《Introduction to Probability》第10章 不等式与极限理论
第10章 不等式与极限理论
Inequalities and limit theorems
“如果我无法精确计算概率或期望,我该怎么办?”几乎每个使用概率论的人有时都必须处理这种情况。不要惊慌。有一些强大的策略可用:模拟它、界定它或近似它。
• 使用蒙特卡罗(Monte Carlo)进行模拟:我们已经在本书中看到了许多模拟的例子;R 语言部分提供了大量示例,其中几行代码和计算机上的几秒钟就足以获得良好的近似答案。“蒙特卡罗”仅仅意味着模拟使用了随机数(该术语起源于摩纳哥的蒙特卡罗赌场)。
蒙特卡罗模拟是一种极其强大的技术,在许多问题中,它是目前唯一可行的合理方法。那么,为什么不总是直接进行模拟呢?以下是几个原因:
- 即使在快速计算机上,模拟也可能需要运行极长的时间。第 12 章介绍的名为马尔可夫链蒙特卡罗(MCMC)的重要扩展,极大地增加了蒙特卡罗模拟可行的题目范围。但即便如此,模拟仍可能需要运行大量的、未知的时间,才能获得对问题的体面答案。
- 我们可能希望针对问题的所有参数值获得一个通用的答案。例如,在赠券收集者问题(示例 4.3.12)中,我们看到对于 \(n\) 种玩具类型,平均需要大约 \(n \log n\) 个玩具才能集齐一套。这是一个简单且令人难忘的答案。对于任何特定的 \(n\)(例如 \(n=20\))运行模拟并得到大约 60 的答案是很容易的,但这并不容易让人看出通用的 \(n \log n\) 结果。
- 模拟结果很容易受到批评:你如何知道运行的时间足够长?你如何知道你的结果接近真相?“接近”又是多接近?我们可能更想要可证明的保证。
• 使用不等式进行界定:概率的界限提供了一个可证明的保证,即概率处于某个特定范围内。在本章的第一部分,我们将介绍概率论中几个重要的不等式。这些不等式通常允许我们缩小精确答案的可能取值范围,即确定上界和/或下界。界限可能无法提供良好的近似——如果我们尝试寻找的概率界限是 [0.2, 0.6],那么精确答案可能处于该范围内的任何地方——但至少我们知道精确答案保证在界限之内。
• 使用极限理论进行近似:在本章稍后部分,我们将讨论概率论中最著名的两个定理:大数定律和中心极限定理。两者都告诉我们,随着我们获得越来越多的数据,样本均值会发生什么变化。极限理论让我们能够进行近似,这些近似在拥有大量数据点时通常运行良好。我们在本章结束时将使用
10.1 不等式
Inequalities
10.1.1 柯西-施瓦茨不等式:联合期望的边缘界限
Cauchy-Schwarz: a marginal bound on a joint expectation
柯西-施瓦茨不等式是全数学领域中最著名的不等式之一。在概率论中,它具有以下形式。
定理 10.1.1 (柯西-施瓦茨)。对于任何方差有限的随机变量 \(X\) 和 \(Y\),有: \[ |E(XY)| \leq \sqrt{E(X^2)E(Y^2)} \]
证明。对于任何 \(t\),有:
\[ 0 \leq E(Y - tX)^2 = E(Y^2) - 2tE(XY) + t^2E(X^2) \]
\(t\) 是从哪里来的?这个想法是引入 \(t\),从而使我们拥有无限多个不等式(对应 \(t\) 的每一个取值),然后我们可以利用微积分找到能给出最佳不等式的 \(t\) 值。对方程式右侧关于 \(t\) 求导并令其等于 0,我们得到 \(t = E(XY)/E(X^2)\) 时右侧取最小值,从而产生最紧致的界限。代入这个 \(t\) 值,我们便得到了柯西-施瓦茨不等式。
如果 \(X\) 和 \(Y\) 不相关,那么 \(E(XY) = E(X)E(Y)\),这仅取决于边缘期望 \(E(X)\) 和 \(E(Y)\)。但在一般情况下,精确计算 \(E(XY)\) 需要知道 \(X\) 和 \(Y\) 的联合分布(并且能够对其进行处理)。柯西-施瓦茨不等式让我们能够根据边缘二阶矩 \(E(X^2)\) 和 \(E(Y^2)\) 来界定 \(E(XY)\)。
如果 \(X\) 和 \(Y\) 的均值为 0,那么柯西-施瓦茨不等式已经有了一个非常熟悉的统计学解释:它表示它们的统计相关性在 -1 和 1 之间。
示例 10.1.2。令 \(E(X) = E(Y) = 0\)。则:
\[ E(XY) = \text{Cov}(X,Y)\\ E(X^2) = \text{Var}(X)\\ E(Y^2) = \text{Var}(Y) \]
因此柯西-施瓦茨不等式简化为 \(|Corr(X,Y)| \leq 1\) 这一陈述。当然,我们从定理 7.3.5 中已经知道了这一点。现在让我们看看如果去掉均值为 0 的假设会发生什么。将柯西-施瓦茨不等式应用于中心化后的随机变量 \(X - E(X)\) 和 \(Y - E(Y)\),我们再次得到 \[ |Corr(X,Y)| \leq 1 \] 柯西-施瓦茨不等式经常可以以创造性的方式被应用。例如,如果我们写成 \(X = X \cdot 1\),那么柯西-施瓦茨不等式给出 \(|E(X \cdot 1)| \leq \sqrt{E(X^2)E(1^2)}\),这可以简化为 \(E(X^2) \geq (EX)^2\)。这为方差是非负的提供了一个快速的新证明。作为另一个例子,我们将获得一个非负随机变量等于 0 的概率的上界。
示例 10.1.3(二阶矩法)。令 \(X\) 为一个非负随机变量,假设我们想要得到 \(P(X = 0)\) 的一个上界。例如,\(X\) 可以是弗雷德在考试中答错的题目数量(那么 \(P(X = 0)\) 就是弗雷德获得满分的概率),或者 \(X\) 可以是聚会上生日相同的人的对数(那么 \(P(X = 0)\) 就是没有生日匹配的概率)。注意: \[ X = X I(X > 0) \]
其中 \(I(X > 0)\) 是 \(X > 0\) 的指示随机变量。这是成立的,因为如果 \(X = 0\),则两边均为 0;而如果 \(X > 0\),则两边均为 \(X\)。根据柯西-施瓦茨不等式: \[ E(X) = E(X I(X > 0)) \leq \sqrt{E(X^2) E(I(X > 0)^2)} \]
整理该式并利用基本桥梁(fundamental bridge),我们有: \[ P(X > 0) \geq \frac{(EX)^2}{E(X^2)} \]
个人注:基本桥梁(Fundamental Bridge):指示随机变量的期望等于该事件发生的概率:
\[E(I(X > 0)) = P(X > 0)\]
因此:
\[E(I(X > 0)^2) = E(I(X > 0)) = P(X > 0)\]
或者等价地: \[ P(X = 0) \leq \frac{Var(X)}{E(X^2)} \]
个人注:
\[P(X = 0) \leq \frac{E(X^2) - (EX)^2}{E(X^2)}\]
代入方差定义
根据方差的定义式 \(Var(X) = E(X^2) - (EX)^2\),分子部分恰好就是方差。
应用这个界限有时被称为二阶矩法。例如,让我们在如下情况下应用该界限: \[ X = I_1 + \dots + I_n \]
其中 \(I_j\) 是不相关的指示随机变量。令 \(p_j = E(I_j)\)。则: \[ Var(X) = \sum_{j=1}^n Var(I_j) = \sum_{j=1}^n (p_j - p_j^2) = \sum_{j=1}^n p_j - \sum_{j=1}^n p_j^2 = \mu - c \]
其中 \(\mu = E(X)\),\(c = \sum_{j=1}^n p_j^2\)。此外,\(E(X^2) = Var(X) + (EX)^2 = \mu^2 + \mu - c\)。所以: \[ P(X = 0) \leq \frac{Var(X)}{E(X^2)} = \frac{\mu - c}{\mu^2 + \mu - c} \leq \frac{1}{\mu + 1} \]
其中最后一个不等式可以通过交叉相乘轻松验证。通常情况下,“如果 \(X\) 有很高的均值,那么它等于 0 的概率就很小”这种说法是错误的,因为 \(X\) 可能通常为 0,但有很小的概率变得极其巨大。但在我们目前的设定下,我们有一个简单、定量的方法来说明:\(X\) 具有高均值确实意味着 \(X\) 不太可能为 0。
个人注:
以上这段话的意思可以总结为:
- 一般情况: 均值 \(\mu \to \infty\) 不能推出 \(P(X=0) \to 0\)(因为可能存在极端孤立的大值点)(方差很大)。
- 本例特殊情况: 当 \(X\) 是由许多不相关的“小增量”(指示变量)组成时,它的结构决定了它不能“平时都是 0,偶尔变极大”。
- 定量保证: 在这种结构下,均值 \(\mu\) 越大,它为 0 的概率就必然越小。二阶矩法给出了一个具体的“保底”概率——即 \(P(X=0)\) 的上界被均值强力压制住了。
例如,假设房间里有 14 个人。有两个人的生日相同或生日相隔一天的可能性有多大?这比生日问题要难得多,因此在示例 4.7.6 中我们使用了泊松近似。但我们可能想要一个来自界限的保证,而不是担心泊松近似是否足够好。令 \(X\) 为“近生日”对的数量。利用指示随机变量,我们有 \(E(X) = \binom{14}{2} \frac{3}{365}\)。因此: \[ P(X = 0) \leq \frac{1}{E(X) + 1} < 0.573 \]
\(P(X = 0)\) 的真实答案证明约为 0.46(保留两位小数),这与该界限是一致的。
柯西-施瓦茨不等式还允许我们从边缘矩生成函数(MGF)的存在性推导出联合 MGF 的存在性;这是能够利用边缘分布量来界定联合分布量所带来的益处的另一个例子。
示例 10.1.4(联合 MGF 的存在性)。令 \(X_1\) 和 \(X_2\) 为联合分布的随机变量,不一定相互独立或同分布。证明如果 \(X_1\) 和 \(X_2\) 各自的边缘 MGF 均存在,则随机向量 \((X_1, X_2)\) 具有联合 MGF。
解答:
回想第 7 章,联合 MGF 定义为 \(M(s, t) = E(e^{sX_1 + tX_2})\),如果该期望在原点周围的一个矩形区域内有限,则称其存在。边缘 MGF 分别为 \(E(e^{sX_1})\) 和 \(E(e^{tX_2})\);每一个都要求在原点周围的一个区间内有限。
假设 \(X_1\) 和 \(X_2\) 的 MGF 在 \((-a, a)\) 上有限。固定 \(s\) 和 \(t\) 处于 \((-a/2, a/2)\) 内。
根据柯西-施瓦茨不等式: \[ E(e^{sX_1 + tX_2}) \leq \sqrt{E(e^{2sX_1}) E(e^{2tX_2})} \]
根据假设,等式右侧是有限的,因此 \(E(e^{sX_1 + tX_2})\) 在矩形区域 \(\{(s, t) : s, t \in (-a/2, a/2)\}\) 内是有限的。因此,\((X_1, X_2)\) 的联合 MGF 存在。
10.1.2 Jensen:关于凸性的不等式
Jensen: an inequality for convexity
在 4.3.13 中,我们讨论了对于非线性函数 \(g\),\(E(g(X))\) 可能与 \(g(E(X))\) 非常不同。如果 \(g\) 是凸函数或凹函数,Jensen 不等式能准确地告诉我们 \(E(g(X))\) 和 \(g(E(X))\) 之中哪一个更大。有关凸函数和凹函数的信息请参阅数学附录。通常我们可以通过二阶导数来测试凸性或凹性:假设 \(g''\) 存在,在定义域内处处有 \(g''(x) \geq 0\) 等价于 \(g\) 是凸函数;在定义域内处处有 \(g''(x) \leq 0\) 等价于 \(g\) 是凹函数。
定理 10.1.5 (Jensen)。令 \(X\) 为随机变量。如果 \(g\) 是凸函数,则 \(E(g(X)) \geq g(E(X))\)。如果 \(g\) 是凹函数,则 \(E(g(X)) \leq g(E(X))\)。在两种情况下,等式成立的唯一方式是存在常数 \(a\) 和 \(b\),使得 \(P(g(X) = a + bX) = 1\)。
