《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models: Language Understanding and Generation》 的目录中文翻译。
这本书将内容分为三个主要部分:理解 \(\text{LLM}\) 的底层原理、使用预训练模型进行应用,以及模型训练和微调的进阶技术。
《动手实践大型语言模型:语言理解与生成》 目录
[cite_start]第一部分:理解语言模型 (\(\text{Understanding Language Models}\)) [cite: 5]
| 章节 | 英文标题 | 中文翻译 | [cite_start]英文页码 [cite: 2, 3] |
|---|---|---|---|
| 第 \(\text{1}\) 章 | An Introduction to Large Language Models | 大型语言模型简介 | \(\text{3}\) |
| What Is Language \(\text{AI}\)? | 什么是语言 \(\text{AI}\)? | \(\text{4}\) | |
| A Recent History of Language \(\text{AI}\) | 语言 \(\text{AI}\) 的近代史 | \(\text{5}\) | |
| Representing Language as a Bag-of-Words | 将语言表示为词袋模型 | \(\text{6}\) | |
| Better Representations with Dense Vector Embeddings | 使用密集向量嵌入实现更好的表示 | \(\text{8}\) | |
| Representation Models: \(\text{Encoder}\)-Only Models | 表征模型:仅编码器 (\(\text{Encoder}\)-Only) 模型 | \(\text{18}\) | |
| Generative Models: \(\text{Decoder}\)-Only Models | 生成模型:仅解码器 (\(\text{Decoder}\)-Only) 模型 | \(\text{20}\) | |
| The Moving Definition of a "Large Language Model" | “大型语言模型”不断变化的定义 | \(\text{25}\) | |
| 第 \(\text{2}\) 章 | Tokens and Embeddings | 分词 (\(\text{Tokens}\)) 与嵌入 (\(\text{Embeddings}\)) | \(\text{37}\) |
| \(\text{LLM}\) Tokenization | \(\text{LLM}\) 分词技术 | \(\text{38}\) | |
| Token Embeddings | 分词嵌入 | \(\text{57}\) | |
| Text Embeddings (for Sentences and Whole Documents) | 文本嵌入(针对句子和整个文档) | \(\text{61}\) | |
| Embeddings for Recommendation Systems | 用于推荐系统的嵌入 | \(\text{67}\) | |
| 第 \(\text{3}\) 章 | Looking Inside Large Language Models | 深入了解大型语言模型内部 | \(\text{73}\) |
| An Overview of \(\text{Transformer}\) Models | \(\text{Transformer}\) 模型概述 | \(\text{74}\) | |
| Inside the \(\text{Transformer}\) Block | \(\text{Transformer}\) 块内部结构 | \(\text{85}\) | |
| Recent Improvements to the \(\text{Transformer}\) Architecture | \(\text{Transformer}\) 架构的最新改进 | \(\text{95}\) |
[cite_start]第二部分:使用预训练语言模型 (\(\text{Using Pretrained Language Models}\)) [cite: 4]
| 章节 | 英文标题 | 中文翻译 | [cite_start]英文页码 [cite: 4, 5] |
|---|---|---|---|
| 第 \(\text{4}\) 章 | Text Classification | 文本分类 | \(\text{111}\) |
| Text Classification with Representation Models | 使用表征模型进行文本分类 | \(\text{113}\) | |
