《Hands-On Large Language Models》第7章 高级文本生成技术与工具
第 \(\text{7}\) 章 高级文本生成技术与工具
Advanced Text Generation Techniques and Tools
在上一章中,我们看到了提示工程可以为您的文本生成大型语言模型 (\(\text{LLM}\)) 的准确性带来奇迹。只需进行一些微小的调整,这些 \(\text{LLM}\) 就能被引导至更有目的、更准确的答案。这表明,使用无需微调 \(\text{LLM}\) 而是更高效地利用 \(\text{LLM}\) 的技术(例如相对直接的提示工程),可以获得巨大的收益。
在本章中,我们将继续这一思路。在无需微调模型本身的情况下,我们还能做些什么来进一步增强我们从 \(\text{LLM}\) 获得的体验和输出?
幸运的是,有大量的方法和技术可以让我们进一步改进上一章中开始的工作。这些更高级的技术是众多以 \(\text{LLM}\) 为中心的系统的基础,并且可以说是用户在设计此类系统时首先实施的事物之一。
在本章中,我们将探索几种用于提高生成文本质量的方法和概念:
- 模型 \(\text{I/O}\) (\(\text{Model I/O}\)):加载和使用 \(\text{LLM}\)。
- 记忆 (\(\text{Memory}\)):帮助 \(\text{LLM}\) 记住信息。
- 智能体 (\(\text{Agents}\)):将复杂行为与外部工具结合。
- 链 (\(\text{Chains}\)):连接方法和模块。
这些方法都已集成到 \(\text{LangChain}\) 框架中,该框架将帮助我们轻松地在本章中使用这些高级技术。\(\text{LangChain}\) 是较早出现的框架之一,它通过有用的抽象简化了与 \(\text{LLM}\) 的协作。值得注意的较新框架有 \(\text{DSPy}\) 和 \(\text{Haystack}\)。其中一些抽象如图 \(\text{7}-1\) 所示。请注意,检索将在下一章中讨论。
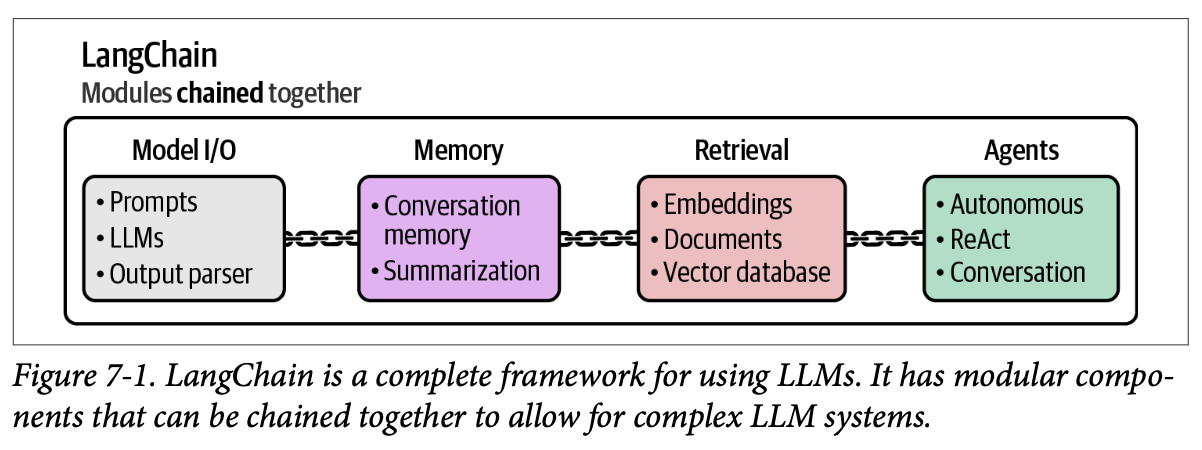
这些技术中的每一项单独来看都具有显著的优势,但它们的真正价值并非孤立存在。只有当您将所有这些技术结合起来时,才能获得具有惊人性能的基于 \(\text{LLM}\) 的系统。正是这些技术的融会贯通,才真正是 \(\text{LLM}\) 大放异彩之处。
模型 \(\text{I/O}\):使用 \(\text{LangChain}\) 加载量化模型
Advanced Text Generation Techniques and Tools
在我们利用 \(\text{LangChain}\) 的功能来扩展 \(\text{LLM}\) 的能力之前,我们需要从加载 \(\text{LLM}\) 开始。与前几章一样,我们将使用 \(\text{Phi}-3\),但略有不同:我们将使用 \(\text{GGUF}\) 模型变体。\(\text{GGUF}\) 模型是通过一种称为量化(\(\text{quantization}\))的方法,对其原始对应物进行的压缩版本,它减少了表示 \(\text{LLM}\) 参数所需的比特(\(\text{bits}\))数量。
比特是一系列 \(\text{0}\) 和 \(\text{1}\),通过以二进制形式编码来表示值。如图 \(\text{7}-2\) 所示,更多比特会导致更宽的取值范围,但存储这些值需要更多内存。
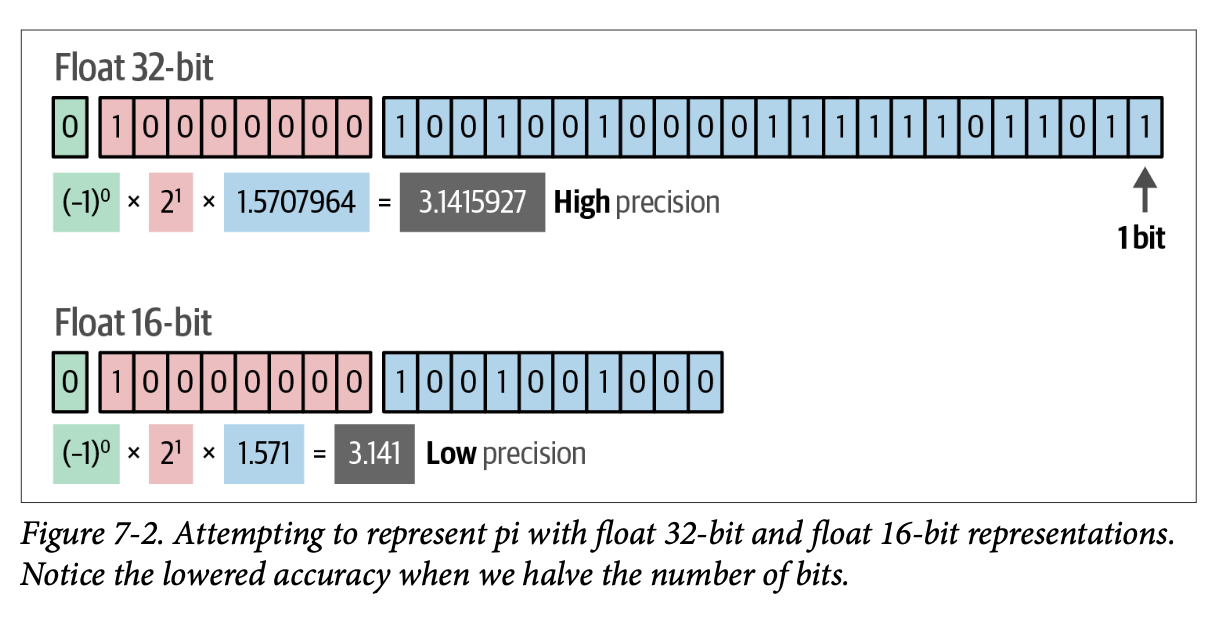
量化在试图保持大部分原始信息的同时,减少了表示 \(\text{LLM}\) 参数所需的比特数量。这会带来一些精度上的损失,但通常可以弥补,因为模型运行速度更快、需要的显存(\(\text{VRAM}\))更少,而且准确性通常几乎与原始模型一样高。
为了说明量化,请考虑这个类比:如果有人问您现在几点,您可能会说“\(\text{14:16}\)”,这是正确的,但不是一个完全精确的答案。您本可以说它是“\(\text{14:16}\) 和 \(\text{12}\) 秒”,这样会更准确。然而,提到秒数很少有帮助,我们通常只是将其以离散数字(即完整的分钟数)表示。量化是一个类似的过程,它在不去除关键信息(例如,保留小时和分钟)的情况下,降低了值的精度(例如,去除秒数)。
在第 \(\text{12}\) 章中,我们将进一步讨论量化在底层的工作原理。您也可以在 \(\text{Maarten Grootendorst}\) 撰写的“\(\text{A Visual Guide to Quantization}\)”(https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization)中看到完整的量化视觉指南。现在,重要的是要知道我们将使用 \(\text{Phi}-3\) 的 \(\text{8}\) 比特变体,而不是原始的 \(\text{16}\) 比特变体,这使得内存需求减少了近一半。
