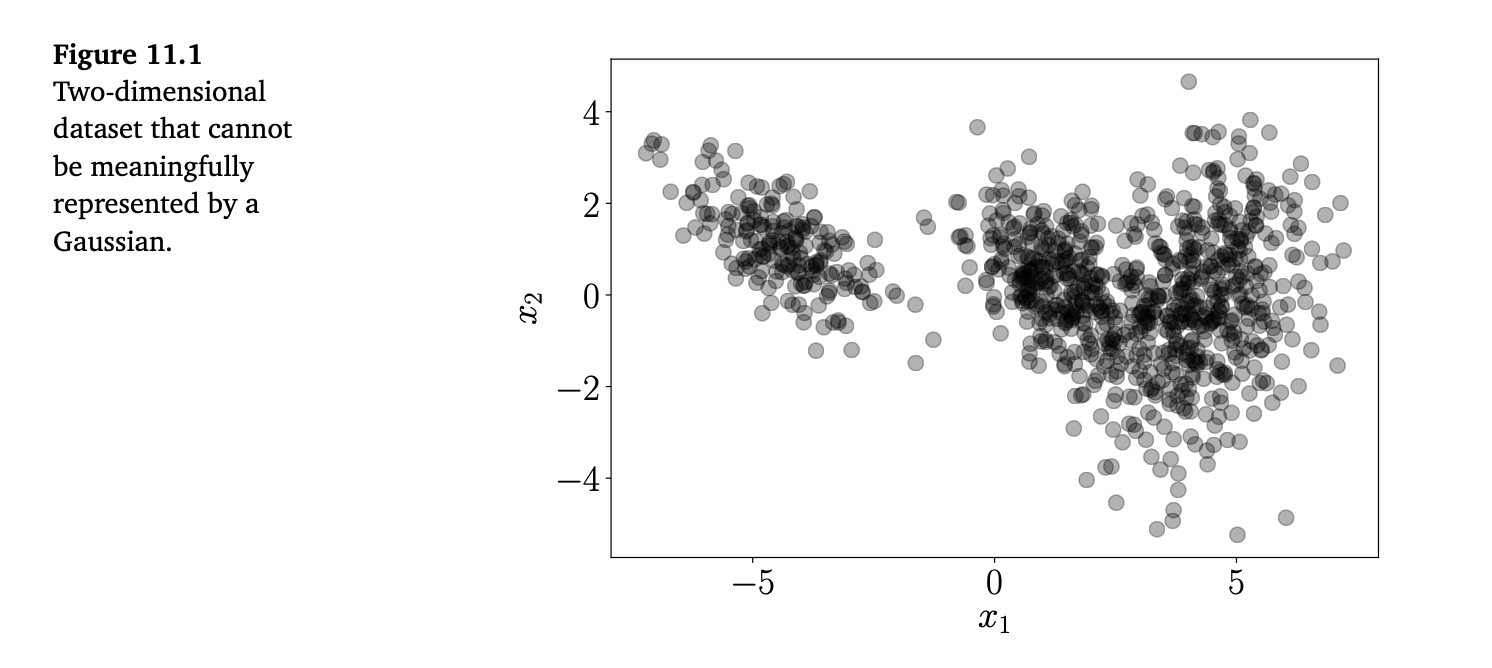
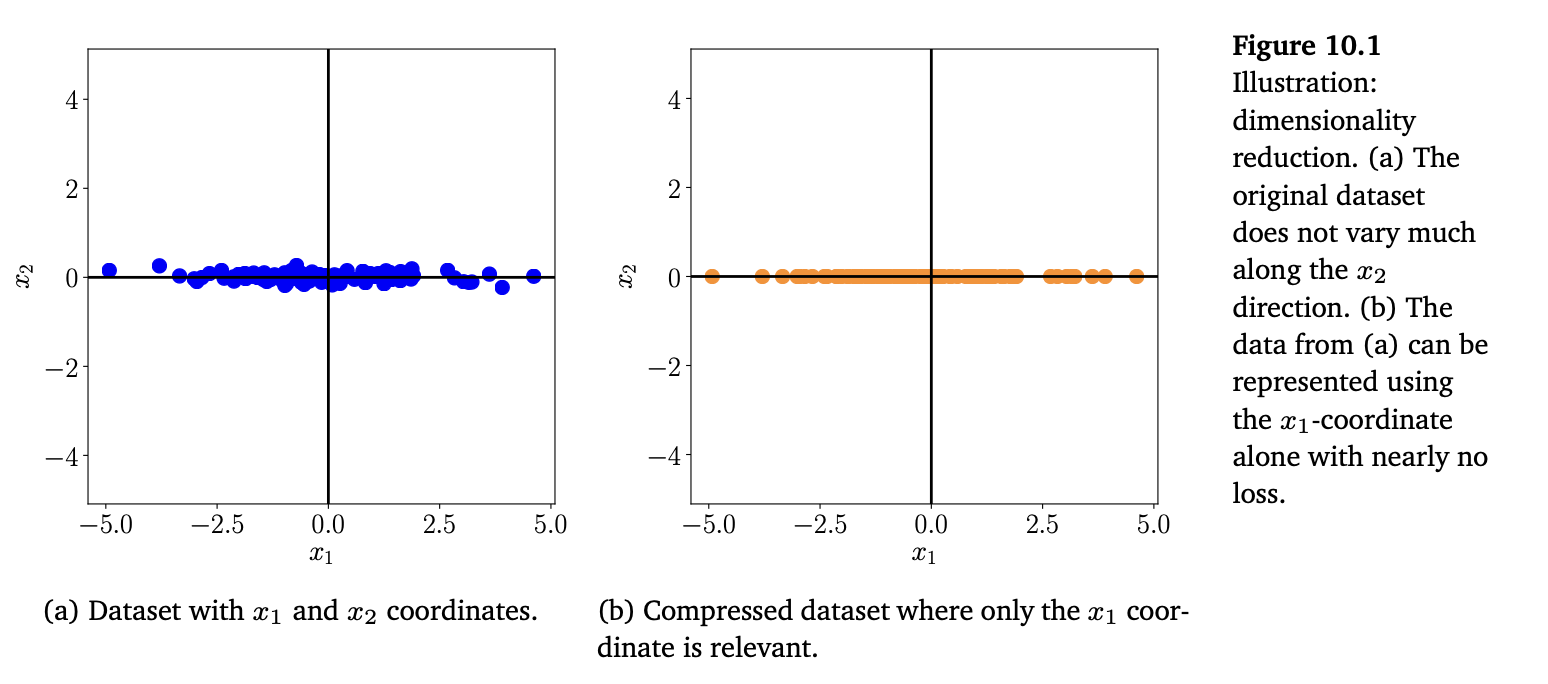
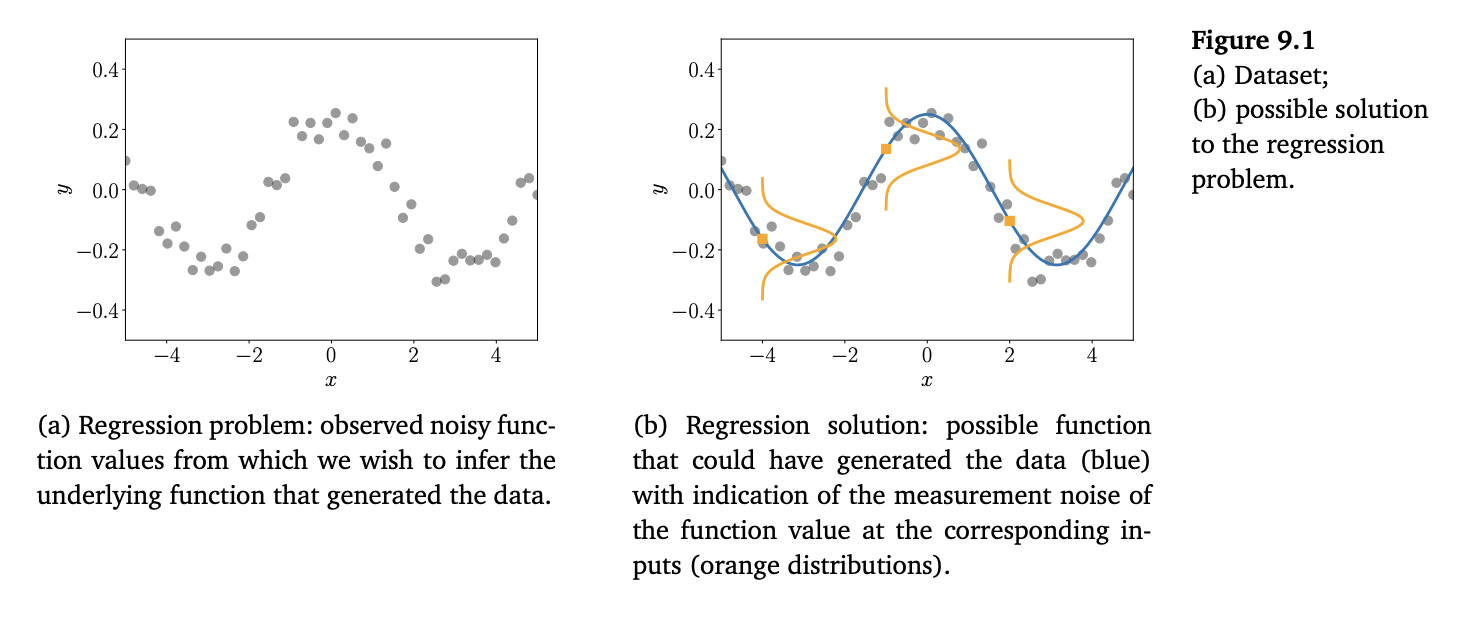
《机器学习的数学基础》第12章"支持向量机分类"
第12章 支持向量机分类
在许多情况下,我们希望机器学习算法能够预测若干(离散)结果中的一个。例如,电子邮件客户端会将邮件分为个人邮件和垃圾邮件,这就有两个结果。另一个例子是望远镜识别夜空中的天体是星系、恒星还是行星。通常结果的数量较少,更重要的是,这些结果之间往往没有额外的结构。 在本章中,我们考虑输出二元值的预测器,也就是说,只有两种可能的结果。这种机器学习任务称为二分类(binary classification)。这与第 9 章形成对比,当时我们讨论的是连续值输出的预测问题。对于二分类,标签/输出可以取的值是二元的,本章中我们用 {+1,−1} 表示。换句话说,我们考虑的预测器形式为 \[ f:\mathbb{R}^D \to \{+1,-1\}. \tag{12.1} \]
