《数据仓库工具箱:维度建模权威指南》读书心得
一本介绍了数据仓库(DW)和商业智能(BI)的建模过程,不过因为主要的难度是在后端的ETL过程,所以本书理论上说重点还是介绍了DW的建模过程,BI更多指向的是前端的报表开发,技术上难度没有后端的ETL大。
本书最大的特点是,针对我们常见行业重点业务过程的建模进行了详细描述,让用户对数据建模有个直观的了解。
在启动BI项目之前,我们必须明白,BI的主要收益是,获得高质量的决策。
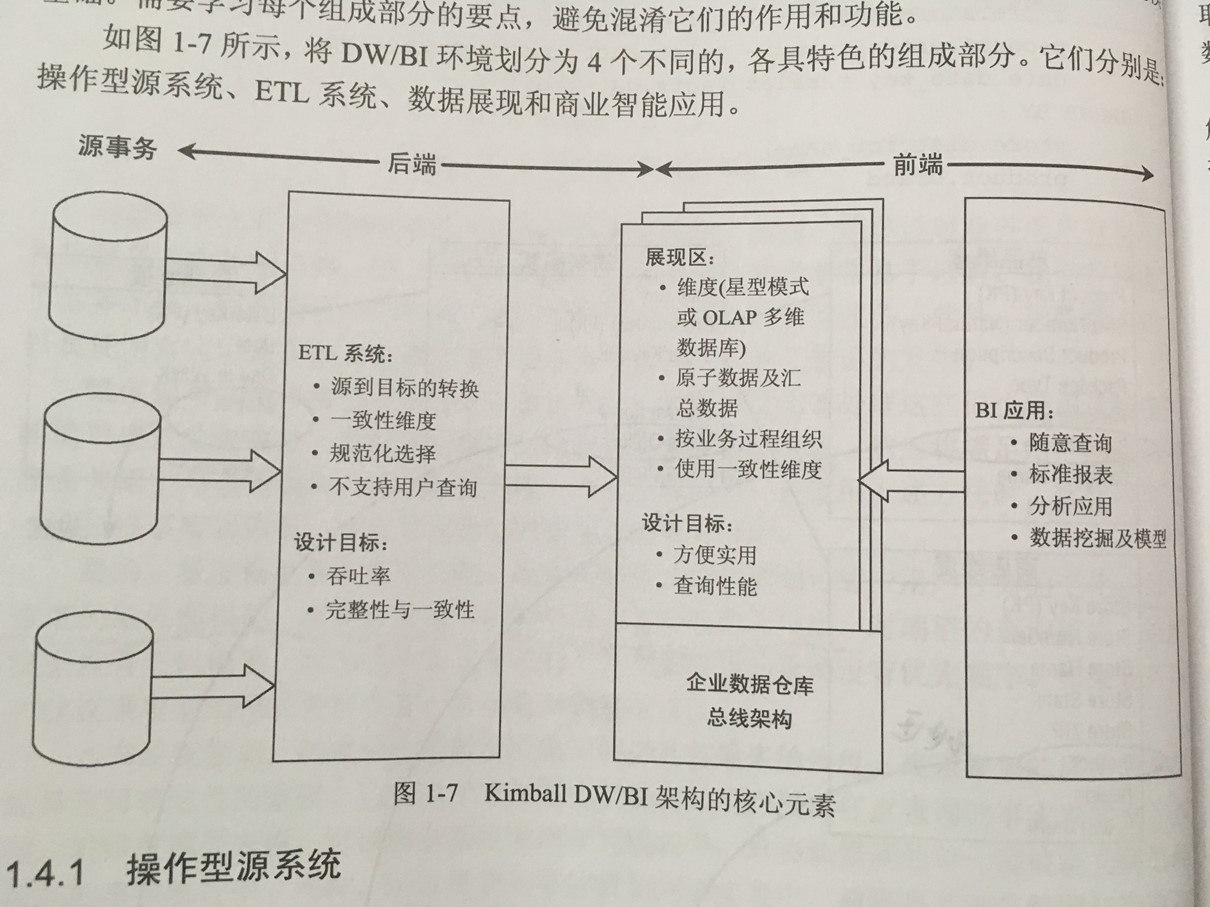
1、数据仓库的核心架构
ETL:
获取(Extract)、转换(Transform)、加载(Load)
E:连接不同的数据源,通过任务调度获取数据源数据,并对数据源的数据做简单的检查;
T:进行数据质量检查及清理、数据转换、一致性维度的检查及转换;
