《Hands-On Large Language Models》第11章 微调用于分类的表征模型
第 \(\text{11}\) 章 微调用于分类的表征模型
Fine-Tuning Representation Models for Classification
在第 \(\text{4}\) 章中,我们使用预训练模型来对文本进行分类。我们保持了预训练模型,没有进行任何修改。这可能会让您思考,如果我们对它们进行微调会发生什么?
如果我们有足够的数据,微调往往会带来性能最佳的模型。在本章中,我们将介绍几种微调 \(\text{BERT}\) 模型的方法和应用。“\(\text{Supervised Classification}\)”(第 \(\text{323}\) 页)将演示微调分类模型的一般过程。然后,在“\(\text{Few-Shot Classification}\)”(第 \(\text{333}\) 页)中,我们将研究 \(\text{SetFit}\),这是一种使用少量训练示例高效微调高性能模型的方法。在“\(\text{Continued Pretraining with Masked Language Modeling}\)”(第 \(\text{340}\) 页)中,我们将探索如何继续训练一个预训练模型。最后,将在“\(\text{Named-Entity Recognition}\)”(第 \(\text{345}\) 页)中探讨词元级别的分类。
我们将重点关注非生成性任务,因为生成模型将在第 \(\text{12}\) 章中介绍。
有监督分类
Supervised Classification
在第 \(\text{4}\) 章中,我们通过利用预训练的表征模型探索了有监督分类任务,这些模型要么经过预测情感的训练(任务特定模型 \(\text{task-specific model}\)),要么经过生成嵌入的训练(嵌入模型 \(\text{embedding model}\)),如图 \(\text{11}-1\) 所示。
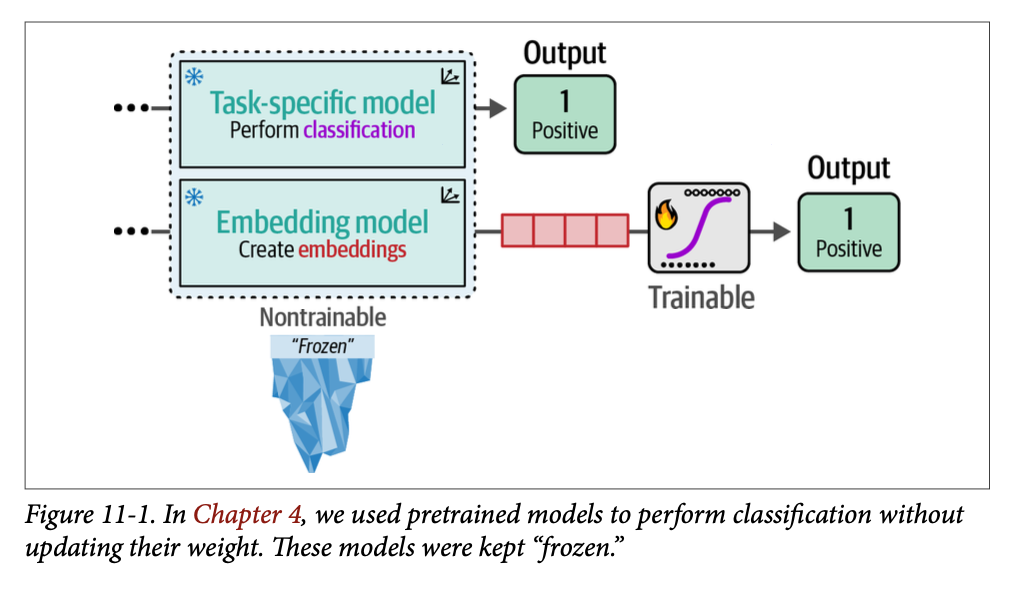
这两个模型都保持冻结(\(\text{frozen}\),即不可训练),以展示利用预训练模型进行分类任务的潜力。嵌入模型使用一个单独的可训练分类头(\(\text{classifier}\))来预测电影评论的情感。
在本节中,我们将采取类似的方法,但允许模型和分类头在训练期间都得到更新。如图 \(\text{11}-2\) 所示,我们将微调一个预训练的 \(\text{BERT}\) 模型来创建一个任务特定模型,而不是使用嵌入模型,这类似于我们在第 \(\text{2}\) 章中使用的模型。与嵌入模型的方法相比,我们将作为一个单一架构对表征模型和分类头进行微调。
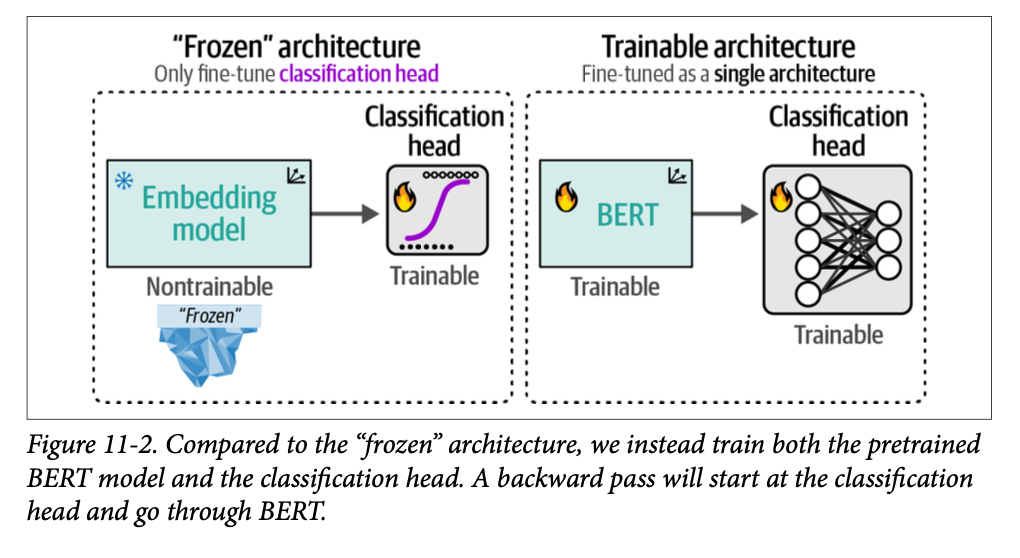
为此,我们不冻结模型,而是允许它可训练并在训练期间更新其参数。如图 \(\text{11}-3\) 所示,我们将使用一个预训练的 \(\text{BERT}\) 模型并添加一个神经网络作为分类头,两者都将为分类进行微调。
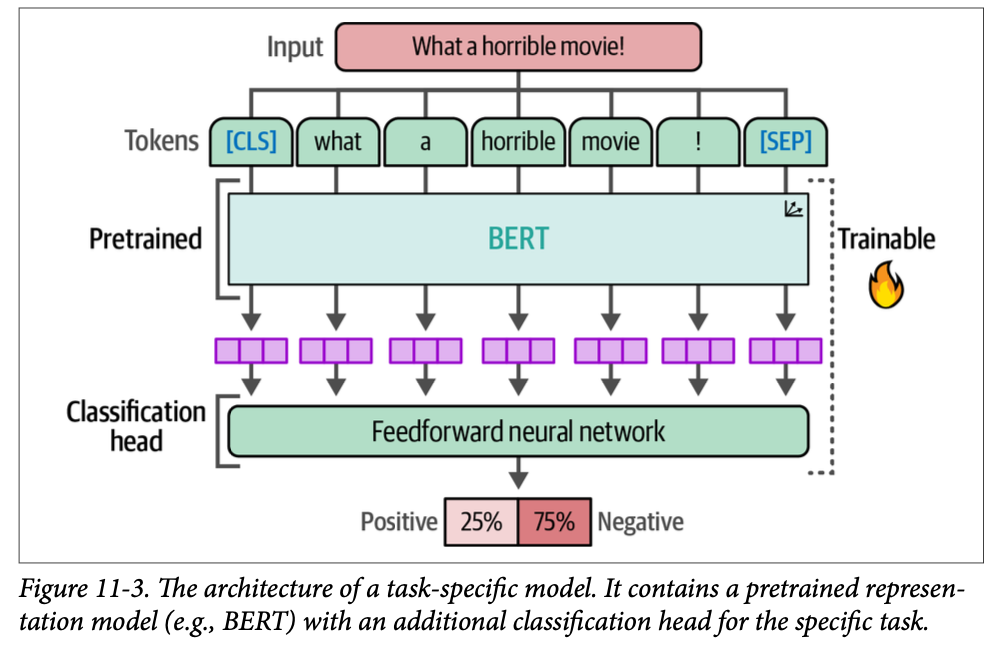
在实践中,这意味着预训练的 \(\text{BERT}\) 模型和分类头会联合更新。它们不是独立的流程,而是相互学习,并允许产生更准确的表征。
微调预训练 \(\text{BERT}\) 模型
Fine-Tuning a Pretrained BERT Model
我们将使用与第 \(\text{4}\) 章中相同的 \(\text{Rotten Tomatoes}\) 数据集来微调我们的模型,该数据集包含来自 \(\text{Rotten Tomatoes}\) 的 \(\text{5,331}\) 条正面和 \(\text{5,331}\) 条负面电影评论:
1 | from datasets import load_dataset |
我们分类任务的第一步是选择我们要使用的底层模型。我们使用 \(\text{"bert-base-cased"}\),它是在英文维基百科以及一个包含未出版书籍的大型数据集上预训练的。
我们预先定义了我们想要预测的标签数量。这对于创建应用于我们预训练模型顶部的 前馈神经网络是必要的:
1 | from transformers import AutoTokenizer, AutoModelForSequenceClassification |
接下来,我们将对数据进行词元化(\(\text{tokenize}\)):
