《Hadoop技术内幕》读书心得
一本比较偏重技术的书,介绍了很多的技术细节,所以只是涉猎的看了一下。
一、Hadoop的基本原理
Hadoop现在已经被看成大数据分析的“神器”。Hadoop有三大重要的模块,即基础公共库、HDFS(分布式文件系统)实现和MapReduce实现(分布式计算框架);
MapReduce由两个阶段组成:Map和Reduce。
通常而言,用户需要处理的数据均以文件形式存储到HDFS上!而非机构化的数据。
1、一个例子
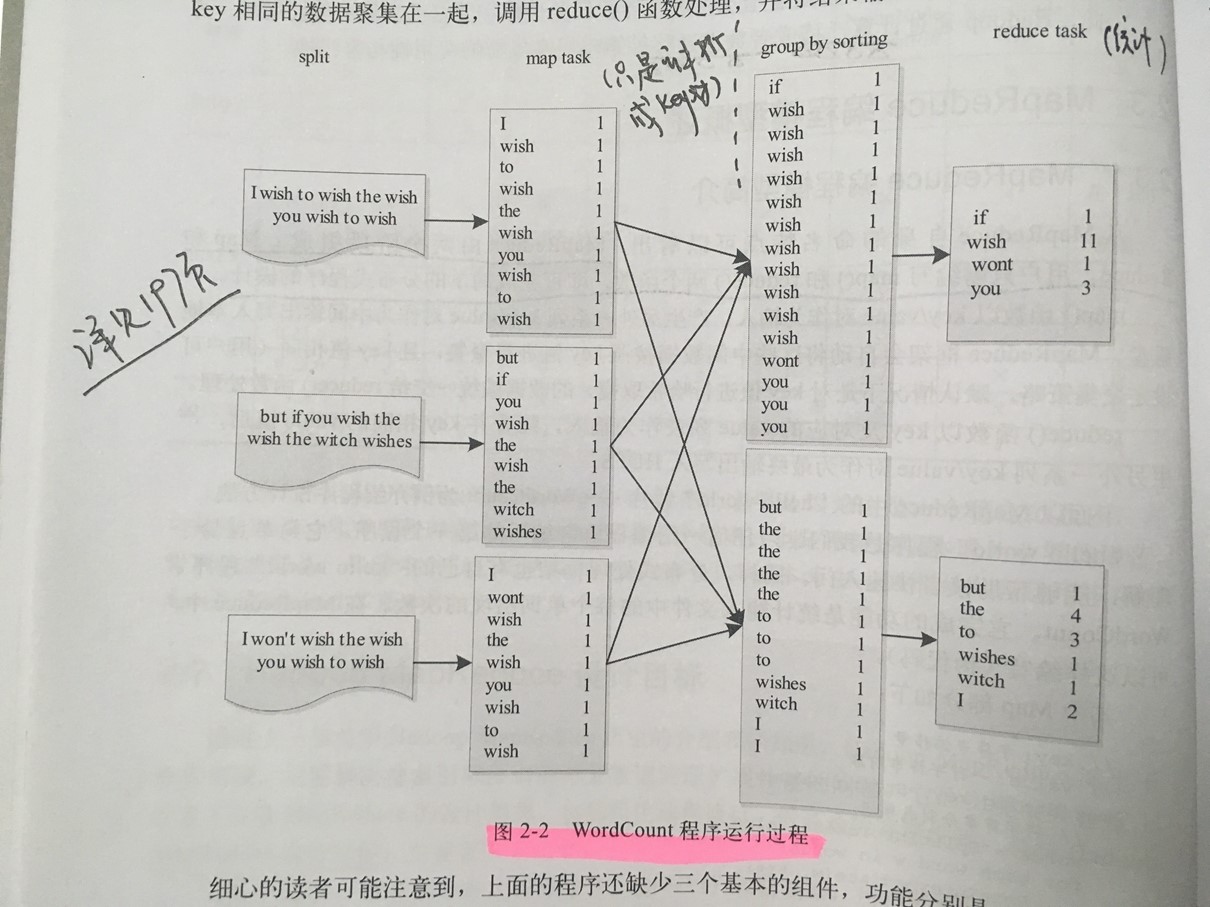
- split的多少决定了Map Task的数目,因为每个split会交由一个Map
Task处理。
- Partitioner的作用是对Mapper产生的中间结果进行分片,以便将同一分组的数据交给同一Reduce处理,它直接影响Reduce阶段的负载均衡。
2、编程步骤
MapReduce能够解决的问题有一个共同的特点:任务可以被分解为多个子问题,且这些子问题相对独立,彼此间不会有牵制,待并行处理完这些子问题后,任务便被解决。