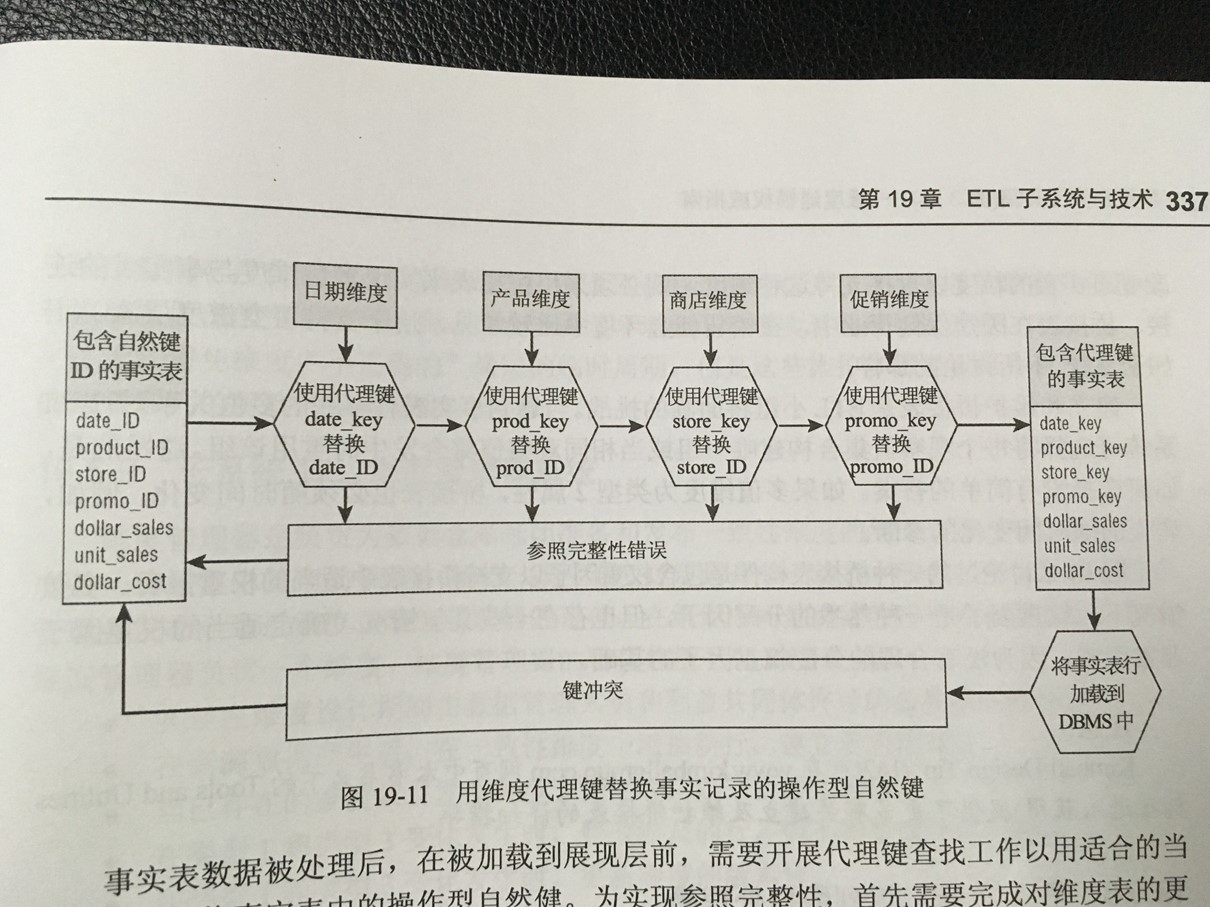
L:把清理转换后的数据加载到目标表,供BI报表工具使用。在加载过程需要考虑相关的代理键生成、一致性检查等。
架构设计就像建房子的蓝图,因为没有架构的结构无法承受压力。架构在需求的基础上,重点关注的涉及时间、可用性和性能方面的需求。例如发布的频率,就涉及相关的同步的频率、时间要求。加载对服务器、带宽等方面的需求。
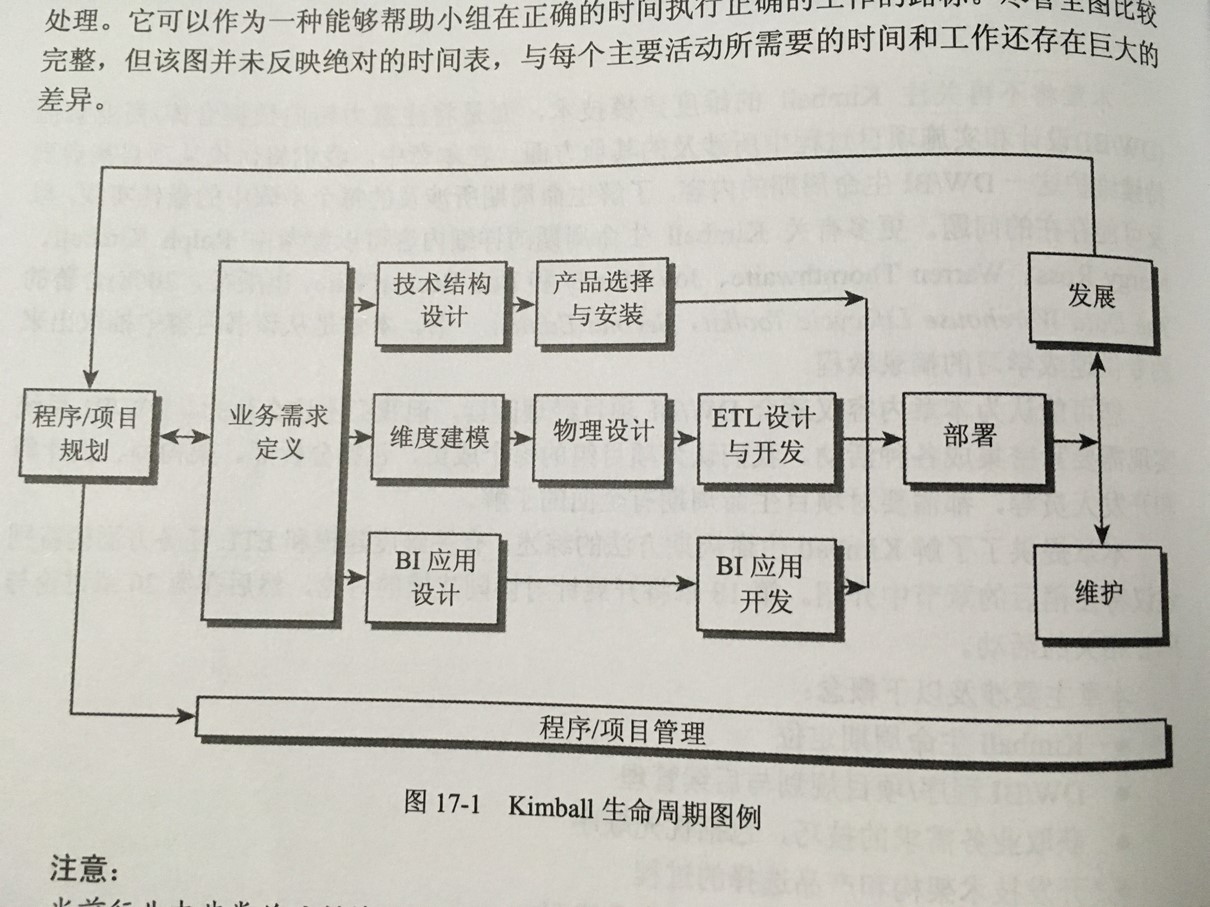
2、Kimball DW/BI生命周期
3、4步骤维度设计过程
- 1)选择业务过程
- 2)声明粒度
- 3)确认维度
- 4)确认事实
4、维度表和事实表
事实表(Fact Table)+ 维度表(Dimensional Table)
