《分布式服务架构》读书心得
外国人写的书偏重于思想,中国人写的书偏向于操作层面,所以国人书里面的案例、代码会多点,可以当手册用;-)。
本书,介绍从单体架构演变到SOA架构,再到微服务架构的历程,然后针对微服务架构中最重要的一致性问题进行阐述。同时,针对互联网企业对服务化系统高性能要求,针对容量的评估和性能保障,通过实际的案例进行讲解,对日常的工作有实际的参考意义。
在运维环节,描述了如何搭建目前流行的ELK大数据日志系统,以及目前市面上常见的应用性能管理系统(APM)产品的实现。最后还提供了作者积累的一系列的运维脚本、工具给到读者。
文章最后详细说明了容器及敏捷开发的一些工具。
总体来说,本书适合作为一个工具书,理论层面只是做了简单的介绍。

- ATAM 互联网架构权衡分析法(Archiecture Tradeoff Analysis
Method) 本书提供了一个架构评审的方法案例。
具体见书的第89页。其实简单的思想就是,业务场景的高峰要求,转换成非性能指标,结合单机的性能指标,推算出需要配备的机器。
具体见:互联网性能与容量评估的方法论和典型案例
- 压测方案和压测场景
具体见书的119页,举了一个例子。简单的实现就是拿一个正常的基准测试的响应时间,然后拿目标的吞吐量的+-梯度值来计算出并发数。(吞吐量=并发数/响应时间);先采用小的吞吐量场景,压测出对应的响应时间,然后拿这个时间,来计算出目标吞吐量的并发数,压测出响应时间;以此类推,不断往上加并发数。测出系统在符合响应时间要求内的最大吞吐量(并发数)。
然后在CPU和内存使用率70%的情况下的负载来测试系统稳定性。
[关于并发数的一篇好文章](https://ruby-china.org/topics/26221)
- APM 应用性能管理
开源的的pinpoint
国内的应用性能监控平台:听云
文章摘要
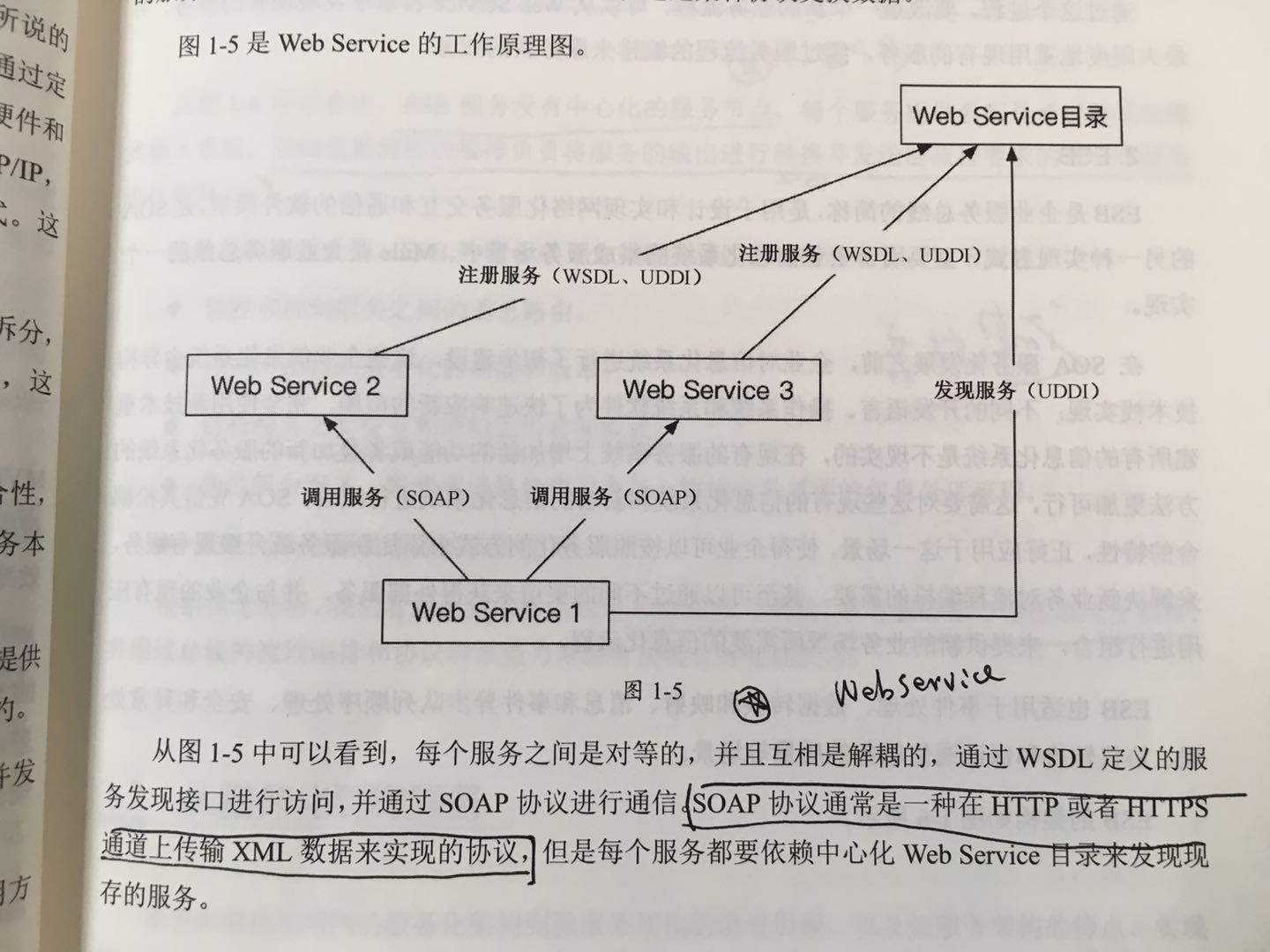
- JEE平台是典型的二八原则的一个应用场景,它将80%通用的与业务无关的逻辑和流程封装在应用服务器的模块化组件里,通过配置的模式提供给应用程序访问,应用程序实现20%的专用逻辑,并通过配置的形式访问应用服务器提供的模块化组件。事实上,应用服务器提供的对象关系映射服务、数据持久服务、事务服务、安全服务、消息服务等通过简单的配置即可在应用程序中使用。
- 由于面向对象领域模型与关系型数据库存在天然的屏障,所以对象模型和关系模型之间需要一个纽带框架,也就是我们常说的ORM框架,它能够将对象转化成关系,也可以将关系转化成对象,于是,Hibernate框架出现了。Hibernate通过配置对象与关系表之间的映射关系,来指导框架对对象进行持久化和查询,并且可以让应用层开发者像执行SQL一样执行对象查找。这大大减少了应用层开发人员写SQL的时间。然而,随着时间的发展,高度抽象的ORM框架被证明性能有瓶颈,因此,后来大家更倾向于使用更加灵活的MyBatis来实现ORM层。
- 在微服务架构中,提倡运维人员也是服务项目团队的一员,倡导谁开发、谁维护,实施终身维护制度。(全功能团队)
- 核心链路以外的服务可以使用异步的消息队列进行异步化。
- 我们一般会将同一类功能划分在一个微服务中,尽量避免过细而导致成本增加,适可而止。
- 切记,永远不要在本地事务中调用远程服务,在这种场景下,如果远程服务出了问题,则会拖长事务,导致应用服务器占用太多的数据库链接,让服务器负载迅速攀升,在严重情况下会压垮数据库。
- Mule
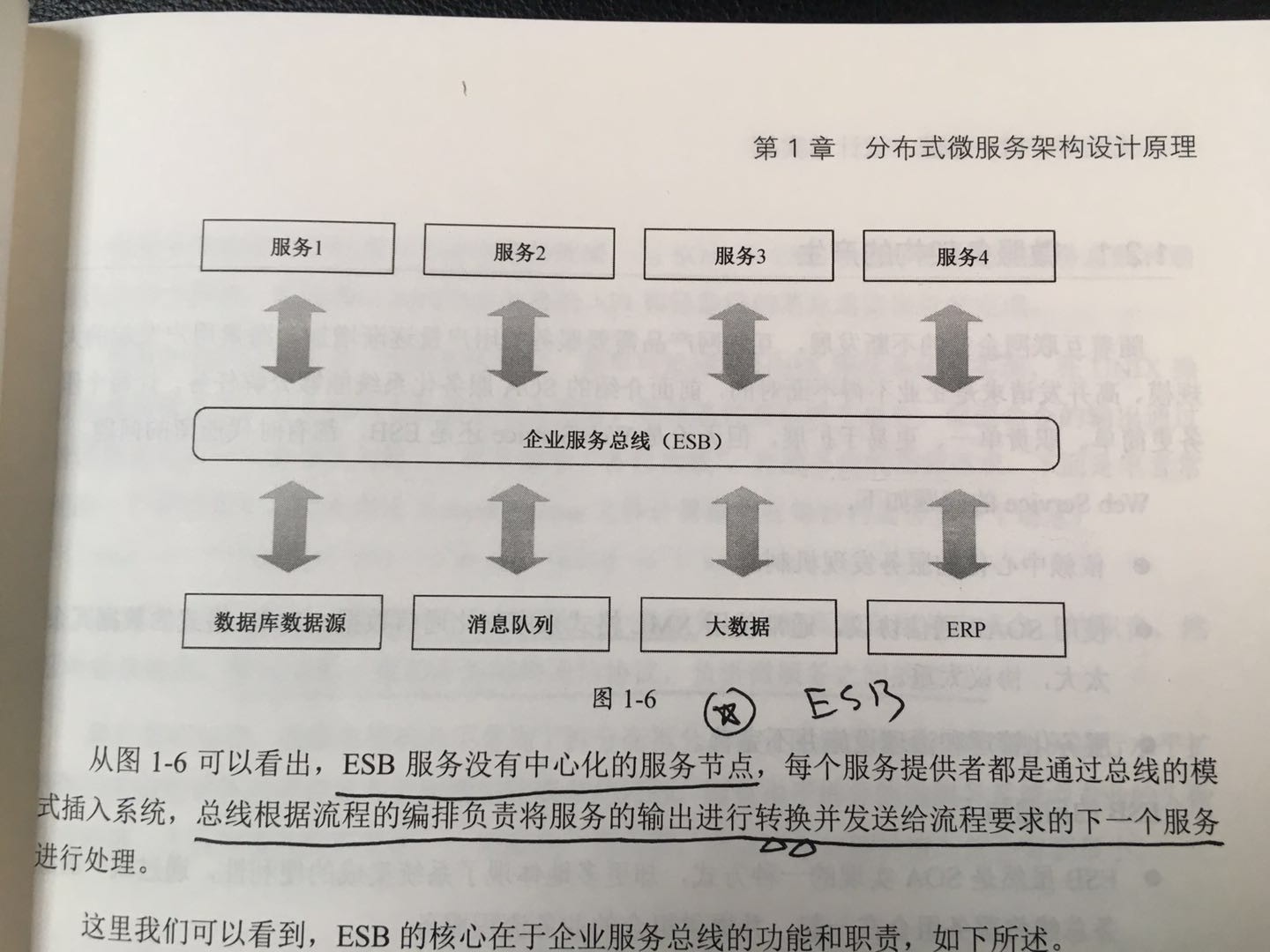
ESB:MuleSoft公司出品的基于Java语言的企业服务总线产品。它的优点是可以把现有的不同技术栈历史遗留系统与新增的服务化系统通过总线进行串联和编排,来满足日新月异的业务功能需求。
- 访问数据库操作无论是查询还是更新,原则上都是短小操作,不需要异步化。不推荐将大数据存储到关系型数据库中,关系型数据库只存储相关的最小化核心信息。
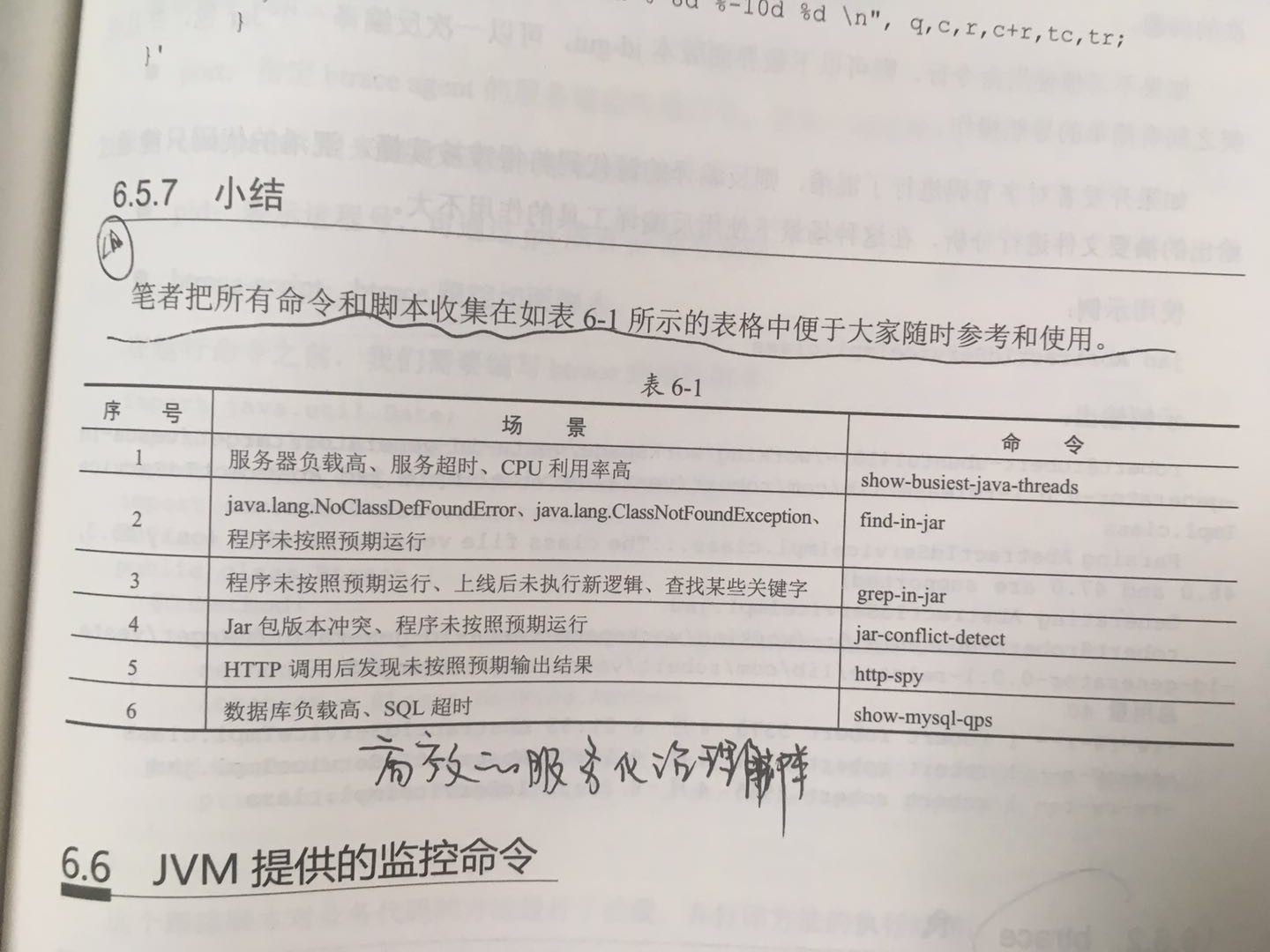
- 在刚上线且不稳定的项目中通常设置成Debug级别日志,便于查找问题;在线上系统稳定后使用Error级别日志即可,这样能有效提高效率。
- 我们在调用远程服务和被远程服务调用时,都需要打点耗时日志,这能够帮助我们排查接口调用的错误或者超时等问题。
- 对异常等错误信息必须打印错误级别及以上的日志,对线上日志要定期检查,没有异常日志产生的服务器才是健康的服务。
- QA环境可以是用debug及以下级别的日志。
刚刚上线的应用还没有到稳定期,使用debug级别的日志。