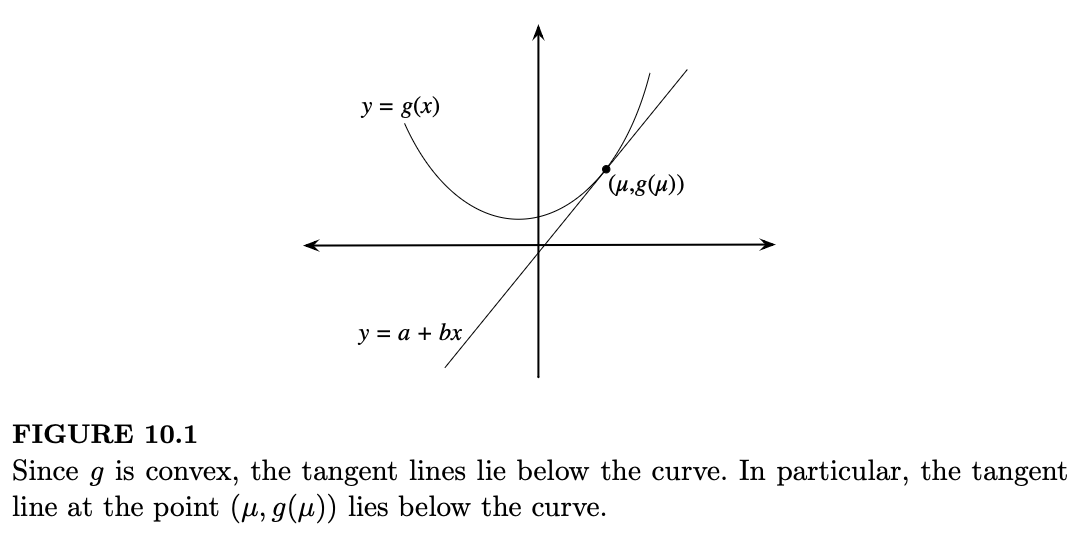
证明。如果 \(g\) 是凸的,那么 \(g\) 的所有切线都位于 \(g\) 的下方(见图 10.1)。特别地,令 \(\mu = E(X)\),并考虑在点 \((\mu, g(\mu))\) 处的切线。(如果 \(g\) 在 \(\mu\) 处可微,则切线是唯一的;否则,选择 \(\mu\) 处的任意一条切线。)将这条切线表示为 \(a + bx\),根据凸性,对于所有 \(x\) 都有 \(g(x) \geq a + bx\),因此 \(g(X) \geq a + bX\)。对两边取期望: \[ E(g(X)) \geq E(a + bX) = a + bE(X) = a + b\mu = g(\mu) = g(E(X)) \]
证毕。如果 \(g\) 是凹的,那么 \(h = -g\) 是凸的,因此我们可以将刚才证明的结论应用于 \(h\),从而发现 \(g\) 的不等式方向与凸函数情况相反。
最后,假设在凸函数情况下等式成立。令 \(Y = g(X) - a - bX\)。那么 \(Y\) 是一个非负随机变量且 \(E(Y) = 0\),故 \(P(Y = 0) = 1\)(即便 \(Y > 0\) 发生的概率微乎其微,也会使 \(E(Y) > 0\))。因此,等式成立当且仅当 \(P(g(X) = a + bX) = 1\)。对于凹函数情况,我们可以对 \(Y = a + bX - g(X)\) 使用相同的论据。
让我们在几个简单的已知案例中检查 Jensen 不等式:
- 因为 \(g(x) = x^2\) 是凸的(其二阶导数为 2),Jensen 不等式说明 \(E(X^2) \geq (EX)^2\),我们已经知道这是正确的,因为方差是非负的(或通过柯西-施瓦茨不等式得出)。
- 在第 4 章的圣彼得堡悖论中,我们发现 \(E(2^N) > 2^{EN}\),其中 \(N \sim FS(1/2)\)。Jensen 不等式对此表示赞同,因为 \(g(x) = 2^x\) 是凸的(求 \(g''(x)\) 时,可将 \(2^x\) 写成 \(e^{x \log 2}\))。此外,它告诉我们,无论 \(N\) 服从什么分布,不等式的方向都是一样的!除非 \(N\) 是常数(概率为 1),否则该不等式将是严格的。
如果我们忘记了 Jensen 不等式的方向,这些简单的案例可以让我们轻松找回正确的方向。以下是 Jensen 不等式的另外几个快速示例:
- \(E|X| \geq |EX|\)
- \(E(1/X) \geq 1/(EX)\),对于正随机变量 \(X\)
- \(E(\log(X)) \leq \log(EX)\),对于正随机变量 \(X\)
作为另一个例子,如果我们使用数据集的样本标准差来估计未知的标准差,我们可以使用 Jensen 不等式来观察偏差的方向。
示例 10.1.6(样本标准差的偏差 Bias of sample standard deviation))。令 \(X_1, \dots, X_n\) 为独立同分布且方差为 \(\sigma^2\) 的随机变量。回想定理 6.3.4,样本方差 \(S_n^2\) 是对 \(\sigma^2\) 的无偏估计。即 \(E(S_n^2) = \sigma^2\)。然而,我们通常对估计标准差 \(\sigma\) 更感兴趣。\(\sigma\) 的一个自然估计量是样本标准差 \(S_n\)。
Jensen 不等式向我们展示了 \(S_n\) 在估计 \(\sigma\) 时是有偏差的。此外,它告诉了我们不等式的方向: \[ E(S_n) = E(\sqrt{S_n^2}) \leq \sqrt{E(S_n^2)} = \sqrt{\sigma^2} = \sigma \]
因此,样本标准差往往会低估真实的标准差。偏差的程度取决于分布(因此没有通用的方法来修正这种偏差,这与“在分母中使用 \(n-1\) 定义样本方差使其对所有分布都无偏”这一事实形成对比)。幸运的是,如果样本量相当大,偏差通常很小。
个人注:有偏无偏估计的说明,太强了!
Jensen 不等式在一个重要的应用领域是信息论,即研究如何量化信息的学科。信息论的原理对于通信和压缩(例如 MP3 和手机)已变得至关重要。以下是 Jensen 不等式应用的几个例子。
示例 10.1.7(熵 Entropy)。得知一个概率为 \(p\) 的事件发生所带来的“惊奇度”(surprise)定义为 \(\log_2(1/p)\),其衡量单位称为“比特”(bits)。低概率事件具有高惊奇度,而概率为 1 的事件其惊奇度为零。使用对数是为了当我们观察到两个独立事件 \(A\) 和 \(B\) 时,总惊奇度与观察到 \(A \cap B\) 的惊奇度相同。对数以 2 为底是为了当我们得知一个概率为 1/2 的事件发生时,惊奇度为 1,这对应于接收到了 1 比特的信息。
令 \(X\) 为一个离散随机变量,其不同的可能取值为 \(a_1, a_2, \dots, a_n\),对应的概率分别为 \(p_1, p_2, \dots, p_n\)(因此 \(p_1 + p_2 + \dots + p_n = 1\))。\(X\) 的熵(Entropy)定义为得知 \(X\) 取值的平均惊奇度: \[ H(X) = \sum_{j=1}^n p_j \log_2(1/p_j) \]
注意,\(X\) 的熵仅取决于概率 \(p_j\),而不取决于取值 \(a_j\)。因此例如 \(H(X^3) = H(X)\),因为 \(X^3\) 的不同可能取值为 \(a_1^3, a_2^3, \dots, a_n^3\),而概率仍为 \(p_1, p_2, \dots, p_n\) —— 与 \(X\) 的 \(p_j\) 列表相同。
利用 Jensen 不等式,证明当 \(X\) 的分布在 \(a_1, a_2, \dots, a_n\) 上呈均匀分布时(即对于所有 \(j\),有 \(p_j = 1/n\)),\(X\) 的熵达到最大可能值。这在直觉上是合理的,因为当 \(X\) 以等概率取任何值时,得知 \(X\) 的取值平均而言传达了最多的信息;而如果 \(X\) 是一个常数,则传达的信息最少。
个人注:不确定性越大(分布越均匀),熵(信息量)就越大。
从定义上看:
- 信息量是针对“某个特定结果”而言的。
- 熵是针对“整个系统”而言的,它代表了你预期能从这个系统里获得多少信息。
为什么两者可以互换理解?
之所以说它们等价,是因为它们描述的是同一个物理过程的两个阶段:
视角 描述对象 状态 熵 (Entropy) 观测前的不确定性 系统还有多少潜在信息没被挖掘? 信息量 (Information) 观测后消除的混乱 通过观测,我获得了多少新知识?
解答:
令 \(X \sim \text{DUnif}(a_1, \dots, a_n)\),则: \[ H(X) = \sum_{j=1}^n \frac{1}{n} \log_2(n) = \log_2(n) \]
令 \(Y\) 为一个随机变量,其取值为 \(1/p_1, \dots, 1/p_n\),对应的概率分别为 \(p_1, \dots, p_n\)(如果 \(1/p_j\) 中存在重复值则进行自然修正,例如若 \(1/p_1 = 1/p_2\) 且无其他重复,则该值的概率为 \(p_1 + p_2\))。根据无意识统计学家定律(LOTUS),\(H(Y) = E(\log_2(Y))\),且 \(E(Y) = n\)(因为 \(E(Y) = \sum p_j (1/p_j) = \sum 1 = n\))。于是根据 Jensen 不等式: \[ H(Y) = E(\log_2(Y)) \leq \log_2(E(Y)) = \log_2(n) = H(X) \]
由于随机变量的熵仅取决于概率 \(p_j\) 而不取决于该随机变量所取的具体值,因此如果我们将其支撑集从 \(1/p_1, \dots, 1/p_n\) 更改为 \(a_1, \dots, a_n\),则 \(Y\) 的熵保持不变。因此,在 \(a_1, \dots, a_n\) 上均匀分布的 \(X\),其熵至少与支撑集为 \(a_1, \dots, a_n\) 的任何其他随机变量的熵一样大。
示例 10.1.8(Kullback-Leibler 散度)。令 \(\mathbf{p} = (p_1, \dots, p_n)\) 和 \(\mathbf{r} = (r_1, \dots, r_n)\) 为概率向量(即每个分量均为非负且总和为 1)。可以将每一个向量看作是一个支撑集包含 \(n\) 个不同取值的随机变量的可能 PMF。\(\mathbf{p}\) 与 \(\mathbf{r}\) 之间的 Kullback-Leibler 散度(KL 散度)定义为: \[ D(\mathbf{p}, \mathbf{r}) = \sum_{j=1}^n p_j \log_2(1/r_j) - \sum_{j=1}^n p_j \log_2(1/p_j) \]
这是当实际概率为 \(\mathbf{p}\) 但我们却使用 \(\mathbf{r}\) 工作时(例如,如果 \(\mathbf{p}\) 未知而 \(\mathbf{r}\) 是我们当前对 \(\mathbf{p}\) 的猜测)所经历的平均惊奇度,与我们直接使用 \(\mathbf{p}\) 工作时的平均惊奇度之间的差值。证明 KL 散度是非负的。
解答:
利用对数的性质,我们有: \[ D(\mathbf{p}, \mathbf{r}) = - \sum_{j=1}^n p_j \log_2 \left( \frac{r_j}{p_j} \right) \]
令 \(Y\) 为一个随机变量,其以概率 \(p_j\) 取值 \(r_j/p_j\),从而根据 LOTUS 有 \(D(\mathbf{p}, \mathbf{r}) = -E(\log_2(Y))\)。接着根据 Jensen 不等式: \[ D(\mathbf{p}, \mathbf{r}) = -E(\log_2(Y)) \geq -\log_2(E(Y)) = -\log_2(1) = 0 \]
(其中 \(E(Y) = \sum p_j (r_j/p_j) = \sum r_j = 1\)),等式成立当且仅当 \(\mathbf{p} = \mathbf{r}\)。这一结果告诉我们,平均而言,当我们使用错误的概率工作时,要比使用正确的概率工作时感到更加惊奇。
示例 10.1.9(对数概率评分)。设想在一次多选题考试中,你被要求为每一个选项分配一个正确概率,而不是只圈出一个选项。你在某个特定题目上的得分是你分配给正确答案的概率的对数。某道题的最高得分是 0,最低得分是 \(-\infty\)(如果你给正确答案分配了零概率,则会得到该分)。
假设你个人对 \(n\) 个选项正确的概率判断为 \(p_1, \dots, p_n\),其中 \(p_j\) 为正且总和为 1。证明如果你报告你的真实概率 \(p_j\),而不是任何其他概率,那么你在该题上的预期得分将达到最大。换句话说,在对数概率评分法下,你没有动力谎报你的信念,也没有动力伪装成比实际情况更有信心或更没信心(假设你的目标是最大化你的预期得分)。
解答:
这个例子与前一个例子是同构的!如果你报告真实概率 \(\mathbf{p}\),你在题目上的预期得分是 \(\sum_{j=1}^n p_j \log p_j\);如果你报告错误的概率 \(\mathbf{r}\),预期得分则是 \(\sum_{j=1}^n p_j \log r_j\)。这两者之间的差值恰好是 \(\mathbf{p}\) 与 \(\mathbf{r}\) 之间的 KL 散度。正如我们在前一个示例中所证明的,这个差值始终是非负的。因此,当你报告真实概率时,你的预期得分最大。
个人注:这个案例在现实中被称为**激励相容(Incentive Compatibility)机制,它的核心应用在于*。
在传统的单选题考试中,如果你不确定答案,你可能会“瞎蒙”一个;但在“对数评分法”下,最明智的策略是如实交代你内心的把握程度。
概率预测的评估。
这是该模型最直接的应用。例如,气象台预报“明天降水概率为 \(70\%\)”,我们如何评价这个预报准不准?
