《TensorFlow机器学习》读书笔记

之前买错了《漫步华尔街》,现在补买回来这本书。本书有点哲学书的味道,讲了很多的人生,可以称之为轻哲学。
本书的核心思想是概率论,而概率论的核心是随机性、非对称、非线形,在生活和社会经济领域皆如此。
点题: 


学习方法
本来是要买塔勒布的《随机漫步的傻瓜》,错买成了这本书。不过作为一部不错的股市、债券、期货、期权入门的书倒还不错。
一定要明白,所谓原则、道理其实都是统计学意义上的合理性,真正的个体并不一定。
股票无非是关注价值还是价格,而价值又可以细分为关注当前价值还是未来价值(增长、成长性),价格关注的是人的心理(普通大众的心理预期),关键是否有人愿意出更高的价格。价值的难点在于需要很高的专业知识和洞察力。
经济发展->民众手中有钱->投资渠道少->从众->泡沫形成
恐慌情绪就像病毒,或者说开闸的洪水,很难软着陆。
就像气球,吹大的时候有个过程,当泄气是一瞬间的事情。上升像爬楼梯,下降像坐电梯。
面对未来的时机选择,风险管理。
巴菲特:价值投资,在别人恐惧时贪婪,在别人贪婪时恐惧。
投资需要平衡很多基本问题,面面俱到,又有机统一。


几何学最早是丈量世界而诞生,从而抽象了现实的世界。
一个人想要谈论某个事物,前提是他必须弄清楚该事物的定义。定义和概念是很重要的,于数学及现实皆然。
学几何学的是其中的逻辑思想,特别是欧几里得几何的研究问题的方法。整个体系的建设,从几个不证自明的公理出发,通过推理、演绎,建立相关的定理、命题,搭建了整个壮丽的几何学大厦。基于不同的公理可以构建不同的几何体系,例如欧氏几何和非欧几何。
数学有很大一部分作用在于,厘清哪些事物是我们暂时或者永远都不用关心的,这种选择性注意是人类理性的基本组成部分。这其实也是抽象的过程,抽象就是省略细节,关注你研究重点的过程,例如算术关注的是数量,而事物的本身是什么并不重要;而拓扑学(庞加莱创立,研究洞的问题)关注的是形状,大小、距离反而不关心;而物理关心的是位置和速度;欧氏几何研究的是长度、面积等不变量。
其实就是考虑研究的特征,把形同特征的事物归类为同一事物,也是一种抽象的过程。
庞加莱:数学是一门给不同事物赋予相同的名称的艺术。
很早就看完的一本书,吴军写的,放车上,一直没有做笔记,书套都找不到了
:),今天在咖啡厅就顺便做了,不过可能经济不景气的原因,咖啡厅的人倒是很少。
本书副标题“世界永远不缺聪明人”,一本心灵鸡汤汇编而成的书,有点像《论语》,主要是教做人的道理。想起赵普的半部论语治天下,这本书倒也可以放车上,偶尔看看。
例如现在的新能源?


