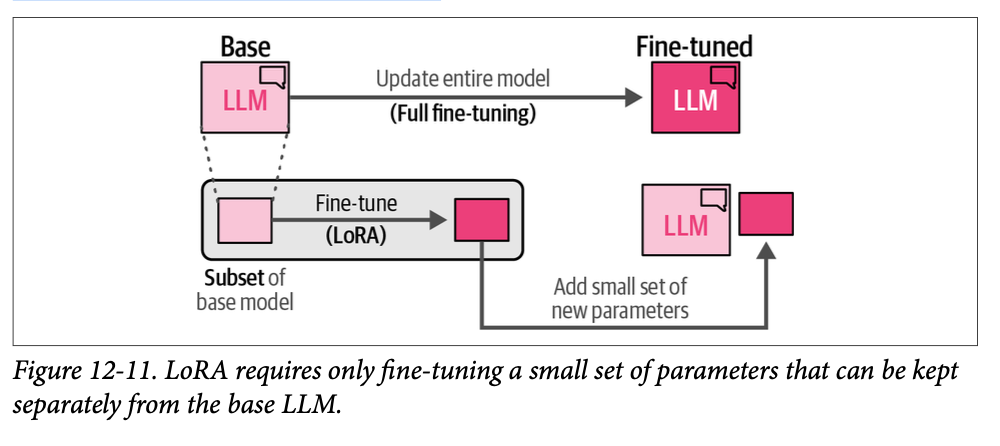
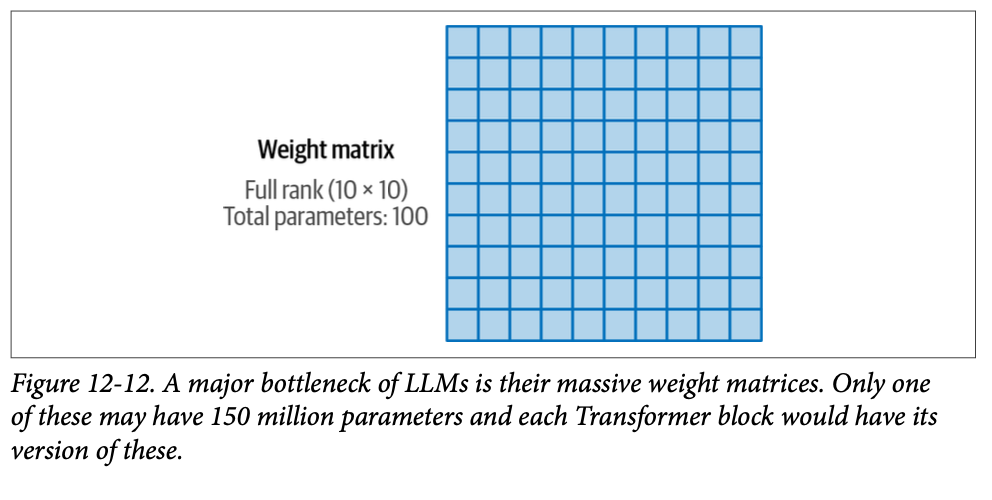
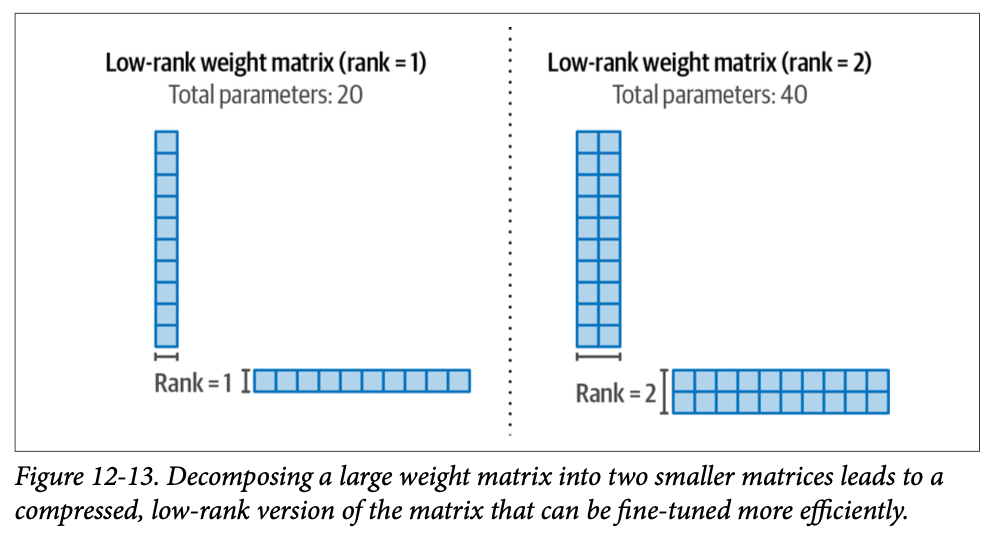
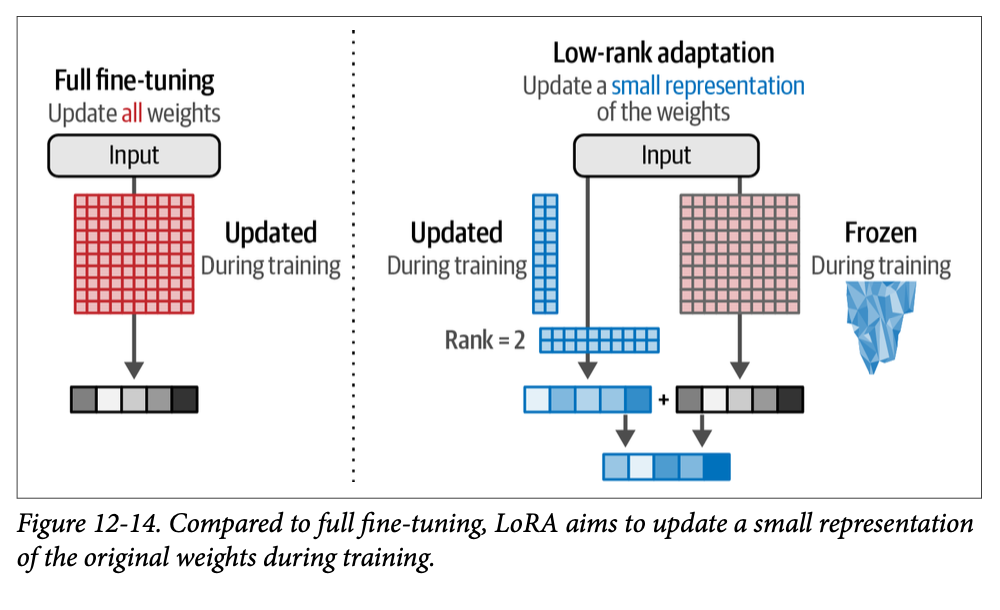
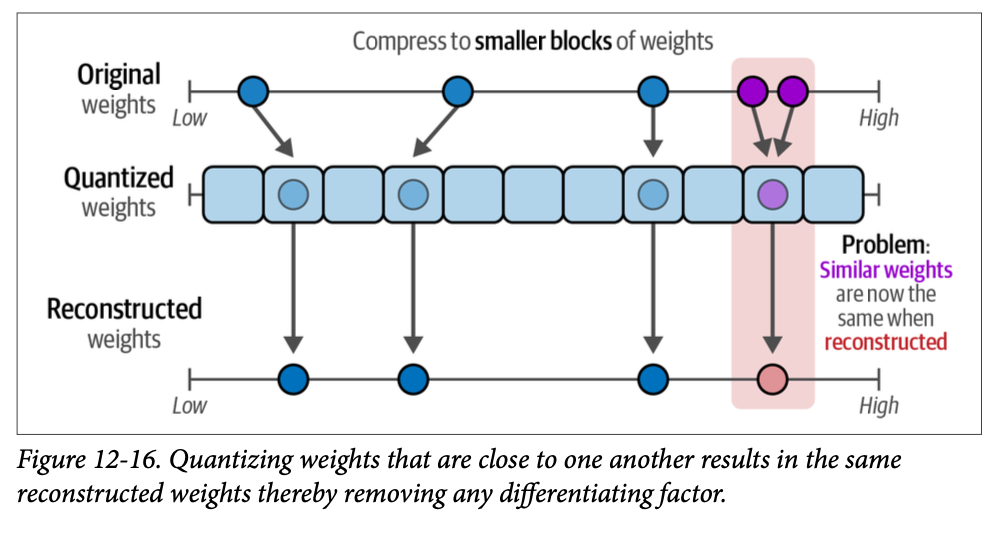
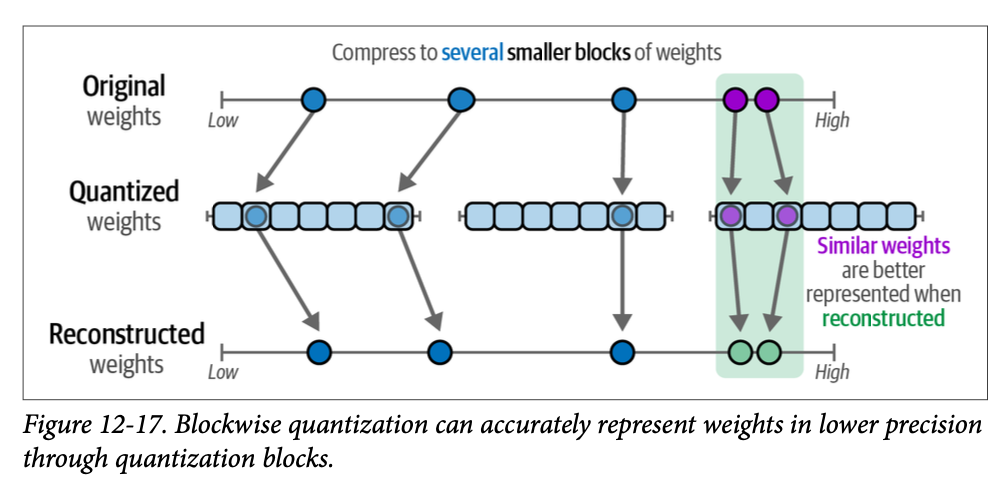
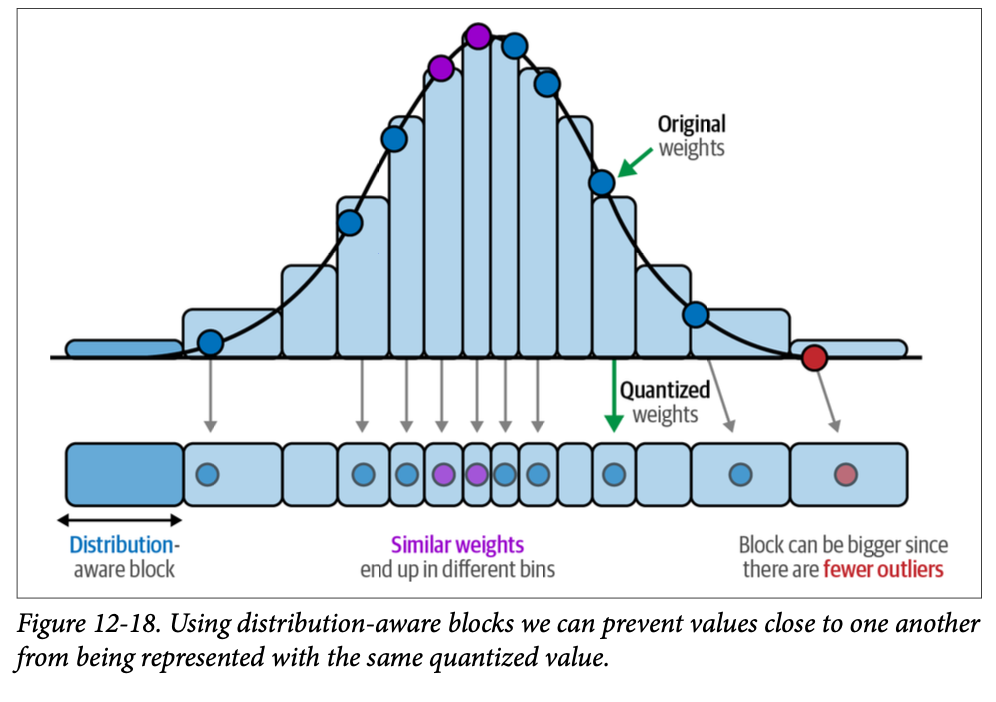
While a monolithic agent architecture can be effective for well-defined problems, its capabilities are often constrained when faced with complex, multi-domain tasks. The Multi-Agent Collaboration pattern addresses these limitations by structuring a system as a cooperative ensemble of distinct, specialized agents. This approach is predicated on the principle of task decomposition, where a high-level objective is broken down into discrete sub-problems. Each sub-problem is then assigned to an agent possessing the specific tools, data access, or reasoning capabilities best suited for that task.
Intelligent behavior often involves more than just reacting to the immediate input. It requires foresight, breaking down complex tasks into smaller, manageable steps, and strategizing how to achieve a desired outcome. This is where the Planning pattern comes into play. At its core, planning is the ability for an agent or a system of agents to formulate a sequence of actions to move from an initial state towards a goal state.
Chapter 5: Tool Use (Function Calling) | 第五章:工具使用(函数调用)
Tool Use Pattern Overview | 工具使用模式概述
So far, we've discussed agentic patterns that primarily involve orchestrating interactions between language models and managing the flow of information within the agent's internal workflow (Chaining, Routing, Parallelization, Reflection). However, for agents to be truly useful and interact with the real world or external systems, they need the ability to use Tools.
