《机器学习的数学基础》第11章"高斯混合模型的密度估计"
第11章 高斯混合模型的密度估计
Density Estimation with Gaussian Mixture Models
在前几章中,我们已经讨论了机器学习中的两个基本问题:回归(第 9 章)和降维(第 10 章)。在本章中,我们将探讨机器学习的第三个支柱:密度估计。在这一过程中,我们会引入一些重要的概念,例如期望最大化(EM)算法,以及通过混合模型来理解密度估计的潜在变量视角。
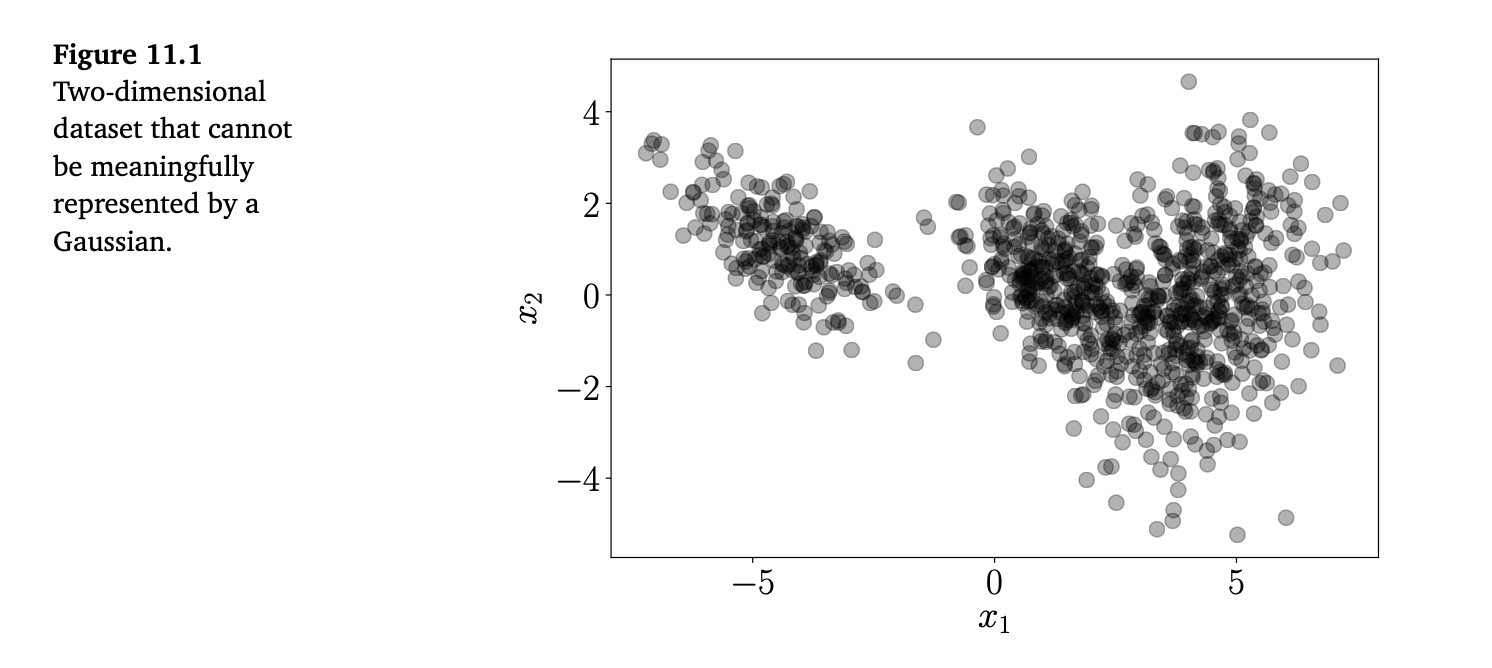
当我们将机器学习应用于数据时,往往希望以某种方式来表示数据。一个直接的方法就是将数据点本身作为数据的表示;例如见图 11.1。 然而,如果数据集非常庞大,或者我们更关心数据的整体特征,那么这种方式可能就不太有用了。在密度估计中,我们通过使用某个参数化分布族中的分布(例如高斯分布或 Beta 分布),来紧凑地表示数据。比如,我们可能希望通过数据集的均值和方差,用一个高斯分布来进行紧凑表示。均值和方差可以通过第 8.3 节讨论的工具(最大似然估计或最大后验估计)来求得。接着,我们就可以用这个高斯分布的均值和方差来表示数据背后的分布,即我们认为该数据集是从这个分布中采样得到的一次典型实现。
个人注:高斯混合模型的密度估计是一种表示数据的方法!其实也是一种建模,因为这个分布就是对应该类数据的模型表达。
在实际应用中,高斯分布(或类似我们迄今遇到的其他分布)具有有限的建模能力。例如,用一个高斯分布去近似图 11.1 中生成数据的真实密度,就会是一个很差的近似。接下来,我们将研究一种更具表现力的分布族,可以用来进行密度估计:混合模型。
混合模型可以通过 K 个简单(基)分布的凸组合 来描述一个分布 \(p(x)\): \[ p(x) = \sum_{k=1}^K \pi_k p_k(x) \tag{11.1} \] 满足: \[ 0 \leq \pi_k \leq 1, \quad \sum_{k=1}^K \pi_k = 1 \tag{11.2} \] 其中,各个成分分布 \(p_k\) 属于某个基本分布族,例如高斯分布、伯努利分布或伽马分布,而 \(\pi_k\) 是混合权重。混合模型比相应的单个基分布更具表现力,因为它们可以表示多峰的数据分布,即能够描述具有多个“簇”的数据集,就像图 11.1 中的例子。
我们将重点讨论高斯混合模型(GMMs),其中的基本分布是高斯分布。给定一个数据集,我们的目标是通过最大化模型参数的似然来训练 GMM。为此,我们将会用到第 5 章、第 6 章和第 7.2 节的结果。然而,与之前讨论过的应用(线性回归或主成分分析)不同,这里我们无法得到最大似然的闭式解。相反,我们将得到一组相互依赖的联立方程,而这些方程只能通过迭代方法来求解。
11.1 高斯混合模型
高斯混合模型(Gaussian Mixture Model, GMM)是一种密度模型,它通过组合有限个 \(K\) 个高斯分布 \(\mathcal{N}(x|\mu_k, \Sigma_k)\) 来表示: \[ p(x|\theta) = \sum_{k=1}^K \pi_k \, \mathcal{N}(x|\mu_k, \Sigma_k) \tag{11.3} \] 其中: \[ 0 \leq \pi_k \leq 1, \quad \sum_{k=1}^K \pi_k = 1, \tag{11.4} \] 我们定义 \[ \theta := \{ \mu_k, \Sigma_k, \pi_k : k = 1, \ldots, K \} \] 为该模型的所有参数集合。
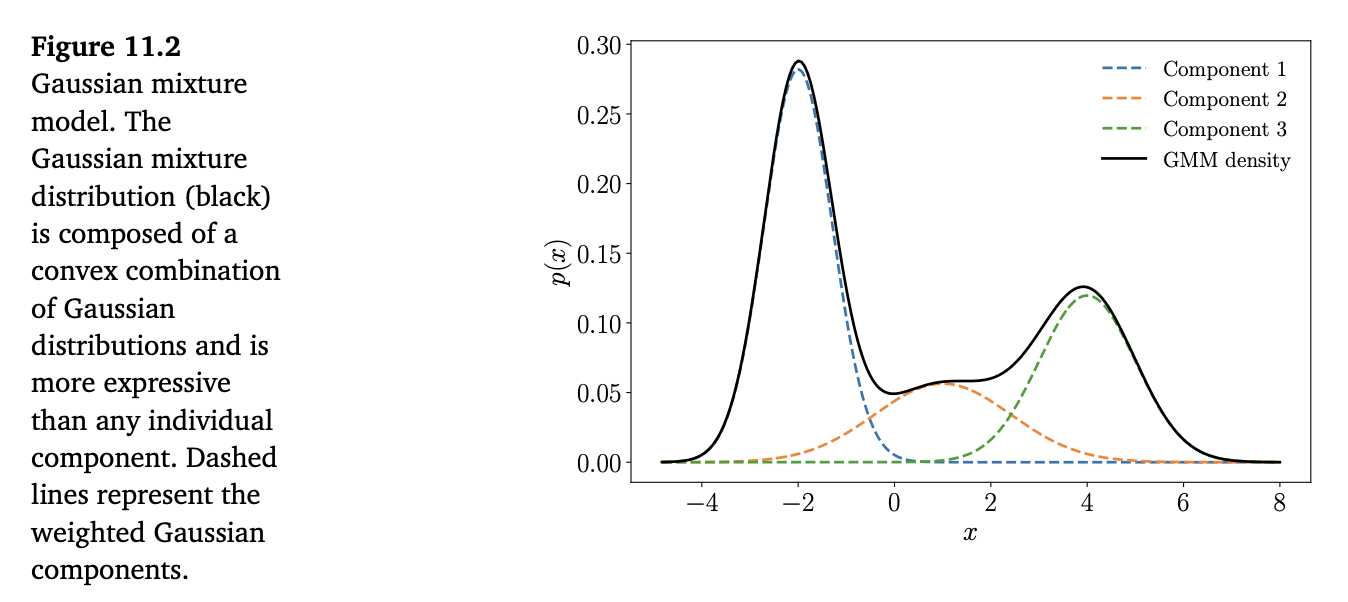
这种对高斯分布的凸组合,相比单一的高斯分布,能为复杂密度的建模提供更强的灵活性(当 \(K=1\) 时,(11.3) 就退化为单一高斯分布)。图 11.2 给出了一个示例,展示了加权后的各个分量以及最终的混合密度: \[
p(x|\theta) = 0.5 \, \mathcal{N}(x|-2, \tfrac{1}{2}) + 0.2 \, \mathcal{N}(x|1, 2) + 0.3 \, \mathcal{N}(x|4, 1). \tag{11.5}
\] 
11.2 最大似然参数学习
假设我们给定一个数据集\(X = \{x_1, \ldots, x_N\},\)其中 \(x_n, n=1,\ldots,N\),是从未知分布 \(p(x)\) 中独立同分布采样得到的。我们的目标是用一个含有 \(K\) 个混合分量的 GMM 来近似/表示这个未知分布 \(p(x)\)。GMM 的参数包括: \(K\) 个均值 \(\mu_k\), 协方差矩阵 \(\Sigma_k\), 混合权重 \(\pi_k\)。我们把这些自由参数统一记为:\(\theta := \{\pi_k, \mu_k, \Sigma_k : k = 1, \ldots, K\}.\)
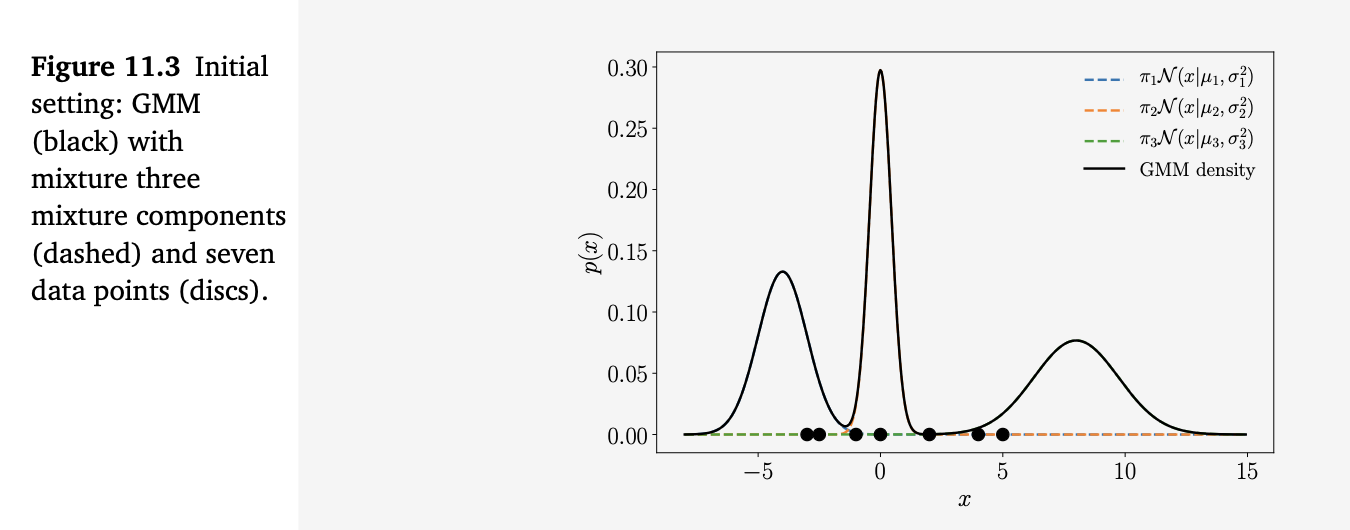
例 11.1(初始设定)
在本章中,我们将用一个简单的贯穿示例来帮助说明和可视化关键概念。我们考虑一个一维数据集
\[ X = \{-3, -2.5, -1, 0, 2, 4, 5\}, \] 它包含 7 个数据点。我们希望用一个含有 \(K=3\) 个分量的 GMM 来建模该数据的密度。初始化混合分量如下: \[ p_1(x) = \mathcal{N}(x|-4, 1) \tag{11.6} \]
\[ p_2(x) = \mathcal{N}(x|0, 0.2) \tag{11.7} \]
\[ p_3(x) = \mathcal{N}(x|8, 3) \tag{11.8} \]
并给它们分配相等的权重: \[ \pi_1 = \pi_2 = \pi_3 = \tfrac{1}{3}. \] 相应的模型(以及数据点)如图 11.3 所示。
在下面的内容中,我们将详细说明如何得到模型参数 θ 的最大似然估计 \(θ_{ML}\)。我们首先写出似然函数,即在给定参数的情况下训练数据的预测分布。我们利用独立同分布 (i.i.d.) 假设,这会导致似然函数的分解形式: \[ p(X|\theta) = \prod_{n=1}^N p(x_n|\theta), \quad p(x_n|\theta) = \sum_{k=1}^K \pi_k \, \mathcal{N}(x_n|\mu_k,\Sigma_k), \tag{11.9} \] 其中每个单独的似然项 \(p(x_n|\theta)\) 都是一个高斯混合密度。然后我们得到对数似然: \[ \log p(X|\theta) = \sum_{n=1}^N \log p(x_n|\theta) = \sum_{n=1}^N \log \Bigg( \sum_{k=1}^K \pi_k \, \mathcal{N}(x_n|\mu_k,\Sigma_k) \Bigg). \tag{11.10} \] 记作 \(L\)。我们的目标是找到能最大化对数似然 \(L\) 的参数 \(\theta^*_{ML}\)。通常的做法是计算对数似然关于模型参数 θ 的梯度 \(dL/d\theta\),令其等于 0,然后解出 θ。
然而,与之前最大似然估计的例子(例如第 9.2 节讨论的线性回归)不同,这里无法得到一个封闭解。但我们可以利用一种迭代方法来找到较好的模型参数 \(θ_{ML}\),这实际上就是用于高斯混合模型 (GMM) 的 EM 算法。关键思想是:在保持其他参数固定的情况下,逐一更新模型参数。
备注:如果我们考虑的目标密度只是单个高斯分布,那么式 (11.10) 中对\(k\)的求和就消失了,此时对数可以直接作用于高斯分布,从而得到: \[ \log \mathcal{N}(x|\mu,\Sigma) = -\frac{D}{2}\log(2\pi) - \tfrac{1}{2}\log \det(\Sigma) - \tfrac{1}{2}(x-\mu)^\top \Sigma^{-1}(x-\mu). \tag{11.11} \] 这个简单的形式使得我们可以得到 \(\mu\) 和 \(\Sigma\) 的封闭形式最大似然估计(第 8 章已讨论)。但在 (11.10) 中,我们无法将对数移入对\(k\)的求和中,因此无法得到简单的封闭解。
任何函数的局部最优点都必须满足梯度关于参数为零的性质(必要条件,见第 7 章)。在我们的情形下,对数似然 (11.10) 关于 GMM 参数 \(\mu_k, \Sigma_k, \pi_k\) 的优化给出了如下必要条件: \[ \begin{align} \frac{\partial \mathcal{L}}{\partial \mu_k} = \mathbf{0}^\top &\iff \sum_{n=1}^N \frac{\partial \log p(x_n \mid \theta)}{\partial \mu_k} = \mathbf{0}^\top, \tag{11.12}\\[1em] \frac{\partial \mathcal{L}}{\partial \Sigma_k} = 0 &\iff \sum_{n=1}^N \frac{\partial \log p(x_n \mid \theta)}{\partial \Sigma_k} = 0, \tag{11.13}\\[1em] \frac{\partial \mathcal{L}}{\partial \pi_k} = 0 &\iff \sum_{n=1}^N \frac{\partial \log p(x_n \mid \theta)}{\partial \pi_k} = 0. \tag{11.14} \end{align} \] 对于所有这三类必要条件,通过应用链式法则(见 5.2.2 节),我们需要如下形式的偏导数: \[ \frac{\partial \log p(x_n|\theta)}{\partial \theta} = \frac{1}{p(x_n|\theta)} \, \frac{\partial p(x_n|\theta)}{\partial \theta}, \tag{11.15} \] 其中 \(\theta = \{\mu_k, \Sigma_k, \pi_k, k=1,\ldots,K\}\) 是模型参数,并且 \[ \frac{1}{p(x_n|\theta)} = \frac{1}{\sum_{j=1}^K \pi_j \, \mathcal{N}(x_n|\mu_j,\Sigma_j)}. \tag{11.16} \] 在接下来的内容中,我们将计算 (11.12) 到 (11.14) 的偏导数。但在此之前,我们先引入一个将在本章余下部分起核心作用的重要量:责任 (responsibilities)。
11.2.1 责任
Responsibilities
我们定义如下量: \[ r_{nk} := \frac{\pi_k \mathcal{N}(x_n|\mu_k, \Sigma_k)}{\sum_{j=1}^K \pi_j \mathcal{N}(x_n|\mu_j, \Sigma_j)} \tag{11.17} \] 它表示第 \(k\) 个混合成分对第 \(n\) 个数据点的责任。第 \(k\) 个混合成分对数据点 \(x_n\) 的责任 \(r_{nk}\),与下式成正比:
\[ p(x_n|\pi_k, \mu_k, \Sigma_k) = \pi_k \mathcal{N}(x_n|\mu_k, \Sigma_k) \tag{11.18} \] 即该混合成分在给定数据点下的似然。因此,当某个数据点更可能是由某个混合成分生成时,该成分对该数据点的责任就会更大。注意:
\[ r_n := [r_{n1}, \ldots, r_{nK}]^\top \in \mathbb{R}^K \] 是一个归一化的概率向量,即满足 \(\sum_k r_{nk} = 1\),且 \(r_{nk} \geq 0\)。这个概率向量在 \(K\) 个混合成分之间分配概率质量,我们可以把 \(r_n\) 看作是对 \(x_n\) 在 \(K\) 个混合成分之间的“软分配”。因此,公式 (11.17) 中的责任 \(r_{nk}\),就代表了 \(x_n\) 是由第 \(k\) 个混合成分生成的概率。
例 11.2 (责任)
针对图 11.3 中的例子,我们计算得到责任 \(r_{nk}\): \[ \begin{bmatrix} 1.0 & 0.0 & 0.0 \\ 1.0 & 0.0 & 0.0 \\ 0.057 & 0.943 & 0.0 \\ 0.001 & 0.999 & 0.0 \\ 0.0 & 0.066 & 0.934 \\ 0.0 & 0.0 & 1.0 \\ 0.0 & 0.0 & 1.0 \end{bmatrix} \in \mathbb{R}^{N \times K}. \tag{11.19} \] 这里,第 \(n\) 行表示所有混合成分对数据点 \(x_n\) 的责任。每个数据点的 \(K\) 个责任(即每一行的和)都等于 1。第 \(k\) 列则概括了第 \(k\) 个混合成分的责任分布。我们可以看到,第三个混合成分(第三列)对前四个数据点没有责任,但在后面的数据点上承担了较多责任。某一列所有元素的和给出了 \(N_k\),即第 \(k\) 个混合成分的总责任。在本例中,我们得到:
\[ N_1 = 2.058, \quad N_2 = 2.008, \quad N_3 = 2.934. \] 下面我们来确定在给定责任值的情况下,模型参数\(\mu_k, \Sigma_k, \pi_k\) 的更新方式。我们将看到,这些更新方程都依赖于责任值,这使得最大似然估计问题无法得到闭式解。然而,在给定责任值的情况下,我们会一次只更新一个模型参数,同时保持其他参数固定。之后,我们会重新计算责任值。通过反复迭代这两个步骤,最终会收敛到一个局部最优解,这就是 EM 算法的一种具体实现。我们将在第 11.3 节更详细地讨论这一点。
11.2.2 更新均值
定理 11.1(GMM 均值的更新)GMM 的均值参数 \(\mu_k, k=1,\dots,K\) 的更新公式为 \[ \mu_k^{\text{new}} = \frac{\sum_{n=1}^N r_{nk} x_n}{\sum_{n=1}^N r_{nk}}, \tag{11.20} \] 其中责任值 \(r_{nk}\) 定义在公式 (11.17) 中。
注释:在公式 (11.20) 中,每个混合成分的均值 \(\mu_k\) 的更新依赖于所有均值、协方差矩阵 \(\Sigma_k\) 和混合权重 \(\pi_k\),因为它们都通过 \(r_{nk}\)(定义见 (11.17))联系起来。因此,我们无法一次性求出所有 \(\mu_k\) 的闭式解。
证明:由 (11.15) 可知,对均值参数 \(\mu_k, k=1,\dots,K\) 的对数似然函数梯度需要我们计算偏导数: \[ \frac{\partial p(x_n|\theta)}{\partial \mu_k} = \sum_{j=1}^K \pi_j \frac{\partial \mathcal{N}(x_n|\mu_j,\Sigma_j)}{\partial \mu_k} = \pi_k \frac{\partial \mathcal{N}(x_n|\mu_k,\Sigma_k)}{\partial \mu_k}, \tag{11.21a} \] 因为只有第 \(k\) 个混合成分依赖于 \(\mu_k\)。进一步得到: \[ = \pi_k (x_n - \mu_k)^\top \Sigma_k^{-1} \mathcal{N}(x_n|\mu_k,\Sigma_k). \tag{11.21b} \] 将 (11.21b) 的结果代入 (11.15),并整理后可以得到所需的对数似然函数关于 \(\mu_k\) 的偏导数: \[ \begin{align} \frac{\partial \mathcal{L}}{\partial \boldsymbol{\mu}_k} &= \sum_{n=1}^{N} \frac{\partial \log p(\mathbf{x}_n \mid \theta)}{\partial \boldsymbol{\mu}_k} \notag\\[6pt] &= \sum_{n=1}^{N} \frac{1}{p(\mathbf{x}_n \mid \theta)} \frac{\partial p(\mathbf{x}_n \mid \theta)}{\partial \boldsymbol{\mu}_k} \tag{11.22a}\\[6pt] &= \sum_{n=1}^{N} \left( \mathbf{x}_n - \boldsymbol{\mu}_k \right)^{\top} \boldsymbol{\Sigma}_k^{-1} \frac{\pi_k \mathcal{N}\!\bigl(\mathbf{x}_n \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k\bigr)} {\sum_{j=1}^{K} \pi_j \mathcal{N}\!\bigl(\mathbf{x}_n \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j\bigr)} \tag{11.22b}\\[6pt] &= \sum_{n=1}^{N} r_{nk} \left( \mathbf{x}_n - \boldsymbol{\mu}_k \right)^{\top} \boldsymbol{\Sigma}_k^{-1} \tag{11.22c} \end{align} \]
其中,\(r_{nk}\) 就是我们在 (11.17) 中定义的责任值。
我们现在解 (11.22c) 关于 \(\mu_k^{\text{new}}\),使得 \[ \frac{\partial L(\mu_k^{\text{new}})}{\partial \mu_k} = 0^\top \] 并得到 \[ \sum_{n=1}^N r_{nk} x_n = \sum_{n=1}^N r_{nk} \mu_k^{\text{new}} \;\;\Longleftrightarrow\;\; \mu_k^{\text{new}} = \frac{\sum_{n=1}^N r_{nk} x_n}{\sum_{n=1}^N r_{nk}} = \frac{1}{N_k} \sum_{n=1}^N r_{nk} x_n, \tag{11.23} \] 其中我们定义 \[ N_k := \sum_{n=1}^N r_{nk} \tag{11.24} \] 为第 \(k\) 个混合成分对整个数据集的总责任值。至此,定理 11.1 的证明完成。
直观上,(11.20) 可以解释为均值的一个带重要性权重的蒙特卡罗估计,其中数据点 \(x_n\) 的重要性权重由第 \(k\) 个簇对 \(x_n\) 的责任值 \(r_{nk}\) 给出,\(k = 1, \dots, K\)。
因此,均值 \(\mu_k\) 会被“拉向”数据点 \(x_n\),其强度由 \(r_{nk}\) 决定。当对应的混合成分对数据点具有较高责任(即较高似然)时,均值会更强烈地被该数据点所吸引。图 11.4 对此进行了说明。

我们还可以将 (11.20) 中的均值更新解释为在如下分布下所有数据点的期望: \[ r_k := \frac{[r_{1k}, \dots, r_{Nk}]^\top}{N_k}, \tag{11.25} \] 这是一个归一化的概率向量,即 \[ \mu_k \;\;\leftarrow\;\; \mathbb{E}_{r_k}[X]. \tag{11.26} \] 例 11.3(均值更新)
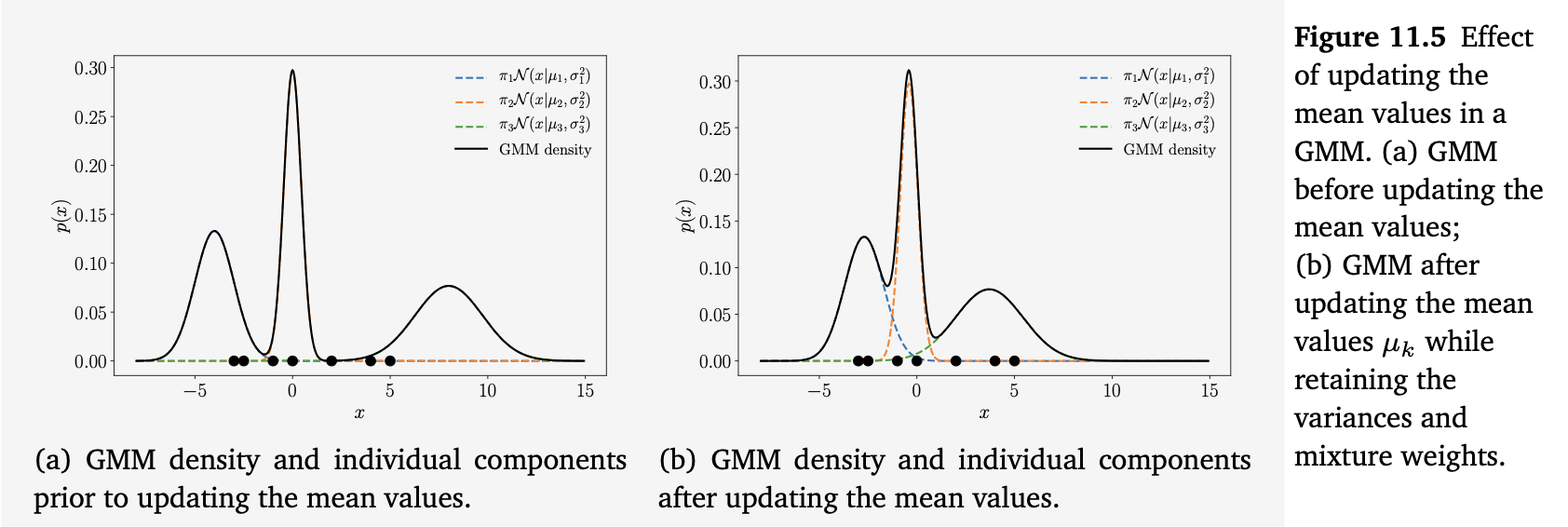
在图 11.3 的例子中,均值的更新如下: \[ \mu_1: -4 \;\to\; -2.7 \tag{11.27} \]
\[ \mu_2: 0 \;\to\; -0.4 \tag{11.28} \]
\[ \mu_3: 8 \;\to\; 3.7 \tag{11.29} \]
这里可以看到,第一个和第三个混合成分的均值向数据所在的区域移动,而第二个成分的均值变化并不显著。图 11.5 展示了这一变化,其中图 11.5(a) 显示了在均值更新之前的 GMM 密度,图 11.5(b) 显示了均值 \(\mu_k\) 更新之后的 GMM 密度。
式 (11.20) 中均值参数的更新看起来相当直接。然而,需要注意的是,责任值 \(r_{nk}\) 是 \(\pi_j, \mu_j, \Sigma_j\) (其中 \(j = 1, \dots, K\))的函数,因此 (11.20) 中的更新依赖于 GMM 的所有参数。而像我们在第 9.2 节(线性回归)或第 10 章(PCA)中得到的那种闭式解,在这里是无法得到的。
11.2.3 协方差的更新
定理 11.2(GMM 协方差的更新)GMM 中第 \(k\) 个分量的协方差参数 \(\Sigma_k, \; k = 1, \dots, K\) 的更新公式为: \[ \Sigma_k^{\text{new}} = \frac{1}{N_k} \sum_{n=1}^N r_{nk}(x_n - \mu_k)(x_n - \mu_k)^\top, \tag{11.30} \] 其中 \(r_{nk}\) 和 \(N_k\) 分别定义在 (11.17) 和 (11.24) 中。
证明 为了证明定理 11.2,我们的方法是对对数似然函数 \(L\) 关于协方差 \(\Sigma_k\) 求偏导,将其设为 0,然后解出 \(\Sigma_k\)。
首先写出一般形式: \[ \frac{\partial L}{\partial \Sigma_k} = \sum_{n=1}^N \frac{\partial \log p(x_n|\theta)}{\partial \Sigma_k} = \sum_{n=1}^N \frac{1}{p(x_n|\theta)} \frac{\partial p(x_n|\theta)}{\partial \Sigma_k}. \tag{11.31} \] 我们已经从 (11.16) 知道了 \(1/p(x_n|\theta)\)。为了得到剩余的偏导 \(\partial p(x_n|\theta)/\partial \Sigma_k\),我们写出高斯分布的定义 \(p(x_n|\theta)\)(见 (11.9)),并只保留第 \(k\) 项: \[ \frac{\partial p(x_n|\theta)}{\partial \Sigma_k} = \frac{\partial}{\partial \Sigma_k} \pi_k (2\pi)^{-\frac{D}{2}} \det(\Sigma_k)^{-\frac{1}{2}} \exp\left(-\tfrac{1}{2}(x_n - \mu_k)^\top \Sigma_k^{-1}(x_n - \mu_k)\right). \tag{11.32} \] 利用以下恒等式: \[ \frac{\partial}{\partial \Sigma_k} \det(\Sigma_k)^{-\tfrac{1}{2}} = -\tfrac{1}{2} \det(\Sigma_k)^{-\tfrac{1}{2}} \Sigma_k^{-1}, \tag{11.33} \]
\[ \frac{\partial}{\partial \Sigma_k} (x_n - \mu_k)^\top \Sigma_k^{-1} (x_n - \mu_k) = -\Sigma_k^{-1}(x_n - \mu_k)(x_n - \mu_k)^\top \Sigma_k^{-1}, \tag{11.34} \]
得到(整理后): \[ \frac{\partial p(x_n|\theta)}{\partial \Sigma_k} = \pi_k \mathcal{N}(x_n|\mu_k, \Sigma_k) \cdot \left[-\tfrac{1}{2}\big(\Sigma_k^{-1} - \Sigma_k^{-1}(x_n - \mu_k)(x_n - \mu_k)^\top \Sigma_k^{-1}\big)\right]. \tag{11.35} \] 代入 (11.31),对数似然函数关于 \(\Sigma_k\) 的偏导为: \[ \frac{\partial L}{\partial \Sigma_k} = \sum_{n=1}^N r_{nk} \cdot \left[-\tfrac{1}{2}\big(\Sigma_k^{-1} - \Sigma_k^{-1}(x_n - \mu_k)(x_n - \mu_k)^\top \Sigma_k^{-1}\big)\right], \tag{11.36} \] 其中 \(r_{nk}\) 就是责任度(见 (11.17))。
将其设为 0,得到最优条件: \[ N_k \Sigma_k^{-1} = \Sigma_k^{-1} \left(\sum_{n=1}^N r_{nk}(x_n - \mu_k)(x_n - \mu_k)^\top \right)\Sigma_k^{-1}. \tag{11.37} \] 解得: \[ \Sigma_k^{\text{new}} = \frac{1}{N_k} \sum_{n=1}^N r_{nk}(x_n - \mu_k)(x_n - \mu_k)^\top. \tag{11.38} \] 其中 \(r_k\) 是定义在 (11.25) 中的概率向量。这样就得到了一个简单的更新规则,从而证明了定理 11.2。
类似于均值更新公式 (11.20),协方差更新公式 (11.30) 可以解释为中心化数据平方的加权期望,其中权重为责任度: \[ \tilde{X}_k := \{x_1 - \mu_k, \dots, x_N - \mu_k\}. \] 也就是说,协方差是以责任值为权重的期望估计。
示例 11.4(方差更新)
在图 11.3 的例子中,方差的更新如下: \[ \sigma^2_1 : 1 \;\to\; 0.14 \tag{11.39} \]
\[ \sigma^2_2 : 0.2 \;\to\; 0.44 \tag{11.40} \]
\[ \sigma^2_3 : 3 \;\to\; 1.53 \tag{11.41} \]
在这里我们看到,第一个和第三个分量的方差显著收缩,而第二个分量的方差则略微增加。
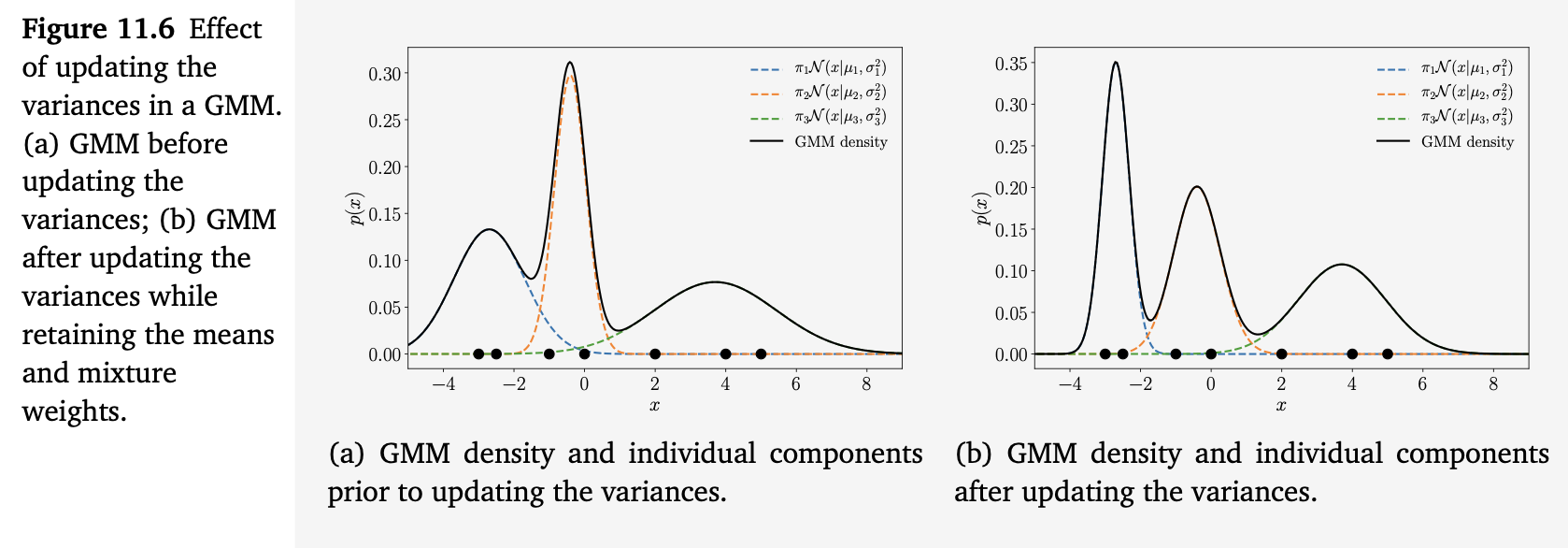
图 11.6 展示了这一情况。图 11.6(a) 与图 11.5(b) 相同(但进行了放大),显示了在更新方差之前的 GMM 密度及其各个分量。图 11.6(b) 显示了更新方差之后的 GMM 密度。
与均值参数的更新类似,我们可以将 (11.30) 理解为对与第 \(k\) 个混合分量相关的数据点 \(x_n\) 的加权协方差的蒙特卡罗估计,其中权重是责任度 \(r_{nk}\)。同样地,正如均值参数的更新,这一更新依赖于所有 \(\pi_j, \mu_j, \Sigma_j\)(\(j = 1, \ldots, K\)),通过责任度 \(r_{nk}\) 体现出来,从而使得无法得到闭式解。
个人注:Monte Carlo estimate 是什么意思?
在概率论里,一个期望可以用样本的平均值(或带权平均)来近似,这种近似就叫 Monte Carlo估计。 比如,协方差的真实定义是: \[ \text{Cov}_k = \mathbb{E}_{\mathbf{x}\sim p_k}\big[ (\mathbf{x}-\boldsymbol{\mu}_k)(\mathbf{x}-\boldsymbol{\mu}_k)^\top \big] \] 我们没有真实的 \(p_k\),只有数据 \(\mathbf{x}_n\),于是我们用样本的加权和来近似它: \[ \hat{\text{Cov}}_k = \frac{\sum_n r_{nk} (\mathbf{x}_n - \boldsymbol{\mu}_k)(\mathbf{x}_n - \boldsymbol{\mu}_k)^\top} {\sum_n r_{nk}} \] 这正是 Monte Carlo 估计的典型形式:用有限样本加权平均来近似真实分布下的期望。
11.2.4 更新混合权重
定理 11.3(GMM 混合权重的更新)。GMM 的混合权重按如下方式更新: \[ \pi^{\text{new}}_k = \frac{N_k}{N}, \quad k=1,\dots,K, \tag{11.42} \]
其中 \(N\) 是数据点的数量,\(N_k\) 定义见 (11.24)。
证明 为了求对权重参数 \(\pi_k, k=1,\dots,K\) 的对数似然函数的偏导数,我们利用拉格朗日乘子法(参见第 7.2 节)来处理约束条件 \(\sum_k \pi_k = 1\)。 拉格朗日函数为:
\[ \mathcal{L} = L + \lambda \left(\sum_{k=1}^K \pi_k - 1\right) \tag{11.43a} \]
\[ = \sum_{n=1}^N \log\left(\sum_{k=1}^K \pi_k \mathcal{N}(x_n|\mu_k,\Sigma_k)\right) + \lambda \left(\sum_{k=1}^K \pi_k - 1\right), \tag{11.43b} \]
其中 \(L\) 是 (11.10) 的对数似然,第二项表示所有混合权重之和为 1 的约束条件。
对 \(\pi_k\) 求偏导得到: \[ \begin{align} \frac{\partial \mathcal{L}}{\partial \pi_k} &= \sum_{n=1}^{N} \frac{\mathcal{N}(\mathbf{x}_n \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^{K} \pi_j \mathcal{N}(\mathbf{x}_n \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)} + \lambda \tag{11.44a}\\[1em] &= \frac{1}{\pi_k} \sum_{n=1}^{N} \frac{\pi_k \mathcal{N}(\mathbf{x}_n \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^{K} \pi_j \mathcal{N}(\mathbf{x}_n \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)} + \lambda = \frac{N_k}{\pi_k} + \lambda, \tag{11.44b} \end{align} \] 对拉格朗日乘子 \(\lambda\) 求偏导:
\[ \frac{\partial \mathcal{L}}{\partial \lambda} = \sum_{k=1}^K \pi_k - 1. \tag{11.45} \]
将两者都置为 0(最优条件)得到方程组:
\[ \pi_k = -\frac{N_k}{\lambda}, \tag{11.46} \]
\[ \sum_{k=1}^K \pi_k = 1. \tag{11.47} \]
把 (11.46) 代入 (11.47) 并解 \(\pi_k\):
\[ \sum_{k=1}^K \pi_k = 1 \quad \Leftrightarrow \quad -\frac{\sum_{k=1}^K N_k}{\lambda}=1 \quad \Leftrightarrow \quad -\frac{N}{\lambda}=1 \quad \Leftrightarrow \quad \lambda=-N. \tag{11.48} \]
于是可以将 \(-N\) 代入 (11.46),得到:
\[ \pi^{\text{new}}_k = \frac{N_k}{N}, \tag{11.49} \]
这就是权重参数 \(\pi_k\) 的更新公式,证明了定理 11.3。
我们可以将 (11.42) 中的混合权重理解为:第 \(k\) 个聚类的总责任(responsibility)占数据点总数的比例。由于 \(N=\sum_k N_k\),数据点总数也可以看作所有混合成分的总责任,因此 \(\pi_k\) 表示第 \(k\) 个混合成分对于数据集的相对重要性。
备注:由于 \(N_k=\sum_{i=1}^N r_{nk}\),(11.42) 中混合权重 \(\pi_k\) 的更新公式也通过责任值 \(r_{nk}\) 依赖于所有的 \(\pi_j,\mu_j,\Sigma_j,j=1,\dots,K\)。
例 11.5(权重参数更新) 在图 11.3 的示例中,混合权重的更新如下: \[ \pi_1 : \frac{1}{3} \rightarrow 0.29 \tag{11.50} \]
\[ \pi_2 : \frac{1}{3} \rightarrow 0.29 \tag{11.51} \]
\[ \pi_3 : \frac{1}{3} \rightarrow 0.42 \tag{11.52} \]
在这里我们可以看到,第三个分量获得了更多的权重/重要性,而其他分量则稍微变得不那么重要。图 11.7 说明了更新混合权重的效果。图 11.7(a) 与图 11.6(b) 完全相同,展示了在更新混合权重之前的 GMM 密度及其各个分量。图 11.7(b) 则展示了更新混合权重之后的 GMM 密度。
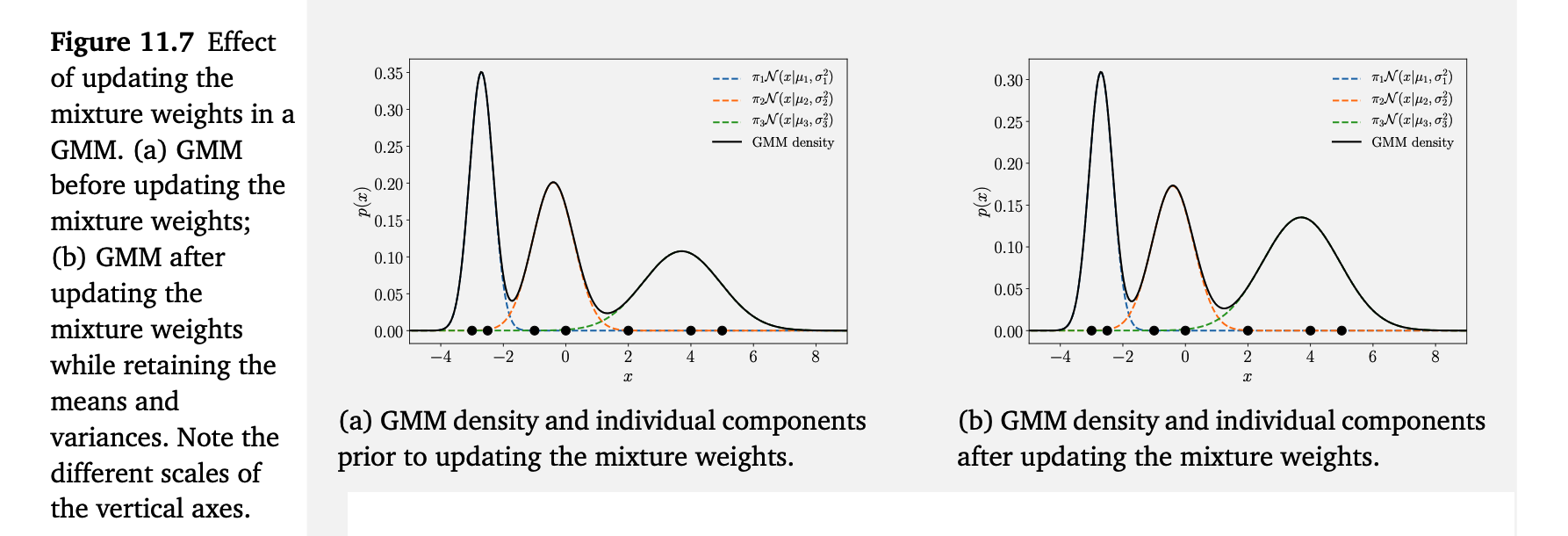
总体而言,当均值、方差以及权重都更新过一次之后,我们得到图 11.7(b) 所示的 GMM。与图 11.3 的初始化相比,我们可以看到,参数更新使 GMM 的密度把部分概率质量向数据点方向移动。
