统计量的选择判断
《Practical
Statistics for Data Scientists》书籍英文版
《面向数据科学家的实用统计学》中文版书籍
统计推断里的一个核心问题,“该用哪个统计量”? 主要取决于 数据类型(连续/分类)、样本大小、已知信息(总体方差是否已知)以及 要检验的问题。 下面是一个常用的判断思路:
《Practical
Statistics for Data Scientists》书籍英文版
《面向数据科学家的实用统计学》中文版书籍
统计推断里的一个核心问题,“该用哪个统计量”? 主要取决于 数据类型(连续/分类)、样本大小、已知信息(总体方差是否已知)以及 要检验的问题。 下面是一个常用的判断思路:
《Practical
Statistics for Data Scientists》书籍英文版
《面向数据科学家的实用统计学》中文版书籍
在理解线性回归中系数的t统计量之前,我们首先要知道这个统计量的作用:它用来检验某个自变量对因变量的影响是否具有统计显著性。
简单来说,t统计量回答了这个问题:“这个自变量的系数,真的不为零吗?”
线性回归中每个系数的t统计量,都是通过一个简单的公式计算出来的:
\(t = \frac{\text{估计的系数}}{\text{系数的标准误}}\)
《Practical
Statistics for Data Scientists》书籍英文版
《面向数据科学家的实用统计学》中文版书籍
在对样本做t检验时,背后没有使用自助法(bootstrap)抽样。
t检验是一种参数假设检验,其核心是基于一些严格的统计假设来工作的,例如: * 样本独立性:数据点是相互独立的。 * 正态性:样本数据来自一个呈正态分布的总体。 * 方差齐性:如果进行双样本t检验,两个总体的方差是相等的(对于独立样本t检验,这一假设不是必须的,但通常会影响选择哪种t检验)。
t检验的原理是计算一个t统计量,然后将这个统计量与t分布的临界值进行比较,以确定样本数据是否提供了足够的证据来拒绝原假设。这个过程完全依赖于t分布的理论性质,而不是通过重复抽样来构建经验分布。
