《Introduction to Probability》第1章 概率与计数
第1章 概率与计数
Probability and counting
运气、巧合、随机性、不确定性、风险、疑虑、命运、机遇。
Luck. Coincidence. Randomness. Uncertainty. Risk. Doubt. Fortune. Chance.
你可能无数次听过这些词,但很有可能它们只是被以一种模糊、随意的方式使用。遗憾的是,尽管概率在科学和日常生活中无处不在,它却可能极其违背直觉。如果我们依赖可靠性存疑的直觉,就会面临做出不准确预测或过度自信决策的严重风险。本书的目标是将概率论作为一种逻辑框架引入,以规范的方式对不确定性和随机性进行量化。我们还旨在加强直觉——无论是在我们的初步猜测与逻辑推理一致时,还是在没那么走运的时候。
1.1 为什么要学习概率?
Why study probability?
数学是确定性的逻辑;概率是不确定的逻辑。概率在众多领域都极其有用,因为它提供了理解和解释变异性、将信号与噪声分离以及对复杂现象进行建模的工具。从不断增长的应用清单中仅举几例:
- 统计学:概率是统计学的基础和语言,它使许多强大的、利用数据来了解世界的方法成为可能。
- 物理学:爱因斯坦有一句名言:“上帝不与宇宙玩骰子”,但目前对量子物理的理解在自然界最基本的层面上沉重地涉及了概率。统计力学是物理学的另一个主要分支,它也建立在概率之上。
- 生物学:遗传学与概率深度交织,无论是在基因遗传还是在建立随机突变模型方面。
- 计算机科学:随机算法在运行时做出随机选择,在许多重要应用中,它们比目前已知的任何确定性替代方案都更简单、更高效。概率在研究算法性能、机器学习和人工智能中也起着至关重要的作用。
- 气象学:天气预报是(或应该是)以概率的形式计算并表达的。
- 博弈:概率论最早的许多研究都旨在回答关于博弈和机会游戏的问题。
- 金融学:冒着与前一例子重复的风险,必须指出概率在量化金融中处于核心地位。对股票价格随时间变化的建模以及确定金融工具的“公平”价格都沉重地依赖于概率。
- 政治学:近年来,政治学变得越来越量化和统计化,其应用包括分析民意调查、评估选区划分(assessing gerrymandering)以及预测选举。
- 医学:随机临床试验的发展,即将患者随机分配接受治疗或安慰剂,改变了近年来的医学研究。正如生物统计学家大卫·哈林顿(David Harrington)所言:“有人推测,这可能是二十世纪科学医学领域最重大的进步……现代科学中一个令人愉悦的讽刺是,随机试验通过在研究设计中引入随机变异,从而在受控实验中‘调整’了已观测到和未观测到的异质性。”
- 生活:生活是不确定的,而概率是不确定的逻辑。虽然在生活中为每一个决定都进行正式的概率计算并不现实,但深入思考概率可以帮助我们避免一些常见的谬误,阐明巧合现象,并做出更好的预测。
概率为有原则地解决问题提供了流程,但它也可能产生陷阱和悖论。例如,我们将在本章中看到,即使是 17 世纪独立发现微积分的两位伟人——戈特弗里德·威廉·莱布尼茨和艾萨克·牛顿爵士,也无法免于在概率上犯下基本错误。在本书中,我们将采用以下策略来帮助避免潜在的陷阱:
- 模拟:概率论的一个美妙之处在于,通常可以通过模拟来研究问题。与其与持有异议的人无休止地争论答案,你大可以运行一次模拟,从经验上观察谁才是正确的。本书的每一章都以一个专门章节结尾,给出如何在 R(一个免费的统计计算环境)中进行计算和模拟的示例。
- 生物危害(Biohazards):研究常见错误对于更深入地理解概率论中哪些推理是有效的、哪些是无效的至关重要。在本书中,常见错误被称为“生物危害”,并用 \(\biohazard\) 符号表示(因为犯此类错误可能会危害健康!)。
- 合理性检查(Sanity checks):在使用一种方法解决问题后,我们通常会尝试用另一种不同的方法来解决同一个问题,或者检查我们的答案在简单及极端情况下是否合理。
1.2 样本空间与卵石世界
Sample spaces and Pebble World
概率的数学框架是建立在集合论之上的。想象正在进行一项实验,其结果是可能结果集合中的某一个。在实验进行之前,尚不清楚哪一个结果会出现;实验之后,结果“结晶”为实际观测到的结果。
定义 1.2.1(样本空间与事件)。实验的样本空间 \(S\) 是该实验所有可能结果的集合。事件 \(A\) 是样本空间 \(S\) 的子集,如果实际结果在 \(A\) 中,我们就说事件 \(A\) 发生了。
实验的样本空间可以是有限的、可数无限的或不可数无限的(有关可数集和不可数集的解释,请参见数学附录的 A.1.5 节)。当样本空间有限时,我们可以将其想象为“卵石世界”,如图 1.1 所示。每颗卵石代表一个结果,而一个事件就是一组卵石。
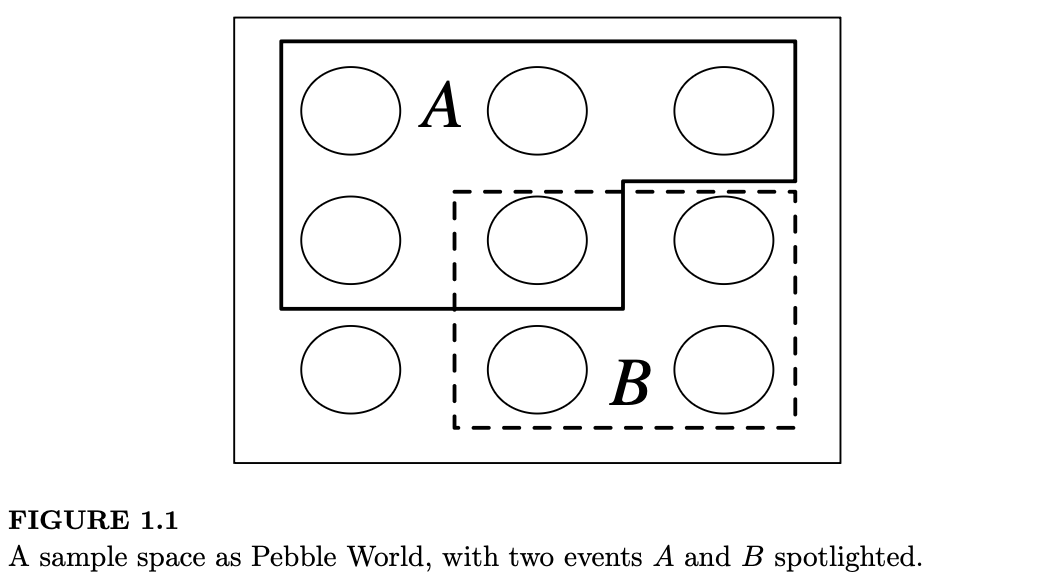
进行实验相当于随机选择一颗卵石。如果所有卵石的质量都相同,那么所有卵石被选中的概率也相同。这种特殊情况是接下来的两节的主题。在 1.6 节中,我们将给出概率的通用定义,允许卵石的质量互不相同。
集合论在概率论中非常有用,因为它为表达和处理事件提供了丰富的语言;数学附录的 A.1 节提供了集合论的复习。集合运算,特别是并集、交集和补集,使得根据已定义的事件构建新事件变得很容易。这些概念还允许我们以多种方式表达一个事件;通常,一个事件的某种表达方式比同个事件的另一种表达方式处理起来要容易得多。
例如,设 \(S\) 为实验的样本空间,并设 \(A, B \subseteq S\) 为事件。那么,并集 \(A \cup B\) 是当且仅当 \(A, B\) 中至少有一个发生时发生的事件;交集 \(A \cap B\) 是当且仅当 \(A\) 和 \(B\) 同时发生时发生的事件;补集 \(A^c\) 是当且仅当 \(A\) 不发生时发生的事件。我们还有德·摩根定律:
\[ (A \cup B)^c = A^c \cap B^c \quad \text{以及} \quad (A \cap B)^c = A^c \cup B^c \]
因为说“\(A\) 和 \(B\) 至少有一个发生的情况并不成立”等同于说“\(A\) 不发生且 \(B\) 不发生”;而说“两者同时发生的情况并不成立”等同于说“至少有一个不发生”。类似的结论也适用于两个以上事件的并集和交集。
在图 1.1 所示的例子中,\(A\) 是一个包含 5 颗卵石的集合,\(B\) 是一个包含 4 颗卵石的集合,\(A \cup B\) 由属于 \(A\) 或 \(B\) 的 8 颗卵石组成(包括同时属于两者的那颗卵石),\(A \cap B\) 由同时属于 \(A\) 和 \(B\) 的那颗卵石组成,而 \(A^c\) 则由不属于 \(A\) 的 4 颗卵石组成。
样本空间的概念非常通用且抽象,因此在脑海中保留一些具体的例子是很重要的。
例 1.2.2(抛硬币)。一枚硬币被抛掷 10 次。将正面记为 H,反面记为 T,一个可能的结果(卵石)是 HHHTHHTTHT,而样本空间是所有长度为 10 的 H 和 T 字符串的集合。我们可以(并且将会)将 H 编码为 1,将 T 编码为 0,这样结果就是一个序列 \((s_1, \dots, s_{10})\),其中 \(s_j \in \{0, 1\}\),而样本空间就是所有此类序列的集合。现在让我们来看一些事件:
- 设 \(A_1\) 为第一次抛掷为正面的事件。作为一个集合,
\[ A_1 = \{(1, s_2, \dots, s_{10}) : 2 \le j \le 10 \text{ 时 } s_j \in \{0, 1\}\} \]
这是样本空间的一个子集,因此它确实是一个事件;说 \(A_1\) 发生等同于说第一次抛掷结果为正面。类似地,设 \(A_j\) 为第 \(j\) 次抛掷为正面的事件,其中 \(j = 2, 3, \dots, 10\)。
设 \(B\) 为至少有一次抛掷为正面的事件。作为一个集合,
\[ B = \bigcup_{j=1}^{10} A_j \]
设 \(C\) 为所有抛掷均为正面的事件。作为一个集合,
\[ C = \bigcap_{j=1}^{10} A_j \]
