《Hands-On Large Language Models》第10章 创建文本嵌入模型
第 \(\text{III}\) 部分 训练与微调大型语言模型
Training and Fine-Tuning Language Models
第 \(\text{10}\) 章 创建文本嵌入模型
Creating Text Embedding Models
文本嵌入模型是许多强大自然语言处理应用的基础。它们为赋能已经令人印象深刻的技术(如文本生成模型)奠定了基础。在本书中,我们已经将嵌入模型用于许多应用,例如有监督分类、无监督分类、语义搜索,甚至为像 \(\text{ChatGPT}\) 这样的文本生成模型赋予记忆。
嵌入模型在这一领域的重要性几乎无法被夸大,因为它们是许多应用背后的驱动力。因此,在本章中,我们将讨论创建和微调嵌入模型的各种方法,以增强其表征和语义能力。
让我们从探索嵌入模型是什么以及它们通常如何工作开始。
嵌入模型
Embedding Models
嵌入和嵌入模型已在相当多的章节(第 \(\text{4}\)、\(\text{5}\) 和 \(\text{8}\) 章)中进行过讨论,从而展示了它们的有用性。在深入探讨如何训练这样的模型之前,让我们回顾一下我们对嵌入模型所学到的知识。
非结构化文本数据本身通常很难处理。它们不是我们可以直接处理、可视化并从中创建可操作结果的数值。我们必须首先将这些文本数据转换为我们可以轻松处理的东西:数值表示。这个过程通常被称为嵌入输入,以输出可用的向量,即嵌入(\(\text{embeddings}\)),如图 \(\text{10}-1\) 所示。
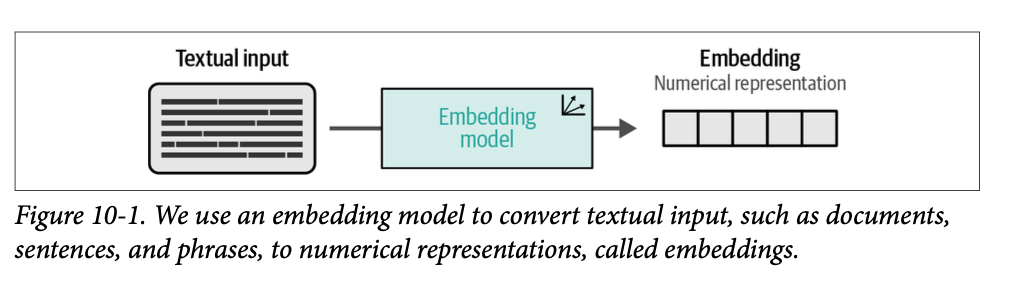
这种嵌入输入的过程通常由一个 \(\text{LLM}\) 执行,我们称之为嵌入模型。这种模型的主要目的是在将文本数据表示为嵌入方面尽可能准确。
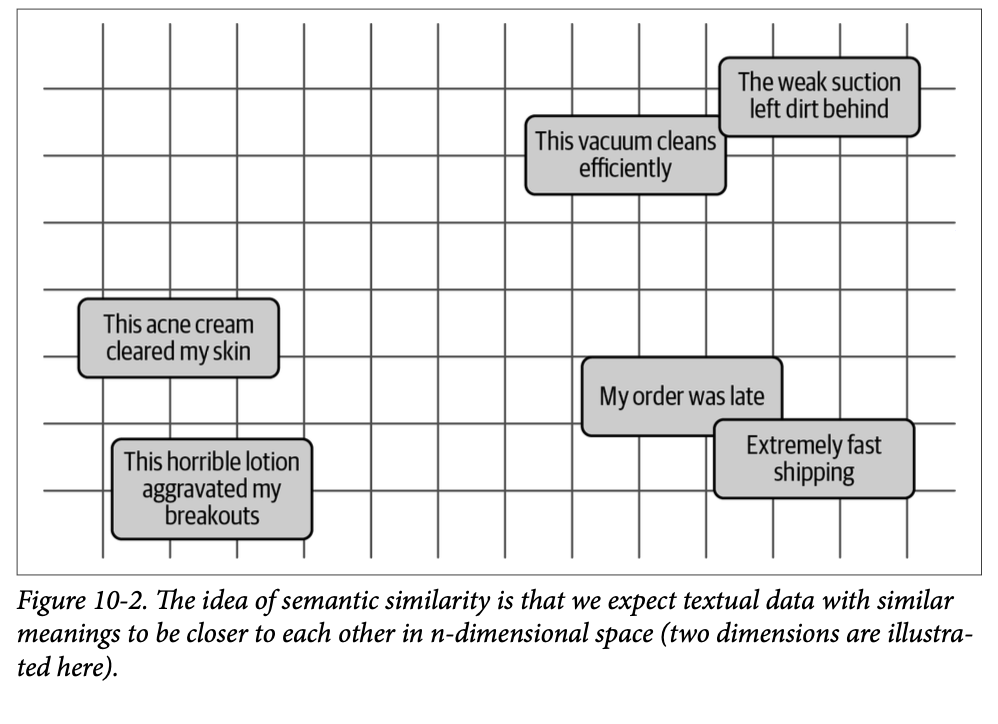
然而,准确表示意味着什么呢?通常,我们希望捕获文档的语义性质——即含义。如果我们能够捕获文档所传达的核心内容,我们就希望已经捕获了文档的主题。在实践中,这意味着我们期望彼此相似的文档的向量是相似的,而各自讨论完全不同事物的文档的嵌入则应该是不相似的。我们在本书中已经多次看到语义相似性的这种思想,它在图 \(\text{10}-2\) 中得到了可视化。这个图是一个简化示例。虽然二维可视化有助于说明嵌入的接近度和相似性,但这些嵌入通常存在于高维空间中。
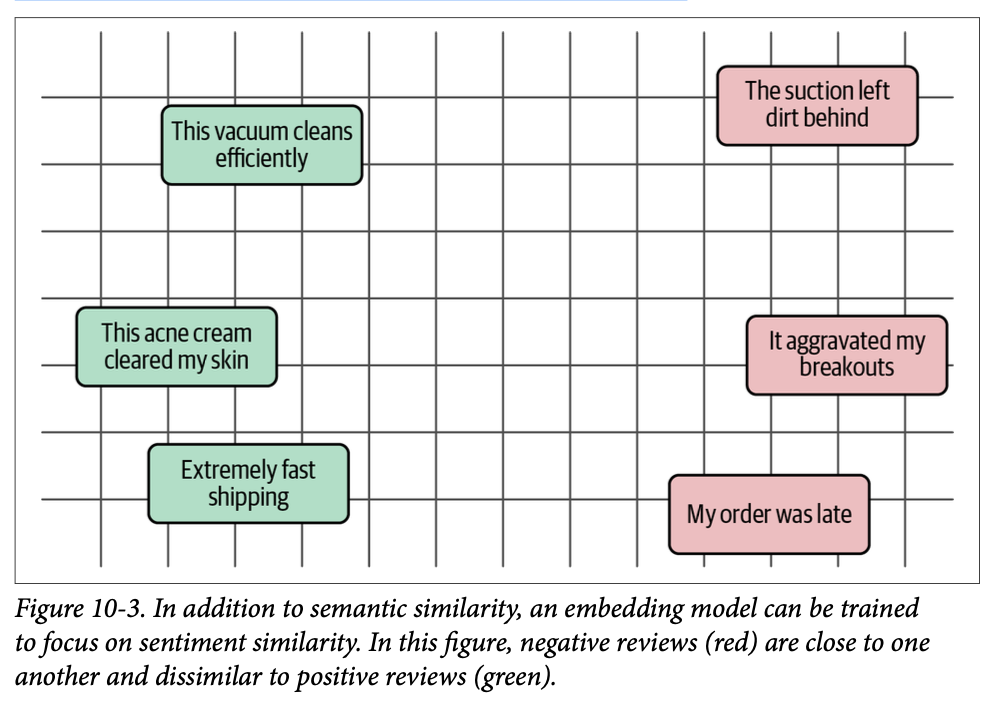
然而,嵌入模型可以针对多种目的进行训练。例如,当我们构建一个情感分类器时,我们更感兴趣的是文本的情感,而不是它们的语义相似性。如图 \(\text{10}-3\) 所示,我们可以微调该模型,使文档在 \(\text{n}\) 维空间中基于它们的情感而不是它们的语义性质更接近。
无论如何,嵌入模型旨在学习是什么使某些文档彼此相似,而且我们可以引导这个过程。通过向模型展示足够多的语义相似文档的示例,我们可以导向语义;而使用情感的示例则会将其导向情感。
有很多方法可以训练、微调和引导嵌入模型,但其中最强大且最广泛使用的技术之一被称为对比学习(\(\text{contrastive learning}\))。
什么是对比学习?
What Is Contrastive Learning?
对比学习(\(\text{contrastive learning}\))是用于训练和微调文本嵌入模型的一项主要技术。对比学习旨在训练一个嵌入模型,使得相似文档在向量空间中更接近,而不相似文档则更远离。如果这听起来很熟悉,那是因为它与第 \(\text{2}\) 章中的 \(\text{word2vec}\) 方法非常相似。我们之前已经在图 \(\text{10}-2\) 和 \(\text{10}-3\) 中看到过这个概念。
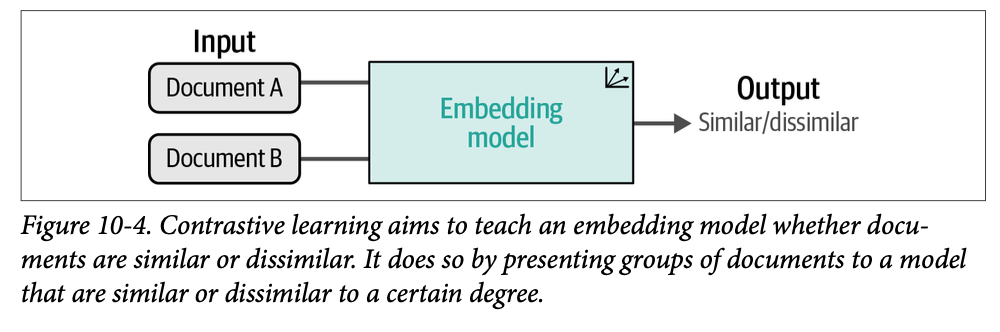
对比学习的基本思想是,学习和建模文档之间相似性/不相似性的最佳方法是向模型提供相似和不相似对的示例。为了准确捕获文档的语义性质,它通常需要与另一个文档进行对比,模型才能学习到是什么使它不同或相似。这种对比过程非常强大,并与文档被撰写的上下文相关。这种高层级过程在图 \(\text{10}-4\) 中得到了演示。
看待对比学习的另一种方式是通过解释的性质。一个很好的例子是一个轶事:一位记者问一个劫匪:“你为什么抢银行?”他回答说:“因为钱在那里。” 尽管这是一个事实正确的答案,但问题的意图并不是他为什么专门抢银行,而是他为什么抢劫。这被称为对比解释(\(\text{contrastive explanation}\)),指的是理解一个特定案例,“为什么是 \(\text{P}\)?”与替代方案的对比,“为什么是 \(\text{P}\) 而不是 \(\text{Q}\)?”在例子中,这个问题可以有多种解释,最好的建模方式可能是提供一个替代方案:“你为什么抢银行 (\(\text{P}\)) 而不是遵守法律 (\(\text{Q}\))?”
替代方案对于理解一个问题的重要性也适用于嵌入模型通过对比学习来学习的方式。通过向模型展示相似和不相似的文档对,它开始学习是什么使事物相似/不相似,更重要的是,为什么。
例如,您可以通过让模型找到“尾巴”、“鼻子”、“四条腿”等特征来教会它理解什么是狗。这个学习过程可能非常困难,因为特征通常定义不明确,可以有多种解释。一个拥有“尾巴”、“鼻子”和“四条腿”的生物也可能是一只猫。为了帮助模型导向我们感兴趣的方向,我们实际上问它:“为什么这是一只狗而不是一只猫?”通过提供两个概念之间的对比,它开始学习定义概念的特征,以及不相关的特征。当我们以对比的方式提出问题时,我们会获得更多信息。我们在图 \(\text{10}-5\) 中进一步说明了对比解释的这个概念。

\(\text{NLP}\) 中最早且最流行的对比学习的例子之一实际上是 \(\text{word2vec}\),正如我们在第 \(\text{1}\) 章和第 \(\text{2}\) 章中讨论的那样。该模型通过在句子中的单个单词上进行训练来学习单词表示。句子中靠近目标单词的词将被构建为正对,而随机采样的词则构成不相似对。换句话说,相邻词的正面示例与随机选择的非相邻词进行对比。虽然不广为人知,但它是 \(\text{NLP}\) 中利用神经网络进行对比学习的最早重大突破之一。
\(\text{SBERT}\)
SBERT
有很多方法可以应用对比学习来创建文本嵌入模型,但最著名的技术和框架之一是 \(\text{sentence-transformers}\)。
尽管对比学习有多种形式,但有一个框架在自然语言处理社区中推广了这项技术,那就是 \(\text{sentence-transformers}\)。它的方法解决了原始 \(\text{BERT}\) 实现在创建句子嵌入方面的一个主要问题,即它的计算开销。在 \(\text{sentence-transformers}\) 之前,句子嵌入通常使用一种称为 \(\text{cross-encoders}\) 的架构结构与 \(\text{BERT}\) 结合。
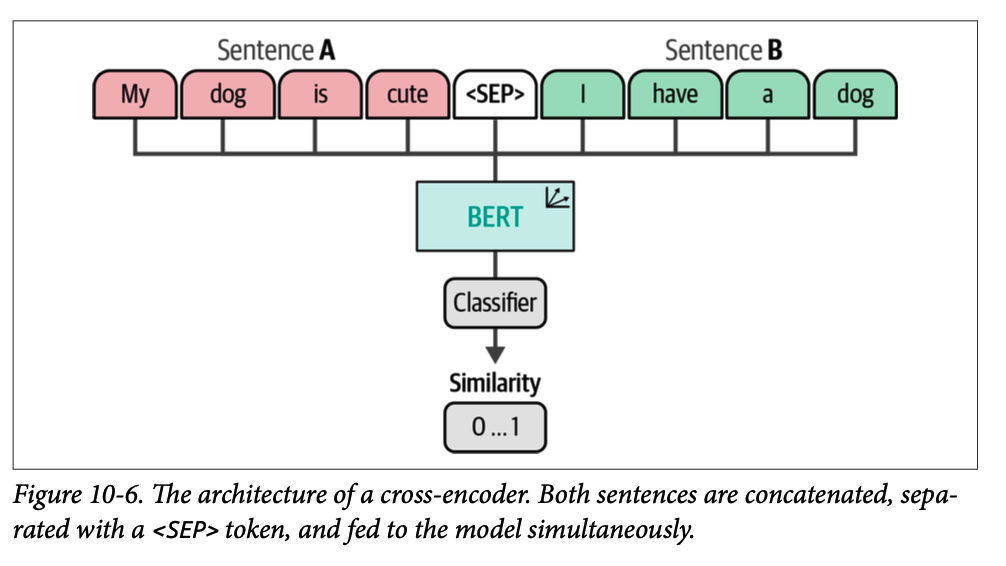
交叉编码器(\(\text{cross-encoder}\))允许同时将两个句子传递给 \(\text{Transformer}\) 网络,以预测这两个句子相似的程度。它通过在原始架构上添加一个分类头来实现,该分类头可以输出一个相似度分数。然而,当您想在包含 \(\text{10,000}\) 个句子的集合中找到相似度最高的句子对时,计算次数会迅速增加。这将需要 \(\text{n}\cdot(\text{n}−\text{1})/\text{2} = \text{49,995,000}\) 次推理计算,因此会产生显著的开销。此外,交叉编码器通常不生成嵌入,如图 \(\text{10}-6\) 所示。相反,它输出输入句子之间的相似度分数。
解决这种开销的一个方法是通过平均 \(\text{BERT}\) 的输出层或使用 \(\text{[CLS]}\) 词元来从 \(\text{BERT}\) 模型生成嵌入。然而,这被证明比简单地平均 \(\text{GloVe}\) 等词向量更差。
相反,\(\text{sentence-transformers}\) 的作者们采取了不同的方法来处理这个问题,并寻找一种快速且能创建可语义比较的嵌入的方法。结果是一种优雅地替代了原始交叉编码器架构的方法。与交叉编码器不同,在 \(\text{sentence-transformers}\) 中,分类头被移除,取而代之的是在最终输出层上使用平均池化(\(\text{mean pooling}\))来生成嵌入。这个池化层对词嵌入进行平均,并返回一个固定维度的输出向量。这确保了固定大小的嵌入。
\(\text{sentence-transformers}\) 的训练使用孪生架构(\(\text{Siamese architecture}\))。在这种架构中,如图 \(\text{10}-7\) 所示,我们有两个相同的 \(\text{BERT}\) 模型,它们共享相同的权重和神经网络架构。这些模型被输入句子,然后通过词元嵌入的池化生成嵌入。接着,模型通过句子嵌入的相似性进行优化。由于两个 \(\text{BERT}\) 模型的权重是相同的,我们可以使用单个模型,并将句子一个接一个地输入给它。
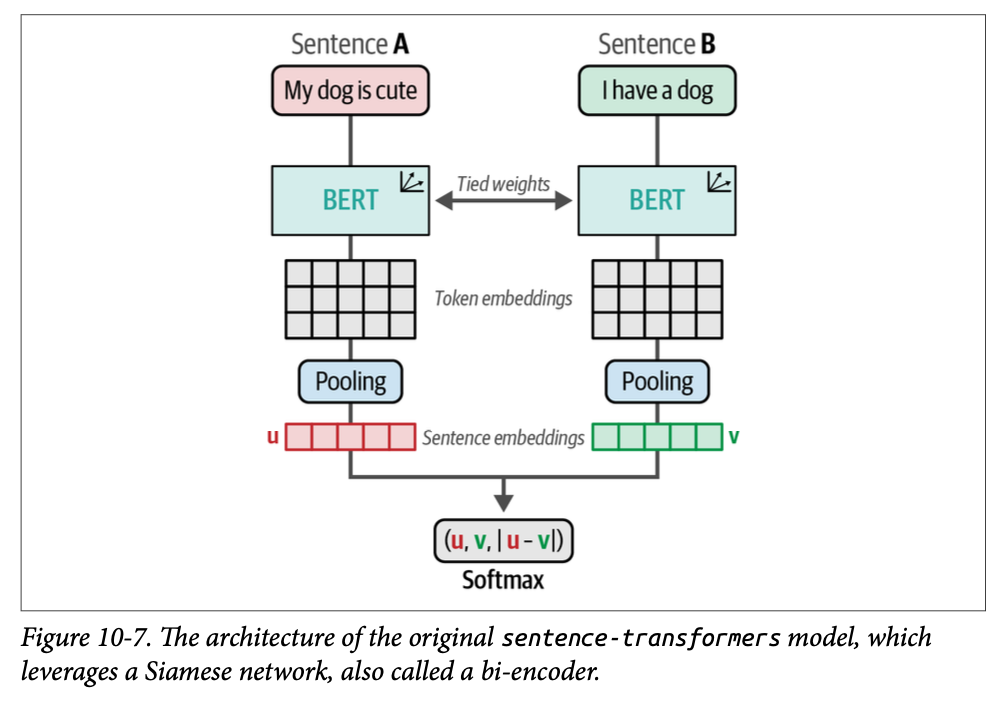