1 | from transformers import DataCollatorWithPadding |
在创建 \(\text{Trainer}\) 之前,我们需要准备一个特殊的数据整理器 (\(\text{DataCollator}\))。\(\text{DataCollator}\) 是一个帮助我们构建数据批次的类,但也允许我们应用数据增强。
在这个词元化过程中,正如第 \(\text{9}\) 章所示,我们将在输入文本中添加填充 (\(\text{padding}\)) 以创建大小相等的表征。我们为此使用了 \(\text{DataCollatorWithPadding}\)。
当然,一个示例不会在没有定义一些指标的情况下完成:
1 | import numpy as np |
通过 \(\text{compute\_metrics}\),我们可以定义我们感兴趣的任意数量的指标,这些指标可以在训练期间打印或记录。这在训练期间特别有帮助,因为它允许检测过拟合行为。
接下来,我们实例化我们的 \(\text{Trainer}\):
1 | from transformers import TrainingArguments, Trainer |
\(\text{TrainingArguments}\) 类定义了我们想要调整的超参数,例如学习率以及我们想要训练的轮数 (\(\text{epochs}\))。\(\text{Trainer}\) 用于执行训练过程。
最后,我们可以训练我们的模型并进行评估:
1 | trainer.evaluate() |
我们获得了 \(\text{0.85}\) 的 \(\text{F1}\) 分数,这比我们在第 \(\text{4}\) 章中使用的任务特定模型 (\(\text{task-specific model}\)),即 \(\text{F1}\) 分数为 \(\text{0.80}\),要高出不少。这表明自己微调模型可能比使用预训练模型更有优势。它只花费了我们几分钟的训练时间。
冻结层
Freezing Layers
为了进一步展示训练整个网络的重要性,下一个示例将演示如何使用 \(\text{Hugging Face Transformers}\) 来冻结网络的某些层。
我们将冻结主要的 \(\text{BERT}\) 模型,并且只允许更新通过分类头。这将是一个很好的比较,因为我们将保持所有其他设置相同,只是冻结了特定的层。
首先,让我们重新初始化模型,以便可以从头开始:
1 | # Load model and tokenizer |
我们的预训练 \(\text{BERT}\) 模型包含许多我们可能想要冻结的层。检查这些层可以深入了解网络的结构以及我们可能想要冻结的部分:
1 | # Print layer names |
有 \(\text{12}\) 个 (\(\text{0}-\text{11}\)) 编码器块,它们由注意力头、密集网络和层归一化组成。我们在图 \(\text{11}-4\) 中进一步说明了这种架构,以展示所有可能被冻结的部分。除此之外,我们还有分类头。
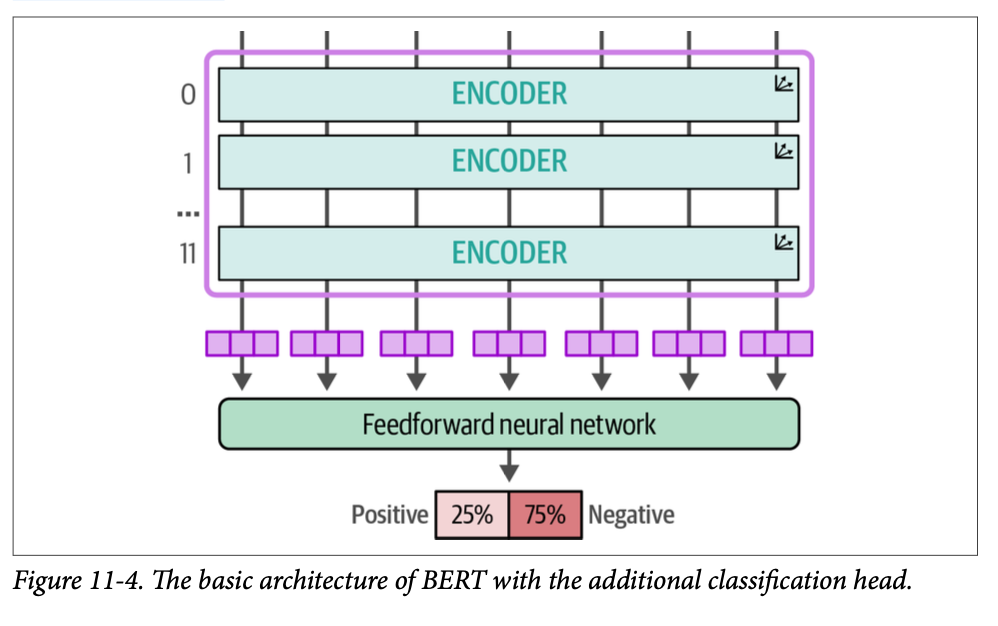
我们可以选择只冻结某些层以加快计算速度,但仍允许主模型从分类任务中学习。一般来说,我们希望可训练层位于冻结层之后。
我们将冻结除分类头之外的所有内容,就像我们在第 \(\text{2}\) 章中所做的那样:
1 | for name, param in model.named_parameters(): |
如图 \(\text{11}-5\) 所示,我们冻结了除前馈神经网络(即我们的分类头)之外的所有内容。
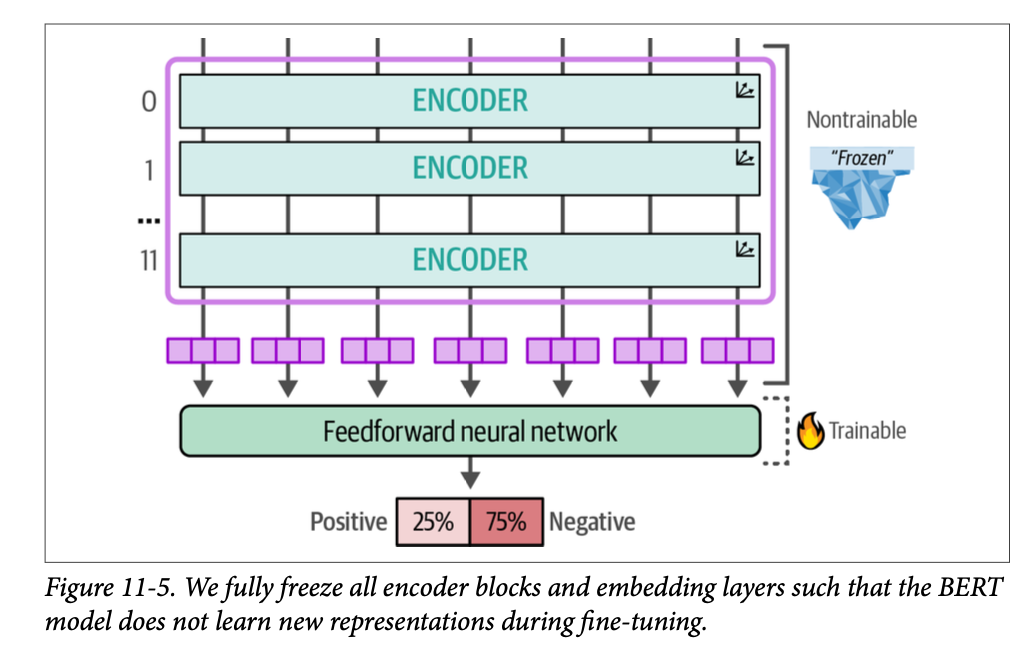
现在我们已经成功冻结了除分类头之外的所有内容,我们可以继续训练我们的模型:
1 | from transformers import TrainingArguments, Trainer |
您可能会注意到训练速度已经快得多了。这是因为我们只训练分类头,与微调整个模型相比,这为我们提供了显著的提速:
1 | trainer.evaluate() |
当我们评估模型时,我们得到的 \(\text{F1}\) 分数只有 \(\text{0.63}\),这比我们最初的 \(\text{0.85}\) 分数要低得多。与其冻结几乎所有层,不如像图 \(\text{11}-6\) 所展示的那样,冻结直到编码器块 \(\text{10}\) 之前的所有内容,看看这对性能有何影响。一个主要的好处是这减少了计算量,但仍然允许更新流经部分预训练模型:
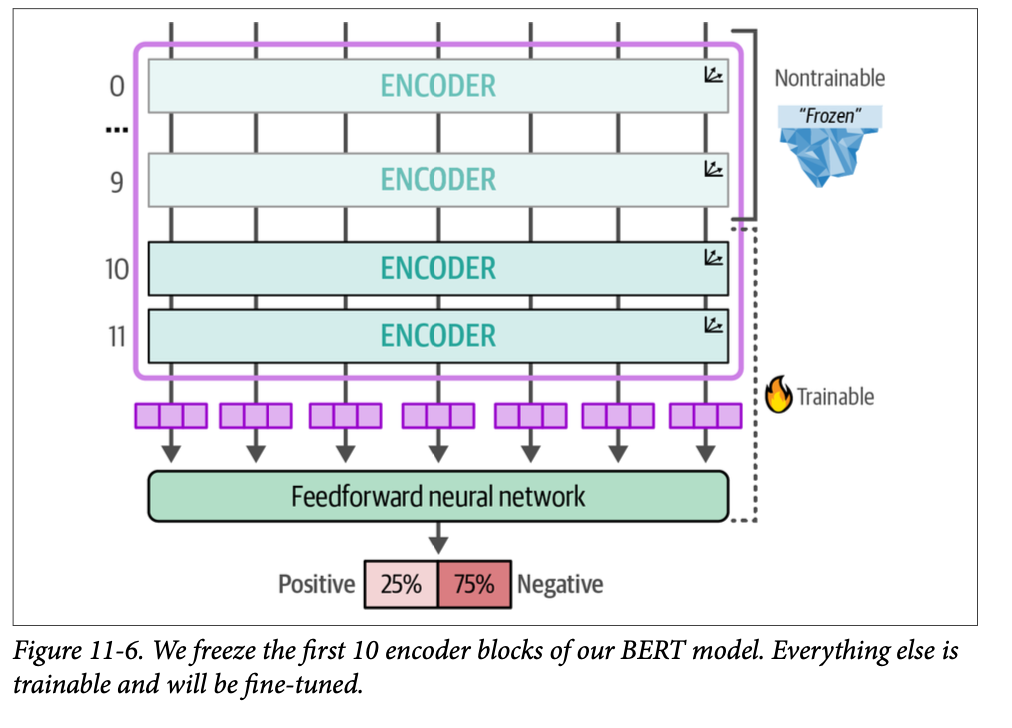
1 | # Load model |
训练后,我们评估结果:
1 | trainer.evaluate() |
我们得到了 \(\text{0.8}\) 的 \(\text{F1}\) 分数,这比我们之前冻结所有层时的 \(\text{0.63}\) 分数要高得多。这表明,尽管我们通常希望训练尽可能多的层,但如果您没有必要的计算能力,训练更少的层也是可以接受的。
为了进一步说明这种效果,我们测试了迭代冻结编码器块并进行微调的影响。如图 \(\text{11}-7\) 所示,只训练前五个编码器块(红色垂直线)就足以几乎达到训练所有编码器块的性能。
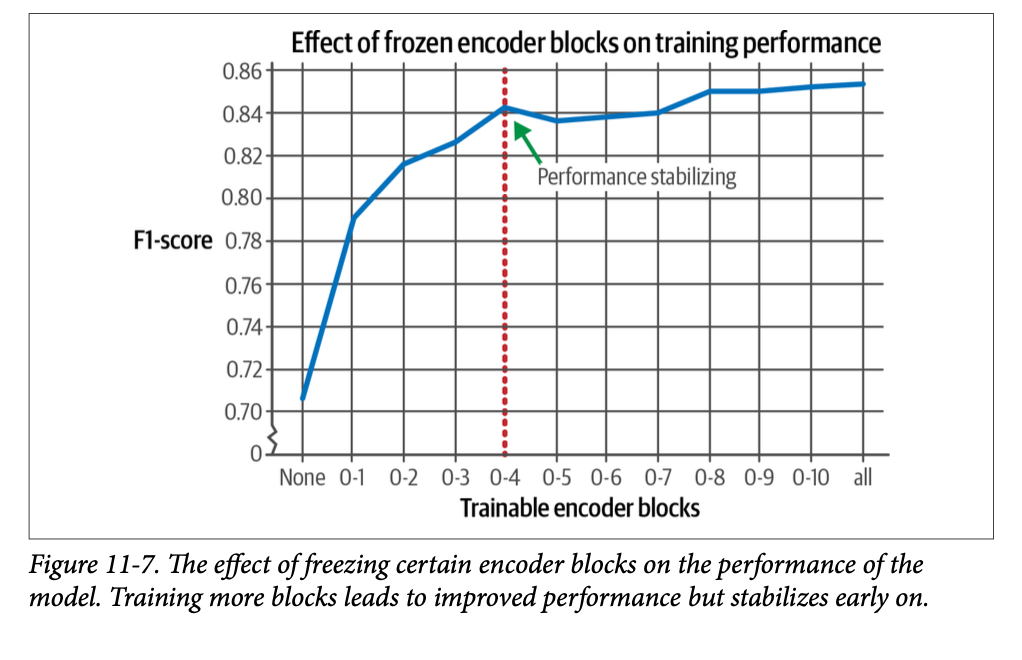
当您进行多轮训练(\(\text{epochs}\))时,冻结与不冻结之间的差异(在训练时间和资源方面)通常会变得更大。因此,建议尝试找到适合您的平衡点。
少样本分类
Few-Shot Classification
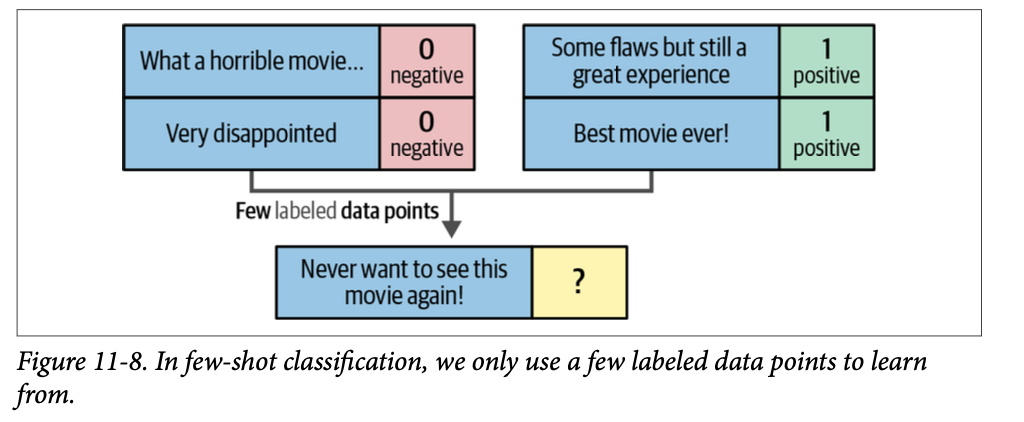
少样本分类(\(\text{Few-shot classification}\))是一种有监督分类中的技术,在这种技术中,您让分类器仅根据少数几个已标注的示例来学习目标标签。当您有一个分类任务但没有大量现成的标注数据点时,这种技术非常有用。换句话说,这种方法允许您为每个类别标注少量高质量的数据点来训练模型。图 \(\text{11}-8\) 展示了使用少量标注数据点来训练模型的想法。
\(\text{SetFit}\): 使用少量训练示例进行高效微调
SetFit: Efficient Fine-Tuning with Few Training Examples
为了执行少样本文本分类,我们使用了一个名为 \(\text{SetFit}\) 的高效框架。它构建在 \(\text{sentence-transformers}\) 的架构之上,用于生成在训练期间会更新的高质量文本表征。对于这个框架来说,只需要少量标注示例就可以与我们在上一个示例中探索的在大型标注数据集上微调 \(\text{BERT}\) 类模型相媲美。
\(\text{SetFit}\) 的底层算法由三个步骤组成:
- 采样训练数据 (\(\text{Sampling training data}\)) 基于已标注数据的类内和类间选择,它会生成正向(相似)和负向(不相似)的句子对。
- 微调嵌入 (\(\text{Fine-tuning embeddings}\)) 基于先前生成的训练数据来微调预训练嵌入模型。
- 训练分类器 (\(\text{Training a classifier}\)) 在嵌入模型之上创建一个分类头,并使用先前生成的训练数据对其进行训练。
在微调嵌入模型之前,我们需要生成训练数据。模型假设训练数据是正向(相似)和负向(不相似)句子对的样本。然而,当我们处理分类任务时,我们的输入数据通常没有以这种方式标注。
例如,假设我们有图 \(\text{11}-9\) 中的训练数据集,它将文本分为两类:关于编程语言的文本和关于宠物的文本。
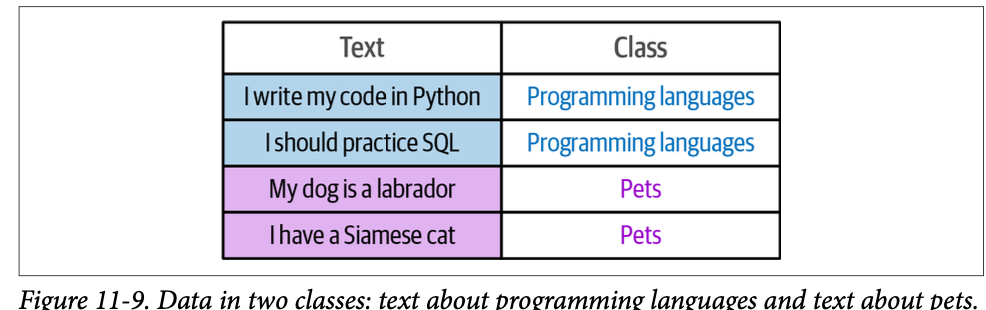
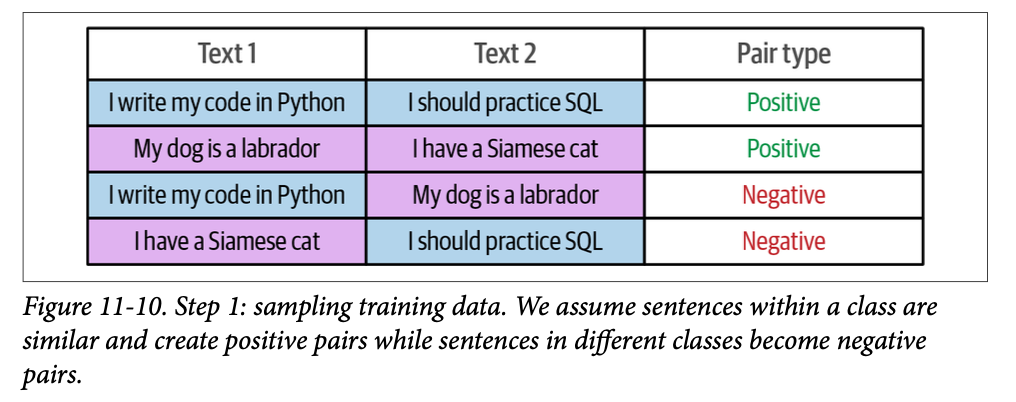
在步骤 \(\text{1}\) 中,\(\text{SetFit}\) 通过基于类内(\(\text{in-class}\))和类间(\(\text{out-class}\))选择来生成必需的数据,从而处理这个问题,如图 \(\text{11}-10\) 所示。例如,当我们有 \(\text{16}\) 个关于运动的句子时,我们可以创建 \(\text{16} \times (\text{16} – \text{1}) / \text{2} = \text{120}\) 个句子对,我们将它们标注为正向对。我们可以使用这个过程通过收集来自不同类别的句子对来生成负向对。
在步骤 \(\text{2}\) 中,我们可以使用生成的句子对来微调嵌入模型。这利用了一种称为对比学习的方法来微调预训练的 \(\text{BERT}\) 模型。正如我们在第 \(\text{10}\) 章中所回顾的,对比学习允许从相似(正向)和不相似(负向)句子对中学习准确的句子嵌入。
由于我们在上一步中生成了这些句子对,我们可以使用它们来微调 \(\text{SentenceTransformers}\) 模型。尽管我们之前讨论过对比学习,但我们再次在图 \(\text{11}-11\) 中说明该方法以供回顾。