维度属性支持报表过滤和标识,事实表支持报表中的数字数值。
事实表一般只包括:
- 主键
- 退化维度
- 外键
- 事实值(性能度量)
事实表的分类:
- 事务事实表
- 周期快照事实表
- 累积快照事实表
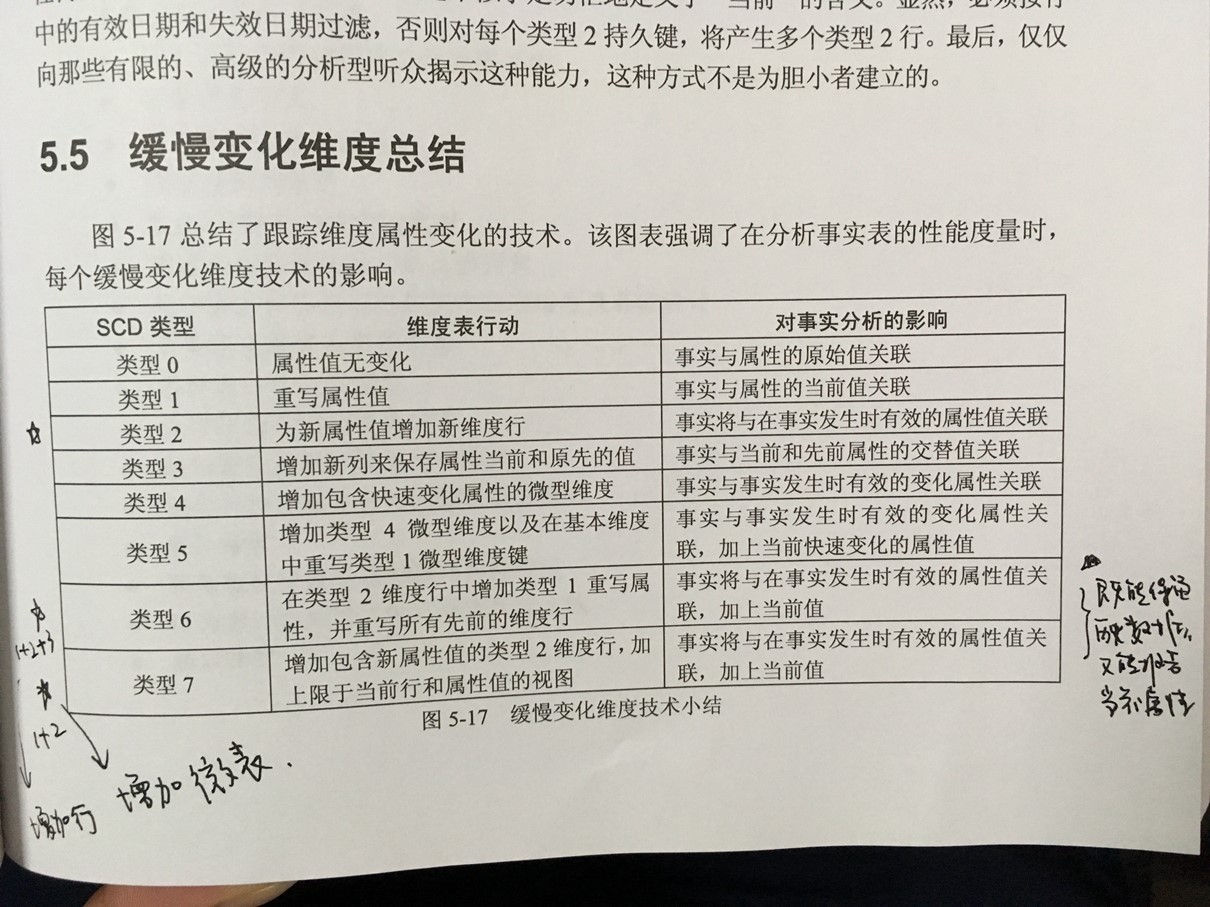
维度表的缓慢变化技术:
- 技术0:不变化
- 技术1:直接修改值
- 技术2:(最常用的技术)增加新行,增加:生效日期、失效日期、目前状态3个列
- 技术x:略
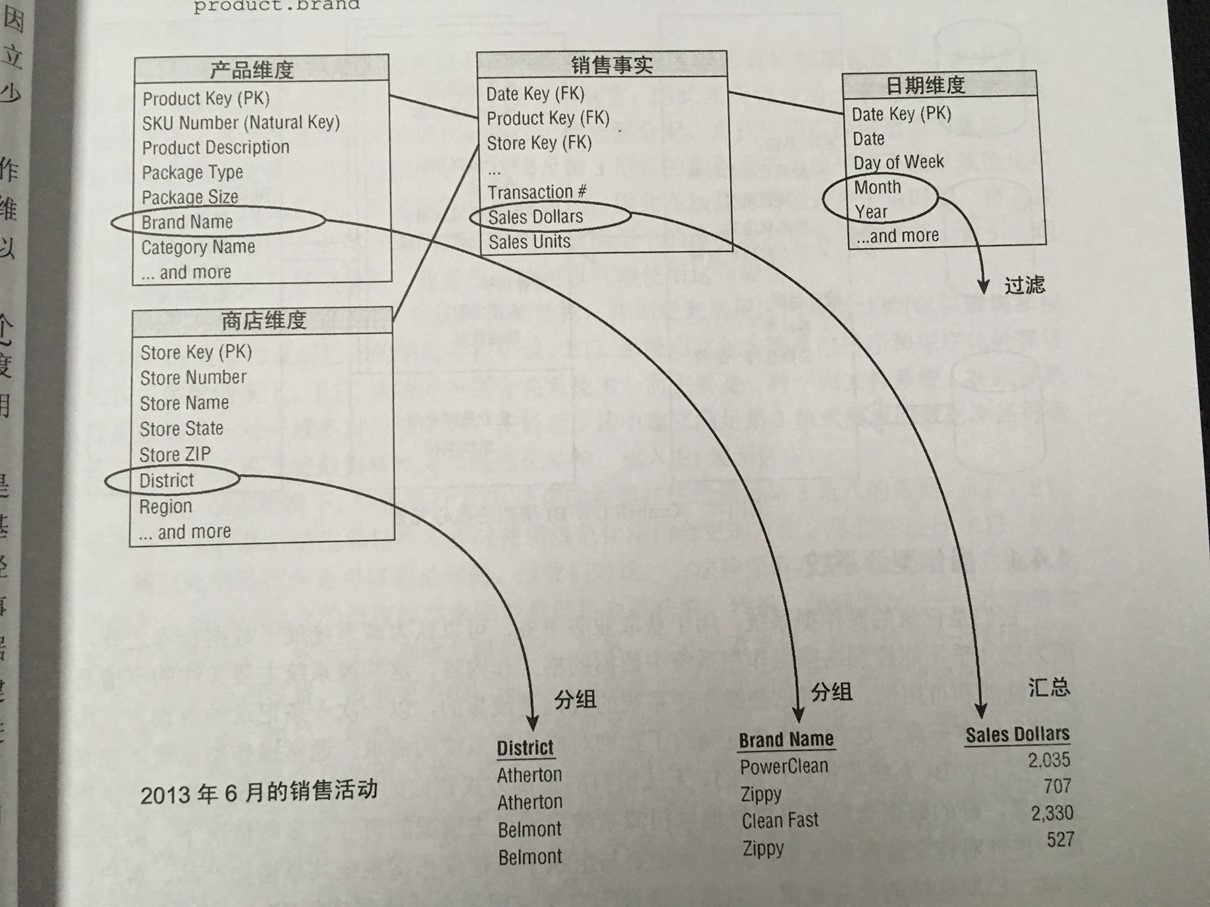
事实表通常像下图一样,采用星型模型

事实表,一般是数值性,针对需要汇总的数据;
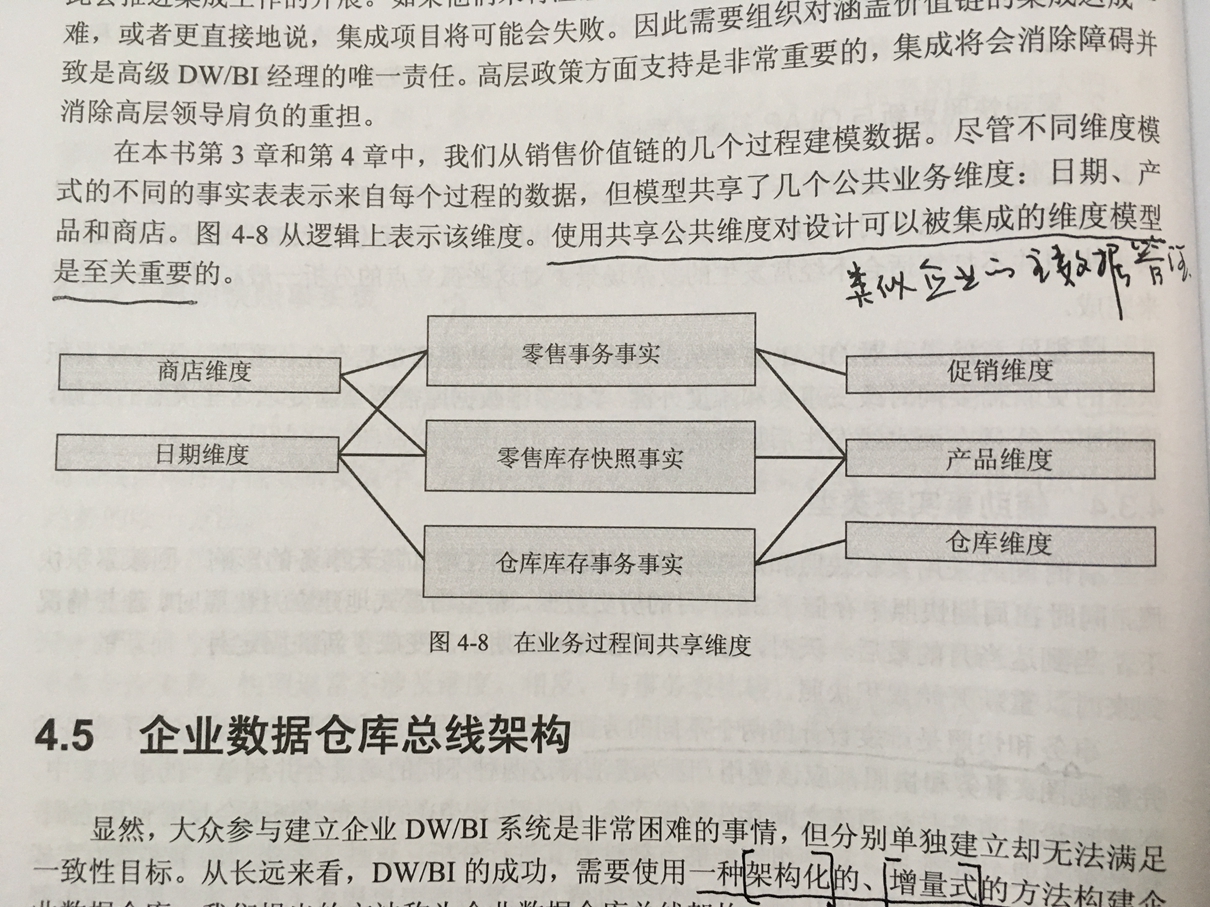
5、数据集成和一致性维度
