似然函数和条件概率的分别
似然函数和条件概率的分别? 这是一个非常重要但容易混淆的问题,尤其是在学习贝叶斯推断时。
- 相同点(为什么它们看起来像一样的东西)
两者在数学形式上确实很相似:
\[ P(x \mid \theta) \]
- 当我们把它当成关于 \(x\) 的函数(已知参数 \(\theta\)):这是条件概率;
- 当我们把它当成关于 \(\theta\) 的函数(已知数据 \(x\)):这是似然函数。
所以:
同一个表达式 \(P(x \mid \theta)\),既可以是条件概率,也可以是似然函数,取决于我们把哪个当变量、哪个当已知!
- 核心区别:函数变量不同
| 概念 | 表达 | 自变量 | 用途 |
|---|---|---|---|
| 条件概率 | \(P(x \mid \theta)\) | \(x\) 是变量,\(\theta\) 是固定参数 | 给定参数,求事件发生的概率 |
| 似然函数 | \(\mathcal{L}(\theta) = P(x \mid \theta)\) | \(\theta\) 是变量,\(x\) 是固定数据 | 给定数据,评估不同参数的“可能性” |
- 直观类比
设想你在射击:
- 条件概率:你知道你的射击技术(参数 \(\theta\)),问你在某个地方击中目标的概率 \(P(x \mid \theta)\)。
- 似然函数:你看到子弹落点(观测结果 \(x\)),你想反推你的技术水平(\(\theta\))到底有多好。
- 应用场景上的区分
| 应用 | 使用哪个? | 说明 |
|---|---|---|
| 频率派统计(MLE) | 似然函数 | 最大化 \(\mathcal{L}(\theta)\),得到参数估计值 |
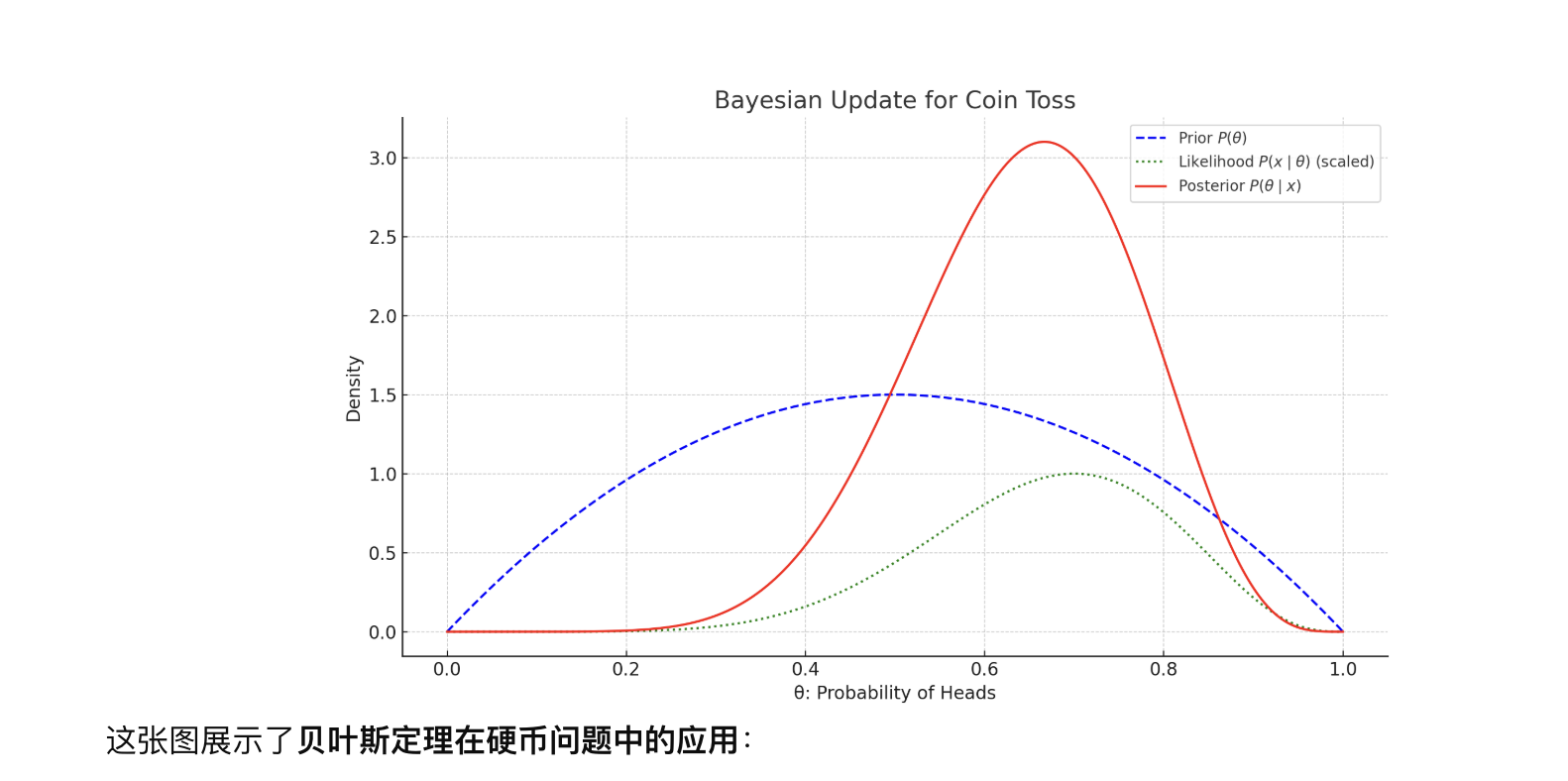
| 贝叶斯推断 | 两者都用 | 用 \(P(x \mid \theta)\) 作为“似然”,乘上先验 \(P(\theta)\),得出后验分布 |
| 预测或模拟 | 条件概率 | 给定参数后,模拟或计算未来数据的概率分布 |
- 一个例子帮你彻底搞懂
例子:抛硬币 10 次,看到 7 次正面
假设硬币正面概率为 \(\theta\)
(A)条件概率: 如果 \(\theta = 0.5\),我们问:出现 7 次正面的概率是多少?
\[ P(x = 7 \mid \theta = 0.5) = \binom{10}{7} (0.5)^7 (0.5)^3 = 0.117 \]
这是“给定参数、问数据”的问题。
(B)似然函数: 如果我们已看到 7 次正面(数据固定),我们要估计 \(\theta\):
\[ \mathcal{L}(\theta) = P(x=7 \mid \theta) = \binom{10}{7} \theta^7 (1-\theta)^3 \]
这是“给定数据,反推哪个 \(\theta\) 值最有可能产生这些数据”的问题。
总结
| 条目 | 条件概率 | 似然函数 |
|---|---|---|
| 表达式 | \(P(x \mid \theta)\) | \(P(x \mid \theta)\) |
| 自变量 | \(x\) | \(\theta\) |
| 参数 | \(\theta\)(固定) | \(x\)(固定) |
| 语义 | 给定模型,事件发生的概率 | 给定结果,参数的合理性评估 |
| 用途 | 用于预测 | 用于估计 |

如图所示,图像展示了条件概率和似然函数之间的关键区别:
左图:条件概率 \(P(x \mid \theta = 0.5)\)
- 固定参数 \(\theta = 0.5\)
- 横轴是可能出现的正面次数 \(x\)
- 描述在固定参数下,各种结果 \(x\) 的概率分布
用途:用于预测或模拟未来数据
、右图:似然函数 \(\mathcal{L}(\theta) = P(x=7 \mid \theta)\)
- 固定观察结果 \(x = 7\)
- 横轴是参数 \(\theta\)(正面概率)
- 描述在不同参数值下,观察到这个数据的“可能性”
用途:用于估计参数(如最大似然估计、贝叶斯更新)
两图长得像,但方向反了:
- 条件概率:已知参数,预测数据
- 似然函数:已知数据,推断参数