《Introduction to Probability》第4章 期望
第4章 期望
Expectation
4.1 期望的定义
Definition of expectation
在上一章中,我们引入了随机变量的分布,它为我们提供了随机变量落入任何特定集合概率的完整信息。例如,我们可以计算随机变量超过 1000、等于 5 或落在区间 \([0, 7]\) 内的可能性有多大。然而,管理这么多概率可能会非常笨拙,因此我们通常只需要一个数字来总结随机变量的“平均”值。
“平均”这个词有多种含义,但到目前为止最常用的是随机变量的均值(mean),也称为其期望值(expected value)。此外,统计学很大程度上是关于理解世界中的变异性,因此了解分布的“离散程度”通常也很重要;我们将通过方差(variance)和标准差(standard deviation)的概念将其正式化。正如我们将看到的,方差和标准差是根据期望值定义的,因此期望值的用途远不止计算平均数。
个人注:统计学研究的本质
期望值 管理这么多概率可能会非常笨拙,因此我们通常只需要一个数字来总结随机变量的“平均”值。
方差(标准差) 统计学很大程度上是关于理解世界中的变异性,因此了解分布的“离散程度”通常也很重要。
给定一组数字 \(x_1, x_2, \dots, x_n\),最常见的平均方法是将它们相加并除以 \(n\)。这被称为算术平均值,定义为: \[ \bar{x} = \frac{1}{n} \sum_{j=1}^{n} x_j \]
更一般地,我们可以将 \(x_1, \dots, x_n\) 的加权平均值定义为: \[ \text{weighted-mean}(x) = \sum_{j=1}^{n} x_j p_j \]
其中权重 \(p_1, \dots, p_n\) 是预先指定的非负数,且总和为 1(因此,当所有 \(j\) 的 \(p_j = 1/n\) 时,即可得到不加权的算术平均值 \(\bar{x}\))。
离散型随机变量期望的定义受到了一组数字加权平均值的启发,其权重由概率给出。
定义 4.1.1(离散随机变量的期望)。设离散随机变量 \(X\) 的所有不同可能取值为 \(x_1, x_2, \dots\),其期望值(也称为期望或均值)定义为: \[ E(X) = \sum_{j=1}^{\infty} x_j P(X = x_j) \]
如果支撑集是有限的,则上述级数变为有限和。我们也可以将其写作: \[ E(X) = \sum_{x} x \cdot P(X = x) \]
其中求和范围是 \(X\) 的支撑集(对于任何不在支撑集内的 \(x\),\(x P(X=x)\) 均为 0)。若 \(\sum_{j=1}^{\infty} |x_j| P(X = x_j)\) 发散,则期望值不存在(未定义),因为此时 \(E(X)\) 的级数要么发散,要么其值取决于 \(x_j\) 列出的顺序。
言语上来说,\(X\) 的期望值是 \(X\) 所有可能取值的加权平均,权重即为其对应的概率。让我们通过几个简单的例子来验证这个定义是否符合直觉:
- 令 \(X\) 为掷一枚公平 6 面骰子的结果,则 \(X\) 以相等的概率取值 \(1, 2, 3, 4, 5, 6\)。直觉上,我们应该能通过将这些值相加并除以 6 来得到平均值。根据定义,期望值为:
\[ E(X) = \frac{1}{6}(1 + 2 + \dots + 6) = 3.5 \]
正如我们所预期的。请注意,在这个例子中 \(X\) 永远不会等于其均值。这类似于某个国家每户家庭的平均孩子数可能是 1.8,但这并不意味着一个典型的家庭真的有 1.8 个孩子!
- 令 \(X \sim \text{Bern}(p)\) 且 \(q = 1 - p\)。那么:
\[ E(X) = 1p + 0q = p \]
这在直觉上是合理的,因为 \(p\) 位于 \(X\) 的两个可能取值之间,并根据每个取值发生的可能性在 0 和 1 之间折中。图 4.1 展示了 \(p < 1/2\) 的情况:两颗小石子在跷跷板上保持平衡。为了使跷跷板平衡,支点(图中以三角形表示)必须位于 \(p\) 处,这在物理学中被称为质心。
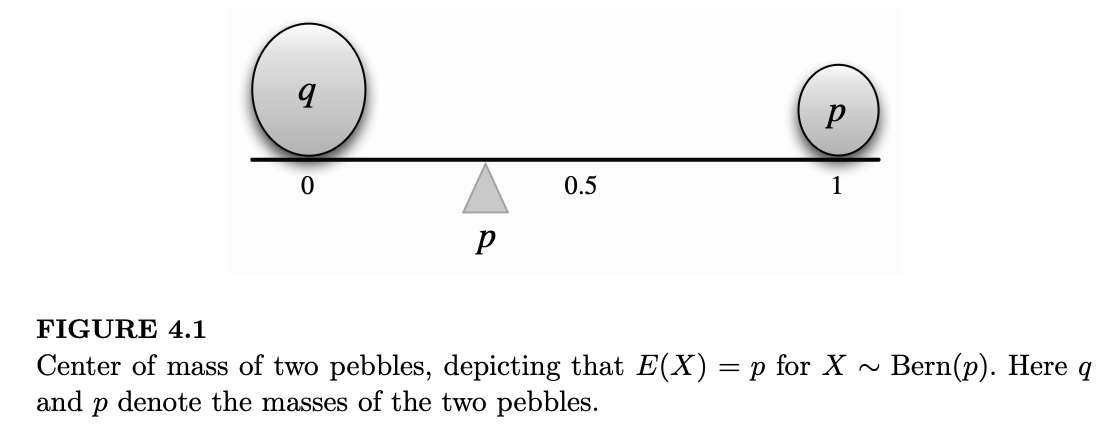
频率论者的解释是:考虑大量独立的伯努利试验,每次试验成功的概率为 \(p\)。将“成功”记为 1,“失败”记为 0,从长期来看,我们预期得到的一系列数字中,1 所占的比例将非常接近 \(p\)。而一串由 0 和 1 组成的数字的算术平均值正是 1 出现的比例。
- 令 \(X\) 有 3 个不同的可能取值 \(a_1, a_2, a_3\),概率分别为 \(p_1, p_2, p_3\)。想象进行一次模拟,生成 \(n\) 个来自 \(X\) 分布的独立抽取结果。当 \(n\) 较大时,我们预期大约会有 \(p_1 n\) 个 \(a_1\),\(p_2 n\) 个 \(a_2\) 和 \(p_3 n\) 个 \(a_3\)。(当我们学习第 10 章的大数定律时,将讨论该例子的更严格数学版本。)如果模拟结果接近这些预期结果,那么模拟结果的算术平均值近似为:
\[ \frac{p_1 n \cdot a_1 + p_2 n \cdot a_2 + p_3 n \cdot a_3}{n} = p_1 a_1 + p_2 a_2 + p_3 a_3 = E(X) \]
请注意,\(E(X)\) 仅取决于 \(X\) 的分布。这直接由定义得出,但因为它非常基础,所以值得记录下来。
个人注:按上章的说法,分布就类似房子的图纸。实际的随机变量就是实际的房子,同一图纸可以建不同的房子。
命题 4.1.2。如果离散随机变量 \(X\) 和 \(Y\) 具有相同的分布,那么 \(E(X) = E(Y)\)(假设两边的期望均存在)。
证明:在 \(E(X)\) 的定义中,我们只需要知道 \(X\) 的 PMF 即可。
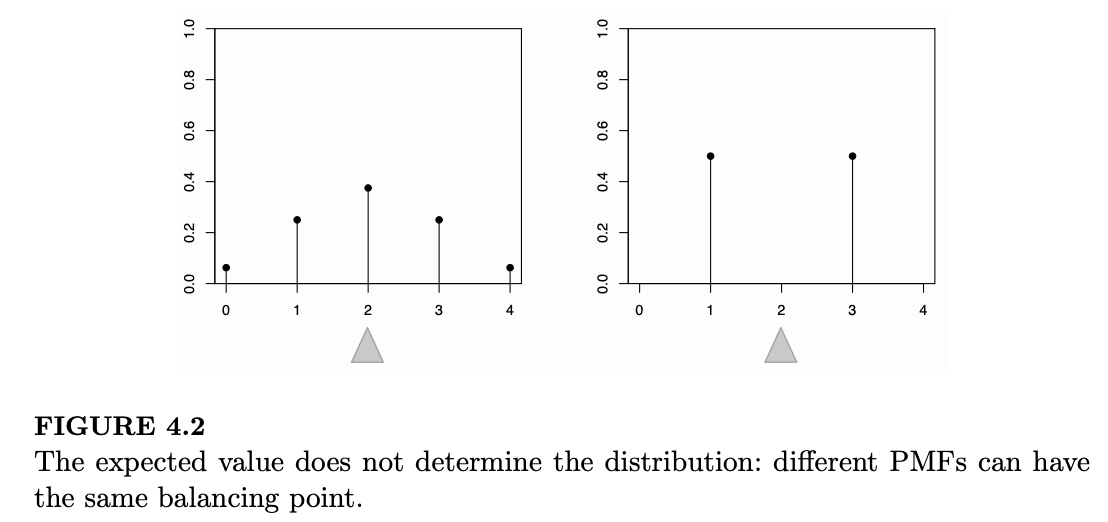
上述命题的逆命题是错误的,因为期望值只是一个单数值总结,远不足以具体化整个分布;它衡量的是分布的“中心”位置,但不能决定分布的离散程度,或者该随机变量为正值的可能性有多大。图 4.2 展示了两个具有相同期望值(即相同的平衡点)但 PMF 截然不同的例子。
4.1.3(将随机变量替换为其期望)。对于任何离散型随机变量 \(X\),其期望值 \(E(X)\) 是一个数值(如果存在)。一个常见的错误是在没有依据的情况下将随机变量替换为其期望值。这种做法在数学上是错误的(\(X\) 是一个函数,而 \(E(X)\) 是一个常数),在统计学上也是错误的(它忽略了 \(X\) 的变异性),除非在 \(X\) 本身就是常数的退化情况下才成立。
记号 4.1.4。我们经常将 \(E(X)\) 简写为 \(EX\)。类似地,我们将 \(E(X^2)\) 简写为 \(EX^2\),将 \(E(X^n)\) 简写为 \(EX^n\)。
4.1.5。在使用期望时,注意运算顺序至关重要。如上所述,\(EX^2\) 是随机变量 \(X^2\) 的期望,而不是数值 \(EX\) 的平方。除非括号明确表示,否则对于一个随机变量幂次的期望,我们应先取幂次,再取期望。例如,\(E(X-1)^4\) 指的是 \(E\left[(X-1)^4\right]\),而不是 \((E(X-1))^4\)。
4.2 期望的线性性质
Linearity of expectation
期望最重要的性质就是线性性质:随机变量之和的期望等于各随机变量期望之和。
定理 4.2.1(期望的线性性质)。对于任何随机变量 \(X, Y\) 和任何常数 \(c\): \[ E(X + Y) = E(X) + E(Y) \]
\[ E(cX) = cE(X) \]
第二个等式说明我们可以从期望中提取常数因子;这在直觉上是合理的,也很容易通过定义验证。第一个等式 \(E(X + Y) = E(X) + E(Y)\),在 \(X\) 和 \(Y\) 独立时看起来也很合理。但令人惊讶的是,即使 \(X\) 和 \(Y\) 相关,该等式依然成立!
为了建立直觉,考虑 \(X\) 始终等于 \(Y\) 的极端情况。此时 \(X + Y = 2X\),等式 \(E(X + Y) = E(X) + E(Y)\) 的两边都等于 \(2E(X)\),因此即便在最极端的相关情况下,线性性质依然成立。
线性性质对所有随机变量都成立,而不仅仅是离散随机变量。但在本章中,我们仅对离散随机变量进行证明。在证明之前,回顾一下关于平均数的基本事实是很有意义的。如果我们有一组数字,比如 \((1, 1, 1, 1, 1, 3, 3, 5)\),我们可以通过将所有值相加并除以列表长度来计算它们的均值,这样列表中的每个元素都获得了 \(1/8\) 的权重: \[ \frac{1}{8}(1 + 1 + 1 + 1 + 1 + 3 + 3 + 5) = 2 \]
但计算均值的另一种方法是将所有的 \(1\)、所有的 \(3\) 和所有的 \(5\) 分组,然后进行加权平均,给 \(1\)、\(3\) 和 \(5\) 分配适当的权重: \[ \frac{5}{8} \cdot 1 + \frac{2}{8} \cdot 3 + \frac{1}{8} \cdot 5 = 2 \]
这一洞察——即平均值可以通过非分组(ungrouped)或分组(grouped)两种方式计算——正是证明线性性质(Linearity)所需的全部依据!