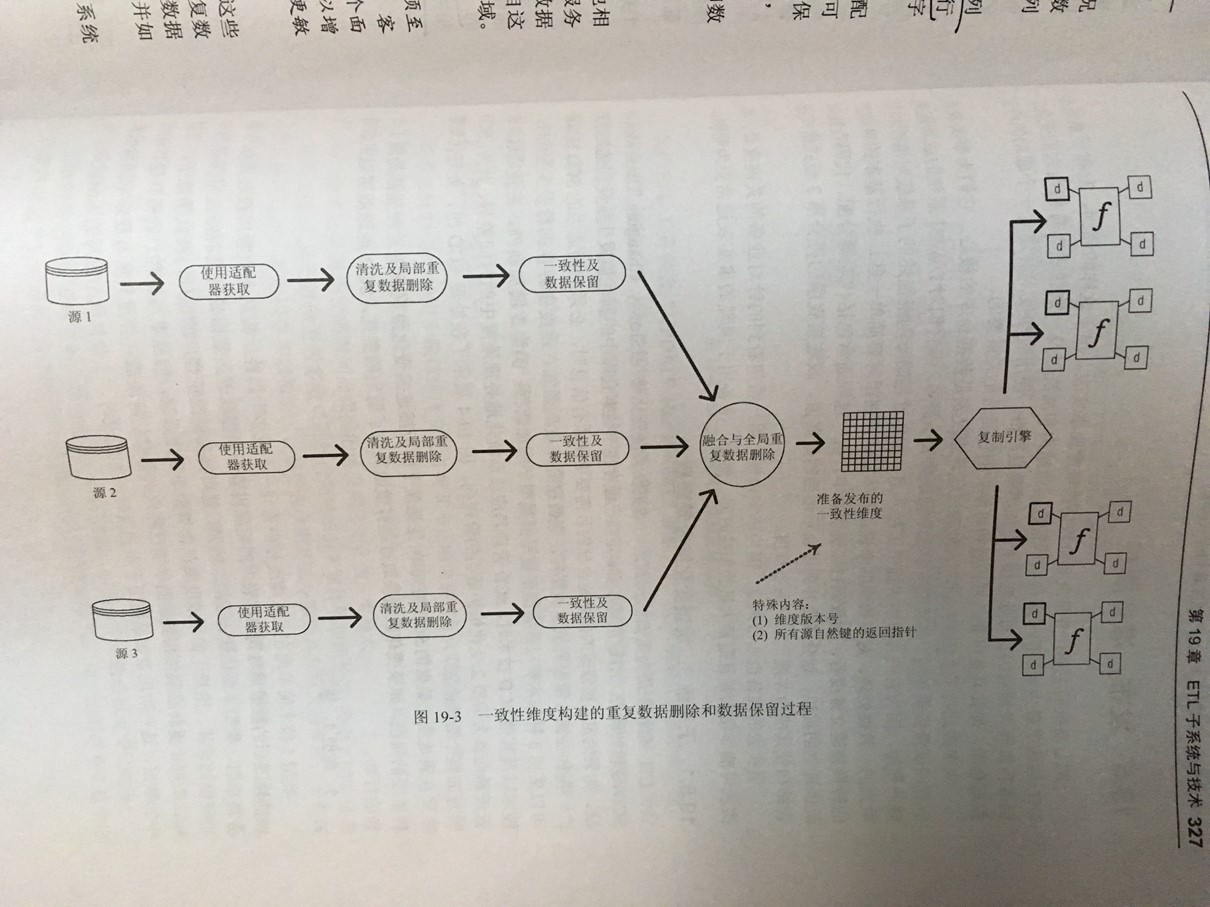
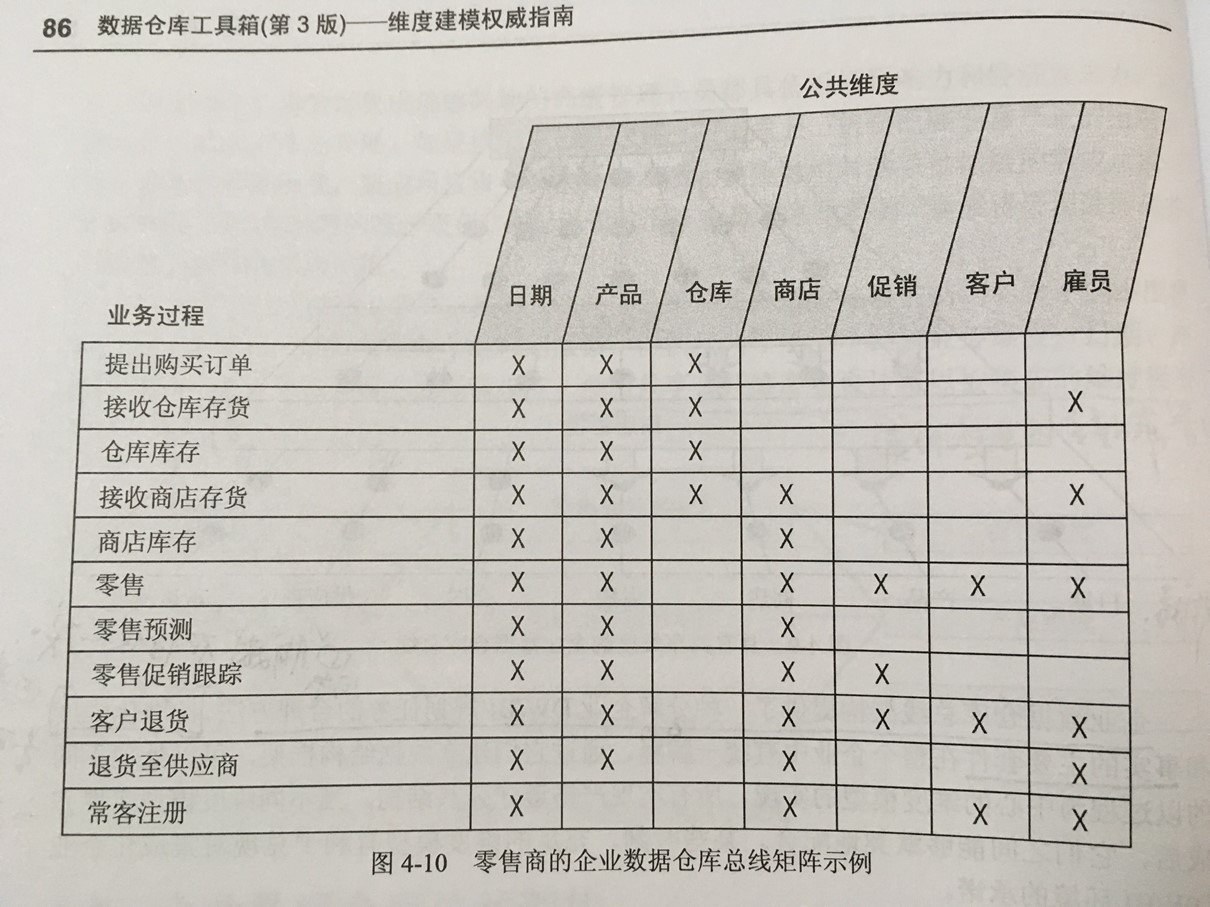
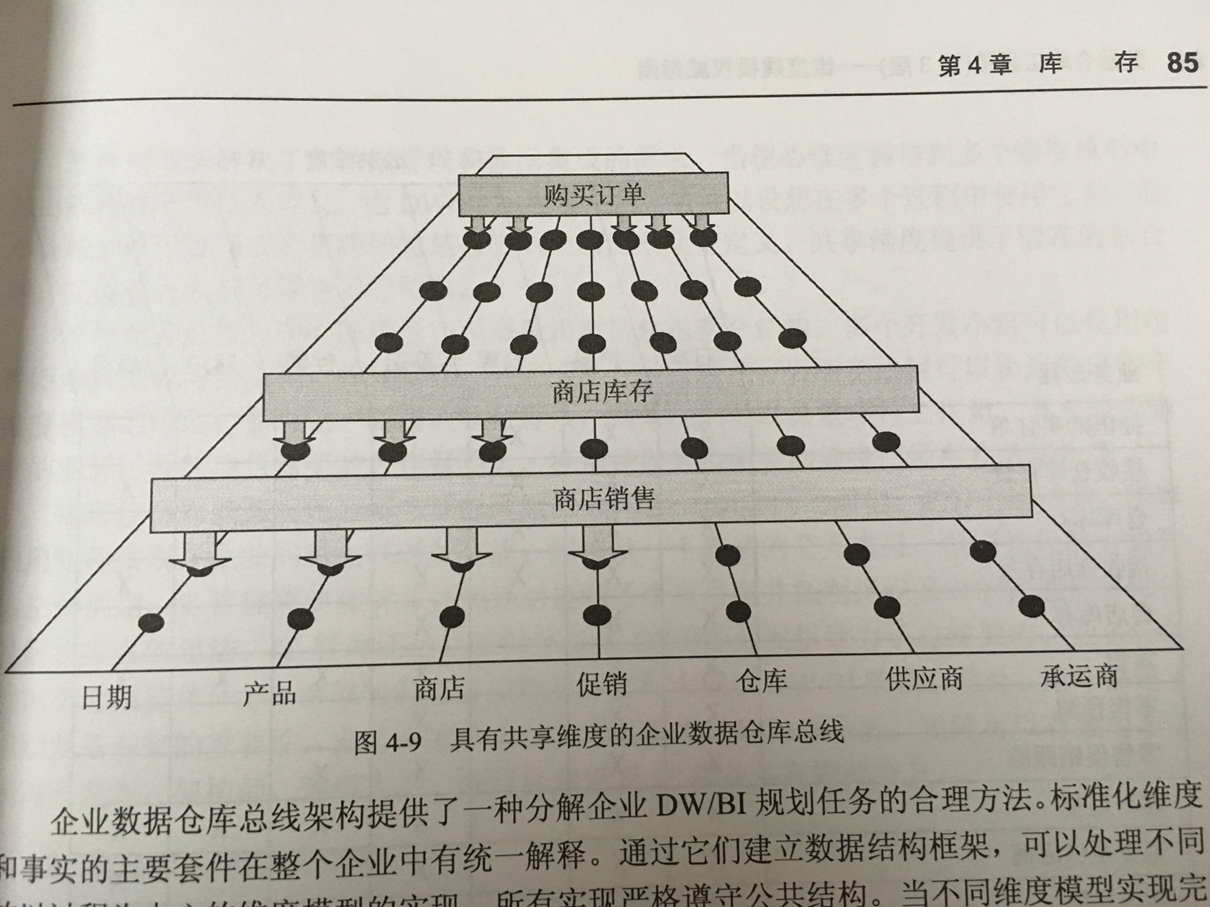
数据集成:企业全景视图。一致性维度意味着跨不同数据库建立公共维度属性,只有这样才能使用这些属性构建横向钻取报表,才能是得KPI等关键指标能通过计算差异和比率来开展数学比较工作。(例如收入、支出的维度必须一致,才能计算利润)。维护一个总线矩阵来保证一致性维度。
6、建模过程常见的原则及问题
1)建表原则
- 事实表的粒度应该一致
- 事实表一般不包括文本字段
- 建议采用最细粒度(灵活性+可扩展性),然后通过汇总聚集、通过总线矩阵保持一致性的维度(避免烟筒式的孤岛)。
- 事实表一般采用代理键
