《Hands-On Large Language Models》第2章 词元与嵌入
第 \(\text{2}\) 章 词元与嵌入
Tokens and Embeddings
词元(\(\text{Tokens}\))和嵌入(\(\text{embeddings}\))是使用大型语言模型(\(\text{LLM}\))的两个核心概念。正如我们在第一章中所见,它们不仅对于理解语言 \(\text{AI}\) 的历史很重要,而且如果不能很好地理解词元和嵌入,我们就无法清晰地了解 \(\text{LLM}\) 是如何工作的、是如何构建的以及它们未来的发展方向,如图 \(\text{2}-1\) 所示。
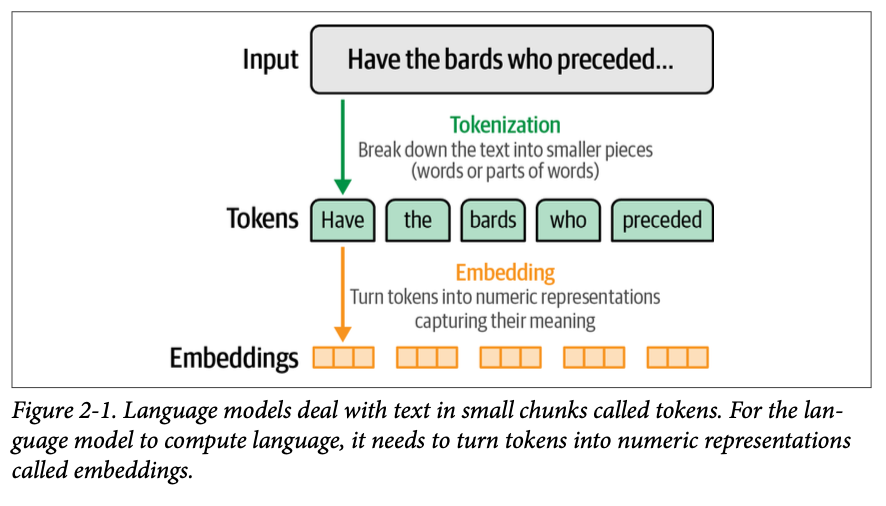
在本章中,我们将更仔细地研究什么是词元以及用于驱动 \(\text{LLM}\) 的分词方法。然后,我们将深入探讨在现代 \(\text{LLM}\) 之前出现的著名的 \(\text{word}2\text{vec}\) 嵌入方法,并了解它如何将词元嵌入的概念扩展到构建商业推荐系统,这些系统为我们使用的许多应用程序提供支持。最后,我们将从词元嵌入转向句子或文本嵌入,其中整个句子或文档可以拥有一个代表它的向量——从而支持语义搜索和主题建模等应用,我们将在本书的第二部分看到这些应用。
\(\text{LLM}\) 分词
LLM Tokenization
在撰写本文时,大多数人与语言模型交互的方式是通过一个网页演练场(\(\text{web playground}\)),它呈现了一个用户与语言模型之间的聊天界面。您可能会注意到,模型不会一次性生成所有输出响应;它实际上是一次生成一个词元。
但词元不仅仅是模型的输出,它们也是模型看待输入的方式。发送给模型的文本提示首先会被分解成词元,我们现在就来看看。
分词器如何准备语言模型的输入
How Tokenizers Prepare the Inputs to the Language Model
从外部来看,生成式 \(\text{LLM}\) 接收一个输入提示并生成一个响应,如图 \(\text{2}-2\) 所示。
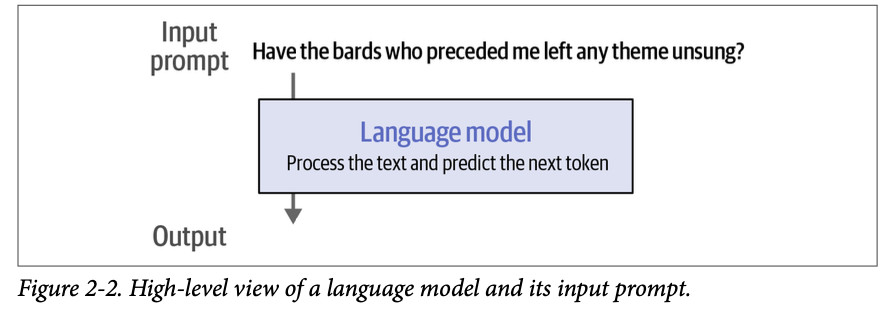
然而,在提示呈现给语言模型之前,它必须先经过一个分词器,将其分解成碎片。您可以在 \(\text{OpenAI Platform}\) 上找到一个展示 \(\text{GPT}-4\) 分词器的示例。如果我们向其输入文本,它会显示图 \(\text{2}-3\) 中的输出,其中每个词元都用不同的颜色显示。
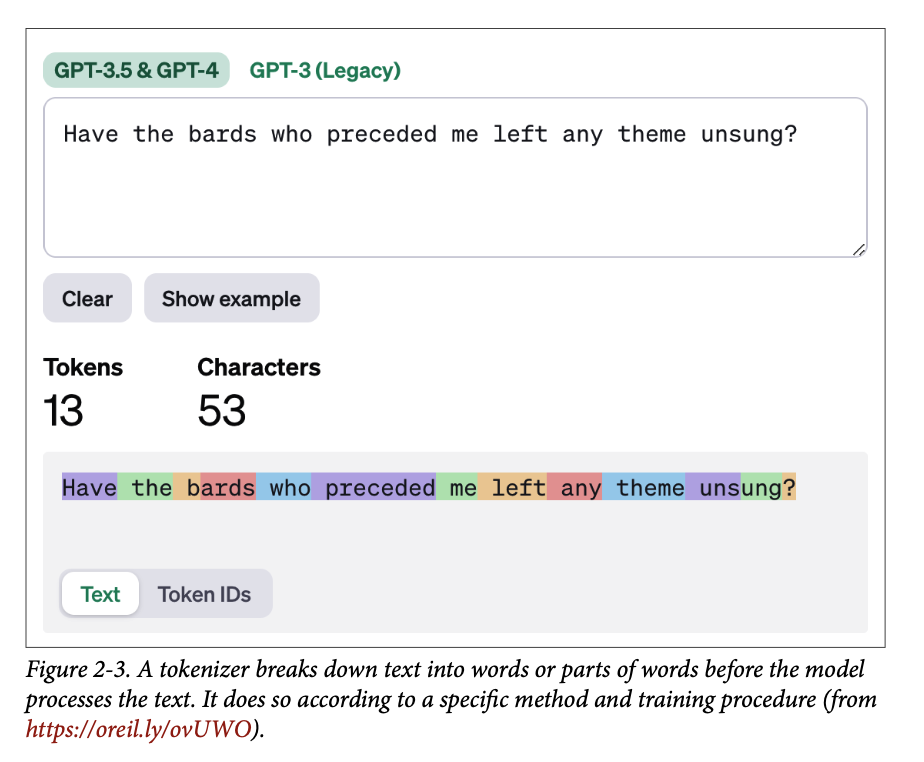
让我们看一个代码示例,自己来与这些词元进行交互。在这里,我们将下载一个 \(\text{LLM}\),并看看如何在用 \(\text{LLM}\) 生成文本之前对输入进行分词。
下载和运行 \(\text{LLM}\)
Downloading and Running an LLM
让我们从加载模型及其分词器开始,就像我们在第 \(\text{1}\) 章中所做的那样:
1 | from transformers import AutoModelForCausalLM, AutoTokenizer |
然后我们可以继续进行实际的生成。我们首先声明我们的提示,然后对其进行分词,然后将这些词元传递给模型,模型将生成其输出。在这种情况下,我们要求模型只生成 \(\text{20}\) 个新的词元:
1 | prompt = "Write an email apologizing to Sarah for the tragic gardening mishap. |
输出:
1 | <s> Write an email apologizing to Sarah for the tragic gardening mishap. |
粗体文本是模型生成的 \(\text{20}\) 个词元(Subject: My Sincere Apologies for the Gardening Mishap Dear)。
查看代码,我们可以看到模型实际上并没有接收文本提示。相反,分词器处理了输入提示,并在 \(\text{input\_ids}\) 变量中返回了模型所需的信息,模型将此作为其输入。
让我们打印 \(\text{input\_ids}\) 来看看它里面包含什么:
1 | tensor([[ 1, 14350, 385, 4876, 27746, 5281, 304, 19235, 363, 278, 25305, 293, |
这揭示了 \(\text{LLM}\) 响应的输入:一个整数序列,如图 \(\text{2}-4\) 所示。每个整数都是特定词元(字符、词或词的一部分)的唯一 \(\text{ID}\)。这些 \(\text{ID}\) 引用了分词器内部的一个表,该表包含它所知道的所有词元。
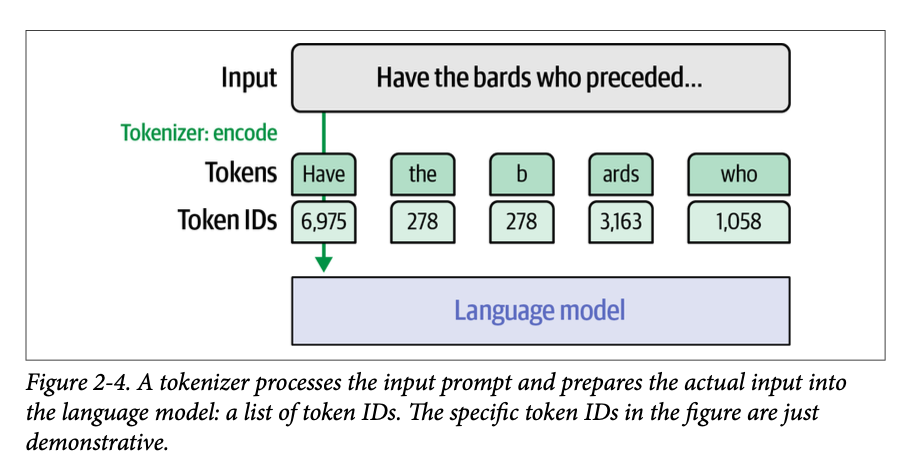
如果我们想检查这些 \(\text{ID}\),我们可以使用分词器的 \(\text{decode}\) 方法将 \(\text{ID}\) 翻译回我们可以阅读的文本:
1 | for id in input_ids[0]: |
这将打印出(每个词元在单独的一行):
1 | <s> |
这就是分词器分解我们输入提示的方式。请注意以下几点:
- 第一个词元是 \(\text{ID 1}\)(\(\text{<s>}\)),这是一个特殊词元,表示文本的开头。
- 一些词元是完整的词(例如,\(\text{Write}\)、\(\text{an}\)、\(\text{email}\))。
- 一些词元是词的一部分(例如,\(\text{apolog}\)、\(\text{izing}\)、\(\text{trag}\)、\(\text{ic}\))。
- 标点符号是它们自己的词元。
请注意空格字符本身没有自己的词元。相反,部分词元(如“\(\text{izing}\)”和“\(\text{ic}\)”)的开头有一个特殊的隐藏字符,表示它们与文本中前一个词元是连接在一起的。没有该特殊字符的词元被假定前面有一个空格。
在输出端,我们也可以通过打印 \(\text{generation\_output}\) 变量来检查模型生成的词元。这会显示输入词元以及输出词元(我们用粗体突出显示新词元):
1 | tensor([[ 1, 14350, 385, 4876, 27746, 5281, 304, 19235, 363, 278, |
这告诉我们模型生成了词元 \(\text{3323}\),即“\(\text{Sub}\)”,紧接着是词元 \(\text{622}\),“\(\text{ject}\)”。它们一起构成了“\(\text{Subject}\)”这个词。然后紧跟着是词元 \(\text{29901}\),它是冒号“\(\text{:}\)”……依此类推。就像在输入端一样,我们在输出端也需要分词器将词元 \(\text{ID}\) 翻译成实际的文本。我们使用分词器的 \(\text{decode}\) 方法来实现这一点。我们可以向它传递单个词元 \(\text{ID}\) 或 \(\text{ID}\) 列表:
1 | print(tokenizer.decode(3323)) |
输出:
1 | Sub |
分词器如何分解文本?
How Does the Tokenizer Break Down Text?
有三个主要因素决定了分词器如何分解输入提示。
首先,在模型设计时,模型的创建者会选择一种分词方法。流行的方法包括字节对编码 (\(\text{BPE}\))(\(\text{GPT}\) 模型广泛使用)和 \(\text{WordPiece}\)(\(\text{BERT}\) 使用)。这些方法相似之处在于它们都旨在优化一组高效的词元来表征一个文本数据集,但它们以不同的方式实现这一目标。
其次,在选择了方法之后,我们需要做出一些分词器设计选择,例如词汇量大小以及要使用的特殊词元。更多内容请参见第 \(\text{46}\) 页的“比较经过训练的 \(\text{LLM}\) 分词器”。
第三,分词器需要在一个特定的数据集上进行训练,以确定它可用于表征该数据集的最佳词汇表。即使我们设置了相同的方法和参数,在一个英文文本数据集上训练的分词器也会与在代码数据集或多语言文本数据集上训练的分词器不同。
如图 \(\text{2}-5\) 所示,除了用于将输入文本处理成语言模型外,分词器还用于语言模型的输出端,将生成的词元 \(\text{ID}\) 转换成与之关联的输出词语或词元。
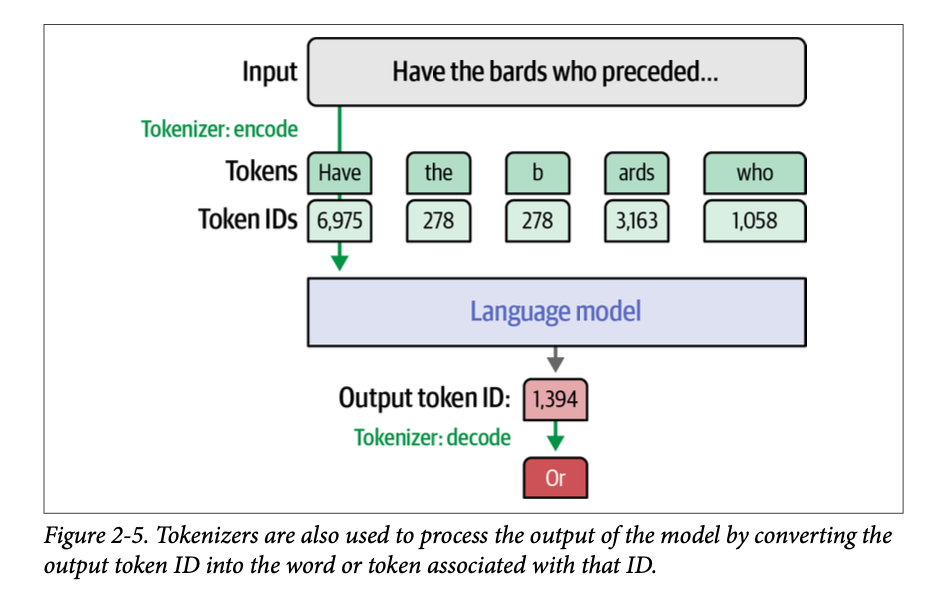
词语词元、子词词元、字符词元与字节词元
Word Versus Subword Versus Character Versus Byte Tokens
我们刚刚讨论的分词方案被称为子词分词(\(\text{subword tokenization}\))。它是最常用的分词方案,但并非唯一的一个。图 \(\text{2}-6\) 中展示了四种值得注意的分词方式。我们来回顾一下:
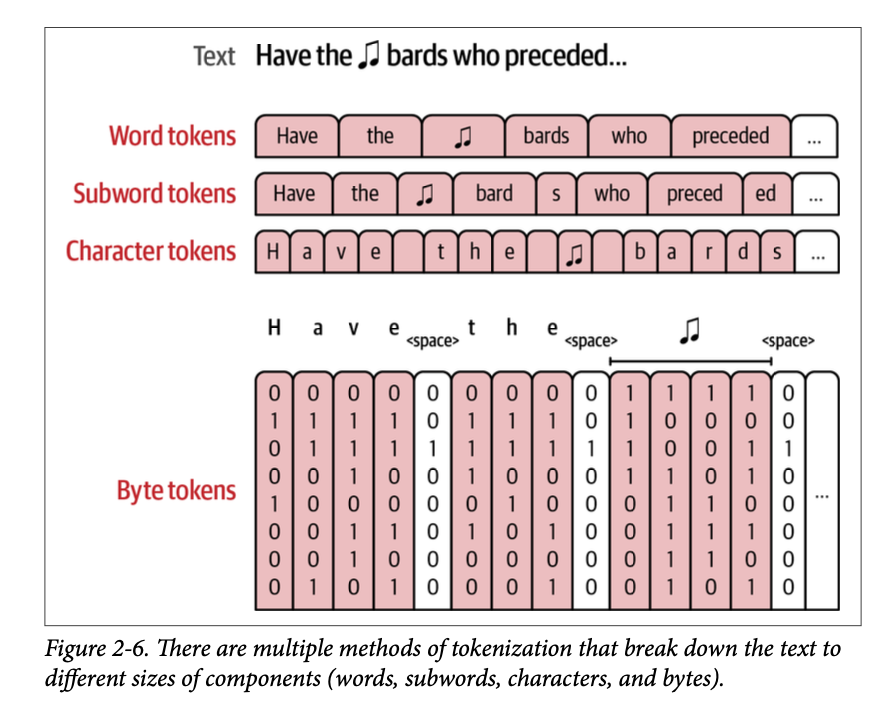
词语词元 (\(\text{Word tokens}\)) 这种方法在像 \(\text{word}2\text{vec}\) 这样的早期方法中很常见,但在 \(\text{NLP}\) 中使用得越来越少。然而,它的用处使其在 \(\text{NLP}\) 之外被用于推荐系统等用例,正如我们将在本章后面看到的那样。词语分词的一个挑战是分词器可能无法处理在训练后进入数据集的新词。这也导致词汇表中有许多词元之间只有微小差异(例如,\(\text{apology}\)、\(\text{apologize}\)、\(\text{apologetic}\)、\(\text{apologist}\))。后一个挑战通过子词分词得到解决,因为它有一个用于 \(\text{apolog}\) 的词元,然后是与其他许多词元常见的后缀词元(例如,\(\text{-y}\)、\(\text{-ize}\)、\(\text{-etic}\)、\(\text{-ist}\)),从而形成了更具表达力的词汇表。
子词词元 (\(\text{Subword tokens}\)) 这种方法包含完整词和部分词。除了前面提到的词汇表表达力之外,这种方法的另一个好处是它能够通过将新词元分解成更小的字符来表征新词,这些字符往往是词汇表的一部分。
字符词元 (\(\text{Character tokens}\)) 这是另一种可以成功处理新词的方法,因为它可以回退到原始字母。虽然这使得表征更容易分词,但它使建模更加困难。对于使用子词分词的模型,它可以将“\(\text{play}\)”表征为一个词元,而使用字符级别词元的模型除了对序列的其余部分进行建模外,还需要对信息进行建模以拼写出“\(\text{p}-\text{l}-\text{a}-\text{y}\)”。 子词词元比字符词元具有优势,因为它能够在 \(\text{Transformer}\) 模型有限的上下文长度内拟合更多的文本。因此,对于上下文长度为 \(\text{1,024}\) 的模型,使用子词分词可以拟合的文本量大约是使用字符词元的三倍(子词词元平均每个词元大约包含三个字符)。
字节词元 (\(\text{Byte tokens}\)) 另一种分词方法将词元分解成用于表征 \(\text{unicode}\) 字符的单个字节。像 《\(\text{CANINE}\):预训练一个高效的无分词编码器用于语言表征》 这样的论文概述了类似的方法,这也被称为“无分词编码”。其他著作,例如 《\(\text{ByT5}\):迈向预训练的字节到字节模型的无词元未来》,表明这是一种有竞争力的方法,尤其是在多语言场景中。
个人注:字节词元和字符词元的区别见《字节词元和字符词元的区别.md》
这里需要强调一个区别:一些子词分词器也会将字节作为词元包含在它们的词汇表中,作为当它们遇到无法以其他方式表征的字符时可以回退的最终构建块。例如,\(\text{GPT}-2\) 和 \(\text{RoBERTa}\) 分词器就采用了这种做法。但这并不会使它们成为无分词的字节级别分词器,因为它们不使用这些字节来表征所有内容,而只表征一个子集,正如我们将在下一节中看到的那样。
如果您想更深入地了解分词器,《设计大型语言模型应用》(《Designing Large Language Model Applications》 by Suhas Pai) 一书中对其进行了更详细的讨论。
比较经过训练的 \(\text{LLM}\) 分词器
Comparing Trained LLM Tokenizers
我们前面指出,有三个主要因素决定了分词器中出现的词元:分词方法、我们用于初始化分词器的参数和特殊词元,以及训练分词器的数据集。让我们比较和对比一些实际的、经过训练的分词器,看看这些选择如何改变它们的行为。这种比较将向我们展示较新的分词器是如何改变它们的行为以提高模型性能的,我们还将看到专业化模型(例如代码生成模型)通常如何需要专业化分词器。
我们将使用一些分词器对以下文本进行编码:
1 | text = |

这将使我们能够看到每个分词器如何处理多种不同类型的词元:
- 大小写。
- 非英语语言。
- 表情符号。
- 带有关键字和常用于缩进的空格的编程代码(例如在 \(\text{Python}\) 等语言中)。
- 数字和位数。
- 特殊词元。这些是具有表征文本以外角色的唯一词元。它们包括指示文本开始或文本结束的词元(模型就是通过这种方式向系统发出信号,表示它已完成此次生成),或我们稍后将看到的其他功能。
让我们从较旧的分词器到较新的分词器依次查看它们如何对这段文本进行分词,以及这可能说明了语言模型的哪些信息。我们将对文本进行分词,然后使用以下函数将每个词元以带颜色背景的方式打印出来:
1 | colors_list = [ |
\(\text{BERT}\) 基础模型(未区分大小写)(\(\text{2018}\))
HuggingFace 模型 \(\text{hub}\) 上的模型链接
分词方法:\(\text{WordPiece}\),在《日语和韩语语音搜索》(\(\text{Japanese and Korean voice search}\)) 中引入。 词汇量大小:\(\text{30,522}\) 特殊词元:
- \(\text{unk\_token}\) [UNK] 分词器没有特定编码的未知词元。
- \(\text{sep\_token}\) [SEP] 一种分隔符,可启用需要向模型提供两段文本的某些任务(在这种情况下,模型被称为交叉编码器)。一个例子是重排序,正如我们将在第 \(\text{8}\) 章中看到的那样。
- \(\text{pad\_token}\) [PAD] 一种填充词元,用于填充模型输入中未使用的位置(因为模型期望一定的输入长度,即其上下文大小)。
- \(\text{cls\_token}\) [CLS] 用于分类任务的特殊分类词元,正如我们将在第 \(\text{4}\) 章中看到的那样。
- \(\text{mask\_token}\) [MASK] 在训练过程中用于隐藏词元的掩码词元。
分词文本:

\(\text{BERT}\) 发布时有两个主要版本:区分大小写(\(\text{cased}\),保留大小写)和不区分大小写(\(\text{uncased}\),所有大写字母首先转换为小写字母)。对于不区分大小写(且更受欢迎)的 \(\text{BERT}\) 分词器版本,我们注意到以下几点:
- 换行符消失了,这使得模型无法感知编码在换行符中的信息(例如,聊天日志中每回合都在新的一行)。
- 所有文本都变成了小写。
- “\(\text{capitalization}\)”这个词被编码为两个子词元:\(\text{capital}\)
##ization。##字符用于表示该词元是一个部分词元,连接到它在文本中前面的词元。这也是一种指示空格位置的方法,因为假定前面没有##的词元前面有一个空格。 - 表情符号和中文字符消失了,被 \([\text{UNK}]\) 特殊词元取代,表示“未知词元”。
\(\text{BERT}\) 基础模型(区分大小写)(\(\text{2018}\))
HuggingFace 模型 \(\text{hub}\) 上的模型链接
分词方法:\(\text{WordPiece}\) 词汇量大小:\(\text{28,996}\) 特殊词元:与不区分大小写的版本相同
分词文本:

\(\text{BERT}\) 区分大小写版本的分词器主要的区别在于包含了大写词元。
请注意“\(\text{CAPITALIZATION}\)”现在被表征为八个词元:\(\text{CA}\)
##PI##TA##L####Z##AT##ION。两个 \(\text{BERT}\) 分词器都将输入文本包装在一个起始的 \(\text{[CLS]}\) 词元和一个结束的 \(\text{[SEP]}\) 词元之中。\(\text{[CLS]}\) 和 \(\text{[SEP]}\) 是用于包装输入文本的实用词元,它们有各自的用途。\(\text{[CLS]}\) 代表分类(\(\text{classification}\)),因为它有时用作句子分类的词元。\(\text{[SEP]}\) 代表分隔符(\(\text{separator}\)),因为它在某些需要向模型传递两个句子的应用中用于分隔句子(例如,在第 \(\text{8}\) 章中,我们将使用一个 \(\text{[SEP]}\) 词元来分隔查询文本和候选结果)。
\(\text{GPT}-2\) (\(\text{2019}\))
HuggingFace 模型 \(\text{hub}\) 上的模型链接
分词方法:字节对编码 (\(\text{BPE}\)),在《使用子词单元的稀有词神经机器翻译》(\(\text{Neural machine translation of rare words with subword units}\)) 中引入。
词汇量大小:\(\text{50,257}\)
特殊词元:\(\text{<|endoftext|>}\)

对于 \(\text{GPT}-2\) 分词器,我们注意到以下几点:
换行符在分词器中得到了表征。
大小写得以保留,“\(\text{CAPITALIZATION}\)”一词被表征为四个词元。
🎵鸟 字符现在每个都被多个词元表征。虽然我们看到这些词元被打印为 字符,但它们实际上代表了不同的词元。例如,🎵 表情符号被分解成词元 \(\text{ID}\) 为 \(\text{8582}\)、\(\text{236}\) 和 \(\text{113}\) 的词元。分词器成功地从这些词元重构了原始字符。我们可以通过打印 \(\text{tokenizer.decode([8582, 236, 113])}\) 来看到这一点,它会打印出 🎵。
两个制表符被表征为两个词元(词汇表中的词元编号都是 \(\text{197}\)),而四个空格被表征为三个词元(编号都是 \(\text{220}\)),最后一个空格是闭合引号字符词元的一部分。
空白字符的意义是什么?它们对于模型理解或生成代码非常重要。一个使用单个词元来表征四个连续空白字符的模型,更适合\(\text{Python}\) 代码数据集。虽然模型也可以将其表征为四个不同的词元,但这会使建模更加困难,因为模型需要跟踪缩进级别,这通常会导致性能下降。这是一个分词选择如何帮助模型在特定任务上改进的例子。
\(\text{Flan-T5}\) (\(\text{2022}\))
分词方法:\(\text{Flan-T5}\) 使用一个名为 \(\text{SentencePiece}\) 的分词器实现,它在《\(\text{SentencePiece}\):一个用于神经文本处理的简单且语言无关的子词分词器和反分词器》 中引入,支持 \(\text{BPE}\) 和一元语言模型(\(\text{unigram language model}\),在《子词正则化:使用多个子词候选改进神经网络翻译模型》 中描述)。
词汇量大小:\(\text{32,100}\)
特殊词元:
- \(\text{unk\_token}\) \(\text{<unk>}\)
- \(\text{pad\_token}\) \(\text{<pad>}\)
分词文本:

\(\text{Flan-T5}\) 系列模型使用 \(\text{SentencePiece}\) 方法。我们注意到以下几点:
- 没有换行符或空白词元;这将使模型处理代码变得具有挑战性。
- 表情符号和中文字符都被 \(\text{<unk>}\) 词元取代,使模型完全无法识别它们。
\(\text{GPT}-4\) (\(\text{2023}\))
分词方法:\(\text{BPE}\)
词汇量大小:略超 \(\text{10}\) 万
特殊词元:
\(\text{<|endoftext|>}\)
中间填充词元(\(\text{Fill in the middle tokens}\))。这三个词元使 \(\text{LLM}\) 能够在不仅给定它之前的文本,而且考虑到它之后的文本的情况下生成补全。这种方法在论文《高效训练语言模型以填充中间部分》(\(\text{Efficient training of language models to fill in the middle}\)) 中有更详细的解释;其确切细节超出了本书的范围。这些特殊词元是:
- \(\text{<|fim\_prefix|>}\)
- \(\text{<|fim\_middle|>}\)
- \(\text{<|fim\_suffix|>}\)
分词文本:

\(\text{GPT}-4\) 分词器的行为与其祖先 \(\text{GPT}-2\) 分词器相似。一些不同之处在于:
- \(\text{GPT}-4\) 分词器将四个空格表征为单个词元。事实上,它为每个最多 \(\text{83}\) 个空白字符的序列都有一个特定的词元。
- \(\text{Python}\) 关键字 \(\text{elif}\) 在 \(\text{GPT}-4\) 中有自己的词元。这一点和前一点都源于模型除了自然语言之外对代码的关注。
- \(\text{GPT}-4\) 分词器使用更少的词元来表征大多数词语。这里的例子包括“\(\text{CAPITALIZATION}\)”(两个词元,而 \(\text{GPT}-2\) 是四个)和“\(\text{tokens}\)”(一个词元,而 \(\text{GPT}-2\) 是三个)。
- 请回顾我们关于 \(\text{GPT}-2\) 分词器中关于 🎵 词元所说的内容。
\(\text{StarCoder}2\) (\(\text{2024}\))
\(\text{StarCoder}2\) 是一个 \(\text{150}\) 亿参数的模型,专注于生成代码,在论文《\(\text{StarCoder 2}\) 和 \(\text{stack v2}\):下一代》 中有所描述,它延续了《\(\text{StarCoder}\):愿源代码与你同在!(may the source be with you!)》(https://arxiv.org/abs/2305.06161) 中描述的原始 \(\text{StarCoder}\) 的工作。
分词方法:字节对编码 (\(\text{BPE}\))
词汇量大小:\(\text{49,152}\)
特殊词元示例:
- \(\text{<|endoftext|>}\)
- 中间填充词元(\(\text{Fill in the middle tokens}\)):
- \(\text{<fim\_prefix>}\)
- \(\text{<fim\_middle>}\)
- \(\text{<fim\_suffix>}\)
- \(\text{<fim\_pad>}\)
- 在表征代码时,管理上下文非常重要。一个文件可能会调用在不同文件中定义的函数。因此,模型需要一种方法来识别同一代码仓库中不同文件中的代码,同时区分不同仓库中的代码。这就是为什么 \(\text{StarCoder}2\) 为仓库名称和文件名使用特殊词元:
- \(\text{<filename>}\)
- \(\text{<reponame>}\)
- \(\text{<gh\_stars>}\)
分词文本:

这是一个专注于代码生成的编码器:
- 与 \(\text{GPT}-4\) 类似,它将空白字符序列编码为单个词元。
- 与我们迄今为止看到的所有模型的主要区别在于,它将每个数字分配了自己的词元(因此 \(\text{600}\) 变成了 \(\text{6}\) \(\text{0}\) \(\text{0}\))。这里的假设是,这将有助于更好地表征数字和数学。例如,在 GPT-2 中,数字 870 被表征为单个词元。但 \(\text{871}\) 被表征为两个词元(\(\text{8}\) 和 \(\text{71}\))。您可以直观地看到这可能会如何使模型感到困惑,以及它如何表征数字。
\(\text{Galactica}\)
论文《\(\text{Galactica}\):一个用于科学的大型语言模型》 中描述的 \(\text{Galactica}\) 模型专注于科学知识,并在许多科学论文、参考资料和知识库上进行训练。它特别关注分词,使其对它所表征的数据集的细微差别更加敏感。例如,它包含了用于引文、推理、数学、氨基酸序列和 \(\text{DNA}\) 序列的特殊词元。
分词方法:字节对编码 (\(\text{BPE}\))
词汇量大小:\(\text{50,000}\)
特殊词元:
- \(\text{<s>}\)
- \(\text{<pad>}\)
- \(\text{</s>}\)
- \(\text{<unk>}\)
- 参考文献(\(\text{References}\)):引文被包裹在两个特殊词元中:
- \(\text{[START\_REF]}\)
- \(\text{[END\_REF]}\)
- 论文中的一个用法示例是:\(\text{Recurrent neural net}\text{works, long short-term memory [START\_REF]Long Short-Term Memory, Hochreiter[END\_REF]}\)
- 逐步推理(\(\text{Step-by-step reasoning}\)):
- \(\text{<work>}\) 是一个有趣的词元,模型用它来进行思维链推理(\(\text{chain-of-thought rea}\text{soning}\))。
分词文本:

\(\text{Galactica}\) 分词器的行为与 \(\text{StarCoder}2\) 相似,因为它也考虑到了代码。它也以相同的方式编码空格:为不同长度的空格序列分配单个词元。然而,它的不同之处在于它也对制表符执行了相同的操作。因此,在我们目前所见的所有分词器中,它是唯一一个为由两个制表符(\t\t)组成的字符串分配单个词元的分词器。
\(\text{Phi}-3\)(和 \(\text{Llama 2}\))
我们在本书中关注的 \(\text{Phi}-3\) 模型重用了 \(\text{Llama 2}\) 的分词器,但添加了一些特殊词元。
分词方法:字节对编码 (\(\text{BPE}\))
词汇量大小:\(\text{32,000}\)
特殊词元:
\(\text{<|endoftext|>}\)
聊天词元(\(\text{Chat tokens}\)):随着聊天 \(\text{LLM}\) 在 \(\text{2023}\) 年的流行,\(\text{LLM}\) 的对话性质开始成为一个主要的用例。分词器通过添加指示对话回合和每个说话者角色的词元来适应这一方向。这些特殊词元包括:
- \(\text{<|user|>}\)
- \(\text{<|assistant|>}\)
- \(\text{<|system|>}\)
我们现在可以并排查看所有这些示例,来回顾我们的旅程。


分词器属性
Tokenizer Properties
前面对经过训练的分词器的导览展示了实际分词器相互之间存在许多不同之处。但是,是什么决定了它们的分词行为呢?有三组主要的设计选择决定了分词器将如何分解文本:分词方法、初始化参数以及分词器所针对的数据领域。
分词方法
正如我们所见,有多种分词方法,其中字节对编码 (\(\text{BPE}\)) 是更流行的一种。这些方法中的每一种都概述了一种算法,用于如何选择一组合适的词元来表征一个数据集。您可以在 \(\text{Hugging Face}\) 总结分词器的页面上找到所有这些方法的精彩概述。
分词器参数
在选择了分词方法之后,\(\text{LLM}\) 设计者需要对分词器的参数做出一些决定。其中包括:
词汇量大小 (\(\text{Vocabulary size}\)) 要在分词器的词汇表中保留多少个词元?(\(\text{30K}\) 和 \(\text{50K}\) 经常被用作词汇量大小的值,但我们越来越多地看到更大的尺寸,例如 \(\text{100K}\)。)
特殊词元 (\(\text{Special tokens}\)) 我们希望模型跟踪哪些特殊词元?我们可以根据需要添加任意数量的特殊词元,特别是如果我们要为特殊用例构建 \(\text{LLM}\) 时。常见的选择包括:
- 文本开始词元(例如,\(\text{<s>}\))
- 文本结束词元
- 填充词元
- 未知词元
- \(\text{CLS}\) 词元
- 掩码词元
除了这些之外,\(\text{LLM}\) 设计者还可以添加有助于更好地建模他们试图关注的问题领域的词元,正如我们在 \(\text{Galactica}\) 的 \(\text{<work>}\) 和 \(\text{[START\_REF]}\) 词元中所看到的那样。
大小写 (\(\text{Capitalization}\)) 在像英语这样的语言中,我们希望如何处理大小写?我们应该将所有内容都转换为小写吗?(名称的首字母大写通常带有有用的信息,但我们是否想在词汇表空间上浪费用于全大写版本词语的词元?)
数据的领域
即使我们选择了相同的方法和参数,分词器的行为也会因为训练所用的数据集而不同(甚至在我们开始模型训练之前)。前面提到的分词方法通过优化词汇表来表征特定数据集而发挥作用。从我们的导览中,我们已经看到这对代码和多语言文本等数据集产生了怎样的影响。

例如,对于代码,我们已经看到一个专注于文本的分词器可能会像这样对缩进空格进行分词(我们将用颜色突出显示一些词元):
这对一个专注于代码的模型来说可能不是最优的。通过做出不同的分词选择,专注于代码的模型通常会得到改进:
这些分词选择使模型的工作变得更容易,从而使其性能改进的可能性更高。
您可以在 \(\text{Hugging Face}\) 课程的分词器部分和《基于 \(\text{Transformer}\) 的自然语言处理(修订版)》(Natural Language Processing with Transformers, Revised Edition)(https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) 中找到关于训练分词器的更详细教程。
词元嵌入
Token Embeddings
既然我们理解了分词,我们就解决了向语言模型表征语言问题的一部分。从这个意义上说,语言是词元的序列。如果我们在一个足够大的词元集上训练一个足够好的模型,它就开始捕获训练数据集中出现的复杂模式:
- 如果训练数据包含大量的英文文本,这种模式就会表现为模型能够表征和生成英语。
- 如果训练数据包含事实信息(例如 \(\text{Wikipedia}\)),模型将具备生成一些事实信息的能力(参见下面的注释)。
这块拼图的下一部分是为这些词元找到最佳的数值表征,模型可以使用这些表征来计算和正确地建模文本中的模式。这些模式向我们展示为模型在特定语言中的连贯性、编程能力,或我们期望语言模型具备的不断增长的能力列表中的任何一项。
正如我们在第 \(\text{1}\) 章中看到的,这就是嵌入(\(\text{embeddings}\))的含义。它们是用于捕获语言中的含义和模式的数值表征空间。
哎呀!然而,达到语言连贯性和优于平均水平的事实生成的良好阈值开始带来了一个新的问题。一些用户开始信任模型的事实生成能力(例如,在 \(\text{2023}\) 年初,一些语言模型被称为“\(\text{Google}\) 杀手”)。但高级用户很快就认识到,单独的生成模型并不是可靠的搜索引擎。这导致了检索增强生成( retrieval-augmented generation)) (\(\text{RAG}\)) 的兴起,它结合了搜索和 \(\text{LLM}\)。我们将在第 \(\text{8}\) 章中更详细地介绍 \(\text{RAG}\)。
语言模型为其分词器的词汇表持有嵌入
A Language Model Holds Embeddings for the Vocabulary of Its Tokenizer
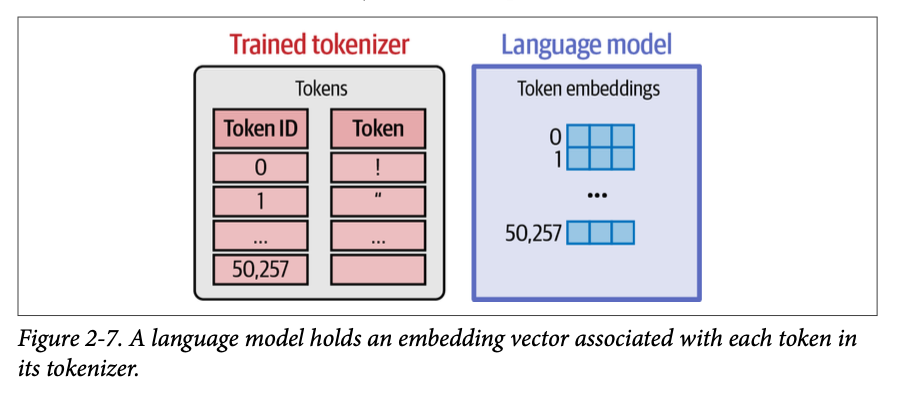
在分词器被初始化和训练之后,它随后被用于其关联语言模型的训练过程中。这就是为什么一个预训练的语言模型与其分词器是链接在一起的,并且无法在不进行训练的情况下使用不同的分词器。
如图 \(\text{2}-7\) 所示,语言模型为分词器词汇表中的每个词元持有一个嵌入向量。当我们下载一个预训练语言模型时,模型的一部分就是这个嵌入矩阵,它保存了所有这些向量。
在训练过程开始之前,这些向量会像模型的其余权重一样随机初始化,但训练过程会为它们分配值,使它们能够执行训练它们所要完成的有用行为。
使用语言模型创建情境化词嵌入
Creating Contextualized Word Embeddings with Language Models
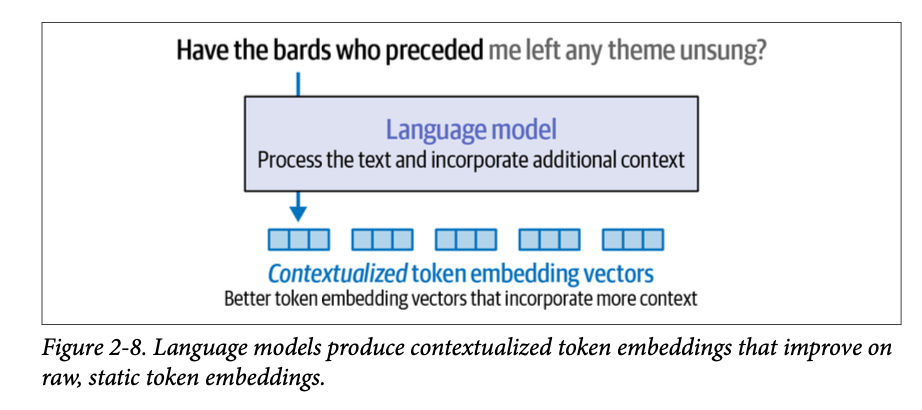
既然我们已经介绍了词元嵌入作为语言模型的输入,接下来我们看看语言模型如何创建更好的词元嵌入。这是使用语言模型进行文本表征的主要方式之一。它增强了诸如命名实体识别(named-entity recognition)或抽取式文本摘要(通过突出显示文本中最重要的部分来总结长文本,而不是生成新的摘要文本)等应用的能力。
语言模型不是用一个静态向量来表征每个词元或词语,而是创建情境化词嵌入(\(\text{contextualized word embeddings}\),如图 \(\text{2}-8\) 所示),它根据一个词的上下文用一个不同的向量来表征它。然后,这些向量可以被其他系统用于各种任务。除了我们上一段提到的文本应用之外,这些情境化向量例如还驱动着像 \(\text{DALL}\cdot\text{E}\)、\(\text{Midjourney}\) 和 \(\text{Stable Diffusion}\) 这样的 \(\text{AI}\) 图像生成系统。
让我们看看如何生成情境化词嵌入;现在您应该对大部分代码都比较熟悉了:
1 | from transformers import AutoModel, AutoTokenizer |
我们在这里使用的模型叫做 \(\text{DeBERTa v3}\),在撰写本文时,它是性能最佳的词元嵌入语言模型之一,同时体积小且效率高。它在论文《\(\text{DeBERTaV3}\):使用 \(\text{ELECTRA}\) 式预训练梯度解耦嵌入共享改进 \(\text{DeBERTa}\)》 中有所描述。
这段代码下载了一个预训练的分词器和模型,然后用它们来处理字符串“\(\text{Hello world}\)”。模型的输出随后保存在 \(\text{output}\) 变量中。
我们首先打印 \(\text{output}\) 变量的维度来检查它(我们期望它是一个多维数组):
1 | output.shape |
这会打印出:
1 | torch.Size([1, 4, 384]) |
跳过第一维,我们可以将其解读为四个词元,每个词元都嵌入在一个包含 \(\text{384}\) 个值的向量中。第一维是批次维度(\(\text{batch dimension}\)),用于当我们希望同时向模型发送多条输入句子时(例如在训练时),它们会同时被处理,从而加快了处理过程。
但是这四个向量是什么呢?分词器是将这两个词分成了四个词元,还是发生了其他事情?我们可以使用我们所学的关于分词器的知识来检查它们:
1 | for token in tokens['input_ids'][0]: |
这会打印出:
1 | [CLS] |
这个特定的分词器和模型是通过在字符串的开头和结尾添加 \(\text{[CLS]}\) 和 \(\text{[SEP]}\) 词元来操作的。
我们的语言模型现在已经处理了文本输入。其输出结果如下:
1 | tensor([[ |
这是语言模型的原始输出。大型语言模型的应用都是构建在像这样的输出之上的。
我们在图 \(\text{2}-9\) 中概述了语言模型的输入分词和生成的输出。从技术上讲,从词元 \(\text{ID}\) 转换为原始嵌入是语言模型内部发生的第一步。
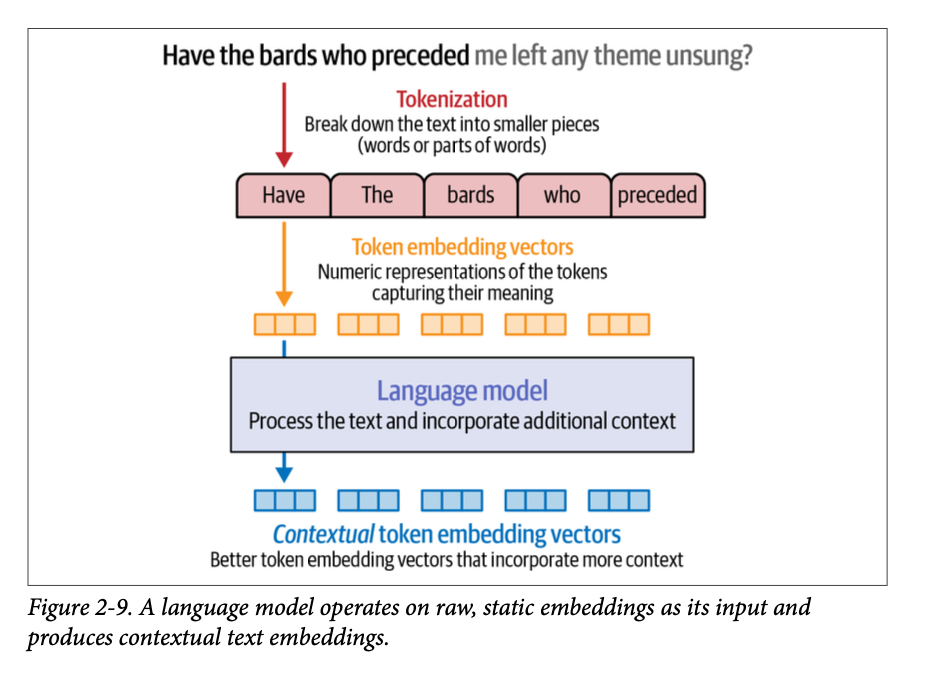
像这样的可视化对于下一章我们开始研究基于 \(\text{Transformer}\) 的 \(\text{LLM}\) 如何工作时至关重要。
文本嵌入(用于句子和整个文档)
Text Embeddings (for Sentences and Whole Documents)
虽然词元嵌入是 \(\text{LLM}\) 运行的关键,但许多 \(\text{LLM}\) 应用程序需要对整个句子、段落,甚至是文本文档进行操作。这催生了特殊语言模型,它们可以生成文本嵌入——一个单一的向量来表征比单个词元更长的一段文本。
我们可以将文本嵌入模型视为接收一段文本,并最终生成一个单一向量,该向量以某种有用的形式表征该文本并捕获其含义。图 \(\text{2}-10\) 展示了这一过程。
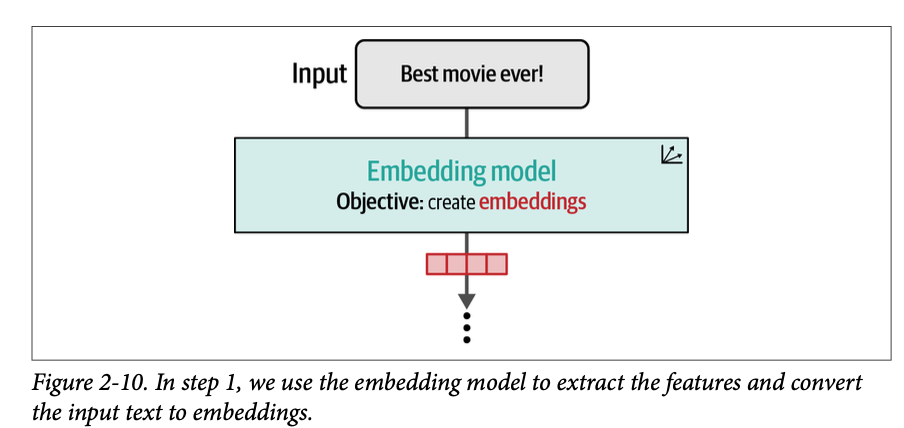
生成文本嵌入向量有多种方法。最常见的方法之一是平均模型生成的所有词元嵌入的值。然而,高质量的文本嵌入模型往往是专门针对文本嵌入任务进行训练的。
我们可以使用 \(\text{sentence}-\text{transformers}\) 来生成文本嵌入,这是一个用于利用预训练嵌入模型的流行软件包。像上一章的 \(\text{transformers}\) 一样,该软件包可用于加载公开可用的模型。为了说明如何创建嵌入,我们使用 \(\text{all-mpnet-base-v2}\) 模型。请注意,在第 \(\text{4}\) 章中,我们将进一步探讨如何为您的任务选择一个嵌入模型。
1 | from sentence_transformers import SentenceTransformer |
嵌入向量的数值数量,即维度,取决于底层的嵌入模型。让我们查看我们模型的维度:
1 | vector.shape |
1 | (768,) |
现在,这个句子被编码在这一个维度为 \(\text{768}\) 个数值的向量中。在本书的第二部分,当我们开始研究应用程序时,我们将看到这些文本嵌入向量在支持从分类到语义搜索再到 \(\text{RAG}\) 的一切应用中的巨大作用。
超越 \(\text{LLM}\) 的词嵌入
Word Embeddings Beyond LLMs
嵌入甚至在文本和语言生成之外也很有用。事实证明,嵌入,或者说为对象分配有意义的向量表征,在许多领域都很有用,包括推荐引擎和机器人技术。在本节中,我们将介绍如何使用预训练的 \(\text{word}2\text{vec}\) 嵌入,并简要介绍该方法如何创建词嵌入。了解 \(\text{word}2\text{vec}\) 是如何训练的,将为您学习第 \(\text{10}\) 章中的对比训练打下基础。然后,在接下来的部分中,我们将看到这些嵌入如何用于推荐系统。
使用预训练词嵌入
Using pretrained Word Embeddings
让我们看看如何使用 \(\text{Gensim}\) 库下载预训练的词嵌入(例如 \(\text{word}2\text{vec}\) 或 \(\text{GloVe}\)):
1 | import gensim.downloader as api |
在这里,我们下载了在 \(\text{Wikipedia}\) 上训练的大量词语的嵌入。然后,我们可以通过查看特定词语(例如“\(\text{king}\)”)的最近邻来探索嵌入空间:
1 | model.most_similar([model['king']], topn=11) |
输出:
1 | [('king', 1.0000001192092896), |
\(\text{Word}2\text{vec}\) 算法与对比训练
The Word2vec Algorithm and Contrastive Training
论文《向量空间中词语表征的有效估计》(\(\text{Efficient estimation of word representations in vector space}\)) 中描述的 \(\text{word}2\text{vec}\) 算法在《\(\text{Illustrated Word}2\text{vec}\)》 一书中有详细描述。我们将中心思想浓缩于此,因为我们将在下一节讨论创建推荐引擎嵌入的方法时以此为基础。
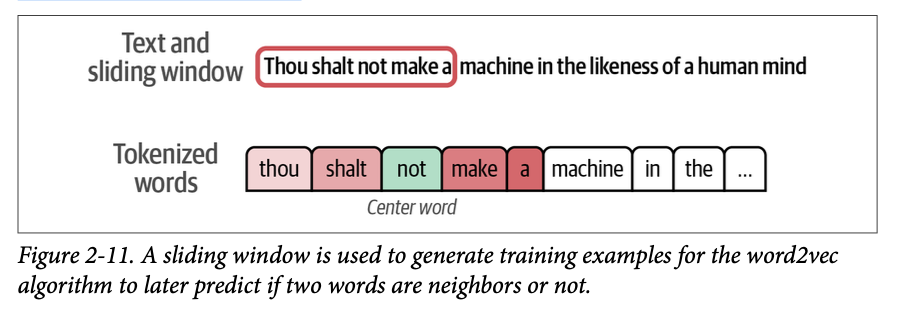
就像 \(\text{LLM}\) 一样,\(\text{word}2\text{vec}\) 是在从文本生成的示例上进行训练的。例如,假设我们有弗兰克·赫伯特(\(\text{Frank Herbert}\))的《沙丘》小说中的文本:“\(\text{Thou shalt not make a machine in the likeness of a human mind}\)”(你不可制造一台模仿人类心智的机器)。该算法使用一个滑动窗口来生成训练示例。例如,我们可以设置窗口大小为二,这意味着我们考虑中心词两侧的两个邻居。
嵌入是从一个分类任务中生成的。该任务用于训练一个神经网络来预测词语是否通常出现在同一上下文中(这里的“上下文”指的是在我们建模的训练数据集中的许多句子中)。我们可以将其视为一个接收两个词语并输出 \(\text{1}\)(如果它们倾向于出现在同一上下文中)或 \(\text{0}\)(如果它们不出现)的神经网络。
在滑动窗口的第一个位置,我们可以生成四个训练示例,如图 \(\text{2}-11\) 所示。
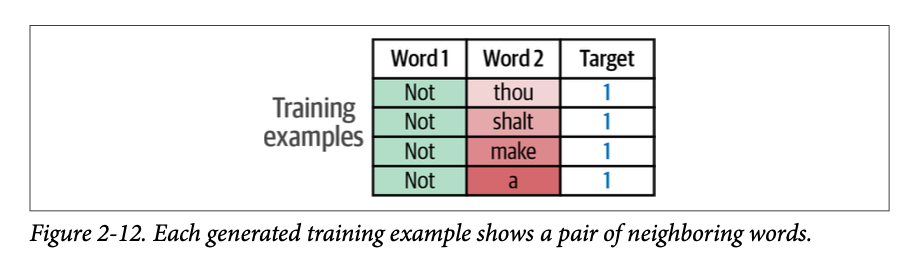
在生成的每个训练示例中,中心词用作一个输入,其每个邻居在每个训练示例中都是一个不同的第二个输入。我们期望最终训练出的模型能够对这种邻居关系进行分类,并在它接收到的两个输入词语确实是邻居时输出 \(\text{1}\)。这些训练示例如图 \(\text{2}-12\) 所示。
然而,如果我们的数据集目标值只有 \(\text{1}\),那么模型可以通过一直输出 \(\text{1}\) 来作弊并取得满分。为了避免这种情况,我们需要用不典型为邻居的词语示例来丰富我们的训练数据集。这些被称为负面示例(\(\text{negative examples}\)),如图 \(\text{2}-13\) 所示。
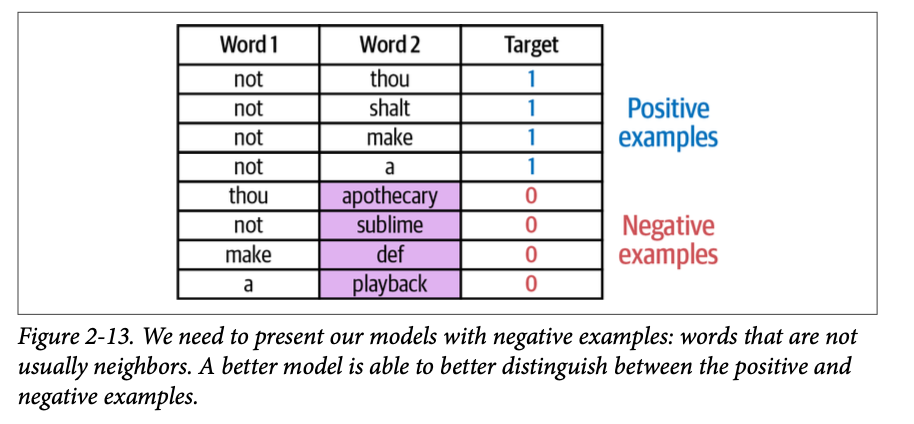
事实证明,我们在选择负面示例时不必过于科学。许多有用的模型都是通过简单地从随机生成的示例中检测正面示例的能力而产生的(灵感来源于一个重要的思想,称为噪声对比估计 (\(\text{noise-contrastive estimation}\)),并在《噪声对比估计:一种用于非标准化统计模型的新的估计原理》 中有所描述)。因此在这种情况下,我们获取随机词语并将它们添加到数据集中,并指出它们不是邻居(因此当模型看到它们时应该输出 \(\text{0}\))。
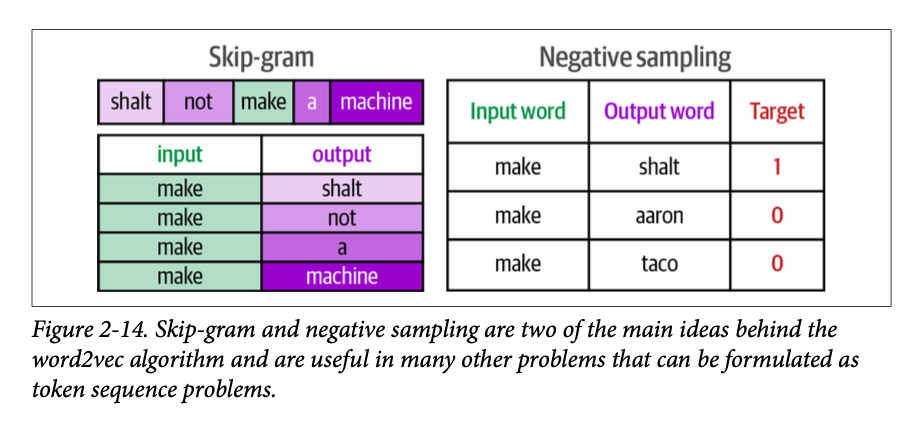
通过这种方式,我们看到了 \(\text{word}2\text{vec}\) 的两个主要概念(图 \(\text{2}-14\)):跳字模型(\(\text{skip-gram}\),选择相邻词语的方法),以及负采样(\(\text{negative sampling}\),通过从数据集中随机采样添加负面示例)。
我们可以从运行的文本中生成数百万甚至数十亿个这样的训练示例。在继续在这个数据集上训练神经网络之前,我们需要做出一些分词决策,就像我们对 \(\text{LLM}\) 分词器所看到的那样,这些决策包括如何处理大小写和标点符号,以及我们希望词汇表中有多少个词元。
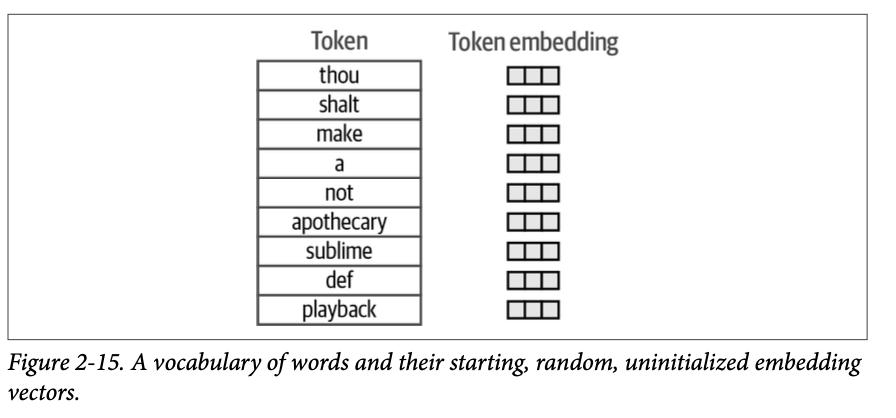
然后我们为每个词元创建一个嵌入向量,并对其进行随机初始化,如图 \(\text{2}-15\) 所示。在实践中,这是一个维度为 \(\text{vocab\_size} \times \text{embedding\_dimensions}\) 的矩阵。
然后,模型在每个示例上进行训练,以接收两个嵌入向量并预测它们是否相关。我们可以在图 \(\text{2}-16\) 中看到它的样子。

根据其预测是否正确,典型的机器学习训练步骤会更新嵌入,以便下一次向模型展示这两个向量时,它有更大的机会是正确的。到训练过程结束时,我们就为词汇表中的所有词元获得了更好的嵌入。
这种模型接收两个向量并预测它们是否具有某种关系的思想是机器学习中最强大的思想之一,并且一次又一次地证明它在语言模型中运作得非常好。这就是为什么我们用第 \(\text{10}\) 章专门介绍这个概念以及它如何为特定任务(如句子嵌入和检索)优化语言模型。
同样的想法也是弥合文本和图像等模态的核心,这对于 \(\text{AI}\) 图像生成模型至关重要,正如我们将在关于多模态模型的第 \(\text{9}\) 章中看到的那样。在这种公式中,模型会得到一张图像和一个标题,它应该预测该标题是否描述了该图像。
推荐系统的嵌入
Embeddings for Recommendation Systems
正如我们所提到的,嵌入的概念在许多其他领域都很有用。例如,在工业界,它被广泛用于推荐系统。
通过嵌入推荐歌曲
Recommending Songs by Embeddings
在本节中,我们将使用 \(\text{word}2\text{vec}\) 算法,利用人工制作的音乐播放列表来嵌入歌曲。想象一下,我们将每首歌曲视为一个词语或词元,并将每个播放列表视为一个句子。然后,这些嵌入可用于推荐在播放列表中经常一起出现的相似歌曲。
我们将使用由康奈尔大学的 \(\text{Shuo Chen}\) 收集的数据集。它包含了美国数百个电台的播放列表。图 \(\text{2}-17\) 展示了这个数据集。

在我们研究它是如何构建的之前,让我们先演示一下最终产品。因此,让我们给它几首歌曲,看看它会推荐什么。
让我们从给出迈克尔·杰克逊的“\(\text{Billie Jean}\)”开始,这首歌的 \(\text{ID}\) 是 \(\text{3822}\):
1 | # We will define and explore this function in detail below |

看起来很合理。麦当娜(\(\text{Madonna}\))、普林斯(\(\text{Prince}\))以及迈克尔·杰克逊(\(\text{Michael Jackson}\))的其他歌曲都是最近的邻居。
让我们从流行乐转向说唱乐,看看 \(\text{2Pac}\) 的“\(\text{California Love}\)” 的邻居:
1 | print_recommendations(842) |

又是一个非常合理的列表!既然我们知道它有效,那么让我们看看如何构建这样一个系统。
训练歌曲嵌入模型
Training a Song Embedding Model
我们将从加载包含歌曲播放列表以及每首歌曲的元数据(例如它的标题和艺术家)的数据集开始:
1 | import pandas as pd |
现在我们已经保存了它们,让我们检查一下 \(\text{playlists}\) 列表。其中的每个元素都是一个包含歌曲 \(\text{ID}\) 列表的播放列表:
1 | print( 'Playlist #1:\n ', playlists[0], '\n') |

让我们来训练模型:
1 | from gensim.models import Word2Vec |
这需要一两分钟来训练,并为我们拥有的每首歌曲计算出嵌入。现在,我们可以使用这些嵌入来查找相似的歌曲,就像我们之前对词语所做的那样:
1 | song_id = 2172 |
输出:

这是嵌入与歌曲 \(\text{2172}\) 最相似的歌曲列表。
在这种情况下,这首歌是:
1 | print(songs_df.iloc[2172]) |

这产生了全部属于同一重金属和硬摇滚流派的推荐:
1 | import numpy as np |

总结
在本章中,我们涵盖了 \(\text{LLM}\) 的词元、分词器,以及使用词元嵌入的有用方法。这为我们准备在下一章中更仔细地研究语言模型,同时也为我们打开了学习嵌入如何用于语言模型之外的大门。
我们探讨了分词器是如何处理 \(\text{LLM}\) 输入的第一步,将原始文本输入转换为词元 \(\text{ID}\)。常见的分词方案包括将文本分解为词语、子词元、字符或字节,具体取决于给定应用程序的特定要求。
对现实世界中预训练分词器(从 \(\text{BERT}\) 到 \(\text{GPT}-2\)、\(\text{GPT}-4\) 和其他模型)的导览向我们展示了某些分词器更优秀的方面(例如,保留大小写、换行符或其他语言中的词元等信息),以及分词器之间仅仅不同的其他方面(例如,它们如何分解某些词语)。
三个主要的分词器设计决策是分词器算法(例如,\(\text{BPE}\)、\(\text{WordPiece}\)、\(\text{SentencePiece}\))、分词参数(包括词汇量大小、特殊词元、大小写的处理以及不同语言的处理),以及训练分词器的数据集。
语言模型也是高质量情境化词元嵌入的创建者,这些嵌入对原始静态嵌入进行了改进。这些情境化词元嵌入用于包括命名实体识别 (\(\text{NER}\))、抽取式文本摘要和文本分类在内的任务。除了生成词元嵌入,语言模型还可以生成涵盖整个句子甚至文档的文本嵌入。这为本书第二部分涵盖语言模型应用的许多应用程序提供了支持。
在 \(\text{LLM}\) 出现之前,\(\text{word}2\text{vec}\)、\(\text{GloVe}\) 和 \(\text{fastText}\) 等词嵌入方法很流行。在语言处理中,它们已基本被语言模型生成的情境化词嵌入所取代。\(\text{word}2\text{vec}\) 算法依赖于两个主要思想:跳字模型(\(\text{skip}-\text{gram}\))和负采样(\(\text{negative sampling}\))。它还使用了与我们在第 \(\text{10}\) 章中将看到的类型相似的对比训练。
正如我们在使用精选歌曲播放列表构建的音乐推荐器中所讨论的,嵌入对于创建和改进推荐系统非常有用。
在下一章中,我们将深入探讨分词之后的流程:\(\text{LLM}\) 如何处理这些词元并生成文本?我们将探讨使用 \(\text{Transformer}\) 架构的 \(\text{LLM}\) 如何工作的一些主要直觉。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调