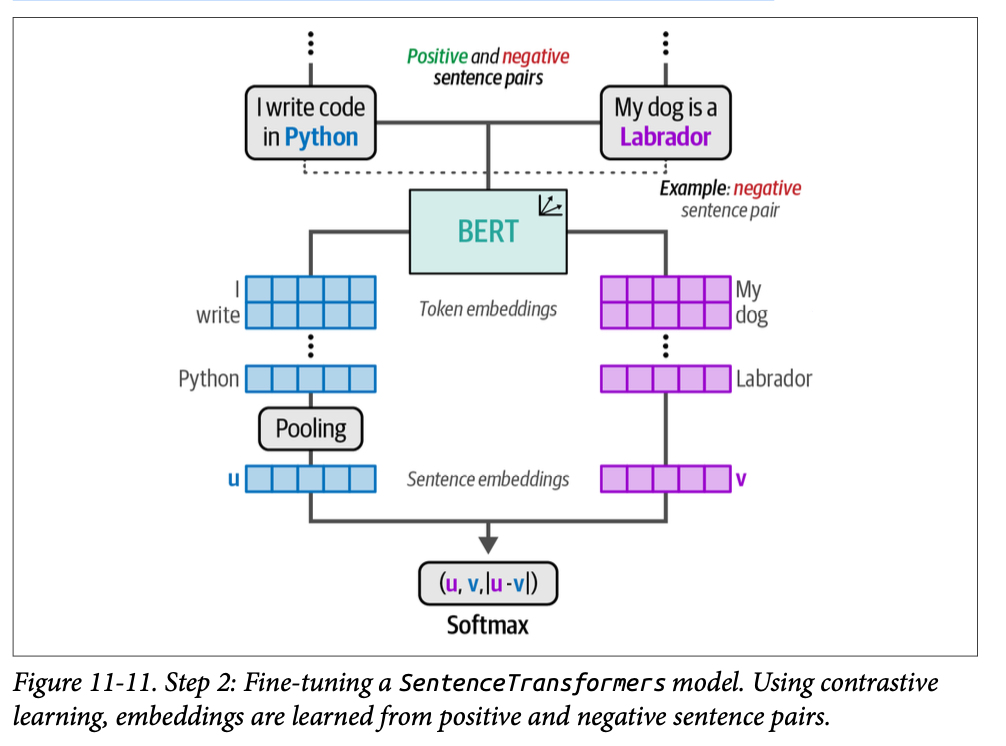
微调这个嵌入模型的目标是使其能够创建针对分类任务进行调整的嵌入。类别之间的相关性及其相对含义通过微调嵌入模型被提炼到嵌入中。
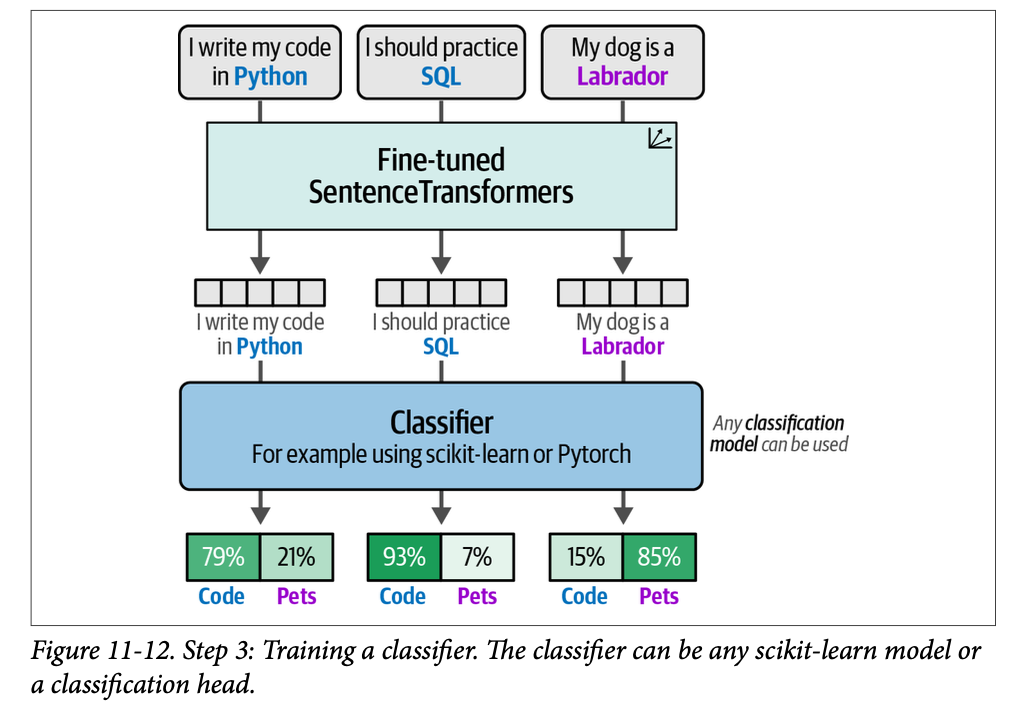
在步骤 \(\text{3}\) 中,我们生成所有句子的嵌入,并将其用作分类器的输入。我们可以使用微调后的 \(\text{SentenceTransformers}\) 模型将我们的句子转换为嵌入,我们可以将其用作特征。分类器从我们微调后的嵌入中学习,以准确预测未见过的句子。这最后一步如图 \(\text{11}-12\) 所示。
当我们把所有步骤结合在一起时,就得到了一个高效且优雅的流程,用于在您每个类别只有少数标签时执行分类。它巧妙地利用了我们拥有标注数据的这个想法,尽管标注的形式并非我们所希望的那样。图 \(\text{11}-13\) 将这三个步骤结合在一起,给出了整个过程的单一概览。
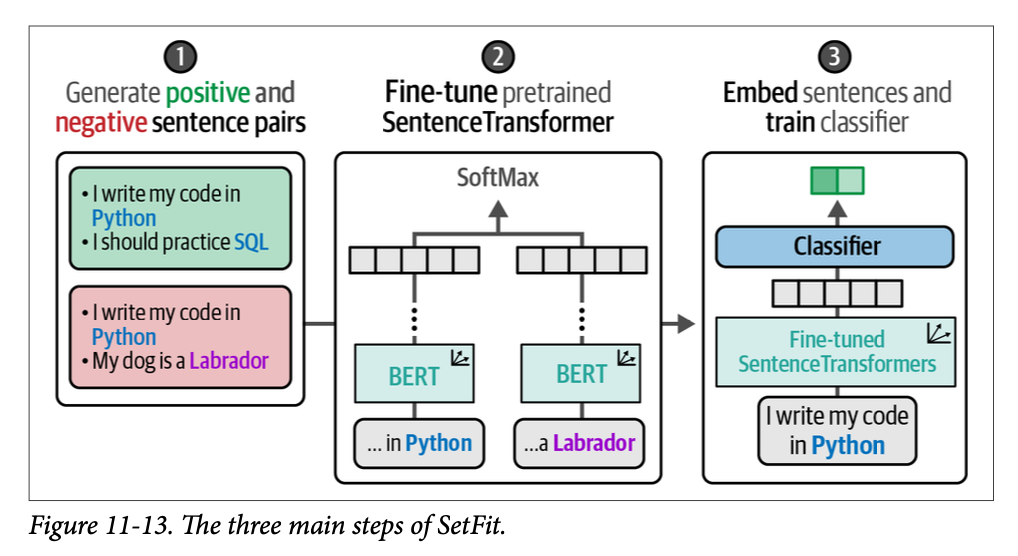
首先,根据类内和类间选择生成句子对。其次,使用这些句子对微调一个预训练的 \(\text{SentenceTransformer}\) 模型。第三,使用微调后的模型对句子进行嵌入,并在这些嵌入上训练一个分类器来预测类别。
少样本分类的微调
Fine-Tuning for Few-Shot Classification
我们之前训练了一个包含大约 \(\text{8,500}\) 条电影评论的数据集。然而,由于这是一个少样本环境,我们将只采样每个类别 \(\text{16}\) 个示例。对于两个类别,我们只有 \(\text{32}\) 个文档进行训练,而我们之前使用了 \(\text{8,500}\) 条电影评论!
1 | from setfit import sample_dataset |
在采样数据后,我们选择一个预训练的 \(\text{SentenceTransformer}\) 模型进行微调。官方文档包含一个预训练 \(\text{SentenceTransformer}\) 模型的概览,我们将使用 \(\text{"sentence-transformers/all-mpnet-base-v2"}\)。它是 \(\text{MTEB}\) 排行榜上性能最佳的模型之一,该排行榜展示了嵌入模型在各种任务上的性能:
1 | from setfit import SetFitModel |
在加载预训练的 \(\text{SentenceTransformer}\) 模型后,我们可以开始定义我们的 \(\text{SetFitTrainer}\)。默认情况下,逻辑回归模型被选作要训练的分类器。
类似于我们使用 \(\text{Hugging Face Transformers}\) 所做的那样,我们可以使用 \(\text{trainer}\) 来定义和调整相关参数。例如,我们将 \(\text{num\_epochs}\) 设置为 \(\text{3}\),以便对比学习将执行三个 \(\text{epoch}\):
1 | from setfit import TrainingArguments as SetFitTrainingArguments |
我们只需要调用 \(\text{train}\) 来开始训练循环。当我们这样做时,我们应该得到以下输出:
1 | # Training loop |
请注意,输出中提到为微调 \(\text{SentenceTransformer}\) 模型生成了 \(\text{1,280}\) 个句子对。默认情况下,为我们数据中的每个样本生成 \(\text{20}\) 个句子对组合,即 \(\text{20} \times \text{32} = \text{680}\) 个样本。我们需要将此值乘以 \(\text{2}\),因为生成了每个正向和负向对,即 \(\text{680} \times \text{2} = \text{1,280}\) 个句子对。考虑到我们最初只有 \(\text{32}\) 个标注句子,生成 \(\text{1,280}\) 个句子对相当令人印象深刻!
当我们没有明确定义分类头时,默认使用的是逻辑回归。如果我们要自己指定一个分类头,可以通过在 \(\text{SetFitTrainer}\) 中指定以下模型来实现:
2
3
4
5
6
7
8
9
10
11
model = SetFitModel.from_pretrained(
"sentence-transformers/all-mpnet-base-v2",