设 \(D\) 为出现至少两次连续正面的事件。作为一个集合,
\[ D = \bigcup_{j=1}^9 (A_j \cap A_{j+1}) \]
例 1.2.3(抽牌,任意一张)。从一副标准的 52 张扑克牌中抽取一张。样本空间 \(S\) 是所有 52 张牌的集合(因此共有 52 颗卵石,每张牌对应一颗)。考虑以下四个事件:
- \(A\):牌是尖子(Ace)。
- \(B\):牌是黑色花色。
- \(D\):牌是方块。
- \(H\):牌是红心。
作为一个集合,\(H\) 包含 13 张牌:
{红心 Ace, 红心 2, ..., 红心 K}。
我们可以根据事件 \(A, B, D\) 和 \(H\) 创建各种其他事件。并集、交集和补集对此特别有用。例如:
\(A \cap H\) 是牌为红心 Ace 的事件。
\(A \cap B\) 是事件 {黑桃 Ace, 梅花 Ace}。
\(A \cup D \cup H\) 是牌为红色或 Ace 的事件。
\((A \cup B)^c = A^c \cap B^c\) 是牌为红色且非 Ace 的事件。
此外,注意 \((D \cup H)^c = D^c \cap H^c = B\),因此 \(B\) 可以用 \(D\) 和 \(H\) 来表达。另一方面,牌是黑桃的事件无法用 \(A, B, D, H\) 来表达,因为它们中没有一个的粒度细到能够区分黑桃和梅花。
在这个样本空间中还可以定义许多其他事件。事实上,本章后面介绍的计数方法表明,尽管只有 52 颗卵石,但在该问题中存在 \(2^{52} \approx 4.5 \times 10^{15}\) 个事件。
如果抽到的牌是王牌(Joker)呢?那将说明我们使用了错误的样本空间;我们假设实验的结果注定是 \(S\) 中的一个元素。
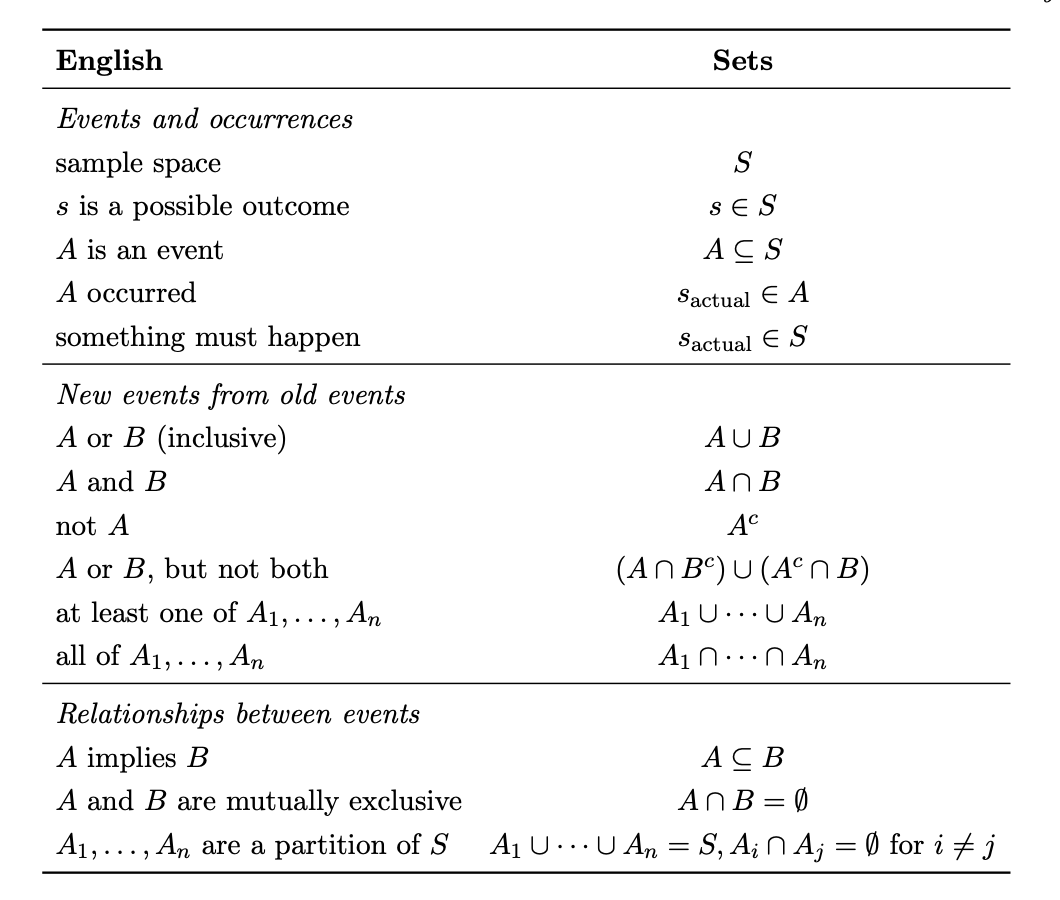
正如上述示例所展示的,事件可以用英文描述,也可以用集合符号描述。有时英文描述更容易理解,而集合符号更容易操作。设 \(S\) 为样本空间,\(s_{actual}\) 为实验的实际结果(即实验进行时最终被选中的那颗卵石)。下面给出了一个用于英文与集合转换的小词典。
1.3 概率的原始定义
Naive definition of probability
从历史上看,关于事件概率最早的定义是计算该事件可能发生方式的数量,并除以该实验可能结果的总数。我们称之为“原始定义”(Naive definition),因为它具有局限性且依赖于强假设;尽管如此,理解这一概念至关重要,且在不被误用的情况下非常有用。
定义 1.3.1(概率的原始定义)。设 \(A\) 为一个样本空间 \(S\) 有限的实验中的事件。\(A\) 的原始概率为:
\[ P_{naive}(A) = \frac{|A|}{|S|} = \frac{\text{对 } A \text{ 有利的结果数量}}{S \text{ 中的总结果数量}} \]
(我们用 \(|A|\) 表示集合 \(A\) 的大小;参见数学附录的 A.1.5 节。)
用“卵石世界”的语言来说,原始定义仅仅是指事件 \(A\) 的概率是位于 \(A\) 中的卵石所占的比例。例如,在图 1.1 中:
\[ P_{naive}(A) = \frac{5}{9}, \quad P_{naive}(B) = \frac{4}{9}, \quad P_{naive}(A \cup B) = \frac{8}{9}, \quad P_{naive}(A \cap B) = \frac{1}{9} \]
对于上述事件的补集:
\[ P_{naive}(A^c) = \frac{4}{9}, \quad P_{naive}(B^c) = \frac{5}{9}, \quad P_{naive}((A \cup B)^c) = \frac{1}{9}, \quad P_{naive}((A \cap B)^c) = \frac{8}{9} \]
通常情况下:
\[ P_{naive}(A^c) = \frac{|A^c|}{|S|} = \frac{|S| - |A|}{|S|} = 1 - \frac{|A|}{|S|} = 1 - P_{naive}(A) \]
在 1.6 节中,我们将看到这个关于补集的结论在概率论中始终成立,即使超出了原始定义的范畴。在试图寻找一个事件的概率时,一个很好的策略是先思考寻找该事件的概率还是其补集的概率会更容易。德·摩根定律在此背景下尤其有用,因为处理交集可能比处理并集更容易,反之亦然。
原始定义的局限性很大,它要求 \(S\) 必须是有限的,且每颗卵石的质量相等。它经常被某些人误用,这些人未经证明就假设结果是等可能的,并提出诸如“要么发生,要么不发生,我们不知道是哪种,所以概率是 50对50”之类的论点。这种推理方式不仅有时会给出荒谬的概率,甚至在逻辑自洽性上都存在问题。例如,它会说火星上存在生命的概率是 1/2(“要么有,要么没有”),但它也会说火星上存在高等智慧生命的概率是 1/2。从直觉上——以及根据 1.6 节中建立的概率性质——显然后者的概率应该严格低于前者。
但在几种重要的类型题中,原始定义是适用的:
- 当问题中存在对称性,使得结果等可能时。 归因于硬币物理上的对称性,通常假设硬币抛掷后正面朝上的概率为 50%。对于一副标准且充分洗过的扑克牌,假设所有排列顺序是等可能的也是合理的。并不会有某些特别积极的牌偏爱待在牌堆顶端;牌堆中的任何特定位置放置 52 张牌中任意一张的可能性是相等的。
- 当结果在设计上就是等可能时。 例如,考虑在 \(N\) 个人的人口中对 \(n\) 个人进行调查。一个共同目标是获得“简单随机样本”,这意味着这 \(n\) 个人是被随机选出的,所有大小为 \(n\) 的子集被选中的概率都相等。如果抽样成功,这确保了原始定义适用,但在实践中这可能难以实现,因为存在各种复杂情况,例如没有完整准确的人口联系方式清单。
- 当原始定义作为一个有用的零模型(Null Model)时。 在这种情形下,我们假设原始定义适用,仅仅是为了观察它会产生什么样的预测,然后我们可以将观测数据与预测值进行比较,以评估“结果等可能”这一假设是否站得住脚。
1.4 如何计数
How to count
计算事件 \(A\) 的原始概率涉及统计 \(A\) 中的卵石数量以及样本空间 \(S\) 中的卵石数量。通常,我们需要计数的集合规模极其庞大。本节介绍一些基础的计数方法;更多方法可以在组合数学(研究计数的数学分支)相关的书籍中找到。
1.4.1 乘法原理
Multiplication rule
在某些问题中,我们可以使用一个基础且通用的原则——乘法原理直接计算可能性的数量。我们将看到,乘法原理自然地推导出“有放回抽样”和“无放回抽样”的计数规则( sampling with replacement and sampling without replacement),这两种场景在概率论和统计学中经常出现。
个人注:乘法原理是概率计数的核心。
定理 1.4.1(乘法原理)。考虑一个由两个子实验(实验 A 和 实验 B)组成的复合实验。假设实验 A 有 \(a\) 种可能的结果,且对于每一个结果,实验 B 都有 \(b\) 种可能的结果。那么该复合实验共有 \(ab\) 种可能的结果。
为了理解乘法原理为何成立,可以想象如图 1.2 所示的树状图。
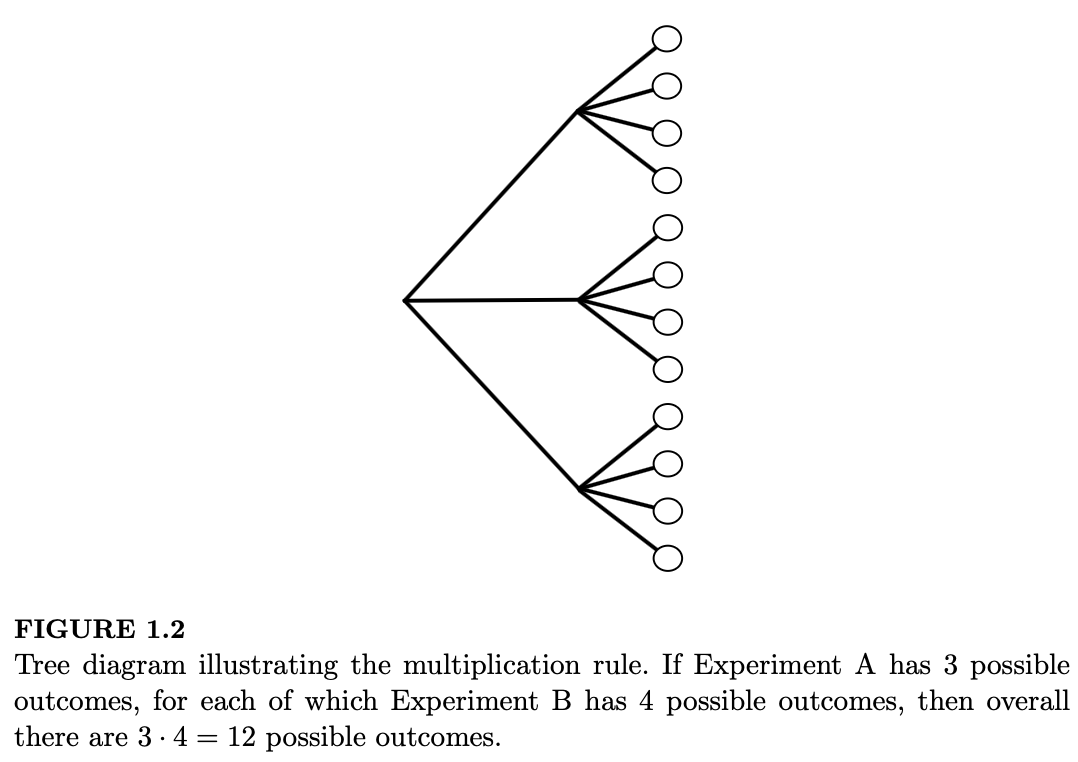
让树根据实验 A 的可能性分出 \(a\) 个分支,对于每一个分支,再为实验 B 创建 \(b\) 个更深层的分支。总共有:
\[ \underbrace{b + b + \dots + b}_{a \text{ 次}} = ab \text{ 种可能性。} \]
1.4.2。将实验设想为按时间先后顺序发生通常更容易思考,但乘法原理并不要求实验 A 必须在实验 B 之前进行。
例 1.4.3(赛跑者)。假设有 10 个人参加比赛。假设不存在并列情况且 10 个人都会完成比赛,因此将会有明确的第一名、第二名和第三名获奖者。那么第一名、第二名和第三名获奖者的组合共有多少种可能性?
