《Hands-On Large Language Models》第9章 多模态大型语言模型
第 \(\text{9}\) 章 多模态大型语言模型
Multimodal Large Language Models
当您想到大型语言模型(\(\text{LLM}\))时,多模态(\(\text{multimodality}\))可能不会是您首先想到的。毕竟,它们是语言模型!但是我们可以很快看到,如果模型能够处理文本以外的其他类型的数据,它们会更有用。例如,如果一个语言模型能够看一眼图片并回答关于它的问题,那就非常有用。一个能够同时处理文本和图像(每种都称为一种模态)的模型被称为多模态模型(\(\text{multimodal}\)),如图 \(\text{9}-1\) 所示。
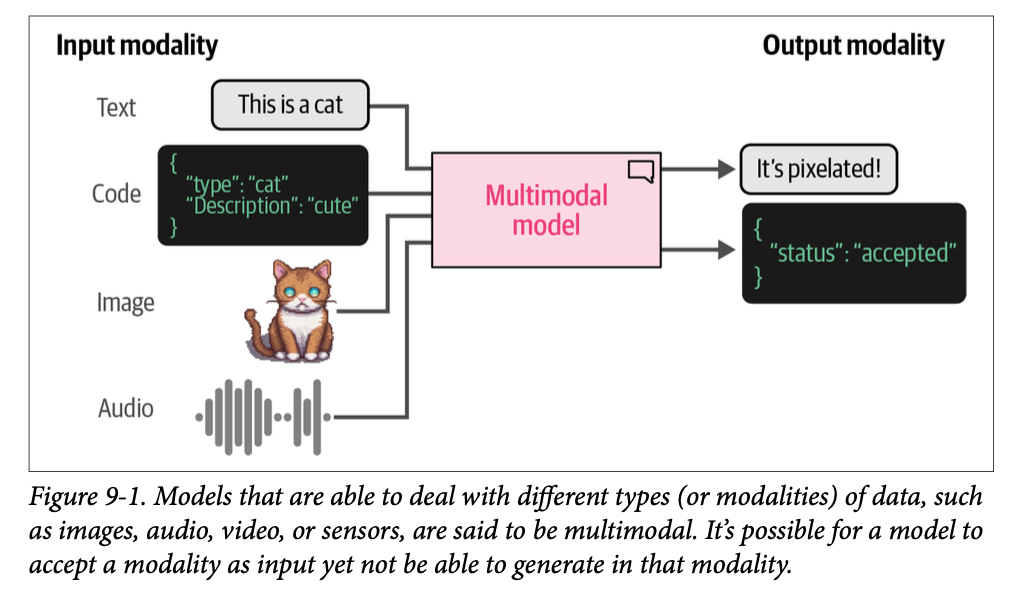
我们已经看到了各种从 \(\text{LLM}\) 中涌现出的新兴行为,从泛化能力和推理到算术和语言学。随着模型的规模变得更大、更智能,它们的技能集也在增加。
接收和使用多模态输入进行推理的能力可能会进一步增强,并有助于解锁以前被限制的能力。在实践中,语言并不仅仅存在于真空中。例如,您的肢体语言、面部表情、语调等都是增强口头表达的交流方式。同样的事情也适用于 \(\text{LLM}\);如果我们可以使它们能够对多模态信息进行推理,它们的能力可能会增加,并且我们能够部署它们来解决新型问题。
在本章中,我们将探讨一些具有多模态能力的 \(\text{LLM}\),以及这对实际用例意味着什么。我们将首先探索如何使用对原始 \(\text{Transformer}\) 技术的改编,将图像转换为数值表示。然后,我们将展示如何使用这种 \(\text{Transformer}\) 来扩展 \(\text{LLM}\) 以包括视觉任务。
用于视觉的 \(\text{Transformer}\) 模型
Transformers for Vision
贯穿本书各章,我们看到了基于 \(\text{Transformer}\) 的模型在各种语言建模任务中取得的成功,从分类和聚类到搜索和生成建模。因此,研究人员一直在寻找一种将 \(\text{Transformer}\) 的部分成功泛化到计算机视觉领域的方法,这可能不会让人感到惊讶。
他们提出的方法被称为 视觉 \(\text{Transformer}\) (\(\text{Vision Transformer}\), \(\text{ViT}\)),与之前默认的卷积神经网络(\(\text{CNNs}\))相比,它在图像识别任务中表现出了巨大的优势。就像原始的 \(\text{Transformer}\) 一样,\(\text{ViT}\) 用于将非结构化数据(一张图像)转换为可用于各种任务(如分类)的表示,如图 \(\text{9}-2\) 所示。
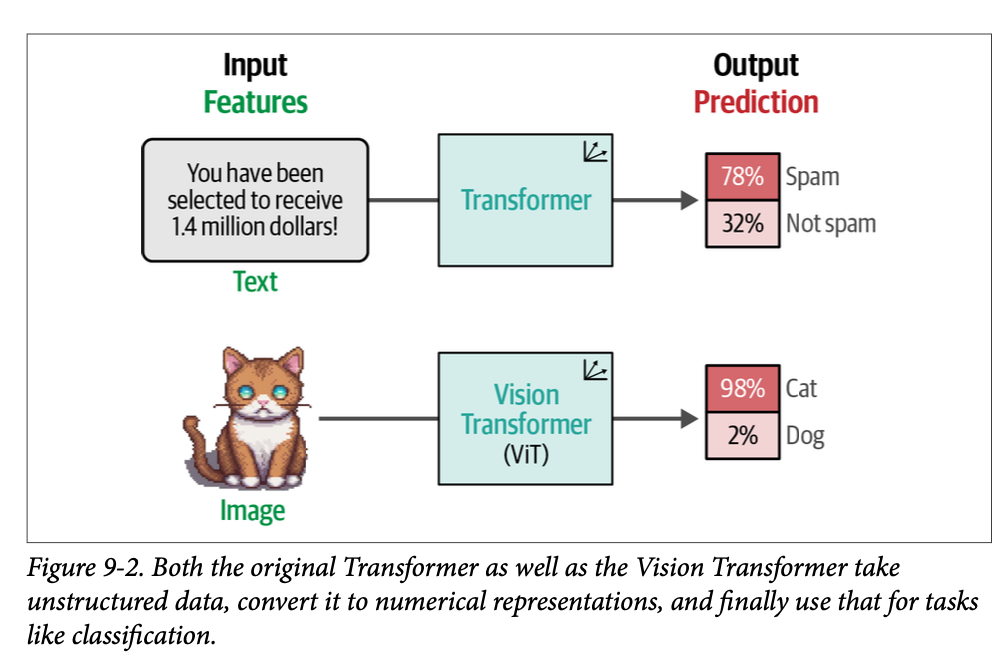
\(\text{ViT}\) 依赖于 \(\text{Transformer}\) 架构的一个重要组件,即编码器(\(\text{encoder}\))。正如我们在第 \(\text{1}\) 章中所见,编码器负责在将文本输入传递给解码器之前,将其转换为数值表示。然而,在编码器执行其职责之前,文本输入需要首先被分词(\(\text{tokenized}\)),如图 \(\text{9}-3\) 所示。
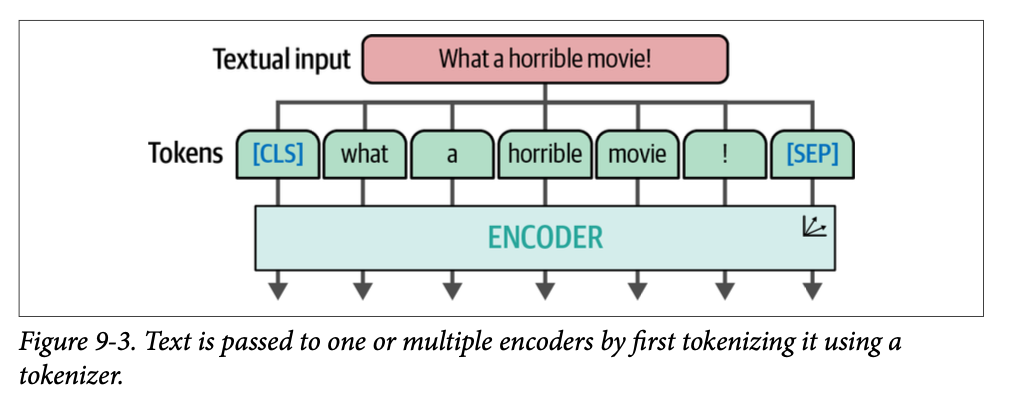
由于图像不包含单词,因此这种分词过程不能用于视觉数据。相反,\(\text{ViT}\) 的作者提出了一种将图像分词为“单词”的方法,这使他们能够使用原始的编码器结构。
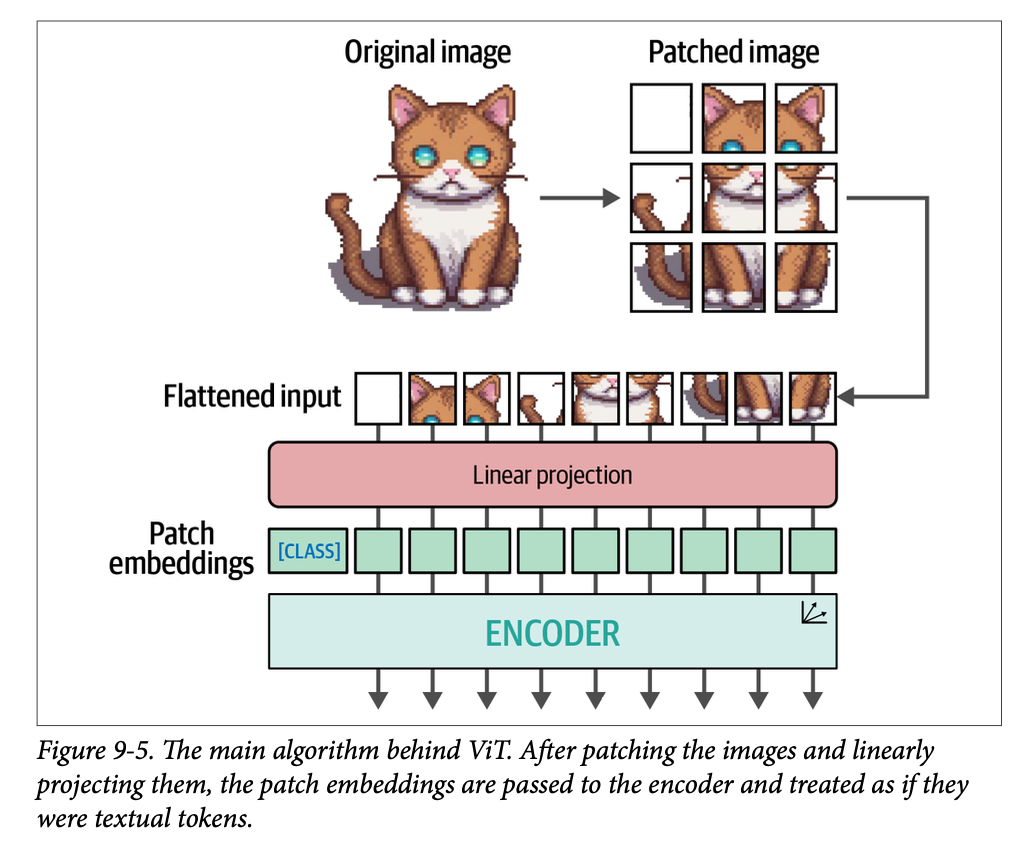
想象您有一张猫的图像。这张图像由许多像素组成,比方说 \(512 \times 512\) 像素。单个像素不能传达太多信息,但是当您组合像素块时,您会逐渐开始看到更多的信息。
\(\text{ViT}\) 使用的原理与此非常相似。它不是将文本分割成词元,而是将原始图像转换成图像块(\(\text{patches of images}\))。换句话说,它会水平和垂直地将图像切割成许多片段,如图 \(\text{9}-4\) 所示。
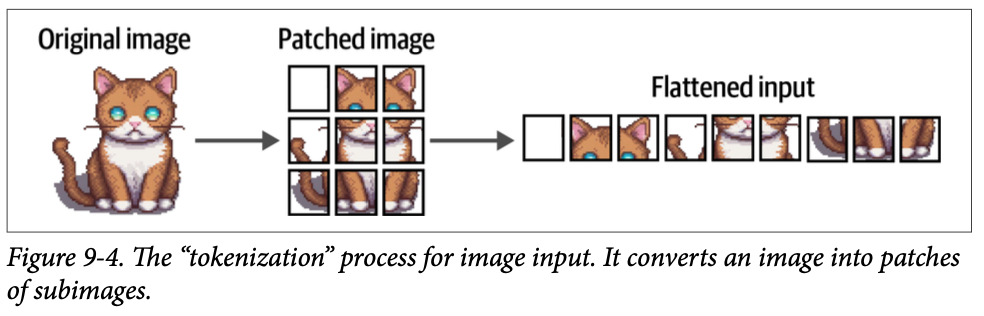
就像我们将文本转换为文本词元一样,我们将图像转换为图像块。展平后的图像块输入可以被视为一段文本中的词元。然而,与词元不同,我们不能简单地为每个图像块分配一个 \(\text{ID}\),因为这些图像块很少会出现在其他图像中,这与文本的词汇表不同。
相反,这些图像块被线性嵌入(\(\text{linearly embedded}\))以创建数值表示,即嵌入。然后,这些嵌入可以用作 \(\text{Transformer}\) 模型的输入。这样,图像块就被视为与词元相同的方式。完整的流程如图 \(\text{9}-5\) 所示。
个人注:线性嵌入 (Linearly Embedded):
每个小的图像块都会被输入到一个线性层(linear layer,即一个全连接层)中进行处理。这个线性层的作用是将图像块的原始像素值(例如 RGB 通道的数值)投射(project)到一个新的、低维或高维的特征空间中。“线性”表示这个转换过程是一个简单的矩阵乘法。
出于说明目的,示例中的图像被分成了 \(3 \times 3\) 个块,但原始实现使用的是 \(16 \times 16\) 个块。毕竟,这篇论文名为《一张图像值得 \(\text{16}\times\text{16}\) 个词》(\(\text{An Image is Worth 16x16 Words}\))。
这种方法的有趣之处在于,当嵌入被传递给编码器的那一刻,它们就被视为文本词元。从那时起,文本和图像的训练方式就没有区别。
由于这些相似性,\(\text{ViT}\) 经常被用来使各种语言模型具备多模态能力。使用它的最直接方法之一是在嵌入模型的训练期间。
多模态嵌入模型
Multimodal Embedding Models
在前面的章节中,我们使用嵌入模型来捕获文本表示(例如论文和文档)的语义内容。我们看到,我们可以使用这些嵌入或数值表示来查找相似文档、应用分类任务,甚至执行主题建模。
正如我们之前多次看到的,嵌入通常是 \(\text{LLM}\) 应用背后的重要驱动力。它们是捕获大规模信息和在信息大海捞针中进行搜索的高效方法。
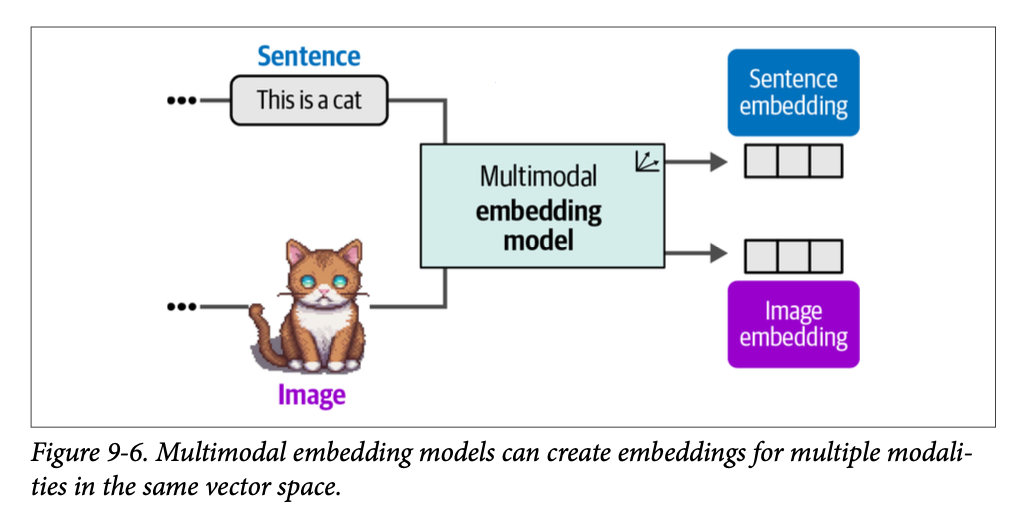
尽管如此,到目前为止,我们只研究了纯文本嵌入模型,它们专注于为文本表示生成嵌入。虽然也存在专门用于嵌入图像的模型,但我们将研究可以同时捕获文本和视觉表示的嵌入模型。我们在图 \(\text{9}-6\) 中对此进行了说明。
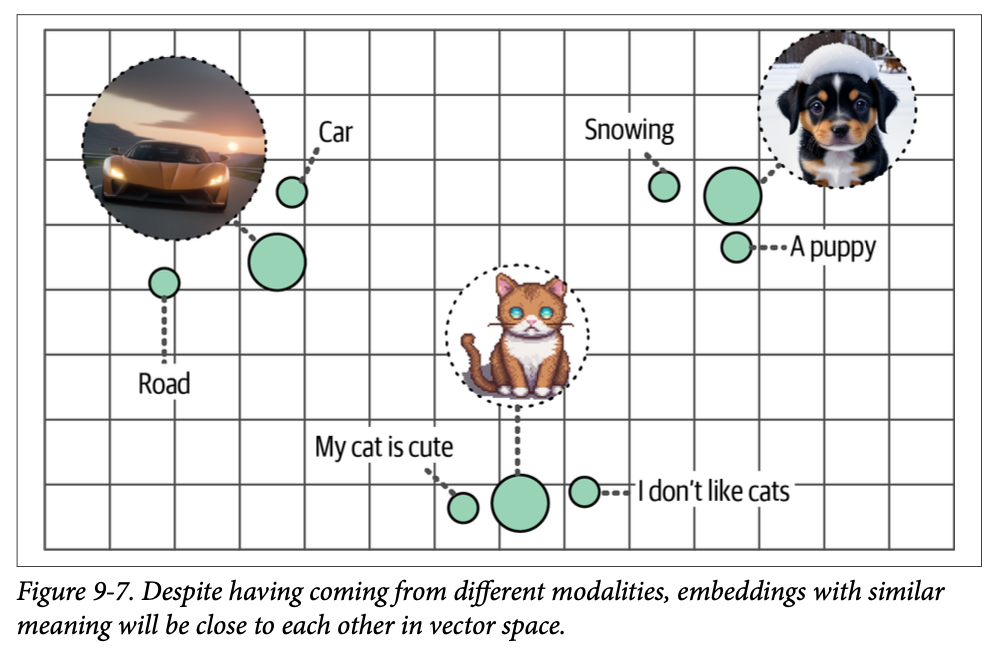
一个优势是,这允许比较多模态表示,因为生成的嵌入位于相同的向量空间中(图 \(\text{9}-7\))。例如,使用这样的多模态嵌入模型,我们可以根据输入文本查找图像。如果我们搜索与“\(\text{pictures of a puppy}\)”(小狗的照片)相似的图像,我们会找到哪些图像?反之亦然也是可能的。哪些文档与这个问题最相关?
有多款多模态嵌入模型,但最知名且目前使用最广泛的模型是对比语言-图像预训练(\(\text{Contrastive Language-Image Pre-training}\), \(\text{CLIP}\))。
\(\text{CLIP}\):连接文本和图像
CLIP: Connecting Text and Images
\(\text{CLIP}\) 是一种嵌入模型,可以计算图像和文本的嵌入。生成的嵌入位于相同的向量空间中,这意味着图像的嵌入可以与文本的嵌入进行比较。这种比较能力使得 \(\text{CLIP}\) 和类似模型可用于以下任务:
- 零样本分类 (\(\text{Zero-shot classification}\)) 我们可以将图像的嵌入与其可能类别的描述的嵌入进行比较,以找到哪个类别最相似。
- 聚类 (\(\text{Clustering}\)) 对图像和关键词集合进行聚类,以找到哪些关键词属于哪些图像集合。
- 搜索 (\(\text{Search}\)) 在数十亿文本或图像中,我们可以快速找到与输入文本或图像相关的内容。
- 生成 (\(\text{Generation}\)) 利用多模态嵌入来驱动图像生成(例如,stable diffusion)。
\(\text{CLIP}\) 如何生成多模态嵌入?
How Can CLIP Generate Multimodal Embeddings?
