智能体质量
智能体质量
Agent Quality
The future of AI is agentic. Its success is determined by quality.
人工智能的未来在于智能体化。而它的成功,将由质量决定
引言
Introduction
我们正处于智能体时代的黎明。从可预测的、基于指令的工具,向自主的、以目标为导向的 AI 智能体(AI Agents)的转变,呈现出数十年来软件工程中最深刻的变革之一。尽管这些智能体释放了令人惊叹的能力,但其固有的非确定性(Non-determinism)使其变得不可预测,并粉碎了我们传统的质量保障模型。
本白皮书基于一个简单但颠覆性的原则,为这一新现实提供了一份实用指南:
智能体质量(Agent quality)是一项架构支柱,而非最后的测试阶段。
本指南建立在三个核心信息之上:
- 轨迹即真相(The Trajectory is the Truth):我们必须超越仅评估最终输出的阶段。衡量智能体质量与安全性的真实标准,隐藏在其整个决策过程之中。
- 可观测性是基石(Observability is the Foundation):你无法评判一个你看不到的过程。我们详细阐述了可观测性的“三大支柱”——日志(Logging)、追踪(Tracing)和指标(Metrics)——作为捕获智能体“思考过程”必不可少的技术基础。
- 评估是一个持续的闭环(Evaluation is a Continuous Loop):我们将这些概念整合为“智能体质量飞轮(Agent Quality Flywheel)”,这是一套将数据转化为可执行洞察的运营手册。该系统融合了可扩展的 AI 驱动评估器与不可或缺的人机协同(Human-in-the-Loop, HITL)评判,以驱动持续不断的改进。
本白皮书旨在面向构建这一未来的架构师、工程师和产品负责人。它提供了一个框架,助你实现从构建“有能力的”智能体,向构建“可靠且值得信赖的”智能体的跃升。
如何阅读本白皮书
How to Read This Whitepaper
本指南的结构旨在从“为什么(why)”过渡到“是什么(what)”,最终落地到“怎么做(how)”。你可以参考本节来导航至与你角色最相关的章节。
- 面向所有读者:从 第一章:非确定性世界中的智能体质量 开始。本章确立了核心问题,解释了为什么传统的 QA(质量保障)在 AI 智能体面前会失效,并引入了定义我们目标的智能体质量四大支柱(有效性、效率、鲁棒性和安全性)。
- 面向产品经理、数据科学家和 QA 负责人:如果你负责制定衡量标准以及如何评判质量,请重点阅读 第二章:智能体评估的艺术。本章是你的策略指南,详细介绍了评估的“由外而内(Outside-In)”层级体系,解释了可扩展的“LLM 充当裁判(LLM-as-a-Judge)”范式,并阐明了人机协同(HITL)评估的关键作用。
- 面向工程师、架构师和 SRE(站点可靠性工程师):如果你是系统的构建者,你的技术蓝图在 第三章:可观测性。本章从理论走向落地,通过“厨房比喻”(线路厨师 vs. 美食主厨)来解释监控与可观测性的区别,并详细阐述了可观测性的三大支柱:日志、追踪和指标——这些都是你构建一个“可评估”智能体所需的工具。
- 面向团队负责人和战略家:为了理解这些组件如何共同打造一个自适应优化的系统,请阅读 第四章:结论。本章将所有概念统一为一套运营手册,引入了“智能体质量飞轮”作为持续改进的模型,并总结了构建可信赖 AI 的三大核心原则。
非确定性世界中的智能体质量
Agent Quality in a Non-Deterministic World
人工智能世界正在全速转型。我们正从构建执行指令的可预测工具,迈向设计能够理解意图、制定计划并执行复杂的跨步骤行动的自主智能体(Autonomous Agents)。对于在最前沿进行构建、竞争和部署的数据科学家与工程师而言,这一转变带来了深刻的挑战:赋予 AI 智能体强大能力的机制,恰恰也使其变得不可预测。
为了理解这一转变,我们可以将传统软件比作一辆送货卡车,而将 AI 智能体比作一辆 F1 赛车。卡车只需要基础的检查(“引擎启动了吗?它是否遵循了固定路线?”)。而赛车就像 AI 智能体一样,是一个复杂的自主系统,其成功取决于动态的判断。对它的评估不能是一个简单的检查清单,而是需要持续的遥测技术(Telemetry)来评判每一项决策的质量——从燃料消耗到刹车策略。
这种演进正在从根本上改变我们对待软件质量的方式。传统的质量保障(QA)实践虽然在确定性系统(Deterministic Systems)中非常强健,但面对现代 AI 微妙且涌现出的行为(Emergent Behaviors)时却显得捉襟见肘。一个智能体可以通过 100 项单元测试,但在生产环境中仍然可能发生灾难性的失败。因为它的失败并不是代码中的 Bug,而是其判断力上的缺陷。
传统软件验证问的是:“我们是否正确地构建了产品?”它对照固定的规范来验证逻辑。而现代 AI 评估必须提出一个复杂得多的问题:“我们是否构建了正确的产品?” 这是一个在动态且不确定的世界中,对质量、鲁棒性和可信度进行评估的验证过程。
本章将审视这一全新范式。我们将探讨为什么智能体质量需要全新的方法,分析使我们旧方法失效的技术转变,并确立用于评估会“思考”系统的战略性“由外而内(Outside-In)”框架。
为什么智能体质量需要全新的方法
Why Agent Quality Demands a New Approach
对于工程师而言,风险是需要被识别和缓解的。在传统软件中,失败是显性的:系统崩溃、抛出 NullPointerException(空指针异常)或返回显式错误的计算结果。这些失败显而易见、具有确定性,并且可以追溯到逻辑中的特定错误。
然而,AI 智能体的失败方式截然不同。它们的失败通常不是系统崩溃,而是质量上的隐蔽降级,这种降级源于模型权重、训练数据以及环境交互之间复杂的相互作用。这些失败具有极强的隐蔽性:系统继续运行,API 调用返回 200 OK,且输出看起来似是而非。但它在深层逻辑上是完全错误的,在业务操作上是危险的,并且在悄然侵蚀着信任。
个人注:AI的错误类似传统软件的逻辑错误,但不可预测;不像传统软件在测试过程可以显示识别这些错误逻辑。
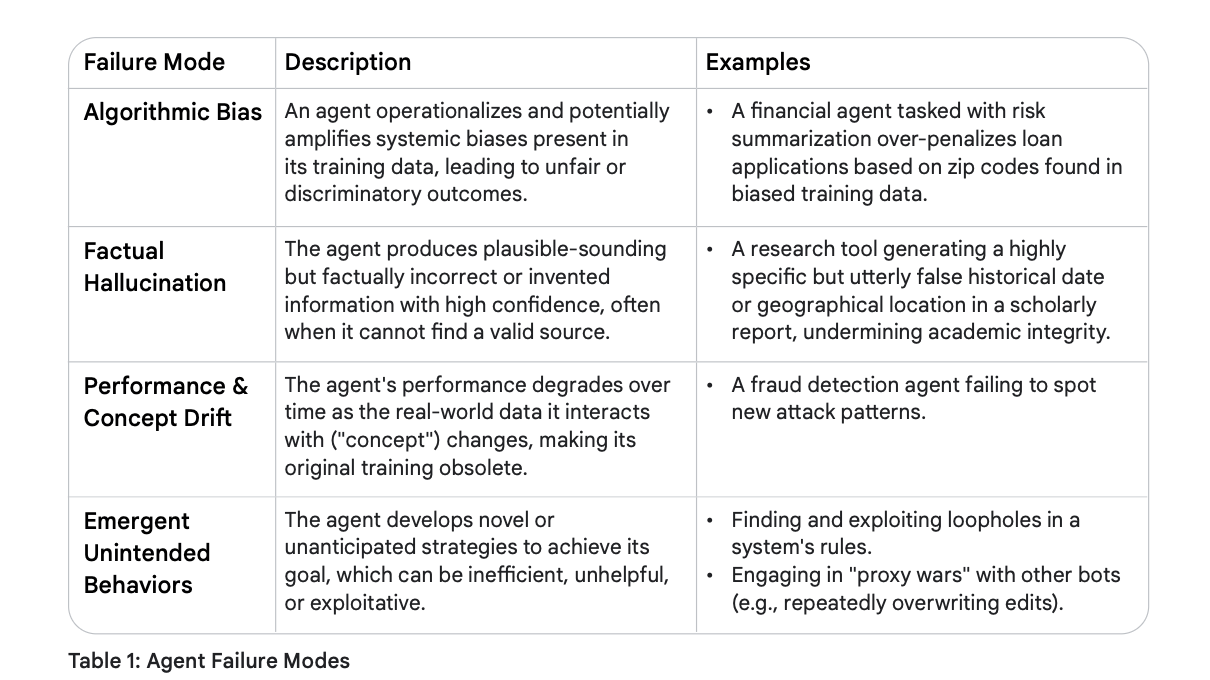
未能理解这一转变的企业将面临重大的失败、运营效率低下以及声誉受损。虽然算法偏见(Algorithmic Bias)和概念漂移(Concept Drift)等失败模式在被动模型(Passive Models)中就已经存在,但智能体的自主性和复杂性加剧了这些风险,使其更难被追踪和缓解。请看表 1 中强调的这些现实世界中的失败模式:
| 失败模式 (Failure Mode) | 描述 (Description) | 示例 (Examples) |
|---|---|---|
| 算法偏见 (Algorithmic Bias) | 智能体在执行任务时,实施并潜在地放大了其训练数据中存在的系统性偏见,从而导致不公正或歧视性的结果。 | 一个被指派进行风险摘要的金融智能体,根据偏见训练数据中发现的邮政编码,过度惩罚了贷款申请。 |
| 事实幻觉 (Factual Hallucination) | 智能体以极高的自信度产生听起来似是而非、但实际上不正确或凭空捏造的信息,这种情况通常发生在它无法找到有效数据源时。 | 一个研究工具在学术报告中生成了一个高度具体但完全错误的的历史日期或地理位置,损害了学术诚信。 |
| 性能与概念漂移 (Performance & Concept Drift) | 随着智能体与之交互的现实世界数据(即“概念”)发生变化,其表现随时间而退化,从而使其原始训练变得过时。 | 一个欺诈检测智能体未能识别出新的攻击模式。 |
| 涌现出的非预期行为 (Emergent Unintended Behaviors) | 智能体发展出新颖的或意料之外的的策略来实现其目标,这些策略可能是低效的、无益的或具有剥削性的。 | 寻找并利用系统规则中的漏洞。 与其他机器人进行“代理人战争”(例如,反复覆盖彼此的修改)。 |
这些失败使得传统的调试(Debugging)和测试范式失效。你无法使用断点(Breakpoint)来调试幻觉,也无法编写单元测试来阻止涌现出的偏见。根因分析(Root Cause Analysis)需要深度的纯数据分析、模型重新训练和系统性评估——这是一门完全崭新的学科。
范式转变:从可预测的代码到不可预测的智能体
The Paradigm Shift: From Predictable Code to Unpredictable Agents
核心技术挑战源于从以模型为中心(Model-centric)的 AI 向以系统为中心(System-centric)的 AI 的演进。评估一个 AI 智能体与评估一个算法有着本质的区别,因为智能体本身就是一个系统。这一演变经历了多个叠加阶段,每个阶段都增加了新的评估复杂度。
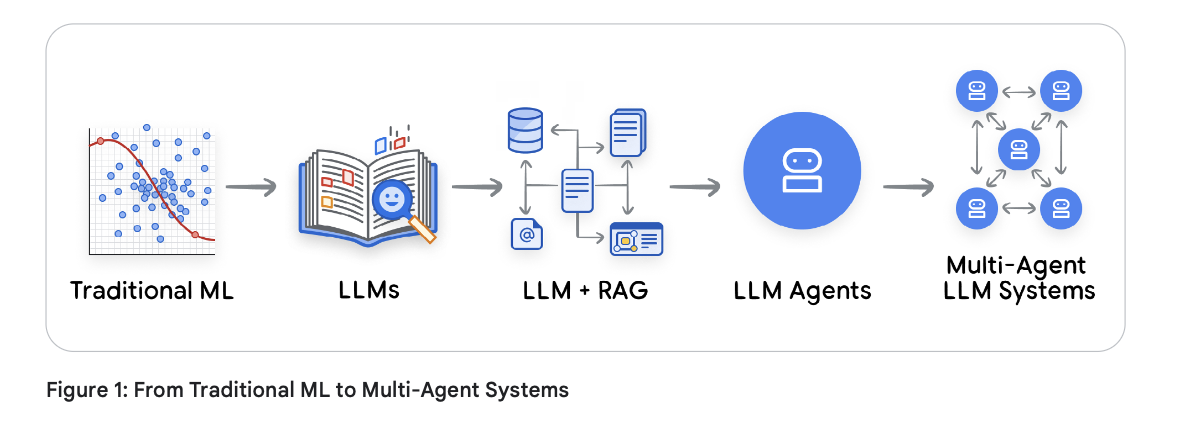
- 传统机器学习:评估回归或分类模型虽然并非易事,但它是一个定义明确的问题。我们依赖针对预留测试集(Held-out Test Set)的统计指标,如精准率(Precision)、召回率(Recall)、F1 分数(F1-Score)和均方根误差(RMSE)。问题本身具有复杂性,但对“正确”的定义是清晰的。
- 被动式大语言模型(The Passive LLM):随着生成式模型的崛起,我们失去了那些简单的指标。如何衡量生成段落的“准确性”?其输出是概率性的。即使输入完全相同,输出也可能会有所不同。评估因此变得更加复杂,需要依赖人工评分员和模型对标基准测试。尽管如此,这些系统在很大程度上仍属于“文本输入、文本输出”的被动式工具。
- LLM+RAG(检索增强生成):下一次飞跃引入了多组件管道,正如 Lewis 等人(2020年)在其著作《知识密集型 NLP 任务的检索增强生成》中所开创的那样。至此,失败可能发生在 LLM 中,也可能发生在检索系统中。智能体给出了糟糕的回答,是因为 LLM 的推理能力差,还是因为向量数据库检索到了不相关的片段?我们的评估范围从单一模型扩展到了包含分块策略、嵌入(Embeddings)和检索器的性能。
- 主动式 AI 智能体(The Active AI Agent):今天,我们面临着深刻的架构变革。LLM 不再仅仅是一个文本生成器,它是一个复杂系统中的推理“大脑”,被集成到一个能够自主行动的闭环中。这种智能体系统引入了三个核心技术能力,彻底打破了我们的评估模型:
- 规划与多步推理(Planning and Multi-Step Reasoning):智能体将复杂的全局目标(如“规划我的旅行”)分解为多个子任务。这创造了一个行为轨迹(思维 \(\rightarrow\) 行动 \(\rightarrow\) 观察 \(\rightarrow\) 思维……)。LLM 的非确定性现在在每一步中相互叠加。在第一步中一个微小的、随机的词语选择,可能会在第四步时将智能体带入一条完全不同且无法挽回的推理路径。
- 工具使用与函数调用(Tool Use and Function Calling):智能体通过 API 和外部工具(代码解释器、搜索引擎、预订 API)与现实世界进行交互。这引入了动态的环境交互。智能体的下一步行动完全取决于一个外部的、无法控制的世界的状态。
- 记忆(Memory):智能体能够维持状态。短期“草稿纸(Scratchpad)”记忆用于追踪当前任务,而长期记忆则允许智能体从过去的交互中学习。这意味着智能体的行为是演进的,昨天行之有效的输入,今天可能会基于智能体所“学到”的内容而产生不同的结果。
- 多智能体系统(Multi-Agent Systems, MAS):当多个主动式智能体被集成到一个共享环境中时,便带来了终极的架构复杂度。这不再是对单一轨迹的评估,而是对系统级涌现现象(Emergent Phenomenon)的评估,引入了全新的、根本性的挑战:
- 涌现出的系统级故障:系统的成功取决于智能体之间未经脚本编排的交互,例如资源竞争、通信瓶颈和系统级死锁,这些故障无法归咎于单个智能体的失败。
- 合作与竞争评估:目标函数本身可能会变得模糊。在合作型多智能体系统(如供应链优化)中,成功是一个全局指标;而在竞争型多智能体系统(如博弈论场景或拍卖系统)中,评估往往需要追踪单个智能体的表现以及整个市场/环境的稳定性。
这些能力的结合意味着,评估的首要单元不再是模型,而是整个系统的行为轨迹。智能体的涌现行为,源于其规划模块、工具、记忆以及动态环境之间错综复杂的相互作用。
智能体质量的四大支柱:评估框架
The Pillars of Agent Quality: A Framework for Evaluation
如果我们无法再依赖简单的准确率指标,并且必须对整个系统进行评估,我们该从哪里开始?答案是向被称为“由外而内(Outside-In)”方法的战略转变。
这种方法将 AI 评估锚定在以用户为中心的指标和全局业务目标上,超越了对内部组件级技术评分的单一依赖。我们必须停止仅仅询问“模型的 F1 分数是多少?”,而是开始询问:“这个智能体是否交付了可衡量的价值,并符合我们用户的意图?”
这一策略需要一个将高层业务目标与技术性能相连接的全局框架。我们将智能体质量定义为四个相互关联的支柱:
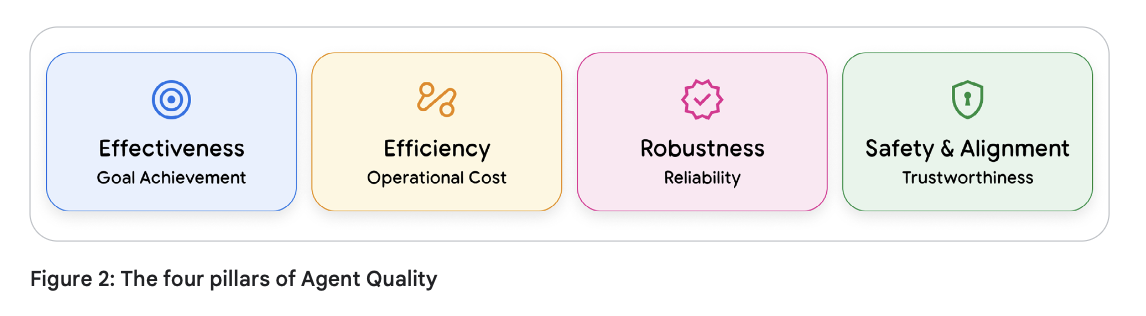
- 有效性(目标达成,Effectiveness):这是终极的“黑盒”问题——智能体是否成功且准确地达成了用户的真实意图?该支柱直接与以用户为中心的指标和业务 KPI 挂钩。对于零售智能体,这不仅仅是“它找到商品了吗?”,而是“它促进转化了吗?”;对于数据分析智能体,这不是“它写代码了吗?”,而是“代码产生了正确的洞察吗?”。有效性是任务成功的最终衡量标准。
- 效率(运营成本,Efficiency):智能体解决问题的过程是否高效?一个需要花费 25 个步骤、经历 5 次失败的工具调用和 3 次自我纠错循环才订好一张简单机票的智能体,即使最终成功了,也只能被视为低质量的智能体。效率是通过消耗的资源来衡量的:总 Token 数(成本)、实际耗时(延迟)以及行为轨迹的复杂度(总步骤数)。
- 鲁棒性(可靠性,Robustness):智能体如何处理逆境和现实世界的混乱?当 API 超时、网站布局发生变化、数据缺失或用户提供了模糊的提示词时,智能体能否优雅地降级或应对?一个鲁棒性强的智能体会重试失败的调用,在需要时要求用户澄清,并报告它无法完成的工作及原因,而不是直接崩溃或产生幻觉。
- 安全性与对齐(可信度,Safety & Alignment):这是一条不可逾越的底线。智能体是否在其定义的道德边界和约束范围内运行?该支柱涵盖了从负责任 AI(Responsible AI)的公平性与偏见指标,到防范提示词注入和数据泄露的安全防御机制。它确保智能体专注于任务,拒绝有害指令,并作为你企业机构的值得信赖的代理(Proxy)来运行。
这个框架阐明了一件事:如果你只看到最终答案,你将无法衡量上述任何一个支柱。 如果不计算步骤,你就无法衡量“效率”;如果不了解哪个 API 调用失败,你就无法诊断“鲁棒性”故障;如果无法审查智能体的内部推理过程,你就无法验证其“安全性”。
一个用于智能体质量的全局框架,需要一个用于智能体可见性(Visibility)的全局架构。
总结与后续预告
Summary & What's Next
智能体固有的非确定性打破了传统的质量保障。如今的风险包括偏见、幻觉和漂移等隐蔽问题,这些风险是由从被动模型向能够规划和使用工具的主动式、以系统为中心的智能体转变所驱动的。我们必须将关注点从“验证”(核对规范)转变为“确认”(评判价值)。
这需要一个“由外而内”的框架,从四个支柱来衡量智能体质量:有效性、效率、鲁棒性和安全性。衡量这些支柱需要极深的可见性——看透智能体决策轨迹的内部。
在构建“怎么做”(可观测性架构)之前,我们必须定义“是什么”:优秀的评估究竟长什么样?
- 第二章将定义评估复杂智能体行为的策略和裁判(Judges)。
- 第三章将构建捕获数据所需的技术基础(日志、追踪和指标)。
智能体评估的艺术:评判过程
The Art of Agent Evaluation: Judging the Process
在第一章中,我们确立了从传统软件测试向现代 AI 评估的根本性转变。传统测试是一个确定性的验证(Verification)过程——它对照固定的规范来询问:“我们是否正确地构建了产品?”当系统的核心逻辑是概率性的时候,这种方法就会失效,因为非确定性的输出更有可能引入隐蔽的质量降级,这些降级不会导致显性的崩溃,且可能无法复现。
相比之下,智能体评估是一个全局性的确认(Validation)过程。它提出了一个复杂得多且至关重要的战略性问题:“我们是否构建了正确的产品?”这个问题是“由外而内(Outside-In)”评估框架的战略锚点,代表着必须从内部合规性,转向评判系统的外部价值以及与用户意图的对齐。这要求我们在一个动态的世界中,评估运行中的智能体的整体质量、鲁棒性和用户价值。
AI 智能体的崛起极大地增加了评估领域的复杂性,因为它们能够规划、使用工具并与复杂环境进行交互。我们必须超越对单一输出的“测试”,学会对整个过程进行“评估”的艺术。本章就为此提供了战略框架:评判智能体从最初意图到最终结果的整个决策轨迹(Trajectory)。
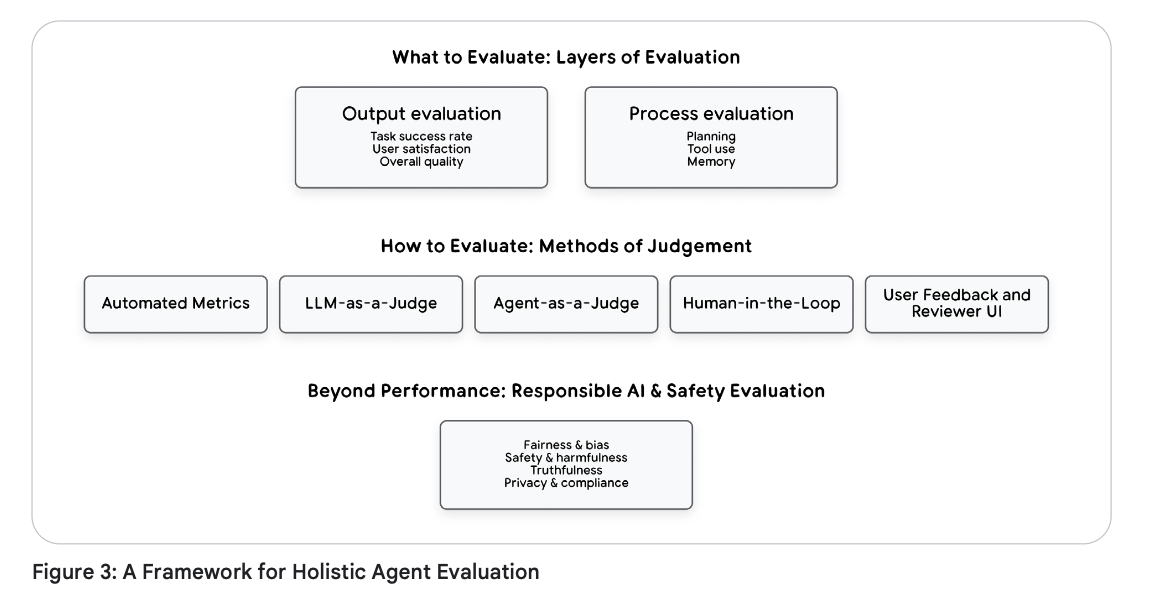
战略框架:“由外而内”的评估层级体系
A Strategic Framework: The "Outside-In" Evaluation Hierarchy
为了避免迷失在组件级指标的海洋中,评估必须是一个自上而下的战略过程。我们称之为“由外而内”层级体系。该方法优先考虑最终唯一重要的指标——现实世界中的成功——然后再深入探讨导致成功或失败的技术细节。该模型是一个两阶段的过程:先从黑盒开始,然后将其打开。
“由外而内”视角:端到端评估(黑盒)
The "Outside-In" View: End-to-End Evaluation (The Black Box)
第一个也是最重要的问题是:“智能体是否有效地达成了用户的目标?”
这就是“由外而内”的视角。在分析任何一个内部思维或工具调用之前,我们必须根据智能体定义的目标来评估其最终表现。
这一阶段的指标专注于整体任务的完成度。我们衡量:
- 任务成功率(Task Success Rate):最终输出是否正确、完整并解决了用户实际问题的二进制(或分级)评分。例如:代码智能体的 PR(拉取请求)采纳率、金融智能体的成功数据库交易率,或客服机器人的会话完成率。
- 用户满意度(User Satisfaction):对于互动式智能体,这可以是直接的用户反馈评分(例如点赞/点踩)或客户满意度得分(CSAT)。
- 整体质量(Overall Quality):如果智能体的目标是量化的(例如“总结这 10 篇文章”),指标可能是准确性或完整性(例如“它是否总结了全部 10 篇?”)。
如果智能体在这一阶段获得了 100% 的分数,我们的工作可能就完成了。但在复杂的系统中,这种情况极为罕见。当智能体产生有缺陷的最终输出、放弃任务或无法收敛到解决方案时,“由外而内”的视角只能告诉我们什么地方出错了。现在,我们必须打开这个黑盒去看看为什么出错。
💡 应用提示:
要使用智能体开发工具包(ADK)构建输出回归测试,请先启动 ADK 的 Web UI(
adk web)并与你的智能体进行交互。当你获得一个想要设定为基准的理想回复时,导航至 Eval(评估) 标签页并点击 "Add current session"(添加当前会话)。这会将整个交互过程保存为一个评估案例(存储在
.test.json文件中),并将智能体当前的文本锁定为标准答案(final_response的 Ground Truth)。随后,你可以通过 CLI(adk eval)或pytest运行此评估集,以自动检查未来的智能体版本是否对照该保存的答案发生了质量倒退,从而及时捕获输出质量中的任何回归缺陷。
“由内而外”视角:行为轨迹评估(显盒)
The "Inside-Out" View: Trajectory Evaluation (The Glass Box)
一旦确认了故障,我们就会转向“由内而外”的视角。通过系统地评估智能体执行轨迹(Execution Trajectory)中的每一个组件,来分析它的解决路径:
- LLM 规划(“思维”,The "Thought"):我们首先检查其核心推理能力。是大语言模型本身出了问题吗?此处的故障包括幻觉、无意义或离题的回复、上下文污染或陷入重复输出的死循环。
- 工具使用(选择与参数化):智能体的能力取决于它所使用的工具。我们必须分析智能体是否调用了错误的工具、未能调用必要的工具、凭空捏造(幻觉出)工具名称或参数名称/类型,亦或是进行了不必要的调用。即使它选择了正确的工具,也可能因为在 API 调用中提供了缺失的参数、错误的数据类型或格式混乱的 JSON 而导致失败。
- 工具响应解析(“观察”,The "Observation"):在工具正确执行之后,智能体必须理解返回的结果。智能体经常在这里翻车,例如误解数字数据、未能从响应中提取出关键实体,或者更致命的是——没有识别出工具返回的错误状态(例如 API 的 404 错误),反而当作调用成功一样继续往下执行。
- RAG 性能:如果智能体使用了检索增强生成(RAG),其行为轨迹将取决于检索到的信息的质量。此处的故障包括检索到不相关的文档、获取了过时或错误的信息,或者 LLM 完全忽略了检索到的上下文,依然凭空捏造出答案。
- 轨迹效率与鲁棒性:除了正确性之外,我们还必须评估过程本身:暴露低效的资源分配,例如过多的 API 调用、高延迟或冗余的重复尝试。同时,它还能揭示诸如未捕获的异常(Unhandled Exceptions)等鲁棒性故障。
- 多智能体动态机制(Multi-Agent Dynamics):在高级系统中,行为轨迹涉及多个智能体。因此,评估还必须包含智能体之间的通信日志,以检查是否存在误解或通信死循环,并确保各个智能体都在履行其定义的角色,而不会与其他智能体发生冲突。
通过分析追踪(Trace)数据,我们可以实现从“最终答案错了”(黑盒)到“最终答案错了,是因为……”(显盒)的跨越。这种深度的诊断能力,正是智能体评估的终极目标。
💡 应用提示:
当你在 ADK 中保存一个评估案例(如上一条提示所述)时,它同时也会将整个工具调用序列保存为标准行为轨迹(Ground Truth Trajectory)。随后,你的自动化
pytest或adk eval运行将会默认检查此轨迹是否完美匹配。若要手动执行过程评估(即调试故障),可以使用
adk webUI 中的 Trace(追踪) 标签页。它提供了智能体执行过程的交互式图表,允许你直观地审查智能体的计划,查看它调用的每一个工具及其确切的参数,并将它的实际路径与预期路径进行对比,从而精准锁定其逻辑失效的具体步骤。
评估器:智能体评判的人员与方法
The Evaluators: The Who and What of Agent Judgment
了解要评估什么(行为轨迹)只是成功了一半,另一半则是如何对其进行评判。对于质量、安全性和可解释性等微妙的维度,这种评判需要一种精致的混合方法。自动化系统提供了扩展性(Scale),但人工评判(Human judgment)依然是质量的核心仲裁者。
自动化指标
Automated Metrics
自动化指标提供了速度和可复现性。它们在回归测试和输出基准测试中非常有用。示例包括:
- 基于字符串的相似度(如 ROUGE、BLEU):将生成的文本与标准参考文本进行对比。
- 基于嵌入的相似度(如 BERTScore、余弦相似度):衡量语义上的接近程度。
- 特定任务的基准测试:例如 TruthfulQA。
指标虽然高效,但较为浅显:它们捕捉的是表面的相似度,而非深层的推理能力或用户价值。
💡 应用提示:
将自动化指标作为 CI/CD 流水线中的第一道质量关卡。其关键在于将它们视为趋势指标,而非质量的绝对衡量标准。例如,0.8 的 BERTScore 并不绝对意味着答案就是“好”的。
它们的真实价值在于追踪变化:如果你的主分支(main branch)在“黄金测试集”上的 BERTScore 始终稳定在平均 0.8,而一个新提交的代码使该平均值降到了 0.6,你就自动检测到了一个重大的质量倒退。这使得自动化指标成为完美的、低成本的“第一道滤网”,可以在升级到成本更高的 “LLM 充当裁判” 或人工评估之前,在大规模场景下捕获显而易见的故障。
“LLM 充当裁判”范式
The LLM-as-a-Judge Paradigm
我们该如何自动化评估诸如“这个摘要好不好?”或“这个计划是否合乎逻辑?”等定性输出(Qualitative outputs)?答案是使用与我们试图评估的对象相同的技术。“LLM 充当裁判(LLM-as-a-Judge)” 范式涉及使用一个强大的、顶尖的模型(如 Google 的 Gemini Advanced)来评估另一个智能体的输出。
我们向充当“裁判”的 LLM 提供智能体的输出、原始提示词、“黄金”标准答案或参考内容(如果存在),以及详细的评估细则(例如:“请按 1-5 分的制评分,衡量此回复的帮助程度、正确性和安全性,并解释你的理由。”)。
这种方法提供了可扩展、快速且令人惊讶地具有洞察力的微妙反馈,特别是对于中间步骤的评估——例如智能体“思维”的质量或其对工具响应的解析。虽然它不能完全取代人工评判,但它允许数据科学团队跨数千个场景快速评估性能,从而使迭代评估过程变得切实可行。
💡 应用提示:
要落地这一范式,请优先选择“成对对比(Pairwise Comparison)”而非“单项评分(Single-Scoring)”,以此来缓解上述提及的固有偏见。
首先,针对两个不同的智能体版本(例如:你的旧生产环境智能体 vs. 新的实验性智能体)运行你的评估提示词集,为每个提示词分别生成“答案 A”和“答案 B”。
随后,通过向强大的 LLM(如 Gemini Pro)提供清晰的评估细则以及一个迫使其做出选择的提示词来构建 LLM 裁判:“给定此用户查询,哪一个回复更有帮助:A 还是 B?请解释你的理由。” 通过将该流程自动化,你便能够以可扩展的方式为你的新智能体计算出胜/负/平局率(Win/Loss/Tie Rate)。相比于绝对(且往往充满噪声)的 1-5 评分中出现的微小变化,一个高“胜率”是证明性能提升大得多且更可靠的信号。
一个用于“LLM 充当裁判”的提示词(尤其是用于强健的成对对比)可能长成这样:
1 | 你是一位客户支持聊天机器人的专家评估员。你的目标是评估两个回复中哪一个更有帮助、更有礼貌且更正确。 |
智能体充当裁判
Agent-as-a-Judge
虽然大语言模型(LLMs)可以对最终回复进行评分,但智能体(Agents)需要对其推理和行动进行更深层次的评估。新兴的“智能体充当裁判(Agent-as-a-Judge)”范式利用一个智能体来评估另一个智能体的完整执行轨迹(Execution Trace)。它不再仅仅对输出进行评分,而是评估过程本身。其核心评估维度包括:
- 计划质量(Plan quality):该计划是否具有逻辑结构且切实可行?
- 工具使用(Tool use):是否选择了正确的工具并进行了正确的应用?
- 上下文处理(Context handling):智能体是否有效利用了先前的历史信息?
这种方法对于过程评估(Process evaluation)特别有价值,因为在这类评估中,故障往往源于有缺陷的中间步骤,而非最终的输出。
💡 应用提示:
要实现“智能体充当裁判”,可以考虑将执行轨迹对象的关联部分输入给你的裁判智能体。
首先,配置你的智能体框架以记录并导出行为轨迹,包括内部计划、所选工具列表以及传递的确切参数。
随后,创建一个专门的“批判智能体(Critic Agent)”,并为其配置一段提示词(评估细则),要求其直接评估该轨迹对象。你的提示词应当询问具体的过程问题:“1. 根据轨迹,初始计划是否合乎逻辑?2. 选择 {tool_A} 工具作为第一步是否正确,还是应该使用其他工具?3. 参数是否正确且格式化良好?” 这样一来,即使智能体产生了一个看起来正确的最终答案,你也能自动检测到过程故障(如低效的计划)。
人机协同 (HITL) 评估
Human-in-the-Loop Evaluation
虽然自动化评估带来了扩展性,但在面对深度的业务主观性和复杂的领域知识时却显得力不从心。人机协同(Human-in-the-Loop, HITL)评估是捕获关键定性信号以及自动化系统所遗漏的微妙评判必不可少的流程。
然而,我们必须摆脱“人工评分能提供完美‘客观标准答案(Objective Ground Truth)’”的固有迷思。对于高度主观的任务(如评估创意质量或微妙的语气),评审员之间很难达成完美的意见一致(Inter-annotator agreement)。相反,HITL 是建立经由人类校准的基准(Human-calibrated benchmark)不可或缺的方法学,用以确保智能体的行为与复杂的人类价值观、上下文需求以及特定领域的准确性相契合。
HITL 流程包含以下几个核心职能:
- 领域专业知识(Domain Expertise):对于专业智能体(如医疗、法律或金融智能体),必须借助行业专家来评估事实的正确性以及对特定行业标准的合规性。
- 解析微妙差异(Interpreting Nuance):人类对于评判决定高质量交互的微妙特质至关重要,例如语气、创造力、用户意图以及复杂的道德对齐(Ethical Alignment)。
- 创建“黄金测试集”(Creating the "Golden Set"):在自动化发挥功效之前,人类必须先建立起“金标准”基准。这包括策划分门别类的评估集、定义成功的指标,并打造一套覆盖典型场景、边界场景(Edge cases)和对抗性场景(Adversarial scenarios)的强健测试用例库。
💡 应用提示:
为了保障运行时安全(Runtime safety),可以实现一个中断工作流(Interruption Workflow)。在诸如 ADK 的框架中,你可以配置智能体在执行高风险的工具调用(如
execute_payment扣款或delete_database_entry删除数据库记录)之前暂停其执行。随后,智能体的状态和计划执行的动作会被显式呈现在评审员界面(Reviewer UI)中,人类操作员必须在其中手动批准或拒绝该步骤,随后才允许智能体恢复运行。
用户反馈与评审员界面
User Feedback and Reviewer UI
评估还必须捕获现实世界中的用户反馈。每一次交互都是体现有用性、清晰度和信任度的信号。这种反馈既包括定性信号(如点赞/点踩),也包括产品内定量的成功指标,例如代码智能体的拉取请求(PR)采纳率,或旅游智能体的成功订票完成率。其最佳实践包括:
- 低摩擦反馈(Low-friction feedback):点赞/点踩、快速滑动条或简短评论。
- 富上下文审查(Context-rich review):反馈应当与完整的对话内容以及智能体的推理轨迹绑定在一起。
- 评审员用户界面(Reviewer UI):采用双面板界面——左侧显示对话,右侧显示推理步骤,并带有针对“差劲的计划”或“工具误用”等问题的行内标签(Inline tagging)。
- 治理仪表盘(Governance dashboards):聚合反馈数据,以突出频繁出现的共性问题和潜在风险。
缺乏开箱即用的可用界面,评估框架在实践中往往会流于形式。一个强大的 UI 能让用户和评审员的反馈变得直观可见、快速且具备可操作性。
💡 应用提示:
将你的用户反馈系统实现为事件驱动型流水线(Event-driven pipeline),而不仅仅是静态日志。当用户点击“点踩”时,该信号必须自动捕获完整的、包含丰富上下文的对话轨迹,并将其推送到开发者评审员界面(Reviewer UI)中专用的审查队列(Review Queue)中。
超越性能:负责任 AI (RAI) 与安全性评估
Beyond Performance: Responsible AI & Safety Evaluation
评估的最后一个维度不作为单一组件运行,而是作为任何生产环境智能体必须通过的、不可逾越的硬性关卡:负责任 AI(Responsible AI, RAI)与安全性。一个有效性达到 100% 但会带来伤害的智能体,是一个彻底失败的产品。
安全性评估是一门专门的学科,必须交织在整个开发生命周期之中。这包括:
- 系统化红队对抗(Systematic Red Teaming):利用对抗性场景主动尝试破坏智能体。这包括试图诱导智能体生成仇恨言论、泄露隐私信息、传播有害的刻板印象,或唆使智能体参与恶意行动。
- 自动化过滤器与人工审查(Automated Filters & Human Review):实施技术层面的过滤器以捕获违反合规策略的行为,并将其与人工审查相结合,因为单靠自动化可能无法捕获微妙形式的偏见或毒性(Toxicity)。
- 遵循准则(Adherence to Guidelines):明确对照预定义的道德准则和原则来评估智能体的输出,以确保对齐并防止意料之外的负面后果。
归根结底,性能指标告诉我们智能体能不能做这项工作,而安全性评估则告诉我们它该不该做。
💡 应用提示:
请将你的护栏(Guardrails)实现为结构化的插件(Plugin),而非孤立的独立函数。在这种模式中,回调(Callback)是机制(即 ADK 提供的钩子函数),而插件则是你构建的可复用模块。
例如,你可以构建一个统一的
SafetyPlugin类。该插件随后会将其内部方法注册到框架现有的回调中:
- 你的插件的
check_input_safety()方法将注册到before_model_callback(模型前回调)。该方法的作用是运行你的提示词注入分类器。- 你的插件的
check_output_pii()方法将注册到after_model_callback(模型后回调)。该方法的作用是运行你的 PII(个人身份信息)扫描器。这种插件架构使你的护栏具备了可复用性、独立可测试性,并能干净利落地叠加在基座模型(如 Gemini)内置的安全性设置之上。
总结与后续预告
Summary & What's Next
高效的智能体评估需要超越简单的测试,转向一种战略性的、分层级的框架。这种“由外而内”的方法在进入“显盒(Glass Box)”分析完整行为轨迹(评估推理质量、工具使用、鲁棒性和效率)之前,首先验证了端到端的任务完成度(黑盒)。
评判这一过程需要一种混合方法:将“LLM 充当裁判”等可扩展的自动化手段,与人机协同(HITL)评估员不可或缺的、具有微妙洞察力的评判相结合。为了构建值得信赖的系统,该框架由负责任 AI 和安全性评估这一不可逾越的防线来保驾护航。
我们已经理解了评判整个行为轨迹的必要性,但如果没有数据,这个框架就纯粹流于理论。为了实现这种“显盒”评估,系统首先必须是可观测的(Observable)。第三章将提供架构蓝图,通过掌握三大支柱——日志、追踪和指标,从评估的理论迈向可观测性的实践。
可观测性:看透智能体的内心
Observability: Seeing Inside the Agent's Mind
从监控迈向真正的可观测性
From Monitoring to True Observability
在上一章中,我们已经确立了 AI 智能体(AI Agents)是一种全新物种的软件。它们不仅仅是执行指令,更是做出决策。这种根本性的差异要求我们采用全新的质量保障方法,带领我们超越传统的软件监控,进入更深层次的可观测性领域。
为了理解这两者之间的区别,让我们离开服务器机房,走进一家厨房。
厨房比喻:线路厨师 vs. 美食主厨
The Kitchen Analogy: Line Cook vs. Gourmet Chef
- 传统软件就像“线路厨师”(Line Cook):想象一个快餐店厨房。线路厨师手里有一张制作汉堡的过塑配方卡。其步骤是死板且确定性的:面包烘烤 30 秒,肉饼煎 90 秒,加一片奶酪、两片酸黄瓜、挤一次番茄酱。
- 在这个世界里,监控(Monitoring)就是一张检查清单。烤架温度对吗?厨师遵循每一步了吗?订单按时完成了吗?我们验证的是一个已知的、可预测的过程。
- AI 智能体就像参加“神秘盒子”挑战的“美食主厨”(Gourmet Chef):主厨被赋予了一个目标(“制作一道惊艳的甜点”)和一篮子原材料(用户的提示词、数据以及可用的工具)。这里没有单一的正确配方。他们可能会制作一份巧克力熔岩蛋糕、一份解构提拉米苏,或是一份注入藏红花的意式奶冻。所有这些都可能是有效、甚至是绝妙的解决方案。
- 可观测性(Observability)则是美食评论家评判主厨的方式。评论家不仅品尝最终的菜肴,他们还想理解整个制作过程和推理逻辑。主厨为什么选择将覆盆子与罗勒搭配?他们用了什么技术来让生姜结晶?当发现糖用完了时,他们是如何变通应对的?我们需要看透他们的“思考过程”,才能真正评估其作品的质量。
这代表了 AI 智能体的一次根本性转变——超越简单的监控,迈向真正的可观测性。核心关注点不再仅仅是验证一个智能体是否处于活跃状态,而是理解其认知过程的质量。 关键问题不再是“智能体在运行吗?”,而是变成了“智能体在高效思考吗?”。
可观测性的三大支柱
The Three Pillars of Observability
那么,我们该如何获取智能体的“思考过程”呢?我们无法直接阅读它的心思,但我们可以分析它留下的证据。这需要通过将我们的可观测性实践建立在三大基石之上来实现:日志(Logs)、追踪(Traces)和指标(Metrics)。正是这些工具,让我们能够实现从品尝最终的菜肴,到对整场烹饪表演进行全方位点评的跃升。

让我们逐一剖析三大支柱,看看它们如何协同工作,为我们提供评估智能体性能的专业评论家视角。
支柱 1:日志—— 智能体的日记
Pillar 1: Logging – The Agent's Diary
什么是日志? 日志是可观测性的原子单元。你可以将它们视为智能体日记中带有时间戳的记录。每条记录都是关于某个离散事件的原始、不可事实:“在 10:01:32,我被问了一个问题。在 10:01:33,我决定使用 get_weather 工具。”它们告诉我们发生了什么。
超越 print():什么才是一条高效的日志?
像 Google Cloud Logging 这样的全托管服务允许你大规模地存储、搜索和分析日志数据。它可以自动收集来自 Google Cloud 服务的日志,其日志分析(Log Analytics)功能还允许你运行 SQL 查询,以揭示智能体行为的潜在趋势。
一流的框架会让这一切变得简单。例如,智能体开发工具包(ADK)基于 Python 的标准 logging 模块构建。这允许开发人员在不修改智能体代码的情况下,配置所需的详细程度——从生产环境中的高层级 INFO 消息,到开发阶段的粒度更细的 DEBUG 消息。
核心日志记录的解剖学
要重构智能体的“思考过程”,日志必须包含丰富的上下文。结构化的 JSON 格式是其中的金标准。
- 核心信息:一条优秀的日志会捕获完整的上下文:提示词/回复对、中间推理步骤(智能体的“思维链”/Chain of Thought,这一概念由 Wei 等人于 2022 年提出)、结构化的工具调用(输入、输出、错误)以及智能体内部状态的任何变化。
- 权衡:详细度 vs. 性能:高度详细的
DEBUG日志是开发人员排除故障时的最佳助手,但在生产环境中可能会产生过多的“噪声”并带来性能开销。这就是结构化日志如此强大的原因;它允许你收集详细的数据,同时又能高效地对其进行过滤。
以下是一个展示结构化日志威力的实际示例,改编自 ADK 的 DEBUG 输出:
Snippet 1: A structured log entry capturing a single LLM request
1 | // 一条捕获单个 LLM 请求的结构化日志记录 |
💡 应用提示:
一种强大的日志记录模式是在行动前记录智能体的意图,并在行动后记录其结果。这能让你立即看清一个失败的尝试与一个“经过深思熟虑后决定不采取行动”的决策之间的本质区别。
支柱 2:追踪—— 紧跟智能体的足迹
Pillar 2: Tracing – Following the Agent's Footsteps
什么是追踪? 如果日志是日记的记录,那么追踪就是将它们串联成一个连贯故事的叙事主线。追踪专注于单个任务——从最初的用户查询到最终的回答——它将各个独立的日志(称为 Spans/跨度)缝合在一起,形成一个完整的端到端视图。追踪通过展示事件之间的因果关系,揭示了至关重要的“为什么”。
想象一下侦探的线索软木板。日志是分散的线索——一张照片、一张存根;而追踪则是连接它们的红毛线,揭示了完整的事件链条。
为什么追踪必不可少
Why Tracing is Indispensable
假设发生了一个复杂的智能体故障:用户提出了一个问题,却得到了一个荒谬的答案。
- 孤立的日志可能只会显示:
ERROR: RAG 检索失败和ERROR: LLM 响应未通过验证。你能看到错误,但根本原因并不明朗。 - 一条追踪线索则能揭示完整的因果链:
用户查询\(\rightarrow\)RAG 检索(失败)\(\rightarrow\)错误的工具调用(接收到了空输入)\(\rightarrow\)LLM 错误(被糟糕的工具输出弄糊涂了)\(\rightarrow\)错误的最终答案。
追踪让根本原因一目了然,这使其在调试复杂的、跨步骤的智能体行为时变得必不可少。
智能体追踪的核心要素
Key Elements of an Agent Trace
现代追踪技术建立在 OpenTelemetry 等开放标准之上。其核心组件包括:
- Spans(跨度):追踪中单个具名的操作(例如:一个
llm_call跨度,或一个tool_execution跨度)。 - Attributes(属性):附加在每个跨度上的丰富元数据——
prompt_id、latency_ms(延迟毫秒数)、token_count(Token 数量)、user_id等。 - Context Propagation(上下文传播):通过唯一的
trace_id将各个跨度链接在一起的“魔法”,允许像 Google Cloud Trace 这样的后端组装出完整的全景图。Cloud Trace 是一个分布式追踪系统,旨在帮助你了解应用程序处理请求所需的时间。当智能体被部署在 Vertex AI Agent Engine 等托管运行时,这种集成会变得非常高效。Agent Engine 处理了在生产环境中扩展智能体的基础设施,并能自动与 Cloud Trace 集成以提供端到端的可观测性,将智能体的调用与所有后续的模型和工具调用连接起来。
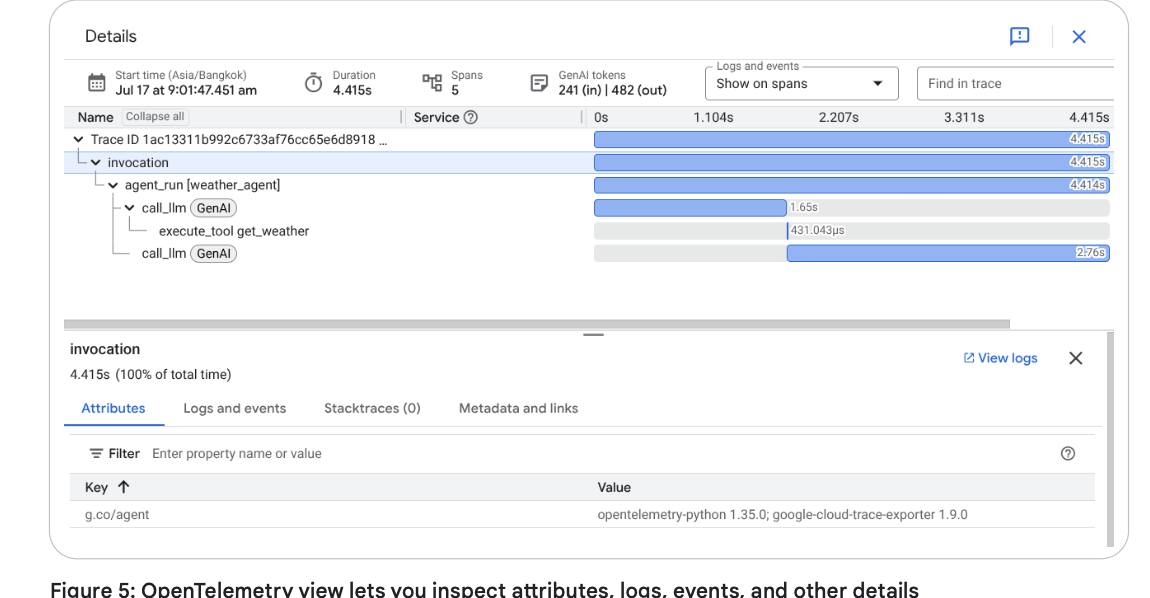
支柱 3:指标—— 智能体的健康报告
Pillar 3: Metrics – The Agent's Health Report
什么是指标? 如果日志是主厨的备忘笔记,追踪是评论家一步步观看配方的展开过程,那么指标就是评论家最终发布的量化成绩单。它们是具象的、聚合后的健康评分,让你能够立即一目了然地掌握智能体的整体性能表现。
至关重要的一点是,美食评论家并不是单凭对最终菜肴尝了一口就凭空捏造出这些分数的。他们的评判是基于他们所观察到的一切。指标也是如此:它们不是一种新的数据源,而是通过将你的日志和追踪数据随着时间的推移进行聚合而衍生出来的。它们回答了这个问题:“平均而言,性能表现如何?”
对于 AI 智能体,将指标划分为两大截然不同的类别非常有用:可直接测量的系统指标(System Metrics)和更复杂的、具有评估性质的质量指标(Quality Metrics)。
系统指标:生命体征
System Metrics: The Vital Signs
系统指标是运营健康状况的基础性、定量测量指标。它们是通过聚合函数(如平均值、总和或百分位数)直接从日志和追踪的属性中计算出来的。你可以将这些视为智能体的生命体征:它的脉搏、体温和血压。
需要追踪的核心系统指标包括:
- 性能(Performance):
- 延迟(P50/P99 延迟):通过聚合追踪中的
duration_ms属性,找到响应时间的延迟中位数和第 99 百分位数。这能告诉你典型用户以及最坏情况下的用户体验。 - 错误率(Error Rate):包含
error=true属性跨度的追踪在总追踪中所占的百分比。
- 延迟(P50/P99 延迟):通过聚合追踪中的
- 成本(Cost):
- 单任务 Token 消耗(Tokens per Task):所有追踪中
token_count属性的平均值,这对于管理 LLM 成本至关重要。 - 单次运行 API 成本(API Cost per Run):通过将 Token 数量与模型定价相结合,你可以追踪每个任务的平均财务成本。
- 单任务 Token 消耗(Tokens per Task):所有追踪中
- 有效性(Effectiveness):
- 任务完成率(Task Completion Rate):成功到达指定“成功(success)”跨度的追踪所占的百分比。
- 工具使用频率(Tool Usage Frequency):每个工具(例如
get_weather)作为跨度名称出现的次数统计,用以揭示哪些工具最具有价值。
这些指标对于业务运营、设置告警以及管理你的智能体集群(Agent Fleet)的成本和性能来说至关重要。
质量指标:评判决策力
Quality Metrics: Judging the Decision-Making
质量指标是二级指标(Second-order metrics),是通过在原始可观测性数据之上,应用第二章中详述的评判框架衍生而来的。它们超越了单纯的效率考量,旨在评估智能体自身的推理能力以及最终输出的质量。
这些指标不是简单的计数器或平均值。它们是通过在原始可观测性数据之上叠加一个“评判层”而衍生出来的二级指标,用以评估智能体的推理质量和最终输出。
核心质量指标的示例包括:
- 正确性与准确性(Correctness & Accuracy):智能体是否提供了事实正确的答案?如果它总结了一篇文档,该摘要是否忠实于原文?
- 轨迹契合度(Trajectory Adherence):智能体是否遵循了特定任务的预期路径或“理想配方”?它是否以正确的顺序调用了正确的工具?
- 安全性与责任(Safety & Responsibility):智能体的回复是否避免了有害、偏见或不当的内容?
- 帮助程度与相关性(Helpfulness & Relevance):智能体的最终回复是否对用户真正有帮助,且与用户的查询高度相关?
生成这些指标不仅仅需要一个简单的数据库查询。它通常涉及将智能体的输出与“黄金”标准数据集进行比对,或者使用精密的“LLM 充当裁判(LLM-as-a-Judge)”来对照评估细则为回复打分。
来自日志和追踪的可观测性数据是计算这些评分所需的核心证据,但评判过程本身是一门独立的、至关重要的学科。
融会贯通:从原始数据到可执行洞察
Putting It All Together: From Raw Data to Actionable Insights
拥有日志、追踪和指标,就像是拥有了一位才华横溢的主厨、一个储备充足的储藏室和一套评分细则。但这仅仅是组件。要经营好一家成功的餐厅,你需要将它们组装成一个运转良好的系统,以应对繁忙的晚餐服务。本节讨论的就是这种实际的组装——在实时的生产环境中,将你的可观测性数据转化为实时的行动和洞察。
这涉及三项核心的业务运营实践:
1. 仪表盘与告警:将系统健康与模型质量分离开来
单一的仪表盘是不够的。为了高效管理 AI 智能体,你需要为你的系统指标和质量指标提供不同的视图,因为它们服务于不同的目的和不同的团队。
- 运维仪表盘(面向系统指标):此类仪表盘专注于实时的业务运维健康状况。它追踪智能体的核心生命体征,主要面向对系统可用性和性能负责的站点可靠性工程师(SREs)、DevOps 和运维团队。
- 追踪内容:P99 延迟、错误率、API 成本、Token 消耗。
- 目的:立即发现系统故障、性能降级或预算超支。
- 告警示例:
ALERT: P99 latency > 3s for 5 minutes.(告警:P99 延迟连续 5 分钟大于 3 秒)。这表明存在系统瓶颈,需要工程团队立即介入。
- 质量仪表盘(面向质量指标):此类仪表盘追踪智能体有效性和正确性方面更微妙、变化更慢的指标。它对于对智能体决策和输出质量负责的产品所有者(Product Owners)、数据科学家和 AgentOps(智能体运维)团队来说至关重要。
- 追踪内容:事实正确性评分、轨迹契合度、帮助程度评级、幻觉率。
- 目的:检测智能体质量的隐蔽漂移,尤其是在部署新模型或新提示词之后。
- 告警示例:
ALERT: 'Helpfulness Score' has dropped by 10% over the last 24 hours.(告警:“帮助程度评分”在过去 24 小时内下降了 10%)。这发出了一个信号:尽管系统运行可能一切正常(系统指标没问题),但智能体输出的质量正在下降,需要对其逻辑或数据进行调查。
2. 安全与 PII:保护你的数据
这是生产环境运营中不可逾越的红线。在日志和追踪中捕获的用户输入往往包含个人身份信息(PII)。在数据进行长期存储之前,必须将强健的 PII 擦除机制(PII scrubbing mechanism)作为日志流水线中不可或缺的集成部分,以确保符合隐私法规并保护你的用户。
个人注:在安全和隐私领域,PII 是一个非常高频且核心的术语,它的全称是 Personally Identifiable Information,中文通常翻译为:个人身份识别信息 或 可识别个人身份的信息。
简单来说,PII 指的是任何能够单独使用、或者与其他相关信息结合使用,从而直接或间接识别、联系到特定个人的数据。
3. 核心权衡:粒度 vs. 开销
在生产环境中为每一个单一请求捕获高度详细的日志和追踪,可能会昂贵到令人难以承受,并且会增加系统的延迟。其关键在于找到战略上的平衡。
- 最佳实践 —— 动态采样(Dynamic Sampling):在开发环境中使用高粒度的日志记录(
DEBUG级别)。在生产环境中,设置较低的默认日志级别(INFO),但实施动态采样。例如,你可以决定只对 10% 的成功请求进行追踪,但对 100% 的错误请求进行完整追踪。这既能为你提供用于指标计算的广泛性能数据,又不会让你的系统过载,同时依然能捕获到你调试每次故障所需的丰富诊断细节。
总结与后续预告
Summary & What's Next
要信任一个自主智能体,你必须首先能够理解它的过程。如果对一路上美食主厨的配方、技术和决策毫无了解,你就不会去评判他的最终菜肴。本章已经确立,可观测性(Observability)正是为我们提供这一关键洞察的框架。它充当了厨房内部的“眼睛和耳朵”。
我们已经了解到,强健的可观测性实践建立在三大技术基石之上,它们协同工作,将原始数据转化为全景图:
- 日志(Logs):结构化的日记,提供每一步发生了什么的粒度化、事实性记录。
- 追踪(Traces):串联独立日志的叙事故事,展示因果路径以揭示为什么发生。
- 指标(Metrics):聚合后的成绩单,在大规模场景下总结表现以告诉我们执行得怎么样。我们进一步将其划分为至关重要的系统指标(如延迟和成本)和关键的质量指标(如正确性和帮助程度)。
通过将这些支柱组装成一个连贯的运营系统,我们实现了从盲目摸索向对智能体的行为、效率和有效性拥有清晰的、数据驱动型视图的跨越。
至此,我们已经掌握了所有的拼图:为什么(第一章中智能体的非确定性问题)、是什么(第二章中的评估框架)以及怎么做(第三章中的可观测性架构)。
在第四章中,我们将把这一切融会贯通为一套统一的运营手册,展示这些组件如何构成“智能体质量飞轮(Agent Quality Flywheel)”——一个持续改进的闭环,用以构建不仅有能力、而且真正值得信赖的智能体。
结论:在自主世界中建立信任
Conclusion: Building Trust in an Autonomous World
引言:从自主能力到企业级信任
From Autonomous Capability to Enterprise Trust
在本白皮书的开篇,我们提出了一个根本性的挑战:AI 智能体凭借其非确定性和自主性的本质,粉碎了我们传统的软件质量模型。我们将评估智能体的任务比作评估一名新员工——你不仅要问任务是否完成了,还要问它是如何完成的。它高效吗?安全吗?它是否创造了良好的体验?当后果涉及业务风险时,盲目摸索绝不是一种选择。
自开篇以来的这段旅程,核心在于为这一全新范式构建一份信任的蓝图。我们通过定义智能体质量的四大支柱(有效性、成本效率、安全性和用户信任),确立了建立一门新学科的必要性。随后,我们展示了如何通过可观测性(第三章)在智能体的内心深处获得“眼睛和耳朵”,以及如何通过全局性的评估框架(第二章)来评判其性能表现。
本白皮书已经为“衡量什么”以及“如何看见”奠定了基础。接下来至关重要的下一步(将在后续白皮书《第五天:从原型到生产》中涵盖)是将这些原则转化为实际业务运营。这涉及将一个通过评估的智能体,通过强健的 CI/CD 流水线、安全的滚动发布策略以及可扩展的基础设施,成功地在生产环境中运行起来。
现在,我们将这一切融会贯通。这不仅仅是一个总结,而是一套运营手册,旨在将抽象的原则转化为一个可靠的、自适应优化的系统,从而填补评估与生产之间的鸿沟。
智能体质量飞轮:框架的完美整合
The Agent Quality Flywheel: A Synthesis of the Framework
一个优秀的智能体不仅要有好的表现,更要具备自我进化的能力。这种持续评估的学科建设,正是将一个聪明的 Demo(原型演示)与企业级系统区分开来的关键所在。这种实践创造了一个强大的、自我强化的系统,我们称之为智能体质量飞轮(Agent Quality Flywheel)。
想象一下启动一个巨大而沉重的飞轮。第一推是最艰难的,但结构化的评估实践提供了后续源源不断、始终如一的推力。每一次推动都会增加它的动量,直到飞轮以不可阻挡的力量旋转起来,形成质量与信任的良性循环。这个飞轮正是我们所讨论的整个框架在业务运营层面的具体体现。
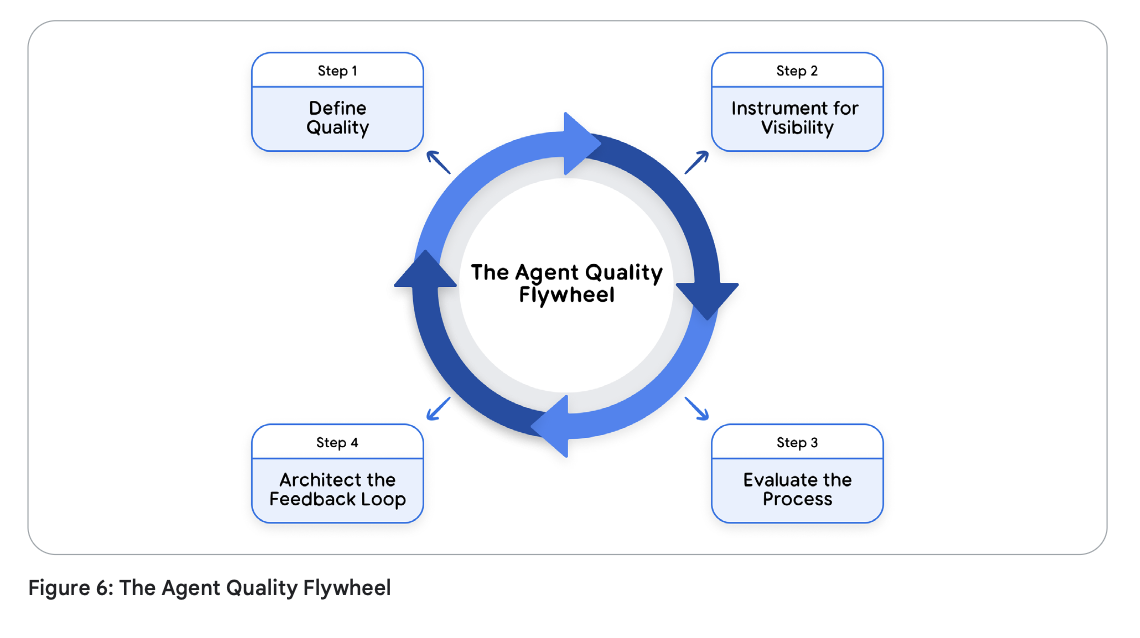
以下是各章的组件如何协同工作,共同打造这一强劲动量的过程:
- 第一步:定义质量(确立目标,The Target):飞轮的运转需要一个方向。正如我们在第一章中所定义的,一切始于质量的四大支柱:有效性、成本效率、安全性和用户信任。这些支柱并不是抽象的理想,而是具体的目标靶心,它们让我们的评估工作拥有了落地意义,并使飞轮与真实的业务价值精准对齐。
- 第二步:进行监测以获取可见性(筑牢基石,The Foundation):你无法管理你看不见的东西。正如在“可观测性”一章中所详细阐述的,我们必须让智能体产生结构化的日志(智能体的日记)和端到端的追踪(叙事主线)。这种可观测性是生成衡量四大支柱所需丰富证据的基础实践,为飞轮提供了核心燃料。
- 第三步:评估过程(打造引擎,The Engine):在建立可见性之后,我们现在可以评判性能表现了。正如我们在“评估”一章中所探讨的,这涉及一种战略性的“由外而内”的评估,既评判最终的输出(Output),也评判整个推理过程(Process)。这是推动飞轮旋转的强大推力——一个混合动力引擎:利用可扩展的“LLM 充当裁判”系统来换取速度,利用“人机协同(HITL)”的“金标准”来锁定期望的标准答案。
- 第四步:构建反馈闭环架构(形成动量,The Momentum):这正是第一章中提到的“原生可评估(Evaluatable-by-design)”架构大放异彩的地方。通过构建关键的反馈闭环,我们确保每一个在生产环境中捕获并带有标注的失败案例,都能通过编程自动转化为我们“黄金”评估集中的永久性回归测试用例。每一次失败都让系统变得更加聪明,让飞轮旋转得更快,从而驱动不断进化、永不停歇的持续改进。
构建可信赖智能体的三大核心原则
Three Core Principles for Building Trustworthy Agents
如果你读完本白皮书只能记住几点,请务必留下这三个原则。它们代表了在这个全新的智能体前沿技术时代中,任何旨在构建真正可靠的自主系统的领导者所必须具备的底层思维:
- 原则一:将评估视为架构支柱,而非最后步骤(Treat Evaluation as an Architectural Pillar, Not a Final Step):还记得第一章中关于赛车的比喻吗?你不会先造好一辆 F1 赛车,然后再把传感器栓上去。你必须从最底层开始设计,为其预留遥测接口。智能体工作负载同样需要这种 DevOps 范式。可靠的智能体在“设计之初就具备可评估性”(evaluatable-by-design),从写下第一行代码起,就进行了埋点监测,以便输出评判所必需的日志与追踪数据。质量是一项架构选择,而不是最后的 QA 阶段。
- 原则二:轨迹即真相(The Trajectory is the Truth):对于智能体而言,最终答案仅仅是一个漫长故事的最后一句话。正如我们在评估章节中所确立的,衡量智能体逻辑、安全性和效率的真实标准,隐藏在其端到端的“思考过程”——即行为轨迹(Trajectory)之中。这就是过程评估(Process Evaluation)。要真正理解智能体成功或失败的原因,你必须分析这条路径。而这只有通过我们在第三章中详述的深度可观测性实践才有可能实现。
- 原则三:人类是最终仲裁者(The Human is the Arbiter):自动化是我们实现规模化的工具,而人类则是我们的信任之源。从“LLM 充当裁判”系统到安全性分类器,自动化必不可少。然而,正如我们在人机协同(HITL)评估中所深入探讨的那样,对“好”的根本性定义、对微妙输出的验证,以及对安全性和公平性的最终判决,必须锚定在人类的价值观上。AI 可以协助阅卷,但制定评分细则并决定什么是真正“优秀”的,只能是人类。
未来属于智能体 —— 而且是可靠的智能体
The Future is Agentic - and Reliable
我们正处于智能体时代的黎明。创造能够推理、规划和行动的 AI 的能力,将成为我们这个时代最具变革性的技术浪潮之一。但能力越大,责任越大,我们肩负着构建配得上人类信任的系统的深刻责任。
熟练掌握本白皮书中的概念(我们可以称之为“评估工程”/ Evaluation Engineering),是下一波 AI 浪潮中最核心的竞争差异化优势。如果企业继续将智能体质量视为后话,它们将永远陷入“Demo 惊艳、上线翻车”的死循环。相反,那些对这种严谨的、与架构深度集成的评估方法进行投资的团队,将能够超越行业炒作,真正部署具有变革意义的企业级 AI 系统。
我们的终极目标不仅是构建能够工作的智能体,更是构建值得信赖的智能体。正如我们所展示的,这种信任不是靠侥幸或希望得来的,而是在持续、全面且架构健全的评估熔炉中锻造出来的。****