谢赫?哈里发?埃米尔?苏丹? 阿拉伯君主称谓有什么不同?
网上看到了一篇讲阿拉伯君主称号的文章,原文虽短也有很多未讲明白的地方,但我觉得格外有意思。于是网上对这几个关键词一顿猛搜,并结合自己的理解,整理了这样一篇比较通俗的文字。文中内容大多也不是自己的学识,纯属泊来,大家看看就好,如有说不对的也莫责怪到我头上。对这个文化知识有兴趣的就看下去,没兴趣的也不要勉强,大家猎个奇而已。
网上看到了一篇讲阿拉伯君主称号的文章,原文虽短也有很多未讲明白的地方,但我觉得格外有意思。于是网上对这几个关键词一顿猛搜,并结合自己的理解,整理了这样一篇比较通俗的文字。文中内容大多也不是自己的学识,纯属泊来,大家看看就好,如有说不对的也莫责怪到我头上。对这个文化知识有兴趣的就看下去,没兴趣的也不要勉强,大家猎个奇而已。
一本灵修方面的书,主体思想有点像佛教。告诉人们通过活在当下,来避免痛苦和恐惧。
这本书好的地方是在阐述的同时,间或插进一些提问进行回答,这些问题往往是读者在读书过程中也会碰到或者想到的问题。
概括这本书来说,就是阐述了以下三点:
1、活在当下!
关于时间,作者认为,时间是过去的痛苦、未来的恐惧之载体。接纳当下,活在当下,就是忘记过去的不幸,摒弃对未来的恐惧,从时间中跳出来,摆脱时间的束缚。
就像作者说的,时刻提醒自己,注意,此时此地。注意,此时此地!
2、停止思维!
思维和对应体现出来的情绪是一个小我,但是我们真正的本体是意识。在作者观念中,思维是有罪的,所以要把这两者分离,让意识占主导地位,而不是受思维的控制。
3、知足常乐!
喜悦是你内在宁静状态的关键部分,我们要学会接受万物无常的本质,只有这样才能找到宁静。
一本纯粹堆积概念的书,没什么干货,就不具体写心得了。
下面简单的就主数据进行一些整理。
其实主数据因为是IT系统在发展过程当中,缺乏整体的规划(包括业务和技术),导致各部门自产自销,只关心本部门本系统的数据,导致各系统中重用的关键的基础信息编码及口径都不一致。
所以目前主数据管理首先要做的是各源系统的主数据合并和清理问题。主要的流程是“合并->清洗->审核->分发”;然后在实际运行过程当中,对新增、变更的部分进行管理,其中新增和变更可以在各个源系统维护,然后提交到MDM系统审核、分发,也可以在MDM系统统一维护,然后分发。
分发可以采用同步WebService接口,也可以采用JMS消息的异步机制。
有一些主数据,例如组织架构,虽然是主数据,但是变化频率还是很高。针对组织架构、项目的架构(期区、单位工程、楼栋)经常发生变化的情况,关键是业务数据必须绑定到原子层面上,如果在原子层面上没有变化,那么业务数据不需要重新绑定。但是,如果原子层面都发生了变化,那就需要调整了。如果原子层面的变化,前后是有映射关系,也可以通过系统来处理。
转自一组图详解元数据、主数据与参考数据
在数据资产管理领域,有着许多相似的概念和词汇。譬如说“数据管理”和“数据治理”,像孪生兄弟一样让人纠结不已。上周,与一个朋友聊起元数据、主数据和参考数据的关系是什么。这个话题我们足足聊了二十分钟。这三个概念我在一开始做数据管理相关工作的时候也纠结了挺久,于是我根据聊起来的内容稍稍总结了一下,就有了这篇文章,希望能给读者减少些许疑惑。
MetaData意思是元数据,也称之为数据的数据。
数据的数据?