💡 经验法则是,至少寻找 \(\text{4}\) 比特量化的模型。这些模型在压缩和准确性之间取得了良好的平衡。虽然也可以使用 \(\text{3}\) 比特甚至 \(\text{2}\) 比特的量化模型,但性能下降会变得明显,届时最好选择精度更高的更小模型。
首先,我们需要下载模型。请注意,该链接包含多个具有不同比特变体的文件。我们选择的 \(\text{FP16}\) 代表 \(\text{16}\) 比特变体:
1 | !wget https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/ |
我们结合使用 \(\text{llama}-\text{cpp}-\text{python}\) 和 \(\text{LangChain}\) 来加载 \(\text{GGUF}\) 文件:
1 | from langchain import LlamaCpp |
在 \(\text{LangChain}\) 中,我们使用 \(\text{invoke}\) 函数来生成输出:
1 | llm.invoke("Hi! My name is Maarten. What is 1 + 1?") |
1 | '' |
不幸的是,我们没有得到任何输出!正如我们在前几章中所见,\(\text{Phi}-3\) 需要一个特定的提示模板(\(\text{prompt template}\))。与我们使用 \(\text{transformers}\) 的示例相比,我们需要显式地使用模板。与其在 \(\text{LangChain}\) 中每次使用 Phi-3 时都复制粘贴这个模板,不如使用 \(\text{LangChain}\) 的核心功能之一,即“链”(\(\text{chains}\))。
💡 本章中的所有示例都可以用任何 \(\text{LLM}\) 运行。这意味着您在学习这些示例时,可以选择使用 Phi-3、\(\text{ChatGPT}\)、\(\text{Llama 3}\) 或任何其他模型。我们将默认使用 Phi-3,但最新技术变化很快,因此可以考虑使用更新的模型。您可以使用 \(\text{Open LLM Leaderboard}\)(一个开源 \(\text{LLM}\) 的排名)(https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/)来选择最适合您用例的模型。
如果您无法访问可本地运行 \(\text{LLM}\) 的设备,可以考虑使用 \(\text{ChatGPT}\):
2
3
# Create a chat-based LLM
chat_model = ChatOpenAI(openai_api_key="MY_KEY")
链 : 扩展 \(\text{LLM}\) 的能力
Chains: Extending the Capabilities of LLMs
\(\text{LangChain}\) 的名称源于其主要方法之一——链(\(\text{chains}\))。虽然我们可以孤立地运行 \(\text{LLM}\),但它们的力量体现在与附加组件一起使用时,甚至在相互结合使用时。链不仅允许扩展 \(\text{LLM}\) 的能力,还允许将多个链连接在一起。
\(\text{LangChain}\) 中链的最基本形式是单个链。尽管一个链可以有多种形式,每种形式的复杂性不同,但它通常将一个 \(\text{LLM}\) 与一些额外的工具、提示或功能连接起来。如图 \(\text{7}-3\) 所示,这就是将一个组件连接到 \(\text{LLM}\) 的理念。
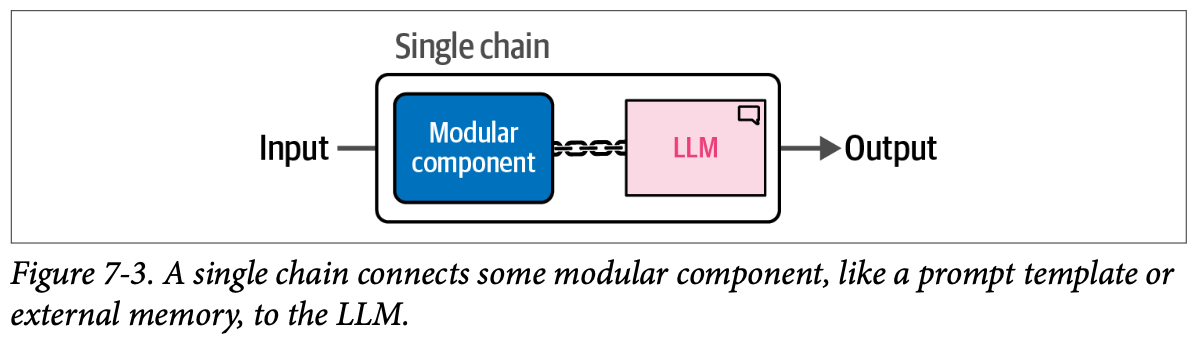
在实践中,链可以很快变得复杂。我们可以随意扩展提示模板,甚至可以将几个独立的链组合在一起,创建复杂的系统。为了彻底理解链中正在发生的事情,让我们探索如何将 \(\text{Phi}-3\) 的提示模板添加到 \(\text{LLM}\) 中。
链中的单个环节:提示模板
A Single Link in the Chain: Prompt Template
我们从创建我们的第一个链开始,即Phi-3 所期望的提示模板。在上一章中,我们探讨了 \(\text{transformers.pipeline}\) 如何自动应用聊天模板。对于其他软件包来说并非总是如此,它们可能需要明确定义提示模板。通过 \(\text{LangChain}\),我们将使用链来创建和使用一个默认的提示模板。它也为使用提示模板提供了一个很好的实践经验。
如图 \(\text{7}-4\) 所示,这个想法是我们将提示模板与 \(\text{LLM}\) 链接在一起,以获得我们想要的输出。这样,我们不需要每次使用 \(\text{LLM}\) 时都复制粘贴提示模板,而只需要定义用户和系统提示。
