《机器学习的数学基础》(6/7)
读书笔记之六:概率与分布
6、概率与分布
Probability and Distributions
概率论可以看作是布尔逻辑的推广。在机器学习的背景下,它经常以这种方式应用于自动推理系统的形式化设计。
在机器学习和统计学中,有两种主要的概率解释:贝叶斯主义和频率主义(Bishop, 2006;Efron and Hastie, 2016)。贝叶斯主义使用概率来指定用户对事件的不确定性程度。它有时被称为“主观概率”或“置信程度”。频率主义则考虑感兴趣的事件与所发生事件的总数的相对频率。一个事件的概率定义为当发生事件的总数趋于无限时,该事件的相对频率。详细例子见《概率中贝叶斯派与经典频率主义区别例子.md》
贝叶斯主义和频率主义两者的核心区别在于:频率主义把参数视为固定值,而贝叶斯主义把参数视为随机变量,因此需要引入先验知识。两者的核心区别确实与“是否考虑先验知识”相关,但更根本的区别在于它们对“参数”的哲学认知不同:固定值 vs. 随机变量。
许多机器学习的概率模型描述使用惰性符号和术语,这会令人困惑的。这篇文章也不例外。有多个不同的概念都被称为“概率分布”,读者往往要从上下文中获知其中的含义。一个有助于理解概率分布的技巧是检查我们是在尝试建立一个分类的(离散的随机变量)模型还是一个连续的(连续的随机变量)模型。我们在机器学习中处理的问题的种类与我们要考虑分类模型还是连续模型密切相关。
注:在抽第二枚硬币之前放回了第一枚抽到的硬币,这意味着两次抽硬币是相互独立的。
6.1 概率空间 \((\Omega, \mathcal{A}, P)\),
示例:连续两次抛硬币
样本空间 \[ \Omega = \{hh, ht, th, tt\} \] 这里每个元素(样本点)表示两次抛硬币的具体结果。例如 \(hh\) = 第一次正面、第二次正面。
事件空间 事件就是样本空间的子集。比如:
- 事件 \(A=\{\text{hh}\}\):两次都是正面。
- 事件 \(B=\{\text{ht},\text{th}\}\):恰好出现一次正面。
- 事件 \(C=\{\text{hh},\text{ht},\text{th}\}\):至少出现一次正面。
所有可能的事件集合(即事件空间 \(\mathcal{A}\))在离散情况下就是 \(\Omega\) 的幂集: \[ \mathcal{A} = \{ \emptyset, \{hh\}, \{ht\}, \{th\}, \{tt\}, \{hh,ht\}, \dots, \Omega \}. \]
概率分布 假设硬币均匀独立,样本空间中每个结果的概率都是 \(1/4\)。那么:
- \(P(A)=P(\{hh\})=1/4\)。
- \(P(B)=P(\{ht,th\})=1/4+1/4=1/2\)。
- \(P(C)=P(\{hh,ht,th\})=3/4\)。
总结
- 样本空间 \(\Omega\):所有可能的基本结果。
- 事件空间 \(\mathcal{A}\):由样本空间的子集组成,每个子集就是一个“事件”。
- 概率 \(P\):为每个事件赋予一个数,满足概率公理。
给定一个概率空间 \((\Omega, \mathcal{A}, P)\),我们希望使用它来模拟一些现实世界的现象。在机器学习中,我们经常避免直接引用概率空间,而是引用感兴趣的量上的概率,我们用 \(\mathcal{T}\) 表示。在这本书中,我们把 \(\mathcal{T}\) 称为目标空间(target space),把 \(\mathcal{T}\) 的元素称为状态。我们引入了一个函数 \(X : \Omega \to \mathcal{T}\)它接受 \(\Omega\) 元素(一个结果,样本点),并返回感兴趣对象 \(x\) 在 \(\mathcal{T}\) 中的特定量(值)。从 \(\Omega\) 到 \(\mathcal{T}\) 的这种关联/映射称为随机变量(random variable)。
例如,考虑投掷两枚硬币并计算正面数。随机变量 \(X\) 映射到三种可能的结果:
\[ \begin{equation} X(hh) = 2, \quad X(ht) = 1, \quad X(th) = 1, \quad X(tt) = 0 \end{equation} \] 在这个特殊的情况下,\(\mathcal{T} = \{0,1,2\}\),我们感兴趣的是 \(\mathcal{T}\) 中元素的概率。对于有限的样本空间 \(\Omega\) 和有限的 \(\mathcal{T}\),随机变量对应的函数本质上是一个查找表。对于任意子集 \(S \subseteq \mathcal{T}\),我们将\(P_X(S) \in [0,1]\)(概率)与随机变量 \(X\) 对应的特定事件联系起来。例 6.1 提供了具体说明。
将 \(X\)输出的概率和\(\Omega\)中样本的概率这两个不同的概念等同起来! 详见原书Example 6.1。
离散状态数值化特别有用,因为我们经常需要考虑随机变量的期望值
不幸的是,机器学习许多相关文献使用的符号和术语隐藏了样本空间 \(\Omega\)、目标空间 \(\mathcal{T}\) 和随机变量 \(X\) 之间的区别。对于随机变量 \(X\) 的一组可能结果的值 \(x\),即 \(x \in \mathcal{T}\),\(p(x)\) 表示随机变量 \(X\) 取结果 \(x\) 的概率。对于离散随机变量,这表示为 \(p(X = x)\),这称为概率质量函数(probability mass function)。概率质量函数通常被称为“分布”。
对于连续变量,\(p(x)\) 称为概率密度函数(probability density function,通常称为密度),而累积分布函数 \(P(x \le X)\) 通常也被称为“分布”。在本章中,我们将使用符号 \(X\) 来表示一元和多元随机变量,并分别用 \(x\) 和 \(\boldsymbol{x}\) 表示状态。
我们用“概率分布”表达离散的概率质量函数以及连续的概率密度函数,尽管这在技术上是不正确的。与大多数机器学习文献一样,我们也依赖上下文来区分“概率分布”这个短语的不同用法。
6.2 加法法则、乘法法则和贝叶斯定理
1、求和法则 \[ p(x) = \begin{cases} \sum_{y \in \mathcal{Y}} p(x,y), & \text{如果 $y$ 是离散的}, \\[1em] \int_{\mathcal{Y}} p(x,y)\,dy, & \text{如果 $y$ 是连续的}. \end{cases} \]
求和法则将联合分布与边缘分布联系了起来。
备注: 概率建模的许多计算困难都是由于应用了求和法则。当有许多变量或具有许多状态的离散变量时,求和法则执行的是高维求和或积分。执行高维求和或积分通常是难以计算,因为没有已知的多项式时间(polynomial-time)算法来精确计算它们。
2、乘法法则
乘法法则(product rule),它将联合分布与条件分布联系起来: \[ \begin{equation} p(\boldsymbol{x}, \boldsymbol{y}) = p(\boldsymbol{y} \mid \boldsymbol{x}) \, p(\boldsymbol{x}) \qquad (6.22) \end{equation} \] 乘积法则可以解释为:两个随机变量的联合分布能被因子分解(乘积形式)为其他两个分布。这两个因子分别是:
- 第一个随机变量的边缘分布\(p(\boldsymbol{x})\)