- 应用:气象部门使用对数评分(Logarithmic Scoring Rule)来考核预报员。如果预报员为了显得自己“很有信心”而报了 \(100\%\),结果没下雨,他会受到极大的惩罚(\(-\infty\) 分);如果他为了保守而报 \(50\%\),他的预期得分也会低于如实上报。
- 效果:这迫使预报员不断精进技术,并诚实地反馈模型输出的概率。
10.1.3 马尔可夫、切比雪夫、切尔诺夫:尾部概率的界限
Markov, Chebyshev, Chernoff: bounds on tail probabilities
本节中的不等式为随机变量在分布的左尾或右尾取“极端值”的概率提供了界限。
定理 10.1.10 (马尔可夫)。对于任何随机变量 \(X\) 和常数 \(a > 0\): \[ P(|X| \geq a) \leq \frac{E|X|}{a} \]
证明。令 \(Y = \frac{|X|}{a}\)。我们需要证明 \(P(Y \geq 1) \leq E(Y)\)。注意: \[ I(Y \geq 1) \leq Y \]
这是因为如果 \(I(Y \geq 1) = 0\),则不等式简化为 \(Y \geq 0\);如果 \(I(Y \geq 1) = 1\),则根据指示变量的定义有 \(Y \geq 1\)。对两边取期望,我们便得到了马尔可夫不等式。
为了直观地解释,令 \(X\) 为从某群体中随机抽取的一名个体的收入。取 \(a = 2E(X)\),马尔可夫不等式说明 \(P(X \geq 2E(X)) \leq 1/2\),即不可能有超过一半的人口收入至少是平均收入的两倍。这显然是正确的,因为如果超过一半的人口收入至少是平均水平的两倍,那么平均收入将会更高!类似地,\(P(X \geq 3E(X)) \leq 1/3\):不可能有超过 \(1/3\) 的人口收入至少是平均收入的三倍,因为这些人本身就会把平均值拉高到现有水平之上。
马尔可夫不等式是一个非常粗略的界限,因为它对 \(X\) 绝对没有任何假设。不等式的右侧可能大于 1,甚至无穷大;当我们试图界定一个已知在 0 到 1 之间的数字时,这并不是很有帮助。令人惊讶的是,以下两个不等式虽然几乎可以在马尔可夫不等式的基础上不费吹灰之力地推导出来,却通常能给出比马尔可夫不等式好得多的界限。
定理 10.1.11 (切比雪夫)。令 \(X\) 的均值为 \(\mu\),方差为 \(\sigma^2\)。则对于任何 \(a > 0\): \[ P(|X - \mu| \geq a) \leq \frac{\sigma^2}{a^2} \]
证明。根据马尔可夫不等式: \[ P(|X - \mu| \geq a) = P((X - \mu)^2 \geq a^2) \leq \frac{E(X - \mu)^2}{a^2} = \frac{\sigma^2}{a^2} \]
令 \(a = c\sigma\)(其中 \(c > 0\)),我们可以得到切比雪夫不等式的如下等价形式: \[ P(|X - \mu| \geq c\sigma) \leq \frac{1}{c^2} \]
这为随机变量偏离其均值超过 \(c\) 个标准差的概率提供了一个上界。例如,随机变量偏离均值 2 个或更多标准差的可能性不会超过 25%。
从马尔可夫推导切比雪夫的思想是将 \(|X - \mu|\) 平方后再应用马尔可夫。类似地,在应用马尔可夫之前进行其他变换通常也是富有成效的。在工程领域广泛使用的切尔诺夫界限就利用了这种思想,并结合了指数函数。
定理 10.1.12 (切尔诺夫)。对于任何随机变量 \(X\) 以及常数 \(a > 0\) 和 \(t > 0\): \[ P(X \geq a) \leq \frac{E(e^{tX})}{e^{ta}} \]
证明。变换 \(g(x) = e^{tx}\) 是可逆且严格递增的。因此,根据马尔可夫不等式,我们有: \[ P(X \geq a) = P(e^{tX} \geq e^{ta}) \leq \frac{E(e^{tX})}{e^{ta}} \]
起初可能不清楚切尔诺夫界限比马尔可夫不等式多提供了什么,但它具有两个非常出色的特征:
- 右侧可以对 \(t\) 进行优化,以给出最紧致的上界,就像在证明柯西-施瓦茨不等式时那样。
- 如果 \(X\) 的 MGF 存在,那么界限中的分子就是 MGF,这样 MGF 的一些有用性质就可以发挥作用。
现在,让我们通过将这三个界限应用于一个已知真实概率的简单示例来对它们进行比较。
示例 10.1.13(正态分布尾部概率的界限)。令 \(Z \sim N(0,1)\)。根据 68-95-99.7% 法则,我们知道 \(P(|Z| > 3)\) 大约为 0.003;精确值为 \(2 \cdot \Phi(-3)\)。让我们看看从马尔可夫、切比雪夫和切尔诺夫不等式中分别能得到什么样的上界。
马尔可夫:在第 5 章中,我们发现 \(E|Z| = \sqrt{2/\pi}\)。则: \[ P(|Z| > 3) \leq \frac{E|Z|}{3} = \frac{1}{3} \cdot \sqrt{\frac{2}{\pi}} \approx 0.27 \]
切比雪夫: \[ P(|Z| > 3) \leq \frac{1}{9} \approx 0.11 \]
切尔诺夫(利用正态分布的对称性后): \[ P(|Z| > 3) = 2P(Z > 3) \leq 2e^{-3t} E(e^{tZ}) = 2e^{-3t} \cdot e^{t^2/2} \]
此处使用了标准正态分布的 MGF。
通过令导数等于 0(可以先取对数,这是一个好主意,因为对数不会改变最小值出现的位置,且意味着我们只需最小化一个二次多项式),发现右侧在 \(t = 3\) 时取得最小值。代入 \(t = 3\),我们得到: \[ P(|Z| > 3) \leq 2e^{-9/2} \approx 0.022 \]
所有这些上界都是正确的,但切尔诺夫界限显然是最好的。正如我们在本章引言中所解释的那样,这个示例也说明了“界限”与“近似”之间的区别。马尔可夫不等式告诉我们尾部概率 \(P(|Z| > 3)\) 至多为 0.27,但如果说 \(P(|Z| > 3)\) 大约为 0.27 将是一个大错特错——我们的误差会达到约 100 倍。
10.2 大数定律
Law of large numbers
接下来我们讨论两个定理:大数定律和中心极限定理。它们描述了当样本量增加时,独立同分布(i.i.d.)随机变量的样本均值的行为。在本节及下一节中,假设我们拥有独立同分布的 \(X_1, X_2, X_3, \dots\),其均值 \(\mu\) 和方差 \(\sigma^2\) 均为有限值。对于所有正整数 \(n\),令 \[ \bar{X}_n = \frac{X_1 + \dots + X_n}{n} \]
为从 \(X_1\) 到 \(X_n\) 的样本均值。样本均值本身也是一个随机变量,其均值为 \(\mu\),方差为 \(\sigma^2/n\): \[ E(\bar{X}_n) = \frac{1}{n} E(X_1 + \dots + X_n) = \frac{1}{n} (E(X_1) + \dots + E(X_n)) = \mu \] \[ Var(\bar{X}_n) = \frac{1}{n^2} Var(X_1 + \dots + X_n) = \frac{1}{n^2} (Var(X_1) + \dots + Var(X_n)) = \frac{\sigma^2}{n} \]
大数定律(LLN)指出,随着 \(n\) 的增加,样本均值 \(\bar{X}_n\) 收敛于真实均值 \(\mu\)(其具体含义将在下文解释)。大数定律有两个版本:“强大数定律”(SLLN)和“弱大数定律”(WLLN),它们对随机变量序列收敛于一个数值使用了略有不同的定义。我们将阐述这两个版本,并利用切比雪夫不等式证明后者。
定理 10.2.1(强大数定律)。样本均值 \(\bar{X}_n\) 以概率 1 逐点收敛于真实均值 \(\mu\)。回想随机变量是从样本空间 \(S\) 到 \(\mathbb{R}\) 的函数,这种形式的收敛是指对于除了某个例外集合 \(B_0\) 之外的每个点 \(s \in S\),都有 \(\bar{X}_n(s) \to \mu\),只要 \(P(B_0) = 0\) 即可。简而言之,\(P(\bar{X}_n \to \mu) = 1\)。
定理 10.2.2(弱大数定律)。对于所有 \(\epsilon > 0\),当 \(n \to \infty\) 时,\(P(|\bar{X}_n - \mu| > \epsilon) \to 0\)。(这种形式的收敛被称为依概率收敛。)
证明。固定 \(\epsilon > 0\)。根据切比雪夫不等式: \[ P(|\bar{X}_n - \mu| > \epsilon) \leq \frac{\sigma^2}{n\epsilon^2} \]
随着 \(n \to \infty\),等式右侧趋于 0,因此左侧也必须趋于 0。
大数定律对于模拟、统计学和科学至关重要。考虑通过计算机模拟或在现实世界中进行大量独立的重复实验来生成“数据”。每当我们使用某些量的重复实验平均值来近似其理论平均值时,我们都在隐式地诉诸大数定律。