(自然键作为退化维度)
主键最好是无意义的字段便于以后扩展,假设以标书编码为主键,以后标书编码填错需要改的时候,关联表都需要跟着改。如果是一个无意义的自增字段是主键就无此问题。
- 维度表一般采取明确的文本说明,而不是一些代码和神秘值
报表的分组也是,最好不要利用键值某几个字节的隐含含义来分组,最好利用明确的属性。这样,在某些业务修改对应标签属性,但是键值没有修改的情况下,不会出错。
- 维度表,需要约束查询或者分类分析的信息;
- 多数商业模型的维度包括5-20个维度之间。(只要不改变事实表,维度能方便的增加)
- 维度模型的设计应反映组织的主要业务过程事件,不应该被设计成仅能发布特定报表或回答特定问题。
- 维度建模注重简单化、易用性、性能,所以严格抵制3NF(数据库建模的第3范式)
第3范式会导致查询复杂化、连接导致性能低效、影响用户的理解。规范化非常适合支持事务处理并保证参照的完整性,但在维度模型主要是用于支持分析处理,所以查询的性能、可理解性反而是最需看重的。
- 建议采用最细粒度(灵活性+可扩展性)
- 通过总线矩阵保持多过程的一致性维度。
- 关系数据库中不能存在多对多关系。用来消除多对多关系的最常用方法是通过添加桥接表来创建两个一对多关系。
- 每个事实表必须有一个指向日期维度的外键,主要用于上卷和过滤。
- 最好将事务代码当成退化维度来处理。
- 维度表通常不能随事实表同时变化的情况存在。一般维度表是相对稳定的。
- 尽量避免使用雪花模式(应该使用星型模型),偶尔使用支架模型可以接受,但是要严格评估。
2)需要避免的常见维度建模错误:
- 错误10:在事实表中放入文本属性。
- 错误9:限制使用冗长的描述符以节省空间。