解答:第一名有 10 种可能性,一旦确定,第二名就有 9 种可能性,当前两者都确定后,第三名就有 8 种可能性。因此根据乘法原理,共有:\(10 \cdot 9 \cdot 8 = 720 \text{ 种可能性。}\)
我们并非必须先考虑第一名。我们同样可以说第三名有 10 种可能性,一旦确定,第二名有 9 种可能性,而前两者确定后,第一名有 8 种可能性。或者想象有三个领奖台,赛后的第一、二、三名将分别站在上面。领奖台分为金牌、银牌和铜牌,分别分配给第一、二、三名赛跑者。同样,赛后领奖台被占据的情况共有 \(10 \cdot 9 \cdot 8 = 720\) 种可能性,并没有理由必须按照(金、银、铜)的顺序来考虑领奖台。
例 1.4.4(棋盘)。如图 1.3 所示,一个 \(8 \times 8\) 的棋盘上有多少个方格?甚至“\(8 \times 8\) 棋盘”这个名字就让这变得很简单:棋盘上有 \(8 \cdot 8 = 64\) 个方格。网格结构清晰地展现了这一点,但我们也可以将其视为乘法原理的一个例子:要确定一个方格,我们可以指定它所在的行和列。行有 8 种选择,对于每一种选择,列也有 8 种选择。

此外,我们无需进行任何计算就能看出,一半的方格是白色的,一半是黑色的。想象将棋盘顺时针旋转 90 度。那么所有原本是白色方格的位置现在都变成了黑色方格,反之亦然,因此白色方格的数量必须等于黑色方格的数量。我们也可以利用乘法原理来计算白色方格的数量:在 8 行中的每一行都有 4 个白色方格,总计 \(8 \cdot 4 = 32\) 个白色方格。
相比之下,计算图 1.3 所示的填字游戏网格中的白色方格数量则需要更多精力。乘法原理在此不适用,因为不同的行有时包含不同数量的白色方格。
例 1.4.5(冰淇淋蛋筒)。假设你要买一个冰淇淋蛋筒。你可以选择要普通蛋筒(cake cone)还是华夫蛋筒(waffle cone),口味则可以选择巧克力、香草或草莓。这个决策过程可以用树状图来可视化,如图 1.4 所示。
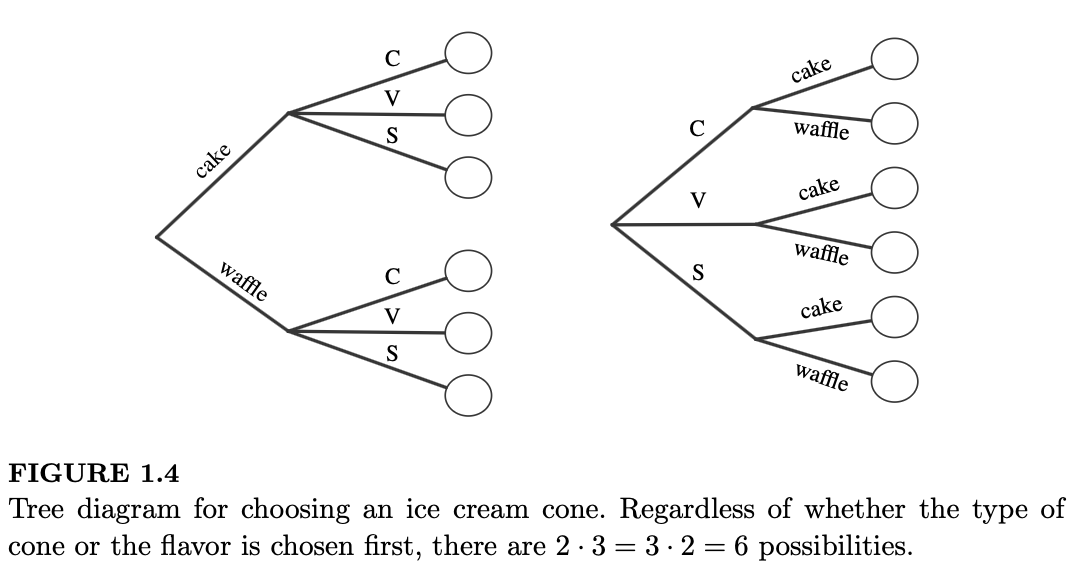
根据乘法原理,共有 \(2 \cdot 3 = 6\) 种可能性。这是一个非常简单的例子,但作为思考和可视化更复杂案例的基础,值得详细推敲。很快我们就会遇到一些例子,如果要把树状图画到清晰可辨的大小,其占用的空间将超过已知宇宙的范围,但在概念上,我们仍然可以按照冰淇淋的例子来思考。
需要注意的几点:
- 无论你是先选蛋筒类型(“我要一个带巧克力冰淇淋的华夫蛋筒”)还是先选口味(“我要华夫蛋筒装的巧克力冰淇淋”)都无关紧要。无论哪种方式,都有 \(2 \cdot 3 = 3 \cdot 2 = 6\) 种可能性。
- 普通蛋筒和华夫蛋筒可提供的口味是否相同并不重要。重要的是,对于每一种蛋筒选择,都恰好有 3 种口味选择。如果出于某种奇怪的原因,规定华夫蛋筒禁止搭配巧克力冰淇淋,且没有替代口味(除了香草和草莓),那么将只有 \(3 + 2 = 5\) 种可能性,乘法原理就不再适用。在更大规模的案例中,此类复杂情况会使计算可能性的数量变得极其困难。
现在假设你在某一天买了两个冰淇淋蛋筒,一个在下午,另一个在晚上。例如,记 (cakeC, waffleV) 表示下午吃巧克力口味普通蛋筒,晚上吃香草口味华夫蛋筒。根据乘法原理,在你这段美妙的复合实验中,共有 \(6^2 = 36\) 种可能性。
但如果你只对那天吃了什么样的冰淇淋蛋筒感兴趣,而不关心吃它们的顺序,也就是说你不想区分(例如) (cakeC, waffleV) 和 (waffleV, cakeC),该怎么办?现在的可能性是 \(36/2 = 18\) 种吗?不,因为像 (cakeC, cakeC) 这样的可能性原本就各自只列出了一次。在有序的可能性 \((x, y)\) 中,满足 \(x \neq y\) 的有 \(6 \cdot 5 = 30\) 种,如果我们视 \((x, y)\) 与 \((y, x)\) 等价,则它们变为 15 种可能性;再加上 6 种形式为 \((x, x)\) 的可能性,总计 21 种可能性。请注意,如果原始的 36 个有序对 \((x, y)\) 是等可能的,那么这里的 21 种可能性就不是等可能的。
例 1.4.6(子集)。一个拥有 \(n\) 个元素的集合共有 \(2^n\) 个子集,包括空集 \(\emptyset\) 和集合本身。这可以由乘法原理推导得出,因为对于每一个元素,我们都可以选择将其包含在子集中或排除在外。例如,集合 \(\{1, 2, 3\}\) 共有 8 个子集:\(\emptyset, \{1\}, \{2\}, \{3\}, \{1, 2\}, \{1, 3\}, \{2, 3\}, \{1, 2, 3\}\)。这一结论解释了为什么在例 1.2.3 中可以定义 \(2^{52}\) 个事件。
我们可以利用乘法原理得出有放回抽样和无放回抽样的公式。概率论和统计学中的许多实验都可以用这两种背景之一来解释,因此这两个公式都直接源于同一种基本计数原理,这一点非常有吸引力。
定理 1.4.7(有放回抽样)。考虑 \(n\) 个物体,从中进行 \(k\) 次选择,每次选择一个并放回(即选中某个物体并不妨碍它再次被选中)。那么共有 \(n^k\) 种可能的结果(这里顺序是重要的,例如,先选物体 3 再选物体 7 被视为与先选物体 7 再选物体 3 不同的结果)。
例如,想象一个装有 \(n\) 个球的罐子,球的编号为 1 到 \(n\)。我们每次抽取一个球并放回,这意味着每次选中一个球后,它都会被放回罐子中。每次抽球都是一个具有 \(n\) 种可能结果的子实验,共进行 \(k\) 次子实验。因此,根据乘法原理,获得大小为 \(k\) 的样本共有 \(n^k\) 种方式。
定理 1.4.8(无放回抽样)。考虑 \(n\) 个物体,从中进行 \(k\) 次选择,每次选择一个且不放回(即选中某个物体后,它不能再次被选中)。那么当 \(1 \le k \le n\) 时,共有 \(n(n-1)\cdots(n-k+1)\) 种可能的结果;当 \(k > n\) 时,共有 0 种可能性(此处顺序同样重要)。按照惯例,当 \(k=1\) 时,\(n(n-1)\cdots(n-k+1) = n\)。
这一结论也直接源于乘法原理:每次抽球同样是一个子实验,且可能结果的数量每次减少 1。注意,对于从 \(n\) 个物体中无放回地抽取 \(k\) 个,我们需要满足 \(k \le n\);而在有放回抽样中,物体是取之不尽的。
例 1.4.9(排列与阶乘)。\(1, 2, \dots, n\) 的一个排列是指将它们按某种顺序进行排列,例如 \(3, 5, 1, 2, 4\) 是 \(1, 2, 3, 4, 5\) 的一个排列。根据定理 1.4.8(取 \(k=n\)),\(1, 2, \dots, n\) 共有 \(n!\) 种排列。例如,\(n\) 个人排队买冰淇淋共有 \(n!\) 种方式。(回顾一下,对于任何正整数 \(n\),\(n!\) 等于 \(n(n-1)(n-2)\cdots 1\),且 \(0! = 1\)。)
定理 1.4.7 和 1.4.8 是关于计数的定理,但当原始定义适用时,我们可以利用它们来计算概率。这就引出了我们的下一个例子——概率论中著名的“生日问题”。该问题的解法同时结合了有放回抽样和无放回抽样。
例 1.4.10(生日问题)。一个房间里有 \(k\) 个人。假设每个人的生日是当年 365 天中的任何一天(我们排除 2 月 29 日)且可能性相等,并且人们的生日是相互独立的(我们稍后会正式定义独立性,但直观上它意味着知道某些人的生日并不能提供关于其他人生日的信息;如果已知其中两人是双胞胎,则这一假设不成立)。那么,这群人中至少有一对人的生日相同的概率是多少?
解答:
为房间里的 \(k\) 个人分配生日共有 \(365^k\) 种方式,因为我们可以想象全年的 365 天被有放回地抽取了 \(k\) 次。根据假设,所有这些可能性都是等可能的,因此适用概率的原始定义。
如果直接使用原始定义,我们需要计算为 \(k\) 个人分配生日且其中两人共享生日的方式总数。但这个计数问题很难,因为可能是艾玛(Emma)和史蒂夫(Steve)生日相同,或者是史蒂夫和内奥米(Naomi),或者是他们三个人,或者他们三个人共享一个生日而组内另外两人共享另一个不同的生日,以及其他各种可能性。
相反,让我们计算其补集:为 \(k\) 个人分配生日且没有两人生日相同的方式总数。这相当于对一年的 365 天进行无放回抽样,因此当 \(k \le 365\) 时,可能性的数量为 \(365 \cdot 364 \cdot 363 \cdots (365 - k + 1)\)。因此,在 \(k\) 个人中没有生日重复的概率为: \[ P(\text{无生日重复}) = \frac{365 \cdot 364 \cdots (365 - k + 1)}{365^k} \] 而至少有一对生日重复的概率为: \[ P(\text{至少 1 对生日重复}) = 1 - \frac{365 \cdot 364 \cdots (365 - k + 1)}{365^k} \]
图 1.5 描绘了至少有一对生日重复的概率随 \(k\) 变化的函数图。概率超过 0.5 时 \(k\) 的第一个取值是 \(k = 23\)。因此,在一群 23 个人中,有超过 50% 的机会至少存在一对生日重复。当 \(k = 57\) 时,重复的概率已经超过了 99%。
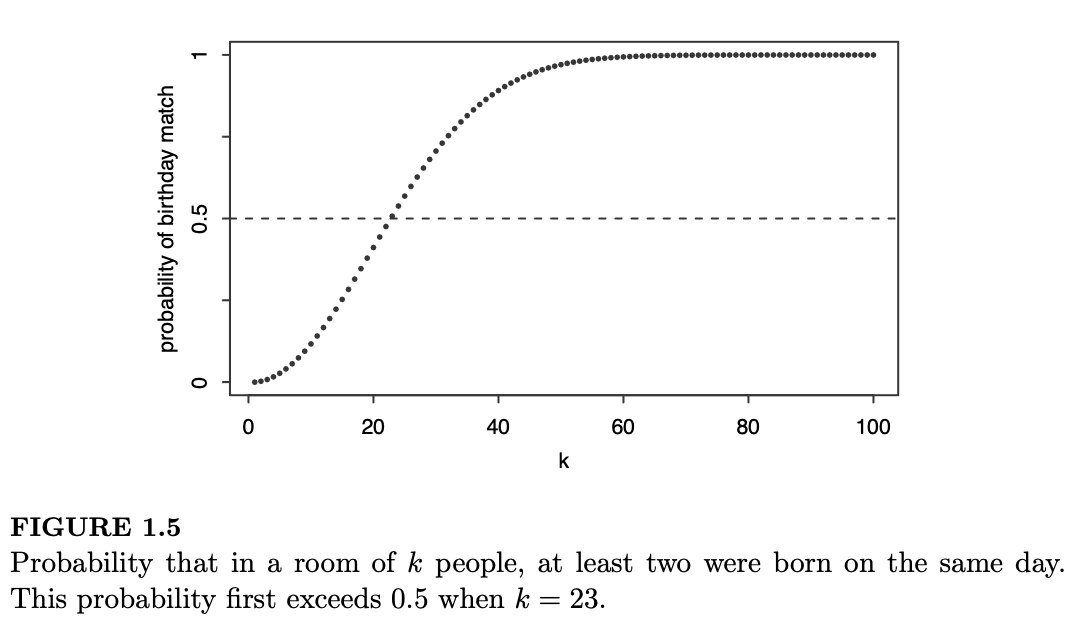
当然,当 \(k = 366\) 时,可以保证一定会有生日重复,但令人惊讶的是,即使在人数少得多时,出现生日重复的可能性也极高。为了快速直观地理解为什么这不该如此令人惊讶,请注意在 23 个人中,存在 \(\binom{23}{2} = 253\) 对人,其中每一对都有可能成为生日匹配的潜在对象。
习题 26 和 27 表明,生日问题远不止是一个有趣的聚会游戏,也不仅仅是建立关于“巧合”直觉的方法;它在统计学和计算机科学中也有重要的应用。习题 62 探讨了更通用的情形,即每一天的概率不一定都是 \(1/365\)。事实证明,在概率不相等的情况下,至少出现一次匹配的可能性会变得更高。
1.4.11(物体标签化)。从总体中抽取样本是统计学中一个非常基础的概念。将总体中的物体或人视为有名有姓或带有标签的,这一点至关重要。例如,如果罐子里有 \(n\) 个球,我们可以想象它们带有从 1 到 \(n\) 的标签,即使在人眼看来这些球长得一模一样。在生日问题中,我们可以给每个人一个 ID(身份证)号码,而不是将人视为不可区分的粒子或面目模糊的群体。
一个相关的例子是莱布尼茨在一个看似简单的问题上犯下的具有启发性的错误(关于此问题及其他各种概率问题的历史视角讨论,请参见 Gorroochurn [14])。
例 1.4.12(莱布尼茨的错误)。如果我们掷两枚公平的骰子,哪种情况的可能性更大:点数之和为 11 还是 12?
解答:
将骰子标记为 A 和 B,并将每一枚骰子视为一个子实验。根据乘法原理,形式为(A 的值,B 的值)的有序对共有 36 种可能的结果,且基于对称性,它们是等可能的。在这些结果中,\((5,6)\) 和 \((6,5)\) 对总和为 11 有利,而只有 \((6,6)\) 对总和为 12 有利。因此,总和为 11 的可能性是总和为 12 的两倍;前者的概率是 \(1/18\),后者的概率是 \(1/36\)。
然而,莱布尼茨错误地认为总和为 11 和总和为 12 的可能性相等,声称每种总和都只有一种实现方式。在这里,莱布尼茨犯了将两枚骰子视为不可区分物体的错误,将 \((5,6)\) 和 \((6,5)\) 视为了同一种结果。
纠正莱布尼茨错误的“良药”是什么?首先,如 1.4.11 中所解释的,我们应该给所讨论的物体贴上标签,而不是将它们视为不可区分的。如果莱布尼茨给他的骰子贴上 A 和 B 的标签,或者涂上绿色和橙色,或者区分左右,他就不会犯这个错误。其次,在我们利用计数来计算概率之前,应该先问问自己原始定义是否适用(关于在应用原始定义前需要谨慎的另一个例子,请参见 1.4.23)。
1.4.2 针对重复计数的调整
Adjusting for overcounting
在许多计数问题中,想要直接且不重不漏地计算每种可能性并不容易。但是,如果我们能够确保每种可能性都恰好被计算了 \(c\) 次(对于某个常数 \(c\)),那么我们就可以通过除以 \(c\) 来进行调整。例如,如果我们对每种可能性都恰好计算了两次,就可以除以 2 来得到正确的计数。我们称之为针对重复计数的调整。
例 1.4.13(委员会与团队)。考虑一组四个人。
选出一个两人委员会共有多少种方式?
将这四个人分成两组(每组两人)共有多少种方式?
解答:
- 一种计算方式是列举出来:将人标记为 1, 2, 3, 4,可能性有:12, 13, 14, 23, 24, 34。
另一种方法是使用带有重复计数调整的乘法原理。根据乘法原理,选择委员会的第一名成员有 4 种方式,选择第二名成员有 3 种方式,但这会将每种可能性计算两次,因为选择 1 和 2 进委员会与选择 2 和 1 进委员会是同一回事。由于我们重复计算了 2 倍,可能性的数量为 \((4 \cdot 3) / 2 = 6\)。
- 这里有 3 种方法可以看出形成团队的方式有 3 种。将人标记为 1, 2, 3, 4,我们可以直接列出可能性:12|34, 13|24, 以及 14|23。不过,如果人数更多,列出所有可能性很快就会变得繁琐或不可行。另一种方法是注意到,只要指定 1 号人的队友就足够了(此时另一组也就随之确定了)。第三种方法是利用 (a) 的结论,即选出一个小组有 6 种方式。这重复计算了 2 倍,因为选择 1 和 2 组成一队等同于选择 3 和 4 组成一队。所以答案再次为 \(6 / 2 = 3\)。
二项式系数用于计算集合中特定大小的子集数量,例如从 \(n\) 个人中选出规模为 \(k\) 的委员会的方式数量。根据定义,集合和子集是无序的,例如 \(\{3, 1, 4\} = \{4, 1, 3\}\),因此我们计算的是从 \(n\) 个物体中无放回地选出 \(k\) 个,且不区分其被选中顺序的方式数量。
定义 1.4.14(二项式系数)。对于任何非负整数 \(k\) 和 \(n\),二项式系数 \(\binom{n}{k}\)(读作“\(n\) 选 \(k\)”)是一个大小为 \(n\) 的集合中大小为 \(k\) 的子集数量。
例如,\(\binom{4}{2} = 6\),如例 1.4.13 所示。二项式系数 \(\binom{n}{k}\) 有时被称为“组合”(combination),但我们在这里不使用该术语,因为“组合”是一个非常有用的通用词汇。在代数上,二项式系数可以按如下方式计算。
定理 1.4.15(二项式系数公式)。当 \(k \le n\) 时,有:
\[ \binom{n}{k} = \frac{n(n-1)\cdots(n-k+1)}{k!} = \frac{n!}{k!(n-k)!} \]
当 \(k > n\) 时,有 \(\binom{n}{k} = 0\)。
证明:设 \(A\) 为一个大小为 \(|A| = n\) 的集合。\(A\) 的任何子集的大小最多为 \(n\),因此当 \(k > n\) 时,\(\binom{n}{k} = 0\)。现在设 \(k \le n\)。根据定理 1.4.8,无放回地有序选择 \(k\) 个元素共有 \(n(n-1)\cdots(n-k+1)\) 种方式。由于我们不关心这些元素的排列顺序,这使得每一个目标子集都被重复计算了 \(k!\) 次。因此,我们可以通过除以 \(k!\) 来得到正确的计数。
1.4.16。二项式系数 \(\binom{n}{k}\) 通常用阶乘来定义,但请记住,如果 \(k > n\),\(\binom{n}{k}\) 为 0,即使负数的阶乘是无定义的。此外,定理 1.4.15 中的中间表达式通常比阶乘表达式更便于计算,因为阶乘增长得极其迅速。例如: \[ \binom{100}{2} = \frac{100 \cdot 99}{2} = 4950 \]
这甚至可以手算完成,而如果通过先计算 \(100!\) 和 \(98!\) 来计算 \(\binom{100}{2} = 100! / (98! \cdot 2!)\),由于涉及的数值极大(\(100! \approx 9.33 \times 10^{157}\)),这种做法既浪费且可能因溢出而产生危险。
例 1.4.17(俱乐部官员)。在一个有 \(n\) 个人的俱乐部中,选出一名主席、一名副主席和一名财务总监共有 \(n(n-1)(n-2)\) 种方式;而选出 3 名不预设头衔的官员则有 \(\binom{n}{3} = \frac{n(n-1)(n-2)}{3!}\) 种方式。
例 1.4.18(单词的排列)。单词 LALALAAA 中的字母共有多少种排列方式?要确定一种排列,我们只需要选择 5 个 A 放置的位置(或者等价地,决定 3 个 L 放置的位置)。因此共有: \[ \binom{8}{5} = \binom{8}{3} = \frac{8 \cdot 7 \cdot 6}{3!} = 56 \text{ 种排列。} \]
单词 STATISTICS 中的字母共有多少种排列方式?这里有两种方法。方法一:我们可以选择放置 S 的位置,然后从剩余位置中选择放置 T 的位置,接着是 I 的位置,最后是 A 的位置(此时 C 的位置已随之确定)。方法二:我们可以从 \(10!\) 开始,然后针对重复计数进行调整,除以 \(3!3!2!\),以修正 S 之间、T 之间以及 I 之间可以任意互换位置的事实。这得到了:
\[ \binom{10}{3}\binom{7}{3}\binom{4}{2}\binom{2}{1} = \frac{10!}{3!3!2!} = 50400 \text{ 种可能性。} \]
例 1.4.19(二项式定理)。二项式定理指出,对于任何非负整数 \(n\): \[ (x+y)^n = \sum_{k=0}^n \binom{n}{k} x^k y^{n-k} \]
为了证明二项式定理,展开以下乘积:
\[ \underbrace{(x+y)(x+y)\dots(x+y)}_{n \text{ 个因子}} \]
正如 \((a+b)(c+d) = ac + ad + bc + bd\) 是从第一个因子中选 \(a\) 或 \(b\)(但不同时选)并从第二个因子中选 \(c\) 或 \(d\)(但不同时选)所得到的各项之和,\((x+y)^n\) 的各项是通过从每个因子中选择 \(x\) 或 \(y\)(但不同时选)而获得的。恰好选择 \(k\) 个 \(x\) 的方式有 \(\binom{n}{k}\) 种,每一种选择都会产生项 \(x^k y^{n-k}\)。二项式定理由此得证。
在许多适用原始定义的题目中,我们可以使用二项式系数来计算概率。
例 1.4.20(德州扑克中的满堂彩)。从一副标准且充分洗好的 52 张扑克牌中分发 5 张。如果这手牌由某个点数的三张牌和另一个点数的两张牌组成,则被称为“满堂彩”(Full house,又称三带二),例如三张 7 和两张 10(顺序不限)。获得满堂彩的概率是多少?
解答:
基于对称性,所有 \(\binom{52}{5}\) 种可能的持牌情况都是等可能的,因此原始定义适用。为了计算满堂彩的组合数,使用乘法原理(并想象其树状图)。哪种点数出现三张共有 13 种选择;为了具体化,假设我们有三张 7,并关注树的这一分支。从 4 张 7 中选出 3 张共有 \(\binom{4}{3}\) 种方式。接下来,剩下 12 种点数可选作那两张牌的点数,假设是 10,则从 4 张 10 中选出 2 张共有 \(\binom{4}{2}\) 种方式。因此:
\[ P(\text{满堂彩}) = \frac{13 \binom{4}{3} 12 \binom{4}{2}}{\binom{52}{5}} = \frac{3744}{2598960} \approx 0.00144 \]
在玩扑克时,十进制近似值更有用,但用二项式系数表示的答案是精确且具有“自注释性”的(看到 \(\binom{52}{5}\) 比看到 2598960 更能暗示其来源)。
例 1.4.21(牛顿-皮皮斯问题)。塞缪尔·皮皮斯(Samuel Pepys)曾就以下问题咨询过艾萨克·牛顿,他希望将这些信息用于博弈。以下哪种事件的概率最高?
A:掷 6 枚公平的骰子,至少出现一个 6。
B:掷 12 枚公平的骰子,至少出现两个 6。
C:掷 18 枚公平的骰子,至少出现三个 6。
解答:
这三个实验分别有 \(6^6\)、\(6^{12}\) 和 \(6^{18}\) 种可能的结果,基于对称性,原始定义适用于所有三个实验。
A:与其计算获得至少一个 6 的方式数,不如计算一个 6 都没有的方式数。没有 6 相当于在数字 1 到 5 中进行 6 次有放回抽样,因此有 \(5^6\) 种结果对 \(A^c\) 有利(而 \(6^6 - 5^6\) 种对 \(A\) 有利)。因此:
\[ P(A) = 1 - \frac{5^6}{6^6} \approx 0.67 \]
B:同样,我们先计算 \(B^c\) 中的结果。在 12 次投掷中,没有 6 的方式有 \(5^{12}\) 种。恰好出现一个 6 的方式有 \(\binom{12}{1} 5^{11}\) 种:我们先选出哪枚骰子结果为 6,然后对其他 11 枚骰子在 1 到 5 之间进行有放回抽样。将这些相加,得到未能获得至少两个 6 的方式数。那么:
\[ P(B) = 1 - \frac{5^{12} + \binom{12}{1} 5^{11}}{6^{12}} \approx 0.62 \]
C:我们计算 \(C^c\) 中的结果,即 18 次投掷中出现 0、1 或 2 个 6 的方式数。没有 6 有 \(5^{18}\) 种方式,恰好一个 6 有 \(\binom{18}{1} 5^{17}\) 种方式,恰好两个 6 有 \(\binom{18}{2} 5^{16}\) 种方式(选出哪两枚骰子为 6,然后决定其他 16 枚的结果)。
\[ P(C) = 1 - \frac{5^{18} + \binom{18}{1} 5^{17} + \binom{18}{2} 5^{16}}{6^{18}} \approx 0.60 \]
因此,事件 A 的概率最高。
牛顿通过类似的计算得出了正确答案。牛顿还向皮皮斯提供了一个直观的论据,解释为什么 A 是三者中最可能的;然而,他的直觉是无效的。正如 Stigler [24] 所解释的,使用灌铅骰子可能会导致 A、B、C 的排序发生变化,但牛顿的直观论据并不依赖于骰子是否公平。
在本书中,我们关注计数并不是为了计数本身,而是因为它有时能帮助我们找到概率。下面是一个巧妙但具有误导性的计数问题示例;其解法非常优雅,但该结果极少能与概率的原始定义结合使用。
例 1.4.22(玻色-爱因斯坦 Bose-Einstein)。如果顺序不重要(我们只关心每个对象被选中的次数,而不关心被选中的顺序),那么从 \(n\) 个对象的集合中有放回地抽取 \(k\) 次共有多少种方式?
解答:
当顺序重要时,根据乘法原理,答案是 \(n^k\),但这个问题要困难得多。我们将通过解决一个同构问题(即以不同形式表现的同一个问题)来解决它。
让我们计算将 \(k\) 个不可区分的粒子放入 \(n\) 个可区分的盒子中的方式数量。也就是说,以任何方式交换粒子都不被视为一种独立的可行方案:唯一重要的是每个盒子中有多少个粒度的计数。这种情景被称为玻色-爱因斯坦问题,因为物理学家萨特延德拉·纳特·玻色(Satyendra Nath Bose)和阿尔伯特·爱因斯坦在 20 世纪 20 年代研究过关于不可区分粒子的相关问题,并利用他们的思想成功预测了一种被称为“玻色-爱因斯坦凝聚态”的奇特物质状态的存在。
任何配置都可以自然地编码为由 \(|\) 和 \(q\) 组成的序列,如图 1.6 所示。
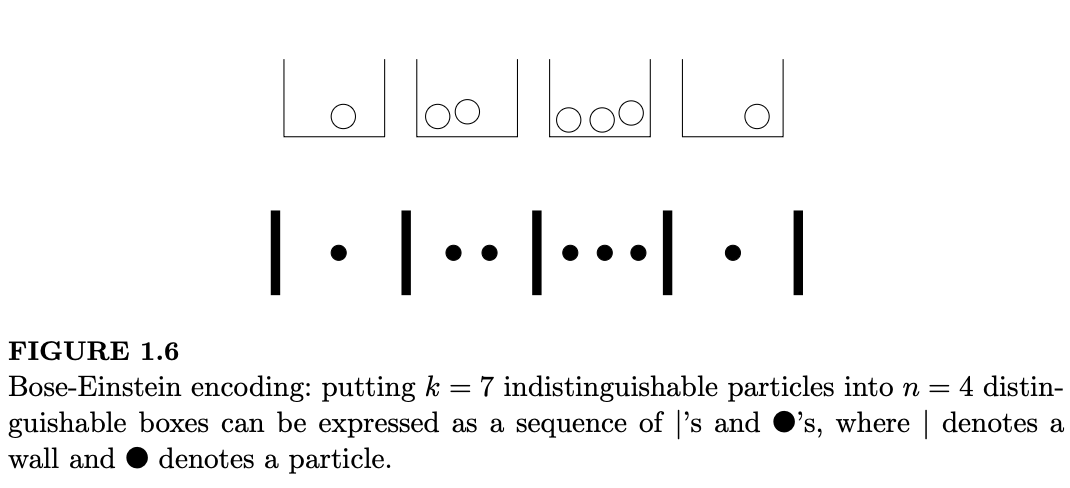
为了使序列有效,它必须以 \(|\) 开头并以 \(|\) 结尾,并且在起始和结束的 \(|\) 之间恰好有 \(n-1\) 个 \(|\) 和恰好 \(k\) 个 \(q\);反之,任何此类序列都是某种粒子在盒子中配置的有效编码。想象我们已经写下了代表外墙的起始和结束的 \(|\),而在外墙之间有 \(n+k-1\) 个填空位置。我们只需要选择在哪里放置 \(k\) 个 \(q\)(因为随后 \(n-1\) 个内部 \(|\) 的位置就完全确定了)。因此,可能性的数量是 \(\binom{n+k-1}{k}\)。这种计数方法有时被称为“隔板法”(stars and bars argument),在这里我们用点代替了星号。
个人注:这个隔板法转化成同构问题的思想太伟大了!
个人注:如何理解“而在外墙之间有 \(n+k-1\) 个填空位置!” 答: 这句话的理解核心在于,我们要把 \(k\) 个物体(点 \(q\))放进 \(n\) 个盒子,本质上是在用 \(n-1\) 个隔板(内部的 \(|\))来把这些点分隔开。
我们可以按照以下步骤拆解这个思维过程:
1. 确定“符号”的总数
为了表示 \(n\) 个盒子,我们需要 \(n-1\) 个内部隔板。加上我们要放入的 \(k\) 个点,我们手上一共有:
- \(k\) 个点(代表对象)
- \(n-1\) 个隔板(代表盒子的边界)
把这些符号全部排列在一起,总共需要的“位置”数量就是:
\[k + (n-1) = n + k - 1\]
2. 为什么是“填空”?
想象你面前有一排空的架子,上面一共有 \(n+k-1\) 个空格。你现在手里拿着 \(k\) 个点(\(q\))和 \(n-1\) 个隔板(\(|\))。
- 只要你从这 \(n+k-1\) 个位置中,选出 \(k\) 个位置放下点(\(q\)),那么剩下的位置就自动变成了隔板(\(|\))的位置。
- 反之亦然,如果你选出 \(n-1\) 个位置放隔板,剩下的就自动全是点。
3. 理解“外墙”
书中提到的“外墙”是指最左边和最右边的边界。
- 因为我们有 \(n\) 个盒子,所以最左边一定有一个起始墙,最右边一定有一个结尾墙。
- 这两堵墙的位置是固定死的,它们不参与排列,也不会改变盒子的数量。
- 我们真正能“操作”的,只有夹在中间的那些内部隔板和点。
为了将这个结果关联回原始问题,我们可以让每个盒子对应 \(n\) 个对象中的一个,并将粒子用作“核对标记”来记录每个对象被选中的次数。例如,如果某个盒子恰好包含 3 个粒子,那意味着该盒子对应的对象恰好被选中了 3 次。粒子不可区分对应于我们不关心对象被选中的顺序这一事实。因此,原始问题的答案也是 \(\binom{n+k-1}{k}\)。
另一个同构问题是计算方程 \(x_1 + x_2 + \dots + x_n = k\) 的解 \((x_1, \dots, x_n)\) 的数量,其中 \(x_i\) 是非负整数。这是等价的,因为我们可以将 \(x_i\) 视为第 \(i\) 个盒子中的粒子数量。
1.4.23。除非在非常特殊的情况下,否则不应在概率的原始定义中使用玻色-爱因斯坦的结果。例如,考虑一项调查,通过从规模为 \(n\) 的总体中一次一个、有放回且概率相等地抽取人来收集规模为 \(k\) 的样本。那么 \(n^k\) 个有序样本是等可能的,这使得原始定义适用;但是 \(\binom{n+k-1}{k}\) 个无序样本(其中唯一重要的是每个人被抽样的次数)并不是等可能的。
个人注:怎么理解“等可能性”
理解这段话的关键在于区分“生成过程”和“统计结果”。
在概率论中,当我们说一个样本空间是“等可能”的,意味着每个基本结果发生的概率是一样的。这段话提醒我们:物理上的操作方式决定了谁才是等可能的。
1. 为什么 \(n^k\)(有序样本)是等可能的?
想象你在抽奖箱里抽球。
- 第一次抽取:每个球被抽中的概率都是 \(1/n\)。
- 第二次抽取:每个球被抽中的概率依然是 \(1/n\)。
- ...
- 第 \(k\) 次抽取:每个球被抽中的概率还是 \(1/n\)。
根据乘法原理,任何一个特定的序列(比如“先抽到张三,再抽到李四”)其概率都是:
\[\frac{1}{n} \times \frac{1}{n} \times \dots \times \frac{1}{n} = \frac{1}{n^k}\]
因为每一个特定序列的概率都等于 \(1/n^k\),所以这 \(n^k\) 个有序序列是等可能的。
2. 为什么 \(\binom{n+k-1}{k}\)(无序样本)不是等可能的?
当我们把“顺序”抹去,只看“每个人被抽到了几次”时,不同的“无序结果”对应的“有序序列”数量是不一样的。
举个极端的例子:
假设总体 \(n=2\)(只有张三、李四),抽 \(k=2\) 次。
所有的有序序列共有 \(2^2=4\) 种,且概率相等(各 \(1/4\)):
- (张三, 张三)
- (李四, 李四)
- (张三, 李四)
- (李四, 张三)
现在我们看无序结果(只关心每个人被抽到几次),一共有 3 种情况:
- 情况 A: 张三 2 次,李四 0 次。对应的有序序列只有 1 个:
(张三, 张三)。概率是 \(1/4\)。- 情况 B: 张三 0 次,李四 2 次。对应的有序序列只有 1 个:
(李四, 李四)。概率是 \(1/4\)。- 情况 C: 张三 1 次,李四 1 次。对应的有序序列有 2 个:
(张三, 李四)和(李四, 张三)。概率是 \(1/4 + 1/4 =\) \(1/2\)。结论:
你会发现,“张三李四各一次”出现的概率(1/2)是“张三两次”出现概率(1/4)的两倍。既然不同结果的概率不等,那么这 \(\binom{2+2-1}{2}=3\) 种无序结果就不是等可能的。
总结
作者的意思是:
- 如果你是“一个接一个”抽人,天然形成的是有序序列。虽然你可以把结果记成无序的形式,但那些无序结果的“权重”是不一样的。
- 玻色-爱因斯坦(B-E)计数假设的是那些无序的配置(比如情况 A、B、C)本身就是等可能的。这在宏观世界的抽样调查中几乎不存在,但在量子力学的某些微观粒子系统中,大自然确实是按照这种方式运作的。
在处理概率问题时,如果你错误地使用了 B-E 计数并假设它们等可能,就会导致你低估了“混合型结果”的概率,高估了“纯一色结果”的概率。
再举一个例子,如果一年有 \(n = 365\) 天且有 \(k\) 个人,共有多少种可能的无序生日列表?例如,当 \(k = 3\) 时,我们要计算像(5月1日,3月31日,4月11日)这样的列表,其中所有的排列都被视为等效的。我们不能进行简单的重复计数调整(如 \(n^k/3!\)),因为例如(5月1日,3月31日,4月11日)有 6 种排列,而(3月31日,3月31日,4月11日)只有 3 种排列。根据玻色-爱因斯坦,列表的数量是 \(\binom{n+k-1}{k}\)。但有序的生日列表是等可能的,无序列表则不然,因此在计算生日概率时不应使用玻色-爱因斯坦的值。
个人注:以上问题可以使用“玻色-爱因斯坦”方法来计数,但不能直接用它来计算概率。
1. 计数:共有多少种无序列表?
如果你只关心“每一天有多少人过生日”,而不关心具体是谁在哪一天过生日(即生日列表是无序的),这完全符合“将 \(k\) 个不可区分的粒子放入 \(n\) 个可区分的盒子”的模型:
- 盒子:一年的 \(n = 365\) 天(可区分)。
- 粒子:\(k\) 个人的生日(不可区分,因为我们只关心日期的组合)。
根据隔板法(玻色-爱因斯坦计数),可能的无序生日列表总数为:
\[\binom{n+k-1}{k} = \binom{365+k-1}{k}\]
2. 核心陷阱:概率问题
虽然你可以数出有多少种无序组合,但你不能假设这些无序组合是等可能的。
在现实世界的生日问题中,由于每个人是独立随机选择生日的,正如前面 1.4.23 节所言,有序的生日序列才是等可能的(共有 \(365^k\) 种)。
如果我们错误地假设无序列表是等可能的,就会得出错误的结论。
对比两种视角:
有序视角(现实情况):
“所有人都在 1 月 1 日过生日”这种结果极其罕见,概率是 \(1/365^k\)。
而“所有人生日都不同”这种情况包含了很多种排列,概率要大得多。
无序视角(玻色-爱因斯坦假设):
如果你假设 \(\binom{365+k-1}{k}\) 种结果是等可能的,那么“所有人都在 1 月 1 日”和“所有人生日都不同”中的某一个特定组合(比如 1 号到一个,2 号到一个...)的概率就被看成是一样的了。
总结
- 如果你只是被问到“有多少种组合”,答案是 \(\binom{365+k-1}{k}\)。
- 如果你要计算“生日相同的概率”,绝对不能使用这个总数作为分母,因为在自然的生日生成过程中,这些无序组合出现的频率并不一致。
1.5 故事证明法
Story proofs
“故事证明法”(Story proof)是一种通过诠释来进行的证明。对于计数问题,这通常意味着用两种不同的方式来计算同一事物,而不是进行枯燥的代数运算。故事证明法往往能避免繁琐的计算,并且比代数证明更能深入地解释为什么结论是正确的。虽然“故事”一词有多种含义(有些比其他的更具数学性),但(在我们所使用的语境下的)故事证明法是完全有效的数学证明。以下是一些故事证明的示例,它们同时也作为计数的进一步案例。
例 1.5.1(选择补集)。对于任何满足 \(k \le n\) 的非负整数 \(n\) 和 \(k\): \[ \binom{n}{k} = \binom{n}{n-k} \]
这在代数上很容易通过阶乘形式来验证,但故事证明能让结果在直觉上更容易理解。
故事证明:考虑从 \(n\) 个人中选出一个规模为 \(k\) 的委员会。我们知道有 \(\binom{n}{k}\) 种可能性。但另一种选择委员会的方法是指定哪 \(n-k\) 个人不在委员会中;确定谁在委员会里也就确定了谁不在委员会里,反之亦然。由于这两者是计算同一事物的两种方法,所以等式两边相等。
例 1.5.2(队委)。对于任何满足 \(k \le n\) 的正整数 \(n\) 和 \(k\): \[ n \binom{n-1}{k-1} = k \binom{n}{k} \]
这在代数上同样容易验证(利用对于任何正整数 \(m\),\(m! = m(m-1)!\) 的性质),但故事证明更具洞察力。
故事证明:考虑一组 \(n\) 个人,从中选出一支 \(k\) 人的队伍,并从中选出一名队长。为了确定一种可能性,我们可以先选出队长(有 \(n\) 种选法),然后从剩下的 \(n-1\) 个人中选出其余的 \(k-1\) 名队员;这对应了等式的左边。等价地,我们可以先选出 \(k\) 名队员(有 \(\binom{n}{k}\) 种选法),然后从这 \(k\) 个人中选出一人担任队长(有 \(k\) 种选法);这对应了等式的右边。
个人注:以上这个故事证明太强了!
例 1.5.3(范德蒙德恒等式)。二项式系数之间有一个著名的关系,称为范德蒙德恒等式(Vandermonde’s identity): \[ \binom{m+n}{k} = \sum_{j=0}^k \binom{m}{j} \binom{n}{k-j} \]
这个恒等式在本书中会多次出现。尝试通过暴力展开所有的二项式系数来证明它将是一场噩梦。但一个故事可以优雅地证明这个结果,并清晰地揭示该恒等式为何成立。
故事证明:考虑一个由 \(m\) 名大三学生和 \(n\) 名大四学生组成的社团,要从中选出一个规模为 \(k\) 的委员会。总的可能性有 \(\binom{m+n}{k}\) 种。如果委员会中有 \(j\) 名大三学生,那么必然有 \(k-j\) 名大四学生。恒等式的右侧即是对所有可能的 \(j\) 情况进行求和。
个人注:以上这个故事证明太强了!(不断Repeat ;) )
例 1.5.4(搭档关系)。让我们用故事证明法来展示: \[ \frac{(2n)!}{2^n \cdot n!} = (2n-1)(2n-3)\cdots 3 \cdot 1 \]
故事证明:我们将证明等式两边都在计算将 \(2n\) 个人分成 \(n\) 组搭档的方法数。取 \(2n\) 个人,给他们分配从 \(1\) 到 \(2n\) 的 ID 编号。我们可以通过让这些人排成一排,然后规定前两个是一对,接下来的两个是一对,依此类推来形成搭档。这种方法重复计算了 \(n! \cdot 2^n\) 倍,因为各组搭档之间的顺序并不重要,每组搭档内部的顺序也无关紧要。另一种计数方法是:观察到 1 号人的搭档有 \(2n-1\) 种选择,然后剩下的人中编号最小的那位(如果 2 号已经和 1 号配对,则是 3 号)有 \(2n-3\) 种选择,依此类推。
1.6 概率的非原始定义
Non-naive definition of probability
我们已经见识了几种统计样本空间中结果数量的方法,这使我们能够在原始定义适用的情况下计算概率。但原始定义的作用非常有限,因为它要求结果必须等可能,并且无法处理无限样本空间。为了推广概率的概念,我们将列出一份关于我们希望概率如何表现的简短“愿望清单”(在数学中,这些清单上的条目被称为公理),然后将概率函数定义为满足我们所需性质的函数!
以下是本书余下部分将使用的概率通用定义。它仅需要两条公理,但从这些公理出发,我们可以证明关于概率的极其丰富的结论。
定义 1.6.1(概率的通用定义)。一个概率空间由一个样本空间 \(S\) 和一个概率函数 \(P\) 组成。概率函数以一个事件 \(A \subseteq S\) 作为输入,并返回一个介于 0 和 1 之间的实数 \(P(A)\) 作为输出。函数 \(P\) 必须满足以下公理:
\(P(\emptyset) = 0\),\(P(S) = 1\)。
如果 \(A_1, A_2, \dots\) 是互不相交的事件,那么:
\[ P\left(\bigcup_{j=1}^{\infty} A_j\right) = \sum_{j=1}^{\infty} P(A_j) \]
(称这些事件互不相交意味着它们是互斥的:对于 \(i \neq j\),有 \(A_i \cap A_j = \emptyset\)。)
在“卵石世界”中,该定义说明概率的行为类似于质量:一堆空卵石的质量为 0,所有卵石的总质量为 1;如果我们有几堆互不重叠的卵石,可以通过将各堆卵石的质量相加来得到它们的总质量。与原始情况不同,我们现在可以拥有质量各异的卵石,并且只要总质量为 1,我们也可以拥有可数无限多个卵石。
我们甚至可以拥有不可数样本空间,例如设 \(S\) 为平面内的一个区域。在这种情况下,我们可以不使用卵石,而是将概率想象为分布在一个区域上的泥土,泥土的总质量为 1。
任何满足这两条公理的函数 \(P\)(将事件映射到区间 \([0,1]\) 内的数字)都被认为是有效的概率函数。然而,公理并没有告诉我们概率应该如何被诠释;目前存在着不同的思想流派。
频率学派的概率观认为,概率代表了在大量重复实验中的长期频率:如果我们说一枚硬币正面朝上的概率是 1/2,这意味着如果我们反反复复地抛掷这枚硬币,它正面朝上的比例会是 50%。
贝叶斯学派的概率观认为,概率代表了对所讨论事件的置信程度,因此我们可以对诸如“候选人 A 将赢得选举”或“被告有罪”等假设赋予概率,即使我们不可能反反复复地进行同一场选举或同一宗犯罪。
贝叶斯和频率学派的视角是互补的,两者对于在后续章节中培养直觉都很有帮助。无论我们选择如何诠释概率,我们都可以利用这两条公理来推导概率的其他性质,而这些结果对于任何有效的概率函数都是成立的。
定理 1.6.2(概率的性质)。对于任何事件 \(A\) 和 \(B\),概率具有以下性质:
- \(P(A^c) = 1 - P(A)\)。
- 如果 \(A \subseteq B\),那么 \(P(A) \le P(B)\)。
- \(P(A \cup B) = P(A) + P(B) - P(A \cap B)\)。
证明:
由于 \(A\) 和 \(A^c\) 是互不相交的,且它们的并集为 \(S\),根据第二条公理得:
\[ P(S) = P(A \cup A^c) = P(A) + P(A^c) \]
又由第一条公理知 \(P(S) = 1\)。所以 \(P(A) + P(A^c) = 1\)。
如果 \(A \subseteq B\),我们可以将 \(B\) 写成 \(A\) 与 \(B \cap A^c\) 的并集,其中 \(B \cap A^c\) 是属于 \(B\) 但不属于 \(A\) 的部分。如下图的韦恩图所示。

由于 \(A\) 和 \(B \cap A^c\) 是互不相交的,我们可以应用第二条公理: \[ P(B) = P(A \cup (B \cap A^c)) = P(A) + P(B \cap A^c) \]
概率是非负的,故 \(P(B \cap A^c) \ge 0\),由此证明了 \(P(B) \ge P(A)\)。
该结论的直观理解可以从如下所示的韦恩图中看出。

阴影区域代表 \(A \cup B\),但该区域的概率并不是 \(P(A) + P(B)\) 之和,因为那样会将橄榄球形的区域 \(A \cap B\) 计算两次。为了修正这一点,我们减去 \(P(A \cap B)\)。这是一个有用的直觉,但并非证明。
若要使用概率公理进行证明,我们可以将 \(A \cup B\) 写成互不相交事件 \(A\) 和 \(B \cap A^c\) 的并集。那么根据第二条公理:
\[ P(A \cup B) = P(A \cup (B \cap A^c)) = P(A) + P(B \cap A^c) \]
因此,只需证明 \(P(B \cap A^c) = P(B) - P(A \cap B)\) 即可。由于 \(A \cap B\) 和 \(B \cap A^c\) 是互不相交的,且它们的并集是 \(B\),再次应用第二条公理得:
\[ P(A \cap B) + P(B \cap A^c) = P(B) \]
所以 \(P(B \cap A^c) = P(B) - P(A \cap B)\),证毕。
第三条性质是容斥原理(inclusion-exclusion)的一个特例,该公式用于计算当事件不一定互不相交时,多个事件并集的概率。我们在上文展示了对于两个事件 \(A\) 和 \(B\):
\[ P(A \cup B) = P(A) + P(B) - P(A \cap B) \]
对于三个事件,容斥原理指出:
\[ P(A \cup B \cup C) = P(A) + P(B) + P(C) - P(A \cap B) - P(A \cap C) - P(B \cap C) + P(A \cap B \cap C) \]
为了获得直观认识,请考虑如图所示的三圆韦恩图。

为了得到阴影区域 \(A \cup B \cup C\) 的总面积,我们首先加上三个圆的面积 \(P(A) + P(B) + P(C)\)。此时三个橄榄球形区域都被重复计算了两次,所以我们接着减去 \(P(A \cap B) + P(A \cap C) + P(B \cap C)\)。最后,中心区域被加了三次,又被减了三次,为了使其恰好被计算一次,我们必须把它再加回来。这确保了图中每个区域都被恰好计算了一次。
现在我们可以写出 \(n\) 个事件的容斥原理。
定理 1.6.3(容斥原理)。对于任何事件 \(A_1, \dots, A_n\): \[ P\left(\bigcup_{i=1}^n A_i\right) = \sum_i P(A_i) - \sum_{i<j} P(A_i \cap A_j) + \sum_{i<j<k} P(A_i \cap A_j \cap A_k) - \dots + (-1)^{n+1} P(A_1 \cap \dots \cap A_n) \]
该公式仅通过公理即可用归纳法证明,但我们将在第 4 章引入一些额外工具后给出一个更简洁的证明。通式中交替加减背后的基本原理与我们已经考虑过的特例是类似的。
下一个例子,德·蒙莫尔匹配问题(de Montmort’s matching problem),是容斥原理的一个著名应用。皮埃尔·雷蒙·德·蒙莫尔(Pierre Rémond de Montmort)是一位法国数学家,他在博弈背景下研究概率,并写了一篇专门分析各种纸牌游戏的论文 [19]。他在 1708 年基于一种名为 Treize 的纸牌游戏提出了以下问题。
例 1.6.4(德·蒙莫尔匹配问题)。考虑一副经过充分洗牌的 \(n\) 张牌,编号为 1 到 \(n\)。你一张接一张地翻开这些牌,同时口中念出数字 1 到 \(n\)。如果在某个时刻,你大声念出的数字恰好与翻开的那张牌上的数字相同(例如,第 7 张翻开的牌编号正是 7),你就赢得了游戏。获胜的概率是多少?
解答:
设 \(A_i\) 为第 \(i\) 张牌的编号恰好为 \(i\) 的事件。我们感兴趣的是并集 \(A_1 \cup \dots \cup A_n\) 的概率:只要至少有一张牌的编号与其在牌堆中的位置相匹配,你就赢得了游戏。(让你输掉游戏的排列被称为“错排”,尽管希望没有人因为输掉这个游戏而变得精神错乱 [deranged]。)
为了计算并集的概率,我们将使用容斥原理。
首先,对于所有的 \(i\),\(P(A_i) = \frac{1}{n}\)。
一种理解方式是使用概率的原始定义和完整的样本空间:牌堆共有 \(n!\) 种可能的排列,且所有排列都是等可能的,其中有 \((n-1)!\) 种排列对 \(A_i\) 有利(固定编号为 \(i\) 的牌在第 \(i\) 个位置,其余 \(n-1\) 张牌可以任意排列)。另一种理解方式是通过对称性:编号为 \(i\) 的牌出现在 \(n\) 个位置中任何一个位置的可能性是相等的,因此它在第 \(i\) 个位置的概率为 \(1/n\)。
其次,\(P(A_i \cap A_j) = \frac{(n-2)!}{n!} = \frac{1}{n(n-1)}\),
因为我们要求编号为 \(i\) 和 \(j\) 的牌分别在第 \(i\) 和第 \(j\) 个位置,而允许其余 \(n-2\) 张牌以任何顺序排列,所以在 \(n!\) 种可能性中有 \((n-2)!\) 种对 \(A_i \cap A_j\) 有利。类似地:
\[ P(A_i \cap A_j \cap A_k) = \frac{1}{n(n-1)(n-2)} \]
以此类推,该模式适用于 4 个事件的交集,等等。
在容斥原理公式中,包含 1 个事件的有 \(n\) 项,包含 2 个事件的有 \(\binom{n}{2}\) 项,包含 3 个事件的有 \(\binom{n}{3}\) 项,依此类推。由于问题的对称性,所有形式为 \(P(A_i)\) 的 \(n\) 项都相等,所有形式为 \(P(A_i \cap A_j)\) 的 \(\binom{n}{2}\) 项也都相等,整个表达式可以大大简化:
\[ P\left(\bigcup_{i=1}^n A_i\right) = n \cdot \frac{1}{n} - \binom{n}{2} \frac{1}{n(n-1)} + \binom{n}{3} \frac{1}{n(n-1)(n-2)} - \dots \]
\[ = 1 - \frac{1}{2!} + \frac{1}{3!} - \dots + (-1)^{n+1} \frac{1}{n!} \]
将此结果与 \(1/e\) 的泰勒级数进行比较(参见数学附录 A.8 节):
\[ e^{-1} = 1 - \frac{1}{1!} + \frac{1}{2!} - \frac{1}{3!} + \dots \]
我们发现,对于较大的 \(n\),赢得游戏的概率极其接近 \(1 - 1/e\),大约为 \(0.63\)。有趣的是,随着 \(n\) 的增加,获胜概率趋近于 \(1 - 1/e\),而不是趋向于 0 或 1。随着牌堆中牌数的增加,可能匹配的位置数量在增加,而任何特定位置匹配的概率在减小,这两种力量相互抵消并达到平衡,给出了约为 \(1 - 1/e\) 的概率。
容斥原理是计算事件并集概率的一个非常通用的公式,但在各事件 \(A_j\) 之间存在对称性时,它对我们的帮助最大;否则,求和过程可能会极其繁琐。通常,在缺乏对称性时,我们应该在求助于容斥原理这一最后手段之前,尝试使用其他工具。
1.7 回顾总结
Recap
概率使我们能够以一种有原则的方式对不确定性和随机性进行量化。概率产生于我们进行实验时:实验所有可能结果的集合被称为样本空间,而样本空间的子集被称为事件。能够熟练地在用自然语言描述事件与用数学集合表示事件(通常使用并集、交集和补集)之间进行转换是非常有用的。
当样本空间有限时,“卵石世界”可以帮助我们直观地理解样本空间和事件。在卵石世界中,每一个结果都是一颗卵石,而一个事件就是一组卵石。如果所有的卵石质量相同(即等可能),我们可以应用概率的原始定义,通过计数来计算概率。
为此,我们讨论了几种计数工具。在计算可能性的数量时,我们经常使用乘法原理。例如,\(1, 2, \dots, n\) 这 \(n\) 个数字共有 \(n!\) 种排列,而一个含有 \(n\) 个元素的集合共有 \(2^n\) 个子集。如果我们不能直接使用乘法原理,有时可以先将每种可能性恰好计算 \(c\) 次,然后除以 \(c\) 得到实际的可能性数量。例如,这种策略对于推导用阶乘表示的二项式系数表达式非常有用。
一个需要避免的重要陷阱是误用概率的原始定义,即在没有正当理由的情况下,含糊或明确地假设结果是等可能的。帮助避免这种情况的一种技巧是给物体贴上标签,以确保精确性,并防止我们倾向于将其视为不可区分的物体。
超越原始定义后,我们将概率定义为一个函数,它接收一个事件并为其分配一个介于 0 和 1 之间的实数。我们要求一个有效的概率函数必须满足两条公理:
\(P(\emptyset) = 0, P(S) = 1\)。
如果 \(A_1, A_2, \dots\) 是互不相交的事件,则:
\[ P\left(\bigcup_{j=1}^{\infty} A_j\right) = \sum_{j=1}^{\infty} P(A_j) \]
从这些公理中可以推导出许多有用的性质。例如,对于任何事件 \(A\),有 \(P(A^c) = 1 - P(A)\);对于任何事件 \(A_1, \dots, A_n\),我们有容斥原理公式:
\[ P\left(\bigcup_{i=1}^n A_i\right) = \sum_i P(A_i) - \sum_{i<j} P(A_i \cap A_j) + \sum_{i<j<k} P(A_i \cap A_j \cap A_k) - \dots + (-1)^{n+1} P(A_1 \cap \dots \cap A_n) \]
当 \(n = 2\) 时,这是形式更美观的结果:
\[ P(A_1 \cup A_2) = P(A_1) + P(A_2) - P(A_1 \cap A_2) \]
图 1.7 展示了概率函数如何将事件映射到 0 和 1 之间的数字。随着我们在概率领域的探索不断深入,我们将向这张图中添加许多新概念。
1.8 R 语言
R 是一款功能强大且广受欢迎的统计计算与图形环境,可免费用于 Mac OS X、Windows 和 UNIX 系统。掌握 R 的使用是一项极其有用的技能。R 及其各类辅助信息可通过 https://www.r-project.org 获取。RStudio 是 R 的一个卓越的备选界面,可在 https://www.rstudio.com 免费下载。
在每章末尾的 R 语言部分,我们提供了 R 代码供你尝试本章中的一些示例,尤其是通过仿真的方式。这些章节并非旨在作为 R 的全面入门教程;网上有许多免费的 R 教程,市面上也有许多关于 R 的书籍。但 R 章节展示了如何实现与每章内容自然契合的各种仿真、计算和可视化。每章末尾的 R 代码也可以在 http://stat110.net 上找到。
向量(Vectors)
R 是围绕向量构建的,熟悉“向量化思维”对于有效使用 R 非常重要。要创建一个向量,我们可以使用 c 命令(代表 combine 或 concatenate)。例如:
v <- c(3,1,4,1,5,9)
将 v 定义为向量 \((3,1,4,1,5,9)\)。(左箭头 <- 是由 < 后跟 - 键入的。虽然也可以使用 = 代替,但箭头更能形象地说明左侧的变量被赋值为右侧的数值。)类似地,n <- 110 将 n 设为 110;R 将 n 视为长度为 1 的向量。
sum(v) 对 v 的各项求和,max(v) 给出最大值,min(v) 给出最小值,而 length(v) 给出向量的长度。
获取向量 \((1,2,\dots,n)\) 的快捷方式是输入 1:n;更一般地,如果 \(m\) 和 \(n\) 是整数,那么 m:n 给出从 \(m\) 到 \(n\) 的整数序列(如果 \(m \le n\) 则为递增顺序,否则为递减顺序)。
要访问向量 v 的第 \(i\) 个条目,使用 v[i]。我们还可以轻松获取子向量:
v[c(1,3,5)]
给出由 v 的第 1、3、5 个条目组成的向量。也可以通过使用负号指定要排除的内容来获取子向量:
v[-(2:4)]
给出移除 v 的第 2 到第 4 个条目后得到的向量(此处需要括号,因为 -2:4 会被解释为 \((-2, -1, \dots, 4)\))。
R 中的许多操作都是按分量进行的。例如,在数学中向量的立方没有标准定义,但在 R 中输入 v^3 只是简单地将每个条目分别求立方。类似地,
1/(1:100)^2
是获取向量 \((1, \frac{1}{2^2}, \frac{1}{3^2}, \dots, \frac{1}{100^2})\) 的一种非常紧凑的方式。
在数学中,如果 \(v\) 和 \(w\) 是长度不同的向量,则 \(v+w\) 是未定义的,但在 R 中,较短的向量会被“循环使用”!例如,v+3 会将 3 加到 v 的每个条目上。
阶乘与二项式系数
我们可以使用 factorial(n) 来计算 \(n!\),以及使用 choose(n,k) 来计算 \(\binom{n}{k}\)。正如我们所见,阶乘的增长速度极其惊人。R 语言中能返回具体数值的最大 \(n!\) 是多少?超过该界限后,R 将返回 Inf(无穷大)并显示警告信息。不过,对于更大的 \(n\) 值,仍可能使用 lfactorial(n),它计算的是 \(\log(n!)\)。类似地,lchoose(n,k) 计算的是 \(\log \binom{n}{k}\)。
抽样与仿真
sample 命令是在 R 中进行随机抽样的常用方法。(从技术上讲,它们是伪随机的,因为底层有一个确定性的算法,但在几乎所有实际应用中,它们看起来都像随机样本。)例如:
R
1 | n <- 10; k <- 5 |
这会从 1 到 10 的数字中随机生成一个长度为 5 的有序样本,采用无放回抽样,且每个数字被选中的概率相等。若要改为有放回抽样,只需添加 replace = TRUE:
R
1 | n <- 10; k <- 5 |
要生成 \(1, 2, \dots, n\) 的随机排列,我们可以使用 sample(n, n)。由于 R 的默认设置,这可以简写为 sample(n)。
我们还可以使用 sample 从非数值向量中抽取。例如,letters 是 R 内置的一个包含 26 个英文小写字母的向量,sample(letters, 7) 将通过无放回抽样从字母表中随机生成一个由 7 个字母组成的“单词”。
sample 命令还允许我们为每个数字指定通用的抽样概率。例如:
R
1 | sample(4, 3, replace = TRUE, prob = c(0.1, 0.2, 0.3, 0.4)) |
这会以 \((0.1, 0.2, 0.3, 0.4)\) 比例的概率,有放回地从 1 到 4 中抽取三个数字。如果是无放回抽样,那么在每个阶段,任何尚未被选中的数字被选中的概率与其原始概率成正比。
生成大量的随机样本使我们能够对概率问题进行仿真。下文解释的 replicate 命令是实现这一目标的便捷方式。
匹配问题的仿真
让我们通过仿真来展示例 1.6.4 中当牌堆足够大时,出现匹配牌的概率近似为 \(1 - 1/e\)。利用 R,我们可以多次执行该实验,观察遇到至少一张匹配牌的次数:
R
1 | n <- 100 |
在第一行中,我们选择牌堆中牌的数量(这里是 100 张)。在第二行,我们由内而外地解析:
sample(n) == (1:n)是一个长度为 \(n\) 的向量,如果第 \(i\) 张牌与其在牌堆中的位置匹配,则第 \(i\) 个元素等于 1,否则为 0。这是因为对于两个数 \(a\) 和 \(b\),表达式a == b在 \(a = b\) 时为TRUE,否则为FALSE;而在 R 中,TRUE被编码为 1,FALSE被编码为 0。sum对向量的各元素求和,得到该次实验运行中匹配牌的数量。replicate执行此操作 \(10^4\) 次。我们将结果存储在r中,这是一个长度为 \(10^4\) 的向量,包含了每次实验运行中匹配牌的数量。
在最后一行中,我们将出现至少一张匹配牌的次数相加,并除以仿真总次数。
为了在代码内部而非单独的文档中解释代码的作用,我们可以使用 # 符号添加注释,以此标记注释的开始。R 会忽略注释,但注释能使读者(也可能是你自己——即使你是唯一使用代码的人,在编写一个月后再看,也很难记住每个部分的含义以及代码的运作方式)更容易理解代码。短注释可以与相应的代码在同一行;较长的注释应另起一行。例如,上述仿真的带注释版本为:
R
1 | n <- 100 # 牌的数量 |
运行代码后你得到了什么?我们得到了 0.63,这与 \(1 - 1/e\) 非常接近。
生日问题的计算与仿真
以下代码使用 prod(用于计算向量元素的乘积)来计算 23 个人中至少有一对生日相同的概率:
R
1 | k <- 23 |
更棒的是,R 拥有内置函数 pbirthday 和 qbirthday 来专门处理生日问题!pbirthday(k) 返回当房间里有 \(k\) 个人时,至少有一对生日匹配的概率。qbirthday(p) 则返回为了使至少有一对匹配的概率达到 \(p\) 所需的人数。例如,pbirthday(23) 的结果是 0.507,而 qbirthday(0.5) 的结果是 23。
我们还可以寻找至少出现一次“三人生日相同”(即三个人的生日在同一天)的概率;我们只需添加参数 coincident=3 来表示我们要寻找的是三人匹配。例如,pbirthday(23, coincident=3) 返回 0.014,因此 23 个人中出现三人生日相同的概率仅为 1.4%。而 qbirthday(0.5, coincident=3) 返回 88,这意味着我们需要 88 个人才能有至少 50% 的机会出现至少一组三人生日相同的情况。
为了仿真生日问题,我们可以使用:
R
1 | b <- sample(1:365, 23, replace = TRUE) |
这会为 23 个人生成随机生日,然后列表统计每一天有多少人生日(命令 table(b) 可以创建一个更美观的表格,但速度较慢)。我们可以按照以下方式进行 \(10^4\) 次重复实验:
R
1 | r <- replicate(10^4, max(tabulate(sample(1:365, 23, replace = TRUE)))) |
如果各天的概率并非全部相等,计算会变得困难得多,但仿真却可以轻松扩展,因为 sample 允许我们指定每一天的概率(默认情况下 sample 分配相等概率,因此在上述代码中,每一天的概率都是 \(1/365\))。
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程