use_differentiable_head=True,
head_params={"out_features": num_classes},
)
# Create trainer
trainer = SetFitTrainer(
model=model,
...
)这里的 \(\text{num\_classes}\) 指的是我们想要预测的类别数量。
接下来,我们评估模型以感受其性能:
1 | # Evaluate the model on our test data |
仅用 \(\text{32}\) 个标注文档,我们就获得了 \(\text{0.85}\) 的 \(\text{F1}\) 分数。考虑到该模型是在原始数据的极小一部分子集上训练的,这非常令人印象深刻!此外,在第 \(\text{2}\) 章中,我们获得了相同的性能,但却是在完整数据的嵌入上训练了一个逻辑回归模型。因此,这个流程展示了花费时间仅标注少量实例的潜力。
\(\text{SetFit}\) 不仅可以执行少样本分类任务,它还支持您完全没有标签的情况,这也被称为零样本分类 (\(\text{zero-shot classification}\))。\(\text{SetFit}\) 从标签名称中生成合成示例,以模拟分类任务,然后在其上训练一个 \(\text{SetFit}\) 模型。例如,如果目标标签是“\(\text{happy}\)”和“\(\text{sad}\)”,那么合成数据可以是“\(\text{The example is happy}\)”和“\(\text{This example is sad}\)”。
使用掩码语言建模进行持续预训练
Continued Pretraining with Masked Language Modeling
在到目前为止的示例中,我们利用了一个预训练模型并对其进行了微调以执行分类。这个过程描述了一个两步过程:首先预训练一个模型(这已经为我们完成),然后针对特定任务对其进行微调。我们在图 \(\text{11}-14\) 中说明了这一过程。
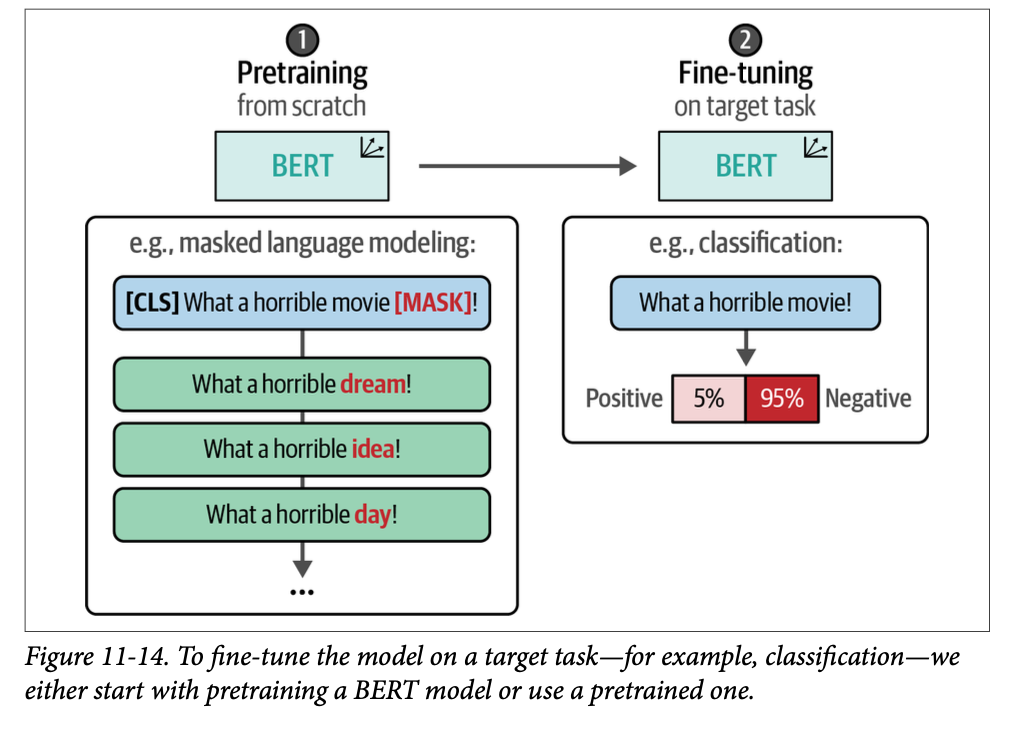
这种两步法通常用于许多应用程序中。当面临特定领域的数据时,它有其局限性。预训练模型通常在非常通用的数据(如维基百科页面)上训练,可能未针对您的领域特定词汇进行调整。
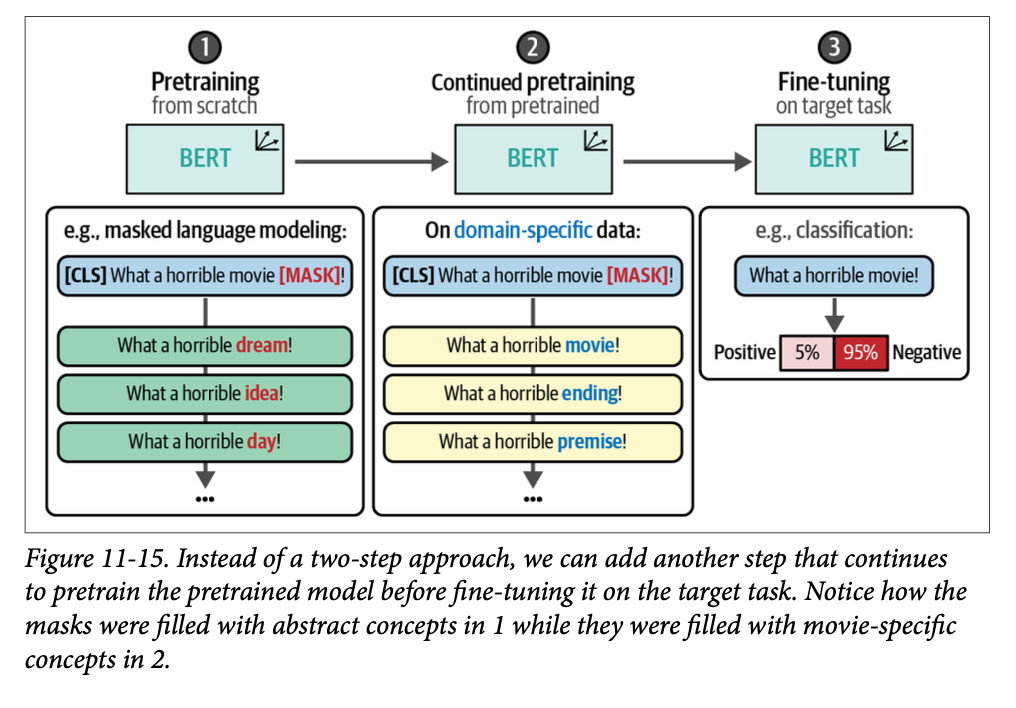
我们可以不采用这种两步法,而是在它们之间挤入另一个步骤,即继续预训练一个已经预训练过的 \(\text{BERT}\) 模型。换句话说,我们可以简单地继续使用掩码语言建模 (\(\text{MLM}\)) 来训练 \(\text{BERT}\) 模型,但改为使用我们领域的数据。这就像是从一个通用 \(\text{BERT}\) 模型,到一个专用于医学领域的 \(\text{BioBERT}\) 模型,再到一个微调后的 \(\text{BioBERT}\) 模型来对药物进行分类。
这将更新子词表征,使其更适应它以前未见过的词汇。这个过程如图 \(\text{11}-15\) 所示,并展示了这个额外步骤如何更新掩码语言建模任务。事实证明,在一个预训练 \(\text{BERT}\) 模型上继续预训练可以提高模型在分类任务中的性能,是微调流程中值得添加的一步。
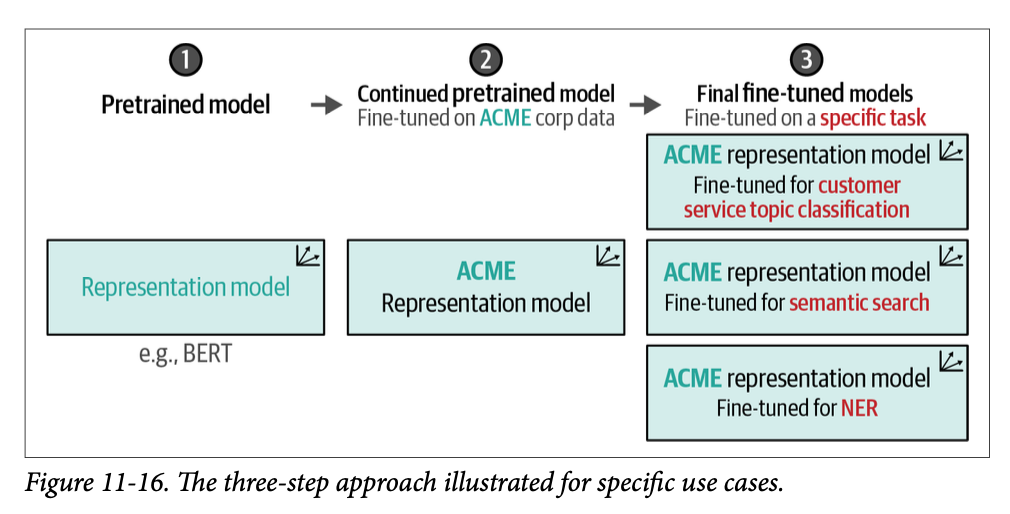
我们不必从头开始预训练整个模型,只需在将其微调用于分类之前,继续进行预训练即可。这也有助于模型适应某个特定领域,甚至是特定组织的行话。一个公司可能希望采用的模型族谱如图 \(\text{11}-16\) 所示。
在本例中,我们将演示如何应用第 \(\text{2}\) 步并继续预训练一个已经预训练的 \(\text{BERT}\) 模型。我们使用我们最初开始使用的相同数据,即 \(\text{Rotten Tomatoes}\) 评论。
我们首先加载我们迄今为止使用的 \(\text{"bert-base-cased"}\) 模型,并为 \(\text{MLM}\) 准备它:
1 | from transformers import AutoTokenizer, AutoModelForMaskedLM |
我们需要对原始句子进行词元化。我们还将移除标签,因为这不是一个有监督任务:
1 | def preprocess_function(examples): |
之前,我们使用了 \(\text{DataCollatorWithPadding}\),它会动态填充接收到的输入。