这可能对模型的性能产生重大影响。在训练期间,每个句子的嵌入与嵌入之间的差异被连接在一起。然后,通过一个 \(\text{softmax}\) 分类器对这个结果嵌入进行优化。
由此产生的架构也称为双编码器(\(\text{bi-encoder}\))或 \(\text{SBERT}\)(即 \(\text{sentence-BERT}\))。尽管双编码器非常快速且能创建准确的句子表示,但交叉编码器通常比双编码器实现更好的性能,不过它不生成嵌入。
双编码器像交叉编码器一样,利用了对比学习;通过优化句子对之间的(不)相似性,模型最终将学习到是什么使得这些句子成为它们本身的东西。
创建嵌入模型
Creating an Embedding Model
要执行对比学习,我们需要两样东西。第一,我们需要构成相似/不相似对的数据。第二,我们需要定义模型如何定义和优化相似性。
创建嵌入模型的方法有很多,但我们通常倾向于对比学习。这是许多嵌入模型的一个重要方面,因为这个过程允许它有效地学习语义表示。
然而,这不是一个免费的过程。我们需要理解如何生成对比示例、如何训练模型以及如何正确评估它。
生成对比示例
Generating Contrastive Examples
在预训练嵌入模型时,您经常会看到使用了来自自然语言推理 (\(\text{NLI}\)) 数据集的数据。\(\text{NLI}\) 指的是调查对于一个给定的前提 (\(\text{premise}\)),它是否推断出假设 (\(\text{hypothesis}\))(蕴含 \(\text{entailment}\))、与假设矛盾(矛盾 \(\text{contradiction}\)),或两者皆非(中性 \(\text{neutral}\))的任务。
例如,当前提是“\(\text{He is in the cinema watching Coco}\)”(他正在电影院看《寻梦环游记》)而假设是“\(\text{He is watching Frozen at home}\)”(他正在家里看《冰雪奇缘》)时,这些陈述是矛盾的。相反,当前提是“\(\text{He is in the cinema watching Coco}\)”(他正在电影院看《寻梦环游记》)而假设是“\(\text{In the movie theater he is watching the Disney movie Coco}\)”(在电影院里他正在看迪士尼电影《寻梦环游记》)时,这些陈述被认为是蕴含。这个原理如图 \(\text{10}-8\) 所示。
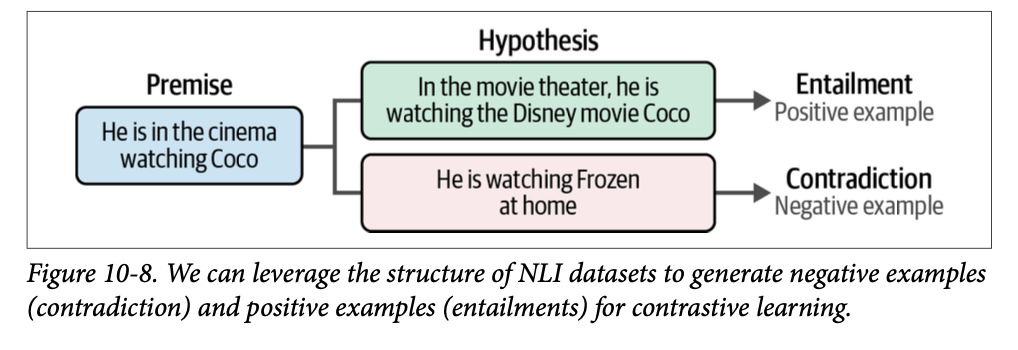
如果您仔细观察蕴含和矛盾,它们描述了两个输入彼此相似的程度。因此,我们可以使用 \(\text{NLI}\) 数据集来为对比学习生成负面示例(矛盾)和正面示例(蕴含)。
我们将要用于创建和微调嵌入模型的数据来源于通用语言理解评估基准 (\(\text{General Language Understanding Evaluation benchmark}, \text{GLUE}\)) 。这个 \(\text{GLUE}\) 基准包括九项语言理解任务来评估和分析模型性能。
其中一项任务是多类型自然语言推理语料库 (\(\text{Multi-Genre Natural Language Inference corpus}, \text{MNLI}\)),它是一个包含 \(\text{392,702}\) 个句子对的集合,并标注了蕴含(矛盾、中性和蕴含)。我们将使用该数据的一个子集(\(\text{50,000}\) 个标注的句子对)来创建一个不需要连续训练数小时的最小示例。但请注意,数据集越小,训练或微调嵌入模型的稳定性就越差。如果可能,假设数据质量仍然很高,则首选更大的数据集:
1 | from datasets import load_dataset |
接下来,我们看一个例子:
1 | dataset[2] |
1 | {'premise': 'One of our number will carry out your instructions minutely.', |
这显示了一个前提和假设之间蕴含的例子,因为它们正相关并且具有几乎相同的含义。
训练模型
Train Model
现在我们有了带有训练示例的数据集,我们需要创建我们的嵌入模型。我们通常会选择一个现有的 \(\text{sentence-transformers}\) 模型并微调该模型,但在本例中,我们将从头开始训练一个嵌入模型。
这意味着我们将不得不定义两件事。第一,一个预训练的 \(\text{Transformer}\) 模型,用作嵌入单个词。我们将使用 \(\text{BERT}\) 基础模型 (\(\text{uncased}\)),因为它是一个很好的入门模型。当然,还有许多其他模型存在,它们也经过了 \(\text{sentence-transformers}\) 的评估。最值得注意的是,当用作词嵌入模型时,\(\text{microsoft/mpnet-base}\) 通常能给出不错的结果。
1 | from sentence_transformers import SentenceTransformer |
默认情况下,\(\text{sentence-transformers}\) 中的 \(\text{LLM}\) 的所有层都是可训练的。虽然可以冻结某些层,但通常不建议这样做,因为在解冻所有层时,性能通常会更好。
接下来,我们需要定义一个我们将优化模型所依据的损失函数。正如本节开头所提到的,\(\text{sentence-transformers}\) 的最早实例之一使用了 \(\text{softmax}\) 损失。出于演示目的,我们现在将使用它,但我们稍后会介绍性能更高的损失函数:
1 | from sentence_transformers import losses |
在训练模型之前,我们定义一个评估器,用于在训练期间评估模型的性能,它也决定了要保存的最佳模型。
我们可以使用语义文本相似度基准 (\(\text{Semantic Textual Similarity Benchmark}, \text{STSB}\)) 来评估我们模型的性能。它是一个人工标注的句子对集合,相似度分数介于 \(\text{1}\) 到 \(\text{5}\) 之间。