| Classification Tasks That Leverage Embeddings | 利用嵌入的分类任务 | \(\text{120}\) | |
| Text Classification with Generative Models | 使用生成模型进行文本分类 | \(\text{127}\) | |
| 第 \(\text{5}\) 章 | Text Clustering and Topic Modeling | 文本聚类与主题建模 | \(\text{137}\) |
| A Common Pipeline for Text Clustering | 文本聚类的常见流程 | \(\text{139}\) | |
| From Text Clustering to Topic Modeling | 从文本聚类到主题建模 | \(\text{146}\) | |
| 第 \(\text{6}\) 章 | Prompt Engineering | 提示工程 | \(\text{167}\) |
| Intro to Prompt Engineering | 提示工程简介 | \(\text{173}\) | |
| Advanced Prompt Engineering | 高级提示工程 | \(\text{177}\) | |
| 第 \(\text{7}\) 章 | Advanced Text Generation Techniques and Tools | 高级文本生成技术与工具 | \(\text{199}\) |
| Chains: Extending the Capabilities of \(\text{LLM}\)s | 链 (\(\text{Chains}\)): 扩展 \(\text{LLM}\) 的能力 | \(\text{202}\) | |
| Memory: Helping \(\text{LLM}\)s to Remember Conversations | 记忆 (\(\text{Memory}\)): 帮助 \(\text{LLM}\) 记住对话 | \(\text{209}\) | |
| Agents: Creating a System of \(\text{LLM}\)s | 代理 (\(\text{Agents}\)): 创建 \(\text{LLM}\) 系统 | \(\text{218}\) | |
| 第 \(\text{8}\) 章 | Semantic Search and Retrieval-Augmented Generation | 语义搜索与检索增强生成 (\(\text{RAG}\)) | \(\text{225}\) |
| Semantic Search with Language Models | 使用语言模型进行语义搜索 | \(\text{228}\) | |
| Retrieval-Augmented Generation (\(\text{RAG}\)) | 检索增强生成 (\(\text{RAG}\)) | \(\text{249}\) | |
| 第 \(\text{9}\) 章 | Multimodal Large Language Models | 多模态大型语言模型 | \(\text{259}\) |
| Multimodal Embedding Models | 多模态嵌入模型 | \(\text{263}\) | |
| Making Text Generation Models Multimodal | 使文本生成模型具备多模态能力 | \(\text{273}\) |
[cite_start]第三部分:训练和微调语言模型 (\(\text{Training and Fine-Tuning Language Models}\)) [cite: 5]
| 章节 | 英文标题 | 中文翻译 | [cite_start]英文页码 [cite: 5] |
|---|---|---|---|
| 第 \(\text{10}\) 章 | Creating Text Embedding Models | 创建文本嵌入模型 | \(\text{289}\) |
| What Is Contrastive Learning? | 什么是对比学习? | \(\text{291}\) | |
| Fine-Tuning an Embedding Model | 微调嵌入模型 | \(\text{309}\) | |
| Unsupervised Learning | 无监督学习 | \(\text{316}\) | |
| 第 \(\text{11}\) 章 | Fine-Tuning Representation Models for Classification | 微调表征模型用于分类 | \(\text{323}\) |
| Fine-Tuning a Pretrained \(\text{BERT}\) Model | 微调预训练的 \(\text{BERT}\) 模型 | \(\text{325}\) | |