在均值、方差和权重都更新过一次之后,图 11.7(b) 中的 GMM 拟合效果已经明显优于图 11.3 中的初始化。这一点也从对数似然值可以看出:从初始化时的 −28.3 提升到了完整更新循环后的 −14.4。
11.3 EM 算法
不幸的是,(11.20)、(11.30) 和 (11.42) 中的更新并不能构成混合模型参数 \(\mu_k, \Sigma_k, \pi_k\) 的一个闭式解,因为职责(responsibilities)\(r_{nk}\) 以复杂的方式依赖于这些参数。不过,这些结果提示了一个简单的迭代方案,可以通过极大似然来求解参数估计问题。期望最大化算法(EM 算法)由 Dempster 等人(1977)提出,是一种通用的迭代方法,用于在混合模型以及更一般的潜变量模型中学习参数(极大似然或 MAP)。在高斯混合模型的例子中,我们选择 \(\mu_k, \Sigma_k, \pi_k\) 的初始值,并在下述两步之间交替迭代直至收敛:
- E 步(Expectation step):计算职责 \(r_{nk}\)(即数据点 \(n\) 属于混合分量 \(k\) 的后验概率)。
- M 步(Maximization step):利用更新后的职责重新估计参数 \(\mu_k, \Sigma_k, \pi_k\)。
EM 算法的每一步都会使对数似然函数增加(Neal 和 Hinton,1999)。为了判断收敛,我们可以检查对数似然值或直接检查参数的变化。
一个具体的 EM 算法用于估计 GMM 的参数如下:
初始化 \(\mu_k, \Sigma_k, \pi_k\)。
E 步:使用当前参数 \(\pi_k, \mu_k, \Sigma_k\) 计算每个数据点 \(x_n\) 的职责 \(r_{nk}\):
\[ r_{nk} = \frac{\pi_k \,\mathcal{N}(x_n|\mu_k,\Sigma_k)} {\sum_j \pi_j \,\mathcal{N}(x_n|\mu_j,\Sigma_j)} \tag{11.53} \]
- M 步:利用 E 步得到的职责 \(r_{nk}\) 重新估计参数 \(\pi_k, \mu_k, \Sigma_k\):
\[ \mu_k = \frac{1}{N_k}\sum_{n=1}^{N} r_{nk}x_n \tag{11.54} \]
\[ \Sigma_k = \frac{1}{N_k}\sum_{n=1}^{N} r_{nk}(x_n-\mu_k)(x_n-\mu_k)^\top \tag{11.55} \]
\[ \pi_k = \frac{N_k}{N} \tag{11.56} \]
例 11.6(GMM 拟合)
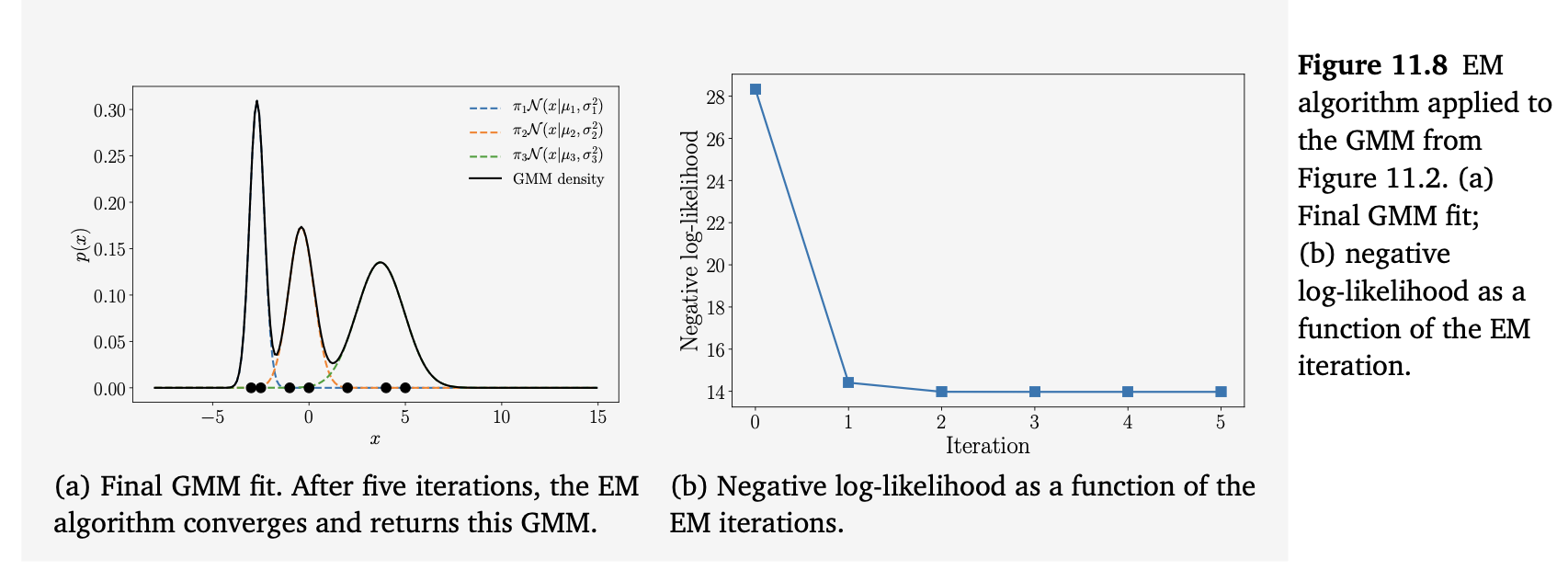
当我们在图 11.3 的例子上运行 EM 算法时,经过 5 次迭代,我们得到的最终结果如图 11.8(a) 所示;图 11.8(b) 则显示了负对数似然随 EM 迭代次数的变化情况。最终的 GMM 表达式为
\[ p(x) = 0.29\,\mathcal{N}(x|-2.75, 0.06) + 0.28\,\mathcal{N}(x|-0.50, 0.25) + 0.43\,\mathcal{N}(x|3.64, 1.63) \tag{11.57} \]
我们将 EM 算法应用到图 11.1 所示的二维数据集上,设混合分量数 \(K=3\)。图 11.9 展示了 EM 算法的一些步骤,并显示了负对数似然随 EM 迭代次数的变化(图 11.9(b))。图 11.10(a) 展示了最终的 GMM 拟合结果。图 11.10(b) 可视化了在 EM 收敛时混合分量对各个数据点的最终职责(responsibilities)。
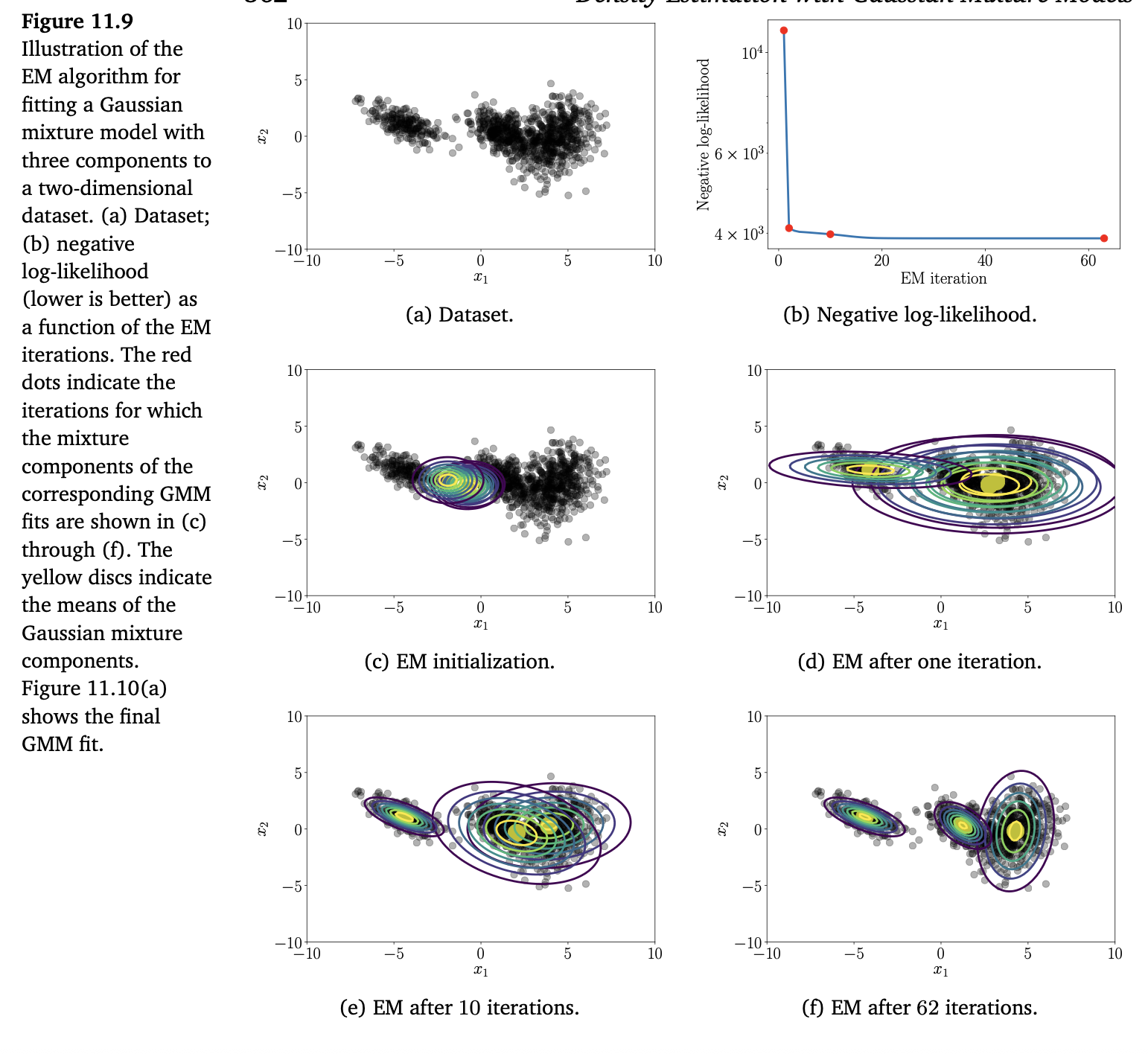
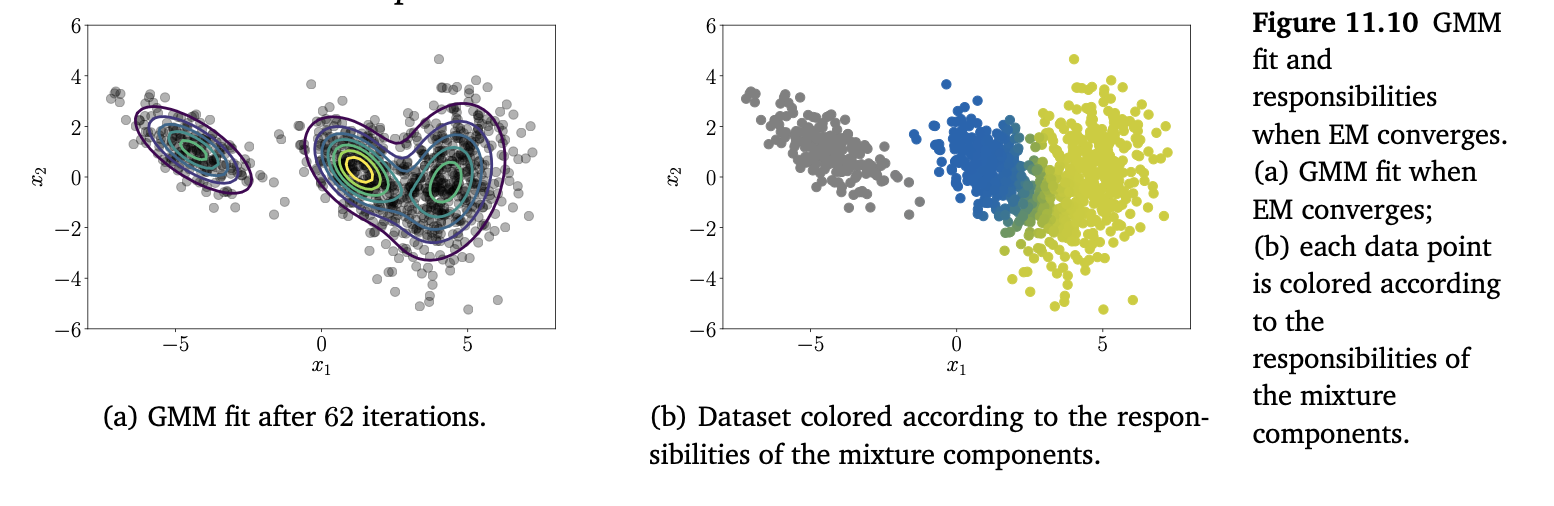
数据集按照混合分量的职责进行着色。左侧的数据显然主要由单一的混合分量负责,而右侧两个数据簇的重叠部分可能由两个混合分量生成。可以清楚地看到,有些数据点无法唯一地分配给单个分量(既非完全蓝色也非完全黄色),因此这两个簇对这些点的职责大约是 0.5。
11.4 潜变量视角
我们可以从离散潜变量模型的角度来看待 GMM(高斯混合模型),即潜变量 \(z\) 只能取有限个值。这与 PCA 形成对比:在 PCA 中,潜变量是 \(\mathbb{R}^M\) 中的连续值。从概率视角来看有以下优点: (i) 它能对我们在前面章节中做出的一些临时性(ad hoc)决定进行合理化; (ii) 它允许我们将责任度(responsibilities)解释为后验概率; (iii) 更新模型参数的迭代算法可以以一种有原则的方式导出,即作为潜变量模型中最大似然参数估计的 EM 算法。
11.4.1 生成过程与概率模型
为了推导 GMM 的概率模型,把它看作生成过程是有用的,也就是使用一个概率模型生成数据的过程。
我们假设一个具有 \(K\) 个成分的混合模型,并且一个数据点 \(x\) 由其中恰好一个混合成分生成。我们引入一个二元指示变量 \(z_k \in \{0,1\}\)(见第 6.2 节),用以指示第 \(k\) 个混合成分是否生成了该数据点,使得:
\[ p(x|z_k=1)=\mathcal{N}\bigl(x\mid \mu_k,\Sigma_k\bigr). \tag{11.58} \]
个人注:式 (11.58) 并非从别的式子推导,而是模型的条件分布定义——“若隐藏变量指示第 \(k\) 个分量被选中,则 \(x\) 就从该分量的高斯分布中产生”。
我们定义 \[ z := [z_1,\ldots,z_K]^\top \in \mathbb{R}^K \]
为一个概率向量,它包含 \(K-1\) 个 0 和恰好一个 1。例如,当 \(K=3\) 时,一个合法的 \(z\) 可以是
\[ z=[z_1,z_2,z_3]^\top=[0,1,0]^\top, \]
这就选择了第二个混合成分,因为 \(z_2=1\)。
注:这种概率分布有时称为“多项伯努利分布(multinoulli)”,是伯努利分布向两个以上值的推广(Murphy,2012)。
由 \(z\) 的性质可知
\[ \sum_{k=1}^K z_k =1。 \]
因此,\(z\) 是一种独热编码(one-hot encoding,也叫 1-of-K 表示)。
到目前为止,我们假设指示变量 \(z_k\) 是已知的。然而在实际中并非如此,因此我们对潜变量 \(z\) 施加先验分布:
\[ p(z)=\pi=[\pi_1,\ldots,\pi_K]^\top,\quad \sum_{k=1}^K \pi_k=1。 \tag{11.59} \]
其中第 \(k\) 个分量
\[ \pi_k=p(z_k=1) \tag{11.60} \]
描述了第 \(k\) 个混合成分生成数据点 \(x\) 的概率。