MapReduce编程模型给出了其分布式编程方法,共5个步骤:
1)迭代(iteration)。遍历输入数据,并将之解析成Key/value对;
2)将输入Key/value映射(Map)成另外一些Key/value对;
3)依据Key对中间数据进行分组(Grouping);
4)以组为单位对数据进行规约(Reduce);
5)迭代。将最终产生的Key/value对保存到输出文件中。
3、MapReduce运行过程
Map Task分解成Read、Map、Collect、Spill和Combine五个阶段,讲Reduce
Task分解成Shuffle、Merge、Sort、Reduce和Write五个阶段。
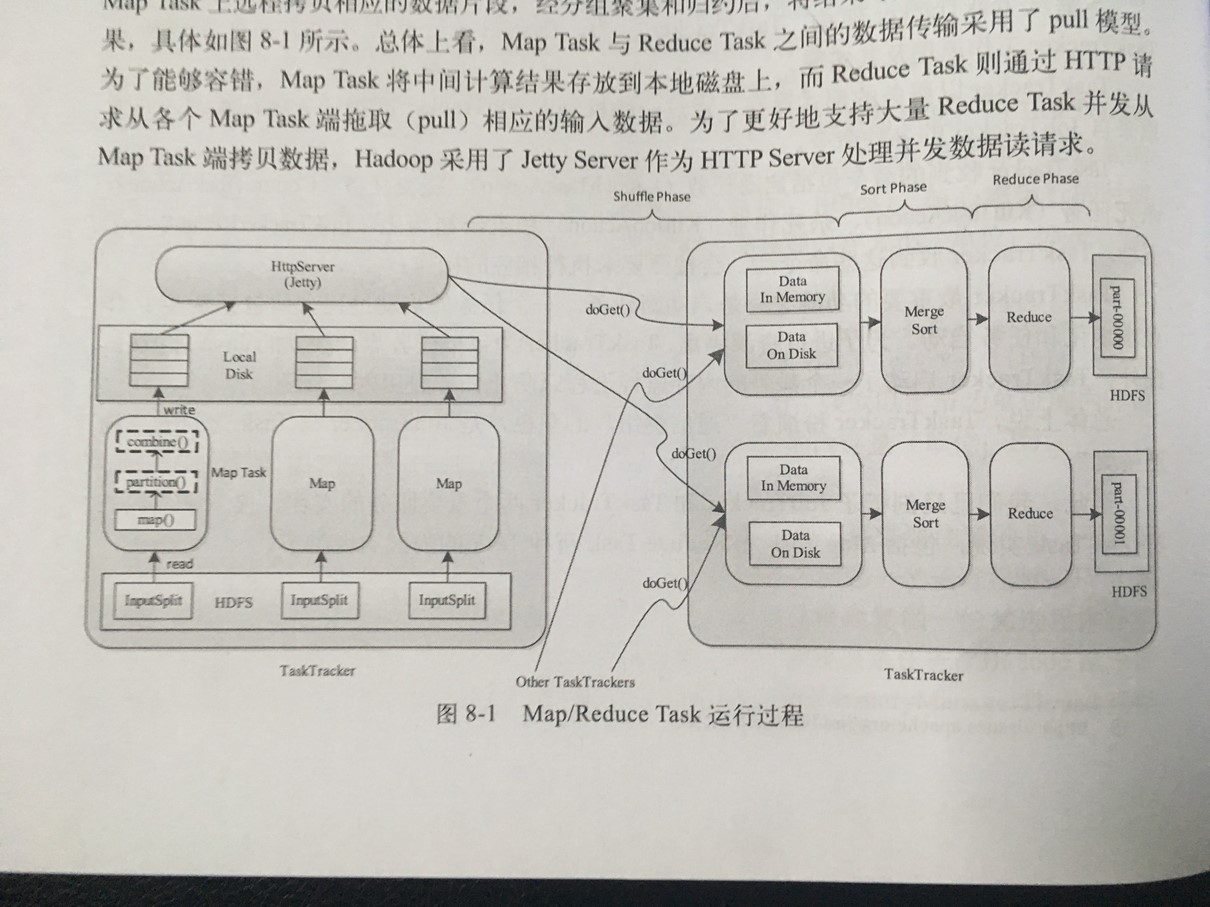
4、Hadoop原理
在Hadoop MapReduce中,不同组件的通信协议均是基于RPC的,它们就像系统的“骨架”,支撑起整个MapReduce系统。
- RPC: Remot Procedure
Call,是一种常用的分布式网络通讯协议。JDK中的RMI(Remote Method
Invocation)也是一种RPC框架。