我们使用这个数据集来探究我们的模型在这个语义相似度任务上的得分如何。此外,我们处理 \(\text{STSB}\) 数据,以确保所有值都在 \(\text{0}\) 到 \(\text{1}\) 之间:
1 | from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator |
现在我们有了评估器,我们创建 \(\text{SentenceTransformerTrainingArguments}\),这与使用 \(\text{Hugging Face Transformers}\) 进行训练类似(我们将在下一章中探讨):
1 | from sentence_transformers.training_args import SentenceTransformerTrainingArgu |
值得注意的参数包括:
- \(\text{num\_train\_epochs}\) 训练的轮数。为了更快的训练,我们将其保持为 \(\text{1}\),但通常建议增加此值。
- \(\text{per\_device\_train\_batch\_size}\) 在训练期间,在每个设备(例如 \(\text{GPU}\) 或 \(\text{CPU}\))上同时处理的样本数量。值越高通常意味着训练速度越快。
- \(\text{per\_device\_eval\_batch\_size}\) 在评估期间,在每个设备(例如 \(\text{GPU}\) 或 \(\text{CPU}\))上同时处理的样本数量。值越高通常意味着评估速度越快。
- \(\text{warmup\_steps}\) 学习率将从零线性增加到为训练过程定义的初始学习率的步数。请注意,我们没有为这个训练过程指定自定义的学习率。
- \(\text{fp16}\) 通过启用此参数,我们允许混合精度训练,其中计算使用 \(\text{16}\) 位浮点数 (\(\text{FP16}\)) 而不是默认的 \(\text{32}\) 位 (\(\text{FP32}\)) 来执行。这可以减少内存使用并可能提高训练速度。
现在我们已经定义了我们的数据、嵌入模型、损失函数和评估器,我们可以开始训练我们的模型了。我们可以使用 \(\text{SentenceTransformerTrainer}\) 来实现:
1 | from sentence_transformers.trainer import SentenceTransformerTrainer |
训练完模型后,我们可以使用评估器来获取该单一任务上的性能:
1 | # Evaluate our trained model |
1 | {'pearson_cosine': 0.5982288436666162, |
我们得到了几种不同的距离度量。我们最感兴趣的是 \(\text{'pearson\_cosine'}\),它是中心化向量之间的余弦相似度。它的值介于 \(\text{0}\) 和 \(\text{1}\) 之间,值越高表示相似度越高。我们得到了一个 \(\text{0.59}\) 的值,我们将其视为贯穿本章的基准。
较大的批量大小往往与多重负样本排序损失 (\(\text{MNR}\) loss) 一起表现得更好,因为较大的批量使任务更困难。这样做的原因是模型需要从更大的潜在句子对集合中找到最匹配的句子。您可以修改代码以尝试不同的批量大小并感受其影响。
深入评估
In-Depth Evaluation
一个好的嵌入模型不仅仅是在 \(\text{STSB}\) 基准上获得一个好分数!正如我们之前观察到的,\(\text{GLUE}\) 基准有许多任务可用于评估我们的嵌入模型。然而,存在更多允许评估嵌入模型的基准。为了统一这种评估程序,开发了海量文本嵌入基准 (\(\text{Massive Text Embedding Benchmark}, \text{MTEB}\))。\(\text{MTEB}\) 涵盖了 \(\text{8}\) 个嵌入任务,涉及 \(\text{58}\) 个数据集和 \(\text{112}\) 种语言。
为了公开比较最先进的嵌入模型,创建了一个排行榜,其中包含每个嵌入模型在所有任务上的分数:
1 | from mteb import MTEB |
1 | {'Banking77Classification': {'mteb_version': '1.1.2', |
这为我们提供了针对这个特定任务的几种评估指标,我们可以使用它们来探究其性能。
这个评估基准的出色之处不仅在于任务和语言的多样性,还在于甚至评估时间也被保存下来。尽管存在许多嵌入模型,但我们通常希望那些既准确又具有低延迟的模型。用于嵌入模型的任务,例如语义搜索,通常受益于并需要快速推理。
由于在整个 \(\text{MTEB}\) 上测试您的模型可能需要几个小时(取决于您的 \(\text{GPU}\)),因此在本章中,我们将继续使用 \(\text{STSB}\) 基准进行说明。
无论何时您完成模型的训练和评估,重新启动 \(\text{notebook}\) 都是很重要的。这将清除您的 \(\text{VRAM}\),以用于本章中的下一个训练示例。通过重新启动 \(\text{notebook}\),我们可以确保所有 \(\text{VRAM}\) 都被清除。
损失函数
Loss Functions
我们使用 \(\text{softmax}\) 损失来训练我们的模型,以说明最早的 \(\text{sentence-transformers}\) 模型之一是如何被训练的。然而,不仅有多种多样的损失函数可供选择,而且通常不建议使用 \(\text{softmax}\) 损失,因为有性能更高的损失函数。
我们不会去逐一介绍所有可用的损失函数,而是介绍通常使用且表现普遍良好的两种损失函数,即:
- 余弦相似度 (\(\text{Cosine similarity}\))
- 多重负样本排序损失 (\(\text{Multiple negatives ranking (MNR) loss}\))