一本比较别具一格的经济类的书,一共四本(佩服作者这么多口水),以案例为出发点,引出经济学的知识。很多观点还是别具一格,令人耳目一新,从常人想不到的角度提出一些新的、还挺有道理的观点。不过因为是以案例为主,整书知识显得有点凌乱,不够系统。
茶余饭后消遣看看可以,猎奇一下。想真正的系统的了解学习经济学就帮不上忙了。
道德代表了人类希望这个世界应该如何运转,而经济学则代表着其实际的运转方式。
经济学,从根本而言,是一门研究动机的学科:人如何得偿所愿或满足所需,尤其是其他人欲求相同的情况下。
人的动机分三大类:总体来说是利己、趋利避害。因为价值观不同,在面临三者的取舍时,不同人会做出不同的选择,例如海瑞会选择道德一样,所以说传统经济学中提出的经济人是理性的(经济动机),是不完全的。
信息就是权力、就是资源。互联网的作用本质上是消除了信息差。有句话说,领导的主要权力就是信息,领导往往比下面人的信息更多,更充分。
有时面对专家的咨询反而加剧了信息的不对称现象,因为专家会利用手中的信息资源优势来获取利益。或者利用信息差来制造恐惧心理,创造需求。
不说假话,但真话不说全,也是一种利用信息不对称获得优势地位的手段。
2022年9月份看的一本书,现在补上读书心得。
思考,个人如何面对经济危机?国家、企业呢?不同层级应该有不同的对策。
一本关于统计学的普及类书籍,从宏观上介绍了统计学的主要概念和关键的原理。写得通俗易懂,作为一本入门的了解统计学的书籍来说还是不错的。
本书的主要目的是需要明白数学在生活中的意义,所以很多的例子是结合生活中的实际场景来展开的,使统计学的概念变得更加直观和便于理解。确实是,学习一门课程,考虑生活意义,从生活意义出发是让学生提高兴趣的最好的方法,避免一开始就进入枯燥的定理和公式,只会劝退大部分的学生。
统计学中重要的区分因果关系和相关性(具有统计学意义)。
从抽样数据来解决大问题。统计学的一个核心功能就是使用手中已有的数据进行合理推测,以回答那些我们还未掌握所有信息的“大”问题。简而言之,我们能够使用“已知世界”的数据来对“未知世界”进行推断。
平均数、中位数、四分位数等。
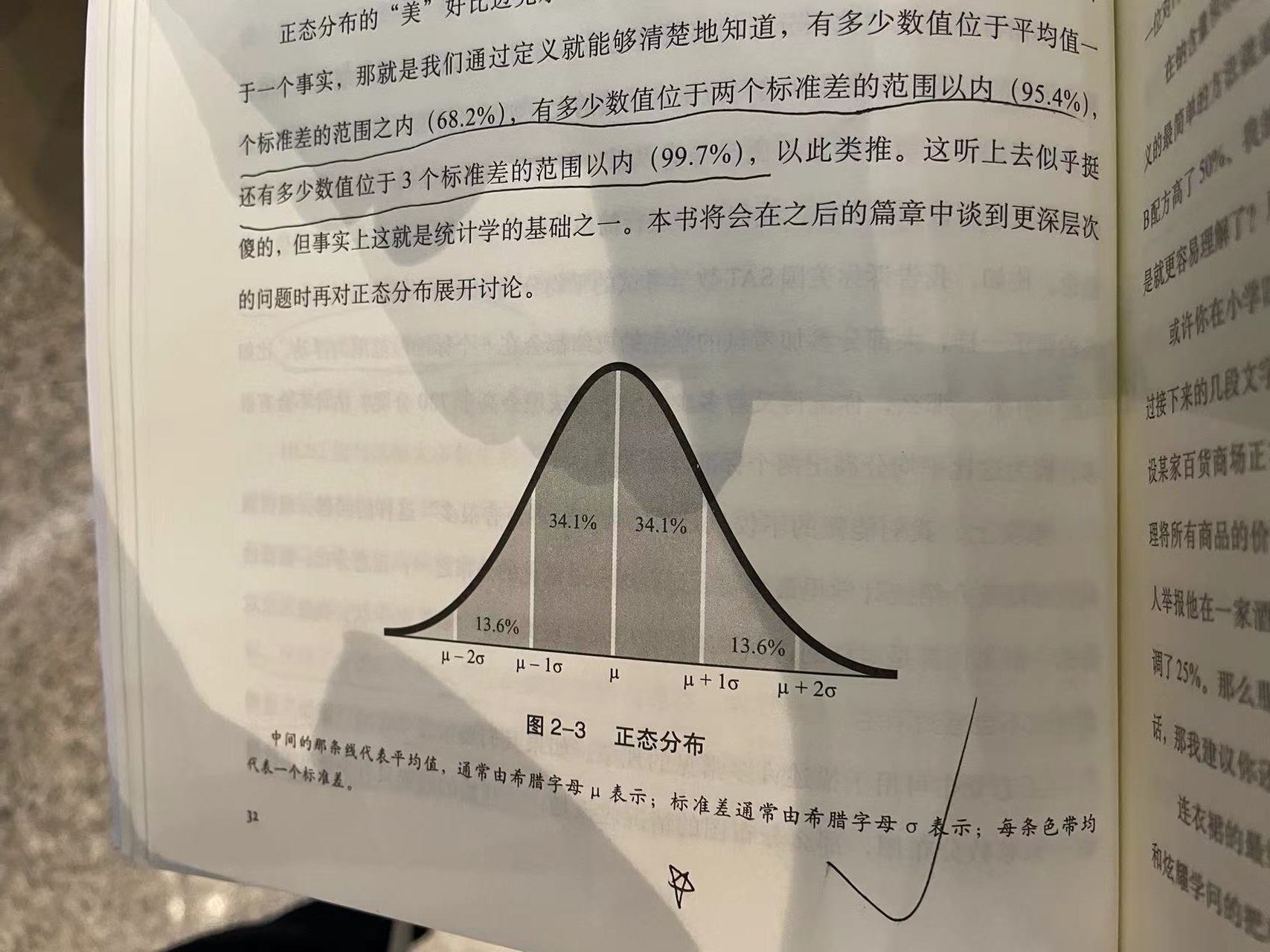
标准差也是一个能让我们在一堆杂乱无章的数字中发现真理的统计数值。我们用它来衡量数据相对于平均值的分散程度,根据标准差,我们可以知道所有观察数值的分散情况。
标准差和方差。