《Hands-On Large Language Models》第3章 深入了解大型语言模型
第 \(\text{3}\) 章 深入了解大型语言模型
Looking Inside Large Language Models
既然我们已经对分词和嵌入有所了解,我们就可以更深入地研究语言模型,看看它是如何工作的。在本章中,我们将探讨 \(\text{Transformer}\) 语言模型工作方式的一些主要直觉。我们将特别关注文本生成模型,以便我们对生成式 \(\text{LLM}\) 有更深入的理解。
我们将同时关注概念和一些演示这些概念的代码示例。让我们从加载一个语言模型并通过声明一个管线(\(\text{pipeline}\))来为生成做好准备。在您第一次阅读时,请随意跳过代码,专注于掌握所涉及的概念。然后在第二次阅读时,代码将引导您开始应用这些概念。
1 | import torch |
\(\text{Transformer}\) 模型概述
An Overview of Transformer Models
让我们从对模型的高层概述开始我们的探索,然后我们将看看自 \(\text{2017}\) 年推出以来,后来的工作是如何改进 \(\text{Transformer}\) 模型的。
一个经过训练的 \(\text{Transformer LLM}\) 的输入和输出
The Inputs and Outputs of a Trained Transformer LLM
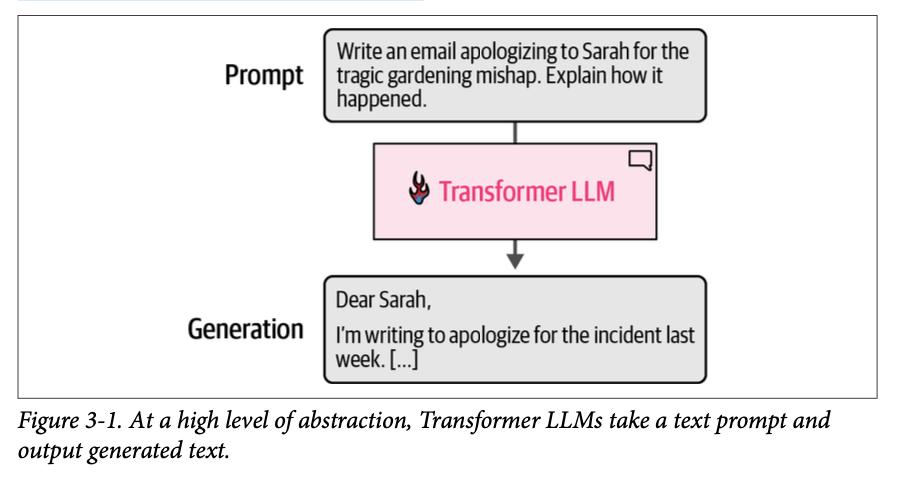
理解 \(\text{Transformer LLM}\) 行为的最常见视角是将其视为一个软件系统,它接收文本并生成文本作为回应。一旦在一个足够大的高质量数据集上训练了一个足够大的文本输入-文本输出模型,它就能生成令人印象深刻且有用的输出。图 \(\text{3}-1\) 展示了这样一个用于撰写电子邮件的模型。
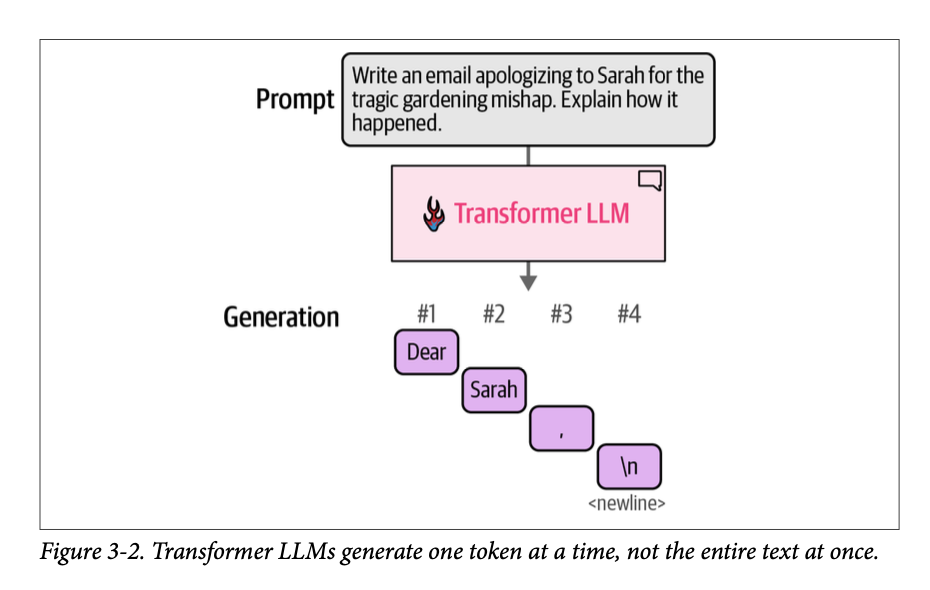
模型并非一次性生成所有文本;它实际上是一次生成一个词元。图 \(\text{3}-2\) 展示了响应输入提示的四个词元生成步骤。每个词元生成步骤都是模型的一次正向传播(\(\text{forward pass}\))(这是机器学习的说法,指输入进入神经网络并流经所需的计算,以在计算图的另一端产生一个输出)。
在每次词元生成之后,我们通过将输出词元附加到输入提示的末尾来调整下一次生成步骤的输入提示。我们可以在图 \(\text{3}-3\) 中看到这一点。
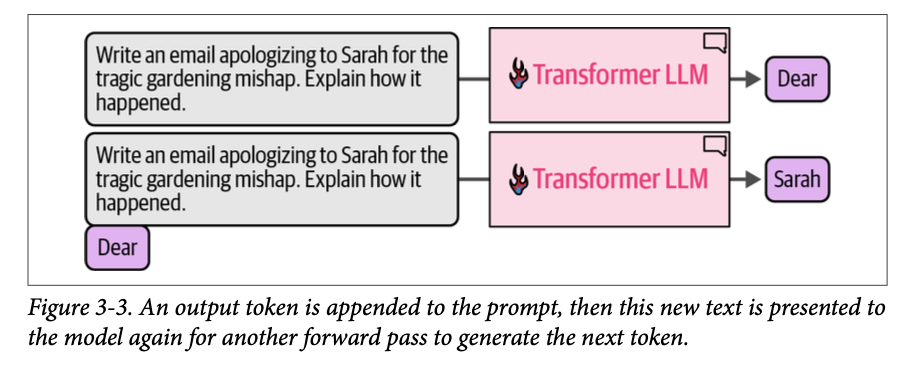
这给了我们一个更准确的模型图景,因为它只是根据输入提示来预测下一个词元。神经网络周围的软件基本上是在一个循环中运行它,以顺序地扩展生成的文本直到完成。
在机器学习中,有一个特定的词语来描述消耗其早期预测以做出后期预测的模型(例如,模型的第一个生成的词元用于生成第二个词元)。它们被称为自回归模型(\(\text{autoregressive models}\))。这就是为什么你会听到文本生成 \(\text{LLM}\) 被称为自回归模型。这通常用于区分文本生成模型和非自回归的文本表征模型,例如 \(\text{BERT}\)。
这种自回归的、逐词元生成就是当我们使用 \(\text{LLM}\) 生成文本时在底层发生的事情,就像我们在这里看到的那样:
1 | prompt = "Write an email apologizing to Sarah for the tragic gardening mishap. |
这生成了文本:
1 | Solution 1: |
我们可以看到模型开始撰写电子邮件,从主题开始。它突然停止了,因为它达到了我们通过设置 \(\text{max\_new\_tokens}\) 为 \(\text{50}\) 个词元所确定的词元限制。如果我们增加这个限制,它将继续直到完成电子邮件。
正向传播的组成部分
The Components of the Forward Pass
除了循环之外,两个关键的内部组件是分词器(\(\text{tokenizer}\))和语言模型头(\(\text{LM head}\))。图 \(\text{3}-4\) 展示了这些组件在系统中的位置。我们在上一章中看到,分词器如何将文本分解为词元 \(\text{ID}\) 序列,然后这些序列成为模型的输入。
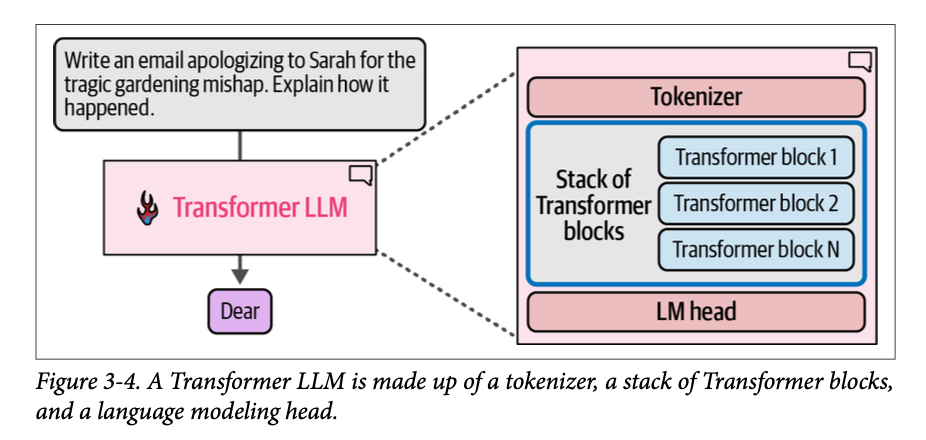
分词器之后是神经网络:一个\(\text{Transformer}\) 块的堆栈,它负责所有的处理工作。该堆栈之后是 \(\text{LM}\) 头,它将堆栈的输出转换为下一个最有可能的词元的概率分数。
回想一下第 \(\text{2}\) 章,分词器包含一个词元表——分词器的词汇表。模型为词汇表中的每个词元关联了一个向量表征(词元嵌入)。图 \(\text{3}-5\) 展示了一个词汇量为 \(\text{5}\) 万词元的模型的词汇表和相关的词元嵌入。
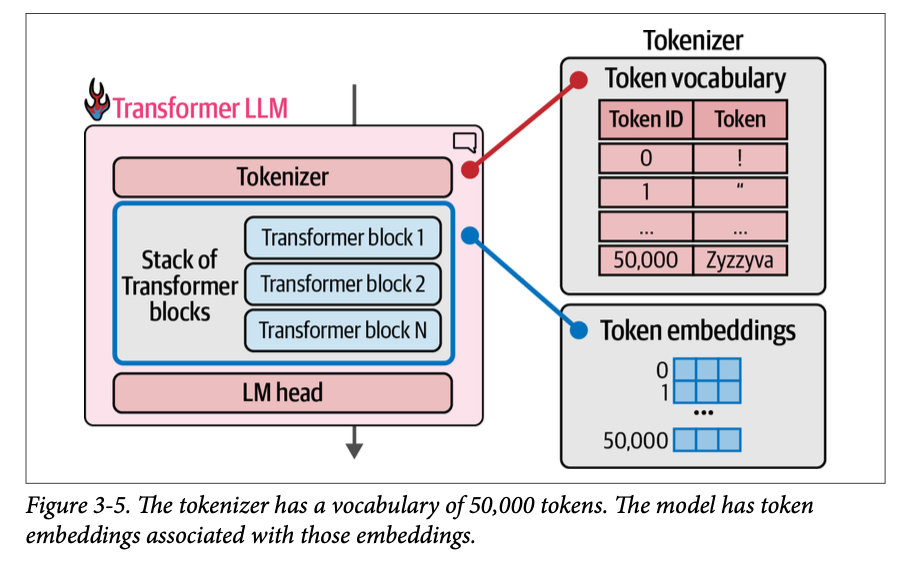
计算流程遵循从上到下的箭头方向。对于每个生成的词元,流程会依次流经堆栈中的每个 \(\text{Transformer}\) 块一次,然后到达 \(\text{LM}\) 头,\(\text{LM}\) 头最终输出下一个词元的概率分布,如图 \(\text{3}-6\) 所示。
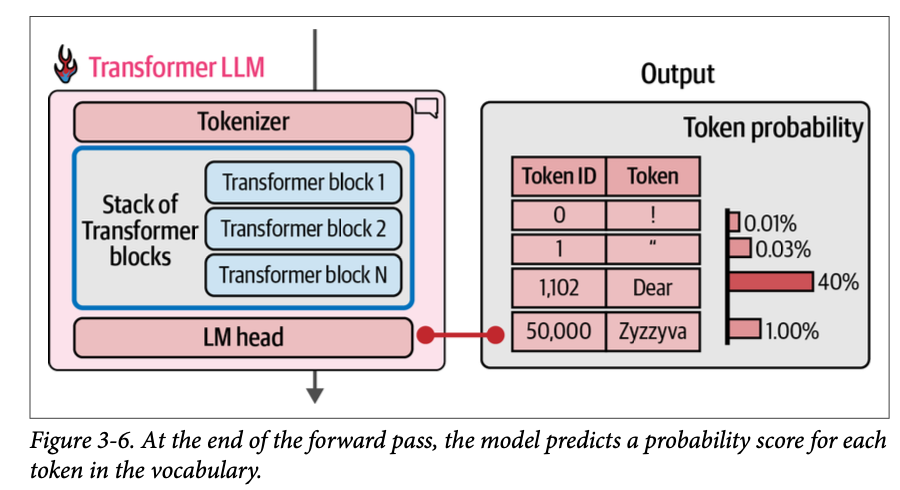
\(\text{LM}\) 头本身是一个简单的神经网络层。它是可以附加到 \(\text{Transformer}\) 块堆栈上以构建不同类型系统的多种可能“头” 之一。其他类型的 \(\text{Transformer}\) 头包括序列分类头和词元分类头。
我们可以通过简单地打印出 \(\text{model}\) 变量来显示层级的顺序。对于这个模型,我们有:
1 | Phi3ForCausalLM( |
查看这个结构,我们可以注意到以下重点:
- 这向我们展示了模型的各种嵌套层。模型的主体标记为 \(\text{model}\),紧随其后的是 \(\text{lm\_head}\)。