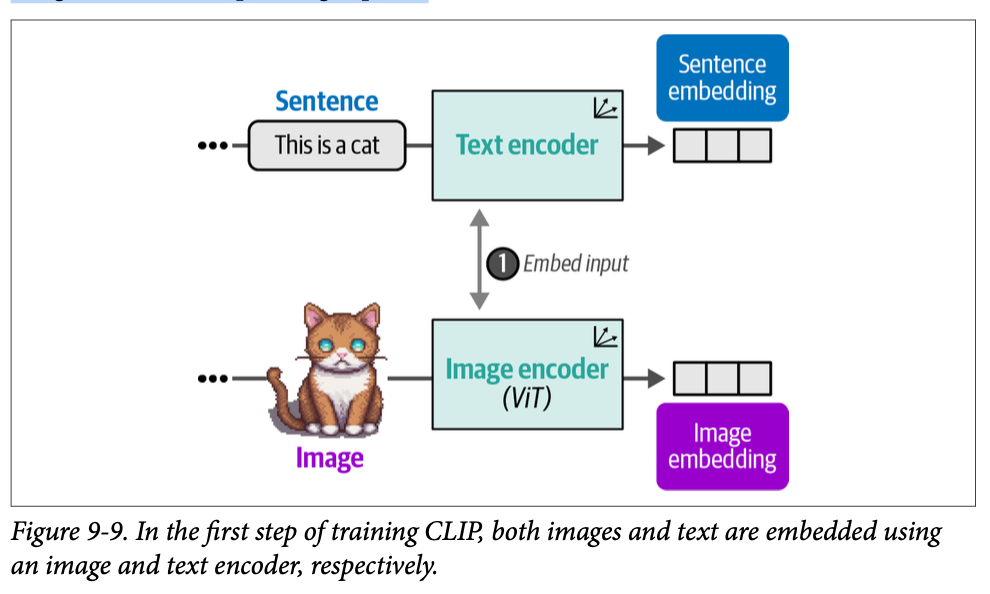
\(\text{CLIP}\) 的过程实际上非常简单直观。想象您有一个包含数百万张图像及其对应说明文字(\(\text{captions}\))的数据集,如图 \(\text{9}-8\) 所示。

这个数据集可以用于为每对数据(图像及其说明文字)创建两种表示。为此,\(\text{CLIP}\) 使用一个文本编码器来嵌入文本,并使用一个图像编码器来嵌入图像。如图 \(\text{9}-9\) 所示,结果就是图像及其相应说明文字的嵌入。
生成的这对嵌入通过余弦相似度进行比较。正如我们在第 \(\text{4}\) 章中所见,余弦相似度是向量之间夹角的余弦值,通过嵌入的点积除以它们的长度的乘积来计算。
当我们开始训练时,图像嵌入和文本嵌入之间的相似度会很低,因为它们尚未优化到同一向量空间中。在训练过程中,我们优化嵌入之间的相似度,并希望最大化相似图像/说明文字对的相似度,而最小化不相似图像/说明文字对的相似度(图 \(\text{9}-10\))。
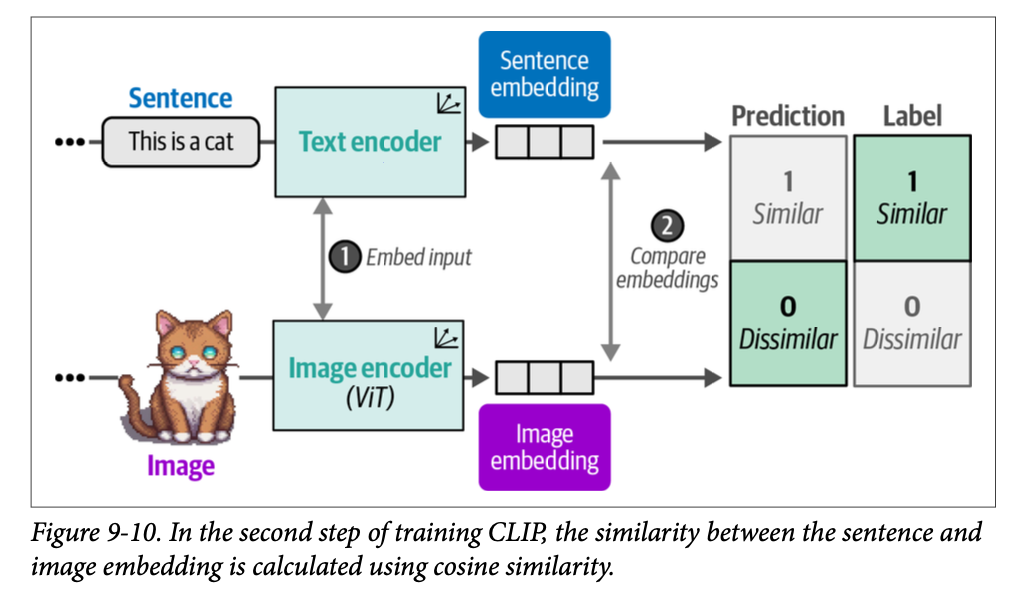
在计算它们的相似度后,模型会更新,然后重新开始新的数据批次和更新后的表示(图 \(\text{9}-11\))。这种方法被称为对比学习(\(\text{contrastive learning}\)),我们将在第 \(\text{10}\) 章中深入探讨其内部工作原理,届时我们将创建我们自己的嵌入模型。
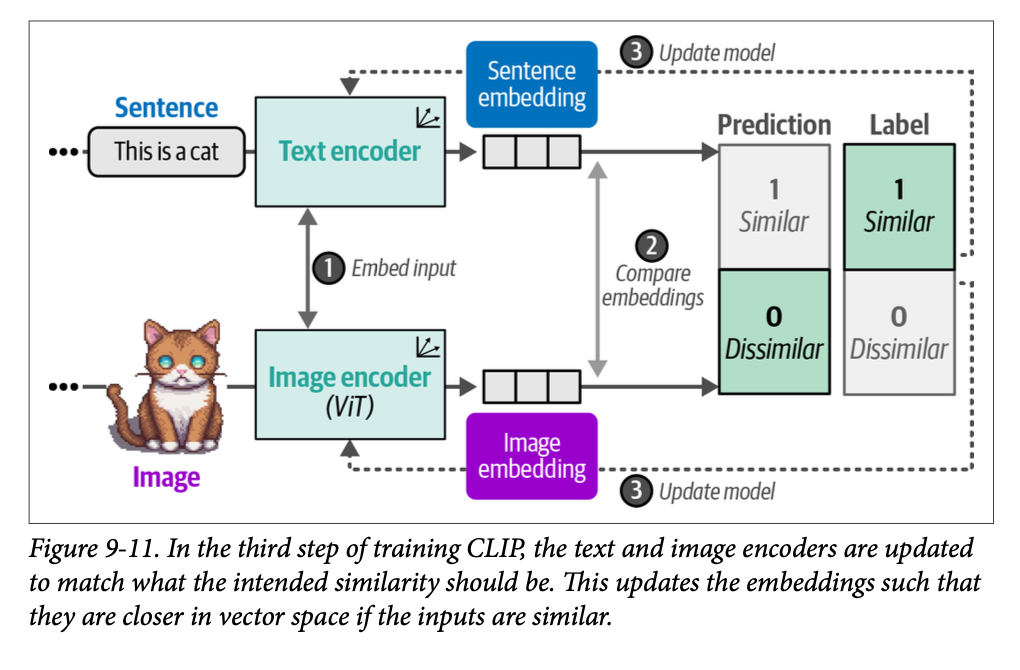
最终,我们期望猫的图像的嵌入将与“一只猫的图片”这句话的嵌入相似。正如我们将在第 \(\text{10}\) 章中看到的,为了确保表示尽可能准确,不相关的图像和说明文字的负面示例也应该包含在训练过程中。建模相似性不仅是知道是什么让事物彼此相似,也是知道是什么让它们不同和不相似。
\(\text{OpenCLIP}\)
OpenCLIP
对于我们的下一个示例,我们将使用 \(\text{CLIP}\) 的开源变体——即 \(\text{OpenCLIP}\) 中的模型。使用 \(\text{OpenCLIP}\) 或任何 \(\text{CLIP}\) 模型,归结为两件事:在将文本和图像输入传递给主模型之前,对它们进行处理。
在此之前,让我们看一个小示例,其中我们将使用我们以前看过的一张图像,即一张 \(\text{AI}\) 生成的(通过stable diffusion)在雪中玩耍的小狗的图像,如图 \(\text{9}-12\) 所示:

1 | from urllib.request import urlopen |
由于我们有这张图像的说明文字,我们可以使用 \(\text{OpenCLIP}\) 来为两者生成嵌入。
为此,我们加载了三个模型:
- 一个用于分词文本输入的分词器(\(\text{tokenizer}\))
- 一个用于预处理和调整图像大小的预处理器(\(\text{preprocessor}\))
- 一个用于将前两个输出转换为嵌入的主模型
1 | from transformers import CLIPTokenizerFast, CLIPProcessor, CLIPModel |
加载模型后,预处理我们的输入就很简单了。让我们从分词器开始,看看如果我们预处理输入会发生什么:
1 | # Tokenize our input |
这将输出一个包含输入 \(\text{ID}\) 的字典:
1 | {'input_ids': tensor([[49406, 320, 6829, 1629, 530, 518, 2583, 49407]]), 'at- |
为了查看这些 \(\text{ID}\) 代表什么,我们可以使用恰当命名的 \(\text{convert\_ids\_to\_tokens}\) 函数将它们转换回词元:
1 | # Convert our input back to tokens |
这将给出以下输出:
1 | ['<|startoftext|>', |
正如我们之前经常看到的,文本被拆分成词元。此外,我们现在还看到文本的开始和结束被指示出来,以将其与潜在的图像嵌入分开。您可能还会注意到 \(\text{[CLS]}\) 词元缺失了。在 \(\text{CLIP}\) 中,\(\text{[CLS]}\) 词元实际上用于表示图像嵌入。
现在我们已经预处理了我们的说明文字,我们可以创建嵌入了:
1 | # Create a text embedding |
这产生了一个单字符串的嵌入,它有 \(\text{512}\) 个值:
1 | torch.Size([1, 512]) |
在我们可以像创建文本嵌入一样创建图像嵌入之前,我们需要先对其进行预处理,因为模型期望输入图像具有特定的特征,例如它的大小和形状。
为此,我们可以使用我们之前创建的处理器:
1 | # Preprocess image |
原始图像是 \(512 \times 512\) 像素。请注意,该图像的预处理将其大小缩小到 \(224 \times 224\) 像素,因为这是它所期望的大小:
1 | torch.Size([1, 3, 224, 224]) |
让我们可视化这个预处理的结果,如图 \(\text{9}-13\) 所示:

1 | import torch |
要将这个预处理后的图像转换为嵌入,我们可以像以前一样调用模型,并查看它返回的形状:
1 | # Create the image embedding |
这给了我们以下形状:
1 | torch.Size([1, 512]) |
请注意,生成的图像嵌入的形状与文本嵌入的形状相同。这很重要,因为它允许我们比较它们的嵌入并查看它们是否相似。
我们可以使用这些嵌入来计算它们的相似度。为此,我们首先对嵌入进行归一化,然后计算点积以得到一个相似度分数:
1 | # Normalize the embeddings |
这给了我们以下分数:
1 | array([[0.33149648]], dtype=float32) |
我们得到了一个 \(\text{0.33}\) 的相似度分数,鉴于我们不知道模型认为低相似度和高相似度的界限在哪里,这个分数很难解释。相反,让我们用更多的图像和说明文字来扩展这个例子,如图 \(\text{9}-14\) 所示。

考虑到与其他图像的相似度要低得多,\(\text{0.33}\) 的分数似乎确实很高。
使用 \(\text{sentence-transformers}\) 加载 \(\text{CLIP}\)
\(\text{sentence-transformers}\) 实现了几种基于 \(\text{CLIP}\) 的模型,这使得创建嵌入更加容易。它只需要几行代码:
1 | from sentence_transformers import SentenceTransformer, util |
使文本生成模型具备多模态能力
Making Text Generation Models Multimodal
传统上,正如您所料,文本生成模型是解释文本表示的模型。像 \(\text{Llama 2}\) 和 \(\text{ChatGPT}\) 这样的模型擅长于对文本信息进行推理并用自然语言进行回应。
然而,它们局限于它们所训练的模态,即文本。正如我们之前在多模态嵌入模型中所见,增加视觉可以增强模型的能力。
对于文本生成模型,我们希望它能够对特定的输入图像进行推理。例如,我们可以给它一张披萨的图片,然后问它包含哪些配料。您可以给它看一张埃菲尔铁塔的照片,然后问它是何时建造的或位于何处。这种对话能力在图 \(\text{9}-15\) 中得到了进一步说明。
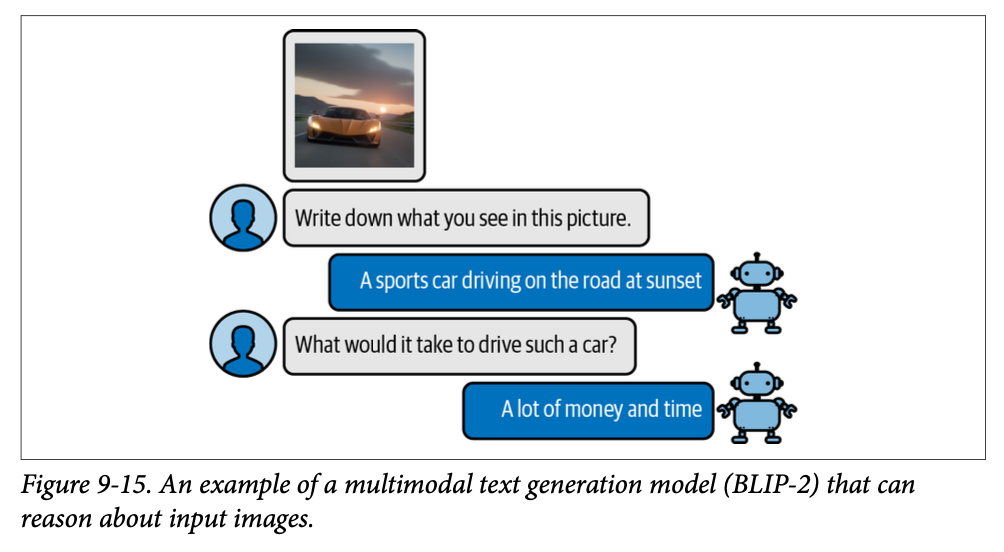
为了弥合这两个领域之间的差距,人们已经尝试为现有模型引入某种形式的多模态。其中一种方法被称为 \(\text{BLIP-2}\):用于统一视觉-语言理解和生成的自举语言-图像预训练 \(\text{2}\)(\(\text{BLIP-2: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 2}\))。\(\text{BLIP-2}\) 是一种易于使用且模块化的技术,允许为现有语言模型引入视觉能力。
\(\text{BLIP-2}\):弥合模态鸿沟
BLIP-2: Bridging the Modality Gap
从头开始创建一个多模态语言模型需要大量的计算能力和数据。我们将不得不使用数十亿张图像、文本和图像-文本对来创建这样一个模型。正如您所想象的,这不容易实现!
\(\text{BLIP-2}\) 没有从头开始构建架构,而是通过构建一座名为查询 \(\text{Transformer}\) (\(\text{Querying Transformer}\), \(\text{Q-Former}\)) 的桥梁来弥合视觉-语言鸿沟,这座桥梁连接了一个预训练的图像编码器和一个预训练的 \(\text{LLM}\)。
通过利用预训练的模型,\(\text{BLIP-2}\) 只需要训练这座桥梁,而不需要从头开始训练图像编码器和 \(\text{LLM}\)。它充分利用了现有的技术和模型!这座桥梁如图 \(\text{9}-16\) 所示。
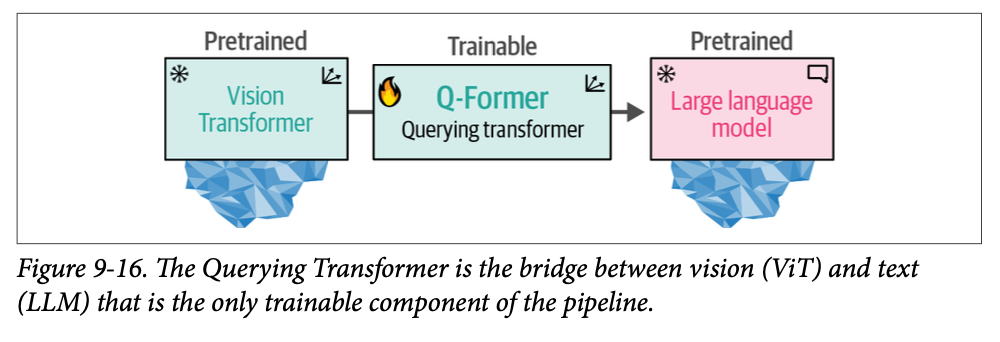
为了连接这两个预训练模型,\(\text{Q-Former}\) 模仿了它们的架构。它有两个共享注意力层的模块:
- 一个图像 \(\text{Transformer}\),用于与冻结的 \(\text{Vision Transformer}\) 交互以进行特征提取。
- 一个文本 \(\text{Transformer}\),可以与 \(\text{LLM}\) 交互。
\(\text{Q-Former}\) 的训练分为两个阶段,每个模态一个阶段,如图 \(\text{9}-17\) 所示。
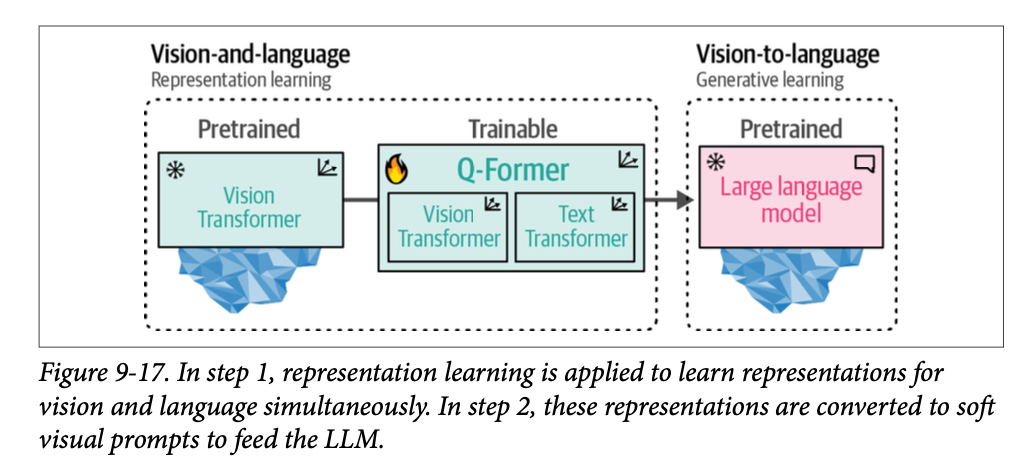
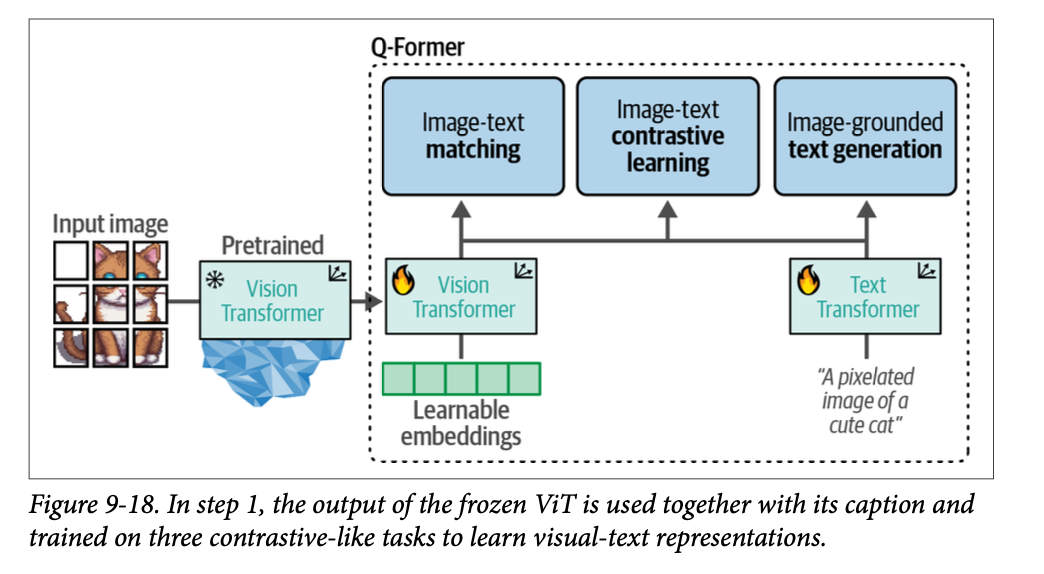
在第一步中,使用图像-文档对来训练 \(\text{Q-Former}\),使其能够表示图像和文本。这些对通常是图像的说明文字(\(\text{captions}\)),就像我们之前在训练 \(\text{CLIP}\) 时看到的那样。
图像被馈送到冻结的 \(\text{ViT}\) 以提取视觉嵌入。这些嵌入被用作 \(\text{Q-Former}\) 的 \(\text{ViT}\) 的输入。说明文字被用作 \(\text{Q-Former}\) 的文本 \(\text{Transformer}\) 的输入。
有了这些输入,\(\text{Q-Former}\) 随后在三个任务上进行训练:
- 图像-文本对比学习 (\(\text{Image-text contrastive learning}\)) 此任务试图对齐图像和文本嵌入对,以最大化它们的互信息。
- 图像-文本匹配 (\(\text{Image-text matching}\)) 这是一个分类任务,用于预测图像和文本对是正向的(匹配 matched)还是负向的(不匹配 unmatched)。
- 以图像为基础的文本生成 (\(\text{Image-grounded text generation}\)) 训练模型根据从输入图像中提取的信息生成文本。
这三个目标是联合优化的,以改进从冻结的 \(\text{ViT}\) 中提取的视觉表示。从某种意义上说,我们正在尝试将文本信息注入到冻结 \(\text{ViT}\) 的嵌入中,以便我们可以在 \(\text{LLM}\) 中使用它们。\(\text{BLIP-2}\) 的这第一步如图 \(\text{9}-18\) 所示。
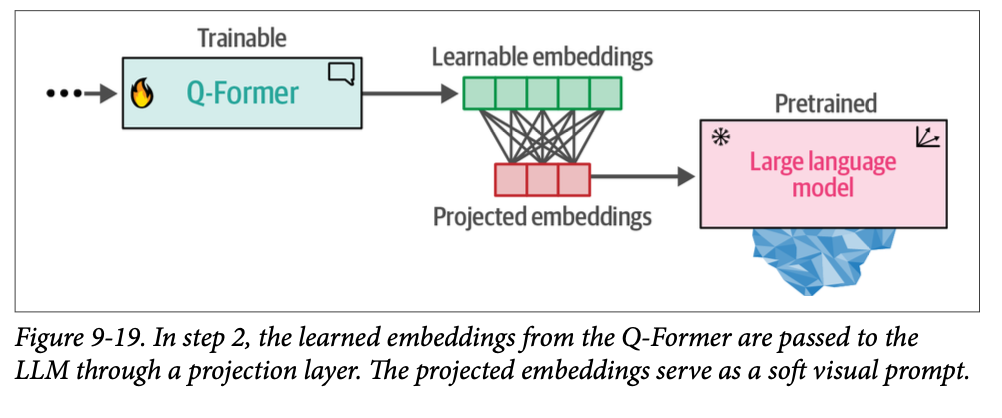
在第二步中,从第一步中获得的可学习嵌入现在在与相应文本信息相同的维度空间中包含视觉信息。然后,这些可学习嵌入被传递给 \(\text{LLM}\)。从某种意义上说,这些嵌入充当了软视觉提示(\(\text{soft visual prompts}\)),用于以 \(\text{Q-Former}\) 提取的视觉表示为条件来调节 \(\text{LLM}\)。
在它们之间还有一个全连接线性层,以确保可学习嵌入具有 \(\text{LLM}\) 所期望的相同形状。将视觉转换为语言的这第二步如图 \(\text{9}-19\) 所示。
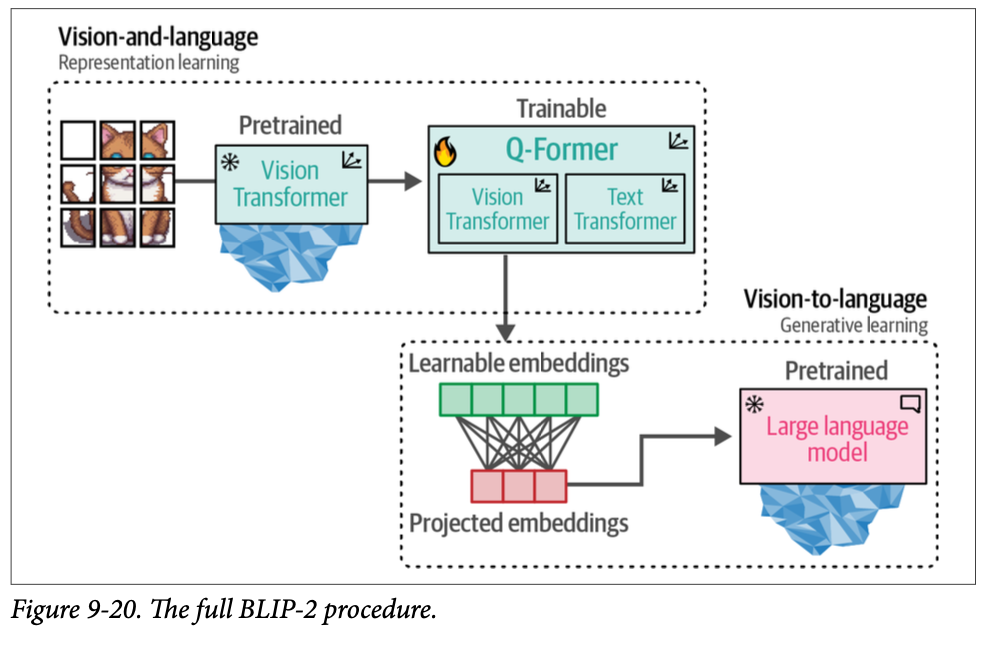
当我们将这些步骤组合在一起时,它们使 \(\text{Q-Former}\) 能够学习相同维度空间中的视觉和文本表示,这些表示可以用作 \(\text{LLM}\) 的软提示(\(\text{soft prompt}\))。结果是,\(\text{LLM}\) 将获得关于图像的信息,其方式类似于您在进行提示时向 \(\text{LLM}\) 提供上下文。完整的深入过程如图 \(\text{9}-20\) 所示。
自 \(\text{BLIP-2}\) 问世以来,许多其他视觉 \(\text{LLM}\) 也相继发布,它们具有相似的过程,例如 \(\text{LLaVA}\)(一个使文本 \(\text{LLM}\) 具备多模态能力的框架)或 \(\text{Idefics 2}\)(一个基于 \(\text{Mistral 7B LLM}\) 的高效视觉 \(\text{LLM}\))。尽管这些视觉 \(\text{LLM}\) 具有不同的架构,但它们都将预训练的类似 \(\text{CLIP}\) 的视觉编码器与文本 \(\text{LLM}\) 连接起来。这些架构的目标是将输入图像中的视觉特征投射到语言嵌入中,以便它们可以用作 \(\text{LLM}\) 的输入。与 \(\text{Q-Former}\) 类似,它们试图弥合图像和文本之间的鸿沟。
预处理多模态输入
Preprocessing Multimodal Inputs
既然我们知道 \(\text{BLIP-2}\) 是如何创建的,那么这种模型就有许多有趣的用例,不仅限于图像加标题(\(\text{captioning images}\))、回答视觉问题,甚至执行提示(\(\text{performing prompting}\))。
在我们介绍一些用例之前,让我们先加载模型并探索如何使用它:
1 | from transformers import AutoProcessor, Blip2ForConditionalGeneration |
使用 \(\text{model.vision\_model}\) 和 \(\text{model.language\_model}\),我们可以分别查看我们加载的 \(\text{BLIP-2}\) 模型中使用了哪个 \(\text{ViT}\) 和生成模型。
我们加载了构成我们完整管线的两个组件:一个处理器和一个模型。处理器可以与语言模型的分词器进行比较。它将非结构化输入,例如图像和文本,转换为模型通常期望的表示。
预处理图像
Preprocessing images
让我们先从探索处理器对图像的作用开始。我们首先加载一张非常宽的图像进行演示:
1 | # Load image of a supercar |

这张图像有 \(520 \times 492\) 像素,这通常是一种不常见的格式。那么我们来看看我们的处理器对它做了什么:
1 | # Preprocess the image |
这给了我们以下形状:
1 | torch.Size([1, 3, 224, 224]) |
结果是一张 \(224 \times 224\) 大小的图像。比我们最初的图像小了很多!这也意味着所有原始的不同形状的图像都将被处理成正方形。所以,输入非常宽或非常高的图像时要小心,因为它们可能会失真。
预处理文本
Preprocessing text
让我们继续用文本来探索处理器的功能。首先,我们可以访问用于分词输入文本的分词器:
1 | blip_processor.tokenizer |
这给了我们以下输出:
1 | GPT2TokenizerFast(name_or_path='Salesforce/blip2-opt-2.7b', vocab_size=50265, |
这里的 \(\text{BLIP-2}\) 模型使用了一个 \(\text{GPT2Tokenizer}\)。正如我们在第 \(\text{2}\) 章中探讨的,分词器处理输入文本的方式可能大不相同。
为了探究 \(\text{GPT2Tokenizer}\) 的工作方式,我们可以用一个小句子来试用它。我们首先将句子转换为词元 \(\text{ID}\),然后再将它们转换回词元:
1 | # Preprocess the text |
这给了我们以下词元:
1 | ['</s>', 'Her', 'Ġvocal', 'ization', 'Ġwas', 'Ġremarkably', 'Ġmel', 'odic'] |
当我们检查这些词元时,您可能会注意到在某些词元的开头有一个奇怪的符号,即 \(\text{Ġ}\) 符号。这实际上应该是一个空格。然而,一个内部函数会获取特定代码点中的字符并将它们上移 \(\text{256}\) 位,以使它们可打印。因此,空格(代码点 \(\text{32}\))变成了 \(\text{Ġ}\)(代码点 \(\text{288}\))。
为了便于说明,我们将它们转换为下划线:
1 | # Replace the space token with an underscore |
这给了我们一个更美观的输出:
1 | ['</s>', 'Her', '_vocal', 'ization', '_was', '_remarkably', '_mel', 'odic'] |
输出显示下划线指示了一个单词的开始。这样,由多个词元组成的单词就可以被识别出来。
用例 \(\text{1}\):图像加标题
Use Case 1: Image Captioning
像 \(\text{BLIP-2}\) 这样的模型最直接的用法是为您数据中的图像创建说明文字(\(\text{captions}\))。您可能是一家想要创建服装描述的商店,或者您可能是一位没有时间手动标记一场婚礼的 \(\text{1,000}\) 多张照片的摄影师。
为图像加标题的过程与处理过程紧密相随。图像被转换为模型可以读取的像素值。这些像素值被传递给 \(\text{BLIP-2}\),转换为软视觉提示(\(\text{soft visual prompts}\)),\(\text{LLM}\) 可以利用这些提示来决定合适的说明文字。
让我们以上面那张超级跑车的图像为例,并使用处理器来导出预期形状的像素:
1 | # Load an AI-generated image of a supercar |

下一步是使用 \(\text{BLIP-2}\) 模型将图像转换为词元 \(\text{ID}\)。完成此操作后,我们可以将 \(\text{ID}\) 转换为文本(即生成的说明文字):
1 | # Generate image ids to be passed to the decoder (LLM) |
\(\text{generated\_text}\) 包含的说明文字是:
1 | an orange supercar driving on the road at sunset |
这看起来是这张图像的完美描述!
图像加标题是在进入更复杂的用例之前学习这个模型的一个很好的方式。您可以自己用一些图像试一试,看看它在哪些方面表现良好,哪些方面表现不佳。特定领域的图像,例如特定卡通人物或想象中的创作的图片,可能会失败,因为模型主要是在公共数据上训练的。
让我们以一个有趣的例子来结束这个用例,即一张来自罗夏墨迹测验(\(\text{Rorschach test}\))的图像,如图 \(\text{9}-21\) 所示。它是一项古老的心理实验的一部分,用于测试个人对墨迹的感知。据说一个人在墨迹中看到了什么,可以说明这个人的个性特征。这是一个相当主观的测试,但这只会让它更有趣!
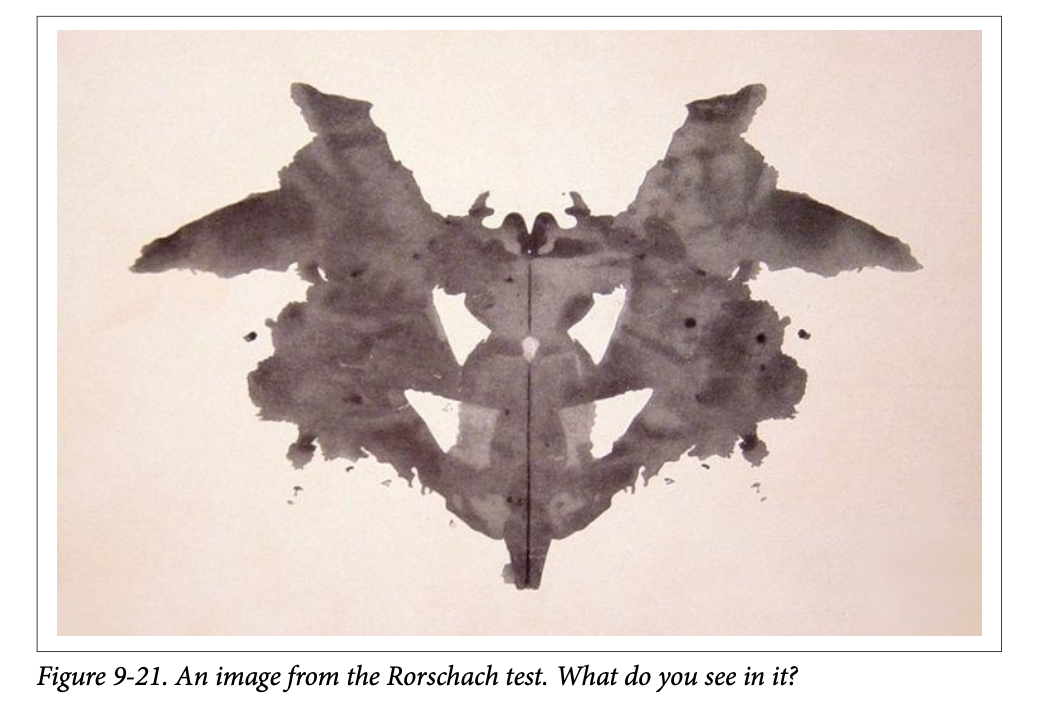
让我们以上面图 \(\text{9}-21\) 所示的图像作为我们的输入:
1 | # Load Rorschach image |
像以前一样,当我们检查 \(\text{generated\_text}\) 变量时,可以看到说明文字:
1 | a black and white ink drawing of a bat |
我完全可以理解模型会用这样的描述来为这张图像添加说明文字。既然这是一个罗夏测验( Rorschach test),您认为这说明了模型具有什么样的特性呢? 🤔
用例 \(\text{2}\):基于聊天的多模态提示
Use Case 2: Multimodal Chat-Based Prompting
虽然加标题(\(\text{captioning}\))是一项重要的任务,但我们可以将它的用例进一步扩展。在前面的例子中,我们展示了从一种模态(视觉/图像)到另一种模态(文本/标题)的线性转换。
我们可以尝试通过执行所谓的视觉问答(\(\text{visual question answering}\)),来同时呈现这两种模态,而不是遵循这种线性结构。在这个特殊的用例中,我们给模型一张图像以及一个关于该特定图像的问题,让它来回答。模型需要同时处理图像和问题。
为了演示,让我们从汽车的图片开始,并要求 \(\text{BLIP-2}\) 描述这张图片。为此,我们首先需要像以前一样多次预处理图像:
1 | # Load an AI-generated image of a supercar |
要执行我们的视觉问答,我们需要给 \(\text{BLIP-2}\) 不仅仅是图像,还需要提示(\(\text{prompt}\))。没有提示,模型将像以前一样生成一个说明文字。我们将要求模型描述我们刚刚处理的图像:
1 | # Visual question answering |
这给了我们以下输出:
1 | A sports car driving on the road at sunset |
它正确地描述了图像。然而,这是一个相当简单的例子,因为我们的问题本质上是要求模型创建一个说明文字。相反,我们可以以基于聊天的方式提出后续问题。
为此,我们可以将我们先前的对话(包括它对我们问题的回答)提供给模型。然后我们问它一个后续问题:
1 | # Chat-like prompting |
这给了我们以下答案:
1 | $1,000,000 |
\(\text{\$1,000,000}\) 是高度具体的!这显示了 \(\text{BLIP-2}\) 具有更像聊天的行为,这使得一些有趣的对话成为可能。
最后,我们可以通过使用 \(\text{ipywidgets}\)(一个允许我们制作交互式按钮、输入文本等的 \(\text{Jupyter}\) 笔记本扩展)来创建一个交互式聊天机器人,从而使这个过程更顺畅一些:
1 | from IPython.display import HTML, display |
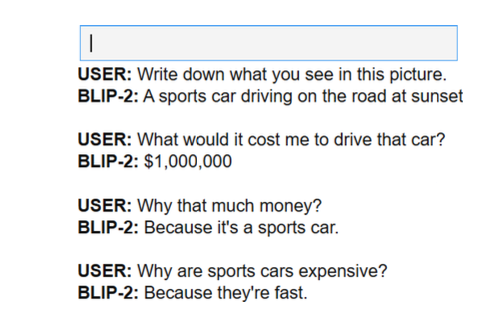
看来我们可以继续对话并提出一堆问题。使用这种基于聊天的方法,我们本质上创建了一个可以对图像进行推理的聊天机器人!
总结
在本章中,我们探讨了各种使 \(\text{LLM}\) 具备多模态能力的方法,通过弥合文本和视觉表示之间的鸿沟。我们首先讨论了用于视觉的 \(\text{Transformer}\) 模型,这些模型将图像转换为数值表示。这是通过使用图像编码器和图像块嵌入来实现的,这使得模型能够处理不同尺度的图像。
然后,我们探讨了如何使用 \(\text{CLIP}\) 创建可以将图像和文本都转换为数值表示的嵌入模型。我们看到了 \(\text{CLIP}\) 如何利用对比学习将图像和文本嵌入对齐到一个共享空间中,从而实现零样本分类、聚类和搜索等任务。本章还介绍了 \(\text{OpenCLIP}\),它是 \(\text{CLIP}\) 的开源变体,易于用于多模态嵌入任务。
最后,我们探索了文本生成模型如何具备多模态能力,并深入研究了 \(\text{BLIP-2}\) 模型。这些多模态文本生成模型的核心思想涉及将输入图像中的视觉特征投射到文本嵌入中,然后 \(\text{LLM}\) 可以使用这些嵌入。我们看到了该模型如何用于图像加标题和基于聊天的多模态提示,其中两种模态被结合起来生成响应。总而言之,本章强调了 \(\text{LLM}\) 中多模态的力量,并展示了其在图像加标题、搜索和基于聊天的提示等各种领域的应用。
在本书的第三部分中,我们将介绍训练和微调技术。在第 \(\text{10}\) 章中,我们将探讨如何创建和微调一个文本嵌入模型,这是驱动许多语言建模应用的核心技术。这下一章将作为训练和微调语言模型的介绍。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调