- 给定第一个随机变量时,第二个随机变量的条件分布\(p(\boldsymbol{y} \mid \boldsymbol{x})\)
联合分布中随机变量的顺序是任意的,这意味着: \[ p(\boldsymbol{x}, \boldsymbol{y}) = p(\boldsymbol{x} \mid \boldsymbol{y}) \, p(\boldsymbol{y}) \] 准确地说,式(6.22)表示的是离散随机变量的概率质量函数。对于连续随机变量,乘积规则用概率密度函数(第 6.2.3 节)表示。
3、贝叶斯定理
在机器学习和贝叶斯统计中,如果我们观察到部分随机变量,我们通常会对未观察到的(潜在的)随机变量的推断感兴趣。假设我们有一些关于未观测随机变量 \(\boldsymbol{x}\) 的先验(prior)知识 \(p(\boldsymbol{x})\),并且我们可以观察到 \(\boldsymbol{x}\) 和第二个随机变量 \(\boldsymbol{y}\) 之间的关系 \(p(\boldsymbol{y} \mid \boldsymbol{x})\)。那么,如果我们观察到 \(\boldsymbol{y}\),就可以利用贝叶斯定理,在给定 \(\boldsymbol{y}\) 的观测值前提下,得出 \(\boldsymbol{x}\) 的一些结论。
贝叶斯定理(也叫贝叶斯法则或贝叶斯定律): \[ \begin{equation} \underbrace{p(\boldsymbol{x} \mid \boldsymbol{y})}_{\text{后验}} = \frac{\overbrace{p(\boldsymbol{y} \mid \boldsymbol{x})}^{\text{似然}} \; \overbrace{p(\boldsymbol{x})}^{\text{先验}}}{\underbrace{p(\boldsymbol{y})}_{\text{证据}}} \qquad (6.23) \end{equation} \] 似然(likelihood,有时也被称为“测量模型”)\(p(\boldsymbol{y} \mid \boldsymbol{x})\)描述了\(\boldsymbol{x}\)和\(\boldsymbol{y}\)是如何相关的。对于离散概率分布,它是在已知潜在变量\(\boldsymbol{x}\)前提下,数据\(\boldsymbol{y}\)的概率。注意,似然\(p(\boldsymbol{y} \mid \boldsymbol{x})\)不是\(\boldsymbol{x}\)的分布,而是\(\boldsymbol{y}\)的分布(个人注:但是关于\(x\)的函数)。并且我们称\(p(\boldsymbol{y} \mid \boldsymbol{x})\)为“\(\boldsymbol{x}\)的似然(给定\(\boldsymbol{y}\))”或“给定\(\boldsymbol{x}\),\(\boldsymbol{y}\)的概率”,但不是\(\boldsymbol{y}\)的似然(MacKay, 2003)。
核心:分清似然函数和条件概率的区别,同一个表达式 \(p(y \mid x)\),既可以是条件概率,也可以是似然函数,取决于我们把哪个当变量、哪个当已知!详见《似然函数和条件概率的分别.md》
贝叶斯定理公式会适合两种情况:
情况1:X、Y 是两个事件 → 计算条件概率。
情况2:X 是参数,Y 是数据序列 → 用新观测更新对参数的信念。
区分标准:看 X 和 Y 是否是不同的事件,还是 一个事件(参数) + 多次观测。
\[ \begin{equation} p(y) := \int p(y \mid x) p(x) \, dx = \mathbb{E}_{X}[p(y \mid x)] \qquad (6.27) \end{equation} \]
是边缘似然 / 证据(marginal likelihood / evidence)。
(6.27) 的右边使用我们在第 6.4.1 节中定义的期望操作符。 根据定义,边缘似然是 (6.23) 贝叶斯公式的分子对潜在变量 \(\boldsymbol{x}\) 的积分。因此,边缘似然与 \(\boldsymbol{x}\) 无关,它保证了后验 \(p(\boldsymbol{x} \mid \boldsymbol{y})\) 被标准化。 边缘似然也可以解释为期望似然,关于先验 \(p(\boldsymbol{x})\) 的期望。 除了用于后验标准化之外,边缘似然在贝叶斯模型选择中也起着重要作用,我们将在第 8.6 节中讨论,证据(evidence)通常很难计算。
贝叶斯定理 (6.23) 允许我们反转由似然给出的 \(\boldsymbol{x}\) 和 \(\boldsymbol{y}\) 之间的关系。 因此,贝叶斯定理有时也被称为概率逆(probabilistic inverse)。
备注: 在贝叶斯统计中,后验分布是我们感兴趣的量,因为它包含了所有来自先验和数据的可用信息。我们把重点放在后验的一些统计量上,例如后验的最大值,这将在8.3节中讨论。然而,只关注后验的统计量会导致信息的丢失。如果我们在更大的背景下思考,那么后验还可以在决策系统中使用。拥有完整的后验非常有用,它可以得到对干扰具有鲁棒性的决策。例如,在基于模型的强化学习中,Deisenroth等人(2015)表明,使用似然转移函数的完全后验分布可以非常快速(数据/样本高效)学习,而关注最大的后验则会导致一致性失败。因此,拥有完整的后验对于下游任务非常有用。在第9章中,我们将在线性回归的背景下继续这个讨论。
6.3 期望值
期望值的概念是机器学习的中心,概率本身的一些基本概念可以从期望值派生 (Whittle, 2000)。
定义 6.3 期望值
关于单变量连续随机变量 \(X \sim
p(X)\) 的函数
\(g : \mathbb{R} \to \mathbb{R}\)
的期望值(expected value)为: \[
\mathbb{E}_{X}[g(x)] = \int_{\mathcal{X}} g(x) \, p(x) \, \mathrm{d}x
\] 相应地,关于离散随机变量 \(X \sim
p(X)\) 的函数 \(g\) 的期望值为:
\[
\mathbb{E}_{X}[g(x)] = \sum_{x \in \mathcal{X}} g(x) \, p(x)
\] 其中 \(\mathcal{X}\)
是随机变量 \(X\)
的可能结果的集合(目标空间)。
在本节中,我们考虑离散随机变量的数值结果。通过观察函数 \(g\) 以实数作为输入可以看出这一点。
定义 6.4 均值:
状态 \(\boldsymbol{x} \in
\mathbb{R}^D\) 的随机变量 \(X\)
的均值(mean)为平均值(average),定义为
\[
\mathbb{E}_{X}[\boldsymbol{x}]
=
\begin{bmatrix}
\mathbb{E}_{X_1}[x_1] \\
\vdots \\
\mathbb{E}_{X_D}[x_D]
\end{bmatrix}
\in \mathbb{R}^{D}
\]
对于 \(d = 1, \ldots, D\):
\[
\mathbb{E}_{X_d}[x_d] :=
\begin{cases}
\int_{\mathcal{X}} x_d \, p(x_d) \, dx_d, & \text{如果 $X$
为连续型随机变量}, \\[1em]
\sum\limits_{x_i \in \mathcal{X}} x_i \, p(x_d = x_i), & \text{如果
$X$ 为离散型随机变量}.