在许多情况下,我们希望机器学习算法能够预测若干(离散)结果中的一个。例如,电子邮件客户端会将邮件分为个人邮件和垃圾邮件,这就有两个结果。另一个例子是望远镜识别夜空中的天体是星系、恒星还是行星。通常结果的数量较少,更重要的是,这些结果之间往往没有额外的结构。 在本章中,我们考虑输出二元值的预测器,也就是说,只有两种可能的结果。这种机器学习任务称为二分类(binary classification)。这与第 9 章形成对比,当时我们讨论的是连续值输出的预测问题。对于二分类,标签/输出可以取的值是二元的,本章中我们用 {+1,−1} 表示。换句话说,我们考虑的预测器形式为 \[ f:\mathbb{R}^D \to \{+1,-1\}. \tag{12.1} \]
回忆第 8 章,我们用 \(D\) 个实数的特征向量表示每个样本(数据点)\(x_n\)。标签通常分别称为正类(positive class)和负类(negative class)。但应当注意,不要根据“正”或“负”字面意义推断+1类的直观属性。例如,在癌症检测任务中,有癌症的患者往往被标记为+1。原则上可以使用任何两个不同的值,例如{True,False}、{0,1}或{red,blue}。二分类问题研究得比较充分,其他方法的综述我们放到 12.6 节再介绍。我们将介绍一种称为支持向量机(Support Vector Machine, SVM)的方法,它用于解决二分类任务。与回归类似,这是一个监督学习任务:我们有一组样本 \(x_n \in \mathbb{R}^D\),以及对应的(二元)标签 \(y_n \in \{+1,-1\}\)。给定一个包含样本–标签对 \(\{(x_1,y_1),\dots,(x_N,y_N)\}\) 的训练数据集,我们希望估计模型参数,使分类错误率最小。类似第 9 章,我们考虑线性模型,并把非线性隐藏在对样本的一个变换 \(\phi\) 中(见式(9.13))。我们将在 12.4 节重新讨论 \(\phi\)。
支持向量机(SVM)在许多应用中都能提供最先进的结果,并且具有坚实的理论保证(Steinwart 和 Christmann, 2008)。我们之所以选择用 SVM 来说明二分类问题,主要有两个原因。
首先,SVM 提供了一种几何方式来思考监督学习问题。 在第 9 章中,我们是从概率模型的角度来看待机器学习问题,并用极大似然估计和贝叶斯推断来解决。而在这里,我们考虑一种替代的方法,即从几何角度来推理机器学习任务。这种方法高度依赖于我们在第 3 章讨论过的内积和投影等概念。
