《Hands-On Large Language Models》第4章 文本分类
第二部分 使用预训练语言模型
Using Pretrained Language Models
第 \(\text{4}\) 章 文本分类
Text Classification
分类是自然语言处理中一个常见的任务。该任务的目标是训练一个模型,为某些输入文本分配一个标签或类别(参见图 \(\text{4}-1\))。文本分类被世界各地广泛应用于各种应用程序,从情感分析和意图检测到实体提取和语言检测。语言模型(无论是表征型还是生成型)对分类的影响是不可低估的。
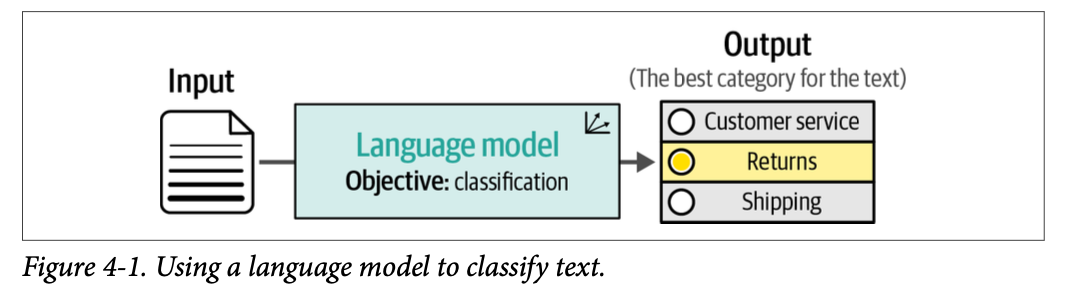
在本章中,我们将讨论使用语言模型进行文本分类的几种方法。它将作为使用已经训练过的语言模型的入门介绍。鉴于文本分类领域的广泛性,我们将讨论几种技术,并用它们来探索语言模型领域:
- 第 \(\text{113}\) 页的“使用表征模型进行文本分类” 演示了非生成模型用于分类的灵活性。我们将涵盖任务特定模型和嵌入模型。
- 第 \(\text{127}\) 页的“使用生成模型进行文本分类” 是对生成语言模型的介绍,因为它们中的大多数都可以用于分类。我们将涵盖一个开源和一个闭源的语言模型。
在本章中,我们将专注于利用预训练语言模型,即已经在大数据量上训练过并可用于文本分类的模型。如图 \(\text{4}-2\) 所示,我们将研究表征模型和语言模型,并探讨它们的区别。
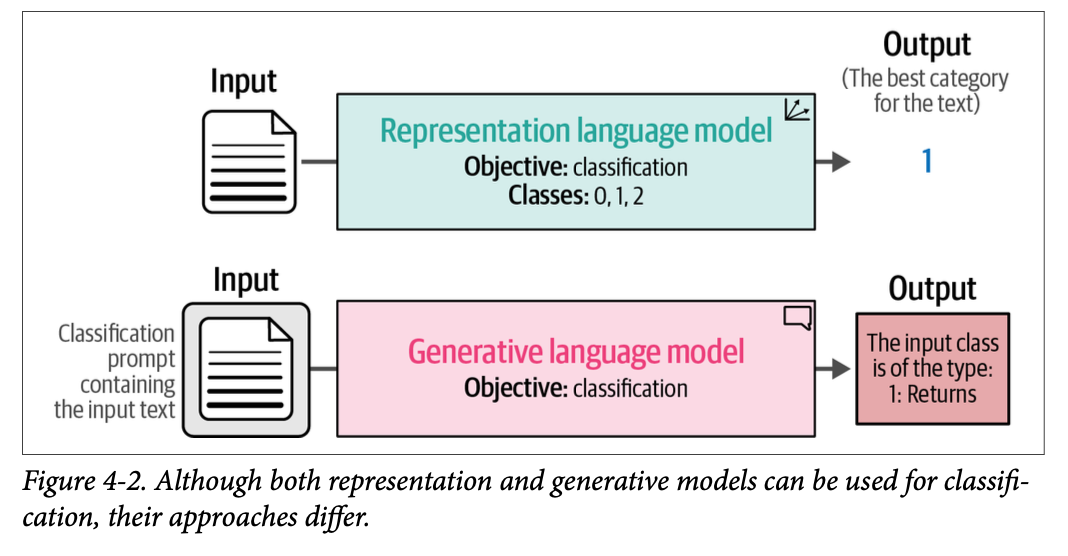
本章将作为各种语言模型(包括生成型和非生成型)的介绍。我们将遇到用于加载和使用这些模型的常见软件包。
💡 尽管本书侧重于 \(\text{LLM}\),但强烈建议将这些示例与经典但强大的基线进行比较,例如使用 \(\text{TF}-\text{IDF}\) 表征文本,并在此基础上训练一个逻辑回归分类器。
电影评论的情感
The Sentiment of Movie Reviews
您可以在 \(\text{Hugging Face Hub}\) 上找到我们用于探索文本分类技术的数据,这是一个托管模型也托管数据的平台。我们将使用著名的 “\(\text{rotten\_tomatoes}\)”数据集来训练和评估我们的模型。它包含了来自烂番茄的 \(\text{5,331}\) 条正面和 \(\text{5,331}\) 条负面电影评论。
为了加载这些数据,我们使用了 \(\text{datasets}\) 软件包,该软件包将在本书中一直使用:
1 | from datasets import load_dataset |
1 | DatasetDict({ |
数据被分割成训练集 (\(\text{train}\))、测试集 (\(\text{test}\)) 和验证集 (\(\text{validation}\))。在本章中,我们在训练模型时将使用训练集,在验证结果时将使用测试集。请注意,如果您使用训练集和测试集进行超参数调整,可以利用额外的验证集来进一步验证泛化能力。
The data is split up into train, test, and validation splits. Throughout this chapter, we will use the train split when we train a model and the test split for validating the results. Note that the additional validation split can be used to further validate generalization if you used the train and test splits to perform hyperparameter tuning.
个人注:train用来训练模型,validattion用来测试训练过程中不同轮次的效果;test用来测试模型的泛化能力。
让我们看一下训练集中的一些示例:
1 | data["train"][0, -1] |
1 | {'text': ['the rock is destined to be the 21st century\'s new " conan " and |
这些简短的评论要么被标记为正面 (\(\text{1}\)),要么被标记为负面 (\(\text{0}\))。这意味着我们将专注于二元情感分类。
使用表征模型进行文本分类
Text Classification with Representation Models
使用预训练表征模型进行分类通常有两种形式,即使用任务特定模型或嵌入模型。正如我们在上一章中探讨的那样,这些模型是通过将基础模型(如 \(\text{BERT}\))在特定的下游任务上进行微调而创建的,如图 \(\text{4}-3\) 所示。
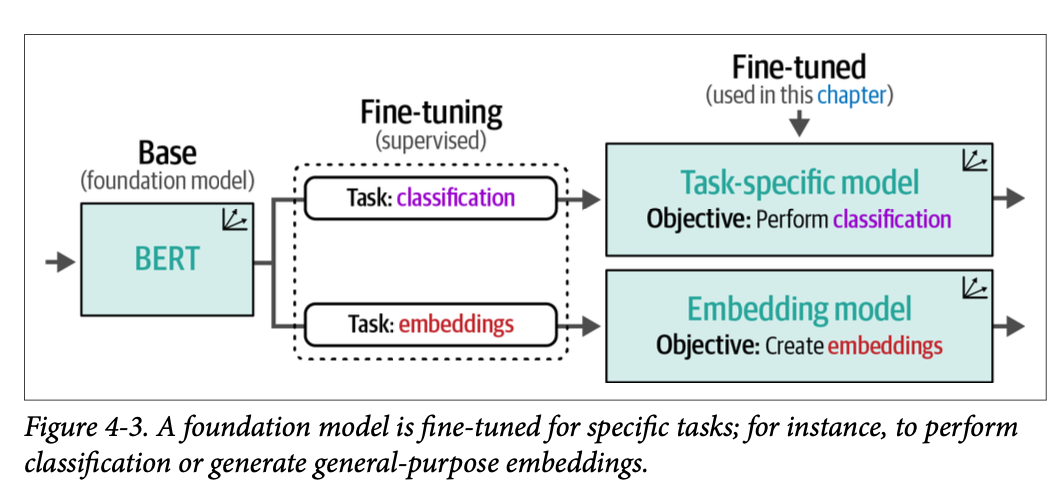
任务特定模型是一个表征模型,例如 \(\text{BERT}\),它是为特定任务(如情感分析)训练的。正如我们在第 \(\text{1}\) 章中探讨的那样,嵌入模型生成通用嵌入,可用于各种任务,不限于分类,例如语义搜索(参见第 \(\text{8}\) 章)。
用于分类的 \(\text{BERT}\) 模型的微调过程将在第 \(\text{11}\) 章中介绍,而创建嵌入模型将在第 \(\text{10}\) 章中介绍。在本章中,我们将保持这两个模型是冻结的(不可训练),仅使用它们的输出,如图 \(\text{4}-4\) 所示。
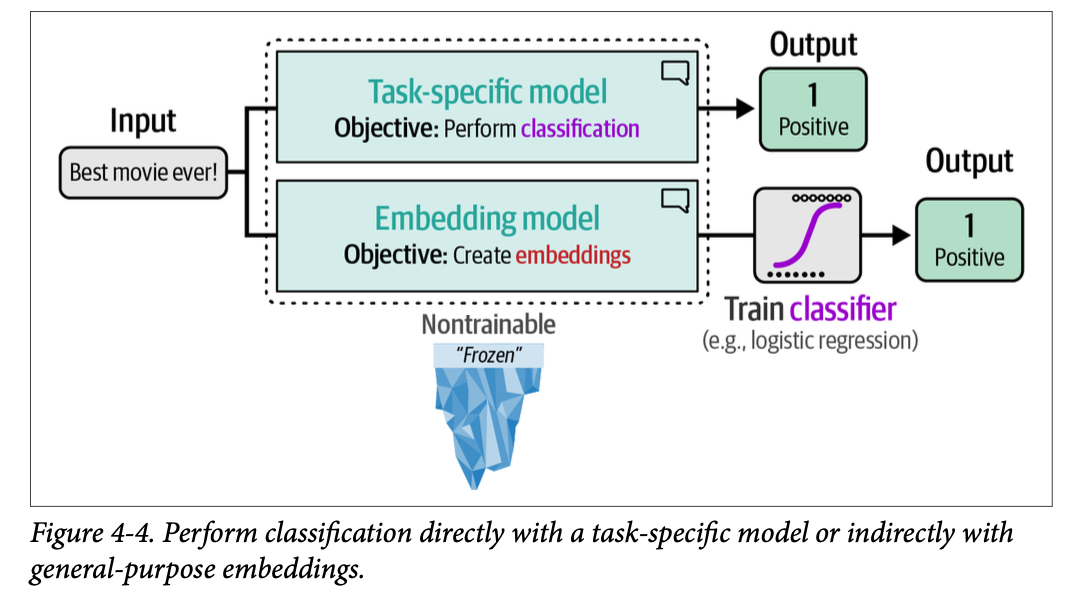
我们将利用其他人已经为我们微调好的预训练模型,并探索如何使用它们来分类我们选定的电影评论。
模型选择
Model Selection
选择合适的模型并非您想象的那么简单,因为在撰写本文时,\(\text{Hugging Face Hub}\) 上有超过 \(\text{60,000}\) 个文本分类模型和超过 \(\text{8,000}\) 个生成嵌入的模型。此外,选择一个适合您的用例的模型至关重要,并且需要考虑其语言兼容性、底层架构、大小和性能。
让我们从底层架构开始。正如我们在第 \(\text{1}\) 章中探讨的那样,\(\text{BERT}\)(一个著名的仅编码器 (\(\text{encoder-only}\)) 架构)是创建任务特定模型和嵌入模型的热门选择。虽然像 \(\text{GPT}\) 家族这样的生成模型令人难以置信,但仅编码器模型在任务特定的用例中同样表现出色,并且往往规模显著更小。
多年来,\(\text{BERT}\) 的许多变体已被开发出来,包括 \(\text{RoBERTa}\)、\(\text{DistilBERT}\)、\(\text{ALBERT}\) 和 \(\text{DeBERTa}\),每个都在各种上下文中进行训练。您可以在图 \(\text{4}-5\) 中找到一些著名的类 \(\text{BERT}\) 模型的概述。
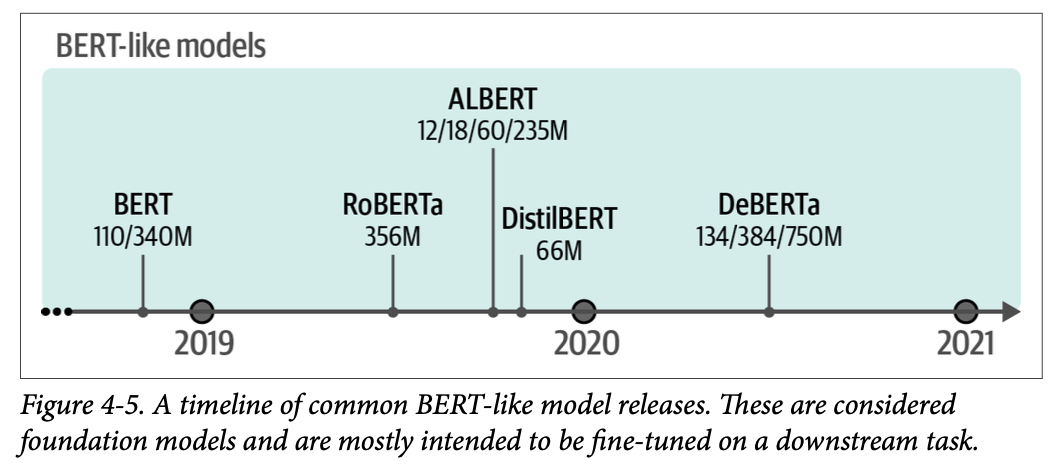
为工作选择合适的模型本身可以算作一门艺术。尝试 \(\text{Hugging Face}\) \(\text{Hub}\) 上可以找到的数千个预训练模型是不可行的,因此我们需要高效地选择模型。话虽如此,有几个模型是很好的起点,并能让您了解这类模型的基线性能。请将它们视为可靠的基线:
- \(\text{BERT}\) 基础模型 (\(\text{uncased}\))
- \(\text{RoBERTa}\) 基础模型
- \(\text{DistilBERT}\) 基础模型 (\(\text{uncased}\))
- \(\text{DeBERTa}\) 基础模型
- \(\text{bert-tiny}\)
- \(\text{ALBERT}\) 基础 \(\text{v}2\)
对于任务特定模型,我们选择 \(\text{Twitter-RoBERTa-base}\) 用于情感分析的模型。这是一个在 \(\text{tweets}\) 上为情感分析微调的 \(\text{RoBERTa}\) 模型。虽然它不是专门为电影评论训练的,但探索这个模型如何泛化是很有趣的。
在选择用于生成嵌入的模型时,\(\text{MTEB}\) 排行榜(https://huggingface.co/spaces/mteb/leaderboard)是一个很好的起点。它包含了在多项任务上进行基准测试的开源和闭源模型。请确保不仅考虑性能。在实际解决方案中,推理速度的重要性不容低估。因此,在本节中,我们将使用 \(\text{sentence-transformers/all-mpnet-base-v2}\) 作为嵌入模型。它是一个小巧但性能出色的模型。
使用任务特定模型
Using a Task-Specific Model
既然我们已经选择了任务特定的表征模型,让我们从加载模型开始:
1 | from transformers import pipeline |
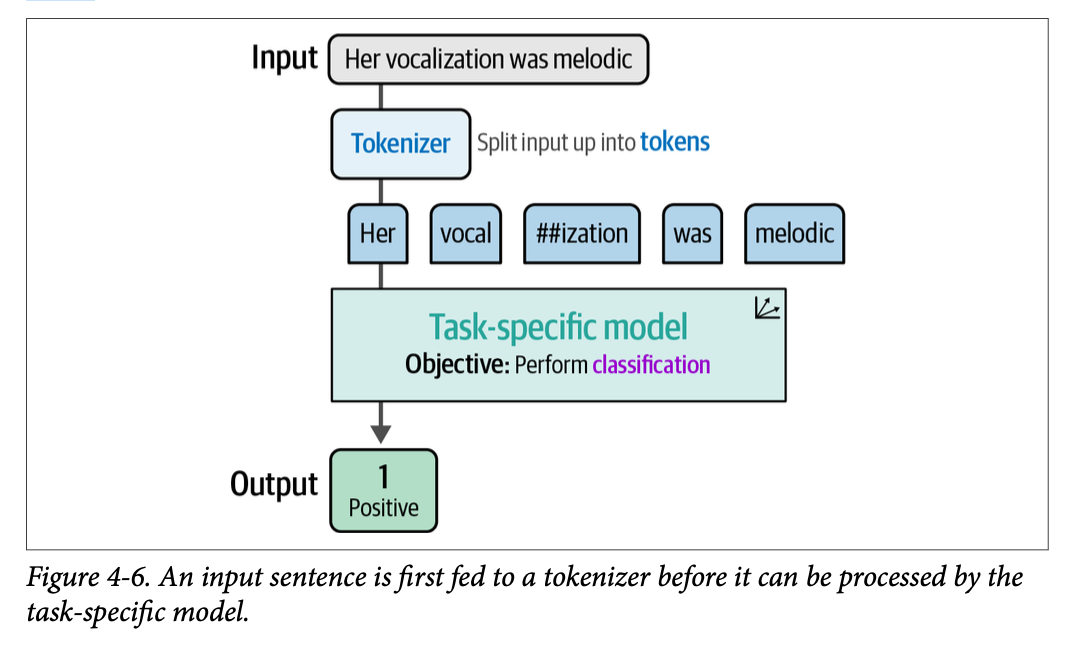
在加载模型时,我们也加载了分词器(\(\text{tokenizer}\)),它负责将输入文本转换为单个词元(\(\text{token}\)),如图 \(\text{4}-6\) 所示。虽然加载时并非必须指定此参数,因为它会自动加载,但它说明了底层发生的情况。
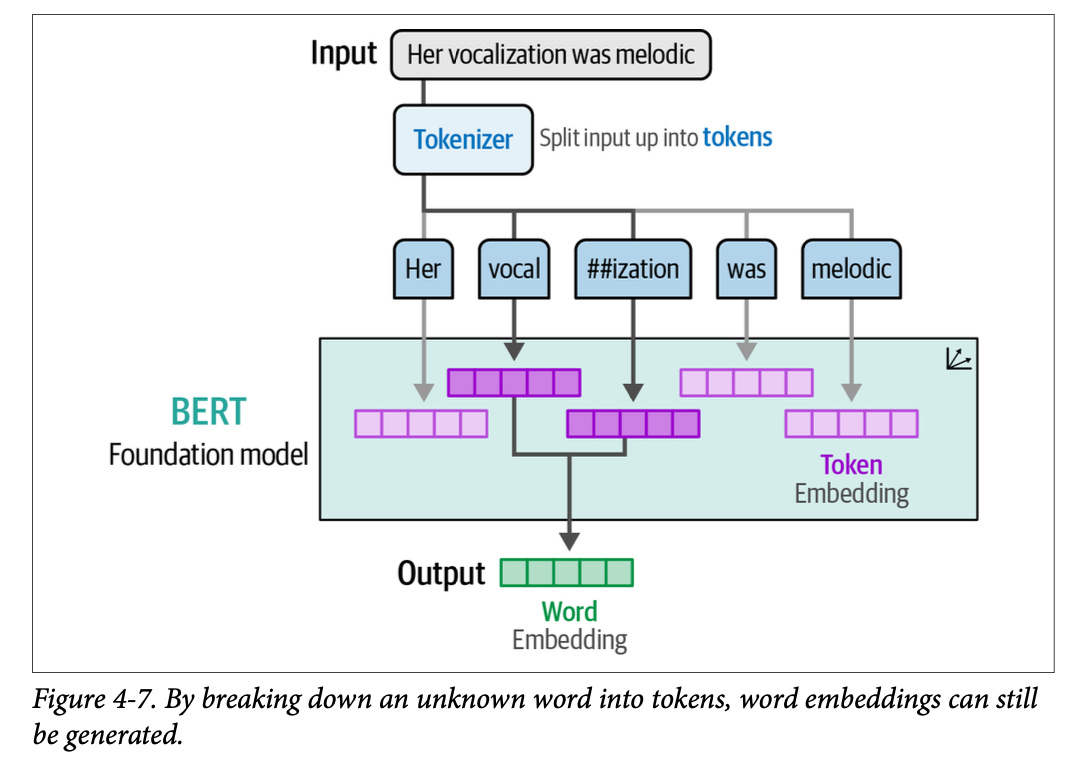
正如第 \(\text{2}\) 章深入探讨的那样,这些词元是大多数语言模型的核心。这些词元的一个主要好处是,即使它们不在训练数据中,也可以将它们组合起来生成表征,如图 \(\text{4}-7\) 所示。
加载所有必需的组件后,我们就可以继续在数据的测试集上使用我们的模型:
1 | import numpy as np |
现在我们已经生成了预测结果,剩下的就是评估。我们创建一个小的函数,可以在本章中轻松使用:
1 | from sklearn.metrics import classification_report |
接下来,让我们创建分类报告:
1 | evaluate_performance(data["test"]["label"], y_pred) |
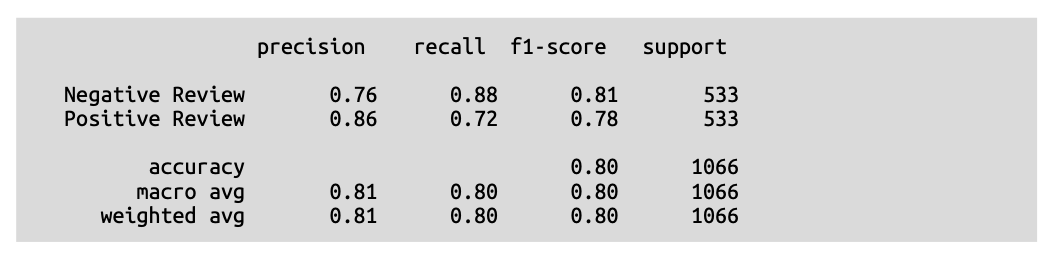
要解读生成的分类报告,我们首先探讨如何识别正确和不正确的预测。根据我们的预测是正确(\(\text{True}\))还是不正确(\(\text{False}\)),以及我们预测的类别是正确类别(\(\text{Positive}\))还是不正确类别(\(\text{Negative}\)),共有四种组合。我们可以将这些组合表示为一个矩阵,通常称为混淆矩阵(\(\text{confusion matrix}\)),如图 \(\text{4}-8\) 所示。
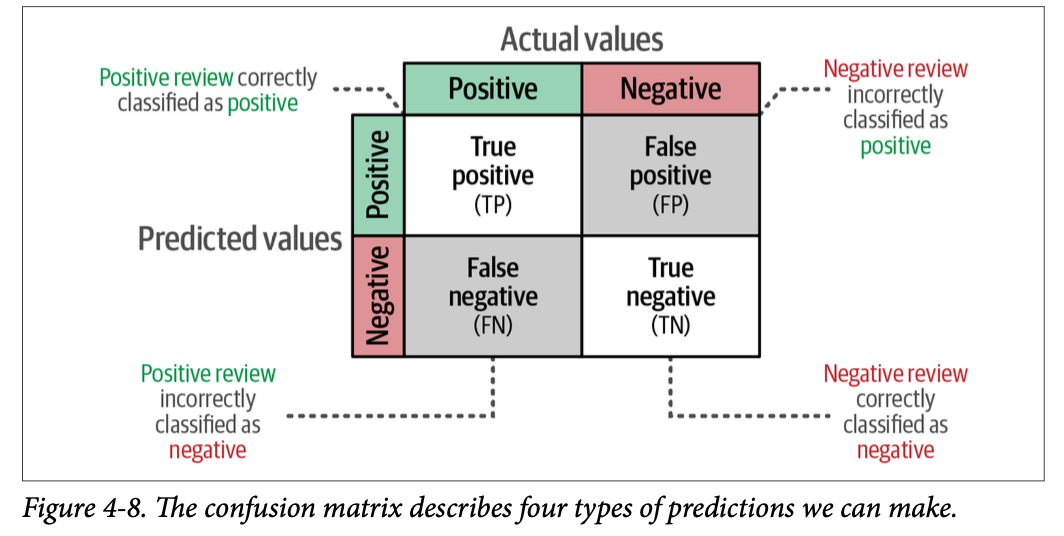
利用混淆矩阵,我们可以推导出几种公式来描述模型的质量。在前面生成的分类报告中,我们可以看到四种这样的度量方法,即精确率(\(\text{precision}\))、召回率(\(\text{recall}\))、准确率(\(\text{accuracy}\))和 \(\text{F}1\) 分数:
- 精确率(\(\text{Precision}\))衡量的是找到的项目中有多少是相关的,这表明了相关结果的准确性。
- 召回率(\(\text{Recall}\))指的是找到了多少相关的类别,这表明了其发现所有相关结果的能力。
- 准确率(\(\text{Accuracy}\))指的是模型在所有预测中做出正确预测的次数,这表明了模型的总体正确性。
- \(\text{F}1\) 分数(\(\text{The F1 score}\))平衡了精确率和召回率,以创建模型的总体性能指标。
这四个指标如图 \(\text{4}-9\) 所示,该图使用前面提到的分类报告来描述它们。
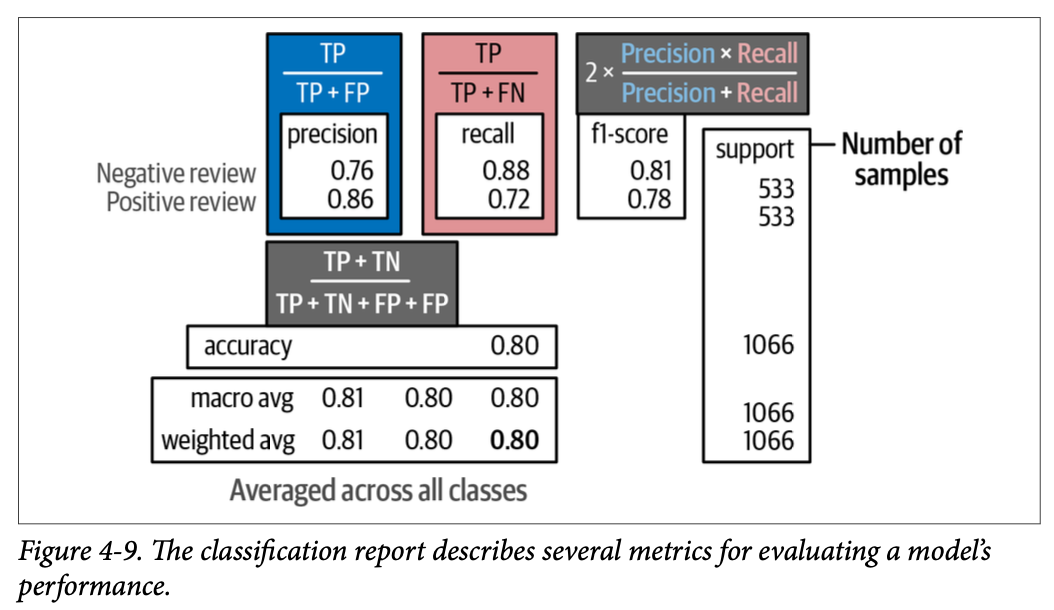
在本书的示例中,我们将考虑 \(\text{F}1\) 分数的加权平均值(\(\text{weighted average of the F1 score}\)),以确保每个类别都得到平等对待。我们预训练的 \(\text{BERT}\) 模型为我们提供了 \(\text{0.80}\) 的 \(\text{F}1\) 分数(我们是从 \(\text{weighted avg}\) 行和 \(\text{f1-score}\) 列读取的),这对于一个不是专门针对我们领域数据训练的模型来说是非常出色的!