注(从 GMM 采样)这种潜变量模型的构造(见图 11.11 中对应的图形模型)自然地导出一个非常简单的采样过程(生成过程)来生成数据:
- 从 \(p(z)\) 中采样 \(z^{(i)}\)。
- 从 \(p\bigl(x\mid z^{(i)}=1\bigr)\) 中采样 \(x^{(i)}\)。
在第一步,我们根据 \(p(z)=\pi\) 随机选择一个混合成分 \(i\)(通过 one-hot 编码 \(z\));在第二步,我们从对应的混合成分中抽取一个样本。当我们丢弃潜变量的样本,仅保留 \(x^{(i)}\) 时,我们就得到了来自 GMM 的有效样本。这种采样方式,即随机变量的样本依赖于其在图模型中父节点的样本,被称为祖先采样(ancestral sampling)。
一般地,一个概率模型是由数据和潜变量的联合分布定义的(见第 8.4 节)。结合 (11.59)、(11.60) 中的先验 \(p(z)\) 以及 (11.58) 中的条件分布 \(p(x|z)\),我们得到该联合分布的所有 \(K\) 个成分:
\[ p(x,z_k=1)=p(x|z_k=1)p(z_k=1)=\pi_k\mathcal{N}\bigl(x\mid \mu_k,\Sigma_k\bigr)\tag{11.61} \]
其中 \(k=1,\ldots,K\),因此
\[ p(x,z)= \begin{bmatrix} p(x,z_1=1)\\ \vdots\\ p(x,z_K=1) \end{bmatrix} = \begin{bmatrix} \pi_1\mathcal{N}\bigl(x\mid \mu_1,\Sigma_1\bigr)\\ \vdots\\ \pi_K\mathcal{N}\bigl(x\mid \mu_K,\Sigma_K\bigr) \end{bmatrix} \tag{11.62} \]
这就完全刻画了该概率模型。
11.4.2 似然
为了在潜变量模型中得到似然 \(p(x|\theta)\),我们需要把潜变量积分(求和)掉(见第 8.4.3 节)。在我们的例子中,可以通过对 (11.62) 中的联合分布 \(p(x,z)\) 对所有潜变量求和得到:
\[ p(x|\theta)=\sum_{z}p(x|\theta,z)p(z|\theta), \quad \theta:=\{\mu_k,\Sigma_k,\pi_k: k=1,\ldots,K\}. \tag{11.63} \]
这里我们显式地对概率模型的参数 \(\theta\) 进行了条件化,而在之前省略了这一点。 在 (11.63) 中,我们对所有 \(K\) 种可能的 one-hot 编码 \(z\) 求和(记作 \(\sum_z\))。因为每个 \(z\) 中只有一个非零条目,所以 \(z\) 只有 \(K\) 种可能的配置。例如,当 \(K=3\) 时,\(z\) 的配置可以是: \[ \begin{bmatrix}1\\0\\0\end{bmatrix},\quad \begin{bmatrix}0\\1\\0\end{bmatrix},\quad \begin{bmatrix}0\\0\\1\end{bmatrix}. \tag{11.64} \]
对 (11.63) 中所有可能的 \(z\) 求和等价于取 \(z\)-向量中非零的那个位置并写成:
\[ p(x|\theta)=\sum_{z}p(x|\theta,z)p(z|\theta)\tag{11.65a} \]
\[ =\sum_{k=1}^K p(x|\theta,z_k=1)p(z_k=1|\theta)\tag{11.65b} \]
从而所需的边缘分布为:
\[ p(x|\theta)=\sum_{k=1}^K p(x|\theta,z_k=1)p(z_k=1|\theta)\tag{11.66a} \]
\[ =\sum_{k=1}^K \pi_k\mathcal{N}\bigl(x\mid \mu_k,\Sigma_k\bigr), \tag{11.66b} \]
我们可以把它识别为 (11.3) 中的 GMM 模型。给定一个数据集 \(X\),我们立刻得到其似然:
\[ p(X|\theta)=\prod_{n=1}^N p(x_n|\theta) =\prod_{n=1}^N \sum_{k=1}^K \pi_k\mathcal{N}\bigl(x_n\mid \mu_k,\Sigma_k\bigr). \tag{11.67} \]
这正是 (11.9) 中的 GMM 似然。因此,带有潜在指示变量 \(z_k\) 的潜变量模型,是理解高斯混合模型的一个等价方式。
11.4.3 后验分布
我们简单看一下潜在变量 \(z\) 的后验分布。根据贝叶斯定理,第 \(k\) 个分量生成数据点 \(x\) 的后验为
\[ p(z_k = 1 \mid x)=\frac{p(z_k=1)p(x\mid z_k=1)}{p(x)} \tag{11.68} \]
其中边际分布 \(p(x)\) 在 (11.66b) 中给出。这就得到了第 \(k\) 个指示变量 \(z_k\) 的后验分布:
\[ p(z_k = 1 \mid x)=\frac{p(z_k=1)p(x\mid z_k=1)} {\sum_{j=1}^K p(z_j=1)p(x\mid z_j=1)} =\frac{\pi_k\mathcal{N}(x\mid\mu_k,\Sigma_k)} {\sum_{j=1}^K\pi_j\mathcal{N}(x\mid\mu_j,\Sigma_j)} \tag{11.69} \]
我们把它识别为第 \(k\) 个混合成分对数据点 \(x\) 的“责任”。注意我们省略了对 GMM 参数 \(\pi_k,\mu_k,\Sigma_k\) (\(k=1,\dots,K\))的显式条件。
11.4.4 扩展到整个数据集
到目前为止,我们只讨论了数据集只包含单个数据点 \(x\) 的情形。然而,先验和后验的概念可以直接扩展到 \(N\) 个数据点的情况 \(X=\{x_1,\dots,x_N\}\)。在 GMM 的概率解释中,每个数据点 \(x_n\) 都有自己的潜在变量
\[ z_n=[z_{n1},\dots,z_{nK}]^\top\in\mathbb{R}^K \tag{11.70} \]
之前(当我们只考虑一个数据点 \(x\) 时)我们省略了下标 \(n\),但现在它变得重要了。
我们在所有潜在变量 \(z_n\) 上共享相同的先验分布 \(\pi\)。对应的图模型如图 11.12 所示,我们使用了 plate 符号。
条件分布 \(p(x_1,\dots,x_N\mid z_1,\dots,z_N)\) 在数据点上是可分解的:
\[ p(x_1,\dots,x_N\mid z_1,\dots,z_N)=\prod_{n=1}^N p(x_n\mid z_n) \tag{11.71} \]