In the preceding chapters, we've explored fundamental agentic patterns: Chaining for sequential execution, Routing for dynamic path selection, and Parallelization for concurrent task execution. These patterns enable agents to perform complex tasks more efficiently and flexibly. However, even with sophisticated workflows, an agent's initial output or plan might not be optimal, accurate, or complete. This is where the Reflection pattern comes into play.
In the previous chapters, we've explored Prompt Chaining for sequential workflows and Routing for dynamic decision-making and transitions between different paths. While these patterns are essential, many complex agentic tasks involve multiple sub-tasks that can be executed simultaneously rather than one after another. This is where the Parallelization pattern becomes crucial.
While sequential processing via prompt chaining is a foundational technique for executing deterministic, linear workflows with language models, its applicability is limited in scenarios requiring adaptive responses. Real-world agentic systems must often arbitrate between multiple potential actions based on contingent factors, such as the state of the environment, user input, or the outcome of a preceding operation. This capacity for dynamic decision-making, which governs the flow of control to different specialized functions, tools, or sub-processes, is achieved through a mechanism known as routing.
Prompt chaining, sometimes referred to as Pipeline pattern, represents a powerful paradigm for handling intricate tasks when leveraging large language models (LLMs). Rather than expecting an LLM to solve a complex problem in a single, monolithic step, prompt chaining advocates for a divide-and-conquer strategy. The core idea is to break down the original, daunting problem into a sequence of smaller, more manageable sub-problems. Each sub-problem is addressed individually through a specifically designed prompt, and the output generated from one prompt is strategically fed as input into the subsequent prompt in the chain.