示例 10.2.3(正面出现的累计比例)。令 \(X_1, X_2, \dots\) 为独立同分布的 \(\text{Bern}(1/2)\)。将 \(X_j\) 理解为一串公平硬币投掷中“正面”的指示变量,则 \(\bar{X}_n\) 是 \(n\) 次投掷后正面的比例。强大数定律指出,以概率 1,当随机变量序列 \(\bar{X}_1, \bar{X}_2, \bar{X}_3, \dots\) 具象化为一个数值序列时,该数值序列将收敛于 1/2。从数学上讲,虽然存在诸如 HHHHHH... 和 HHTHHTHHTHHT... 等怪异的结果,但它们发生的概率总和为零。弱大数定律则指出,对于任何 \(\epsilon > 0\),通过增大 \(n\),可以使 \(\bar{X}_n\) 偏离 1/2 超过 \(\epsilon\) 的概率变得任意小。
作为说明,我们模拟了六组公平硬币投掷序列,并针对每个序列计算了作为 \(n\) 的函数的 \(\bar{X}_n\)。当然,在现实生活中我们无法模拟无限次的硬币投掷,因此我们在 300 次投掷后停止。图 10.2 绘制了每个序列的 \(\bar{X}_n\) 随 \(n\) 变化的函数图。
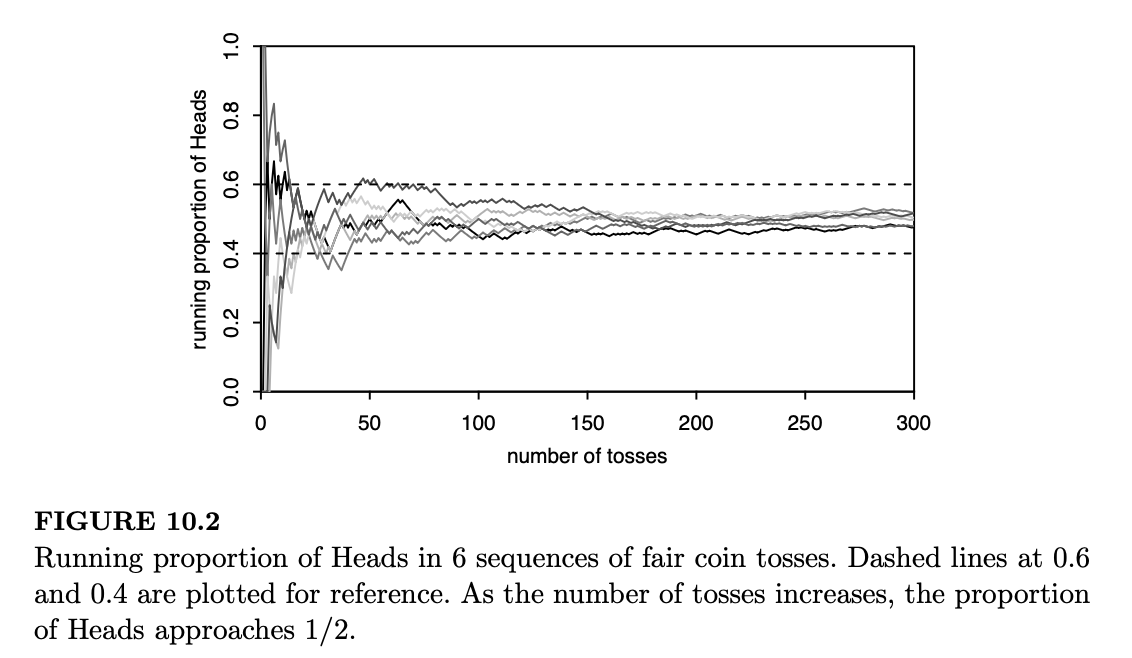
在开始阶段,我们可以看到累计正面比例存在相当大的波动。然而,随着投掷次数的增加,\(Var(\bar{X}_n)\) 变得越来越小,\(\bar{X}_n\) 趋近于 1/2。
10.2.4(大数定律与硬币无记忆性并不矛盾)。在上述示例中,大数定律指出正面比例收敛于 1/2,但这并不意味着在一长串正面之后,硬币“注定”会出现反面来平衡局面。相反,这种收敛是通过“淹没”(swamping)实现的:过去的投掷结果被未来即将到来的无限次投掷所淹没。
独立同分布的伯努利序列是大数定律(LLN)最简单的例子,但正如以下示例所示,这一简单情形构成了统计学中极其重要的方法论基础。
示例 10.2.5(蒙特卡罗积分)。令 \(f\) 为一个复杂的函数,我们想要近似计算其积分 \(\int_a^b f(x)dx\)。假设 \(0 \leq f(x) \leq c\),以便我们知道该积分是有限的。从表面上看,这个问题并不涉及概率,因为 \(\int_a^b f(x)dx\) 只是一个数值。但哪里没有随机性,我们就可以自己创造随机性!蒙特卡罗积分技术利用随机样本,在精确积分方法不可用时获得定积分的近似值。
令 \(A\) 为 \((x,y)\) 平面上由 \(a \leq x \leq b\) 和 \(0 \leq y \leq c\) 构成的矩形。令 \(B\) 为在 \(a \leq x \leq b\) 范围内,曲线 \(y = f(x)\) 下方(且在 \(x\) 轴上方)的区域,因此我们想要的积分就是区域 \(B\) 的面积。我们的策略是从 \(A\) 中提取随机样本,然后计算落在区域 \(B\) 内的样本比例。这如图 10.3 所示:区域 \(B\) 内的点为黑色,不在 \(B\) 内的点为白色。
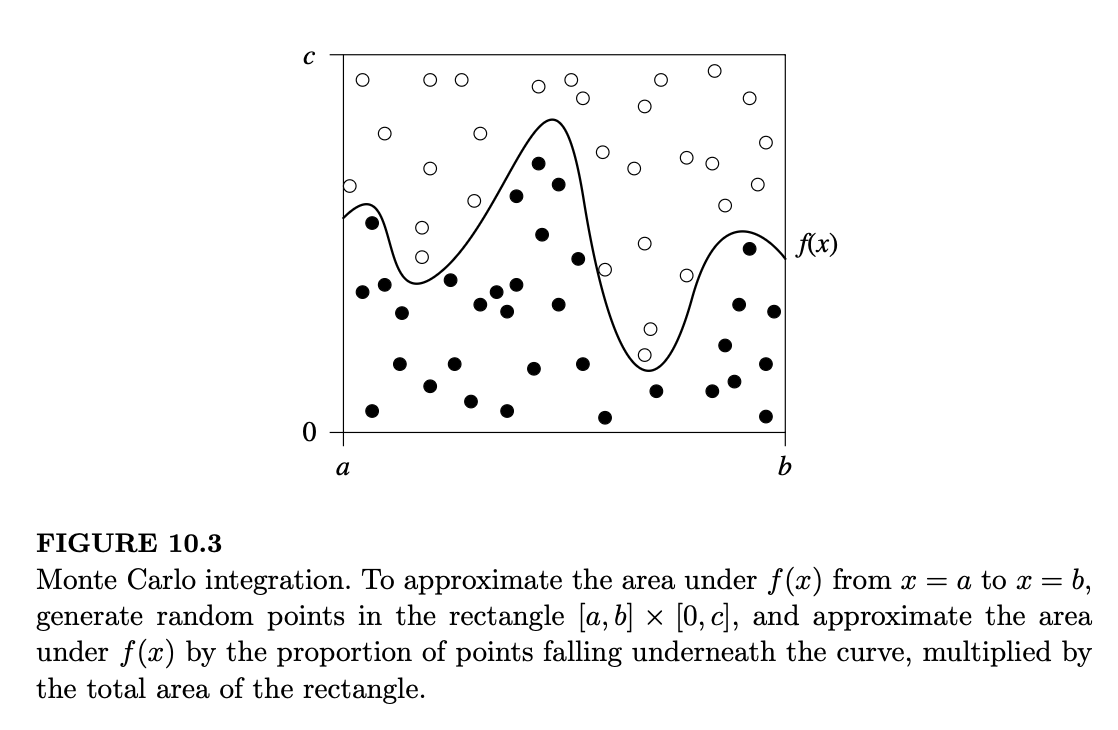
为了理解其原理,假设我们在矩形 \(A\) 中均匀地选取独立同分布的点 \((X_1,Y_1), (X_2,Y_2), \dots, (X_n,Y_n)\)。定义指示随机变量 \(I_1, \dots, I_n\),若 \((X_j,Y_j)\) 在 \(B\) 中则令 \(I_j = 1\),否则 \(I_j = 0\)。那么 \(I_j\) 是伯努利随机变量,其成功概率恰好是区域 \(B\) 的面积与区域 \(A\) 的面积之比。令 \(p = E(I_j)\),则: \[ p = E(I_j) = P(I_j = 1) = \frac{\int_a^b f(x)dx}{c(b-a)} \]
我们可以利用 \(\frac{1}{n}\sum_{j=1}^n I_j\) 来估计 \(p\),进而估计所需的积分: \[ \int_a^b f(x)dx \approx c(b-a) \frac{1}{n} \sum_{j=1}^n I_j \]
由于 \(I_j\) 是均值为 \(p\) 的独立同分布变量,根据大数定律可知,随着点数趋于无穷大,该估计值以概率 1 收敛于积分的真实值。
示例 10.2.6(经验累积分布函数的收敛性)。令 \(X_1, \dots, X_n\) 为具有累积分布函数(CDF)\(F\) 的独立同分布随机变量。对于每一个数值 \(x\),令 \(R_n(x)\) 统计 \(X_1, \dots, X_n\) 中有多少个小于或等于 \(x\);即: \[ R_n(x) = \sum_{j=1}^n I(X_j \leq x) \]
由于指示变量 \(I(X_j \leq x)\) 是独立同分布的,且成功概率为 \(F(x)\),我们知道 \(R_n(x)\) 服从参数为 \(n\) 和 \(F(x)\) 的二项分布。
\(X_1, \dots, X_n\) 的经验累积分布函数(empirical CDF)定义为: \[ \hat{F}_n(x) = \frac{R_n(x)}{n} \]
将其视为 \(x\) 的函数。在我们观测到 \(X_1, \dots, X_n\) 之前,对于每个 \(x\),\(\hat{F}_n(x)\) 都是一个随机变量。在我们观测到 \(X_1, \dots, X_n\) 之后,\(\hat{F}_n(x)\) 在每个 \(x\) 处具象化为一个特定的值,因此 \(\hat{F}_n\) 具象化为一个特定的 CDF,当真实的 \(F\) 未知时,它可以被用来估计 \(F\)。
例如,假设 \(n = 4\) 且我们观测到 \(X_1 = x_1, X_2 = x_2, X_3 = x_3, X_4 = x_4\)。那么 \(\frac{R_4(x)}{4}\) 的图形从 0 开始,每当到达一个 \(x_j\) 时就跳跃 1/4。换句话说,\(\frac{R_4(x)}{4}\) 是一个在 \(x_1, \dots, x_4\) 处取值、每个值概率均为 1/4 的离散随机变量的 CDF。这如图 10.4 所示。
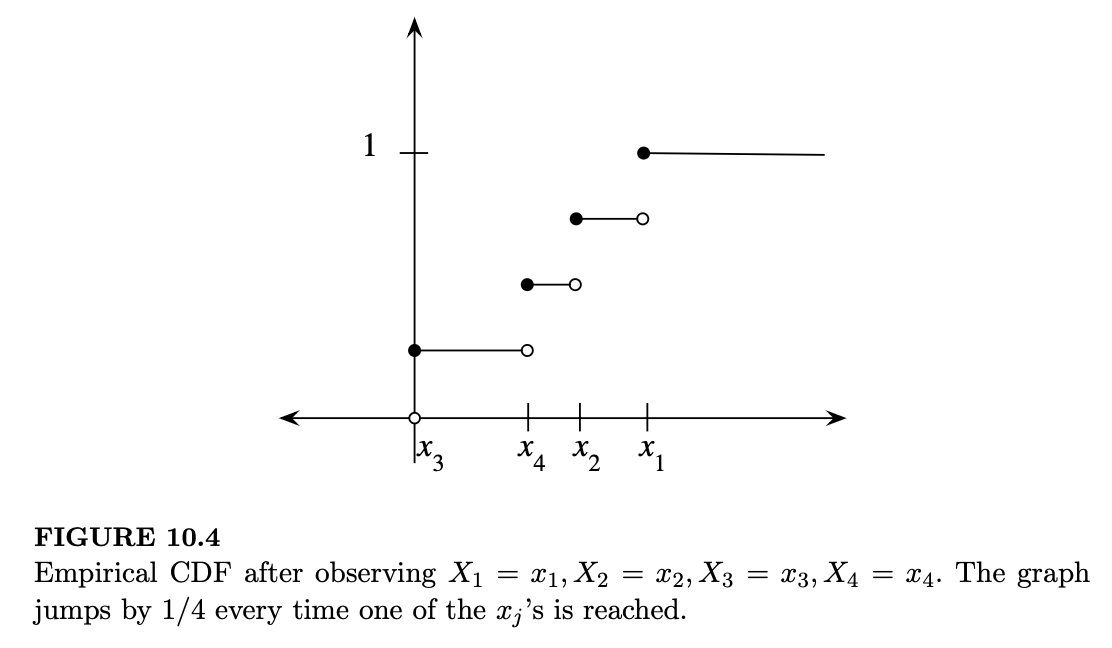
现在我们可以问,当 \(n \to \infty\) 时,\(\hat{F}_n\) 会发生什么?如果我们使用 \(\hat{F}_n\) 作为真实 \(F\) 的估计,这是一个自然的问题:这种近似在极限情况下表现良好吗?大数定律提供了答案:对于每个 \(x\),\(R_n(x)\) 是 \(n\) 个独立同分布的 \(\text{Bern}(p)\) 随机变量之和,其中 \(p = F(x)\)。因此根据强大数定律(SLLN),当 \(n \to \infty\) 时,\(\hat{F}_n(x) \to F(x)\) 以概率 1 成立。
经验 CDF 常用于非参数统计,这是统计学的一个分支,旨在不对方程来源的分布族做出强假设的情况下理解随机样本。例如,非参数方法不假设 \(X_1, \dots, X_n \sim N(\mu, \sigma^2)\),而是允许 \(X_1, \dots, X_n \sim F\)(其中 \(F\) 为任意 CDF),然后使用经验 CDF 作为 \(F\) 的近似。大数定律向我们保证了这种近似在收集越来越多样本的极限情况下是有效的:在每一个 \(x\) 值处,经验 CDF 都会收敛到真实的 CDF。
10.3 中心极限定理
Central limit theorem(CLT)
与上一节相同,令 \(X_1, X_2, X_3, \dots\) 为均值为 \(\mu\)、方差为 \(\sigma^2\) 的独立同分布随机变量。大数定律指出,当 \(n \to \infty\) 时,\(\bar{X}_n\) 收敛于常数 \(\mu\)(以概率 1)。但在其演变为常数的过程中,它的分布是什么样的呢?这便是中心极限定理(CLT)所要解决的问题。正如其名,它是统计学中具有核心重要性的极限理论。
CLT 指出,对于较大的 \(n\),\(\bar{X}_n\) 经过标准化后的分布趋近于标准正态分布。所谓标准化,是指我们减去 \(\bar{X}_n\) 的均值 \(\mu\),并除以 \(\bar{X}_n\) 的标准差 \(\sigma/\sqrt{n}\)。
定理 10.3.1(中心极限定理 CLT)。当 \(n \to \infty\) 时, \[ \frac{\sqrt{n}(\bar{X}_n - \mu)}{\sigma} \to N(0,1) \quad \text{在分布上收敛 in distribution.} \]
用文字表述,这意味着左侧表达式的 CDF 会收敛于标准正态分布的 CDF \(\Phi\)。
证明。虽然该定理在更普遍的情况下依然成立,但我们将假设 \(X_j\) 的矩生成函数(MGF)存在来证明 CLT。令 \(M(t) = E(e^{tX_j})\),并且在不失一般性的情况下,令 \(\mu = 0, \sigma^2 = 1\)(因为定理最终会对 \(\bar{X}_n\) 进行标准化,我们不妨从一开始就对 \(X_j\) 进行标准化)。那么 \(M(0) = 1, M'(0) = \mu = 0\) 且 \(M''(0) = \sigma^2 = 1\)。