第二个原因是,与第 9 章不同,SVM 的优化问题没有解析解,因此需要借助第 7 章介绍的各种优化工具。 SVM 对机器学习的理解与第 9 章的极大似然方法存在细微的差异:极大似然方法是基于数据分布的概率观点提出一个模型,再由此推导出一个优化问题;而 SVM 的方法则是从几何直觉出发,先设计一个需要在训练过程中被优化的函数。我们已经在第 10 章看到过类似的情况,当时我们从几何原理出发推导了 PCA。在 SVM 的例子中,我们通过设计一个损失函数来度量训练数据上的误差,并遵循经验风险最小化原则(第 8.2 节),在训练中加以最小化。
Density Estimation with Gaussian Mixture Models
在前几章中,我们已经讨论了机器学习中的两个基本问题:回归(第 9 章)和降维(第 10 章)。在本章中,我们将探讨机器学习的第三个支柱:密度估计。在这一过程中,我们会引入一些重要的概念,例如期望最大化(EM)算法,以及通过混合模型来理解密度估计的潜在变量视角。
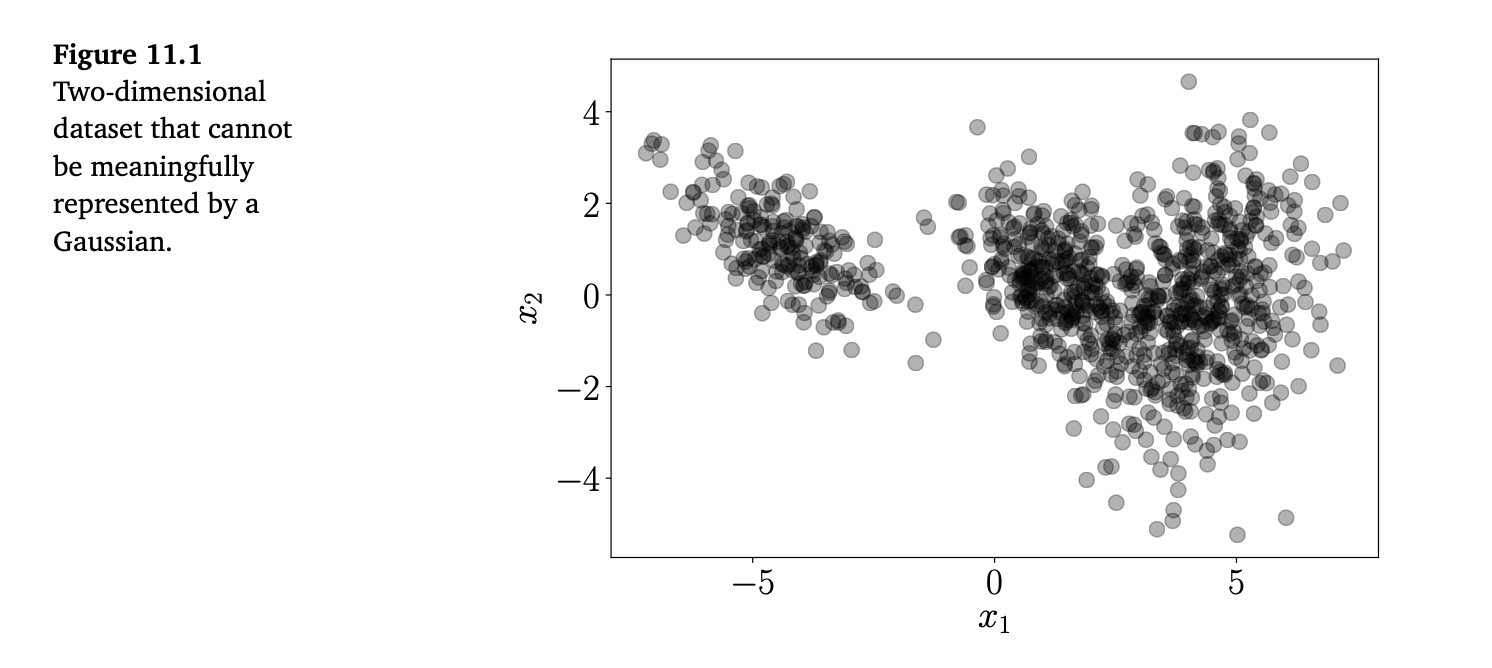
当我们将机器学习应用于数据时,往往希望以某种方式来表示数据。一个直接的方法就是将数据点本身作为数据的表示;例如见图 11.1。 然而,如果数据集非常庞大,或者我们更关心数据的整体特征,那么这种方式可能就不太有用了。在密度估计中,我们通过使用某个参数化分布族中的分布(例如高斯分布或 Beta 分布),来紧凑地表示数据。比如,我们可能希望通过数据集的均值和方差,用一个高斯分布来进行紧凑表示。均值和方差可以通过第 8.3 节讨论的工具(最大似然估计或最大后验估计)来求得。接着,我们就可以用这个高斯分布的均值和方差来表示数据背后的分布,即我们认为该数据集是从这个分布中采样得到的一次典型实现。
个人注:高斯混合模型的密度估计是一种表示数据的方法!其实也是一种建模,因为这个分布就是对应该类数据的模型表达。
Dimensionality Reduction with Principal Component Analysis
直接处理高维数据(例如图像)会带来一些困难:它很难分析、难以解释、几乎无法可视化,并且(从实际角度来看)存储这些数据向量的代价可能很高。然而,高维数据往往具有一些可以利用的性质。例如,高维数据通常是 过完备的(overcomplete),即许多维度是冗余的,可以由其他维度的组合来解释。此外,高维数据中的各个维度往往是相关的,因此数据实际上存在一个 内在的低维结构。降维 就是利用这种结构和相关性,使我们能够以更紧凑的方式表示数据,理想情况下还能避免信息丢失。我们可以将降维看作是一种压缩技术,类似于 jpeg 或 mp3,它们分别是图像和音乐的压缩算法。