论文《AdapterHub: A framework for adapting transformers》引入了 \(\text{Adapter Hub}\) 作为共享适配器的中央存储库。许多早期的适配器更侧重于 \(\text{BERT}\) 架构。最近,这个概念已被应用于文本生成 \(\text{Transformer}\) 模型中,例如论文《LLaMA-Adapter: Efficient fine-tuning of language models with zero-init attention》。
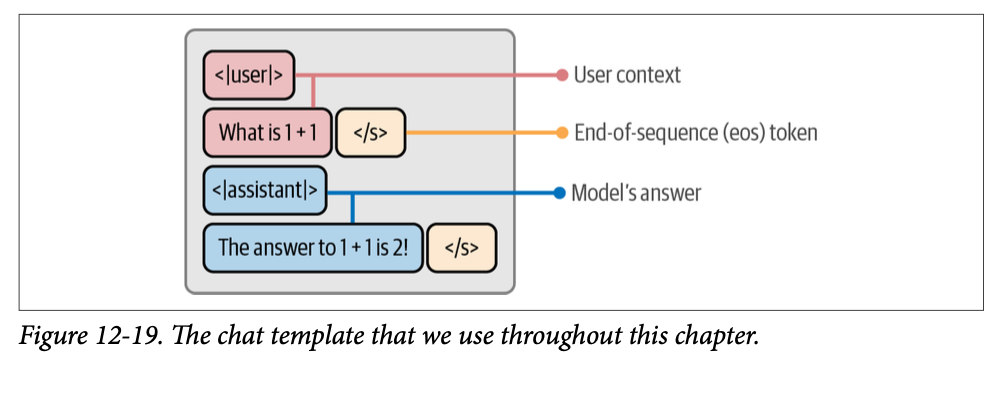
from transformers import AutoTokenizer from datasets import load_dataset # Load a tokenizer to use its chat template template_tokenizer = AutoTokenizer.from_pretrained( "TinyLlama/TinyLlama-1.1BChat-v1.0" ) defformat_prompt(example): """Format the prompt to using the <|user|> template TinyLLama is using""" # Format answers chat = example["messages"] prompt = template_tokenizer.apply_chat_template(chat, tokenize=False) return {"text": prompt} # Load and format the data using the template TinyLLama is using dataset = ( load_dataset("HuggingFaceH4/ultrachat_200k", split="test_sft") .shuffle(seed=42) .select(range(3_000)) ) dataset = dataset.map(format_prompt)
# Example of formatted prompt print(dataset["text"][2576]) <|user|> Given the text: Knock, knock. Who's there? Hike. Can you continue the joke based on the given text material "Knock, knock. Who's there? Hike"?</s> <|assistant|> Sure! Knock, knock. Who's there? Hike. Hike who? Hike up your pants, it's cold outside!</s> <|user|> Can you tell me another knock-knock joke based on the same text material "Knock, knock. Who's there? Hike"?</s> <|assistant|> Of course! Knock, knock. Who's there? Hike. Hike who? Hike your way over here and let's go for a walk!</s>
from peft import AutoPeftModelForCausalLM model = AutoPeftModelForCausalLM.from_pretrained( "TinyLlama-1.1B-qlora", low_cpu_mem_usage=True, device_map="auto", ) # Merge LoRA and base model merged_model = model.merge_and_unload()