我们希望证明 \(\sqrt{n}\bar{X}_n = (X_1 + \dots + X_n)/\sqrt{n}\) 的 MGF 会收敛于 \(N(0,1)\) 分布的 MGF(即 \(e^{t^2/2}\))。这是一个有效的策略,因为有一个定理指出:如果 \(Z_1, Z_2, \dots\) 是随机变量序列,其 MGF 收敛于连续随机变量 \(Z\) 的 MGF,那么 \(Z_n\) 的 CDF 也会收敛于 \(Z\) 的 CDF。(由于涉及复杂的分析,我们略去此结论的证明。但鉴于随机变量的 MGF 决定了其分布,这至少看起来是合理的。)
利用 MGF 的性质: \[ E(e^{t(X_1 + \dots + X_n)/\sqrt{n}}) = E(e^{tX_1/\sqrt{n}}) E(e^{tX_2/\sqrt{n}}) \dots E(e^{tX_n/\sqrt{n}}) = \left[ M\left( \frac{t}{\sqrt{n}} \right) \right]^n \]
当 \(n \to \infty\) 时,我们得到了 \(1^\infty\) 这一未定式。因此,我们应该取对数的极限 \(n \log M(t/\sqrt{n})\),最后再取指数。计算如下: \[ \begin{aligned} \lim_{n \to \infty} n \log M\left( \frac{t}{\sqrt{n}} \right) &= \lim_{y \to 0} \frac{\log M(yt)}{y^2} \quad (\text{其中 } y = 1/\sqrt{n}) \\ &= \lim_{y \to 0} \frac{t M'(yt)}{2y M(yt)} \quad (\text{根据洛必达法则}) \\ &= \frac{t}{2} \lim_{y \to 0} \frac{M'(yt)}{y} \quad (\text{因为 } M(yt) \to 1) \\ &= \frac{t}{2} \lim_{y \to 0} \frac{t M''(yt)}{1} \quad (\text{再次根据洛必达法则}) \\ &= \frac{t^2}{2} \end{aligned} \]
因此,\(\sqrt{n}\bar{X}_n\) 的 MGF \(\left[ M(t/\sqrt{n}) \right]^n\) 趋于 \(e^{t^2/2}\),即 \(N(0,1)\) 的 MGF。
CLT 是一个渐近结果,它告诉我们当 \(n \to \infty\) 时 \(\bar{X}_n\) 的极限分布,但它同时也为 \(n\) 较大但有限时的 \(\bar{X}_n\) 分布提供了一种近似。
近似 10.3.2(中心极限定理,近似形式)。对于较大的 \(n\),\(\bar{X}_n\) 的分布近似为 \(N(\mu, \sigma^2/n)\)。
证明。将 CLT 中的箭头更改为 \(\dot{\sim}\)(近似分布符号): \[ \frac{\sqrt{n}(\bar{X}_n - \mu)}{\sigma} \dot{\sim} N(0,1) \]
然后通过位置-尺度变换(location-scale transformation): \[ \bar{X}_n \dot{\sim} N(\mu, \sigma^2/n) \]
当然,我们通过期望和方差的性质已经知道 \(\bar{X}_n\) 的均值为 \(\mu\),方差为 \(\sigma^2/n\);而中心极限定理为我们提供了额外的信息,即 \(\bar{X}_n\) 近似服从具有上述均值和方差的正态分布。
让我们花点时间赞叹一下这一结果的普适性。只要均值和方差有限,单个 \(X_j\) 的分布可以是世界上的任何分布。我们可以拥有像二项分布那样的离散分布、像 Beta 分布那样的有界分布、像对数正态分布那样的偏态分布,或者具有多个峰值和谷值的分布。无论如何,求平均值的行为都会导致正态性的显现。
在图 10.5 中,我们展示了 4 种不同的初始分布在 \(n=1, 5, 30, 100\) 时 \(\bar{X}_n\) 分布的直方图。随着 \(n\) 的增加,无论 \(X_j\) 服从何种分布,\(\bar{X}_n\) 的分布都开始看起来像正态分布。
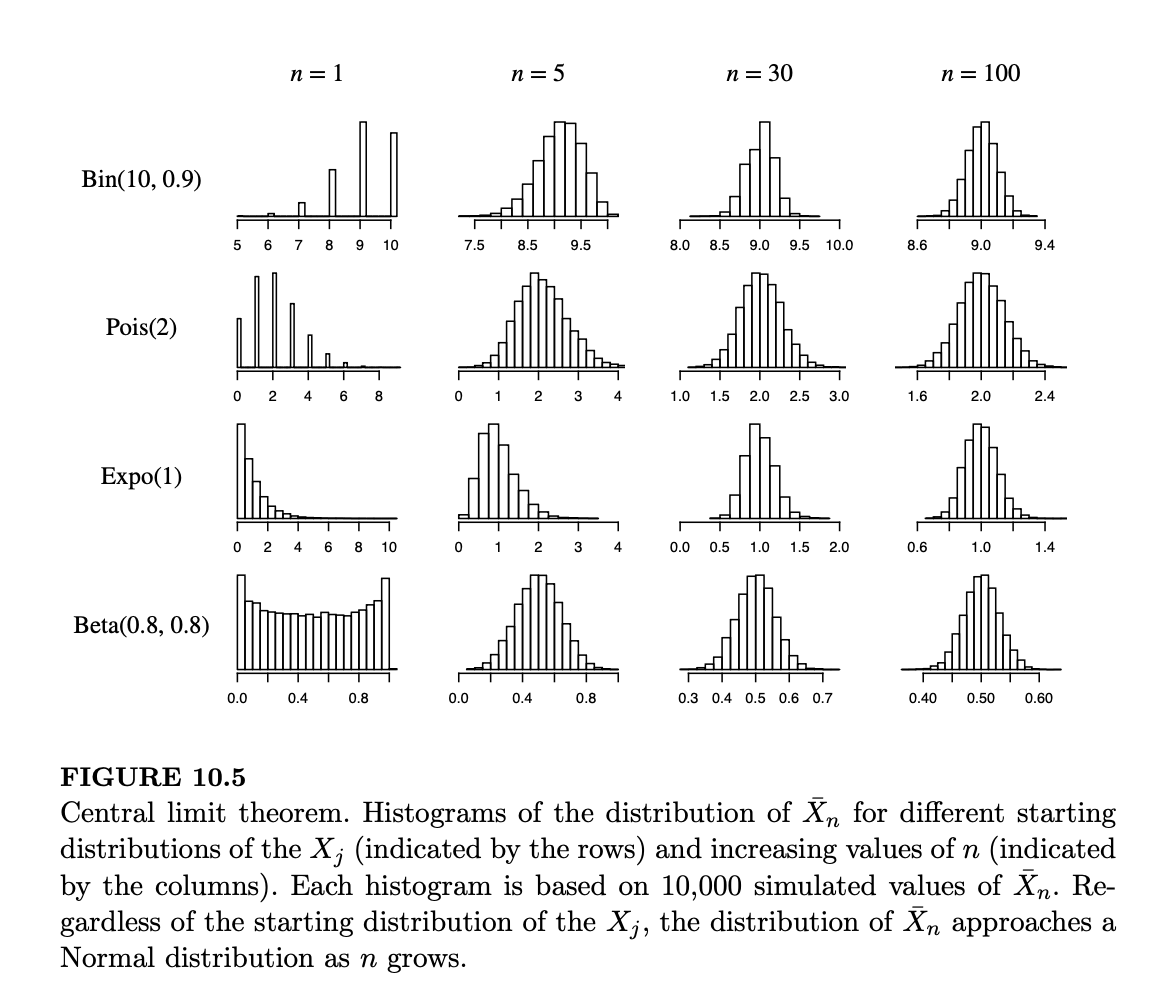
然而,这并不意味着 \(X_j\) 的分布是无关紧要的。如果 \(X_j\) 具有高度偏态或多峰分布,在正态近似变得准确之前,我们可能需要 \(n\) 非常大;而在另一个极端情况下,如果 \(X_j\) 已经是独立同分布的正态变量,那么对于所有的 \(n\),\(\bar{X}_n\) 的分布都精确地为 \(N(\mu, \sigma^2/n)\)。由于现实世界中不存在无限的数据集,有限 \(n\) 下正态近似的质量是一个重要的权衡因素。
示例 10.3.3(正面出现的累计比例,重访)。如示例 10.2.3 所示,令 \(X_1, X_2, \dots\) 为独立同分布的 \(\text{Bern}(1/2)\)。此前,我们利用大数定律得出结论:当 \(n \to \infty\) 时,\(\bar{X}_n \to 1/2\)。现在,利用中心极限定理,我们可以说得更多:\(E(\bar{X}_n) = 1/2\),\(Var(\bar{X}_n) = 1/(4n)\),因此对于较大的 \(n\): \[ \bar{X}_n \dot{\sim} N\left(\frac{1}{2}, \frac{1}{4n}\right) \]
这一额外信息允许我们量化:对于给定的 \(n\),什么样的偏离均值的情况是典型的。例如,当 \(n = 100\) 时,\(SD(\bar{X}_n) = 1/20 = 0.05\)。因此,如果正态近似有效,根据 68-95-99.7% 法则,\(\bar{X}_n\) 有 95% 的概率落在区间 \([0.40, 0.60]\) 内。
CLT 说明样本均值 \(\bar{X}_n\) 近似服从正态分布,但由于总和 \(W_n = X_1 + \dots + X_n = n\bar{X}_n\) 只是 \(\bar{X}_n\) 的缩放版本,CLT 同样意味着 \(W_n\) 近似服从正态分布。如果 \(X_j\) 的均值为 \(\mu\),方差为 \(\sigma^2\),则 \(W_n\) 的均值为 \(n\mu\),方差为 \(n\sigma^2\)。CLT 进而指出,对于较大的 \(n\): \[ W_n \dot{\sim} N(n\mu, n\sigma^2) \]
这与 \(\bar{X}_n\) 的近似完全等价,但将其写成这种形式非常有用,因为我们研究过的许多著名分布都可以被视为独立同分布随机变量的总和。以下是三个快速示例。
示例 10.3.4(泊松分布收敛于正态分布)。令 \(Y \sim \text{Pois}(n)\)。根据定理 4.8.1,我们可以将 \(Y\) 视为 \(n\) 个独立同分布的 \(\text{Pois}(1)\) 随机变量之和。因此,对于较大的 \(n\): \[ Y \dot{\sim} N(n, n) \]
示例 10.3.5(伽马分布收敛于正态分布)。令 \(Y \sim \text{Gamma}(n, \lambda)\)。根据定理 8.4.3,我们可以将 \(Y\) 视为 \(n\) 个独立同分布的 \(\text{Expo}(\lambda)\) 随机变量之和。因此,对于较大的 \(n\): \[ Y \dot{\sim} N\left(\frac{n}{\lambda}, \frac{n}{\lambda^2}\right) \]
示例 10.3.6(二项分布收敛于正态分布)。令 \(Y \sim \text{Bin}(n, p)\)。根据定理 3.8.8,我们可以将 \(Y\) 视为 \(n\) 个独立同分布的 \(\text{Bern}(p)\) 随机变量之和。因此,对于较大的 \(n\): \[ Y \dot{\sim} N(np, np(1-p)) \]
这可能是统计学中使用最广泛的正态近似。为了补偿 \(Y\) 的离散性,我们将概率 \(P(Y = k)\)(在正态近似下其值精确为 0)写成 \(P(k - 1/2 < Y < k + 1/2)\)(使其成为一个宽度不为零的区间),并将正态近似应用于后者。这被称为连续性修正(continuity correction),它得出了如下 \(Y\) 的 PMF 近似公式: \[ P(Y = k) = P(k - 1/2 < Y < k + 1/2) \approx \Phi\left(\frac{k + 1/2 - np}{\sqrt{np(1-p)}}\right) - \Phi\left(\frac{k - 1/2 - np}{\sqrt{np(1-p)}}\right) \]
二项分布的正态近似与第 4 章讨论的泊松近似是互补的。泊松近似在 \(p\) 较小时效果最好,而正态近似在 \(n\) 较大且 \(p\) 在 1/2 左右(使得 \(Y\) 的分布对称或接近对称)时效果最好。
我们将以一个同时使用大数定律(LLN)和中心极限定理(CLT)的示例作为结束。
示例 10.3.7(波动的股票)。每一天,一只波动剧烈的股票价格会以相等的概率上涨 70% 或下跌 50%,且不同日期的价格变动相互独立。令 \(Y_n\) 为 \(n\) 天后的股价,初始价格 \(Y_0 = 100\)。
说明为什么当 \(n\) 较大时,\(\log Y_n\) 近似服从正态分布,并给出其参数。
当 \(n \to \infty\) 时,\(E(Y_n)\) 会发生什么变化?
利用大数定律找出当 \(n \to \infty\) 时,\(Y_n\) 会发生什么变化。
解答:
- 我们可以将 \(Y_n\) 写成 \(Y_n = Y_0(0.5)^{n-U_n}(1.7)^{U_n}\),其中 \(U_n \sim \text{Bin}(n, 1/2)\) 是前 \(n\) 天中股票上涨的次数。由此得: \[ \log Y_n = \log Y_0 - n \log 2 + U_n \log 3.4 \]
这是 \(U_n\) 的一个位置-尺度变换。根据中心极限定理(CLT),当 \(n\) 较大时,\(U_n\) 近似服从 \(N(n/2, n/4)\),因此 \(\log Y_n\) 近似服从正态分布,其均值为: \[ E(\log Y_n) = \log 100 - n \log 2 + (\log 3.4) \cdot E(U_n) \approx \log 100 - 0.081n \]
方差为: \[ Var(\log Y_n) = (\log 3.4)^2 \cdot Var(U_n) \approx 0.374n \]
- 我们有 \(E(Y_1) = (1.7 \cdot 100 + 0.5 \cdot 100)/2 = 110\)。同理: \[ E(Y_{n+1}|Y_n) = \frac{1}{2}(1.7Y_n) + \frac{1}{2}(0.5Y_n) = 1.1Y_n \]
所以: \[ E(Y_{n+1}) = E(E(Y_{n+1}|Y_n)) = 1.1E(Y_n) \]
因此 \(E(Y_n) = 1.1^n E(Y_0) = 100 \cdot 1.1^n\),当 \(n \to \infty\) 时,该值趋于 \(\infty\)。
- 如 (a) 中所述,令 \(U_n \sim \text{Bin}(n, 1/2)\) 为前 \(n\) 天股票上涨的次数。注意,尽管 \(E(Y_n) \to \infty\),但如果股票某天上涨 70% 紧接着第二天下跌 50%,那么整体上它下跌了 15%,因为 \(1.7 \cdot 0.5 = 0.85\)。因此在很多天后,如果股票上涨 70% 和下跌 50% 的时间各占一半左右,股价 \(Y_n\) 将变得非常小——而大数定律保证了情况正是如此!为了应用大数定律,我们将 \(Y_n\) 用 \(U_n/n\) 表示: \[ Y_n = Y_0 (0.5)^{n-U_n} (1.7)^{U_n} = Y_0 \left( \frac{3.4^{U_n/n}}{2} \right)^n \]
由于 \(U_n/n \to 0.5\) 以概率 1 成立,因此 \(3.4^{U_n/n} \to \sqrt{3.4} < 2\) 以概率 1 成立,故 \(Y_n \to 0\) 以概率 1 成立。
矛盾的是,\(E(Y_n) \to \infty\) 但 \(Y_n \to 0\) 以概率 1 成立。为了直观理解这一结果,考虑一个极端的例子:一名赌徒从 100 美元开始,每天有一半的概率让钱翻四倍,一半的概率输光所有财产。那么平均而言,赌徒的财富每天都会翻倍,这听起来不错,直到你注意到终有一天赌徒会破产。赌徒实际的财富以概率 1 趋于 0,而期望值趋于无穷大是由于获得极其巨大数额资金的极小概率导致的,就像圣彼得堡悖论中那样。
10.3.8(邪恶的柯西分布 The evil Cauchy)。中心极限定理要求 \(X_j\) 的均值和方差有限,我们对弱大数定律(WLLN)的证明也依赖于相同的条件。在示例 7.1.25 中引入的柯西(Cauchy)分布没有均值或方差,因此柯西分布既不服从大数定律也不服从中心极限定理。可以证明,\(n\) 个柯西分布随机变量的样本均值仍然是柯西分布,无论 \(n\) 变得多大。因此,样本均值永远不会趋近于正态分布,这与 CLT 中观察到的行为相反。由于没有真实的均值可供 \(\bar{X}_n\) 收敛,大数定律(LLN)同样不适用。
10.4 卡方分布与学生 t 分布
Chi-Square and Student-t
我们将通过介绍本书中最后两个连续分布来圆满结束本章,这两个分布都与正态分布密切相关。
定义 10.4.1(卡方分布)。令 \(V = Z_1^2 + \dots + Z_n^2\),其中 \(Z_1, Z_2, \dots, Z_n\) 是独立同分布的 \(N(0,1)\) 变量。则称 \(V\) 服从自由度为 \(n\) 的卡方分布。我们记作 \(V \sim \chi_n^2\)。
事实证明,\(\chi_n^2\) 分布是伽马分布的一个特例。
定理 10.4.2。\(\chi_n^2\) 分布即为 \(\text{Gamma}(\frac{n}{2}, \frac{1}{2})\) 分布。
证明。首先,我们验证 \(Z_1^2 \sim \chi_1^2\) 的 PDF 等于 \(\text{Gamma}(\frac{1}{2}, \frac{1}{2})\) 的 PDF:对于 \(x > 0\), \[ F(x) = P(Z_1^2 \leq x) = P(-\sqrt{x} \leq Z_1 \leq \sqrt{x}) = \Phi(\sqrt{x}) - \Phi(-\sqrt{x}) = 2\Phi(\sqrt{x}) - 1 \]
故 \[ f(x) = \frac{d}{dx}F(x) = 2\phi(\sqrt{x}) \frac{1}{2} x^{-1/2} = \frac{1}{\sqrt{2\pi x}} e^{-x/2} \]
这确实是 \(\text{Gamma}(\frac{1}{2}, \frac{1}{2})\) 的 PDF。接着,因为 \(V = Z_1^2 + \dots + Z_n^2 \sim \chi_n^2\) 是 \(n\) 个独立的 \(\text{Gamma}(\frac{1}{2}, \frac{1}{2})\) 随机变量之和,由伽马分布的性质可知 \(V \sim \text{Gamma}(\frac{n}{2}, \frac{1}{2})\)。
根据我们对伽马分布均值和方差的了解,有 \(E(V) = n\) 且 \(Var(V) = 2n\)。我们也可以利用 \(V\) 是独立同分布正态变量平方和这一事实,结合第 6 章推导出的正态矩来获得均值和方差: \[ E(V) = nE(Z_1^2) = n \] \[ Var(V) = nVar(Z_1^2) = n[E(Z_1^4) - (EZ_1^2)^2] = n(3 - 1) = 2n \]
要获得卡方分布的 MGF,只需将 \(n/2\) 和 \(1/2\) 代入定理 8.4.3 中更一般的 \(\text{Gamma}(a, \lambda)\) MGF 公式 \(\left( \frac{\lambda}{\lambda - t} \right)^a\)(当 \(t < \lambda\) 时)。这得出: \[ M_V(t) = \left( \frac{1}{1 - 2t} \right)^{n/2}, \quad t < 1/2 \]
卡方分布在统计学中非常重要,因为它与样本方差的分布有关,样本方差可用于估计分布的真实方差。当我们的随机变量是独立同分布的正态变量时,样本方差经过适当缩放后的分布即为卡方分布。
样本方差和卡方分布详见文件《样本方差和卡方分布.md》
- 样本方差的概念:是为了通过局部(样本)来推测全体(总体)的波动情况。
- 卡方分布的作用:它告诉我们样本方差这种“推测”到底有多大的不确定性。
如果没有“样本方差是一个分布”的概念,我们就无法评估我们的测量结果到底有多可靠。
The Chi-Square distribution is important in statistics because it is related to the distribution of the sample variance, which can be used to estimate the true variance of a distribution. When our random variables are i.i.d. Normals, the distribution of the sample variance after appropriate scaling is Chi-Square.
