽样:
1 | p <- p[-(1:(niter/2))] |
(注:原文代码 N[-1:(niter/2))] 括号不匹配且有误,应为 N[-(1:(niter/2))])。要查看剩余抽取值的情况,可以使用 hist(p) 和 hist(N) 创建直方图,这正是我们创建图 12.5 的方法。我们还可以计算汇总统计量,如 mean(p) 或 median(p)。
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程