除了这里讨论的损失函数之外,还有更多可供选择的损失函数。例如,像 \(\text{MarginMSE}\) 这样的损失函数非常适用于训练或微调交叉编码器。在 \(\text{sentence-transformers}\) 框架中实现了一些有趣的损失函数。
余弦相似度
Cosine similarity
余弦相似度损失(\(\text{Cosine similarity loss}\))是一种直观且易于使用的损失函数,适用于许多不同的用例和数据集。它通常用于语义文本相似度 (\(\text{Semantic Textual Similarity, STS}\)) 任务。在这些任务中,相似度分数被分配给文本对,我们依据这个分数来优化模型。
我们不要求句子对是严格的正面或负面关系,而是假设句子对之间存在一定程度的相似或不相似。通常,这个值在 \(\text{0}\) 到 \(\text{1}\) 之间,分别表示不相似和相似(图 \(\text{10}-9\))。
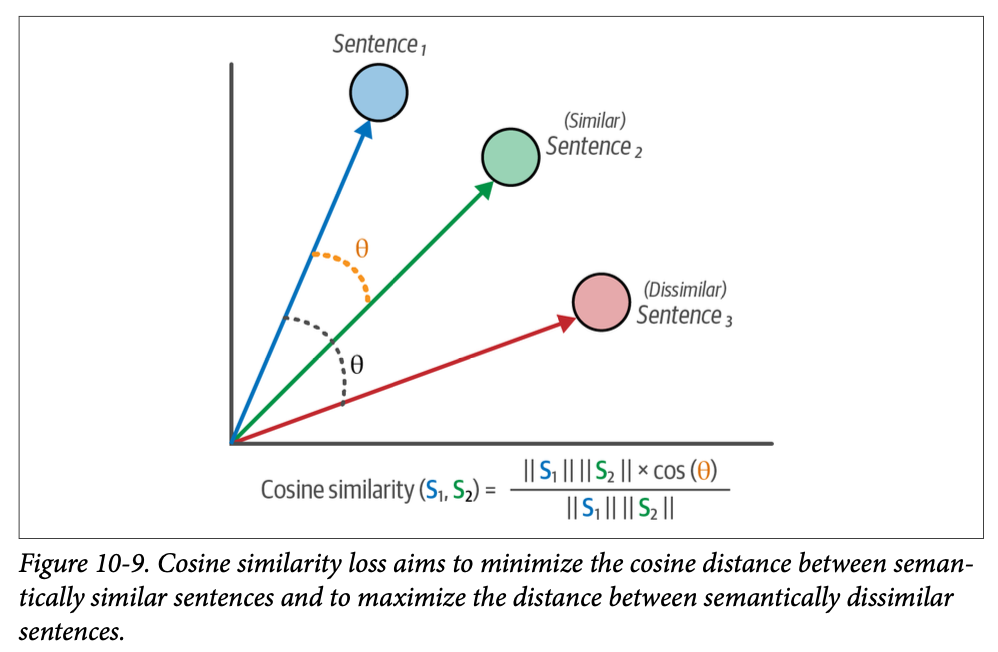
余弦相似度损失非常简单——它计算两个文本嵌入之间的余弦相似度,并将该值与标注的相似度分数进行比较。模型将学习识别句子之间的相似程度。
余弦相似度损失在您拥有句子对和指示其相似度在 \(\text{0}\) 到 \(\text{1}\) 之间的标签的数据上,直观上效果最好。要将这种损失用于我们的 \(\text{NLI}\) 数据集,我们需要将蕴含 (\(\text{0}\))、中性 (\(\text{1}\)) 和矛盾 (\(\text{2}\)) 标签转换为介于 \(\text{0}\) 和 \(\text{1}\) 之间的值。蕴含表示句子之间具有高相似度,因此我们给它一个 \(\text{1}\) 的相似度分数。相比之下,由于中性和矛盾都表示不相似,我们给这些标签一个 \(\text{0}\) 的相似度分数:
1 | from datasets import Dataset, load_dataset |
和以前一样,我们创建评估器:
1 | from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator |
然后,我们遵循与之前相同的步骤,只是选择了不同的损失函数:
1 | from sentence_transformers import losses, SentenceTransformer |
训练后评估模型,我们得到以下分数:
1 | # Evaluate our trained model |
1 | {'pearson_cosine': 0.7222322163831805, |
\(\text{Pearson}\) 余弦分数为 \(\text{0.72}\),与 \(\text{softmax}\) 损失示例(得分为 \(\text{0.59}\))相比,这是一个巨大的改进。这证明了损失函数对性能的影响。
请确保重新启动您的 \(\text{notebook}\),以便我们可以探索一个更常见且性能更高的损失函数,即多重负样本排序损失。
多重负样本排序损失
Multiple negatives ranking loss
多重负样本排序 (\(\text{Multiple Negatives Ranking}, \text{MNR}\)) 损失,通常被称为 \(\text{InfoNCE}\) 或 \(\text{NTXentLoss}\),是一种使用句子正对或包含一对正向句子和一个额外不相关句子的三元组的损失函数。这个不相关的句子被称为负样本(\(\text{negative}\)),代表了正向句子之间的不相似性。
例如,您可能有问答对、图像/图像说明文字对、论文标题/论文摘要对等。这些配对的绝妙之处在于我们可以确信它们是硬正样本对(\(\text{hard positive pairs}\))。在 \(\text{MNR}\) 损失中(图 \(\text{10}-10\)),负样本对是通过将一个正样本对与另一个正样本对混合来构建的。在论文标题和摘要的例子中,您可以通过将一篇论文的标题与一篇完全不同论文的摘要结合来生成一个负样本对。这些负样本被称为批内负样本(\(\text{in-batch negatives}\)),它们也可以用于生成三元组。
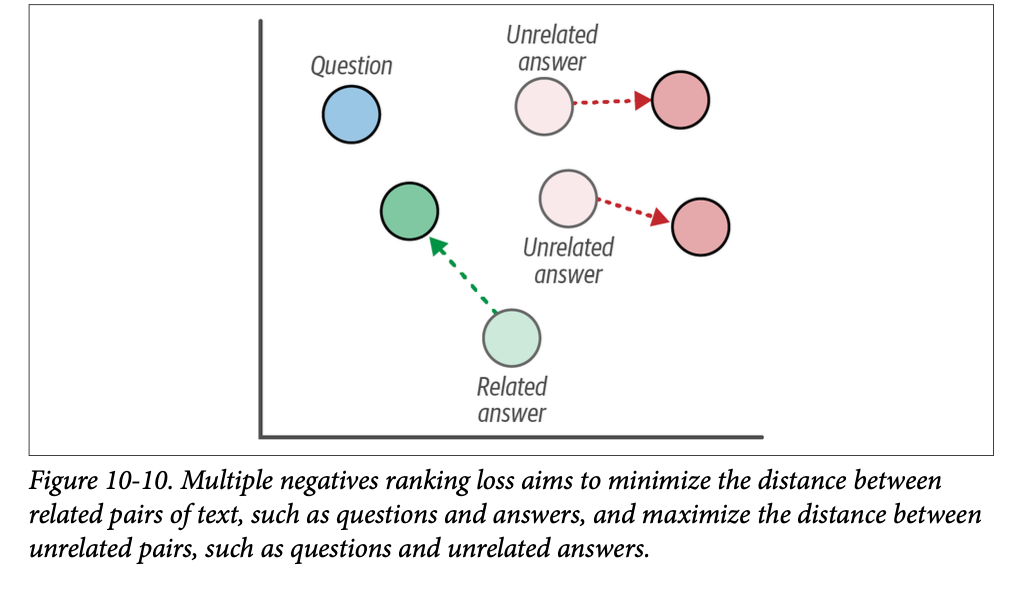
在生成这些正样本对和负样本对之后,我们计算它们的嵌入并应用余弦相似度。然后,这些相似度分数被用来回答一个问题:这些对是负样本还是正样本?换句话说,它被视为一个分类任务,我们可以使用交叉熵损失(\(\text{cross-entropy loss}\))来优化模型。
为了制作这些三元组,我们从一个锚定句(\(\text{anchor sentence}\))(即被标记为“\(\text{premise}\)”)开始,它用于比较其他句子。然后,使用 \(\text{MNLI}\) 数据集,我们只选择那些正向的句子对(即被标记为“\(\text{entailment}\)”)。为了添加负向句子,我们随机采样句子作为“\(\text{hypothesis}\)”。
1 | import random |
由于我们只选择了被标记为“\(\text{entailment}\)”的句子,行数从 \(\text{50,000}\) 行减少到 \(\text{16,875}\) 行。
让我们定义评估器:
1 | from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator |
然后,我们像以前一样进行训练,但改用 \(\text{MNR}\) 损失:
1 | from sentence_transformers import losses, SentenceTransformer |
让我们看看这个数据集和损失函数与我们之前的示例相比如何:
1 | # Evaluate our trained model |
1 | {'pearson_cosine': 0.8093892326162132, |
与我们之前使用 \(\text{softmax}\) 损失训练的模型(\(\text{0.72}\))相比,我们使用 \(\text{MNR}\) 损失训练的模型(\(\text{0.80}\))似乎准确得多!