为了得到后验分布 \(p(z_{nk}=1\mid x_n)\),我们像 11.4.3 节一样应用贝叶斯定理得到:
$$ \[\begin{align} p(z_{nk} = 1 \mid \boldsymbol{x}_n) & = \frac{p(\boldsymbol{x}_n \mid z_{nk} = 1) p(z_{nk} = 1)}{\sum_{j=1}^{K} p(\boldsymbol{x}_n \mid z_{nj} = 1) p(z_{nj} = 1)} \tag{11.72a} \\ & = \frac{\pi_k \mathcal{N}(\boldsymbol{x}_n \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)}{\sum_{j=1}^{K} \pi_j \mathcal{N}(\boldsymbol{x}_n \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)} = r_{nk}. \tag{11.72b} \end{align}\] $$
这意味着 \(p(z_k=1\mid x_n)\) 是第 \(k\) 个混合成分生成数据点 \(x_n\) 的(后验)概率,并对应于我们在 (11.17) 中引入的责任 \(r_{nk}\)。现在这些责任不仅有了直观含义,而且也有了作为后验概率的数学解释。
11.4.5 EM 算法再探
我们前面介绍过 EM 算法,作为最大似然估计的一种迭代方案;其实,它可以从潜在变量的视角以一种更有原则的方法推导出来。给定模型参数的当前设置 \(\theta^{(t)}\),E 步计算期望对数似然: \[ Q(\theta|\theta^{(t)}) = \mathbb{E}_{z|x,\theta^{(t)}}[\log p(x,z|\theta)] \tag{11.73a} \]
\[ = \int \log p(x,z|\theta)\,p(z|x,\theta^{(t)})\,dz \tag{11.73b} \]
其中 \(\log p(x,z|\theta)\) 的期望是关于潜在变量的后验 \(p(z|x,\theta^{(t)})\) 取的。M 步则通过最大化式 (11.73b) 来选择更新后的模型参数 \(\theta^{(t+1)}\)。
虽然每次 EM 迭代都会增加对数似然,但并没有保证 EM 会收敛到最大似然解。EM 算法有可能收敛到对数似然的局部最大值。为了减少陷入糟糕局部最优的风险,可以在多次 EM 运行中使用不同的 \(\theta\) 初始值。我们在此不作进一步展开,读者可以参考 Rogers 和 Girolami (2016) 以及 Bishop (2006) 的精彩阐述。
11.5 延伸阅读
高斯混合模型(GMM)可以被视为生成式模型,因为可以很容易地通过祖先采样来生成新数据(Bishop, 2006)。给定 GMM 的参数 \(\pi_k,\mu_k,\Sigma_k, k=1,\ldots,K\),我们先从概率向量 \([\pi_1,\ldots,\pi_K]^\top\) 中采样一个索引 \(k\),再从正态分布 \(x \sim \mathcal{N}(\mu_k,\Sigma_k)\) 中采样一个数据点。如果重复该过程 \(N\) 次,就能得到一个由 GMM 生成的数据集。图 11.1 就是用这种方法生成的。
在本章中,我们始终假设混合成分数 \(K\) 是已知的。但在实践中往往不是这样。我们可以用 8.6.1 节讨论过的嵌套交叉验证来寻找合适的模型。高斯混合模型与 K-means 聚类算法密切相关。K-means 同样使用 EM 算法将数据点分配到簇。如果把 GMM 中的均值视为聚类中心并忽略协方差(或设为 \(I\)),就得到 K-means。正如 MacKay (2003) 所描述的,K-means 对数据点作“硬”分配到簇中心 \(\mu_k\),而 GMM 则通过责任值作“软”分配。
我们只略微涉及了 GMM(高斯混合模型)和 EM 算法的潜在变量视角。需要注意的是,EM 算法可以用于一般潜在变量模型的参数学习,例如非线性状态空间模型(Ghahramani 和 Roweis, 1999;Roweis 和 Ghahramani, 1999)以及 Barber (2012) 讨论的强化学习。因此,从潜在变量的角度理解 GMM,有助于以更有原则的方法推导出对应的 EM 算法(Bishop, 2006;Barber, 2012;Murphy, 2012)。
我们只讨论了通过 EM 算法进行最大似然估计来求解 GMM 参数。对最大似然的标准批评同样适用于此处:
- 就像在线性回归中一样,最大似然可能会出现严重的过拟合。在 GMM 情形下,当某个混合成分的均值恰好与某个数据点重合且协方差趋于 0 时,就会发生这种情况。此时似然值趋于无穷大。Bishop (2006) 和 Barber (2012) 对这一问题有详细讨论。
- 我们只得到参数 \(\pi_k,\mu_k,\Sigma_k, k=1,\ldots,K\) 的点估计,这并不能反映参数值的不确定性。贝叶斯方法会对参数施加先验,从而得到参数的后验分布。这个后验可以用来计算模型证据(即边际似然),并可用于模型比较,从而以更有原则的方式确定混合成分的个数。不幸的是,在此模型中没有共轭先验,因此无法得到封闭形式的推断。但可以使用近似方法(如变分推断)来获得参数后验的近似(Bishop, 2006)。
本章我们讨论了用于密度估计的混合模型。可用的密度估计技术非常多。在实际中,我们常使用直方图和核密度估计。直方图提供了一种非参数方式来表示连续密度,最早由 Pearson (1895) 提出。直方图的构建方法是对数据空间进行“分箱”,并统计每个箱中有多少数据点。然后在每个箱的中心画出一个矩形柱,其高度与该箱内数据点的数量成正比。箱宽是一个关键的超参数,不合适的选择会导致过拟合或欠拟合。可以通过第 8.2.4 节讨论过的交叉验证来确定一个合适的箱宽。核密度估计是由 Rosenblatt (1956) 和 Parzen (1962) 各自独立提出的一种非参数密度估计方法。给定 \(N\) 个独立同分布样本,核密度估计器将底层分布表示为
\[ p(x) = \frac{1}{Nh}\sum_{n=1}^{N} k\!\left(\frac{x-x_n}{h}\right) \tag{11.74} \]
其中 \(k\) 是核函数,即一个非负且积分为 1 的函数,\(h>0\) 是平滑/带宽参数,它的作用类似于直方图的箱宽。注意,我们对数据集中每一个样本点 \(x_n\) 都放置了一个核。常用的核函数有均匀分布核和高斯核。核密度估计与直方图密切相关,但通过选择合适的核函数,我们可以保证密度估计的平滑性。图 11.13 展示了在一个包含 250 个数据点的数据集上,直方图与高斯核密度估计的差异。