- 在 \(\text{Phi3Model}\) 内部,我们看到了嵌入矩阵 \(\text{embed\_tokens}\) 及其维度。它有 \(\text{32,064}\) 个词元,每个词元的向量大小为 \(\text{3,072}\)。
- 暂时跳过 \(\text{dropout}\) 层,我们可以看到下一个主要组件是 \(\text{Transformer}\) 解码器层的堆栈。它包含 \(\text{32}\) 个 \(\text{Phi3DecoderLayer}\) 类型的块。
- 这些 \(\text{Transformer}\) 块中的每一个都包含一个注意力层(\(\text{attention layer}\))和一个前馈神经网络(\(\text{feedforward neural network}\),也称为 \(\text{mlp}\) 或多层感知器)。我们将在本章后面更详细地介绍这些内容。
- 最后,我们看到 \(\text{lm\_head}\) 接收一个大小为 \(\text{3,072}\) 的向量,并输出一个等同于模型所知词元数量的向量。该输出是每个词元的概率分数,它帮助我们选择输出词元。
从概率分布中选择单个词元(采样/解码)
Choosing a Single Token from the Probability Distribution (Sampling/Decoding)
正如我们前面在图 \(\text{3}-6\) 中看到的,在处理结束时,模型的输出是词汇表中每个词元的概率分数。从概率分布中选择单个词元的方法称为解码策略(\(\text{decoding strategy}\))。图 \(\text{3}-7\) 展示了在一个示例中,这如何导致选择了词元“\(\text{Dear}\)”。
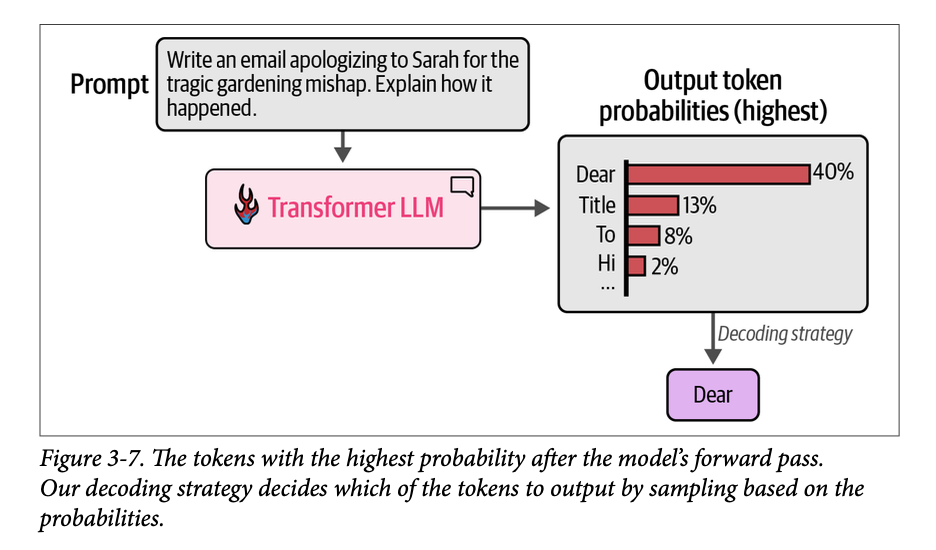
最简单的解码策略是总是选择具有最高概率分数的词元。在实践中,这在大多数用例中往往不会产生最佳输出。一种更好的方法是添加一些随机性,有时选择第二高或第三高概率的词元。统计学家会说,这里的想法是根据概率分数从概率分布中进行采样。
对于图 \(\text{3}-7\) 中的示例,这意味着如果词元“\(\text{Dear}\)”有 \(\text{40\%}\) 的概率成为下一个词元,那么它就有 \(\text{40\%}\) 的机会被选中(而不是贪婪搜索,后者会因为它是最高分数而直接选择它)。因此,通过这种方法,所有其他词元都有根据其分数被选中的机会。
每次都选择得分最高的词元被称为贪婪解码(\(\text{greedy decoding}\))。这是当您将 \(\text{LLM}\) 中的温度 (\(\text{temperature}\)) 参数设置为零时所发生的情况。我们将在第 \(\text{6}\) 章中介绍温度的概念。
让我们更仔细地看看演示这个过程的代码。在这个代码块中,我们将输入词元通过模型,然后通过 \(\text{lm\_head}\):
1 | prompt = "The capital of France is" |
现在,\(\text{lm\_head\_output}\) 的形状是 \([\text{1}, \text{6}, \text{32064}]\)。我们可以使用 \(\text{lm\_head\_output[0,-1]}\) 来访问最后一个生成的词元的词元概率分数,其中索引 \(\text{0}\) 遍历批次维度;索引 \(-\text{1}\) 得到序列中的最后一个词元。这现在是所有 \(\text{32,064}\) 个词元的概率分数列表。我们可以得到得分最高的词元 \(\text{ID}\),然后对其进行解码,从而得出生成的输出词元的文本:
1 | <CODE> |
在这种情况下,结果是:
1 | Paris |
并行词元处理和上下文大小
Parallel Token Processing and Context Size
\(\text{Transformer}\) 最引人注目的特性之一是,它们比以前的语言处理神经网络架构更适合并行计算。在文本生成中,当我们观察每个词元如何被处理时,我们对此有了初步的了解。我们从上一章知道,分词器会将文本分解为词元。然后,这些每个输入词元都流经自己的计算路径(至少这是一个很好的初步直觉)。我们可以在图 \(\text{3}-8\) 中看到这些独立的处理轨迹或流。
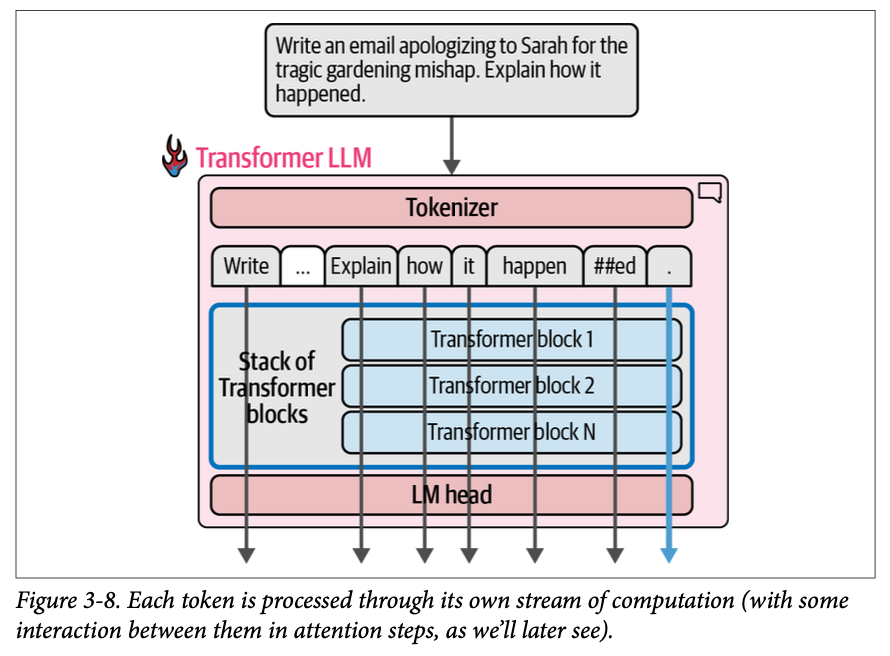
当前的 \(\text{Transformer}\) 模型对于它们可以一次性处理多少个词元有一个限制。这个限制被称为模型的上下文长度(\(\text{context length}\))。一个具有 \(\text{4K}\) 上下文长度的模型只能处理 \(\text{4K}\) 个词元,并且将只有 \(\text{4K}\) 个这样的流(\(\text{streams}\))。
每个词元流都以一个输入向量开始(嵌入向量和一些位置信息;我们将在本章后面讨论位置嵌入)。如图 \(\text{3}-9\) 所示,在流的末端,会产生另一个向量,作为模型处理的结果。
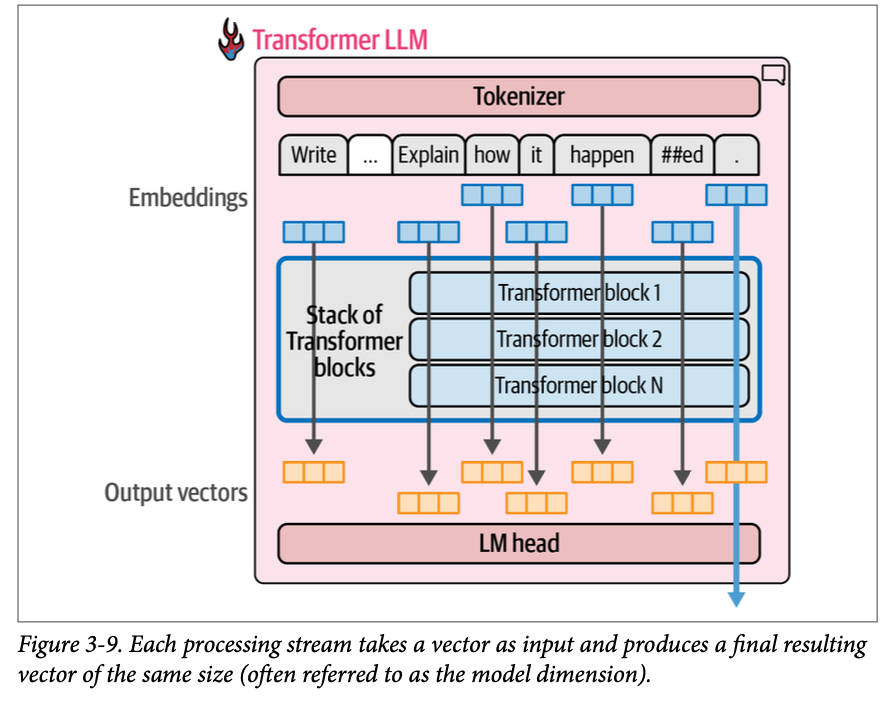
对于文本生成,只有最后一个流的输出结果用于预测下一个词元。该输出向量是 \(\text{LM}\) 头计算下一个词元概率时的唯一输入。
您可能想知道,如果我们丢弃除最后一个词元之外的所有流的输出,为什么还要费力地计算所有词元流。答案是之前流的计算在计算最终流时是必需且被使用的。是的,我们没有使用它们的最终输出向量,但在 \(\text{Transformer}\) 块的注意力机制中,我们使用了较早的输出(在每个 \(\text{Transformer}\) 块中)。
如果您正在跟进代码示例,请回想一下 \(\text{lm\_head}\) 的输出形状是 \([\text{1}, \text{6}, \text{32064}]\)。这是因为它的输入形状是 \([\text{1}, \text{6}, \text{3072}]\),这是一个包含六个词元的输入字符串的批次,其中每个词元都由一个大小为 \(\text{3,072}\) 的向量表征,该向量对应于 \(\text{Transformer}\) 块堆栈之后的输出向量。
我们可以通过打印来访问这些矩阵并查看它们的维度:
1 | model_output[0].shape |
输出:
1 | torch.Size([1, 6, 3072]) |
同样,我们可以打印 \(\text{LM}\) 头的输出:
1 | lm_head_output.shape |
输出:
1 | torch.Size([1, 6, 32064]) |
通过缓存键和值加速生成
Speeding Up Generation by Caching Keys and Values
回想一下,在生成第二个词元时,我们只需将输出词元附加到输入,然后进行另一次正向传播通过模型。如果我们让模型能够缓存先前计算的结果(特别是注意力机制中的一些特定向量),我们就不再需要重复先前流的计算。这次唯一需要的计算是最后一个流的计算。这是一项称为键和值 (\(\text{kv}\)) 缓存的优化技术,它能显著加快生成过程。键和值是注意力机制的一些核心组成部分,我们将在本章后面看到。
图 \(\text{3}-10\) 展示了在生成第二个词元时,由于我们缓存了先前流的结果,只有一个处理流处于活动状态。
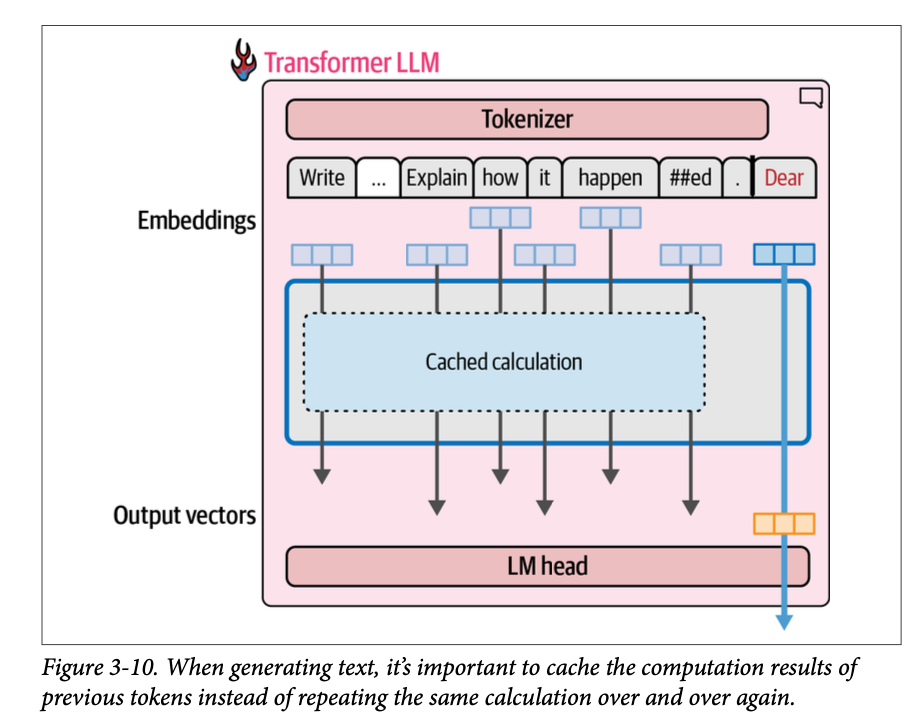
在 \(\text{Hugging Face Transformers}\) 中,缓存默认是启用的。我们可以通过设置 \(\text{use\_cache}\) 为 \(\text{False}\) 来禁用它。我们可以通过要求进行长时间生成,并对启用和禁用缓存的生成进行计时来查看速度上的差异:
1 | prompt = "Write a very long email apologizing to Sarah for the tragic gardening |
然后,我们对启用缓存生成 \(\text{100}\) 个词元所需的时间进行计时。我们可以使用 \(\text{Jupyter}\) 或 \(\text{Colab}\) 中的 %%timeit 魔术命令来计时执行所需的时间(它会运行命令多次并取平均值):
1 | %%timeit -n 1 |
在具有 \(\text{T}4\) \(\text{GPU}\) 的 \(\text{Colab}\) 上,这大约需要 \(\text{4.5}\) 秒。但是,如果我们禁用缓存,这需要多长时间呢?
1 | %%timeit -n 1 |
这大约需要 \(\text{21.8}\) 秒。这是一个巨大的差异。事实上,从用户体验的角度来看,即使是四秒的生成时间,对于一个盯着屏幕等待模型输出的用户来说,也往往是一段漫长的等待时间。这就是为什么 \(\text{LLM}\) \(\text{API}\) 会在模型生成输出词元时实时流式传输它们,而不是等待整个生成完成的原因之一。
\(\text{Transformer}\) 块的内部
Inside the Transformer Block
我们现在可以讨论发生绝大部分处理的地方:\(\text{Transformer}\) 块。如图 \(\text{3}-11\) 所示,\(\text{Transformer LLM}\) 由一系列 \(\text{Transformer}\) 块组成(数量通常在最初 \(\text{Transformer}\) 论文中的六个,到许多大型 \(\text{LLM}\) 中的一百多个不等)。每个块处理其输入,然后将处理结果传递给下一个块。
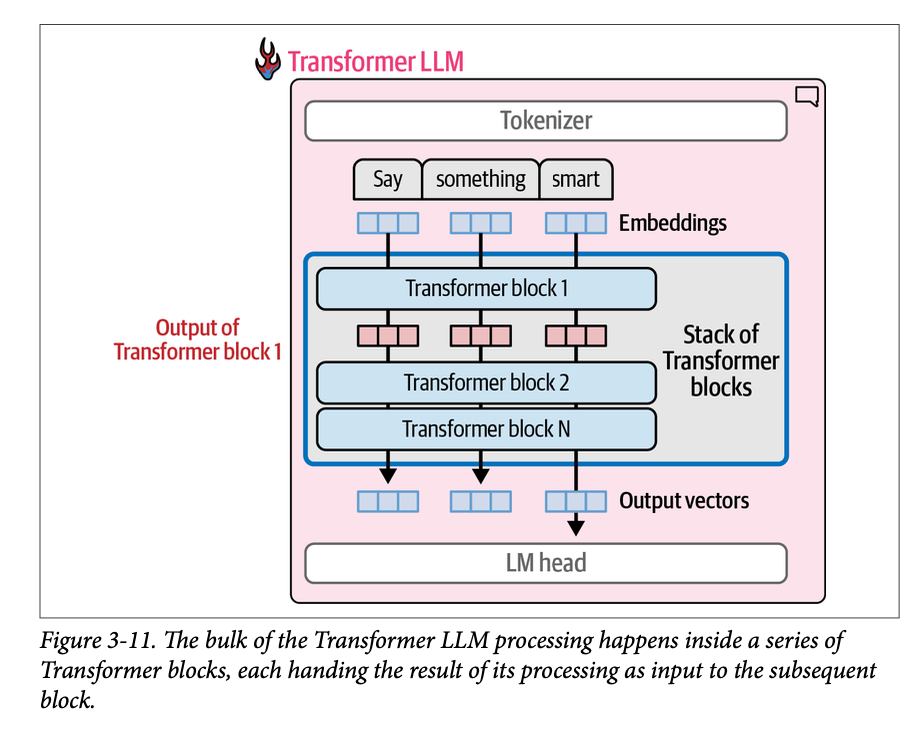
一个 \(\text{Transformer}\) 块(图 \(\text{3}-12\))由两个连续的组件构成:
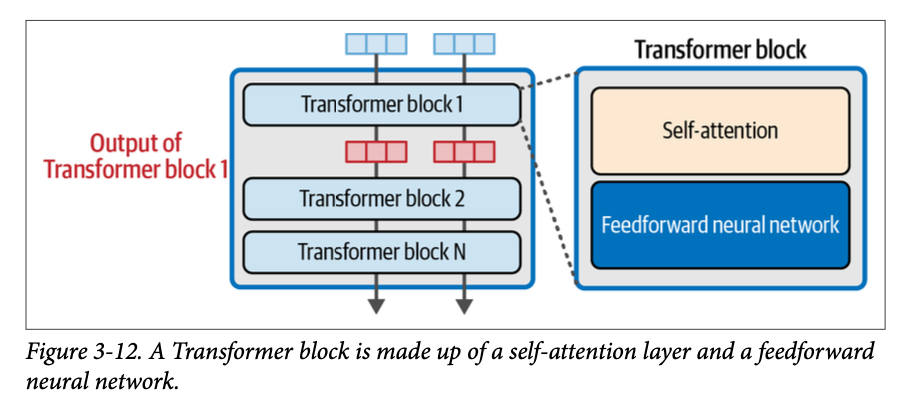
- 注意力层(\(\text{attention layer}\))主要关注整合来自其他输入词元和位置的相关信息。
- 前馈层(\(\text{feedforward layer}\))承载了模型的大部分处理能力。
前馈神经网络概览
The feedforward neural network at a glance
一个给出前馈神经网络直觉的简单例子是,如果我们向一个语言模型输入简单的“\(\text{The Shawshank}\)”,期望它能生成“\(\text{Redemption}\)”作为最可能的下一个词(指的是 \(\text{1994}\) 年的电影)。
前馈神经网络(集体地位于所有模型层中)是这些信息的来源,如图 \(\text{3}-13\) 所示。当模型被成功训练来建模一个庞大的文本档案(其中包含许多对“\(\text{The Shawshank Redemption}\)”的提及)时,它就学习并存储了使它能成功完成这项任务的信息(和行为)。
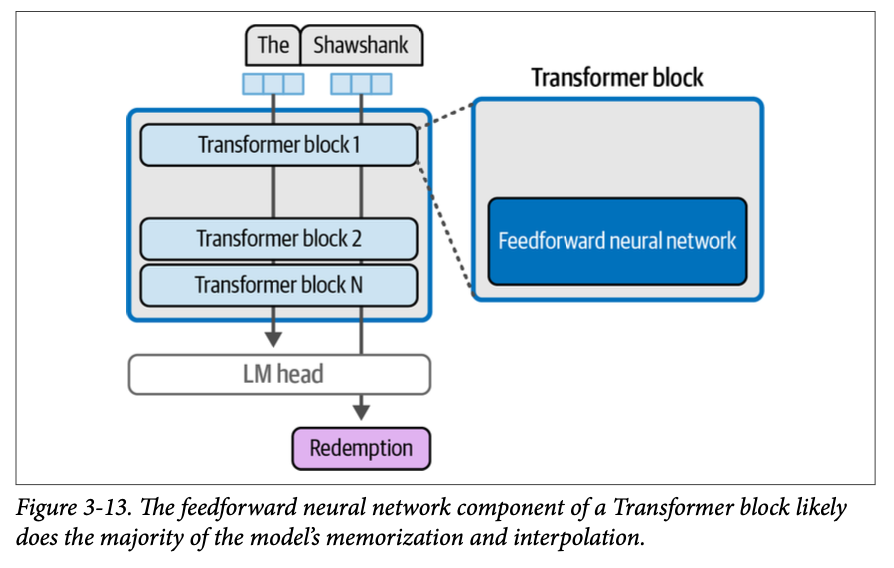
要成功训练一个 \(\text{LLM}\),它需要记忆大量信息。但它不仅仅是一个大型数据库。记忆只是令人印象深刻的文本生成秘诀中的一个要素。模型能够使用相同的机制在数据点和更复杂的模式之间进行插值(\(\text{interpolate}\)),从而能够泛化(\(\text{generalize}\))——这意味着对它以前没有见过且不在其训练数据集中的输入也能表现良好。
当您使用现代商业 \(\text{LLM}\) 时,您获得的输出并非前面提到的严格意义上的“语言模型”输出。将“\(\text{The Shawshank}\)”传递给像 \(\text{GPT}-4\) 这样的聊天 \(\text{LLM}\) 会产生如下输出:
"The Shawshank Redemption" is a 1994 film directed by Frank Darabont and is based on the novella "Rita Hayworth and Shawshank Redemption" written by Stephen King. ...etc.
这是因为原始语言模型(如 \(\text{GPT}-3\))对人们来说难以正确利用。这就是为什么语言模型随后会经过指令微调(\(\text{instruction}-\text{tuning}\))和人类偏好与反馈微调(\(\text{human preference and feedback fine}-\text{tuning}\))的训练,以匹配人们对模型应该输出什么的期望。
注意力层概览
The attention layer at a glance
上下文对于正确建模语言至关重要。仅凭简单的记忆和基于前一个词元的插值只能带我们走这么远。我们知道这一点,因为这曾是神经网络出现之前构建语言模型的主要方法之一(参见 \(\text{Daniel Jurafsky}\) 和 \(\text{James H. Martin}\) 的《语音与语言处理》第 \(\text{3}\) 章“N-gram 语言模型”)。
注意力(\(\text{Attention}\))是一种机制,它帮助模型在处理特定词元时整合上下文。思考以下提示:
“\(\text{The dog chased the squirrel because it}\)”(狗追松鼠因为它)
对于模型来说,要预测“\(\text{it}\)”之后的内容,它需要知道“\(\text{it}\)”指的是狗还是松鼠?
在一个经过训练的 \(\text{Transformer LLM}\) 中,注意力机制负责做出这种判断。注意力将来自上下文的信息添加到“\(\text{it}\)”词元的表征中。我们可以在图 \(\text{3}-14\) 中看到一个简单的版本。
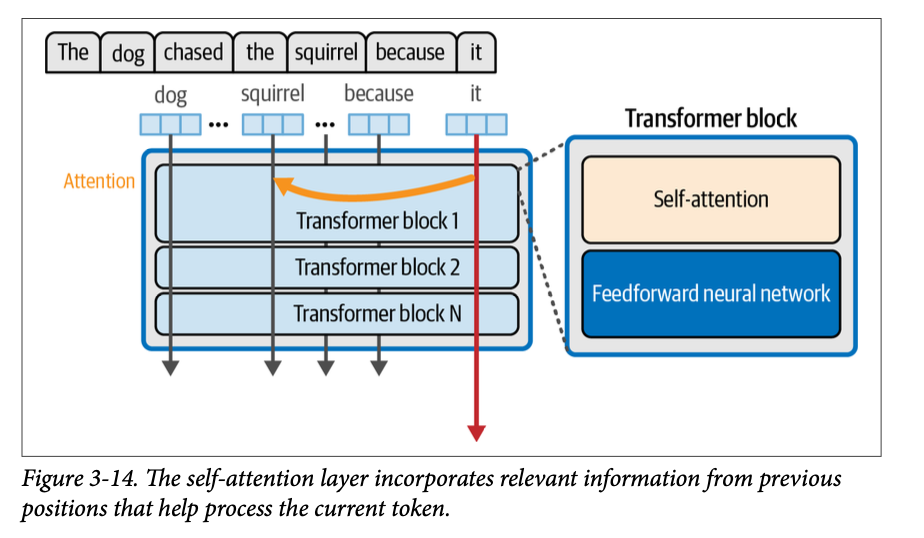
模型是根据从训练数据集中看到和学到的模式来做到这一点的。也许前面的句子也提供了更多线索,例如,将狗称为“\(\text{she}\)”,从而明确“\(\text{it}\)”指的是松鼠。
注意力就是你所需要的一切
Attention is all you need
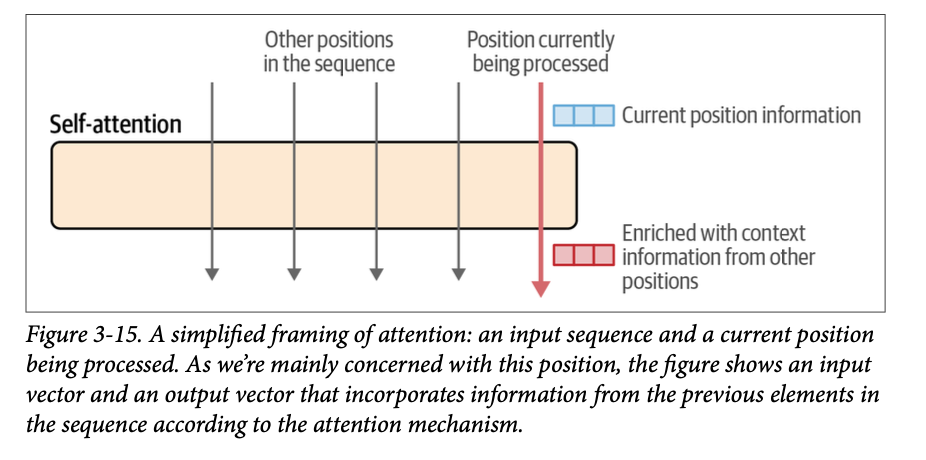
有必要更深入地探讨注意力机制。该机制最精简的版本如图 \(\text{3}-15\) 所示。它显示了多个词元位置进入注意力层;最后一个是当前正在处理的位置(粉色箭头)。注意力机制作用于该位置的输入向量。它将上下文中的相关信息整合到它为该位置产生的输出向量中。
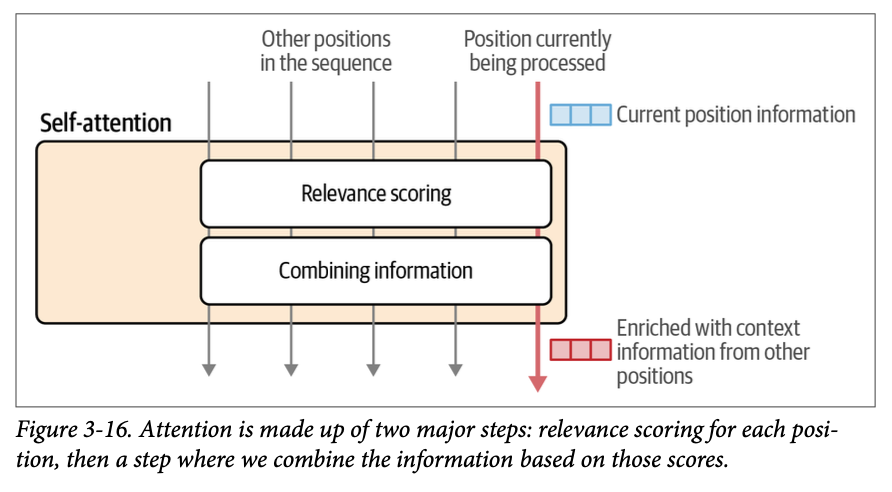
注意力机制涉及两个主要步骤:
- 一种对每个先前输入词元与当前正在处理的词元(在粉色箭头中)的相关程度进行评分的方法。
- 使用这些分数,我们将来自不同位置的信息组合成一个单一的输出向量。
图 \(\text{3}-16\) 展示了这两个步骤。
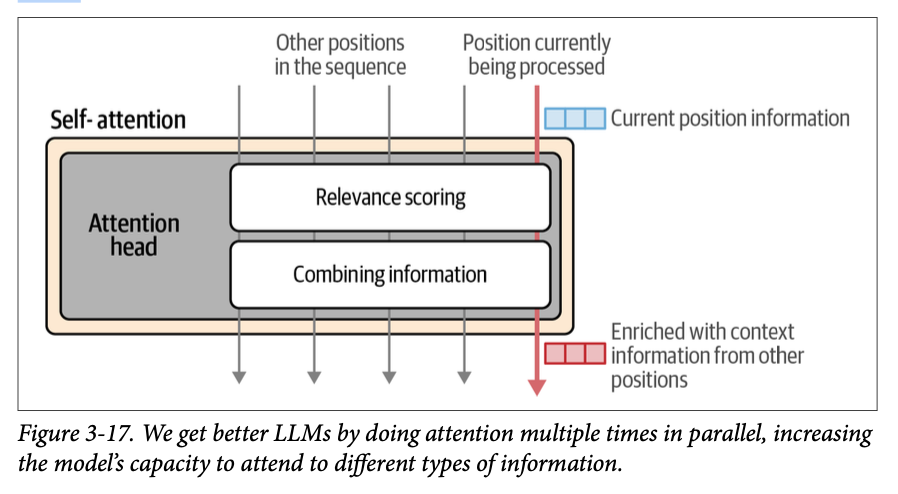
为了赋予 \(\text{Transformer}\) 更广泛的注意力能力,注意力机制被复制并并行执行多次。这些并行的注意力应用中的每一次都在一个注意力头(\(\text{attention head}\))中进行。这增加了模型对输入序列中需要同时关注不同模式的复杂模式进行建模的能力。
图 \(\text{3}-17\) 展示了注意力头如何并行运行的直觉,包括前面的信息拆分步骤和后面的组合所有头部结果的步骤。
注意力如何计算
How attention is calculated
让我们看看在单个注意力头内部如何计算注意力。在我们开始计算之前,让我们观察以下作为起始位置:
- 注意力层(在一个生成式 \(\text{LLM}\) 中)正在为单个位置处理注意力。
- 该层的输入是:
- 当前位置或词元的向量表征。
- 先前词元的向量表征。
- 目标是产生一个新的当前位置表征,该表征整合了来自先前词元的相关信息:
- 例如,如果我们正在处理句子“\(\text{Sarah fed the cat because it}\)”中的最后一个位置,我们希望“\(\text{it}\)”代表猫——因此注意力会从“\(\text{cat}\)”词元中烘焙(\(\text{bakes in}\))“猫的信息”。
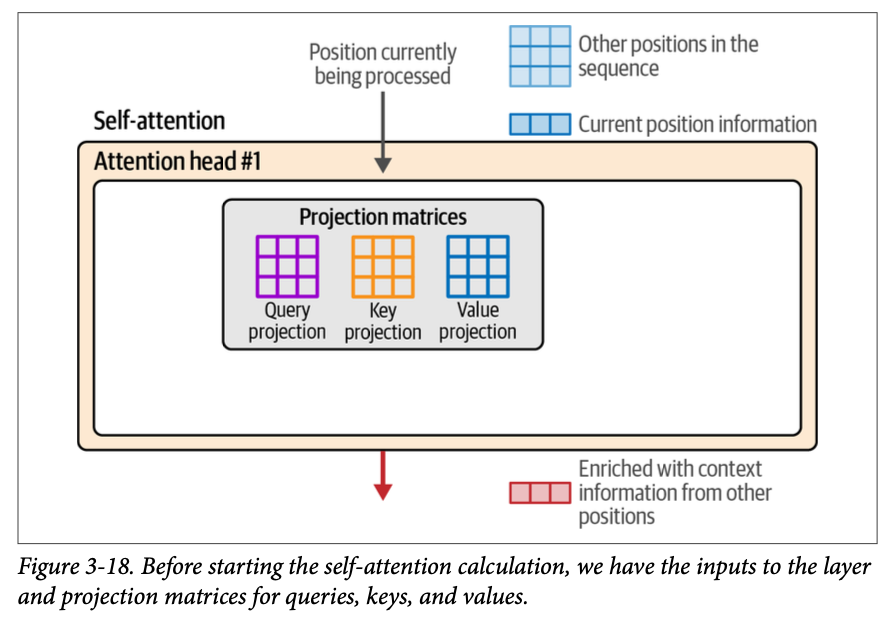
- 训练过程会产生三个投影矩阵,这些矩阵产生在这个计算中相互作用的组件:
- 查询投影矩阵(\(\text{A query projection matrix}\))
- 键投影矩阵(\(\text{A key projection matrix}\))
- 值投影矩阵(\(\text{A value projection matrix}\))
图 \(\text{3}-18\) 展示了在注意力计算开始之前所有这些组件的起始位置。为简单起见,我们只看一个注意力头,因为其他头具有相同的计算,但使用它们各自的投影矩阵。