将适配器与基础模型合并后,我们就可以使用我们之前定义的提示模板来使用它:
1 2 3 4 5 6 7 8 9
from transformers import pipeline # Use our predefined prompt template prompt = """<|user|> Tell me something about Large Language Models.</s> <|assistant|> """ # Run our instruction-tuned model pipe = pipeline(task="text-generation", model=merged_model, tokenizer=tokenizer) print(pipe(prompt)[0]["generated_text"])
1 2 3
Large Language Models (LLMs) are artificial intelligence (AI) models that learn language and understand what it means to say things in a particular language. They are trained on huge amounts of text…
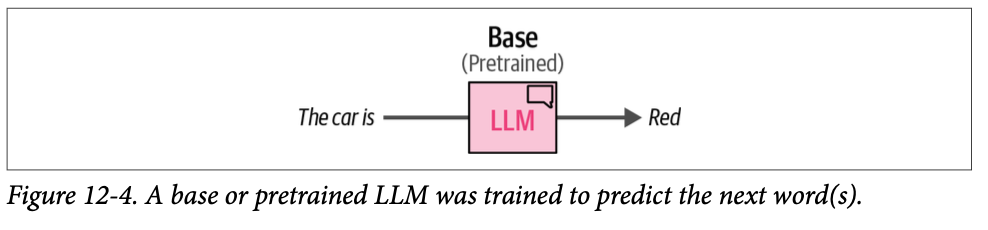
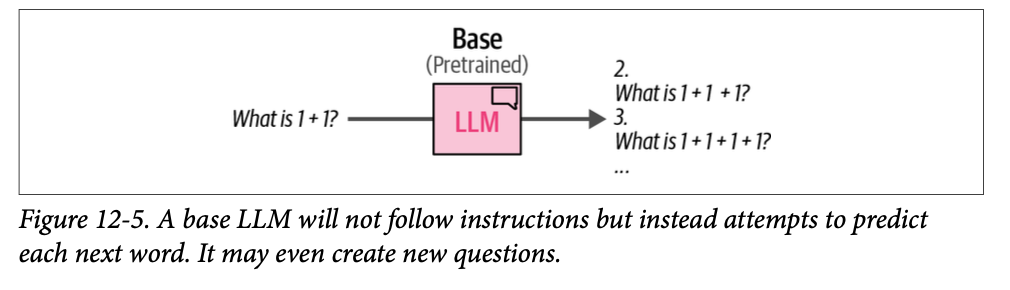
在 \(\text{LLM}\) 的背景下,当使用特定的基准测试时,我们倾向于为该基准测试进行优化,而不顾后果。例如,如果我们纯粹专注于优化生成语法正确的句子,模型可能会学会只输出一个句子:“\(\text{This is a sentence.}\)”(这是一个句子。)它在语法上是正确的,但没有告诉你任何关于其语言理解能力的信息。因此,模型可能擅长某个特定的基准测试,但可能会牺牲其他有用的能力。
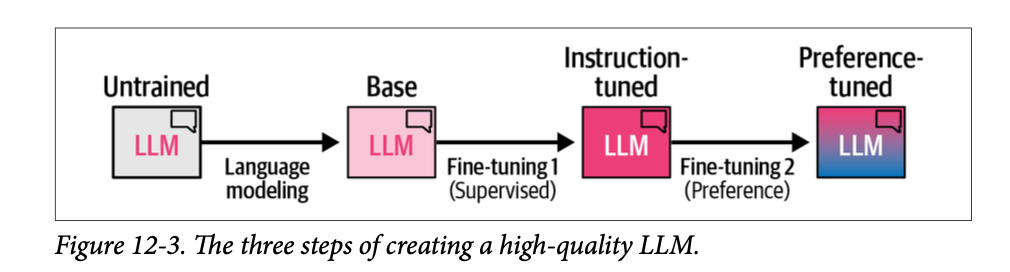
偏好调整/对齐/强化学习自人类反馈
Preference-Tuning / Alignment / RLHF
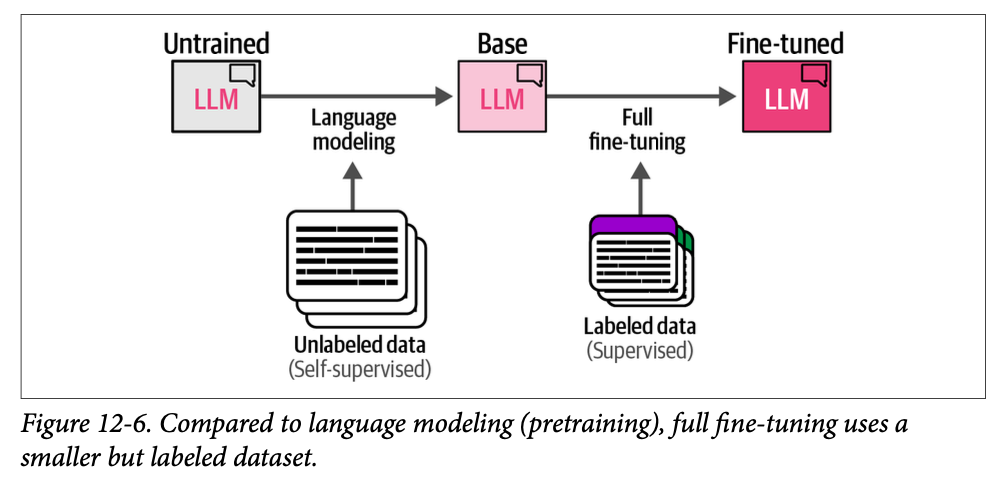
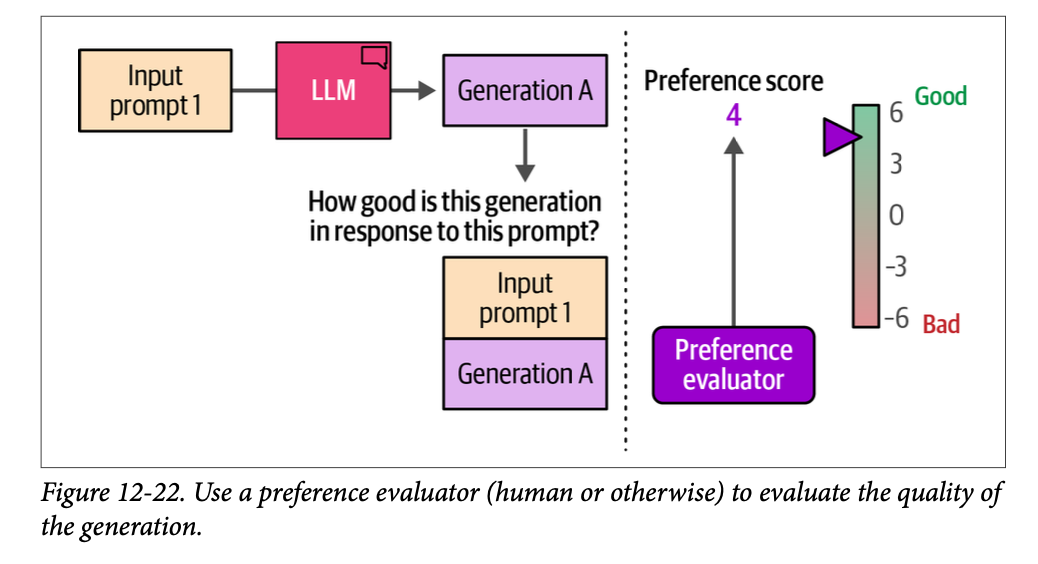
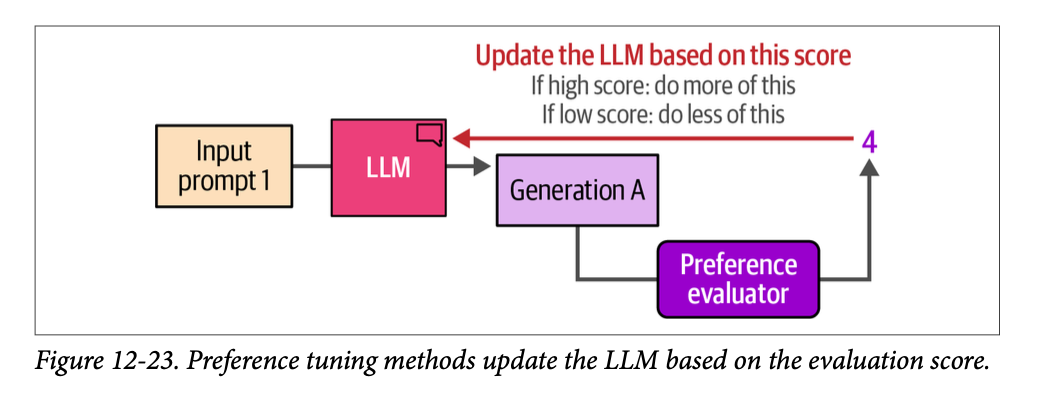
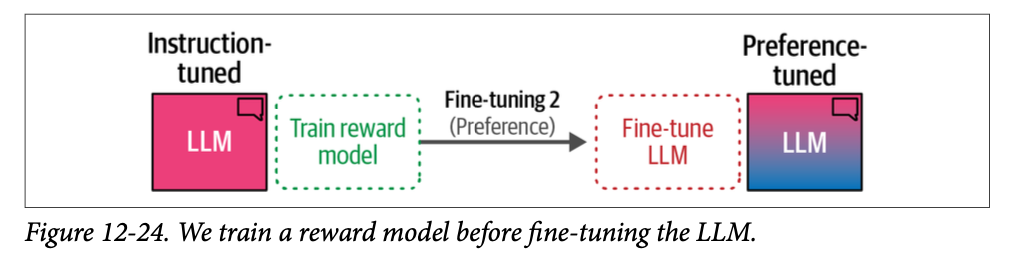
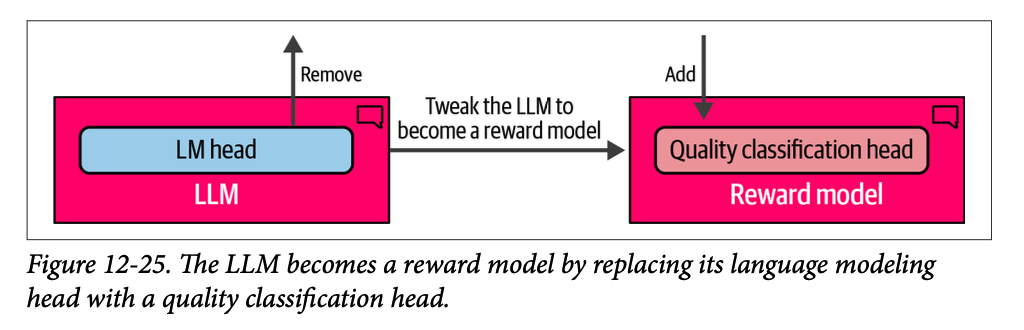
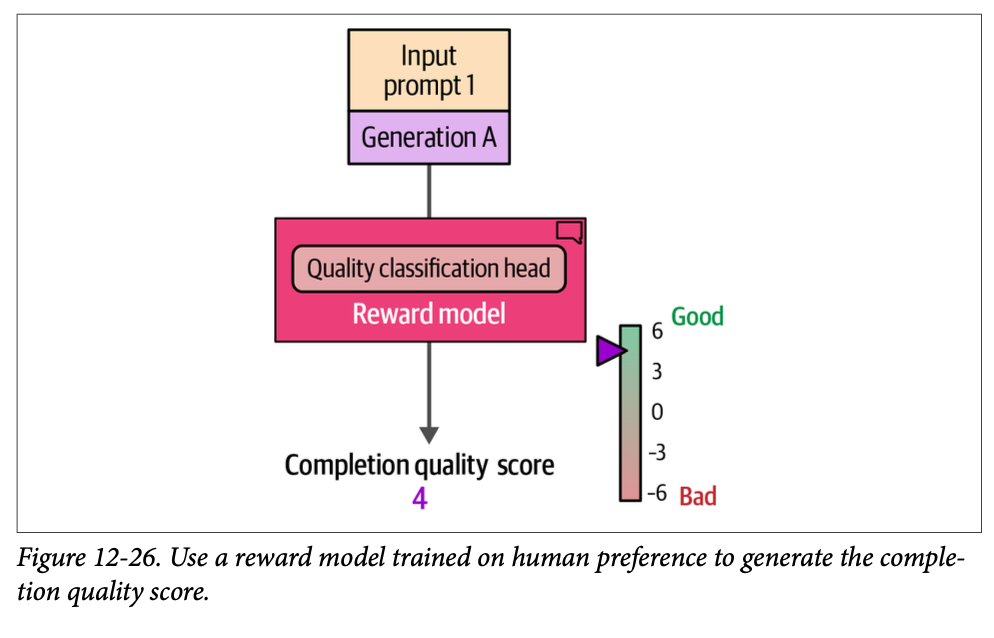
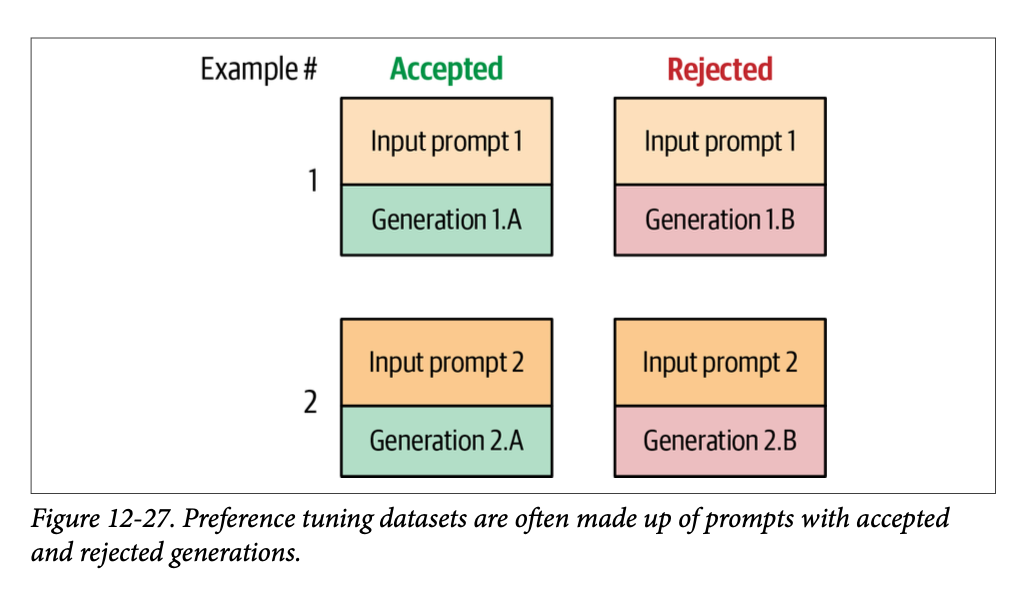
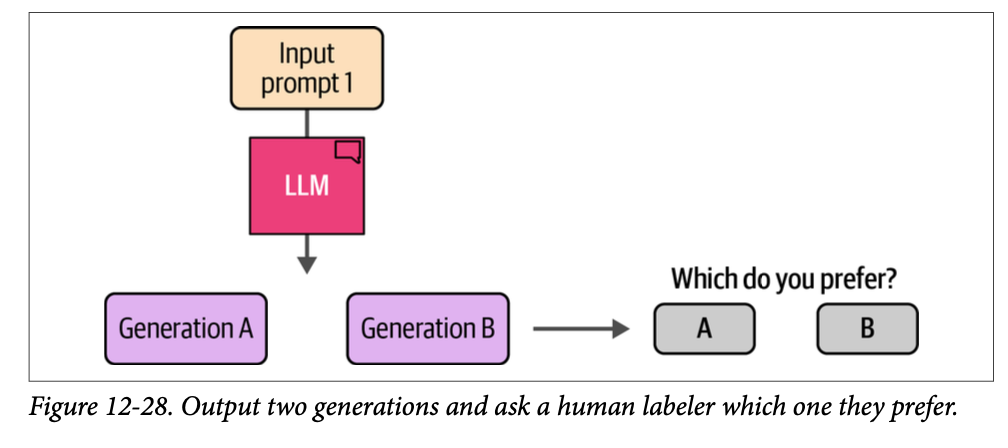
尽管我们的模型现在可以遵循指令,但我们可以通过最后的训练阶段进一步改进其行为,使其与我们期望它在不同场景下的行为保持一致。例如,当被问到“\(\text{What is an LLM?}\)”(什么是 \(\text{LLM}\)?)时,我们可能更喜欢一个详细描述 \(\text{LLM}\) 内部结构的答案,而不是没有进一步解释的“\(\text{It is a large language model}\)”(它是一个大型语言模型)这样的答案。我们究竟如何将我们(人类)对一个答案的偏好(优于另一个答案)与 \(\text{LLM}\) 的输出对齐呢?
from transformers import AutoTokenizer, AutoModelForSequenceClassification # Load model and tokenizer model_id = "bert-base-cased" model = AutoModelForSequenceClassification.from_pretrained( model_id, num_labels=2 ) tokenizer = AutoTokenizer.from_pretrained(model_id)
接下来,我们将对数据进行词元化(\(\text{tokenize}\)):
1 2 3 4 5 6 7 8 9
from transformers import DataCollatorWithPadding # Pad to the longest sequence in the batch data_collator = DataCollatorWithPadding(tokenizer=tokenizer) defpreprocess_function(examples): """Tokenize input data""" return tokenizer(examples["text"], truncation=True) # Tokenize train/test data tokenized_train = train_data.map(preprocess_function, batched=True) tokenized_test = test_data.map(preprocess_function, batched=True)
# Load model and tokenizer model = AutoModelForSequenceClassification.from_pretrained( model_id, num_labels=2 ) tokenizer = AutoTokenizer.from_pretrained(model_id)
from transformers import TrainingArguments, Trainer # Trainer which executes the training process trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_train, eval_dataset=tokenized_test, tokenizer=tokenizer, data_collator=data_collator, compute_metrics=compute_metrics, ) trainer.train()
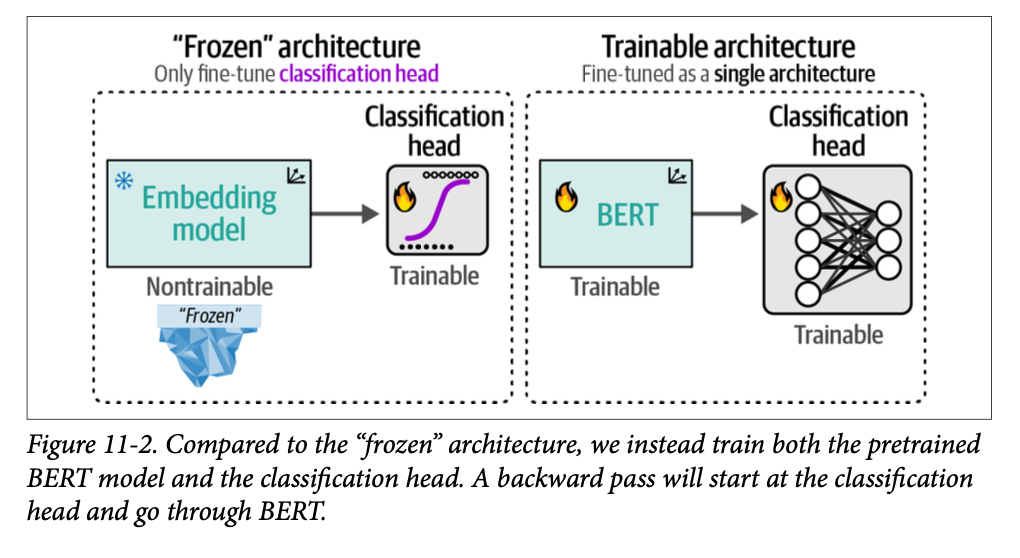
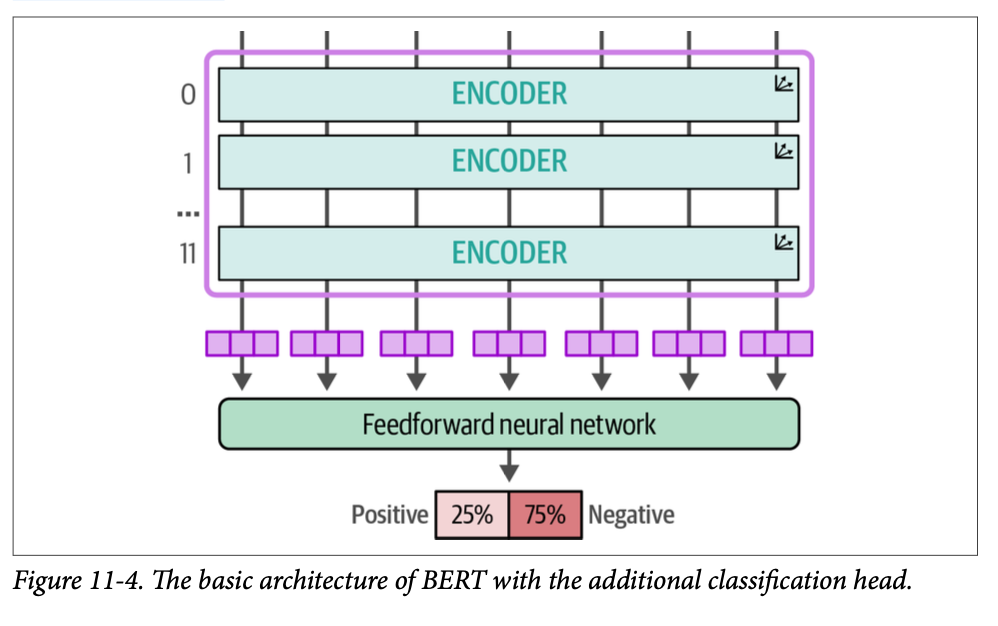
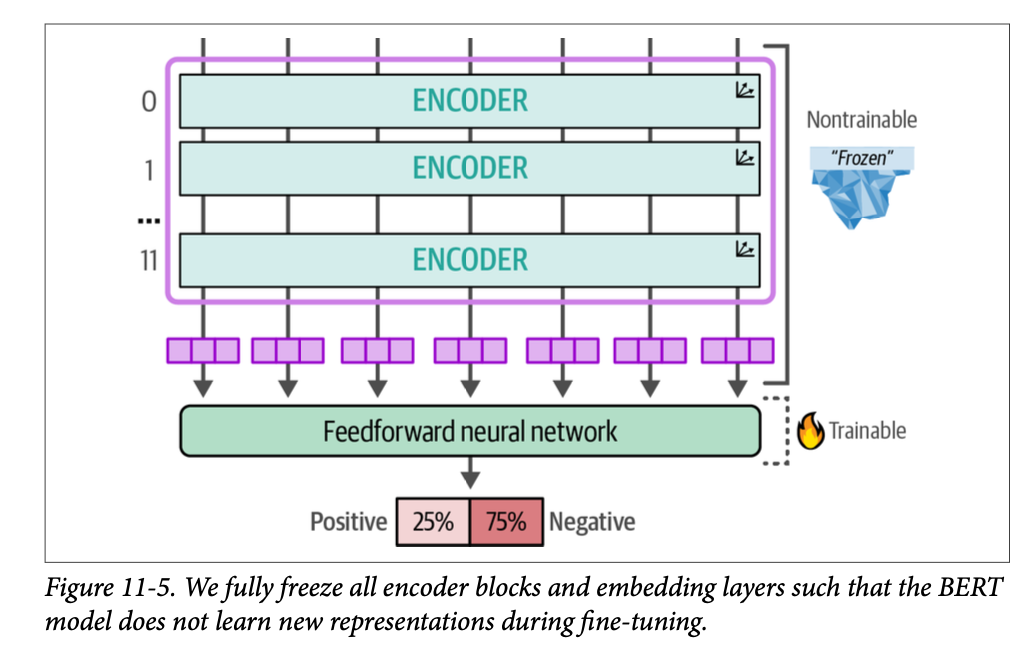
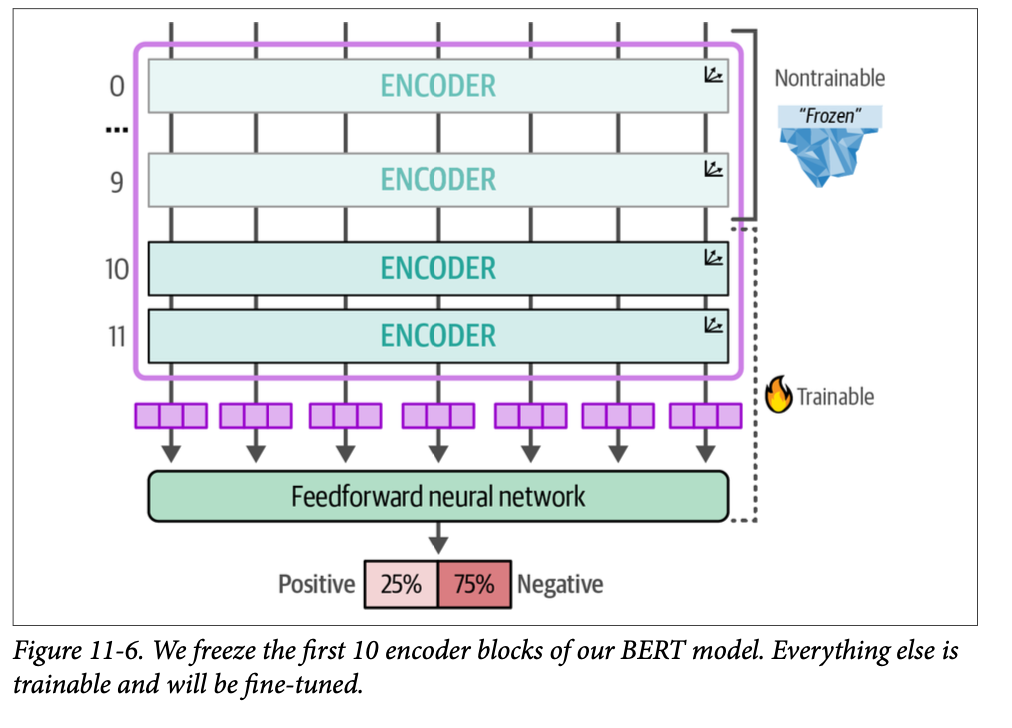
# Load model model_id = "bert-base-cased" model = AutoModelForSequenceClassification.from_pretrained( model_id, num_labels=2 ) tokenizer = AutoTokenizer.from_pretrained(model_id) # Encoder block 11 starts at index 165 and # we freeze everything before that block for index, (name, param) inenumerate(model.named_parameters()): if index < 165: param.requires_grad = False # Trainer which executes the training process trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_train, eval_dataset=tokenized_test,
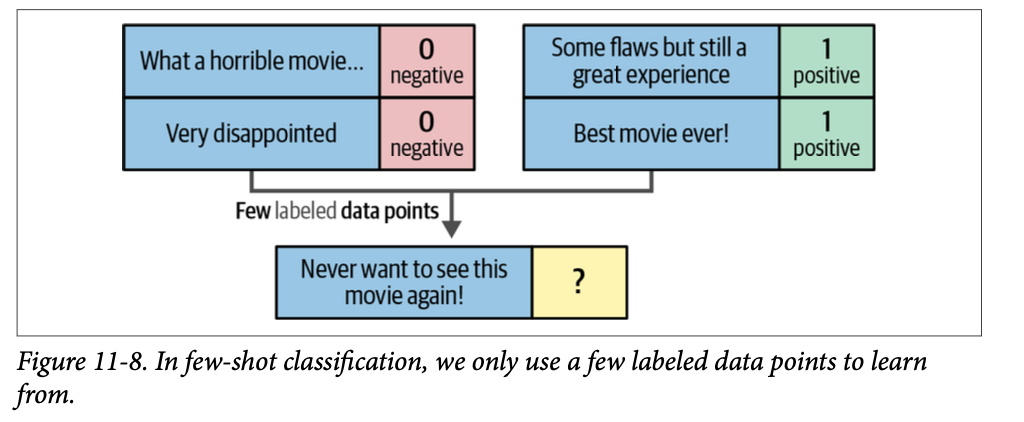
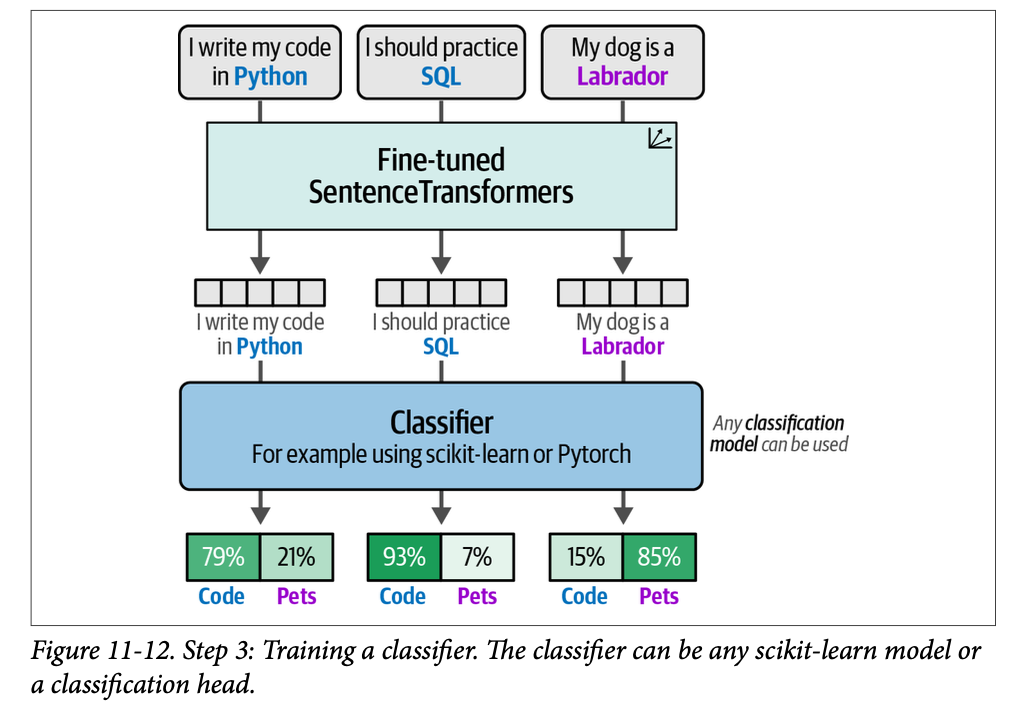
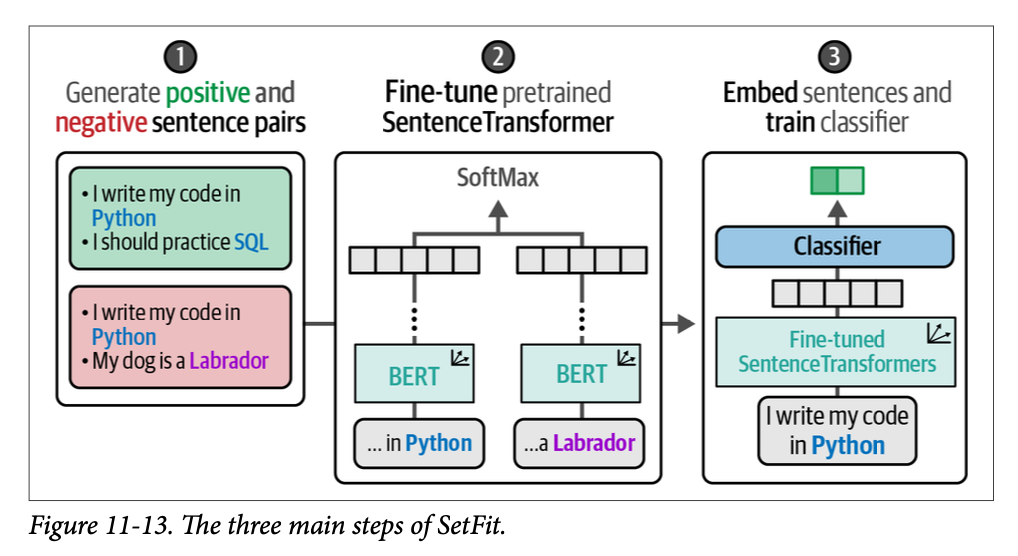
from setfit import sample_dataset # We simulate a few-shot setting by sampling 16 examples per class sampled_train_data = sample_dataset(tomatoes["train"], num_samples=16)
from setfit import SetFitModel # Load a pretrained SentenceTransformer model model = SetFitModel.from_pretrained("sentence-transformers/all-mpnet-base-v2")
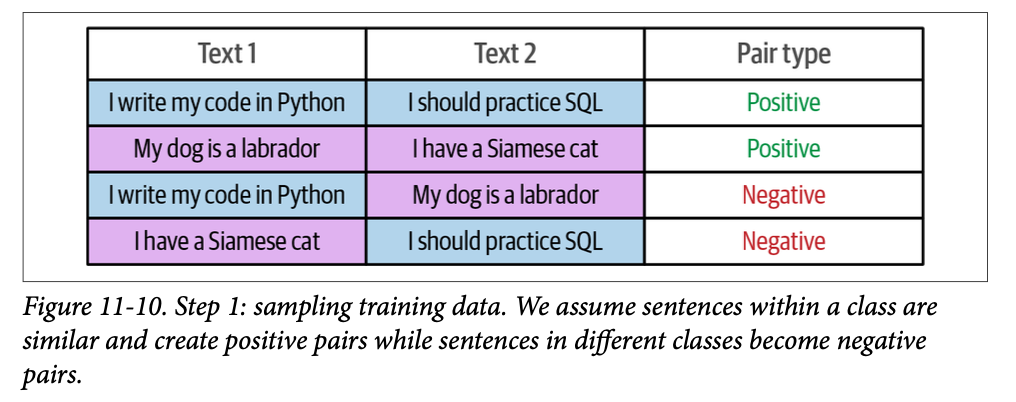
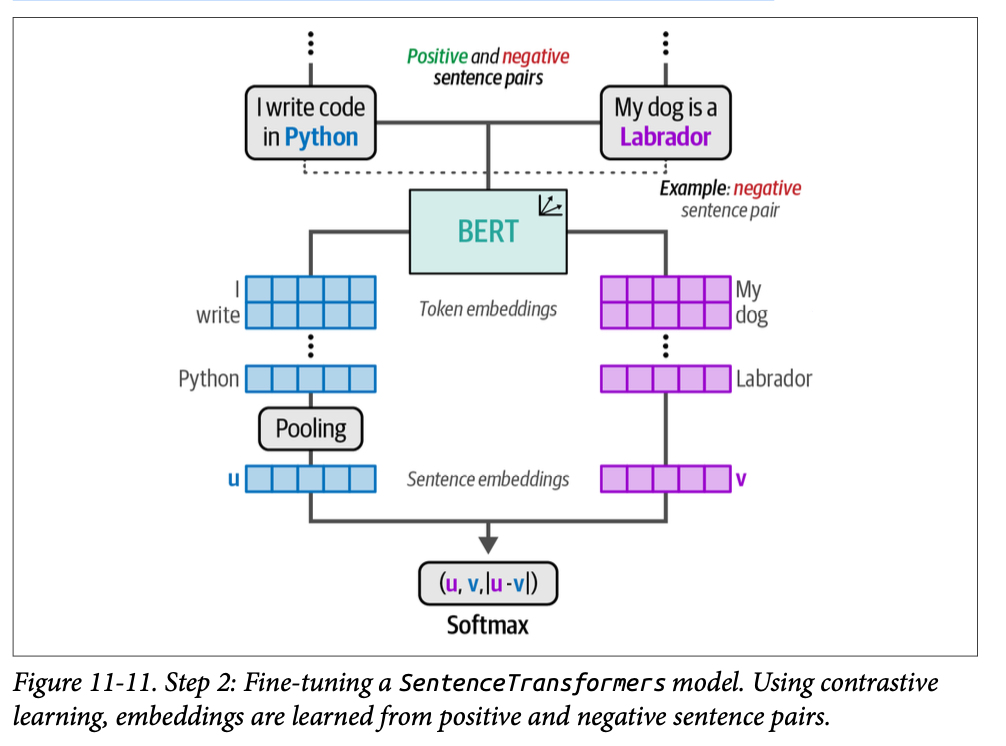
from setfit import TrainingArguments as SetFitTrainingArguments from setfit import Trainer as SetFitTrainer # Define training arguments args = SetFitTrainingArguments( num_epochs=3, # The number of epochs to use for contrastive learning num_iterations=20# The number of text pairs to generate ) args.eval_strategy = args.evaluation_strategy # Create trainer trainer = SetFitTrainer( model=model, args=args, train_dataset=sampled_train_data, eval_dataset=test_data, metric="f1" )