一个数据存储在共享卷里时,我们可以直接看到它是一个文档、或图片、或视频、或数据库文件,这些都是数据本身。然而在存储该数据时,文件系统还会产生很多无法直接看到的,与该数据有关的数据,如文件系统中文件检索表,路径信息、地址信息等,而这些数据就称之为文档、图片、视频等在共享卷中的元数据。
SAN网络存储共享软件管理的主要内容就是元数据,控制元数据在多主机之间的传输。
我们可以在很多地方看到元数据的存储,网上DOWN下来的电影本身一个视频文件数据,而点击右键查到看的视频文件属性,如存储路径、码率、文件大小、及导演、演员、制作单位等就是视频文件的元数据。
在地理空间信息中用于描述地理数据集的内容、质量、表示方式、空间参考、管理方式以及数据集的其他特征,它是实
现地理空间信息共享的核心标准之一。
借:生产成本(成本类科目-5001)
贷:原材料(资产类科目-1403)
借:库存商品(资产类科目-1405)
贷:生产成本(成本类科目-5001)
借:现金/银行存款/应收账款
贷:主营业务收入
应交税费-增值税-销项税额
借:主营业务成本(损益类科目-6401)
贷:库存商品(资产类科目-1405)
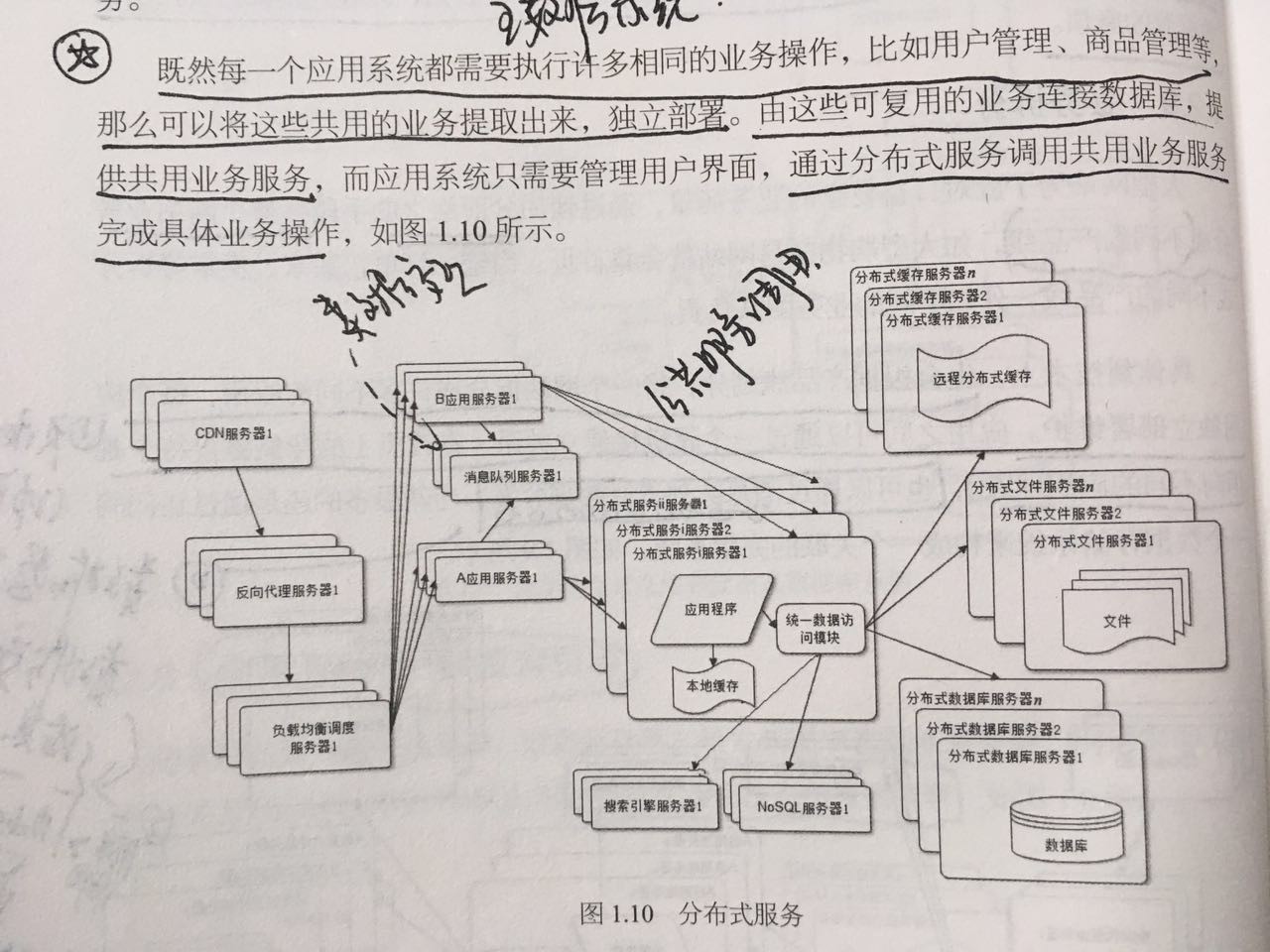
初始阶段的网站架构(单台服务器)->
应用服务器和数据服务分离(数据库和文件服务器都单独成一个服务器) ->
使用缓存改善网站性能(本地缓存、分布式缓存) ->
使用应用服务器集群改善网站的并发处理能力 -> 数据库读写分离 ->
使用反向代理(网站中心机房)和CDN(网络运营商那里)加速网站响应(缓存静态、热点内容)->使用分布式文件系统和分布式数据库系统(更常用的是业务分库)
->使用NoSQL和搜索引擎 -> 业务拆分 ->分布式服务