为了提高我们所选模型的性能,我们可以做几件不同的事情,包括选择一个在我们领域数据(在本例中是电影评论)上训练的模型,比如 \(\text{DistilBERT base uncased finetuned SST}-2\)。我们也可以将重点转向另一种风味的表征模型,即嵌入模型。
利用嵌入的分类任务
Classification Tasks That Leverage Embeddings
在前面的示例中,我们使用了预训练的任务特定模型进行情感分析。但是,如果我们找不到一个针对该特定任务进行预训练的模型怎么办?我们是否需要自己微调一个表征模型?答案是否定的!
如果您拥有足够的计算资源,有时您可能希望自己微调模型(参见第 \(\text{11}\) 章)。然而,并非每个人都能获得大量计算资源。这就是通用嵌入模型发挥作用的地方。
监督分类
Supervised Classification
与前面的示例不同,我们可以从一个更经典的视角入手,自己完成部分训练过程。我们不直接使用表征模型进行分类,而是使用嵌入模型来生成特征。然后,这些特征可以输入到分类器中,从而创建一个两步法,如图 \(\text{4}-10\) 所示。
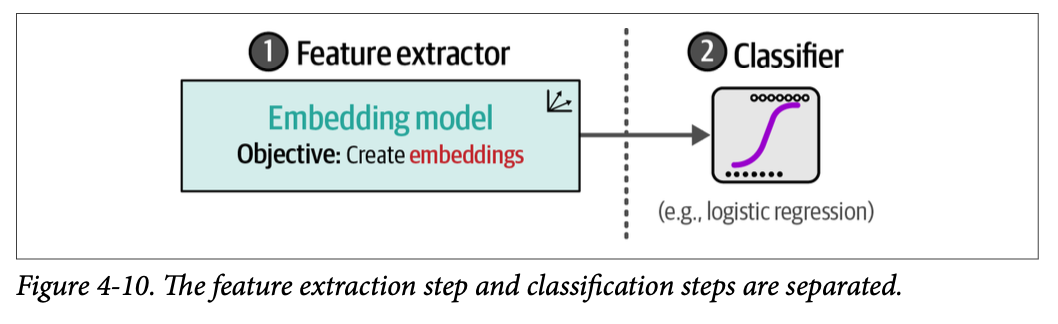
这种分离的一个主要好处是,我们不需要微调我们的嵌入模型,这可能是昂贵的。相比之下,我们可以在 \(\text{CPU}\) 上训练一个分类器,比如逻辑回归。
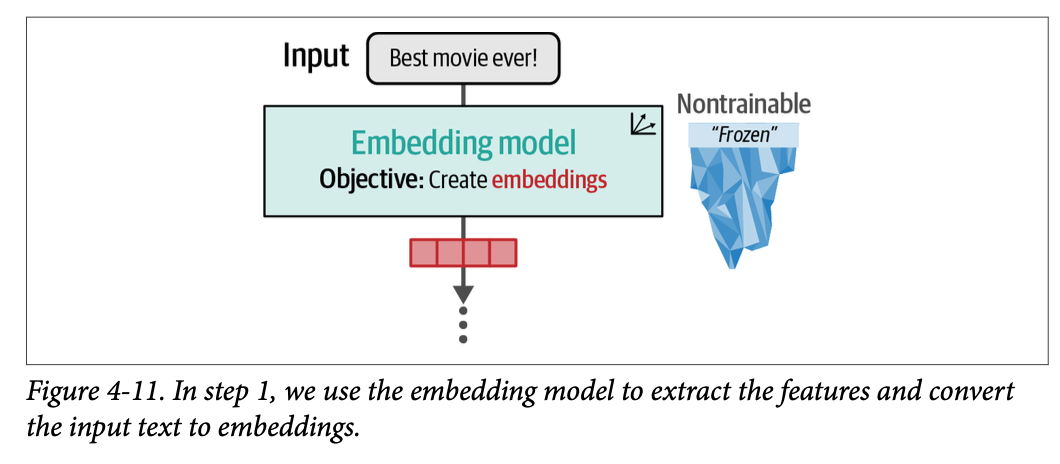
在第一步中,我们使用嵌入模型将文本输入转换为嵌入,如图 \(\text{4}-11\) 所示。请注意,该模型同样保持冻结,在训练过程中不会被更新。
我们可以使用 \(\text{sentence-transformer}\)(一个用于利用预训练嵌入模型的流行软件包)来执行此步骤。创建嵌入非常简单:
1 | from sentence_transformers import SentenceTransformer |
正如我们在第 \(\text{1}\) 章中介绍的那样,这些嵌入是输入文本的数值表征。嵌入的数值数量或维度取决于底层的嵌入模型。让我们探究我们模型的维度:
1 | train_embeddings.shape |
1 | (8530, 768) |
这表明我们 \(\text{8,530}\) 个输入文档中的每个都有一个 \(\text{768}\) 的嵌入维度,因此每个嵌入包含 \(\text{768}\) 个数值。
在第二步中,这些嵌入作为分类器的输入特征,如图 \(\text{4}-12\) 所示。该分类器是可训练的,不限于逻辑回归,只要它执行分类,就可以采用任何形式。
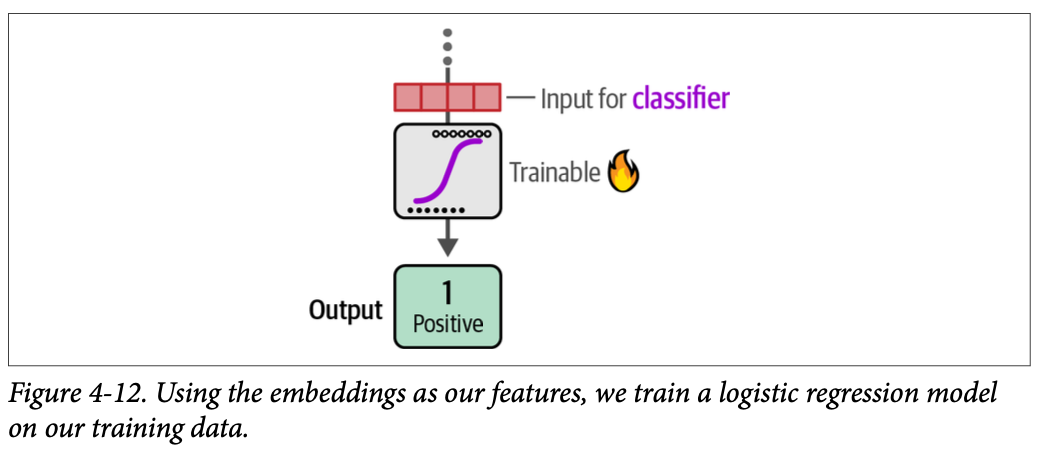
我们将使这一步骤保持简单,并使用逻辑回归作为分类器。要训练它,我们只需使用生成的嵌入以及我们的标签:
1 | from sklearn.linear_model import LogisticRegression |
接下来,让我们评估我们的模型:
1 | # Predict previously unseen instances |
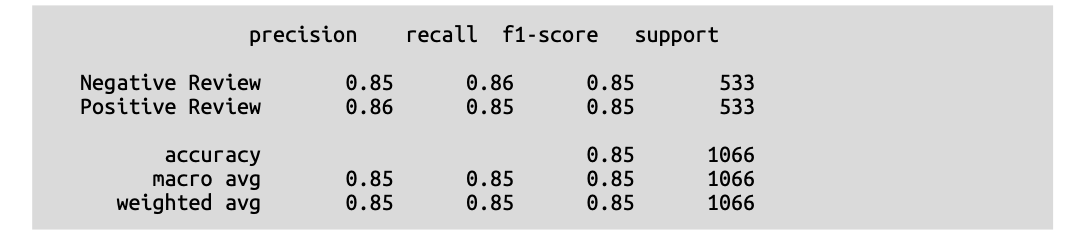
通过在我们的嵌入之上训练一个分类器,我们设法获得了 \(\text{0.85}\) 的 \(\text{F}1\) 分数!这证明了在保持底层嵌入模型冻结的情况下,训练一个轻量级分类器的可能性。
💡 在本例中,我们使用 \(\text{sentence}-\text{transformers}\) 来提取我们的嵌入,它受益于 \(\text{GPU}\) 来加速推理。然而,我们可以通过使用外部 \(\text{API}\) 来创建嵌入从而移除这种 \(\text{GPU}\) 依赖。生成嵌入的流行选择是 \(\text{Cohere}\) 和 \(\text{OpenAI}\) 提供的服务。因此,这将允许整个管线完全在 \(\text{CPU}\) 上运行。
如果我们没有带标签的数据怎么办?
What If We Do Not Have Labeled Data?
在我们之前的例子中,我们有可以利用的带标签的数据,但在实践中并非总是如此。获取带标签的数据是一项资源密集型任务,可能需要大量的人力。此外,收集这些标签是否真的值得?
为了验证这一点,我们可以执行零样本分类(\(\text{zero-shot classification}\)),即我们没有带标签的数据,来探索该任务是否可行。尽管我们知道标签的定义(它们的名称),但我们没有带标签的数据来支持它们。零样本分类尝试预测输入文本的标签,即使它没有经过这些标签的训练,如图 \(\text{4}-13\) 所示。
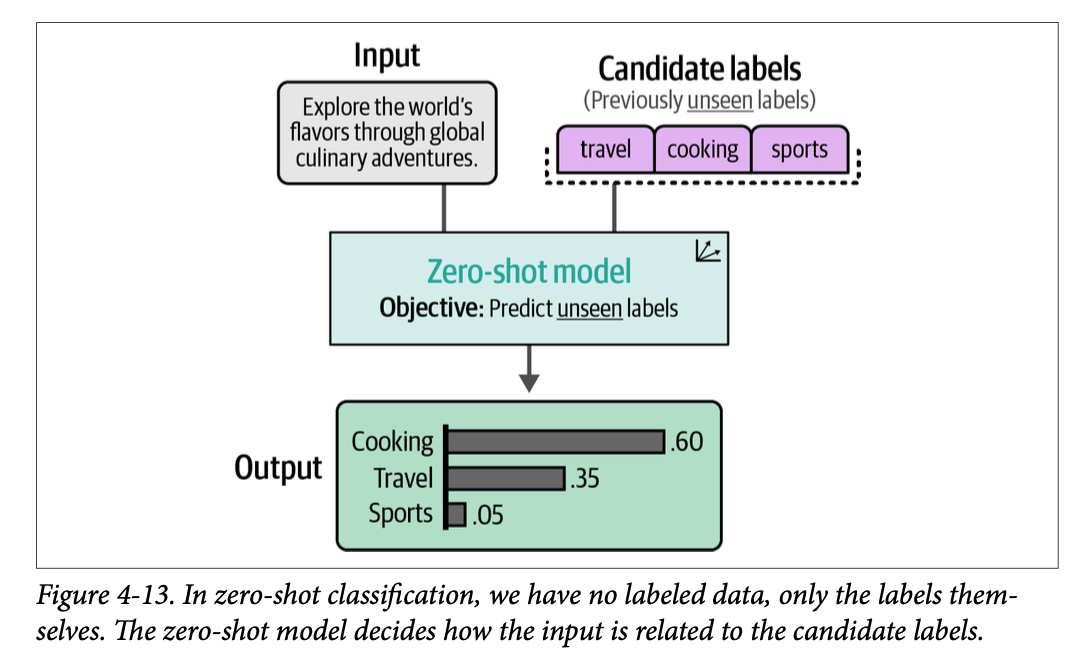
要使用嵌入进行零样本分类,我们可以使用一个巧妙的技巧。我们可以根据标签应代表的内容来描述它们。例如,电影评论的负面标签可以被描述为“\(\text{This is a negative movie review}\)”(这是一条负面电影评论)。通过描述和嵌入(\(\text{embedding}\))标签和文档,我们就有可以处理的数据了。如图 \(\text{4}-14\) 所示,这个过程允许我们生成自己的目标标签,而无需实际拥有任何带标签的数据。
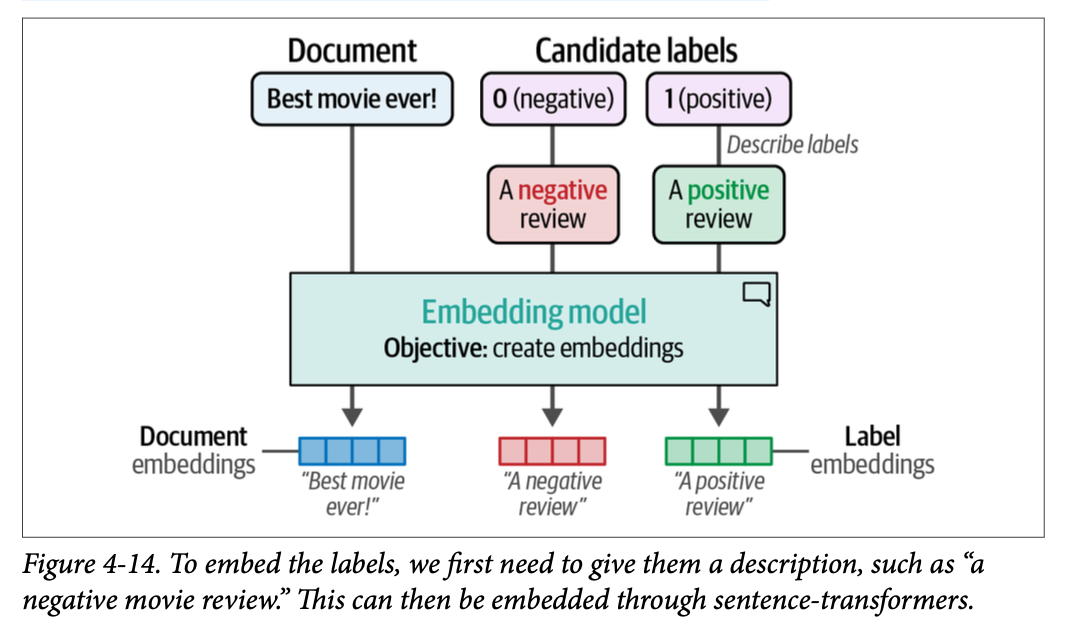
我们可以像前面那样使用 \(\text{.encode}\) 函数来创建这些标签嵌入:
1 | # Create embeddings for our labels |
为了给文档分配标签,我们可以对文档-标签对应用余弦相似度(\(\text{cosine similarity}\))。这是向量之间夹角的余弦值,通过嵌入的点积除以它们的长度的乘积来计算,如图 \(\text{4}-15\) 所示。
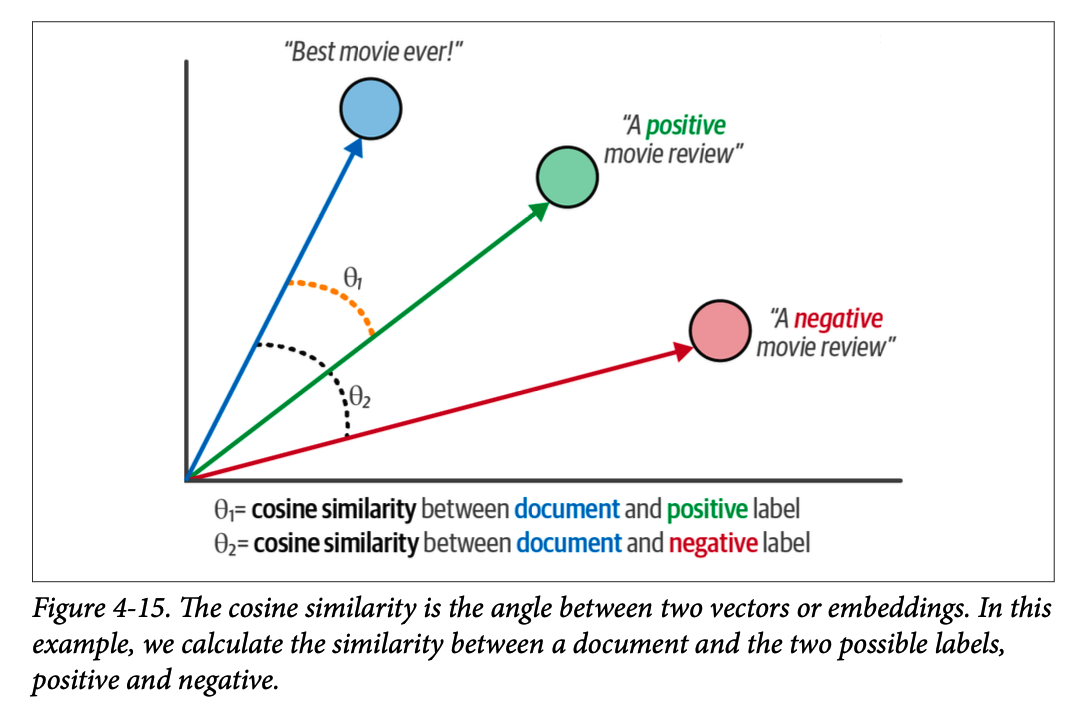
我们可以使用余弦相似度来检查给定文档与候选标签描述的相似程度。与文档相似度最高的标签被选中,如图 \(\text{4}-16\) 所示。
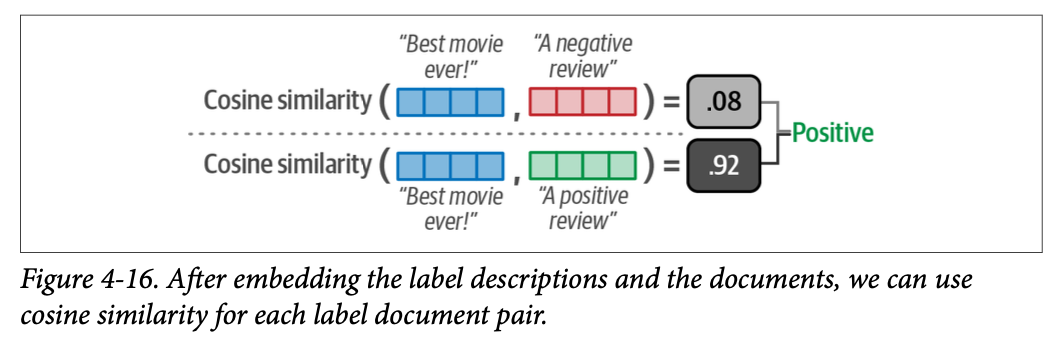
要在嵌入上执行余弦相似度,我们只需比较文档嵌入与标签嵌入并找到最匹配的对:
1 | from sklearn.metrics.pairwise import cosine_similarity |
就这样!我们只需要为我们的标签想出名称就可以执行我们的分类任务。让我们看看这种方法的效果如何:
1 | evaluate_performance(data["test"]["label"], y_pred) |
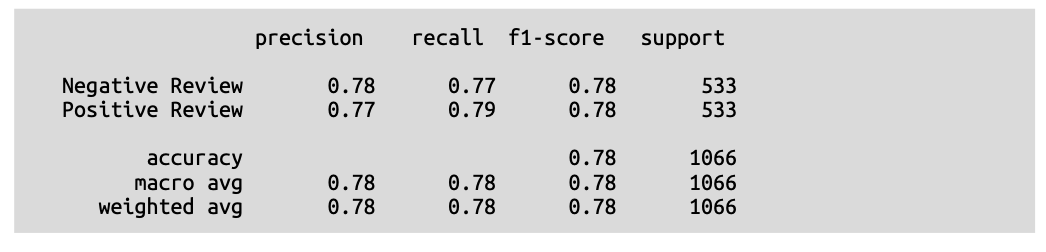
如果您熟悉使用基于 \(\text{Transformer}\) 的模型进行零样本分类,您可能会想知道为什么我们选择用嵌入而不是 \(\text{Transformer}\) 模型来演示它。虽然自然语言推理模型在零样本分类方面表现出色,但这里的示例旨在展示嵌入在各种任务中的灵活性。正如您将在本书中看到的那样,嵌入几乎存在于所有语言 \(\text{AI}\) 用例中,而且通常是一个被低估但极其重要的组件。
考虑到我们根本没有使用任何带标签的数据,\(\text{0.78}\) 的 \(\text{F}1\) 分数是相当令人印象深刻的!这正好说明了嵌入是多么通用和有用,特别是如果你在使用它们时能发挥一点创意。
让我们来测试一下这种创意。我们决定使用“一个负面/正面评论”作为标签名称,但这可以改进。相反,我们可以通过使用“一个非常负面/正面的电影评论”来使它们更具体、更贴近我们的数据。这样,嵌入将捕捉到它是一个电影评论,并将更关注两个标签的极端。请尝试一下,探索它如何影响结果。
使用生成模型进行文本分类
Text Classification with Generative Models
使用生成语言模型(例如 \(\text{OpenAI}\) 的 \(\text{GPT}\) 模型)进行分类,与我们迄今为止所做的工作略有不同。这些模型将文本作为输入并生成文本,因此被恰当地命名为序列到序列模型(\(\text{sequence}-\text{to}-\text{sequence models}\))。这与我们的任务特定模型形成了鲜明对比,后者输出的是一个类别,如图 \(\text{4}-17\) 所示。
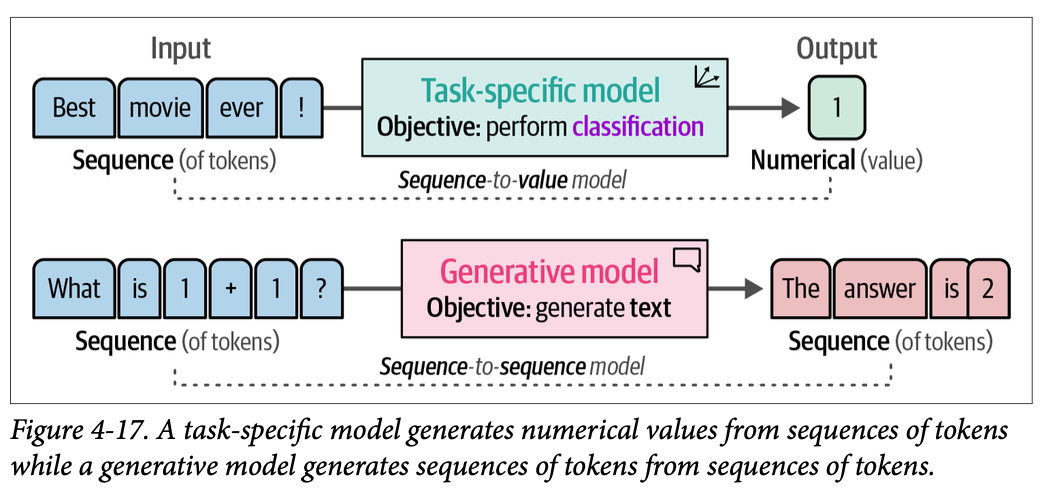
这些生成模型通常在各种任务上进行训练,并且通常不能直接执行您的用例。例如,如果我们给一个生成模型一个没有任何上下文的电影评论,它不知道该如何处理。
相反,我们需要帮助它理解上下文并引导它找到我们正在寻找的答案。如图 \(\text{4}-18\) 所示,这个引导过程主要是通过您提供给模型的指令或提示(\(\text{prompt}\))来完成的。迭代地改进您的提示以获得您偏好的输出被称为提示工程(\(\text{prompt engineering}\))。
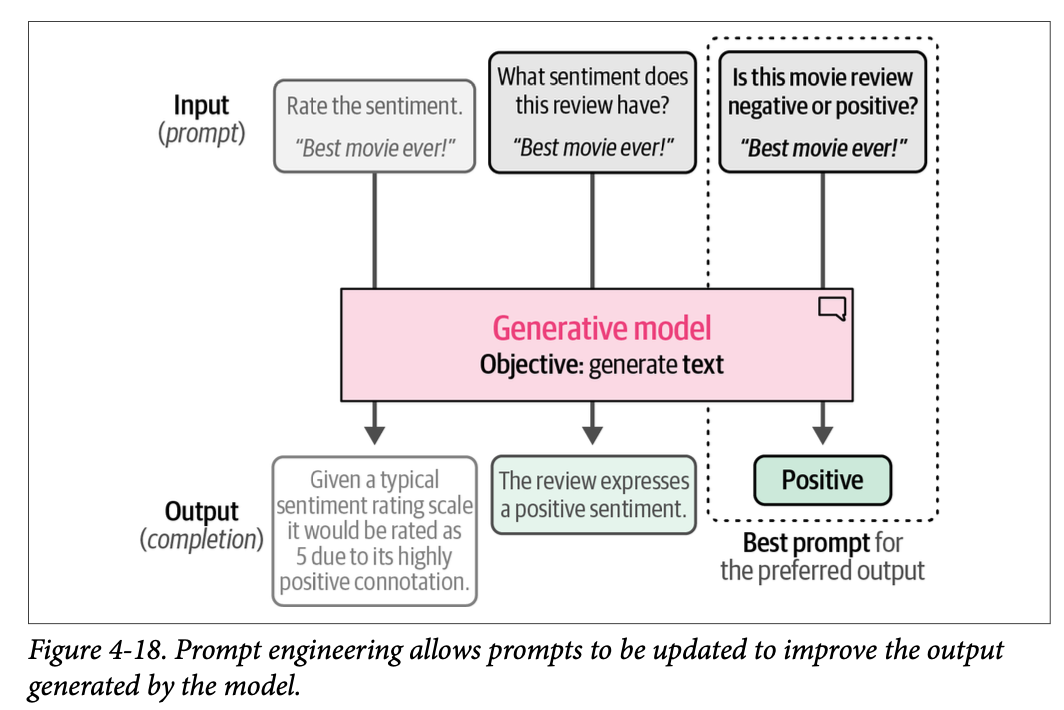
在本节中,我们将演示如何利用不同类型的生成模型来使用我们的烂番茄数据集进行分类。
使用文本到文本传输 \(\text{Transformer}\)
Using the Text-to-Text Transfer Transformer
在本书中,我们将主要探讨仅编码器(表征)模型(如 \(\text{BERT}\))和仅解码器(生成)模型(如 \(\text{ChatGPT}\))。然而,正如第 \(\text{1}\) 章所讨论的,原始 \(\text{Transformer}\) 架构实际上由编码器-解码器架构组成。与仅解码器模型一样,这些编码器-解码器模型是序列到序列模型,通常属于生成模型的范畴。
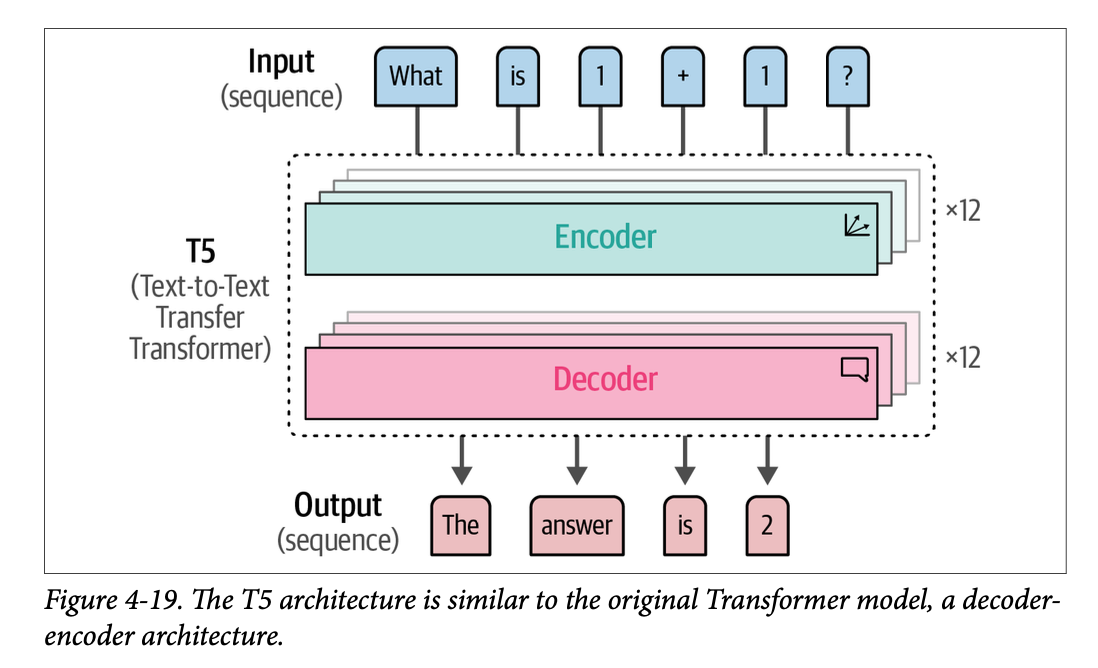
利用这种架构的一个有趣的模型家族是文本到文本传输 \(\text{Transformer}\) 或 \(\text{T5}\) 模型。如图 \(\text{4}-19\) 所示,它的架构类似于原始 \(\text{Transformer}\),其中\(\text{12}\) 个解码器和 \(\text{12}\) 个编码器堆叠在一起。
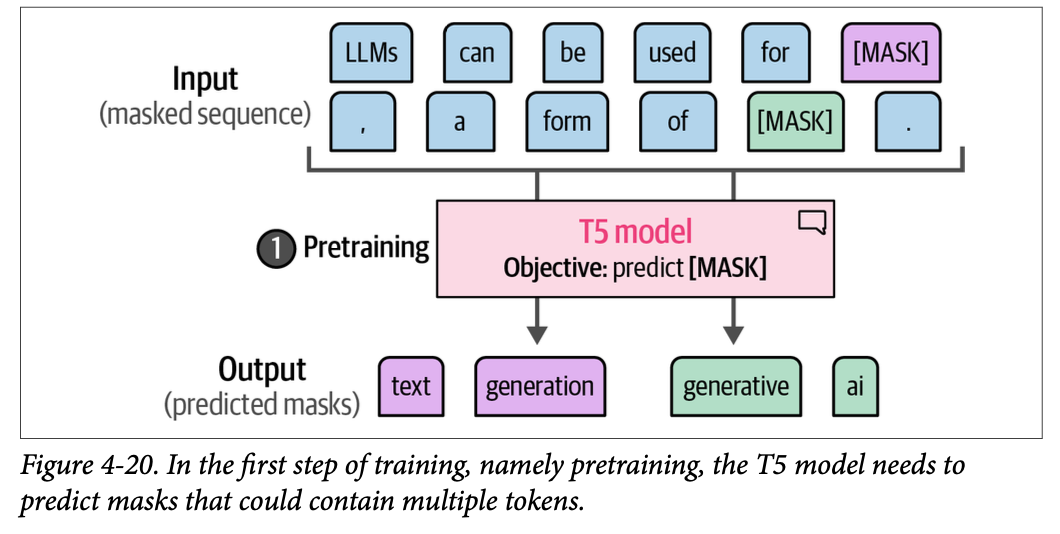
借助这种架构,这些模型首先使用掩码语言建模(\(\text{masked language modeling}\))进行预训练。如图 \(\text{4}-20\) 所示,在训练的第一步中,在预训练期间,被掩盖的不是单个词元,而是词元集(或词元跨度)。
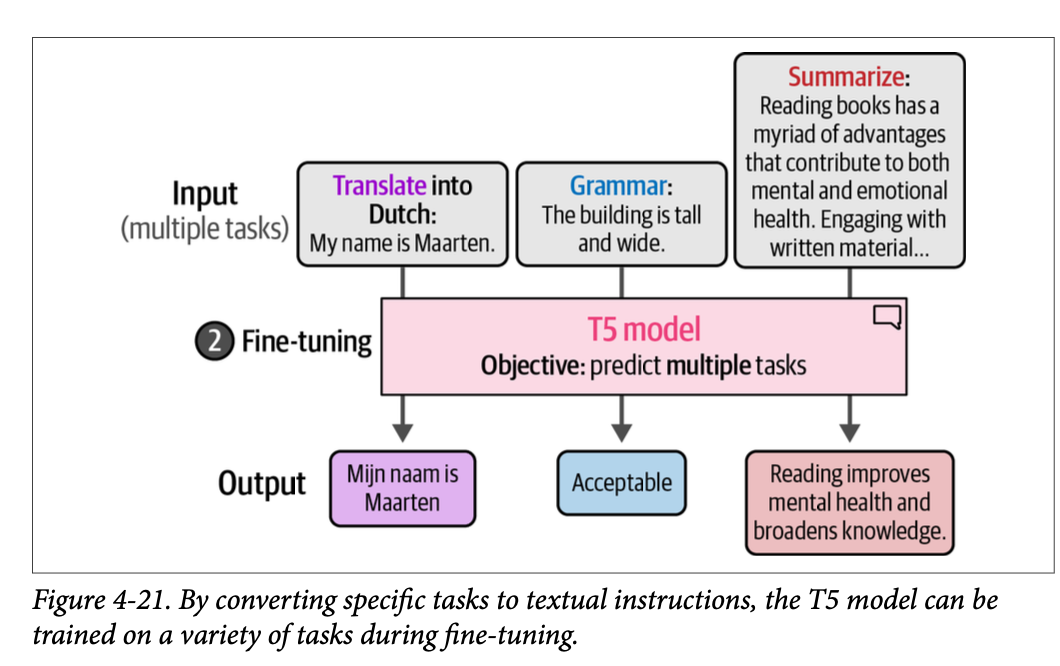
训练的第二步,即对基础模型进行微调,才是真正神奇的地方。不是针对一个特定任务对模型进行微调,而是将每个任务都转换为序列到序列任务并同时进行训练。如图 \(\text{4}-21\) 所示,这使得模型能够在各种任务上进行训练。
这种微调方法在论文《扩展指令微调语言模型》 中得到了扩展,该论文在微调过程中引入了一千多个任务,使其更紧密地遵循我们从 \(\text{GPT}\) 模型中了解到的指令。这产生了 \(\text{Flan-T5}\) 家族的模型,它们受益于这种广泛的任务多样性。
为了使用这个预训练的 \(\text{Flan-T5}\) 模型进行分类,我们将首先通过 “\(\text{text}2\text{text}-\text{generation}\)”任务来加载它,该任务通常是为这些编码器-解码器模型保留的:
1 | # Load our model |
\(\text{Flan-T5}\) 模型有各种尺寸(\(\text{flan}-\text{t5}-\text{small}/\text{base}/\text{large}/\text{xl}/\text{xxl}\)),我们将使用最小的来稍微加快速度。不过,您可以随意尝试更大的模型,看看是否可以改进结果。
与我们的任务特定模型相比,我们不能只是给模型一些文本,然后希望它能输出情感。相反,我们必须指示模型这样做。
因此,我们为每个文档加上“\(\text{Is the following sentence positive or negative?}\)”的提示:
1 | # Prepare our data |

在创建了我们更新后的数据之后,我们可以运行管线,类似于任务特定模型的示例:
1 | # Run inference |
由于这个模型生成文本,我们确实需要将文本输出转换为数值。输出词“\(\text{negative}\)”被映射为 \(\text{0}\),而“\(\text{positive}\)”被映射为 \(\text{1}\)。
现在,这些数值允许我们以与之前相同的方式测试模型的质量:
1 | evaluate_performance(data["test"]["label"], y_pred) |
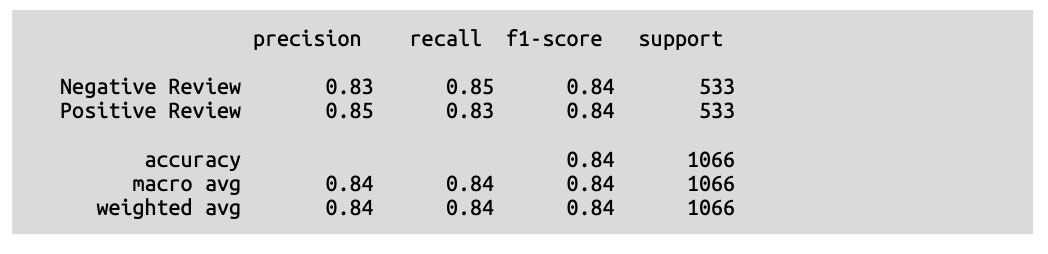
\(\text{F}1\) 分数为 \(\text{0.84}\),显然这款 \(\text{Flan}-\text{T5}\) 模型是生成模型能力的惊人初探。
\(\text{ChatGPT}\) 用于分类
ChatGPT for Classification
尽管我们在本书中主要关注开源模型,但语言 \(\text{AI}\) 领域的另一个主要组成部分是闭源模型,特别是 \(\text{ChatGPT}\)。虽然原始 \(\text{ChatGPT}\) 模型 (\(\text{GPT}-3.5\)) 的底层架构并未公开,但从它的名称我们可以推断,它基于我们迄今为止在 \(\text{GPT}\) 模型中看到的仅解码器架构。
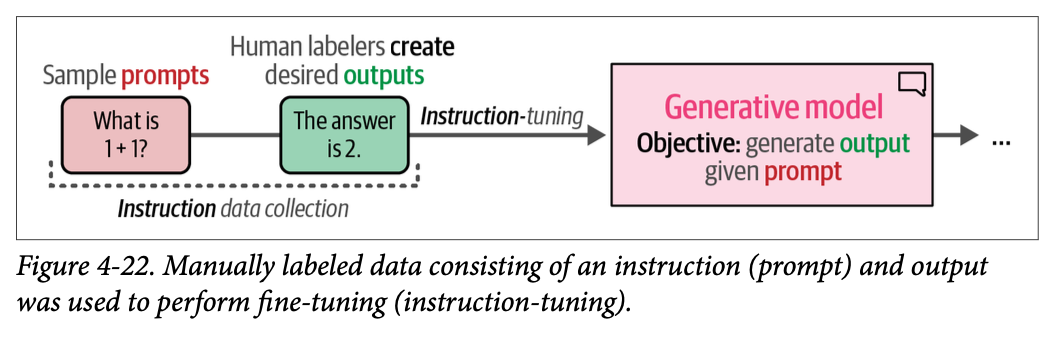
幸运的是,\(\text{OpenAI}\) 分享了训练过程的概述,其中涉及一个重要组成部分,即偏好调优(\(\text{preference tuning}\))。如图 \(\text{4}-22\) 所示,\(\text{OpenAI}\) 首先手动创建了对输入提示(instruction data 指令数据)的期望输出,并使用该数据创建了其模型的第一个变体。
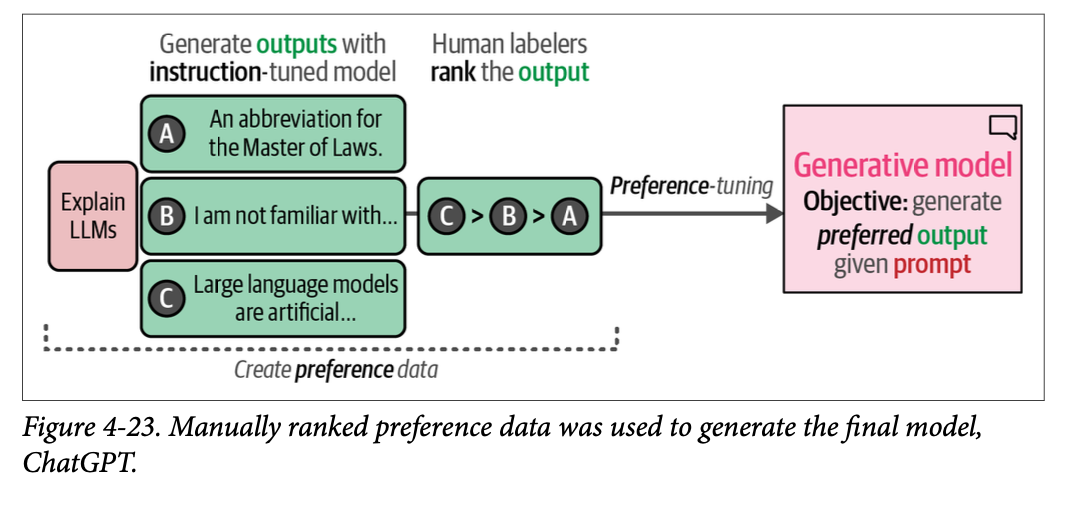
\(\text{OpenAI}\) 使用由此产生的模型生成了多个输出,并手动将其从最好到最差进行排名。如图 \(\text{4}-23\) 所示,这个排名展示了对某些输出的偏好(偏好数据),并被用于创建其最终模型 \(\text{ChatGPT}\)。
使用偏好数据(preference data)而非指令数据(instruction data)的一个主要好处是它所代表的细微差别。通过展示好输出和更好输出之间的区别,生成模型学会了生成符合人类偏好的文本。在第 \(\text{12}\) 章中,我们将探讨这些微调和偏好调优方法的工作原理,以及如何自己进行。
使用闭源模型的过程与我们迄今为止看到的开源示例大不相同。我们不加载模型,而是通过 \(\text{OpenAI}\) 的 \(\text{API}\) 来访问模型。
在我们深入研究分类示例之前,您首先需要在 https://oreil.ly/AEXvA 上创建一个免费账户,并在 https://oreil.ly/lrTXl 创建一个 \(\text{API}\) 密钥。完成之后,您就可以使用您的 \(\text{API}\) 与 \(\text{OpenAI}\) 的服务器进行通信。
我们可以使用此密钥来创建客户端:
1 | import openai |
使用这个客户端,我们创建了 \(\text{chatgpt\_generation}\) 函数,它允许我们根据特定的提示、输入文档和选定的模型来生成文本:
1 | def chatgpt_generation(prompt, document, model="gpt-3.5-turbo-0125"): |
接下来,我们将需要创建一个模板来要求模型执行分类:
1 | # Define a prompt template as a base |
这个模板只是一个示例,您可以随意更改。目前,我们将其保持尽可能简单,以说明如何使用这样的模板。
在您将此方法用于一个潜在的大数据集之前,始终跟踪您的使用量非常重要。如果您执行大量请求,像 \(\text{OpenAI}\) 提供的外部 \(\text{API}\) 可能会很快变得昂贵。在撰写本文时,使用 “\(\text{gpt}-\text{3.5}-\text{turbo}-\text{0125}\)”模型运行我们的测试数据集成本为 \(\text{3}\) 美分,这包含在免费账户内,但未来可能会有所变化。
💡 在处理外部 \(\text{API}\) 时,您可能会遇到速率限制错误(\(\text{rate limit errors}\))。当您过于频繁地调用 \(\text{API}\) 时,就会出现这些错误,因为某些 \(\text{API}\) 可能会限制您每分钟或每小时的使用速率。为了防止这些错误,我们可以实现几种重试请求的方法,包括一种称为指数退避(\(\text{exponential backoff}\))的方法。它会在每次遇到速率限制错误时执行短暂的休眠,然后重试失败的请求。如果再次失败,休眠时间会增加,直到请求成功或达到最大重试次数。
要将其与 \(\text{OpenAI}\) 配合使用,有一个很好的指南可以帮助您入门。
接下来,我们可以对测试数据集中的所有评论运行此函数,以获取其预测结果。如果您想节省您的(免费)额度用于其他任务,可以跳过此步骤。
1 | # You can skip this if you want to save your (free) credits |
与前面的示例一样,我们需要将输出从字符串转换为整数以评估其性能:
1 | # Extract predictions |
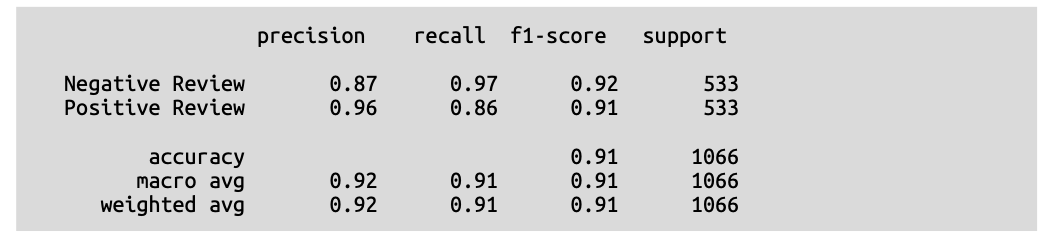
\(\text{0.91}\) 的 \(\text{F}1\) 分数已经让我们一睹将生成式 \(\text{AI}\) 带给大众的模型的性能。然而,由于我们不知道该模型是在什么数据上训练的,我们不能轻易使用这些类型的指标来评估模型。据我们所知,它很可能在我们的数据集上进行过训练!
在第 \(\text{12}\) 章中,我们将探讨如何在一些更具普遍性的任务上评估开源和闭源模型。
总结
在本章中,我们讨论了执行各种分类任务的许多不同技术,从微调整个模型到完全不进行调优!对文本数据进行分类并非表面上看起来那么简单,其中蕴含着令人难以置信的创意技术。
在本章中,我们探索了使用生成式和表征式语言模型进行文本分类。我们的目标是为输入文本分配一个标签或类别,以进行评论情感的分类。
我们探索了两种类型的表征模型:任务特定模型和嵌入模型。任务特定模型是在一个大型数据集上专门为情感分析预训练的,并向我们展示了预训练模型是分类文档的绝佳技术。嵌入模型用于生成多用途嵌入,我们将其用作训练分类器的输入。
类似地,我们探索了两种类型的生成模型:一个开源编码器-解码器模型(\(\text{Flan}-\text{T5}\))和一个闭源仅解码器模型(\(\text{GPT}-\text{3.5}\))。我们在文本分类中使用了这些生成模型,而不需要对领域数据或带标签的数据集进行特定(额外)的训练。
在下一章中,我们将继续进行分类,但重点将转向无监督分类。如果我们的文本数据没有任何标签,我们可以做些什么?我们可以提取什么信息?我们将专注于对数据进行聚类以及使用主题建模技术为聚类进行命名。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调