- 错误8:将层次划分为多个维度
- 错误7:忽略对维度变化跟踪的需要。
- 错误6:使用更多的硬件解决所有的性能问题。(通过创建聚集、建立分区、建立索引等)
- 错误5:使用操作型键连接维度和事实。
- 错误4:忽视对事实粒度的声明并混淆事实粒度。
- 错误3:使用报表设计维度模型。
- 错误2:希望用户查询规范化的原子数据。
- 错误1:违反事实和维度的一致性要求
3)ETL重要的瓶颈问题:(通过ETL工作流监视器来监控性能)
考虑ETL的瓶颈,有两个来源,一是从客户的反馈获取,二是通过监控的工具监控性能和容量的趋势。
- 针对源系统或者中间表的低效索引查询;
- SQL语法导致优化器做出错误的选择;
- 随机访问内存(RAM)不足导致的内存颠簸
- 在RDBMS中进行的排序操作;
- 缓慢的转换步骤;
- 过多的I/O操作;
- 不必要的读写;
- 重新开始删除并重建聚集而不是增量式的执行这一操作;
- 在流水线中过滤(改变数据获取)操作应用太迟;
- 未利用并行化和流水线方式;
- 不必要的事务日志,特别是在更新时存在的事务日志;
- 网络通信及文件传输的开销。
4)项目成功评估要素
- 1)强有力的业务责任人;
- 2)项目强烈的动机;(获取竞争性资源)
- 3)项目可行性(技术可行性、资源可行性、数据可行性)
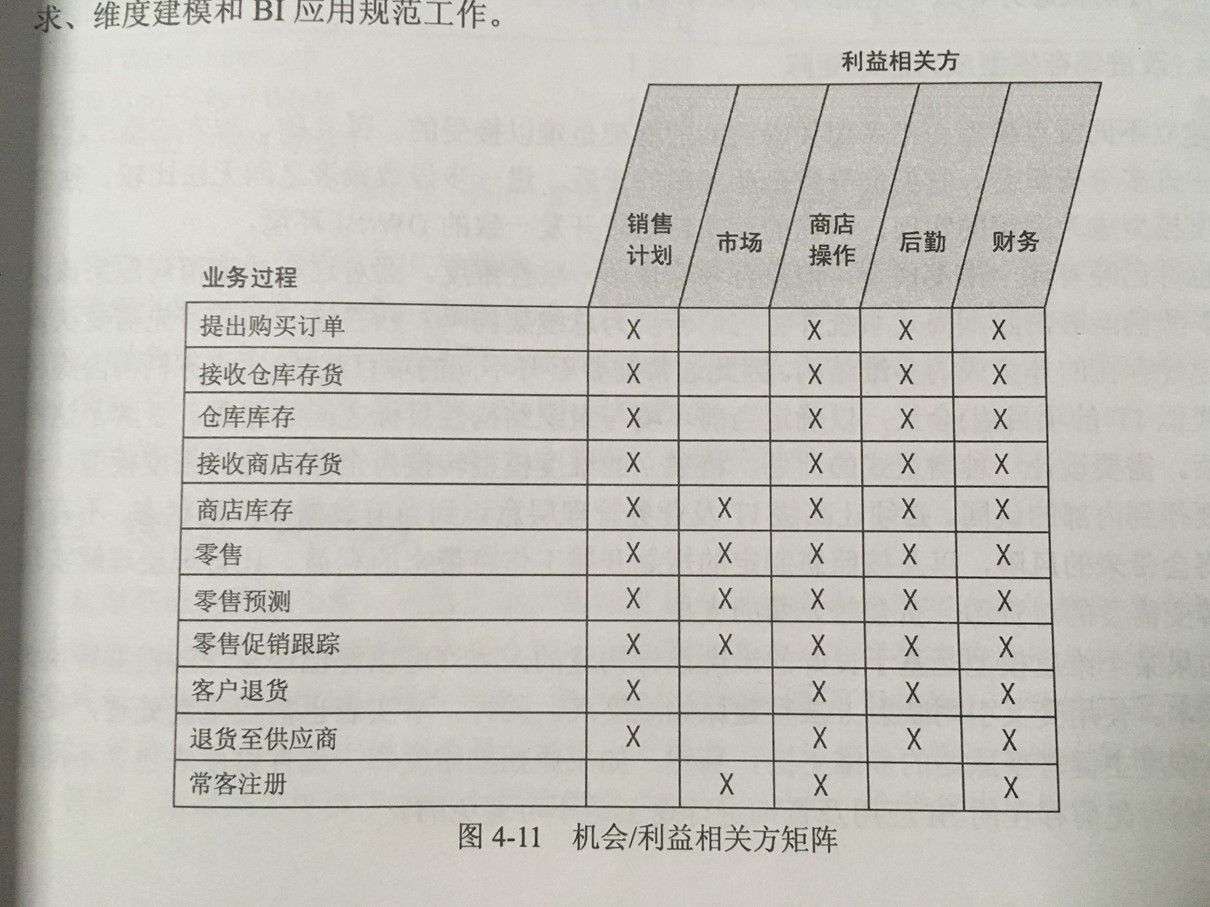
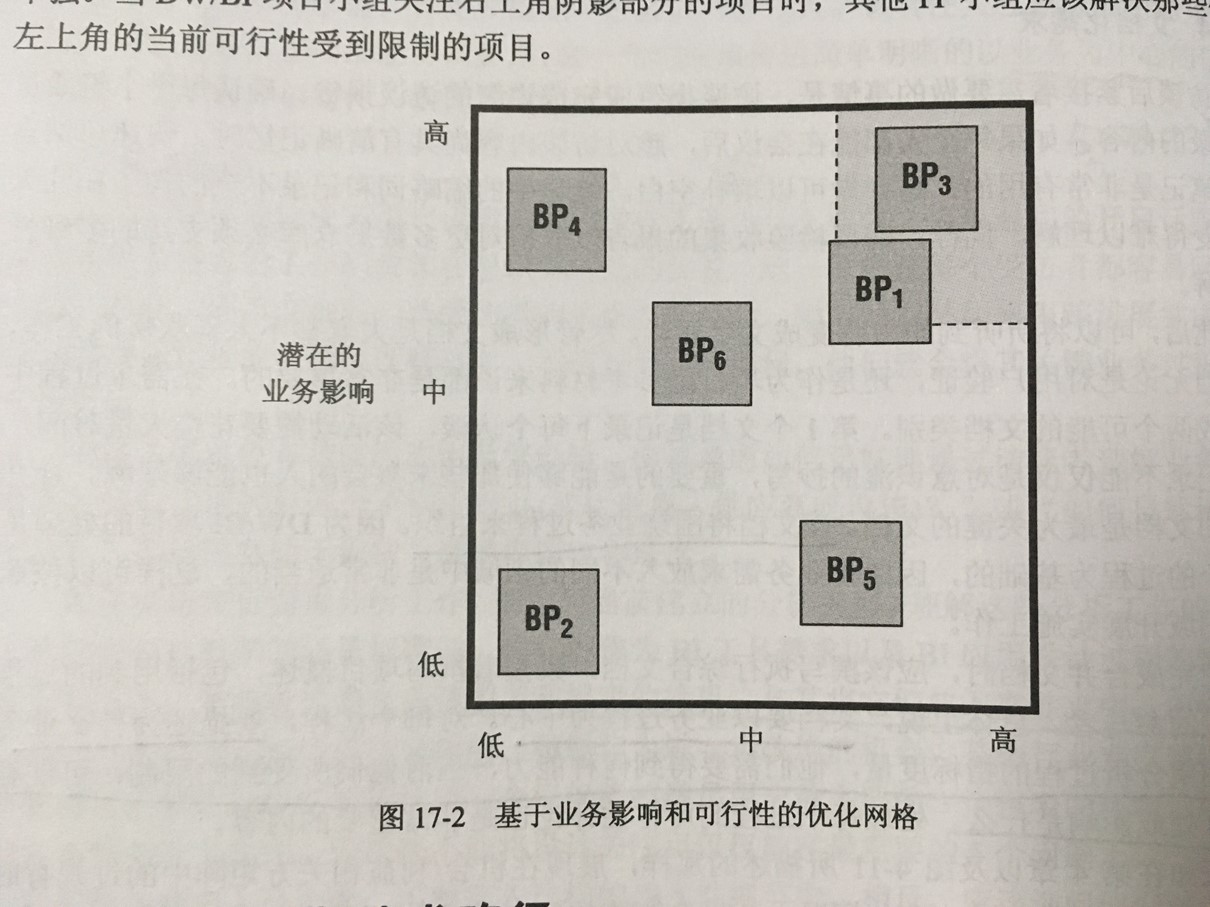
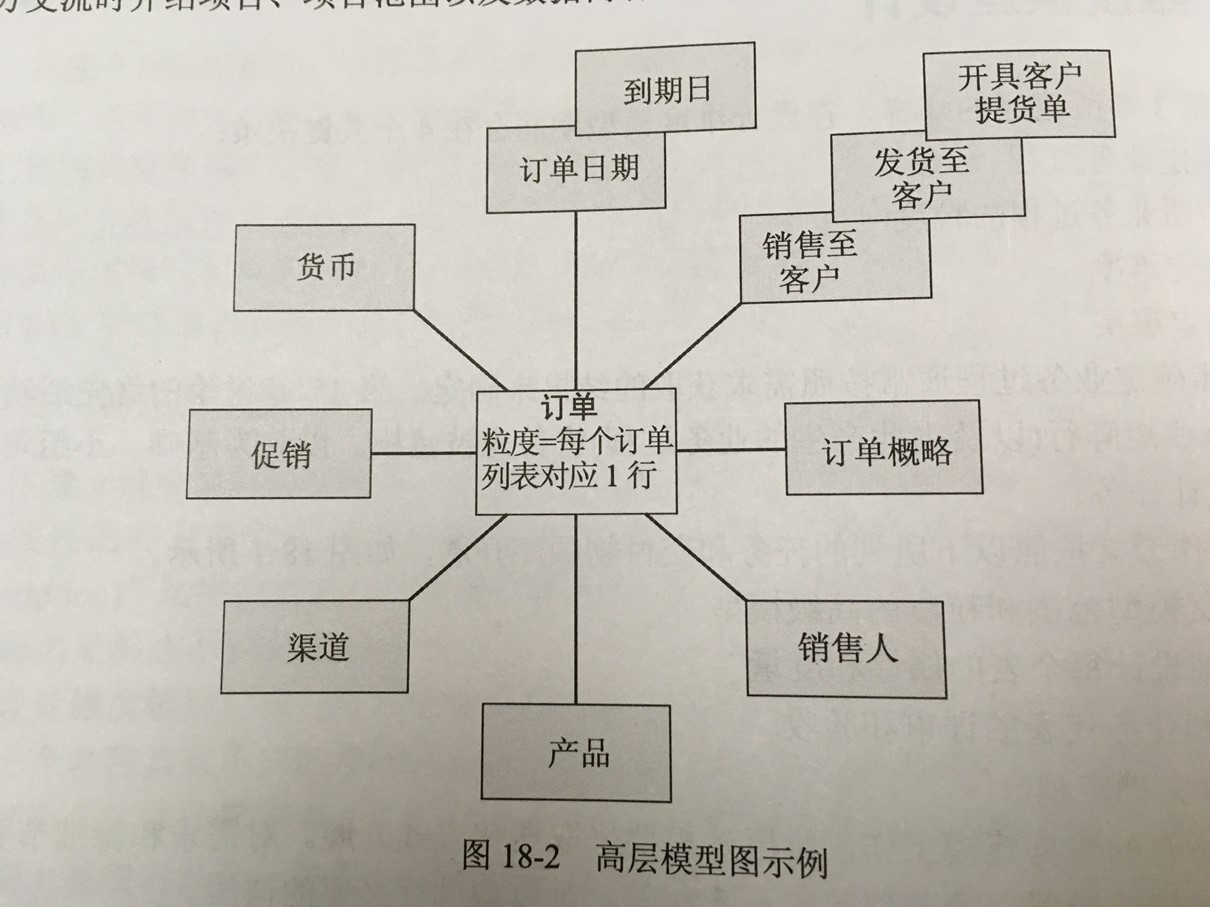
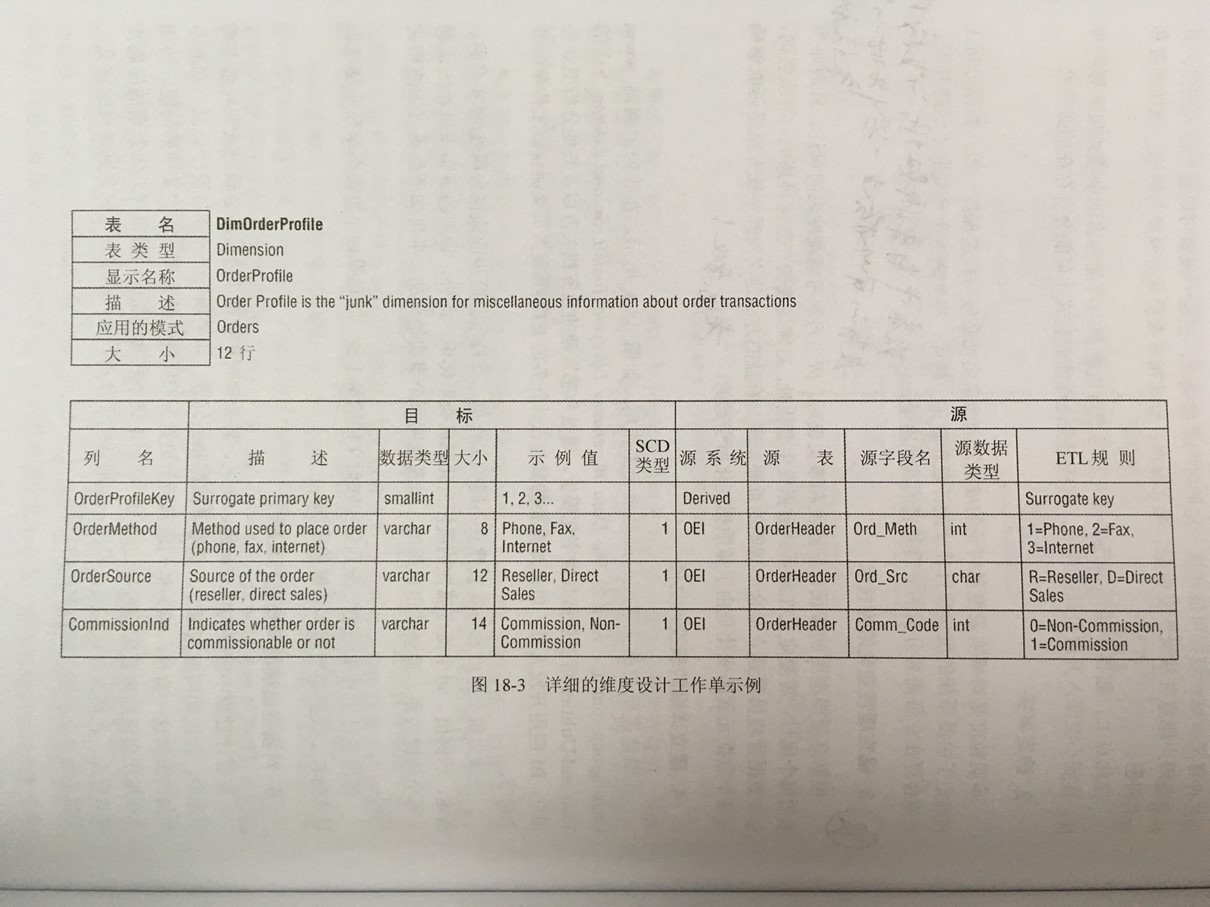
本书重点内容图片摘选