相反,我们将使用一个 \(\text{DataCollator}\) 来为我们执行词元掩码 (\(\text{masking of tokens}\))。通常使用两种方法:词元掩码 (\(\text{token masking}\)) 和整词掩码 (\(\text{whole-word masking}\))。使用词元掩码,我们随机掩盖句子中 \(\text{15\%}\) 的词元。可能会发生一个词的一部分被掩盖的情况。为了实现对整个词的掩盖,我们可以应用整词掩码,如图 \(\text{11}-17\) 所示。
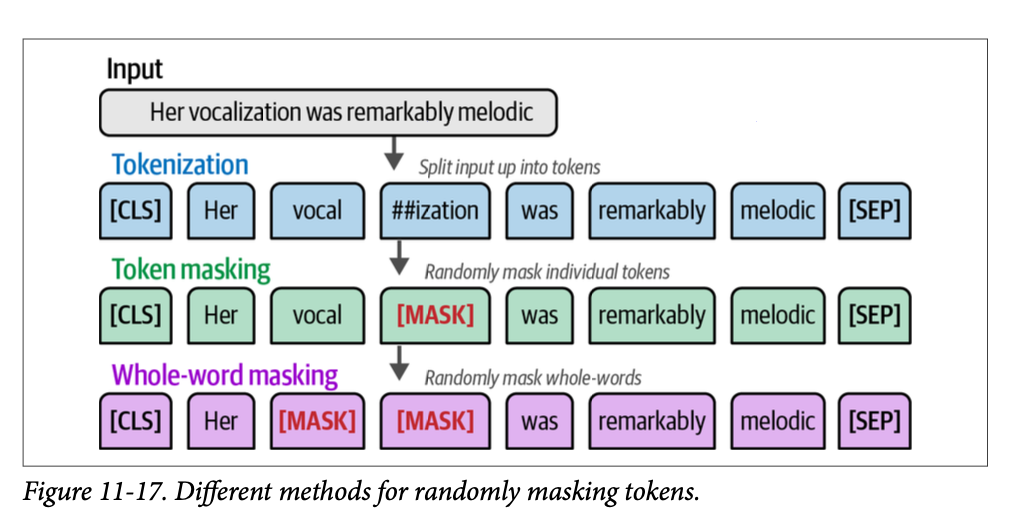
一般来说,预测整个词汇往往比词元更复杂,这使得模型在训练期间需要学习更准确和精确的表征,从而表现更好。然而,它往往需要更多时间才能收敛。
在本例中,我们将使用 \(\text{DataCollatorForLanguageModeling}\) 进行词元掩码,以实现更快的收敛。不过,我们可以通过将 \(\text{DataCollatorForLanguageModeling}\) 替换为 \(\text{DataCollatorForWholeWordMask}\) 来使用整词掩码。最后,我们将给定句子中词元被掩码的概率设置为 \(\text{15\%}\) (\(\text{mlm\_probability}\)):
1 | from transformers import DataCollatorForLanguageModeling |
接下来,我们将创建用于运行 \(\text{MLM}\) 任务的 \(\text{Trainer}\) 并指定某些参数:
1 | # Training arguments for parameter tuning |
有几个参数值得注意。我们训练了 \(\text{20}\) 个 \(\text{epoch}\) 并保持任务简短。您可以尝试学习率和权重衰减,以确定它们是否有助于微调模型。
在我们开始训练循环之前,我们首先会保存我们预训练的 \(\text{tokenizer}\)。\(\text{tokenizer}\) 在训练期间不会更新,因此没有必要在训练后保存它。但是,我们将在继续预训练后保存我们的模型:
1 | # Save pre-trained tokenizer |
这为我们在 \(\text{mlm}\) 文件夹中提供了一个更新后的模型。要评估其性能,我们通常会在各种任务上微调该模型。然而,出于我们的目的,我们可以运行一些掩码任务,看看它是否从持续训练中有所学习。
我们将通过加载在我们继续预训练之前的预训练模型来完成此操作。使用句子 “\(\text{What a horrible [MASK]!}\)” 模型将预测哪个词将取代 \(\text{[MASK]}\):
1 | from transformers import pipeline |
输出展示了像 “\(\text{idea}\)”、“\(\text{dream}\)” 和 “\(\text{day}\)” 这样的概念,这绝对合理。接下来,让我们看看我们更新后的模型预测了什么:
1 | # Load and create predictions |
一个“\(\text{horrible movie}\)”(可怕的电影)、“\(\text{film}\)”(影片)、“\(\text{mess}\)”(烂摊子)等清楚地表明,与预训练模型相比,该模型更偏向于我们提供给它的数据。
下一步将是微调这个模型以进行我们在本章开头所做的分类任务。只需按如下方式加载模型,即可开始:
1 | from transformers import AutoModelForSequenceClassification |
命名实体识别
Named-Entity Recognition
在本节中,我们将深入探讨专门针对命名实体识别 (\(\text{NER}\)) 微调预训练 \(\text{BERT}\) 模型的过程。这项过程不是对整个文档进行分类,而是允许对单个词元 (\(\text{token}\)) 和/或词汇进行分类,包括人名和地点。当涉及敏感数据时,这对于去识别化 (\(\text{de-identification}\)) 和匿名化任务特别有帮助。
\(\text{NER}\) 与我们在本章开头探讨的分类示例有相似之处。然而,一个关键的区别在于数据的预处理和分类。鉴于我们专注于对单个词汇进行分类而不是整个文档,我们必须对数据进行预处理以考虑这种细粒度的结构。图 \(\text{11}-18\) 提供了这种词汇级别方法的视觉表示。
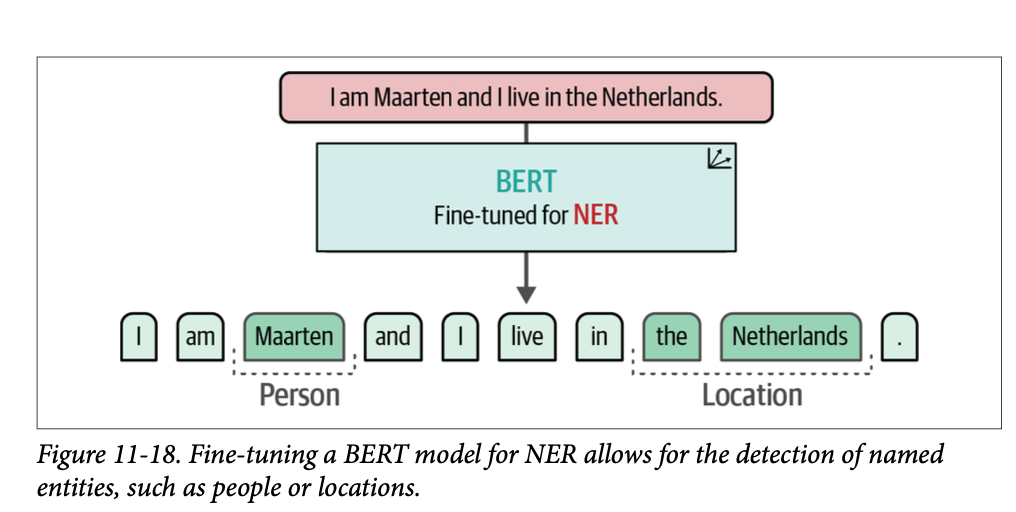
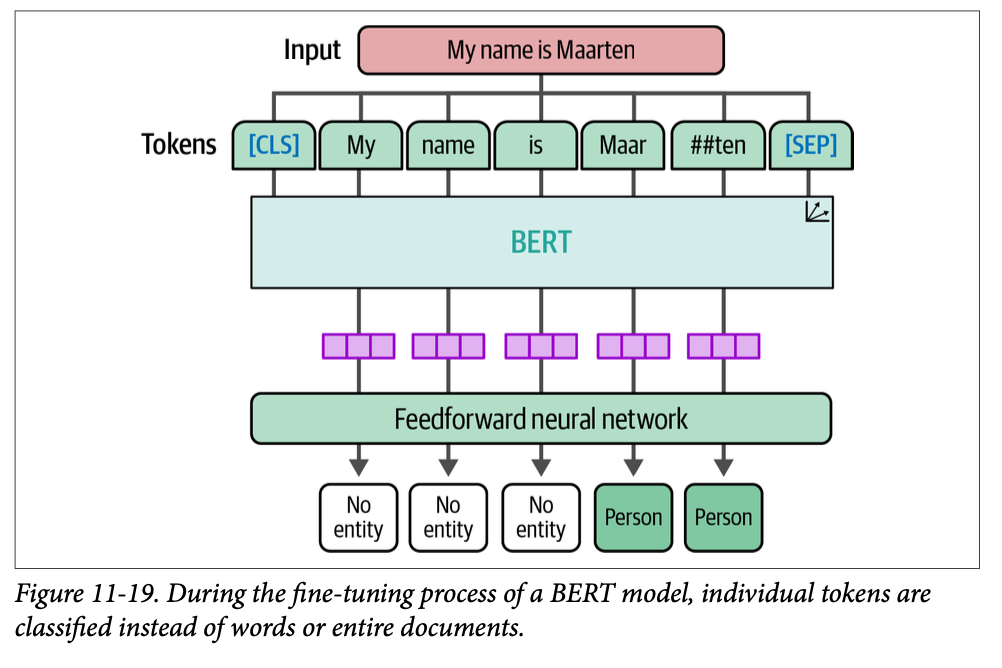
微调预训练 \(\text{BERT}\) 模型遵循类似于我们观察到的文档分类的架构。然而,分类方法发生了根本性的转变。模型现在不是依赖于词元嵌入的聚合或池化,而是对序列中的单个词元进行预测。至关重要的是要强调,我们的词汇级别分类任务并不意味着对整个词汇进行分类,而是对共同构成这些词汇的词元进行分类。图 \(\text{11}-19\) 提供了这种词元级别分类的视觉表示。
为命名实体识别准备数据
Preparing Data for Named-Entity Recognition
在本例中,我们将使用 \(\text{CoNLL-2003}\) 数据集的英文版本,该数据集包含几种不同类型的命名实体(人名、组织、地点、杂项和无实体),并有大约 \(\text{14,000}\) 个训练样本。
1 | # The CoNLL-2003 dataset for NER |
在研究本示例要使用的数据集时,我们还想分享另外几个: \(\text{wnut\_17}\) 是一个专注于新兴和稀有实体的任务,这些实体更难发现。此外,\(\text{tner/mit\_movie\_trivia}\) 和 \(\text{tner/mit\_restaurant}\) 数据集也很有趣。 \(\text{tner/mit\_movie\_trivia}\) 用于检测演员、情节和配乐等实体,而 \(\text{tner/mit\_restaurant}\) 旨在检测设施、菜肴和美食等实体。
让我们通过一个示例来检查数据的结构:
1 | example = dataset["train"][848] |
该数据集为句子中给出的每个词提供了标签。这些标签可以在 \(\text{ner\_tags}\) 键中找到,它指的是以下可能的实体:
1 | label2id = { |
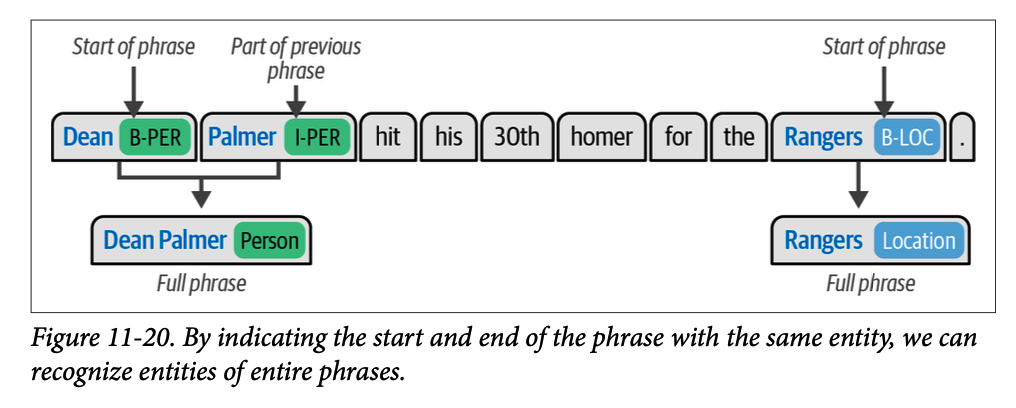
这些实体对应于特定的类别:人名 (\(\text{PER}\))、组织 (\(\text{ORG}\))、地点 (\(\text{LOC}\))、杂项实体 (\(\text{MISC}\)) 和无实体 (\(\text{O}\))。请注意,这些实体都带有 \(\text{B}\) (起始 \(\text{beginning}\)) 或 \(\text{I}\) (内部 \(\text{inside}\)) 的前缀。如果连续的两个词元属于同一个短语,则该短语的起始用 \(\text{B}\) 表示,随后是 \(\text{I}\),以表明它们相互关联而非独立的实体。
这个过程在图 \(\text{11}-20\) 中得到了进一步的说明。在图例中,由于 “\(\text{Dean}\)” 是短语的起始,而 “\(\text{Palmer}\)” 是内部,我们知道 “\(\text{Dean Palmer}\)” 是一个人名,并且 “\(\text{Dean}\)” 和 “\(\text{Palmer}\)” 不是独立的个体。
我们的数据已经经过预处理并分割成词汇,但尚未分割成词元。为此,我们将使用本章中一直使用的预训练模型 \(\text{bert-base-cased}\) 的 \(\text{tokenizer}\) 对其进行进一步的词元化:
1 | from transformers import AutoModelForTokenClassification |
让我们探索 \(\text{tokenizer}\) 将如何处理我们的示例:
1 | # Split individual tokens into sub-tokens |
正如我们在第 \(\text{2}\) 章和第 \(\text{3}\) 章中所学到的,\(\text{tokenizer}\) 添加了 \(\text{[CLS]}\) 和 \(\text{[SEP]}\) 词元。请注意,单词 “\(\text{homer}\)” 被进一步拆分为词元 “\(\text{home}\)” 和 “##r”。
这给我们带来了一个小问题,因为我们在词汇级别有标注数据,但在词元级别没有。这可以通过在词元化过程中将标签与其子词元对应物对齐来解决。
让我们考虑单词 “\(\text{Maarten}\)”,它的标签是 \(\text{B-PER}\),表示这是一个人名。如果我们将这个词通过 \(\text{tokenizer}\),它会将这个词拆分成词元 “\(\text{Ma}\)”、“##arte” 和 “##n”。我们不能对所有词元都使用 \(\text{B-PER}\) 实体,因为这将表示这三个词元都是独立的个体。每当一个实体被拆分成词元时,第一个词元应该带有 \(\text{B}\) (起始),而后续的词元应该带有 \(\text{I}\) (内部)。