\end{cases}
\qquad (6.32)
\]
其中下标 \(d\) 表示 \(\boldsymbol{x}\) 对应的维度。上式是对随机变量 \(X\) 的目标空间状态 \(\mathcal{X}\) 的积分以及求和。
在一个维度中,还有另外两个直观的“平均”概念,即 中位数 (median) 和 众数 (mode)。
如果我们对这些值进行排序,中位数就是“最中间”的值,即 \(50\%\) 的值大于中位数,\(50\%\) 的值小于中位数。这一思想可以推广到连续值,考虑累计分布函数(定义 6.2)为 \(0.5\) 的值。 对于不对称或有长尾的分布,中位数提供了一个典型值的估计,该值比平均值更接近人类的直觉。 此外,中位数对异常值的鲁棒性比平均值强。中位数向更高维度的推广是非平凡的,因为目前没有方法可以在不止一个维度中“排序” (Hallin et al., 2010; Kong and Mizera, 2012)。
众数 (mode)是最常出现的值。对于离散随机变量,众数定义为出现频率最高的 \(x\) 的值。 对于连续随机变量,众数定义为密度 \(p(\boldsymbol{x})\) 上的一个峰值。 一个特定的密度 \(p(\boldsymbol{x})\) 可能有不止一个众数,而且在高维分布中可能有大量的众数。 因此,找到一个分布的所有众数在计算上是具有挑战性的。
注:在统计学中局部最值也常被称为“众数”(更准确叫 local modes),严格意义上的众数应该是全局的最值。
定义 6.3 定义了符号 \(\mathbb{E}_X\) 的意义,作为一个算子,它表示我们应该取关于概率密度的积分(对于连续分布)或关于所有状态的和(对于离散分布)。均值的定义(定义 6.4),是期望值的一种特殊情况,通过取 \(g\) 为恒等函数得到。
6.4 协方差
对于两个随机变量,我们可以描述它们之间的对应关系。协方差直观地表示随机变量之间的相关性。
方差的概念是从协方差引出的,而不是相反!
协方差(一元)
两个单变量随机变量 \(X, Y \in
\mathbb{R}\)
之间的协方差(covariance)由其偏离各自均值的期望积给出,即
\[
\operatorname{Cov}_{X, Y}[x, y] := \mathbb{E}_{X, Y}\left[ \left(x -
\mathbb{E}_{X}[x]\right)\left(y - \mathbb{E}_{Y}[y]\right) \right]
\] 术语:多元随机变量的协方差 \(\operatorname{Cov}[x, y]\)
有时被称为交叉协方差(cross-covariance),其中协方差指的是 \(\operatorname{Cov}[x, x]\)。
协方差衡量两个随机变量是否一起增减,以及一起变化的强弱与方向。
备注: 当与期望或协方差相关的随机变量的参数明确时,下标通常被去掉(例如,\(\mathbb{E}_X[x]\) 经常被写成 \(\mathbb{E}[x]\))。
利用期望的线性性,定义 6.5
中的表达式可以改写为乘积的期望值减去期望值的乘积,即
\[
\operatorname{Cov}[x, y] = \mathbb{E}[xy] - \mathbb{E}[x]\,\mathbb{E}[y]
\] 一个变量与自身的协方差 \(\operatorname{Cov}[x, x]\)
称为方差(variance),用 \(\mathbb{V}_X[x]\)
表示。方差的平方根称为标准差(standard deviation),通常用 \(\sigma(x)\)
表示。协方差的概念可以推广到多元随机变量。
定义 6.6 协方差(多元)
如果我们考虑两个多元随机变量 \(\mathbf{X}\) 和 \(\mathbf{Y}\),分别对应状态 \(\mathbf{x} \in \mathbb{R}^D\) 和 \(\mathbf{y} \in \mathbb{R}^E\),则 \(\mathbf{X}\) 和 \(\mathbf{Y}\) 之间的协方差定义为: \[ {Cov}[\mathbf{x}, \mathbf{y}] = \mathbb{E}\!\left[\mathbf{x} \mathbf{y}^{\top}\right] - \mathbb{E}[\mathbf{x}]\,\mathbb{E}[\mathbf{y}]^{\top} = \operatorname{Cov}[\mathbf{y}, \mathbf{x}]^{\top} \in \mathbb{R}^{D \times E}. \] 定义 6.6 可以应用于两个相同的多元随机变量,从而产生一个有用的概念,直观地捕捉随机变量的“扩散程度”。对于一个多元随机变量,方差描述了该随机变量的单个维度之间的关系。
方差与协方差矩阵 状态为 \(\boldsymbol{x} \in \mathbb{R}^{D}\)
且均值向量为 \(\boldsymbol{\mu} \in
\mathbb{R}^{D}\) 的随机变量 \(X\) 的方差 (variance) 定义为
\[
\begin{align}
V_X[\boldsymbol{x}]
&= \mathrm{Cov}_X[\boldsymbol{x}, \boldsymbol{x}] \\
&= \mathbb{E}_X \big[ (\boldsymbol{x} -
\boldsymbol{\mu})(\boldsymbol{x} - \boldsymbol{\mu})^\top \big] \\
&= \mathbb{E}_X[\boldsymbol{x} \boldsymbol{x}^\top] -
\mathbb{E}_X[\boldsymbol{x}] \ \mathbb{E}_X[\boldsymbol{x}]^\top \\
&=
\begin{bmatrix}
\mathrm{Cov}[x_1, x_1] & \mathrm{Cov}[x_1, x_2] & \cdots &
\mathrm{Cov}[x_1, x_D] \\
\mathrm{Cov}[x_2, x_1] & \mathrm{Cov}[x_2, x_2] & \cdots &
\mathrm{Cov}[x_2, x_D] \\
\vdots & \vdots & \ddots & \vdots \\
\mathrm{Cov}[x_D, x_1] & \mathrm{Cov}[x_D, x_2] & \cdots &
\mathrm{Cov}[x_D, x_D]
\end{bmatrix}.