- Stub程序:客户端和服务器端均包含Stub程序,可将之看做代理程序。它使得远程函数调用表现的跟本地调用一样,对用户程序完全透明。
- RPC 通用架构
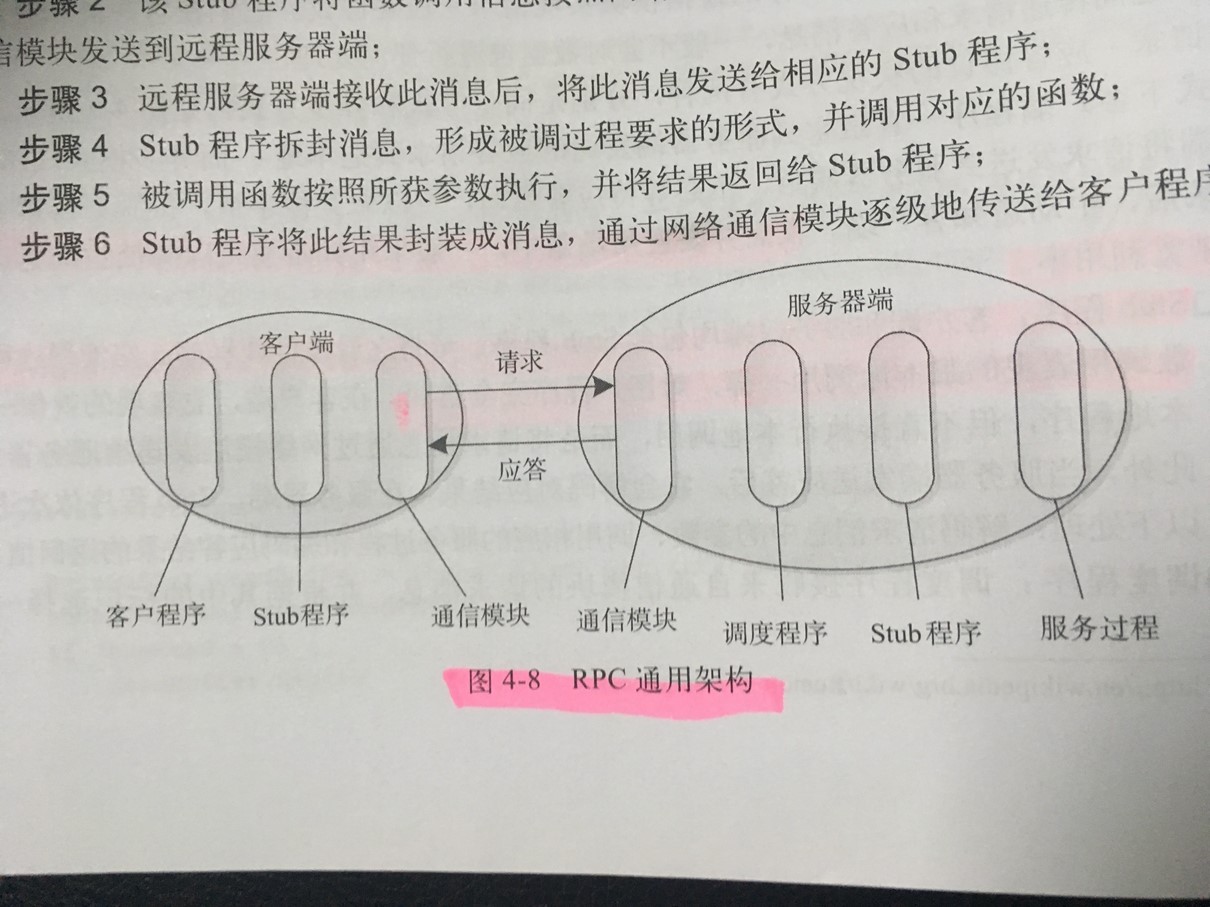
- IDL:开源RPC框架提供了一套接口描述语言(Interfae Description Language,IDL)。它提供了一套通用的数据类型,并以这些数据类型来定义更为复杂的数据类型和对外服务接口。一旦用户按照IDL定义的语法编写完成接口文件后,即可根据实际应用需要生成特定的编程语言(例如Java,C++,Python等)的客户端和服务器端代码。
任务推测执行原理:Hadoop采用了推测执行(Speculative Execution)机制。它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理一份数据,并最终选用最先成功完成任务的计算结果作为最终结果。
二、下一代MapReduce框架
下一代MapReduce框架的基本设计思想是蒋JobTracker的两个主要功能,即资源管理和作业控制(包括作业监控、容错等),分拆成两个独立的进程。