回忆第 8 章,我们用 \(D\) 个实数的特征向量表示每个样本(数据点)\(x_n\)。标签通常分别称为正类(positive class)和负类(negative class)。但应当注意,不要根据“正”或“负”字面意义推断+1类的直观属性。例如,在癌症检测任务中,有癌症的患者往往被标记为+1。原则上可以使用任何两个不同的值,例如{True,False}、{0,1}或{red,blue}。二分类问题研究得比较充分,其他方法的综述我们放到 12.6 节再介绍。我们将介绍一种称为支持向量机(Support Vector Machine, SVM)的方法,它用于解决二分类任务。与回归类似,这是一个监督学习任务:我们有一组样本 \(x_n \in \mathbb{R}^D\),以及对应的(二元)标签 \(y_n \in \{+1,-1\}\)。给定一个包含样本–标签对 \(\{(x_1,y_1),\dots,(x_N,y_N)\}\) 的训练数据集,我们希望估计模型参数,使分类错误率最小。类似第 9 章,我们考虑线性模型,并把非线性隐藏在对样本的一个变换 \(\phi\) 中(见式(9.13))。我们将在 12.4 节重新讨论 \(\phi\)。
支持向量机(SVM)在许多应用中都能提供最先进的结果,并且具有坚实的理论保证(Steinwart 和 Christmann, 2008)。我们之所以选择用 SVM 来说明二分类问题,主要有两个原因。
首先,SVM 提供了一种几何方式来思考监督学习问题。 在第 9 章中,我们是从概率模型的角度来看待机器学习问题,并用极大似然估计和贝叶斯推断来解决。而在这里,我们考虑一种替代的方法,即从几何角度来推理机器学习任务。这种方法高度依赖于我们在第 3 章讨论过的内积和投影等概念。
第二个原因是,与第 9 章不同,SVM 的优化问题没有解析解,因此需要借助第 7 章介绍的各种优化工具。 SVM 对机器学习的理解与第 9 章的极大似然方法存在细微的差异:极大似然方法是基于数据分布的概率观点提出一个模型,再由此推导出一个优化问题;而 SVM 的方法则是从几何直觉出发,先设计一个需要在训练过程中被优化的函数。我们已经在第 10 章看到过类似的情况,当时我们从几何原理出发推导了 PCA。在 SVM 的例子中,我们通过设计一个损失函数来度量训练数据上的误差,并遵循经验风险最小化原则(第 8.2 节),在训练中加以最小化。