因此,“\(\text{Ma}\)” 将获得 \(\text{B-PER}\) 来表示短语的开始,而 “##arte” 和 “##n” 将获得 \(\text{I-PER}\) 来表示它们属于同一个短语。这个对齐过程如图 \(\text{11}-21\) 所示。
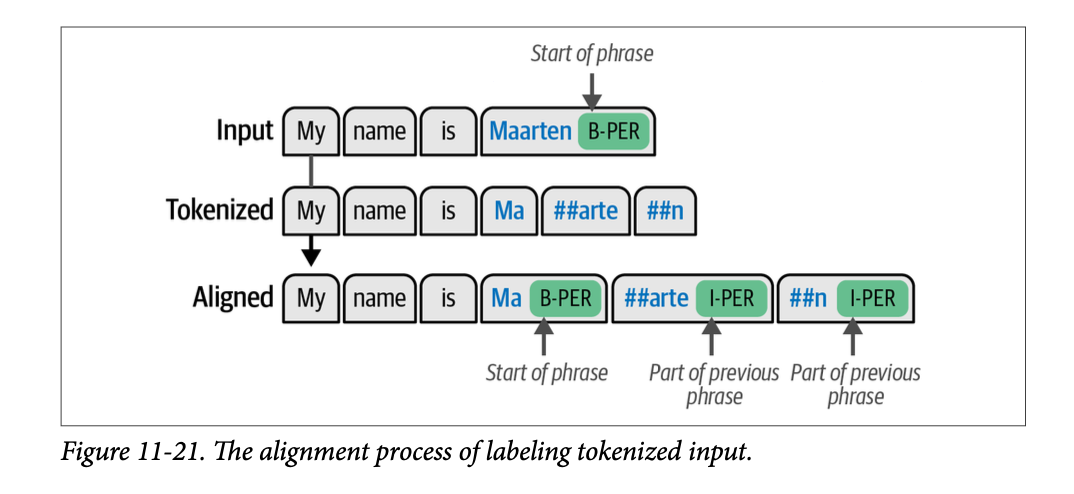
我们创建一个名为 \(\text{align\_labels}\) 的函数,它将在词元化过程中对输入进行词元化,并将其与更新后的标签对齐:
1 | def align_labels(examples): |
查看我们的示例,请注意 \(\text{[CLS]}\) 和 \(\text{[SEP]}\) 词元添加了额外的标签 (\(\text{-100}\)):
1 | # Difference between original and updated labels |
现在我们已经对标签进行了词元化和对齐,我们可以开始考虑定义我们的评估指标。这也不同于我们之前所见。现在,我们每个文档有多个预测(即每个词元),而不是每个文档只有一个预测。
我们将使用 \(\text{Hugging Face}\) 的 \(\text{evaluate}\) 包来创建一个 \(\text{compute\_metrics}\) 函数,它允许我们在词元级别评估性能:
1 | import evaluate |
命名实体识别的微调
Fine-Tuning for Named-Entity Recognition
我们快完成了。我们不再使用 \(\text{DataCollatorWithPadding}\),而是需要一个适用于词元级别分类的整理器,即 \(\text{DataCollatorForTokenClassification}\):
1 | from transformers import DataCollatorForTokenClassification |
现在我们已经加载了模型,剩下的步骤与本章中之前的训练过程相似。我们定义一个带有可以调整的特定参数的训练器,并创建一个 \(\text{Trainer}\):
1 | # Training arguments for parameter tuning |
然后,我们评估我们创建的模型:
1 | # Evaluate the model on our test data |
最后,让我们保存模型并将其用于推理管道 (\(\text{pipeline}\))。这使我们能够检查某些数据,从而手动检查推理过程中发生的情况以及我们是否对输出感到满意:
1 | from transformers import pipeline |
在句子 “\(\text{My name is Maarten}\)” 中,单词 “\(\text{Maarten}\)” 及其子词元被正确地识别为人名 (\(\text{person}\))! ### 总结 Summary
在本章中,我们探索了几种用于在特定分类任务上微调预训练表征模型的任务。我们首先演示了如何微调预训练的 \(\text{BERT}\) 模型,并通过冻结其架构的某些层来扩展了这些示例。
我们尝试了一种名为 \(\text{SetFit}\) 的少样本分类技术,它涉及使用有限的标注数据来微调预训练的嵌入模型和分类头。该模型仅使用少量标注数据点,就产生了与我们在前几章中探索的模型相似的性能。
接下来,我们深入研究了持续预训练 (\(\text{continued pretraining}\)) 的概念,我们使用预训练的 \(\text{BERT}\) 模型作为起点,并使用不同的数据继续训练它。底层过程,即掩码语言建模 (\(\text{masked language modeling}\)),不仅用于创建表征模型,还可以用于持续预训练模型。
最后,我们研究了命名实体识别 (\(\text{named-entity recognition}\)),这是一项涉及在非结构化文本中识别特定实体(例如人名和地点)的任务。与之前的示例相比,这种分类是在词汇级别而非文档级别上完成的。
在下一章中,我们将继续探讨微调语言模型的领域,但会转而关注生成模型。我们将使用两步法,探索如何微调生成模型以正确遵循指令,然后微调它以符合人类偏好。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调