在本章中,我们将讨论 主成分分析(PCA),这是一种线性的降维算法。PCA 由 Pearson (1901) 和 Hotelling (1933) 提出,至今已有一百多年历史,但仍然是数据压缩和数据可视化中最常用的技术之一。它还被广泛用于识别高维数据中的简单模式、潜在因子以及数据结构。在信号处理领域,PCA 也被称为 Karhunen-Loève 变换。在本章中,我们将从最基本的原理推导 PCA,依赖于我们对 基和基变换(第 2.6.1 和 2.7.2 节)、投影(第 3.8 节)、特征值(第 4.2 节)、高斯分布(第 6.5 节)以及 约束优化(第 7.2 节)的理解。
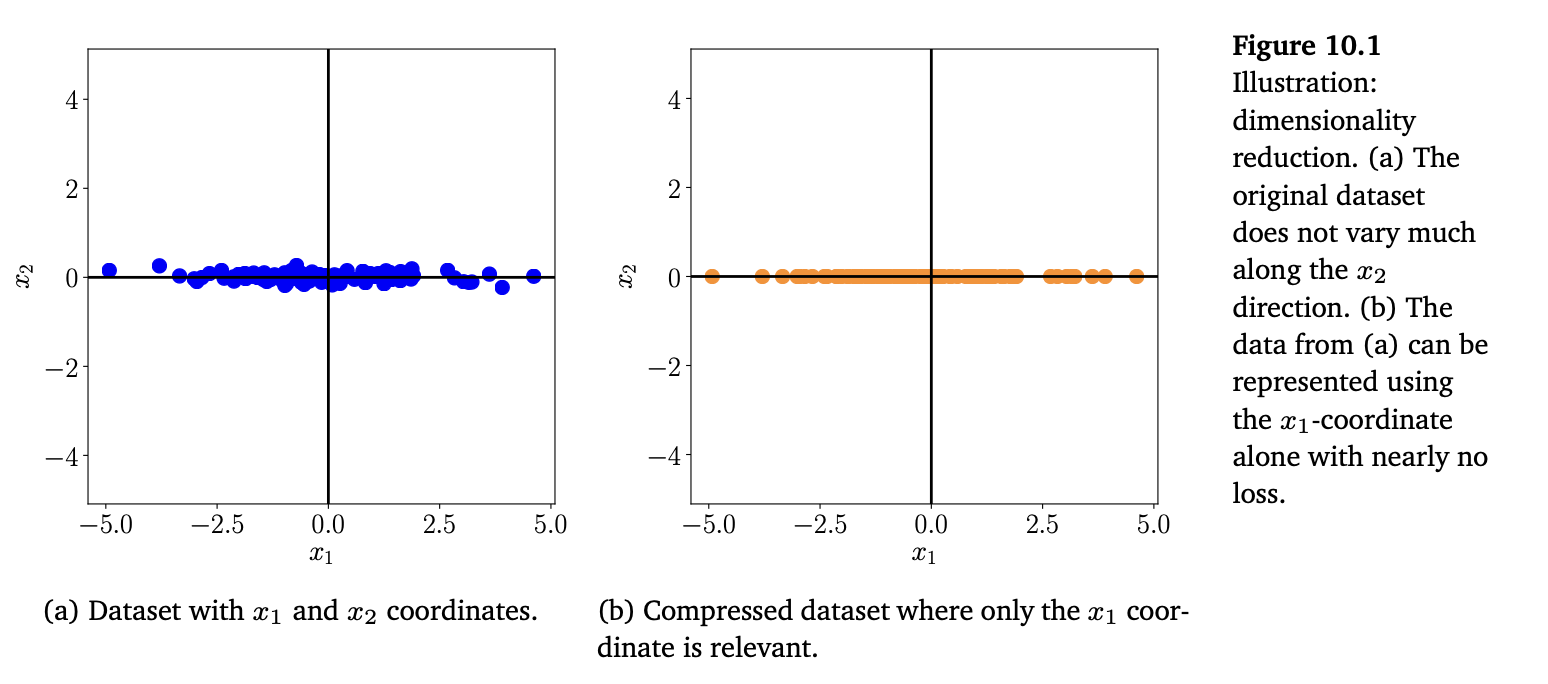
降维通常利用高维数据(例如图像)的一个性质:它们往往位于低维子空间上。图 10.1 给出了一个二维的示例说明。虽然图 10.1(a) 中的数据并不完全落在一条直线上,但它在 \(x_2\)-方向上的变化很小,因此我们几乎可以把它看作是落在一条直线上——几乎没有信息损失;见图 10.1(b)。为了描述图 10.1(b) 中的数据,只需要 \(x_1\)-坐标即可,此时数据位于 \(\mathbb{R}^2\) 的一个一维子空间中。
Linear Regression
在本章中,我们将应用第 2、5、6 和 7 章中的数学概念来解决线性回归(曲线拟合 curve fitting)问题。在回归中,我们的目标是找到一个函数 \(f\),它将输入 \(x \in \mathbb{R}^D\) 映射到相应的函数值 \(f(x) \in \mathbb{R}\)。
我们假设给定了一组训练输入 \(x_n\) 及其对应的带噪观测值 \(y_n = f(x_n) + \varepsilon\),其中 \(\varepsilon\) 是独立同分布(i.i.d.)的随机变量,用来描述测量/观测噪声以及可能未建模的过程(本章中我们不再考虑后者)。在整个章节中,我们假设噪声是零均值高斯噪声。
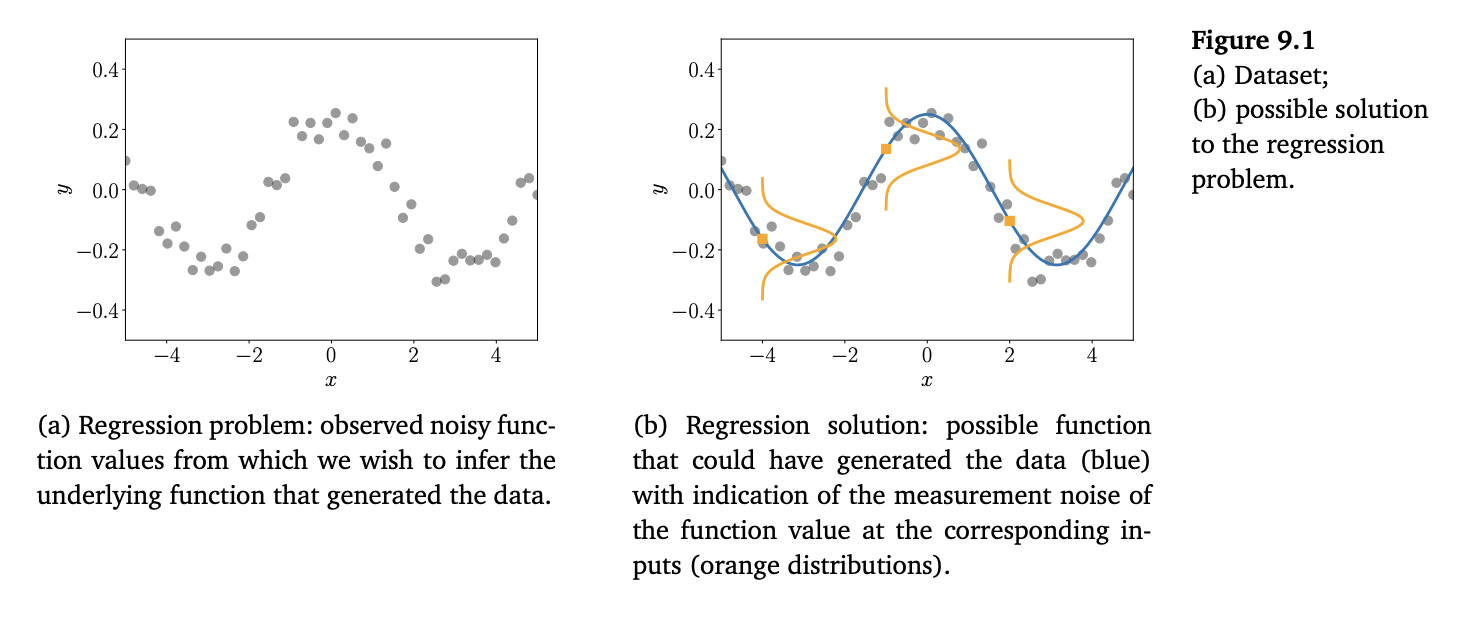
我们的任务是找到一个函数,该函数不仅能够拟合训练数据,还能够很好地推广到预测训练数据之外输入位置的函数值(见第 8 章)。图 9.1 展示了这样一个回归问题的例子。典型的回归场景如图 9.1(a):对于一些输入值 \(x_n\),我们观测到带噪声的函数值 \(y_n = f(x_n) + \varepsilon\)。任务是推断出生成这些数据的函数 \(f\),并且能很好地推广到新的输入位置。图 9.1(b) 给出了一个可能的解答,其中我们同时展示了以函数值 \(f(x)\) 为中心的三个分布,用来表示数据中的噪声。
回归是机器学习中的一个基本问题,回归问题广泛出现在各种研究领域和应用中,包括:
在本书的第一部分,我们介绍了许多机器学习方法所依赖的数学基础。希望读者能够从第一部分学习到数学语言的基本形式,而我们接下来将利用这些形式来描述和讨论机器学习。本书的第二部分介绍了机器学习的四大支柱:
本书这一部分的主要目标是展示如何利用第一部分介绍的数学概念来设计机器学习算法,从而解决四大支柱范围内的任务。我们无意介绍高级的机器学习概念,而是希望提供一套实用的方法,使读者能够运用第一部分所学的知识。同时,这部分内容也为已经熟悉数学的读者提供了进入更广泛机器学习文献的入口。
原书《MATHEMATICS FOR MACHINE LEARNING》 原书英文版
本书分两部分:
马斯克的第一性原理、评价一个好学生就说他概念很清晰。这些都指向了基本的理解概念的重要性;正是这本书的特点;不过因为在一本书里面讲解了很多概念,包括线性代数、解析几何、微积分、概率等,所以还是需要读者有一定的数学基础,同时有些时候需要借助ChatGPT等工具进行概念的理解。
本书把涉及机器学习的数学的概念梳理了一遍;以介绍概念为主,从数学的角度、用数学的语言,从概念的角度引申出各知识点。这本书的优点是把涉及机器学习部分的数学概念讲得系统并深入浅出,把各个概念之间的关联性讲得很透彻,整体性很强,而不是简单概念的罗列。
不过,学习就是理论联系实际的过程,学习概念然后实践(练习、看书、应用等等),在实践中会发现对概念理解不透彻的地方,回头去理解概念,然后得到升华。概念就譬如对人的定义,在中国你可能觉得人就是黄种人的样子,但当你出国发现欧洲人之后,你回头去看人的定义,会增加对人这个概念的理解。
这本书通过数学语言定义了很多概念,直指本质;例如向量、内积;很多定义推翻了我们常识中的一些认定,例如内积,之前的通常的认知都是点积,其实真正内积的内涵广泛得多,应用也广泛得多。
核心的概念内积!!!!!!!内积的定义以及从内积引申出的正定矩阵、范数、距离等概念。
数学是这个世界上最精确的语言!
本笔记结合原版和网上中文翻译做了笔记。
中文翻译收录在这个专栏(只翻译了数学基础这一部分。):
https://binaryai.blog.csdn.net/article/details/115050415
不过,中文版的译作者修改和加了一些内容,例如例6.1中,就把$换成人民币¥;还有矩阵那里增加了分块矩阵的运算!还有最后一章节的“信息论”原书并没有。
注意函数和曲面的区别。详见《函数与曲面.md》
以下是本书的一些摘录。
ESL读书笔记
《The Elements of Statistical Learning - Data Mining, Inference and Prediction - 2nd Edition (ESLII_print4)》
引用“统计学的那些事” (https://cosx.org/2011/12/stories-about-statistical-learning)
文章看得差不多了,就反复看他们的那本书“The Elements of Statistical learning”(以下简称 ESL)。说实话,不容易看明白,也没有人指导,我只好把文章和书一起反复看,就这样来来回回折腾。比如为看懂 Efron 的“Least angle regression”,我一个人前前后后折腾了一年时间(个人资质太差)。当时国内还有人翻译了这本书(2006 年),把名字翻译为“统计学习基础”。我的神啦,这也叫“基础”!还要不要人学啊!难道绝世武功真的要练三五十年?其实正确的翻译应该叫“精要”。在我看来,这本书所记载的是绝世武功的要义,强调的是整体的理解,联系和把握,绝世武功的细节在他们的文章里。
核心是贝叶斯定理,贝叶斯定理在统计中的应用就像牛顿定理在物理学的地位一样。
贝叶斯定理的核心是需要理解似然函数。
P(A|B) = P(B|A)P(A) / P(B) 这个公式是针对离散的概率。
条件概率的核心是根据三个条件:样本总体的分布+先验信息(P(A))+样本的信息(P(B|A)) , 得到后验概率(分布)(P(A|B))。
贝叶斯推断中,我们需要确定一个在给定参数时数据的采样模型 $(Z;) $(密度函数或者概率质量函数),以及反映我们在得到数据之前对于 \(\theta\) 认知的先验分布 \(\Pr(\theta)\).然后计算后验分布: \[ \Pr(\theta\mid\mathbf Z)=\frac{\Pr(\mathbf Z\mid\theta)\cdot \Pr(\theta)}{\int \Pr(\mathbf Z\mid \theta)\cdot \Pr(\theta)d\theta}\tag{8.23} \] 它表示当我们知道数据后更新对 \(\theta\) 的认知.为了理解这一后验分布,可以从中抽取样本或者通过计算均值或众数来描述它.贝叶斯方法与一般推断方法的不同之处在于,用先验分布来表达知道数据之前的这种不确定性,而且在知道数据之后允许不确定性继续存在,将它表示成后验分布.
自己学会举一个生活中的例子,就说明你理解了。
自由度;也就是无约束参数的个数?
有偏无偏估计,个人理解例如Lasso这些方法增加了约束条件就是有偏估计?
二次规划问题:二次规划 = 二次目标函数 + 线性约束 + 有限维变量空间的凸优化问题。
广义线性模型类,它们都是以同样的方式扩展为广义可加模型。
怎么判断函数的凸性:对于任意两点之间的连线,总是在函数图像之上或重合。
中心化:使得均值为 0; 标准化:使得均值为 0 、方差为 1
为什么引入随机效应后会有如此神奇的疗效?
假设检验:基于小概率的反证法。 提出假设(置信水平),计算抽样的样本统计量,计算概率,判断是否小概率事件(根据置信水平);如果是小概率事件则假设不成立。
标准差:是衡量样本个体的离散程度; 标准误:样本统计量的标准差;是衡量抽样样本水平(样本统计量,均值是其中一个统计量)的离散程度(或者叫抽样误差的程度)。
t-检验可用于对回归系数的检验。 t = (样本统计量 - 总体参数)/ 样本统计量标准差(或者叫标准误) t检验本质是:当数据服从t分布的时候,检验某一样本统计量是否与总体参数相等。
条件概率和似然函数的区别 同一个表达式 \(P(x \mid \theta)\),既可以是条件概率,也可以是同一个表达式 \(P(x \mid \theta)\),既可以是条件概率,也可以是似然函数,取决于我们把哪个当变量、哪个当已知!,取决于我们把哪个当变量、哪个当已知!
偏差(bias):真实值 - 预测值(拟合的结果) bias, the amount by which the average of our estimate differs from the true mean。
偏差 (deviance):偏差是用来比较两个不同模型的。我们通过将一个模型的偏差减去另一个模型的偏差来进行比较。 一篇写得很棒的博客,What is deviance? -- by kjytay
有效参数个数 (effective number of parameters)
我们知道了一个变量的分布,要生成一批样本服从这个分布,这个过程就叫采样。 听起来好像很简单,对一些简单的分布函数确实如此,比如,均匀分布、正太分布,但只要分布函数稍微复杂一点,采样这个事情就没那么简单了。为什么要采样在讲具体的采样方法之前,有必要弄清楚采样的目的。为什么要采样呢?有人可能会这样想,样本一般是用来估计分布参数的,现在我都知道分布函数了,还采样干嘛呢?其实采样不只是可以用来估计分布参数,还有其他用途,比如说用来估计分布的期望、高阶动量等。
贝叶斯误差(Bayes Error) 是统计学习理论中的一个核心概念,指的是在已知真实分布的最优分类器下,仍然不可避免的分类错误率。它代表了任何分类器都无法超越的理论最小错误率,是分类问题中的“理论下限”。
独立与不相关 统计上, 连续型随机变量 \(X\) 与 \(Y\) 独立的定义为 \[ p(x, y)=p_X(x)p_Y(y)\;\forall x,y \] 而不相关的定义为 \[ \text {Cov}(X, Y)=0 \] 独立意味着不相关,但反之不对.对于二元正态随机变量,两者等价.
不相关但不独立的例子: \(X\) 是从区间 \([-1, 1]\) 上均匀分布的随机变量; \(Y = X^2\) 则: \(X\) 和 \(Y\) 是不相关的(因为 \(E[X] = 0\),\(E[XY] = 0\)) 但 \(X, Y\) 不是独立的,因为知道 \(X\) 的值后,\(Y\) 就完全确定。
马尔科夫蒙特卡洛法 (Markov chain Monte Carlo).我们将要看到吉布斯采样(一个 MCMC 过程)
吉布斯采样(Gibbs Sampling) 吉布斯采样是MCMC的一个特例,吉布斯采样的牛逼之处在于只需要知道条件概率的分布,便可以通过采样得到联合概率分布的样本;核心在七个字:一维一维的采样:
具体步骤:
初始化:首先给每个变量一个初始值(通常是随机选择的)。
循环抽样:依次更新每个变量,具体过程是:
在给定当前所有其他变量的情况下,从该变量的条件分布中抽样。
用新的样本值替代当前变量的值,并更新系统。
迭代收敛:重复上述抽样过程足够多次,随着迭代进行,样本将会逐渐收敛于目标的联合分布。
自然三次样条 (详见原书 5.2 分段多项式和样条)
三次样条(cubic spline)是将数据区间划分为若干个小区间,每个区间内用一个三次多项式拟合,且整体函数在区间连接点处保持:
自然三次样条(Natural cubic spline)是在此基础上,对两端的两个点添加了“自然”条件:\(f''(x_1) = f''(x_n) = 0\)
也就是说,样条函数在两端的二阶导数为 0,表示在端点处“趋于线性”。