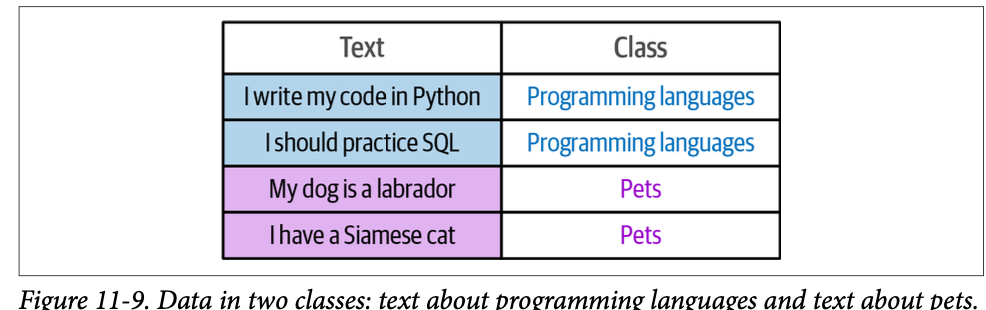
\(\text{SetFit}\)不仅可以执行少样本分类任务,它还支持您完全没有标签的情况,这也被称为零样本分类 (\(\text{zero-shot classification}\))。\(\text{SetFit}\) 从标签名称中生成合成示例,以模拟分类任务,然后在其上训练一个 \(\text{SetFit}\) 模型。例如,如果目标标签是“\(\text{happy}\)”和“\(\text{sad}\)”,那么合成数据可以是“\(\text{The example is happy}\)”和“\(\text{This example is sad}\)”。
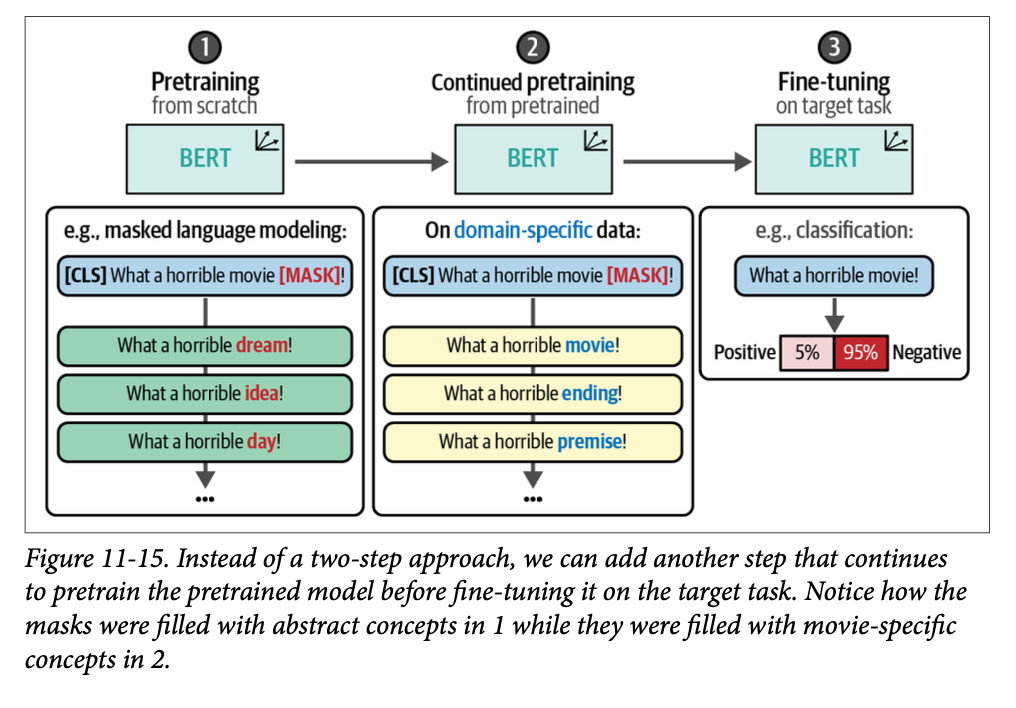
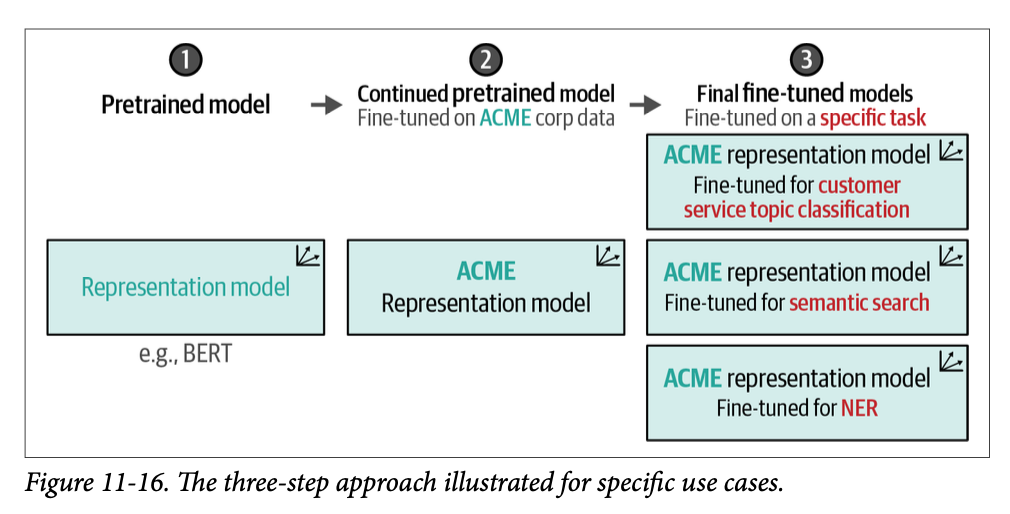
使用掩码语言建模进行持续预训练
Continued Pretraining with Masked Language Modeling
from transformers import AutoTokenizer, AutoModelForMaskedLM # Load model for masked language modeling (MLM) model = AutoModelForMaskedLM.from_pretrained("bert-base-cased") tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
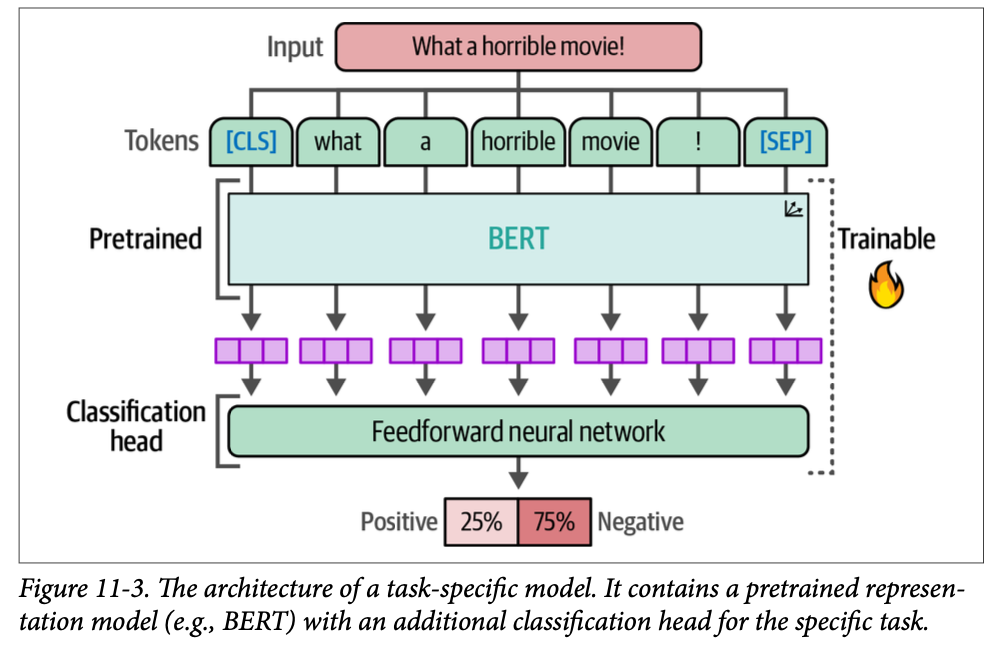
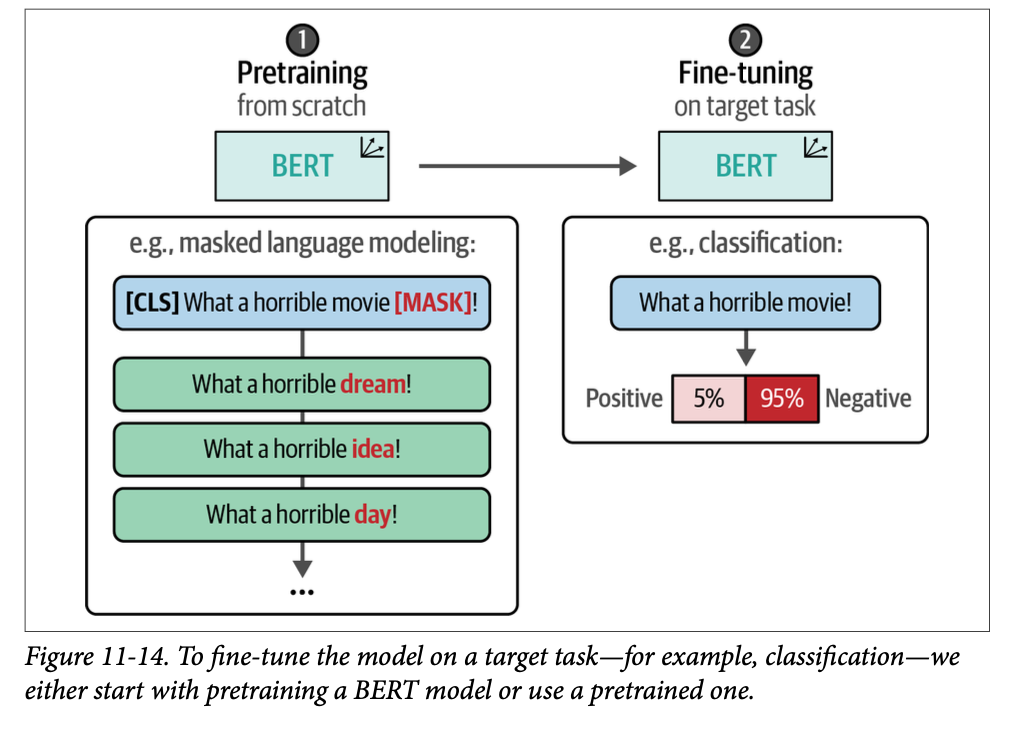
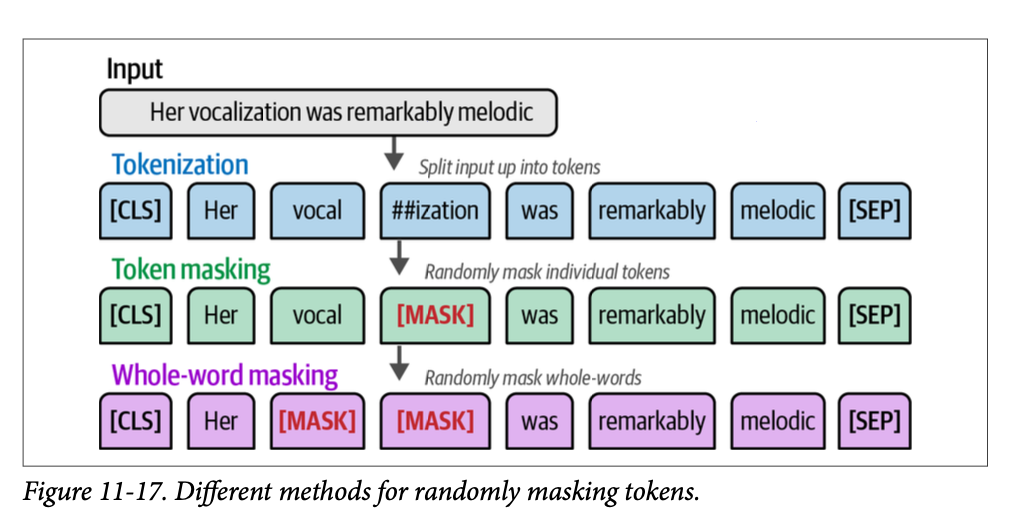
我们将通过加载在我们继续预训练之前的预训练模型来完成此操作。使用句子 “\(\text{What a horrible [MASK]!}\)” 模型将预测哪个词将取代 \(\text{[MASK]}\):
1 2 3 4 5 6 7 8 9 10 11 12
from transformers import pipeline # Load and create predictions mask_filler = pipeline("fill-mask", model="bert-base-cased") preds = mask_filler("What a horrible [MASK]!") # Print results for pred in preds: print(f">>> {pred["sequence"]}") >>> What a horrible idea! >>> What a horrible dream! >>> What a horrible thing! >>> What a horrible day! >>> What a horrible thought!