上线后稳定的应用,使用info级别的日志。
常年不出现问题的应用使用error级别的日志即可。
- 推荐使用日志框架原生的按照日期滚动的Appender来记录日志,这样不对I/O产生冲击,是轻量级的日志滚动功能实现。
- 每一次上线都必须有快速回滚的方案。
- 容器是对应用层的抽象,而虚拟机是在物理硬件层面上的虚拟化。
Docker将集装箱思想运用到了对软件的打包上,为代码提供了一个基于容器的标准化运输系统,可以将任何应用及其依赖打包成一个轻量级的、可移植的、自包含的容器中,可以运行在几乎所有操作系统上。
- 海恩法则(Heinrich's
Law),是德国飞机涡轮机的发明者德国人帕布斯·海恩提出的一个在航空界关于安全飞行的法则,海恩法则指出:
每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。法则强调两点:一是事故的发生是量的积累的结果;二是再好的技术,再完美的规章,在实际操作层面,也无法取代人自身的素质和责任心。
- 墨菲定律的本质其实是:你只会注意到那些你不愿意接受的结果,而把出现概率相同的满意的结果视为理所当然并在统计的时候忽略掉。最明显的例子就是开车变道。每个人都说:我换到哪条道上,哪条道就忽然变成最慢的了。事实上,他至少有一半以上的机会是变道之后比刚才快了,但他不会注意到,不会在心里说:“我擦,这次选对了”,只会一边超过旁边的车一边寻找更快的一条道。
- 墨菲定律指“凡是可能出错的事都会在未来出错。”(Anything that
can go wrong will go
wrong.)。引申为“所有的程序都有缺陷”,或“若缺陷有很多个可能性,则它必然会朝往令情况最坏的方向发展”,讲白话一点“明明之前应该都没问题,偏偏关键时刻就是出错了”。
行政管理涉及的因素非常复杂,单就人为而言,管理学家也是极难解释,故此,管理者自不能避免目标制订和执行永不出错,这个管理原则说明,如果一个危机将要发生,它总会出事,换言之,管理者需要时时刻刻做好准备,面对到来的失误和失败。
墨菲理论没带有事情必坏或必好的成果,他只是让管理者知道,能发生的事,总会发生,换言之,管理者必须对所有可能会发生的事情作好周全的准备,这也就是为何泳池等场所也要配备灭火器等设备的原因之一。
- 幸存者偏差:最早来源于英军对战斗机改进做的统计,根据对飞回来的受损灰机的统计发现其主要受损部位集中在机翼,所以结论是应当减少机腹的装甲加强机翼的装甲?这个结论显然是可笑的,造成这种偏差的原因是机腹中弹的灰机大多数都坠毁了,统计结论产生了偏差,这个偏差被命名为“幸存者偏差”。在现实生活中该偏差比比皆是,举个最简单的栗子,老有人说“读书有什么用,我的小学同学XXX,他从小成绩一塌糊涂,初中都没念完就退学了,现在生意做得可大了,我本科毕业还不是租着房吃着泡面朝九晚五。”实际情况是一个班会读书的那帮孩子日后也有生意做得不错的、也有租房吃泡面的、也有在家啃老的,平均生活水准高于不读书的,但是不读书的孩子中有一些已经吸毒吸成鬼了、赌博欠一屁股债躲起来了、在家乡加入黑社会被砍死了,这些人你看不到,你只能看到那些幸存者,生意做得可大了。