对于 \(\text{MNR}\) 损失,较大的批量大小往往表现得更好,因为较大的批量使任务更困难。这样做的原因是模型需要从更大的潜在句子对集合中找到最匹配的句子。您可以修改代码以尝试不同的批量大小并感受其影响。
我们使用这种损失函数的方式有一个缺点。由于负样本是从其他问答对中采样的,我们使用的这些批内或“简单”负样本(\(\text{easy negatives}\))可能与问题完全不相关。结果是,嵌入模型找到问题正确答案的任务变得相当容易。
相反,我们希望负样本是与问题高度相关但不是正确答案的。这些负样本被称为困难负样本(\(\text{hard negatives}\))。由于这会使嵌入模型的任务更困难(因为它必须学习更细致入微的表示),因此嵌入模型的性能通常会提高不少。
困难负样本的一个很好的例子如下。假设我们有以下问题:“\(\text{How many people live in Amsterdam?}\)”(阿姆斯特丹有多少人居住?)一个相关的答案会是:“\(\text{Almost a million people live in Amsterdam.}\)”(阿姆斯特丹有近一百万人居住。)为了生成一个好的困难负样本,我们理想情况下希望答案包含一些关于阿姆斯特丹和居住人数的内容。例如:“\(\text{More than a million people live in Utrecht, which is more than Amsterdam.}\)”(超过一百万人居住在乌得勒支,这比阿姆斯特丹要多。)这个答案与问题相关,但不是实际的答案,因此这是一个很好的困难负样本。图 \(\text{10}-11\) 说明了简单负样本和困难负样本之间的区别。
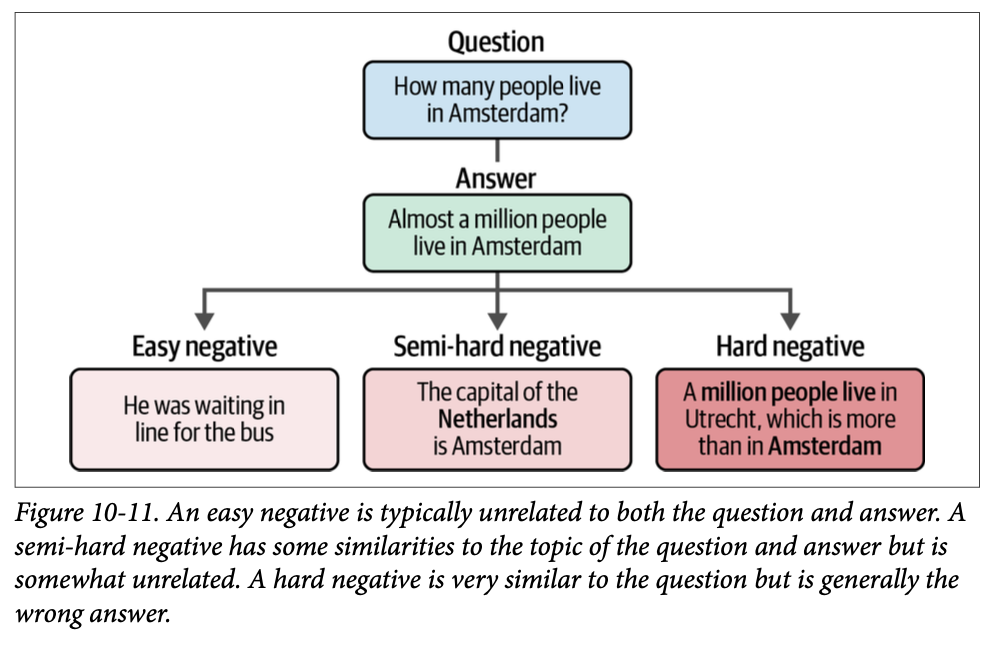
收集负样本大致可以分为以下三个过程:
- 简单负样本 (\(\text{Easy negatives}\)) 通过像我们之前所做的那样随机采样文档。
- 半困难负样本 (\(\text{Semi-hard negatives}\)) 使用预训练的嵌入模型,我们可以对所有句子嵌入应用余弦相似度,以找到高度相关的那些。通常,这不会产生困难负样本,因为此方法仅找到相似的句子,而不是问答对。
- 困难负样本 (\(\text{Hard negatives}\)) 这些通常需要手动标注(例如,通过生成半困难负样本)或者您可以使用生成模型来判断或生成句子对。
请确保重新启动您的 \(\text{notebook}\),以便我们可以探索微调嵌入模型的不同方法。
微调嵌入模型
Fine-Tuning an Embedding Model
在上一节中,我们回顾了从头开始训练嵌入模型的基础知识,并了解了如何利用损失函数来进一步优化其性能。这种方法虽然非常强大,但需要从头创建嵌入模型。这个过程可能成本高昂且耗时。
相反,\(\text{sentence-transformers}\) 框架允许几乎所有嵌入模型用作微调的基底。我们可以选择一个已经在大量数据上训练过的嵌入模型,并针对我们特定的数据或目的对其进行微调。
微调模型有多种方法,具体取决于数据可用性和领域。我们将介绍其中两种方法,并展示利用预训练嵌入模型的强大之处。
有监督
Supervised
微调嵌入模型最直接的方法是重复我们之前训练模型的过程,但将 \(\text{'bert-base-uncased'}\) 替换为预训练的 \(\text{sentence-transformers}\) 模型。有很多模型可供选择,但通常 \(\text{all-MiniLM-L6-v2}\) 在许多用例中表现良好,并且由于其体积小而速度非常快。
我们使用与我们在 \(\text{MNR}\) 损失示例中训练模型时使用的相同数据,但改为使用预训练的嵌入模型进行微调。像往常一样,让我们从加载数据和创建评估器开始:
1 | from datasets import load_dataset |
训练步骤与我们之前的示例相似,但我们没有使用 \(\text{'bert-base-uncased'}\),而是使用了一个预训练的嵌入模型:
1 | from sentence_transformers import losses, SentenceTransformer |
评估这个模型,我们得到以下分数:
1 | # Evaluate our trained model |
尽管 \(\text{0.85}\) 的分数是我们迄今为止看到的最高分,但我们用于微调的预训练模型已经在完整的 \(\text{MNLI}\) 数据集上进行了训练,而我们只使用了 \(\text{50,000}\) 个示例。这看起来可能有些多余,但这个例子演示了如何在你自己的数据上微调一个预训练的嵌入模型。
你可以不使用像 \(\text{'bert-base-uncased'}\) 这样的预训练 \(\text{BERT}\) 模型或像 \(\text{'all-mpnet-base-v2'}\) 这样可能超出领域的模型,而是先对预训练的 \(\text{BERT}\) 模型执行掩码语言建模(\(\text{masked language modeling}\)),使其适应你的领域。然后,你可以使用这个微调过的 \(\text{BERT}\) 模型作为训练你的嵌入模型的基底。这是一种领域适应的形式。在下一章中,我们将对预训练模型应用掩码语言建模。
请注意,训练或微调模型的主要难点在于找到合适的数据。对于这些模型,我们不仅希望拥有非常大的数据集,而且数据本身需要具有高质量。开发正样本对通常是直截了当的,但添加困难负样本对会显著增加创建高质量数据的难度。
像往常一样,重新启动您的 \(\text{notebook}\) 以释放 \(\text{VRAM}\),用于接下来的示例。
增强型 \(\text{SBERT}\)
Augmented SBERT
训练或微调这些嵌入模型的一个缺点是它们通常需要大量的训练数据。其中许多模型是在超过十亿个句子对上训练的。为您的用例提取如此大量的句子对通常是不可能的,因为在许多情况下,只有几千个标注数据点可用。
幸运的是,有一种方法可以增强您的数据,使得在只有少量标注数据可用的情况下,也可以对嵌入模型进行微调。这个过程被称为增强型 \(\text{SBERT}\) (\(\text{Augmented SBERT}\))。