回想一下,随机变量 \(X\) 是一个将样本空间中的每一个结果 \(s\) 映射为一个实数的函数。随机变量 \(X\) 可能会将相同的值赋予多个不同的样本结果。当这种情况发生时,我们对期望值的定义会将所有这些结果“分到一组”,形成一个“超级卵石(super-pebble)”,其权重 \(P(X = x)\) 等于组成它的所有原始卵石的权重总和。
这种分组过程在图 4.3 中有所展示,图中假设了一个取值为 \(\{0, 1, 2\}\) 的随机变量。因此,我们对期望值的定义,实际上对应的是计算平均值时的分组方式。
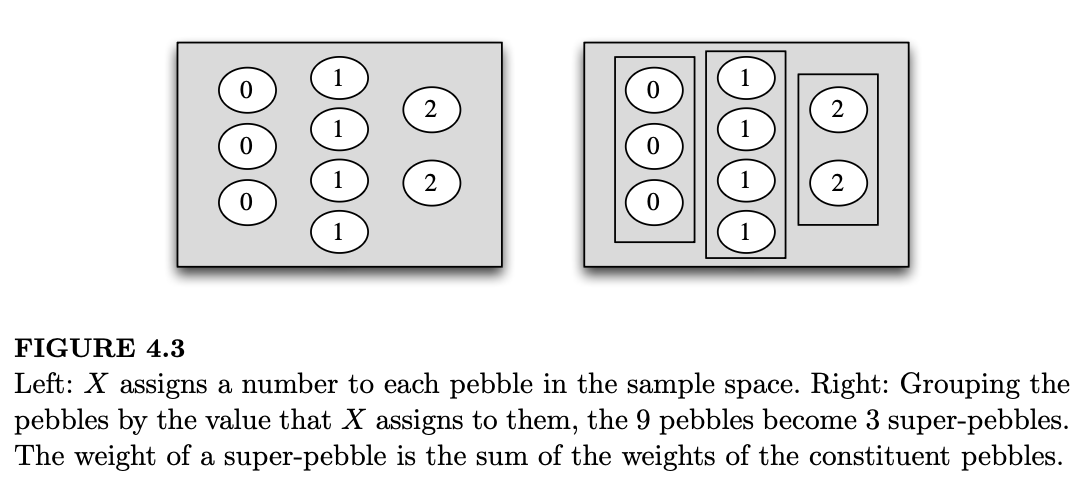
这种定义的优点是它允许我们直接使用 \(X\) 的分布,而无需回到样本空间。其缺点出现在我们需要证明此类定理时:因为如果在同一个样本空间上有另一个随机变量 \(Y\),\(Y\) 创建的“超级小石子”与 \(X\) 创建的不同,权重 \(P(Y = y)\) 也不同;这使得将 \(\sum x P(X = x)\) 和 \(\sum y P(Y = y)\) 结合起来变得很困难。
幸运的是,我们知道还有另一种同样有效的计算平均值的方法:我们可以对单个小石子的值进行加权平均。换句话说,如果 \(X(s)\) 是 \(X\) 分配给小石子 \(s\) 的值,我们可以计算加权平均: \[ E(X) = \sum_{s \in S} X(s) P(\{s\}) \]
其中 \(P(\{s\})\) 是小石子 \(s\) 的权重。这对应于未分组的平均值计算方式。这种定义的优点在于它将样本空间分解为最小的单位,因此对于定义在该样本空间上的每一个随机变量,我们现在都使用相同的权重 \(P(\{s\})\)。如果 \(Y\) 是另一个随机变量,那么: \[ E(Y) = \sum_{s \in S} Y(s) P(\{s\}) \]
我们可以将两个求和式结合起来: \[ E(X) + E(Y) = \sum_{s \in S} X(s) P(\{s\}) + \sum_{s \in S} Y(s) P(\{s\}) = \sum_{s \in S} (X + Y)(s) P(\{s\}) = E(X + Y) \]
这种方法清晰地展示了线性性质的本质。
关于期望线性性质的另一种直觉来自于模拟(Simulation)的概念。如果我们对 \(X\) 的分布进行多次模拟,模拟值的直方图将非常接近 \(X\) 的真实 PMF。特别是,模拟值的算术平均值将非常接近 \(E(X)\) 的真实值(这种收敛的精确性质由大数定律描述),这是我们将在第 10 章详细讨论的一个重要定理)。
设 \(X\) 和 \(Y\) 是总结某次实验的两个随机变量。假设我们将实验重复进行 \(n\) 次(\(n\) 是一个非常大的数),并记录下每次实验中 \(X\) 和 \(Y\) 的观测值。对于每一次重复,我们都会得到一个 \(X\) 值、一个 \(Y\) 值,以及(通过相加得到的)一个 \(X+Y\) 值。在图 4.4 中,每一行代表实验的一次重复。左列包含 \(X\) 的抽取结果,中列包含 \(Y\) 的抽取结果,右列包含 \(X+Y\) 的抽取结果。

计算最后一列所有数字之和有两种方法:
- 直接将最后一列的所有数字相加。
- 将第一列的所有数字相加,再将第二列的所有数字相加,最后将这两列的总和相加。
将结果除以 \(n\),我们论证了以下两个过程是等价的:
- 计算最后一列所有数字的算术平均值。根据大数定律,这非常接近 \(E(X+Y)\)。
- 计算第一列和第二列的算术平均值,然后将这两个平均值相加。根据大数定律,这非常接近 \(E(X) + E(Y)\)。
因此,期望的线性性质表现为一个关于算术的简单事实(我们只是以两种不同的顺序加总数字)!请注意,在我们的论证中,完全没有依赖于 \(X\) 和 \(Y\) 是否独立。事实上,在图 4.4 中,\(X\) 和 \(Y\) 看起来是相关的:当 \(X\) 较大时 \(Y\) 往往也较大,当 \(X\) 较小时 \(Y\) 往往也较小(用第 7 章的语言来说,我们称 \(X\) 和 \(Y\) 是正相关的)。但这种相关性无关紧要:即使打乱 \(Y\) 的抽取顺序会完全改变 \(X\) 和 \(Y\) 之间的相关模式,却不会对列的总和产生任何影响。
线性性质是计算期望值的一种极其便利的工具,通常能让我们完全绕过期望值的原始定义。让我们利用线性性质来求二项分布和超几何分布的期望。
例 4.2.2(二项分布的期望)。对于 \(X \sim \text{Bin}(n, p)\),我们用两种方法求 \(E(X)\)。
方法 1:根据定义 \[ E(X) = \sum_{k=0}^{n} k P(X = k) = \sum_{k=0}^{n} k \binom{n}{k} p^k q^{n-k} \]
根据例 1.5.2,我们知道 \(k \binom{n}{k} = n \binom{n-1}{k-1}\),所以: \[ E(X) = n \sum_{k=1}^{n} \binom{n-1}{k-1} p^k q^{n-k} = np \sum_{k=1}^{n} \binom{n-1}{k-1} p^{k-1} q^{(n-1)-(k-1)} \]
令 \(j = k-1\),则: \[ E(X) = np \sum_{j=0}^{n-1} \binom{n-1}{j} p^j q^{n-1-j} = np \]
倒数第二行的求和等于 1,因为它是 \(\text{Bin}(n-1, p)\) 分布所有 PMF 的和(或者根据二项式定理)。因此,\(E(X) = np\)。
方法 2:利用线性性质
这种证明要求我们记住组合恒等式并处理二项式系数。而利用期望的线性性质,我们可以获得一条更简捷的路径。我们将 \(X\) 写成 \(n\) 个独立的 \(\text{Bern}(p)\) 随机变量之和: \[ X = I_1 + I_2 + \dots + I_n \]
其中每个 \(I_j\) 的期望为 \(E(I_j) = 1p + 0q = p\)。根据线性性质: \[ E(X) = E(I_1) + E(I_2) + \dots + E(I_n) = np \]
例 4.2.3(超几何分布的期望)。令 \(X \sim HGeom(w, b, n)\),其含义为从装有 \(w\) 个白球和 \(b\) 个黑球的瓮中,无放回地抽取 \(n\) 个球所得到的白球数量。与二项分布的情况类似,我们可以将 \(X\) 写成伯努利随机变量之和: \[ X = I_1 + \dots + I_n \]
其中,如果样本中第 \(j\) 个球是白色的,则 \(I_j = 1\),否则为 \(0\)。基于对称性,\(I_j \sim \text{Bern}(p)\),其中 \(p = w/(w+b)\)。这是因为在无任何前提信息(无条件)的情况下,第 \(j\) 次被抽中的球是瓮中任何一个球的概率是相等的。
与二项分布不同,这里的 \(I_j\) 不是独立的,因为抽样是无放回的:已知样本中某个球是白色的,那么样本中另一个球也是白色的概率就会降低。然而,线性性质对于相关的随机变量依然成立! 因此: \[ E(X) = n \cdot \frac{w}{w+b} \]
个人注:以上这个例子说明了期望的线性性质的厉害之处!
作为线性性质强大力量的另一个例子,我们可以快速证明“较大的随机变量具有较大的期望”这一直观想法。
命题 4.2.4(期望的单调性)。设 \(X\) 和 \(Y\) 是随机变量,满足 \(P(X \ge Y) = 1\)(即 \(X\) 以概率 1 大于等于 \(Y\))。那么 \(E(X) \ge E(Y)\),且等号成立当且仅当 \(P(X = Y) = 1\)。
证明:该结论对所有随机变量均成立,但由于本章侧重于离散型,我们仅在此框架下证明。随机变量 \(Z = X - Y\) 是非负的(以概率 1 为准),因此 \(E(Z) \ge 0\),因为 \(E(Z)\) 被定义为一系列非负项的和。根据线性性质: \[ E(X) - E(Y) = E(X - Y) \ge 0 \]
从而得证。如果 \(E(X) = E(Y)\),根据线性性质我们也有 \(E(Z) = 0\);这意味着 \(P(X = Y) = P(Z = 0) = 1\),因为在定义 \(E(Z)\) 的求和式中,如果哪怕有一项是正的,那么整个和式就会是正的。
4.3 几何分布与负二项分布
Geometric and Negative Binomial
我们现在介绍另外两个著名的离散分布:几何分布和负二项分布,并计算它们的期望值。
个人注:注意是先介绍了超几何分布,才介绍集合分布;因为超几何分布是和二项分布有关联的。
背景故事 4.3.1(几何分布)。考虑一系列独立的伯努利试验,每次试验具有相同的成功概率 \(p \in (0, 1)\)。试验一直进行到第一次成功出现为止。令 \(X\) 为第一次成功之前的失败次数。那么 \(X\) 服从参数为 \(p\) 的几何分布,记作 \(X \sim \text{Geom}(p)\)。
例如,如果我们反复抛掷一枚公平硬币直到第一次出现正面,那么在第一个正面出现之前的反面次数服从 \(\text{Geom}(1/2)\) 分布。
为了从背景故事中推导出几何分布的 PMF,可以将伯努利试验想象成一串以 0(失败)开头、以单个 1(成功)结尾的序列。每个 0 的概率为 \(q = 1-p\),最后的 1 概率为 \(p\)。因此,\(k\) 次失败后紧跟一次成功的概率为 \(q^k p\)。
定理 4.3.2(几何分布 PMF)。若 \(X \sim \text{Geom}(p)\),则 \(X\) 的 PMF 为: \[ P(X = k) = q^k p \]
对于 \(k = 0, 1, 2, \dots\),其中 \(q = 1-p\)。
这是一个有效的 PMF,因为通过几何级数求和(参见数学附录): \[ \sum_{k=0}^{\infty} q^k p = p \sum_{k=0}^{\infty} q^k = p \cdot \frac{1}{1-q} = \frac{p}{p} = 1 \]
正如二项式定理证明了二项分布 PMF 的有效性一样,几何级数证明了几何分布 PMF 的有效性!几何级数同样可以用来推导几何分布的 CDF。
定理 4.3.3(几何分布 CDF)。若 \(X \sim \text{Geom}(p)\),则 \(X\) 的 CDF 为: \[ F(x) = \begin{cases} 1 - q^{\lfloor x \rfloor + 1} & \text{若 } x \ge 0 \\ 0 & \text{若 } x < 0 \end{cases} \]
其中 \(q = 1-p\),\(\lfloor x \rfloor\) 是小于或等于 \(x\) 的最大整数。
证明:设 \(F\) 为 \(X\) 的 CDF。
对于 \(x < 0\),\(F(x) = 0\),因为 \(X\) 不能取负值。
对于非负整数 \(n\):
\[ F(n) = \sum_{k=0}^{n} P(X = k) = p \sum_{k=0}^{n} q^k = p \cdot \frac{1 - q^{n+1}}{1 - q} = 1 - q^{n+1} \]
我们也可以通过“互补事件”得到相同的结果:事件 \(X \ge n+1\) 意味着前 \(n+1\) 次试验全部失败:
\[ F(n) = 1 - P(X > n) = 1 - P(X \ge n+1) = 1 - q^{n+1} \]
- 对于实数 \(x \ge 0\),由于 \(X\) 只取整数值:
\[ F(x) = P(X \le x) = P(X \le \lfloor x \rfloor) \]
例如,\(P(X \le 3.7) = P(X \le 3)\)。由此得证。
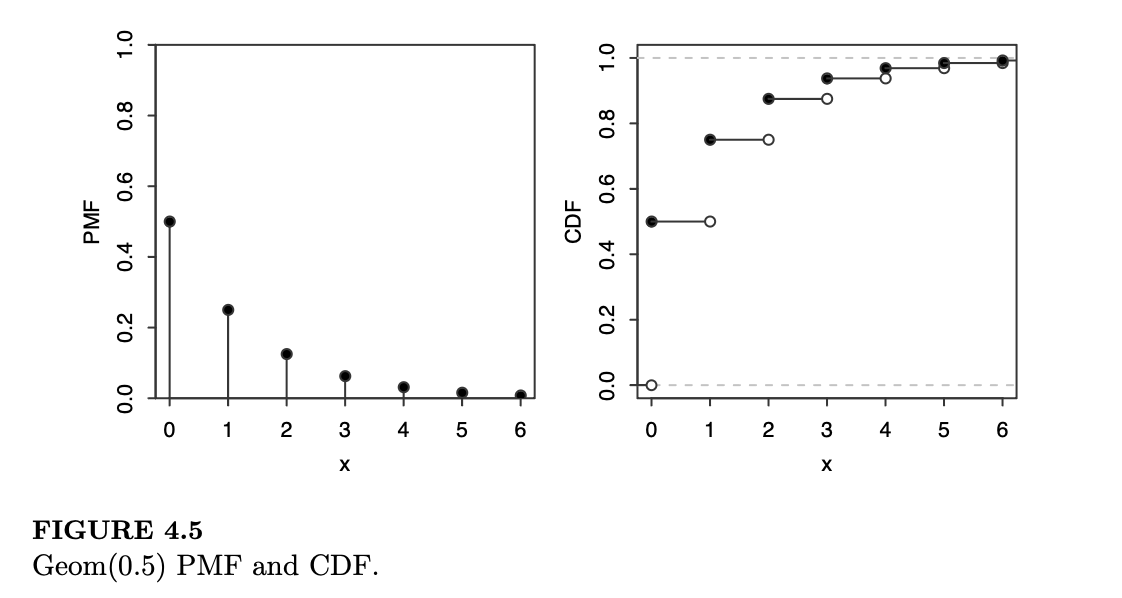
图 4.5 展示了 \(0\) 到 \(6\) 之间的 \(\text{Geom}(0.5)\) 的 PMF 和 CDF。所有的几何分布 PMF 都有类似的形状;成功概率 \(p\) 越大,PMF 衰减到 \(0\) 的速度就越快。
4.3.4(关于几何分布的惯例)。关于几何分布的定义存在不同的惯例:有些资料将几何分布定义为总试验次数(包括最后那次成功)。在本书中,几何分布不包括那次成功,而“首通分布”(First Success distribution)则包括那次成功。
定义 4.3.5(首通分布)。在成功概率为 \(p\) 的一系列独立伯努利试验中,令 \(Y\) 为直到第一次成功为止的试验次数(包括成功的那次)。则称 \(Y\) 服从参数为 \(p\) 的首通分布,记作 \(Y \sim \text{FS}(p)\)。
在这两种定义之间转换很容易,但必须谨慎确认使用的是哪种惯例。如果 \(Y \sim \text{FS}(p)\),那么 \(Y-1 \sim \text{Geom}(p)\)。我们可以通过以下方式在 \(Y\) 和 \(Y-1\) 的 PMF 之间转换: \[ P(Y = k) = P(Y-1 = k-1) \]
反之,如果 \(X \sim \text{Geom}(p)\),那么 \(X+1 \sim \text{FS}(p)\)。
例 4.3.6(几何分布的期望)。令 \(X \sim \text{Geom}(p)\)。根据定义: \[ E(X) = \sum_{k=0}^{\infty} k q^k p \]
其中 \(q = 1-p\)。这个求和看起来不太友善;因为它比几何级数多了一个 \(k\)。但我们注意到每一项看起来都类似于 \(k q^{k-1}\),即 \(q^k\)(对 \(q\))的导数。所以我们从这里开始: \[ \sum_{k=0}^{\infty} q^k = \frac{1}{1-q} \]
由于 \(0 < q < 1\),该几何级数收敛。对等式两边关于 \(q\) 求导,得: \[ \sum_{k=0}^{\infty} k q^{k-1} = \frac{1}{(1-q)^2} \]
最后,如果我们将等式两边同时乘以 \(pq\),就能恢复我们要找的原始求和式: \[ E(X) = \sum_{k=0}^{\infty} k q^k p = pq \sum_{k=0}^{\infty} k q^{k-1} = pq \frac{1}{(1-q)^2} = \frac{pq}{p^2} = \frac{q}{p} \]
在例 9.1.8 中,我们将基于“第一步分析法”(first-step analysis)给出相同结果的故事证明:对 \(X\) 的故事背景中第一次试验的结果进行条件概率分解。如果第一次试验成功,则 \(X=0\);如果失败,我们就浪费了一次试验,然后回到了起点。
例 4.3.7(首通分布的期望)。由于我们可以将 \(Y \sim \text{FS}(p)\) 写成 \(Y = X+1\)(其中 \(X \sim \text{Geom}(p)\)),根据线性性质有: \[ E(Y) = E(X+1) = \frac{q}{p} + 1 = \frac{1-p+p}{p} = \frac{1}{p} \]
负二项分布是几何分布的推广:我们不再只等待一次成功,而是等待预定数量 \(r\) 次成功。
背景故事 4.3.8(负二项分布)。在成功概率为 \(p\) 的一系列独立伯努利试验中,如果 \(X\) 是第 \(r\) 次成功之前的失败次数,则称 \(X\) 服从参数为 \(r\) 和 \(p\) 的负二项分布,记作 \(X \sim \text{NBin}(r, p)\)。
二项分布和负二项分布都基于独立的伯努利试验;它们的区别在于停止规则以及计数对象。二项分布是在固定的试验次数中计算成功次数;负二项分布则是计算直到达到固定成功次数为止的失败次数。
鉴于这些相似性,负二项分布 PMF 的推导与二项分布的推导非常相似也就不足为奇了。
定理 4.3.9(负二项分布 PMF)。若 \(X \sim \text{NBin}(r, p)\),则 \(X\) 的 PMF 为: \[ P(X = n) = \binom{n + r - 1}{r - 1} p^r q^n \]
对于 \(n = 0, 1, 2, \dots\),其中 \(q = 1 - p\)。
证明:想象一串由 0 和 1 组成的序列,1 代表成功。任何包含 \(n\) 个 0 和 \(r\) 个 1 的特定序列的概率都是 \(p^r q^n\)。那么有多少种这样的序列呢?因为我们一旦达到第 \(r\) 次成功就会停止,所以序列必须以 1 结尾。在剩下的 \(n + r - 1\) 个位置中,我们需要选出 \(r - 1\) 个位置来放置剩余的 1。因此,在第 \(r\) 次成功之前恰好有 \(n\) 次失败的总概率为: \[ P(X = n) = \binom{n + r - 1}{r - 1} p^r q^n, \quad n = 0, 1, 2, \dots \]
正如二项随机变量可以表示为 i.i.d. 伯努利变量之和一样,负二项随机变量也可以表示为 i.i.d. 几何随机变量之和。
定理 4.3.10。令 \(X \sim \text{NBin}(r, p)\),视其为一系列成功概率为 \(p\) 的独立伯努利试验中第 \(r\) 次成功前的失败次数。那么我们可以写成 \(X = X_1 + \dots + X_r\),其中 \(X_i\) 是 i.i.d. 的 \(\text{Geom}(p)\)。
证明:令 \(X_1\) 为第一次成功前的失败次数,\(X_2\) 为第一次成功和第二次成功之间的失败次数,一般地,令 \(X_i\) 为第 \(i-1\) 次成功和第 \(i\) 次成功之间的失败次数。
根据几何分布的故事,\(X_1 \sim \text{Geom}(p)\)。在第一次成功之后,直到下一次成功所需的额外失败次数仍然服从几何分布!因此 \(X_2 \sim \text{Geom}(p)\),对于所有的 \(X_i\) 也是如此。此外,由于所有试验彼此独立,这些 \(X_i\) 也是相互独立的。将这些 \(X_i\) 相加,我们就得到了第 \(r\) 次成功前的失败总数,即 \(X\)。
利用线性性质,负二项分布的期望推导就不再需要任何额外的计算了。
例 4.3.11(负二项分布的期望)。令 \(X \sim \text{NBin}(r, p)\)。根据前一个定理,我们可以将 \(X\) 写成 \(X = X_1 + \dots + X_r\),其中 \(X_i\) 是 i.i.d. 的 \(\text{Geom}(p)\)。根据线性性质: \[ E(X) = E(X_1) + \dots + E(X_r) = r \cdot \frac{q}{p} \]
接下来的例子是概率论中的一个著名问题,也是几何分布和首通分布的一个极具启发性的应用。它通常被表述为收集优惠券的问题,因此得名,但我们将使用玩具代替优惠券。
例 4.3.12(赠券收集者问题,Coupon collector)。假设有 \(n\) 种类型的玩具,你一个接一个地收集它们,目标是集齐一整套。在收集玩具时,每次获得的玩具类型是随机的(就像谷物盒里或快餐店儿童餐附赠的玩具一样)。假设每次你收集一个玩具,它等概率地为 \(n\) 种类型中的任何一种。集齐一整套所需的玩具总数的期望是多少?