涉及到数据查找比对,首先考虑到使用HashSet。HashSet最大的好处就是实现查找时间复杂度为O(1)。使用HashSet需要解决一个重要问题:冲突问题。对比研究了网上一些字符串哈希函数,发现几乎所有的流行的HashMap都采用了DJB Hash Function,俗称“Times33”算法。Times33的算法很简单,就是对字符串逐字符迭代乘以33,见下面算法原型:hash(i)=33*hash(i-1)+str[i]
1 | uint32_t time33(char const *str, int len) |
把乘法操作换成位操作(Java版)
1 | public String time33(String skey) { |
现在敏捷开发是越来越火了,人人都在谈敏捷,人人都在学习Scrum和XP...
为了不落后他人,于是我也开始学习Scrum,今天主要是对我最近阅读的相关资料,根据自己的理解,用自己的话来讲述Scrum中的各个环节,主要目的有两个,一个是进行知识的总结,另外一个是觉得网上很多学习资料的讲述方式让初学者不太容易理解;所以我决定写一篇扫盲性的博文,同时试着也与园内的朋友一起分享交流一下,希望对初学者有帮助。
敏捷开发(Agile
Development)是一种以人为核心、迭代、循序渐进的开发方法。
怎么理解呢?首先,我们要理解它不是一门技术,它是一种开发方法,也就是一种软件开发的流程,它会指导我们用规定的环节去一步一步完成项目的开发;而这种开发方式的主要驱动核心是人;它采用的是迭代式开发;
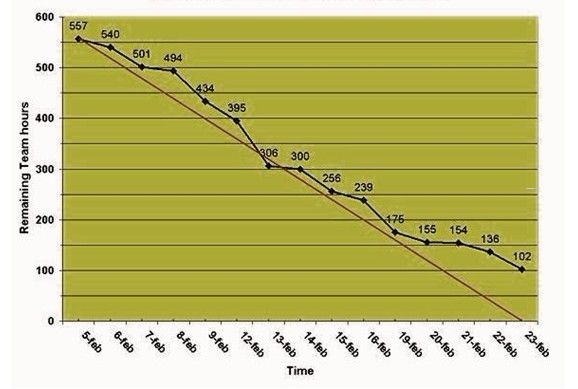
Burn down
chart翻译为燃尽图或燃烧图,很形象,是Scrum中展示项目进展的一个指示器。我一直认为用户故事、每日站立会议、燃尽图、sprint
review、sprint
retrospective真是越琢磨越有味道的好东西,也因此很喜欢scrum这种方法,这些实践简单有效、经典!
燃尽图的样例如下: