从原型到生产
从原型到生产
Prototype to Production
Building an agent is easy. Trusting it is hard.
构建一个智能体很容易,但信任它却很难。
摘要
Abstract
本白皮书为 AI 智能体(AI Agents)的业务运维生命周期提供了全面的技术指南,重点关注部署、扩展与生产落地。在第四天关于评估与可观测性内容的基础之上,本指南强调了如何通过强健的 CI/CD 流水线和可扩展的基础设施,建立将智能体推向生产环境所需的必要信任。它深入探讨了将基于智能体的系统从原型过渡到企业级解决方案时面临的挑战,并对智能体之间(Agent2Agent, A2A)的互操作性给予了特别关注。本指南为 AI/ML 工程师、DevOps 专业人员和系统架构师提供了实用的见解。
引言:从原型到生产
Introduction: From Prototype to Production
你可以在几分钟、甚至几秒钟内快速搭建出一个 AI 智能体原型。但是,要把那个聪明的 Demo 变成一个企业可以信赖、能够依赖的生产级系统?这才是真正工作的开始。欢迎来到生产落地的“最后一公里”鸿沟。在与客户的实践中,我们始终观察到这样一个现象:大约 80% 的精力并不是花在智能体的核心智能上,而是花在了使其可靠和安全所需的基础设施、安全防御和验证工作上。
跳过这些最后的步骤可能会引发诸多问题。例如:
- 由于忘记设置正确的护栏(Guardrails),客服智能体被诱骗免费赠送商品。
- 用户的身份验证配置不当,发现自己竟然可以通过你的智能体访问机密的内部数据库。
- 智能体在周末产生了巨额的消耗账单,但由于没有设置任何监控,没人知道是为什么。
- 一个昨天还运行得完美的关键智能体突然停摆,而你的团队由于缺乏持续评估机制而正陷入一片混乱。
这些不仅仅是技术问题,更是重大的业务失败。虽然 DevOps 和 MLOps 的原则提供了至关重要的基石,但仅凭它们自身还远远不够。部署智能体系统引入了一类全新的挑战,需要我们的运维学科进行演进。与传统的机器学习(ML)模型不同,智能体是自主交互的、有状态的,并且遵循动态的执行路径。
这带来了独特的运维难题,需要专门的应对策略:
- 动态工具编排(Dynamic Tool Orchestration):智能体的“行为轨迹”是在其挑选和选择工具时动态组装的。对于一个每次运行表现都不同的系统,这需要强健的版本控制、访问控制和可观测性。
- 可扩展的状态管理(Scalable State Management):智能体可以在多次交互中记住事情。在大规模场景下安全且一致地管理会话和内存,是一个复杂的系统设计问题。
- 不可预测的成本与延迟(Unpredictable Cost & Latency):智能体可以采取许多不同的路径来寻找答案,如果没有智能的预算控制和缓存机制,其成本和响应时间将变得极其难以预测和控制。
为了成功应对这些挑战,你需要一个建立在三大核心支柱之上的坚实基础:自动化评估、自动化部署(CI/CD)和全方位可观测性。
本白皮书是为你构建该基础并开辟生产落地之路的逐步实操手册!我们将从生产前(Pre-production)的要点开始,向你展示如何设置自动化的 CI/CD 流水线,并将严谨的评估作为关键的质量检查手段。从那里开始,我们将深入探讨在真实复杂的现实世界中运行智能体所面临的挑战,涵盖扩展、性能调优和实时监控的策略。最后,我们将展望多智能体系统(Multi-Agent Systems)充满前景的世界,介绍“智能体间(Agent-to-Agent)”协议,并探索如何让它们实现安全高效的通信。
💡 实际落地指南:
在本白皮书中,实际示例均参考了 Google Cloud Platform Agent Starter Pack——这是一个 Python 工具包,为 Google Cloud 提供了生产就绪的生成式 AI 智能体模板。它包含了预构建的智能体、自动化的 CI/CD 设置、Terraform 部署、Vertex AI 评估集成以及内置的 Google Cloud 可观测性。该启动包通过可在几分钟内完成部署的可用代码,生动演示了此处讨论的核心概念。
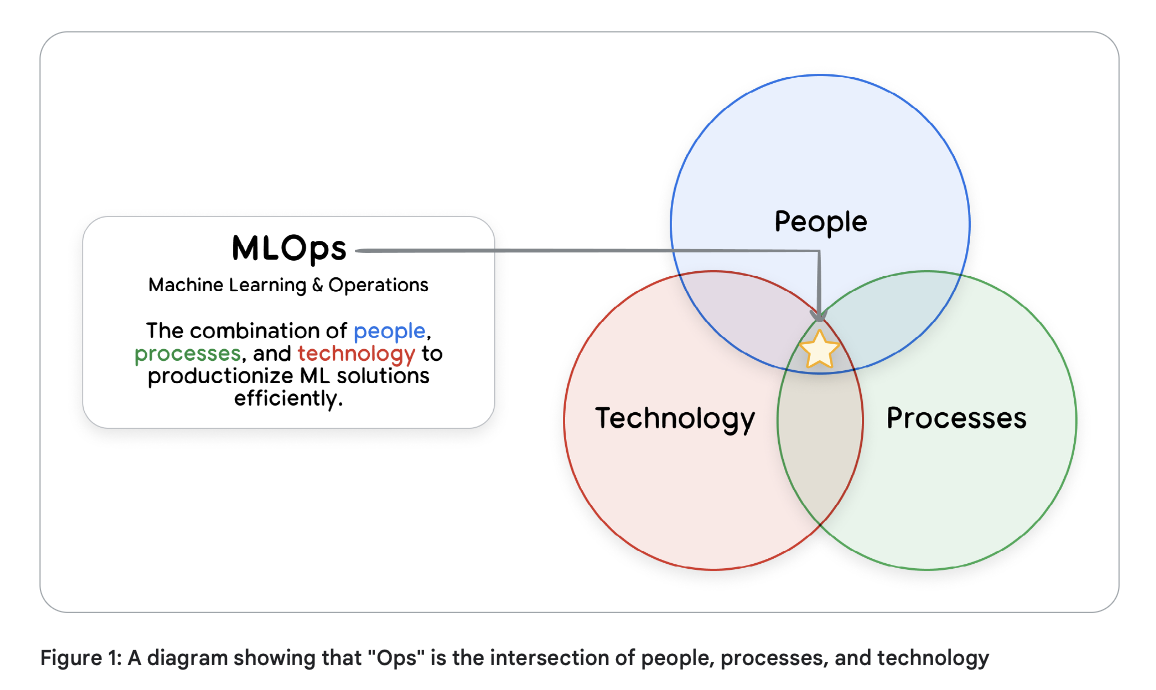
人员与流程
People and Process
在探讨了诸多关于 CI/CD、可观测性和动态流水线的内容之后,为什么还要将焦点放在“人员与流程”上?因为如果没有合适的团队来构建、管理和治理,世界上最好的技术也将无法发挥效用。
客服智能体并不会施展魔法来自动阻止自己赠送免费商品,而是由 AI 工程师(AI Engineer) 和 提示词工程师(Prompt Engineer) 共同设计并实施了安全护栏。机密内部数据库的安全也不是靠一个抽象的概念来保障的,而是由 云平台团队(Cloud Platform Team) 配置了身份验证。每一个成功的、生产级别的智能体背后,都活跃着一支协同作战的专家团队。在本节中,我们将介绍其中的核心角色。
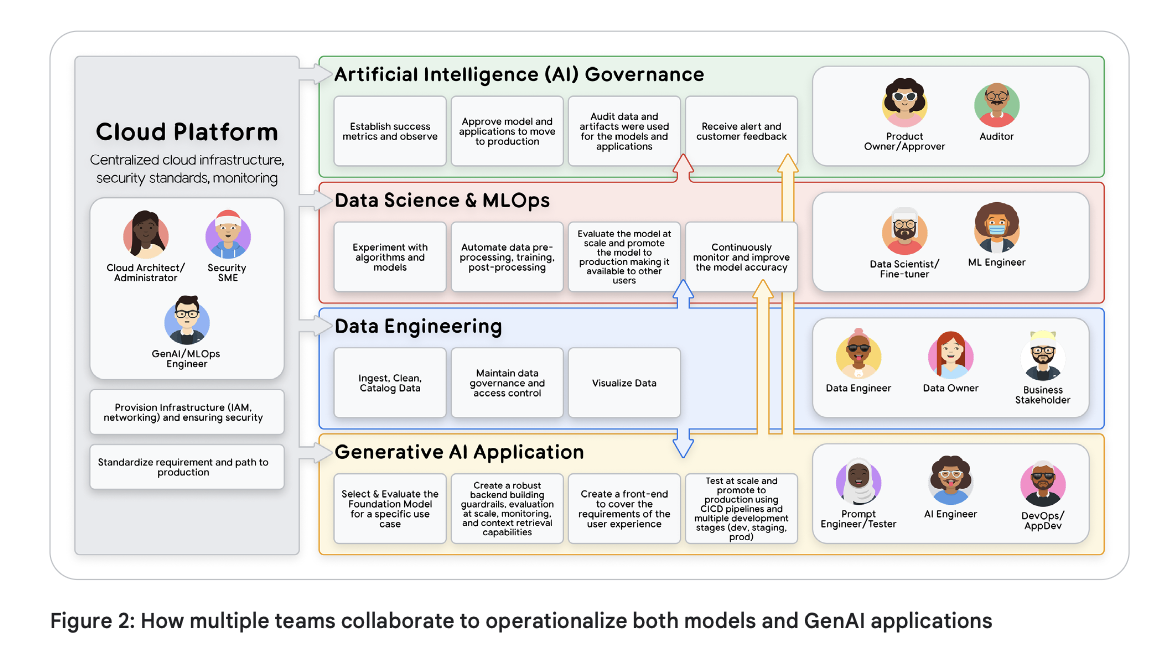
在传统的 MLOps 领域,这涉及几个核心团队:
- 云平台团队(Cloud Platform Team):由云架构师、管理员和安全专家组成,该团队负责管理底层的云基础设施、安全防御和访问控制。该团队向工程师和服务账号授予“最小权限”角色,确保其仅能访问必要的资源。
- 数据工程团队(Data Engineering Team):数据工程师和数据所有者负责构建和维护数据流水线,处理数据摄取、数据准备并把控数据质量标准。
- 数据科学与 MLOps 团队(Data Science and MLOps Team):这包括负责实验和训练模型的数据科学家,以及利用 CI/CD 在大规模场景下实现端到端 ML 流水线(如预处理、训练、后处理)自动化的 ML 工程师。MLOps 工程师则通过构建和维护标准化的流水线基础设施来提供支持。
- 机器学习治理团队(Machine Learning Governance):这是一项中心化的职能,包含产品所有者和审计员,负责监督整个 ML 生命周期,充当资产和指标的存储库,以确保合规性、透明度和问责制。
而生成式 AI(Generative AI) 的引入,为这一领域增添了全新层面的复杂性以及更为专业化的角色:
- 提示词工程师(Prompt Engineers):虽然这一职位的名称在行业中仍在不断演变,但此类人员融合了精湛的提示词编写技术与深厚的领域专业知识。他们定义了模型应该回答的正确问题以及预期的标准答案。不过在实践中,根据企业组织成熟度的不同,这项工作也可能由 AI 工程师、行业专家或全职专家来承担。
- AI 工程师(AI Engineers):他们负责将生成式 AI 解决方案扩展到生产环境,构建强健的后端系统,并将大规模评估、安全护栏以及 RAG/工具集成融入其中。
- DevOps/应用开发人员(DevOps/App Developers):这些开发人员负责构建前端组件和用户友好的交互界面,并将其与生成式 AI 后端进行对接集成。
企业组织的规模和结构会影响这些角色的分工。在较小的公司中,个人可能会身兼数职;而在成熟的企业机构中,则会拥有分工更细的专业化团队。高效地协调所有这些不同的角色,对于建立强健的运维基础、并成功将传统 ML 和生成式 AI 项目推向生产落地至关重要。
迈向生产环境的旅程
The Journey to Production
现在我们已经组装好了团队,接下来转向流程。我们该如何将所有这些专家的工作成果,转化为一个值得信赖、可靠且准备好交付给用户的系统?
答案在于一个规范的生产前(Pre-production)流程,它建立在一个核心原则之上:评估准入型部署(Evaluation-Gated Deployment)。这个理念简单却强大:任何智能体版本在通过全面的评估以证明其质量和安全性之前,都不应该接触到用户。在这个生产前阶段,我们用自动化的确定性取代了人工的不确定性。该阶段由三大支柱组成:作为质量关卡的严谨评估流程、强制执行该流程的自动化 CI/CD 流水线,以及用于降低迈向生产环境最后一步风险的安全滚动发布策略。
评估作为质量关卡
Evaluation as a Quality Gate
为什么我们需要为智能体设置一个特殊的质量关卡?传统的软件测试对于具备推理和自适应能力的系统来说是捉襟见肘的。此外,评估一个智能体与评估一个大语言模型(LLM)截然不同;它不仅需要评估最终的答案,还需要评估为了完成任务而采取的整个推理和行动的行为轨迹(Trajectory)。一个智能体可以通得过其工具的 100 个单元测试,但仍可能因为选错了工具或凭空捏造(幻觉)出回复而一败涂地。我们需要评估它的行为质量,而不仅仅是它的功能正确性。这一关卡主要可以通过两种方式来实现:
1. 人工“PR 前”评估
对于追求灵活性或刚刚开始评估流程的团队,质量关卡是通过团队流程来强制执行的。在提交拉取请求(pull request )(PR)之前,AI 工程师或提示词工程师(或在你企业组织中对智能体行为负责的人员)在本地运行评估套件。随后,将生成一份将新智能体与生产环境基线进行对比的性能报告,并将其链接到 PR 说明中。这使得评估结果成为人工审查必须交付的资产。审查人员(通常是另一位 AI 工程师或机器学习治理者)现在不仅要评估代码,还要根据护栏违规情况和提示词注入漏洞来评估智能体的行为变化。
2. 流水线内自动化关卡
对于成熟的团队,由数据科学与 MLOps 团队构建和维护的评估测试座(Evaluation Harness)被直接集成到 CI/CD 流水线中。未通过的评估会自动阻止部署,从而对机器学习治理团队定义的质量标准进行硬性的、程序化的强制执行。这种方法用人工审查的灵活性换取了自动化的连贯一致性。CI/CD 流水线可以配置为自动触发评估任务,将新智能体的响应与黄金测试集进行对比。如果核心指标(例如“工具调用成功率”或“帮助程度”)低于预设阈值,部署将在程序上升高拦截。
无论采用哪种方法,其原则都是相同的:没有经过质量检查,任何智能体都不能进入生产环境。 我们在第四天的深度探讨中已经涵盖了衡量什么以及如何构建这种评估测试座的具体细节(参考《第 4 天:智能体质量:可观测性、日志、追踪、评估与指标》)。该内容探索了从构建“黄金测试集”(一个为了评估智能体的预期行为和护栏合规性而精心策划的、具有代表性的测试用例集),到实施“LLM 充当裁判”的技术,并最终利用类似 Vertex AI Evaluation 的服务来驱动评估的方方面面。
自动化 CI/CD 流水线
The Automated CI/CD Pipeline
AI 智能体是一个复合系统,它不仅包含源代码,还包含提示词、工具定义以及配置文件。这种复杂性引入了重大的挑战:我们如何确保对提示词的修改不会降低工具的性能?在这些资产交付给用户之前,我们如何测试它们之间的相互交织与影响?
解决方案是引入 CI/CD(持续集成/持续部署)流水线。它不仅仅是一个自动化脚本,更是一个结构化的流程,帮助团队中的不同成员协同管理复杂性并把控质量。它的工作原理是分阶段测试变更,在智能体发布给用户之前,全流程增程协作地建立信心。
一个强健的流水线被设计为一个漏斗。它会尽可能及早且低成本地捕获错误,这种实践通常被称为“左移(Shifting Left)”。它将快速的、合并前的检查,与更全面、资源密集型的合并后部署分离开来。这种渐进式的工作流通常结构化为三个截然不同的阶段:
1. 第一阶段:合并前集成(CI)
流水线的首要职责是向提交了拉取请求(PR)的 AI 工程师或提示词工程师提供快速反馈。这一 CI 阶段由系统自动触发,充当了主分支(main branch)的看门人。它运行诸如单元测试、代码规范检查(Linting)和依赖项扫描等快速检查。至关重要的一点是,这是运行由提示词工程师设计的智能体质量评估套件的理想阶段。 这能在代码合并之前,针对核心业务场景,就某一变更究竟是提升还是降低了智能体的性能提供即时反馈。通过在这里拦截问题,我们可以防止污染主分支。使用 Agent Starter Pack(ASP)生成的 PR 检查配置模板,就是利用 Cloud Build 落地该阶段的一个实用示例。
2. 第二阶段:分段环境中的合并后验证(CD)
一旦变更通过了包括性能评估在内的所有 CI 检查并被成功合并,关注点就从代码和性能的正确性,转移到了集成系统的运维就绪度上。通常由 MLOps 团队管理的持续部署(CD)流程,会将智能体进行打包,并将其部署到分段环境(Staging Environment)中——这是一个对生产环境进行高保真还原的副本。在这里,系统会运行更全面、资源密集型的测试,例如压力测试以及针对远程服务的集成测试。这也是内部用户测试(通常称为“尝鲜测试/Dogfooding”)的关键阶段,公司内部的人员可以在智能体接触最终用户之前与其进行交互并提供定性反馈。这确保了智能体作为一个集成系统,在被考虑发布之前,能够在模拟生产的环境下可靠且高效地运行。来自 ASP 的分段部署模板展示了这种部署的一个示例。
3. 第三阶段:向生产环境的准入型部署
在分段环境中对智能体进行彻底验证后,最后一步是部署到生产环境。这几乎从来不是完全自动化的,通常需要产品所有者(Product Owner)进行最终的签字确认(Sign-off),以确保人机协同。一旦获得批准,在分段环境中经过测试和验证的完全相同的部署资产(Artifact)将被晋升到生产环境中。这个通过 ASP 生成的生产部署模板,展示了最终阶段如何获取经过验证的资产,并在适当的安全防护机制下将其部署到生产环境中。
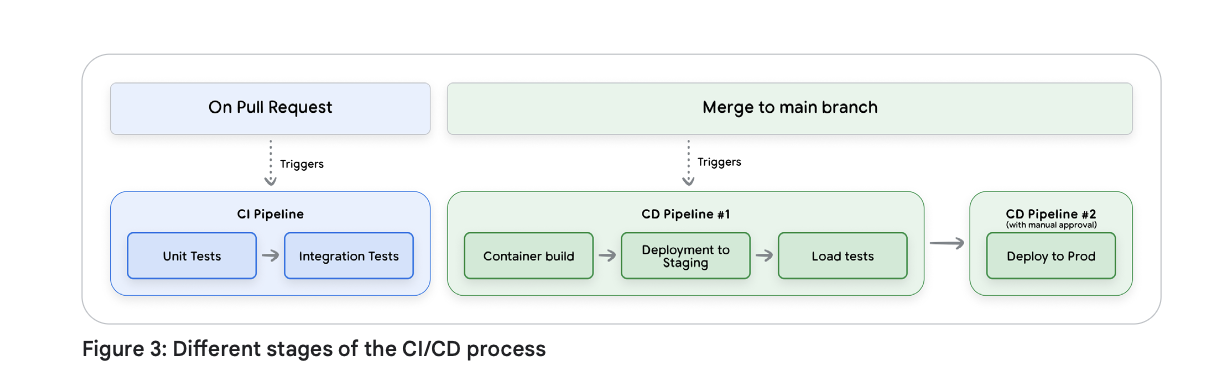
要让这种三阶段的 CI/CD 工作流成为可能,需要强健的自动化基础设施和妥善的密钥管理(Secrets Management)。这种自动化由两项核心技术驱动:
- 基础设施即代码(IaC):Terraform 等工具通过编程方式定义环境,确保它们是完全一致、可重复且版本受控的。例如,通过 Agent Starter Pack 生成的模板提供了包含 Vertex AI、Cloud Run 和 BigQuery 资源的完整智能体基础设施的 Terraform 配置。
- 自动化测试框架:Pytest 等框架在每个阶段执行测试和评估,处理智能体特有的资产,如对话历史记录、工具调用日志和动态推理轨迹。
此外,诸如工具的 API 密钥等敏感信息应当使用 Secret Manager 等服务进行安全管理,并在运行时注入到智能体的环境中,而不是硬编码在代码仓库中。
安全滚动发布策略
Safe Rollout Strategies
尽管生产前的全面检查至关重要,但现实世界的实际应用中不可避免地会暴露一些无法预见的问题。与其一次性将 100% 的用户切换到新版本,不如考虑通过细致监控的渐进式发布来最小化风险。
以下是四种行之有效的模式,能够帮助团队在部署过程中稳步建立信心:
- 金丝雀发布(Canary):首先面向 1% 的用户开放,重点监控提示词注入(Prompt injections)和未预期的工具使用行为。随后逐步扩大规模,或在出现异常时瞬间回滚。
- 蓝绿部署(Blue-Green):同时运行两个完全相同的生产环境。在向“绿色”环境部署新版本时,将流量全部路由到“蓝色”环境,随后进行瞬间切换。如果新版本出现问题,立即切回原环境——实现零停机时间与瞬间恢复。
- A/B 测试(A/B Testing):在真实业务指标上对比不同智能体版本的表现,从而做出数据驱动的决策。这既可以面向内部用户,也可以面向外部用户开展。
- 特性开关(Feature Flags):将代码部署上线,但通过开关动态控制功能的释放,优先让特定用户群体测试新的能力。
所有这些策略都共享一个核心基石:严谨的版本控制。系统的每一个组件——代码、提示词、模型端点、工具 Schema、记忆结构,甚至是评估数据集——都必须进行版本化管理。当问题突破防线依然发生时,版本控制能够让你瞬间回滚到已知的正常状态。请将此视为你在生产环境中的“撤销(Undo)”按钮!
你可以使用 Agent Engine 或 Cloud Run 来部署智能体,然后利用 Cloud Load Balancing(云负载均衡)来实现跨版本的流量管理,或将其连接到其他微服务。Agent Starter Pack 提供了开箱即用的模板,并支持 GitOps 工作流——在这里,每一次部署都是一次 git commit,每一次回滚都是一次 git revert,你的代码仓库成为了当前状态以及完整部署历史的唯一事实来源(Single source of truth)。
原生安全建设
Building Security from the Start
安全的部署策略可以保护你免受 Bug 和停机的影响,但智能体面临着一个独特的挑战:它们能够自主地进行推理和行动。一个完美部署的智能体,如果未能在构建之初融入妥善的安全与责任机制,依然可能会带来伤害。这就需要一套从第一天起就深度嵌入、而非事后才缝缝补补的全面治理策略。
与遵循预定路径的传统软件不同,智能体拥有决策能力。它们能够解析模糊的请求、访问多个工具并在多次会话中维持记忆。这种自主性创造了截然不同的风险:
- 提示词注入与越权攻击(Prompt Injection & Rogue Actions):恶意用户可以通过诱骗智能体执行非预期的操作或绕过既定限制。
- 数据泄露(Data Leakage):智能体可能会在回复或使用工具的过程中,不经意地暴露敏感信息。
- 记忆污染(Memory Poisoning):存储在智能体记忆中的虚假信息可能会腐蚀其后续所有的交互行为。
幸运的是,诸如谷歌的“构建安全的 AI 智能体方法(Secure AI Agents approach)”以及“谷歌安全 AI 框架(SAIF)”等架构,通过以下三层防御阵线攻克了这些挑战:
- 策略定义与系统指令(智能体的宪法)
整个流程始于为智能体的预期和非预期行为定义明确的策略。这些策略被工程化为系统指令(System Instructions, SIs),充当智能体的核心宪法。
- 安全护栏、防护保障与过滤(强制执行层)
这一层充当了硬性拦截的强制执行机制。
- 输入过滤(Input Filtering):利用分类器和类似 Perspective API 的服务来分析提示词,在恶意输入触达智能体之前将其拦截。
- 输出过滤(Output Filtering):在智能体生成回复后,利用 Vertex AI 内置的安全过滤器进行最终检查,以识别有害内容、PII(个人身份信息)或违规行为。例如,在将回复发送给用户之前,它会通过 Vertex AI 的内置安全过滤器,这些过滤器可以配置为拦截包含特定 PII、毒性言论或其他有害内容的输出。
- 人机协同(HITL)升级机制:对于高风险或模糊不清的操作,系统必须暂停执行,并升级给人工操作员进行审查和批准。
- 持续保障与测试
安全不是一劳永逸的配置,它需要持续的评估与调优。
- 严谨的评估(Rigorous Evaluation):对模型或其安全系统做出的任何改动,都必须触发完整重跑基于 Vertex AI Evaluation 的全面评估流水线。
- 专职的负责任 AI 测试(Dedicated RAI Testing):通过创建专用数据集或使用模拟智能体,针对特定风险进行严谨测试,包括中立观点(NPOV)评估和公平性(Parity)评估。
- 主动式红队对抗(Proactive Red Teaming):通过富有创造性的人工测试以及 AI 驱动的基于画像的模拟(Persona-based simulation),主动尝试攻破安全防护系统。
生产环境运维
Operations in-Production
你的智能体已经正式上线。现在,关注点从开发阶段转移到了一个截然不同的挑战上:在与成千上万名用户交互时,如何保持系统的可靠性、成本效益和安全性。**传统服务运行在可预测的逻辑之上,相比之下,智能体是一个自主的行动者。**它能够遵循未曾预料的推理路径,这意味着它可能会表现出涌现行为(Emergent behaviors),并在没有直接监督的情况下产生高额成本。
管理这种自主性需要一种不同的运维模型。高效的团队不再采用静态监控,而是拥抱一个持续的闭环:实时“观测(Observe)”系统行为、采取“行动(Act)”以维持性能与安全,并基于生产环境中的沉淀认知来“演进(Evolve)”智能体。 这一整合的循环,是在生产环境中成功运营智能体的核心学科。
观测:智能体的感官系统
Observe: Your Agent’s Sensory System
要信任和管理一个自主智能体,你必须首先理解它的运行过程。可观测性提供了这一关键洞察,为随后的“行动(Act)”和“演进(Evolve)”阶段充当感官系统。强健的可观测性实践建立在三大技术支柱之上,它们协同工作以提供智能体行为的全景图:
- 日志(Logs):关于发生了什么的粒度化、事实性日记,记录了每一次工具调用、错误和决策。
- 追踪(Traces):串联独立日志的叙事故事,揭示了智能体为何采取某种行动的因果路径。
- 指标(Metrics):聚合后的成绩单,在大规模场景下总结性能、成本和运维健康状况,以展示系统运行得怎么样。
例如,在 Google Cloud 中,这是通过云运维套件(Operations Suite)来实现的:用户的请求会在 Cloud Trace 中生成一个唯一的 ID,该 ID 将 Vertex AI Agent Engine 的调用、模型调用以及具有显式持续时间的工具执行串联在一起。详细的日志会流向 Cloud Logging,而 Cloud Monitoring 仪表盘则会在延迟超出阈值时发出告警。智能体开发工具包(ADK)提供了内置的 Cloud Trace 集成,用于对智能体运维进行自动化的埋点监测。
通过实施这些支柱,我们实现了从盲目运营向对智能体行为拥有清晰的、数据驱动型视图的跨越,为在生产环境中对其进行高效管理奠定了必要的基础。(关于这些概念的完整讨论,请参阅《智能体质量:可观测性、日志、追踪、评估与指标》)。
行动:运维控制的杠杆
Act: The Levers of Operational Control
没有行动的观测,只是昂贵的仪表盘。“行动(Act)”阶段核心在于实时干预——即你根据观测到的情况,用以管理智能体性能、成本和安全性的控制杠杆。
请将“行动(Act)”视为系统的自动化反射机制,旨在实时维持稳定性。相比之下,稍后将涵盖的“演进(Evolve)”则是从行为中学习以打造一个从根本上更优质系统的战略过程。
由于智能体是自主的,你无法预先为每一种可能的结果编写好程序。相反,你必须构建强健的机制来影响其在生产环境中的行为。这些运维杠杆主要分为两个核心类别:管理系统健康和管理系统风险。
管理系统健康:性能、成本与规模
Managing System Health: Performance, Cost, and Scale
与传统的微服务不同,智能体的工作负载是动态且有状态的。管理其健康状况需要一套应对这种不可预测性的策略。
- 面向规模的设计(Designing for Scale)
其核心基石是将智能体的逻辑与其状态进行解耦。
- 水平扩展(Horizontal Scaling):将智能体设计为无状态的容器化服务。通过将状态外部化,任何实例都可以处理任何请求,从而使 Cloud Run 或托管的 Vertex AI Agent Engine 运行时等无服务器平台能够实现自动扩缩容。
- 异步处理(Asynchronous Processing):对于耗时较长的任务,利用事件驱动模式来分流工作。这能让智能体保持即时响应,同时在后台处理复杂的任务。例如在 Google Cloud 上,服务可以将任务发布到 Pub/Sub,随后触发 Cloud Run 服务进行异步处理。
- 外部化状态管理(Externalized State Management):由于 LLM 本身是无状态的,将记忆持久化到外部是不可逾越的硬性要求。这凸显了一个关键的架构选择:Vertex AI Agent Engine 提供了内置且持久化的会话(Session)与记忆服务;而 Cloud Run 则提供了直接与 AlloyDB 或 Cloud SQL 等数据库集成的灵活性。
- 平衡相互竞争的目标(Balancing Competing Goals)
扩展系统总是需要平衡三个相互冲突的目标:速度、可靠性和成本。
- 速度(延迟 / Latency):通过并行化设计、激进的缓存策略以及在常规任务中使用更小、更高效的模型,来保持智能体的快速响应。
- 可靠性(异常处理 / Handling Glitches):智能体必须具备处理临时故障的能力。当调用失败时,应自动进行重试,理想情况下采用指数退避(Exponential backoff)策略,以给予服务恢复的时间。这要求将工具设计为“可安全重试”的(即具备幂等性 / Idempotent),以防止引发诸如重复扣款之类的 Bug。
- 成本(Cost):通过缩短提示词、在简单任务中使用更便宜的模型以及批量发送请求(Batching),来保持智能体成本的可控性。
管理风险:安全响应演练手册
Managing Risk: The Security Response Playbook
由于智能体能够自主行动,你需要一套用于快速控制事态的演练手册。当检测到威胁时,响应应当遵循明确的流程序列:控制、分流与解决。
- 第一步是立即控制(Containment):首要任务是阻止伤害扩大,通常通过“断路器(Circuit Breaker)”来实现——即利用特性开关(Feature flag)瞬间禁用受影响的工具。
- 接下来是分流(Triage):在威胁得到控制后,将可疑请求路由到人机协同(HITL)审查队列中,以调查漏洞利用的范围和影响。
- 最后,重点转向彻底解决(Resolution):团队开发一个补丁——例如升级输入过滤器或更新系统提示词——并通过自动化的 CI/CD 流水线进行部署,确保修复方案在彻底封堵漏洞之前通过完整测试。
演进:从生产环境中学习
Evolve: Learning from Production
如果说“行动(Act)”阶段提供了系统即时的、战术性的反射机制,那么“演进(Evolve)”阶段则关乎长期的、战略性的持续改进。它始于对可观测性数据中所收集到的模式和趋势进行审视,并提出一个至关重要的问题:“我们如何根除病因,让这个问题永不再现?”
在这一阶段,你将从对生产环境事件的被动响应,转变为主动让你的智能体变得更聪明、更高效、更安全。你将“观测”阶段获得的原始数据,转化为智能体架构、逻辑和行为上的持久性改进。
演进的引擎:通往生产环境的自动化之路
The Engine of Evolution: An Automated Path to Production
来自生产环境的深度洞察只有在能够被快速执行时才具有价值。如果你的团队需要耗时六个月才能部署一个补丁,那么即便观测到有 30% 的用户在某个特定任务上遭遇失败,也毫无意义。
正因如此,你在生产前阶段(第 3 节)构建的自动化 CI/CD 流水线,成为了运维闭环中最核心的组件。它是驱动快速演进的引擎。一条快速、可靠的通往生产环境之路,能让你在几小时或几天内(而非几周或几个月)完成从“观测”到“改进”的闭环。
当你发现一个潜在的改进点——无论是优化后的提示词、一个新工具,还是升级后的安全护栏——其标准流程应当是:
- 提交变更:将提议的改进内容提交到你的版本控制代码仓库中。
- 触发自动化:代码提交自动触发你的 CI/CD 流水线。
- 严谨验证:流水线对照你更新后的数据集,运行全套单元测试、安全扫描和智能体质量评估套件。
- 安全部署:一旦通过验证,利用安全滚动发布策略将变更部署到生产环境中。
这种自动化工作流将“演进”从一个缓慢、高风险的人工项目,转变为了一个快速、可重复且数据驱动的流程。
演进工作流:从洞察到部署落地
The Evolution Workflow: From Insight to Deployed Improvement
- 分析生产数据:从生产日志中识别用户行为趋势、任务成功率和安全事件。
- 更新评估数据集:将生产环境中的失败案例转化为明天的测试用例,以此来扩充你的黄金测试集。
- 精炼并部署:提交改进内容以触发自动化流水线——无论是精炼提示词、添加工具还是更新安全护栏。
这创造了一个良性循环,让你的智能体在每一次用户交互中实现持续的自我进化。
💡 演进闭环实战案例:
一个零售智能体的日志(观测 / Observe)显示,15% 的用户在询问“相似商品”时会收到错误。产品团队随即采取行动(Act),创建了一张高优先级的工单。
随后进入**演进(Evolve)**阶段:团队利用生产日志在评估数据集中创建了一个全新的、处于失败状态的测试用例。AI 工程师精炼了智能体的提示词,并添加了一个全新、更强健的相似度检索工具。该变更被提交后,在 CI/CD 流水线中成功通过了最新更新的评估套件,并通过金丝雀部署安全上线。最终,在不到 48 小时内彻底解决了该用户问题。
演进安全性:生产环境反馈闭环
Evolving Security: The Production Feedback Loop
虽然基础的安全与责任框架已在生产前阶段(第 3.4 节)确立,但安全工作从来都不是一劳永逸的。安全不是一张静态的检查清单,而是一个动态的、不断适应的持续过程。生产环境是终极的检验场,在其中收集到的洞察,对于巩固智能体防御现实世界威胁的能力至关重要。
这正是“观测 $\rightarrow$ 行动 $\rightarrow$ 演进”闭环对安全性至关重要的原因。该流程是演进工作流的直接延伸:
- 观测(Observe):你的监控和日志系统检测到一个新的威胁向量。这可能是一种绕过了你现有过滤器的全新提示词注入技术,也可能是一个导致轻微数据泄露的意外交互。
- 行动(Act):应急安全响应团队立即对威胁进行控制(如第 4.2 节所述)。
- 演进(Evolve):这是实现长期韧性(Resilience)的关键一步。安全性洞察被反馈到你的开发生命周期中:
- 更新评估数据集:将这种全新的提示词注入攻击作为一个永久性的测试用例,添加到你的评估套件中。
- 精炼安全护栏:提示词工程师或 AI 工程师精炼智能体的系统提示词、输入过滤器或工具使用策略,以封堵这一新的攻击向量。
- 自动化与部署:工程师提交变更并触发完整的 CI/CD 流水线。更新后的智能体对照新扩充的评估集进行严谨的验证,随后部署到生产环境,从而彻底修复该漏洞。
这创造了一个强大的反馈闭环,让每一次生产环境事件都使你的智能体变得更强大、更有韧性,将你的安全态势从被动防御转化为持续、主动的自我改进。
💡 如需深入了解负责任 AI 以及保障 AI 智能体系统安全的更多信息,请参阅白皮书《谷歌构建安全的 AI 智能体方法》与《谷歌安全 AI 框架(SAIF)》。
超越单智能体运维
Beyond Single-Agent Operations
你已经掌握了在生产环境中运营单个智能体的核心,并能够高频高效地交付它们。然而,随着企业组织扩展到拥有数十个专职的智能体——且每一个都由不同的团队利用不同的框架构建而成——一个新的挑战浮出水面:这些智能体之间无法协同作战。
下一节将探索标准化的协议如何将这些孤立的智能体转化为一个具备互操作性的生态系统,通过智能体之间的协同合作释放出成倍的商业价值。
A2A —— 可复用性与标准化
A2A - Reusability and Standardization
你在整个企业组织中构建了数十个专职的智能体。客服团队拥有他们的支持智能体,分析团队构建了预测系统,风险管理团队则创建了欺诈检测机制。但问题随之而来:这些智能体彼此之间无法交谈——无论是因为它们是在不同的框架下、不同的项目中创建的,还是完全部署在不同的云端。
这种孤立导致了巨大的低效。每个团队都在重复构建相同的能力,关键的洞察被困在各自的孤岛之中。你需要的是互操作性(Interoperability)——即任何智能体都能够利用其他任何智能体的能力,而无需关心它是谁构建的,或者使用了什么框架。
为了解决这个问题,需要一套规范的标准化方法,该方法建立在两个截然不同但又互补的协议之上。虽然我们在关于智能体工具与 MCP 互操作性的章节中详细介绍的模型上下文协议(Model Context Protocol, MCP)为工具集成提供了通用标准,但对于智能体之间复杂、有状态的协同合作而言,它还远远不够。这正是现在由 Linux 基金会(Linux Foundation)托管的 Agent2Agent(A2A) 协议旨在解决的问题。
这两者之间的区别至关重要。当你需要一个简单的、无状态的功能(如获取天气数据或查询数据库)时,你需要一个支持 MCP 的工具。但当你需要委派一个复杂的业务目标时,例如“分析上季度的客户流失情况并推荐三种干预策略”,你需要的是一个能够通过 A2A 进行自主推理、规划和行动的智能伙伴。简而言之,MCP 让你能够下达指令:“做这件具体的事”;而 A2A 则让你能够委派任务:“实现这个复杂的业务目标”。
A2A 协议:从概念到落地
A2A Protocol: From Concept to Implementation
A2A 协议旨在打破组织内部的孤岛,实现智能体之间的无缝协同。设想这样一个场景:欺诈检测智能体发现了可疑活动。为了了解完整的背景信息,它需要来自另一个独立的交易分析智能体的数据。在没有 A2A 的情况下,必须由人工分析师来手动桥接这一鸿沟——这个过程可能需要耗费数小时。而通过 A2A,智能体之间可以自发进行协同,在几分钟内就能解决问题。
协同的第一步是寻找最合适的智能体来进行任务委派——这通过 Agent Cards(智能体名片)得以实现。Agent Cards 是标准化的 JSON 规范,充当每个智能体的“名片”。一张 Agent Card 描述了该智能体能做什么、它的安全要求、它的技能以及如何与其取得联系(URL 路径),从而允许生态系统中的任何其他智能体动态地发现其同伴。请参见下方的 Agent Card 示例:
Snippet 1: A sample agent card for the check_prime_agent
1 | { |
采用该协议并不需要对系统架构进行大刀阔斧的重构。类似 ADK 的开发框架显著简化了这一过程。你只需通过单次函数调用,就能使现有的智能体兼容 A2A 协议,该调用会自动生成其 AgentCard 并将其发布到网络中。
Snippet 2: Using the ADK’s to_a2a utility to wrap an existing agent and expose it for A2A communication
1 | # Example using ADK: Exposing an agent via A2A |
一旦某个智能体对外公开,其他任何智能体都可以通过引用其 AgentCard 来消费它的服务。例如,客服智能体现在可以直接查询远程的商品目录智能体,而无需了解其内部的运行机制。
Snippet 3: Using the ADK’s RemoteA2aAgent class to connect to and consume a remote agent
1 | # Example using ADK: Consuming a remote agent via A2A |
这解锁了强大的、层级化的组合能力。你可以配置一个根智能体(Root agent),让它既能编排本地子智能体来处理简单任务,又能通过 A2A 调度远程的专职智能体,从而打造出一个能力更强悍的系统。
Snippet 4: Using a remote A2A agent (prime_agent) as a sub-agent within a hierarchical agent structure in the ADK
1 | # Example using ADK: Hierarchical agent composition |
然而,开启这种级别的自主协同,也引入了两项不可逾越的硬性技术要求。第一是分布式追踪(Distributed Tracing),每一个请求都必须携带唯一的追踪 ID(Trace ID),这对于跨多个智能体进行调试和维持连贯的审计追踪至关重要。第二是强健的状态管理(State Management)。A2A 交互本质上是有状态的,需要一个精密的持久化层来追踪任务进度并确保事务的完整性。
A2A 协议最适合用于需要持久服务契约(Service contract)的、正式的跨团队集成。而对于单个应用程序内部紧密耦合的任务,轻量级的本地子智能体通常仍然是更高效的选择。随着生态系统的日益成熟,新开发的智能体在构建之初就应当原生支持这两种协议,确保每一个新组件都具备即时可发现性、互操作性和可复用性,从而让整个系统的价值呈指数级复合增长。
A2A 与 MCP 如何协同工作
How A2A and MCP Work Together
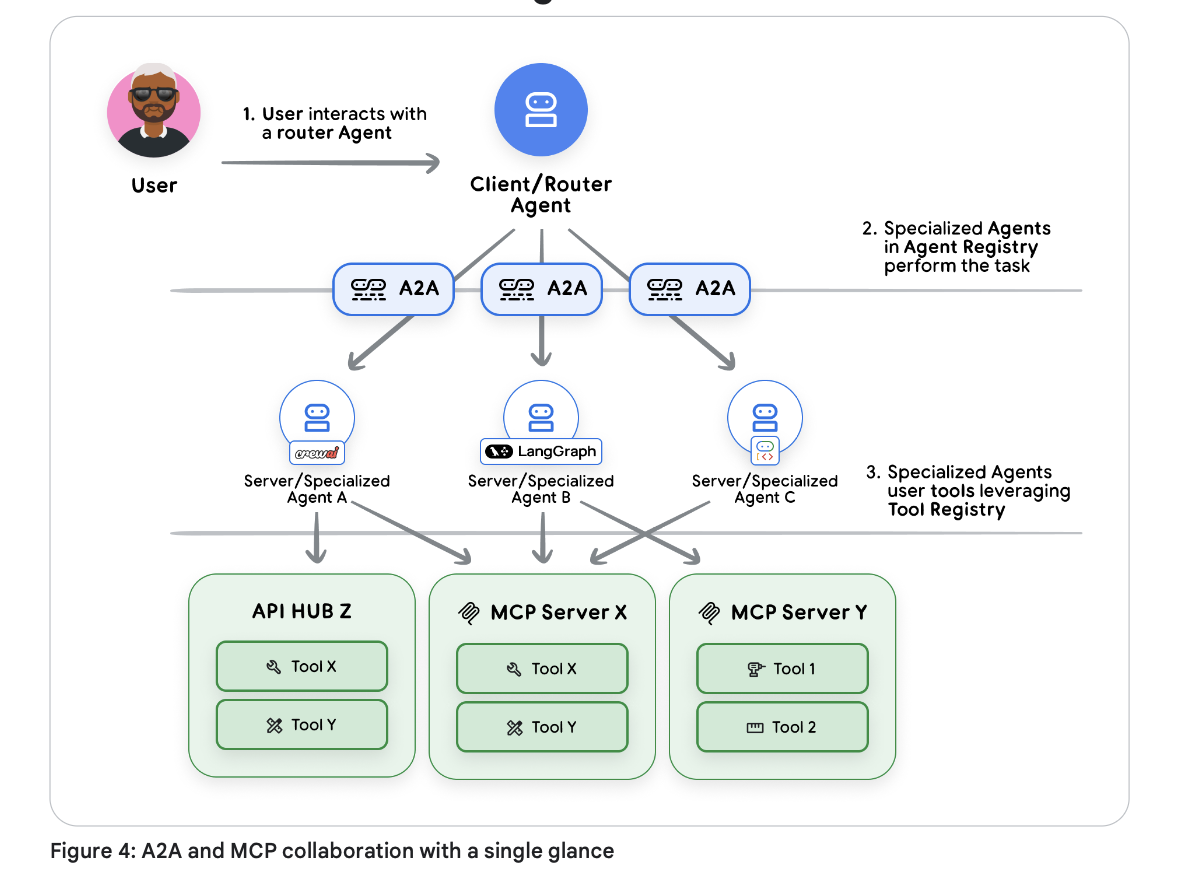
A2A 和 MCP 并不是相互竞争的标准,而是旨在不同抽象层次上运行的互补协议。两者的区别取决于智能体正在与什么进行交互。MCP 属于工具和资源的范畴——即具有明确定义的结构化输入和输出的底层原子能力,例如计算器或数据库 API。A2A 则属于其他智能体的范畴——即能够进行推理、规划、使用多种工具并维持状态以实现复杂目标的自主系统。
最强大的智能体系统会在分层架构中同时使用这两种协议。一个应用程序可以主要使用 A2A 来编排多个智能体之间的高层级协同合作,而这些智能体中的每一个在内部则使用 MCP 来与其自身特定的工具和资源集进行交互。
一个形象的实际类比是一个由自主 AI 智能体员工组成的汽车维修店:
- 用户到智能体(A2A):客户使用 A2A 与“店长(Shop Manager)”智能体进行沟通,描述一个高层级的问题:“我的车一直在发出咔哒咔哒的异响。”
- 智能体到智能体(A2A):店长进行多轮诊断对话,然后同样通过 A2A 将任务委派给专业的“维修工(Mechanic)”智能体。
- 智能体到工具(MCP):维修工智能体现在需要执行具体的动作。它使用 MCP 来调用其专业工具:在诊断扫描仪上运行
scan_vehicle_for_error_codes(),通过get_repair_procedure()查询维修手册数据库,并利用raise_platform()操作平台举升机。 - 智能体到智能体(A2A):在诊断出问题后,维修工智能体确定需要一个配件。它再次通过 A2A 与外部的“配件供应商(Parts Supplier)”智能体进行沟通,询问库存情况并下达订单。
在这一工作流中,A2A 促进了客户、车店智能体以及外部供应商之间更高层级的、对话式的和面向任务的交互。与此同时,MCP 提供了标准化的管道,使维修工智能体能够可靠地使用其特定的、结构化的工具来完成它的工作。
注册表架构:何时以及如何构建
Registry Architectures: When and How to Build Them
为什么有些企业需要构建注册表(Registries),而另一些企业却不需要?答案在于规模与复杂度。当你有 50 个工具时,手动配置运行得很好。但当你拥有散布在不同团队和环境中的 5000 个工具时,你将面临一个必须要用系统化方案来解决的“发现难题”(Discovery problem)。
工具注册表(Tool Registry)利用类似 MCP 的协议来编目所有资产(从函数到 API)。你无需让智能体直接访问数千个工具,而是创建精心策划的筛选列表。这衍生出了三种常见的模式:
- 全能型智能体(Generalist agents):访问完整的工具目录,用速度和准确率换取更广泛的能力范围。
- 专职型智能体(Specialist agents):使用预定义的工具子集,以获取更高的性能表现。
- 动态型智能体(Dynamic agents):在运行时动态查询注册表,以自适应接入新的工具。
其首要核心效益在于供人类进行资产发现——开发人员可以在动手开发前检索现有的工具,避免重复造轮子;安全团队可以审计工具的访问权限;产品所有者也能清晰掌握其智能体的能力边界。
智能体注册表(Agent Registry)将相同的概念应用于智能体本身,使用诸如 A2A 的 AgentCards 等格式。它能帮助团队发现并复用现有的智能体,减少冗余开发。这也为自动化的“智能体到智能体任务委派”奠定了基石,尽管这目前仍属于一种新兴模式。
注册表在提供发现与治理能力的同时,也带来了维护成本。你可以考虑在初期不使用注册表,只有当你的生态规模真正需要中心化管理时,再着手构建它!
注册表决策框架 (Decision Framework for Registries)
- 工具注册表(Tool Registry):当工具的检索和发现成为研发瓶颈,或安全合规需要中心化审计时,请构建它。
- 智能体注册表(Agent Registry):当多个团队需要发现并复用专职智能体,且不希望产生紧密耦合时,请构建它。
融会贯通:AgentOps 完整生命周期
Putting It All Together: The AgentOps Lifecycle
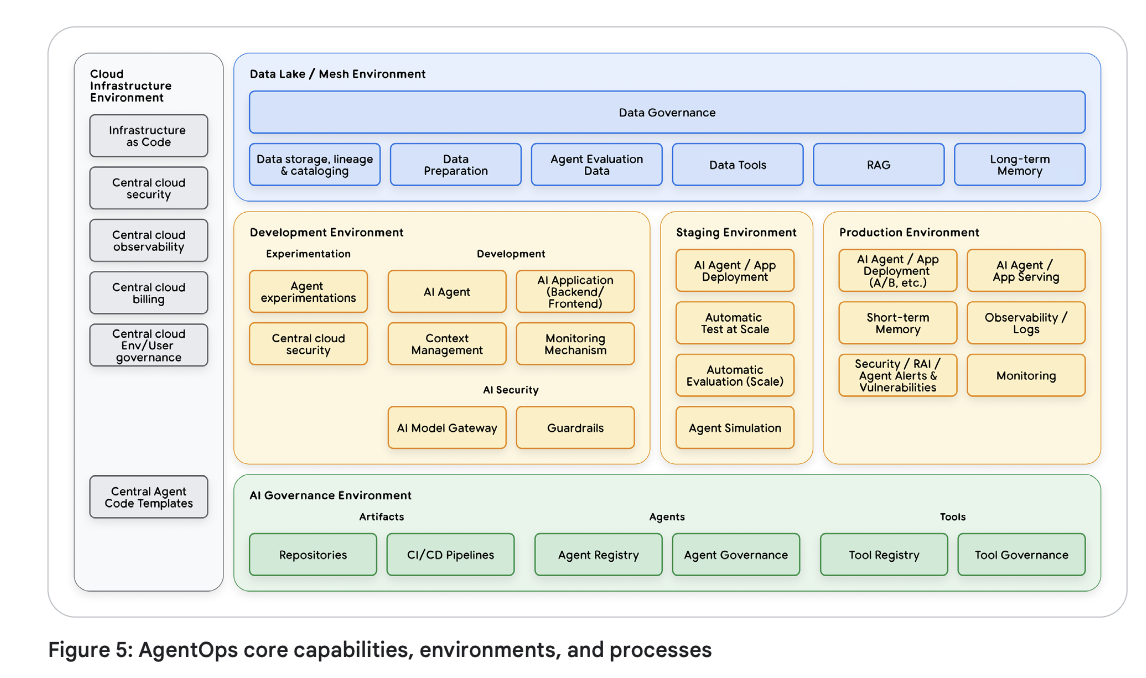
我们现在可以将这些技术支柱整合为一个统一、连贯的参考架构!该生命周期始于开发者的内部循环(Inner loop)——这是一个通过快速本地测试和原型设计来塑造智能体核心逻辑的阶段。一旦变更准备就绪,它就会进入正式的生产前引擎(Pre-production engine),在此处,自动化的评估关卡将对照黄金测试集来验证其质量和安全性。通过验证后,系统利用安全滚动发布(Safe rollouts)策略将其释放到生产环境中。在生产环境中,全方位的可观测性(Comprehensive observability)将捕获真实的现实世界数据,为持续演进的闭环提供动力,从而将每一次洞察转化为下一次的系统改进。
💡 如需全面了解如何将 AI 智能体转化为实际业务运营(包括评估、工具管理、CI/CD 标准化以及高效的架构设计),请观看 Google Cloud 官方 YouTube 频道上的 《AgentOps: Operationalize AI Agents》 专题视频。
结语:通过 AgentOps 跨越最后一公里
Conclusion: Bridging the Last Mile with AgentOps
将 AI 原型推进为生产级系统是一场企业组织层面的变革,它需要一门全新的运维学科:AgentOps(智能体运维)。
大多数智能体项目之所以在“最后一公里”折戟沉沙,并非由于技术本身的限制,而是因为低估了自主系统的运维复杂度。本指南为你绘制了跨越这一鸿沟的路径:它始于将“人员与流程”确立为治理的基石;紧接着,通过建立在“评估准入型部署”之上的“生产前策略”,实现高风险发布的自动化管理;一旦系统上线,持续的“观测 $\rightarrow$ 行动 $\rightarrow$ 演进”闭环将每一次用户交互都转化为潜在的优化洞察;最后,通过“互操作性协议”对系统进行横向扩展,将孤立的智能体转化为协同作战的智能生态系统。
这些立竿见影的收益——例如拦截一次安全漏洞或实现快速回回滚——完全对得起前期的研发投入。但其真正的商业价值在于交付速度(Velocity)。成熟的 AgentOps 实践允许团队在几小时内(而非几周)部署改进方案,从而将静态的部署产物演变为持续自我进化的生命体产品。
你的前行之路 (Your Path Forward)
- 如果你刚刚起步:请专注于夯实基础。构建你的第一个评估数据集,落地 CI/CD 流水线,并建立全方位的监控体系。Agent Starter Pack 是一个极佳的起点——它能在几分钟内创建一个内置了这些强健基石、生产就绪的智能体项目。
- 如果你正在规模化扩展:请进一步提升你的工程实践。将“从生产洞察到部署落地”的反馈闭环全自动化运行,并在互操作性协议上推进标准化建设,从而构建起一个富有凝聚力的生态系统,而不仅仅是零散的单点解决方案。
个人注:什么是:Agent Starter Pack
市面上常见的几类 Agent Starter Pack
- Google ADK / GenAI SDK Starter Pack:这通常是指官方提供的一套示例代码库(通常放在 GitHub 上)。它用最简洁的 Python 代码展示了如何用最新的 Gemini 模型、配合 Session 服务和 Callbacks 机制,快速搭起来一个智能家居或客服智能体。
- Vercel AI SDK Starter Pack:前端/全栈领域极其著名的起步套件(基于 Next.js 和 TypeScript)。如果你想做个类似 ChatGPT 的网页端 AI 智能体应用,用它可以在 5 分钟内一键部署到云端。
- LangChain / CrewAI Starter Templates:开源社区的多智能体起步包,里面甚至帮你配置好了“主经理智能体 + 员工智能体”的多角色协作模板。
总结:价值
Agent Starter Pack 的核心存在意义就是“消除重复造轮子的痛苦”。
它把复杂的、枯燥的底层协议(比如环境配置、API 鉴权、异常重试、日志追踪)全部隐藏在后台,让开发者可以把 100% 的精力,集中在编写最核心的业务逻辑、提示词调优(Prompt Engineering)以及自定义工具(Custom Tools)上。对于新手来说,它是学习智能体设计模式(Agent Design Patterns)的最佳实战教科书。
下一代前沿技术不仅在于构建更优秀的单个智能体,更在于编排那些能够自主学习与协同作战的复杂多智能体系统(Multi-agent systems)。而 AgentOps 的运维规范,正是让这一切成为现实的底层基石。
我们希望本实操手册能够赋能你构建出下一代智能、可靠且值得信赖的 AI 系统。因此,跨越最后一公里绝不是项目的终点,而是创造商业价值的起点!