在这个过程中,我们旨在增强少量标注数据,使其可以用于常规训练。它利用较慢但更准确的交叉编码器 (\(\text{cross-encoder}\)) 架构 (\(\text{BERT}\)) 来增强和标注一组更大的输入对。然后,这些新标注的对被用于微调双编码器 (\(\text{bi-encoder}\)) (\(\text{SBERT}\)) 。
如图 \(\text{10}-12\) 所示,增强型 \(\text{SBERT}\) 涉及以下步骤:
- 使用小型、已标注的数据集(黄金数据集 \(\text{gold dataset}\))微调一个交叉编码器 (\(\text{BERT}\))。
- 创建新的句子对。
- 使用微调后的交叉编码器对新的句子对进行标注(白银数据集 \(\text{silver dataset}\))。
- 在扩展后的数据集(黄金 + 白银数据集)上训练一个双编码器 (\(\text{SBERT}\))。
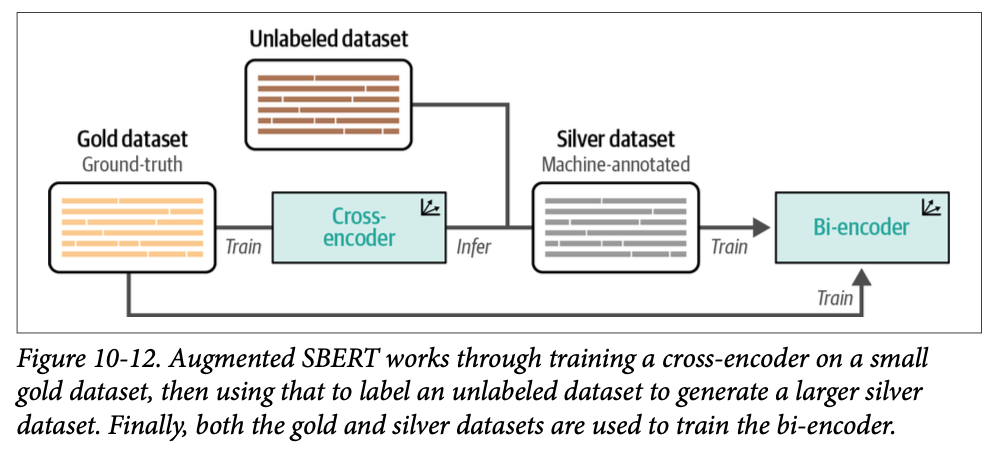
在这里,黄金数据集是一个小型但完全标注的数据集,它包含真实标签(\(\text{ground truth}\))。白银数据集也完全标注,但不一定代表真实标签,因为它是由交叉编码器的预测生成的。
在我们开始执行上述步骤之前,让我们先准备数据。我们不使用最初的 \(\text{50,000}\) 个文档,而是取一个 \(\text{10,000}\) 个文档的子集来模拟我们标注数据有限的场景。正如我们在余弦相似度损失的示例中所做的那样,蕴含获得分数 \(\text{1}\),而中性和矛盾获得分数 \(\text{0}\):
1 | import pandas as pd |
这是黄金数据集,因为它已标注并代表了我们的真实标签。
使用这个黄金数据集,我们训练我们的交叉编码器(步骤 \(\text{1}\)):
1 | from sentence_transformers.cross_encoder import CrossEncoder |
在训练完我们的交叉编码器之后,我们将剩余的 \(\text{400,000}\) 个句子对(来自我们最初的 \(\text{50,000}\) 个句子对数据集)用作我们的白银数据集(步骤 \(\text{2}\)):
1 | # Prepare the silver dataset by predicting labels with the cross-encoder |
如果您没有任何额外的未标注句子对,您可以从原始的黄金数据集中随机采样。举例来说,您可以从一行中取出前提,从另一行中取出假设,从而创建一个新的句子对。这使您可以轻松地生成多达 \(\text{10}\) 倍的句子对,然后可以使用交叉编码器进行标注。
然而,这种策略很可能产生比相似对多得多的不相似对。相反,我们可以使用预训练的嵌入模型来嵌入所有候选句子对,并使用语义搜索为每个输入句子检索 \(\text{top-k}\) 个句子。这种粗略的重排序过程使我们能够专注于可能更相似的句子对。尽管这些句子仍然是基于近似值选择的(因为预训练的嵌入模型未在我们的数据上训练),但这比随机采样要好得多。
请注意,在本例中,我们假设这些句子对是未标注的。我们将使用我们微调过的交叉编码器来标注这些句子对(步骤 \(\text{3}\)):
1 | import numpy as np |
现在我们有了白银数据集和黄金数据集,我们只需将它们结合起来,并像以前一样训练我们的嵌入模型:
1 | # Combine gold + silver |
一如既往,我们需要定义我们的评估器:
1 | from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator |
我们像以前一样训练模型,但现在使用增强后的数据集:
1 | from sentence_transformers import losses, SentenceTransformer |
最后,我们评估模型:
1 | evaluator(embedding_model) |
原始的余弦相似度损失示例在完整数据集上的得分为 \(\text{0.72}\)。而我们仅使用 \(\text{20\%}\) 的数据,就成功地获得了 \(\text{0.71}\) 的分数!
这种方法使我们能够增加您已有数据集的大小,而无需手动标注数十万个句子对。您可以通过仅在黄金数据集上训练您的嵌入模型来测试白银数据的质量。性能上的差异表明您的白银数据集可能为模型质量贡献了多少。
您可以最后一次重新启动您的 \(\text{notebook}\),以进行最后一个示例,即无监督学习。
无监督学习
Unsupervised Learning
为了创建嵌入模型,我们通常需要标注数据。然而,并非所有现实世界的数据集都带有我们可以使用的一套很好的标签。因此,我们寻找无需任何预定标签即可训练模型的技术——即无监督学习。存在许多方法,例如简单对比句嵌入学习 (\(\text{SimCSE}\))、对比张力 (\(\text{CT}\))、基于 \(\text{Transformer}\) 的序列去噪自编码器 (\(\text{TSDAE}\)) 和生成伪标签 (\(\text{GPL}\))。
Simple Contrastive Learning of Sentence Embeddings (SimCSE), Contrastive Tension (CT),Transformer-based Sequential Denoising Auto-Encoder (TSDAE), and Generative Pseudo-Labeling (GPL)
在本节中,我们将重点关注 \(\text{TSDAE}\),因为它在无监督任务和领域适应方面表现出色。
基于 \(\text{Transformer}\) 的序列去噪自编码器
Transformer-Based Sequential Denoising Auto-Encoder
\(\text{TSDAE}\) 是一种非常优雅的、用于通过无监督学习创建嵌入模型的方法。该方法假设我们根本没有标注数据,并且不需要我们人为地创建标签。
\(\text{TSDAE}\) 的基本思想是:我们通过从输入句子中移除一定百分比的词来为其添加噪声。这个“受损的”句子通过一个编码器(顶部带有一个池化层),将其映射到一个句子嵌入。然后,一个解码器尝试从这个句子嵌入中,重构出原始句子,但不包含人为的噪声。这里的主要概念是:句子嵌入越准确,重构的句子就越准确。