随着互联网的告诉发展,基于数据密集型应用的计算框架不断出现。从支持离线处理的MapReduce,到支持在线处理的Storm,从迭代式计算框架Spark到流式处理框架S4,各种框架诞生与不同的公司或者实验室。一种可能的技术方案如下:网页建索引采用MapReduce框架,自然语言处理/数据挖掘算法用MPI邓。考虑到资源利用率、运维成本、数据共享等因素,公司一般希望将所有这些框架部署到一个公共的集群中,让他们共享集群的资源,并对资源进行统一使用,这样,便诞生了资源统一管理与调度平台。
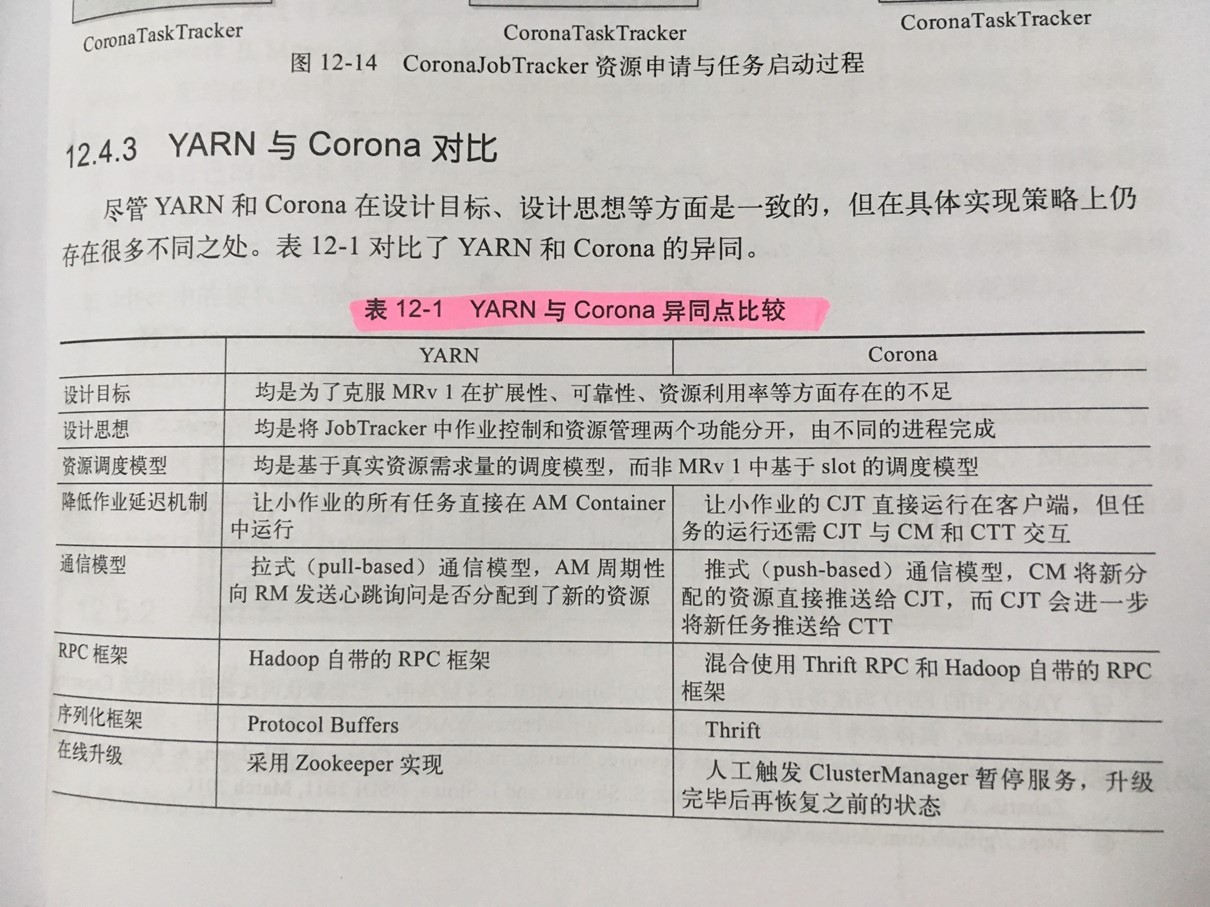
YRAN是Apache的下一代MapReduce框架;Corona是Facebook于2012年11月开源的下一代MapReduce框架;
YARN与Corona比较:
文章摘录
- Apache软件基金会:支持开源软件项目而办的一个非营利性组织。
- Rack:架子、机架;
- DAG:Directed Acqlic Graph,作业,工作流,有向无环图。