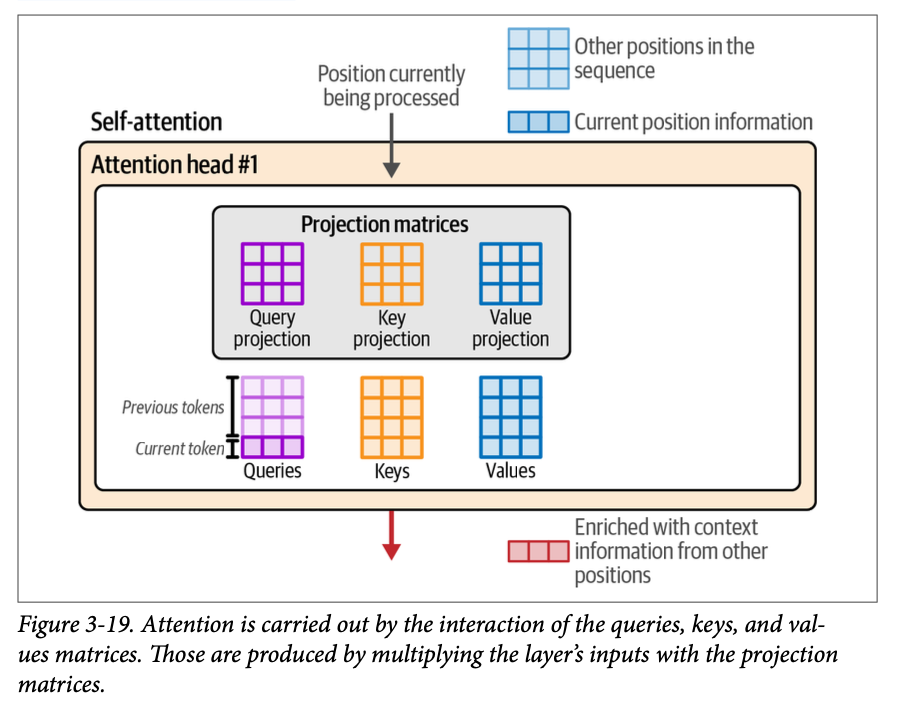
注意力通过将输入乘以投影矩阵开始,以创建三个新矩阵。它们被称为查询 (\(\text{Queries}\)) 矩阵、键 (\(\text{Keys}\)) 矩阵和值 (\(\text{Values}\)) 矩阵。这些矩阵包含了输入词元被投影到三个不同空间的信息,有助于执行注意力的两个步骤:
- 相关性评分
- 组合信息
图 \(\text{3}-19\) 展示了这三个新矩阵,以及它们最底行如何与当前位置相关联,而其上方各行则与先前位置相关联。
自注意力:相关性评分
Self-attention: Relevance scoring
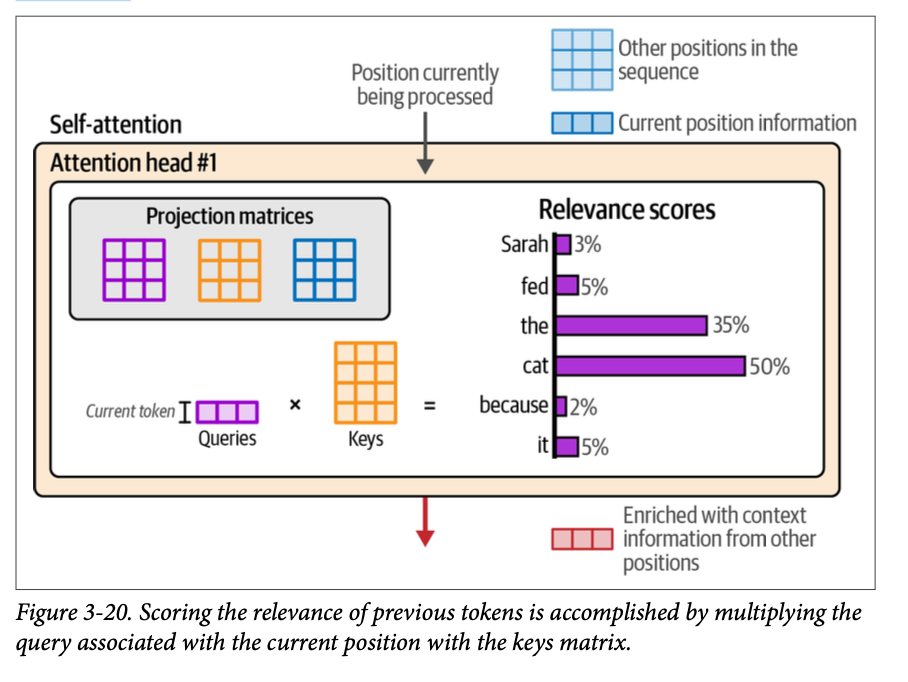
在生成式 \(\text{Transformer}\) 中,我们是一次生成一个词元。这意味着我们是一次处理一个位置。因此,这里的注意力机制只关注这一个位置,以及如何引入来自其他位置的信息来为这个位置提供参考。
注意力的相关性评分步骤是通过将当前位置的查询 (\(\text{Query}\)) 向量与键 (\(\text{Keys}\)) 矩阵相乘来进行的。这会产生一个分数,表明每个先前词元的相关程度。通过 \(\text{softmax}\) 运算,这些分数被归一化,使其总和为 \(\text{1}\)。图 \(\text{3}-20\) 展示了该计算产生的相关性分数。
个人注:其实是 \(Q_n \cdot K_i\),得出n和不同i得相关程度分数;然后归一处理。
自注意力:组合信息
Self-attention: Combining information
现在我们有了相关性分数,我们将与每个词元关联的值 (\(\text{Value}\)) 向量乘以该词元的分数。将这些结果向量相加,就产生了这一注意力步骤的输出,如图 \(\text{3}-21\) 所示。
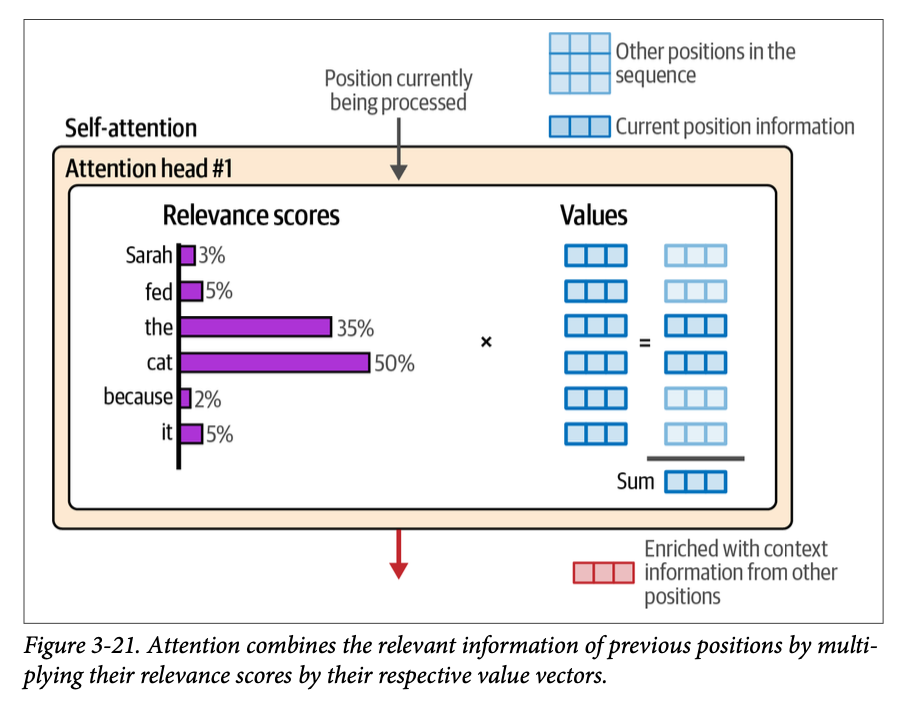
个人注:以上其实就是:最后,模型用这些分数作为权重,来加权求和所有词的 V 向量。
\(\text{Transformer}\) 架构的最新改进
Recent Improvements to the Transformer Architecture
自 \(\text{Transformer}\) 架构发布以来,已经进行了大量工作来改进它并创建更好的模型。这涵盖了在更大的数据集上进行训练,以及对训练过程和使用的学习率进行优化,但也延伸到了架构本身。在撰写本文时,原始 \(\text{Transformer}\) 的许多想法仍然保持不变。有一些架构思想已被证明是有价值的。它们有助于像 \(\text{Llama 2}\) 这样更近期的 \(\text{Transformer}\) 模型的性能。在本章的最后一部分,我们将回顾 \(\text{Transformer}\) 架构的一些重要的最新发展。
更高效的注意力
More Efficient Attention
研究界最关注的领域是 \(\text{Transformer}\) 的注意力层。这是因为注意力计算是整个过程中计算成本最高的部分。
局部/稀疏注意力(\(\text{Local/sparse attention}\)) 随着 \(\text{Transformer}\) 开始变得越来越大,像稀疏注意力(\(\text{sparse attention}\),《使用稀疏 \(\text{Transformer}\) 生成长序列》)和滑动窗口注意力(\(\text{sliding window attention}\),《\(\text{Longformer}\):长文档 \(\text{Transformer}\)》)这样的想法为注意力计算的效率带来了改进。稀疏注意力限制了模型可以关注的先前词元的上下文,如图 \(\text{3}-22\) 所示。
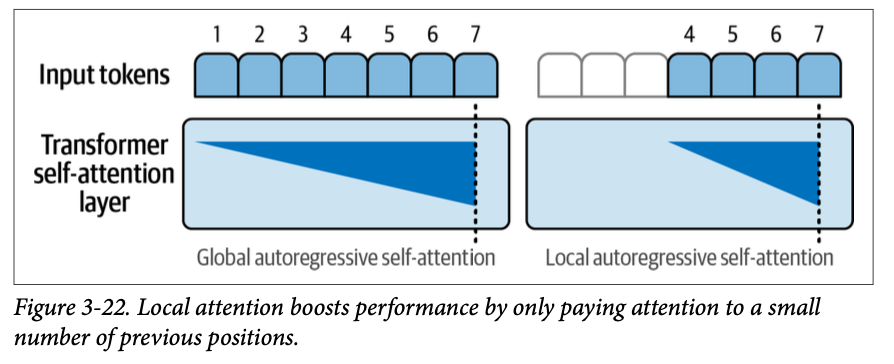
一个采用了这种机制的模型是 \(\text{GPT}-3\)。但它并未对所有的 \(\text{Transformer}\) 块都使用这种机制——如果模型只能看到少量先前词元,生成质量将大大下降。 \(\text{GPT}-3\) 架构交织了全注意力 (\(\text{full-attention}\)) 和高效注意力 (\(\text{efficient-attention}\)) \(\text{Transformer}\) 块。因此,\(\text{Transformer}\) 块在全注意力(例如,第 \(\text{1}\) 块和第 \(\text{3}\) 块)和稀疏注意力(例如,第 \(\text{2}\) 块和第 \(\text{4}\) 块)之间交替。
为了展示不同类型的注意力,请回顾图 \(\text{3}-23\),它展示了不同的注意力机制如何工作。每张图都显示了在处理当前词元(深蓝色)时,可以关注哪些先前词元(浅蓝色)。
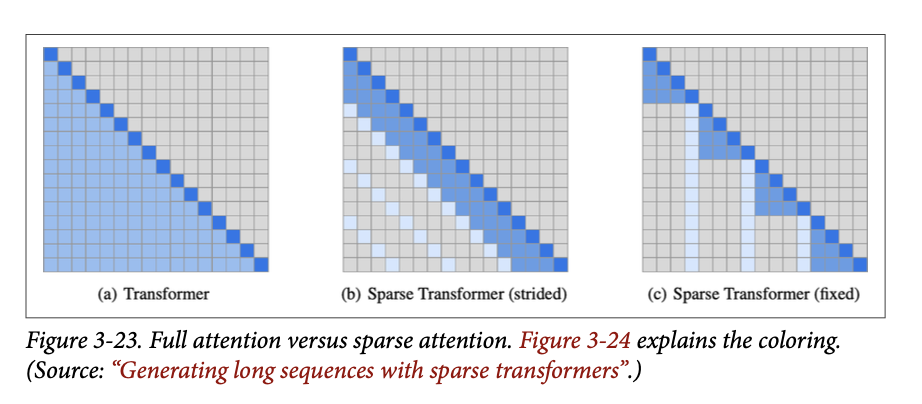
每一行对应于正在处理的一个词元。颜色编码指示了模型在处理深蓝色单元格中的词元时,能够关注哪些词元。图 \(\text{3}-24\) 更清晰地描述了这一点。
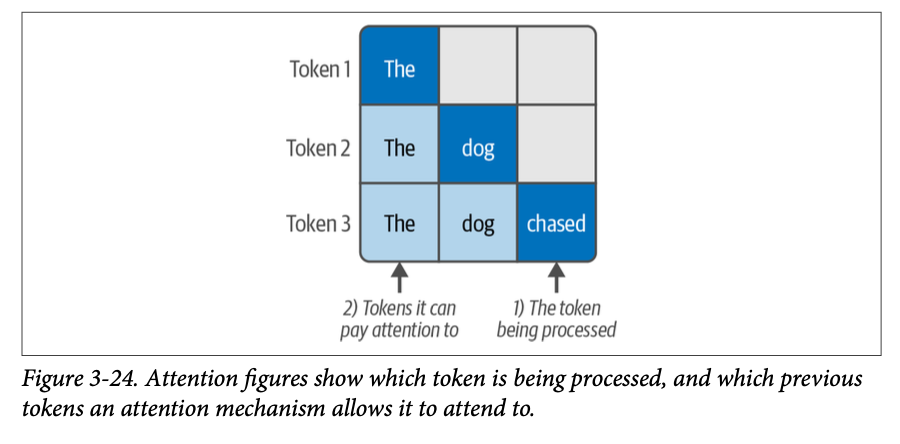
该图还展示了解码器 \(\text{Transformer}\) 块(构成大多数文本生成模型)的自回归性质;它们只能关注先前的词元。这与 \(\text{BERT}\) 形成对比,\(\text{BERT}\) 可以关注两侧的词元(因此 \(\text{BERT}\) 中的 \(\text{B}\) 代表双向)。
多查询和分组查询注意力
Multi-query and grouped-query attention
对 \(\text{Transformer}\) 进行的一项更近期的高效注意力调整是分组查询注意力(\(\text{grouped-query attention}\),《\(\text{GQA}\):从多头检查点训练广义多查询 \(\text{Transformer}\) 模型》),被像 \(\text{Llama 2}\) 和 \(\text{3}\) 这样的模型所使用。图 \(\text{3}-25\) 展示了这些不同类型的注意力,下一节将继续解释它们。
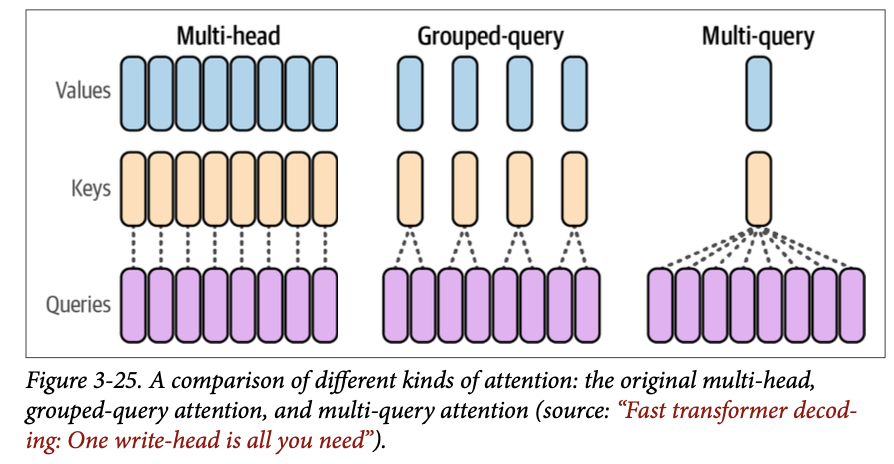
分组查询注意力建立在多查询注意力(\(\text{multi-query attention}\),《快速 \(\text{Transformer}\) 解码:一个写入头就够了》)的基础上。这些方法通过减少所涉及矩阵的大小来提高更大模型的推理可扩展性。
优化注意力:从多头到多查询再到分组查询
Optimizing attention: From multi-head to multi-query to grouped query
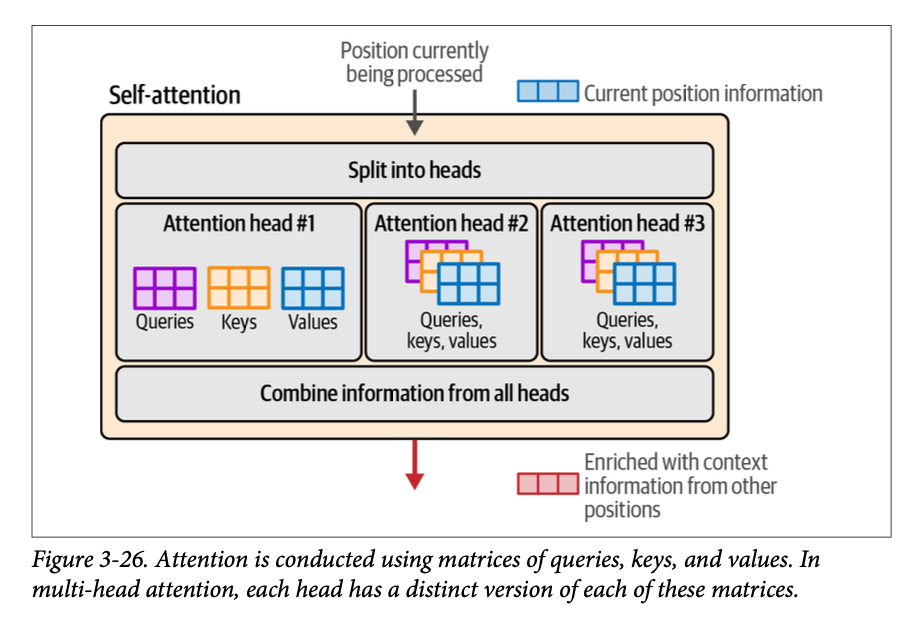
在本章前面,我们展示了 \(\text{Transformer}\) 论文如何描述多头注意力。《图解 \(\text{Transformer}\)》 (https://jalammar.github.io/illustrated-transformer/)详细讨论了查询 (\(\text{Queries}\))、键 (\(\text{Keys}\)) 和值 (\(\text{Values}\)) 矩阵是如何用于进行注意力操作的。图 \(\text{3}-26\) 展示了每个“注意力头”如何为给定的输入计算自己独特的查询、键和值矩阵。
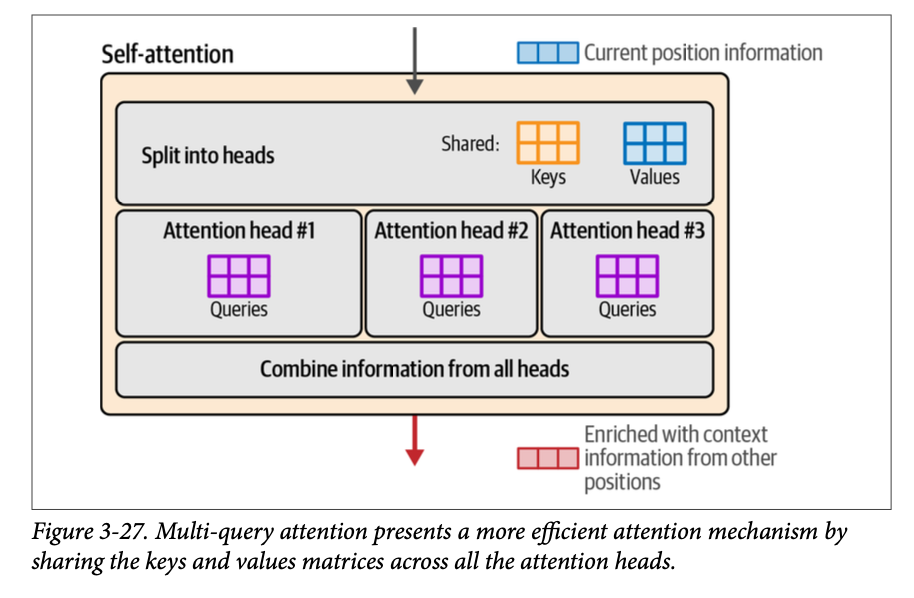
多查询注意力优化这一点的方式是在所有头之间共享键和值矩阵。因此,每个头唯一的矩阵将只有查询矩阵,如图 \(\text{3}-27\) 所示。
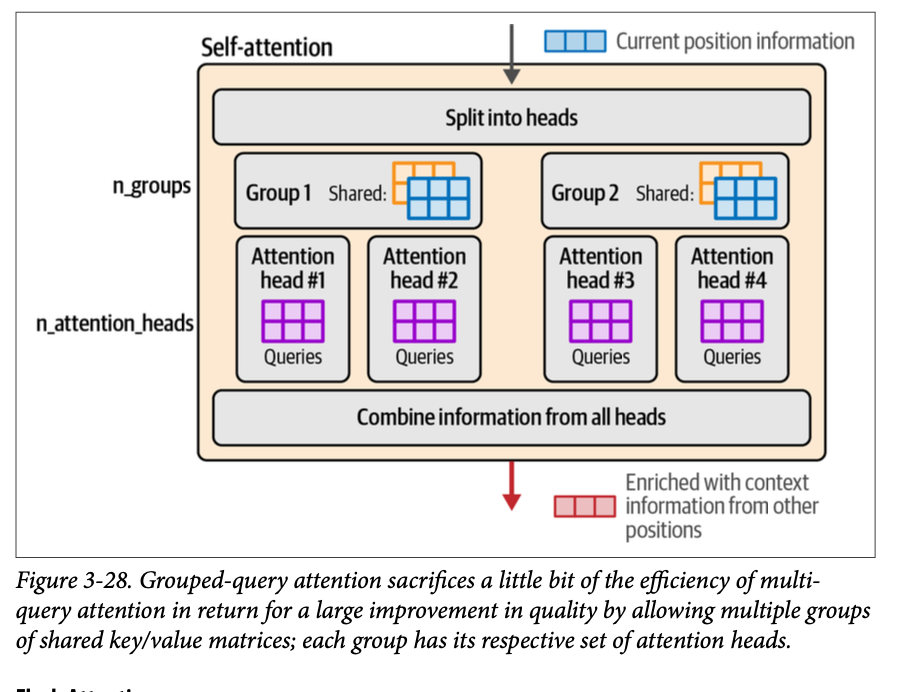
然而,随着模型规模的增长,这种优化可能过于苛刻,我们可以承受使用稍多一点的内存来提高模型的质量。这就是分组查询注意力发挥作用的地方。它没有将键和值矩阵的数量减少到各一个,而是允许我们使用更多(但少于头的数量)。图 \(\text{3}-28\) 展示了这些分组,以及每组注意力头如何共享键和值矩阵。
\(\text{Flash Attention}\)
\(\text{Flash Attention}\) 是一种流行的方法和实现,它为 \(\text{GPU}\) 上的 \(\text{Transformer LLM}\) 的训练和推理提供了显著的加速。它通过优化在 \(\text{GPU}\) 的共享内存 (\(\text{SRAM}\)) 和高带宽内存 (\(\text{HBM}\)) 之间加载和移动的值来加速注意力计算。它在论文《\(\text{FlashAttention}\):具有 \(\text{IO}\) 感知的快速且内存高效的精确注意力》 以及随后的《\(\text{FlashAttention}-2\):通过更好的并行性和工作分区实现更快的注意力》 中有详细描述。
\(\text{Transformer}\) 块
The Transformer Block
回想一下,\(\text{Transformer}\) 块的两个主要组成部分是注意力层和前馈神经网络。如图 \(\text{3}-29\) 所示,更详细地查看该块还会揭示残差连接(\(\text{residual connections}\))和层归一化(\(\text{layer}-\text{normalization}\))操作。
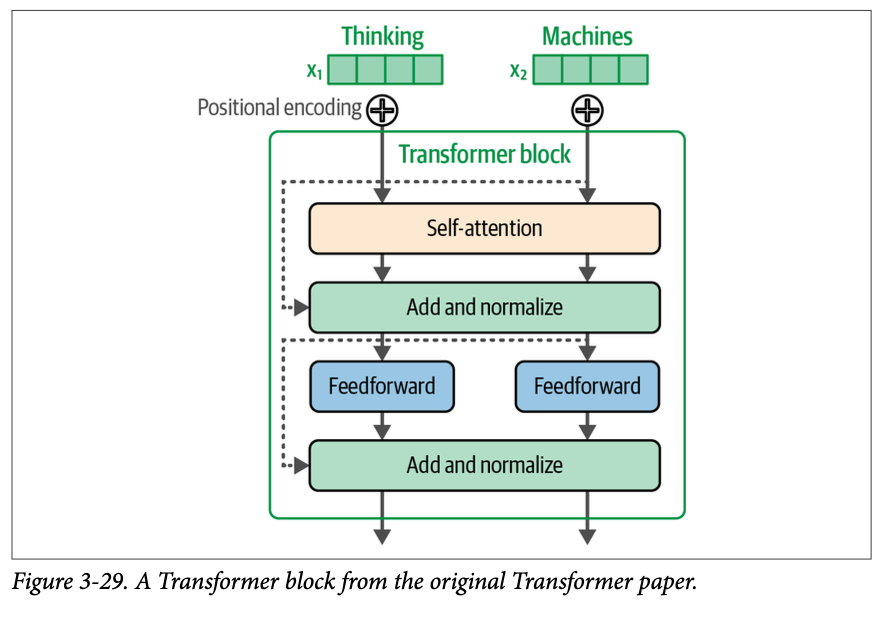
在撰写本文时,最新的 \(\text{Transformer}\) 模型仍然保留了主要的组件,但进行了一些调整,如图 \(\text{3}-30\) 所示。
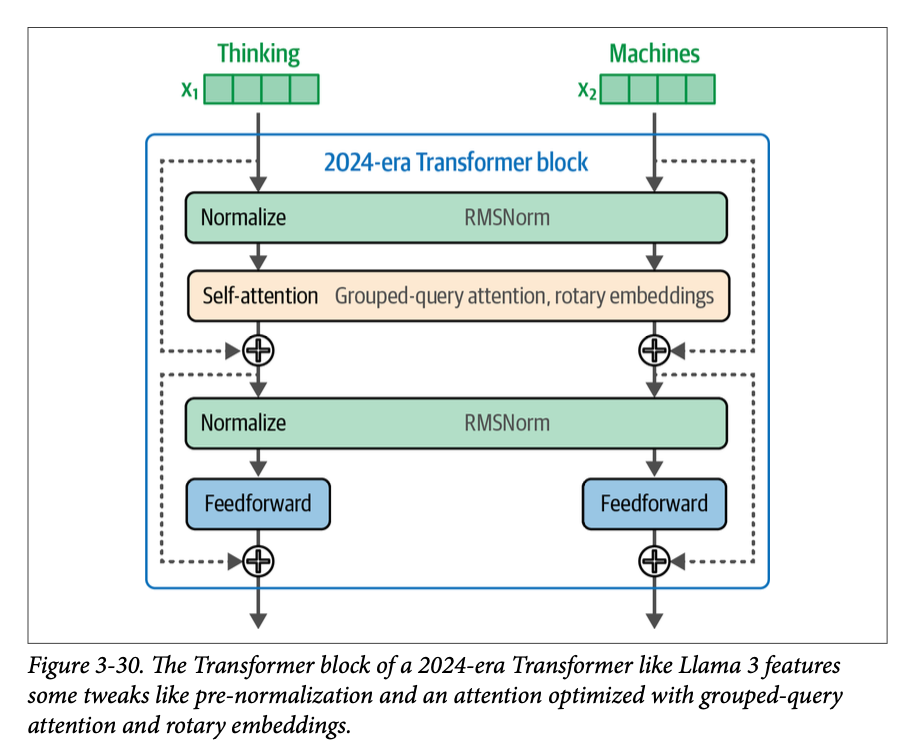
我们在这个版本的 \(\text{Transformer}\) 块中看到的一个区别是,归一化发生在注意力层和前馈层之前。据报道,这可以减少所需的训练时间(阅读:《关于 \(\text{Transformer}\) 架构中的层归一化》)。这里的另一个归一化改进是使用了 \(\text{RMSNorm}\),它比原始 \(\text{Transformer}\) 中使用的 \(\text{LayerNorm}\) 更简单、更高效(阅读:《均方根层归一化》)。最后,代替原始 \(\text{Transformer}\) 的 \(\text{ReLU}\) 激活函数,像 \(\text{SwiGLU}\) 这样的较新变体(在《\(\text{GLU}\) 变体改进 \(\text{Transformer}\)》 中有所描述)现在更为常见。
位置嵌入 (\(\text{RoPE}\))
Positional Embeddings (RoPE)
位置嵌入(\(\text{Positional embeddings}\))自原始 \(\text{Transformer}\) 以来一直是其关键组成部分。它们使模型能够跟踪序列/句子中词元/词语的顺序,这是语言中不可或缺的信息来源。在过去几年提出的众多位置编码方案中,旋转位置嵌入(\(\text{rotary positional embeddings}\),或简称 \(\text{RoPE}\),在《\(\text{RoFormer}\):增强型 \(\text{Transformer}\) 与旋转位置嵌入》 中引入)尤其重要。
原始 \(\text{Transformer}\) 论文和一些早期变体使用了绝对位置嵌入,本质上是将第一个词元标记为位置 \(\text{1}\),第二个为位置 \(\text{2}\),依此类推。这些可以是静态方法(位置向量使用几何函数生成),也可以是学习方法(模型训练在学习过程中为其分配值)。当扩展模型时,此类方法会带来一些挑战,需要我们找到提高其效率的方法。
例如,高效训练具有大上下文的模型的挑战之一是,训练集中的许多文档比该上下文短得多。将整个(例如)\(\text{4K}\) 上下文分配给一个短的 \(\text{10}\) 个词的句子将是低效的。因此,在模型训练期间,文档被打包在一起放入训练批次的每个上下文中,如图 \(\text{3}-31\) 所示。
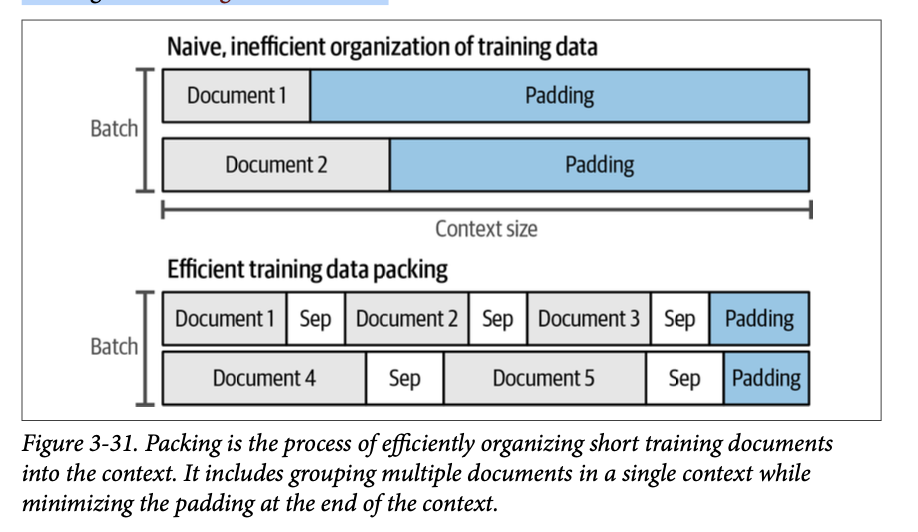
阅读《高效的序列打包且无交叉污染:加速大型语言模型而不影响性能》 以及观看《引入 \(\text{packed BERT}\):在自然语言处理中将训练速度提高 \(\text{2}\) 倍》 中的精彩视觉效果,了解有关打包的更多信息。
位置嵌入方法必须适应这一点以及其他实际考虑因素。例如,如果文档 \(\text{50}\) 从位置 \(\text{50}\) 开始,那么如果我们告诉模型第一个词元的编号是 \(\text{50}\),我们就会误导模型,这将影响其性能(因为它会假设有先前的上下文,而实际上较早的词元属于模型应该忽略的、不相关的不同文档)。
旋转嵌入(\(\text{rotary embeddings}\))不是在正向传播开始时添加的静态、绝对嵌入,而是一种编码位置信息的方法,它捕获了绝对和相对的词元位置信息。它基于在嵌入空间中旋转向量的思想。在正向传播中,它们被添加在注意力步骤中,如图 \(\text{3}-32\) 所示。
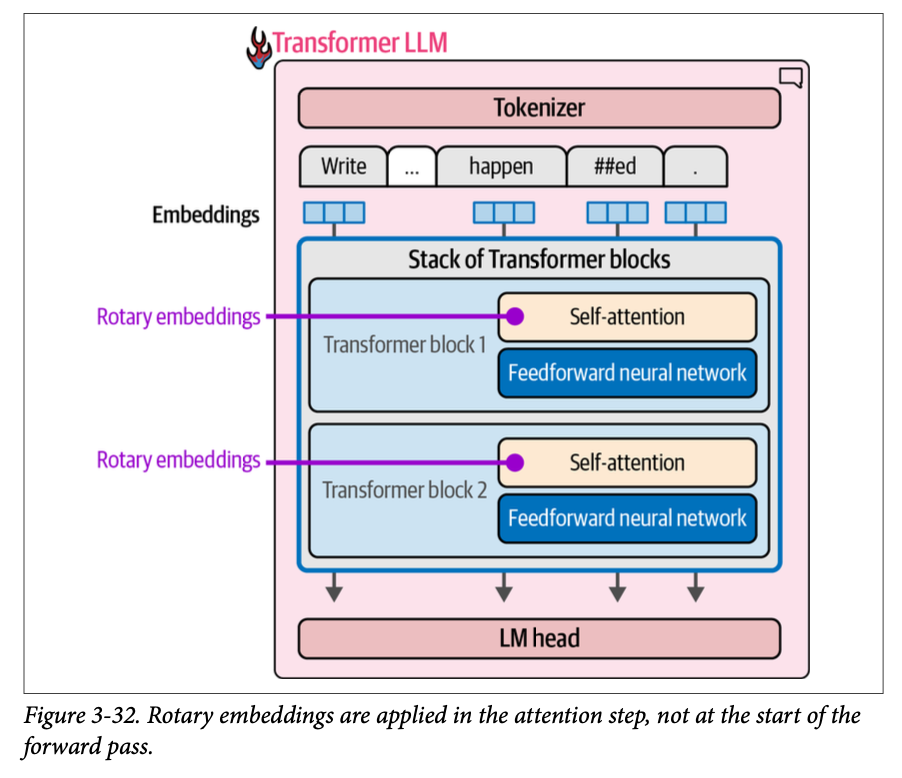
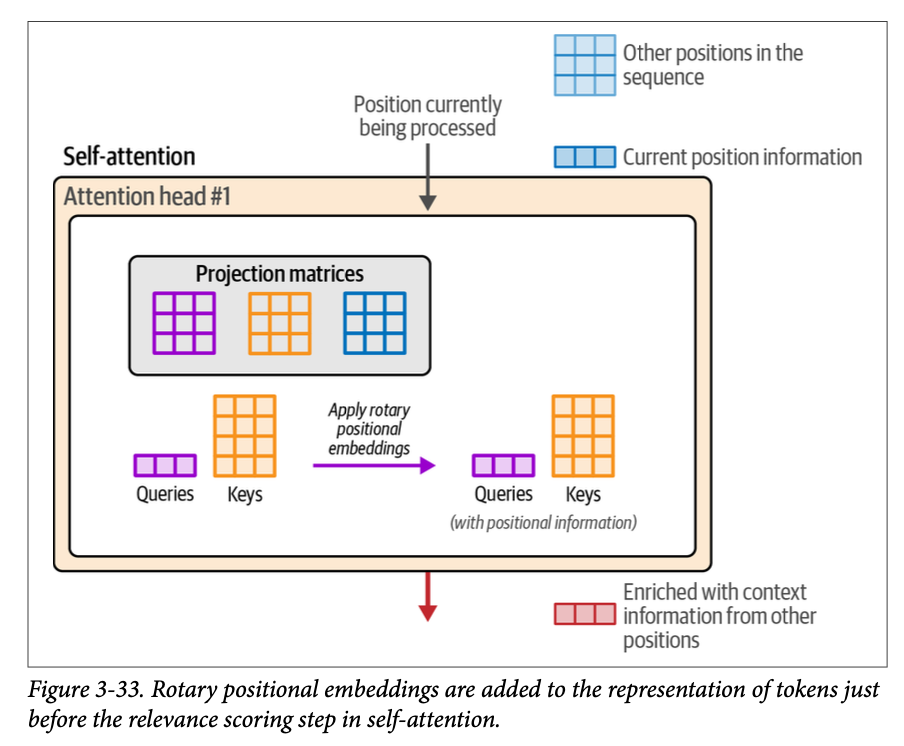
在注意力(\(\text{attention}\))过程中,位置信息会被专门混合到查询 (\(\text{queries}\)) 和键 (\(\text{keys}\)) 矩阵中,就在我们将它们相乘以进行相关性评分之前,如图 \(\text{3}-33\) 所示。
其他架构实验和改进
Other Architectural Experiments and Improvements
许多对 \(\text{Transformer}\) 的调整被持续地提出和研究。《\(\text{Transformer}\) 综述》 强调了其中几个主要方向。\(\text{Transformer}\) 架构也一直在不断地适应超越 \(\text{LLM}\) 的领域。计算机视觉是一个正在进行大量 \(\text{Transformer}\) 架构研究的领域(参见:《\(\text{Transformer}\) 在视觉中的综述》 和 《视觉 \(\text{Transformer}\) 综述》)。其他领域包括机器人技术(参见《开放式 \(\text{X}\) 具身:机器人学习数据集和 \(\text{RT}-\text{X}\) 模型》)和时间序列(参见《\(\text{Transformer}\) 在时间序列中的综述》)。
总结
在本章中,我们讨论了 \(\text{Transformer}\) 的主要直觉以及实现最新 \(\text{Transformer}\) \(\text{LLM}\) 的最新发展。我们回顾了许多新概念,现在让我们分解一下本章讨论的关键概念:
- 一个 \(\text{Transformer LLM}\) 一次生成一个词元。
- 输出词元被附加到提示中,然后这个更新后的提示再次被呈现给模型,进行另一次正向传播以生成下一个词元。
- \(\text{Transformer LLM}\) 的三个主要组成部分是分词器、\(\text{Transformer}\) 块的堆栈和语言建模头(\(\text{LM head}\))。
- 分词器包含模型的词元词汇表。模型有与这些词元相关的词元嵌入。将文本分解为词元并使用这些词元的嵌入是词元生成过程的第一步。
- 正向传播一次性按顺序流经所有阶段。
- 临近过程结束时,\(\text{LM}\) 头对下一个可能的词元的概率进行评分。解码策略决定了选择哪个实际词元作为本次生成步骤的输出(有时它是最可能的下一个词元,但并非总是如此)。
- \(\text{Transformer}\) 表现出色的原因之一是它能够并行处理词元。每个输入词元都流入其各自的处理轨道或流。流的数量是模型的“上下文大小”,这代表了模型可以操作的最大词元数量。
- 因为 \(\text{Transformer LLM}\) 是循环以一次生成一个词元的文本,所以缓存每个步骤的处理结果是一个好主意,这样我们就不会重复处理工作(这些结果以层内各种矩阵的形式存储)。
- 大部分处理发生在 \(\text{Transformer}\) 块内。它们由两个组件组成。其中之一是前馈神经网络,它能够存储信息并根据其训练数据进行预测和插值。
- \(\text{Transformer}\) 块的第二个主要组成部分是注意力层。注意力整合上下文信息,使模型能够更好地捕获语言的细微差别。
- 注意力发生在两个主要步骤中:(\(\text{1}\))相关性评分和(\(\text{2}\))组合信息。
- \(\text{Transformer}\) 注意力层并行进行多次注意力操作,每次操作都在一个注意力头内部发生,它们的输出被聚合以构成注意力层的输出。
- 通过在所有头之间或多组头之间共享键和值矩阵(分组查询注意力),可以加速注意力。
- 像 \(\text{Flash Attention}\) 这样的方法通过优化在 \(\text{GPU}\) 不同内存系统上执行操作的方式来加速注意力计算。
- \(\text{Transformer}\) 在不断出现新的发展和拟议的调整,以在不同的场景中改进它们,包括语言模型和其他领域和应用。
在本书的第二部分,我们将涵盖 \(\text{LLM}\) 的一些实际应用。在第 \(\text{4}\) 章中,我们将从文本分类开始,这是语言 \(\text{AI}\) 中的一个常见任务。下一章将作为应用生成式和表征模型的介绍。
书籍各章的机翻md文件:
《Hands-On Large Language Models》目录及前言
《Hands-On Large Language Models》第1章 大型语言模型简介
《Hands-On Large Language Models》第2章 词元与嵌入
《Hands-On Large Language Models》第3章 深入了解大型语言模型
《Hands-On Large Language Models》第4章 文本分类
《Hands-On Large Language Models》第5章 文本聚类和主题建模
《Hands-On Large Language Models》第6章 提示工程
《Hands-On Large Language Models》第7章 高级文本生成技术与工具
《Hands-On Large Language Models》第8章 语义搜索与检索增强生成
《Hands-On Large Language Models》第9章 多模态大型语言模型
《Hands-On Large Language Models》第10章 创建文本嵌入模型
《Hands-On Large Language Models》第11章 微调用于分类的表征模型
《Hands-On Large Language Models》第12章 生成模型的微调