| Few-Shot Classification | 少样本分类 | \(\text{333}\) | |
| Named-Entity Recognition | 命名实体识别 | \(\text{345}\) | |
| 第 \(\text{12}\) 章 | Fine-Tuning Generation Models | 微调生成模型 | \(\text{355}\) |
| Supervised Fine-Tuning (\(\text{SFT}\)) | 有监督微调 (\(\text{SFT}\)) | \(\text{357}\) | |
| Instruction Tuning with \(\text{QLoRA}\) | 使用 \(\text{QLoRA}\) 进行指令调优 | \(\text{367}\) | |
| Evaluating Generative Models | 评估生成模型 | \(\text{373}\) | |
| Preference-Tuning / Alignment / \(\text{RLHF}\) | 偏好调优 / 对齐 / \(\text{RLHF}\) | \(\text{378}\) |
- [cite_start]后记 (\(\text{Afterword}\)) [cite: 5] \(\text{391}\)
- [cite_start]索引 (\(\text{Index}\)) [cite: 5] \(\text{393}\)
前言
大型语言模型(\(\text{LLM}\))对世界产生了深远而广泛的影响。通过使机器能够更好地理解和生成类似人类的语言,\(\text{LLM}\) 在 \(\text{AI}\) 领域开启了新的可能性,并影响了整个行业。
本书提供了一个全面且高度可视化的 \(\text{LLM}\) 世界入门介绍,涵盖了概念基础和实际应用。从早于深度学习的词汇表示,到(在撰写本文时)前沿的 \(\text{Transformer}\) 架构,我们将探索 \(\text{LLM}\) 的历史和演变。我们深入探讨 \(\text{LLM}\) 的内部工作原理,探索它们的架构、训练方法和微调技术。我们还将研究 \(\text{LLM}\) 在文本分类、聚类、主题建模、聊天机器人、搜索引擎等各种应用。
我们希望,凭借其独特的直觉构建、应用和图解风格的结合,本书能为那些希望探索 \(\text{LLM}\) 激动人心世界的人们提供理想的基础。无论您是初学者还是专家,我们都邀请您加入我们,开始使用 \(\text{LLM}\) 进行构建。
直觉优先的理念
本书的主要目标是为 \(\text{LLM}\) 领域提供直觉。语言 \(\text{AI}\) 领域的发展速度快得令人难以置信,试图跟上最新的技术可能会让人感到沮丧。因此,我们专注于 \(\text{LLM}\) 的基础知识,并旨在提供一个有趣且轻松的学习过程。
为了实现这种直觉优先的理念,我们大量使用了可视化语言。插图将有助于为 \(\text{LLM}\) 学习过程中涉及的主要概念和过程提供视觉上的标识。通过我们图解式的叙事方法,我们希望带您踏上这一激动人心、可能改变世界的领域的旅程。
在整本书中,我们明确区分了表征语言模型和生成语言模型。表征模型是不生成文本的 \(\text{LLM}\),但通常用于特定任务的用例,例如分类;而生成模型是生成文本的 \(\text{LLM}\),例如 \(\text{GPT}\) 模型。尽管生成模型通常是想到 \(\text{LLM}\) 时首先想到的,但表征模型仍然有很多用途。我们对大型语言模型中的“大”一词也采取了较为宽泛的使用,并且通常只称它们为语言模型,因为尺寸描述通常相当武断,并不总是能力的指标。
先决条件
本书假设您具有一定的 \(\text{Python}\) 编程经验,并熟悉机器学习的基础知识。重点将是建立强大的直觉,而不是推导数学方程。因此,插图结合动手实践的例子将贯穿本书的示例和学习过程。
本书假设读者不具备 \(\text{PyTorch}\) 或 \(\text{TensorFlow}\) 等流行的深度学习框架的预先知识,也不具备生成建模的任何先验知识。
如果您不熟悉 \(\text{Python}\),一个很好的起点是 \(\text{Learn Python}\),您可以在其中找到许多关于该语言基础知识的教程。为了进一步简化学习过程,我们已将所有代码上传到 \(\text{Google Colab}\),这是一个您无需在本地安装任何东西即可运行所有代码的平台。
书籍结构
本书大致分为三个部分。它们如图 \(\text{P}-1\) 所示,以便您全面了解本书。请注意,每个章节都可以独立阅读,因此对于您已经熟悉的内容,请随意略读。
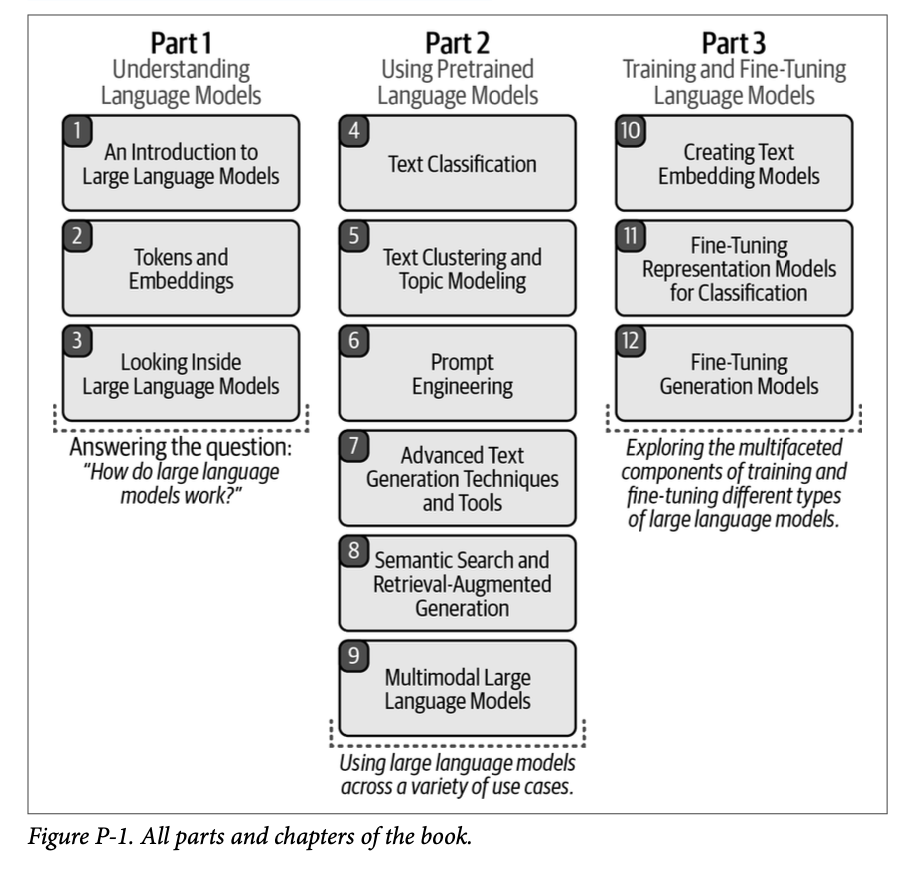
第一部分:理解语言模型
在本书的第一部分,我们将探讨语言模型(无论大小)的内部工作原理。我们首先概述该领域和常用技术(参见第 \(\text{1}\) 章),然后转向这些模型的两个核心组成部分——分词 (\(\text{tokenization}\)) 和嵌入 (\(\text{embeddings}\))(参见第 \(\text{2}\) 章)。本部分最后将以 \(\text{Jay}\) 著名的《图解 \(\text{Transformer}\)》的更新和扩展版本结束,该版本深入探讨了这些模型的架构(参见第 \(\text{3}\) 章)。本书将介绍贯穿始终的许多术语和定义。
第二部分:使用预训练语言模型
在本书的第二部分,我们将通过常见的用例来探讨如何使用 \(\text{LLM}\)。我们将使用预训练模型,并在无需微调的情况下展示其功能。
您将学习如何使用语言模型进行有监督分类(参见第 \(\text{4}\) 章)、文本聚类和主题建模(参见第 \(\text{5}\) 章)、利用嵌入模型进行语义搜索(参见第 \(\text{6}\) 章)、生成文本(参见第 \(\text{7}\) 章和第 \(\text{8}\) 章),以及将文本生成的能力扩展到视觉领域(参见第 \(\text{9}\) 章)。
学习这些独立的语言模型功能将为您提供使用 \(\text{LLM}\) 解决问题和构建越来越高级的系统和流程所需的技能。
第三部分:训练和微调语言模型
在本书的第三部分,我们将通过训练和微调各种语言模型来探索高级概念。我们将探讨如何创建和微调嵌入模型(参见第 \(\text{10}\) 章),回顾如何微调 \(\text{BERT}\) 进行分类(参见第 \(\text{11}\) 章),并以微调生成模型的几种方法结束本书(参见第 \(\text{12}\) 章)。
硬件和软件要求
运行生成模型通常是一项计算密集型任务,需要配备功能强大的 \(\text{GPU}\) 的计算机。由于并非所有读者都具备 \(\text{GPU}\),本书中的所有示例都设置为使用在线平台运行,即 \(\text{Google Colaboratory}\)(通常缩写为 \(\text{Google Colab}\))。在撰写本文时,该平台允许您免费使用 \(\text{NVIDIA}\) \(\text{GPU}\) (\(\text{T}4\)) 来运行代码。该 \(\text{GPU}\) 具有 \(\text{16 GB}\) 的 \(\text{VRAM}\)(即您的 \(\text{GPU}\) 内存),这是我们在本书示例中要求的最低 \(\text{VRAM}\) 量。
并不是所有章节都需要最低 \(\text{16 GB}\) \(\text{VRAM}\),因为有些示例(例如训练和微调)比其他示例(例如提示工程)对计算的要求更高。在代码库中,您可以找到每个章节所需的最低 \(\text{GPU}\) 要求。
所有代码、要求和附加教程都可在本书的代码库中获取。如果您想在本地运行这些示例,我们建议使用至少 \(\text{16 GB}\) \(\text{VRAM}\) 的 \(\text{NVIDIA}\) \(\text{GPU}\)。对于本地安装,例如使用 \(\text{conda}\),您可以按照以下设置来创建您的环境:
1 | conda create -n thellmbook python=3.10 |
您可以通过 \(\text{fork}\) 或克隆代码库,然后在您新建的 \(\text{Python 3.10}\) 环境中运行以下命令来安装所有必要的依赖项:
1 | pip install -r requirements.txt |
以下是书籍《\(\text{Hands-On Large Language Models}\)》中您提供的关于 \(\text{API}\) 密钥、书籍约定和 O’Reilly 信息的中文翻译:
\(\text{API}\) 密钥
我们在示例中同时使用了开源模型和专有模型,以展示两者的优缺点。对于专有模型,即 \(\text{OpenAI}\) 和 \(\text{Cohere}\) 提供的产品,您需要创建一个免费账户:
\(\text{OpenAI}\)
点击网站上的“注册”(\(\text{sign up}\))来创建免费账户。该账户允许您创建一个 \(\text{API}\) 密钥,可用于访问 \(\text{GPT}-3.5\)。然后,转到“\(\text{API}\) 密钥”来创建一个密钥(\(\text{secret key}\))。
\(\text{Cohere}\)
在网站上注册一个免费账户。然后,转到“\(\text{API}\) 密钥”来创建一个密钥(\(\text{secret key}\))。
请注意,这两个账户都有速率限制(\(\text{rate limits}\)),并且这些免费的 \(\text{API}\) 密钥只允许每分钟进行有限次数的调用。在所有示例中,我们都考虑了这一点,并在必要时提供了本地替代方案。
对于开源模型,您无需创建账户,第 \(\text{2}\) 章中的 \(\text{Llama 2}\) 模型除外。要使用该模型,您需要一个 \(\text{Hugging Face}\) 账户:
\(\text{Hugging Face}\)
点击 \(\text{Hugging Face}\) 网站上的“注册”(\(\text{sign up}\))来创建免费账户。然后,在“设置”(\(\text{Settings}\))中转到“访问令牌”(\(\text{Access Tokens}\)),创建一个令牌,您可以使用该令牌下载某些 \(\text{LLM}\)。
本书中使用的约定
本书使用以下排版约定:
斜体 表示新术语、\(\text{URL}\)、电子邮件地址、文件名和文件扩展名。
等宽字体 用于程序清单,以及段落内引用程序元素(例如变量或函数名称、数据库、数据类型、环境变量、语句和关键字)时。
等宽粗体 显示应由用户按字面输入的命令或其他文本。
等宽斜体 显示应替换为用户提供的值或由上下文确定的值的文本。
使用代码示例
补充材料(代码示例、练习等)可在以下网址下载:
\(\text{[https://github.com/HandsOnLLM/Hands-On-Large-Language-Models](https://github.com/HandsOnLLM/Hands-On-Large-Language-Models)}\)
如果您有技术问题或在使用代码示例时遇到问题,请发送电子邮件至 \(\text{support@oreilly.com}\)。
本书旨在帮助您完成工作。一般来说,如果本书提供了示例代码,您可以在您的程序和文档中使用它。除非您要复制代码的重要部分,否则您无需联系我们征求许可。例如,编写一个使用本书中几段代码的程序不需要许可。出售或分发 \(\text{O’Reilly}\) 书籍中的示例则需要许可。引用本书并引用示例代码来回答问题不需要许可。将本书中大量的示例代码纳入您的产品文档中则需要许可。
我们感激(但通常不要求)注明出处。出处通常包括书名、作者、出版商和 \(\text{ISBN}\)。例如:“《\(\text{Hands-On Large Language Models}\)》,作者 \(\text{Jay Alammar}\) 和 \(\text{Maarten Grootendorst}\) (\(\text{O’Reilly}\))。版权所有 \(\text{2024}\) \(\text{Jay Alammar}\) 和 \(\text{Maarten Pieter Grootendorst}\),\(\text{978-1-098-15096-9}\)。”
如果您认为您对代码示例的使用超出了合理使用或上述许可范围,请随时通过 \(\text{permissions@oreilly.com}\) 联系我们。
O’Reilly 在线学习
\(\text{40}\) 多年来,\(\text{O’Reilly Media}\) 一直提供技术和商业培训、知识和见解,以帮助企业取得成功。
我们独特的专家和创新者网络通过书籍、文章和我们的在线学习平台分享他们的知识和专业技能。\(\text{O’Reilly}\) 的在线学习平台为您提供按需访问实时培训课程、深入学习路径、交互式编码环境以及来自 \(\text{O’Reilly}\) 和 \(\text{200}\) 多家其他出版商的海量文本和视频。欲了解更多信息,请访问 \(\text{[https://oreilly.com](https://oreilly.com)}\)。
如何联系我们
请将有关本书的评论和问题发送给出版商:
\(\text{O’Reilly Media, Inc.}\) \(\text{1005 Gravenstein Highway North}\) \(\text{Sebastopol, CA 95472}\)
\(\text{800-889-8969}\) (美国或加拿大境内) \(\text{707-827-7019}\) (国际或本地) \(\text{707-829-0104}\) (传真) \(\text{support@oreilly.com}\) \(\text{[https://www.oreilly.com/about/contact.html](https://www.oreilly.com/about/contact.html)}\)
我们为本书提供了一个网页,其中列出了勘误表、示例和任何附加信息。您可以通过 https://oreil.ly/hands_on_LLMs_1e 访问此页面。
要获取有关我们书籍和课程的新闻和信息,请访问 \(\text{[https://oreilly.com](https://oreilly.com)}\)。
在 \(\text{LinkedIn}\) 上关注我们:https://linkedin.com/company/oreilly-media。
在 \(\text{YouTube}\) 上观看我们:https://youtube.com/oreillymedia。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调
书籍各章的机翻md文件:
目录及前言
“test”
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调