\end{align}
\] 上式中的 \(D \times
D\) 矩阵称为多元随机变量 \(X\)
的 协方差矩阵 (covariance matrix)。
协方差矩阵是对称的,且半正定,它描述了数据的扩散程度。协方差矩阵的对角线元素包含了边缘分布
\[
\begin{equation}
p(x_i) = \int p(x_1, \ldots, x_D) \ \mathrm{d}x_{\backslash i}
\end{equation}
\] 的方差,其中符号 \(\backslash
i\)表示“除了 \(i\)
之外的所有变量”。 非对角线元素为交叉协方差项 \(\mathrm{Cov}[x_i, x_j]\),其中 \(i, j = 1, \ldots, D, \ i \neq j\)。
6.5 相关
当我们想比较不同随机变量对之间的协方差时,每个随机变量的方差都会影响协方差的值。协方差的标准化版本称为相关(correlation)
两个随机变量 \(X, Y\) 的相关(correlation)为: \[ \operatorname{corr}[x, y] = \frac{\operatorname{Cov}[x, y]}{\sqrt{\mathbb{V}[x] \, \mathbb{V}[y]}} \in [-1, 1] \] 相关矩阵是被标准化的随机变量\(x/{\sigma(x)}\)协方差矩阵。换句话说,每个随机变量在相关矩阵中都除以其标准差(方差的平方根)。
经验均值和协方差
为什么 \(N-1\) 是“无偏(unbiased)”?
当我们从总体中抽样时,用样本均值 \(\bar{x}\) 和 \(\bar{y}\) 代替真实均值,会引入低估总体方差和协方差的偏差。分母用 \(N-1\) 而不是 \(N\) 可以修正这个偏差,使得估计值的期望等于真实值。
6.6 方差的三个表达式
1、方差的标准定义
与协方差的定义(定义6.5)相对应,是随机变量 \(X\) 与其期望值 \(\mu\) 的平方偏差的期望,即
\[
\begin{equation}
\mathbb{V}_{X}[x] := \mathbb{E}_{X} \left[ (x - \mu)^{2} \right]
\tag{6.43}
\end{equation}
\] 式(6.43)中的期望和平均值\(\mu =
\mathbb{E}_{X}(x)\)使用(6.32)计算,取决于 \(X\)
是离散的还是连续的随机变量。式(6.43)中表示的方差可以说是一个新的随机变量\(Z := (X - \mu)^{2}\)的均值。
当根据经验估计(6.43)中的方差时,我们需要使用一个两阶段的算法:首先利用数据使用(6.41)计算平均值
\(\mu\),然后使用这个估计值 \(\hat{\mu}\) 计算方差。
2、事实证明,我们可以通过整理表达式来避免两个阶段。方差的标准定义: \[ \begin{equation} \mathbb{V}_{X}[x] := \mathbb{E}_{X}\left[(x-\mu)^2\right] \end{equation} \] (6.43)可以转换为所谓的“方差的原始分数公式”(raw-score formula for variance): \[ \begin{equation} \mathbb{V}_{X}[x] = \mathbb{E}_{X}\left[x^2\right] - \left(\mathbb{E}_{X}[x]\right)^2 \qquad (6.44) \end{equation} \] (6.44)中的表达式可以这样记住:“平方的均值减去均值的平方”。这种方法只需对数据进行一次遍历计算,因为我们可以同时计算每个观测值 \(x_i\) 的平均值 \(\bar{x} = \frac{1}{n}\sum_i x_i\) 和平方平均值 \(\frac{1}{n}\sum_i x_i^2\)。
不幸的是,如果以这种方式计算,它在数值上可能不稳定,尤其是当 \(x_i\) 的数值很大时,减法可能导致有效数字损失。
3、理解方差的第三种方式是,它可以表示为所有观测值对的差的总和。
考虑随机变量 \(X\) 的一个样本 \(x_1, \ldots, x_N\),我们计算 \(x_i\) 和 \(x_j\)
对之间的平方差。通过展开平方差,可以证明 \(N^2\)
个观测值对的差的总和正好与观测值的经验方差相关: \[
\begin{equation}
\frac{1}{N^2} \sum_{i,j=1}^{N} (x_i - x_j)^2 = 2 \left[ \frac{1}{N}
\sum_{i=1}^{N} x_i^2 - \left( \frac{1}{N} \sum_{i=1}^{N} x_i \right)^2
\right] \qquad (6.45)
\end{equation}
\] 由此可见,(6.45) 是原始分数公式 (6.44)
的两倍。这意味着,我们可以用观测值两两之间的距离总和(\(N^2\) 个)来表示偏离均值的偏离值总和(\(N\) 个)。
从几何上来看,这意味着在一个点集中,点两两之间的距离总和与每个点到点集中心的距离总和是等价的。
6.7 随机变量的和与变换
均值和协方差在随机变量的仿射变换中表现出一些有用的特性。
假设随机变量 \(\boldsymbol{X}\)
的均值向量为 \(\boldsymbol{\mu}\),协方差矩阵为 \(\boldsymbol{\Sigma}\),且 \(\boldsymbol{X}\) 的(确定性)仿射变换为:
\[
\boldsymbol{y} = \boldsymbol{A} \boldsymbol{x} + \boldsymbol{b}
\] 由于 \(\boldsymbol{y}\)
本身是一个随机变量,其均值向量和协方差矩阵分别为: \[
\begin{equation}
\mathbb{E}_Y[\boldsymbol{y}] = \mathbb{E}_X[\boldsymbol{A}\boldsymbol{x}
+ \boldsymbol{b}]
= \boldsymbol{A}\,\mathbb{E}_X[\boldsymbol{x}] + \boldsymbol{b}
= \boldsymbol{A}\boldsymbol{\mu} + \boldsymbol{b} \qquad (6.50)
\end{equation}
\]
\[ \begin{equation} \mathbb{V}_Y[\boldsymbol{y}] = \mathbb{V}_X[\boldsymbol{A}\boldsymbol{x} + \boldsymbol{b}] = \mathbb{V}_X[\boldsymbol{A}\boldsymbol{x}] = \boldsymbol{A}\,\mathbb{V}_X[\boldsymbol{x}]\,\boldsymbol{A}^\top = \boldsymbol{A}\boldsymbol{\Sigma}\boldsymbol{A}^\top \qquad (6.51) \end{equation} \]
此外,\(\boldsymbol{X}\) 与 \(\boldsymbol{Y}\) 的协方差为: \[ \begin{align} \mathrm{Cov}[\boldsymbol{x}, \boldsymbol{y}] &= \mathbb{E}\big[\boldsymbol{x} (\boldsymbol{A}\boldsymbol{x} + \boldsymbol{b})^\top\big] - \mathbb{E}[\boldsymbol{x}]\,\mathbb{E}[\boldsymbol{A}\boldsymbol{x} + \boldsymbol{b}]^\top \\ &= \mathbb{E}[\boldsymbol{x}]\boldsymbol{b}^\top + \mathbb{E}[\boldsymbol{x}\boldsymbol{x}^\top]\boldsymbol{A}^\top - \boldsymbol{\mu}\boldsymbol{b}^\top - \boldsymbol{\mu}\boldsymbol{\mu}^\top \boldsymbol{A}^\top \\ &= (\mathbb{E}[\boldsymbol{x}\boldsymbol{x}^\top] - \boldsymbol{\mu}\boldsymbol{\mu}^\top)\,\boldsymbol{A}^\top = \boldsymbol{\Sigma}\,\boldsymbol{A}^\top \end{align} \] 其中,\(\boldsymbol{\Sigma} = \mathbb{E}[\boldsymbol{x}\boldsymbol{x}^\top] - \boldsymbol{\mu}\boldsymbol{\mu}^\top\) 为 \(\boldsymbol{X}\) 的方差矩阵。
6.8 (统计)独立性
独立推出不相关(协方差为0)
但这一点是充分不必然的,即,两个随机变量的协方差为零,但在统计上可能不独立。为了理解为什么,回想一下协方差是只能测量线性相关。而非线性相关的随机变量可能协方差也为零。
详见《协方差只反映线性相关.md》
6.9 随机变量的内积
把协方差作为内积的一个例子,协方差符合内积的定义。例如点积符合内积的定义一样。
两个随机变量的“正交”就意味着它们协方差为零。具体的内积的定义见前文。在用协方差定义内积空间后,可以得出:
\[ \|X\| = \sqrt{\mathbb{V}[X]} = \sigma[X] \] 这就是标准差。
在普通向量空间里,向量长短衡量了它在空间中“延伸”的程度。在随机变量空间里,“长度”衡量的是它在概率空间中“波动”的程度。如果 \(\sigma[X] = 0\),那么 \(\mathbb{V}[X] = 0\),意味着 \(X\) 在概率意义上是常数,不会随机变化。
如果我们考虑两个随机变量 \(X\)、\(Y\) 之间的夹角 \(\theta\),我们得到: \[ \begin{equation} \cos\theta = \frac{\langle X, Y \rangle}{\|X\|\,\|Y\|} = \frac{\operatorname{Cov}[x, y]}{\sqrt{\mathbb{V}[x]\,\mathbb{V}[y]}} \end{equation} \] 这是两个随机变量之间的相关性(定义 6.8)。这意味着,当我们从几何角度考虑两个随机变量时,可以把它们的相关性看作是两个随机变量之间夹角的余弦。
根据定义 3.7,我们知道:\(X \perp Y \quad \Longleftrightarrow \quad \langle X, Y\rangle = 0\) 在我们的例子中,这意味着 \(X\) 和 \(Y\) 是正交的当且仅当:\(\operatorname{Cov}[X, Y] = 0\)即它们是不相关的。图 6.6 说明了这种关系。
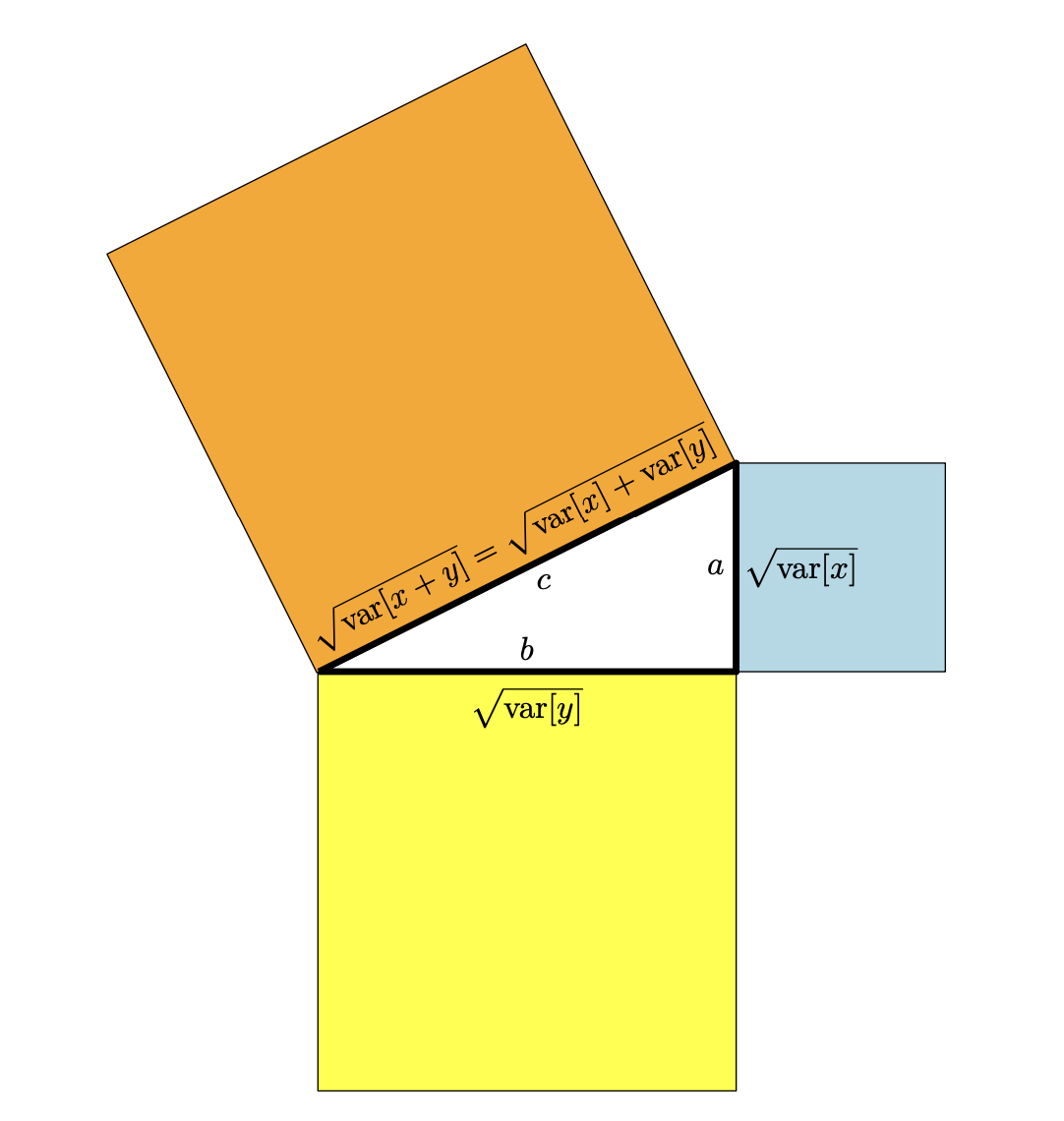
随机变量的几何。如果随机变量\(X\)和\(Y\)不相关,则它们是对应向量空间中的正交向量,且勾股定理也适用。
6.10 概率分布的距离定义
使用之前内积定义的欧几里得距离来比较概率分布似乎是个不错的选择,但不幸的是,这不是获得分布之间距离的最佳方法。回想一下,概率质量(或密度)是正的,需要加起来等于1。这些限制意味着分布存在于一种叫做统计流形(statistical manifold)的东西上。对概率分布空间的研究被称为信息几何( information geometry)。计算分布之间的距离通常使用Kullback-Leibler散度(KL散度)来完成,它是距离的推广,它解释了统计流形的性质。正如欧氏距离是矩阵的一种特殊情况一样(第3.3节),KL散度是另外两种广义散度的一种特殊情况,它们被称为Bregman散度和f ff-散度。关于它们区别的研究超出了这本书的范围,读者可以参考信息几何领域的创始人之一Amari(2016)的新书了解更多细节。
具体的例子见《概率分布的距离定义.md》
6.11 高斯分布
由于高斯分布完全由其均值和协方差来表示,我们通常可以通过对随机变量的均值和协方差进行变换来得到变换后的分布。高斯分布的边缘分布和条件分布是高斯分布。高斯随机变量的任何线性/仿射变换后依然服从高斯分布。
6.12 共轭与指数族
在应用概率运算法则时,存在一些“封闭性”,如贝叶斯定理。封闭是指对一类对象应用特定操作后返回相同类型的对象。
6.12.1 Beta分布
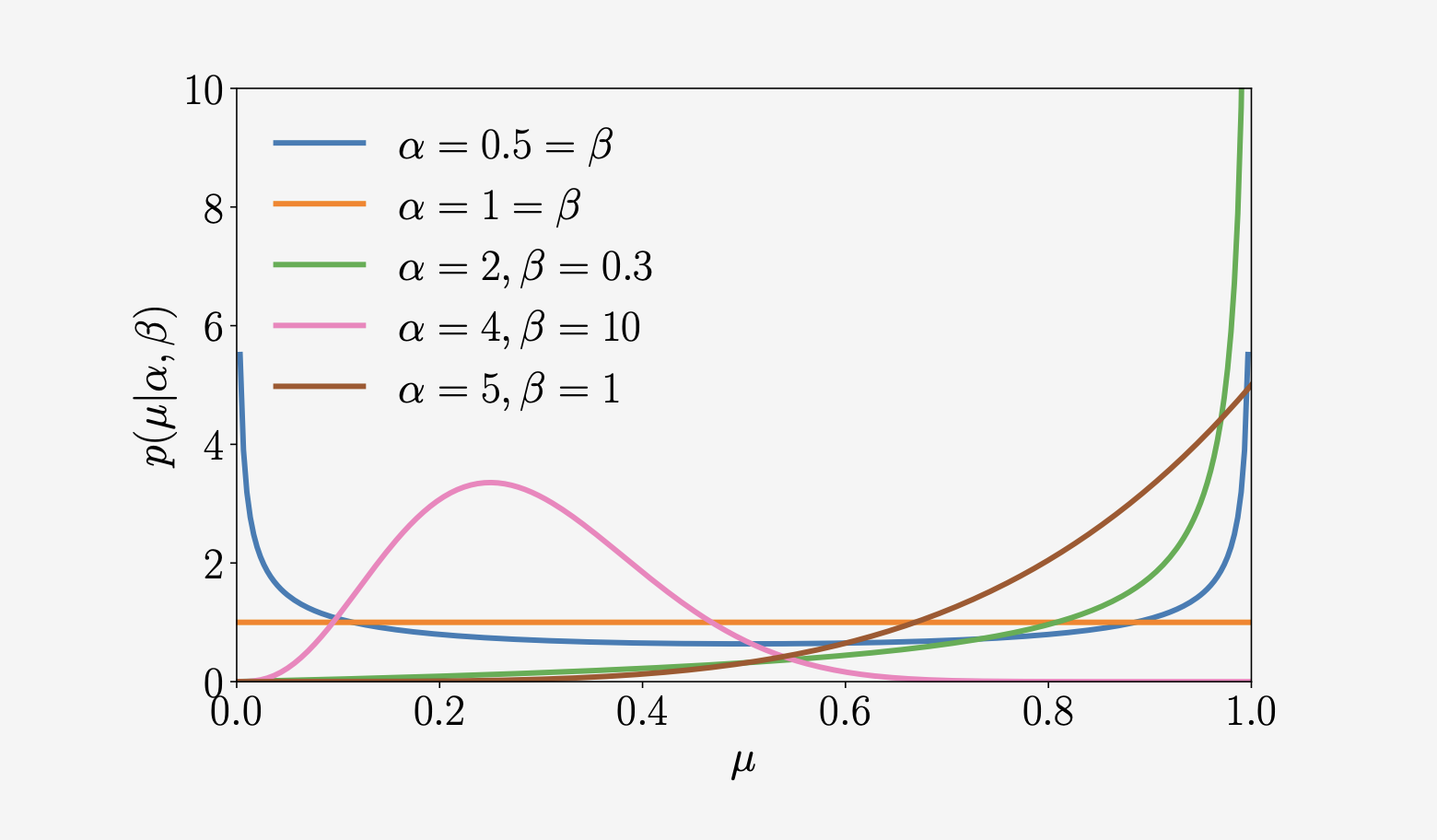
我们可能想在有限区间上建立一个连续随机变量的模型。Beta分布是一个连续随机变量 \(\mu \in [0,1]\) 上的分布,通常用来表示一些二值事件的概率(例如,控制伯努利分布的参数)。Beta分布 \(\mathrm{Beta}(\alpha, \beta)\)(如图6.11所示)本身由两个参数控制 \(\alpha > 0, \ \beta > 0\),并被定义为 \[ \begin{equation} p(\mu \mid \alpha, \beta) = \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha) \, \Gamma(\beta)} \, \mu^{\alpha-1} (1-\mu)^{\beta-1} \end{equation} \]
\[ \mathbb{E}[\mu] = \frac{\alpha}{\alpha+\beta}, \quad \mathbb{V}[\mu] = \frac{\alpha \beta}{(\alpha+\beta)^2 (\alpha+\beta+1)} \]
其中 \(\Gamma(\cdot)\) 为伽马(Gamma)函数,定义为: \[ \Gamma(t) := \int_{0}^{\infty} x^{t-1} e^{-x} \, dx, \quad t > 0, \qquad \Gamma(t+1) = t \, \Gamma(t) \] 注意,(6.98)中的Gamma函数的分数标准化了Beta分布。
直观地看,\(\alpha\) 将概率质量移向 \(1\),而 \(\beta\) 将概率质量移向 \(0\)。一些特殊的情况:
- 对于 \(\alpha = 1 = \beta\),我们得到均匀分布 \(\mathcal{U}[0,1]\)。
- 对于 \(\alpha, \beta < 1\),我们得到双峰分布,峰值在 \(0\) 和 \(1\) 处。
- 对于 \(\alpha, \beta > 1\),分布是单峰的。
- 对于 \(\alpha, \beta > 1\) 且 \(\alpha = \beta\),分布是单峰对称的,且集中在区间 \([0,1]\),即均值在 \(1/2\)。
有一大堆有名字的分布,它们以不同的方式相互联系(Leemis和McQueston, 2008)。值得记住的是,每个被命名的分布都是为了特定的原因而创建的,但是可能还有其他的应用。了解创建特定分布背后的原因可以知道如何最好地使用它。
6.12.2 共轭
共轭先验
如果后验与先验具有相同的形式/类型,则先验是似然函数的共轭(conjugate)。共轭特别方便,因为我们可以通过更新先验分布的参数来用代数方法计算后验分布。
备注: 在考虑概率分布的几何时,共轭先验保留了似然的距离结构(Agarwal and Daum´e III, 2010)
对于二项分布似然函数中的参数\(\mu\),Beta先验是共轭的。Beta分布是伯努利分布的共轭先验。

表6.2列出了一些用于概率建模的标准似然的参数的共轭先验。分布如多项式分布、逆Gamma分布、逆Wishart分布和Dirichlet分布可以在任何统计文本中找到,例如在Bishop(2006)中就进行了描述。
Beta分布是二项分布和伯努利分布似然中关于参数\(\mu\)的共轭先验。对于高斯似然函数,我们可以在均值上设置一个共轭高斯先验。高斯似然在表中出现两次的原因是我们需要区分一元和多元情况。在一元(标量)情况下,逆Gamma是方差的共轭先验。在多元情形下,我们使用逆Wishart分布作为协方差矩阵的共轭先验。Dirichlet分布是多项式似然函数的共轭先验。
6.12.3 指数族
分布三个抽象级别:
在考虑分布(离散或连续的随机变量)时,我们可以有三个可能的抽象级别。
在第一级(这是最具体的级别),我们有一个具有固定参数的特定“命名”分布,例如一个均值为零,方差为单位矩阵的一元高斯分布 \(\mathcal{N}(0,1)\)。
而在机器学习中,我们经常使用第二层抽象,即我们采用参数形式固定的分布(如一元高斯分布),并从数据中推断出它的参数。例如,我们假设一个未知均值 \(\mu\) 和未知方差 \(\sigma^2\) 的一元高斯分布 \(\mathcal{N}\left(\mu, \sigma^{2}\right)\),并使用最大似然拟合来确定最佳参数 \((\mu, \sigma^2)\)。我们将在第9章讨论线性回归时看到一个例子。
第三个抽象的层次是考虑分布的族,在本书中,我们考虑指数族。一元高斯分布是指数族中的一个例子。许多广泛使用的统计模型,包括表 6.2 中所有的“命名”模型,都属于指数族。它们都可以统一成一个概念。
我们研究指数族的主要动机是它们具有有限维的充分统计信息。此外,共轭分布很容易写出来,而且也来自一个指数族。从推理的角度来看,指数族的极大似然估计表现得很好,因为它的充分统计量的经验估计是充分统计量总体的最佳估计(回忆一下高斯分布的均值和协方差)。从优化的角度来看,指数族的的对数似然函数是凹的,允许我们应用有效的优化方法(第7章)。
6.13 变量替换/逆变换
似乎有很多已知的分布,但实际上,我们可以命名的分布是非常有限的。因此,理解随机变量在变换后是如何分布的通常很有用。
详见《常见分布在变换后的分布.md》
例如,假设 \(X\) 是根据一元正态分布 \(\mathcal{N}(0,1)\) 得到的一个随机变量。那么 \(X^2\) 的分布是什么? 另一个在机器学习中很常见的例子是,假设 \(X_1\) 和 \(X_2\) 是一元标准正态分布,那么 \(\frac{1}{2} (X_1 + X_2)\)的分布是什么?计算 \(\frac{1}{2} (X_1 + X_2)\) 的分布的一个选择是计算 \(X_1\) 和 \(X_2\) 的均值和方差,然后组合它们。正如我们在第 6.4.4 节中看到的,当我们考虑随机变量的仿射变换时,我们可以计算变换后得到的随机变量的均值和方差。 然而,我们也可能无法得到变换后分布的函数形式。此外,我们还可能关心随机变量的非线性变换,这时变换后的封闭形式的表达式是不容易得到的。
我们将介绍两种通过随机变量变换获取分布的方法:一种是使用累积分布函数定义的直接方法,另一种是使用微积分的链式法则(第5.2.2节)的变量替换(change-of-variable)方法。变量替换方法被广泛使用,因为它提供了一个用于计算由于转换而产生的分布的“秘诀”。我们将解释关于一元随机变量的变量替换技术,并将简要地给出多元随机变量的一般情况的结果。
6.13.1 分布函数技术
均匀分布在统计中的重要性
- 基准分布:在随机数生成和蒙特卡罗模拟中,均匀分布是最常用的基础分布(大多数随机数生成器先生成 \(U(0,1)\),再通过变换得到其他分布)。
- 概率积分变换:定理 6.15 就是基于这个思想:如果 \(X\) 的 CDF 是严格单调的,那么 \(Y = F_X(X)\) 服从 \(U(0,1)\)。
将随机变量\(X\)的累积分布函数\(F_X(x)\)作为变换函数\(U(x)\),可以得到一个有用的结果,这导出了下面的定理。
任何分布都能化为[0,1]均匀分布。
定理 6.15 令 \(X\) 为连续随机变量,且具有严格单调的累积分布函数 \(F_X(x)\)。 那么定义为 \[ Y := F_X(X) \] 的随机变量 \(Y\) 具有均匀分布。
证明:
对任意 \(y\in[0,1]\),由于 \(F_X\) 严格单调且连续,存在反函数 \(F_X^{-1}:(0,1)\to \mathbb{R}\)。于是 \[ \begin{aligned} F_Y(y) &:=\mathbb{P}(Y\le y) =\mathbb{P}\big(F_X(X)\le y\big) \\ &=\mathbb{P}\big(X\le F_X^{-1}(y)\big) =F_X\!\big(F_X^{-1}(y)\big) = y,\qquad y\in[0,1]. \end{aligned} \] 对区间外的 \(y\),有 \(F_Y(y)=0\)(当 \(y<0\))和 \(F_Y(y)=1\)(当 \(y>1\))。 因此 \(F_Y(y)=y\)(\(y\in[0,1]\)),即 \(Y\sim \mathrm{Unif}(0,1)\)。
定理6.15被称为概率积分变换(probability integral transform),它用于推导从分布中采样的算法,这个算法通过均匀随机变量的采样结果进行变换(Bishop,2006)。该算法的工作原理是首先从均匀分布生成样本,然后通过逆累计密度函数(假设这是可以得到的)对其进行变换,以从所需分布获得样本。概率积分变换也用于假设检验样本是否来自特定分布(Lehmann和Romano,2005)。累积分布函数的输出是均匀分布的这一观点也构成了copulas的基础(Nelsen,2006)。
以上这段话采样的例子详见《概率积分变换的采样原理.md》
直观理解:
- 均匀分布随机数就像一个“百分比刻度”
- 逆 CDF 就是把这个刻度映射到目标分布的位置
- 这样就能用均匀分布随机数生成任何我们想要的分布样本
6.13.2 变量替换
区间可逆的函数要么严格递增要么严格递减。
事件的等价变换不会改变概率
微积分的基本定理中,有一个非常经典的结论:积分上限函数求导,它把导数与积分直接联系了起来。
详见《积分上限函数求导.md》。
备注:
“变量替换”这个名字来源于当我们面对一个困难的积分时改变积分变量的想法。
对于一元函数,我们使用换元积分法:
\[
\begin{equation}
\int f(g(x)) g^{\prime}(x)\, \mathrm{d}x
= \int f(u)\, \mathrm{d}u,
\quad \text{其中} \quad u = g(x)
\qquad (6.133)
\end{equation}
\] 该法则的推导基于微积分的链式法则
(5.32),以及应用两次微积分基本定理。
微积分基本定理证明了积分和微分在某种程度上是互“逆”的。
通过(松散地)考虑方程\(u =
g(x)\)的微小变化(微分),即把\(\Delta
u = g^{\prime}(x)\, \Delta x\)看作 \(u
= g(x)\) 的微分,可以直观地理解这个规则。 将 \(u = g(x)\) 代入,积分 (6.133)
右边的参数变成了 \(f(g(x))\)。 通过假设
\(\mathrm{d}u \approx \Delta u =
g^{\prime}(x)\, \Delta x,\mathrm{d}x \approx \Delta
x,\)我们最终得到了 (6.133)。
定理 6.16:
令 \(f(\boldsymbol{x})\) 是多变量连续随机变量 \(\boldsymbol{X}\) 的概率密度函数。如果向量值函数 \(\boldsymbol{y} = U(\boldsymbol{x})\)在定义域内对于所有 \(\boldsymbol{x}\) 可微且可逆,那么对应的随机变量 \(\boldsymbol{Y} = U(\boldsymbol{X})\)的概率密度函数由下式给出: \[ f(\boldsymbol{y}) = f_{\boldsymbol{x}}\bigl(U^{-1}(\boldsymbol{y})\bigr) \cdot \left|\frac{d}{d \boldsymbol{y}} U^{-1}(\boldsymbol{y})\right|, \] 其中 \(\left|\frac{d}{d \boldsymbol{y}} U^{-1}(\boldsymbol{y})\right|\) 表示雅可比矩阵的行列式的绝对值。
这个定理的关键是多元随机变量的变量替换遵循单变量变量替换的过程。首先需要求出逆变换 \(U^{-1}\),并将其代入 \(\boldsymbol{x}\) 的密度函数 \(f_{\boldsymbol{x}}(\boldsymbol{x})\) 中,然后计算雅可比矩阵的行列式,并与密度函数相乘得到结果。
全书的读书笔记(共7篇)如下:
《机器学习的数学基础》读书笔记之一 :导言
《机器学习的数学基础》读书笔记之二 :线性代数
《机器学习的数学基础》读书笔记之三 :解析几何
《机器学习的数学基础》读书笔记之四 :矩阵分解
《机器学习的数学基础》读书笔记之五 :向量微积分
《机器学习的数学基础》读书笔记之六 :概率与分布
《机器学习的数学基础》读书笔记之七 :连续优化