示例 10.4.3(样本方差的分布 Distribution of sample variance)。对于独立同分布的 \(X_1, \dots, X_n \sim N(\mu, \sigma^2)\),样本方差是随机变量: \[ S_n^2 = \frac{1}{n-1} \sum_{j=1}^n (X_j - \bar{X}_n)^2 \]
证明: \[ \frac{(n-1)S_n^2}{\sigma^2} \sim \chi_{n-1}^2 \]
解答:
首先,让我们证明对于标准正态随机变量 \(Z_1, \dots, Z_n\),有 \(\sum_{j=1}^n (Z_j - \bar{Z}_n)^2 \sim \chi_{n-1}^2\)。这与我们要证明的一般性结果是一致的,也是一个有用的垫脚石。我们从以下恒等式开始(这是定理 6.3.4 证明中恒等式的一个特例): \[ \sum_{j=1}^n Z_j^2 = \sum_{j=1}^n (Z_j - \bar{Z}_n)^2 + n\bar{Z}_n^2 \]
现在对等式两边取 MGF。根据示例 7.5.9,\(\sum_{j=1}^n (Z_j - \bar{Z}_n)^2\) 与 \(n\bar{Z}_n^2\) 是相互独立的,因此它们和的 MGF 等于各自 MGF 的乘积。此外,已知 \(\sum_{j=1}^n Z_j^2 \sim \chi_n^2\) 且 \(n\bar{Z}_n^2 \sim \chi_1^2\)(因为 \(\sqrt{n}\bar{Z}_n \sim N(0,1)\)),所以: \[ \left( \frac{1}{1-2t} \right)^{n/2} = \text{E}\left[ e^{t\sum (Z_j - \bar{Z}_n)^2} \right] \cdot \left( \frac{1}{1-2t} \right)^{1/2} \]
这意味着: \[ \text{E}\left[ e^{t\sum (Z_j - \bar{Z}_n)^2} \right] = \left( \frac{1}{1-2t} \right)^{(n-1)/2} \]
这正是 \(\chi_{n-1}^2\) 的 MGF。由于 MGF 唯一确定分布,我们得出 \(\sum_{j=1}^n (Z_j - \bar{Z}_n)^2 \sim \chi_{n-1}^2\)。
对于一般的 \(X_1, \dots, X_n\),使用位置-尺度变换,令 \(X_j = \mu + \sigma Z_j\) 且 \(\bar{X}_n = \mu + \sigma \bar{Z}_n\)。当我们用 \(Z_j\) 表示 \(\sum_{j=1}^n (X_j - \bar{X}_n)^2\) 时,\(\mu\) 会被抵消,而 \(\sigma\) 以平方形式提取出来: \[ \sum_{j=1}^n (X_j - \bar{X}_n)^2 = \sum_{j=1}^n (\mu + \sigma Z_j - (\mu + \sigma \bar{Z}_n))^2 = \sigma^2 \sum_{j=1}^n (Z_j - \bar{Z}_n)^2 \]
综上所述: \[ \frac{(n-1)S_n^2}{\sigma^2} = \frac{1}{\sigma^2} \sum_{j=1}^n (X_j - \bar{X}_n)^2 = \frac{1}{\sigma^2} \cdot \sigma^2 \sum_{j=1}^n (Z_j - \bar{Z}_n)^2 \sim \chi_{n-1}^2 \]
这正是我们想要的结果。这也意味着 \(E(S_n^2) = \sigma^2\),与我们在定理 6.3.4 中展示的一致:样本方差是真实方差的无偏估计。
学生 \(t\) 分布(Student-t distribution)是通过将其表示为一个标准正态随机变量和一个 \(\chi_n^2\) 随机变量的关系来定义的。
定义 10.4.4(学生 t 分布)。令 \[ T = \frac{Z}{\sqrt{V/n}} \]
其中 \(Z \sim N(0,1)\),\(V \sim \chi_n^2\),且 \(Z\) 与 \(V\) 相互独立。则称 \(T\) 服从自由度为 \(n\) 的学生 t 分布。我们记作 \(T \sim t_n\)。“学生 t 分布”通常简称为“t 分布”。
学生 t 分布由威廉·戈塞特(William Gosset)于 1908 年引入,他当时是健力士(Guinness)啤酒厂的酿造大师,正致力于啤酒质量控制的研究。由于公司要求,他必须以笔名发表作品,于是他选择了“Student(学生)”这个名字。t 分布构成了被称为 t 检验的假设检验程序的基础,这在实践中应用极其广泛(由于 t 检验的细节更适合在统计推断课程中介绍,此处不再赘述)。
t检验详见文件《t检验.md》
自由度为 \(n\) 的学生 t 分布的 PDF 看起来与标准正态分布相似,只是尾部更厚(如果 \(n\) 很小,尾部会厚得多;如果 \(n\) 很大,则差别不大)。其 PDF 公式为: \[ f_T(t) = \frac{\Gamma((n+1)/2)}{\sqrt{n\pi}\Gamma(n/2)} (1 + t^2/n)^{-(n+1)/2} \]
我们不打算证明这个公式,因为推导过程非常繁琐,而且学生 t 分布最重要的性质通过其定义(即正态变量与 \(\chi_n^2\) 变量的关系)来理解要比通过 PDF 进行枯燥计算容易得多。以下是其中的一些性质。
定理 10.4.5(学生 t 分布的性质)。\(t_n\) 分布具有以下性质:
- 对称性:如果 \(T \sim t_n\),那么 \(-T\) 也服从 \(t_n\)。
- 柯西分布是其特例:\(t_1\) 分布与示例 7.1.25 中引入的柯西分布相同。
- 收敛于正态分布:随着 \(n \to \infty\),\(t_n\) 分布趋于标准正态分布。
证明。在每项性质的证明中,我们都援引定义 10.4.4。
- 将 \(T\) 表示为 \(T = Z/\sqrt{V/n}\),其中 \(Z \sim N(0,1)\),\(V \sim \chi_n^2\) 且两者独立。那么 \(-T = -Z/\sqrt{V/n}\)。因为 \(-Z \sim N(0,1)\),所以 \(-T \sim t_n\)。
- 回想柯西分布定义为 \(X/Y\) 的分布,其中 \(X, Y\) 独立同分布于 \(N(0,1)\)。根据定义,\(T \sim t_1\) 可表示为 \(T = Z/\sqrt{V}\),其中 \(\sqrt{V} = \sqrt{Z_1^2} = |Z_1|\),且 \(Z_1\) 与 \(Z\) 独立。由对称性可知,\(Z/|Z_1|\) 与 \(Z/Z_1\) 的分布相同,而 \(Z/Z_1\) 是柯西分布。因此 \(t_1\) 与柯西分布是相同的。
- 这可以由强大数定律(SLLN)得出。考虑独立同分布的标准正态序列 \(Z_1, Z_2, \dots\),令 \(V_n = Z_1^2 + \dots + Z_n^2\)。根据 SLLN,\(V_n/n \to E(Z_1^2) = 1\) 以概率 1 成立。现在令 \(Z \sim N(0,1)\) 独立于所有的 \(Z_j\),并令 \(T_n = Z/\sqrt{V_n/n}\)。那么根据定义 \(T_n \sim t_n\),且由于分母收敛于 1,我们有 \(T_n \to Z \sim N(0,1)\)。因此,\(T_n\) 的分布趋于 \(Z\) 的分布。
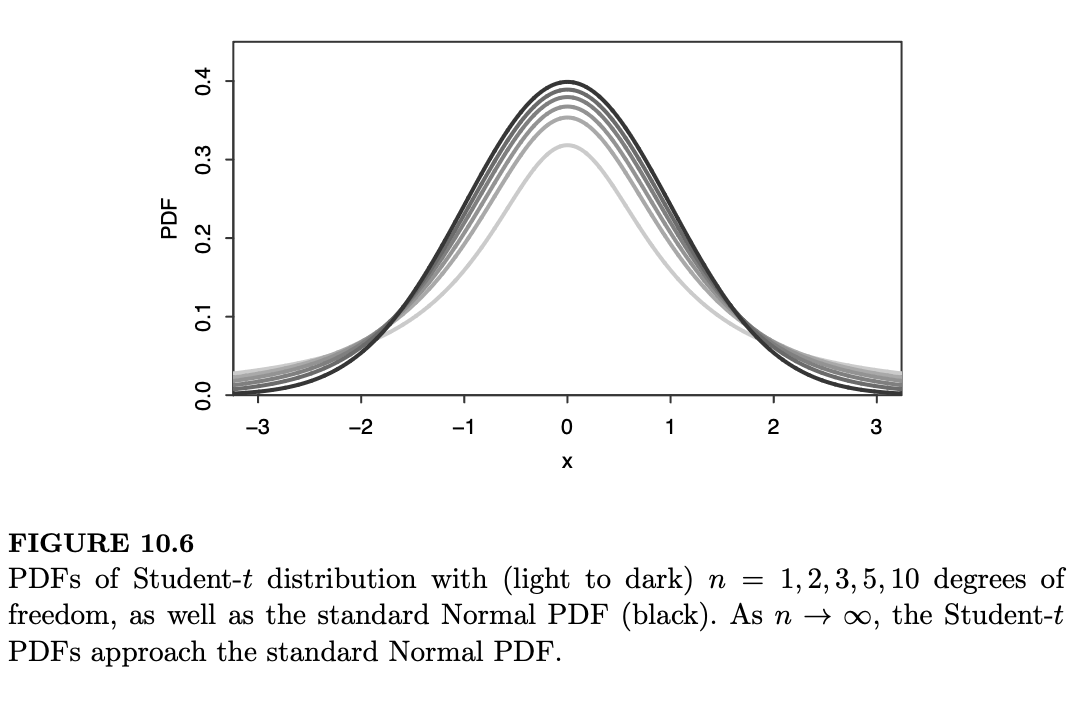
图 10.6 绘制了不同 \(n\) 值下的学生 t 分布 PDF,展示了上述定理的所有三个性质:PDF 全都关于 0 对称;\(n=1\) 时的 PDF 看起来像柯西分布;随着 \(n \to \infty\),厚尾变薄,PDF 趋于标准正态分布。
10.5 小结
不等式和极限理论是处理我们不希望精确计算的期望和概率的两种不同方法。不等式允许我们获得未知值的下界和/或上界:柯西-施瓦茨不等式(Cauchy-Schwarz)和 Jensen 不等式为我们提供了期望的界限;而马尔可夫(Markov)、切比雪夫(Chebyshev)和切尔诺夫(Chernoff)不等式则为我们提供了尾部概率的界限。
两个极限理论——大数定律(LLN)和中心极限定理(CLT),描述了均值为 \(\mu\)、方差为 \(\sigma^2\) 的独立同分布变量 \(X_1, X_2, \dots\) 的样本均值 \(\bar{X}_n\) 的行为。强大数定律(SLLN)指出,当 \(n \to \infty\) 时,样本均值 \(\bar{X}_n\) 以概率 1 收敛于真实均值 \(\mu\)。中心极限定理(CLT)指出,\(\bar{X}_n\) 在标准化后的分布收敛于标准正态分布: \[ \frac{\sqrt{n}(\bar{X}_n - \mu)}{\sigma} \to N(0,1) \]
这可以转化为对 \(\bar{X}_n\) 分布的一个近似: \[ \bar{X}_n \dot{\sim} N(\mu, \sigma^2/n) \]
等价地,我们也可以说总和 \(S_n = X_1 + \dots + X_n = n\bar{X}_n\) 在标准化后的分布收敛于标准正态分布: \[ \frac{S_n - n\mu}{\sigma\sqrt{n}} \to N(0,1) \]
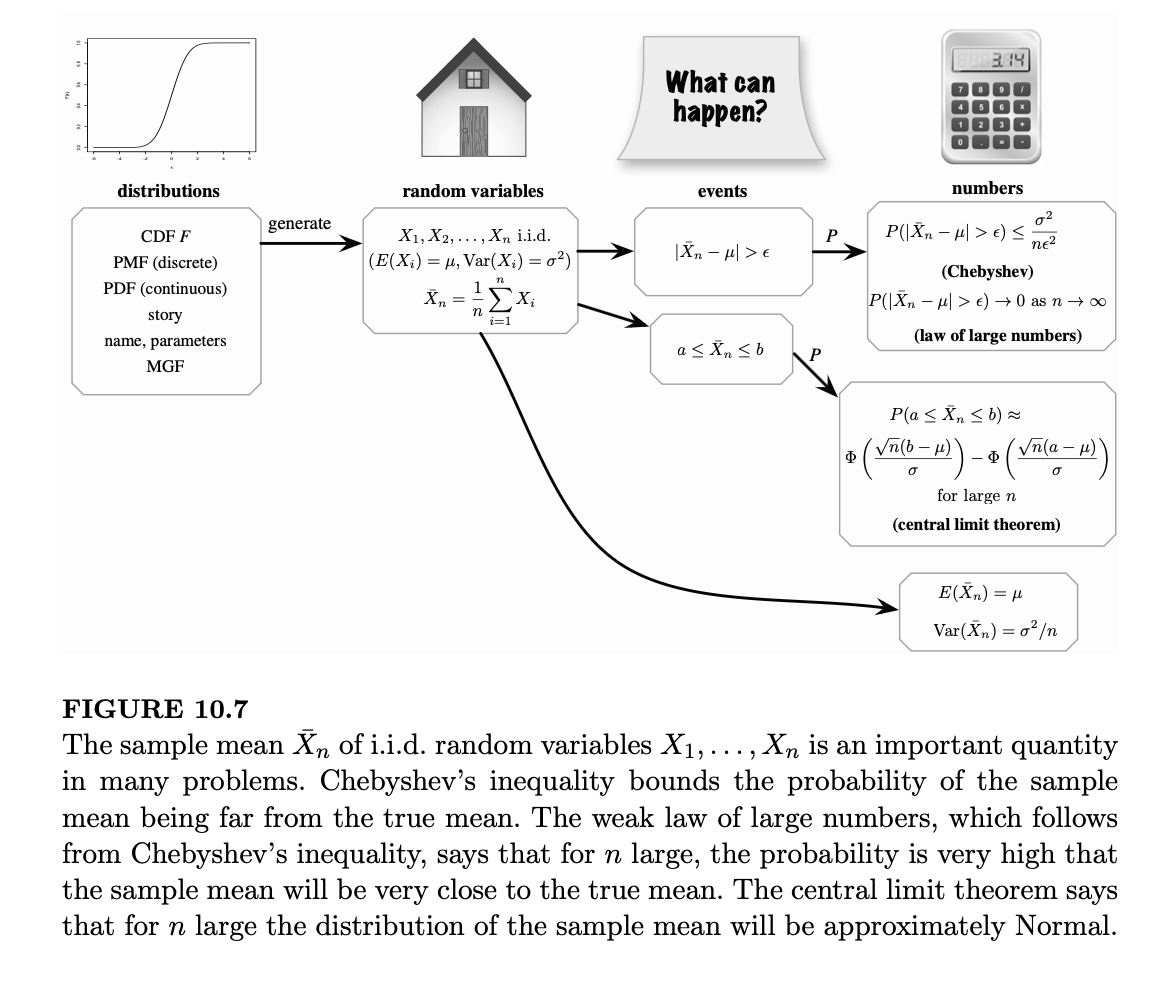
图 10.7 展示了从一个分布到具有该分布的独立同分布随机变量的过程,从中可以形成样本均值并将其作为随机变量进行研究。切比雪夫不等式、大数定律和中心极限定理都提供了关于样本均值行为的重要信息。
卡方分布和学生 t 分布是统计学中两个重要的命名分布。卡方分布是伽马分布的一个特例。学生 t 分布具有钟形 PDF,其尾部比正态分布更厚,并随着自由度的增加收敛于标准正态分布。
最后一次展示命名分布之间的关系图,图中已更新,包括了卡方分布(作为伽马分布的特例)和学生 t 分布(以柯西分布为特例)。我们还添加了箭头来显示泊松分布、伽马分布和学生 t 分布向正态性的收敛;前两者是中心极限定理的结果,而第三者是大数定律的结果。
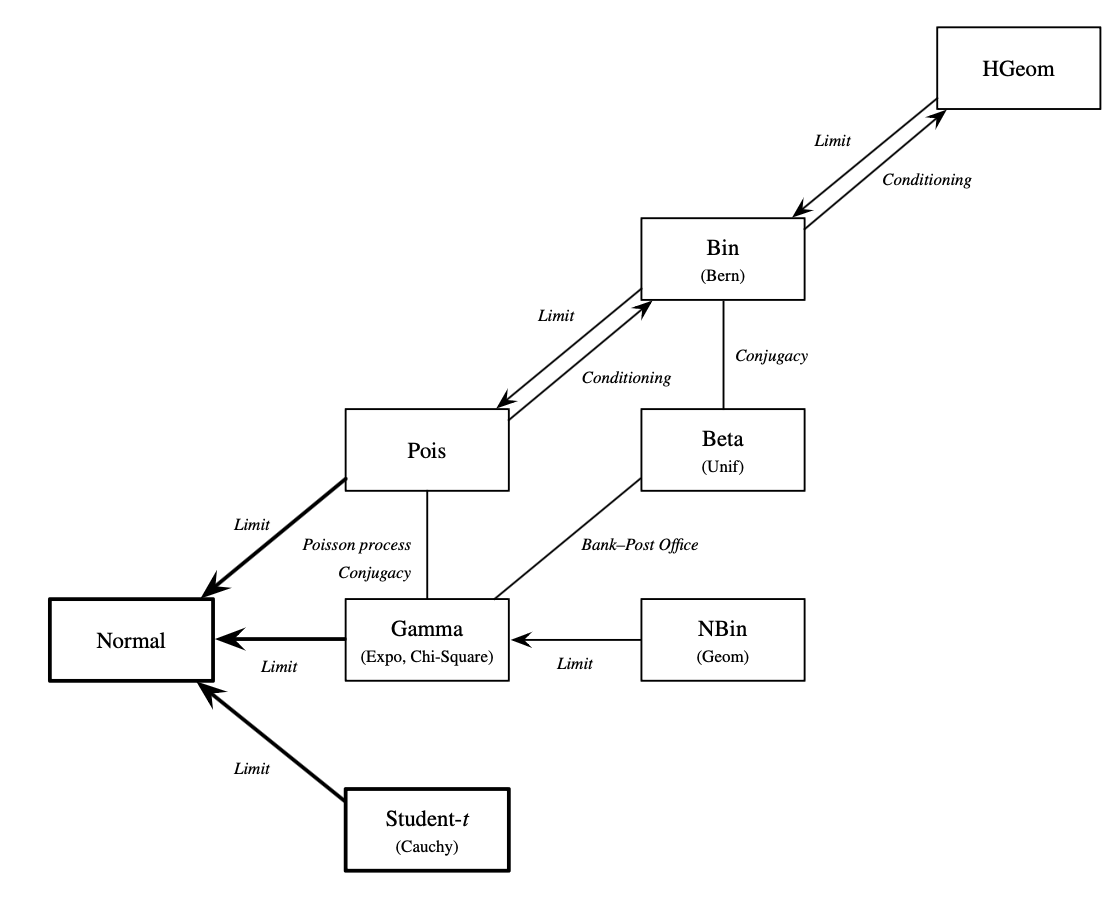
现在我们可以看到,所有命名的分布彼此之间都是相互关联的!
10.6 R 语言实现
Jensen 不等式
R 语言可以轻松地比较给定函数 \(g\) 下 \(X\) 与 \(g(X)\) 的期望,这让我们能够验证 Jensen 不等式的一些特殊情况。例如,假设我们从 \(\text{Expo}(1)\) 分布中模拟 \(10^4\) 次:
R
1 | x <- rexp(10^4) |
根据 Jensen 不等式,\(E(\log X) \leq \log EX\)。前者可以用 mean(log(x)) 近似,后者可以用 log(mean(x)) 近似。计算两者:
R
1 | mean(log(x)) |
对于 \(\text{Expo}(1)\) 分布,我们发现 mean(log(x)) 大约为 \(-0.6\)(真实值约为 \(-0.577\)),而 log(mean(x)) 大约为 \(0\)(真实值正是 \(0\))。这确实验证了 \(E(\log X) \leq \log EX\)。你也可以无限尝试其他组合,比如比较 mean(x^3) 与 mean(x)^3,或 mean(sqrt(x)) 与 sqrt(mean(x))。
大数定律的可视化
要绘制一系列独立公平硬币投掷中正面的累计比例,我们首先生成投掷数据:
R
1 | nsim <- 300 |
然后我们计算每个 \(n\) 值对应的 \(\bar{X}_n\) 并存储在 xbar 中:
R
1 | xbar <- cumsum(x) / (1:nsim) |
上述代码对两个向量 cumsum(x) 和 1:nsim 进行了逐元素除法。最后,我们将 xbar 对投掷次数进行绘图:
R
1 | plot(1:nsim, xbar, type="l", ylim=c(0,1)) |
根据大数定律(LLN),你应该能看到 xbar 的值逐渐趋近于 \(p\)。
\(\pi\) 的蒙特卡罗估计
蒙特卡罗积分的一个著名例子是估计 \(\pi\)。单位圆盘 \(\{(x,y) : x^2 + y^2 \leq 1\}\) 内切于正方形 \([-1,1] \times [-1,1]\),正方形面积为 4。如果我们生成大量在正方形上均匀分布的点,落在圆盘内的点所占的比例大约等于圆盘面积与正方形面积之比,即 \(\pi/4\)。因此,估计 \(\pi\) 的方法就是计算圆内点的比例再乘以 4。
在 R 中,我们可以利用示例 7.1.23 的结果,独立生成 \(x\) 和 \(y\) 坐标作为 \(\text{Unif}(-1,1)\) 变量:
R
1 | nsim <- 10^6 |
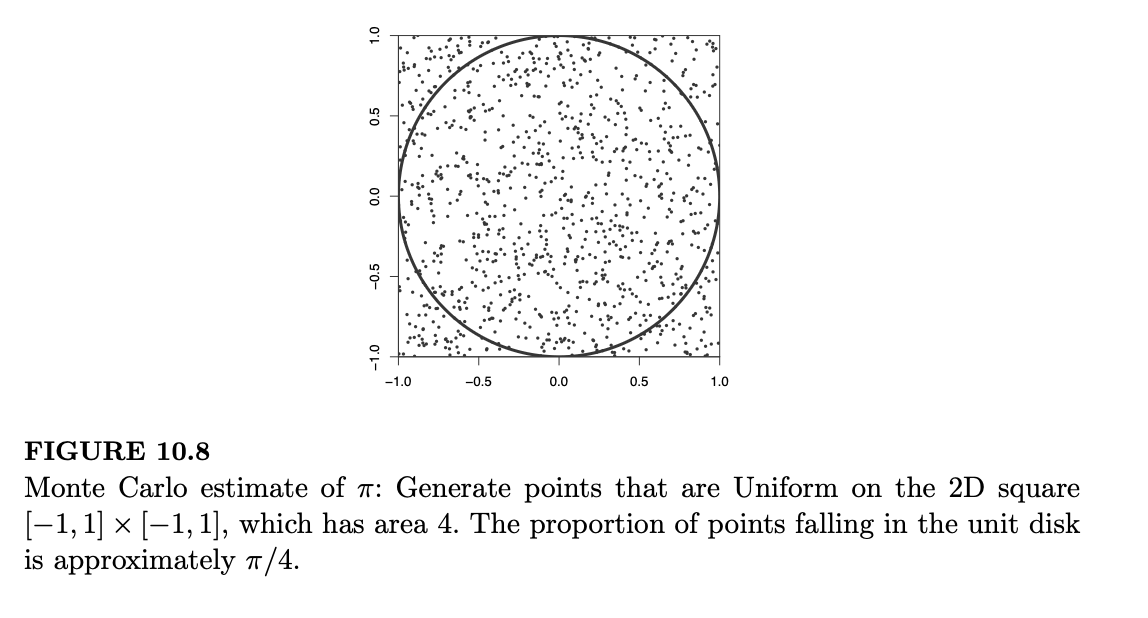
统计圆盘内的点数:使用 sum(x^2 + y^2 < 1)。向量 x^2 + y^2 < 1 是一个指示向量,如果第 \(i\) 个点在圆内,则第 \(i\) 个元素为 1,否则为 0。最后转换为比例并乘以 4:
R
1 | 4 * sum(x^2 + y^2 < 1) / nsim |
中心极限定理的可视化
可视化中心极限定理的一种方法是针对不同 \(n\) 值绘制 \(\bar{X}_n\) 的分布。假设我们感兴趣的是 \(\text{Unif}(0,1)\) 分布,且令 \(n=12\)。以下代码创建了一个包含 12 列的矩阵,每行代表一次 \(X_1\) 到 \(X_{12}\) 的实现:
R
1 | nsim <- 10^4 |
使用 rowMeans 函数获取每行的平均值(即 \(\bar{X}_{12}\) 的实现):
R
1 | xbar <- rowMeans(x) |
由于 \(\text{Unif}(0,1)\) 是对称的,CLT 发挥作用很快,即使 \(n=12\) 正态近似效果也很好。如果将 runif 改为 rexp(指数分布),你会发现当 \(n=12\) 时分布依然偏斜,需要更大的 \(n\) 才能看到理想的正态近似。
此外,animation 包中有一个关于 高尔顿板(quincunx/bean machine) 的内置动画,它是统计学家弗朗西斯·高尔顿发明的,用于演示正态分布:
R
1 | library(animation) |
卡方分布与学生 t 分布
尽管卡方分布是伽马分布的特例,R 仍为其提供了专用函数:dchisq(PDF)、pchisq(CDF)和 rchisq(生成随机数)。例如,rchisq(nsim, n) 生成 \(nsim\) 个自由度为 \(n\) 的独立同分布卡方变量。
学生 t 分布则拥有 dt、pt 和 rt 函数。使用 dt(x, n) 计算自由度为 \(n\) 的 \(t\) 分布在 \(x\) 处的 PDF。值得注意的是,dt(x, 1) 与柯西分布的 dcauchy(x) 是完全相同的。
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程