# Load and create predictions mask_filler = pipeline("fill-mask", model="mlm") preds = mask_filler("What a horrible [MASK]!") # Print results for pred in preds: print(f">>> {pred["sequence"]}") >>> What a horrible movie! >>> What a horrible film! >>> What a horrible mess! >>> What a horrible comedy! >>> What a horrible story!
from transformers import AutoModelForSequenceClassification # Fine-tune for classification model = AutoModelForSequenceClassification.from_pretrained("mlm", num_labels=2) tokenizer = AutoTokenizer.from_pretrained("mlm")
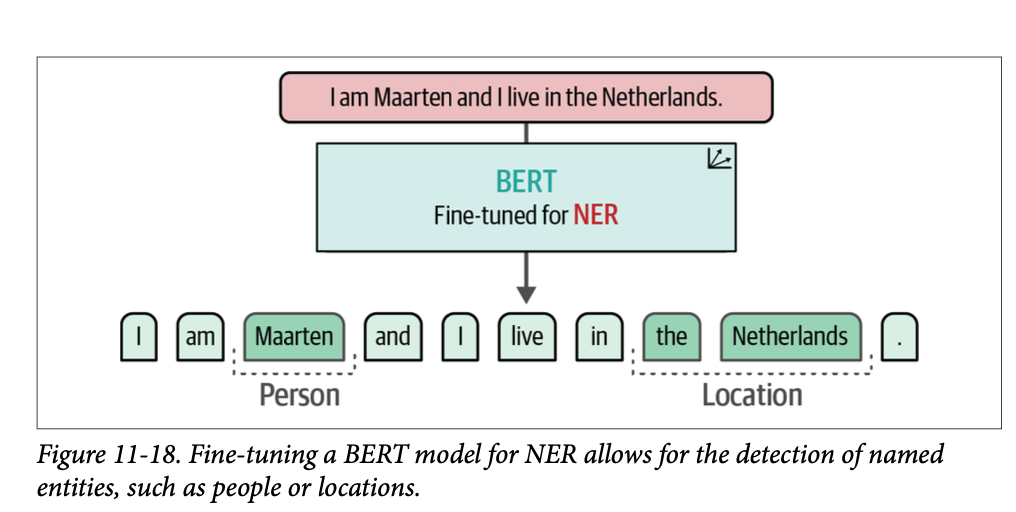
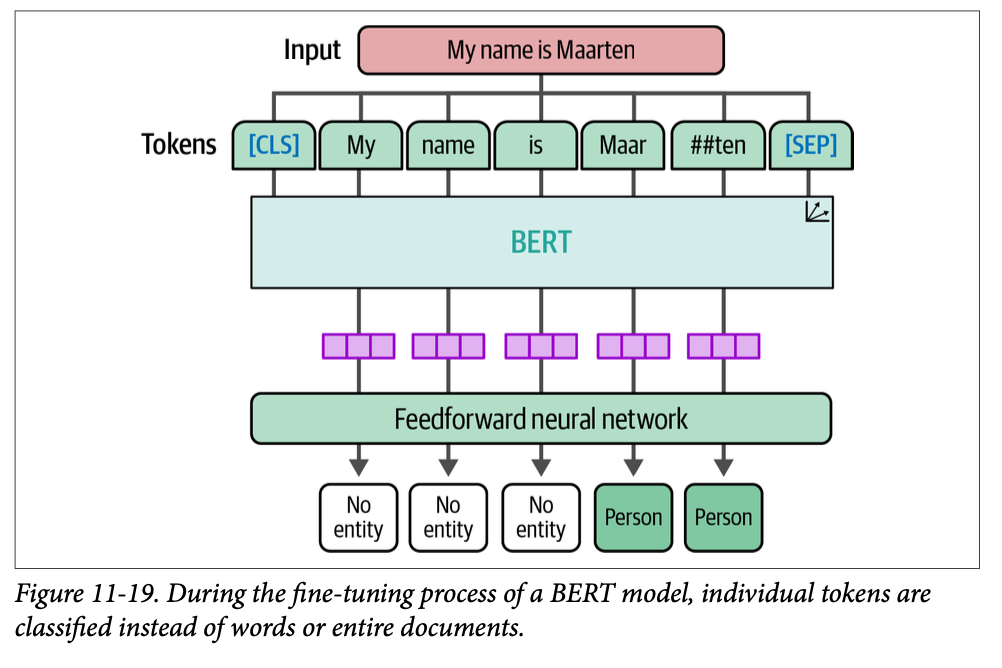
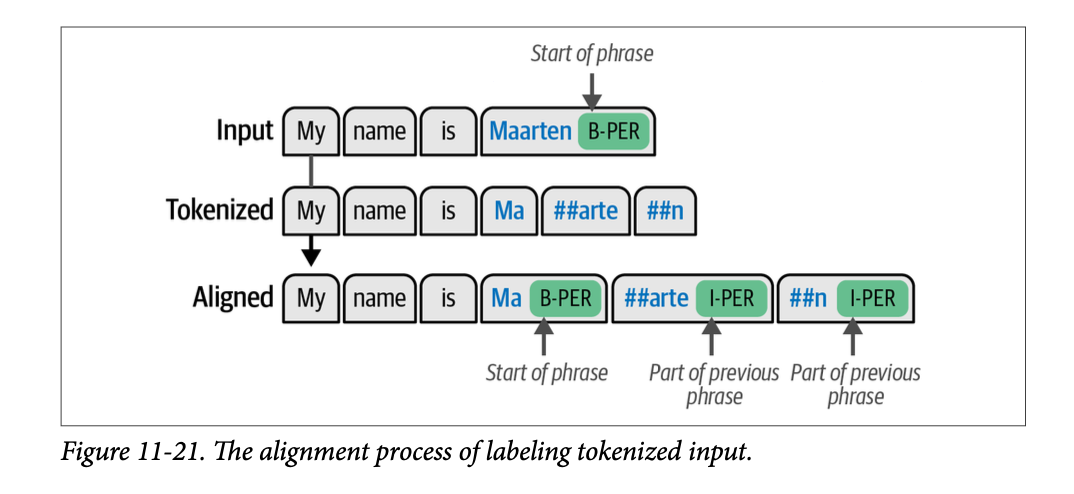
defalign_labels(examples): token_ids = tokenizer( examples["tokens"], truncation=True, is_split_into_words=True ) labels = examples["ner_tags"] updated_labels = [] for index, label inenumerate(labels): # Map tokens to their respective word word_ids = token_ids.word_ids(batch_index=index) previous_word_idx = None label_ids = [] for word_idx in word_ids: # The start of a new word if word_idx != previous_word_idx: previous_word_idx = word_idx updated_label = -100if word_idx isNoneelse label[word_idx] label_ids.append(updated_label) # Special token is -100 elif word_idx isNone: label_ids.append(-100) # If the label is B-XXX we change it to I-XXX else: updated_label = label[word_idx] if updated_label % 2 == 1: