《看漫画学统计学》读书心得
大学学过统计学,但现在也都忘光光了,之前也看过《数学桥--对高等数学的一次观赏之旅》,不过这本书因为是专业的书籍,偏向于公式的推断,陷入了细节。所以一直对于统计学中关键的几个分布正态分布、二项分布、泊松分布,感觉还是没有很好的理解。
像本书作者所说太拘泥于公式,常常会看不到事物的本质,所以一直以来,对于统计学,感觉自己都是只见树木不见森林。
现在有空看了这本《看漫画学统计学》,终于可以跳出公式来看待公式的本质了。
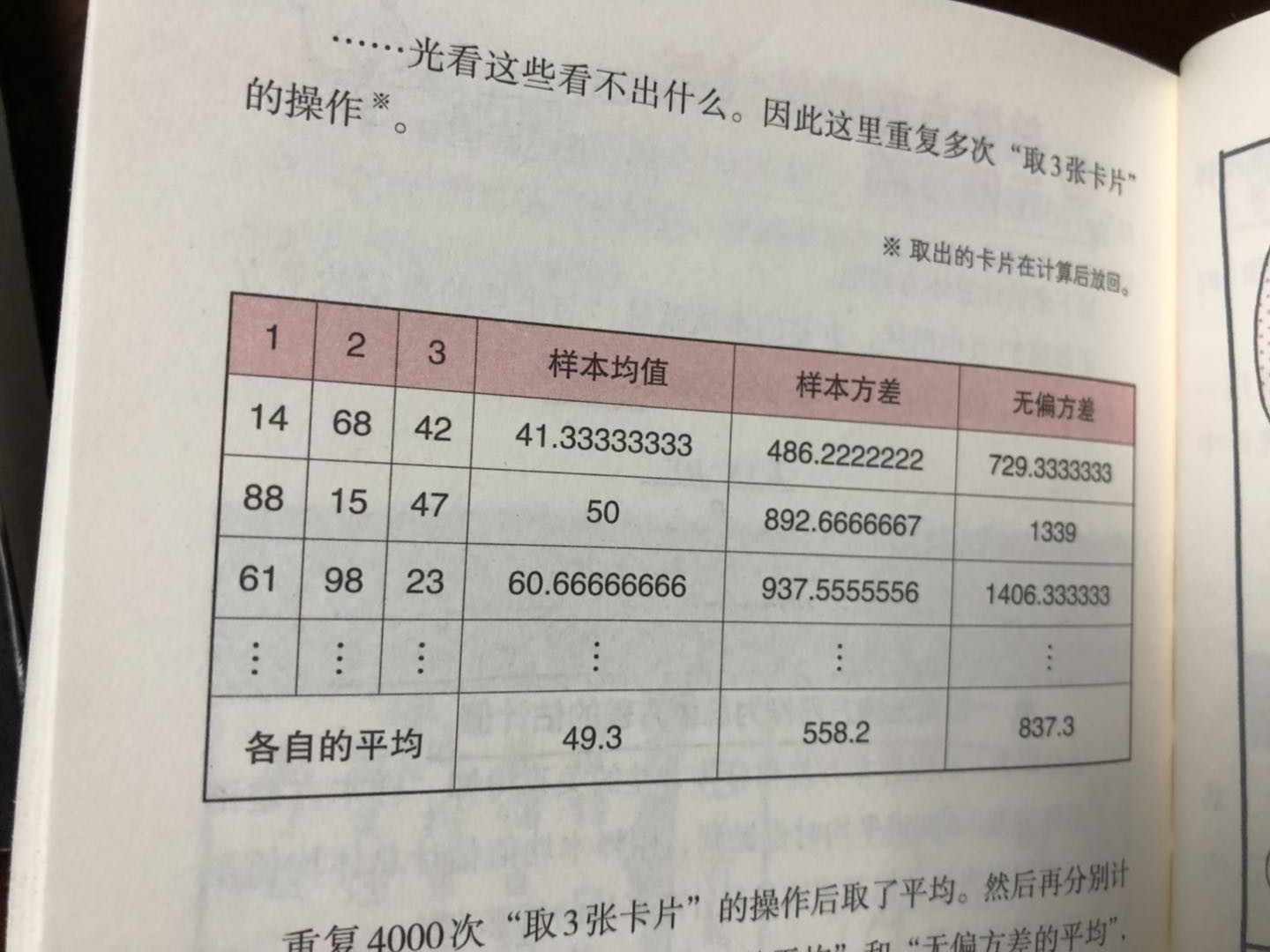
作者提到,统计学上最重要的定理是中心极限定理,确实是,回头看来,中心极限定理其实是后面很多推断的基石,而之前我们往往忽视了中心极限定理的存在。
中心极限定理
大量相互独立的随机变量,在采样次数足够大的时候(一般要超过30次以上),其均值或者和的分布以正态分布为极限。
中心极限定理的有趣的地方在于,无论随机变量呈现出什么分布,只要你抽取次数无限大,抽取样本的均值就接近于正态分布。
对,mark一下重点就是:- 样本的平均值约等于总体的平均值;
- 不管总体是什么分布,但是样本的均值都会围绕在总体的整体平均值周围并呈现正态分布。
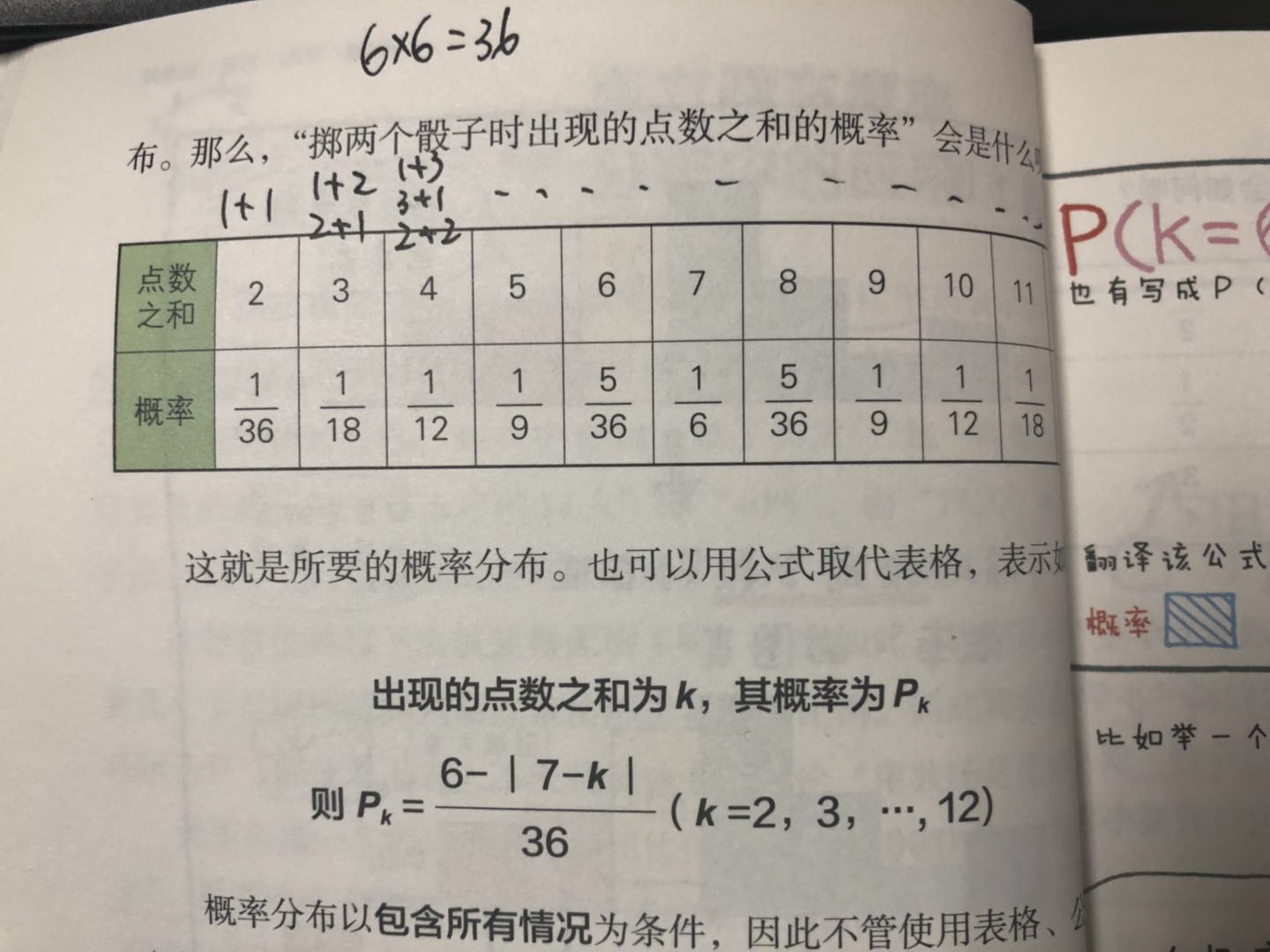
eg:比如你投6枚筛子,对每次的6个数求平均\(X_{n}\) ,则\(X_{1}\) -- \(X_{n}\) 的分布就满足与正态分布
那中心极限定理的用处是什么呢?
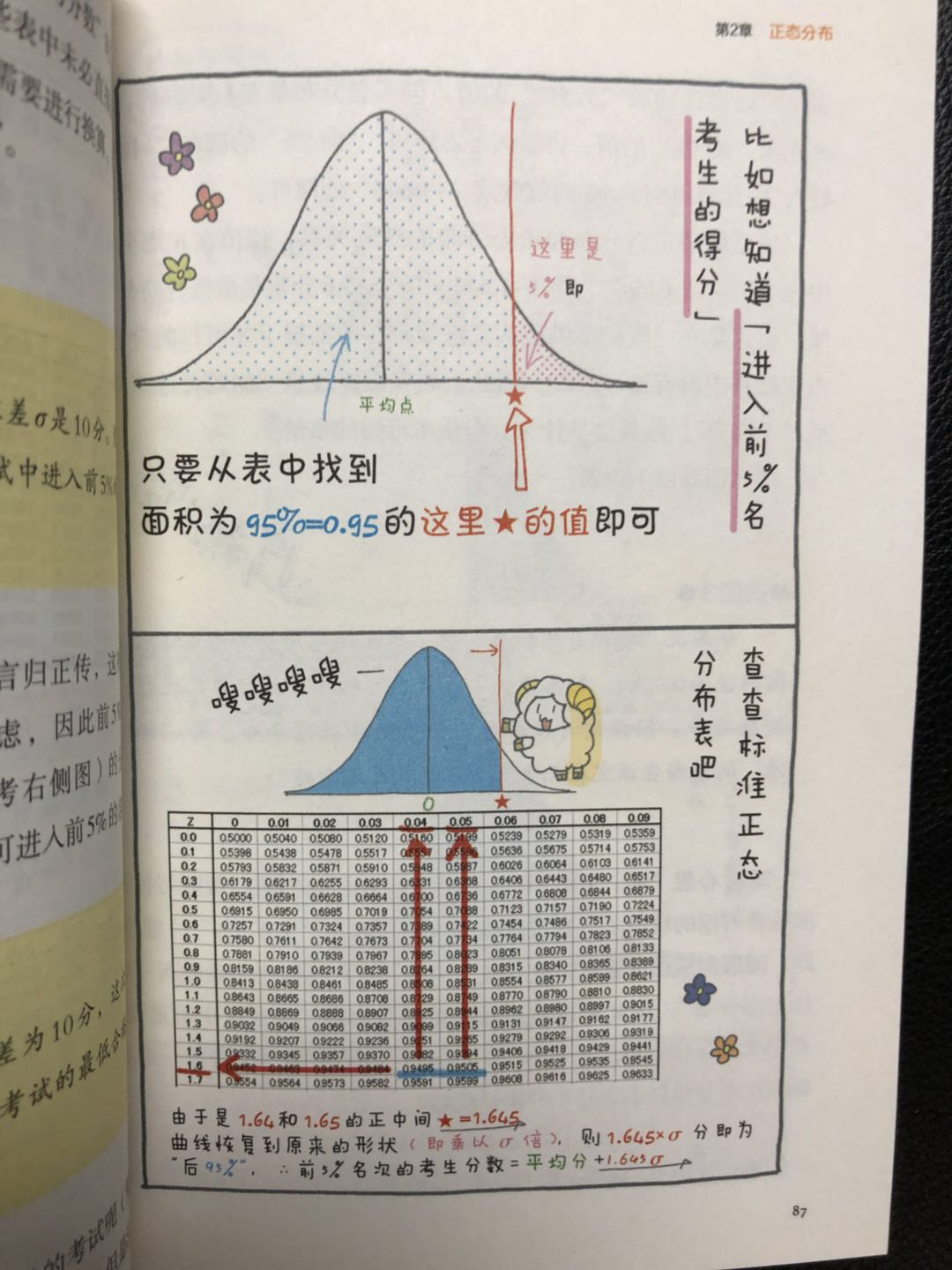
eg:你要预测一件事情发生的概率,比如查验食品合格率,你只需要抽查部分就可判断整体合格率,这就用到中心极限定理了,因为样本的均值分布是在总体样本的均值附近呈现正态分布,这样你就知道有68%的样本在总体平均值的一个标准差范围内波动,有95%的样本平均值在总体平均值的两个标准误差范围内,99.7%的在总体平均值三个标准差单位内波动,如果一个样本均值与总体均值的差大于三个标准差,那么我们可以说这个样本不属于这个总体,所以这就是我们拿样本均值估计总体均值的原因所在(当然自我感觉其实再计算一下标准差对估计的评估效果会好一点)。
中心极限定理:当样本容量n增大时,不论原来的总体是否服从正态分布,样本均值的抽样分布都将趋于服从正态分布。比如你要调查一个国家人民的体重的平均值,每次取1000个体重值作为样本,对应就有一个样本均值。你再从总体中重復抽取n多次1000个样本,就对应有n个样本均值。随着n增大,把所有样本均值画出来,得到的就是一个接近正态分布的图。
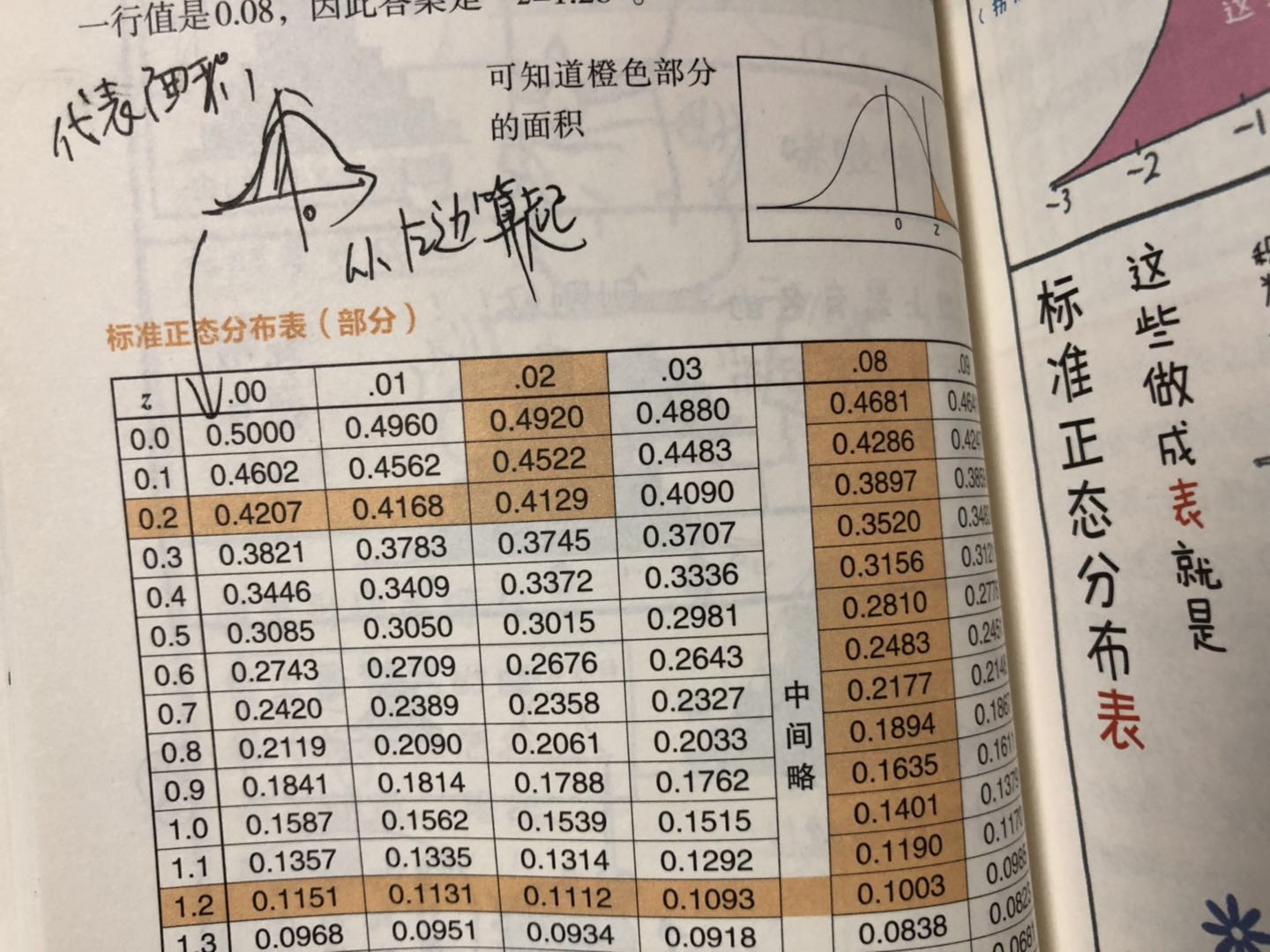
而正态分布是我们日常生活中最常见的分布,很多生活现象都可以用正态分布来模拟。标准正态分布的概率(从左到右的面积)可以通过正态分布表来查到。在日常生活中,例如某个考试不同科目的含金量,可以通过正态分布表来比较,例如可以使用公式表示:
(得分 - 平均分) / 标准差
(代表分数与平均分有几个标准差),来比较不同科目在整体中的位置,而不能纯粹以分数的绝对值来比较分数的含金量。
另外,看了本书终于明白,正态分布、泊(bó)松分布是在不同情况下,来近似计算二项分布的一种方法。
有如此多种近似计算的方法,是因为准确计算二项分布非常困难,因此,祖先们绞尽脑汁想出了多种近似计算的方法。由于是近似,所以,可以根据情况选择“更加合适的近似”。而且,有些情况下也可以直接计算,而不是近似计算,因为,首先应该研究是否可以直接计算,因为这才是最准确的。然后在不能用手中的工具做计算时,就考虑做近似计算。
特别是泊松分布,在实验次数n非常大,发生概率P非常小的情况下可以通过泊松分布来近似计算二项分布,例如交通事故的发生概率就是满足以上条件的最著名的二项分布的例子。并且,在用泊松分布近似计算的时候,一个重要的要素,就是没有用到n的值,这样,对于没有总量的概率计算就很有效。一般泊松分布是在知道某个期间的平均概率的情况下,预测某个期间出现某状况次数为k的概率。这些在日常生活中的应用是非常广的。
在讲了这些描述统计学之后,作者也提到了推断统计学。描述统计学和推断统计学最大的不同之处在于“是否掌握全部数据”。描述统计学主要讲的是怎样解释所收集信息的内容。而推断统计学是根据部分数据估计整体的统计学。关于推断统计,其基础还是概率计算。于是,最后还是回到大部分都服从正态分布的问题(例如体重的分布、财富的分布就不符合正态分布)。在推断统计学中,样本量少时服从t分布,当样本量较大时,就可以当做正态分布处理。准确的说应该是,无论n大或者小,使用的都是t分布。但n较大是也可以使用正态分布。
概念
直方图、平均值、方差、标准差

标准正态分布、正态分布(N(μ,σ²))

标准正态分布表
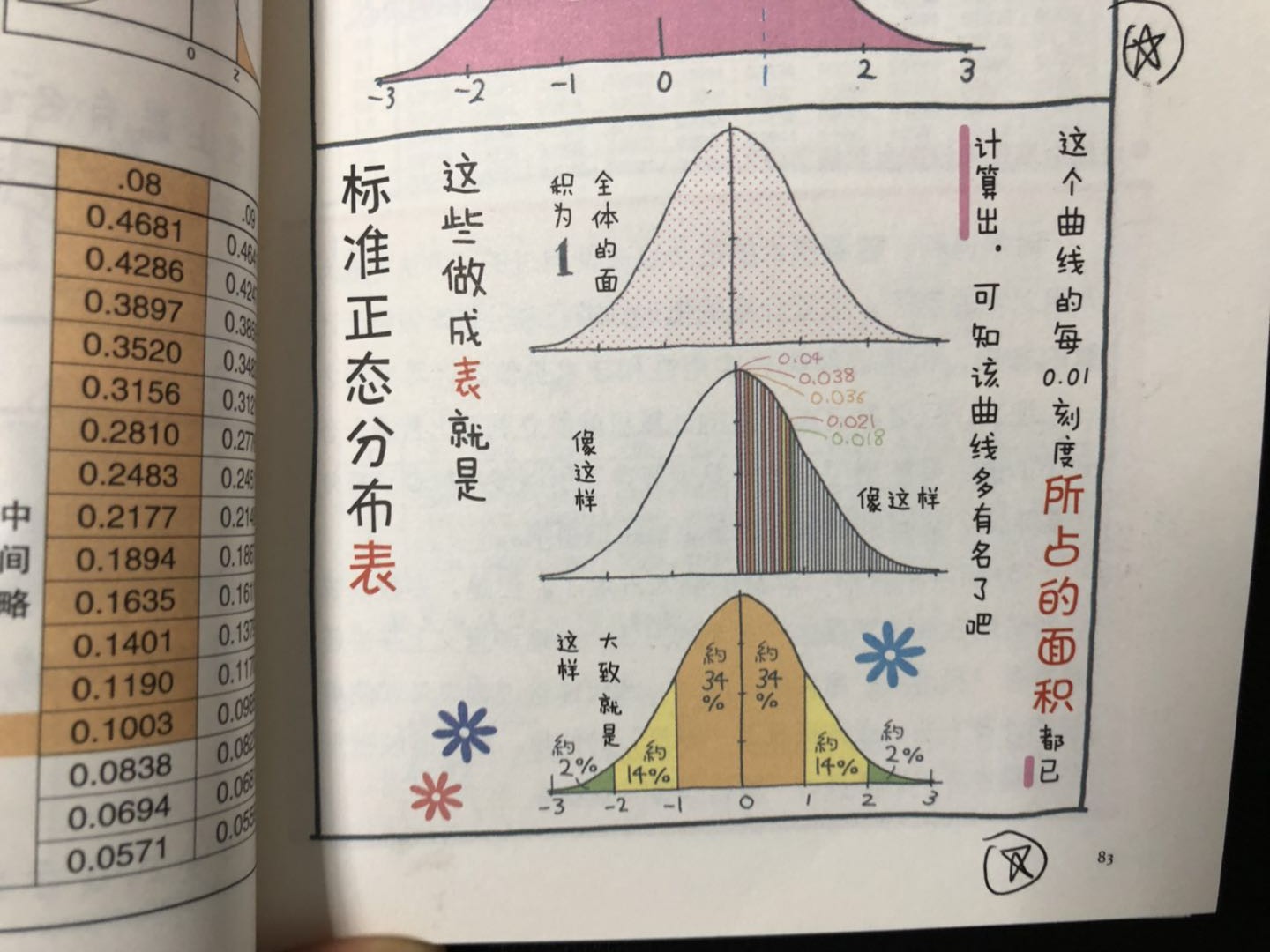
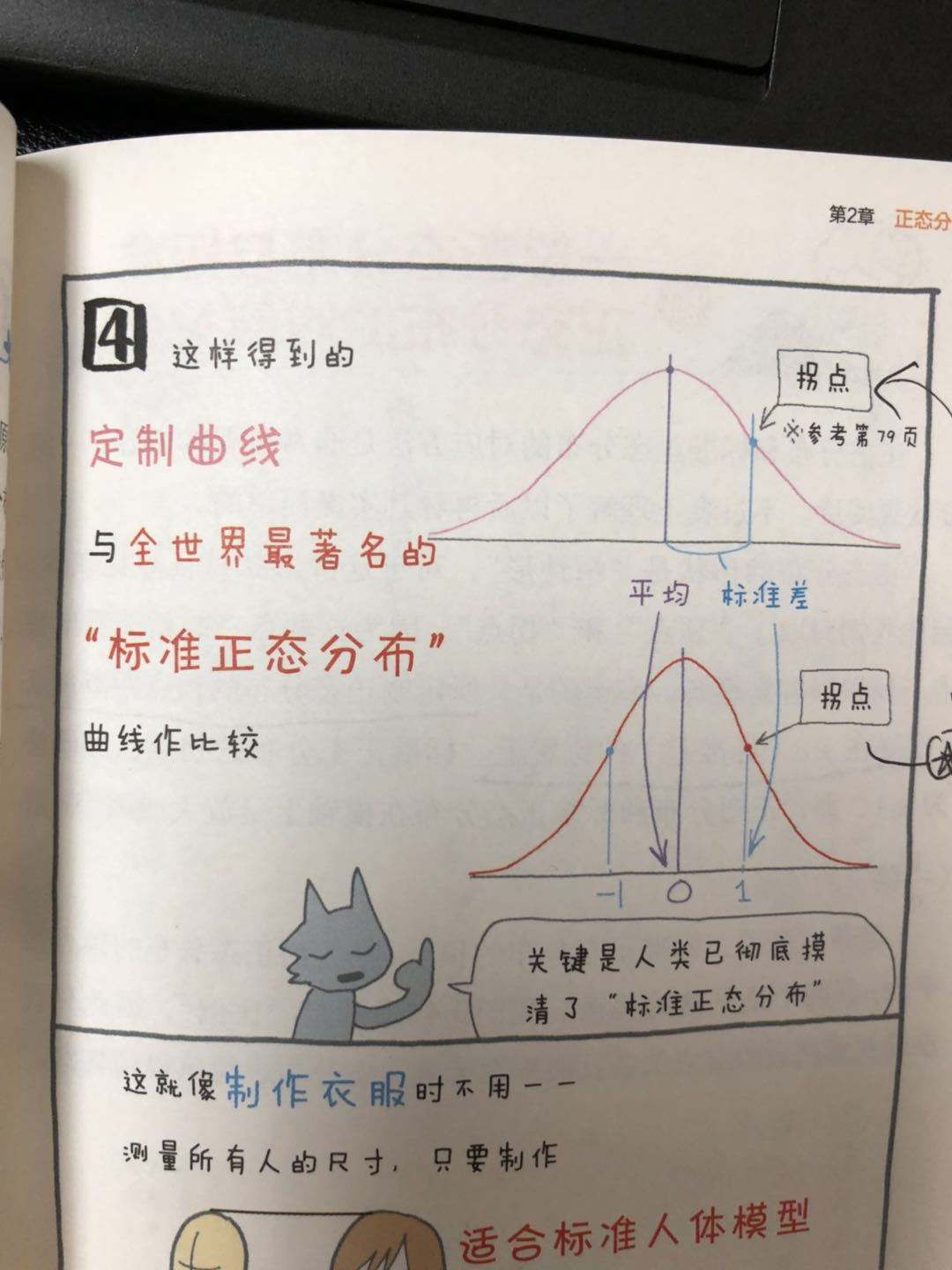
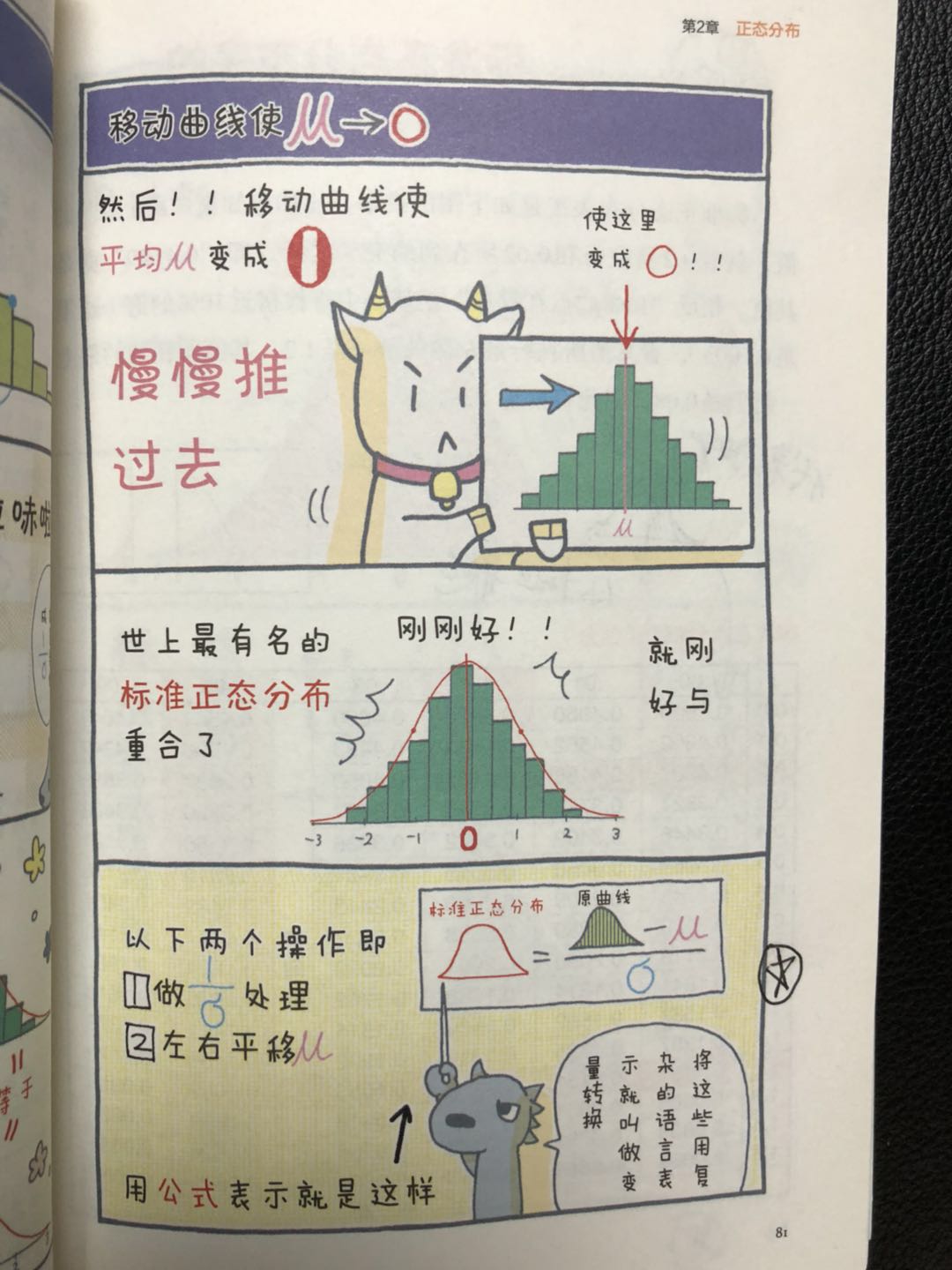
我们认为标准的正态分布是彻底已知的,这就如同,测量物体是不会全部逐个测量尺寸,而是使用模型的数据进行倍数换算来测量的原理。因此,可以说标准正态分布是一把“尺子”。
正态分布和标准正态分布在横轴上是放大或缩小倍σ(1/σ倍)的关系。
正态分布的推导


二项分布
二项分布 B(n,p)
二项分布是指在只有两个结果的n次独立的伯努利试验中,所期望的结果出现次数的概率。在单次试验中,结果A出现的概率为p,结果B出现的概率为q,p+q=1。那么在n=10,即10次试验中,结果A出现0次、1次、……、10次的概率各是多少呢?这样的概率分布呈现出什么特征呢?这就是二项分布所研究的内容。

二项分布的近似计算
用正态分布近似计算二项分布
用正态分布求解二项分布,二项分布可以用正态分布做近似计算.
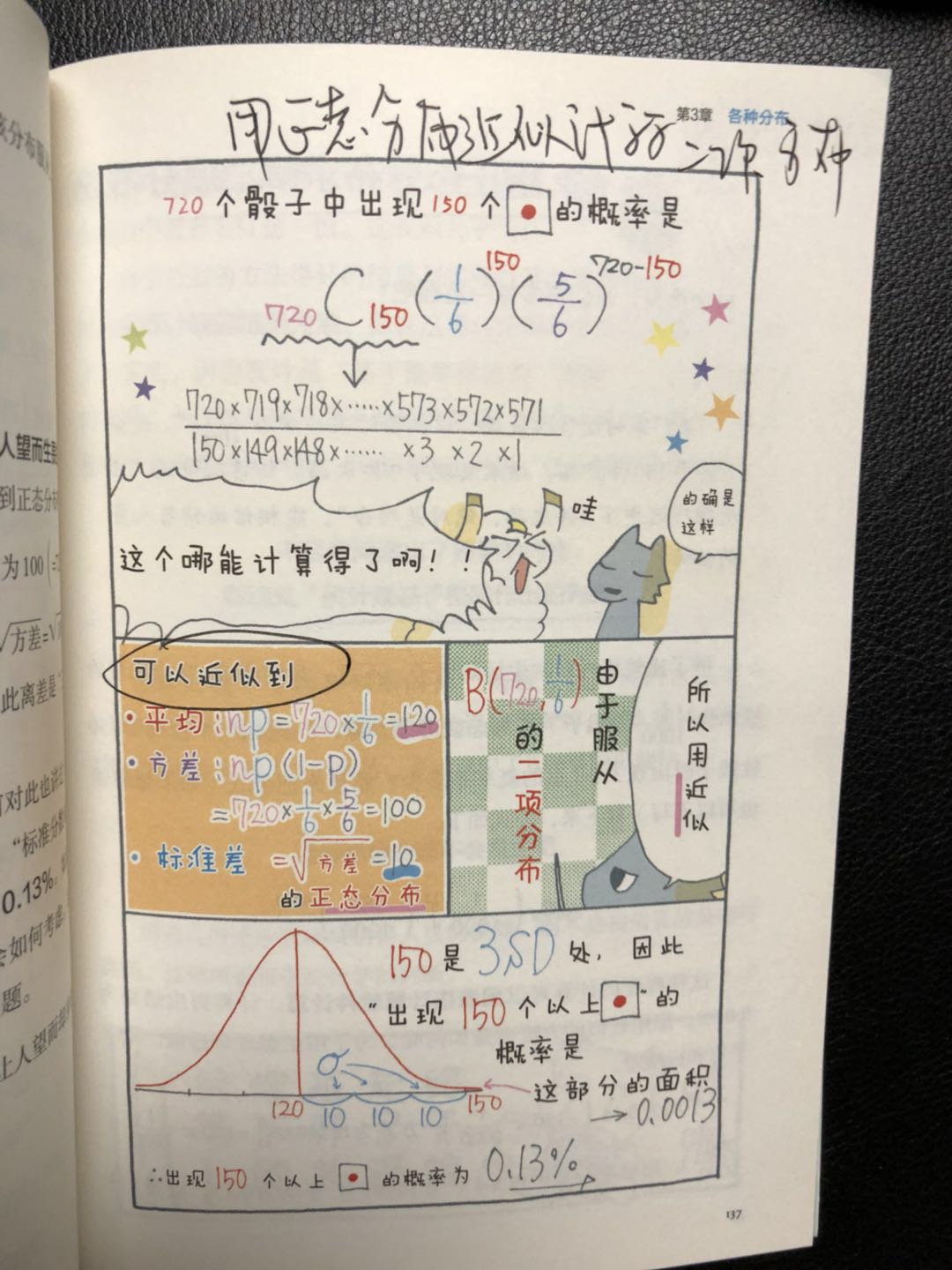
用泊松分布近似计算二项分布
但实际上还有一种做近似计算的方法,那就是使用“泊松分布”。
用泊松分布做近似计算的条件如下:
- 实验次数n非常大。比如1万次或以上;
- 发生概率P非常小。 1/1000或者更小等;
交通事故的发生概率就是满足以上条件的最著名的二项分布的例子。
在用泊松分布近似计算的时候,一个重要的要素,就是没有用到n的值,这样,对于没有总量的概率计算就很有效。一般泊松分布是在知道某个期间的平均概率的情况下,预测某个期间出现某状况次数为K的概率

推断统计学
推断统计的前提是:
- 以随机抽样为前提;
- 以原始分布是正态分布为前提。
描述统计学和推断统计学最大的不同之处在于“是否掌握全部数据”。描述统计学主要讲的是怎样解释所收集信息的内容。而推断统计学是根据部分数据估计整体的统计学。关于推断统计,其基础还是概率计算。于是,最后还是回到大部分都服从正态分布的问题(例如体重的分布、财富的分布就不符合正态分布)。
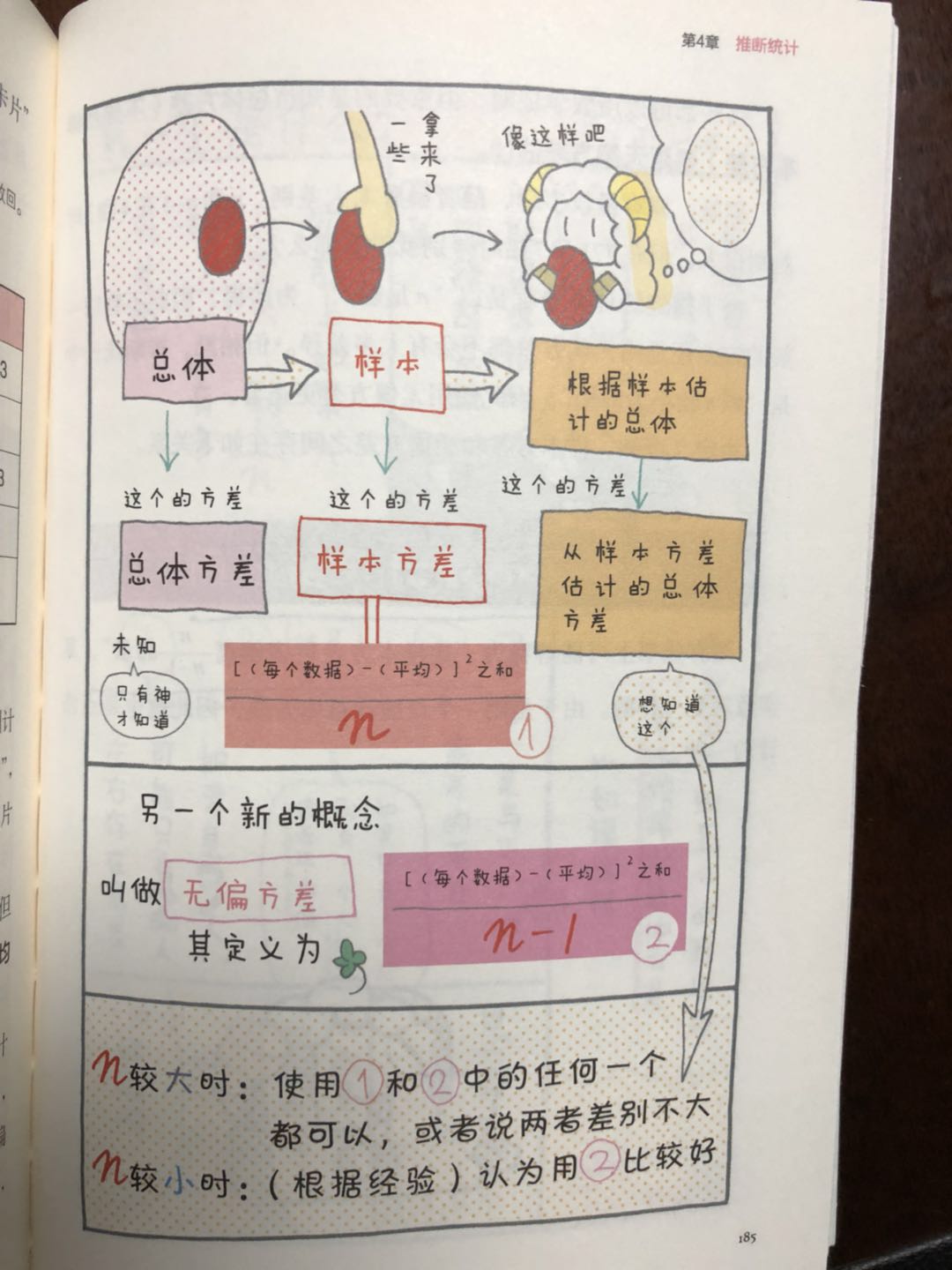
样本量少时服从t分布,当样本量较大时,就可以当做正态分布处理。准确的说应该是,无论n大或者小,使用的都是t分布。但n较大是也可以使用正态分布。
文章摘要
- 处理数据的第一步是画直方图,实际上,判断直方图是否是单峰非常重要,因为统计学基本上是围绕单峰型的直方图构成的学问。直方图或者次数分布表,在多数情况下使用比率来表示会更方便。用比例画出的直方图叫做“概率分布”。
- 按照某一期间分组的方法叫做“组距分组”。好的组距分组是:组距小到可充分说明数据的特点,同时让观者容易理解的分组。
- 尝试----错误法
- 要意识到,不正常的直方图一定有其原因。
- 大数据除了样本数据量大之外,还包括数据的要素信息也很多(包括不同的维度标签)
- 运行程序越复杂伴随的漏洞也就越多(换句话说:越简单越稳定)
- 用曲线的面积表示概率是件非常了不起的创意。...这种函数由于“其面积表示概率”,因此称之为“概率密度函数”。...“概率密度函数”的曲线图表中,“高度”是概率密度,即“曲线的面积是概率”。
- 正态分布,简单地说就是“所收集的数据以平均值为中心前后大致对称分散的状态
- 这个复杂的正态分布公式,并不是某位天才数学家的一时灵感,而是通过质朴且零碎的理论一一堆砌而成,即它不是神的启发,而是人类的智慧。
- 正态分布的特点:
- 有一个最高点;
- 以最高点为中心左右对称;
- 以指数函数的速度趋近于0;
- 面积为1(因为是概率分布),
- 有一个最高点;
- 要求事事完美也是失败的原因。
- 大数定律,它说的是,实验次数无限多时,接近概率的理论值。
- 重要的是,但你走投无路时退一步,站在远处俯瞰整体。