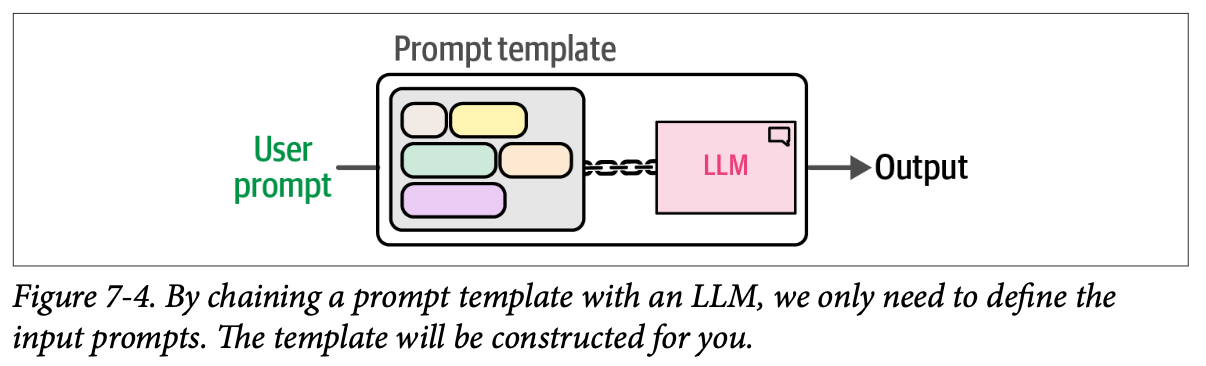
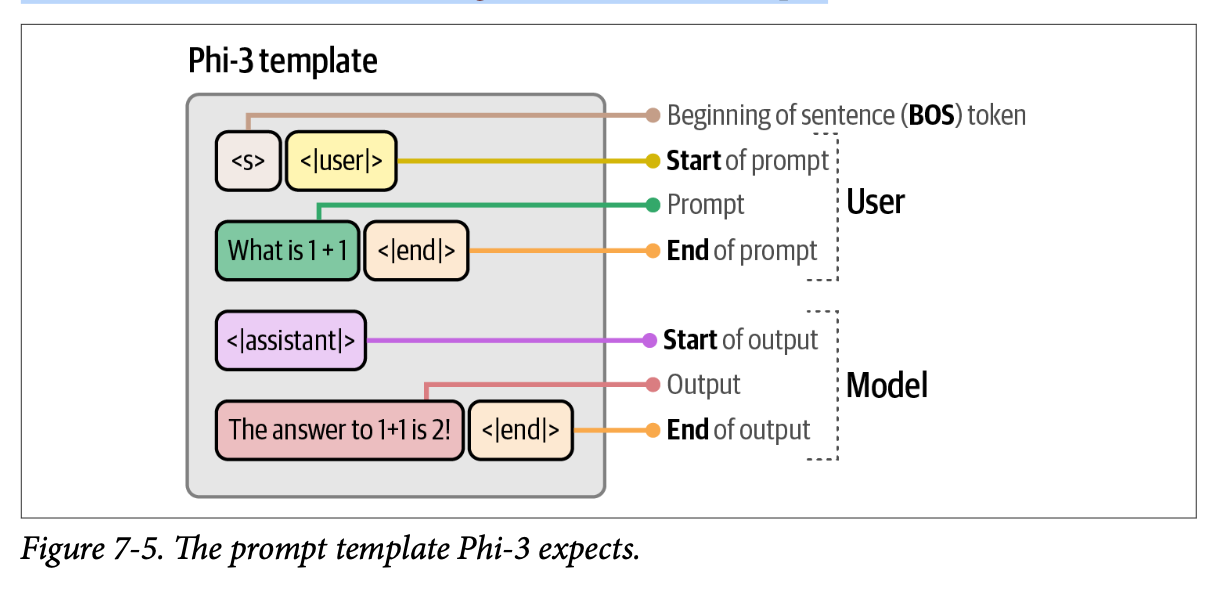
\(\text{Phi}-3\) 的模板主要由四个核心组成部分构成:
- \(\text{<s>}\):表示提示的开始。
- \(\text{<|user|>}\):表示用户提示的开始。
- \(\text{<|assistant|>}\):表示模型输出的开始。
- \(\text{<|end|>}\):表示提示或模型输出的结束。
图 \(\text{7}-5\) 进一步通过一个例子对此进行了说明。
为了创建我们的简单链,我们首先需要创建一个符合 \(\text{Phi}-3\) 预期模板的提示模板。使用这个模板,模型接收一个 \(\text{system\_prompt}\)(系统提示,通常描述我们对 \(\text{LLM}\) 的期望)。然后,我们可以使用 \(\text{input\_prompt}\)(输入提示)来向 \(\text{LLM}\) 询问具体问题:
1 | from langchain import PromptTemplate |
要创建我们的第一个链,我们可以同时使用我们创建的提示和 \(\text{LLM}\),并将它们链接在一起:
1 | basic_chain = prompt | llm |
要使用这个链,我们需要使用 \(\text{invoke}\) 函数,并确保我们使用 \(\text{input\_prompt}\) 来插入我们的问题:
1 | # Use the chain |
1 | The answer to 1 + 1 is 2. It's a basic arithmetic operation where you add one |
输出给我们提供了响应,没有任何不必要的词元。现在我们已经创建了这个链,我们不必每次使用 \(\text{LLM}\) 时都从头创建提示模板。请注意,我们没有像之前那样禁用采样,因此您的输出可能会有所不同。为了使这个管线更加透明,图 \(\text{7}-6\) 展示了使用单个链连接提示模板和 \(\text{LLM}\) 的过程。

💡 这个示例假设 \(\text{LLM}\) 需要一个特定的模板。但并非总是如此。对于 \(\text{OpenAI}\) 的 \(\text{GPT}-\text{3.5}\),其 \(\text{API}\) 会处理底层的模板。
您也可以使用提示模板来定义提示中可能变化的其他变量。例如,如果我们要为企业创建有趣的名称,为不同的产品一遍又一遍地重新输入相同的问题可能会耗费时间。
相反,我们可以创建一个可重复使用的提示:
2
3
4
5
6
template = "Create a funny name for a business that sells {product}."
name_prompt = PromptTemplate(
template=template,
input_variables=["product"]
)
向链中添加提示模板只是增强 \(\text{LLM}\) 能力所需的第一步。在本章中,我们将看到许多可以将额外的模块化组件添加到现有链中的方法,我们将从记忆(\(\text{memory}\))开始。
包含多个提示的链
A Chain with Multiple Prompts
在我们上一个例子中,我们创建了一个由提示模板和 \(\text{LLM}\) 组成的单个链。由于我们的示例非常简单直接,\(\text{LLM}\) 处理该提示没有问题。然而,一些应用程序涉及更复杂的细节,需要冗长或复杂的提示才能生成捕获这些复杂细节的响应。
相反,我们可以将这个复杂的提示分解成更小的、可以顺序运行的子任务。如图 \(\text{7}-7\) 所示,这将需要多次调用 \(\text{LLM}\),但使用的是更小的提示和中间输出。
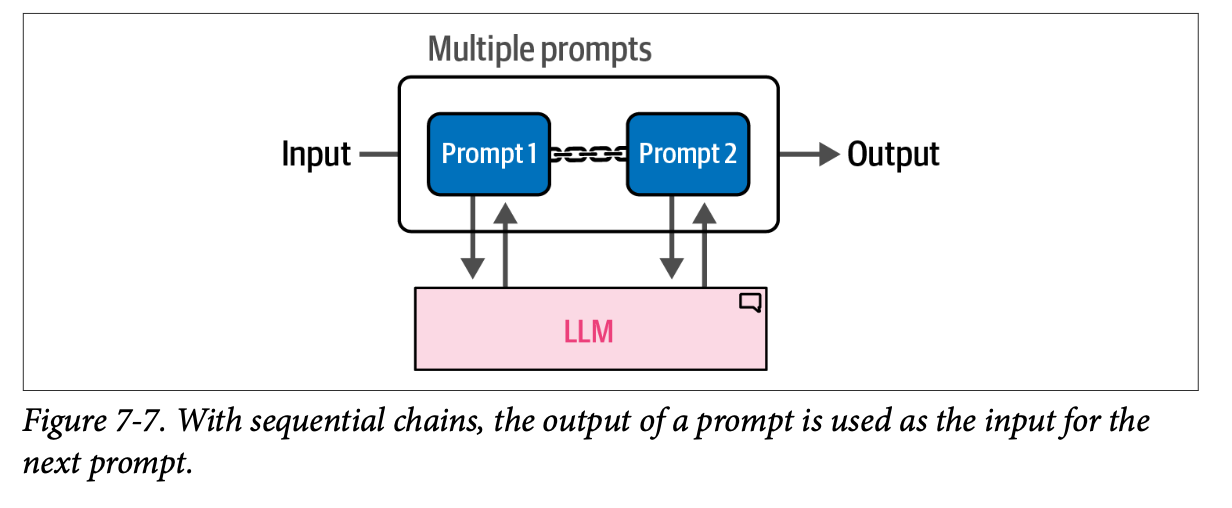
这种使用多个提示的过程是我们先前示例的延伸。我们不使用单个链,而是链接多个链,其中每个链接处理一个特定的子任务。
例如,考虑生成一个故事的过程。我们可以要求 \(\text{LLM}\) 生成一个故事,并附带复杂细节,如标题、摘要、人物描述等。与其试图将所有这些信息放入单个提示中,不如将这个提示分解成可管理的小任务。
让我们用一个例子来说明。假设我们要生成一个包含三个组件的故事:
- 一个标题
- 一个主角的描述
- 一个故事的摘要
我们不一次性生成所有内容,而是创建一个只需要用户输入一次,然后顺序生成这三个组件的链。这个过程如图 \(\text{7}-8\) 所示。
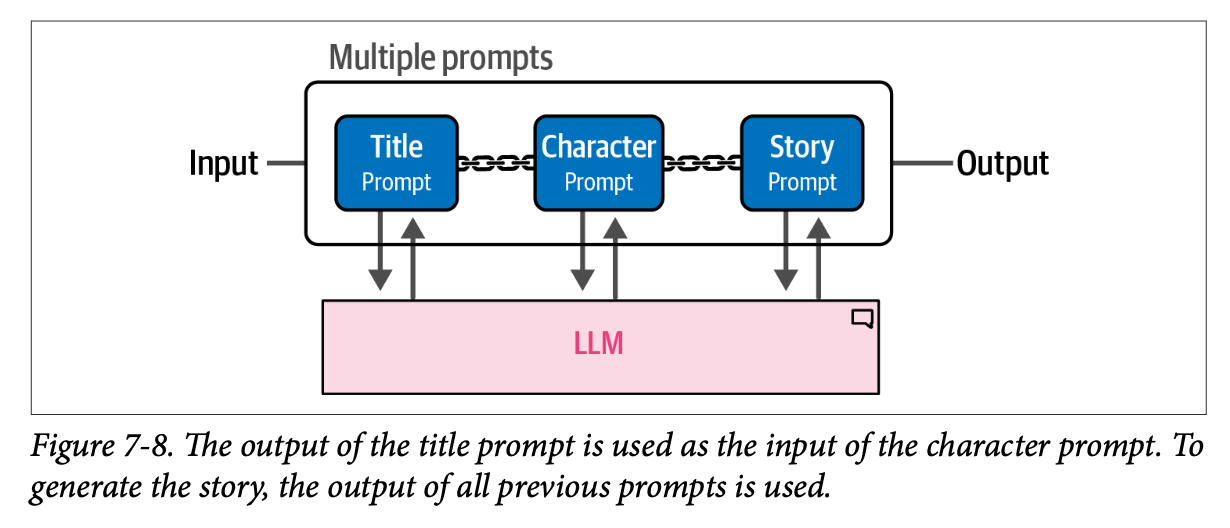
为了生成这个故事,我们使用 \(\text{LangChain}\) 来描述第一个组件,即标题。这个第一个链接是唯一需要用户输入的组件。我们定义模板,并使用 \(\text{"summary"}\) 变量作为输入变量,使用 \(\text{"title"}\) 作为输出。