这种方法与掩码语言建模(\(\text{masked language modeling}\))非常相似,在掩码语言建模中,我们尝试重构和学习某些被掩码的词。在这里,我们不是重构被掩码的词,而是尝试重构整个句子。
训练完成后,我们可以使用编码器从文本中生成嵌入,因为解码器仅用于判断嵌入是否能准确重构原始句子(图 \(\text{10}-13\))。
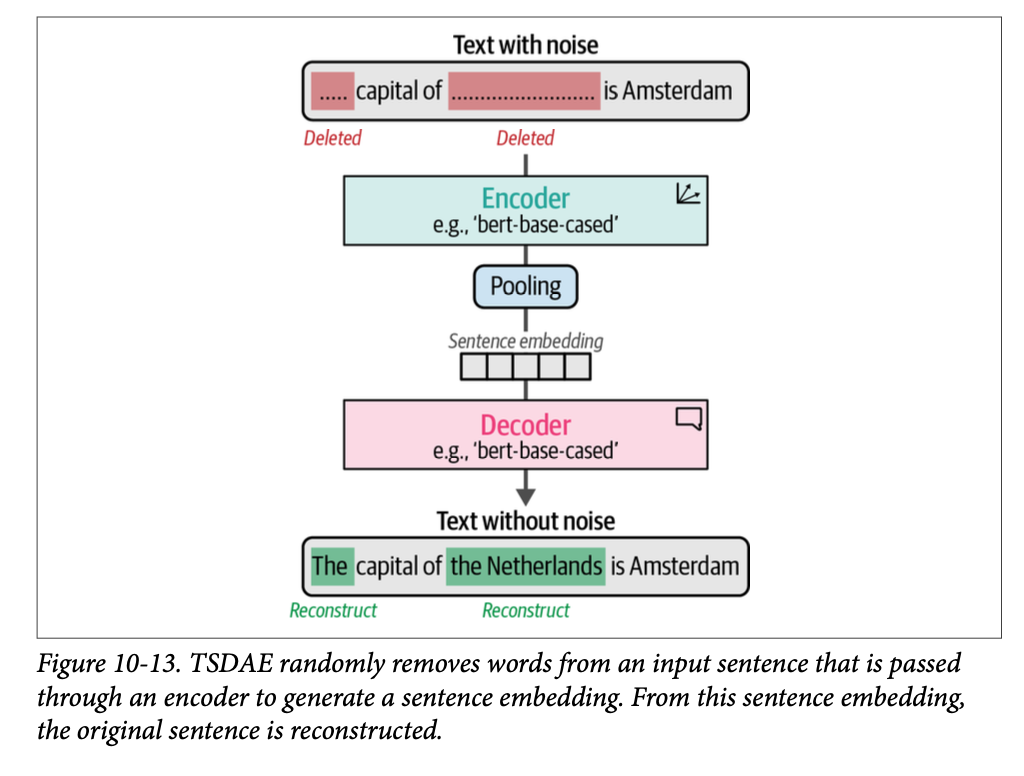
由于我们只需要一堆没有标签的句子,训练这个模型是简单明了的。我们首先下载一个外部 \(\text{tokenizer}\),它用于去噪过程:
1 | # Download additional tokenizer |
然后,我们从我们的数据中创建扁平化的句子,并移除我们拥有的任何标签,以模仿无监督环境:
1 | from tqdm import tqdm |
这创建了一个包含 \(\text{50,000}\) 个句子的数据集。当我们检查数据时,请注意第一个句子是受损的句子,而第二个句子是原始句子:
1 | train_dataset[0] |
第一个句子显示了“带噪声的”数据,而第二个句子显示了原始输入句子。在创建数据后,我们像以前一样定义评估器:
1 | from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator |
接下来,我们像以前一样运行训练,但使用 \(\text{[CLS]}\) 词元作为池化策略,而不是词元嵌入的平均池化(\(\text{mean pooling}\))。在 \(\text{TSDAE}\) 论文中,这被证明更有效,因为平均池化会丢失位置信息,而使用 \(\text{[CLS]}\) 词元则不会:
1 | from sentence_transformers import models, SentenceTransformer |
使用我们的句子对,我们将需要一个尝试使用噪声句子重构原始句子的损失函数,即 \(\text{DenoisingAutoEncoderLoss}\)。通过这样做,它将学习如何准确地表示数据。这类似于掩码,但不知道实际的掩码在哪里。
此外,我们绑定(\(\text{tie}\))了两个模型的参数。编码器的嵌入层和解码器的输出层不是拥有单独的权重,而是共享相同的权重。这意味着一个层中权重的任何更新也将反映在另一个层中:
1 | from sentence_transformers import losses |
最后,训练我们的模型与我们之前多次看到的一样,但我们降低了批量大小,因为内存会随着这种损失函数而增加:
1 | from sentence_transformers.trainer import SentenceTransformerTrainer |
训练完成后,我们评估我们的模型,以探究这种无监督技术的表现如何:
1 | # Evaluate our trained model |
在拟合我们的模型后,我们获得了 \(\text{0.70}\) 的分数,考虑到我们所有这些训练都是用未标注的数据完成的,这相当令人印象深刻。
使用 \(\text{TSDAE}\) 进行领域适应
Using TSDAE for Domain Adaptation
当您拥有很少或没有标注数据时,您通常会使用无监督学习来创建文本嵌入模型。然而,无监督技术通常不如有监督技术,并且难以学习特定领域 (\(\text{domain-specific}\)) 的概念。
这就是领域适应 (\(\text{domain adaptation}\)) 发挥作用的地方。其目标是将现有嵌入模型更新到包含与源领域不同主题的特定文本领域。图 \(\text{10}-14\) 演示了领域在内容上可能存在的差异。目标领域(或域外 \(\text{out-domain}\))通常包含在源领域(或域内 \(\text{in-domain}\))中找不到的词汇和主题。
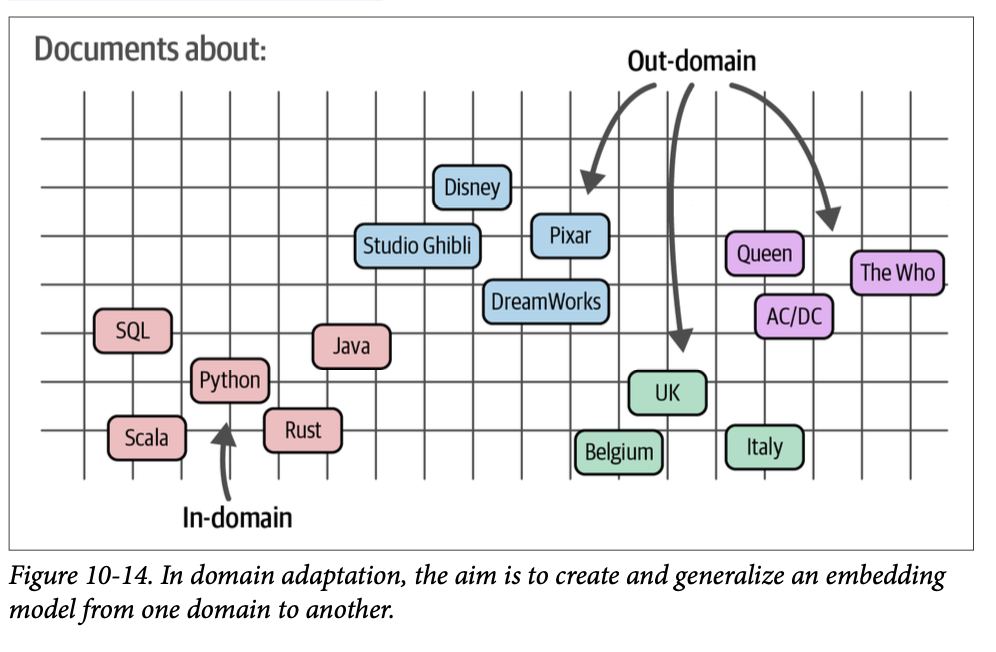
一种用于领域适应的方法称为自适应预训练 (\(\text{adaptive pretraining}\))。您首先使用无监督技术(例如我们前面讨论的 \(\text{TSDAE}\) 或掩码语言建模)对您的特定领域语料库进行预训练。然后,如图 \(\text{10}-15\) 所示,您使用一个可以在目标领域内或领域外的训练数据集来微调该模型。虽然目标领域的数据更受青睐,但域外数据也有效,因为我们已经从目标领域的无监督训练开始了。
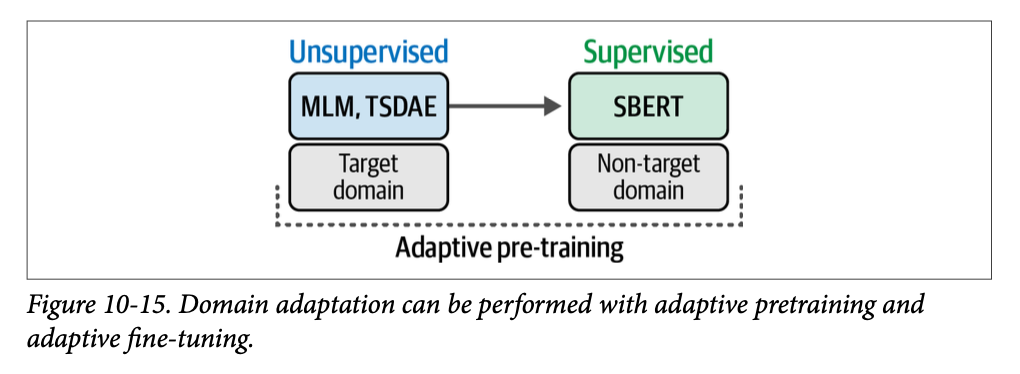
利用您在本章学到的所有知识,您应该能够重现这个流程!首先,您可以使用 \(\text{TSDAE}\) 在您的目标领域上训练一个嵌入模型,然后使用常规的有监督训练或增强型 \(\text{SBERT}\) 对其进行微调。
总结
在本章中,我们研究了通过各种任务创建和微调嵌入模型。我们讨论了嵌入的概念及其在将文本数据以数值格式表示中的作用。然后,我们探讨了许多嵌入模型的基础技术,即对比学习 (\(\text{contrastive learning}\)),它主要从文档的(不)相似对中学习。
接着,我们使用流行的嵌入框架 \(\text{sentence-transformers}\),通过预训练的 \(\text{BERT}\) 模型创建了嵌入模型,同时探讨了不同的损失函数,例如余弦相似度损失和 \(\text{MNR}\) 损失。我们讨论了收集文档的(不)相似对或三元组对于所得模型性能的重要性。
在接下来的部分中,我们探讨了微调嵌入模型的技术。我们讨论了有监督和无监督技术,例如用于领域适应的增强型 \(\text{SBERT}\) 和 \(\text{TSDAE}\)。与从头创建嵌入模型相比,微调通常需要较少的数据,并且是使现有嵌入模型适应您的领域的绝佳方法。
在下一章中,我们将讨论用于分类的表示微调方法。届时,\(\text{BERT}\) 模型和嵌入模型都将出现,以及广泛的微调技术。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调