《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
第 \(\text{8}\) 章 语义搜索与检索增强生成
Semantic Search and Retrieval-Augmented Generation
搜索是最先获得广泛行业应用的语言模型应用之一。在开创性的论文《\(\text{BERT}\): 用于语言理解的深度双向 \(\text{Transformer}\) 预训练》(\(\text{2018}\))发布后的数月,谷歌宣布它正在使用 \(\text{BERT}\) 为 \(\text{Google}\) 搜索提供支持,并称这代表了“搜索历史上最大的飞跃之一”。微软 \(\text{Bing}\) 也不甘落后,声明“从今年四月开始,我们使用大型 \(\text{Transformer}\) 模型,为我们的 \(\text{Bing}\) 用户带来了过去一年中最大的质量提升。”
这是对这些模型力量和实用性的明确证明。它们的加入即时且显著地改进了数十亿人赖以生存的一些最成熟、维护最完善的系统。它们增加的能力被称为语义搜索(\(\text{semantic search}\)),它支持通过意义进行搜索,而不仅仅是关键词匹配。
在另一个独立的领域,文本生成模型的快速采用促使许多用户向模型提问并期望得到事实性的答案。然而,虽然模型能够流利且自信地回答,但它们的答案并非总是正确或最新的。这个问题逐渐被称为模型的“幻觉”(\(\text{hallucinations}\)),而减少这种现象的主要方法之一是构建能够检索相关信息并将其提供给 \(\text{LLM}\),以帮助其生成更具事实性的答案的系统。这种方法,被称为 \(\text{RAG}\),是 \(\text{LLM}\) 最流行的应用之一。
语义搜索与 \(\text{RAG}\) 概览
Overview of Semantic Search and RAG
关于如何最好地利用语言模型进行搜索,有大量的研究。这些模型主要分为三个大类:稠密检索 (\(\text{dense retrieval}\))、重排序 (\(\text{reranking}\)) 和 \(\text{RAG}\)。以下是对这三类模型的概览,本章的其余部分将对此进行更详细的解释:
稠密检索
稠密检索系统依赖于嵌入(\(\text{embeddings}\))这一概念,这与我们在前几章中遇到的概念相同。它将搜索问题转化为检索搜索查询的最近邻(在查询和文档都被转换为嵌入之后)。图 \(\text{8}-1\) 展示了稠密检索如何接收一个搜索查询,查阅其文本档案,并输出一组相关结果。
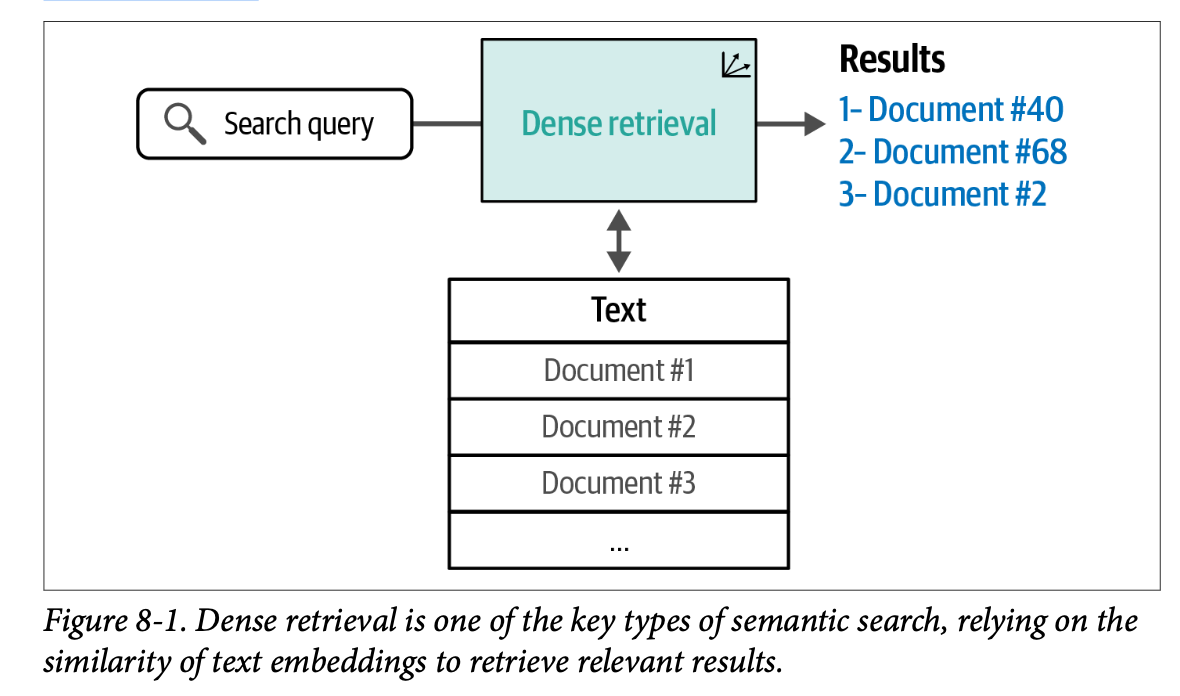
重排序
搜索系统通常是多步骤的管线。重排序语言模型是其中一个步骤,其任务是根据查询对结果子集的相关性进行评分;然后根据这些分数改变结果的顺序。图 \(\text{8}-2\) 展示了重排序器与稠密检索的不同之处在于,它们接收一个额外的输入:来自搜索管线中上一步的搜索结果集。
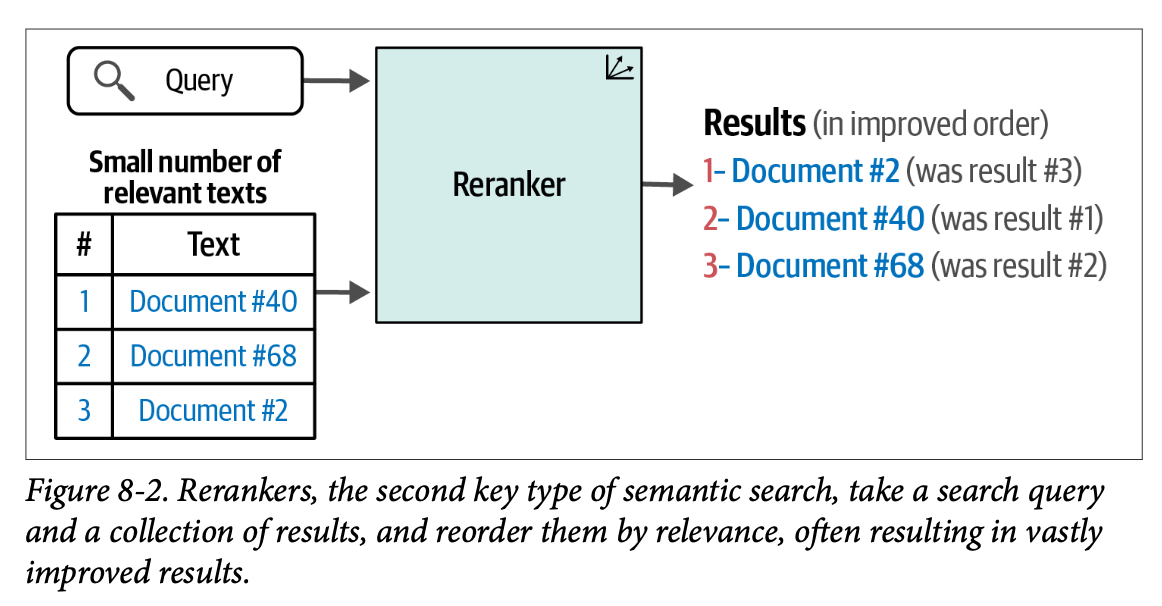
\(\text{RAG}\)
文本生成模型不断增长的能力催生了一种新型的搜索系统,这种系统包含一个生成模型,它生成一个答案来回应查询。图 \(\text{8}-3\) 展示了这样一个生成式搜索系统的例子。
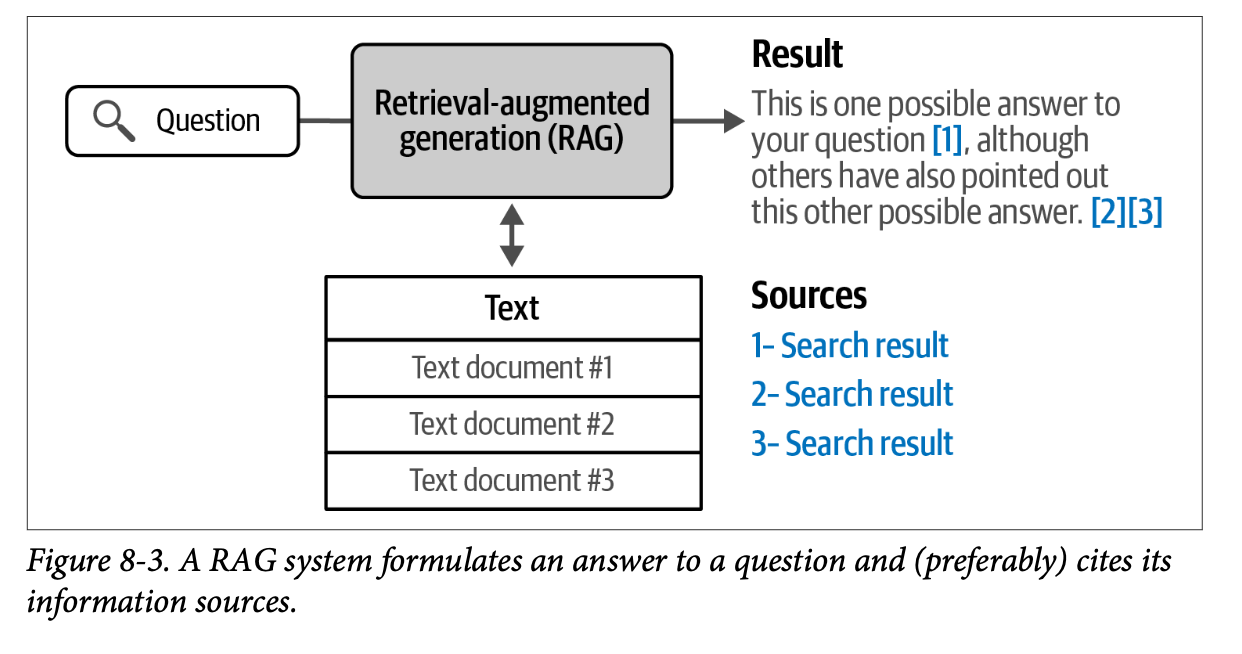
生成式搜索是更广义系统类别的一个子集,该类别更好地被称为 \(\text{RAG}\) 系统。这些是结合了搜索能力的文本生成系统,用于减少幻觉、提高事实性和/或将生成模型建立在特定数据集的基础上。
本章的其余部分将更详细地介绍这三类系统。虽然它们是主要的类别,但它们并非语言模型在搜索领域的唯一应用。
使用语言模型进行语义搜索
Semantic Search with Language Models
现在让我们更详细地探讨可以升级我们语言模型搜索能力的主要系统类别。我们将从稠密检索开始,然后依次转向重排序和 \(\text{RAG}\)。
稠密检索
Dense Retrieval
回想一下,嵌入将文本转化为数值表示。正如我们在图 \(\text{8}-4\) 中所见,这些数值可以被视为空间中的点。彼此靠近的点意味着它们所代表的文本是相似的。因此,在这个例子中,文本 \(\text{1}\) 和文本 \(\text{2}\) 彼此更相似(因为它们靠近),而比文本 \(\text{3}\) 相似度更高(因为它更远)。
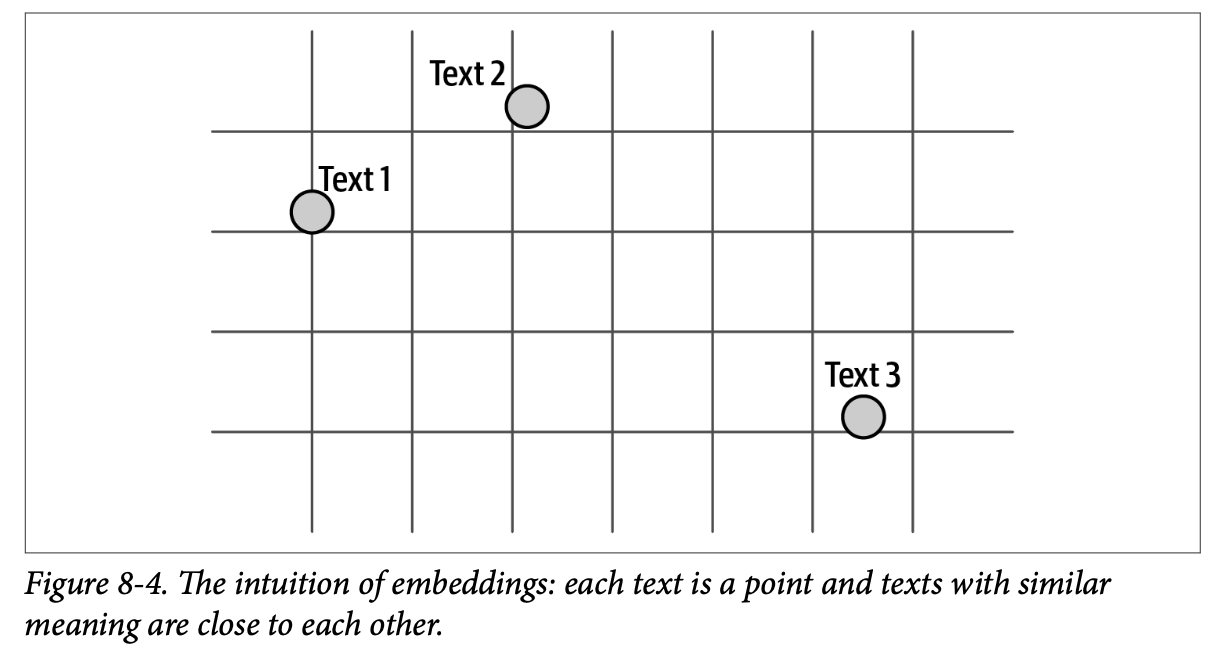
这就是用于构建搜索系统的特性。在这种情况下,当用户输入一个搜索查询时,我们嵌入该查询,从而将其投影到与我们的文本档案相同的空间中。然后,我们只需找到该空间中离查询最近的文档,这些文档就是搜索结果(图 \(\text{8}-5\))。

从图 \(\text{8}-5\) 中的距离来判断,“文本 \(\text{2}\)”是该查询的最佳结果,其次是“文本 \(\text{1}\)”。然而,这里可能会出现两个问题:
- 文本 \(\text{3}\) 是否应该作为结果返回? 这是您,即系统设计者的决定。有时,为了过滤掉不相关的结果(以防语料库中没有与查询相关的结果),设置一个最大的相似度分数阈值是可取的。
- 查询和它的最佳结果在语义上是否相似? 并非总是如此。这就是为什么语言模型需要在问答对上进行训练,以提高检索能力。这个过程将在第 \(\text{10}\) 章中更详细地解释。
图 \(\text{8}-6\) 展示了我们如何对文档进行分块,然后继续对每个分块进行嵌入。这些嵌入向量随后被存储在向量数据库中,并准备好进行检索。
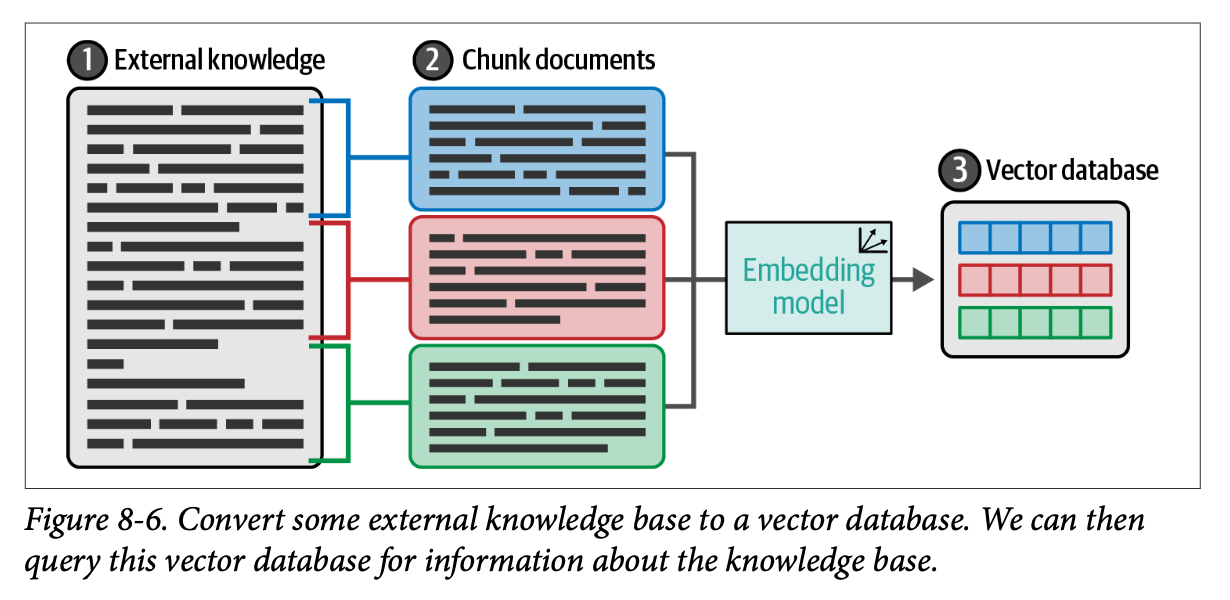
稠密检索示例
Dense retrieval example
让我们通过使用 \(\text{Cohere}\) 搜索电影《\(\text{Interstellar}\)》(星际穿越)的维基百科页面,来看一个稠密检索的例子。在这个例子中,我们将执行以下操作:
- 获取我们想要进行搜索的文本,并进行一些轻量级处理,将其分块成句子。
- 嵌入这些句子。
- 构建搜索索引。
- 搜索并查看结果。
您可以通过在 https://oreil.ly/GxrQ1 注册来获取您的 \(\text{Cohere API}\) 密钥。将其粘贴到以下代码中。运行此示例您无需支付任何费用。
让我们导入所需的库:
1 | import cohere |
获取文本档案并进行分块
Getting the text archive and chunking it.
让我们使用维基百科关于电影《\(\text{Interstellar}\)》文章的第一部分。我们将获取文本,然后将其分解成句子:
1 | text = |
嵌入文本块
Embedding the text chunks.
现在我们来嵌入这些文本。我们会将它们发送到 \(\text{Cohere API}\),并为每段文本获取一个向量:
1 | # Get the embeddings |
这输出 \(\text{(15, 4096)}\),这表明我们有 \(15\) 个向量,每个向量的大小为 \(4096\)。
构建搜索索引
Building the search index
在我们搜索之前,我们需要构建一个搜索索引。索引存储了这些嵌入,并且经过优化,即使我们有大量的点,也能快速检索到最近的邻居:
1 | import faiss |
搜索索引
Search the index.
我们现在可以使用任何我们想要的查询来搜索数据集。我们只需嵌入查询,并将其嵌入向量提供给索引,索引将检索出维基百科文章中最相似的句子。
让我们定义我们的搜索函数:
1 | def search(query, number_of_results=3): |
我们现在可以编写一个查询并搜索文本了!
1 | query = "how precise was the science" |
这将产生以下输出:

第一个结果的距离最小,因此与查询的相似度最高。看它一眼,它完美地回答了这个问题。请注意,如果我们只进行关键词搜索,这是不可能实现的,因为排名靠前的结果并未包含查询中的相同关键词。
我们实际上可以通过定义一个关键词搜索函数来验证这一点,以便进行比较。我们将使用 \(\text{BM25}\) 算法,它是领先的词汇搜索方法之一。有关这些代码片段的来源,请参阅此 \(\text{notebook}\):
1 | from rank_bm25 import BM25Okapi |
现在,当我们搜索相同的查询时,我们从稠密检索搜索中得到了一组不同的结果:
1 | keyword_search(query = "how precise was the science") |
结果:
1 | Input question: how precise was the science |
请注意,第一个结果并没有真正回答问题,尽管它与查询共享了“\(\text{science}\)”一词。在下一节中,我们将看到添加重排序器如何改进这个搜索系统。但在此之前,让我们通过查看稠密检索的注意事项并回顾一些将文本分解成块的方法来完成稠密检索的概述。
稠密检索的注意事项
Caveats of dense retrieval
了解稠密检索的一些缺点以及如何解决它们是很有用的。例如,如果文本中不包含答案会发生什么?我们仍然会得到结果和它们的距离。例如:

在这种情况下,一种可能的启发式方法是设置一个阈值——例如,相关性的最大距离。许多搜索系统会向用户展示它们能得到的最佳信息,并由用户来决定它是否相关。
追踪用户是否点击了某个结果(以及是否满意)的信息可以改进搜索系统的未来版本。
稠密检索的另一个注意事项是当用户想要找到一个特定短语的精确匹配时。这种情况非常适合关键词匹配。这也是为什么建议使用混合搜索(\(\text{hybrid search}\),它包含语义搜索和关键词搜索),而不是仅仅依赖稠密检索的原因之一。
稠密检索系统在与它们训练时所处的领域不同的领域中也难以正常工作。因此,举例来说,如果您在互联网和维基百科数据上训练了一个检索模型,然后将其部署到法律文本上(训练集中没有足够的法律数据),那么该模型在那个法律领域中就不会工作得那么好。
我们想指出的最后一点是,在前面的例子中,每个句子都包含一条信息,我们展示的查询是专门询问该信息的。但是,答案跨越多个句子的问题该怎么办呢?这突出显示了稠密检索系统的一个重要设计参数:将长文本分块的最佳方法是什么?以及为什么我们首先需要将它们分块?
对长文本进行分块
Chunking long texts
\(\text{Transformer}\) 语言模型的一个限制是它们的上下文大小是有限的(\(\text{limited in context sizes}\)),这意味着我们不能向它们馈送超过模型支持的单词或词元数量的非常长的文本。那么,我们如何嵌入长文本呢?
有几种可能的方法,如图 \(\text{8}-7\) 所示的两种可能的方法包括:对每个文档索引一个向量和对每个文档索引多个向量。

每个文档一个向量
One vector per document.
在这种方法中,我们使用单个向量来表示整个文档。这里有几种可能性:
- 仅嵌入文档的代表性部分,而忽略其余文本。 这可能意味着仅嵌入标题,或仅嵌入文档的开头。这对于快速开始构建演示很有用,但它会留下大量信息未被索引,因此无法搜索。作为一种方法,它可能更适用于文档开头捕捉了主要观点的文档(想想:维基百科文章)。但对于一个真实的系统来说,这并不是最好的方法,因为大量信息将被排除在索引之外,从而无法被搜索。
- 将文档分块、嵌入这些块,然后将这些块聚合成一个向量。 这里常用的聚合方法是平均这些向量。这种方法的缺点是它会产生一个高度压缩的向量,丢失了文档中的大量信息。
这种方法可以满足某些信息需求,但不能满足其他需求。很多时候,搜索是为了文章中包含的特定信息片段,如果该概念有自己的向量,则可以更好地捕获。
每个文档多个向量
Multiple vectors per document.
在这种方法中,我们将文档分块成更小的片段,并嵌入这些块。然后,我们的搜索索引就变成了块嵌入的集合,而不是整个文档的嵌入。图 \(\text{8}-8\) 显示了多种可能的文本分块方法。
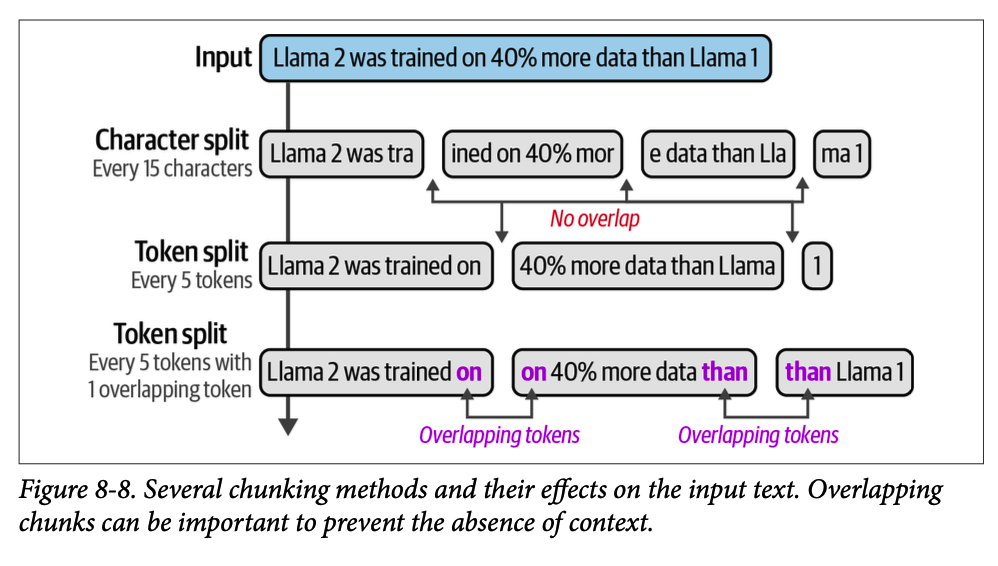
分块方法更好,因为它完全覆盖了文本,并且因为这些向量倾向于捕获文本内部的各个概念。这会产生一个更具表现力的搜索索引。图 \(\text{8}-9\) 展示了多种可能的方法。

对长文本进行分块的最佳方法将取决于您的系统预期的文本类型和查询类型。方法包括:
- 每个句子是一个块。 这里的问题是这可能过于精细,并且向量无法捕获足够的上下文。
- 每个段落是一个块。 如果文本由短段落组成,这会很棒。否则,可能是每 \(\text{3}\) 到 \(\text{8}\) 个句子作为一个块。
- 有些块的意义很大程度上来源于周围的文本。 因此,我们可以通过以下方式纳入一些上下文:
- 将文档的标题添加到块中。
- 将它们之前和之后的一些文本添加到块中。 这样,这些块就可以重叠,从而包含一些也出现在相邻块中的周围文本。这就是我们在图 \(\text{8}-10\) 中可以看到的。
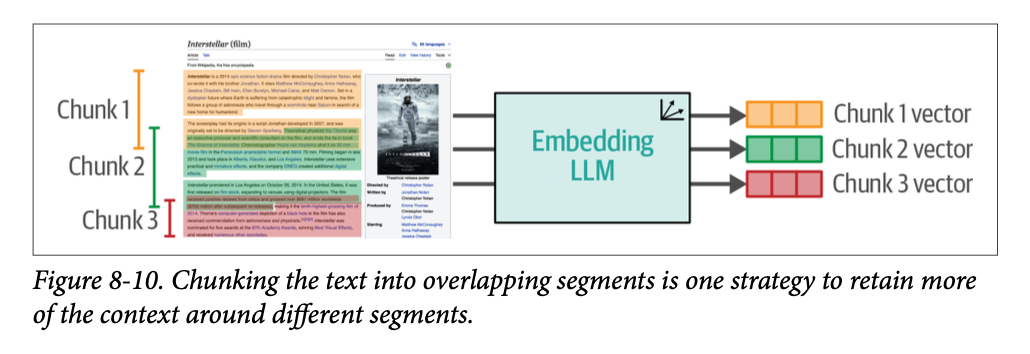
随着该领域的发展,预计会出现更多分块策略——其中一些甚至可能使用 \(\text{LLM}\) 来动态地将文本分割成有意义的块。
最近邻搜索与向量数据库
Nearest neighbor search versus vector databases
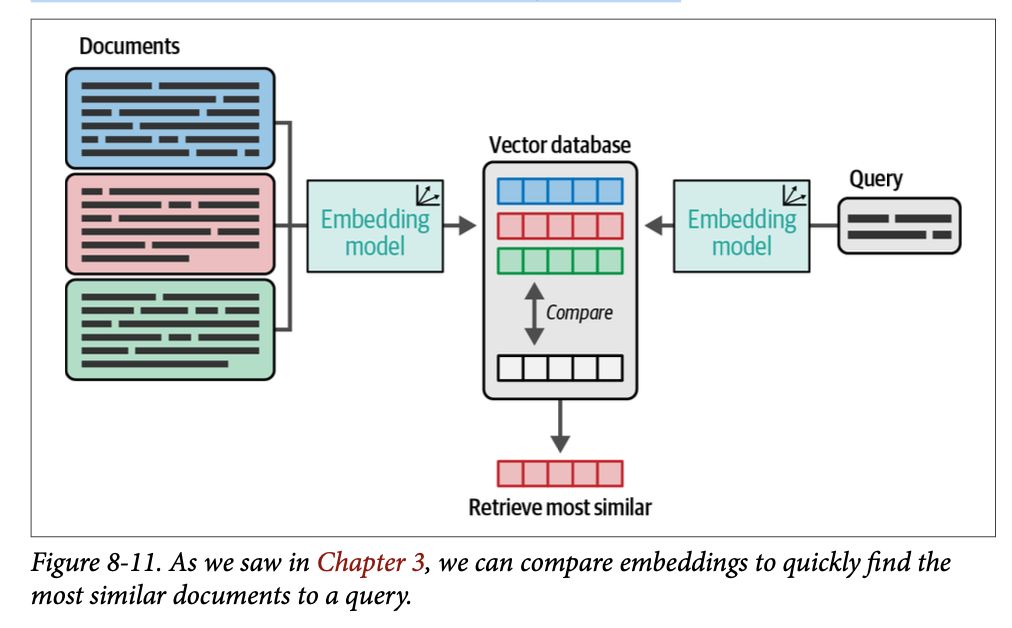
一旦查询被嵌入,我们需要从我们的文本档案中找到距离它最近的向量,如图 \(\text{8}-11\) 所示。找到最近邻最直接的方法是计算查询和档案之间的距离。如果您的档案中有数千或数万个向量,这是一种合理的方法,可以轻松地使用 \(\text{NumPy}\) 完成。
当您扩展到数百万个向量以上时,一种优化的检索方法是依赖于 近似最近邻搜索(\(\text{approximate nearest neighbor search}\))库,例如 \(\text{Annoy}\) 或 \(\text{FAISS}\)。这些库允许您在毫秒内从大规模索引中检索结果,其中一些可以通过利用 \(\text{GPU}\) 并扩展到机器集群来服务于超大型索引,从而提高其性能。
另一类向量检索系统是向量数据库(\(\text{vector databases}\)),如 \(\text{Weaviate}\) 或 \(\text{Pinecone}\)。向量数据库允许您添加或删除向量而无需重建索引。它们还提供了过滤搜索或以超出单纯向量距离的方式自定义搜索的方法。
为稠密检索微调嵌入模型
Fine-tuning embedding models for dense retrieval
正如我们在第 \(\text{4}\) 章中讨论文本分类时所说,我们可以使用微调(\(\text{fine-tuning}\))来提高 \(\text{LLM}\) 在特定任务上的性能。在这种情况下,检索需要优化文本嵌入,而不仅仅是词元嵌入。这个微调过程需要训练数据,这些数据由查询和相关结果组成。
让我们来看一个来自我们数据集的例子:句子“\(\text{Interstellar premiered on October 26, 2014, in Los Angeles.}\)”对于这个句子来说,两个可能的相关查询是:
- 相关查询 \(\text{1}\): “\(\text{Interstellar release date}\)”
- 相关查询 \(\text{2}\): “\(\text{When did Interstellar premier}\)”
微调过程旨在使这些查询的嵌入与结果句子的嵌入距离更近。它还需要查看与该句子不相关的查询的负面示例,例如:
- 不相关查询: “\(\text{Interstellar cast}\)”
有了这些例子,我们现在有三对——两对正例和一对负例。正如我们在图 \(\text{8}-12\) 中所见,假设在微调之前,所有三个查询与结果文档的距离都相同。这并不牵强,因为它们都与《星际穿越》有关。
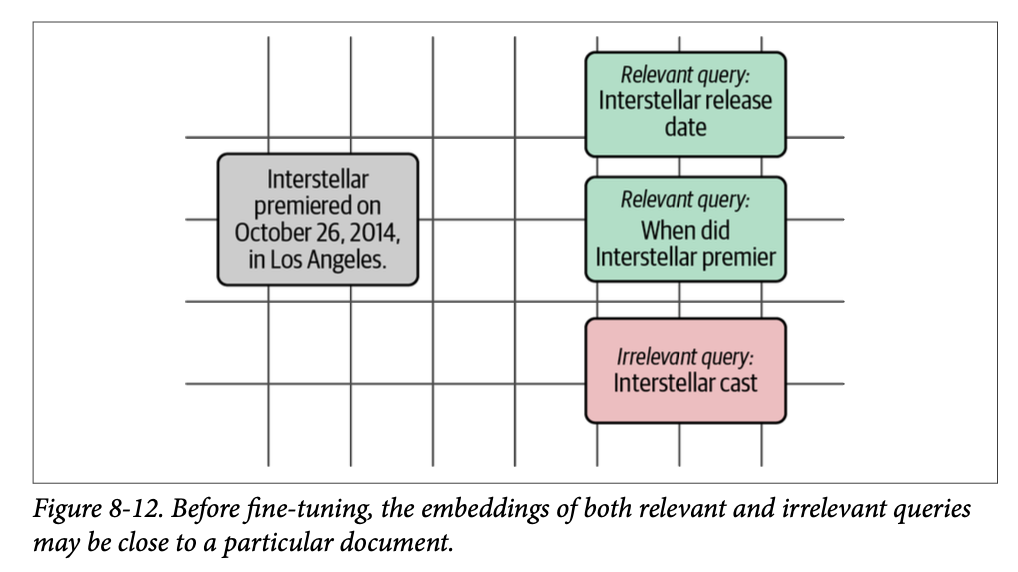
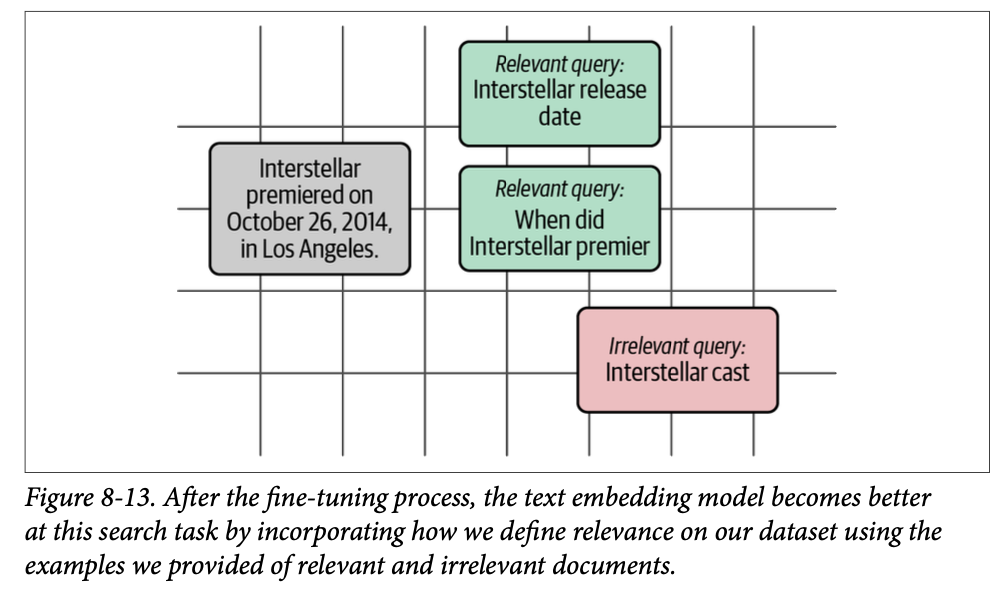
微调步骤的作用是使相关查询更靠近文档,同时使不相关查询更远离文档。我们可以在图 \(\text{8}-13\) 中看到这种效果。
重排序
Reranking
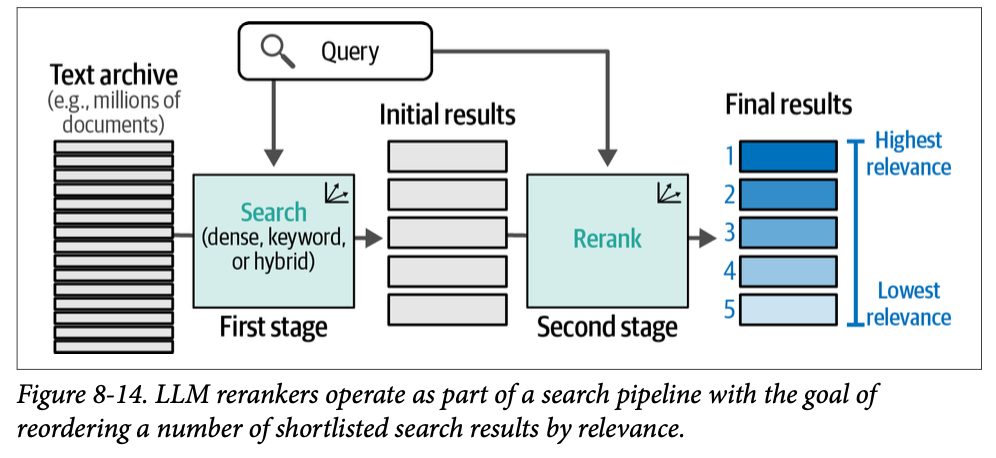
许多组织已经构建了搜索系统。对于这些组织来说,将语言模型纳入其搜索管线的一种更简单方法是作为最后一步。这一步的任务是根据与搜索查询的相关性来更改搜索结果的顺序。这一个步骤就可以极大地改进搜索结果,事实上,这也是微软 \(\text{Bing}\) 添加 \(\text{BERT}\) 类模型以实现搜索结果改进的方式。图 \(\text{8}-14\) 展示了重排序搜索系统作为两阶段搜索系统中第二阶段的结构。
重排序示例
Reranking example
重排序器(\(\text{reranker}\))接收搜索查询和多个搜索结果,并返回这些文档的最佳排序,使与查询最相关的结果排在更高的位置。\(\text{Cohere}\) 的 \(\text{Rerank}\) 端点是开始使用第一个重排序器的一种简单方法。我们只需将查询和文本传递给它,即可获得结果。我们不需要对其进行训练或调整:
1 | query = "how precise was the science" |
我们可以打印这些结果:
1 | for idx, result in enumerate(results.results): |
输出:
1 | 0 0.1698185 It has also received praise from many astronomers for its scien- |
这表明重排序器对第一个结果更加确信,为其分配了 \(0.16\) 的相关性分数,而其他结果的相关性得分要低得多。
在这个基本示例中,我们将所有 \(15\) 个文档都传递给了重排序器。然而,更常见的情况是,我们的索引会有数千或数百万个条目,我们需要筛选出(比如)一百或一千个结果,然后将这些结果呈现给重排序器。这个筛选步骤被称为搜索管线的第一阶段。
第一阶段的检索器可以是关键词搜索、稠密检索,或者更好的是使用两者的混合搜索。我们可以重新审视我们之前的示例,看看在关键词搜索系统之后添加一个重排序器如何提高其性能。
让我们修改我们的关键词搜索函数,使其使用关键词搜索检索出排名前 \(\text{10}\) 的结果列表,然后使用重排序来从这 \(\text{10}\) 个结果中选择排名前 \(\text{3}\) 的结果:
1 | def keyword_and_reranking_search(query, top_k=3, num_candidates=10): |
现在我们可以发送我们的查询,并检查关键词搜索的结果,以及关键词搜索筛选出前 \(\text{10}\) 个结果,然后将它们传递给重排序器的最终结果:
1 | keyword_and_reranking_search(query = "how precise was the science") |
结果:
1 | Input question: how precise was the science |
我们看到关键词搜索只为共享某些关键词的两个结果分配了分数。在第二组结果中,重排序器将第二个结果恰当地提升为与查询最相关的结果。这是一个玩具示例,让我们初窥其效果,但在实践中,这样的管线可以显著提高搜索质量。在像 \(\text{MIRACL}\) 这样的多语言基准测试中,重排序器可以将性能从 \(\text{36.5}\) 提升到 \(\text{62.8}\),以 \(\text{nDCG}@\text{10}\) 衡量(关于评估的更多内容将在本章后面讨论)。
使用 \(\text{Sentence Transformers}\) 进行开源检索和重排序
Open source retrieval and reranking with sentence transformers
如果您想在自己的机器上本地设置检索和重排序,那么可以使用 \(\text{Sentence Transformers}\) 库。请参阅 https://oreil.ly/jJOhV 上的文档进行设置。查看“\(\text{Retrieve \& Re-Rank}\)”部分,获取有关如何在库中执行这些步骤的说明和代码示例。
重排序模型的工作原理
How reranking models work
构建 \(\text{LLM}\) 搜索重排序器的一种流行方法是,将查询和每个结果呈现给一个充当交叉编码器(\(\text{cross-encoder}\))的 \(\text{LLM}\)。这意味着查询和可能的搜索结果同时呈现给模型,允许模型在分配相关性分数之前查看这两段文本,如图 \(\text{8}-15\) 所示。所有文档都是批量同时处理的,但每个文档都是针对查询独立评估的。然后,这些分数决定了结果的新顺序。这种方法在题为“\(\text{Multi-stage document ranking with BERT}\)”的论文中有更详细的描述,有时被称为 \(\text{monoBERT}\)。
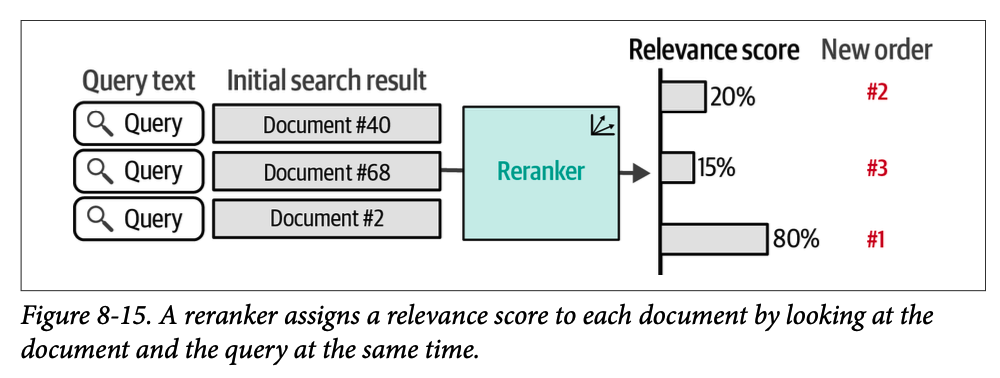
这种将搜索表述为相关性评分的方法基本上归结为一个分类问题。给定这些输入,模型输出一个从 \(\text{0}\) 到 \(\text{1}\) 的分数,其中 \(\text{0}\) 表示不相关,\(\text{1}\) 表示高度相关。这应该与我们在第 \(\text{4}\) 章中关于分类的讨论相一致。
要了解更多关于使用 \(\text{LLM}\) 进行搜索的发展,强烈推荐阅读《\(\text{Pretrained transformers for text tanking: BERT and beyond}\)》,它回顾了直到大约 \(\text{2021}\) 年这些模型的发展。
检索评估指标
Retrieval Evaluation Metrics
语义搜索是使用信息检索(\(\text{Information Retrieval}\), \(\text{IR}\))领域的指标进行评估的。让我们讨论其中一个流行的指标:平均精度均值(\(\text{mean average precision}\), \(\text{MAP}\))。
评估搜索系统需要三个主要组成部分:一个文本档案、一组查询,以及相关性判断,指明哪些文档与每个查询相关。我们在图 \(\text{8}-16\) 中可以看到这些组件。
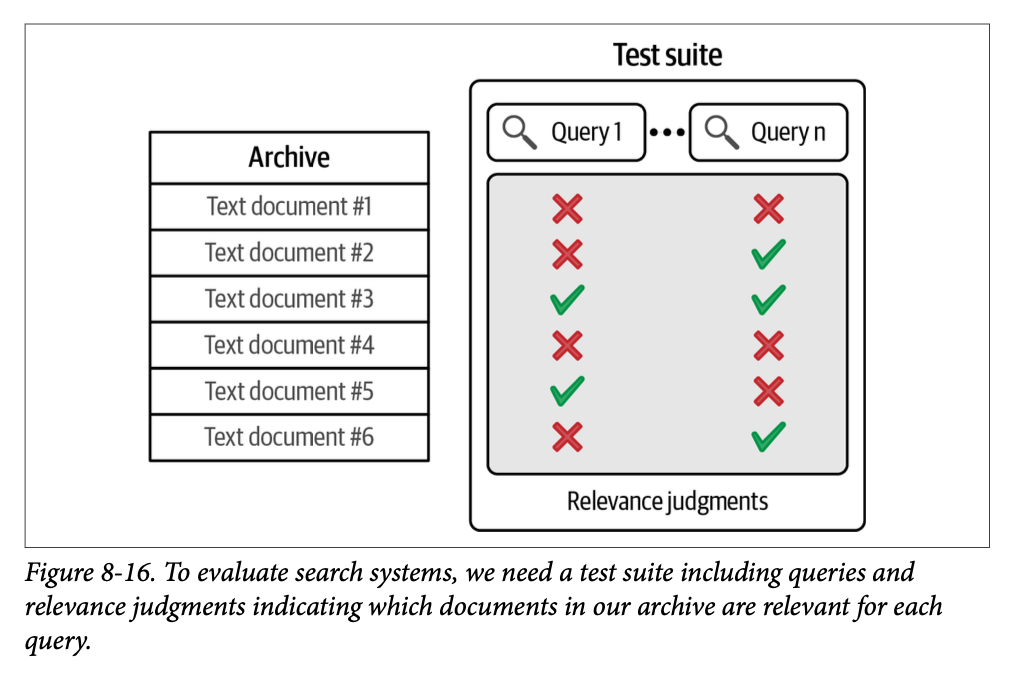
使用这个测试套件,我们可以继续探索搜索系统的评估。让我们从一个简单的例子开始。假设我们向两个不同的搜索系统传递查询 \(\text{1}\)。并得到两组结果。假设我们将结果数量限制为三个,如图 \(\text{8}-17\) 所示。
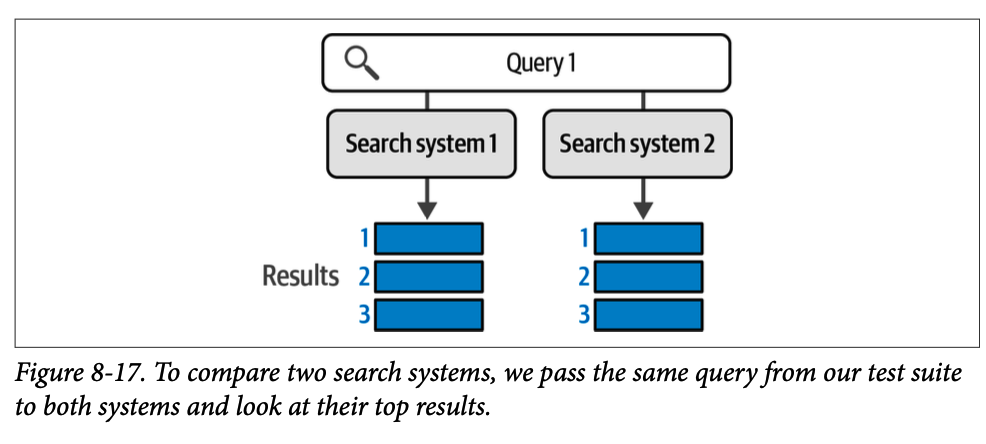
为了判断哪个系统更好,我们求助于我们拥有的关于该查询的相关性判断。图 \(\text{8}-18\) 显示了返回的结果中哪些是相关的。
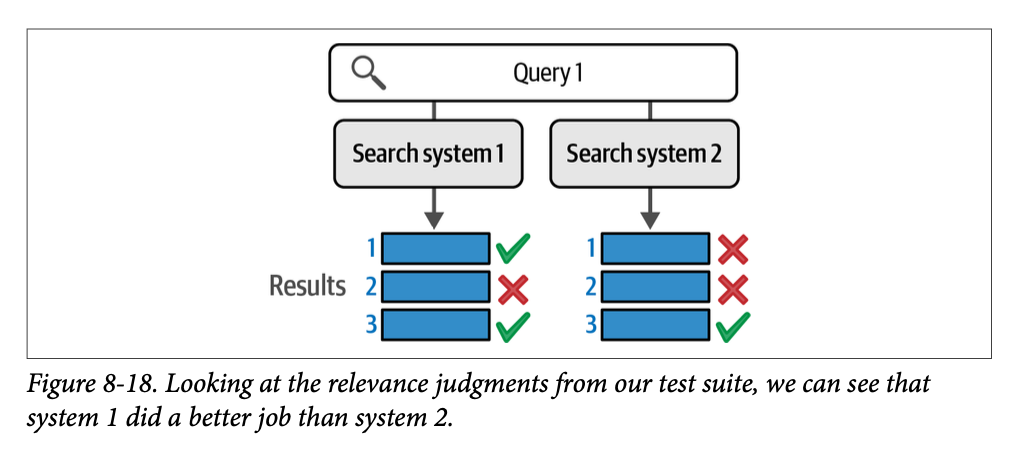
这向我们展示了一个清晰的案例,即系统 \(\text{1}\) 优于系统 \(\text{2}\)。直观上,我们可以简单地计算每个系统检索到的相关结果数量。系统 \(\text{1}\) 在 \(\text{3}\) 个结果中得到了两个正确的,而系统 \(\text{2}\) 在 \(\text{3}\) 个结果中只得到了一个正确的。但是,对于如图 \(\text{8}-19\) 所示的案例呢?在这两种情况下,两个系统在 \(\text{3}\) 个结果中都只得到一个相关结果,但它们处于不同的位置。
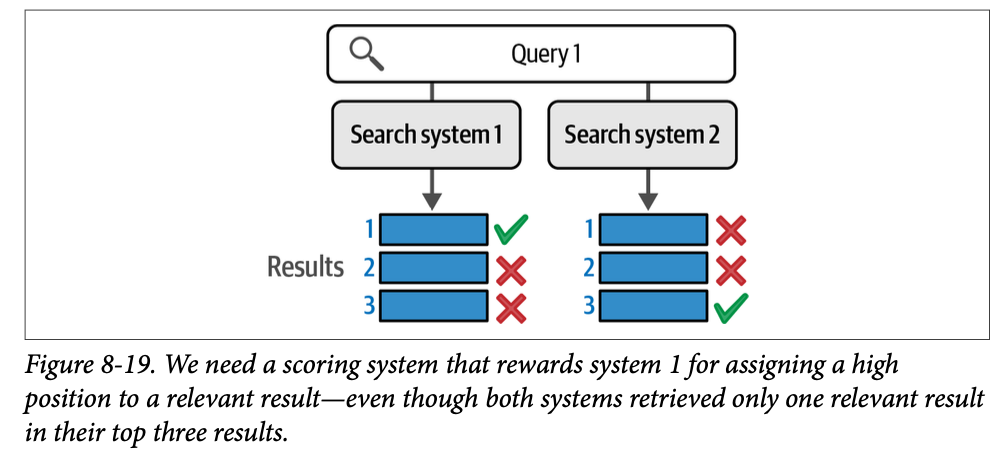
在这种情况下,我们可以凭直觉认为系统 \(\text{1}\) 比系统 \(\text{2}\)做得更好,因为第一个位置(最重要的位置)的结果是正确的。但是,我们如何为这种更好的程度分配一个数值或分数呢?平均精度均值就是一种能够量化这种区别的度量。
在这种情景中,一种常见的分配数值分数的方法是平均精度(\(\text{average precision}\)),它评估系统 \(\text{1}\) 对该查询的结果为 \(\text{1}\),系统 \(\text{2}\) 的结果为 \(\text{0.3}\)。因此,让我们看看平均精度是如何计算来评估一组结果的,以及如何将它聚合起来以评估测试套件中所有查询的系统。
用平均精度对单个查询评分
Scoring a single query with average precision
要对搜索系统在这个查询上的表现进行评分,我们可以专注于对相关文档进行评分。让我们从一个在测试套件中只有一个相关文档的查询开始看。
第一个很容易:搜索系统将相关结果(该查询唯一可用的结果)放置在最前面。这使系统获得了满分 \(\text{1}\) 分。图 \(\text{8}-20\) 展示了这种计算:查看第一个位置,我们有一个相关结果,导致位置 \(\text{1}\) 处的精度为 \(\text{1.0}\)(计算方法是位置 \(\text{1}\) 处的相关结果数量除以我们当前查看的位置)。
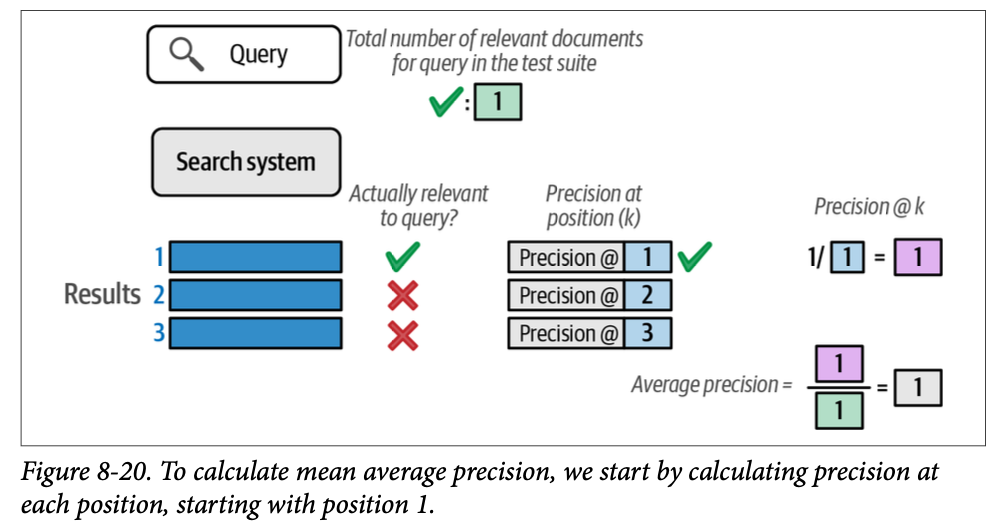
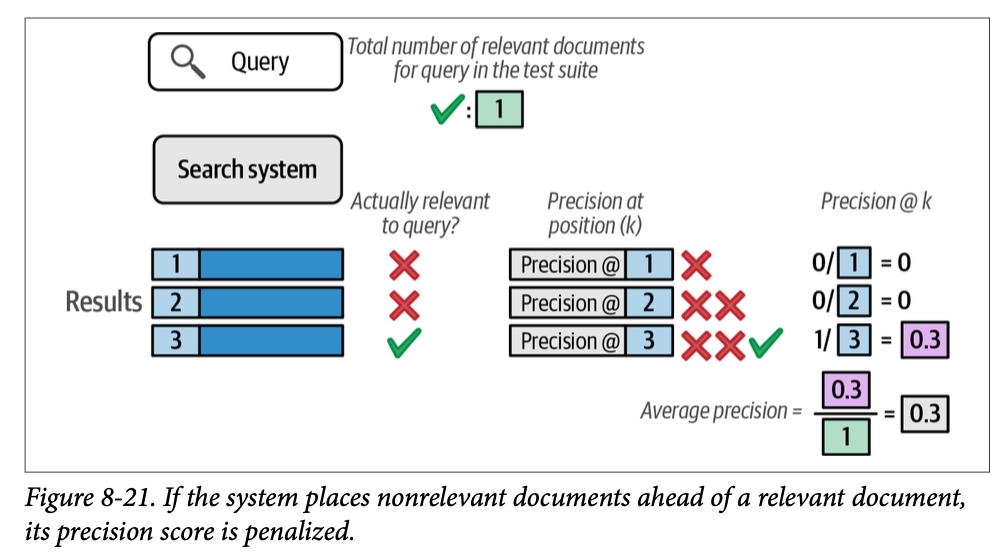
由于我们只对相关文档进行评分,我们可以忽略不相关文档的分数并在此处停止计算。但是,如果系统将唯一的相关结果放在第三个位置,这会如何影响分数呢?图 \(\text{8}-21\) 展示了这会如何导致惩罚。
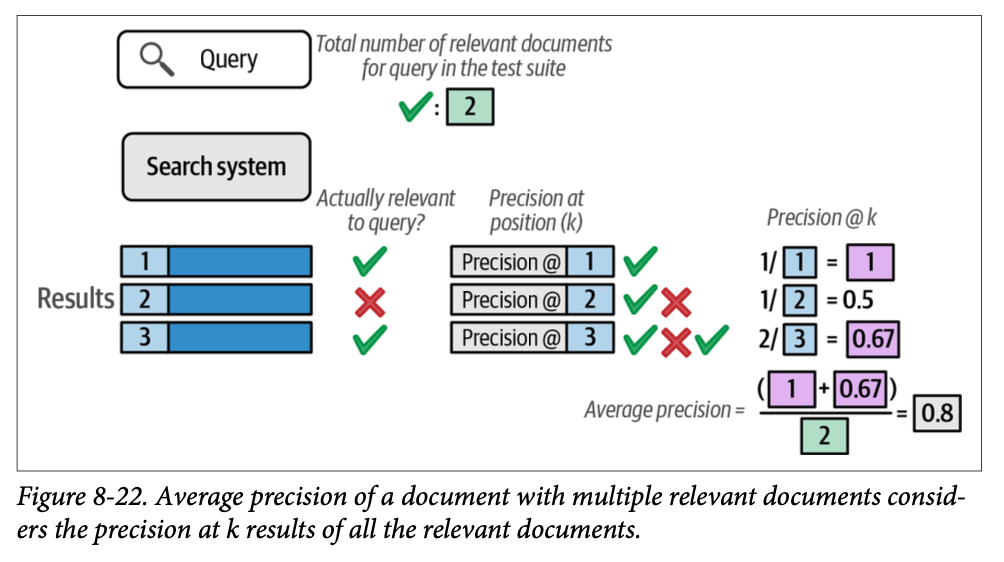
现在让我们来看一个有多个相关文档的查询。图 \(\text{8}-22\) 展示了这种计算,以及平均是如何介入的。
用平均精度均值(\(\text{mean average precision}\))对多个查询评分
Scoring across multiple queries with mean average precision
既然我们熟悉了位置 \(k\) 处的精度和平均精度,我们就可以将这个知识扩展到一个可以针对我们测试套件中所有查询对搜索系统进行评分的指标。这个指标被称为平均精度均值(\(\text{mean average precision}\))。图 \(\text{8}-23\) 展示了如何通过取每个查询的平均精度的平均值来计算这个指标。
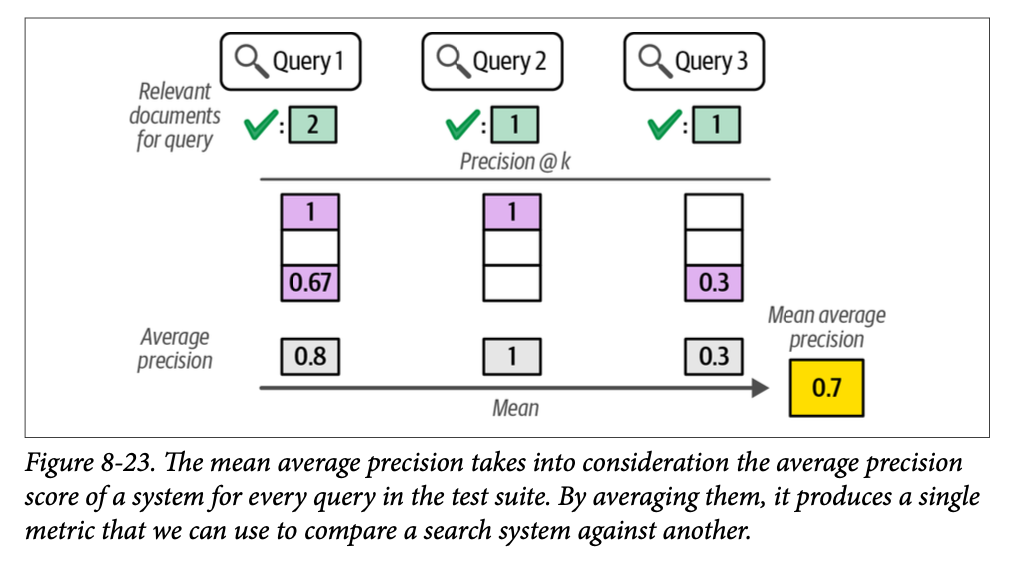
您可能想知道为什么同一个操作被称为“均值”(\(\text{mean}\))和“平均”(\(\text{average}\))。这很可能是一种美学选择,因为 \(\text{MAP}\) 听起来比“平均平均精度”更好。
现在我们有了一个单一的指标,可以用来比较不同的系统。如果您想了解更多关于评估指标的信息,请参阅 \(\text{Christopher D. Manning}\)、\(\text{Prabhakar Raghavan}\) 和 \(\text{Hinrich Schütze}\) 所著的《信息检索导论》(\(\text{Introduction to Information Retrieval}\))(剑桥大学出版社)中的“信息检索中的评估”一章。
除了平均精度均值之外,另一个常用于搜索系统的指标是归一化折损累计增益(\(\text{normalized discounted cumulative gain}\), \(\text{nDCG}\)),它更细致入微,因为文档的相关性不是二元的(相关与不相关),并且在测试套件和评分机制中,一个文档可以被标记为比另一个更相关。
检索增强生成
Retrieval-Augmented Generation (RAG)
\(\text{LLM}\) 的大规模采用很快导致人们向它们提问并期望得到事实性的答案。虽然模型可以正确回答一些问题,但它们也自信地回答了许多不正确的问题。业界为纠正这种行为而转向的主要方法是 \(\text{RAG}\),该方法在论文《用于知识密集型 \(\text{NLP}\) 任务的检索增强生成》(\(\text{Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks}\))(\(\text{2020}\))中有所描述,如图 \(\text{8}-24\) 所示。
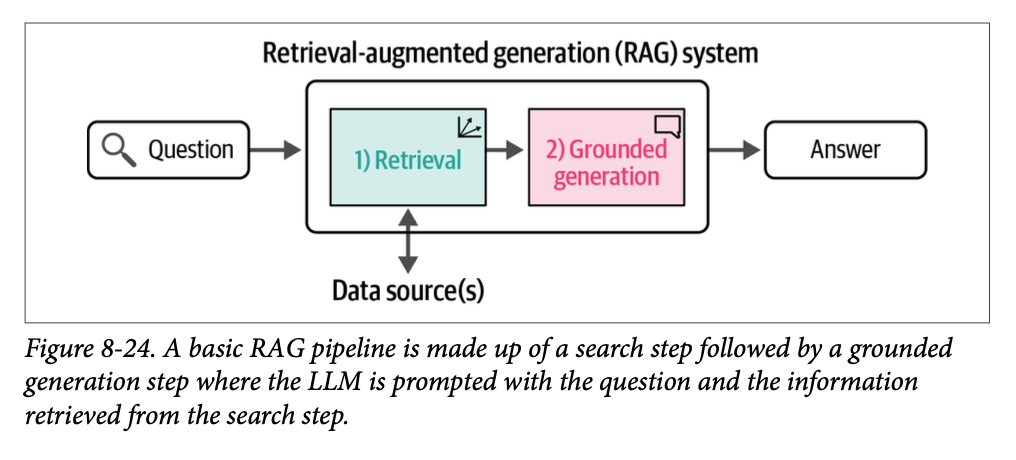
\(\text{RAG}\) 系统在生成能力之外,还整合了搜索能力。它们可以被视为对生成系统的改进,因为它们减少了幻觉并提高了事实性。它们还支持“与我的数据聊天”的用例,个人和公司可以使用这些系统来将 \(\text{LLM}\) 建立在内部公司数据或特定的感兴趣数据源(例如,与一本书聊天)的背景上。
这也扩展到了搜索系统。越来越多的搜索引擎正在整合 \(\text{LLM}\) 来总结结果或回答提交给搜索引擎的问题。例子包括 \(\text{Perplexity}\)、\(\text{Microsoft Bing AI}\) 和 \(\text{Google Gemini}\)。
从搜索到 \(\text{RAG}\)
From Search to RAG
现在让我们将我们的搜索系统转变为一个 \(\text{RAG}\) 系统。我们通过在搜索管线的末端添加一个 \(\text{LLM}\) 来实现这一点。我们将问题和检索到的最相关的文档呈现给 \(\text{LLM}\),并要求它根据搜索结果提供的上下文来回答问题。我们可以在图 \(\text{8}-25\) 中看到一个例子。
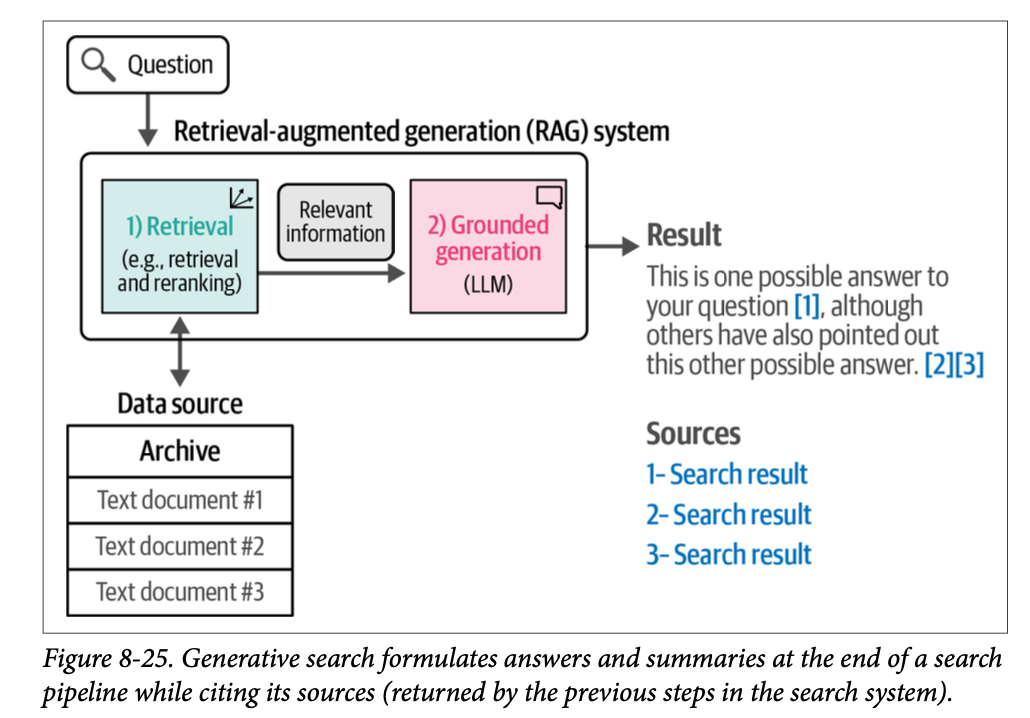
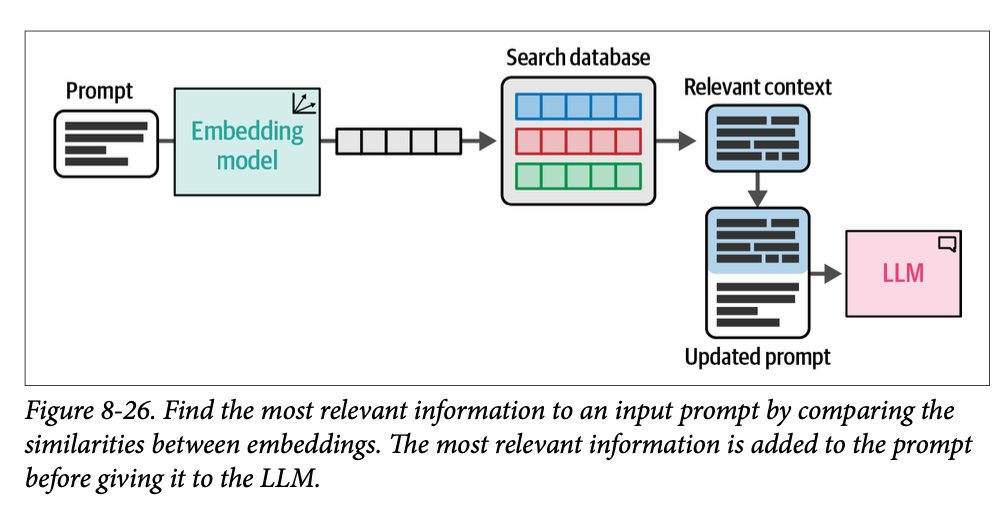
这个生成步骤被称为基于事实的生成(\(\text{grounded generation}\)),因为我们提供给 \(\text{LLM}\) 的检索到的相关信息建立了一个特定的上下文,将 \(\text{LLM}\) 建立在我们感兴趣的领域中。图 \(\text{8}-26\) 展示了如果我们继续我们前面提到的嵌入搜索示例,基于事实的生成是如何在搜索之后起作用的。
示例:使用 \(\text{LLM API}\) 进行基于事实的生成
Example: Grounded Generation with an LLM API
让我们看看如何在搜索结果之后添加一个基于事实的生成步骤来创建我们的第一个 \(\text{RAG}\) 系统。对于这个示例,我们将使用 \(\text{Cohere}\) 的托管 \(\text{LLM}\),它建立在我们本章前面看到的搜索系统之上。我们将使用嵌入搜索来检索最相关的文档,然后我们将这些文档与问题一起传递给 \(\text{co.chat}\) 端点,以提供一个基于事实的答案:
1 | query = "income generated" |
结果:
1 | print(response.text) |
1 | The film generated a worldwide gross of over $677 million, or $773 million |
我们对一些文本进行了高亮显示,因为模型表明这些文本片段的来源是我们传入的第一个文档:
1 | citations=[ChatCitation(start=21, end=36, text='worldwide gross', docu- |
示例:使用本地模型的 \(\text{RAG}\)
Example: RAG with Local Models
现在让我们用本地模型来复制这个基本功能。我们将失去进行跨度引用的能力,而且较小的本地模型效果不如较大的托管模型,但演示这个流程很有用。我们将从下载一个量化模型开始。
加载生成模型
Loading the generation model
我们从下载我们的模型开始:
1 | !wget https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-fp16.gguf |
我们使用 \(\text{llama.cpp}\)、\(\text{llama-cpp-python}\) 和 \(\text{LangChain}\) 来加载文本生成模型:
1 | from langchain import LlamaCpp |
加载嵌入模型
Loading the embedding model
现在我们来加载一个嵌入语言模型。在这个例子中,我们将选择 \(\text{BAAI/bge-small-en-v1.5}\) 模型。在撰写本文时,它在 \(\text{MTEB}\) 嵌入模型排行榜上名列前茅,并且相对较小:
1 | from langchain.embeddings.huggingface import HuggingFaceEmbeddings |
我们现在可以使用这个嵌入模型来设置我们的向量数据库:
1 | from langchain.vectorstores import FAISS |
\(\text{RAG}\) 提示
The RAG prompt
提示模板在 \(\text{RAG}\) 管线中起着至关重要的作用。它是我们向 \(\text{LLM}\) 传达相关文档的核心位置。为此,我们将创建一个名为 \(\text{context}\) 的额外输入变量,它可以为 \(\text{LLM}\) 提供检索到的文档:
1 | from langchain import PromptTemplate |
现在我们准备好调用模型并提出问题了:
1 | rag.invoke('Income generated') |
结果:
1 | The Income generated by the film in 2014 was over $677 million worldwide. |
一如既往,我们可以调整提示来控制模型的生成(例如,回答的长度和语气)。
高级 \(\text{RAG}\) 技术
还有一些额外的技术可以提高 \(\text{RAG}\) 系统的性能。其中一些技术如下:
查询重写
Query rewriting
如果 \(\text{RAG}\) 系统是一个聊天机器人,那么如果一个问题过于冗长,或者引用对话中先前消息的上下文,前面简单的 \(\text{RAG}\) 实现很可能会在搜索步骤中遇到困难。因此,一个好主意是使用一个 \(\text{LLM}\) 将查询重写成一个有助于检索步骤获取正确信息的查询。例如,一条消息可能是:
用户问题:“我们明天有一个论文要交。我们得写一些关于动物的东西。我喜欢企鹅。我可以写它们。但我也可以写海豚。它们是动物吗?也许吧。我们写海豚吧。例如,它们生活在哪里?”
这实际上应该被重写成一个像这样的查询:
查询:“海豚生活在哪里”
这种重写行为可以通过提示(或通过 \(\text{API}\) 调用)来完成。例如,\(\text{Cohere}\) 的 \(\text{API}\) 为 \(\text{co.chat}\) 设有一个专门的查询重写模式。
多查询 \(\text{RAG}\)
Multi-query RAG
我们可以引入的下一个改进是扩展查询重写,使其能够搜索多个查询,如果回答特定问题需要多个查询的话。例如:
用户问题:“比较 \(\text{Nvidia}\) 在 \(\text{2020}\) 年和 \(\text{2023}\) 年的财务业绩”
我们可能会找到一份包含两年结果的文档,但更可能的情况是,我们最好进行两次搜索查询:
查询 \(\text{1}\):“\(\text{Nvidia 2020}\) 财务业绩” 查询 \(\text{2}\):“\(\text{Nvidia 2023}\) 财务业绩”
然后,我们将这两个查询的靠前结果呈现给模型,用于基于事实的生成。这里还有一个小的额外改进,是也赋予查询重写器一个选项,使其能够判断是否不需要搜索,以及是否可以直接自信地生成答案而不进行搜索。
多跳 \(\text{RAG}\)
Multi-hop RAG
一个更高级的问题可能需要一系列按顺序的查询。例如,一个问题可能是:
用户问题:“\(\text{2023}\) 年最大的汽车制造商是哪些?它们各自生产电动汽车 (\(\text{EVs}\)) 吗?”
为了回答这个问题,系统必须首先搜索:
步骤 \(\text{1}\),查询 \(\text{1}\):“\(\text{2023}\) 年最大的汽车制造商”
然后,在获取到这些信息(结果可能是丰田、大众和现代)之后,它应该提出后续问题:
步骤 \(\text{2}\),查询 \(\text{1}\):“丰田汽车公司电动汽车” 步骤 \(\text{2}\),查询 \(\text{2}\):“大众汽车集团电动汽车” 步骤 \(\text{2}\),查询 \(\text{3}\):“现代汽车公司电动汽车”
查询路由
Query routing
另一个增强功能是赋予模型搜索多个数据源的能力。例如,我们可以为模型指定:如果它收到了一个关于人力资源(\(\text{HR}\))的问题,它应该搜索公司的 \(\text{HR}\) 信息系统(例如 \(\text{Notion}\)),但如果问题是关于客户数据的,它应该搜索客户关系管理(\(\text{CRM}\))系统(例如 \(\text{Salesforce}\))。
智能体式
Agentic RAG
您现在可能已经注意到,前面提到的增强功能列表正在缓慢地将越来越多的责任委托给 \(\text{LLM}\),以解决越来越复杂的问题。这依赖于 \(\text{LLM}\) 衡量所需信息需求的能力以及其利用多个数据源的能力。\(\text{LLM}\) 的这种新性质开始越来越接近于一个作用于世界的智能体(\(\text{agent}\))。数据源现在也可以抽象成工具。例如,我们看到我们可以搜索 \(\text{Notion}\),同理,我们也应该能够发布到 \(\text{Notion}\)。
并非所有的 \(\text{LLM}\) 都具备这里提到的 \(\text{RAG}\) 能力。在撰写本文时,可能只有最大的托管模型才能尝试这种行为。值得庆幸的是,\(\text{Cohere}\) 的 \(\text{Command R+}\) 在这些任务上表现出色,并且也作为开源权重模型提供。
\(\text{RAG}\) 评估
RAG Evaluation
关于如何评估 \(\text{RAG}\) 模型,目前仍有持续的进展。一篇关于这个主题的优秀论文是《评估生成式搜索引擎中的可验证性》(\(\text{Evaluating verifiability in generative search engines}\))(\(\text{2023}\)),它对不同的生成式搜索系统进行了人工评估。它沿着四个轴评估结果:
- 流畅性 (\(\text{Fluency}\)) 生成的文本是否流畅且连贯。
- 感知效用 (\(\text{Perceived utility}\)) 生成的答案是否有帮助且信息丰富。
- 引用召回率 (\(\text{Citation recall}\)) 生成的关于外部世界的陈述中,完全由其引用支持的比例。
- 引用准确率 (\(\text{Citation precision}\)) 生成的引用中,支持其相关陈述的比例。
虽然人工评估总是首选,但也有一些方法试图自动化这些评估,即让一个有能力的 \(\text{LLM}\) 充当裁判(称为 \(\text{LLM}\)-作为-裁判),并沿着不同的轴对不同的生成内容进行评分。\(\text{Ragas}\) 就是一个完全执行此操作的软件库。它还对一些额外的有用指标进行评分,例如:
- 忠实度 (\(\text{Faithfulness}\)) 答案是否与提供的上下文一致。
- 答案相关性 (\(\text{Answer relevance}\)) 答案与问题的相关程度。
\(\text{Ragas}\) 文档网站提(https://docs.ragas.io/en/stable/)供了关于实际计算这些指标的公式的更多细节。
总结
在本章中,我们研究了使用语言模型的不同方法来改进现有搜索系统,甚至成为新的、更强大的搜索系统的核心。其中包括:
- 稠密检索 (\(\text{Dense retrieval}\)),它依赖于文本嵌入的相似性。这些系统嵌入一个搜索查询,并检索嵌入与该查询嵌入最近的文档。
- 重排序器 (\(\text{Rerankers}\)),这类系统(如 \(\text{monoBERT}\))查看一个查询和候选结果,并对每个文档与该查询的相关性进行评分。然后,这些相关性分数用于根据它们与查询的相关性对筛选后的结果进行排序,通常会产生改进的结果排名。
- \(\text{RAG}\),即搜索系统在管线的末端有一个生成式 \(\text{LLM}\),用于根据检索到的文档并引用来源来形成答案。
我们还研究了评估搜索系统的可能方法之一。平均精度均值(\(\text{Mean average precision}\))允许我们对搜索系统进行评分,以便在查询及其已知相关性的测试套件中进行比较。然而,评估 \(\text{RAG}\) 系统需要多个轴,例如忠实度、流畅性以及其他可以由人工或 \(\text{LLM}\)-作为-裁判评估的指标。
在下一章中,我们将探讨如何使语言模型具备多模态能力,不仅能对文本进行推理,还能对图像进行推理。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调