我们要求 \(\text{LLM}\) “\(\text{Create a title for a story about \{summary\}}\)”(为一个关于 \(\text{\{summary\}}\) 的故事创建一个标题),其中 \(\text{\{summary\}}\) 将是我们的输入:
1 | from langchain import LLMChain |
让我们运行一个例子来展示这些变量:
1 | title.invoke({"summary": "a girl that lost her mother"}) |
1 | {'summary': 'a girl that lost her mother', |
这已经为我们的故事提供了一个很棒的标题!请注意,我们可以看到输入(“\(\text{summary}\)”)和输出(“\(\text{title}\)”)。
接下来,我们生成下一个组件,即人物描述。我们使用摘要和先前生成的标题来生成此组件。为了确保链使用这些组件,我们创建了一个带有 \(\text{\{summary\}}\) 和 \(\text{\{title\}}\) 标签的新提示:
1 | # Create a chain for the character description using the summary and title |
尽管我们现在可以手动使用 \(\text{character}\) 变量来生成人物描述,但在自动化链中,它将被用作其中一部分。
让我们创建最后一个组件,它使用摘要(\(\text{summary}\))、标题(\(\text{title}\))和人物描述(\(\text{character}\))来生成故事的简短描述:
1 | # Create a chain for the story using the summary, title, and character descrip |
现在我们已经生成了所有三个组件,我们可以将它们链接在一起以创建我们的完整链:
1 | # Combine all three components to create the full chain |
我们可以使用我们之前用过的相同示例来运行这个新创建的链:
1 | llm_chain.invoke("a girl that lost her mother") |
1 | {'summary': 'a girl that lost her mother', |
运行这个链会给出我们所有三个组件。这只要求我们输入一个简短的提示——摘要。将问题分解成更小的任务的另一个优势是,我们现在可以访问这些单独的组件。我们可以轻松地提取标题;如果使用单个提示,这可能就无法实现了。
记忆 (\(\text{Memory}\)): 帮助 \(\text{LLM}\) 记住对话
Memory: Helping LLMs to Remember Conversations
当我们直接使用 \(\text{LLM}\) 时,它们不会记住对话中说过的内容。您可以在一个提示中告诉它您的名字,但到下一个提示时,它就会忘记。
让我们用我们之前创建的 \(\text{basic\_chain}\) 来举例说明这一现象。首先,我们告诉 \(\text{LLM}\) 我们的名字:
1 | # Let's give the LLM our name |
1 | Hello Maarten! The answer to 1 + 1 is 2. |
接下来,我们要求它重复我们给它的名字:
1 | # Next, we ask the LLM to reproduce the name |
1 | I'm sorry, but as a language model, I don't have the ability to know personal |
不幸的是,\(\text{LLM}\) 不知道我们给它的名字。这种健忘行为的原因是这些模型是无状态的(\(\text{stateless}\))——它们没有关于任何先前对话的记忆!
如图 \(\text{7}-9\) 所示,与一个没有任何记忆的 \(\text{LLM}\) 对话体验并不理想。
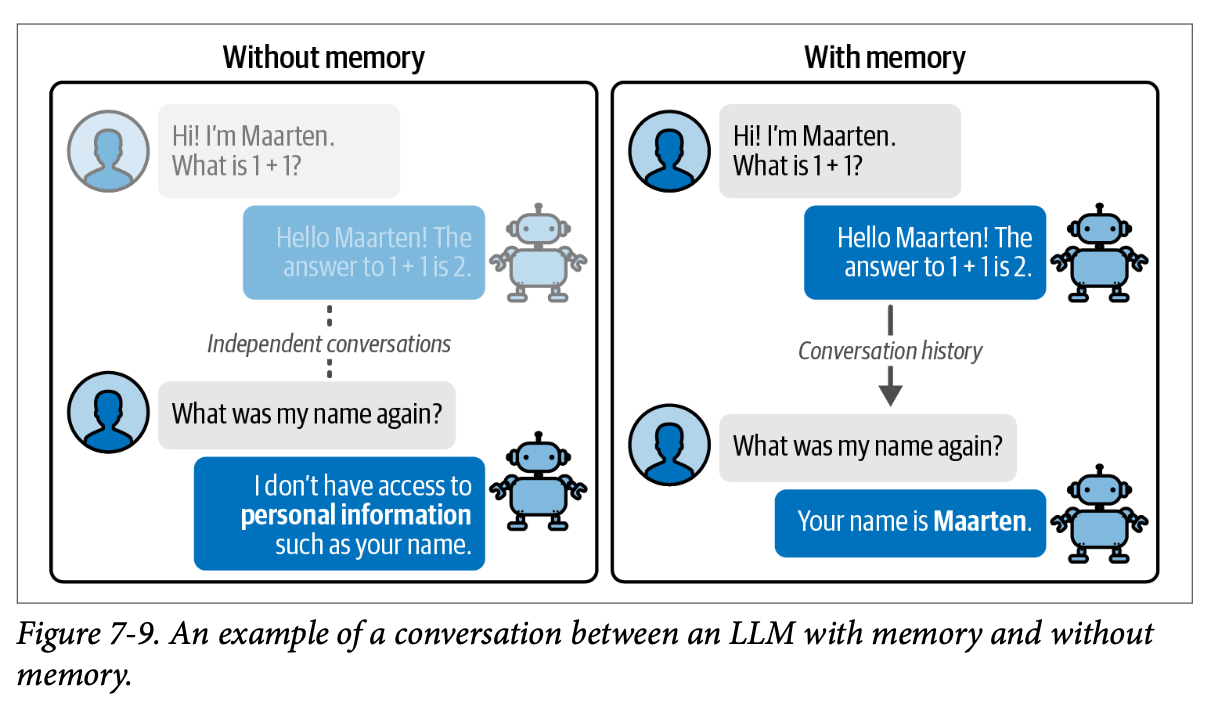
为了使这些模型有状态(\(\text{stateful}\)),我们可以向我们之前创建的链中添加特定类型的记忆。在本节中,我们将介绍两种帮助 \(\text{LLM}\) 记住对话的常用方法:
- 对话缓冲器 (\(\text{Conversation buffer}\))
- 对话摘要 (\(\text{Conversation summary}\))
对话缓冲器
Conversation Buffer
赋予 \(\text{LLM}\) 记忆的最直观形式之一就是简单地提醒它们过去发生的一切。如图 \(\text{7}-10\) 所示,我们可以通过复制完整的对话历史并将其粘贴到我们的提示中来实现这一点。
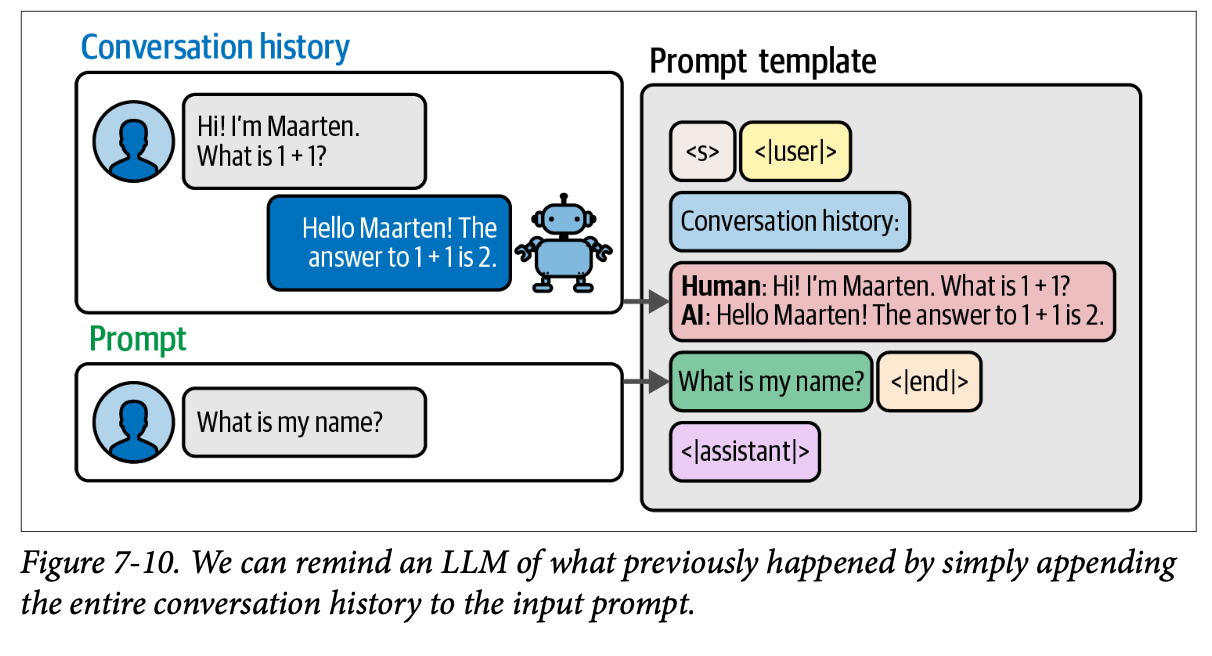
在 \(\text{LangChain}\) 中,这种形式的记忆被称为 \(\text{ConversationBufferMemory}\)。它的实现要求我们更新先前的提示以包含聊天的历史记录。
我们首先创建这个提示:
1 | # Create an updated prompt template to include a chat history |
请注意,我们添加了一个额外的输入变量,即 \(\text{chat\_history}\)。这是在向 \(\text{LLM}\) 提问之前提供对话历史记录的地方。
接下来,我们可以创建 \(\text{LangChain}\) 的 \(\text{ConversationBufferMemory}\)(对话缓冲器记忆),并将其分配给 \(\text{chat\_history}\) 输入变量。\(\text{ConversationBufferMemory}\) 将存储我们迄今为止与 \(\text{LLM}\) 进行过的所有对话。
我们将所有内容放在一起,将 \(\text{LLM}\)、记忆和提示模板链接起来:
1 | from langchain.memory import ConversationBufferMemory |
为了检验我们是否正确执行了,让我们通过问一个简单的问题来创建与 \(\text{LLM}\) 的对话历史:
1 | # Generate a conversation and ask a basic question |
1 | {'input_prompt': 'Hi! My name is Maarten. What is 1 + 1?', |
您可以在 \(\text{'text'}\) 键中找到生成的文本,在 \(\text{'input\_prompt'}\) 中找到输入提示,在 \(\text{'chat\_history'}\) 中找到聊天历史记录。请注意,由于这是我们第一次使用这个特定的链,所以没有聊天历史记录。
接下来,我们通过询问 \(\text{LLM}\) 是否记得我们使用的名字来跟进:
1 | # Does the LLM remember the name we gave it? |
1 | {'input_prompt': 'What is my name?', |
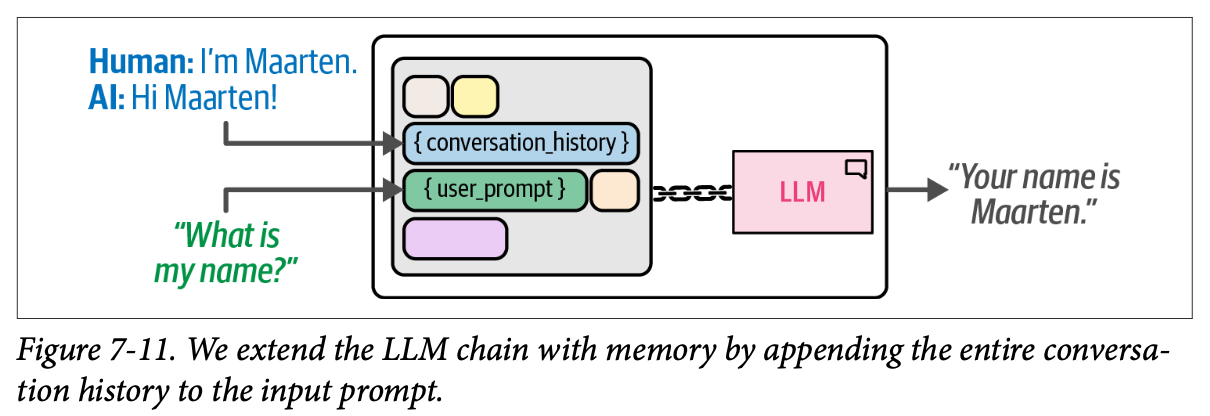
通过用记忆扩展链,\(\text{LLM}\) 能够使用聊天历史记录来找到我们先前给它的名字。如图 \(\text{7}-11\) 所示,这个更复杂的链概述了这项额外的功能。
窗口式对话缓冲器
Windowed Conversation Buffer
在我们上一个例子中,我们本质上创建了一个聊天机器人。您可以与它交谈,它会记住您迄今为止的对话。然而,随着对话规模的增长,输入提示的大小也会随之增长,直到超出词元限制。
最小化上下文窗口的一种方法是使用最近的 \(k\) 次对话,而不是维护完整的聊天历史记录。在 \(\text{LangChain}\) 中,我们可以使用 \(\text{ConversationBufferWindowMemory}\) 来决定将多少次对话传递给输入提示:
1 | from langchain.memory import ConversationBufferWindowMemory |
使用这种记忆类型,我们可以尝试一系列问题来演示哪些内容会被记住。我们从两次对话开始:
1 | # Ask two questions and generate two conversations in its memory |
1 | {'input_prompt': 'What is 3 + 3?', |
我们迄今为止的互动显示在 \(\text{"chat\_history"}\) 中。请注意,在底层,\(\text{LangChain}\) 将其保存为您(用 \(\text{Human}\) 表示)和 \(\text{LLM}\)(用 \(\text{AI}\) 表示)之间的互动。
接下来,我们可以检查模型是否确实知道我们给它的名字:
1 | # Check whether it knows the name we gave it |
1 | {'input_prompt': 'What is my name?', |
根据 \(\text{'text'}\) 中的输出,它正确地记住了我们给它的名字。请注意,聊天历史记录已用上一个问题进行了更新。
现在我们又增加了一次对话,总共有三次对话。考虑到记忆只保留最近的两次对话(\(\text{k}=2\)),我们最早的第一个问题没有被记住。
由于我们在第一次互动中提供了年龄,我们检查 \(\text{LLM}\) 是否确实不再知道年龄了:
1 | # Check whether it knows the age we gave it |
1 | {'input_prompt': 'What is my age?', |
\(\text{LLM}\) 确实无法获取我们的年龄,因为它没有被保留在聊天历史记录中。
尽管这种方法减少了聊天历史记录的大小,但它只能保留最近的几次对话,这对于冗长的对话来说并不理想。让我们探讨一下如何对聊天历史记录进行摘要。
对话摘要
Conversation Summar
正如我们之前讨论的,赋予您的 \(\text{LLM}\) 记住对话的能力对于良好的互动体验至关重要。然而,当使用 \(\text{ConversationBufferMemory}\) 时,对话的大小开始增加,并会逐渐接近您的词元限制。尽管 \(\text{ConversationBufferWindowMemory}\) 在一定程度上解决了词元限制的问题,但它只保留了最近的 \(k\) 次对话。
虽然一个解决方案是使用具有更大上下文窗口的 \(\text{LLM}\),但这些词元在生成新词元之前仍然需要被处理,这会增加计算时间。因此,让我们转向一种更复杂的技巧:\(\text{ConversationSummaryMemory}\)(对话摘要记忆)。顾名思义,这种技术会总结整个对话历史,将其提炼成要点。
这个摘要过程是通过另一个 \(\text{LLM}\) 启用的,这个 \(\text{LLM}\) 接收对话历史作为输入,并被要求创建一个简洁的摘要。使用外部 \(\text{LLM}\) 的一个很好的优势是,我们不局限于在对话中使用同一个 \(\text{LLM}\)。如图 \(\text{7}-12\) 所示,这就是摘要过程的工作方式。
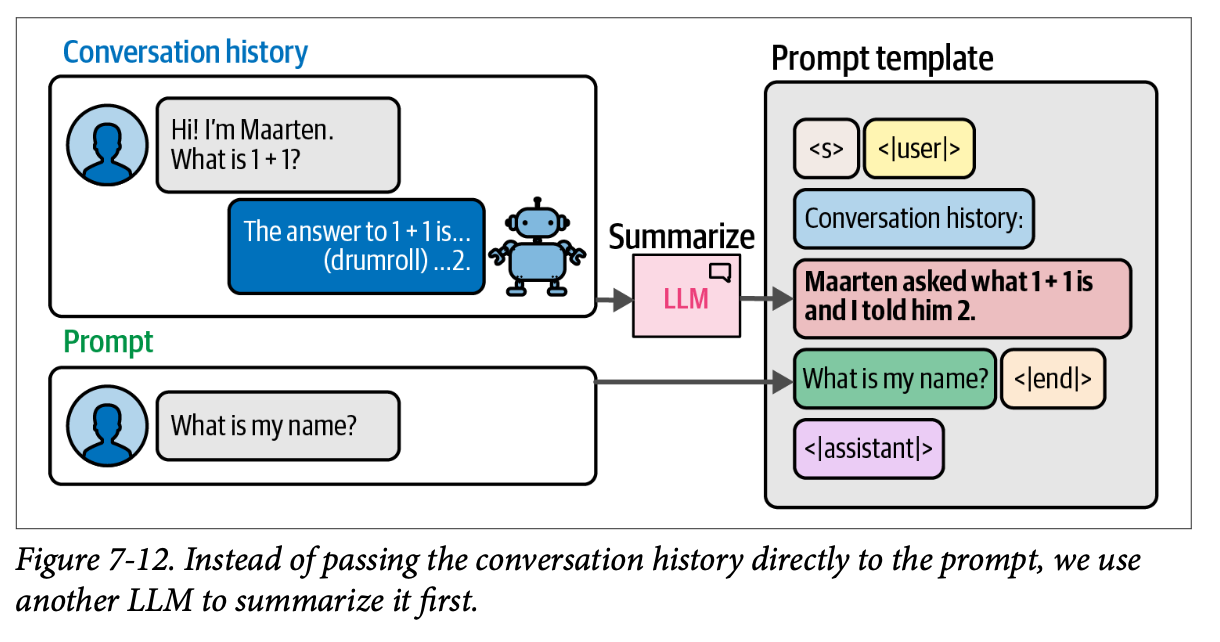
这意味着每当我们向 \(\text{LLM}\) 提问时,会发生两次调用:
- 用户提示(\(\text{The user prompt}\))
- 摘要提示(\(\text{The summarization prompt}\))
要在 \(\text{LangChain}\) 中使用此功能,我们首先需要准备一个将用作摘要提示的摘要模板:
1 | # Create a summary prompt template |
在 \(\text{LangChain}\) 中使用 \(\text{ConversationSummaryMemory}\) 与我们之前的示例类似。主要区别在于,我们额外需要为其提供一个执行摘要任务的 \(\text{LLM}\)。尽管我们使用相同的 \(\text{LLM}\) 进行摘要和用户提示,但您可以使用一个更小的 \(\text{LLM}\) 来执行摘要任务,以加快计算速度:
1 | from langchain.memory import ConversationSummaryMemory |
创建好我们的链之后,我们可以通过创建一个简短的对话来测试它的摘要能力:
1 | # Generate a conversation and ask for the name |
1 | {'input_prompt': 'What is my name?', |
在每一步之后,该链都会总结截至该点的对话。请注意,第一次对话是如何通过创建对话描述被摘要到 \(\text{'chat\_history'}\) 中的。
我们可以继续对话,每一步,对话都将被摘要,并根据需要添加新信息:
1 | # Check whether it has summarized everything thus far |
1 | {'input_prompt': 'What was the first question I asked?', |
在问了另一个问题后,\(\text{LLM}\) 更新了摘要以包含之前的对话,并正确地推断出最初的问题。
要获取最新的摘要,我们可以访问我们之前创建的 \(\text{memory}\) 变量:
1 | # Check what the summary is thus far |
1 | {'chat_history': ' Maarten, identified in this conversation, initially asked |
如图 \(\text{7}-13\) 所示,这个更复杂的链概述了这项额外的功能。
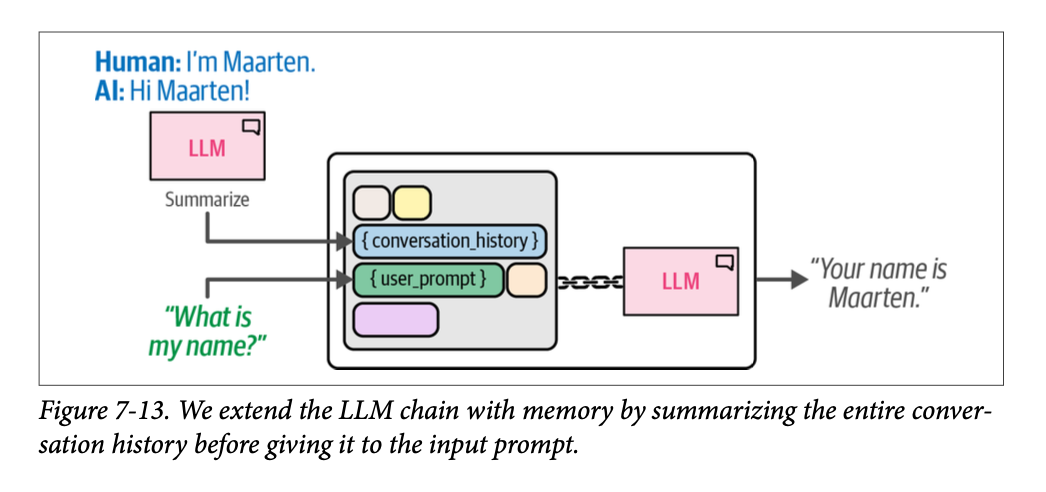
这种摘要方法有助于保持聊天历史记录相对较小,同时在推理过程中不会使用过多的词元。然而,由于原始问题没有明确地保存在聊天历史记录中,模型需要根据上下文进行推断。如果需要存储特定信息,这是一个缺点。此外,还需要多次调用同一个 \(\text{LLM}\),一次用于提示,一次用于摘要。这会降低计算时间。
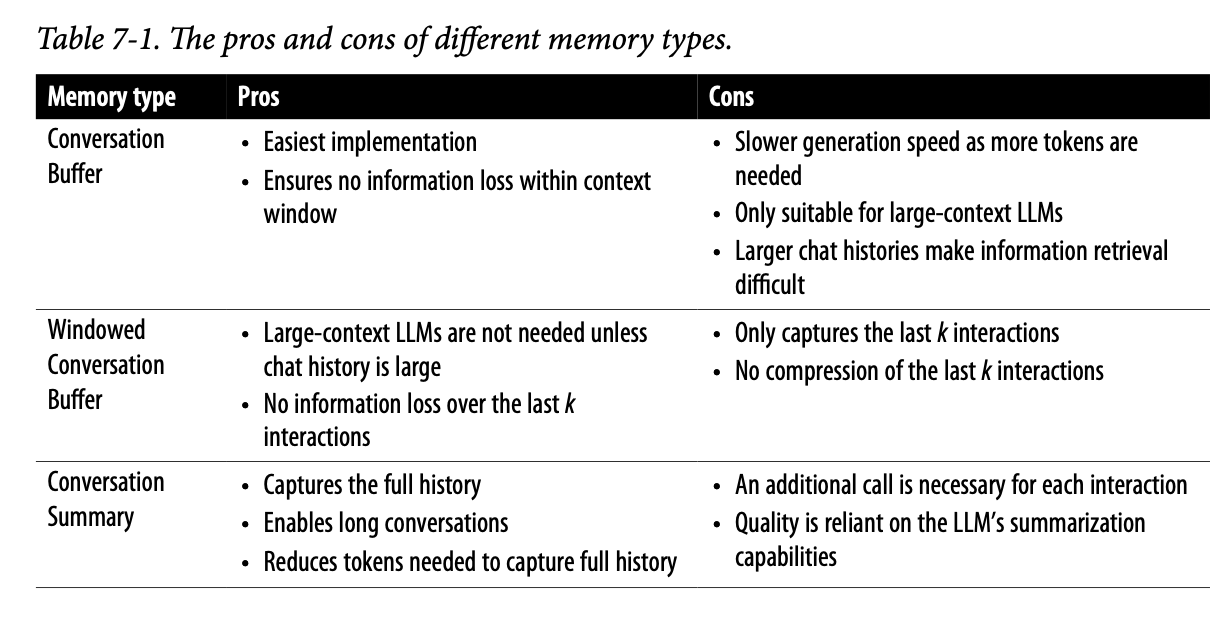
通常,这是一个速度、内存和准确性之间的权衡。\(\text{ConversationBufferMemory}\) 速度快但占用词元,而 \(\text{ConversationSummaryMemory}\) 速度慢但释放了可用的词元。我们迄今为止探索的这些记忆类型的其他优缺点如表 \(\text{7}-1\) 所示。
智能体 (\(\text{Agents}\)): 创建 \(\text{LLM}\) 系统
Agents: Creating a System of LLMs
到目前为止,我们创建的系统都遵循用户定义的一系列步骤。\(\text{LLM}\) 中最有前景的概念之一是它们决定自己可以采取哪些行动的能力。这个想法通常被称为智能体(\(\text{agents}\)),即利用语言模型来决定应该采取哪些行动以及以何种顺序采取的系统。
智能体可以利用我们迄今为止看到的一切,例如模型 \(\text{I/O}\)、链和记忆,并用两个关键组件进一步扩展:
- 工具 (\(\text{Tools}\)):智能体可以用来做自身无法完成的事情。
- 智能体类型 (\(\text{The agent type}\)):规划要采取的行动或使用的工具。
与我们迄今为止看到的链不同,智能体能够展示出更高级的行为,例如创建和自我纠正实现目标的路线图。它们可以通过使用工具来与真实世界互动。因此,这些智能体可以执行超出 \(\text{LLM}\) 孤立能力范围的各种任务。
例如,\(\text{LLM}\) 在数学问题上是出了名的差,经常无法解决简单的基于数学的任务,但如果我们提供计算器的访问权限,它们就能做更多事情。如图 \(\text{7}-14\) 所示,智能体的基本思想是,它们利用 \(\text{LLM}\) 不仅是为了理解我们的查询,还为了决定何时以及使用哪个工具。
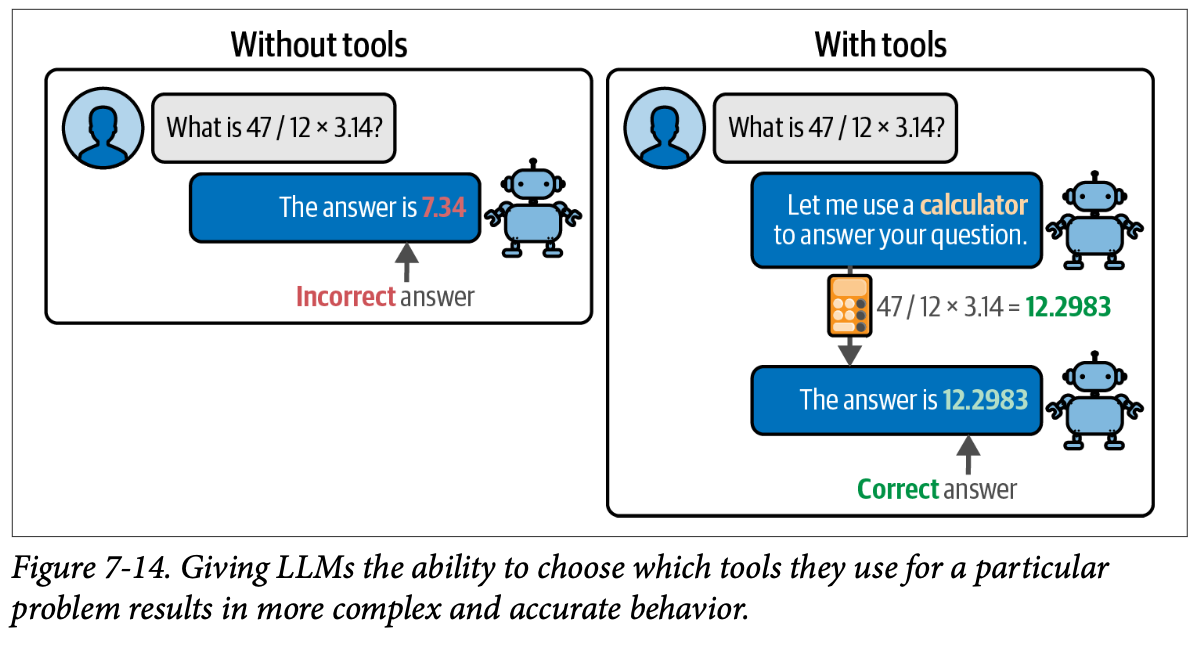
在这个例子中,我们期望 \(\text{LLM}\) 在面临数学任务时使用计算器。现在想象一下,我们将此扩展到数十个其他工具,比如搜索引擎或天气 \(\text{API}\)。突然之间,\(\text{LLM}\) 的能力显着增加。
换句话说,利用 \(\text{LLM}\) 的智能体可以成为强大的通用问题解决器。尽管它们使用的工具很重要,但许多基于智能体的系统的驱动力是使用一种称为推理(Reasoning)和行动 (\(\text{ReAct}\)) 的框架。
智能体背后的驱动力:循序渐进的推理
The Driving Power Behind Agents: Step-by-step Reasoning
\(\text{ReAct}\) 是一个强大的框架,它结合了行为中的两个重要概念:推理 (\(\text{reasoning}\)) 和行动 (\(\text{acting}\))。正如我们在第 \(\text{5}\) 章中详细探讨的那样,\(\text{LLM}\) 在推理方面异常强大。
行动则有所不同。\(\text{LLM}\) 无法像您我一样行动。要赋予它们行动的能力,我们可以告诉 \(\text{LLM}\) 它可以使用某些工具,例如天气预报 \(\text{API}\)。然而,由于 \(\text{LLM}\) 只能生成文本,因此需要指示它们使用特定的查询来触发这个预报 \(\text{API}\)。
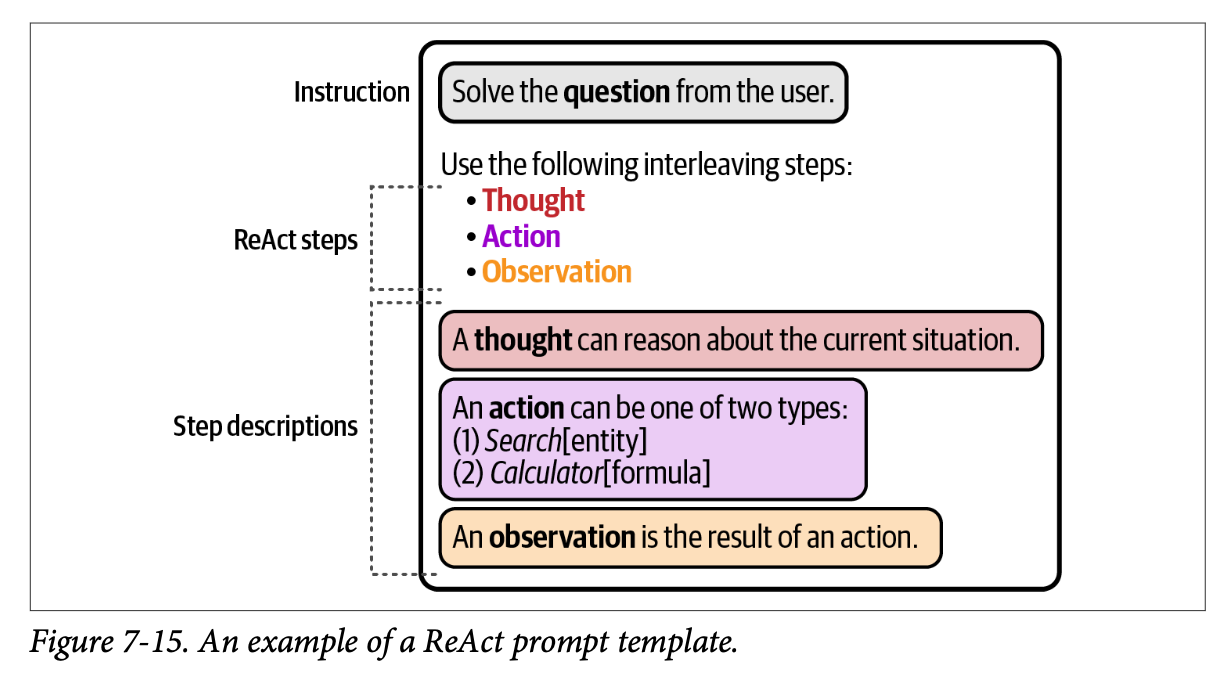
\(\text{ReAct}\) 框架将这两个概念融合在一起,允许推理影响行动,行动反过来影响推理。在实践中,该框架包括迭代地遵循这三个步骤:
- 思维 (\(\text{Thought}\))
- 行动 (\(\text{Action}\))
- 观察 (\(\text{Observation}\))
如图 \(\text{7}-15\) 所示,系统要求 \(\text{LLM}\) 对输入提示产生一个“思维”。这类似于询问 \(\text{LLM}\) 认为它接下来应该做什么以及为什么。然后,根据这个“思维”,触发一个“行动”。该行动通常是一个外部工具,如计算器或搜索引擎。最后,在“行动”的结果返回给 \(\text{LLM}\) 之后,它“观察”输出,这通常是它检索到的任何结果的摘要。
为了用一个例子来说明,想象您在美国度假并想购买一台 \(\text{MacBook Pro}\)。您不仅想知道价格,还需要将其兑换成欧元(\(\text{EUR}\)),因为您住在欧洲,对这些价格更习惯。
如图 \(\text{7}-16\) 所示,智能体将首先搜索网页以获取当前价格。根据搜索引擎的不同,它可能会找到一个或多个价格。在检索到价格后,它将使用计算器将美元 (\(\text{USD}\)) 转换为欧元 (\(\text{EUR}\)),前提是我们知道汇率。
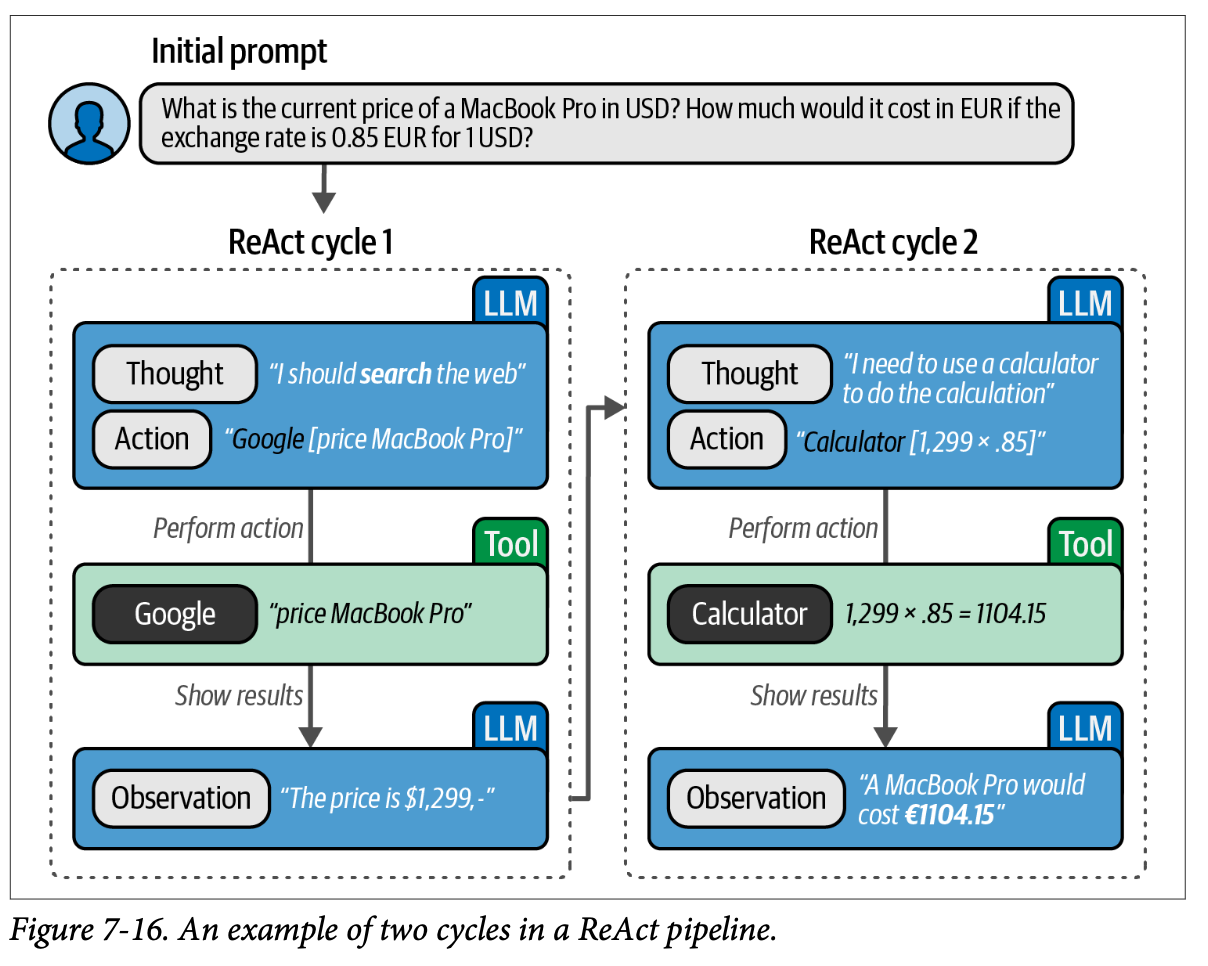
在这个过程中,智能体描述了它的思维(它应该做什么)、它的行动(它将做什么)和它的观察(行动的结果)。这是一个思维、行动和观察的循环,最终产生智能体的输出。
\(\text{LangChain}\) 中的 \(\text{ReAct}\)
ReAct in LangChain
为了说明智能体在 \(\text{LangChain}\) 中如何工作,我们将构建一个能够搜索网页以获取答案并使用计算器执行计算的管线。这些自主过程通常需要一个足够强大以正确遵循复杂指令的 \(\text{LLM}\)。
我们迄今为止使用的 \(\text{LLM}\) 相对较小,不足以运行这些示例。因此,我们将使用 \(\text{OpenAI}\) 的 \(\text{GPT}-\text{3.5}\) 模型,因为它能更准确地遵循这些复杂指令:
1 | import os |
💡 尽管我们在本章中一直使用的 \(\text{LLM}\) 不足以运行此示例,但这并不意味着只有 \(\text{OpenAI}\) 的 \(\text{LLM}\) 才足够。存在更大、更有用的 \(\text{LLM}\),但它们需要显著更多的计算资源和显存(\(\text{VRAM}\))。例如,本地 \(\text{LLM}\) 通常有不同的大小,在同一模型家族中,增加模型大小会带来更好的性能。为了将所需的计算量保持在最低限度,我们在本章的示例中选择了较小的 \(\text{LLM}\)。
然而,随着生成模型领域的发展,这些较小的 \(\text{LLM}\) 也在发展。如果最终较小的 \(\text{LLM}\)(例如本章中使用的模型)能够胜任运行此示例,我们一点也不会感到惊讶。
完成上述步骤后,我们将定义智能体的模板。正如我们之前展示的,它描述了智能体需要遵循的 \(\text{ReAct}\) 步骤:
1 | # Create the ReAct template |
这个模板阐明了从提出问题开始,并生成中间的思维、行动和观察的整个过程。
为了让 \(\text{LLM}\) 与外部世界互动,我们将描述它可以使用的工具:
1 | from langchain.agents import load_tools, Tool |
这些工具包括 \(\text{DuckDuckGo}\) 搜索引擎和一个允许它访问基本计算器的数学工具(\(\text{llm-math}\))。
最后,我们创建 \(\text{ReAct}\) 智能体并将其传递给 \(\text{AgentExecutor}\),后者负责执行这些步骤:
1 | from langchain.agents import AgentExecutor, create_react_agent |
为了测试智能体是否工作,我们使用之前的例子,即查找 \(\text{MacBook Pro}\) 的价格:
1 | # What is the price of a MacBook Pro? |
在执行过程中,模型会生成多个中间步骤,类似于图 \(\text{7}-17\) 中所示的步骤。

这些中间步骤说明了模型如何处理 \(\text{ReAct}\) 模板以及它访问了哪些工具。这使我们能够调试问题并探索智能体是否正确地使用了工具。
完成后,模型会给出类似以下的输出:
1 | {'input': 'What is the current price of a MacBook Pro in USD? How much would |
考虑到智能体拥有的工具有限,这非常令人印象深刻!仅使用搜索引擎和计算器,智能体就能给我们一个答案。
然而,应该考虑这个答案是否真的正确。通过创建这种相对自主的行为,我们没有参与到中间步骤中。因此,没有人参与来判断输出的质量或推理过程。
这把双刃剑要求仔细设计系统以提高其可靠性。例如,我们可以让智能体返回它找到 \(\text{MacBook Pro}\) 价格的网站 \(\text{URL}\),或者在每一步询问输出是否正确。
总结
在本章中,我们探索了通过添加模块化组件来扩展 \(\text{LLM}\) 能力的几种方法。我们首先创建了一个简单但可重用的链,它将 \(\text{LLM}\) 与提示模板连接起来。然后,我们通过向链中添加记忆来扩展这个概念,这使得 \(\text{LLM}\) 能够记住对话。我们探讨了三种不同的添加记忆的方法,并讨论了它们的优点和缺点。
接着,我们深入研究了智能体(\(\text{agents}\))的世界,它们利用 \(\text{LLM}\) 来决定自己的行动和做出决策。我们探讨了 \(\text{ReAct}\) 框架,它使用一个直观的提示框架,允许智能体对自己的思维进行推理、采取行动并观察结果。这使我们能够构建一个能够自由使用其可用工具(例如搜索网页和使用计算器)的智能体,展示了智能体的潜在力量。
有了这个基础,我们现在可以探索如何利用 \(\text{LLM}\) 来改进现有的搜索系统,甚至成为新的、更强大的搜索系统的核心,正如下一章将讨论的那样。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调