解答:
令 \(N\) 为所需的玩具总数;我们要求 \(E(N)\)。我们的策略是将 \(N\) 分解为更简单的随机变量之和,以便应用线性性质。因此,写成: \[ N = N_1 + N_2 + \dots + N_n \]
其中,\(N_1\) 是得到第一种从未见过的玩具类型所需的玩具数(它总是 1,因为第一个玩具必然是新类型);\(N_2\) 是得到第二种新玩具类型所需的额外玩具数,依此类推。图 4.6 展示了 \(n=3\) 种玩具类型时的定义。
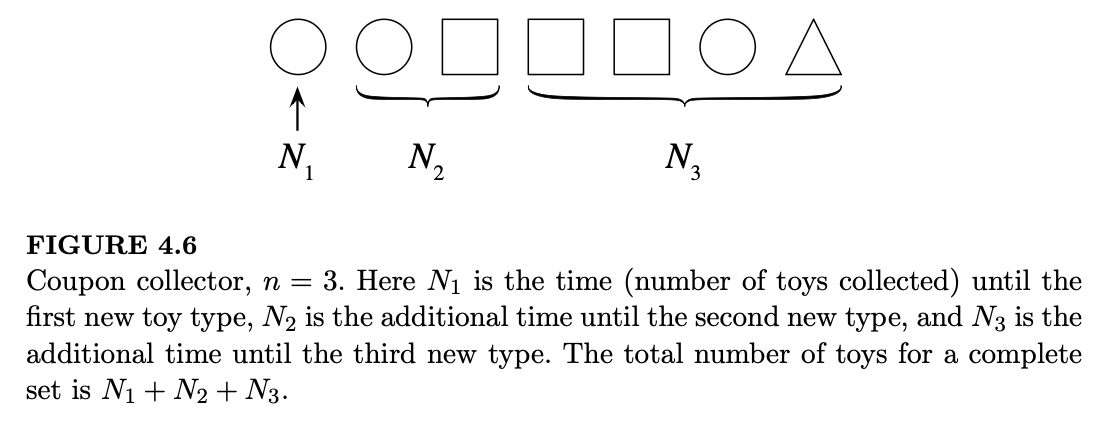
根据首通分布(FS)的故事,\(N_2 \sim \text{FS}((n-1)/n)\):在收集到第一种玩具后,有 \(1/n\) 的概率得到已有的玩具(失败),有 \((n-1)/n\) 的概率得到新的玩具(成功)。类似地,\(N_3\)(得到第三种新玩具所需的额外数量)服从 \(\text{FS}((n-2)/n)\)。一般地: \[ N_j \sim \text{FS}\left(\frac{n-j+1}{n}\right) \]
根据线性性质: \[ E(N) = E(N_1) + E(N_2) + E(N_3) + \dots + E(N_n) \]
\[ = 1 + \frac{n}{n-1} + \frac{n}{n-2} + \dots + \frac{n}{1} \]
\[ = n \left( \frac{1}{n} + \frac{1}{n-1} + \dots + 1 \right) = n \sum_{j=1}^{n} \frac{1}{j} \]
对于较大的 \(n\),该结果非常接近 \(n(\ln n + 0.577)\)。其中 \(0.577\) 是欧拉-马斯刻若尼常数(Euler-Mascheroni constant)。
在离开这个例子之前,让我们花点时间将其与定理 4.3.10 的证明(即将负二项分布表示为 i.i.d. 几何分布之和)联系起来。在这两个问题中,我们都在等待指定数量的“成功”,并且都通过考虑成功之间的间隔来处理问题。但它们有两个主要区别:
- 在定理 4.3.10 中,我们不包括成功本身,因此两次成功之间的失败次数是几何分布(Geometric)。在赠券收集者问题中,我们包括了成功,因为我们要计算玩具的总数,所以我们使用的是首通分布(First Success)随机变量。
- 在定理 4.3.10 中,每次试验成功的概率始终不变,因此失败总数是 i.i.d. 几何分布之和。而在赠券收集者问题中,每次成功后成功的概率都会降低,因为找到尚未见过的新玩具类型变得越来越难;因此 \(N_j\) 不是同分布的,尽管它们仍然是相互独立的。
4.3.13 (随机变量非线性函数的期望)期望是线性的,但通常情况下,对于任意函数 \(g\),并不成立 \(E(g(X)) = g(E(X))\)。当 \(g\) 不是线性函数时,我们必须小心,不能随意移动期望符号 \(E\)。接下来的例子展示了 \(E(g(X))\) 与 \(g(E(X))\) 截然不同的情况。
例 4.3.14(圣彼得堡悖论,St. Petersburg paradox)。假设一位富有的陌生人提议和你玩以下游戏:你反复抛掷一枚公平的硬币,直到第一次出现正面为止。如果游戏在第 1 轮结束,你得到 2 美元;如果第 2 轮结束,你得到 4 美元;第 3 轮结束得到 8 美元;一般地,如果游戏持续了 \(n\) 轮,你将得到 \(2^n\) 美元。这个游戏的公平价值(即期望收益)是多少?你愿意支付多少钱来玩一次这个游戏?
解答:
令 \(X\) 为你玩游戏的收益。根据定义,\(X = 2^N\),其中 \(N\) 是游戏持续的轮数。那么,\(X\) 以 \(1/2\) 的概率为 2,以 \(1/4\) 的概率为 4,以 \(1/8\) 的概率为 8,依此类推。因此: \[ E(X) = \frac{1}{2} \cdot 2 + \frac{1}{4} \cdot 4 + \frac{1}{8} \cdot 8 + \dots = 1 + 1 + 1 + \dots = \infty \]
期望收益是无穷大!另一方面,游戏持续的轮数 \(N\) 是直到第一次出现正面的投掷次数,所以 \(N \sim \text{FS}(1/2)\) 且 \(E(N) = 2\)。于是我们发现 \(E(2^N) = \infty\),而 \(2^{E(N)} = 2^2 = 4\)。无穷大显然不等于 4,这说明了在 \(g\) 不是线性函数时,混淆 \(E(g(X))\) 和 \(g(E(X))\) 是非常危险的。
这个问题通常被称为悖论,因为尽管游戏的期望收益是无穷大,但大多数人并不愿意花很多钱去玩(即使他们负担得起损失)。一种解释是现实世界的货币总量是有限的。假设如果游戏持续超过 40 轮,这位富有的陌生人就会逃离出境,你将一无所获。由于 \(2^{40} \approx 1.1 \times 10^{12}\),这仍然让你有潜力赚到超过一万亿美元,而且游戏持续超过 40 轮的可能性微乎其微。但在这种设定下,你的期望值变为: \[ E(X) = \sum_{n=1}^{40} \frac{1}{2^n} \cdot 2^n + \sum_{n=41}^{\infty} 0 = 40 + 0 = 40 \]
这种急剧下降是因为陌生人可能逃跑吗?让我们换个假设:如果游戏持续超过 40 轮,陌生人将你的奖金封顶在 \(2^{40}\) 美元,而不是让你空手而归。现在你的期望值是: \[ E(X) = \sum_{n=1}^{40} \frac{1}{2^n} \cdot 2^n + \sum_{n=41}^{\infty} \frac{1}{2^n} \cdot 2^{40} = 40 + 1 = 41 \]
相较于前一种情况,期望值仅增加了 1 美元。圣彼得堡悖论中的 \(\infty\) 是由极罕见事件带来的极大收益所组成的“无限尾部”驱动的。在现实世界中,在某一点切断这个尾部是合情合理的,而这样做会剧烈降低游戏的期望值。
4.4 指示随机变量与基本桥梁
Indicator r.v.s and the fundamental bridge
本节专门讨论指示随机变量(Indicator random variables)。虽然我们在前一章已经遇到过它,但在这里我们将进行更详细的探讨。特别是,我们将展示指示随机变量是计算期望值的一种极其有用的工具。
回想一下,对于事件 \(A\),指示随机变量 \(I_A\)(或 \(I(A)\))定义为:如果 \(A\) 发生则为 1,否则为 0。因此,\(I_A\) 是一个伯努利随机变量,其中“成功”定义为“\(A\) 发生”,“失败”定义为“\(A\) 未发生”。指示随机变量的一些有用性质总结如下:
定理 4.4.1(指示随机变量的性质)。设 \(A\) 和 \(B\) 为事件,则以下性质成立:
- 对于任何正整数 \(k\),\((I_A)^k = I_A\)。
- \(I_{A^c} = 1 - I_A\)。
- \(I_{A \cap B} = I_A I_B\)。
- \(I_{A \cup B} = I_A + I_B - I_A I_B\)。
证明:性质 1 成立是因为对于任何正整数 \(k\),\(0^k = 0\) 且 \(1^k = 1\)。性质 2 成立是因为当 \(A\) 不发生时 \(1 - I_A\) 为 1,当 \(A\) 发生时为 0。性质 3 成立是因为只有当 \(I_A\) 和 \(I_B\) 均为 1 时,\(I_A I_B\) 才为 1,否则为 0。性质 4 成立是因为: \[ I_{A \cup B} = 1 - I_{A^c \cap B^c} = 1 - I_{A^c} I_{B^c} = 1 - (1 - I_A)(1 - I_B) = I_A + I_B - I_A I_B \]
指示随机变量在概率和期望之间提供了一种联系,我们称之为基本桥梁。
定理 4.4.2(概率与期望之间的基本桥梁)。事件与指示随机变量之间存在一一对应关系,且事件 \(A\) 的概率等于其指示随机变量 \(I_A\) 的期望值: \[ P(A) = E(I_A) \]
证明:对于任何事件 \(A\),我们都有一个指示随机变量 \(I_A\)。这是一一对应的,因为 \(A\) 唯一地确定了 \(I_A\),反之亦然(从 \(I_A\) 回到 \(A\),我们可以利用 \(A = \{s \in S : I_A(s) = 1\}\) 这一事实)。由于 \(I_A \sim \text{Bern}(p)\) 且 \(p = P(A)\),故 \(E(I_A) = P(A)\)。
基本桥梁将事件与它们的指示变量连接起来,并允许我们将任何概率表示为期望。作为一个例子,我们将利用指示变量给出容斥原理以及相关的 Boole 不等式(或称 Bonferroni 不等式)的一个简短证明。
例 4.4.3(Boole 不等式、Bonferroni 不等式与容斥原理)。设 \(A_1, A_2, \dots, A_n\) 为事件。注意: \[ I(A_1 \cup \dots \cup A_n) \le I(A_1) + \dots + I(An) \]
因为如果左边为 0,不等式显然成立;如果左边为 1,则右边至少有一项必须为 1。对两边取期望,利用线性性质和基本桥梁,我们得到: \[ P(A_1 \cup \dots \cup A_n) \le P(A_1) + \dots + P(A_n) \]
这被称为 Boole 不等式或 Bonferroni 不等式。
要证明 \(n=2\) 时的容斥原理,我们只需对定理 4.4.1 性质 4 的两边取期望。对于一般的 \(n\),我们可以利用指示随机变量的性质如下推导: \[ 1 - I(A_1 \cup \dots \cup A_n) = I(A_1^c \cap \dots \cap A_n^c) \]
\[ = (1 - I(A_1)) \dots (1 - I(A_n)) \]
\[ = 1 - \sum_i I(A_i) + \sum_{i<j} I(A_i)I(A_j) - \dots + (-1)^n I(A_1) \dots I(A_n) \]
对等式两边取期望,通过基本桥梁,我们就证明了容斥原理定理。
反之,基本桥梁在许多期望值问题中也极其有用。我们经常可以将一个分布未知的复杂离散随机变量表示为若干个极其简单的指示随机变量之和。基本桥梁让我们能轻松求出这些指示变量的期望;然后利用线性性质,就能得到原始随机变量的期望。这种策略非常强大且多才多艺——事实上,我们在本章前面推导二项分布和超几何分布的期望时已经用到它了!
识别哪些问题适用此策略并定义合适的指示随机变量需要练习,因此研究大量示例并解决大量问题非常重要。在将此策略应用于计算[名词]数量的随机变量时,我们应该为每一个潜在的[名词]定义一个指示变量。这个[名词]可以是人、地点或事物;我们将看到这三类例子的应用。
我们首先回顾第 1 章中的两个问题:德·蒙莫尔匹配问题(de Montmort’s matching problem)和生日问题。
例 4.4.4(匹配问题续)。我们有一副洗好的 \(n\) 张牌,标记为 \(1\) 到 \(n\)。如果一张牌在牌组中的位置与其标签一致,则称其为“匹配”。令 \(X\) 为匹配的总数;求 \(E(X)\)。
解答:
首先,我们检查 \(X\) 是否服从我们学过的任何命名分布。由于 \(X\) 的值必须是 \(0\) 到 \(n\) 之间的整数,二项分布和超几何分布是仅有的两个候选。但这两个分布的支撑集都不正确,因为 \(X\) 不可能取 \(n-1\):如果 \(n-1\) 张牌都匹配了,那么第 \(n\) 张牌也必然匹配。因此,\(X\) 不属于我们学过的命名分布,但我们可以利用指示随机变量轻松求出其均值。
将 \(X\) 写成 \(X = I_1 + I_2 + \dots + I_n\),其中: \[ I_j = \begin{cases} 1 & \text{若牌组中第 } j \text{ 张牌匹配} \\ 0 & \text{否则} \end{cases} \]
换句话说,\(I_j\) 是事件 \(A_j\)(第 \(j\) 张牌匹配)的指示变量。我们可以想象,如果某张牌匹配了,对应的 \(I_j\) 就会“举手”计数;将所有举起的手相加,就得到了匹配的总数 \(X\)。
根据基本桥梁:
对于所有的 \(j\),\(E(I_j) = P(A_j) = \frac{1}{n}\)。
(因为在所有 \(n!\) 种排列中,第 \(j\) 张牌在第 \(j\) 个位置的情况有 \((n-1)!\) 种,即 \(\frac{(n-1)!}{n!} = \frac{1}{n}\))。
因此,根据线性性质: \[ E(X) = E(I_1) + \dots + E(I_n) = n \cdot \frac{1}{n} = 1 \]
无论 \(n\) 是多少,匹配牌数的期望值始终为 1。尽管 \(I_j\) 之间存在复杂的依赖关系(这导致 \(X\) 的分布既不是二项分布也不是超几何分布),但线性性质依然成立。
例 4.4.5(不同的生日,生日匹配)。在一组 \(n\) 个人中,在关于生日的常规假设下(即一年 365 天,每人出生在每一天的概率相等且相互独立),这 \(n\) 个人所拥有的不同生日的期望个数是多少(即:至少有一个人生日在那一天的天数期望值)?此外,生日匹配(即:生日相同的两人对)的期望个数是多少?
解答:
- 不同生日的期望个数:
令 \(X\) 为不同生日的数量,我们可以将其写成 \(X = I_1 + \dots + I_{365}\),其中: \[ I_j = \begin{cases} 1 & \text{若第 } j \text{ 天至少有一个人生日} \\ 0 & \text{否则} \end{cases} \]
我们为一年中的每一天都创建一个指示变量,因为 \(X\) 统计的是被代表的天数。根据基本桥梁: \[ E(I_j) = P(\text{第 } j \text{ 天被代表}) = 1 - P(\text{没有人出生在第 } j \text{ 天}) = 1 - \left(\frac{364}{365}\right)^n \]
对于所有 \(j\) 均成立。利用线性性质: \[ E(X) = 365 \left[ 1 - \left(\frac{364}{365}\right)^n \right] \]
- 生日匹配(两人对)的期望个数:
令 \(Y\) 为生日匹配的对数。将这 \(n\) 个人标记为 \(1, 2, \dots, n\),并以某种确定的方式对这 \(\binom{n}{2}\) 对人进行排序。我们可以写成: \[ Y = J_1 + \dots + J_{\binom{n}{2}} \]
其中 \(J_i\) 是第 \(i\) 对人拥有相同生日的指示变量。我们为每一对人都创建一个指示变量,因为 \(Y\) 统计的是生日相同的两人对数量。任何两人生日相同的概率为 \(1/365\)。再次利用基本桥梁和线性性质: \[ E(Y) = \binom{n}{2} \cdot \frac{1}{365} = \frac{n(n-1)}{2 \cdot 365} \]
除了基本桥梁和线性性质外,最后两个例子还利用了一种基本的对称性来极大地简化计算:在指示随机变量的求和式中,每个指示变量都具有相同的期望值。例如,在匹配问题中,第 \(j\) 张牌匹配的概率与 \(j\) 无关,因此我们只需将第一个指示变量的期望值乘以 \(n\) 即可。
当其他形式的对称性可用时,它们也会非常有帮助。接下来的两个例子展示了一种源于“等概率排列”的对称性。请注意对称性、线性性质和基本桥梁是如何协同作用,使看似非常困难的问题变得易于处理的。
例 4.4.6(普特南数学竞赛题)。对于 \(1, 2, \dots, n\) 的一个排列 \(a_1, a_2, \dots, a_n\),如果 \(a_j > a_{j-1}\) 且 \(a_j > a_{j+1}\)(对于 \(2 \le j \le n-1\)),则称位置 \(j\) 处有一个局部极大值;对于边界情况,当 \(j=1\) 时,局部极大值意味着 \(a_1 > a_2\);当 \(j=n\) 时,意味着 \(a_n > a_{n-1}\)。例如,\(4, 2, 5, 3, 6, 1\) 在位置 1、3 和 5 处有 3 个局部极大值。2006 年的普特南竞赛(这是一项著名的、难度极高的数学竞赛,中位数得分通常为 0 分)提出了这样一个问题:对于 \(n \ge 2\),在所有 \(n!\) 种等概率排列中,局部极大值数量的平均值(期望)是多少?
解答:
利用指示随机变量、对称性和基本桥梁,这个问题可以很快得到解决。令 \(I_1, \dots, I_n\) 为指示随机变量,其中 \(I_j\) 在位置 \(j\) 为局部极大值时取 1,否则取 0。我们关注的是 \(\sum_{j=1}^{n} I_j\) 的期望值。
- 对于 \(1 < j < n\)(中间位置):\(E(I_j) = 1/3\)。因为在位置 \(j\) 出现局部极大值等价于 \(a_j\) 是 \(\{a_{j-1}, a_j, a_{j+1}\}\) 这三个数中的最大值。由于所有排列等概率,这三个数的任何相对大小顺序也是等概率的,因此其中某一个数(即中间那个)最大的概率为 \(1/3\)。
- 对于 \(j = 1\) 或 \(j = n\)(边界位置):\(E(I_j) = 1/2\)。因为此时它只有一个邻居,两个数中 \(a_j\) 较大的概率为 \(1/2\)。
因此,根据线性性质: \[ E\left( \sum_{j=1}^{n} I_j \right) = 2 \cdot \frac{1}{2} + (n-2) \cdot \frac{1}{3} = 1 + \frac{n-2}{3} = \frac{n+1}{3} \]
接下来的例子将引入负超几何分布(Negative Hypergeometric distribution),它补全了下表。该表展示了四种抽样方案下的分布:抽样可以是有放回或无放回的,而停止规则可以要求固定抽样次数或固定成功次数。

个人注:
二项分布 : \(X \sim \text{Bin}(n, p)\) 超几何分布 : \(X \sim \text{HGeom}(w, b, n)\)
负二项分布:\(X \sim \text{NBin}(r, p)\) 负超几何分布:\(X \sim \text{NHGeom}(w, b, r)\)。
几何分布 : \(X \sim \text{Geom}(p)\) 失败次数,负二项分布由此引出。有放回,意味着每次的概率不变。
例 4.4.7(负超几何分布)。一个瓮中装有 \(w\) 个白球和 \(b\) 个黑球,随机无放回地一个接一个地取出,直到获得 \(r\) 个白球为止。在抽到第 \(r\) 个白球之前抽出的黑球数量服从参数为 \(w, b, r\) 的负超几何分布,记作 \(X \sim \text{NHGeom}(w, b, r)\)。当然,我们假设 \(r \le w\)。例如,如果我们洗好一副牌并一张张发出,在看到第一张尖子(Ace)之前发出的牌的数量服从 \(\text{NHGeom}(4, 48, 1)\)。
另一个例子:假设一所大学提供 \(g\) 门好课和 \(b\) 门差课,一名学生想选到 4 门好课。学生不知道哪些课是好的,于是随机尝试,直到凑够 4 门好课为止。那么该学生尝试过的差课数量服从 \(\text{NHGeom}(g, b, 4)\)。
我们可以通过以下方式得到 \(X \sim \text{NHGeom}(w, b, r)\) 的 PMF:在抽球背景下,\(X = k\) 意味着第 \((r+k)\) 次抽到的是白球,且在前 \((r+k-1)\) 次抽取中恰好有 \((r-1)\) 个白球。这给出: \[ P(X=k) = \frac{\binom{w}{r-1}\binom{b}{k}}{\binom{w+b}{r+k-1}} \cdot \frac{w-r+1}{w+b-r-k+1} \]
对于 \(k=0, 1, \dots, b\)。
或者,我们可以想象继续抽球直到瓮被抽空。将 \(w+b\) 个球看作随机排列在一行中,白球在行中位置的 \(\binom{w+b}{w}\) 种可能性是等概率的。由此可得 PMF 的另一种稍简单的表达式: \[ P(X=k) = \frac{\binom{r+k-1}{r-1}\binom{w+b-r-k}{w-r}}{\binom{w+b}{w}} \]
直接从定义计算负超几何分布的期望会涉及复杂的求和,但结果却非常简洁:对于 \(X \sim \text{NHGeom}(w, b, r)\),有 \(E(X) = \frac{rb}{w+1}\)。
我们利用指示随机变量来证明这一点。首先考虑 \(r=1\) 的情况。将黑球标记为 \(1, 2, \dots, b\),令 \(I_j\) 为黑球 \(j\) 在任何白球之前被抽出的指示变量。那么 \(P(I_j=1) = 1/(w+1)\)。因为如果我们只看黑球 \(j\) 和那 \(w\) 个白球出现的顺序(忽略其他球),由对称性可知,这 \(w+1\) 个球的任何排列顺序都是等概率的,而 \(I_j=1\) 等价于黑球 \(j\) 排在这组球的首位。根据线性性质: \[ E\left( \sum_{j=1}^{b} I_j \right) = \sum_{j=1}^{b} E(I_j) = \frac{b}{w+1} \]
合理性检查: 这个答案是合理的,因为它随 \(b\) 增加,随 \(w\) 减少。此外,\(\frac{b}{w+1}\) 与 \(\frac{b}{w}\)(即有放回抽样的 \(\text{Geom}(\frac{w}{w+b})\) 的期望)非常相似,但严格小于它。这符合直觉:无放回抽样比有放回抽样能更早抽到目标。正如找东西时,不重复寻找已经排除的地方会更快。
对于一般的 \(r\),令 \(X = X_1 + X_2 + \dots + X_r\),其中 \(X_1\) 是第一个白球前的黑球数,\(X_2\) 是第一个和第二个白球之间的黑球数,依此类推。通过与 \(r=1\) 相同的对称性论证,每个 \(X_j\) 的期望都是 \(E(X_j) = \frac{b}{w+1}\)。由线性性质得: \[ E(X) = \frac{rb}{w+1} \]
与指示随机变量紧密相关的是非负整数值随机变量 \(X\) 期望的另一种表达方式。我们不需要计算 \(X\) 的值乘以其 PMF 的总和,而是可以对形式为 \(P(X > n)\) 的概率(称为尾概率,tail probabilities)在所有非负整数 \(n\) 上求和。
定理 4.4.8(通过生存函数求期望)。设 \(X\) 为非负整数值随机变量。令 \(F\) 为 \(X\) 的 CDF,且 \(G(x) = 1 - F(x) = P(X > x)\)。函数 \(G\) 被称为 \(X\) 的生存函数(survival function)。那么: \[ E(X) = \sum_{n=0}^{\infty} G(n) \]
也就是说,我们可以通过对生存函数求和(或者说,对分布的尾概率求和)来获得 \(X\) 的期望。
证明:为了简单起见,我们仅证明 \(X\) 有界的情况,即存在一个非负整数 \(b\) 使得 \(X\) 总是小于等于 \(b\)。我们可以将 \(X\) 表示为指示随机变量之和:\(X = I_1 + I_2 + \dots + I_b\),其中 \(I_n = I(X \ge n)\)。例如,如果发生了 \(X = 7\),那么 \(I_1\) 到 \(I_7\) 都等于 1,而其他的指示变量等于 0。
根据线性性质、基本桥梁,以及 \(\{X \ge k\}\) 与 \(\{X > k-1\}\) 是同一个事件这一事实: \[ E(X) = \sum_{k=1}^{b} E(I_k) = \sum_{k=1}^{b} P(X \ge k) = \sum_{n=0}^{b-1} P(X > n) = \sum_{n=0}^{\infty} G(n) \]
作为一个快速示例,我们利用上述结论再次推导几何分布的均值。
例 4.4.9(再探几何分布期望)。令 \(X \sim \text{Geom}(p)\),且 \(q = 1 - p\)。根据几何分布的背景故事,\(\{X > n\}\) 意味着前 \(n+1\) 次试验全部失败。因此,根据定理 4.4.8: \[ E(X) = \sum_{n=0}^{\infty} P(X > n) = \sum_{n=0}^{\infty} q^{n+1} = q + q^2 + q^3 + \dots \]
这是一个首项为 \(q\),公比为 \(q\) 的无穷几何级数: \[ E(X) = \frac{q}{1-q} = \frac{q}{p} \]
这验证了我们之前已知的几何分布均值。
4.5 无意识统计学家定律 (LOTUS)
Law of the unconscious statistician (LOTUS)
正如我们在圣彼得堡悖论中所见,如果 \(g\) 不是线性的,通常情况下 \(E(g(X))\) 并不等于 \(g(E(X))\)。那么我们该如何正确计算 \(E(g(X))\) 呢?由于 \(g(X)\) 本身也是一个随机变量,一种方法是先求出 \(g(X)\) 的分布,然后根据期望的定义进行计算。但令人惊讶的是,事实证明我们可以直接利用 \(X\) 的分布来求 \(E(g(X))\),而无需先求出 \(g(X)\) 的分布。这就是通过无意识统计学家定律(Law of the Unconscious Statistician,简称 LOTUS)来实现的。
定理 4.5.1 (LOTUS)。若 \(X\) 是一个离散随机变量,\(g\) 是一个从 \(\mathbb{R}\) 到 \(\mathbb{R}\) 的函数,则: \[ E(g(X)) = \sum_{x} g(x) P(X = x) \]
其中求和是对 \(X\) 的所有可能取值进行的。
这意味着,只要知道 \(X\) 的 PMF(即 \(P(X=x)\)),我们就能得到 \(g(X)\) 的期望值,而不需要知道 \(g(X)\) 的 PMF。这个名字的由来是:在从 \(E(X)\) 过渡到 \(E(g(X))\) 时,人们很容易在定义中机械地将 \(x\) 改为 \(g(x)\),这种操作简单到甚至可以在“无意识状态”下完成。乍一看,这种不需要求出 \(g(X)\) 分布就能计算期望的好事似乎“美得不真实”,但 LOTUS 证明了它确实成立。
在给出一般性的证明之前,让我们看看为什么它在某些特殊情况下是成立的。设 \(X\) 的支撑集为 \(0, 1, 2, \dots\),概率分别为 \(p_0, p_1, p_2, \dots\),即 PMF 为 \(P(X=n) = p_n\)。那么 \(X^3\) 的支撑集为 \(0^3, 1^3, 2^3, \dots\),概率同样为 \(p_0, p_1, p_2, \dots\)。因此: \[ E(X) = \sum_{n=0}^{\infty} n p_n \]
\[ E(X^3) = \sum_{n=0}^{\infty} n^3 p_n \]
正如 LOTUS 所言,要将 \(E(X)\) 的表达式修改为 \(E(X^3)\) 的表达式,我们只需将 \(p_n\) 前面的 \(n\) 改为 \(n^3\) 即可。由于函数 \(g(x) = x^3\) 是一一对应的,这个例子比较简单。
但 LOTUS 的适用范围要广得多。证明一般函数 \(g\) 的 LOTUS 定律,其核心思路与我们证明线性性质时的思路一致:\(g(X)\) 的期望可以写成未分组的形式: \[ E(g(X)) = \sum_{s \in S} g(X(s)) P(\{s\}) \]
这里的求和是对样本空间中的所有“小石子”进行的。但我们也可以根据 \(X\) 分配给它们的值,将这些小石子分组成“超级小石子”。在“超级小石子” \(X=x\) 内部,\(g(X)\) 总是取值 \(g(x)\)。因此: \[ E(g(X)) = \sum_{s \in S} g(X(s)) P(\{s\}) \]
\[ = \sum_{x} \sum_{s: X(s)=x} g(X(s)) P(\{s\}) \]
\[ = \sum_{x} g(x) \sum_{s: X(s)=x} P(\{s\}) \]
\[ = \sum_{x} g(x) P(X = x) \]
在最后一步中,我们利用了 \(\sum_{s: X(s)=x} P(\{s\})\) 正是超级小石子 \(X=x\) 的总权重这一事实。
4.6 方差
Variance
LOTUS 定律的一个重要应用是求随机变量的方差(Variance)。与期望值一样,方差也是随机变量分布的一个单数值总结。如果说期望值告诉我们分布的“质心”,那么方差则告诉我们分布的“离散程度”。
定义 4.6.1(方差与标准差)。随机变量 \(X\) 的方差定义为: \[ Var(X) = E(X - EX)^2 \]
方差的平方根称为标准差(Standard Deviation,简称 SD): \[ SD(X) = \sqrt{Var(X)} \]
请记住,当我们写下 \(E(X - EX)^2\) 时,我们指的是随机变量 \((X - EX)^2\) 的期望值,而不是 \((E(X - EX))^2\)(根据线性性质,后者恒等于 \(0\))。
\(X\) 的方差衡量了 \(X\) 平均离其均值有多远。我们没有简单地计算 \(X\) 与均值 \(EX\) 之间的平均差值,而是计算了平均平方差。原因在于,根据线性性质,\(X\) 对均值的平均偏差 \(E(X - EX)\) 总是等于 \(0\);正负偏差会相互抵消。通过平方处理,我们确保了正偏差和负偏差都能对整体波动性有所贡献。然而,由于方差是平均平方距离,它的单位是不对的:如果 \(X\) 的单位是美元,那么 \(Var(X)\) 的单位就是“平方美元”。为了回到原始单位,我们取平方根,这就得到了标准差。
你可能会好奇,为什么方差不定义为 \(E|X - EX|\)?这样既能计入正负偏差,又能保持与 \(X\) 相同的单位。但这种衡量波动性的方式远不如 \(E(X - EX)^2\) 流行,原因有很多。最显著的一点是,绝对值函数在 \(0\) 处不可微,而平方函数处处可微,并且在诸如勾股定理等各种基本数学结论中处于核心地位。
方差的一个等价表达式是 \(Var(X) = E(X^2) - (EX)^2\)。在进行实际计算时,这个公式通常更容易使用。由于这是我们会反复用到的方差公式,我们将其列为一条定理。
定理 4.6.2。对于任何随机变量 \(X\): \[ Var(X) = E(X^2) - (EX)^2 \]
证明:令 \(\mu = EX\)。展开 \((X - \mu)^2\) 并利用线性性质,可得: \[ E(X - \mu)^2 = E(X^2 - 2\mu X + \mu^2) = E(X^2) - 2\mu E(X) + \mu^2 \]
\[ = E(X^2) - 2\mu^2 + \mu^2 = E(X^2) - \mu^2 \]
方差具有以下性质。前两条很容易从定义中验证,第三条将在后续章节中详细讨论,最后一条在陈述后立即给出证明。
\(Var(X + c) = Var(X)\)(对于任何常数 \(c\))。直观上,如果我们向左或向右平移一个分布,这会影响分布的质心(均值),但不会改变其离散程度(分布的形状)。
\(Var(cX) = c^2 Var(X)\)(对于任何常数 \(c\))。
如果 \(X\) 和 \(Y\) 相互独立,则 \(Var(X + Y) = Var(X) + Var(Y)\)。我们将在第 7 章证明这一点并展开讨论。如果 \(X\) 和 \(Y\) 相关,这通常不成立。例如,在 \(X\) 总是等于 \(Y\) 的极端情况下,若 \(Var(X) > 0\),则
\[ Var(X + Y) = Var(2X) = 4Var(X) > 2Var(X) = Var(X) + Var(Y) \]
- \(Var(X) \ge 0\),等号成立当且仅当 \(P(X = a) = 1\)(对于某个常数 \(a\))。换句话说,唯一方差为零的随机变量是常数(可视为“退化”随机变量);所有其他随机变量的方差均为正。
证明最后一条性质:由于 \(Var(X)\) 是非负随机变量 \((X - EX)^2\) 的期望值,因此 \(Var(X) \ge 0\)。如果 \(P(X = a) = 1\),则 \(E(X) = a\) 且 \(E(X^2) = a^2\),故 \(Var(X) = a^2 - a^2 = 0\)。反之,假设 \(Var(X) = 0\),则 \(E(X - EX)^2 = 0\),这表明 \((X - EX)^2 = 0\) 的概率为 1,进而说明 \(X\) 以概率 1 等于其均值。
4.6.3(方差是非线性的)与期望不同,方差不具有线性性质。在 \(Var(cX) = c^2 Var(X)\) 中,常数是以平方形式提取出来的;此外,如果随机变量之间相互依赖,随机变量之和的方差可能并不等于它们各自方差的和。
例 4.6.4(几何分布与负二项分布的方差)。在本例中,我们将利用 LOTUS 定律来计算几何分布的方差。
设 \(X \sim \text{Geom}(p)\)。我们已知 \(E(X) = q/p\)。根据 LOTUS 定律: \[E(X^2) = \sum_{k=0}^{\infty} k^2 P(X=k) = \sum_{k=0}^{\infty} k^2 p q^k = \sum_{k=1}^{\infty} k^2 p q^k\] 我们将采用与计算期望类似的策略,即从几何级数开始并求导: \[ \sum_{k=0}^{\infty} q^k = \frac{1}{1-q} \] 由于 \(k=0\) 时项为 0,我们将求和从 \(k=1\) 开始。对 \(q\) 求一次导: \[ \sum_{k=1}^{\infty} k q^{k-1} = \frac{1}{(1-q)^2} \] 如果现在再次求导,我们会得到 \(k(k-1)\) 而不是我们想要的 \(k^2\)。因此,先通过两边乘以 \(q\) 来“补充” \(q\) 的幂次: \[ \sum_{k=1}^{\infty} k q^k = \frac{q}{(1-q)^2} \] 现在准备好进行第二次求导: \[ \sum_{k=1}^{\infty} k^2 q^{k-1} = \frac{(1-q)^2 + 2q(1-q)}{(1-q)^4} = \frac{1+q}{(1-q)^3} \] 于是可得: \[ E(X^2) = p q \sum_{k=1}^{\infty} k^2 q^{k-1} = p q \frac{1+q}{(1-q)^3} = \frac{q(1+q)}{p^2} \] 最后,计算方差: \[ Var(X) = E(X^2) - (EX)^2 = \frac{q+q^2}{p^2} - \left(\frac{q}{p}\right)^2 = \frac{q+q^2-q^2}{p^2} = \frac{q}{p^2} \] 这也是首通分布(First Success distribution)的方差,因为平移常数不会影响方差。
由于根据定理 4.3.10,一个 \(\text{NBin}(r, p)\) 随机变量可以表示为 \(r\) 个 i.i.d. 的 \(\text{Geom}(p)\) 随机变量之和,且方差对独立随机变量具有可加性,因此 \(\text{NBin}(r, p)\) 分布的方差为: \[ r \cdot \frac{q}{p^2} \] LOTUS 是计算任何 \(E(g(X))\) 的通用工具,但因为它通常会导致复杂的求和计算,所以应将其作为最后的手段。在方差计算中,我们信赖的指示随机变量有时可以替代 LOTUS,如下一个例子所示。
例 4.6.5(二项分布的方差)。让我们利用指示随机变量来计算 \(X \sim \text{Bin}(n, p)\) 的方差,从而避免繁琐的求和计算。
将 \(X\) 表示为 \(X = I_1 + I_2 + \dots + I_n\),其中 \(I_j\) 是第 \(j\) 次试验成功的指示变量。每个 \(I_j\) 的方差为: \[ Var(I_j) = E(I_j^2) - (E(I_j))^2 = p - p^2 = p(1-p) \] (回想一下,\(I_j^2 = I_j\),因此 \(E(I_j^2) = E(I_j) = p\)。)
由于 \(I_j\) 是相互独立的,我们可以将它们的方差相加来得到它们之和的方差: \[ Var(X) = Var(I_1) + \dots + Var(I_n) = np(1-p) \] 另一种方法:我们可以通过先求 \(E \binom{X}{2}\) 来求 \(E(X^2)\)。这听起来更复杂,但实际上更简单,因为 \(\binom{X}{2}\) 代表成功试验的两人对的数量。为每一对试验创建一个指示随机变量,我们有: \[ E \binom{X}{2} = \binom{n}{2} p^2 \] 同时,根据定义: \[ E \binom{X}{2} = E\left(\frac{X(X-1)}{2}\right) = \frac{1}{2} (E(X^2) - E(X)) = \frac{1}{2} (E(X^2) - np) \] 因此: \[ E(X^2) - np = n(n-1)p^2 \] 再次代入方差公式: \[ Var(X) = E(X^2) - (EX)^2 = (n(n-1)p^2 + np) - (np)^2 = np(1-p) \] 练习题 48 利用这种策略(即考虑“两人对”的期望)来求解超几何分布的方差。
4.7 泊松分布
Poisson
本章介绍的最后一个离散分布是泊松分布(Poisson distribution)。它在离散数据建模中极其受欢迎。我们将介绍它的 PMF、均值和方差,然后详细讨论它的背景故事。
定义 4.7.1(泊松分布)。若随机变量 \(X\) 的 PMF 为: \[ P(X = k) = \frac{e^{-\lambda} \lambda^k}{k!}, \quad k = 0, 1, 2, \dots \] 其中 \(\lambda > 0\),则称 \(X\) 服从参数为 \(\lambda\) 的泊松分布,记作 \(X \sim \text{Pois}(\lambda)\)。
根据泰勒级数 \(\sum_{k=0}^{\infty} \frac{\lambda^k}{k!} = e^\lambda\),可以证明这是一个有效的 PMF。
例 4.7.2(泊松分布的期望与方差)。设 \(X \sim \text{Pois}(\lambda)\)。我们将证明其均值和方差都等于 \(\lambda\)。
均值推导: \[ E(X) = e^{-\lambda} \sum_{k=0}^{\infty} \frac{k \lambda^k}{k!} = e^{-\lambda} \sum_{k=1}^{\infty} \frac{k \lambda^k}{k!} \] 由于 \(k=0\) 时项为 0,我们从 \(k=1\) 开始求和。约去 \(k\) 并提一个 \(\lambda\): \[ E(X) = \lambda e^{-\lambda} \sum_{k=1}^{\infty} \frac{\lambda^{k-1}}{(k-1)!} = \lambda e^{-\lambda} e^\lambda = \lambda \] 此处我们利用了剩余部分恰好是 \(e^\lambda\) 的泰勒级数展开。
方差推导:
为了得到方差,我们先求 \(E(X^2)\)。根据 LOTUS 定律: \[ E(X^2) = \sum_{k=0}^{\infty} k^2 P(X=k) = e^{-\lambda} \sum_{k=0}^{\infty} \frac{k^2 \lambda^k}{k!} \] 接下来的推导与几何分布方差的推导非常相似。对熟悉的级数 \(\sum_{k=0}^{\infty} \frac{\lambda^k}{k!} = e^\lambda\) 关于 \(\lambda\) 求导并“补充”幂次:
- 第一次求导:\(\sum_{k=1}^{\infty} \frac{k \lambda^{k-1}}{k!} = e^\lambda\)
- 两边同乘 \(\lambda\):\(\sum_{k=1}^{\infty} \frac{k \lambda^k}{k!} = \lambda e^\lambda\)
- 再次关于 \(\lambda\) 求导:\(\sum_{k=1}^{\infty} \frac{k^2 \lambda^{k-1}}{k!} = e^\lambda + \lambda e^\lambda = e^\lambda(1 + \lambda)\)
- 再次同乘 \(\lambda\):\(\sum_{k=1}^{\infty} \frac{k^2 \lambda^k}{k!} = e^\lambda \lambda(1 + \lambda)\)
因此: \[ E(X^2) = e^{-\lambda} \cdot e^\lambda \lambda(1 + \lambda) = \lambda(1 + \lambda) \] 最后计算方差: \[ Var(X) = E(X^2) - (EX)^2 = \lambda(1 + \lambda) - \lambda^2 = \lambda \] 由此可见,\(\text{Pois}(\lambda)\) 随机变量的均值和方差都等于 \(\lambda\)。
图 4.7 展示了 \(k = 0\) 到 \(k = 10\) 范围内 \(\text{Pois}(2)\) 和 \(\text{Pois}(5)\) 分布的 PMF 和 CDF。可以观察到,\(\text{Pois}(2)\) 的均值在大约 2 左右,\(\text{Pois}(5)\) 的均值在大约 5 左右,这与我们之前的发现一致。\(\text{Pois}(2)\) 的 PMF 呈现明显的偏态(skewed),但随着 \(\lambda\) 的增大,偏态减弱,PMF 变得更像钟形。
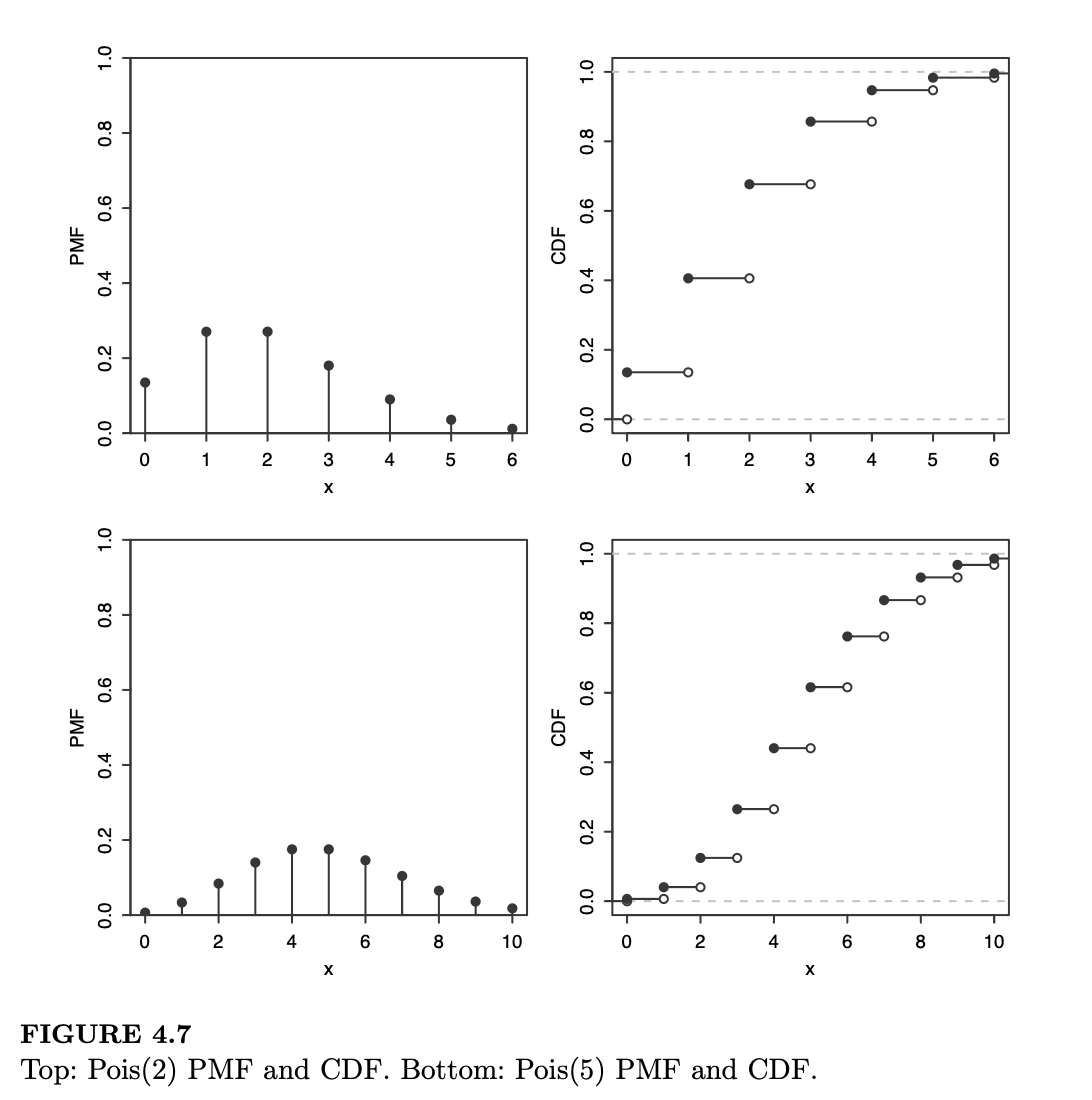
泊松分布通常用于统计在特定区域或时间间隔内发生的“成功”次数,且前提是有大量的试验,而每次试验成功的概率都很小。例如,以下随机变量可能近似服从泊松分布:
个人注:负二项分布是计算失败的次数!
- 一小时内收到的电子邮件数量:在一个小时内,有很多人可能会给你发邮件,但任何特定的人在这一小时内实际给你发邮件的可能性很小。或者,想象将一小时细分为毫秒。一小时有 \(3.6 \times 10^6\) 毫秒,但在任何特定的毫秒内收到邮件的可能性极低。
- 一块巧克力曲奇饼干中的巧克力碎片数量:想象将饼干切成许多微小的立方体;在单个微小立方体中出现碎片的概率很小,但立方体的总数很大。
- 某地区一年内发生的地震次数:在任何给定的时间和地点,发生地震的概率都很小,但一年中地震可能发生的时间和地点数量却非常多。
参数 \(\lambda\) 被解释为这些稀有事件发生的速率(rate)。在上述例子中,\(\lambda\) 可能是 20(封邮件/小时)、10(个碎片/饼干)或 2(次地震/年)。泊松范式(Poisson paradigm)指出,在类似于上述的应用场景中,我们可以用泊松分布来近似这些事件发生次数的分布。
近似 4.7.3(泊松范式Poisson paradigm)。设 \(A_1, \dots, A_n\) 为事件,其概率为 \(p_j = P(A_j)\)。如果 \(n\) 很大,\(p_j\) 很小,且 \(A_j\) 之间相互独立或弱相关。令 \[ X = \sum_{j=1}^{n} I(A_j) \] 表示发生的事件总数。那么 \(X\) 近似服从参数为 \(\lambda\) 的泊松分布,其中 \(\lambda = \sum_{j=1}^{n} p_j\)。
证明上述近似的优劣非常困难,这首先需要对“弱相关”(衡量随机变量相关性的方式有很多)和“良好近似”(衡量近似程度的方式也有很多)给出精确定义。一个著名的定理指出:如果 \(A_j\) 相互独立,\(N \sim \text{Pois}(\lambda)\),且 \(B\) 为任何非负整数集合,则: \[ |P(X \in B) - P(N \in B)| \le \min\left(1, \frac{1}{\lambda}\right) \sum_{j=1}^{n} p_j^2 \] 这为使用泊松近似时可能产生的误差提供了一个上限。它还更精确地说明了 \(p_j\) 应该有多小:我们希望 \(\sum_{j=1}^{n} p_j^2\) 非常小,或者至少相对于 \(\lambda\) 来说非常小。
泊松范式也被称为稀有事件定律(law of rare events)。对“稀有”的解释是 \(p_j\) 很小,而不是 \(\lambda\) 很小。例如,在电子邮件的例子中,特定某人在一小时内给你发邮件的低概率,被可能发邮件的庞大人数所抵消了。
在上面给出的例子中,实际发生的事件数量并不完全服从泊松分布,因为泊松随机变量没有上限,而 \(A_1, \dots, A_n\) 发生的数量最多为 \(n\),且一块饼干里能塞进的巧克力碎片数量也是有限的。但泊松分布通常能给出很好的近似。
请注意,泊松范式成立的条件相当灵活:这 \(n\) 次试验可以有不同的成功概率,且试验之间不一定要独立,只要不是强相关即可。因此,有很多情况都可以归入泊松范式的框架。这使得泊松分布成为处理非负整数数据(统计学中称为计数数据,count data)时非常受欢迎的模型,或者至少是一个起始模型。
例 4.7.4(球与盒子)。有 \(k\) 个可区分的球和 \(n\) 个可区分的盒子。将球随机放入盒子中,所有 \(n^k\) 种可能性均等。这类背景下的问题被称为占用问题(Occupancy problems),是计算机科学中许多广泛使用的算法的核心。
个人注:计数详见 例 1.4.22。
求空盒数量的期望值(要求完全简化,不以求和形式表示)。
求至少有一个空盒的概率。将答案表示为不超过 \(n\) 项的求和式。
现令 \(n = 1000\),\(k = 5806\)。此时空盒数量的期望值大约为 3。请找出一个良好的十进制近似值,表示至少有一个空盒的概率。提示:利用 \(e^3 \approx 20\) 这一便捷事实。
解答:
- 令 \(I_j\) 为第 \(j\) 个盒子为空的指示随机变量。那么: \[ E(I_j) = P(I_j = 1) = \left(1 - \frac{1}{n}\right)^k \] (因为对于每一个球,它不在第 \(j\) 个盒子的概率是 \((n-1)/n\)。)
根据线性性质: \[ E\left( \sum_{j=1}^n I_j \right) = \sum_{j=1}^n E(I_j) = n \left(1 - \frac{1}{n}\right)^k \] (b) 当 \(k < n\) 时,该概率为 1(根据鸽巢原理,一定会有空盒)。一般情况下,令 \(A_j\) 为第 \(j\) 个盒子为空的事件。利用容斥原理: \[ P(A_1 \cup A_2 \cup \dots \cup A_n) = \sum_{j=1}^{n-1} (-1)^{j+1} \binom{n}{j} P(A_1 \cap \dots \cap A_j) \]
\[ = \sum_{j=1}^{n-1} (-1)^{j+1} \binom{n}{j} \left(1 - \frac{j}{n}\right)^k \]
(注:求和只需到 \(n-1\),因为 \(n\) 个盒子不可能同时为空。)
- 空盒的数量 \(X\) 近似服从 \(\text{Pois}(3)\) 分布。这是因为盒子的数量很多,但每个盒子为空的可能性很小;特定盒子为空的概率为 \((1 - 1/n)^k = \frac{1}{n} E(X) \approx 0.003\)。因此: \[ P(X \ge 1) = 1 - P(X = 0) \approx 1 - e^{-3} \approx 1 - \frac{1}{20} = 0.95 \] 泊松近似极大地简化了第 1 章中讨论的生日问题的近似求解过程,并且使得处理那些难以精确求解的各种变体成为可能。
例 4.7.5(再探生日问题)。如果有 \(m\) 个人并做出关于生日的常规假设,那么每一对人拥有相同生日的概率为 \(p = 1/365\),且总共有 \(\binom{m}{2}\) 对人。根据泊松范式,生日匹配的数量 \(X\) 近似服从 \(\text{Pois}(\lambda)\) 分布,其中 \(\lambda = \binom{m}{2} \cdot \frac{1}{365}\)。那么至少有一对匹配的概率为: \[ P(X \ge 1) = 1 - P(X = 0) \approx 1 - e^{-\lambda} \] 对于 \(m = 23\),\(\lambda = 253/365 \approx 0.693\),且 \(1 - e^{-\lambda} \approx 0.500002\)。这与我们在第 1 章中的发现一致,即需要 23 人才能有 50% 的机会出现生日匹配。请注意,虽然 \(m = 23\) 相对较小,但该问题中相关的数量实际上是 \(\binom{m}{2} = 253\),这是成功匹配的总“试验次数”,因此泊松近似依然表现良好。
例 4.7.6(邻近生日问题)。如果我们想知道需要多少人才能有 50% 的机会让两个人的生日在一天之内(即同一天或相隔一天)?与原始生日问题不同,这个问题很难获得精确解,但泊松范式依然适用。
任意两个人生日相差在一天之内的概率是 \(3/365\)(先选定第一个人的生日,然后第二个人需要出生在那一天、前一天或后一天)。同样有 \(\binom{m}{2}\) 个可能的对,因此“一天之内匹配”的数量近似服从 \(\text{Pois}(\lambda)\),其中 \(\lambda = \binom{m}{2} \cdot \frac{3}{365}\)。通过类似于上面的计算,我们可以得出需要 \(m = 14\) 或更多人。这只是一个快速的近似计算,但事实证明 \(m = 14\) 正是精确答案!
例 4.7.7(出生的分钟与小时)。某大学有 1600 名大二学生。在整个例子中,沿用生日问题的常规假设。
(a) 求一个泊松近似值,表示至少有两名大二学生不仅出生在一年中的同一天,而且在同一小时、同一分钟(例如,两人都出生在 3 月 31 日晚上 8:20,不要求是同一年)。
(b) 在 (a) 的假设下,至少有四名大二学生出生在同一天且同一小时(例如,四人都出生在 3 月 31 日下午 2 点到 3 点之间)的概率是多少?针对该值给出两种不同的泊松近似方法:一种基于为每四个学生组成的四元组创建指示变量,另一种基于为每个可能的日期-小时创建指示变量。你认为哪种更准确?
解答:
- 这本质上是一个有 \(c = 365 \times 24 \times 60 = 525,600\) 个类别的生日问题。令 \(n = 1600\)。为每对学生创建一个指示变量,根据线性性质,出生在同一天-小时-分钟的学生对数的期望值为: \[ \lambda_1 = \binom{n}{2} \frac{1}{c} = \frac{1600 \times 1599}{2} \cdot \frac{1}{525600} \approx 2.4338 \] 根据泊松近似,至少有一对匹配的概率约为: \[ 1 - \exp(-\lambda_1) \approx 1 - e^{-2.4338} \approx 0.9122 \] 这个近似非常精确:在 R 语言中输入 pbirthday(1600, classes=3652460) 得到的结果是 0.9125。
(b) 此时有 \(b = 365 \times 24 = 8760\) 个类别。我们探索两种不同的泊松近似方法:
方法 1:为每 4 个人的集合创建指示变量。
根据线性性质,这 4 个人出生在同一个“日期-小时”的期望集合数是:
\[ \lambda_2 = \binom{n}{4} \frac{1}{b^3} \]
(因为第一个人可以出生在任何时间,后三个人必须与第一人匹配,概率各为 \(1/b\))。
泊松近似给出目标概率约为: \[ 1 - \exp(-\lambda_2) \approx 0.333 \]
方法 2:为每个可能的“日期-小时”创建指示变量。
令 \(I_j\) 为第 \(j\) 个“日期-小时”内至少有 4 人出生的指示变量。令 \(p = 1/b\) 且 \(q = 1-p\)。每个人落在该时间段的概率服从二项分布,则:
\[ E(I_j) = P(I_j = 1) = 1 - P(\text{该时段内出生人数 } \le 3) \]
\[ = 1 - \left[ q^n + npq^{n-1} + \binom{n}{2}p^2q^{n-2} + \binom{n}{3}p^3q^{n-3} \right] \]
至少有 4 人出生的“日期-小时”数的期望值为 \(\lambda_3 = b \cdot E(I_1)\)。
代入计算得泊松近似: \[ 1 - \exp(-\lambda_3) \approx 0.295 \] 结论:
R 语言命令 pbirthday(1600, classes = 8760, coincident=4) 给出的正确答案是 0.296。因此,方法 2 比方法 1 准确得多。
一个直观的解释是,方法 1 中的指示变量之间存在更显著的依赖性。例如,如果已知学生 1, 2, 3, 4 出生在同一时段,这会极大地增加学生 1, 2, 3, 5 也出生在同一时段的概率。相比之下,知道某个特定的“日期-小时”内是否有至少 4 人,对于另一个特定的“日期-小时”内是否有至少 4 人提供的信息非常少。
4.8 泊松分布与二项分布的联系
Connections between Poisson and Binomial
泊松分布与二项分布之间有着紧密的联系,这种关系与我们在上一章中探讨的二项分布与超几何分布之间的关系完全对应:我们可以通过条件概率从泊松分布推导出二项分布,也可以通过取极限从二项分布推导出泊松分布。
这些结论依赖于一个事实:独立泊松随机变量之和仍服从泊松分布,正如独立二项随机变量之和仍服从二项分布(当成功概率 \(p\) 相同且试验总数相加时)。我们目前将利用全概率公式来证明这一结论;在第 6 章中,我们将学习一种利用“矩生成函数”的更快捷方法。
定理 4.8.1(独立泊松变量之和)。若 \(X \sim \text{Pois}(\lambda_1)\),\(Y \sim \text{Pois}(\lambda_2)\),且 \(X\) 与 \(Y\) 相互独立,则 \(X + Y \sim \text{Pois}(\lambda_1 + \lambda_2)\)。
证明:
为了得到 \(X+Y\) 的 PMF,我们对 \(X\) 进行条件化并使用全概率公式: \[ P(X + Y = k) = \sum_{j=0}^{k} P(X + Y = k | X = j) P(X = j) \]
\[ = \sum_{j=0}^{k} P(Y = k - j) P(X = j) \]
\[ = \sum_{j=0}^{k} \frac{e^{-\lambda_2} \lambda_2^{k-j}}{(k-j)!} \cdot \frac{e^{-\lambda_1} \lambda_1^j}{j!} \]
我们将常数项提取到求和符号外,并为了构造二项式展开式而乘以 \(\frac{k!}{k!}\): \[ = \frac{e^{-(\lambda_1 + \lambda_2)}}{k!} \sum_{j=0}^{k} \frac{k!}{j!(k-j)!} \lambda_1^j \lambda_2^{k-j} \]
\[ = \frac{e^{-(\lambda_1 + \lambda_2)}}{k!} \sum_{j=0}^{k} \binom{k}{j} \lambda_1^j \lambda_2^{k-j} \]
最后一步利用了二项式定理: \[ = \frac{e^{-(\lambda_1 + \lambda_2)} (\lambda_1 + \lambda_2)^k}{k!} \] 由于我们推导出了 \(\text{Pois}(\lambda_1 + \lambda_2)\) 的 PMF,因此证明了 \(X + Y \sim \text{Pois}(\lambda_1 + \lambda_2)\)。
直观解释:
泊松分布的“故事”为这一结果提供了直观理解。如果两种不同类型的事件分别以速率 \(\lambda_1\) 和 \(\lambda_2\) 独立发生,那么总事件的发生速率显然是 \(\lambda_1 + \lambda_2\)。
定理 4.8.2(给定泊松之和下的泊松分布)。若 \(X \sim \text{Pois}(\lambda_1)\),\(Y \sim \text{Pois}(\lambda_2)\),且 \(X\) 与 \(Y\) 相互独立,那么在已知 \(X + Y = n\) 的条件下,\(X\) 的条件分布为 \(\text{Bin}(n, \frac{\lambda_1}{\lambda_1 + \lambda_2})\)。
证明:
与前一章证明二项分布与超几何分布关系的方法完全相同,我们使用贝叶斯定理来计算条件 PMF \(P(X=k | X+Y=n)\): \[ P(X=k | X+Y=n) = \frac{P(X+Y=n | X=k)P(X=k)}{P(X+Y=n)} \]
\[ = \frac{P(Y=n-k)P(X=k)}{P(X+Y=n)} \]
现在我们将 \(X\)、\(Y\) 以及 \(X+Y\) 的 PMF 代入;根据前一条定理,已知 \(X+Y\) 服从 \(\text{Pois}(\lambda_1 + \lambda_2)\)。代入后得: \[ P(X=k | X+Y=n) = \frac{\frac{e^{-\lambda_2} \lambda_2^{n-k}}{(n-k)!} \cdot \frac{e^{-\lambda_1} \lambda_1^k}{j!}}{\frac{e^{-(\lambda_1 + \lambda_2)} (\lambda_1 + \lambda_2)^n}{n!}} \] 整理各项: \[ = \frac{n!}{k!(n-k)!} \cdot \frac{\lambda_1^k \lambda_2^{n-k}}{(\lambda_1 + \lambda_2)^n} \]
\[ = \binom{n}{k} \left( \frac{\lambda_1}{\lambda_1 + \lambda_2} \right)^k \left( \frac{\lambda_2}{\lambda_1 + \lambda_2} \right)^{n-k} \]
这正是 \(\text{Bin}(n, \frac{\lambda_1}{\lambda_1 + \lambda_2})\) 的 PMF,证毕。
直观理解(故事背景):
想象你正在观察两种类型的稀有事件(如:收到的垃圾邮件 \(X\) 和非垃圾邮件 \(Y\))。它们分别以速率 \(\lambda_1\) 和 \(\lambda_2\) 发生。如果你知道在过去的一个小时里总共收到了 \(n\) 封邮件,那么其中每一封邮件是垃圾邮件的概率就是 \(\lambda_1 / (\lambda_1 + \lambda_2)\),且每封邮件的类型相互独立。因此,垃圾邮件的总数自然服从二项分布。
相反地,如果我们让 \(\text{Bin}(n, p)\) 分布在 \(n \to \infty\) 且 \(p \to 0\) 的过程中保持 \(np\) 为定值,我们就会得到泊松分布。这为二项分布的泊松近似提供了数学基础。
定理 4.8.3(二项分布的泊松近似)。若 \(X \sim \text{Bin}(n, p)\),令 \(n \to \infty\) 且 \(p \to 0\),使得 \(\lambda = np\) 保持不变,则 \(X\) 的 PMF 收敛于 \(\text{Pois}(\lambda)\) 的 PMF。更广泛地说,只要 \(n \to \infty, p \to 0\) 且 \(np \to \lambda\)(常数),结论同样成立。
这是泊松范式的一个特例,即所有事件 \(A_j\) 相互独立且概率相等,因此 \(\sum_{j=1}^n I(A_j)\) 服从二项分布。在这种特殊情况下,我们可以直接通过对二项分布 PMF 取极限来证明泊松近似的合理性。
证明:
我们证明在 \(\lambda = np\) 固定,且 \(n \to \infty, p \to 0\) 的情况下,二项分布的 PMF 收敛于泊松分布的 PMF。对于 \(0 \le k \le n\): \[ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k} \]
\[ = \frac{n(n-1)\dots(n-k+1)}{k!} \left(\frac{\lambda}{n}\right)^k \left(1 - \frac{\lambda}{n}\right)^{n-k} \]
我们将各项重新排列: \[ = \frac{n(n-1)\dots(n-k+1)}{n^k} \cdot \frac{\lambda^k}{k!} \cdot \left(1 - \frac{\lambda}{n}\right)^n \cdot \left(1 - \frac{\lambda}{n}\right)^{-k} \] 当 \(k\) 固定且 \(n \to \infty\) 时:
- \(\frac{n(n-1)\dots(n-k+1)}{n^k} \to 1\)(因为分子是 \(k\) 个趋于 \(n\) 的项相乘)。
- \(\left(1 - \frac{\lambda}{n}\right)^n \to e^{-\lambda}\)(这源于数学附录 A.2.5 中的复利公式/极限定义)。
- \(\left(1 - \frac{\lambda}{n}\right)^{-k} \to 1^ {-k} = 1\)。
因此: \[ P(X = k) \to \frac{e^{-\lambda} \lambda^k}{k!} \] 这正是 \(\text{Pois}(\lambda)\) 的 PMF。
该定理意味着,如果 \(n\) 很大,\(p\) 很小,且 \(np\) 适中,我们可以用 \(\text{Pois}(np)\) 的 PMF 来近似 \(\text{Bin}(n, p)\) 的 PMF。这里最关键的一点是 \(p\) 应该很小;事实上,在泊松范式陈述后提到的结论指出,在这种情况下,对于 \(X \sim \text{Bin}(n, p)\) 和 \(N \sim \text{Pois}(np)\),使用 \(P(X \in B) \approx P(N \in B)\) 进行近似所产生的误差最大不超过 \(\min(p, np^2)\)。
例 4.8.4(网站访客)。某网站的所有者正在研究该网站访客人数的分布。每天有一百万人独立决定是否访问该网站,每人访问的概率为 \(p = 2 \times 10^{-6}\)。请给出某一天至少有三名访客的概率的一个良好近似值。
解答:
令 \(X \sim \text{Bin}(n, p)\) 为访客人数,其中 \(n = 10^6\)。由于 \(n\) 极大且 \(p\) 极小,在该分布的精确计算中很容易遇到计算困难或数值误差。但由于 \(n\) 很大,\(p\) 很小,且 \(np = 2\) 适中,因此 \(\text{Pois}(2)\) 是一个良好的近似。这给出: \[ P(X \ge 3) = 1 - P(X < 3) \approx 1 - e^{-2} - e^{-2} \cdot 2 - e^{-2} \cdot \frac{2^2}{2!} = 1 - 5e^{-2} \approx 0.3233 \] 事实证明该结果极其精确。
4.9 *利用概率和期望证明存在性
Using probability and expectation to prove existence
一个令人惊叹且优美的法则是,我们可以利用概率和期望来证明具有我们所关心的属性的对象的存在性。这种技术被称为概率方法(probabilistic method),它基于两个简单但出人意料地强大的想法。假设我想证明在一个集合中存在一个具有某种属性的对象。这种诉求起初似乎与概率毫无关系;我大可以逐一检查集合中的每个对象,直到找到一个具有所需属性的对象为止。
概率方法拒绝了这种艰苦的检查,转而采用随机选择:我们的策略是从集合中随机抽取一个对象,并证明该随机对象具有所需属性的概率为正。请注意,我们并不需要计算出准确的概率,而仅仅需要证明它大于 0。如果我们能证明该属性成立的概率为正,那么我们就知道一定存在一个具有该属性的对象——即使我们不知道如何明确地构造出这样一个对象。
同样地,假设每个对象都有一个得分,而我想证明存在一个具有“好”得分的对象——即得分超过特定阈值的对象。我们同样通过选择一个随机对象并考虑其得分 \(X\) 来进行。我们知道集合中一定存在一个对象,其得分至少为 \(E(X)\)——因为不可能每个对象都低于平均水平!如果 \(E(X)\) 已经是一个好的得分,那么集合中也一定存在一个具有好得分的对象。因此,我们可以通过证明平均得分已经很好,来证明存在一个具有好得分的对象。
让我们正式地阐述这两个核心理念:
- 可能性原理(The possibility principle):令 \(A\) 为集合中随机选择的对象具有某种属性的事件。如果 \(P(A) > 0\),则存在一个具有该属性的对象。
- 好分原理(The good score principle):令 \(X\) 为随机选择对象的得分。如果 \(E(X) \ge c\),则存在一个得分至少为 \(c\) 的对象。
为了理解为什么可能性原理是正确的,可以考虑其逆否命题:如果没有对象具有所需的属性,那么随机选择的对象具有该属性的概率就是 0。同样地,好分原理的逆否命题是“如果所有对象的得分都低于 \(c\),那么平均得分就低于 \(c\)”,这是正确的,因为小于 \(c\) 的数字的加权平均值必然是一个小于 \(c\) 的数。
概率方法并没有告诉我们如何找到一个具有所需属性的对象;它只是向我们保证了这样的对象一定存在。
例 4.9.1。一组 100 人被分配到 15 个规模为 20 人的委员会中,使得每个人在 3 个委员会中任职。证明存在 2 个委员会,它们至少共有 3 名成员。
解答:
在这种情况下,采用直接方法是不可取的:人们必须列出所有可能的委员会分配方案,并针对每种方案计算每对委员会中共有的成员人数。概率方法让我们能够绕过这种暴力计算。
为了证明存在两个重叠人数至少为三人的委员会,我们将计算在任意委员会分配方案中,随机选择两个委员会时的平均重叠人数。因此,随机选择两个委员会,令 \(X\) 为同时属于这两个委员会的人数。我们可以将 \(X\) 表示为 \(X = I_1 + I_2 + \dots + I_{100}\),其中如果第 \(j\) 个人同时在两个委员会中,则 \(I_j = 1\),否则为 \(0\)。基于对称性,所有指示变量具有相同的期望值,因此 \(E(X) = 100 E(I_1)\),我们只需要求出 \(E(I_1)\)。
根据基本桥梁(fundamental bridge),\(E(I_1)\) 是第 1 个人(我们称他为鲍勃)同时在两个委员会(我们称之为 A 和 B)中的概率。计算这个概率有多种方法;一种方法是将鲍勃所在的委员会看作是 15 只麋鹿种群中的 3 只被标记的麋鹿。那么 A 和 B 就是从中抽取的 2 只麋鹿的无放回样本。利用 \(HGeom(3, 12, 2)\) 的 PMF,这两只麋鹿都被标记(即两个委员会都包含鲍勃)的概率为: \[ \frac{\binom{3}{2} \binom{12}{0}}{\binom{15}{2}} = \frac{3}{105} = \frac{1}{35} \] 因此, \[ E(X) = \frac{100}{35} = \frac{20}{7} \] 这个数值略低于我们期望的“好分数” 3。但希望并未破灭!好分原理指出,存在两个重叠人数至少为 \(20/7\) 的委员会,但由于两个委员会之间的重叠人数必须是整数,重叠人数至少为 \(20/7\) 意味着重叠人数至少为 3。因此,存在两个至少共有 3 名成员的委员会。
4.9.1 *在噪声信道上的通信
Communicating over a noisy channel
概率方法的另一个主要应用是在信息论中,该学科研究(除其他事项外)如何跨越有噪声的信道实现可靠通信。考虑在存在噪声时尝试发送消息的问题。数百万人每天都会遇到这个问题,例如在拨打电话时(你可能会被听错)。假设你想要发送的消息表示为一个二进制向量 \(x \in \{0, 1\}^k\),并且你希望使用一种编码(code)来提高消息成功传输的几率。
定义 4.9.2(编码与速率)。给定正整数 \(k\) 和 \(n\),编码是一个函数 \(c\),它为每个输入消息 \(x \in \{0, 1\}^k\) 分配一个码字 \(c(x) \in \{0, 1\}^n\)。该编码的速率(rate)为 \(k/n\)(即每个输出位对应的输入位数)。在发送 \(c(x)\) 后,解码器获取接收到的消息(这可能是 \(c(x)\) 的受损版本),并尝试恢复出正确的 \(x\)。
例如,一种显而易见的编码是重复多次,连续发送 \(x\) 若干次,假设发送 \(m\) 次(\(m\) 为奇数);这被称为重复码。接收者随后可以通过“少数服从多数”的方式进行解码,例如,如果 \(x\) 的第一位接收到的 1 比 0 多,则将其解码为 1。但这种编码可能非常低效;为了让失败概率变得非常小,你可能需要重复非常多次,导致通信速率 \(1/m\) 变得非常低。
信息论的创始人克劳德·香农(Claude Shannon)展示了一些令人惊叹的结论:即使在噪声非常大的信道中,也存在一种编码,能够以一个不随失败概率降低而趋于 0 的速率实现非常可靠的通信。他的证明过程更加惊人:他研究了一个完全随机编码的性能。曾与香农在贝尔实验室共事的理查德·汉明(Richard Hamming)这样描述香农的方法:
“勇气是那些成就伟业者的另一个特质。香农就是一个很好的例子。有一段时间,他会在上午 10:00 左右来上班,下棋直到下午 2:00,然后回家。
重点在于他是如何下棋的。当受到攻击时,他很少(如果有的话)防守自己的阵地,而是反击。这种下棋方法很快就会产生一个非常错综复杂的棋局。然后他会停顿一下,思考,推进他的皇后并说道:‘我什么都不怕。’ 我花了一段时间才意识到,这正是他能够证明优良编码方法存在的原因。除了香农,还有谁会想到对所有随机编码取平均值,并期望发现平均值接近理想状态呢?我从他那里学会了在陷入困境时对自己说同样的话,在某些情况下,他的方法使我获得了重大的研究成果。” [15]
我们将证明香农结论的一个版本,即针对发送的每一位都以概率 \(p\) 独立发生翻转(从 0 变 1 或从 1 变 0)的信道。首先我们需要两个定义。衡量二进制向量之间距离的一种自然度量是汉明距离(以汉明命名):
定义 4.9.3(汉明距离 Hamming distance)。对于两个长度相同的二进制向量 \(v\) 和 \(w\),汉明距离 \(d(v,w)\) 是它们在相应位置上取值不同的个数。我们可以将其写为: \[ d(v,w) = \sum_{i} |v_i - w_i| \] 以下函数在信息论中极其频繁地出现。
定义 4.9.4(二进制熵函数)。对于 \(0 < p < 1\),二进制熵函数 \(H\) 的表达式为: \[ H(p) = -p \log_2 p - (1-p) \log_2(1-p) \] 我们还定义 \(H(0) = H(1) = 0\)。
在信息论中,\(H(p)\) 的含义是观察一个 \(\text{Bern}(p)\) 随机变量所能获得的平均信息量;\(H(1/2) = 1\) 表示一次公平的硬币投掷提供 1 位的消息量,而 \(H(1) = 0\) 表示如果硬币总是正面朝上,那么被告知投掷结果时并没有获得任何信息,因为我们已经预知了结果。
现在考虑一个每位都以概率 \(p\) 独立翻转的信道。直观上,似乎 \(p\) 越小越好,但请注意 \(p=1/2\) 实际上是最糟糕的情况。在这种情况下(技术上称为“无用信道”),跨越信道发送信息是不可能的:输出将独立于输入!类比来说,在决定是否看某部电影时,你更愿意听取一个总是和你意见相左的人的评论,还是听取一个只有一半时间和你意见一致的人的评论?我们现在证明,对于 \(0 < p < 1/2\),可以以非常接近 \(1-H(p)\) 的速率进行极其可靠的通信。
定理 4.9.5(香农定理 Shannon)。考虑一个每位传输位都以概率 \(p\) 独立翻转的信道。令 \(0 < p < 1/2\) 且 \(\epsilon > 0\)。存在一种速率至少为 \(1 - H(p) - \epsilon\) 的编码,其解码错误概率小于 \(\epsilon\)。
证明:我们可以假设 \(1 - H(p) - \epsilon > 0\),否则对速率没有约束。令 \(n\) 为一个很大的正整数(根据下文给出的条件选择),且 \[ k = \lceil n(1 - H(p) - \epsilon) \rceil + 1 \] 这里使用向上取整函数是因为 \(k\) 必须是整数。选择 \(p' \in (p, 1/2)\) 使得 \(|H(p') - H(p)| < \epsilon/2\)(由于 \(H\) 是连续的,这是可以做到的)。现在我们研究一个随机编码 \(C\) 的性能。为了生成随机编码 \(C\),我们需要为所有可能的输入消息 \(x\) 生成随机的加密消息 \(C(x)\)。
对于每个 \(x \in \{0, 1\}^k\),选择 \(C(x)\) 为 \(\{0, 1\}^n\) 中的均匀随机向量(独立地进行这些选择)。因此我们可以将 \(C(x)\) 看作是由 \(n\) 个独立同分布(i.i.d.)的 \(\text{Bern}(1/2)\) 随机变量组成的向量。根据定义,速率 \(k/n\) 超过了 \(1 - H(p) - \epsilon\),但让我们看看解码接收到的消息的效果如何!
令 \(x \in \{0, 1\}^k\) 为输入消息,\(C(x)\) 为加密消息,\(Y \in \{0, 1\}^n\) 为接收到的消息。目前,将 \(x\) 视为确定的。但 \(C(x)\) 是随机的,因为码字是随机选择的;\(Y\) 也是随机的,因为 \(C(x)\) 是随机的,且信道中存在随机噪声。直观上,我们希望 \(C(x)\) 与 \(Y\) 在汉明距离上接近,而对于所有 \(z \neq x\),\(C(z)\) 与 \(Y\) 远离,在这种情况下,如何解码 \(Y\) 将会非常清晰,且解码会成功。为了精确起见,按如下方式解码 \(Y\):
如果存在唯一的 \(z \in \{0, 1\}^k\) 使得 \(d(C(z), Y) \le np'\),则将 \(Y\) 解码为该 \(z\);否则,宣布解码失败。
我们将证明,对于足够大的 \(n\),解码器无法恢复正确 \(x\) 的概率小于 \(\epsilon\)。有两种可能出错的情况:
\(d(C(x), Y) > np'\),或者
存在某个“冒充者” \(z \neq x\) 使得 \(d(C(z), Y) \le np'\)。
注意 \(d(C(x), Y)\) 是一个随机变量,因此 \(d(C(x), Y) > np'\) 是一个事件。为了处理 (a),将其表示为: \[ d(C(x), Y) = B_1 + \dots + B_n \sim \text{Bin}(n, p) \] 其中 \(B_i\) 是第 \(i\) 位被翻转的指示变量。大数定律(见第 10 章)指出,随着 \(n\) 的增大,随机变量 \(d(C(x), Y)/n\) 将非常接近于 \(p\)(其期望值),因此极不可能超过 \(p'\): \[ P\left( \frac{B_1 + \dots + B_n}{n} > p' \right) \to 0 \quad \text{当 } n \to \infty \] 因此,通过选择足够大的 \(n\),我们可以使: \[ P(d(C(x), Y) > np') < \epsilon/4 \] 为了处理 (b),注意对于 \(z \neq x\),\(d(C(z), Y) \sim \text{Bin}(n, 1/2)\),因为 \(C(z)\) 中的 \(n\) 位是独立同分布的 \(\text{Bern}(1/2)\),且独立于 \(Y\)(为了更详细地证明这一点,可以使用全概率公式对 \(Y\) 取条件)。令 \(B \sim \text{Bin}(n, 1/2)\)。根据布尔不等式: \[ P(z \neq x \text{ 中存在某个 } z \text{ 使得 } d(C(z), Y) \le np') \le (2^k - 1)P(B \le np') \] 为了简化符号,假设 \(np'\) 是一个整数。对一个包含 \(m\) 项的求和进行上界估计的一种粗略方法是使用 \(m\) 乘以其中最大的一项;而对二项式系数 \(\binom{n}{j}\) 进行上界估计的一种粗略方法是对于任何 \(r \in (0,1)\) 使用 \(r^{-j}(1-r)^{-(n-j)}\)。结合这两种粗略方法: \[ P(B \le np') = \frac{1}{2^n} \sum_{j=0}^{np'} \binom{n}{j} \le \frac{np'+1}{2^n} \binom{n}{np'} \le (np'+1) 2^{nH(p')-n} \] 这里利用了事实:对于 \(q'=1-p'\),有 \((p')^{-np'}(q')^{-nq'} = 2^{nH(p')}\)。因此, \[ 2^k P(B \le np') \le (np'+1) 2^{n(1-H(p)-\epsilon)+2+n(H(p)+\epsilon/2)-n} = 4(np'+1) 2^{-n\epsilon/2} \to 0 \] 所以我们可以选择 \(n\) 使得 \(P(d(C(z), Y) \le np' \text{ 对于某些 } z \neq x) < \epsilon/4\)。
假设 \(k\) 和 \(n\) 已按照上述要求选定,令 \(F(c, x)\) 为使用编码 \(c\) 处理输入消息 \(x\) 时发生失败的事件。综合以上结果,我们已经证明了对于随机编码 \(C\) 和任何固定的 \(x\): \[ P(F(C, x)) < \epsilon/2 \] 由此可知,对于每个 \(x\),都存在一个编码 \(c\) 使得 \(P(F(c, x)) < \epsilon/2\)。但这还不够:我们需要一个对所有 \(x\) 都表现良好的编码!令 \(X\) 为 \(\{0,1\}^k\) 中均匀随机选择的输入消息,且独立于 \(C\)。根据全概率公式(LOTP),我们有: \[ P(F(C, X)) = \sum_x P(F(C, x)) P(X=x) < \epsilon/2 \] 再次利用全概率公式,但这次对 \(C\) 取条件,我们有: \[ \sum_c P(F(c, X)) P(C=c) = P(F(C, X)) < \epsilon/2 \] 因此,存在一个编码 \(c\) 使得 \(P(F(c, X)) < \epsilon/2\),即对于一个随机输入消息 \(X\),该编码 \(c\) 的失败概率小于 \(\epsilon/2\)。最后,我们将改进 \(c\),从而获得一个对所有 \(x\)(而不只是随机的 \(x\))都表现良好的编码。我们通过剔除(expurgating)最差的 50% 的 \(x\) 来实现这一点。也就是说,从合法输入消息中删除对于编码 \(c\) 而言失败概率最高的 \(2^{k-1}\) 个 \(x\) 值。对于所有剩余的 \(x\),我们有 \(P(F(c, x)) < \epsilon\),否则超过一半的 \(x \in \{0,1\}^k\) 的失败概率将超过平均失败概率的两倍(参见第 10 章中关于马尔可夫不等式的类似论证)。通过使用 \(\{0,1\}^{k-1}\) 中的向量对剩余的 \(x\) 重新标记,我们获得了一个编码 \(c' : \{0,1\}^{k-1} \to \{0,1\}^n\),其速率为 \((k-1)/n \ge 1-H(p)-\epsilon\),且对于 \(\{0,1\}^{k-1}\) 中的所有输入消息,失败概率均小于 \(\epsilon\)。
上述定理还有一个逆定理,证明了如果我们要求速率至少为 \(1-H(p) + \epsilon\),那么就不可能找到使错误概率任意小的编码。这就是为什么 \(1-H(p)\) 被称为该信道的信道容量(capacity)。香农还针对更一般的信道获得了类似的结果。这些结果给出了理论上的性能极限,但没有明确说明该使用哪些编码。随后数十年的工作一直致力于开发在实践中表现良好的特定编码,这些编码通过接近香农极限并允许高效的编解码来实现。
4.10 本章小结
离散随机变量 \(X\) 的期望为: \[ E(X) = \sum_{x} xP(X=x) \] 另一种等价的、“未分组”的期望计算方法是: \[ E(X) = \sum_{s} X(s)P(\{s\}) \] 其中求和是在样本空间中的每个样本点(pebbles)上进行的。期望是一个总结分布质量中心的单一数值。而总结分布离散程度的单一数值是方差,其定义为: \[ Var(X) = E(X-EX)^2 = E(X^2)-(EX)^2 \] 方差的平方根被称为标准差。
期望具有线性性质: \[ E(cX) = cE(X) \quad \text{且} \quad E(X+Y) = E(X) + E(Y) \] 无论 \(X\) 和 \(Y\) 是否独立,该性质均成立。方差则不具有线性性质: \[ Var(cX) = c^2Var(X) \] 且通常情况下: \[ Var(X+Y) \neq Var(X) + Var(Y) \] (一个重要的例外是当 \(X\) 和 \(Y\) 相互独立时)。
计算离散随机变量 \(X\) 期望的一个非常重要的策略是将其表示为指示随机变量之和,然后应用线性性质和基本桥梁。由于指示随机变量不需要相互独立,且线性性质对相关随机变量依然成立,因此这一技术特别强大。该策略可以概括为以下三个步骤:
- 将随机变量 \(X\) 表示为指示随机变量之和。在决定如何定义指示变量时,思考 \(X\) 统计的是什么。例如,如果 \(X\) 是局部极大值的数量(如 Putnam 数学竞赛题中所示),那么我们应该为每一个可能出现的局部极大值创建一个指示变量。
- 利用基本桥梁计算每个指示变量的期望值。在适用时,对称性在此阶段会非常有帮助。
- 根据期望的线性性质,通过将所有指示变量的期望相加来得到 \(E(X)\)。
另一个计算期望的工具是 LOTUS(无意识统计学家法则),它指出我们可以仅利用 \(X\) 的 PMF 来计算 \(g(X)\) 的期望,即: \[ E(g(X)) = \sum_{x} g(x)P(X=x) \]
如果 \(g\) 是非线性的,那么试图通过交换 \(E\) 和 \(g\) 的位置来计算 \(E(g(X))\) 是一个严重的错误。
我们的列表新增了四个离散分布:几何分布(Geometric)、负二项分布(Negative Binomial)、负超几何分布(Negative Hypergeometric)和泊松分布(Poisson)。\(\text{Geom}(p)\) 随机变量是在独立伯努利试验序列(成功概率为 \(p\))中,第一次成功之前的失败次数;而 \(\text{NBin}(r, p)\) 随机变量是第 \(r\) 次成功之前的失败次数。负超几何分布与负二项分布类似,不同之处在于:从瓮中抽球时,负超几何分布采用无放回抽样,而负二项分布采用有放回抽样。(我们还介绍了首成分布,它只是几何分布的平移,即将成功的那次也计入在内。)
泊松随机变量通常用于近似在存在许多独立或弱相关的试验,且每次试验成功概率都很小时,发生的成功次数。在二项分布的背景中,所有试验都有相同的成功概率 \(p\);但在泊松近似中,不同的试验可以有不同(但很小)的成功概率 \(p_j\)。
泊松分布、二项分布和超几何分布通过条件化和取极限的操作相互联系,如图 4.8 所示。在本书的后续部分,我们将继续介绍新的命名分布并将其加入到这个家族树中,直到所有内容都联系在一起!
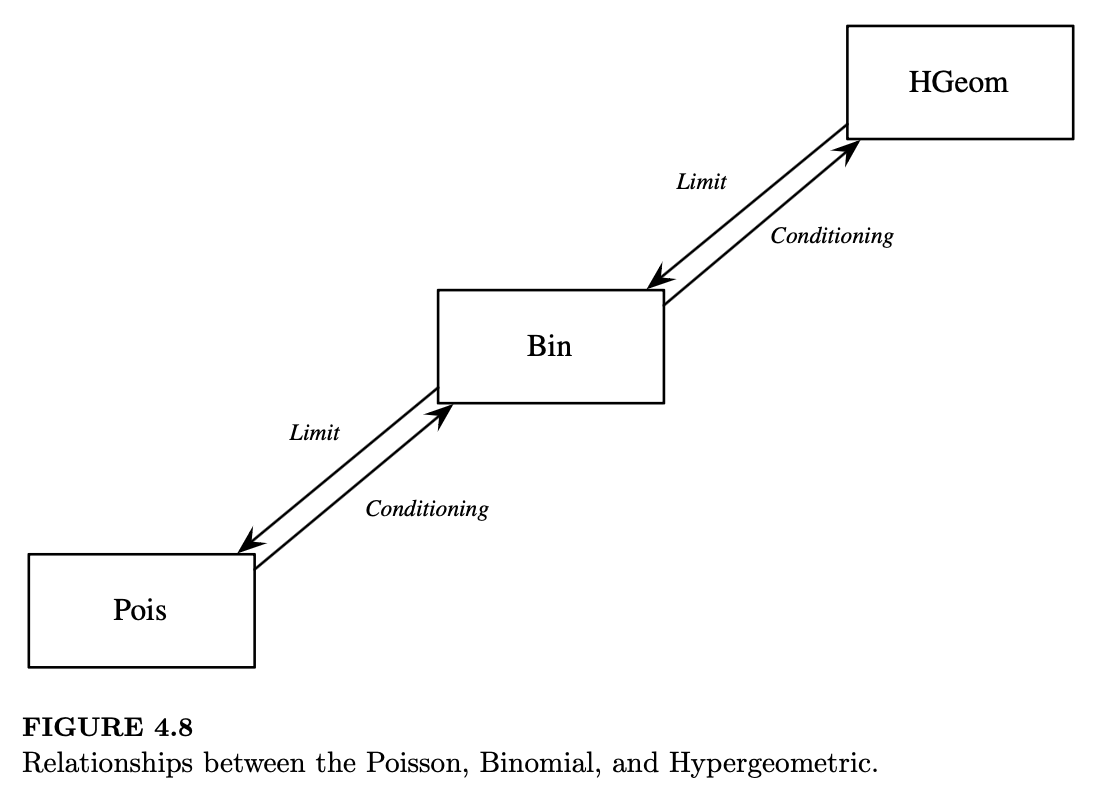
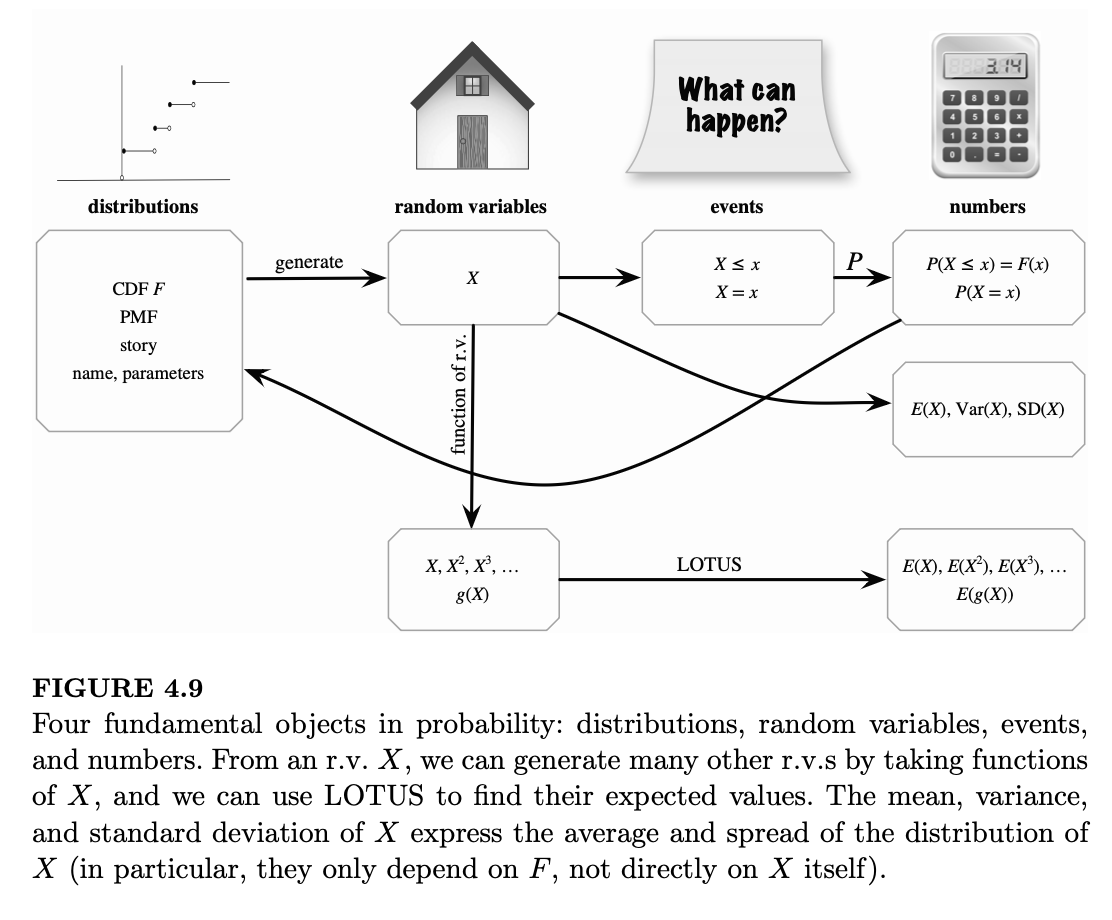
图 4.9 在前一章相应图示的基础上进行了扩展,进一步探讨了我们所考虑的四个基本对象之间的联系:分布、随机变量、事件和数值。
4.11 R 语言操作
几何分布、负二项分布与泊松分布
R 中用于几何分布的三个函数是 dgeom、pgeom 和 rgeom,分别对应 PMF、CDF 和随机数生成。对于 dgeom 和 pgeom,我们需要提供以下输入:(1) 用于评估 PMF 或 CDF 的值,以及 (2) 参数 \(p\)。对于 rgeom,我们需要输入 (1) 要生成的随机变量个数,以及 (2) 参数 \(p\)。
例如,要计算 \(X \sim \text{Geom}(0.5)\) 时 \(P(X = 3)\) 和 \(P(X \le 3)\) 的值,我们分别使用 dgeom(3, 0.5) 和 pgeom(3, 0.5)。要生成 100 个独立同分布的 \(\text{Geom}(0.8)\) 随机变量,我们使用 rgeom(100, 0.8)。如果想要 100 个独立同分布的 \(\text{FS}(0.8)\)(首成分布)随机变量,只需加 1 以包含成功的那次:rgeom(100, 0.8) + 1。
对于负二项分布,我们有 dnbinom、pnbinom 和 rnbinom。这些函数需要三个输入。例如,要计算 \(\text{NBin}(5, 0.5)\) 在 3 处的 PMF 值,输入 dnbinom(3, 5, 0.5)。
最后,对于泊松分布,三个函数分别是 dpois、ppois 和 rpois。它们需要两个输入。例如,要求 \(\text{Pois}(10)\) 在 2 处的 CDF 值,输入 ppois(2, 10)。
匹配问题的模拟
延续例 4.4.4,让我们使用模拟来计算一副牌中匹配数量的期望值。与第 1 章一样,令 \(n\) 为牌数,并使用 replicate 进行 \(10^4\) 次实验。
R
1 | n <- 100 |
现在 r 包含了 \(10^4\) 次模拟中每一次的匹配数量。但这次我们不再像第 1 章那样观察至少有一个匹配的概率,而是要求匹配数量的期望值。我们可以通过所有模拟结果的平均值(即 r 中元素的算术平均数)来近似。这可以通过 mean 函数实现:
R
1 | mean(r) |
命令 mean(r) 等价于 sum(r) / length(r)。我们得到的结果非常接近 1,这证实了我们在例 4.4.4 中使用指示随机变量进行的计算。你可以验证,无论选择多大的 \(n\),mean(r) 都会非常接近 1。
不同生日数量的模拟
让我们通过模拟来计算 \(k\) 个人中不同生日数量的期望值。我们令 \(k = 20\),但你也可以选择任何你喜欢的 \(k\) 值。
R
1 | k <- 20 |
在第二行中,replicate 将大括号内的表达式重复执行 \(10^4\) 次,所以我们只需要理解大括号内的内容。首先,我们从 1 到 365 之间进行 \(k\) 次有放回抽样,并将这些结果作为 \(k\) 个人的生日 bdays。然后,unique(bdays) 移除向量 bdays 中的重复项,length(unique(bdays)) 计算移除重复项后的向量长度。这两个命令需要用分号分隔。
现在 r 包含了在 \(10^4\) 次模拟中每次观察到的不同生日数量。这 \(10^4\) 次模拟中不同生日数量的平均值即为 mean(r)。我们可以将模拟值与例 4.4.5 中利用指示随机变量得到的理论值进行比较:
R
1 | mean(r) |
当我们运行这些代码时,模拟值和理论值都给出了大约 19.5。
书籍各章的机翻md文件:
《Introduction to Probability》前言
《Introduction to Probability》第1章 概率与计数
《Introduction to Probability》第 2 章 条件概率
《Introduction to Probability》第3章 随机变量及其分布
《Introduction to Probability》第4章 期望
《Introduction to Probability》第5章 连续随机变量
《Introduction to Probability》第 6 章 矩
《Introduction to Probability》第7 章 联合分布
《Introduction to Probability》第8章 变换
《Introduction to Probability》第9章 条件期望
《Introduction to Probability》第10章 不等式与极限理论
《Introduction to Probability》第11章 马尔可夫链
《Introduction to Probability》第12章 马尔可夫链蒙特卡罗
《Introduction to Probability》第13章 泊松过程